Probabilistic Forecasting of Localized Wildfire Spread Based on Conditional Flow Matching
This study presents a probabilistic surrogate model for localized wildfire spread based on a conditional flow matching algorithm. The approach models fire progression as a stochastic process by learning the conditional distribution of fire arrival ti…
Authors: Bryan Shaddy, Haitong Qin, Brianna Binder
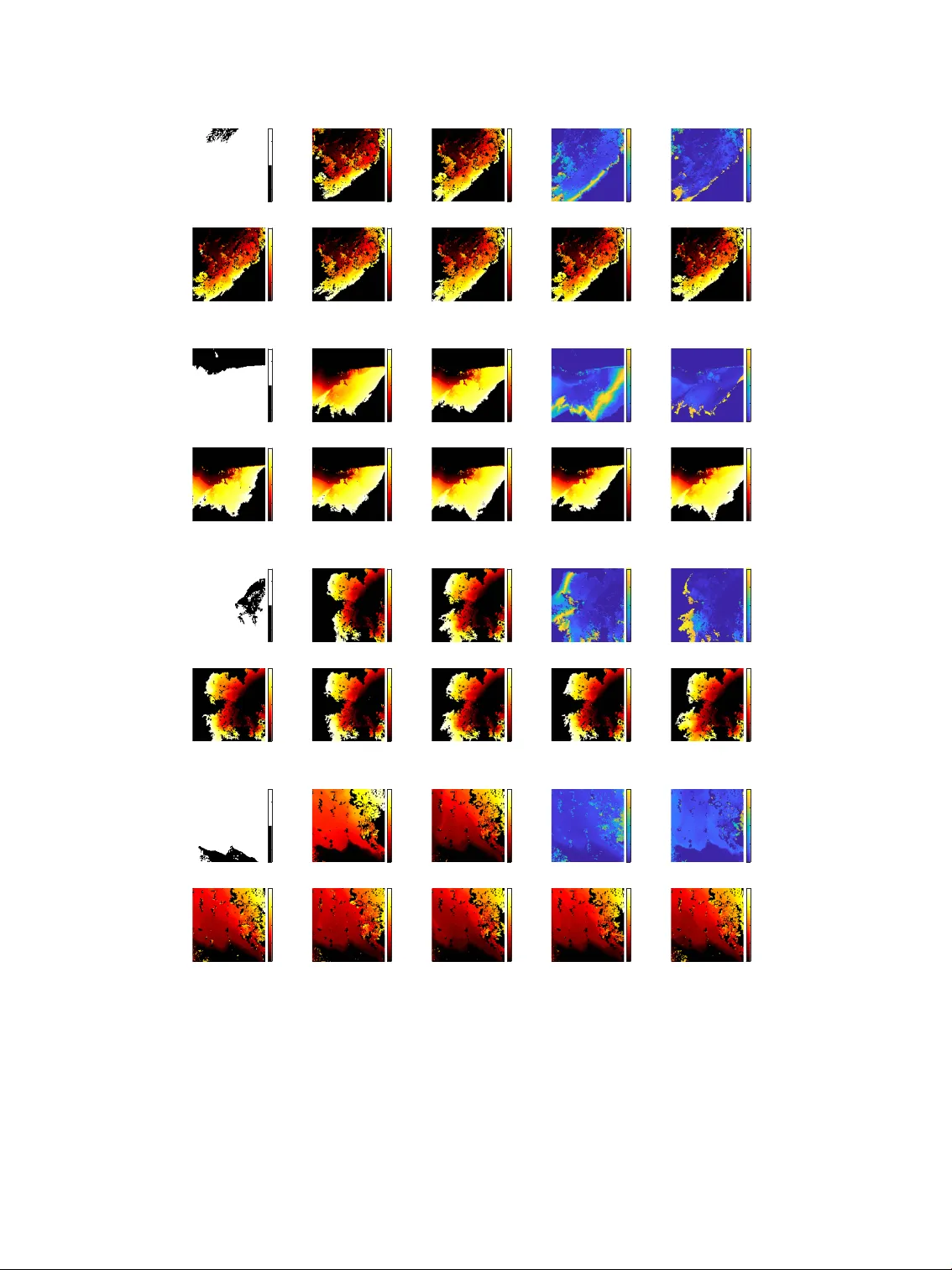
Generated using the official AMS L A T E X template v6.1 Probabilistic F orecasting of Localized W ildfire Spread Based on Conditional Flo w Matching Bryan Shaddy , a Haitong Qin, b Brianna Binder, a James Hale y , c Riy a Duddalw ar , d K y le Hilburn, c Assad Oberai, a a Department of Aer ospace and Mec hanical Engineering, U niv ersity of Southern Calif ornia b Department of Mathematics, U niv er sity of Southern Calif ornia c Cooper ativ e Institut e f or R esear c h in t he Atmospher e, Color ado Stat e U niv ersity d Department of Computer Science, U niv er sity of Southern Calif ornia Corr esponding author : Bry an Shaddy , bshaddy@usc.edu This W ork has not y e t been peer -review ed and is pro vided by the contributing Aut hor(s) as a means to ensur e timely dissemination of scholar ly and tec hnical W ork on a noncommer cial basis. Copyright and all rights ther ein ar e maintained by the Author(s) or by other copyright owner s. It is unders tood that all per sons copying this inf or mation will adher e to t he terms and constr aints inv oked by eac h Author’ s copyright. This W ork may no t be r epos ted without explicit permission of the copyright o wner . 1 ABSTRA CT : This s tudy presents a probabilistic sur rog ate model f or localized wildfire spread based on a conditional flo w matching algor ithm. The approach models fire progression as a stoc has tic process b y learning the conditional dis tr ibution of fire arr ival times giv en the current fire state along with en vironmental and atmospher ic inputs. Model in puts include current burned area, near -surface wind components, temperature, relativ e humidity , ter rain height, and fuel categor y inf or mation, all defined on a high-resolution spatial g rid. The outputs are samples of ar r iv al time within a three-hour time windo w , conditioned on the input variables. T raining data are g enerated from coupled atmosphere–wildfire spread simulations using WRF-SFIRE, paired with w eather fields from the North Amer ican Mesoscale model. The proposed framew ork enables efficient generation of ensembles of ar rival times and e xplicitly represents uncertainty arising from incomplete kno wledg e of the fire–atmosphere sys tem and unresol ved v ar iables. The model suppor ts localized prediction o ver subdomains, reducing computational cost relative to ph y sics- based simulators while retaining sensitivity to ke y dr iv ers of fire spread. Model per f or mance is e valuated agains t WRF-SFIRE simulations f or both single-step (3-hour) and recursive multi-step (24-hour) f orecasts. R esults demonstrate that the method captures variability in fire e v olution and produces accurate ensemble predictions. The frame w ork pro vides a scalable approach f or probabilistic wildfire f orecasting and offers a pathwa y f or integrating machine lear ning models with operational fire prediction sy stems and data assimilation. 2 1. Introduction The increasing impact of wildfires in recent decades has dr iv en the de velopment of a wide rang e of wildfire spread prediction tools. These tools span a spectr um from simplified two-dimensional models based on semi-empir ical rate-of-spread formulations to high-fidelity models that resolv e small-scale combustion processes (Bakhshaii and Johnson (2019); F inney (1998); Linn et al. (2002); R other mel (1972)). S tate-of-the-ar t operational models include coupled atmosphere–wildfire sys- tems such as WRF-SFIRE, which account f or fire–weather feedbac k mechanisms that are cr itical f or accurate prediction of fire behavior (Mandel et al. (2011)). More recently , machine lear ning- based approaches hav e also been e xplored f or wildfire prediction (Jain et al. (2020)). Despite these adv ances, e v en the most sophisticated models e xhibit significant de viations from reality o ver time horizons of one to tw o day s. These limitations ar ise from the inherentl y chaotic nature of wildfire spread, incomplete representation of phy sical processes, and uncer tainty in ke y inputs such as fine-scale fuel structure. This loss of predictiv e accuracy motivates the use of data assimilation techniq ues that incor porate obser v ations of wildfire e volution to impro ve f orecasts. Data assimilation methods f or high-dimensional, nonlinear sy stems typically rel y on ensembles of predictions, which poses challeng es when using computationally intensiv e wildfire models. This limitation motivates the de velopment of lightweight yet accurate sur rogate models capable of efficiently g enerating prediction ensembles. While e xisting ph y sics-based wildfire models capture man y of the processes go verning fire spread, their computational cost restricts their use in ensemble-based frame w orks. These models, ho we v er , provide a strong f oundation f or machine learning-based emulation. By training sur rog ate models to reproduce the behavior of ph ysics- based simulations, it is possible to achie v e substantial computational speedup while retaining ke y ph ysical c haracter istics and accuracy . Existing machine learning approaches to wildfire prediction emplo y a range of methodologies and data sources. Some approac hes resemble cellular automata, where transition r ules are lear ned from historical wildfire data (Zheng et al. (2017)). Other methods utilize conv olutional neural netw orks trained on historical obser v ations or simulated outputs from models such as F ARSITE (Hodg es and Lattimer (2019); Burg e et al. (2023); Radke et al. (2019); Bolt et al. (2022); Marjani et al. (2024)). While these approaches demonstrate promise, the y often suffer from limitations related to data quality and incomplete representation of rele vant ph y sical processes. In many cases, 3 these limitations stem from the use of simplified training data that omit k ey dynamics, such as fire–w eather interactions. As a result, sev eral exis ting machine lear ning-based wildfire prediction models e xhibit limited applicability to real-w orld scenarios, reducing their ability to produce accurate and phy sicall y con- sistent predictions (Andr ianar iv ony and Akhloufi (2024)). Fur thermore, sev eral models represent fire progression using coarse temporal metrics, such as bur ned area or probability of bur ning, which complicates their integ ration with data assimilation frame works that lev erag e high-resolution ob- servational data from satellites (Radke et al. (2019); Khennou et al. (2021); Hodg es and Lattimer (2019)). In addition, most e xisting approaches produce deterministic predictions, which limits their utility in ensemble-based settings (Burg e et al. (2023); Bolt et al. (2022)). Constraints on domain size fur ther restrict the applicability of some models to larg e, long-duration wildfire e vents. In this w ork, w e dev elop a probabilistic sur rog ate model f or wildfire spread based on conditional flo w matching (Lipman et al. (2022); Dasgupta et al. (2026)). The model predicts fire growth o v er a 3 . 2 km × 3 . 2 km domain at 25 m resolution, incor porating w eather , ter rain, and fuel inf or mation to simulate fire progression o v er a 3-hour time step. The proposed approach pro vides a computationall y efficient frame work f or g enerating ensembles of fire spread predictions, making it w ell suited f or sequential data assimilation and operational f orecasting. The model requires onl y the cur rent fire e xtent as input, enabling straightf or w ard initialization from observed perimeters, such as those obtained from airborne measurements, or from pre vious model outputs. This f or mulation allo ws the model to be applied autoregressivel y to simulate fire ev olution o v er e xtended time horizons. A dditionally , b y decomposing the domain into smaller subregions, the approach could be applied to fires of varying sizes while maintaining high spatial resolution. This patch-based strategy also enables targ eted prediction of fire gro wth in regions of interest without requiring simulation of the full fire e xtent. The conditional flo w matching model is trained on WRF-SFIRE simulations of wildfires oc- cur ring across the contiguous U nited States (CONUS) dur ing 2023, together with cor responding w eather data from the N or th Amer ican Mesoscale (N AM) model. Model inputs include the cur rent burned area, zonal (east–w est) and meridional (nor th–south) wind components, relativ e humidity , temperature, ter rain ele v ation, and fuel categor y data. The model outputs fire prog ression o v er a 3-hour inter v al in the f or m of fire ar r iv al times, which indicate the time at which the fire first 4 reaches each location in the domain. This f or mulation enables incor poration of k e y dr iv ers of wildfire spread while relying onl y on readily a vailable atmospheric and static en vironmental data. The probabilistic frame w ork allo w s sampling from the conditional dis tr ibution of fire arr iv al times giv en the inputs, thereb y enabling g eneration of prediction ensembles and quantification of uncer - tainty ar ising from incomplete kno w ledg e of factors such as fuel moisture and the fully coupled atmosphere–fire state. The proposed approach differs from pr ior methods in sev eral impor tant wa y s (Hodges and Lattimer (2019); Burg e et al. (2023); Radke et al. (2019); Bolt et al. (2022); Marjani et al. (2024); Khennou et al. (2021)). F irst, it lev erages training data from coupled atmosphere–wildfire simulations of real e v ents, impro ving g eneralizability and enabling incor poration of more realistic fire dynamics. Second, it adopts a probabilistic f or mulation, allo wing uncer tainty to be e xplicitly represented and enabling efficient generation of ensembles without requiring input per turbations. Third, the model suppor ts localized prediction of fire spread, allo wing simulation of subregions of a fire per imeter without the computational burden associated with full-domain ph y sics-based models. The remainder of the manuscript is organized as f ollow s. Section 2 describes the problem f or mulation, training data generation, and the conditional flo w matching methodology . Section 3 presents model e valuation, including sensitivity analy sis and validation agains t WRF-SFIRE f or both single-step predictions and multi-step recursiv e f orecasts. Finall y , Section 4 summar izes the findings and outlines directions f or future w ork. 2. Methods In the f ollo wing section w e discuss the methods utilized to constr uct the probabilistic wildfire spread sur rog ate model dev eloped here. Firs t, w e present the formulation f or the problem of probabilistic estimation of wildfire spread based on w eather , ter rain, and fuel data. Ne xt, w e describe the constr uction of training data from WRF-SFIRE solutions and NAM w eather data. Finall y , w e present a description of the flow matc hing algor ithm and ho w it is trained. 5 a. Problem F or mulation The problem is f or mulated o v er a spatial domain of extent 3 . 2 km × 3 . 2 km. This domain is discretized using a unif or m gr id with a resolution of 25 meters, resulting in a computational mesh of 128 × 128 points on which all rele v ant v ar iables are defined. The pr imary objectiv e is to predict fire gro wth o v er a specified time inter v al. In par ticular , giv en the per imeter of an activ e fire at time 𝑡 𝑛 , the underl ying ter rain, the spatial distribution of fuel, and w eather conditions ev aluated at the inter mediate time 𝑡 𝑛 + Δ 𝑡 / 2, the goal is to deter mine the e volution of the fire o ver the interv al ( 𝑡 𝑛 , 𝑡 𝑛 + Δ 𝑡 ) , where Δ 𝑡 = 3 hours. Fire gro wth is represented through an arr iv al time map, which encodes the time at whic h the fire reaches each gr id point in the domain. This quantity is denoted by y , where y ∈ Ω 𝑦 ≡ R 128 × 128 , with each entry cor responding to the fire ar rival time at a specific spatial location. The model takes as in put the f ollowing set of v ariables: • The burned area at time 𝑡 𝑛 , represented as a single binary field. • W eather variables, including zonal and mer idional wind components, temperature, and relative humidity , e v aluated at the midpoint between time steps, 𝑡 𝑛 + Δ 𝑡 / 2. These are represented as f our real-valued scalar fields. • S tatic ter rain height data, represented as a single real-valued scalar field. • S tatic fuel categor y data, in which each Anderson fuel categor y is encoded as a separate v ar iable using a one-hot representation. This results in f our teen binary scalar fields, including one cor responding to the absence of fuel. Each input v ar iable is defined as a scalar field o ver the same computational g rid as y . All input variables are concatenated to f or m a composite conditioning tensor, denoted b y x ∈ Ω 𝑥 ≡ R 128 × 128 × 20 . Although the proposed model incor porates a comprehensiv e set of input v ar iables, it does not include all v ar iables that define the state in a WRF-SFIRE simulation. For ex ample, omitted v ar iables include those describing fuel moisture and the state of the atmosphere at multiple ele vation le vels. As a consequence of these omissions, as well as the inherentl y chaotic nature of wildfire spread, we e xpect that a giv en set of input v ar iables ma y cor respond to multiple plausible fire e volution scenar ios. This obser v ation motiv ates the dev elopment of a probabilis tic model f or 6 wildfire spread that explicitl y captures this one-to-many mapping. In par ticular , w e represent the predicted fire arr iv al time as a random v ector , Y ∈ Ω 𝑦 , and the input v ar iables as a random v ector , X ∈ Ω 𝑥 . Our objective is to characterize the conditional density , 𝑃 Y | X , such that f or a giv en realization X = x , w e can dra w samples of Y from this distribution. T o sample from the tar g et conditional density , 𝑃 Y | X , w e emplo y a conditional g enerativ e model- ing approach based on conditional flo w matching (Lipman et al. (2022); Wildber g er et al. (2023); T ong et al. (2023); Dasgupta et al. (2026)). The model is trained on samples ( Y , X ) dra wn from the joint distr ibution 𝑃 Y X . Once trained, the flo w matching model enables sampling from the learned conditional density 𝑃 Y | X f or a giv en realization X = x , thereb y g enerating cor responding samples of Y . These samples can subsequently be used to compute statis tics of interest. In par ticular , w e consider the medoid, defined as the sample with the smallest av erage distance to all other samples, which ser v es as a representativ e prediction, as well as the pixel-wise standard de viation, which pro vides a measure of predictive uncertainty . T raining tuples are constructed by first sampling X from the marginal distribution 𝑃 X , which characterizes typical wildfire conditions. F or each suc h sample, a numer ical wildfire spread model (WRF-SFIRE in our case) is used to simulate fire progression o v er a time inter v al of Δ 𝑡 = 3 hours. This yields cor responding samples of Y dra wn from the conditional distribution 𝑃 Y | X . The resulting tuple ( Y , X ) theref ore constitutes a sample from the joint dis tr ibution 𝑃 Y X . By repeating this procedure, a collection of samples from the joint distribution 𝑃 Y X is obtained and used to train the flo w matching model. In practice, this data g eneration process is car r ied out b y r unning simulations from ignition and e vol ving the fire ov er e xtended time horizons, thereb y producing the required training dataset. b. T r aining Data Generation W e generate training data using the coupled atmosphere–wildfire model WRF-SFIRE, which integrates the W eather R esearch and Forecas ting (WRF) model with a wildfire spread propag ation model. The wildfire component, SFIRE, emplo y s a lev el-set method, with spread rates computed using the semi-empirical Rothermel rate-of-spread model (Mandel et al. (2011); R other mel (1972)). W e use the wrfxpy sys tem to e xecute WRF-SFIRE simulations. This system automates the full simulation workflo w , including domain configuration, acquisition and processing of meteorological 7 data for initial and boundar y conditions, preprocessing of ter rain and fuel data, and the ex ecution and monitoring of simulations (Mandel et al. (2019)). In the f ollo wing sections, w e describe the configuration of the WRF-SFIRE simulations and the procedure used to construct training data from their outputs. 1) WRF-SFIRE Solutions A total of 140 WRF-SFIRE simulations of wildfires across the contiguous U nited S tates (CONUS) f or 2023 w ere generated to cons tr uct the training dataset, with an additional 12 simula- tions reser v ed f or testing and model validation. Incidents w ere selected based on their simulated spatial e xtent after an initial 24-hour growth per iod. Fires that w ere either too larg e to be contained within the simulation domain or too small to be representative were manually e x cluded. Simula- tions w ere initialized using ignition locations and times derived from GOES and VIIRS activ e fire detections pro vided b y NO AA ’ s Ne xt Generation Fire Sys tem (NGFS). The NGFS clusters satellite detections into incident g roups and associates them with repor ted fires catalog ed b y the N ational Interag ency F ire Center (NIFC). Ignition times were defined as the times tamp of the ear liest detec- tion associated with each fire e v ent. Ignition locations w ere estimated using the a verag e position of all VIIRS detections within the f ootpr int of the initial GOES detection. In cases where no VIIRS detections were a vailable within the first f our hours f ollo wing the initial GOES detection, the ignition location w as instead estimated using the a v erage position of the GOES detections. W e conducted the simulations on a domain of size 30 km × 30 km, with an atmospher ic gr id resolution of 1 km. The atmospher ic model emplo y ed 40 v er tical lev els, with a model top at appro ximately 5000 P a (corresponding to an altitude of about 20 km). T o represent wildfire dynamics, w e used a 1200 × 1200 fire g rid with a spatial resolution of 25 m, yielding a gr id refinement ratio of 40:1 betw een the atmospheric and fire gr ids. Ignition locations w ere positioned near the center of each domain. W e prescr ibed initial and boundary atmospheric conditions using data from the N or th American Mesoscale (N AM) Forecas t Sys tem Grid 227, which has a spatial resolution of 5 km. These data w ere pro vided at 3-hour inter v als throughout each simulation. Fuel inf or mation was obtained from the 2019 LANDFIRE 13 Anderson Fire Behavior F uel Models (FBFM13) dataset, and ter rain ele vation data w ere sourced from the USGS National Ele vation Dataset (NED). Using this 8 configuration, we simulated wildfire e volution o v er the first 48 hours f ollo wing ignition. These simulations produced fire ar r iv al time maps, which we used to construct both fire area inputs and fire ar rival time outputs f or training the flo w matching model. The cor responding weather inputs w ere der iv ed from the N AM data used to drive the simulations, while terrain and fuel inputs w ere obtained from the respectiv e static datasets. 2) Training D a t a Constr uction Using fire ar rival time maps obtained from WRF-SFIRE, tog ether with cor responding w eather data from N AM at 3-hour intervals, as w ell as terrain and fuel category data, w e cons tr uct training data tuples. W e use N AM w eather data, or iginall y emplo y ed to dr iv e the boundar y conditions of the WRF-SFIRE simulations, to define the weather inputs f or our model. This choice av oids the need to model the full y coupled atmospheric state dur ing prediction and enables the use of readily a vailable f orecast data. W e generate training samples through a data augmentation procedure that includes random rotation, f orecast time selection, and spatial patch e xtraction. F or each WRF-SFIRE simulation, w e denote the full 48-hour fire ar r iv al time map by τ and appl y the f ollo wing steps: 1. R esample the w eather data onto the 25 m resolution fire g rid on which ar rival times, ter rain, and fuel v ar iables are defined. 2. Appl y a random rotation to τ , along with the cor responding w eather , ter rain, and fuel data, using an angle dra wn from the unif or m distribution 𝑈 ( 0 ◦ , 360 ◦ ) . 3. R otate the wind v ectors accordingly and then project them back onto a fix ed east–w est and nor th–south coordinate sy stem. 4. Sample a forecas t time 𝑇 𝑛 ∼ 𝑈 ( 𝑇 ign , 𝑇 max − Δ 𝑡 ) , where 𝑇 ign denotes the ignition time (i.e., the minimum value of τ ), 𝑇 max is the total simulated duration, and Δ 𝑡 = 3 hours is the prediction interval. 5. Construct the fire area used as in put by assigning all pix els denoted by the inde x pairs ( 𝑖 , 𝑗 ) a v alue of − 1 if 𝜏 𝑖 𝑗 ≤ 𝑇 𝑛 , and a v alue of 1 if 𝜏 𝑖 𝑗 > 𝑇 𝑛 . 9 6. Construct the fire ar rival time to be used as output 𝑦 𝑖 𝑗 as f ollo ws: 𝑦 𝑖 𝑗 = 𝑇 𝑛 , 𝜏 𝑖 𝑗 ≤ 𝑇 𝑛 𝑇 𝑛 + Δ 𝑡 , 𝜏 𝑖 𝑗 > 𝑇 𝑛 + Δ 𝑡 𝜏 𝑖 𝑗 , otherwise (1) 7. Linear ly inter polate betw een av ailable w eather data snapshots to obtain w eather v ar iables at time 𝑇 𝑛 + Δ 𝑡 / 2. 8. Extract a randomly selected spatial patch of size 128 × 128 pix els, ensur ing that the patch contains sufficient inf or mation from the fire area in put. The sequence of s teps descr ibed abo v e yields a single sample ( Y , X ) from a WRF-SFIRE solution. For each WRF-SFIRE solution, w e per f or m 10 rotations descr ibed in Step 2 abo ve and for each rotation select 10 f orecasting times 𝑇 𝑛 described in Step 4 abo v e. This results in the generation of 100 samples f or each WRF-SFIRE solution, which yields 14 , 000 samples f or training data and 1 , 200 samples f or test data. The w eather , ter rain, fuel and output ar r iv al time data are then nor malized as f ollo ws: • Wind components are nor malized b y dividing by the standard deviation computed across all samples. • R elative humidity and temperature are nor malized b y subtracting their respective global mean and dividing b y their respective global s tandard deviation. • T er rain height is first shifted b y subtracting the sample-wise minimum, and is then normalized b y subtracting the global mean and dividing by the global s tandard deviation. • Fuel category data are represented using a one-hot encoding, resulting in 14 binar y masks that indicate the presence of each fuel type. • Output arr ival times are normalized b y linearl y scaling the ( 𝑇 𝑛 , 𝑇 𝑛 + Δ 𝑡 ) inter v al to ( − 1 , 1 ) . In Figure 1 we present tw o samples from the training data; one where the entire fire e xtent is contained within the domain and another demonstrating where only a por tion of the fire e xtent is captured in the domain. The training data contains a mixture of these two types of data. 10 (a) Sampl e 1 (b) Sampl e 2 Inpu ts Inpu ts Outpu t Outpu t Fig. 1. T w o training samples, with input v ar iables and cor responding fire ar r iv al time outputs display ed. The wind field sho wn is plotted using the magnitude and direction computed from the zonal and mer idional wind components and fuel categor y data is additionally display ed as a single categor ical image deter mined from the one-hot encoded data used f or training. 11 c. Flow Matc hing In the f ollo wing section w e provide a br ief revie w of the conditional flo w-matc hing algor ithm. The reader is ref er red to Lipman et al. (2022); Wildberg er et al. (2023); T ong et al. (2023); Dasgupta et al. (2026) f or a detailed descr iption of this algorithm. W e begin by defining a pseudo-time v ar iable 𝑡 ∈ ( 0 , 1 ) , and f or each value of 𝑡 define a ne w random v ar iable Y 𝑡 defined as Y 𝑡 = Z ( 1 − 𝑡 ) + Y 𝑡 , (2) where Z ∼ 𝑃 Z = 𝑁 ( 0 , 1 ) is the standard nor mal random variable, and Y ∼ 𝑃 Y | X . W e note that Y 𝑡 has a f ew important proper ties, including that at time 𝑡 = 0, Y 0 = Z and at time 𝑡 = 1, Y 1 = Y . Theref ore, at an y time 𝑡 , Y 𝑡 can be thought of as a mixture of Z and Y . As shown in Dasgupta et al. (2026), from the definition of Y 𝑡 , w e conclude that there exis ts a v elocity field, v 𝑡 ( Y , X ) which has the f ollo wing useful proper ty . If w e select samples Y 0 ∼ 𝑃 Z , and integrate in pseudo-time using 𝑑 Y 𝑡 𝑑 𝑡 = v 𝑡 ( Y 𝑡 , X ) , (3) then w e are guaranteed that the collection Y 1 ∼ 𝑃 Y | X . That is, we can g enerate samples from the conditional distribution 𝑃 Y | X b y first generating samples from 𝑃 Z and integrating them in time using the ordinary differential equation abo ve. Further , it can be shown that the v elocity field used in (3), denoted b y v 𝑡 is the field that minimizes the loss function, 𝐿 ( v 𝑡 ) = ∫ 1 0 ∫ Ω 𝑦 ∫ Ω 𝑦 ∫ Ω 𝑥 | v 𝑡 ( y 𝑡 , x ) − ( y − z ) | 2 𝑃 Y X ( Y , X ) 𝑃 Z ( z ) 𝑑 x 𝑑 y 𝑑 z 𝑑 𝑡 , (4) where y 𝑡 = z ( 1 − 𝑡 ) + y 𝑡 . The integral in this loss can be approximated as a Monte Carlo sum by sampling 𝑡 ( 𝑖 ) ∼ 𝑈 ( 0 , 1 ) , z ( 𝑖 ) ∼ 𝑁 ( 0 , 1 ) , and ( y ( 𝑖 ) , x ( 𝑖 ) ) ∼ 𝑃 Y X , leading to 𝐿 ( v 𝑡 ) = 1 𝑁 𝑁 𝑖 = 1 | v 𝑡 ( 𝑖 ) ( y 𝑡 ( 𝑖 ) , x ( 𝑖 ) ) − ( y ( 𝑖 ) − z ( 𝑖 ) ) | 2 . (5) 12 Note that the e valuation of this loss requires samples z ( 𝑖 ) from 𝑁 ( 0 , 1 ) and samples of ( y ( 𝑖 ) , x ( 𝑖 ) ) from 𝑃 Y X , which are both a v ailable. The v elocity field in the loss function (5) is appro ximated using a neural netw ork. Once this netw ork is trained b y minimizing the loss, this velocity field can be used in (3) to obtain a sample of y ∼ 𝑃 Y | X f or a giv en input x . W e model the v elocity field using an adapted DDPM U-Net architecture, follo wing Ho et al. (2020); Nic hol and Dhar iw al (2021). W e implement the netw ork in PyT orch and train it on a single NVIDIA A100 GPU for 45,000 mini-batc hes, cor responding to appro ximately 320 epochs. W e use a batch size of 100 and optimize the model parameters using the A damW optimizer with a lear ning rate of 10 − 4 , w eight deca y set to 0, 𝛽 1 = 0 . 9, 𝛽 2 = 0 . 999, and 𝜖 = 10 − 8 . Throughout training, w e maintain an e xponential mo ving a v erage (EMA) of the model parameters with a deca y rate of 0.9999. The final repor ted model cor responds to these EMA parameters. W e compute and track training losses using the EMA parameters, and w e select the final chec kpoint f or e v aluation based on the minimum test loss observ ed dur ing training. 3. Results In this section we f ocus on validating the wildfire spread sur rogate model and demons trating its performance across se v eral scenarios. W e begin with a sensitivity analy sis, where w e e v aluate the ability of the sur rog ate model to reproduce meaningful relations betw een input weather and terrain v ar iables and the resulting fire spread. N ext, w e verify the accuracy of the solutions generated b y the sur rog ate model f or a single timestep of 3 hours agains t the cor responding WRF-SFIRE solutions. Lastl y , we assess the per f or mance of the model dur ing a recursiv e roll-out, where fire gro wth is predicted o v er a per iod of 24 hours star ting from both an ignition point and from a kno wn burned area for an ongoing wildfire. a. Sensitivity Analysis With the wildfire spread sur rog ate model trained, we first per f or m a sensitivity anal y sis to assess the influence of individual input variables on predicted fire gro wth. T o this end, w e prescr ibe a simplified and controlled set of conditions consis ting of spatiall y uniform w eather , ter rain, and fuel, together with a circular initial fire per imeter . This configuration remo v es asymmetr ies in the 13 wildfire spread problem and enables independent e valuation of the effect of eac h input variable on the predicted fire gro wth area. The anal ysis produces relationships betw een fire area and each in put v ar iable, thereb y pro viding insight into how the model responds to variations in the conditioning inputs. W e e x clude fuel categor y from this analy sis due to its strong dependence on w eather conditions, which w ould require a more comprehensiv e, joint sensitivity study across multiple en vironmental regimes. W e define a control case with unif or m wind v elocities of 0 m s − 1 in both the zonal ( 𝑢 ) and meridional ( 𝑣 ) directions, a relativ e humidity of 24%, a temperature of 80 ◦ F , flat ter rain, and a unif or m fuel type cor responding to Anderson category 10 (timber, litter , and understor y). The initial fire per imeter is additionall y specified as a circle with a diameter of 150 m. S tar ting from this baseline configuration, w e vary each input variable independentl y to ev aluate its impact on the total predicted fire area. W e v ary the wind components 𝑢 and 𝑣 ov er the range [ − 3 , 3 ] m s − 1 . This rang e reflects the distribution of wind values in the NAM dataset used f or training, where appro ximately 82% of v alues lie within this inter v al. Relativ e humidity is varied from 0% to 110%, and temperature is v ar ied from 40 ◦ F to 115 ◦ F . For ter rain, w e prescr ibe an inclined planar surface and vary the angle of inclination from 0 ◦ to 45 ◦ . For eac h set of prescr ibed conditions, w e g enerate 200 stochas tic predictions of fire spread o v er a single 3-hour inter v al and compute the cor responding fire g ro wth. From these samples, w e estimate the mean and standard deviation of the predicted fire area. W e then plot the mean fire area as a function of each input variable and represent v ar iability using the cor responding standard de viation. Figure 2 summarizes the results of this sensitivity analy sis. The results in Figure 2 indicate that the model captures phy sicall y meaningful relationships consistent with the training data. As wind magnitude increases, the model predicts increased fire gro wth, with minimal gro wth occur ring near 0 m s − 1 . A slight asymmetry is observed in the wind sensitivity curves, with the minimum shifted mar ginally a wa y from zero. For relativ e humidity , the model predicts decreasing fire gro wth with increasing humidity , con- sistent with the expected dampening effect of atmospher ic moisture. Similarl y , higher temperatures lead to increased predicted fire gro wth. Finall y , as the ter rain slope increases, the model predicts larg er fire areas, reflecting the kno wn influence of slope on fire spread dynamics. T ogether , these 14 U-Wind -2 0 2 m/s 30 35 40 45 50 55 60 acres V-Wind -2 0 2 m/s 30 35 40 45 50 55 acres Relative Humidity 0 50 100 % 20 25 30 35 40 45 50 acres Temperature 40 60 80 100 120 ° F 20 30 40 50 60 70 acres Terrain Slope 0 10 20 30 40 ° 20 40 60 80 100 acres mean mean +/- SD U-Wind -2 0 2 m/s 30 35 40 45 50 55 60 acres V-Wind -2 0 2 m/s 30 35 40 45 50 55 acres Relative Humidity 0 50 100 % 20 25 30 35 40 45 50 acres Temperature 40 60 80 100 120 ° F 20 30 40 50 60 70 acres Terrain Slope 0 10 20 30 40 ° 20 40 60 80 100 acres mean mean +/- SD (a) U - Wi n d (b) V - Wi n d (c) Rel at iv e Hu midi ty (d) Te m p e r a t u r e (e) Te r r a i n S l o p e U-Wind -2 0 2 m/s 30 35 40 45 50 55 60 acres V-Wind -2 0 2 m/s 30 35 40 45 50 55 acres Relative Humidity 0 50 100 % 20 25 30 35 40 45 50 acres Temperature 40 60 80 100 120 ° F 20 30 40 50 60 70 acres Terrain Slope 0 10 20 30 40 ° 20 40 60 80 100 acres mean mean +/- SD U-Wind -2 0 2 m/s 30 35 40 45 50 55 60 acres V-Wind -2 0 2 m/s 30 35 40 45 50 55 acres Relative Humidity 0 50 100 % 20 25 30 35 40 45 50 acres Temperature 40 60 80 100 120 ° F 20 30 40 50 60 70 acres Terrain Slope 0 10 20 30 40 ° 20 40 60 80 100 acres mean mean +/- SD Fig. 2. Predicted fire area v ersus (a) 𝑢 wind speed, (b) 𝑣 wind speed, (c) relativ e humidity , (d) temperature, and (e) ter rain slope. For each plot, the mean predicted area is shown along with variability indicated by the standard de viation. results demonstrate that the sur rog ate model reproduces ke y qualitativ e dependencies obser v ed in wildfire beha vior . b. V alidation for t hree hour int er val Ha ving demons trated that the model captures e xpected phy sics-based relationships, we next e valuate its perf or mance on realistic wildfire scenarios dra wn from the testing dataset, which includes heterog eneous and comple x weather , ter rain, and fuel conditions. W e apply the model to 1,200 test cases, generating 200 stochas tic predictions of fire progression o ver a single 3-hour interval f or each case. From these samples, w e compute the medoid prediction, which ser v es as a representativ e estimate, as w ell as the pix el-wise standard de viation, which quantifies predictiv e uncer tainty . Figure 3 presents results f or three representativ e cases. This figure includes the input 15 conditions, a subset of g enerated samples, the medoid prediction, the associated standard de viation plot, the targ et fire progression, and the absolute er ror betw een the medoid and the targ et. The results in Figure 3 indicate that the model generates a set of plausible fire spread scenar ios that are consistent with the input conditions and closely approximate the targ et solutions. The g enerated samples e xhibit no e xtreme outliers or non-ph y sical behavior . In all cases, the medoid prediction captures the ov erall patter n of fire g ro wth, although localized discrepancies in ar r iv al times are obser v ed. F or ex ample, in the third case, the medoid slightly under -predicts fire spread along the nor thern boundary . Ho w ev er , e xamination of the full set of generated samples rev eals that some realizations more closely matc h the targ et, indicating that the predictive distr ibution often encompasses the true outcome. Notabl y , regions of higher prediction er ror tend to coincide with regions of ele v ated standard deviation, sugges ting that the model appropriately reflects increased uncer tainty in the areas where the error is higher . T o fur ther quantify per f ormance across all 1,200 test cases, we compare the total predicted fire gro wth with the cor responding targ et values. For each case, we compute the number of gr id cells burned ov er the 3-hour inter v al in both the medoid prediction and the tar g et. Panels (a) and (b) of Figure 4 sho w scatter plots of predicted v ersus targ et bur ned area o ver the full rang e of values and o v er a restricted range f or smaller fires. In most cases, the predicted g ro wth closely matches the targ et, with points cluster ing near the line of per f ect agreement. Some spread is obser v ed, which is e xpected given the reduced set of input variables a vailable to the sur rog ate model compared to the full WRF-SFIRE simulations. W e further assess spatial ag reement betw een predicted and targ et bur ned areas using the Sørensen–Dice coefficient (SC). For each test case, w e compute the number of true positiv e pix els (TP), false positives (FP), and f alse neg atives (FN), where TP denotes pix els correctly predicted as burned, FP denotes pixels predicted as bur ned but not bur ned in the targ et, and FN denotes pix els burned in the target but not predicted as suc h. The SC is then giv en b y 𝑆𝐶 = 2 𝑇 𝑃 2 𝑇 𝑃 + 𝐹 𝑃 + 𝐹 𝑁 . (6) Panels (c) and (d) of Figure 4 present SC values as a function of targ et bur ned area. Most cases yield SC values between 0.8 and 0.9, indicating strong spatial agreement. Lo wer SC v alues are more common f or smaller fires, where ev en minor spatial discrepancies can significantl y affect the 16 Fire Area Inputs -1 1 burned / unburned Wind Field 0 5 10 m/s Relative Humidity 0 50 100 % Temperature 260 280 300 320 K Terrain Height 0 200 400 600 800 m Fuel Category 2 4 6 8 10 12 14 category # Sample 1 Samples 0 1 2 3 hours Sample 2 0 1 2 3 hours Sample 3 0 1 2 3 hours Sample 4 0 1 2 3 hours Sample 5 0 1 2 3 hours Sample 6 0 1 2 3 hours Target Results 0 1 2 3 hours Medoid 0 1 2 3 hours Standard Deviation 0 0.5 1 hours Absolute Error 0 1 2 3 hours (a) Cas e 1 (b ) Ca se 2 (c) Cas e 3 Fire Area Inputs -1 1 burned / unburned Wind Field 0 5 10 m/s Relative Humidity 0 50 100 % Temperature 260 280 300 320 K Terrain Height 0 200 400 600 800 m Fuel Category 2 4 6 8 10 12 14 category # Sample 1 Samples 0 1 2 3 hours Sample 2 0 1 2 3 hours Sample 3 0 1 2 3 hours Sample 4 0 1 2 3 hours Sample 5 0 1 2 3 hours Sample 6 0 1 2 3 hours Target Results 0 1 2 3 hours Medoid 0 1 2 3 hours Standard Deviation 0 0.5 1 hours Absolute Error 0 1 2 3 hours Fire Area Inputs -1 1 burned / unburned Wind Field 0 5 10 m/s Relative Humidity 0 50 100 % Temperature 260 280 300 320 K Terrain Height 0 200 400 600 800 m Fuel Category 2 4 6 8 10 12 14 category # Sample 1 Samples 0 1 2 3 hours Sample 2 0 1 2 3 hours Sample 3 0 1 2 3 hours Sample 4 0 1 2 3 hours Sample 5 0 1 2 3 hours Sample 6 0 1 2 3 hours Target Results 0 1 2 3 hours Medoid 0 1 2 3 hours Standard Deviation 0 0.5 1 hours Absolute Error 0 1 2 3 hours Fig. 3. R esults f or three cases from the testing dataset. The first row show s conditioning inputs, the second ro w sho ws six sampled predictions, and the third ro w presents the targ et, medoid prediction, pixel-wise standard de viation, and absolute er ror betw een the medoid and targ et. 17 0 500 1000 1500 2000 target growth [acres] 0 500 1000 1500 2000 predicted growth [acres] 0 100 200 300 400 500 target growth [acres] 0 100 200 300 400 500 predicted growth [acres] 0 500 1000 1500 2000 target growth [acres] 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 SC 0 100 200 300 400 500 target growth [acres] 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 SC 0 500 1000 1500 2000 target growth [acres] 0 500 1000 1500 2000 predicted growth [acres] 0 100 200 300 400 500 target growth [acres] 0 100 200 300 400 500 predicted growth [acres] 0 500 1000 1500 2000 target growth [acres] 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 SC 0 100 200 300 400 500 target growth [acres] 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 SC (a) Pred ic ted vs T arge t Growt h (Full Ra nge) (b) Predi ct ed vs T a rget Gr owth (Detailed V iew) (C) Sorens en - Di ce Co eff i ci en t v s Fi re a re a (Full Ra nge) (d) Soren sen - Di ce C oe ffi ci e nt v s Fi re a r ea (Detailed V iew) Fig. 4. Perf or mance of the wildfire spread surrogate model on the testing dataset. P anels (a) and (b) show medoid predicted v ersus targ et bur ned area o v er the full and restricted ranges, respectiv ely . P anels (c) and (d) sho w the Sørensen–Dice coefficient (SC) as a function of target burned area o ver the same rang es. metric. Ne v er theless, as seen in Figure 4 (a) , the model g enerall y captures the cor rect magnitude of fire gro wth ev en in these cases. 18 c. Recursiv e Prediction fr om Ignition W e ne xt e v aluate the recursiv e application of the sur rog ate model to predict wildfire gro wth o ver multiple timesteps. In this setting, w e initialize the model with a kno wn fire area, either from an ignition point or an observed per imeter . The model then predicts fire g ro wth o v er a single timestep using the corresponding w eather inputs. The predicted fire ar rival times are subsequently con verted into a binar y bur ned/unburned map, which ser v es as input f or the ne xt time step along with updated w eather data. This procedure is repeated f or the desired number of timesteps. T o propagate uncer tainty through time, w e adopt an ensemble-based approach. Star ting from a single initial fire area, we g enerate an ensemble of predictions f or the first timestep. For subsequent timesteps, each ensemble member produces a single prediction, resulting in a one-to-one mapping betw een ensemble members and predictions. In this wa y , the ensemble size remains constant throughout the recursiv e process. W e apply the surrogate model recursiv ely to predict wildfire spread from ignition up to 24 hours f or 12 test cases dra wn from the WRF-SFIRE simulations in the testing dataset. These cases w ere not used dur ing training. For each case, w e generate 200 realizations of fire ar rival times, requiring appro ximately nine minutes per case on a single NVIDIA A100 GPU . Figure 5 presents results f or f our representativ e cases, including the initial fire area, the targ et 24-hour fire ar rival time map, the medoid prediction, the pixel-wise standard deviation, and the absolute er ror between the medoid and the targ et. The results in Figure 5 indicate that the model produces reasonable multi-step g ro wth predictions, with the dis tr ibution of generated samples captur ing the targ et e volution in most cases. Some discrepancies are observed in the medoid predictions. F or e xample, in case 3, a region of growth on the w estern side of the fire is under -predicted b y the medoid. How ev er , other ensemble members capture this g ro wth more accurately , and the cor responding region e xhibits elev ated standard de viation, indicating increased uncer tainty . A cross all 12 cases, the model achie v es an a verag e Sørensen–Dice coefficient of 0.87 when comparing predicted (medoid) and targ et bur ned areas after 24 hours, indicating strong spatial agreement. W e fur ther ev aluate per f or mance using the probability of detection (POD) and false alarm ratio (F AR), defined in terms of true positiv es (TP), false positiv es (FP), and f alse neg atives 19 SC: 0.87568, POD: 0.89461, FAR: 0.14247, Err-SD Corr. Coef.: 0.56508 Fire Area -1 1 burned / unburned Target 0 6 12 18 24 hours Medoid 0 6 12 18 24 hours Standard Deviation 0 3 6 9 12 hours Absolute Error 0 6 12 18 24 hours Sample 1 0 6 12 18 24 hours Sample 2 0 6 12 18 24 hours Sample 3 0 6 12 18 24 hours Sample 4 0 6 12 18 24 hours Sample 5 0 6 12 18 24 hours SC: 0.80762, POD: 0.68743, FAR: 0.021262, Err-SD Corr. Coef.: 0.70762 Fire Area -1 1 burned / unburned Target 0 6 12 18 24 hours Medoid 0 6 12 18 24 hours Standard Deviation 0 3 6 9 12 hours Absolute Error 0 6 12 18 24 hours Sample 1 0 6 12 18 24 hours Sample 2 0 6 12 18 24 hours Sample 3 0 6 12 18 24 hours Sample 4 0 6 12 18 24 hours Sample 5 0 6 12 18 24 hours SC: 0.97085, POD: 0.94642, FAR: 0.0034351, Err-SD Corr. Coef.: 0.48536 Fire Area -1 1 burned / unburned Target 0 6 12 18 24 hours Medoid 0 6 12 18 24 hours Standard Deviation 0 3 6 9 12 hours Absolute Error 0 6 12 18 24 hours Sample 1 0 6 12 18 24 hours Sample 2 0 6 12 18 24 hours Sample 3 0 6 12 18 24 hours Sample 4 0 6 12 18 24 hours Sample 5 0 6 12 18 24 hours SC: 0.90391, POD: 0.82899, FAR: 0.0062872, Err-SD Corr. Coef.: 0.5623 Fire Area -1 1 burned / unburned Target 0 6 12 18 24 hours Medoid 0 6 12 18 24 hours Standard Deviation 0 3 6 9 12 hours Absolute Error 0 6 12 18 24 hours Sample 1 0 6 12 18 24 hours Sample 2 0 6 12 18 24 hours Sample 3 0 6 12 18 24 hours Sample 4 0 6 12 18 24 hours Sample 5 0 6 12 18 24 hours (a) Case 1 (b) Case 2 (c) Case 3 (d) Case 4 Fig. 5. R esults from recursiv e application of the wildfire spread sur rog ate model to predict growth from ignition to 24 hours f or f our cases. The first row show s the initial fire area, targ et growth, medoid prediction, standard de viation, and absolute er ror . The second row sho ws representativ e samples of predicted fire g ro wth. 20 (FN) as 𝑃𝑂 𝐷 = 𝑇 𝑃 𝑇 𝑃 + 𝐹 𝑁 , 𝐹 𝐴 𝑅 = 𝐹 𝑃 𝑇 𝑃 + 𝐹 𝑃 . (7) The POD rang es from 0 to 1, with higher values indicating better detection, while the F AR rang es from 0 to 1, with lo wer v alues indicating f e wer f alse positives. A cross the 12 cases, w e obtain an a v erag e POD of 0.85 and an av erage F AR of 0.07, demonstrating that the model captures fire gro wth effectivel y without substantial o v er - or under -prediction. Finall y , we assess the relationship betw een predictiv e uncer tainty and er ror by computing the P earson cor relation coefficient betw een the pix el-wise standard de viation and the pix el-wise abso- lute er ror across all cases. The a v erage cor relation of 0.46 indicates a moderate positive relation- ship, sugg esting that regions of higher predicted uncer tainty tend to cor respond to larg er prediction er rors. This result highlights the utility of the uncer tainty estimates pro vided by the model. d. Recursiv e Prediction fr om a Known P erimeter W e ne xt apply the sur rogate model to localized subsections of activel y bur ning fires in order to predict gro wth from a kno wn per imeter . As in the ignition-based setting, w e begin with a single initial fire area and generate an ensemble of predictions f or the first timestep. Subsequent predictions proceed in a one-to-one manner , where each ensemble member produces a single realization at each times tep. W e apply the model to the same 12 wildfire cases used in pr ior ev aluations, no w initializing from the fire extent at 12 hours after ignition. The computational domain is positioned along a por tion of the fire perimeter . From this initial condition, w e g enerate 200 realizations of fire gro wth o v er a 24-hour period. Figure 6 presents results f or f our representativ e cases. Plots f or each case include the initial fire e xtent, the target spread solution, the medoid prediction, the pix el-wise standard de viation, and the absolute er ror between the medoid and the targ et, along with representativ e samples. The results in Figure 6 sho w that the medoid prediction agrees well with the targ et spread solution across all cases. As in the predictions that w ere initialized from ignition, the generated samples e xhibit a reasonable div ersity of plausible fire spread scenarios, with the standard deviation pro viding a meaningful measure of variability . The highest v ar iability is typically observ ed along the advancing fire front, indicating that uncer tainty is pr imarily associated with the e xtent of fire 21 SC: 0.98153, POD: 0.99823, FAR: 0.034621, Err-SD Corr. Coef.: 0.22375 Fire Area -1 1 burned / unburned Target 0 6 12 18 24 hours Medoid 0 6 12 18 24 hours Standard Deviation 0 3 6 9 12 hours Absolute Error 0 6 12 18 24 hours Sample 1 0 6 12 18 24 hours Sample 2 0 6 12 18 24 hours Sample 3 0 6 12 18 24 hours Sample 4 0 6 12 18 24 hours Sample 5 0 6 12 18 24 hours SC: 0.90459, POD: 0.97543, FAR: 0.15665, Err-SD Corr. Coef.: 0.56289 Fire Area -1 1 burned / unburned Target 0 6 12 18 24 hours Medoid 0 6 12 18 24 hours Standard Deviation 0 3 6 9 12 hours Absolute Error 0 6 12 18 24 hours Sample 1 0 6 12 18 24 hours Sample 2 0 6 12 18 24 hours Sample 3 0 6 12 18 24 hours Sample 4 0 6 12 18 24 hours Sample 5 0 6 12 18 24 hours SC: 0.9643, POD: 0.94587, FAR: 0.016545, Err-SD Corr. Coef.: 0.40215 Fire Area -1 1 burned / unburned Target 0 6 12 18 24 hours Medoid 0 6 12 18 24 hours Standard Deviation 0 3 6 9 12 hours Absolute Error 0 6 12 18 24 hours Sample 1 0 6 12 18 24 hours Sample 2 0 6 12 18 24 hours Sample 3 0 6 12 18 24 hours Sample 4 0 6 12 18 24 hours Sample 5 0 6 12 18 24 hours SC: 0.92986, POD: 0.94617, FAR: 0.085892, Err-SD Corr. Coef.: 0.49107 Fire Area -1 1 burned / unburned Target 0 6 12 18 24 hours Medoid 0 6 12 18 24 hours Standard Deviation 0 3 6 9 12 hours Absolute Error 0 6 12 18 24 hours Sample 1 0 6 12 18 24 hours Sample 2 0 6 12 18 24 hours Sample 3 0 6 12 18 24 hours Sample 4 0 6 12 18 24 hours Sample 5 0 6 12 18 24 hours (a) Case 1 (b) Case 2 (c) Case 3 (d) Case 4 Fig. 6. Results from recursiv e application of the wildfire spread sur rogate model to a subsection of an activ e fire, initialized from the 12-hour perimeter and propagated to 36 hours. The first ro w show s the initial fire area, targ et growth, medoid prediction, standard deviation, and absolute er ror . The second ro w show s representative prediction samples. 22 gro wth o v er the prediction hor izon. For ex ample, in case 1, elev ated uncer tainty is obser v ed near the souther n boundar y of the fire, which coincides with regions of larg er prediction er ror . This fur ther highlights the utility of the uncertainty estimates. A cross the 12 cases, the model achie v es an a v erage Sørensen–Dice coefficient of 0.90, a prob- ability of detection (POD) of 0.96, and a f alse alarm ratio (F AR) of 0.14 f or 24-hour growth predictions initialized from a 12-hour per imeter . Relativ e to predictions initialized from ignition, these results indicate a modest impro v ement in SC and POD, accompanied by a slight increase in F AR, sugges ting a tendency to ward mild ov er -prediction in this setting. The cor relation between predicted uncer tainty and er ror remains moderate, with an a verag e Pearson correlation coefficient of 0.45. Ov erall, these results demonstrate that the sur rog ate model perf or ms effectiv ely when applied to subsections of activel y burning fires, while providing substantial computational speed-up relativ e to phy sics-based models. In contrast, ph y sics-based approaches face challeng es in initializing from par tial fire per imeters and typically require simulation of the entire fire domain, making localized prediction significantl y more computationally demanding. 4. Conclusions and Future W ork In this work, w e hav e de veloped a probabilistic surrogate model f or wildfire spread that enables the efficient generation of ensembles of fire prog ression predictions. The model is based on conditional flo w matching and is trained using simulations of historical wildfires generated with the coupled atmosphere–wildfire model WRF-SFIRE, together with cor responding weather data from the North Amer ican Mesoscale (N AM) model. Giv en the cur rent fire extent, along with wind, relativ e humidity , temperature, ter rain, and fuel inf or mation, the model predicts fire prog ression o v er a 3-hour inter v al. The model relies e xclusiv ely on readily a v ailable inputs and does not require the e xecution of additional parameter izations or atmospher ic models. Further more, it can be applied to localized subsections of a fire per imeter , enabling targ eted predictions without simulating the full fire e xtent. Because the model requires only the cur rent fire area as input, it can additionall y be initialized using obser v ed per imeters, such as those obtained from airbor ne measurements, without requiring kno wledg e of pr ior fire e v olution. 23 W e e valuated the model through a sensitivity analy sis designed to assess the learned relationships betw een input v ar iables and predicted fire gro wth. The results demonstrated that the model captures ph ysicall y meaningful dependencies, with fire g ro wth responding appropriately to v ar iations in w eather and ter rain conditions. W e fur ther e valuated its perf or mance on 1,200 tes t cases, corresponding to 3-hour (single timestep) fire gro wth. In each case, w e used the model to g enerate 200 samples. These results sho wed that the model produces realistic fire spread patterns o v er a single time step and achie ves strong agreement with targ et solutions. Using the Sørensen–Dice coefficient (SC) to quantify spatial agreement, w e f ound that mos t cases yielded v alues betw een 0.8 and 0.9. Low er SC v alues w ere obser v ed f or smaller fires, reflecting the sensitivity of the metr ic to small spatial discrepancies. Ne v er theless, the model accurately captured the o v erall magnitude of fire gro wth in these cases, indicating that it reliabl y represents the dominant fire dynamics. T o assess longer -ter m predictiv e per f or mance, we applied the model recursiv ely to simulate 24 hours of fire growth starting from ignition. This procedure inv olv ed eight sequential predictions, with each step using the output of the previous step as input. A cross 12 test cases, the model achie v ed an av erage Sørensen–Dice coefficient (SC) of 0.87, a probability of detection (POD) of 0.85, and a false alar m ratio (F AR) of 0.07, indicating strong agreement with the reference WRF-SFIRE simulations and limited ov er -prediction. The Pearson cor relation coefficient be- tw een predicted uncer tainty (s tandard de viation) and error w as 0.46, demonstrating that the model pro vides inf or mativ e uncer tainty estimates that are moderatel y cor related with er ror . W e also e valuated the model on subsections of activ e fires b y initializing from a 12-hour perimeter and predicting 24 hours of gro wth. In this setting, the model achie v ed an a v erag e SC of 0.90, POD of 0.96, and F AR of 0.14 across 12 cases indicating strong ov erall per f or mance. The cor relation betw een uncer tainty and er ror remained consistent, with an a v erage v alue of 0.45. The proposed sur rog ate model pro vides a substantial computational speed-up relativ e to phy sics- based approaches, generating 200 samples f or a single 3-hour prediction in just o ver one minute while maintaining reliable accuracy . These characteristics make the model w ell suited f or ap- plications such as sequential data assimilation, where rapid g eneration of prediction ensembles is essential. The model also sho ws promise f or operational deplo yment, offering probabilistic 24 f orecasts of wildfire spread along with associated uncer tainty estimates that can support decision- making in firefighting and resource allocation. Despite these adv ances, se v eral c halleng es remain. In its current f or m, the model can be applied independentl y to subsections of larg e fires; ho we v er , impro v ed domain decomposition s trategies are needed to ensure consistency and inf or mation e xc hange across adjacent regions, thereby a v oiding discontinuities in predicted fire growth (Chan and Mathew (1994); Dolean et al. (2015)). Future w ork will f ocus on integ rating the sur rog ate model with data assimilation frame works, including coupling with update models based on conditional generativ e approaches (Shaddy et al. (2024, 2026)), to enable real-time assimilation of obser v ational data and further enhance predictiv e capability . 25 Ac know ledgments. The NO AA Bipar tisan Infrastructure Law project N A22O AR4050672I sup- por ted the creation of the f orecasts. The N AS A Disasters project 80NSSC19K1091 sup- por ted the high-per f or mance computing f or r unning the f orecasts. The N ASA FireSense project 80NSSC23K1344 suppor ted de v elopment and e v aluation of the mac hine learning approach. AA O ackno w ledg es suppor t from AR O g rant W911NF2410401. The authors ackno w ledge the Center f or A dvanced R esearch Computing (C AR C) at the Univ ersity of Souther n Calif ornia, US A f or pro viding the computing resources that ha v e contr ibuted to the research results repor ted within this publication. Ref erences Andrianar iv ony , H. S., and M. A. Akhloufi, 2024: Machine learning and deep lear ning f or wildfire spread prediction: A revie w . F ire , 7 (12) , 482. Bakhshaii, A., and E. A. Johnson, 2019: A re vie w of a ne w generation of wildfire–atmosphere modeling. Can. J. F or . Res. , 49 (6) , 565–574, https://doi.org/10.1139/cjfr - 2018- 0138. Bolt, A., C. Huston, P . Kuhnert, J. J. Dabro wski, J. Hilton, and C. Sanderson, 2022: A spatio- temporal neural network f orecasting approach for emulation of firefront models. 2022 Signal Pr ocessing: Algorithms, Ar chit ectures, Arr ang ements, and Applications (SP A) , IEEE, 110–115. Burg e, J., M. R. Bonanni, R. L. Hu, and M. Ihme, 2023: R ecur rent conv olutional deep neural netw orks f or modeling time-resolv ed wildfire spread behavior . F ire T echnology , 59 (6) , 3327– 3354. Chan, T . F ., and T . P . Mathe w , 1994: Domain decomposition algorithms. Acta numerica , 3 , 61–143. Dasgupta, A., A. F ardisi, M. Amin y , B. Binder , B. Shaddy , and A. Oberai, 2026: Sol ving ph y sics- constrained in v erse problems with conditional flo w matching. arXiv preprint arXiv :2603.14135 . Dolean, V ., P . Joliv et, and F . N ataf, 2015: An introduction to domain decomposition methods: algorithms, theory, and par allel implementation . SIAM. Finne y , M. A., 1998: F ARSITE, Fir e Area Simulator –model dev elopment and evaluation . 4, US Depar tment of A g riculture, Forest Service, R ocky Mountain R esearch S tation. 26 Ho, J., A. Jain, and P . A bbeel, 2020: Denoising diffusion probabilistic models. Advances in neural inf or mation pr ocessing syst ems , 33 , 6840–6851. Hodg es, J. L., and B. Y . Lattimer , 2019: Wildland fire spread modeling using con v olutional neural netw orks. F ire t echnology , 55 , 2115–2142. Jain, P ., S. C. Coogan, S. G. Subramanian, M. Cro w ley , S. T a y lor , and M. D. Flannigan, 2020: A re vie w of machine lear ning applications in wildfire science and manag ement. Envir onmental Review s , 28 (4) , 478–505. Khennou, F ., J. Ghaoui, and M. A. Akhloufi, 2021: Forest fire spread prediction using deep learning. Geospatial informatics XI , SPIE, V ol. 11733, 106–117. Linn, R., J. R eisner, J. J. Colman, and J. W interkamp, 2002: S tudying wildfire behavior using firetec. International journal of wildland fire , 11 (4) , 233–246. Lipman, Y ., R. T . Chen, H. Ben-Hamu, M. Nic kel, and M. Le, 2022: Flo w matc hing f or g enerativ e modeling. arXiv pr eprint arXiv :2210.02747 . Mandel, J., J. Beezley , and A. K ochanski, 2011: Coupled atmosphere-wildland fire modeling with wrf-fire version 3.3. Geoscientific Model Dev elopment Discussions , 4 (1) , 497–545. Mandel, J., M. V ejmelka, A. K ochanski, A. Far guell, J. Hale y , D. Mallia, and K. Hilburn, 2019: An interactiv e data-driven hpc sys tem f or f orecasting weather , wildland fire, and smoke. 2019 IEEE/A CM HPC for U rg ent Decision Making (U rg entHPC) , IEEE, 35–44. Marjani, M., M. Mahdianpar i, and F . Mohammadimanesh, 2024: Cnn-bilstm: A no v el deep learning model f or near -real-time daily wildfire spread prediction. R emot e Sensing , 16 (8) , 1467. Nichol, A. Q., and P . Dhariw al, 2021: Impro v ed denoising diffusion probabilis tic models. Int erna- tional conf erence on mac hine learning , PMLR, 8162–8171. Radke, D., A. Hessler , and D. Ellsw or th, 2019: Firecas t: Le v eraging deep lear ning to predict wildfire spread. IJCAI , 4575–4581. R other mel, R. C., 1972: A mathematical model for pr edicting fir e spr ead in wildland fuels . R esearch Paper , INT -115. US Depar tment of Agr iculture, Inter mountain Forest and Rang e Exper iment Station. 27 Shaddy , B., and Coauthors, 2024: Generativ e algor ithms f or fusion of ph y sics-based wildfire spread models with satellite data f or initializing wildfire f orecasts. Artificial Intellig ence f or the Earth Sys tems . Shaddy , B., and Coauthors, 2026: Generative algor ithms f or wildfire prog ression reconstruction from multi-modal satellite activ e fire measurements and ter rain height. Remo te Sensing , 18 (2) , 227. T ong, A., N. Malkin, G. Huguet, Y . Zhang, J. Rector -Brooks, K. F atras, G. W olf, and Y . Bengio, 2023: Conditional flo w matching: Simulation-free dynamic optimal transpor t. arXiv preprint arXiv :2302.00482 , 2 (3) . Wildber ger , J., M. Dax, S. Buchholz, S. Green, J. H. Mack e, and B. Sch ¨ olk opf, 2023: Flo w matching f or scalable simulation-based inf erence. Advances in N eural Information Processing Sys tems , 36 , 16 837–16 864. Zheng, Z., W . Huang, S. Li, and Y . Zeng, 2017: Forest fire spread simulating model using cellular automaton with e xtreme lear ning machine. Ecological Modelling , 348 , 33–43. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment