Are LLMs Good For Quantum Software, Architecture, and System Design?
Quantum computers promise massive computational speedup for problems in many critical domains, such as physics, chemistry, cryptanalysis, healthcare, etc. However, despite decades of research, they remain far from entering an era of utility. The lack…
Authors: Sourish Wawdhane, Poulami Das
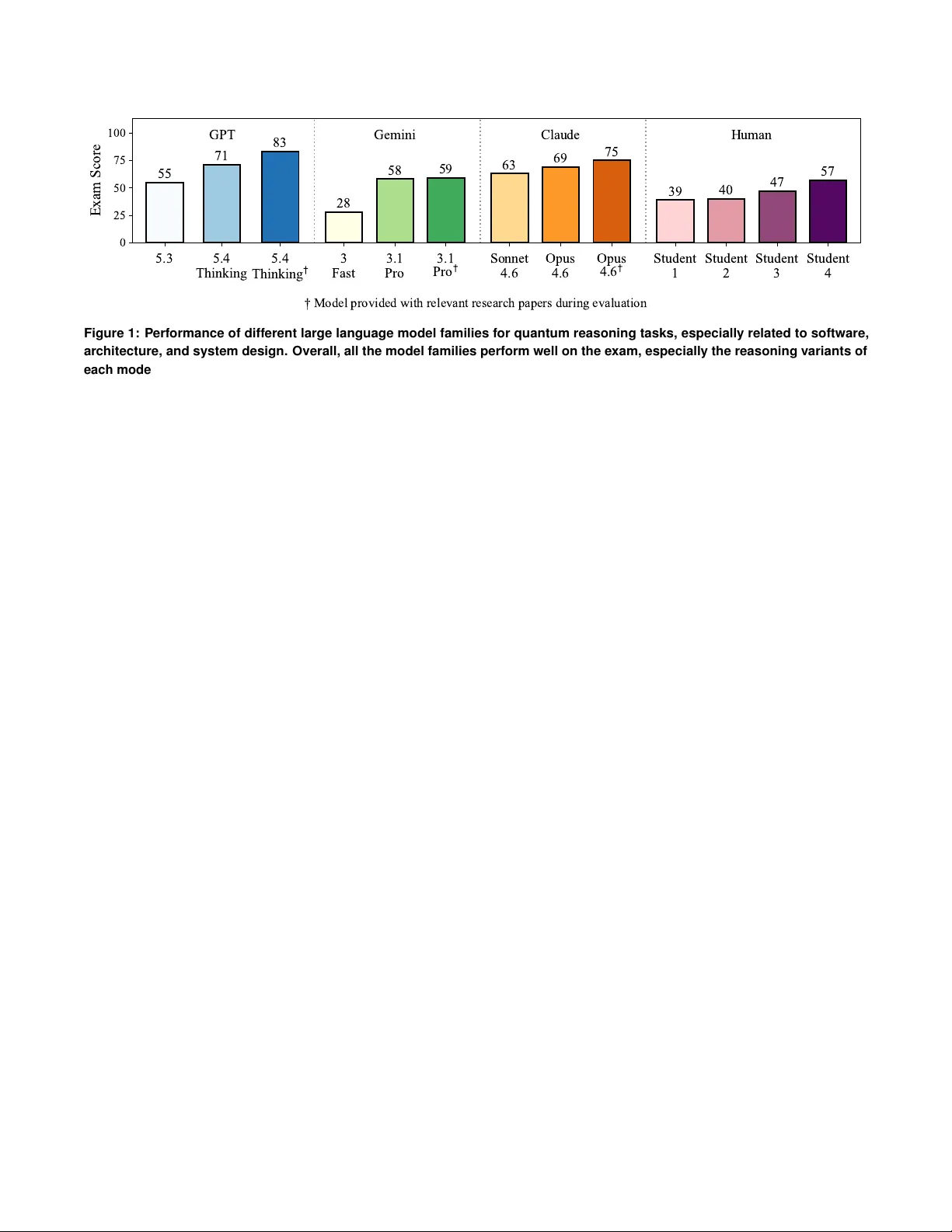
NSF W orkshop on Systems Research at the Quantum-AI Frontier , 2026 Ar e LLMs Good For Quantum Softwar e, Ar chitecture, and System Design? Sourish W a wdhane, Poulami Das The Uni versity of T e xas at Austin {sourishw , poulami.das}@ute xas.edu 1. Introduction Quantum computers promise massi ve computational speedup for problems in many critical domains, such as physics, chem- istry , cryptanalysis, healthcare, etc [ 1 – 3 ]. Howe ver , despite decades of research, they remain far from entering an era of utility . The lack of mature software, architecture, and systems solutions capable of translating quantum-mechanical proper - ties of algorithms into physical state transformations on qubit devices remains a ke y factor underlying the slow pace of tech- nological progress. Algorithmic research at the top, such as designing efficient algorithms to map applications or b uilding quantum error correction (QEC) protocols to tolerate de vice errors, are largely limited to theoretical studies. In contrast, device le vel research at the bottom is either dri ven by indus- try that focus on a single qubit modality or academic labs that ov er-optimize qubit devices at a small scale; ho wev er , these optimizations are often fragile and tend to break do wn as system sizes increase. The problem worsens due to sig- nificant reliance on domain-specific expertise, especially for software dev elopers, computer architects, and systems engi- neers. T o address these limitations and accelerate lar ge-scale high-performance quantum system design, we ask: Can large language models (LLMs) help with solving quan- tum software, architecture, and systems problems? 2. Background: A Case Study T o answer this question, we perform a preliminary case study . W e are the instructors (primary instructor and teaching assis- tant) for the "Introduction to Quantum Computing Systems" course at UT Austin [ 4 ]. This course: (1) introduces quantum computing basics to ECE/CS students, (2) familiarizes them with on-going research in the field (with particular emphasis on programming, compiler optimizations, architectural and systems models, based on recently published research papers at premier IEEE and ACM conferences, such as ISCA, MI- CR O, ASPLOS, HPCA, QCE), and (3) trains them to optimize quantum software and architecture. A critical component of the course focuses on in-class exams in which the students use their existing kno wledge to solve quantum system design problems. The exam duration is one hour and thirty minutes and students are allowed to bring in calculators and a cheat- sheet written by themselv es (although the students generally claim that cheat sheets are not so helpful for them to attempt the questions). For our case study , we take one of these exams and study the performance of dif ferent LLMs from OpenAI, Google, and Anthropic. T able 1 offers a detailed summary of these model families and versions. T able 1: Summary of LLMs used. For each provider and model family , we use tw o variants- a lightweight version for producing fast outputs and an advanced version with reasoning abilities. Provider Model Family Lightweight Reasoning OpenAI GPT [ 5 ] 5.3 5.4-Thinking Google Gemini [ 6 ] 3 Fast 3.1-Pro Anthropic Claude [ 7 ] Sonnet 4.6 Opus 4.6 The exam cov ered topics related fault-tolerant quantum systems, including trade-offs in QEC codes, decoder de- signs [ 8 , 9 ], synchronizing QEC c ycles [ 10 ], and design- ing flag-proxy networks [ 11 ]. T o compare the performance against human experts , we show the test scores of four stu- dent participants. Note that these students willingly partic- ipated in the study and FERP A laws are not violated. The performance of the models and students were both manu- ally graded by the instructors. T o measure performance, we use the exam score out of a total of 100 points. The exam, rubric, solutions, and exam scores are av ailable at https://tinyurl . com/arellmsgoodatquantum . 3. Preliminary Results Figure 1 shows the performance (exam score) for dif ferent model configurations and compares against the performance of the students. W e make the follo wing observations. 1. All six LLMs used performed well with an a verage score of 57 . 33 . The minimum is 28 using the Gemini-3 Fast model while the maximum is 71 using the GPT -5.4 Thinking model. 2. Reasoning models outperform lightweight variants with an av erage score of 66 compared to 48 . 67 . Reasoning models increase scores by 1 . 3 × and 2 . 1 × respectiv ely for the GPT and Gemini models, compared to only 1 . 1 × for the Claude models. GPT 5.4 Thinking used the largest reasoning traces (1m 57s without papers and 4m 18s with papers). Gemini Pro used 56s without papers and 1m 23 seconds with papers. In contrast, Claude reasoning models chose not to reason. 3. Assisting the reasoning LLMs to use relev ant research papers [ 8 , 10 , 11 ] increases the av erage score further to 72 . 33 . The improv ements are much more pronounced for the GPT and Claude models than the Gemini model. 4. The GPT models outperform the other two LLM f amilies for each configuration and attains the ov erall highest score of 83, outperforming the students by a significant margin. 5. LLMs performed poorly on a question requiring test-tak ers to map QEC codes to hardware. LLMs struggled to discover optimal mappings and reason about error masking. 5.3 5.4 Thinking 5.4 T h i n k i n g 3 Fast 3.1 Pro 3.1 P r o Sonnet 4.6 Opus 4.6 Opus 4 . 6 Student 1 Student 2 Student 3 Student 4 0 25 50 75 100 Exam Score 55 71 83 28 58 59 63 69 75 39 40 47 57 GPT Gemini Claude Human Model provided with relevant research papers during evaluation Figure 1: P erformance of different large language model families for quantum reasoning tasks, especially related to software, architecture, and system design. Overall, all the model families perform well on the exam, especially the reasoning variants of each model. The performance also increases when assisted by a human exper t. 4. Future: Quantum Systems Aided by AI Based on this preliminary case-study , we think research at the quantum and AI frontier is a promising and critical direction. A Promising Outlook: The overall performance of LLMs on the exam (which the instructors as well as the students con- sider to be significantly dif ficult) is promising and highlights the possibility of using LLMs to accelerate quantum software, architecture, and systems development. A fundamental re- search question on this front remains: how do we b uild a gentic workflows specifically for quantum system design? Creating Quantum Specific LLMs: Modern day LLMs are primarily designed for coding tasks, content creation, summa- rization, Q&A settings. Howe ver , we lack LLMs specifically trained for quantum reasoning tasks. Creating dedicated mod- els or fine-tuning existing LLMs ha ve the potential to impro ve performance e ven further . W e should spend research and en- gineering eff orts into this stream to effecti vely use LLMs for quantum reasoning tasks. In particular , all the models used in our study show e xcellent performance in error decoder design questions in the context of QEC and surface codes. Accurate, fast, and scalable decoders are critical to enable QEC at scale. Using quantum-specific LLMs hav e the potential to further assist in their dev elopment. Need f or T raining Datasets: W e understand that the current case-study is done in a very limited setting and requires more in volv ed expert participation to refine the scope and assess the headroom for improvement. It also requires advanced training recipes to steer the model to generate more accurate and nuanced outputs. For example, a similar study designed and led by researchers from Harvard Univ ersity along with participants from various top-ranked computer engineering programs [ 12 ] sho w that using curated datasets for computer architecture problems improv e the reasoning capability of tra- ditional LLMs. W e anticipate a similar methodology to remain effecti ve ev en for quantum reasoning tasks. W e recommend concerted ef forts in this space to expand the capabilities of LLMs for quantum tasks. Role of Human Experts Remain Critical: The performance of all three model families used in our case study improv es when the reasoning models are assisted by the instructor to use the right research paper . Especially in a field like quantum computing and topics in volving software, architecture, and systems design, the human expert still plays a critical role in the adoption of LLMs. It also remains unclear if moving to larger models with more parameters and advanced reasoning capabilities can close the gap by reducing the reliance on the expert or we would hit a parameter wall. This also poses a more crucial question- how do we maximize the utility of the human experts gi ven the limited workforce in this domain and the criticality of their inputs. LLMs Struggle On Certain Advanced T opics: All the LLMs performed poorly on a quantum reasoning task designed around optimal design of flag-proxy networks. Flag proxy net- works optimally use flag and proxy qubits to reduce error propagation and o vercome the limited connecti vity of super- conducting quantum systems. For higher resource ef ficiency and error performance, designing these netw orks with minimal qubits is critical. Six models failed to generate v alid flag con- nectivity configurations that minimized flag usage or required swaps. Moreov er , all the LLMs under study were unable to reason about multi-error scenarios, where error propagation can mask syndromes via interference. These findings suggest that current LLMs struggle with certain complex reasoning tasks, motiv ating the use and improvement of multi-modal LLMs to solve these problems with higher accurac y . 5. Conclusion LLM-assisted workflo ws and AI-based frame works promise rev olutionary impact in traditional software ecosystems. In this paper, we show how LLMs can also be used to power quantum software, architecture, and systems de velopment by ev aluating the performance of traditional LLMs on quantum reasoning tasks. Based on our study , we ha ve recommended se veral directions along which research and engineering de vel- opment efforts must be pursued. 2 Acknowledgments W e thank Shashank Nag, Allison Seigler, Dongwhee Kim, and Pa wan Kashyap, for their participation in this study . W e thank A vinash Kumar for generating Claude responses. W e hav e open sourced the exam as well as the rubric and we encourage others to contribute to the dataset as well. References [1] IBM. Quantum protein folding algorithms. https://protein- folding- demo . mybluemix . net/ , year=2016. [2] Seth Lloyd. Universal quantum simulators. Science , 1996. [3] Peter W Shor . Algorithms for quantum computation: discrete log- arithms and factoring. In Pr oceedings 35th annual symposium on foundations of computer science . IEEE, 1994. [4] Poulami Das. Ece-382v: Introduction to quantum computing systems: From a software and architecture perspecti ve. [5] OpenAI. Openai api and model documentation. https:// platform . openai . com/docs/models , 2024. [6] Gemini T eam and Google DeepMind. Gemini: A family of highly capable multimodal models. arXiv preprint , 2024. [7] Anthropic. Claude model documentation. https: //docs . anthropic . com , 2024. [8] Narges Alavisamani, Suhas V ittal, Ramin A yanzadeh, Poulami Das, and Moinuddin Qureshi. Promatch: Extending the reach of real-time quantum error correction with adapti ve predecoding. In Pr oceedings of the 29th ACM International Confer ence on Arc hitectural Support for Pr ogramming Languag es and Operating Systems, V olume 3 , pages 818–833, 2024. [9] Poulami Das et al. Afs: Accurate, fast, and scalable error-decoding for fault-tolerant quantum computers. In 2022 IEEE International Symposium on High-P erformance Computer Architectur e (HPCA) , pages 259–273. IEEE, 2022. [10] Satvik Maurya and Swamit T annu. Synchronization for fault-tolerant quantum computers. In Proceedings of the 52nd Annual International Symposium on Computer Ar chitectur e , pages 1370–1385, 2025. [11] Suhas V ittal, Ali Ja vadi-Abhari, Andre w W Cross, Lev S Bishop, and Moinuddin Qureshi. Flag-proxy networks: Overcoming the architec- tural, scheduling and decoding obstacles of quantum ldpc codes. In 2024 57th IEEE/ACM International Symposium on Micr oarchitectur e (MICR O) , pages 718–734. IEEE, 2024. [12] Shvetank Prakash, Andre w Cheng, Jason Yik, Arya Tschand, Radhika Ghosal, Ikechukwu Uchendu, Jessica Quaye, Jeffre y Ma, Shreyas Grampurohit, Sofia Giannuzzi, Arnav Balyan, Fin Amin, Aadya Pipersenia, Y ash Choudhary , Ankita Nayak, Amir Y azdanbakhsh, and V ijay Janapa Reddi. Quarch: A question-answering dataset for ai agents in computer architecture, 2025. 3
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment