Fast Topology-Aware Lossy Data Compression with Full Preservation of Critical Points and Local Order
Many scientific codes and instruments generate large amounts of floating-point data at high rates that must be compressed before they can be stored. Typically, only lossy compression algorithms deliver high-enough compression ratios. However, many of…
Authors: Alex Fallin, Nathaniel Gorski, Tripti Agarwal
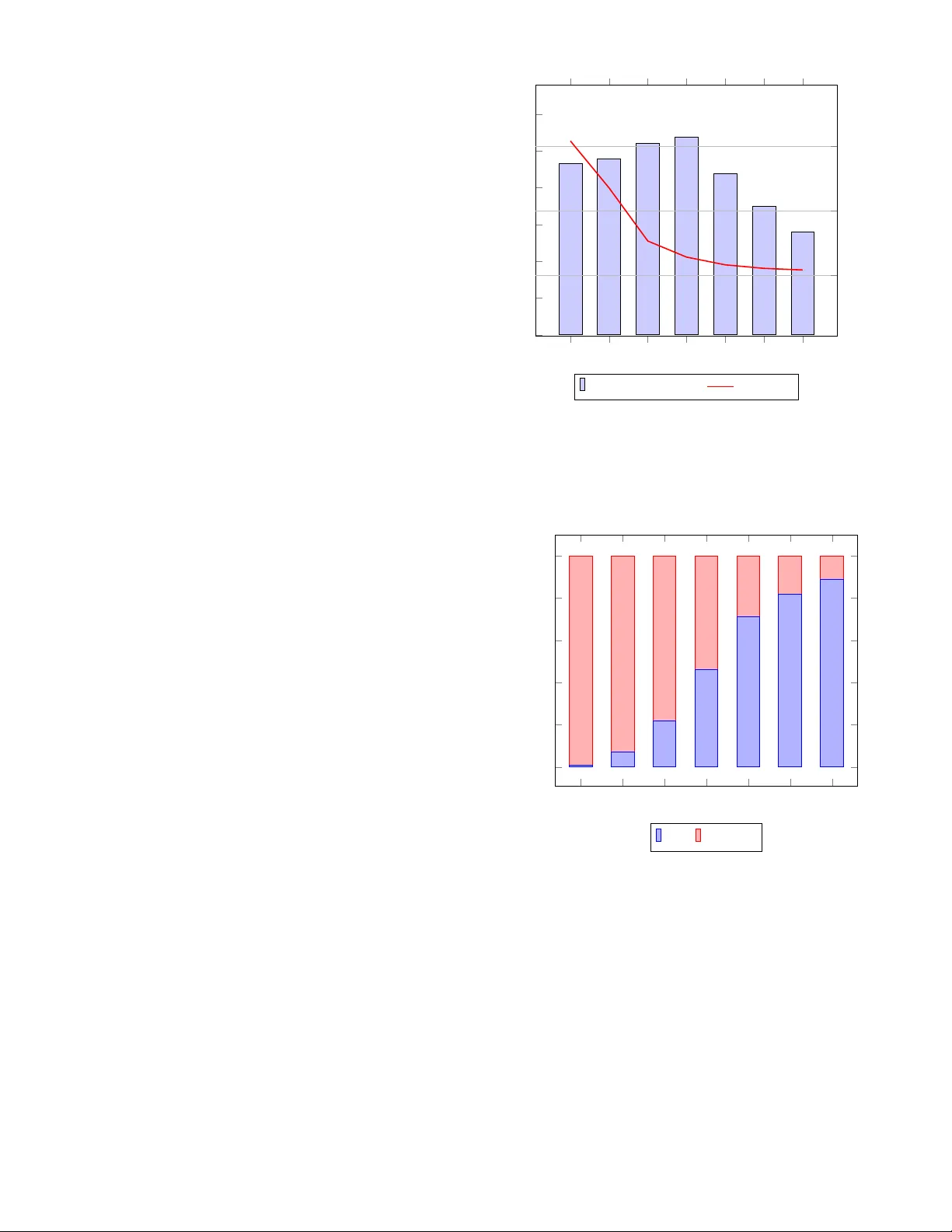
F ast T opology-A ware Lossy Data Compression with Full Preserv ation of Critical Points and Local Order Alex Fallin ∗ , Nathaniel Gorski † , Tripti Agarwal † , Bei W ang † , Ganesh Gopalakrishnan † , Martin Burtscher ∗ ∗ T exas State Univ ersity , USA † Univ ersity of Utah, USA Emails: { waf13, burtscher } @txstate.edu, { gorski, beiwang } @sci.utah.edu, { tripti.agarwal@, ganesh@cs. } utah.edu Abstract —Many scientific codes and instruments generate large amounts of floating-point data at high rates that must be compressed befor e they can be stored. T ypically , only lossy compression algorithms deliver high-enough compression ratios. Howev er , many of them pr ovide only point-wise err or bounds and do not preserve topological aspects of the data such as the rela- tive magnitude of neighboring points. Even topology-preserving compressors tend to mer ely preserve some critical points and are generally slow . Our Local-Order-Pr eserving Compressor is the first to preserve the full local order (and thus all critical points), runs orders of magnitude faster than prior topology- preser ving compressors, yields higher compression ratios than lossless compressors, and produces bit-for -bit the same output on CPUs and GPUs. Index T erms —lossy data compression, critical-point preserva- tion, local-order preserv ation, parallel execution I . I N T RO D U C T I O N Many scientific instruments and simulations generate data volumes that far exceed what can be practically managed, both in terms of throughput and storage capacity [21]. T o address this challenge, two primary compression strategies are employed: lossless and lossy . Lossless compression reproduces the original data exactly but often fails to achiev e the high compression ratios required for large-scale scientific work- flows. In contrast, lossy compression can provide substantially higher compression ratios depending on the chosen error bound, at the cost of discarding some information, making perfect reconstruction of the original data impossible. T opological data analysis (TD A) employs structures such as critical points, contour trees [5], and Morse-Smale com- plex es [11] to describe, summarize, and analyze complex data. These topological descriptors are deriv ed from global properties of the data, making the local guarantees provided by standard scientific data compressors insufficient for their preservation. T o ov ercome this limitation, a variety of com- pressors and frameworks have been de veloped to preserve various topological aspects of scalar fields [17], [24], [34], [40], vector fields [25], [39], and tensor fields [16]. Unfortunately , existing topology-preserving compressors suffer from sev eral drawbacks. First, they tend to be rela- tiv ely slo w: the preservation of topological information often requires substantial computation, taking orders of magnitude longer than conv entional compression methods [40]. Second, most approaches preserve only limited topological informa- tion, such as the critical points on the contour tree [40]. Third, many lossy compressors claim error control but do not strictly guarantee the error bound [15]. Our Local-Order-Preserving Compressor (LOPC) addresses these challenges by providing a strict error-bound guarantee, incorporating a new algorithm that preserves the full local order (and thus all critical points), and leveraging parallelism- friendly CPU and GPU implementations to significantly ac- celerate computation. Whereas the topology of the data—defined here as the relationships among critical points—is inherently a global property , our approach focuses on preserving the relative ordering of neighboring points, referred to as the local or der . Maintaining the local order serves as a foundational step tow ard preserving global topology: it improv es the accuracy of local gradient flows, reduces visual artifacts such as jagged structures, and yields more accurate deriv ed quantities. Critical points of scalar fields (namely local minima, max- ima, and saddles) are fundamental topological features that are determined entirely by the local order of the data. They serve as essential descriptors in visualization and form the basis for more complex topological constructs, such as the contour tree and the Morse-Smale complex. Moreover , critical points often carry direct physical meaning in a wide range of domains, including chemistry [4], climate science [23], and physics [35]. Because local order is defined solely from local information, it is an ideal property to preserve under lossy compression. Our method perfectly preserves the local order and, by extension, all critical points. T o the best of our kno wledge, no prior lossy data compressor fully preserves either property . Since LOPC preserves more information, it compresses less than the other tested topology-preserving compressors. Howe ver , it is faster e ven serially . When run in parallel, it reaches speeds that are orders of magnitude higher than the related work, all while preserving local ordering, critical points, and a guaranteed error bound, a unique set of attrib utes among compressors in the literature. Our main contributions include: • A local-order -preserving compression algorithm : LOPC is the first algorithm that guarantees full preservation of the local order and works in combination with a guaranteed error-bounded lossy compressor . • Theoretical guarantees : W e show that LOPC preserves all critical-point locations and types (despite the lossy nature of the underlying compressor), introduces no spurious critical points, and terminates. • Implementation and optimization : W e provide a detailed description of the implementation, optimization, and paral- lelization strategies used in LOPC for CPUs and GPUs. • Comprehensiv e evaluation : W e compare LOPC to 8 state- of-the-art compressors, 3 of which are topology-preserving, demonstrating its superior ef fectiv eness in preserving critical points and local order . Upon conclusion of the anonymization phase, our LOPC C++/OpenMP and CUDA codes will be open-sourced. The rest of this paper is organized as follo ws. Section II provides background. Section III summarizes related work. Section IV explains the LOPC algorithm. Section V describes the ev al- uation methodology . Section VI presents and discusses the results. Section VII concludes the paper with a summary . I I . B A C K G RO U N D Piecewise-Linear Scalar Fields : LOPC targets piece wise- linear (PL) scalar functions defined on triangular (2D) or tetrahedral (3D) meshes. Let X be a triangular mesh and f : X → R a PL function. Then, the v alue of f is explicitly stored for each vertex v of X and extended to all of X by linear interpolation. Let σ be a triangular cell of X with vertices v 1 , v 2 , and v 3 . Then, any x ∈ σ can be written uniquely in terms of its barycentric coordinates x = t 1 v 1 + t 2 v 2 + t 3 v 3 , where t i ≥ 0 and P i t i = 1 . W e set f ( x ) = P i t i f ( v i ) , which also holds for the analogous definition in 3D. LOPC works with scalar data defined on regular 2D and 3D grids, which it subdivides into triangular and tetrahedral meshes, respectively , as is done in prior work [37]. Critical Points : The critical points of a PL function f : X → R are defined as follows. Let v ∈ X be a vertex. The link of v , Lk ( v ) , is the set of vertices of X adjacent to v . The lower link of v is the set Lk − ( v ) = { v ′ ∈ Lk ( v ) : f ( v ′ ) < f ( v ) } . Similarly , the upper link is the set Lk + ( v ) = { v ′ ∈ Lk ( v ) : f ( v ′ ) > f ( v ) } . If Lk − ( v ) = ∅ , then v is a local maximum. If Lk + ( v ) = ∅ , then v is a local maximum. If LK − ( v ) and Lk + ( v ) are both nonempty and contain vertices belonging to a single connected component each, then v is an ordinary (non- critical) point. Otherwise, v is a saddle point. This strategy assumes that neighboring points have different function values. W e guarantee that they do using Simulation of Simplicity [12]. I I I . R E L A T E D W O R K This section describes the state-of-the-art floating-point compressors with which we compare LOPC. Note that all lossless compressors necessarily preserve the full topology . A. Lossless Compressors FPzip [29] is a CPU-based library that supports both lossy and lossless compression of scientific data. It exploits floating- point data coherency to predict values in the input, computes the residuals, stores the data as integers, and uses a fast entropy encoder to achieve not only high compression ratios but also fast compression and decompression. Zstandard [6] (ZSTD) is a parallel CPU compressor that is based on LZ77 [22], ANS [10], and Huf fman [18] coding. Unlike many of the other tested compressors, ZSTD is a general-purpose compressors and does not specifically target floating-point data. FPCompress [3] is a CPU/GPU parallel lossless floating- point compressor that targets smooth scientific data. It of fers two versions for both single- and double-precision floating- point data, one that targets compression speed and one that targets compression ratio. Both speed versions use delta en- coding, transformation from two’ s complement to magnitude sign, and leading bit elimination. The single-precision ratio version uses the same delta encoding and two’ s complement transformation stage but follows it with a bit shuffling step and repeated zero-byte elimination as the final step. The double- precision ratio version is similar , but a finite context method (FCM) predictor is added before the common compression pipeline. The FCM stage internally increases the data size by a factor of 2, but similar to our splitting of the bins and the subbins (see belo w), this increase in data size is to enable greater compression do wn the line. For the purpose of this work, we compare to the GPU versions of both the speed and ratio algorithms from FPCompress. B. Non-topology Preserving Lossy Compr essors SZ3 [26], [28], [41] is similar to its predecessor SZ2 [27] but generally produces better compression ratios with about the same throughput. It uses Lorenzo prediction [19] and dynamic spline interpolation. It also adopts entropy coding plus lossless compression after the lossy stage (e.g., Huffman [18] followed by GZIP [8] or ZSTD [7]). SZ3 is a CPU-only compressor and guarantees that the user-requested error bound will not be violated. W e both directly and indirectly compare to SZ3, as it is the base compressor used in T opoA (described below). Similar to the SZ compressors, we also use quantization as a lossy step, and our lossless stages also rearrange the data b ut utilizing different transformations. While both LOPC and the SZ compressors are lossy , the SZ compressors do not maintain the topological information from the original file. PFPL [13] is a high-throughput CPU and GPU compatible lossy compressor . It first quantizes the input and con verts the bin values to magnitude-sign representation, but stores outliers inline rather than separately for performance reasons. It then, like LOPC, splits the input into 16kB chunks to allow for fast parallel compression. Each chunk is compressed using a pipeline of lossless data transformations. First, the data is delta encoded [20] and conv erted to negabinary . Second, the data is bit shuffled, similar to how it is done in ZFP . Last, the data is compressed using repeated zero-byte elimination. Like SZ3 and LOPC, PFPL guarantees that the user-requested error bound will not be violated. C. T opology Pr eserving Lossy Compr essors Sev eral topology preserving lossy compressors for scalar field data exist. The oldest such compressor is T opoQZ [34]. It takes a single persistence parameter and focuses on pre- serving critical point pairs with a high persistence [36]. The decompressed data contains all pairs of critical points with a persistence abov e the threshold but no other critical points. Moreov er , the locations of the preserved critical points may shift. Unlike T opoQZ, LOPC preserves all critical points as well as their locations. Howe ver , T opoQZ preserves persis- tence relationships, which LOPC does not. T opoSZ [40] modifies SZ 1.4 [9] to preserve the con- tour tree [5] of the original data after persistence simpli- fication [36]. It losslessly stores each critical point in the contour tree. For each other point, it computes upper and lower bounds based on the contour tree. It then iterativ ely tightens these upper and lower bounds until the contour tree of the decompressed data matches the ground truth. LOPC focuses on preserving all critical points, not just those stored in the contour tree. Ho wev er , it does not ensure that the internal connections of the contour tree are preserved. T opoA [17] is a framew ork designed to augment existing lossy compressors. It achie ves the same goal as T opoSZ and uses a similar approach but employs a progressive strategy to tighten the upper and lo wer bounds. This bypasses iterativ ely recomputing the contour tree and boosts performance. It also introduces a more efficient quantization scheme to achieve improv ed compression ratios. W e compare to the T opoA- augmented version of SZ3 because it is the best compressing of the augmented guaranteed-error lossy compressors. I V . L O P C A L G O R I T H M A N D I M P L E M E N T A T I O N LOPC incorporates a modular approach to preserve the critical points and local ordering. A. Quantization The first step in LOPC is the lossy quantization. This is where the error bounding of the data occurs. LOPC supports both the point-wise absolute (ABS) error bound and the point- wise normalized absolute error bound (NO A). This means that, for an ABS error bound of ε , each value x must satisfy | x orig inal − x reconstr ucted | ≤ ε . The normalized absolute error bound is the ABS error normalized by the v alue range R = x max − x min , that is, the range between the largest and the smallest value in the input. It is commonly found in other topology preserving codes. The quantizer uses the supplied error bound ε to map each floating-point value to a bin. This is accomplished by multiplying the value by 1 /ε and rounding the result to the nearest integer , which yields the bin number . Normal ABS quantization uses bins that are twice as large and decodes to the center of the bin, which is ne ver more than ± ε from the original value. W e must halve the bin size to accommodate the later intra-bin adjustments of the reconstructed values (see below) to maintain the local ordering of the input. In addition to the ABS quantization bins, LOPC also utilizes a set of “subbins” to adjust the values up or down in their bin range without violating the error bound. For example, with an ABS error bound of 0.1, the quantizer maps all values between 0.95 and 1.05 to bin number 10. W ithout subbins, all of those values would be reconstructed to 1.0. W ith the subbins, they are strategically reconstructed to some value between 0.95 and 1.05, all of which lie within the prescribed error bound, such that the critical-point locations and types of the input are retained as explained next. B. Pr eserving Critical P oints and Local Order Rather than explicitly preserving critical points, LOPC iter- ativ ely corrects all values that violate the less-than relationship (i.e., local order) with their neighbors that hav e the same bin number . It suffices to fix only values that map to the same bin because the local ordering of values mapped to different bins is automatically preserved, as the quantization function is monotonic incr easing . Notably , preserving local order is a stronger condition than preserving critical points; it guarantees not only the existence but also the exact types of critical points. This is accomplished using an iterati ve approach. Algorithm 1 sho ws the ov erall operation of LOPC, and Algorithm 2 outlines the operations of a single iteration of the local-order preservation step. Algorithm 1 Main LOPC Operation 1: for each point p do ▷ parallel loop 2: p bin ← ABS or NOA quantized input of p v al ; 3: p subbin ← 0; 4: p f lag s ← 0; 5: for each point p do ▷ parallel loop 6: for each neighbor n of p do 7: p f lag s ← p f lag s ∪ ( n bin = p bin ); 8: p f lag s ← p f lag s ∪ ( n < p ); ▷ with tie breaker 9: worklist1 ← all input points; 10: while worklist1 is not empty do 11: worklist2 ← empty; 12: Algorithm 2; 13: swap(worklist1, worklist2); Algorithm 2 Parallel Subbin Computation (one iteration) 1: for each point p in worklist1 do ▷ parallel loop 2: n max ← 0; 3: for each same-bin neighbor n of p do ▷ using p f lag s 4: if n should be less than p then ▷ using p f lag s 5: tie ← ( n idx > p idx ); ▷ tie breaker: 0 or 1 6: val ← atomicRead( n subbin ); 7: n max ← max(n max, v al + tie); 8: if atomicMax( p subbin , n max) < n max then 9: worklist2 ← worklist2 ∪ { p ’ s greater same-bin neighbors } ; At the outset, the subbins are zero and the original data has been binned. Then, LOPC computes a set of flags for each point p in the input. For each neighbor of p , the flags record whether the neighbor has the same bin number . If so, the flags further record whether the neighbor’ s v alue is less than p ’ s value. A deterministic tiebreaker is used to guarantee that a point is always greater or less than any neighboring point, nev er equal. The flags represent the ground truth that the final v alues must match in terms of local order . Next, the iterativ e process starts. In each iteration, every point p checks its same-bin neighbors n that should be less than p , which are identified quickly by checking the flags. If they all meet the condition, nothing is done. Otherwise, p ’ s subbin value is set to the highest such neighbor’ s subbin value (or that value plus 1 if the tie breaker is in fav or of the neighbor) to establish the correct less-than relationship. Note that subbin values are never decreased. This process repeats until no more changes are made, in which case it terminates. In the end, the subbin values are as lo w as possible while guaranteeing the same less-than relationships in the recon- structed data as in the original data. T ypically , most subbins end up with small integer values near zero, which is important for compressibility . C. Compr ession The abov e computation con verts each input value into two values, a bin number and a subbin number, effecti vely doubling the original data size. The result is two arrays holding very different information. First is the quantized bin numbers, which contain the information required to reconstruct the original data values within the requested error bound. Second is the subbin numbers, which contain the information required to recreate the original local ordering. The information density of these two arrays varies greatly depending on the chosen error bound. For example, if the error bound is small, neighboring values tend to be mapped to distinct bins. Hence, the first array contains most of the information of the original data whereas the second array contains mostly zeros as the subbins are not needed. Howe ver , if the error bound is large, neighboring values tend to be mapped to the same bin number . In this case, the first array contains little information whereas the second array contains most of the local ordering of the data. T o boost the compression ratio, we use distinct compression algorithms for the bins and the subbins that are customized to compress the two types of data well. LOPC uses SLEEK’ s quantizer [1] to compute the bin numbers, which allows for guaranteed binning within the error bound without special handling of outliers. T o losslessly compress the resulting bin numbers, LOPC employs the lossless portion of PFPL ’ s com- pression algorithm [13], [14]. SLEEK and PFPL are effecti ve, fast, and support both CPU and GPU ex ecution. T o create good CPU- and GPU-parallel lossless compressors and decompressors for the subbin data, we used the LC framew ork [2]. For 32-bit subbins (single-precision data), it generated the 3-stage algorithm BIT 4 RZE 4 RZE 1. For 64-bit subbins (double-precision data), it generated the 3-stage algorithm BIT 8 RZE 8 RZE 1. In both cases, the first two stages match the word size and the final stage operates at byte granularity . The BIT stages, whose operation is outlined in Figure 1, perform a bit transposition (or bit shuffle). They group the first bit of every value together , then all the second bits, and so on. The RZE (Repeated Zero Elimination) stages, illustrated in Figure 2, generate a bitmap in which each bit corresponds to a word in the input and indicates whether the word is zero. All zero words are then removed. The compressed output consists of the non-zero words from the input and the bitmap, which itself is repeatedly compressed with a similar algorithm that identifies repeating words rather than zero words. More detail on these stages can be found elsewhere [3]. D. P arallelization and Optimization LOPC uses already parallel CPU and GPU code from PFPL and SLEEK for computing, compressing, and decompressing the bin information. Moreov er , it uses LC-generated CPU- and GPU-parallel lossless compressors and decompressors for the subbin data. The subbin decoder is embarrassingly parallel as ev ery bin/subbin pair can be independently processed to reconstruct the floating-point value. The parallelization of the subbin encoder is more inv olved. The flag computation (see Sec- tion IV -B) and the subbin initialization are embarrassingly parallel. The iterati ve phase that raises the subbin values is parallelized as follows. Each iteration runs in a separate barrier interval and increases subbins using an atomicMax operation, making the implementation lock-free. On the GPU, we assign each point to a separate thread. On the CPU, we use a blocked assignment of points to threads. Since most points require little, if any , adjustment, many subbins reach their final value in the first few iterations. For this reason, processing every point in later iterations is often inefficient. As a remedy , LOPC employs a worklist on which it stores only the greater neighbors of a point whose subbin has just been raised so that only those points will be processed in the next iteration. Moreover , we employ two worklists, one that is read and another that is written. At the end of each iteration, we zero out the size of the old worklist and swap the pointers to the two worklists and their sizes. When filling the worklist, we use an atomicAdd to both increment the worklist size and obtain a unique slot for writing the ne w element. T o av oid duplicates on the worklist, for each point, we record and atomically update the most recent iteration in which it was placed on the worklist. E. Corr ectness and T ermination This subsection explains ho w the LOPC algorithm preserves local ordering, including all critical points, while guaranteeing termination and error boundedness. Since our quantization is an increasing function, the local order is always correct between neighbors that are quantized to distinct bin numbers. Hence, in the rest of the explanation, we only consider same- bin neighbors. Initially , all subbin numbers are zero. In each iteration, the algorithm examines, for ev ery point, all neighbors that belong to the same bin and whose value should be lower . If a point fails the less-than relationship with any of these neighbors, 0 0 0 0 000000011111000101111001 1 1 1 0 0 0 0 0 000000000001100000010100 0 0 1 0 0 0 0 0 000000000000000010111000 1 1 1 0 000 000 000 000 00000000000000000000 01001001001001100000000001100011 00101111101010000100 101 101 111 000 Bit Shuffling Fig. 1. Example of bit-shuffling lossless stage; for larger inputs, the sequences of bits with the same color are longer 00000000000000000000000000000000 01001001001001100000000001100011 00101111101010000100101101111000 00000000 00000000 00000000 01100011 00000000 00101111 01001001 00100110 00000000 10101000 01111000 01001011 1 2 3 4 5 6 7 8 9 10 1 1 12 0 0 0 0 1 1 0 1 1 1 1 1 1 2 3 4 5 6 7 8 9 10 1 1 12 01100011 00101111 01001001 00100110 10101000 01111000 01001011 5 6 8 9 10 1 1 12 Convert to Bytes Output Nonzero Bytes Add Bitmap Fig. 2. Example of zero-byte elimination lossless stage; further compression of the bitmap is not shown the subbin number of that point is raised according to one of two rules. (1) The subbin number is raised to match that of the highest violating neighbor if that neighbor’ s index is lower . (2) The subbin number is raised one higher than that of the highest violating neighbor if that neighbor’ s index is higher . These two rules ensure that the local ordering among neighboring points gradually becomes consistent (even in the presence of ties) with the local order of the original data. The algorithm terminates when no violation remains, i.e., all local relationships are satisfied, thereby fully preserving the local order . Since preserving local order implies preserving lo- cal maxima, minima, and saddle points, this in turn guarantees that all critical points and their types are preserved as well. LOPC is guaranteed to terminate because the update process is non-decreasing and bounded. In each iteration, if a violation occurs, at least one subbin number increases. This mono- tonicity ensures continuous progress and prev ents oscillations (i.e., livelock). Moreov er , the highest number a subbin can reach is finite. T o see why , it helps to consider the connected component (CC) of same-bin values to which a point belongs. (1) Each such CC must contain at least one local minimum (due to the tie breaker), and the subbin number of a local minimum is never raised because it has no lo wer same-bin neighbors. (2) No point ever raises its subbin number to more than one higher than its highest same-bin neighbor . (3) The targeted less-than relationships are necessarily acyclic since they stem from the original input data. T ogether , these properties limit the possible range of subbin numbers in a CC with n points to between 0 and n − 1 . Hence, after a finite number of updates, all violations disappear and the process terminates. In the worst case, when all n points form an increasing chain, the algorithm con verges after O ( n 2 ) iterations since we can create the values 0 through n − 1 with n × ( n − 1) / 2 = O ( n 2 ) individual increments. The only remaining concern is whether the subbin range provides enough resolution to represent all necessary or- dering distinctions while remaining within the quantization bin, thereby guaranteeing error boundedness. This is also guaranteed because the maximum number of subbin levels required to preserve local order within any CC is directly tied to the number of distinct floating-point values present in this CC in the original data. Note that decompression maps each value within its quantization bin such that subbin 0 decodes to the lowest representable value within the bin, subbin 1 to the next lowest, and so on. Thus, the algorithm guarantees the local order without running out of subbin range and without violating the user-pro vided error bound. V . E X P E R I M E N TA L M E T H O D O L O G Y W e compare LOPC to the compressors described in Sec- tion III on the two systems listed in T able I. W e ran the GPU codes on System 1 and the CPU codes on System 2. W e compiled the CPU codes using the build processes supplied by their respectiv e authors. When not specified, we used the “-O3 -march=nati ve” flags. Unless automatically determined, the thread count was set to the number of CPU cores as hyperthreading usually does not help. W e compiled the GPU codes using “-O3 -arch=sm 89” for the R TX 4090. For all compressors, we measured the execution time of the compression and decompression functions, excluding reading the input file, verifying the results, and transferring data to and from the device. W e ran each experiment 9 times and collected the compression ratio, median compression throughput, and median decompression throughput as well as the critical- point false positives, false negati ves, and false types. For all compressors, we used NOA error bounds of 1E-2 and 1E- 4. For T opoA augmented SZ3, we ran two experiments, one where the persistence threshold ϵ is 1 . 5 × and another where it is 0 . 5 × the NOA error bound. These settings reflect a normal lev el of persistence and an over -preserving lev el, respectiv ely . If a compressor runs for more than an hour (wall-clock time), we report ‘TO’ (timeout). If a compressor crashes, fails, or runs out of memory , we report ‘DNF’ (did not finish). T ABLE I S Y ST E M S U S E D F O R E X P ER I M E NT S System 1 System 2 CPU Threadripper 2950X Threadripper 3970X Base Clock 3.5 GHz 3.7 GHz Sockets 1 1 Cores Per Socket 16 32 Threads Per Core 2 2 Main memory 64 GB 256 GB GPU R TX 4090 N/A Compute Capability 8.9 N/A Base Clock 2.2 GHz N/A Boost Clock 2.5 GHz N/A SMs 128 N/A CUD A Cores per SM 128 N/A Main memory 24 GB HBM2e N/A Operating System Fedora 37 Ubuntu 24.04.1 L TS g++ V ersion 12.2.1 13.3.0 nvcc V ersion 12.0 N/A GPU Driver 525.85 N/A T ABLE II I N FO R M A T I O N A B O UT T H E U S E D I N P UT S Name Description Format Dimensions Size (MB) Isabel W eather Sim. Single 90 × 500 × 500 90 T angaroa W eather Sim. Single 300 × 180 × 120 26 Earthquake T eraShake 2 Sim. Double 375 × 188 × 50 28 Ionization Ionization Sim. Double 310 × 128 × 128 41 Miranda Hydrodynamics Double 384 × 384 × 256 302 S3D W eather Sim. Double 500 × 500 × 500 1000 SCALE-LETKF LETKF Double 1200 × 1200 × 98 1129 QMCP A CK Quantum MC Double 69 × 69 × 115 4 W e used the 2 single- and 6 double-precision inputs listed in T able II as inputs for the compressors. The Earthquake dataset is from the T eraShake 2 earthquake simulation [30], [31]. The Ionization dataset is timestep 125 from cluster 2 of an ionization front simulation [38]. The T angaroa dataset is the wind velocity field from a simulation of the T angaroa research vessel [32]. The remaining inputs are sourced from the SDR- Bench repository [33], [42], which hosts real-world scientific datasets from various domains for compression e valuation. The table lists the input name, a short description, the data type, input dimensions, and file size. W e chose these inputs because they are commonly used as benchmarks in topology w ork [17], [40] and represent the kind of scientific data that may hav e important topological information to preserve. V I . R E S U L T S In this section, we ev aluate the performance of the com- pressors discussed in Section III on the inputs described in Section V. W e first discuss the preservation of critical points and local ordering for the tested compressors. Next, we compare the compression ratios achiev ed by each compressor using NO A error bounds. Then, we analyze the compression and decompression speed. Next, we study the effect of error bounding on the compression quality and speed. Finally , we ev aluate the reconstruction quality yielded by the tested compressors. A. Critical-P oint and Local-Order Preservation T able III shows the quality at which the critical points are preserved. The key strength of LOPC is immediately obvious: it preserves all critical points and local ordering whereas none of the other compressors do, not ev en the topology-preserving compressors. While T opoA and T opoSZ preserve the critical points on the contour tree, and T opoQZ preserves the critical point pairs, our results show the generally high number of false positiv es, false negati ves, and false types that the other topology-preserving compressors introduce. Comparing the other topology-preserving compressors to the non-topology-preserving lossy compressors makes it clear that a large portion of the critical points are missed when only preserving the contour tree or critical point pairs. LOPC av oids introducing any false positiv es, false negati ves, or false types by preserving the full local ordering. The results in the table further demonstrate that it is not straightforward for other topology-preserving compressors to preserve more critical points by lo wering the persistence threshold. In many cases, doing so actually introduces more erroneous critical points in a giv en category . Additionally , lowering the persistence threshold introduces significant addi- tional runtime, leading to timeouts. LOPC av oids these issues without the need for a tunable parameter . B. Compr ession Ratios The compression ratios of the ev aluated compressors across the two tested error bounds are shown in the first section of T ables IV, V, VI, and VII. Due to its CPU/GPU parity guarantee, LOPC maintains the same compression ratio across both devices. Compared to the other compressors that maintain local order information, namely the lossless compressors (FPZip, ZSTD, and FPCompress), LOPC compresses more in all but one case. On the Ionization input with an error bound of 1E-4, LOPC’ s compression ratio is a little lo wer than that of ZSTD. In all other cases, its compression ratio is higher, on average by a factor of 3.7 and, in one case, by over a factor of 8.7. In general, LOPC yields lower compression ratios than the other topology preserving compressors and significantly lower compression ratios than the lossy non-topology preserving compressors. This is expected for the following three reasons. First, because LOPC preserves all local ordering, it often preserves many relationships that the other topology preserv- ing compressors do not (see Section VI-A). Of course, it preserves e ven more relationships than the lossy non-topology- preserving compressors. This large amount of extra informa- tion is the main reason for the lower compression ratio. Second, by storing bins and subbins separately , the infor- mation density of each part of the compressed file changes with the user-requested error bound. For example, if the user requests a strict error bound, most of the topological information ends up in the quantization bins, making them T ABLE III C O UN T O F FA L SE P O SI T I V ES , FA LS E N EG ATI V E S , A N D FA L S E T Y PE S ( ‘M ’ = MI L L I ON , ‘ K ’ = T H OU S A N D ) . T opoA SZ3 LOPC ϵ = 1.5x EB ϵ = 0.5x EB T opoSZ T opoQZ SZ3 PFPL EB = 1E-2 Isabel 0/0/0 686K/16K/2K 734K/13K/3K 2M/16K/3K 461K/20K/639 28K/22K/493 430K/22K/314 T angaroa 0/0/0 380K/2K/565 514K/2K/500 DNF 57K/4K/236 15K/5K/711 35K/7K/421 Earthquake 0/0/0 218K/95K/8K 180K/83K/8K 448K/95K/11K 22K/100K/1K 25K/110K/2K 10K/112K/398 Ionization 0/0/0 95K/12K/1K 110K/10K/1K DNF 13K/15K/753 23K/18K/2K 16K/20K/1K Miranda 0/0/0 1M/12M/214K T O 644K/13M/255 566/13M/3 81K/13M/9K 2K/13M/2 S3D 0/0/0 7M/23K/5K TO 133K/50K/218 2M/26K/2K 83K/40K/4K 2M/46K/2K SCALE 0/0/0 4M/216K/36K TO 8/315K/0 456K/258K/5K 268K/303K/6K 2M/310K/2K QMCP A CK 0/0/0 22K/168/34 15K/163/33 85K/313/78 11K/167/36 2K/575/16 6K/584/5 EB = 1E-4 Isabel 0/0/0 3K/2K/162 3K/1K/132 TO 5K/4K/103 8K/5K/557 14K/8K/305 T angaroa 0/0/0 12K/135/9 14K/128/8 70K/203/22 8K/292/15 7K/356/30 17K/540/41 Earthquake 0/0/0 183K/36K/9K TO 199K/43K/11K 50K/41K/4K 196K/52K/13K 78K/60K/6K Ionization 0/0/0 87K/4K/1K 118K/4K/1K 458K/4K/1K 10K/7K/814 53K/6K/1K 10K/8K/864 Miranda 0/0/0 624K/13M/74K T O 1M/12M/779K 7/13M/0 215K/13M/22K 25/13M/0 S3D 0/0/0 27K/2K/204 T O TO 53K/5K/295 7K/5K/409 252K/10K/715 SCALE 0/0/0 0/0/0 TO TO 84K/129K/957 219K/155K/9K 210K/187K/3K QMCP A CK 0/0/0 122/84/16 120/84/16 268/138/25 316/119/34 135/159/25 1K/341/35 T ABLE IV C O MPA R IS O N WI T H TO P O LO G Y - P R E SE RV I NG C O MP R E S SO R S F O R T HE 1 E -2 N OA E RR OR B O U ND LOPC T opoA SZ3 Ser OMP CUDA ϵ = 1.5x EB ϵ = 0.5x EB T opoSZ T opoQZ Compression Ratio Isabel 5.47 5.47 5.47 64.40 28.43 27.50 4.67 T angaroa 4.39 4.39 4.39 28.36 20.91 DNF 3.33 Earthquake 8.79 8.79 8.79 85.44 25.09 65.85 7.08 Ionization 10.19 10.19 10.19 93.45 62.69 DNF 5.78 Miranda 10.05 10.05 10.05 239.09 TO 92.01 9.14 S3D 9.48 9.48 9.48 35.90 TO 11,336.58 5.82 SCALE 10.74 10.74 10.74 37.16 TO 401,765.12 5.82 QMCP ACK 9.07 9.07 9.07 102.04 82.48 12.01 9.08 Geomean 8.18 8.18 8.18 68.32 37.80 457.04 6.04 Compression Throughput (MB/s) Isabel 9 17 750 1 1 0 14 T angaroa 1 1 104 1 1 DNF 14 Earthquake 7 13 940 2 1 1 21 Ionization 3 4 313 1 1 DNF 11 Miranda 5 8 414 0 TO 1 8 S3D TO 9 408 2 TO 2 24 SCALE TO TO 34 1 TO 2 34 QMCP ACK 12 16 730 1 0 0 13 Geomean 5 8 314 1 1 0 16 Decompression Throughput (MB/s) Isabel 310 2,601 28,754 13 13 281 4 T angaroa 316 2,592 19,059 11 11 DNF 4 Earthquake 441 1,896 28,200 15 14 564 8 Ionization 339 3,628 33,305 13 13 DNF 9 Miranda 422 4,314 30,199 10 TO 702 8 S3D TO 3,448 123,457 14 TO 446 5 SCALE TO TO 112,896 14 TO 649 5 QMCP ACK 429 4,380 10,950 13 13 438 9 Geomean 372 3,142 35,229 13 13 492 6 more challenging to compress easily , while the subbins contain almost no information. The rev erse is true for a loose error bound because the topological information must now be stored in the subbins. This makes it difficult for a single compression algorithm to be effecti ve in all cases due to the greatly changing information density . W e discuss this relationship more in Section VI-D. Third, LOPC is designed to work on both CPUs and GPUs. As a consequence, its compression algorithm cannot exploit some of the effecti ve serial transformations that the CPU-only compressors include. C. Compr ession and Decompr ession Speed The speeds at which the ev aluated compressors compress and decompress our inputs are listed in the middle and last section of T ables IV, V, VI, and VII, respectiv ely . The speed of the topology-preserving compressors is very input dependent. T ABLE V C O MPA R IS O N WI T H TO P O LO G Y - P R E SE RV I NG C O MP R E S SO R S F O R T HE 1 E -4 N OA E RR OR B O U ND LOPC T opoA SZ3 Ser OMP CUD A ϵ = 1.5x EB ϵ = 0.5x EB T opoSZ T opoQZ Compression Ratio Isabel 4.60 4.60 4.60 11.92 11.51 TO 2.65 T angaroa 4.13 4.13 4.13 15.49 15.33 10.52 2.35 Earthquake 7.73 7.73 7.73 14.51 TO 6.82 4.85 Ionization 8.36 8.36 8.36 33.31 30.78 13.78 4.46 Miranda 8.81 8.81 8.81 47.85 TO 24.63 4.56 S3D 9.11 9.11 9.11 51.49 TO TO 4.56 SCALE 9.53 9.53 9.53 2.53 TO TO 3.98 QMCP ACK 8.23 8.23 8.23 39.60 39.59 11.07 4.66 Geomean 7.26 7.26 7.26 19.63 21.53 12.19 3.89 Compression Throughput (MB/s) Isabel 79 8,182 8,411 1 1 TO 12 T angaroa 46 199 2,592 1 1 0 13 Earthquake 83 470 7,050 2 TO 0 21 Ionization 48 102 4,063 2 1 0 11 Miranda 7 13 643 1 TO 1 8 S3D 8 568 21,044 3 TO TO 22 SCALE TO 3 179 1 TO TO 31 QMCP ACK 146 438 4,380 2 2 1 13 Geomean 38 173 3,003 1 1 0 15 Decompression Throughput (MB/s) Isabel 307 2,894 31,142 13 13 TO 2 T angaroa 324 2,057 27,284 11 11 259 4 Earthquake 470 1,986 21,793 15 TO 403 6 Ionization 406 4,515 29,921 12 12 508 8 Miranda 425 3,355 33,780 10 TO 559 7 S3D 383 3,448 50,618 15 TO TO 4 SCALE TO 3,421 112,896 8 TO TO 3 QMCP ACK 438 4,380 10,950 13 12 438 8 Geomean 389 3,132 32,253 12 12 419 5 For example, even for LOPC, the serial and OpenMP versions time out on the SCALE input. Additionally , for the other topology-preserving compressors, the persistence threshold ϵ has a large impact on the runtime. T opoA augmented SZ3 with a persistence threshold less than the error bound times out on 3 of the 8 inputs for the 1E-2 error bound and on 4 of the 8 inputs for the 1E-4 error bound. These results highlight the need for fast (parallelized) topology preserving compressors like LOPC. W e further discuss the effect that error bound and persistence threshold hav e on performance in Section VI-D. On the SCALE input at an error bound of 1E-4, only LOPC and T opoA with a large persistence threshold are able to finish within an hour . In this case, howe ver , T opoA takes 22 minutes whereas LOPC only takes 6.3 seconds on the GPU, making it 209.9 times faster than T opoA. Further , T opoA is only able to T ABLE VI C O MPA R IS O N WI T H NO N - TO P O L OG Y - P RE S E RVI N G CO M P R ES S O R S F O R T H E 1 E - 2 N OA E R RO R B O U ND LOPC FPCompress Ser OMP CUDA SZ3 PFPL FPZip ZSTD Speed Ratio Compression Ratio Isabel 5.47 5.47 5.47 1,258.13 33.56 2.42 1.16 1.52 1.73 T angaroa 4.39 4.39 4.39 285.80 34.55 3.85 1.43 1.76 2.12 Earthquake 8.79 8.79 8.79 1,336.56 102.00 1.31 1.18 1.19 1.19 Ionization 10.19 10.19 10.19 422.57 66.92 2.26 9.50 1.47 2.89 Miranda 10.05 10.05 10.05 1,350.33 94.05 2.06 2.07 1.84 1.88 S3D 9.48 9.48 9.48 3,097.37 63.69 1.68 1.09 1.33 1.33 SCALE 10.74 10.74 10.74 1,334.26 120.57 1.48 2.76 1.35 1.36 QMCP ACK 9.07 9.07 9.07 853.99 57.97 1.53 1.61 1.33 1.43 Geomean 8.18 8.18 8.18 995.92 65.32 1.96 1.92 1.46 1.67 Compression Throughput (MB/s) Isabel 9 17 750 268 229,479 96 4 234,375 194,805 T angaroa 1 1 104 240 207,480 130 3 75,349 63,066 Earthquake 7 13 940 424 166,903 130 5 76,011 11,515 Ionization 3 4 313 469 171,798 183 1 103,390 12,209 Miranda 5 8 414 460 223,927 169 2 434,518 9,798 S3D TO 9 408 456 241,723 164 2 469,043 9,859 SCALE TO TO 34 488 241,089 139 1 473,557 13,157 QMCP ACK 12 16 730 327 52,124 137 6 12,959 5,566 Geomean 5 8 314 379 176,190 141 3 142,869 18,234 Decompression Throughput (MB/s) Isabel 310 2,601 28,754 644 314,809 60 526 201,794 143,770 T angaroa 316 2,592 19,059 607 278,159 68 298 72,000 62,760 Earthquake 441 1,896 28,200 992 340,120 63 513 85,455 126,457 Ionization 339 3,628 33,305 1,034 351,053 81 726 117,775 32,821 Miranda 422 4,314 30,199 979 429,901 72 651 378,433 184,703 S3D TO 3,448 123,457 979 392,667 68 792 458,505 210,084 SCALE TO TO 112,896 1,009 430,160 66 495 464,975 211,455 QMCP ACK 429 4,380 10,950 693 164,518 17 17 14,504 54,752 Geomean 372 3,142 35,229 849 325,142 57 354 142,613 106,719 T ABLE VII C O MPA R IS O N WI T H NO N - TO P O L OG Y - P RE S E RVI N G CO M P R ES S O R S F O R T H E 1 E - 4 N OA E R RO R B O U ND LOPC FPCompress Ser OMP CUD A SZ3 PFPL FPZip ZSTD Speed Ratio Compression Ratio Isabel 4.60 4.60 4.60 23.06 6.90 2.42 1.16 1.52 1.73 T angaroa 4.13 4.13 4.13 24.49 7.32 3.85 1.43 1.76 2.12 Earthquake 7.73 7.73 7.73 33.99 13.97 1.31 1.18 1.19 1.19 Ionization 8.36 8.36 8.36 54.59 16.29 2.26 9.50 1.47 2.89 Miranda 8.81 8.81 8.81 81.92 30.34 2.06 2.07 1.84 1.88 S3D 9.11 9.11 9.11 127.02 13.91 1.68 1.09 1.33 1.33 SCALE 9.53 9.53 9.53 30.03 20.93 1.48 2.76 1.35 1.36 QMCP ACK 8.23 8.23 8.23 80.89 12.58 1.53 1.61 1.33 1.43 Geomean 7.26 7.26 7.26 47.63 13.75 1.96 1.92 1.46 1.67 Compression Throughput (MB/s) Isabel 79 8,182 8,411 195 225,361 96 4 234,375 194,805 T angaroa 46 199 2,592 206 205,793 130 3 75,349 63,066 Earthquake 83 470 7,050 329 162,953 130 5 76,011 11,515 Ionization 48 102 4,063 384 170,300 183 1 103,390 12,209 Miranda 7 13 643 434 223,080 169 2 434,518 9,798 S3D 8 568 21,044 407 229,240 164 2 469,043 9,859 SCALE TO 3 179 376 244,565 139 1 473,557 13,157 QMCP ACK 146 438 4,380 251 49,738 137 6 12,959 5,566 Geomean 38 173 3,003 310 172,953 141 3 142,869 18,234 Decompression Throughput (MB/s) Isabel 307 2,894 31,142 416 304,679 60 526 201,794 143,770 T angaroa 324 2,057 27,284 446 275,136 68 298 72,000 62,760 Earthquake 470 1,986 21,793 652 335,459 63 513 85,455 126,457 Ionization 406 4,515 29,921 772 348,070 81 726 117,775 32,821 Miranda 425 3,355 33,780 835 426,173 72 651 378,433 184,703 S3D 383 3,448 50,618 864 384,781 68 792 458,505 210,084 SCALE TO 3,421 112,896 608 402,804 66 495 464,975 211,455 QMCP ACK 438 4,380 10,950 602 164,518 17 17 14,504 54,752 Geomean 389 3,132 32,253 630 318,677 57 354 142,613 106,719 compress this input using the aforementioned large persistence threshold, which causes fe wer critical points to be preserved on the contour tree, while LOPC is able to preserve all critical points. Serially , LOPC performs better than the other topology preserving compressors as well. This is likely due to the other compressors building a new contour tree in each iteration, a step that LOPC is able to forgo due to its entirely different approach for preserving the topology . Naturally , LOPC is slower than the non-topology-preserving compressors, though its CUDA version is on par with some of the serial compressors. Compared to other GPU-based compressors like PFPL and FPCompress that do not need to preserve topology , LOPC can be slower by ov er a factor of 100 (e.g., on the S3D input). This is expected because LOPC performs most of its topology preservation work during compression and explains why its decompression performance is much closer to the non-topology-preserving compressors. D. Effects of Error Bound on LOPC Compr ession The user -requested error bound af fects all tested lossy compressors in terms of both compression ratio and compres- sion/decompression speed. In this section, we discuss how each compressor behav es when the error bound is changed. Lossy compressors that do not preserve topology tend to produce significantly lo wer compression ratios for smaller error bounds but only incur minor slowdo wns [13]. For these compressors, the computation is not directly affected by the error bound, and the slowdo wn stems from the increased amount of data that needs to be written due to the lower compressibility with tighter error bounds. For the topology-preserving compressors, the compression speed is largely determined by how much correction needs to be performed. Figure 3 illustrates this for LOPC on 7 error bounds. For the loosest tested error bound, where almost all information is lost, LOPC must perform a large amount of correction and, thus, has the highest runtime. In contrast, the tightest tested error bound yields the lowest runtime because LOPC is “correcting” data that already has many of the local- order relationships intact. Similar runtime behavior is observed in T ables IV and V for the compressors that preserve the contour tree within a persistence threshold. These compressors hav e an additional parameter for the persistence threshold, which also affects how much correction must be performed. In particular, more correction must be done and, therefore, more time is taken when the persistence threshold is smaller than the error bound. Figure 3 includes LOPC’ s compression ratio. The rela- tionship between the error bound and the compression ratio is not as straightforward as the runtime relationship. The geometric-mean compression ratio is 9 . 3 at an error bound of 1, increases to a maximum of 10 . 8 at an error bound of 1E-3, and then decreases to 5 . 6 at the lowest error bound of 1E-6. This behavior is due to the dual-compression design of LOPC. Since LOPC processes the bins and subbins separately , there is an optimal error bound where the information is most ev enly split between the bin and subbin values. T opoA beha ves 1E-0 1E-1 1E-2 1E-3 1E-4 1E-5 1E-6 0 2 4 6 8 10 12 9 . 34 9 . 58 10 . 4 10 . 77 8 . 78 7 . 01 5 . 58 Compression Ratio 0 0 . 2 0 . 4 Runtime (s) Compression ratio Runtime Fig. 3. Geometric-mean compression ratio and compression runtime of LOPC on 7 NOA error bounds. similarly , where the best compressing base compressor does not always yield the highest final compression ratio [17]. 1E-0 1E-1 1E-2 1E-3 1E-4 1E-5 1E-6 0 20 40 60 80 100 99 93 78 54 29 18 11 1 7 22 46 71 82 89 % of Compressed File Bins Subbins Fig. 4. A verage portion of the compressed file that is bin data and subbin data for LOPC on 7 NOA error bounds. Figure 4 sho ws the av erage fraction of the compressed file taken up by the compressed bin data and the compressed subbin data across the 7 tested error bounds. These results help explain the compression ratio results from Figure 3. As discussed, at the loosest error bound of 1, the main data (i.e., the bin information) is almost entirely lost. Hence, the bin data is extremely compressible as it contains almost no information. In contrast, the subbins contain the corrections for the main data to maintain local order . For this reason, the subbins are much less compressible and make up 99% of the compressed file. Howe ver , the overall compression ratio is still high because the subbins only contain small numbers that are relativ ely easy to compress. As the error bound decreases, the bin data starts to take up a larger portion of the compressed file. The highest observed compression ratio is seen at an error bound of 1E-3, where the bins and subbins take up an approximately equal portion of the compressed file. As discussed in Section IV, we used the LC tool to generate good the compression algorithms for the bins and subbins. W e targeted this search around the commonly used 1E-3 error bound, which contributes to the compression ratio peaking for LOPC at 1E-3. The worst compression ratios are seen at the tightest error bounds, where the bins take up most of the compressed file. This is because at these error bounds, most of the information is stored in the bins. In fact, we are approaching lossless compression with these tight error bounds, meaning most of the original floating-point information is actually retained. In summary , all lossy compressors are af fected by changes in the user-pro vided parameters. The non-topology-preserving lossy compressors, which tend to be memory bound, are mainly affected in compression ratio, with only a slight slowdo wn at lower error bounds. In contrast, the compute- bound topology-preserving compressors actually run faster at tighter error bounds, ev en while producing lo wer compression ratios, due to the decreased amount of topology correction that must be performed. E. Quality of Reconstructed Data T ables VIII and IX sho w the quality of the reconstructed data yielded by each tested compressor . W e show peak signal- to-noise ratio (PSNR) and the structural similarity index mea- sure (SSIM). Both are higher-is-better quality metrics that are commonly used when ev aluating reconstructed lossy data. Overall, T opoA augmented SZ3 produces the highest- quality reconstructed data, follo wed by LOPC. This is ex- plained by the dif ferences in how T opoA fix es errors compared to LOPC. When T opoA finds a topology problem, it tightens the error bound, bringing that value closer to the original, which necessarily mov es the values closer to lossless encoding. This is in contrast to LOPC, which fixes problems with local ordering by monotonically increasing subbin values. This means that, while the local order is preserved, the individual values may be shifted further from their original v alue than traditional quantization. Even with this consideration, LOPC consistently produces higher quality reconstructions than the other topology-preserving compressors all while exceeding their speed by a large margin. V I I . S U M M A RY A N D C O N C L U S I O N S This paper describes LOPC, a local-order-preserving data compression algorithm. It is the first lossy compressor that fully preserves the local order (and, by extension, all critical points) of scalar fields. Moreov er , it strictly guarantees the user-specified point-wise error bound. W e e valuated LOPC, three state-of-the-art topology- preserving lossy compressors, and five other leading com- pressors on 2 single- and 6 double-precision inputs. LOPC is the fastest topology-preserving compressor in all cases. At the maximum, it compresses 152,000 times faster than T opoSZ. On av erage, is 345 times faster than T opoA-augmented SZ3 at an error bound of 1E-4 and a persistence threshold of 1.5E-3. This speed is important for scientific simulations and instruments that produce data at high rates, where the prior state of the art in topology-preserving lossy compression is too slow to be effecti vely utilized. LOPC guarantees not only the error bound, which many lossy compressors do not, but also that local ordering and all critical points are preserved. None of the prior topology- preserving compressors can do this without setting the persis- tence threshold to 0, which slows them down ev en more. W e hope that LOPC helps enable topology preservation in science where it was previously prohibitiv ely slow to do so. A C K N O W L E D G M E N T S This work has been supported by the U.S. Department of Energy , Office of Science, Office of Advanced Scientific Research (ASCR), under contract DE-SC0022223. R E F E R E N C E S [1] Anju Mongandampulath Akathoott, Andrew Rodriguez, and Martin Burtscher . SLEEK: Compressing Memory Copies for Floating-Point Data on GPUs. In 2026 IEEE International P arallel and Distributed Pr ocessing Symposium (IPDPS) , May 2026. [2] Noushin Azami, Alex Fallin, Brandon Burtchell, Andrew Rodriguez, Benila Jerald, Y iqian Liu, and Martin Burtscher . LC Git Repository. https://github .com/burtscher/LC- frame work, 2025. Accessed: 2025-01- 07. [3] Noushin Azami, Alex Fallin, and Martin Burtscher . Efficient Lossless Compression of Scientific Floating-Point Data on CPUs and GPUs. In Pr oceedings of the 30th A CM International Confer ence on Architectur al Support for Pr ogramming Languages and Oper ating Systems, V olume 1 , ASPLOS ’25, pages 395–409, New Y ork, NY , USA, 2025. Association for Computing Machinery . [4] Harsh Bhatia, Attila G Gyulassy , V incenzo Lordi, John E Pask, V alerio Pascucci, and Peer-T imo Bremer. T opoMS: Comprehensiv e topological exploration for molecular and condensed-matter systems. Journal of computational chemistry , 39(16):936–952, 2018. [5] Hamish Carr, Jack Snoeyink, and Ulrike Axen. Computing contour trees in all dimensions. Computational Geometry , 24(2):75–94, 2003. [6] Y ann Collet. Zstandard compression. GitHub repository , 2016. [7] Y ann Collet and Murray Kucherawy . Zstandard Compression and the ‘application/zstd’ Media T ype. RFC 8878, February 2021. [8] L. Peter Deutsch. GZIP file format specification version 4.3. RFC 1952, May 1996. [9] Sheng Di and Franck Cappello. Fast Error-Bounded Lossy HPC Data Compression with SZ. In 2016 IEEE International P arallel and Distributed Pr ocessing Symposium (IPDPS) , pages 730–739, Los Alamitos, CA, USA, may 2016. IEEE Computer Society . [10] Jarek Duda. Asymmetric numeral systems, 2009. [11] Herbert Edelsbrunner , John Harer, and Afra Zomorodian. Hierarchical Morse complexes for piecewise linear 2-manifolds. In Proceedings of the seventeenth annual symposium on Computational geometry , pages 70–79, 2001. [12] Herbert Edelsbrunner and Ernst Peter M ¨ ucke. Simulation of simplicity: a technique to cope with degenerate cases in geometric algorithms. ACM T ransactions on Graphics (tog) , 9(1):66–104, 1990. [13] Alex Fallin, Noushin Azami, Sheng Di, Franck Cappello, and Martin Burtscher . Fast and Effecti ve Lossy Compression on GPUs and CPUs with Guaranteed Error Bounds. In 2025 IEEE International P arallel and Distributed Pr ocessing Symposium (IPDPS) , pages 874–887, June 2025. [14] Alex Fallin, Noushin Azami, Sheng Di, Franck Cappello, and Martin Burtscher . PFPL Git Repository. https://github.com/b urtscher/PFPL, 2025. Accessed: 2025-02-10. T ABLE VIII C O MPA R IS O N OF P S N R A N D S S I M F O R TH E 1 E -2 N OA E RR OR B O UN D T opoA SZ3 LOPC ϵ = 1.5x EB ϵ = 0.5x EB T opoSZ T opoQZ SZ3 PFPL PSNR Isabel 52.9 55.2 57.3 50.4 53.0 50.8 44.8 T angaroa 53.0 56.7 58.4 DNF 57.7 53.0 45.0 Earthquake 53.3 59.3 63.0 47.8 50.0 53.1 47.4 Ionization 51.4 54.7 54.7 DNF 50.0 53.9 49.2 Miranda 59.9 46.3 T O 41.1 49.1 54.7 52.0 S3D 56.0 62.6 T O 11.7 64.4 54.2 44.7 SCALE 56.3 49.1 TO 8.0 51.2 51.2 46.5 QMCP ACK 53.1 55.3 60.6 49.6 51.5 47.6 44.5 Geomean 54.4 54.7 58.7 27.8 53.1 52.3 46.7 SSIM Isabel 1.00 1.00 1.00 1.00 1.00 1.00 0.97 T angaroa 1.00 1.00 1.00 DNF 1.00 1.00 0.97 Earthquake 0.92 0.98 0.99 0.75 0.82 0.94 0.71 Ionization 1.00 1.00 1.00 DNF 1.00 1.00 1.00 Miranda 0.31 0.26 T O 0.29 0.30 0.27 0.31 S3D 0.69 0.95 T O 0.01 0.94 0.98 0.44 SCALE 0.62 0.68 TO 0.00 0.62 0.67 0.59 QMCP ACK 0.99 1.00 1.00 0.98 0.99 0.97 0.95 Geomean 0.77 0.80 1.00 0.14 0.78 0.80 0.69 T ABLE IX C O MPA R IS O N OF P S N R A N D S S I M F O R TH E 1 E -4 N OA E RR OR B O UN D T opoA SZ3 LOPC ϵ = 1.5x EB ϵ = 0.5x EB T opoSZ T opoQZ SZ3 PFPL PSNR Isabel 95.1 94.6 94.4 TO 91.5 86.4 84.8 T angaroa 95.1 96.7 96.6 90.4 90.9 87.8 84.8 Earthquake 95.1 94.5 T O 90.4 91.8 85.4 84.7 Ionization 95.7 97.0 97.8 88.7 90.5 89.4 86.4 Miranda 95.6 94.0 TO 83.2 89.3 89.6 90.0 S3D 92.2 93.4 TO TO 91.2 89.4 84.8 SCALE 91.1 inf TO TO 96.0 86.7 84.4 QMCP ACK 95.1 99.3 99.3 90.8 90.9 88.9 84.8 Geomean 94.3 95.6 97.0 88.7 91.5 87.9 85.5 SSIM Isabel 1.00 1.00 1.00 TO 1.00 1.00 1.00 T angaroa 1.00 1.00 1.00 1.00 1.00 1.00 0.99 Earthquake 1.00 1.00 T O 1.00 1.00 1.00 1.00 Ionization 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Miranda 0.34 0.30 TO 0.30 0.34 0.30 0.33 S3D 1.00 1.00 TO TO 1.00 1.00 1.00 SCALE 0.81 1.00 TO T O 0.86 0.85 0.76 QMCP ACK 1.00 1.00 1.00 1.00 1.00 1.00 1.00 Geomean 0.85 0.86 1.00 0.78 0.86 0.84 0.84 [15] Alex Fallin and Martin Burtscher . Lessons Learned on the Path to Guaranteeing the Error Bound in Lossy Quantizers, 2024. [16] Nathaniel Gorski, Xin Liang, Hanqi Guo, and Bei W ang. TFZ: T opology-Preserving Compression of 2D Symmetric and Asymmetric Second-Order T ensor Fields. arXiv pr eprint arXiv:2508.09235 , 2025. [17] Nathaniel Gorski, Xin Liang, Hanqi Guo, Lin Y an, and Bei W ang. A General Framework for Augmenting Lossy Compressors with T opolog- ical Guarantees. IEEE T ransactions on V isualization and Computer Graphics , 2025. [18] David A. Huffman. A Method for the Construction of Minimum- Redundancy Codes. Proceedings of the IRE , 40(9):1098–1101, 1952. [19] Lawrence Ibarria, Peter Lindstrom, Jarek Rossignac, and Andrzej Szymczak. Out-of-core Compression and Decompression of Large n- dimensional Scalar Fields. Comput. Graph. F orum , 22:343–348, 09 2003. [20] F . Jager . Delta Modulation — A Method of PCM Transmission Using the One Unit Code. Philips Res. Repts. , 7, 01 1952. [21] J. E. Kay , C. Deser, A. Phillips, A. Mai, C. Hannay , G. Strand, J. M. Arblaster , S. C. Bates, G. Danabasoglu, J. Edwards, M. Holland, P . Kushner, J.-F . Lamarque, D. Lawrence, K. Lindsay , A. Middleton, E. Munoz, R. Neale, K. Oleson, L. Polvani, and M. V ertenstein. ”The Community Earth System Model (CESM) Large Ensemble Project: A Community Resource for Studying Climate Change in the Presence of Internal Climate V ariability”. Bulletin of the American Meteorolo gical Society , 96(8):1333–1349, 2015. [22] Abraham Lempel and Jacob Ziv . A Universal Algorithm for Sequen- tial Data Compression. IEEE T ransactions on Information Theory , 23(3):337–343, May 1977. [23] Mingzhe Li, Dwaipayan Chatterjee, Franziska Glassmeier , Fabian Senf, and Bei W ang. T racking Low-Le vel Cloud Systems with T opology. arXiv preprint arXiv:2505.10850 , 2025. [24] Y uxiao Li, Xin Liang, Bei W ang, Y ongfeng Qiu, Lin Y an, and Hanqi Guo. Msz: An efficient parallel algorithm for correcting morse-smale segmentations in error-bounded lossy compressors. IEEE T ransactions on V isualization and Computer Graphics , 2024. [25] Xin Liang, Sheng Di, Franck Cappello, Mukund Raj, Chunhui Liu, K enji Ono, Zizhong Chen, T om Peterka, and Hanqi Guo. T oward feature- preserving vector field compression. IEEE T ransactions on V isualization and Computer Graphics , 29(12):5434–5450, 2022. [26] Xin Liang, Sheng Di, Dingwen T ao, Sihuan Li, Shaomeng Li, Hanqi Guo, Zizhong Chen, and Franck Cappello. Error-Controlled Lossy Compression Optimized for High Compression Ratios of Scientific Datasets. In 2018 IEEE International Confer ence on Big Data (Big Data) , pages 438–447, 2018. [27] Xin Liang, Sheng Di, Dingwen T ao, Sihuan Li, Shaomeng Li, Hanqi Guo, Zizhong Chen, and Franck Cappello. Error-Controlled Lossy Compression Optimized for High Compression Ratios of Scientific Datasets. In 2018 IEEE International Confer ence on Big Data (Big Data) , pages 438–447, 2018. [28] Xin Liang, Kai Zhao, Sheng Di, Sihuan Li, Robert Underwood, Ali M. Gok, Jiannan Tian, Junjing Deng, Jon C. Calhoun, Dingwen T ao, Zizhong Chen, and Franck Cappello. SZ3: A Modular Framework for Composing Prediction-Based Error -Bounded Lossy Compressors. IEEE T ransactions on Big Data , 9(2):485–498, 2023. [29] Peter Lindstrom and Martin Isenburg. Fast and efficient compression of floating-point data. IEEE transactions on visualization and computer graphics , 12(5):1245–1250, 2006. [30] K. B. Olsen, S. M. Day , J. B. Minster , Y . Cui, A. Chourasia, D. Okaya, P . Maechling, and T . Jordan. T eraShake2: Spontaneous Rupture Sim- ulations of Mw 7.7 Earthquakes on the Southern San Andreas Fault. Bulletin of the Seismological Society of America , 98(3):1162–1185, 06 2008. [31] Mathieu Pont, Jules V idal, Julie Delon, and Julien Tiern y . W asserstein Distances, Geodesics and Barycenters of Merge Trees. IEEE T ransac- tions on V isualization and Computer Graphics , 28(1):291–301, 2022. [32] St ´ ephane Popinet, Murray Smith, and Craig Stevens. Experimental and Numerical Study of the Turb ulence Characteristics of Airflow around a Research V essel. Journal of Atmospheric and Oceanic T echnology , 21(10):1575–1589, 2004. [33] SDRBench Inputs, https://sdrbench.github .io/, 2023. [34] Maxime Soler, M ´ elanie Plainchault, Bruno Conche, and Julien T ierny . T opologically controlled lossy compression. In 2018 IEEE P acific V isualization Symposium (P acificV is) , pages 46–55. IEEE, 2018. [35] Thierry Sousbie. The persistent cosmic web and its filamentary structure–I. Theory and implementation. Monthly notices of the royal astr onomical society , 414(1):350–383, 2011. [36] Julien T ierny and V alerio Pascucci. Generalized topological simplifica- tion of scalar fields on surfaces. IEEE transactions on visualization and computer graphics , 18(12):2005–2013, 2012. [37] Jules V idal, Pierre Guillou, and Julien Tierny . A Progressive Approach to Scalar Field T opology . IEEE T ransactions on V isualization and Computer Graphics , 27(6):2833–2850, 2021. [38] Daniel Whalen and Michael L. Norman. Ionization Front Instabilities in Primordial H II Regions. The Astrophysical J ournal , 673(2):664, feb 2008. [39] Mingze Xia, Bei W ang, Y uxiao Li, Pu Jiao, Xin Liang, and Hanqi Guo. TspSZ: An Efficient Parallel Error-Bounded Lossy Compressor for T opological Skeleton Preservation. In 2025 IEEE 41st International Confer ence on Data Engineering (ICDE) , pages 3682–3695. IEEE Computer Society , 2025. [40] Lin Y an, Xin Liang, Hanqi Guo, and Bei W ang. T opoSZ: Preserving topology in error-bounded lossy compression. IEEE T ransactions on V isualization and Computer Graphics , 30(1):1302–1312, 2023. [41] Kai Zhao, Sheng Di, Maxim Dmitriev , Thierry-Laurent D. T onellot, Zizhong Chen, and Franck Cappello. Optimizing Error-Bounded Lossy Compression for Scientific Data by Dynamic Spline Interpolation. In 2021 IEEE 37th International Conference on Data Engineering (ICDE) , pages 1643–1654, 2021. [42] Kai Zhao, Sheng Di, Xin Lian, Sihuan Li, Dingwen T ao, Julie Bessac, Zizhong Chen, and Franck Cappello. SDRBench: Scientific Data Re- duction Benchmark for Lossy Compressors. In 2020 IEEE International Confer ence on Big Data (Big Data) , pages 2716–2724, 2020.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment