Efficiently Reproducing Distributed Workflows in Notebook-based Systems
Notebooks provide an author-friendly environment for iterative development, modular execution, and easy sharing. Distributed workflows are increasingly being authored and executed in notebooks, yet sharing and reproducing them remains challenging. Ev…
Authors: Talha Azaz, Raza Ahmad, Md Saiful Islam
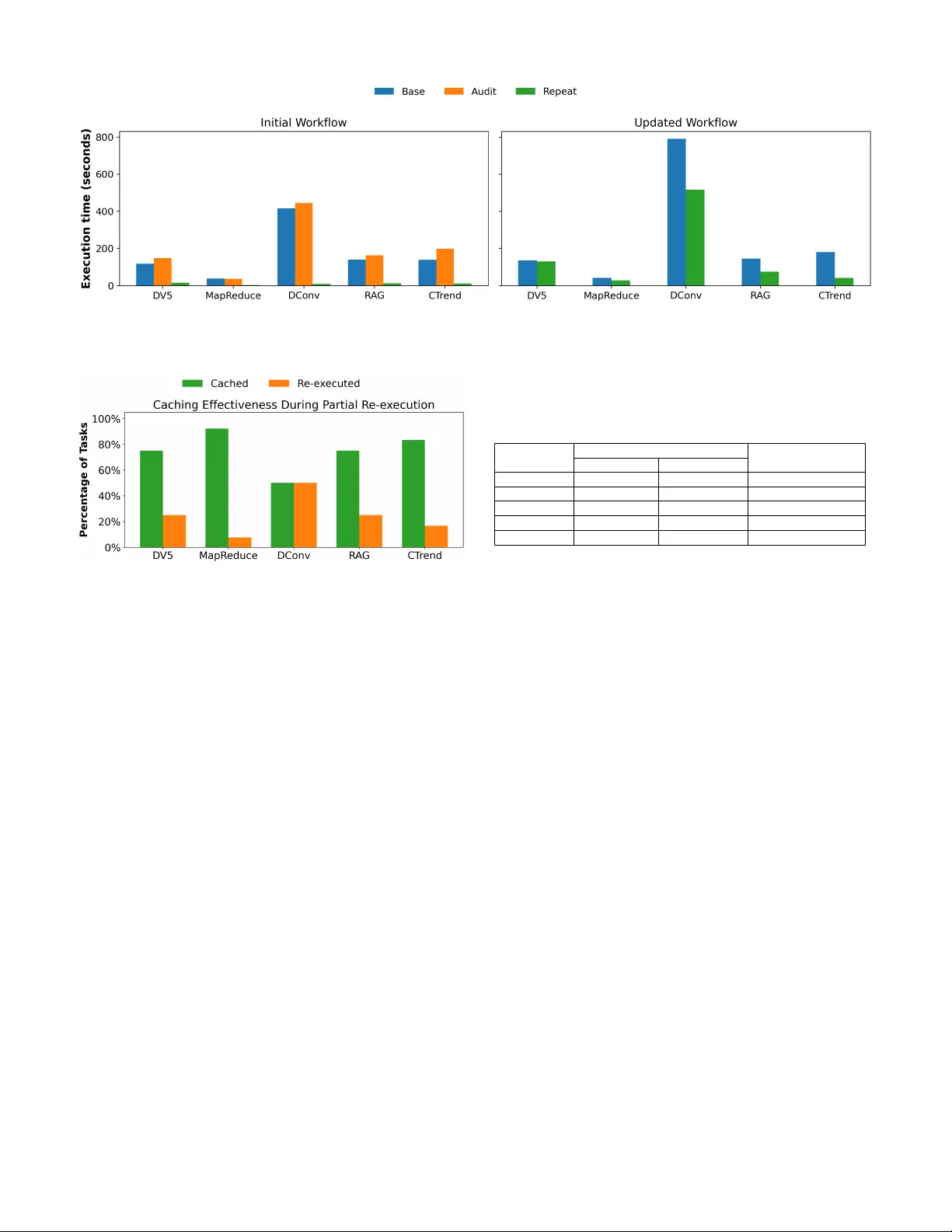
Ef ficiently Reproducing Distrib uted W orkflo ws in Notebook-based Systems T alha Azaz ∗ , Raza Ahmad † , Md Saiful Islam ‡ , Douglas Thain ‡ , T anu Malik ∗ ∗ University of Missouri, Columbia, MO, USA; † DeP aul University , Chicago, IL, USA; ‡ University of Notr e Dame, Notr e Dame, IN, USA; tay2f, tanu@missouri.edu, raza.ahmad@depaul.edu, mislam5, dthain@nd.edu Abstract —Notebooks pro vide an author-friendly en vironment for iterati ve dev elopment, modular execution, and easy sharing. Distributed workflo ws are increasingly being authored and exe- cuted in notebooks, yet sharing and reproducing them remains challenging. Ev en small code or parameter changes often for ce full end-to-end re-execution of the distrib uted workflow , limiting iterative development for such w orkloads. Current methods for impro ving notebook execution operate on single-node work- flows, while optimization techniques for distrib uted workflows typically sacrifice repr oducibility . W e introduce NBRewind, a notebook kernel system for efficient, reproducible execution of distributed workflows in notebooks. NBRewind consists of two kernels—audit and repeat. The audit kernel performs incre- mental, cell-level checkpointing to avoid unnecessary re-runs; repeat reconstructs checkpoints and enables partial re-execution including notebook cells that manage distrib uted workflo w . Both kernel methods are based on data-flow analysis across cells. W e show how checkpoints and logs when packaged as part of standardized notebook specification improv e sharing and repr o- ducibility . Using real-world case studies we show that creating incremental checkpoints adds minimal overhead and enables portable, cross-site reproducibility of notebook-based distributed workflows on HPC systems. Index T erms —Notebooks, Incremental Computation, Dis- tributed W orkflows, W orkflow Systems, Reproducibility I . I N T R O D U CT I O N Notebooks [1] provide an author-friendly en vironment that enables iterative development, modular cell-level ex ecution, and easy dissemination of computational analyses across sci- entific disciplines [2]–[5]. Increasingly , distributed scientific workflo ws are prototyped and executed within notebook in- terfaces. For example, users may dev elop a notebook using libraries like Dask [6] (as shown in Figure 1), Parsl [7] or T askV ine [8], which enable specification of the distrib uted workflo w from within notebooks. While such notebooks are often helpful for iterativ e dev elopment, they are difficult to share and reproduce across different cluster en vironments— often essential in collaborati ve scientific settings [9]. A core strength of notebooks is the ability to efficiently explore variations in parameters or code while preserving consistency of results. Consider the distributed workflo w in Figure 1, where Cell 1 performs an expensiv e data-loading operation, Cell 2 defines a distributed map, group by , and aggregation, and a risk_score function to be computed ov er aggregated rows. Cell 3 triggers the ex ecution of the distributed computation on multiple nodes using compute , producing a parquet file output. In a typical scenario, a scientist executes all cells, inspects the results, and then varies downstream parameters such as the risk_score threshold, for e xample, changing from 10.0 to 8.0. If the kernel remains aliv e and Dask has retained intermediate data in memory , the scientist may re-run only Cell 3. Howe ver , the in-memory state of Dask is lost when the notebook is moved to another HPC cluster due to kernel restart, or when the notebook is shared with a collaborator . The collaborator inherits the notebook but none of its intermediate workflow state, forcing complete re- ex ecution from raw data. Although some systems of fer coarse-grained checkpointing, existing notebook savepoints are manual and not designed for distributed w orkflo ws. Even if checkpointing is av ailable, full checkpoints incur significant storage overhead, but more importantly , they do not determine which distributed computa- tions must be partially re-executed when changes to notebook cells occur . In our running e xample, a checkpoint may allow skipping the expensi ve data-loading in Cell 1, b ut if the user modifies the risk_score formula in Cell 2, both Cells 2 and 3 must be re-run. Rerunning entire Cell 3 is wasteful, since only part of Cell 3’ s distributed computation is logically affected by the edit — the distrib uted group-by aggregation remains v alid, and only the risk_score computation should change. Current notebook systems have no mechanism to checkpoint distributed computation within a cell or to reuse previous distributed results while selecti vely re-executing only the modified portion. In this paper , we address the dual challenge of re- peating entire notebooks and entire distributed computation within a notebook by (i) checkpointing cell-lev el kernel state—including intermediate distrib uted workflo w results, and (ii) selecti vely replaying only those tasks whose inputs or code have changed. The checkpoints of cells and the list of distributed tasks are created incrementally to save on checkpoint size. W e present NBRewind , a system consisting of two note- book kernels: audit and repeat. NBRewind ’ s audit kernel performs automatic, incremental checkpointing : as users exe- cute each cell during iterati ve dev elopment, the kernel detects changes in the notebook’ s kernel state and checkpoints only the variables and objects whose values have been updated relativ e to prior cells. This change detection is implemented [c 1 ] Load Data from dask.distributed import Client import dask.dataframe as ddf # Connect to an existing Dask cluster on the HPC system client = Client ( “tcp://scheduler:8786” ) # Lazy-load a large dataset of climate simulations from shared filesystem df = ddf . read_parquet ( "run_24-06.parquet" ) # Lazy preprocessing df = df [ df [ "temperature" ] . notnull ()] df = df . assign ( anomaly = df [ "temperature”]- df [ "temperature_baseline" ]) raw_df = df [c 2 ] Wor ker Code # Group by region and day and compute summary statistics across all worker nodes daily_stats = ( raw_df . groupby ([ "region" , "day" ]) . agg ({ "anomaly" :[ "mean" , "std" ], "precipitation" : "sum" }) . persist ()) # Compute risk score def risk_score ( row ): return 1.0 *row [( "anomaly" , "mean" )] + 0.1 * row [( "precipitation" , "sum" )] stats_ref = daily_stats daily_stats = daily_stats . map_partitions ( lambda part : part . assign ( risk_score = part . apply ( risk_score , axis = 1 ))) Distributed Workflow [c 3 ] # Run distributed computation and get a subset of the result high_risk = daily_stats [ daily_stats [ "risk_score" ] > 10.0 ] # large-scale distributed execution result = high_risk . compute () # Save summary for analysis and visualization result . to_parquet ( "high_risk_24-06.parquet" ) Fig. 1. Example of a distrib uted workflo w in a notebook with a manager creating worker threads to compute summary statistics. by analyzing the variables in code and comparing them with other shared variables using a rev erse index mapping of mem- ory to variable names, ef ficiently determining which objects differ across cell boundaries. Incremental checkpointing is essential for controlling storage cost, as naiv ely checkpointing full kernel state after e very cell leads to substantial space consumption. W e show that without incremental checkpoints, users must provision prohibitiv ely large storage volumes to support reproducibility . For cells that contain distributed workflo ws, the audit kernel also interacts with the underlying distributed workflo w engine These persisted objects are likewise index ed using a hash- based structure so that the system can determine which dis- tributed tasks produce identical outputs and which must be in validated when notebook code changes. When a distributed workflo w notebook is shared and executed in a new cluster en vironment, NBRewind ’ s repeat kernel is used. The repeat kernel reconstructs the full state of any notebook cell by composing the previously sav ed incremental checkpoints. It then selectiv ely replays distributed computation within that cell by determining which tasks are in validated due to code or dataflow changes in the notebook. Only the in validated tasks are re-executed; all other tasks reuse memoized intermediate results captured by the audit kernel. This enables partial re- ex ecution of distributed workflows, ensuring that logically unaffected portions of a workflow are not recomputed. The split-kernel design of NBRewind builds on our prior work on containerizing dependencies for single-node note- books [10]. This design pattern has prov en effecti ve because it requires minimal changes to the notebook interface, preserv es the interactivity of the notebook UI, and av oids intrusiv e modifications to user code. It is also compatible with emerg- ing standardization efforts such as “backpack”-style artifacts that encapsulate notebook dependencies, data, and software en vironments [9]. The audit and repeat kernels automatically provide the metadata and state snapshots required to construct such portable bundles. Our primary contributions in this paper are as follows: 1) Introducing incremental checkpointing and partial re- ex ecution mechanisms for notebook cells that contain both single-node and distrib uted workflo ws. 2) Designing a hash-based data structure for efficiently determining the minimal set of tasks that must be re- ex ecuted. 3) Constructing a functional prototype of the audit and repeat kernels that implements automatic incremental checkpointing, distributed task memoization, and partial re-ex ecution across notebook cells. The rest of the paper is organized as follows. Section IV explains the mechanics of distributed computation in notebook workflo ws. Section III gives an overvie w of the NBRewind system and its architecture. Section IV explains the check- pointing mechanism for saving local notebook state. Section V details the process and methodology of partial re-ex ecution in notebooks for distributed workflows. Section VI highlights our experiments and ev aluates the ef fectiveness of NBRewind on our dataset of notebooks. W e conclude in Section VIII with a summary of our work and future directions. I I . D I S T R I B U T E D W O R K FL OW S I N N O T E B O O K S W e describe rele v ant processes that maintain execution state of distributed workflo ws within a notebook. In general, notebooks are clients which users access and edit through a web browser . The code within each cell is ex ecuted on the server as part of a programming language- specific interactive kernel process, as shown in Figure 2. Because the kernel persists across cells, the state produced by one cell (variables, objects, functions, configurations) becomes the starting point for subsequent cells. The output of the cell- lev el code ev aluations from the kernel process is relayed to the notebook client. Since the kernel ex ecutes the user code, Notebook Client code cell Kernel Environment Cell Code Output Notebook Server Fig. 2. The notebook en vironment comprising web-based notebook client running the notebook code which interacts with the kernel process in the notebook server . the kernel is also aware of the computational en vironment and the set of dependencies needed to run those code. Thus the notebook sends the user code one cell at a time, ex ecutes it using its configured environment, and returns the response of the executed code in the form of text and/or visualization, which is then displayed to the user through a web browser . When distributed workflows are dev eloped in notebooks, one or more cells of the notebook may run some of their code either in a process spawned by the kernel or a remote node, giving rise to a distributed workflo w within the ex ecution life cycle of that cell. T ypically a distrib uted workflo w comprises of a manager and a collection of distributed w orkers. The man- ager instructs workers to run some tasks, which are essentially processes running in parallel. The tasks read and write files from a shared file system as sho wn in Figure 3. Depending on the distrib uted workflo w system, the manager may organize tasks into a directed ac yclic graph (DA G) structure to manage inputs and outputs and determine if a task is in progress or waiting for other tasks to finish. D AG-based management of tasks also helps in efficient resource utilization. T o enable the distributed workflo w within the notebook cell, users may use popular libraries such as T askV ine [8], Dask [6], Parsl [7], which have Python extensions for use within notebooks. The distributed workflow in notebooks may span multiple cells. The k ernel maintains local Python objects representing the w orkflow (e.g.,T askV ine task handles), while the manager process of the distributed system simultaneously maintains the remote state including partially completed tasks and cached intermediate results. Thus, the complete workflo w state at any moment consists of both the kernel’ s local state and the distributed ex ecution’ s state. I I I . N B R E W I N D : N O T E B O O K C H E C K P O I N T I N G A N D P A RT I A L R E - E X E C U T I O N NBRewind is a system consisting of two notebook kernels: audit and r epeat . Both kernels are wrappers around base kernels e.g., the Python or Xeus-SQL kernel. The user uses the audit kernel to execute the notebook using the language interpreter . As the audit kernel executes the notebook, it automatically checkpoints after every cell. This checkpointing allows a user to go back in time and use the state of the KERNEL MANAGER Shared Filesystem Server Node T ASK T ASK T ASK W orker Node inputs outputs Fig. 3. The distributed notebook workflo w is illustrated when the kernel launches the manager which spawns sev eral worker threads that run in parallel on the worker node. notebook at time t instead of ex ecuting the other prerequisite cells from time < t . The audit kernel also intercepts the ex ecution to determine all data and en vironment dependencies used by the notebook. When the notebook is shared along with the checkpoints, data and environment dependencies, the user re-runs the note- book using the repeat kernel. The repeat kernel determines if there is a change in the notebook code cell. If there is no change, the repeat kernel bypasses execution of the cell and returns the stored output. If the repeat kernel determines that the cell’ s code has changed, this cell must be re-ex ecuted. For a changed cell, the repeat kernel reconstructs the checkpoint to ex ecute the changed cell. Section IV describes how to efficiently create and reconstruct checkpoints for each of the kernels respectiv ely . When a distrib uted workflo w is run within the notebook, the user still uses NBRewind ’ s audit and repeat kernels as described above. Howe ver during distributed execution, the audit kernel also determines if a cell issues any tasks. If so, the corresponding manager issuing the tasks is audited for task submissions. The audit kernel creates a log of all tasks that were submitted during execution. This log is av ailable for sharing similar to checkpoints, and other data and environment dependencies. The repeat kernel uses the task log to optimize on re-execution when re-running the notebooks. Specifically , the repeat kernel bypasses e xecution of any task whose inputs hav e not changed. Section V describes how to intercept the distributed workflow manager and audit tasks for partial re- ex ecution of distributed notebook workflows. The combined checkpointing of notebook cells and auditing of distributed tasks allows NBRewind to improv e scalabil- ity and reproducibility of notebooks, especially when users make changes and attempt to re-ex ecute a shared notebook on a target cluster . Figure 4 shows the notebook’ s use of NBRewind ’ s audit and repeat kernels to create checkpoints, task logs, input and intermediate data files and environment, which need to be containerized to make it shareable and reproducible across platforms. Our approach is to containerize the notebook program using application virtualization which captures all dependencies of the notebook by observing its Audit Kernel Stateful Manager Host Cluster T ar get Cluster Notebook Create Share Execute Notebook Execute Stateful Manager Redirect Share Repeat Kernel Check Point Data Federation Environment Cache Data Notebook Container T ask Log Data Env Notebook Container T ask Log Data Env Ta s k Ta s k Ta s k Ta s k Ta s k Ta s k Fig. 4. Architecture of NBRewind is illustrated The audit kernel on the host cluster ex ecutes a notebook and creates its corresponding notebook container . The notebook and its container are shared with a collaborator to be executed in a target cluster using the repeat kernel. Large volumes of data in a notebook container may be fetched dynamically from a remote data store. ex ecution [10]. The audit phase generates a lightweight note- book container that includes all necessary dependency files to reproduce the notebook, while the repeat phase uses this container to seamlessly execute the corresponding notebook in the target en vironment. The outputs of the audit kernel can be standardized using recently proposed notebook backpacks [9]. Similarly audited data for inputs, intermediate task outputs, en vironment files and checkpoints can be hosted either locally within the cluster or onto a data federation such as Open Science Data Federation [11] or the National Science Data Fabric [12]. I V . C H E C K P O I N T I N G I N N O T E B O O K S The audit kernel creates a checkpoint after each cell ex- ecution. T o create a checkpoint, the kernel could, in princi- ple, capture its o wn state using an OS-level checkpointing mechanism such as Checkpoint/Restart in Userspace (CRIU), which snapshots the entire process, including memory , file descriptors, threads, and other OS-managed resources. While OS-lev el checkpointing is programming-language agnostic, it captures a substantial low-le vel state that is unnecessary for reproducing notebook execution and is expensi ve to store and restore. Instead, the NBRewind audit kernel performs application- lev el checkpointing of the Python session executing within the kernel process. Python maintains execution state in a global dictionary that maps names—such as variables, functions, and imported modules—to runtime objects. Naively persisting this dictionary after each cell execution is impractical due to its size and the high frequency of updates. T o reduce checkpoint ov erhead, NBRewind performs incremental checkpointing, persisting only those v ariables whose v alues may ha ve changed as a result of executing a cell. As a first step, NBRewind applies static notebook slicing similar to NBSlicer [13], by parsing the cell’ s abstract syntax tree (AST) to conservati vely identify variables that are read or written in the cell. This static analysis bounds the set of candidate variables that may af fect the notebook state. Static slicing alone, howe ver , is insufficient to capture runtime dependencies arising from mutation and shared ref- erences. Therefore, NBRewind augments static slicing with dynamic dependency tracking by observing object identities and shared memory references during e xecution. NBRewind tracks shared variables, variables that reference the same un- derlying runtime object, and uses this information to determine additional variables that must be checkpointed transiti vely . T o support this process, NBRewind maintains a rev erse memory index, which maps memory references to all vari- ables that alias them. Incremental checkpoints are constructed by combining statically identified v ariables with dynamically discov ered shared dependencies. When a rollback is requested, the kernel reconstructs the notebook state by restoring the rel- ev ant subset of the globals dictionary from the corresponding incremental checkpoints. T o illustrate incremental checkpointing and shared-variable inference, Figure 5 presents a running example with two notebook cells. The second ro w of the figure shows the variables identified for each cell via abstract syntax tree (AST) parsing. This static analysis conserv atively captures all variables declared or referenced within a cell. For example, in Cell 1 the parsed variables are [Client, client, ddf, df] , while Cell 2 yields a different set of variables. Using the re verse index of memory locations (shown in the last ro w of Figure 5 for Cell 1), NBRewind identifies shared variables, i.e., variables that reference the same underlying runtime object. For instance, the variable r aw d f shares a memory location with d f due to the assignment in Line 7 of Cell 1 (shown in the third row of Figure 5), and is therefore marked as a shared v ariable. from dask.distributed import Client import dask.dataframe as ddf client = Client ( “tcp://scheduler:8786” ) df = ddf . read_parquet ( "run_24-06.parquet" ) df = df [ df [ "temperature" ] . notnull ()] df = df . assign ( anomaly = df [ "temperature”] - df [ "temperature_baseline" ]) raw_df = df daily_stats = ( raw_df . groupby ([ "region" , "day" ]) . agg ({ "anomaly" : [ "mean" , "std" ], "precipitation" : "sum" }) . persist ()) def risk_score ( row ): return 1.0 *row [( "anomaly" , "mean" )] + 0.1 * row [( "precipitation" , "sum" )] stats_ref = daily_stats daily_stats = daily_stats . map_partitions ( lambda part : part . assign ( risk_score = part . apply ( risk_score , axis = 1 ))) AST V ariables Notebook Cells Cell 1 Cell 2 Client, client, ddf, df, raw_df daily_stats, raw_df, risk_score, stats_ref Shared V ariables df, raw_df None V ariables to Checkpoint Client, client, ddf, df, raw_df daily_stats, risk_score, raw_df, df, stats_ref Global State Space 0x7f8a1c001a40 -> Client 0x7f8a1c0060a0 -> daily_stats 0x7f8a1c002c60 -> client 0x7f8a1c005f90 -> risk_score 0x7f8a1c001b50 -> ddf 0x7f8a1c004e80 -> stats_ref 0x7f8a1c003d70 -> df, raw_df 1 2 3 4 5 6 7 1 4 3 2 Fig. 5. The internal states maintained during the NBRewind workflo w to create checkpoints, as illustrated by the first two cells of our example notebook. { 'Client' : { 'obj' : , # Serializable (class from module) 'code' : 'from dask.distributed import Client', 'deps' : [] }, 'client' : { 'obj' : None, # Non-serializable (Client instance with network connections) 'code' : 'client = Client("tcp:// scheduler:8786")', 'deps' : ['Client'] }, 'daily_stats' : { 'obj' : , # Serializable (task graph) ' code' : 'daily_stats = (raw_df.groupby(...)’, 'deps' : [‘raw_df', 'risk_score'] }, } Fig. 6. The schema of the checkpoint created by NBRewind includes the name, code, and dependencies of each persisted object. In contrast, in Cell 2, although state r ef is initially as- signed to daily stats , the y are not marked as shared v ariables. This is because daily stats is subsequently reassigned in Line 4 of Cell 2, breaking the shared memory relationship. Since shared-variable determination is performed at cell-level granularity , the position of declarative and assignment state- ments affects the inferred sharing. For example, if Line 4 of Cell 2 were moved to a subsequent cell, then within Cell 2, NBRewind would infer statef ref and dail y stats as shared variables. Ho wever , NBRewind updates shared- variable information immediately upon reassignment, ensuring correctness of incremental checkpoints. Checkpointing decisions are based on the union of variables identified via AST parsing and those inferred through shared- variable tracking. As a result, in Cell 2, e ven though raw d f is the only variable parsed from the AST , NBRewind also checkpoints d f , since r aw d f is shared with d f through prior assignments. Figure 6 further shows the metadata checkpointed for each variable at each cell. This metadata includes: (i) the serialized Python object when possible, (ii) the code that produced the object, and (iii) any en vironment or execution dependencies required for reconstruction. For example, Client is a Python class that can be serialized directly and has no prior code dependencies. In contrast, the client object represents a live Dask connection and cannot be serialized; such objects are not checkpointed. Instead, NBRewind reconstructs them during replay by re-executing the relev ant initialization code. The variable dail y stats , a Dask DataFrame, is serializable, and its checkpoint includes both the object and the code expression that produced it, along with its transitive dependencies. Finally , NBRewind performs checkpoint deduplication across cells. As shown in Figure 5, se veral v ariables (e.g., d f and r aw d f ) appear in multiple checkpoints. Although these v ariables are included in successi ve checkpoints due to the possibility of change, their serialized representations may be identical. NBRewind detects and eliminates duplicate checkpoint entries across cells, significantly reducing storage ov erhead, as demonstrated in our experimental e v aluation. V . P A RT I A L R E - E X E C U T I O N A. Stateless Distributed W orkflows Consider the Dask-based climate analysis workflo w shown in Figure 1. Figure 7 illustrates an abstracted version of its task dependency graph, where Dask partitions the dataset into 3 chunks for parallel processing. The workflo w spawns tasks that (1) load temperature data from a Parquet file (T1–T3), followed by tasks to (2) filter nulls values (T4–T6), and (3) computes anomalies (T7–T9). Then it performs (4) parallel aggregation by region and day (T10–T12) and (6) a reduce operation to persist the intermediate aggregated result (T13). It then runs tasks to (7) map partitions that apply the risk score function (T14–T16), and finally (8) a reduce operation that persists the results (T17). During iterativ e development, users frequently modify such workflo ws. Adding a new weather station file creates a new parallel branch while leaving T1 through T12 unchanged. Modifying the risk score function affects only T14, T15, T16, T17 while leaving T1 through T13 unmodified. Howe ver , standard ex ecution with Dask and DaskV ine forces complete re-ex ecution because neither framework maintains persistent state across runs. DaskV ine acts as a stateless ex ecutor that submits tasks to T askV ine without awareness of previous ex ecutions, and T askV ine does not track task history or cache outputs between workflow inv ocations. When modifying the risk score function, only 3 of 16 tasks require re-execution, yet the stateless model re-ex ecutes all 16 tasks. B. Stateful Execution with Re windManag er W e introduce a persistence layer that transforms T askV ine into a stateful workflo w manager . The architecture adds RewindManager , which wraps the standard T askV ine manager and interposes on task submission and completion. The exe- cution flow becomes: Dask → DaskV ine → RewindManager → T askV ine. RewindManager maintains a transaction log recording task fingerprints and execution metadata, plus a task cache storing output files. When a task is submitted, RewindManager computes a fingerprint capturing the task’ s code and inputs, then queries the transaction log. On cache hit, it retrieves cached output files and returns a synthetic task result without e xecuting it. On cache miss, the task proceeds to T askV ine for execution, and upon completion, the fingerprint and outputs are logged to the cache. Returning to Figure 7, when modifying the risk score function, tasks T1 through T13 produce identical fingerprints and hit the cache, while T14, T15, T16, 17 have changed fingerprints and execute with the modified function. When adding a ne w weather station file, tasks T1 through T9 hit the cache, the new branch ex ecutes, and downstream aggre gation tasks re-execute because their input fingerprints change. C. T ask F ingerprinting Mechanism T ask fingerprinting captures all elements including compu- tational logic and input dependencies influencing task output. The strategy differs between command-based and Python function tasks. Command-Based T asks. The fingerprint hashes the command string concatenated with SHA-256 content hashes of all de- clared input files. For each input, the system reads file contents and computes a hash. The complete representation is serialized to JSON with sorted keys and hashed with SHA-256. This provides strong guarantees when all inputs are declared. Python Function T asks. Fingerprinting proceeds in two stages. First, a core hash captures function logic and argu- ments independent of input files. Arguments are canonical- ized to remove non-deterministic UUID suf fixes that Dask injects (e.g., subgraphcallable-a1b2c3d4 normalizes to subgraphcallable ). The system identifies user-defined functions in arguments, extracts their source code via in- trospection, and includes source code hashes. In Figure 7, tasks T14, T15, T16 include the risk_score function as an argument; modifying this function changes the source code hash, in validating cached results. Arguments are serialized and hashed as well. The core hash combines hashed arguments, and user function source hashes. Second, the core hash is combined with input file hashes. Similar to command based tasks, for each user-declared input file, the system computes a SHA-256 hash. Input hashes are sorted and appended to the core hash to compute the final fingerprint. D. F ingerprinting Challenges Undeclared Dependencies. Shell commands may reference files not declared as inputs assuming a shared file system (e.g., bash process.sh data/ * .csv depends on both CSV files and process.sh ). If process.sh is not declared, its modifications are in visible to fingerprinting, causing incorrect cache hits. Non-Determinism The system assumes deterministic func- tions where identical inputs produce identical outputs. Func- tions depending on external state (timestamps, random num- bers) as part of the closure violate this assumption, causing cached outputs to div erge from fresh ex ecution. F or e xample when you de-serialize a Dask generated task function its byte representation will be dif ferent in each run ev en though the task has not changed because it might reference some workflo w identifiers that are non-deterministic. Dask generates unique identifiers for intermediate results ( finalize-abc123 , subgraphcallable-xyz789 ) that appear in task keys and arguments. Canonicalization strips the kno wn UUID formats through pattern matching, though this is frame work specific and fragile and unrecognized formats may cause unnecessary cache misses. V I . E X P E R I M E N T S A N D E V A L U A T I O N W e ev aluate NBRewind by applying it to real-world scien- tific notebook workflo ws that contain distributed computations and benefit from re-ex ecution optimization. Our ev aluation demonstrates that NBRewind can significantly reduce note- book re-ex ecution time through incremental checkpointing and partial re-execution of distributed tasks, while maintaining T1 T2 T4 T5 T3 T6 T7 T8 T9 T10 T1 1 T12 T13 T14 T15 T16 T17 Read Filters Anomaly Group By Reduce Risk Score Reduce Fig. 7. Partial execution of task graph from example shown in Figure 1. Update in ‘risk score‘ re-executes tasks sho wn in red and returns cached results for unchanged tasks shown in green. reproducibility guarantees. W e assess NBRewind ’ s ef fective- ness across three key dimensions: (1) checkpoint creation ov erhead during audit mode, (2) time savings during repeat ex ecution with unchanged notebooks, and (3) selective task re-ex ecution efficienc y when notebooks are modified. A. Experimental Setup Computing Infrastructure. All experiments were con- ducted on a SLR UM cluster with 4 compute nodes connected via a high-speed network. Each node was equipped with dual Intel Xeon Platinum 8259CL CPUs running at 2.50GHz and 4GB of memory . The cluster used NFS4 for shared file system access and XFS for local storage. W orker processes were configured with a minimum of 1 and maximum of 2 processes per node, allo wing T askV ine to dynamically allocate resources based on workload demands. Dataset Description. Our ev aluation dataset comprises 5 notebooks from di verse scientific domains, each demonstrating different computational characteristics, data dependencies, and distributed ex ecution patterns. T able I provides a detailed characteristics of each notebook. B. Methodology Our experimental methodology is designed to e valuate NBRewind across realistic notebook de velopment and sharing scenarios. W e compare notebook ex ecution under 5 distinct conditions organized into three categories furthemore modifi- cations to each notebook are explained later in this section: Dataset Description. Our ev aluation dataset comprises 5 notebooks from di verse scientific domains, each demonstrating different computational characteristics, data dependencies, and distributed ex ecution patterns. T able I provides a detailed characteristics of each notebook. Baseline Execution (Without NBRewind ): 1) Initial Run: Ex ecute the original notebook from top to bottom using the standard Python kernel without any checkpointing or task caching. This represents typical first-time execution and establishes the performance baseline. 2) Modified Run: Execute a modified version of the note- book using the standard Python kernel. Modifications include either adding new input data files or changing workflo w code. This simulates iterative development where users make incremental changes and must re- ex ecute the entire w orkflo w . A udit Phase (W ith NBRewind Checkpointing): 1) Initial Run: Execute the notebook using NBRewind ’ s audit kernel with incremental checkpointing enabled. The kernel creates checkpoints after each cell ex ecution, persisting only variables and objects that ha ve changed since the previous cell or they were used in this cell. NBRewind ’ s T askV ine manager simultaneously logs all completed tasks with their input fingerprints and caches task outputs. Repeat Phase (With NBRewind Restoration): 1) Repeat Without Change: Ex ecute the notebook using NBRewind ’ s repeat kernel without any modifications. The kernel restores cell outputs from checkpoints for unchanged cells and replays cached task results for all distrib uted tasks. This simulates sharing a notebook with a collaborator who wants to verify results without changes. 2) Repeat With Change: Ex ecute the modified notebook as used in Baseline modified run using NBRewind ’ s repeat kernel. The kernel identifies which cells and tasks are affected by the modifications and selectiv ely re- ex ecutes only the in v alidated portions. Unchanged cells are restored in-order from checkpoints, and unchanged tasks are replayed from the cache. This simulates the iterativ e de velopment process. W e add additional input data files or modify a task and ex- pect the workflow to be executed partially . For each notebook, we also report the expected tasks to be replayed from the cache and re-executed. This expected behavior is confirmed from the results shown in Figure 9 and explained later in results. W e apply the following modifications to each notebook for partial re-ex ecution ev aluation. • D V5: Added 1 additional R OO T file containing ev ents. Expected: 3 out of 4 tasks cached. • MapReduce: Modified reduce function to compute group counts in addition to total counts. Expected: 12 out of 13 tasks cached. • DCon v: Added 1 new kernel matrix (Gaussian filter). Expected: 1024 out 2048 tasks cached. • RA G: Added 1 additional book ( ∼ 500KB text). Ex- pected: 3 out of 4 tasks cached. • CT rend: Added 10 new weather station CSV files. Ex- pected: 100 out of 121 tasks cached. For each experimental condition, we measure: • Execution time: T otal time from notebook e xecution start to completion, including all distributed task ex ecution. • T ask level cache statistics: Number of tasks submitted, cached, and re-executed during repeat phase with modi- fications. • Storage overhead: Size of checkpoints (after content- based de-duplication) and task cache (transaction log and intermediate files). W e assume that input data files do not change between successiv e runs, though ne w files may be added. Additionally , input data file names remain consistent between runs to enable accurate task fingerprinting and cache lookup. These T ABLE I C H AR AC T E R IS T I C S A ND D E SC R I P TI O N O F T H E FI V E N OT E B OO K S I N TH E DA TAS E T . Notebook Cells Unique V ariables Shared V ariables Dataset Size Distributed T asks Description D V5 11 60 7 952 KB 4 High energy physics analysis performing distributed ev ent processing on CMS detector data using Dask and Coffea frameworks. MapReduce 8 70 10 768 KB 13 Distributed word count pipeline implementing map- reduce pattern. Creates 12 parallel map and combine tasks for word counting and 1 reduce task for aggre- gation. DCon v 7 27 5 16.4 MB 1024 T ile based image con volution applying kernel func- tions to partitioned image tiles using Python Imaging Library . Processes 1024 tiles with 2 different kernels. RA G 14 54 15 6.2 MB 4 Document chunking and indexing pipeline for BM25 based retriev al. Splits books into semantic chunks and builds inv erted index for similarity search. CT rend 12 80 7 27.44 MB 120 Climate trend analysis processing temperature data from NOAA weather stations. Performs data clean- ing, anomaly calculation relativ e to baseline period, and trend aggregation with statistical analysis. assumptions align with common scientific workflow practices where input datasets are treated as immutable and ne w data is added as separate files. W e also assume that the task functions do not contain any non deterministic v alues as arguments or in it’ s closure so that we can get a stable fingerprint of the task for effecti ve caching. C. Results and Analysis Figure 8 presents the ex ecution times for each notebook un- der all experimental conditions. W e observ e that NBRewind provides substantial benefits across all notebooks, with the magnitude depending on the notebook’ s workflow structure and modification patterns. A udit Ov erhead. Audit mode incurs an av erage of 18% ov erhead across notebooks ranging from 7-42% : DV5 (25%), MapReduce (1%), DCon v (7%), RA G (16%), and CT rend (42%). Figure 8 shows these ex ecution times. This overhead is attributed to caching the tasks and checkpointing the note- book state after the ex ecution of each cell. This overhead becomes negligible when compared to the performance gains we achiev e when repeating the notebook. Repeat Execution Without Modifications. Repeat mode con- sists of (1) local kernel state reconstruction from incremental checkpoints, and (2) distributed task execution by replaying cached task results. This simulates sharing a notebook with a collaborator who wants to verify results without changes. Comparing repeat mode against baseline normal runs reveals significant speedup from eliminating redundant computation. NBRewind achie ves an average performance gain of 18.4x ranging from 8x to 46.2x: DV5 (118.29s → 15.69s), MapRe- duce (38.79s → 2.78s), DConv (416s → 9s), RA G (140s → 12s), and CTrend (139s → 11s) by restoring kernel check- points and replaying cached task outputs. Since DCon v has the most time spent in distributed computation, it achie ves the highest performance gains. These results re veal that using NBRewind we can improv e the speed of reproducing dis- tributed workflo w by order of magnitude. Repeat Execution With Modifications. Comparing repeat ex ecution with modifications against baseline modified runs demonstrates NBRewind ’ s effecti veness in executing partially updated workflows. The average performance gain is 2.08x, ranging from 1.04x to 4.41x depending on the modifica- tion scope: D V5 (136s → 130.50s), MapReduce (41.23s → 27.67s), DConv (791s → 516s), RA G (145s → 76s), and CT rend (181s → 41s). Since adding 10 ne w weather stations in CT rend requires processing only 20 new tasks while caching 100 existing tasks we gain the most time savings. T ask Caching Effectiveness. The observed cache hit rates as shown in Figure-9 range from 50% to 92.3% across notebooks: D V5 (75%, 3 of 4 tasks cached), MapReduce (92.3%, 12 of 13 tasks cached), DCon v (50%, 1024 of 2048 tasks cached), RAG (75%, 3 of 4 tasks cached), and CTrend (83.3%, 100 of 120 tasks cached). The av erage hit rate for all notebooks is 75.1%. This reveals that NBRewind ’ s effecti veness is determined by modification patterns and workflow structure. W e identify two primary factors that govern caching behavior: adding new data versus modifying existing code, and the workflow D AG contains independent parallel tasks versus connected dependent tasks. For workflows with group of tasks that are processed independent of other tasks (D V5, RA G, CT rend), adding new input files creates a separate branch of tasks that leaves existing tasks unaffected. Adding 10 CSV files to CT rend, for instance, creates 20 ne w tasks while successfully caching the 100 existing tasks, achieving an 83.3% hit rate. This pattern generalizes across workflows where each input file spawns independent processing pipelines. Code modifications exhibit more complex behavior depend- ing on modification location within the D A G. For example, modifying the reduce function in MapReduce re-executes only 1 of 13 tasks (92.3% hit rate) because the change occurs at the workflow’ s terminal stage, leaving all upstream map tasks cacheable. In contrast, modifying early stage functions would cascade through all downstream tasks, eliminating caching benefits entirely . F or instance, in DCon v , updating the kernel Fig. 8. Execution time in seconds for notebooks for both audit and repeat phases compared with the baseline. Fig. 9. Percentage of Cached and Re-executed tasks in the updated workflow . matrix in conv olution triggers a complete re-execution of workflo w whereas extending the workflo w with another kernel will achiev e a 50% cache hit. Storage Overhead. T able II re veals that NBRewind ’ s storage costs decompose into two distinct components with differ - ent scaling beha viors: Python kernel state checkpoints and distributed task intermediate files. Incremental checkpointing with content-based de-duplication keeps kernel state storage minimal, ranging from 0% to 57% reduction in checkpoint size with an av erage reduction of 27.3%. DCon v achie ves the highest de-duplication sa vings at 57% (250 MB reduced to 108 MB) due to repeated references to lar ge image arrays across multiple cells. The de-duplication mechanism effecti vely elim- inates redundant data referenced by multiple variables and stores it only once. In contrast, intermediate file storage scales with the D AG structure. DCon v’ s 1024 conv olution tasks each produce an output image tile, generating substantial intermediate storage that persists for task cache replay . These intermediate files, while not directly visible to end users in the final notebook output, enable NBRewind ’ s selectiv e re- ex ecution capability by preserving task-le vel outputs. V I I . R E L A T E D W O R K Distributed workflows in Jupyter notebooks have become quite popular in various scientific disciplines. They can also be used to ef ficiently execute lar ge-scale multi-user deplo yments T ABLE II S TO R AG E O VE R H EA D B RE A K DO W N S H OW I NG I NC R E M EN TA L C H EC K P O IN T S I Z E S B E FO R E A N D A F T ER C ON T E N T - BA S E D D E DU P L I CATI O N , A N D T H E I N TE R M E DI ATE T A S K C AC H E FI LE S . Notebook Checkpoint Size Intermediate Files (Pre-Dedup) (P ost-Dedup) D V5 420 KB 264 KB 112 KB MapReduce 380 KB 332 KB 300 KB DCon v 250 MB 108 MB 159 MB RA G 116 MB 81 MB 8.4 MB CT rend 1.9 MB 1.9 MB 400 KB where notebooks launch distributed jobs in HPC en viron- ments [14], [15], [16]. Similarly , Colonnelli et al. [17] e xtend the Jupyter model so each cell maps to a workflo w step that can run in cloud or on HPC resources. This has become faster and con venient, especially with the rise of systems like Floability [9] which provide rapid, portable, and reproducible deployment of complex scientific workflows across a wide range of cyberinfrastructures. Intermediate state preservation has been shown to reduce redundant re-execution and enhance interactiv e performance in traditional HPC environments [18] and interactive notebook system [19]. Kishu [20] is a system for versioning notebook session states through incremental checkpointing. Li et al. propose ElasticNotebook [21] which enables live migration of notebook sessions across machines via lightweight state monitoring and graph-based optimization. Sato et al. [22] dev eloped a computational notebook engine called Multiv erse Notebook which allows user to time travel to any past state through cell-wise checkpointing using the POSIX fork to keep track of the state of cells, besides de veloping their o wn garbage collection strategy . Brown et al. focus on the relationships between cell and data dependencies in notebooks [23]. While these efforts have made adv ances in capturing de- pendencies and guiding users through execution lineage, they typically either address portability , reproducibility , or prov e- nance without e xplicitly targeting the optimization of notebook re-ex ecution performance. Additionally , they do not monitor any distributed computation taking place in a notebook cell. NBRewind distinguishes itself by unifying incremental check- pointing, content-based de-duplication, and application virtu- alization to explicitly optimize the performance of notebook re-ex ecution for distributed workflo ws. For containerization, That et al. [24] introduce Sciunit to create reusable research objects which uses a command- line tool to audit, store, and repeat program ex ecutions. Re- proZip [25] uses a similar approach to Sciunit and automat- ically track and b undles all dependencies of a computational experiment in a self-contained package. For reproducibility in notebook en vironments, Ahmad et al. build FLINC [26] using Sciunit which creates reproducible notebook containers by virtualizing the user kernel through additional kernels for audit and repeat. Shankar et al. NBSLICER [13] is another notebook-based tool that creates the forward and the backward program slices as a result of execution of each cell. V I I I . C O N C L U S I O N W ith the increase in popularity of distrib uted workflo ws in notebooks, sharing them with collaborators and reproducing them in different compute environments remains a challenge. W e introduce NBRewind which improv es the efficiency and reproducibility of distributed workflows within notebook en vi- ronments by implementing a split-kernel architecture consist- ing of audit and repeat kernels. It enables users to sav e and restore the notebook state at cell-lev el by efficiently storing the notebook state using application lev el checkpointing. It tracks fine-grained state changes using a re verse index map of memory addresses to variables and uses content-based de- duplication for efficient space consumption. NBRewind also integrates task-lev el memoization and logging in a distributed workflo w through a stateful distributed workflo w manager , allowing the system to selectiv ely replay only those compu- tations af fected by code or data modifications. Using a note- book dataset of real-world case studies, we demonstrate that NBRewind significantly reduces re-execution ov erhead while maintaining the portability required for cross-site collaboration on HPC systems. In future, we will focus on expanding NBRewind ’ s capabil- ities to support a broader range of parallel and distrib uted com- puting systems and platforms. W e will also perform improv ed integration with automated ”backpack-like” packaging mech- anisms for containerization and reproducibility to facilitate sharing with collaborators. W e will also enhance the efficienc y of NBRewind to handle large-scale data-intensive distributed scientific computing workflows to facilitate seamless sharing of computational artifacts through integration with global data federations such as the National Science Data Fabric. R E F E R E N C E S [1] T . Kluyver , B. Ragan-Kelle y , F . P ´ erez, B. Granger , M. Bussonnier, J. Frederic, K. Kelle y , J. Hamrick, J. Grout, S. Corlay et al. , “Jupyter notebooks–a publishing format for reproducible computational work- flows, ” in P ositioning and power in academic publishing: Players, agents and agendas . IOS press, 2016, pp. 87–90. [2] K. M. Mendez, L. Pritchard, S. N. Reinke, and D. I. Broadhurst, “T oward collaborativ e open data science in metabolomics using jupyter notebooks and cloud computing, ” Metabolomics , vol. 15, no. 10, p. 125, 2019. [3] J. Bascu ˜ nana, S. Le ´ on, M. Gonz ´ alez-Miquel, E. Gonz ´ alez, and J. Ram ´ ırez, “Impact of jupyter notebook as a tool to enhance the learning process in chemical engineering modules, ” Education for Chemical Engineers , vol. 44, pp. 155–163, 2023. [4] R. Castilla and M. Pe ˜ na, “Jupyter notebooks for the study of advanced topics in fluid mechanics, ” Computer Applications in Engineering Edu- cation , vol. 31, no. 4, pp. 1001–1013, 2023. [5] Y .-D. Choi, B. Roy , J. Nguyen, R. Ahmad, I. Maghami, A. Nassar, Z. Li, A. M. Castronova, T . Malik, S. W ang et al. , “Comparing containerization-based approaches for reproducible computational mod- eling of en vironmental systems, ” Envir onmental Modelling & Software , vol. 167, p. 105760, 2023. [6] M. Rocklin, “Dask: Parallel computation with blocked algorithms and task scheduling, ” in SciPy , 2015. [7] Y . Babuji, A. W oodard, Z. Li, D. S. Katz, B. Clifford, R. Kumar , L. Lacinski, R. Chard, J. M. W ozniak, I. Foster et al. , “Parsl: Per- vasi ve parallel programming in python, ” in Pr oceedings of the 28th International Symposium on High-P erformance P arallel and Distributed Computing , 2019, pp. 25–36. [8] B. Sly-Delgado, T . S. Phung, C. Thomas, D. Simonetti, A. Hennessee, B. T ovar , and D. Thain, “T askV ine: Managing In-Cluster Storage for High-Throughput Data Intensiv e W orkflows, ” in 18th W orkshop on W orkflows in Support of Large-Scale Science , 2023. [9] M. S. Islam, T . Azaz, R. Ahmad, A. S. M. S. Hossain, F . Baig, S. W ang, K. Lannon, T . Malik, and D. Thain, “Backpacks for notebooks: En- abling containerized notebook workflows in distributed environments, ” in Pr oceedings of the 21st IEEE International Conference on e-Science (eScience ’25) , 2025, to appear . [10] R. Ahmad, N. N. Manne, and T . Malik, “Improving reproducibility of interactiv e notebooks using application virtualization, ” Futur e Genera- tion Computer Systems , p. 108043, 2025. [11] F . Andrijauskas, D. W eitzel, and F . W uerthwein, “Open science data federation - operation and monitoring, ” ser . PEARC ’24. Ne w Y ork, NY , USA: Association for Computing Machinery , 2024. [Online]. A vailable: https://doi.org/10.1145/3626203.3670557 [12] J. Luettgau, H. Martinez, P . Olaya, G. Scorzelli, G. T arcea, J. Lofstead, C. Kirkpatrick, V . Pascucci, and M. T aufer, “Nsdf-services: Integrating networking, storage, and computing services into a testbed for democratization of data deliv ery , ” in Proceedings of the 16th IEEE/ACM International Confer ence on Utility and Cloud Computing , ser . UCC ’23. New Y ork, NY , USA: Association for Computing Machinery , 2024. [Online]. A vailable: https://doi.org/10.1145/3603166.3632136 [13] S. Shankar , S. Macke, S. Chasins, A. Head, and A. Parameswaran, “Bolt- on, compact, and rapid program slicing for notebooks, ” Proceedings of the VLDB Endowment , vol. 15, no. 13, pp. 4038–4047, 2022. [14] A. Zonca and R. S. Sinkovits, “Deploying jupyter notebooks at scale on xsede resources for science gateways and workshops, ” in Pr oceedings of the Practice and Experience on Advanced Resear ch Computing: Seamless Creativity , 2018, pp. 1–7. [15] M. Milligan, “Interactiv e hpc gate ways with jupyter and jupyterhub, ” ser . PEARC ’17. New Y ork, NY , USA: Association for Computing Machinery , 2017. [Online]. A vailable: https://doi.org/10.1145/3093338.3104159 [16] R. Thomas and S. Cholia, “Interactiv e supercomputing with jupyter , ” Computing in Science & Engineering , vol. 23, no. 2, pp. 93–98, 2021. [17] I. Colonnelli, M. Aldinucci, B. Cantalupo, L. Pado vani, S. Rabellino, C. Spampinato, R. Morelli, R. Di Carlo, N. Magini, and C. Cavazzoni, “Distributed workflo ws with jupyter , ” Future Generation Computer Systems , vol. 128, pp. 282–298, 2022. [18] K. Arya, R. Gar g, A. Y . Polyakov , and G. Cooperman, “Design and implementation for checkpointing of distributed resources using process- lev el virtualization, ” in 2016 ieee international confer ence on cluster computing (cluster) . IEEE, 2016, pp. 402–412. [19] H. Fang, S. Chockchoww at, H. Sundaram, and Y . Park, “Lar ge-scale ev aluation of notebook checkpointing with ai agents, ” in Pr oceedings of the Extended Abstracts of the CHI Conference on Human F actors in Computing Systems , 2025, pp. 1–8. [20] Z. Li, S. Chockchowwat, R. Sahu, A. Sheth, and Y . Park, “Kishu: T ime-trav eling for computational notebooks, ” arXiv preprint arXiv:2406.13856 , 2024. [21] Z. Li, S. Chockcho wwat, H. Fang, R. Sahu, S. Thakurdesai, K. Pridapha- trakun, and Y . Park, “Demonstration of elasticnotebook: Migrating live computational notebook states, ” in Companion of the 2024 International Confer ence on Management of Data , 2024, pp. 540–543. [22] S. Sato and T . Nakamaru, “Multiv erse notebook: Shifting data scientists to time travelers, ” Pr oceedings of the ACM on Pr ogramming Languages , vol. 8, no. OOPSLA1, pp. 754–783, 2024. [23] C. Brown, H. Alhoori, and D. K oop, “Facilitating dependency explo- ration in computational notebooks, ” in Pr oceedings of The workshop on human-in-the-loop data analytics , 2023, pp. 1–7. [24] D. H. T . That, G. Fils, Z. Y uan, and T . Malik, “Sciunits: Reusable research objects, ” in 2017 IEEE 13th International Confer ence on e- Science (e-Science) . IEEE, 2017, pp. 374–383. [25] F . Chirigati, R. Rampin, D. Shasha, and J. Freire, “Reprozip: Compu- tational reproducibility with ease, ” in Proceedings of the 2016 Interna- tional Conference on Management of Data , 2016, pp. 2085–2088. [26] R. Ahmad, N. N. Manne, and T . Malik, “Reproducible notebook con- tainers using application virtualization, ” in 2022 IEEE 18th International Confer ence on e-Science (e-Science) . IEEE, 2022, pp. 1–10.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment