Strategic Candidacy in Generative AI Arenas
AI arenas, which rank generative models from pairwise preferences of users, are a popular method for measuring the relative performance of models in the course of their organic use. Because rankings are computed from noisy preferences, there is a con…
Authors: Chris Hays, Rachel Li, Bailey Flanigan
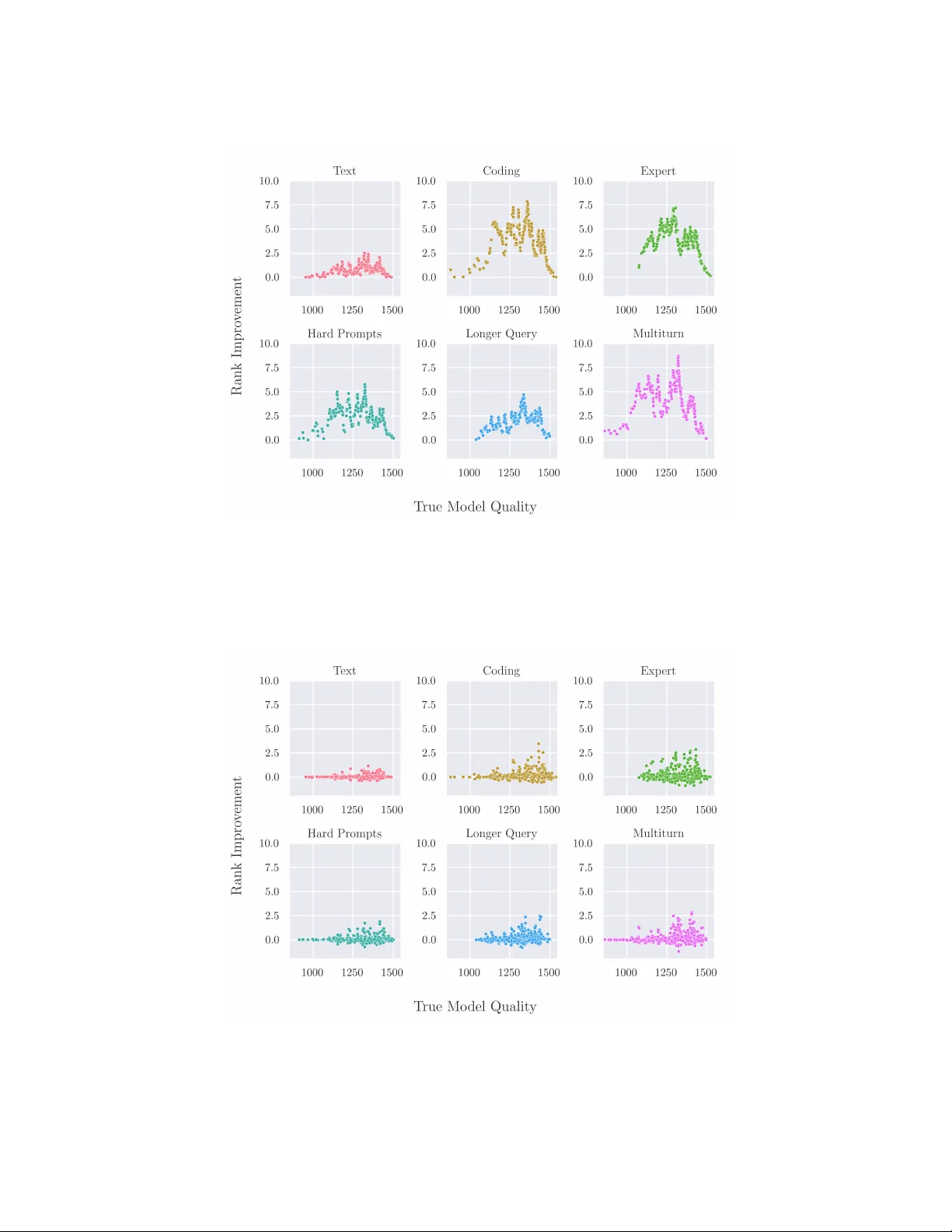
Strategic Candidacy in Generativ e AI Arenas Chris Ha ys, Rachel Li, Bailey Flanigan, and Manish Ragha v an MIT {jhays,rachelli,baileyf,mragh}@mit.edu Marc h 31, 2026 Abstract AI arenas, whic h rank generative models from pairwise preferences of users, are a p opular metho d for measuring the relative p erformance of mo dels in the course of their organic use. Because rankings are computed from noisy preferences, there is a concern that mo del pro ducers can exploit this randomness by submitting many mo dels (e.g., m ultiple v arian ts of essen tially the same mo del) and thereb y artificially improv e the rank of their top mo dels. This can lead to degradations in the quality , and therefore the usefulness, of the ranking. In this pap er, w e b egin by establishing, b oth theoretically and in sim ulations calibrated to data from the platform Arena (formerly LMArena, Chatb ot Arena), conditions under which pro ducers can b enefit from submitting clones when their goal is to b e rank ed highly . W e then prop ose a new mec hanism for ranking mo dels from pairwise comparisons, called Y ou-Rank-W e-Rank (YR WR). It requires that pro ducers submit rankings ov er their own mo dels and uses these rankings to correct statistical estimates of mo del qualit y . W e pro ve that this mec hanism is appro ximately clone-robust, in the sense that a pro ducer cannot impro ve their rank m uc h by doing an ything other than submitting each of their unique models exactly once. Moreo ver, to the exten t that mo del producers are able to correctly rank their o wn mo dels, YR WR impro v es o verall ranking accuracy . In further simulations, we sho w that indeed the mechanism is appro ximately clone-robust and quantify impro vemen ts to ranking accuracy , even under pro ducer misranking. 1 In tro duction As generativ e AI mo dels proliferate, there is a need to systematically compare their per- formance. Such ev aluations allo w AI users to make informed choices b etw een mo dels, for organizations to make informed pro curemen t decisions, for inv estors to allo cate in vestmen ts to more promising AI labs, for AI researchers to iden tify promising mo del developmen t tec hniques to wards making further progress, and for the researc h comm unit y to fo cus its efforts on common tasks (Donoho, 2024, 2017). This need has motiv ated the emergence of 1 gener ative AI ar enas , in which p eople vote on the outputs of pairs of differen t mo dels. These comparisons are then aggregated into an ov erall ranking o ver mo dels in the arena (where higher-rank ed mo dels are those that win pairwise comparisons more often). This ev aluation approac h offers the k ey adv antage (ov er, e.g., static b enchmarks) that ev aluation o ccurs in the course of organic use, and so qualit y is measured on arguably user-relev ant dimensions that might otherwise b e difficult to capture. A ccordingly , since 2024, man y suc h arenas hav e emerged (Chiang et al., 2024; Zhao et al., 2025; Chi et al., 2025; Miro yan et al., 2025; Jiang et al., 2024): foremost among them currently is Arena (formerly LMArena, Chatb ot Arena) (Chiang et al., 2024), whic h w e will use as our protot ypical example. Although these platforms are new, there is already evidence that their rankings are substantiv ely imp ortant: consumers (Morrison, 2024), in v estors (Glo ver, 2025), and tec h companies themselves (Alibaba Cloud Communit y, 2025) consider generativ e AI arenas to b e a credible and economically relev ant signal ab out the quality of mo dels. As these arenas’ rankings b ecome more imp ortan t, so grow incentiv es for companies to try to impro ve the standing of their mo dels. In recen t work, Singh et al. (2025) highlight the risks of strategic manipulations: They submit several iden tical copies (whic h we’ll call clones ) of the same mo dels to Arena, finding that one is rank ed several places ab o ve the other. 1 In tuitively , conditions on these platforms may b e fa vorable to strategic candidacy: rankings are formed through a relativ ely small n umber of comparisons (typically tens to hundreds p er pair of mo dels on Arena, or thousands to tens of thousands of comparisons p er mo del) and pairwise win margins b etw een models are small (for example, at the time of writing, the 1st-rank ed mo del has a 58% win rate against the 20th-rank ed mo del). In this low-data, tigh tly comp etitiv e regime, small amounts of noise can substantially affect outcomes. Th us, mo del pro ducers hav e b oth the incentiv e and th e abilit y to impro ve their arena p osition by simply submitting identical or near-iden tical 2 mo dels. With this as a starting p oint, we study t wo central questions: 1. When can pro ducers b enefit from clones in existing ranking systems, and if they can, b y ho w muc h? 2. Can we design clone-robust ranking systems for this setting? Our approac h and con tributions. W e b egin with a formal mo d el of the generative AI arenas. W e assume that voter preferences are generated via the statistical mo d el used for inference in these arenas (Chiang et al., 2024), a Bradley-T erry (BT) mo del. Thus, voter b eha vior is in some sense “ideal” and the status quo statistical mo del used for ranking is not missp ecified. How ev er, b ecause the num b er of voter preferences are limited, there is noise in the rankings generated from these preferences. W e then analyze the choices of mo del pro ducers, who we assume hav e an exogenous set of distinct mo dels (where distinctness of 1 Arena publishes confidence interv als around estimates of mo del qualities, and the confidence interv als for the estimated scores for the mo dels in the Singh et al. (2025) exp erimen t were ov erlapping. Such uncertain ty quan tification strategies would b e useful for assigning tie s in the ranks b etw een mo dels. Ho w ever, in this w ork, we consider the (p erhaps more difficult) problem of mo del ranking mechanisms where ties are not allo wed, and indeed, at the time of writing, Arena do es not allow ties in the ranks it assigns to mo dels. 2 F or example, near-identical submissions might o ccur if a pro ducer submits multiple, qualitatively similar c heckpoints from the same training run. 2 mo dels is not observ ed b y the platform) and ma y submit m ultiple copies of the same mo del to the ranking mechanism. Key to our formulation is the idea that pro ducers ma y hop e to increase the ranking of their top mo dels b y exploiting noise in v oter preferences. 3 In our formalization of mo del pro ducer incentiv es, pro ducers derive utility from b eing rank ed first within v arious subsets of mo dels ("leaderb oards"), like all mo dels, all op en-w eight mo dels, mo dels b elo w a given cost or latency threshold, or other intrinsic features of mo dels on which a mo del pro ducer wishes to comp ete. W e mak e t wo primary contributions, corresp onding to the research questions ab ov e: Establishing clone-nonr obustness of status quo me chanisms. In Section 3, w e formally pro ve conditions under which the intuition ab ov e is correct: the status-quo mechanism — whic h fits BT via maxim um lik eliho o d estimation and directly rep orts the implied ranking — indeed rew ards pro ducers for submitting mo del clones. Eac h clone effectiv ely gives the pro ducer an extra chance of getting “lucky” with their ranking p osition. W e confirm that this problem is significan t in sim ulations calibrated to Arena data: we sho w that some mo dels can substantially improv e their rank by submitting one or a few clones to the mechanism. T o our knowledge, ours is the first pro of of clone-nonrobustness of a Bradley-T erry mo dels under a correctly sp ecified, homogeneous human preference mo del. Existing non-robustness results in the literature hold in circumstances when voters hav e heterogeneous preferences, so the Bradley-T erry mo del is missp ecified (Pro caccia et al., 2025). Pr op osing a new ac cur acy-impr oving me chanism, Y ou-R ank-W e-R ank (YR WR), with clone-r obustness guar ante es. In Section 4, w e prop ose a new mechanism, which w e pro ve is O p 1 { ? s q -strategypro of, where s is the total num b er of samples p er pairwise comparison. That is, a pro ducer cannot gain more than O p 1 { ? s q utilit y from doing anything other then submitting exactly one copy of ev ery mo del in their set of distinct mo dels. Our mec hanism asks each pro ducer to submit a ranking ov er their o wn mo dels. W e show that this precisely negates the p oten tial b enefits from adding a clone. W e also establish that, if pro ducers truthfully rep ort rankings, the mechanism only makes the r anking mor e ac cur ate , and pro vide conditions under whic h the mec hanism is truthful. Our semisynthetic exp eriments confirm that YR WR is b oth clone-robust and increases ov erall ranking accuracy , even when pro ducers do not necessarily rep ort the correct ranking ov er their own mo dels. W e giv e an ov erview of our mechanism versus the status quo in Figure 1. Related w ork. There is a gro wing literature on clone-robustness of Bradley-T erry mo dels (Pro caccia et al., 2025; Gölz et al., 2025; Siththaranjan et al., 2024). These w orks fo cus on a setting where voters may hav e heterogeneous preferences: differen t t yp es of voters might ha ve different preference orderings ov er candidates. Our w ork is complemen tary to these in that w e explore clone nonrobustness even when voter pr efer enc es ar e homo gene ous , so that in infinite data, there would b e one “correct” ranking ov er mo dels. In other w ords, their w ork 3 This is related to but different from the concerns around “hand pic k ed” scores highligh ted in Singh et al. (2025). In their work, the fo cus is on using priv ate testing (where preference data is collected b efore a mo del is included in a ranking) to try to exploit selection effects b y releasing only the mo del rank ed b est during priv ate testing. There is no suc h notion of priv ate testing in our work: all mo dels submitted to the mec hanism are assumed to b e released publicly . Instead, in our mo del, the producers’ incentiv e to submit m ultiple mo dels comes from the fact that their utilit y is determined b y their b est-p erforming models, rather than the a v erage p erformance of their mo dels. 3 studies clone nonrobustness stemming from missp ecification of the BT mo del, and our w ork studies clone nonrobustness stemming from finite-sample effects. Our prop osed mec hanism is similar to that of Su (2022); Su et al. (2025) implemented at ICML, whic h consider incen tives in the academic p eer review pro cess: b oth inv olv e asking participan ts to rank their own submissions to the mechanism. How ev er, w e incorp orate the ranking differently: Whenev er the ranking induced b y fitted Bradley-T erry scores disagrees with the pro ducer’s own ranking, our mec hanism resolves disagreemen t by assigning all of the mo dels in question the minimum of their scores as opp osed to fitting an isotonic regression (which effectively tak es the mean of scores when reviewer scores disagree with author rankings). In their setting, the self-ranking helps denoise scores for a fixed, exogenous set of candidates; in ours, it also enables clone-robustness when the set of candidates is endogenous — participan ts in the mechanism can c ho ose which (and how many) candidates to submit. Our setting is also differen t b ecause we hav e to accoun t for dep endencies among fitted scores (b ecause v otes are o ver p airs of mo dels), whereas there is no suc h dep endency in their mo del. One reason for the differences b etw een their settings and ours is that their motiv ating applications are reinforcemen t learning from human feedbac k (RLHF) (i.e., ev aluating mo del resp onses for a giv en prompt against each other) and ours are mo del ranking (i.e., ev aluating mo dels against each other). Our work contributes to a gro wing b o dy of work in strategic b ehavior in AI ev aluations. In particular, Chen et al. (2026) analyze a Stac kleb erg game b et ween a b enchmark pro ducer and m ultiple mo del pro ducers, where mo del pro ducers ma y try to game the b enchmark by making b enchmark-specific improv ements to their mo del. Another line of w ork explores strategic or adversarial voting on generative AI arenas (Huang et al., 2026, 2025; Min et al., 2025). More broadly , our work sits in a growing literature on strategy-robust statistics (Spiess, 2025; Bates et al., 2024; Shi et al., 2025), which treat statistical proto cols as mechanism design problems. 2 Setup There are n mo del pro ducers. Each pro ducer i P r n s has a set K i of distinct mo dels where k i “ | K i | is a constan t. The full set of distinct mo dels will b e denoted K “ Ť i Pr n s K i where k “ | K | . Pro ducer actions. Each pro ducer i decides ho w man y copies of each distinct mo del j P K i to submit to the mec hanism. In particular, they may submit clones of the same mo del to try to b enefit from ev aluation noise. F ormally , a pro ducer i ’s action space is z i P Z k i ě 0 , where z ij denotes the n um b er of copies of mo del j submitted by pro ducer i . W e use z ´ i to represent the actions of all pla yers b esides i , and z ´p i,j q to represent the actions corresp onding to all mo dels except pro ducer i ’s distinct mo del j . W e write z “ p z 1 , . . . , z n q to denote a full assignmen t of actions to pro ducers. The full set of mo dels submitted by pro ducer i to the mechanism is M i p z i q “ ď j P K i t j p 1 q , . . . , j p z ij q u , 4 Pr oducer 1’ s models Submit models Submit ranked models ≻ ≻ Pairwise labels MLE scor es R ( 1 ) Final ranking 1 model per ot her pr oducer W ithin-pr oducer rank- corr ected scor es ≻ ≻ R 1 R 2 ≻ R 3 R 4 R 6 R 5 ≻ ≻ ≻ ≻ R 4 R 2 R 3 R 4 R 6 R 5 ≻ ≻ ≻ ≻ ≻ Status quo YR WR R ( 2 ) R ( 3 ) R ( 4 ) R ( 5 ) R ( 6 ) R ( 1 ) R ( 4 ) R ( 6 ) R ( 4 ) R ( 4 ) R ( 6 ) Incr easing R ( j ) R Producer ’ s models i Submit models Submit ranked models Pairwise comparisons MLE scores Models from other producers Within-producer rank enforcement ≻ Status quo YRWR R R ˇ R ≻ ≻ ≻ ≻ ≻ ≻ ≻ ≻ ≻ Figure 1: The Status Quo ( sq ) mechanism (top half ) and the Y ou-R ank-W e-R ank ( yr wr ) mec hanism (b ottom half ). and w e write m i p z i q “ | M i p z i q| . The full set of mo dels submitted to the mec hanism b y all pro ducers is M p z q “ Ť i Pr n s M i p z i q , and w e write m p z q “ ř i Pr n s m i p z i q . When it is clear from con text or when w e are sp eaking ab out a generic set of mo dels, w e will drop the argument z . P airwise v oting. After the pro ducers submit their mo dels for an action z , the users vote on pairwise comparisons. After seeing outputs from t wo anon ymous models j, j 1 P M p z q , the user answers either j ą j 1 ( j is preferred) or j 1 ą j . F ollowing the classic Bradley-T erry (BT) mo del (Bradley and T erry, 1952), we assume each mo del j P M has some latent qualit y R j P R ě 0 , and eac h v ote is dra wn as an indep endent Bernoulli random v ariable with probabilit y Pr p j ą j 1 q “ exp R j exp R j ` exp R j 1 . (Of course, if t wo mo dels j, j 1 are clones, then R j “ R j 1 .) W e use p j ą j 1 “ Pr p j ą j 1 q as shorthand. W e use R to denote the v ector of qualities, and R p ℓ q to denote the ℓ -th largest v alue in R (and w e will use analogous notation for estimated qualities as w ell). This voter preference mo del is exactly that for which Arena’s ranking pro cedure is sp ecified correctly . Our analysis is thus delib erately fav orable to the status quo. Let there be s P N v otes p er pairwise mo del comparison. W e use v j ą j 1 to denote the (random) num b er of v otes in whic h j ą j 1 (and thus, v j 1 ą j ` v j ą j 1 “ s .) W e’ll write v “ t v j 1 ą j u j 1 ‰ j to denote the full set of vote counts. The parameters describing mo del pro ducers are the num b er of pro ducers n , distinct mo dels K , mo del qualities R and pairwise v ote counts s . T ogether, we will refer to fixed v alues of these parameters as a pr oblem instanc e . Throughout this pap er, w e will imp ose the following regularit y condition on R . Assumption 2.1. There exists a universal constant C suc h that, for all problem instances and j, j 1 P K , it holds | R j ´ R j 1 | ď C . The assumption sa ys that the qualities of any tw o pro ducers may not b e arbitrarily differen t, and that this maximum difference do es not grow even when w e analyze problem instances with man y distinct mo dels (e.g., large K ). W e’ll assume that estimated ˆ R ob eys the same constraint. This kind of condition is standard in analyses of Bradley-T erry mo dels (cf. Simons and Y ao (1999)) and is useful in our analysis b ecause it ensures that, when the n umber of mo dels is large, no one mo del can ha v e to o muc h influence ov er the rankings of other mo dels. In practice, pairwise win rates are t ypically b ounded aw a y from 0 and 1, ev en when the pair of mo dels are ranked far apart. 5 Mec hanism. A mec hanism G is a mapping from mo dels M and votes v o ver pairs of mo dels j, j 1 P M to a ranking σ o ver all mo dels in M . W e denote mec hanism outputs as G p M p z q ; v q , where we drop the v when it is clear from con text. W e let Σ p G p M p z qq b e the distribution of ranks (ov er the randomness in v otes) induced from running G on an instance where play ers pla y z . W e will write σ p ℓ q to indicate the mo del ranked ℓ -th in the ranking and σ ´ 1 p j q to indicate the ranking of mo del j . W e use the preference relation ą σ to indicate a comparison according to the ranking σ . Finally , we will often talk ab out rankings o ver subsets of mo dels, ordered according to a reward vector. F or a generic reward vector r P R m and a subset of mo dels S Ď M , w e define the ranking ov er S according to r as rank p S, r q “ σ : σ j ą σ j 1 ð ñ r j ě r j 1 . Utilities and leaderb oards. Finally , w e m ust formalize pro ducer utilities. A natural goal for pro ducers, in tuitively , is to hav e one of their mo dels rank ed first among all mo dels in the arena. How ev er, treating winning ov erall as the sole source of utilit y fails to explain b eha vior in practice, where pro ducers routinely submit mo dels that will not rank highly , even against their o wn existing mo dels. 4 Instead, w e prop ose a utility mo del that rewards pro ducers for b eing b est in a given class of r elevant mo dels , even if they do not rank first in the ov erall arena. F ormally , w e consider a collection of le aderb o ar ds L Ď t 0 , 1 u M , where eac h leaderb oard L P L is a set of comp eting mo dels. F or example, pro ducers might b e interested in ranking first among op en-weigh t mo dels, in which case the relev an t leaderb oard L w ould consist of t j P M : j is op en-weigh t u . Similarly , w e migh t consider leaderb oards for non-reasoning mo dels, mo dels under a certain size/cost/latency threshold, or models supported b y a particular IDE. Leaderb oards need not b e disjoint. Intuitiv ely , they capture the idea that differen t consumers hav e different requiremen ts, and indeed w e could microfound this with a consumer choice mo del where eac h leaderb oard is a consumer’s consideration set. Under this utilit y mo del, pro ducers ma y would b e incentivised to submit “weak” mo dels that hav e no c hance of ranking first in the ov erall leaderb oard if these mo dels ha ve a c hance of winning on some other relev an t leaderb oard. With this, we can formally define pro ducer utilit y . Eac h pro ducer i assigns some imp or- tance ν i p L q P r 0 , 1 s to eac h leaderb oard L , whic h corresp onds to the utilit y i receiv es for ha ving the top-ranked mo del in L — that is, for eac h leaderb oard L P L , pro ducer i gets utility ν i p L q for winning L and 0 otherwise. W e normalize these utilities so that ř L P L ν i p L q “ 1 . F ormally , w e let σ L b e the sub-ranking of σ o ver the mo dels in leaderb oard L ; i.e., for all j, j 1 P L, j ą σ j 1 ð ñ j ą σ L j 1 . Then, if the ov erall ranking from the mec hanism is σ , pro ducer i ’s utility is u i p σ q “ ÿ j P M i ÿ L P L ν i p L q ¨ 1 p σ L p 1 q “ j q . Naturally , clones must b elong to the same leaderb oards, as leaderb oard mem b ership is based on a mo del’s fixed c haracteristics (e.g., size, cost). 4 F or example, in August 2025, Op enAI released (and even tually submitted to Arena) several op en-weigh t mo dels (the oss series) despite the fact that their p erformance was clearly limited compared to their existing flagship (closed) mo dels; see https://openai.com/index/introducing-gpt-oss/. 6 Throughout, w e use nonasymptotic big-O notation, so that, e.g., for sequences t a i u 8 i “ 1 , t b i u 8 i “ 1 w e write b i “ O p a i q if there exists a universal constant C suc h that b i ď C a i for all i . 3 The Status Quo Mec hanism The Status Quo mechanism ( sq ) used by Arena (Chiang et al., 2024) is depicted in the top half of Figure 1 and is formally defined in Algorithm 1. sq takes in a set of mo dels presen t in the arena and the pairwise vote count ov er them. Using the votes, it fits estimated rewards ˆ R “ p ˆ R 1 , . . . , ˆ R m q via maximum lik eliho o d estimation. 5 Then, it outputs the ranking implied b y ˆ R . Ties can b e brok en arbitrarily . In the text, w e will refer to sq on inputs M , v as sq p M q , dropping the v argumen t when it is clear from context. The effects of clones. Before w e formalize our main result for this section, w e identify the key intuition for how cloning can affect the ranking distribution induced b y sq . 1. The “L ottery Ticket” Effe ct. The cloned mo del provides an extra chance for the pro ducer to win, since it receiv es its own random dra w of pairwise votes, which we call the lottery- ticket effe ct . The pro ducer b enefits from taking the b est outcome among these random dra ws, thereby increasing the probability of winning. This is a direct consequence of the fact that there are a finite n umber of v otes p er pair of mo dels, which leads to randomness in the final ranking — if there w ere infinite comparisons, the ranking would b e deterministic and this effect would disapp ear. 2. The “New Comp etitor” Effe ct. In tro ducing a clone causes a new-c omp etitor effe ct : new pairwise v otes must b e collected b etw een the cloned mo del and the existing mo dels. This c hanges the comp etitive environmen t faced by each mo del. Intuitiv ely , if the clone is very strong, most existing mo dels will lose more of their matc hups relativ e to the coun terfactual without the clone; if it is very weak, they win more. These changes propagate to the fitted Bradley–T erry scores, p oten tially increasing or de cr e asing any individual mo del’s win probability , adding complexity to our analysis. How ever, our w orkhorse lemma, Lemma C.1, establishes that the new comp etitor effect is small: the c hange to an y individual mo del’s win probabilit y is no more than O p 1 { ? s q . In tuitively , a clone is v aluable as long as the lottery tic ket effect (which is alwa ys p ositiv e) out weighs the new comp etitor effect (whic h can either b e p ositive or negative). Our main result characterizes when the lottery tick et effect out weigh ts the potential dra wbacks of the new comp etitor effect. In tuitiv ely , this is when a pro ducers’ mo dels hav e a reasonable (but uncertain) chance of winning a (set of ) leaderb oard(s) of non-negligible imp ortance. W e next formalize these conditions via a definition. Informally , the definition says that, across leaderb oards with p ositiv e total w eight to a pro ducer i , t wo quan tities are b ounded a w ay from 0: the mo del j ’s c hance of winning, and 5 The Bradley-T erry mo del parameters are inv ariant to addition by a constan t vector (i.e., data generated b y parameters R and R ` c 1 are equal in distribution), so to fit MLE it is necessary to enforce an identifiabilit y constrain t lik e ř j P M ˆ R j “ 0 . 7 Algorithm 1: Status Quo ( sq ) Input: Models M ; pairwise vote coun ts v Compute p R Ð arg max R P R m ÿ j ‰ j 1 v j ą j 1 log ´ exp p R j q exp p R j q ` exp p R j 1 q ¯ return σ “ rank p M , p R q (breaking ties arbitrarily) pro ducer i ’s chance that none of their mo dels win. These conditions are imp ortan t for a mo del to b e worth cloning b ecause, if a mo del has no c hance of winning, a cloned version of that mo del also w on’t hav e a chance of winning. Similarly , if a pro ducer is guaran teed to win on a set of leaderb oards, there is no need to clone mo dels to improv e the pro ducer’s chances on those leaderb oards. Definition 3.1 ( p ε, δ q -comp etitiv e mo del) . F or a fixed strategy profile z , a mo del j P M i for pro ducer i is said to b e p ε, δ q -c omp etitive if there exists a set of leaderb oards S Ă L suc h that ř L P S ν i p L q ě ε and, for all L P S , Pr σ „ Σ p sq p M p z qqq p σ L p 1 q “ j q ě δ, and Pr σ „ Σ p sq p M p z qqq p σ L p 1 q R M i q ě δ. The parameter ε represen ts ho w imp ortan t the set of leaderb oards m ust be, and δ represen ts the minimum probabilit y that mo del j wins on these leaderb oards. The condition that there must exist a set of leaderb oards with total utility more than ε is imp ortant b ecause of dep endencies across leaderb oards: if a clone helps the pro ducer win on an inconsequential leaderb oard ( ν i p L q « 0 ) but harms the pro ducer on another leaderb oard with non-negligible p oten tial utilit y , then the costs of cloning migh t outw eigh the b enefits. W e are no w ready to state our main theorem in this section. It establishes that if a pro ducer has a p ε, δ q -comp etitiv e mo del, then for a sufficien tly large set of mo dels and votes p er pair of mo dels, pro ducers are incen tivised to submit another copy of that mo del. Theorem 3.2 (Clone-nonrobustness of the status quo mechanism) . F or al l c onstants ε, δ ą 0 , ther e exists s 0 , m 0 such that for al l s ě s 0 , m ě m 0 , the fol lowing holds. F or any pr o duc er i , any str ate gy pr ofiles z and any p ε, δ q -c omp etitive mo del j , pr o duc er i would b enefit fr om submitting an additional c opy of j . F ormal ly, let z 1 “ p z i,j ` 1 , z ´ i,j q . Then E σ „ Σ p sq p M p z 1 qq r u i p σ qs ą E σ „ Σ p sq p M p z qq r u i p σ qs . In tuitively , the smaller ε and δ are, the w eaker the b enefits to cloning ma y b e — smaller ϵ means that the cloned mo del sits on less imp ortan t (to the mo del pro ducer) leaderb oards and smaller δ means that the lottery tick et effect of an additional copy of the ( ϵ , δ )-comp etitiv e mo del are smaller. Th us, smaller ε, δ imply larger s 0 , m 0 , since new comp etitor effects decrease in s and m . The pro of of Theorem 3.2 is given in Section D. W e hav e thus established conditions under which a pro ducer can b enefit from clones. It is trivial to demonstrate that the gains from clones can b e p oten tially v ery large: Example 3.3 (Constant p ossible gain) . Consider n pro ducers with one distinct mo del, eac h of iden tical quality . Eac h p ro ducer wins with probability 1 { n . No w, supp ose pro ducer 1 submits 8 Figure 2: Ranks gained via cloning under the Status Quo v ersus Y ou-R ank-W e-R ank mec ha- nisms, across several of Arena’s mo del arenas. k clones (including their original mo del); their new probabilit y of winning is k {p k ` n ´ 1 q , whic h is constan t (in n and m ) for k P Ω p n q and approaches 1 as k Ñ 8 . The fact that the ab ov e example sets all rew ards identically is for simplicit y of intuition; what it illustrates more broadly is that a pro ducer can flo o d the system with mo dels and driv e their win probability upw ards arbitrarily . 3.1 Sim ulation study with Arena data T o demonstrate the implications of Theorem 3.2, we conduct a set of simulations calibrated to Arena data to explore how muc h pro ducers can b enefit from clones. T o do this, w e snapshot Arena on January 1, 2026 and fo cus on the largest arenas (those with the most mo dels). F or each such arena, we treat all listed mo dels as distinct and use the platform’s published BT scores as “ground-truth” qualities, with mo del pro ducers given by the asso ciated organization metadata. Thus, our empirical approac h is designed to sho w what w ould happ en in the idealized case (fav orable to the status quo) in which (1) the Bradley-T erry mo del was correctly sp ecified and (2) Arena had p erfectly estimated mo del qualities. Holding these qualities fixed, we then v ary the n umber of clones of each mo del j o ver ℓ P t 1 , 2 , 3 , 4 , 5 u , eac h time, pro ducing some new syn thetic set of mo dels M with the original mo dels and the clones. F or each of these mo del sets M , w e generate syn thetic pairwise outcomes: for eac h unordered pair p j, j 1 q , w e draw s iid Bernoulli comparisons with BT win probability p j ą j 1 , where s is the arena’s av erage num b er of votes p er mo del-pair. This pro duces our vote counts v p j,ℓ q (where j is cloned ℓ times). W e also rep eat this pro cedure in the raw instance with no clones, the vote coun ts for which w e call v . Co de to repro duce the simulations and plots is av ailable at https://github.com/johnchrishays/strategic- candidacy- in- genai- arenas . W e then run sq with v ote counts v p j,ℓ q for all j P L, ℓ P t 1 , 2 , 3 , 4 , 5 u , and also on the ra w instance v (using the corresp onding multiset of mo dels eac h time). F or eac h mo del j , w e report the highest rank among all of its clones, capturing the idea that pro ducers are rew arded for their highest-rank ed mo del in a given leaderb oard. W e show the results in Figure 2, where w e plot the a verage, 5th, and 95th p ercen tile of the num b er of ranks gained across mo dels j P L b et ween 0 clones (ra w instance) and ℓ clones, across arenas. The results 9 for sq are on the left p er arena; the righ t sho ws analogous results for our mec hanism yr wr , whic h w e will unpac k in Section 4.6. F o cusing on the lines p ertaining to sq , we see that across arenas, cloning a mo del leads it to gain in rank p osition, with some mo dels moving up ě 7 p ositions with just one clone. With additional clones, rank p osition can b e reliably increased further with mild diminishing marginal returns. W e remark that there are larger b enefits from clones in arenas (lik e Co ding, Exp ert, and Multiturn) with few er pairwise votes p er pair of mo dels ( s ď 30 ). Second, we conduct additional data analysis in Section A to show that the mo dels that b enefit from clones ha ve scores that are clustered together with sev eral other mo dels, whic h means that small increases to fitted scores yield large increases in p osition on the arena. 4 The Y ou-Rank-W e-Rank Mec hanism The YR WR mechanism is depicted in the b ottom half of Figure 1 and defined formally in Algorithm 2. It augmen ts the status-quo mec hanism first b y taking an additional input: a set of pr o duc er-define d r ankings π “ t π i u i Pr n s , where π i is a ranking ov er M i . Our main result do es not require us to assume that this ranking is “correct” in any sense; this can b e though t of as a pro ducer’s prioritization o ver their mo dels with resp ect to the mechanism. W e will discuss this in more formality later. W e will refer to YR WR on inputs M , π , v as yr wr p M , π ; v q , again dropping the v from the notation when clear from con text. As in sq , yr wr first estimates quality scores p R via MLE. Then, instead of directly outputting the implied ranking, it p erforms a monotone sc or e c orr e ction within each pro ducer: for every mo del j P M i , its corrected score q R j is the minimum estimated score among all mo dels j 1 P M i rank ed ahead of j according to π i . Finally , yr wr outputs a global ranking implied by q R . Notably , our mechanism receives no external information ab out which mo dels are clones and whic h are distinct. This is motiv ated b y key practical c hallenges: the platform ma y ha ve no access to proprietary mo dels’ weigh ts or logits and tests of whether mo dels pro duce similar outputs might b e computationally or statistically in tractable. Moreov er, even if the mec hanism could require white-b ox mo del insp ection, producers migh t minimally change the parameters of similar mo dels or otherwise manipulate their submissions to ev ade clone detection. Before w e state our main result of this section, w e provide intuition ab out wh y the self-ranking mechanism provides clone-robustness. In tuition: Wh y do pro ducers’ rankings help? Enforcing that scores ob ey pro ducer ranks help produce more accurate rankings and disincen tivise clones. T o see why this is true, consider the distribution of fitted scores of 2 copies of mo del j by pro ducer i , denoted j p 1 q , j p 2 q , where without loss of generalit y , w e assume j p 1 q ą π i j p 2 q . Because of the minimum op eration to compute q R j p 1 q , q R j p 2 q , the distribution of their maximum is exactly that of p R j p 1 q : max t q R j p 1 q , q R j p 2 q u d “ p R j p 1 q . Put another wa y , with yr wr , the pro ducer’s fitted score is the maxim um of t wo dra ws half the time (if p R j p 1 q ą p R j p 2 q , agreeing with the pro ducer ranking π i ) and the minimum otherwise. 10 Algorithm 2: Y ou-Rank-W e-Rank ( yr wr ) Input: Models M ; rankings t π i u i Pr n s ; v ote coun ts v Compute p R Ð arg max R P R | M | ÿ j ‰ j 1 v j ą j 1 log ´ exp p R j q exp p R j q ` exp p R j 1 q ¯ foreac h pr o duc er i P r n s do foreac h j P M i do q R j Ð min t p R π i p k q : k ď π ´ 1 i p j qu Output: σ “ rank p M , q R q (breaking ties within each producer i according to π i and ties b etw een pro ducers arbitrarily). And for tw o identically distributed random v ariables, the distribution of a random v ariable whic h is the maxim um of the tw o v ariables with probabilit y half and the minimum with probabilit y half is exactly equal to the distribution of each random v ariable. This means, from the p ersp ective of the top pro ducer-rank ed mo del in the clones of j , it is no b etter to submit tw o mo dels than it is to submit a single mo del. The k ey idea w e are leveraging is that when submitting clones, the pro ducer cannot know whic h will do b etter — the pro ducer will ha ve had to “pick a winner” b etw een the clones in adv ance. By contrast, under sq , the distribution of max t p R j p 1 q , p R j p 2 q u sto c hastically dominates that of p R j p 1 q . This creates the selection-on-winners effect whic h pro ducers could b enefit from. Finally , w e note that this mechanism remov es the incentiv es for clones despite not having an y sp ecial information ab out whic h mo dels are clones. 4.1 Appro ximate clone-robustness of YR WR. W e no w sho w our main result in this section: for all pro ducers i , it is an approximate dominan t strategy to submit one copy of each distinct mo del, r e gar d less of pro ducers’ submitted rankings π . Theorem 4.1 (Appro ximate clonepro ofness) . F or al l ε ą 0 , ther e exists s 0 , m 0 such that for al l s ě s 0 and m ě m 0 , the fol lowing holds. Fix any π , z , and let z 1 “ p 1 , z ´ i q b e the pr ofile wher e i inste ad plays one c opy of e ach mo del. Then E σ „ Σ p yr wr p M p z 1 q ,π q r u i p σ qsq ě E σ „ Σ p yr wr p M p z q ,π qq r u i p σ qs ´ ε. Our pro of of this result is in Section E. It relies on the intuition pro vided ab ov e along with an application our w orkhorse distributional stability result, Lemma C.1: W e observe that the distribution of the first mec hanism-ranked clone is equal to that of the first pro ducer-rank ed clone, b y isotonicit y . Then, using Lemma C.1, we establish that the win probabilit y of the first pro ducer-ranked clone is approximately (up to additive ε ) equal to the distribution of a single mo del under the strategy with one cop y of eac h mo del. 11 4.2 A ccuracy of YR WR. Th us far, w e hav e established approximate clone-robustness of the YR WR mec hanism. It is natural to ask whether this clone-robustness prop erty comes at a cost to ranking accuracy . After all, our mec hanism may mo dify estimated BT scores, even when there are no clones and when the pairwise preference data is generated by a BT mo del. Naturally , the impact of pro ducer rankings on the accuracy of the mechanism dep ends to some degree on the quality of pro ducers’ submitted rankings — but we no w sho w that if pro ducers’ submitted rankings are consistent with the ground-truth ranking, our mec hanism only makes the sc or es mor e ac cur ate , at least with resp ect to ℓ 8 distance. W e will henceforth refer to the correct ranking as π ˚ i : “ rank p M i , R q with π ˚ : “ t π ˚ i u i Pr n s . Prop osition 4.2 ( yr wr is accuracy-impro ving) . Fix R, M and let p R “ sq p M q and q R “ yr wr p M , π ˚ q . Then, } q R ´ R } 8 ď } p R ´ R } 8 . The pro of of Prop osition 4.2 is in Section F and follows from the fact that yr wr ’s score-correction replaces each score by a minimum ov er a fixed subset of scores — a mapping that is 1 -Lipschitz in } ¨ } 8 , so the correction cannot increase ℓ 8 error. Prop osition 4.2 directly implies that that yr wr main tains the asymptotic correctness prop erties of sq . W e formalize this next. Corollary 4.3 (Efficiency and correctness of yr wr ) . Fix R, M , and let q R “ yr wr p M , π ˚ q . Then, • q R is a ? s -c onsistent estimator of R • If D γ ą 0 : min j ‰ j 1 P M | R j ´ R j 1 | ą γ ą 0 , then P r rank p M , q R q “ σ ˚ s Ñ 1 as s Ñ 8 . Informally , the corollary states that, under truthful pro ducer rankings, the mo dified scores pro duced b y yr wr inherit the statistical efficiency and asymptotic almost sure ranking correctness of the sq mec hanism. 4.3 T ruthfulness in pro ducer rankings π . The accuracy results ab ov e rely on pro ducers ranking their mo dels according to R . How ev er, it is not immediately ob vious that they will alw ays hav e an incen tiv e or kno wledge to do so. In general, misrep orted pro ducer rankings could lead to reductions in the accuracy of the ranking: Even with infinite data, if a pro ducer misrep orts their ranking, the mechanism could drastically change the ranking to enforce isotonicity , leading to rankings which are far from correct. W e explore pro ducer’s ranking strategies and their implications next. 12 Incen tives for pro ducer misrep orts. Ev en if a pro ducer knows the ground-truth ranking o ver their own mo dels, they ma y not b e incen tivised to truthfully rep ort the ranking. The problem is pro ducers’ differential utilities across different leaderb oards; we illustrate this with the following example. Example 4.4. Supp ose pro ducer i has tw o mo dels a, b with similar true rewards but where R a ą R b . Supp ose a is closed-weigh t and b is op en-weigh t. Assume the pro ducer kno ws that they ha ve a negligible chance of winning the leaderb oard L all consisting of all mo dels. I.e., P p σ L all p 1 q P t a, b uq « 0 . Moreov er, supp ose the pro ducer assigns non-negligible w eight to the leaderb oard for op en-weigh t mo dels L open , on which b is eligible but a is not, i.e., b P L open , a R L open , and ν i p L q " 0 . Also, supp ose mo del b has a non-negligible chance of winning L open , i.e., P p σ L open p 1 q “ b q " 0 . Under the yr wr score correction, if the pro ducer rep orts a ą b , then b ’s corrected score is ˇ R b “ min t ˆ R a , ˆ R b u , so a low realized ˆ R a —whic h can o ccur purely due to estimation noise, despite the fact that R a ą R b —will c ap b ’s corrected score and reduce b ’s chance of winning leaderb oard L open . In tuitively , what is happ ening is that pro ducer i misranks their mo dels to “protect” model b from b eing p enalized due to noisy estimates of low er priority mo dels. This problem is resolv ed if the qualities of mo dels that c ould win or c ould dr ag down winners are sufficien tly separated relative to s suc h that the noise p oses no risk. While one can formulate sufficien t conditions for truthfulness of this flav or, w e next state the simpler claim that once s is large enough, yr wr is truthful in π : Prop osition 4.5 (Asymptotic truthfulness) . F or al l z and ε ą 0 , ther e exists sufficiently lar ge s 0 P N such that for al l s ě s 0 , E σ „ Σ p yr wr p M p z q , p π ˚ i ,π ´ i qqq r u i p σ qs ě E σ „ Σ p yr wr p M p z q , p π i ,π ´ i qqq r u i p σ qs ´ ε. In other words, truthfulness is an appro ximately dominan t strategy for sufficiently large s . Of course, the large s regime is exactly where the yr wr mechanism is least necessary (since in large samples, there are smaller incentiv es for strategic candidacy). T o address the concern of pro ducer misranking, in the next section, we consider a v ariant of YR WR whic h o verrides pro ducer rankings when enough votes hav e b een collected to confiden tly order pairs of mo dels. 4.4 An uncertain t y-aw are YR WR v arian t Ev en if a pro ducer wishes to truthfully rep ort their ranking ov er models, they ma y hav e uncertain ty ov er the relativ e p erformance of their mo dels. This could again lead to degrada- tions in the quality of the ranking: If a pro ducer has no information ab out whic h mo dels are b etter than others, their ranking can b e no b etter than random and , ev en with infinite data, the mec hanism would likely pro duce an incorrect ranking. There are tw o wa ys to mitigate incorrect pro ducer rankings due to pro ducer uncertaint y . First, the platform could implement priv ate testing, which allows for the collection of preference data b efore a mo del is submitted to public leaderb oards. Priv ate testing can serve as a useful to ol in circumstances where mo del pro ducers are uncertain about the relativ e 13 p erformances of their mo dels: the pro ducer can collect preference data ab out the relative p erformance of their mo dels, and use it to inform the ranking they submit to the mechanism. Indeed, if each pro ducer has only a small n umber of mo dels, priv ate testing can b e v ery statistically efficient: There are only a small n umber of pairwise comparisons to make, so high-qualit y pro ducer rankings can b e computed with m uch less data than necessary for a high-qualit y ov erall ranking. Platforms like Arena already provide priv ate testing, and as long as fresh data is collected (i.e., priv ate testing data is not used to form the ranking) when the mo del is released publicly , mo del pro ducers cannot b enefit from selection effects due to noise in preference data during priv ate testing. Second, the platform could implemen t a v ariant of the YR WR mechanism that only enforces pro ducer rankings among fitted mo del scores that ha ve ov erlapping confidence in terv als. That is, at confidence level α { ` m 2 ˘ , let x CI α { p m 2 q p j q b e a ? s -consisten t confidence in terv al for mo del j con taining the MLE estimate ˆ R (p erhaps as computed in Chiang et al. (2024)). Then this unc ertainty-awar e (UA) YR WR v arian t, called ua-yr wr , w ould b e defined b y fitting the BT-MLE scores as in Algorithm 2 but correcting scores as q R UA j Ð min t p R π i p k q : k ď π ´ 1 i p j q , x CI α p j q X x CI α p k q ‰ ∅ u , and using these scores to pro duce a ranking. Lik e the v anilla yr wr , the mechanism will tak e M , π as arguments, but it will also take a simultaneous confidence lev el α , which will b e assumed to construct a set of confidence interv als that hold sim ultaneously with probabilit y at least 1 ´ α . This v arian t of the mechanism is app ealing b ecause it ignores pro ducer rankings in regimes where there is enough data to confidently rank mo dels. Th us, in infinite data, the ranking pro duced b y this v ariant would b e correct, regardless of the rankings submitted by mo del pro ducers. T o achiev e approximate clone-robustness with high probabilit y , the confidence level α w ould hav e to b e chosen to ensure simultaneous v alidity across all confidence interv als. W e next pro v e analogous results for the uncertaint y-a ware v ariant as w e did for the v anilla v arian t in Theorem 4.1 and Corollary 4.3. Pro ofs are deferred to Section F. Corollary 4.6 (to Theorem 4.1) establishes approximate clone-robustness. Corollary 4.6 is iden tical to Theorem 4.1, except that it is lo oser by the simultaneous confidence level α . The argument for Corollary 4.6 is almost directly implied by Theorem 4.1: If the confidence in terv als cov er R , the argumen t for Theorem 4.1 go es through directly . If not, the c hange in utilit y can b e at most the confidence level α . Corollary 4.6 (Approximate clonepro ofness of ua-yr wr ) . F or al l ε ą 0 , ther e exists s 0 , m 0 such that for al l s ě s 0 and m ě m 0 , the fol lowing holds. Fix any π , z , and let z 1 “ p 1 , z ´ i q b e the pr ofile wher e i inste ad plays one c opy of e ach mo del. F or any simultane ous c onfidenc e level for ua-yr wr α ą 0 , it holds E σ „ Σ p ua-yr wr p M p z 1 q ,π ,α q r u i p σ qsq ě E σ „ Σ p ua-yr wr p M p z q ,π ,α qq r u i p σ qs ´ ε ´ α. Prop osition 4.7 establishes ? s -consistency of the fitted scores and asymptotic correctness of the estimated ranking. Prop osition 4.7 is considerably stronger than Corollary 4.3: it holds for an y pro ducer ranking, rather than just truthful ones. The argumen t for the prop osition is also different: Since w e do not assume the pro ducer ranking is truthful, we cannot app eal to Prop osition 4.2, so in the pro of we mak e a direct argument for efficiency and correctness. 14 Prop osition 4.7 (Efficiency and correctness of ua-yr wr ) . Fix R, M , and any set of pr o duc er r ankings π . L et q R UA “ ua-yr wr p M , π , α q . Then, • q R UA is a ? s -c onsistent estimator of R • If D γ ą 0 : min j ‰ j 1 P M | R j ´ R j 1 | ą γ ą 0 , then P r rank p M , q R UA q “ σ ˚ s Ñ 1 as s Ñ 8 . 4.5 A within-leaderb oard YR WR v ariant In the results w e ha ve presented so far, we hav e established that yr wr incen tivizes truthful rep orts in the asymptotic regime (Prop osition 4.5) but that in general, producers ma y misrep ort their true rankings in finite samples (Example 4.4). How ev er, if we mo dify the mec hanism to p erform within-le aderb o ar d instead of global score correction, mo del pro ducers are incentivised to submit truthful rankings in finite samples as w ell, as we show in our next result. F ormally , this mo dified mechanism, called local-yr wr , is the same as yr wr except that its score correction is p erformed within eac h leaderb oard: q R local j ; π ,L : “ min ! ˆ R π i p k q : k ď π ´ 1 i p j q and π i p k q P L ) . T o implemen t this approac h, leaderboards m ust b e explicitly defined on the platform, rather than implicitly defined by , e.g., a user who will choose the first among a subset of mo dels. That is, the platform m ust b e able to pro vide separate rankings for differen t leaderb oards. T o accomplish this, platforms could provide filters on the rankings within each arena, using metadata ab out each mo del, like mo del size, cost, latency , or other factors. Th us, users who w anted, e.g., to see the ranking among mo dels b elo w a given cost threshold, could see a ranking generated to b e b oth truthful and clone-robust. 6 Our next result establishes truthfulness of the local-yr wr mec hanism. Prop osition 4.8 (T ruthfulness of local-yr wr ) . Fix any pr o duc er i , any str ate gy pr ofile z in which pr o duc er i submits exactly one c opy of e ach mo del p M i “ K i q , and fix any other-pr o duc er r ankings π ´ i . Then for every finite s and every alternative r ep ort π i , E σ „ Σ p local-yr wr p M p z q , p π ‹ i ,π ´ i qqq r u i p σ qs ě E σ „ Σ p local-yr wr p M p z q , p π i ,π ´ i qqq r u i p σ qs . An analogous appro ximate strategy-pro ofness result holds for local-yr wr as for yr wr , using the same argument as in the pro of of Theorem 4.1. In tuitiv ely , it is alwa ys appro ximately utilit y impro ving to remov e clones from any rank correction op erating ov er a set of clone, regardless of whic h other mo dels b y the same pro ducer migh t or migh t not b e in the same leaderb oard. 6 Ho wev er, ev en if such a filter system could b e feasibly implemented, a p ossible downside of local-yr wr is that it can lead to inconsisten t rankings b etw een pairs of mo dels across leaderb oards, which users might find confusing or difficult to interpret. 15 (a) Correct pro ducer rankings. (b) Noisy pro ducer rankings. Figure 3: Difference in Kendall-T au distance to the ground truth under the Status Quo v ersus Y ou-R ank-W e-R ank mechanisms, across Arena’s v arious arenas. Difference greater than 0 implies that the YR WR mechanism is closer to the true ranking. 4.6 Sim ulation study with Arena data yr wr vs sq on rank p ositions gained (Figure 2). W e now unpack the results on yr wr presen ted in Figure 2, which are shown on the righthand side for each arena. Our metho ds are exactly the same as in Section 3.1 except that when testing yr wr , w e had to additionally generate each pro ducer i ’s ranking ov er their own mo dels π i , including any p otential clones. F or a given set of submitted mo dels pro duced b y pro ducer i , in the simulations for Figure 2, w e assume the pro ducer ranked them accurately , i.e., as π i “ rank p M i , R q . W e see a striking difference b et w een the t w o mec hanisms: even on arenas where s is small, yr wr admits essential ly zer o gains in rank for any mo del via cloning — ev en as the num b er of clones increases. Nonetheless , there are mo dels that see small rank improv emen ts from submitting clones to the mec hanism, as a result of the new comp etitor effect. In Section A, Figure 5, w e visualize the b enefits of cloning for eac h mo del relativ e to mo del quality . W e sho w that mo dels near the middle of the ranking and for which there are man y mo dels are similar qualit y are the main b eneficiaries of cloning under yr wr , while mo dels with top or b ottom true qualities see nearly zero b enefits to cloning. W e leav e further analysis of ho w the new comp etitor effect v aries with fitted score and comp etitiveness of the mo del for future w ork. yr wr v ersus sq on A ccuracy (Figures 3a and 3b) Our theory tells us that under correct pro ducer rankings π i , yr wr should pro duce more ac cur ate rew ard estimates than sq (in infinity norm). Unsurprisingly , w e find that these more accurate rew ard estimates translate to more accurate rankings: in Figure 3, we compare the bubble-sort distances (also called Kendall-T au distance (Kendall, 1938)) from the resp ectiv e rankings pro duced b y yr wr and sq to rank p M , R q , the ground-truth ranking. W e see that across all six arenas and all n umbers of clones, yr wr has low er distance to the true ranking than sq , often b y man y tens of swaps. This is increasingly true as the num b er of clones increases, illustrating the imp ortance of clone-robustness in reco vering accurate rankings. Our theory lea ves op en whether these gains in accuracy are robust to inac cur acies in pro ducers’ rankings, i.e., scenarios in whic h π i ‰ rank p M i , R q . W e test this by rep eating 16 the analysis in with pro ducers’ rankings p erturb ed via a random utilit y mo del. T o compute p erturb ed pro ducer rankings ˜ π i , we add i.i.d Gaussian noise ϵ to the mo del qualities: ˜ R j “ R j ` ε W e sweep ov er the v ariance of ε suc h that the Kendall-T au distance b etw een the p erturb ed and true rankings is b et w een 10% the length of the list and more than 100% of the length of the list, so that for a ranking of ab out 300 mo dels, the Kendall T au distance b etw een ˜ R and R is b et ween 30 and 400. W e sho w the results of this analysis in Figure 3b. W e see that the ranking by yr wr remains substan tially more accurate than sq for most settings of the noise v ariance across arenas, with the accuracy adv an tage diminishing as the noise increases. Even tually , when pro ducer rankings are sufficiently noisy , the accuracy b enefits of yr wr drop b elow zero, although this only happ ens when the noise in rankings is on the same order as the n umber of mo dels. 5 Discussion Generativ e AI arenas serv e as imp ortant and useful mec hanisms to compare AI mo dels under realistic use conditions. Our work studies a simple vulnerabilit y in status quo mec hanisms: pro ducers can leverage the noise inherent to these rankings by submitting identical or near- iden tical mo dels. Suc h cloning-based manipulations can in turn further deplete samples, leading noise to dro wn out signal. The alternative mechanism we prop ose, yr wr , reduces incen tives for this type of strategic b eha vior. F uture work could build on the framework w e introduce to contin ue the study of strategic b eha vior in the face of noisy ev aluation. Our mo del could b e extended to study online ev aluation, where v otes and mo del submissions arrive sequentially , as they do in real-w orld liv e rankings. Online extensions of our problem ma y presen t new risks for status quo mec hanisms, since pro ducer strategies could incorp orate time-v arying and data-dep endent mo del release decisions. It would also presen t challenges for the naiv e extension of the YR WR mec hanism to the online setting, since allowing mo del pro ducers to delete and add mo dels to their rankings could still allo w sequential clone attacks. F or example, a mo del provider could sequen tially submit clones to the mechanism, observe the p erformance of eac h clone, and then inserting a new clone ab ov e all preceding clones, until one of the clones achiev ed a sufficien tly high rank. Our mo del could also b e extended in other w a ys to more closely match current practice on leading platforms lik e Arena. F or example, one could consider non-uniform allo cations of v otes o ver pairs of mo dels (p erhaps using this to improv e statistical efficiency or encourage desirable mo del pro ducer b ehavior). Also, one could consider analyzing the impacts of style con trol, where the platform “controls for” v arious asp ects of mo del b ehavior that influence preference data but are misaligned with model qualit y , like the length of resp onses. Our mo del could also b e extended to analyze the kind of utility functions of pro ducers that lead to clone non-robustness. Key to our results is the idea that pro ducers are optimizing for the maxim um p erformance of their mo dels. W e exp ect that similar results should hold for general 17 classes of conv ex or sup er-linearly increasing (in mo del rank) pro ducer utility functions, where maxim um p erformance matters more than a verage p erformance. More generally , one could consider more flexible utility functions ov er ranking outcomes than the ones studied here in order to b etter reflect pro ducer incentiv es; for example, one could assign (p oten tially declining) scores to the top d rank p ositions, reflecting that there is b enefit to b eing among the top mo dels. Metho ds to detect clones with only blac k-b ox access could also feature in to mec hanisms that could dissuade clone submission in practice. And finally , platforms need not explicitly rank mo dels; groupin g them into equiv alence classes or pro ducing some entirely different kind of assessment w ould change the incentiv es for strategic b eha vior. As these arenas increasingly guide the dev elopmen t and adoption of AI mo dels, dev eloping mechanisms that are resilient to strategic manipulation is essential to ensuring that rankings remain a trust worth y and accurate signal for the en tire comm unity . A c kno wledgmen ts The authors thank Nathan Jo, Juanky P erdomo, Jann Spiess, Tijana Zrnic and the participants of the Stanford Causal Inference seminar for helpful discussions and feedback on this work. References Alibaba Cloud Comm unit y (2025). Alibaba cloud’s qw en2.5-max secures top rankings in c hatb ot arena. Alibaba Cloud Communit y . Bates, S., Jordan, M. I., Sklar, M., and Soloff, J. A. (2024). Incen tive-Theoretic Ba yesian Inference for Collab orative Science. arXiv:2307.03748 [stat]. Ben tkus, V. (2005). A Lyapuno v-t yp e Bound in Rd. The ory of Pr ob ability & Its Applic ations , 49(2):311–323. _eprin t: https://doi.org/10.1137/S0040585X97981123. Bradley , R. A. and T erry , M. E. (1952). Rank Analysis of Incomplete Blo ck Designs: I. The Metho d of Paired Comparisons. Biometrika , 39(3/4):324–345. Chen, Y., Zhang, G., and Hardt, M. (2026). Leaderb oard Incen tives: Mo del Rankings under Strategic Post-T raining. arXiv:2603.08371 [cs]. Chi, W., Chen, V., Angelop oul os, A. N., Chiang, W.-L., Mittal, A., Jain, N., Zhang, T., Stoica, I., Donahue, C., and T alwalk ar, A. (2025). Copilot Arena: A Platform for Co de LLM Ev aluation in the Wild. arXiv:2502.09328 [cs]. Chiang, W.-L., Zheng, L., Sheng, Y., Angelop oulos, A. N., Li, T., Li, D., Zhang, H., Zh u, B., Jordan, M., Gonzalez, J. E., and Stoica, I. (2024). Chatb ot Arena: An Op en Platform for Ev aluating LLMs b y Human Preference. arXiv:2403.04132 [cs]. Donoho, D. (2017). 50 Y ears of Data Science. Journal of Computational and Gr aphic al Statistics , 26(4):745–766. _eprint: h ttps://doi.org/10.1080/10618600.2017.1384734. 18 Donoho, D. (2024). Data Science at the Singularity. Harvar d Data Scienc e R eview , 6(1). Glo ver, G. (2025). Deepseek sp o oks the sto c k mark et. wh y c hina’s ai mo del is a big concern for u.s. tech. Barron’s (up dated Jan 27, 2025). Gölz, P ., Haghtalab, N., and Y ang, K. (2025). Distortion of AI Alignmen t: Do es Preference Optimization Optimize for Preferences? arXiv:2505.23749 [cs]. Huang, J. Y., Shen, Y., W ei, D., and Bro deric k, T. (2026). Dropping Just a Handful of Preferences Can Change T op Large Language Mo del Rankings. arXiv:2508.11847 [stat]. Huang, Y., Nasr, M., Angelop oulos, A., Carlini, N., Chiang, W.-L., Cho quette-Cho o, C. A., Ipp olito, D., Jagielski, M., Lee, K., Liu, K. Z., Stoica, I., T ramer, F., and Zhang, C. (2025). Exploring and Mitigating A dversarial Manipulation of V oting-Based Leaderb oards. arXiv:2501.07493 [cs]. Jiang, D., Ku, M., Li, T., Ni, Y., Sun, S., F an, R., and Chen, W. (2024). GenAI Arena: An Op en Ev aluation Platform for Generative Mo dels. A dvanc es in Neur al Information Pr o c essing Systems , 37:79889–79908. Kendall, M. G. (1938). A new measure of rank correlation. Biometrika , 30(1–2):81–93. Min, R., Pang, T., Du, C., Liu, Q., Cheng, M., and Lin, M. (2025). Improving Y our Mo del Ranking on Chatb ot Arena b y V ote Rigging. arXiv:2501.17858 [cs]. Miro yan, M., W u, T.-H., King, L., Li, T., Pan, J., Hu, X., Chiang, W.-L., Angelopoulos, A. N., Darrell, T., Norouzi, N., and Gonzalez, J. E. (2025). Search Arena: Analyzing Searc h-Augmented LLMs. arXiv:2506.05334 [cs]. Morrison, R. (2024). Claude takes the top sp ot in ai chatbot ranking — finally knocking gpt-4 down to second place. T om’s Guide. Nazaro v, F. (2003). On the Maximal Perimeter of a Conv ex Set in $\math bb{R}^n$with Resp ect to a Gaussian Measure. In Milman, V. D. and Sc hech tman, G., editors, Ge ometric Asp e cts of F unctional Analysis: Isr ael Seminar 2001-2002 , pages 169–187. Springer, Berlin, Heidelb erg. Pro caccia, A. D., Sc hiffer, B., and Zhang, S. (2025). Clone-Robust AI Alignmen t. arXiv:2501.09254 [cs]. Shi, F. C., W ainwrigh t, M. J., and Bates, S. (2025). Instance-Adaptiv e Hyp othesis T ests with Heterogeneous Agents. arXiv:2510.21178 [cs]. Simons, G. and Y ao, Y.-C. (1999). Asymptotics When the Num b er of Parameters T ends to Infinit y in the Bradley-T erry Mo del for Paired Comparisons. The Annals of Statistics , 27(3):1041–1060. Singh, S., Nan, Y., W ang, A., D’Souza, D., Kap o or, S., Üstün, A., K oy ejo, S., Deng, Y., Longpre, S., Smith, N. A., Ermis, B., F adaee, M., and Ho oker, S. (2025). The Leaderb oard Illusion. arXiv:2504.20879 [cs]. 19 Sith tharanjan, A., Laidlaw, C., and Hadfield-Menell, D. (2024). Distributional Preference Learning: Understanding and A ccounting for Hidden Context in RLHF. [cs]. Spiess, J. (2025). Optimal Estimation When Researc her and So cial Preferences Are Misaligned. Ec onometric a , 93(5):1779–1810. Su, B., Zhang, J., Collina, N., Y an, Y., Li, D., Cho, K., F an, J., Roth, A., and Su, W. (2025). The ICML 2023 Ranking Exp erimen t: Examining Author Self-Assessmen t in ML/AI P eer Review. arXiv:2408.13430 [stat]. Su, W. J. (2022). Y ou Are the Best Review er of Y our Own P ap ers: An Owner-Assisted Scoring Mechanism. arXiv:2110.14802 [cs]. Zhao, Y., Zhang, K., Hu, T., W u, S., Le Bras, R., Liu, Y., T ang, X., Chang, J. C., Do dge, J., Bragg, J., et al. (2025). Sciarena: An op en ev aluation platform for non-v erifiable scientific literature-grounded tasks. In The Thirty-ninth Annual Confer enc e on Neur al Information Pr o c essing Systems Datasets and Benchmarks T r ack . 20 A A dditional empirical results In this section, w e provide additional empirical results corresp onding to our semisynthetic exp erimen ts on Arena data. In Figure 4, we plot the rank improv emen t attained on a verage b y adding an additional clone. The horizon tal axis is the ground truth score in our simulations (i.e., the score assigned b y Arena), and the vertical axis is the n umber of p ositions the av erage (across sim ulations) of the maximum of the ranks of the clones minus the a verage rank of the mo del without a clone. The mean rank difference v aries widely across mo dels and b etw een leaderb oards. There are some mo dels and leaderb oards, like Exp ert, Multiturn and Co ding, where cloning a single mo del can pro duce a ranking increase of around 8 p ositions on av erage. The fact that there ma y b e large b enefits to clones on these leaderb oards in particular ma y b e related to tw o factors. First, there are many fewer v otes p er pair of mo dels on these more sp ecialized leaderb oards: each of exp ert, multiturn and co ding hav e few er than 30 votes p er pair of mo dels on a verage. Second, the mo dels that b enefit from clones in these leaderb oards ha ve scores that are clustered together with several other mo dels, which means that small increases to fitted scores yield large increases in p osition on the leaderb oard. By contrast, sev eral leaderb oards, like T ext, exhibit m uch smaller b enefits to clones. This is b ecause there are relatively more voters p er pair of mo dels. W e also note that the b enefits of clones mostly disapp ear for the v ery b est mo dels (furthest to the righ t on eac h plot) and the very w orst mo dels (furthest to the left on each plot). This ma y b e related to the fact that mo del qualities are less concen trated at the tails. Also, the v ery b est mo dels can only b enefit from clones insofar as they are not rank ed first in the sim ultations without clones, whic h creates a ceiling for the b enefits that can b e attained via clones. F or example, a mo del that is never ranked b elow 3rd place without clones can only impro ve by up to tw o p ositions. W e plot the analogous results for the YR WR mec hanism in Figure 5. In each of the panels, the b enefits of clones under YR WR av erage around zero, although there are some mo dels that can see rank impro vemen t of up to around tw o p ositions due to the vote reweigh ting effect. The leaderb oards for whic h some mo dels still see b enefits of clones are those for whic h there are the most incen tives for clones in the status quo mec hanism: this is a result of the fact that the vote rew eighting effect is larger when the n umber of votes p er mo del is small. 21 Figure 4: Rank difference b etw een submitting one clone and no clones under the sq mechanism. Figure 5: Rank difference b et ween submitting one clone and no clones under the yr wr mec hanism. 22 B Preliminary Lemmata The following theorem is rephrased from Siththaranjan et al. (2024) in our notation. W e pro vide a pro of for completeness. Lemma B.1 (Siththaranjan et al. (2024), Theorem 3.1) . The r ankings pr o duc e d by BT-MLE and Bor da c ounts ar e e quivalent under e qual matchup c ounts. F ormal ly, let s b e the numb er of votes b etwe en e ach p air of c andidates i, j . L et σ BT ´ MLE b e the r anking induc e d by fitting a Br ad ley-T erry mo del via MLE on v as in Algorithm 1. L et σ BC b e the r anking induc e d by the Bor da c ount on v . I.e., for two c andidates j, j 1 j ą BC j 1 ð ñ ÿ ℓ P M ,ℓ ‰ j v j ℓ ă ÿ ℓ P M ,ℓ ‰ j 1 v j 1 ℓ . Then σ BC p u q “ σ BT ´ MLE p u q for al l u “ 1 , 2 , . . . . As w e will see in the pro of, the fact that matc h ups are evenly distributed ov er pairs of mo dels is imp ortan t to the pro of: if matc hups are not ev enly distributed, the result may not hold. Pr o of. The claim is equiv alent to sho wing that for any tw o mo dels j , j 1 , ÿ ℓ P M ,ℓ ‰ j v j ℓ ă ÿ ℓ P M ,ℓ ‰ j 1 v j 1 ℓ ð ñ p R j ă p R j 1 No w, recall that p R “ arg max R P R m ÿ j,j 1 P M ; j ‰ j 1 v j ą j 1 log ´ exp p R j q exp p R j q ` exp p R j 1 q ¯ . By concavit y of the ob jectiv e, it holds ∇ R ÿ j,j 1 P M ; j ‰ j 1 v j ą j 1 log ´ exp p R j q exp p R j q ` exp p R j 1 q ¯ ˇ ˇ ˇ ˇ ˆ R “ 0 . Also, we can rewrite eac h partial deriv ative as B B R j ÿ j,j 1 P M ; j ‰ j 1 v j ą j 1 log ´ exp p R j q exp p R j q ` exp p R j 1 q ¯ “ ÿ j 1 P M ,j 1 ‰ j B B R j v j ą j 1 log ´ exp p R j q exp p R j q ` exp p R j 1 q ¯ ` p s ´ v j ą j 1 q log ´ exp p R j 1 q exp p R j 1 q ` exp p R j q ¯ “ ÿ j 1 P M ,j 1 ‰ j v j ą j 1 ´ s 1 ` exp p R j 1 ´ R j q . Th us, w e hav e 1 s ÿ j 1 P M ,j 1 ‰ j v j ą j 1 “ ÿ j 1 P M ,j 1 ‰ j 1 1 ` exp p p R j 1 ´ p R j q 23 b y applying the fact that the partial deriv ativ e is zero at R “ p R . Now, the LHS is the (normalized) Borda count. Thus, for any t wo mo dels j, j 1 ÿ ℓ P M ,ℓ ‰ j v j ℓ ă ÿ ℓ P M ,ℓ ‰ j 1 v j 1 ℓ ð ñ ÿ ℓ P M ,ℓ ‰ j 1 1 ` exp p p R ℓ ´ p R j q ă ÿ ℓ P M ,ℓ ‰ j 1 1 1 ` exp p p R ℓ ´ p R j 1 q ð ñ 2 1 ` exp p R j 1 ´ R j q ´ 1 ` ÿ ℓ P M ,ℓ ‰ j,ℓ ‰ j 1 1 1 ` exp p p R ℓ ´ p R j q ´ 1 1 ` exp p p R ℓ ´ p R j 1 q ă 0 . Finally , note that ˆ 2 1 ` exp p R j 1 ´ R j q ´ 1 ˙ ` ÿ ℓ P M ,ℓ ‰ j,ℓ ‰ j 1 ˜ 1 1 ` exp p p R ℓ ´ p R j q ´ 1 1 ` exp p p R ℓ ´ p R j 1 q ¸ ă 0 ð ñ R j ´ R j 1 ă 0 since each term inside the large parentheses is p ositiv e if R j ą R j 1 and negative if R j ă R j 1 . C New Comp etitor Effect Analysis In this section, we pro vide our w orkhorse stabilit y lemma, which b ounds the new comp etitor effect. Intuitiv ely , it sa ys that if the total num b er of v otes is sufficien tly large, the distributions of mo del scores b efore and after the in tro duction of an mo del cannot b e to o large. Since this result ma y b e of indep enden t interest, we state the result for the general Bradley- T erry mo del and (re)introduce notation: In this section, w e will consider tw o Bradley-T erry estimation problems: 1. an MLE ˆ R m fit on a set of m ě 2 candidates, and 2. an MLE ˆ R m ` 1 fit on a set of m ` 1 candidates, where the first m are the same as in (1). W e’ll index candidates j “ 1 , 2 , . . . , m ` 1 , and when fitting the MLE, w e will enforce the iden tifiability constraint that ÿ j Pr m s ˆ R m j “ ÿ j Pr m s ˆ R m ` 1 j “ 0 , i.e., the first m en tries of each vector must sum to zero. W e’ll call these iden tifiable subspaces 1 K m , and it will b e clear from con text whether we are talking ab out the subspace in R m or R m ` 1 , dep ending on whether we are working with the first or second BT estimation problems. Pro jecting onto 1 K m ensures that ˆ R m ´ ˆ R m ` 1 1: m Ñ 0 as s Ñ 8 (whereas some other iden tifiability constrain t migh t lead to conv ergence to a non-zero constan t). W e will let R P R m denote the ground-truth qualities of the original m mo dels (where, without loss of generalit y , ř j Pr m s R j “ 0 ), and we’ll write ˆ R m ` 1 1: m for the en tries of ˆ R m ` 1 24 corresp onding to the first m candidates. F or a matrix A , w e will similarly use index slice notation so that A 1: i, 1: j is the first i ro ws and j columns of A . W e’ll make use of Assumption 2.1 in this section, which w e restate here: Assumption 2.1. There exists a universal constant C suc h that, for all problem instances and j, j 1 P K , it holds | R j ´ R j 1 | ď C . W e’ll write S “ s ` m 2 ˘ to denote the total num b er of pairwise comparisons, where s is the n umber of comparisons p er pair. Define P m to b e the probabilit y measure of ˆ R m on 1 K m Ă R m , and define P 1 m to b e the probabilit y measure of ˆ R m ` 1 1: m for 1 K m Ă R m ` 1 . Lemma C.1 (New Comp etitor Effect) . L et C b e the set of c onvex events me asur able with r esp e ct to P m and P 1 m . Then, under Assumption 2.1, ther e exist c onstants C ą 0 and t C m u m ě 2 such that for al l m ě 2 and s ě 1 , sup A P C | P m p A q ´ P 1 m p A q| ď C ? m ` C m ? s . Pr o of. A t a high level, our goal will b e to upp er b ound the con vex set distance b etw een P m and P 1 m b y the sum of three con vex set distances: the distance b etw een P m and its Gaussian appro ximation, the distance b etw een P 1 m and its Gaussian approximation, and the distance b et ween the tw o Gaussian approximations. W e then pro v e the Gaussian appro ximation error b ounds in Lemma C.2 and the distance b etw een Guassians in Lemma C.3 whic h immediately yield the inequality in the lemma. F ormally , let ¯ P m denote the la w of the centered and scaled estimator ? S p ˆ R m ´ R q on 1 K m , and let ¯ P 1 m denote the la w of ? S p ˆ R m ` 1 1: m ´ R q on the same subspace. By ? S -consistency and asymptotic normalit y of the MLE, there exist Normal laws G m , G 1 m on 1 K m suc h that ¯ P m d Ñ G m and ¯ P 1 m d Ñ G 1 m in S . G m , G 1 m are giv en by N p 0 , I ´ 1 m q , N p 0 , p I 1 ´ 1 m q 1: m, 1: m q where I m , I 1 m are the resp ective Fisher information matrices pro jected on to 1 K m . Denote the conv ex-set distance as d C p P , P 1 q def . “ sup A P C | P p A q ´ P 1 p A q| . Observ e that, b y the triangle inequality , d C p ¯ P m , ¯ P 1 m q ď d C p ¯ P m , G m q ` d C p G m , G 1 m q ` d C p G 1 m , ¯ P 1 m q . Lemma C.3 gives d C p G m , G 1 m q ď C ? m for a universal constant C ą 0 . Lemma C.2 yields d C p ¯ P m , G m q ď C m ? s , d C p ¯ P 1 m , G 1 m q ď C 1 m ? s , for constants C m , C 1 m dep ending only on m . Com bining these b ounds gives d C p ¯ P m , ¯ P 1 m q ď C ? m ` C m ` C 1 m ? s . 25 Finally , since ˆ R m ÞÑ ? S p ˆ R m ´ R q is an inv ertible affine map on the iden tifiable subspace and C is the class of con vex sets on that subspace, the conv ex-set distance is inv ariant under applying the same in vertible affine map to b oth distributions. Therefore the same b ound holds for the unscaled la ws P m and P 1 m , which prov es the claim. Lemma C.2 (Gaussian appro ximation error for the BT–MLE) . Under Assumption 2.1, ther e exists a universal c onstant C ą 0 such that max ␣ d C p ¯ P m , G m q , d C p ¯ P 1 m , G 1 m q ( ď C m 3 { 4 ? s ` o ˆ 1 ? s ˙ . Lemma C.3 (Gaussian stability under adding one mo del) . Under Assumption 2.1, ther e exists a universal c onstant C ą 0 such that d C p G m , G 1 m q ď C ? m . W e no w pro ceed with the pro ofs for the ab ov e tw o lemmas. W e first (re)establish general notation and basic facts we will use throughout this section. Let the win probability b etw een candidate i and j be p i ą j “ exp R i exp R j ` exp R i and ˆ p i ą j the same quan tity substituting p R for R . Let v i ą j „ Bin p s, p i ą j q coun t the wins of mo del i o ver mo del j . Let v p k q i ą j „ Ber p p i ą j q denote the indicator outcome of the k -th comparison. Let L m p R q b e the log-lik eliho o d for m candidates: L m p R q “ ÿ j,j 1 Pr m s ; j ‰ j 1 v j ą j 1 log ´ 1 1 ` exp p R j 1 ´ R j q ¯ “ ÿ j,j 1 Pr m s ; j ‰ j 1 v j ą j 1 log p j ą j 1 Let ℓ m p R q “ ∇ L m p R q b e the score function (first deriv ativ e with resp ect to R ), i.e., for j P r m s , ℓ m p R q j “ ÿ j 1 Pr m s ; j 1 ‰ j v j ą j 1 ´ sp j ą j 1 (C.1) and let H m p R q “ ∇ 2 L m p R q b e the Hessian (second deriv ative), i.e., for j, j 1 P r m s , H m p R q j,j 1 “ # ´ s ř ℓ Pr m s ; ℓ ‰ j p j ą ℓ p 1 ´ p j ą ℓ q if j “ j 1 sp j ą j 1 p 1 ´ p j ą j 1 q otherwise “ ´ s ÿ 1 ď j ă j 1 ď m p j ą j 1 ` 1 ´ p j ą j 1 ˘ p e j ´ e j 1 qp e j ´ e j 1 q J . (C.2) where e j denotes the j th standard basis vector. Let S “ s ` m 2 ˘ “ O p sm 2 q b e the total num b er of pairwise comparisons. Let I m “ ´ E r H m p R qs ˇ ˇ 1 K m b e the Fisher information matrix for the m -mo del Bradley-T erry , pro jected onto the rank- p m ´ 1 q subspace. Let I m ` 1 b e the Fisher information for the p m ` 1 q -mo del Bradley-T erry pro jected onto the rank- m subspace. 26 C.1 Pro of of Lemma C.2 W e will just show the b ound holds for ¯ P m , G m ; the argumen t for ¯ P 1 m , G 1 m is identical. Our pro of pro ceeds as follo ws: 1. W e’ll first write the normalized deviation of ˆ R m from R using T aylor’s theorem, so that it is (up to higher-order terms) equal to the sum of indep enden t score contributions. 2. W e’ll then use this linear approximation to break the conv ex set distance into three terms, which we can analyze separately . 3-5. Analyses of each of the terms. Step 1. Applying T a ylor’s theorem to the score function ℓ p¨q around the MLE ˆ R m , we hav e ℓ m p ˆ R m q “ ℓ m p R q ` H m p ˜ R qp ˆ R m ´ R q for ˜ R on the line segment b et w een R and ˆ R m . Also, 0 “ ℓ m p ˆ R m q b y the fact that the MLE is a maximum. Applying this fact and rearranging, we hav e ˆ R m ´ R “ ´ H m p ˜ R q ´ 1 ℓ m p R q . Scaling by ? S and adding/subtracting the Fisher information ? S p ˆ R m ´ R q “ ? S ¨ I ´ 1 m ℓ m p R q lo ooooo omo ooooo on Linear Approximation T erm W m ` ? S ´ ´ H m p ˜ R q ´ 1 ´ I ´ 1 m ¯ ℓ m p R q lo ooooooooooooooooo omo ooooooooooooooooo on Remainder r m Step 2. W e now break the con vex set distance in to three terms. First, we pro v e an upp er b ound. F or A P C , define A t “ t x : inf a P A } x ´ a } 2 ď t u to b e the t -neigh b orho o d of A . Observe for all t ą 0 , P p ? S p ˆ R m ´ R q P A q “ P p W m ` r m P A q (Definition of W m , r m ) ď P p W m P A t Y } r m } 2 ě t q ( W m ` r m P A Ď W m P A t Y } r m } 2 ě t ) ď P p W m P A t q ` P p} r m } 2 ě t q . (Union b ound) Subtracting P p ˜ Z P A t q from b oth sides, w e ha ve P p ? S p ˆ R m ´ R q P A q ´ P p ˜ Z P A t q ď P p W m P A t q ´ P p ˜ Z P A t q ` P p} r m } 2 ě t q ù ñ P p ? S p ˆ R m ´ R q P A q ´ P p ˜ Z P A q ď | P p W m P A t q ´ P p ˜ Z P A t q| ` P p ˜ Z P A t z A q ` P p} r m } 2 ě t q (C.3) where the implication follo ws from the fact that P p ˜ Z P A t q “ P p ˜ Z P A q ` P p ˜ Z P A t z A q and taking the absolute v alue. Note that A t P C : the Minko wski sum of conv ex even ts is a conv ex ev ent. 27 W e can write the low er b ound analogously . Let us o verload notation and write A ´ t “ t a P A : inf x R A } x ´ a } 2 ě t u . Observ e for all t ą 0 that P p ? S p ˆ R m ´ R q P A q “ P p W m ` r m P A q (Definition of W m , r m ) ě P p W m P A ´ t q ´ P p} r m } 2 ě t q . (Union b ound and rearranging) Then P p ? S p ˆ R m ´ R q P A q ´ P p ˜ Z P A ´ t q ě P p W m P A ´ t q ´ P p ˜ Z P A ´ t q ´ P p} r m } 2 ě t q ù ñ P p ? S p ˆ R m ´ R q P A q ´ P p ˜ Z P A q ě ´ ˇ ˇ ˇ P p W m P A ´ t q ´ P p ˜ Z P A ´ t q ˇ ˇ ˇ ´ P p ˜ Z P A z A ´ t q ´ P p} r m } 2 ě t q . (C.4) Similarly , note that A ´ t P C . In steps 3-5, we b ound each of the terms in the right-hand side of Equation (C.3). In particular, plugging in the RHS expressions in Equations (C.5) to (C.7) yields, for t ą 0 P p ? S p ˆ R m ´ R q P A q ´ P p ˜ Z P A q ď C m 3 { 4 ? s ` C ts ´ 1 { 2 m ´ 1 { 4 ` m exp ˆ ´ C st 2 m 2 ˙ . Cho osing t “ O p m q yields P p ? S p ˆ R m ´ R q P A q ´ P p ˜ Z P A q ď C m 3 { 4 ? s . (where as usual the constan t C across inequalities ma y c hange). The corresp onding terms in Equation (C.4) are b ounded using the same argumen t, and yield the same b ound. Step 3. W e will show for a generic conv ex even t A , there exists a universal constant C suc h that | P p W m P A q ´ P p ˜ Z P A q| ď C m 3 { 4 ? s . (C.5) Plugging in A t or A ´ t yields our upp er b ound on the first terms in Equations (C.3) and (C.4), resp ectiv ely . T o do this, w e will first prov e an approximation b ound on the score function ℓ m p R q and then translate it into a b ound on ? S I ´ 1 m ℓ m p R q . F or the b ound on ℓ m p R q , observe that the score function at the true R is a sum of S “ s ` m 2 ˘ indep enden t score contributions ℓ m p R q “ ÿ i ă j s ÿ k “ 1 ψ p k q ij “ ÿ i ă j s ÿ k “ 1 p v p k q i ą j ´ p i ą j qp e i ´ e j q , E r ψ p k q ij s “ 0 , where e j denotes the j -th standard basis vector. Since each term is a mean-zero indep endent random v ariable, we can apply the following theorem to b ound the Gaussian appro ximation error on the linear term. 28 Theorem C.4 (Theorem 1.1 Ben tkus (2005)) . Supp ose X 1 , . . . , X n P R d ar e indep endent and E X i “ 0 for al l i . L et S “ ř i X i and define Σ “ V ar p S q . L et Z „ N p 0 , Σ q . Ther e exists a universal c onstant c such that sup A P C | P p S P A q ´ P p Z P A q| ď cd 1 { 4 β wher e β “ n ÿ i “ 1 } Σ ´ 1 { 2 X i } 3 2 . Since Co v p ℓ m q “ I m , the target Gaussian is Z „ N p 0 , I m q . Plugging this in to the b ound from Theorem C.4 yields sup A P C | P p ℓ m P A q ´ P p Z P A q| ď c p m ´ 1 q 1 { 4 β where β “ ÿ i ă j s ÿ k “ 1 E } I ´ 1 { 2 m ψ p k q ij } 3 2 . No w it suffices to b ound β . Observe that p v p k q i ą j ´ p i ą j qq P r´ 1 , 1 s so E } ψ p k q ij } 3 2 “ E }p v p k q i ą j ´ p i ą j qqp e i ´ e j q} 3 2 ď } e i ´ e j } 3 2 “ ? 2 3 By Lemma C.6, we also hav e } I ´ 1 { 2 m } op ď O ˆ 1 ? sm ˙ whic h implies β ď ÿ i ă j s ÿ k “ 1 O pp sm q ´ 3 { 2 q “ O p sm 2 q O pp sm q ´ 3 { 2 q “ O p m 1 { 2 q O p s ´ 1 { 2 q . Putting the norm upp er b ounds together, w e obtain sup A P C | P p ℓ m p R q P A q ´ P p Z P A q| ď O ˆ m 3 { 4 ? s ˙ . Finally , we must translate these b ounds in to b ounds on even ts for ? S I ´ 1 m ℓ m p R q (rather than ℓ m p R q ). Since con vex sets are closed under linear maps, we can define the target Guassian for the scaled linear term to b e ˜ Z „ N p 0 , S I ´ 1 m q since Co v p ? S I ´ 1 m ℓ m p R qq “ S I ´ 1 m Co v p ℓ m p R qq I ´ 1 m “ S I ´ 1 m and thus hav e sup A P C | P p W m P A q ´ P p ˜ Z P A q| “ sup A P C | P p ℓ m p R q P A q ´ P p Z P A q| ď O ˆ m 3 { 4 ? s ˙ . Step 4. W e will sho w P p ˜ Z P A t z A q ď C ts ´ 1 { 2 m ´ 1 { 4 . (C.6) T o do so, we apply the follo wing theorem: 29 Theorem C.5 (Nazaro v (2003)) . Ther e exist universal c onstants 0 ă C 1 ă C 2 P R such that, for any me an-zer o multivariate Gaussian me asur e F on R d with varianc e matrix W , it holds C 1 a } W } F ď sup A P C ,t ą 0 F p A z A t q t ď C 2 a } W } F . In particular, w e hav e } Σ } F ď ? m } Σ } op ď ? mO p 1 {p sm qq where the last inequality follows from Lemma C.6. Thus, there is a universal constant C suc h that sup Q P C ,h ą 0 P p ˜ Z P Q h z Q q h ď C s ´ 1 { 2 m ´ 1 { 4 Th us, for fixed t , we ha ve P p ˜ Z P A t z A q “ t ¨ P p ˜ Z P A t z A q t ď t ¨ sup Q P C ,h ą 0 P p ˜ Z P Q h z Q q h ď C ts ´ 1 { 2 m ´ 1 { 4 . Step 5. Finally , we establish P p} r m } 2 ě t q ď m exp ˆ ´ C st 2 m 2 ˙ (C.7) Notice } r m } 2 “ › › › ? S ´ ´ H m p ˜ R q ´ 1 ´ I ´ 1 m ¯ ℓ m p R q › › › 2 ď ? S › › › ´ H m p ˜ R q ´ 1 ´ I ´ 1 m › › › op } ℓ m p R q} 2 ď ? S ˆ › › › H m p ˜ R q ´ 1 › › › op ` › › I ´ 1 m › › op ˙ } ℓ m p R q} 2 No w, we b ound each of these terms. F rom Lemma C.6, we ha ve } I ´ 1 m } op “ O pp sm q ´ 1 q . Moreo ver, using the same pro of as for Lemma C.6, under the assumption that max j,j 1 | ˆ R j ´ ˆ R j 1 | is b ounded and the fact that ˜ R is a conv ex combination of R, ˆ R , it holds } H m p ˜ R q ´ 1 } op “ O pp sm q ´ 1 q . Th us, } r m } 2 ď O p s ´ 1 q} ℓ m p R q} 2 . Moreo ver, from Lemma C.7, for all t , we hav e P p} ℓ m p R q} ě t q ď m exp ˆ ´ t 2 3 sm 2 ˙ Plugging in O p s ¨ t q for t , we hav e P p} r m } ě t q “ m exp ˆ ´ C ¨ s ¨ t 2 m 2 ˙ . 30 C.2 Pro of of Lemma C.3 Let Σ “ I ´ 1 m and Σ 1 “ p I ´ 1 m ` 1 q 1: m, 1: m . By asymptotic normalit y (as s Ñ 8 ) of the MLE, we can write out G m , G 1 m explicitly ? S p ˆ R m ´ R q Ñ N p 0 , S Σ q ? S p ˆ R m ` 1 1: m ´ R q Ñ N p 0 , S Σ 1 q Since conv ex-set distance is inv arian t under scaling by a constant, we define ˜ G m “ N p 0 , Σ q ˜ G 1 m “ N p 0 , Σ 1 q Then d C p G m , G 1 m q “ d C p ˜ G m , ˜ G 1 m q ď d TV p ˜ G m , ˜ G 1 m q (C.8) ď c 1 2 KL p ˜ G m } ˜ G 1 m q “ 1 2 ˆ tr p Σ 1´ 1 Σ q ´ p m ´ 1 q ` log det Σ 1 det Σ ˙ . (C.9) where the last line is the form ula for the KL-div ergence b et ween tw o centered multiv ariate normal distributions. Th us, showing that the con vex-set distance b etw een G m , G 1 m is small can b e done in terms of Σ , Σ 1 b y sho wing Equation (C.9) is small. T o b ound Equation (C.9), we will pro ceed with the follo wing steps: 1. W e will decomp ose Σ 1 “ p Σ ` K q ´ 1 for some matrix K determined b y the change in log-lik eliho o d due to the additional mo del. 2. W e will establish } K } op ď s { 4 and use this to upp er b ound the expression for the KL-div ergence b et ween multiv ariate normals. Step 1. With an additional mo del added, w e can write the log-lik eliho o d as L m ` 1 p R 1: m , R m ` 1 q def . “ L m p R 1: m q lo oo omo oo on original comparisons ` L new p R 1: m , R m ` 1 q lo ooooooo omo ooooooo on comparisons inv olving the new mo del , where L m p R 1: m q is the log-likelihoo d for comparisons b et ween the original m mo dels, and L new p R 1: m , R m ` 1 q def . “ ÿ j Pr m s v j ą m ` 1 log p j ą m ` 1 ` p s ´ v j ą m ` 1 q log p 1 ´ p j ą m ` 1 q . By linearity of exp ectations and gradients, we then hav e, I m ` 1 “ ´ E r ∇ 2 R L m p R 1: m qs ´ E r ∇ 2 R L new p R 1: m , R m ` 1 qs . 31 W e will further simplify these expressions by writing a blo ck decomp osition for each term. F or the first term, L m dep ends only on R 1: m , so ´ E r ∇ 2 L m p R qs “ ˆ I m 0 0 0 ˙ . The second term can b e written as ´ E r ∇ 2 R L new p R 1: m , R m ` 1 qs “ ˆ I new 1: m, 1: m I new 1: m, p m ` 1 q I new p m ` 1 q , 1: m I new p m ` 1 q , p m ` 1 q ˙ where I new 1: m, 1: m def . “ ´ E “ ∇ 2 R 1: m L new p R q ‰ , I new 1: m, p m ` 1 q def . “ ´ E „ ∇ R 1: m B B R m ` 1 L new p R q ȷ , and I new p m ` 1 q , p m ` 1 q def . “ ´ E „ B 2 B 2 R m ` 1 L new p R q ȷ . Th us the Fisher information for the log-likelihoo d with the additional mo del is I m ` 1 “ ˆ I m ` I new 1: m, 1: m I new 1: m, p m ` 1 q I new p m ` 1 q , 1: m I new p m ` 1 q , p m ` 1 q ˙ Applying the blo ck inv ersion formula yields Σ 1 “ p I ´ 1 m ` 1 q 1: m, 1: m “ ´ I m ` I new 1: m, 1: m ´ I new 1: m, p m ` 1 q p I new p m ` 1 q , p m ` 1 q q ´ 1 I new p m ` 1 q , 1: m ¯ ´ 1 Finally , define K def . “ I new 1: m, 1: m ´ I new 1: m, p m ` 1 q p I new p m ` 1 q , p m ` 1 q q ´ 1 I new p m ` 1 q , 1: m so Σ 1 “ p I m ` K q ´ 1 . Step 2. Since K is the Sch ur complement of I new p m ` 1 q , p m ` 1 q ľ 0 , it holds K ľ 0 . W e write out the partial deriv atives under Bradley-T erry . Let d i “ s ¨ p i,m ` 1 p 1 ´ p i,m ` 1 q ď s { 4 and D “ diag p d q . Then, ´ ∇ 2 R 1: m L new p R q “ s ¨ D ´ ∇ R 1: m B B R m ` 1 L new p R q “ ´ s ¨ d, and ´ B 2 B 2 R m ` 1 L new p R q “ s 1 J d. Th us, taking exp ectations (all terms are deterministic), we hav e I new 1: m, 1: m “ s ¨ D I new 1: m, p m ` 1 q “ I new J p m ` 1 q , 1: m “ ´ s ¨ d I new p m ` 1 q , p m ` 1 q “ s ¨ 1 J d 32 Then we can rewrite K as K “ I new 1: m, 1: m ´ I new 1: m, p m ` 1 q p I new p m ` 1 q , p m ` 1 q q ´ 1 I new p m ` 1 q , 1: m “ D ´ dd J 1 J d . Moreo ver, D ´ K ľ 0 , since for any vector x , it holds p x J d qp d J x q “ p x J d q 2 ě 0 and 1 J d ą 0 . Also, let I b e the iden tity matrix and u “ D 1 { 2 1 { ? 1 J d , D ´ dd J 1 J d “ D 1 { 2 ` I ´ uu J ˘ D 1 { 2 So } K } op ď } D 1 { 2 } 2 op › › I ´ uu J › › op . Finally , › › I ´ uu J › › op ď 1 since } u } 2 “ 1 so the non-zero eigenv alue of uu J is 1, which means that the eigen v alues of I ´ uu J are all 1 except one which is zero. Thus, } K } op ď } D } op ď s 4 . (C.10) With these facts in hand, we now pro ceed to upp er b ound Equation (C.9). Denote the relativ e p erturbation matrix A “ Σ 1 { 2 K Σ 1 { 2 “ I ´ 1 { 2 m K I ´ 1 { 2 m . Observ e that A ľ 0 since for an y v ector x , x T Σ 1 { 2 K Σ 1 { 2 x “ p x T Σ 1 { 2 q K p Σ 1 { 2 x q ě 0 b y p ositiv e semidefiniteness of K . Moreov er, } A } op ď } Σ 1 { 2 } 2 op } K } op ď O ˆ 1 sm ˙ s 4 ď O ˆ 1 m ˙ under Assumption 2.1 by applying Lemma C.6 and Equation (C.10). W e first compute the trace term in Equation (C.9). Observe, tr p Σ 1´ 1 Σ q “ tr ` p I m ` K q I ´ 1 m ˘ “ tr p I q ` tr p K I ´ 1 m q “ p m ´ 1 q ` tr p I ´ 1 { 2 m K I ´ 1 { 2 m q “ p m ´ 1 q ` tr p A q where the last equality applies the cyclic prop ert y of trace. Next, for the determinant term in Equation (C.9), observe that Σ 1 “ p I m ` K q ´ 1 “ Σ 1 { 2 p I ` A q ´ 1 Σ 1 { 2 33 whic h implies det p Σ 1 q “ det p Σ q det ` p I q ` A q ´ 1 ˘ . Therefore, log det Σ 1 det Σ “ log det ` p I ` A q ´ 1 ˘ “ ´ log det p I ` A q Substituting into the KL div ergence form ula yields KL p ˜ G m } ˜ G 1 m q “ 1 2 ´ tr p A q ´ log det p I ` A q ¯ Let λ 1 , . . . , λ m ´ 1 denote the eigenv alues of A , then tr p A q “ ÿ i λ i , det p I ` A q “ ź i p 1 ` λ i q , and KL p ˜ G m } ˜ G 1 m q “ 1 2 m ´ 1 ÿ i “ 1 ` λ i ´ log p 1 ` λ i q ˘ . F or all λ ě 0 , it is true that log p 1 ` λ q ě λ ´ λ 2 2 and it follows that λ i ´ log p 1 ` λ i q ď λ i ´ ˆ λ i ´ λ 2 i 2 ˙ “ λ 2 i 2 Summing ov er all eigenv alues giv es: KL p ˜ G m } ˜ G 1 m q ď 1 4 m ´ 1 ÿ i “ 1 λ 2 i ď 1 4 } A } 2 F ď p m ´ 1 q 4 } A } 2 op ď O p 1 { m q Th us, d C p G m , G 1 m q ď O p m ´ 1 { 2 q as desired. Lemma C.6. Under Assumption 2.1, ther e exists a universal c onstant η P p 0 , 1 { 2 q such that } I m } op ě η p 1 ´ η q sm (C.11) and henc e } I ´ 1 m } op ď p η p 1 ´ η q sm q ´ 1 . Pr o of of L emma C.6. Note that under Assumption 2.1, there exists a univ ersal constant η “ 1 {p 1 ` exp p C qq P p 0 , 1 { 2 q suc h that p i ą j P r η , 1 ´ η s for all i ‰ j , and hence p i ą j p 1 ´ p i ą j q ě η p 1 ´ η q ą 0 . Therefore, for any x P 1 K suc h that } x } 2 “ 1 , x J I m x “ s ÿ i ă j p i ą j ` 1 ´ p i ą j ˘ p x i ´ x j q 2 ě sη p 1 ´ η q ÿ i ă j p x i ´ x j q 2 . 34 Since ÿ i ă j p x i ´ x j q 2 “ 1 2 ÿ i,j x 2 i ` x 2 j ´ 2 x i x j “ m ÿ i x 2 i ´ ˜ ÿ i x i ¸ 2 “ m on 1 K , we obtain x J I m x ě sη p 1 ´ η q m , which implies } I m } op ě sη p 1 ´ η q m and } I ´ 1 m } op ď 1 sη p 1 ´ η q m . Lemma C.7. Under Assumption 2.1, ther e exists a universal c onstant such that, for al l ε ą 0 and s ě 3 log p 2 m { ε q{ η , it holds with pr ob ability at le ast 1 ´ ε that, } ℓ m p R q} 2 ď C a sm 2 log p m { ε q Pr o of. Recall, } ℓ m p R q} 2 2 “ ÿ j Pr m s ¨ ˝ ÿ j 1 Pr m s ; j 1 ‰ j v j ą j 1 ´ sp j ą j 1 ˛ ‚ 2 . No w, applying a Chernoff b ound , w e ha ve with probabilit y 1 ´ ε { m ˇ ˇ ˇ ˇ ˇ ˇ ÿ j 1 Pr m s ; j 1 ‰ j v j ą j 1 ´ sp j ą j 1 ˇ ˇ ˇ ˇ ˇ ˇ ď d 3 s log p 2 m { ε q ÿ j 1 Pr m s ; j ‰ j 1 p j ą j 1 ď a 3 sm log p 2 m { ε q . Th us, with probabilit y at least 1 ´ ε , ÿ j Pr m s ¨ ˝ ÿ j 1 Pr m s ; j 1 ‰ j v j ą j 1 ´ sp j ą j 1 ˛ ‚ 2 ď ÿ j Pr m s 3 sm log p 2 m { ε q “ 3 sm 2 log p 2 m { ε q . D Pro of of Theorem 3.2 W e first restate the result for reference. 35 Theorem 3.2 (Clone-nonrobustness of the status quo mechanism) . F or al l c onstants ε, δ ą 0 , ther e exists s 0 , m 0 such that for al l s ě s 0 , m ě m 0 , the fol lowing holds. F or any pr o duc er i , any str ate gy pr ofiles z and any p ε, δ q -c omp etitive mo del j , pr o duc er i would b enefit fr om submitting an additional c opy of j . F ormal ly, let z 1 “ p z i,j ` 1 , z ´ i,j q . Then E σ „ Σ p sq p M p z 1 qq r u i p σ qs ą E σ „ Σ p sq p M p z qq r u i p σ qs . In our pro of, we’ll call the set of cand idates induced b y z the “original candidates” and ȷ p z ιȷ ` 1 q the “additional clone”. Similarly , we’ll call the vote distributions induced by z , z 1 resp ectiv ely as the “original distribution” and the “additional clone distribution”. At a high lev el, our pro of will pro ceed as follows: 1. W e’ll observe that the win probability of a pro ducer with an additional clone is equal to the probability that some mo del b y the pro ducer is rank ed ab o v e all of the original candidates. 2. Next, we’ll argue that the even t that the additional clone ranks ab ov e all original candidates and the even t that any of the original candidates b y the same pro ducer rank ab o ve the original candidates are anticorrelated. This implies the probability (with resp ect to the additional clone distribution) that a mo del b y the pro ducer with the additional clone is ranked first is no less than the probabilit y the additional clone is rank ed first plus the probabilit y one of the original candidates by the pro ducer is ranked first minus the pro duct of these tw o probabilities. 3. W e then translate these t wo probabilities into even ts that are measurable with resp ect to the original distribution, and apply Lemma C.1 to establish that the probabilities of these t wo even ts ma y differ from their probabilities in th e original distribution by at most O p 1 { ? s q . 4. These facts together imply that if Definition 3.1 is satisfied, the pro ducer’s win proba- bilit y with a clone is greater than without it, whic h completes the pro of. Without loss of generality , supp ose pro ducer i “ 1 ’s mo del j “ 1 satisfies Definition 3.1. Let w “ z 1 , 1 ` 1 . Th us, the clone is indexed 1 p w q . Define M ´ 1 “ M p z qz M 1 p z 1 q to b e all candidates but those submitted b y pro ducer 1 . F or a mo del j by pro ducer 1 , a leaderb oard L , and a random ranking σ , define the even t A j p L q “ ␣ σ ´ 1 p j q ă σ ´ 1 p ℓ q @ ℓ P M ´ 1 X L ( . That is, A j p L q is the ev ent that a mo del j ranks ab ov e all those by other pro ducers M ´ 1 in the leaderb oard L . W e will ov erload notation and write, for a set of candidates S , A S p L q “ ď j P S A j p L q . F or S Ď M 1 p z 1 q and σ „ Σ p sq , z q , note that A S “ t σ L p 1 q P S u . 36 That is, if an y mo del b y pro ducer 1 ranks ab o v e all candidates by other pro ducers in L under actions z , a mo del by pro ducer 1 m ust b e rank ed first in L . Moreo ver, if model 1 p w q P S , S Ď M i , and σ „ Σ p sq , z 1 q , then A S “ t σ L p 1 q P S u : if S con tains the new clone and is a subset of pro ducer 1 s candidates, one mo del in S m ust b e rank ed first in L for pro ducers’ actions z 1 . No w, for the exp ectation and probabilities taken with resp ect to σ „ Σ p sq , z 1 q , observe E r u 1 p σ qs “ ÿ L P L ν 1 p L q Pr p σ L p 1 q P M 1 p z 1 1 qq (Definition of utility .) No w, notice Pr p A M 1 p z 1 1 q p L qq “ Pr p A M 1 p z 1 q p L q Y A 1 p w q p L qq ( M 1 p z 1 1 q “ M 1 p z 1 q Y t 1 p w q u ) “ Pr p A M 1 p z 1 q p L qq ` Pr p A 1 p w q p L qq ´ Pr p A M 1 p z 1 1 q p L q X A 1 p w q p L qq (Inclusion-exclusion formula.) ě Pr p A M 1 p z 1 q p L qq ` Pr p A 1 p w q p L qq ´ Pr p A M 1 p z 1 1 q p L qq Pr p A 1 p w q p L qq (Lemma D.1) “ Pr p A M 1 p z 1 q p L qq ` Pr p A 1 p 1 q p L qq ´ Pr p A M 1 p z 1 1 q p L qq Pr p A 1 p 1 q p L qq . ( σ ´ 1 L p 1 p 1 q q d “ σ ´ 1 L p 1 p w q q ) Plugging the last expression in to the sum ab ov e, we hav e E r u 1 p σ qs “ ÿ L P L ν 1 p L q ` Pr p A M 1 p z 1 q p L qq ` Pr p A 1 p 1 q p L qq ´ Pr p A M 1 p z 1 1 q p L qq Pr p A 1 p 1 q p L qq ˘ No w, observ e that the ev ents A M 1 p z q p L q and A 1 p 1 q p L q are measurable with respect to σ „ Σ p sq , z q (the original distribution). Thus, applying Lemma C.1, for all ν ą 0 , there exists s 0 , m 0 suc h that for s ě s 0 , m ě m 0 , Pr σ „ Σ p sq ,z 1 q p A M 1 p z q p L qq ě Pr σ „ Σ p sq ,z q p A M 1 p z q p L qq ´ ν, and Pr σ „ Σ p sq ,z 1 q p A 1 p 1 q p L qq ě Pr σ „ Σ p sq ,z q p A 1 p 1 q p L qq ´ ν. Com bining these with the expression ab o ve, w e ha ve E σ „ Σ p sq ,z 1 q r u 1 p σ qs ě ÿ L P L ν 1 p L q ˜ Pr σ „ Σ p sq ,z q p A M 1 p z q p L qq ` Pr σ „ Σ p sq ,z q p A 1 p 1 q p L qq ´ Pr σ „ Σ p sq ,z q p A M 1 p z q p L qq ¨ Pr σ „ Σ p sq ,z q p A 1 p 1 q p L qq ¸ ´ ν ě ÿ L P L ν 1 p L q Pr σ „ Σ p sq ,z q p A M 1 p z q p L qq ` ÿ L P L ν 1 p L q δ ` 1 ´ Pr σ „ Σ p sq ,z q p A M 1 p z q p L qq ˘ ´ ν (Definition 3.1, first inequality) 37 ě ÿ L P L ν 1 p L q Pr σ „ Σ p sq ,z q p A M 1 p z q p L qq ` ÿ L P L ν 1 p L q δ 2 ´ ν (Definition 3.1, second inequality) ě ÿ L P L ν 1 p L q Pr σ „ Σ p sq ,z q p A M 1 p z q p L qq ` εδ 2 ´ ν (Definition 3.1, ε condition) Finally , as long as we set ν ă εδ 2 , we hav e ÿ L P L ν 1 p L q Pr σ „ Σ p sq ,z q p A M 1 p z q p L qq ` εδ 2 ´ ν ě ÿ L P L ν 1 p L q Pr σ „ Σ p sq ,z q p A M 1 p z q p L qq “ E σ „ Σ p sq ,z q r u 1 p σ qs where the last line is by definition. Lemma D.1. It holds Pr p A M 1 p z 1 q p L q X A 1 p w q qp L q ď Pr p A M 1 p z 1 q p L qq Pr p A 1 p w q p L qq . Pr o of of L emma D.1. F rom Lemma B.1, since match up counts are allo cated evenly across pairs, the rankings induced by Bradley-T erry fit with MLE and Borda counts are equiv alent. Th us, if the set of candidates submitted to the mec hanism is M p z 1 q , we hav e that A j p L q “ $ & % ÿ ℓ P M p z 1 q v j ą ℓ ą ÿ ℓ P M p z 1 q v j 1 ą ℓ @ j 1 P M ´ 1 X L , . - , and similarly for A S p L q . Now, let F “ t v 1 p w q ą j u j P M 1 b e all vote counts b et ween the additional clone and pro ducer 1 ’s original candidates, M 1 . Let F C “ v z F b e all other v ote counts, k eeping one cop y of eac h independent v ote coun t and excluding all t v j ą 1 p w q u j P M 1 . (I.e., if v j ą j 1 P F C then v j 1 ą j R F C , since v j ą j 1 ` v j 1 ą j “ s .) W e will argue that Pr p A M 1 p z 1 q p L q X A 1 p w q p L q | F C q ď Pr p A M 1 p z 1 q p L q | F p C q q Pr p A 1 p w q p L q | F p C q q . (D.1) This implies the result since the conditional probabilities for all F p C q imply the unconditional ones (by taking exp ectations with resp ect to F p C q for the left- and right-hand sides of the equation). T o show Equation (D.1), we will apply the Harris inequality . Note that the measure induced b y F (conditional on F C ) is a pro duct measure, since vote coun ts b et ween different pairs of candidates are indep enden t. Thus, it is sufficien t to sho w that A M 1 p z 1 q is a decreasing even t and A 1 p w q is an increasing even t. No w, writing each even t in terms of the Borda count, we can rewrite A 1 p w q p L q as ÿ ℓ P M i p z 1 i q ,ℓ ‰ 1 p w q v 1 p w q ą ℓ ą ÿ ℓ P M p z 1 q ,ℓ ‰ j v j ą ℓ ´ ÿ ℓ P M ´ 1 v 1 p w q ą ℓ , @ j P M ´ 1 X L. Note that the left-hand side sum is ov er elemen ts in F and the righ t-hand side sums are o ver elements determined by F C . No w, b y insp ecting the left-hand side, note that the ev ent 38 A 1 p w q | F C is increasing: if the inequalit y is satisfied and we increase an entry of v 1 p w q ą ℓ , the inequalit y is still satisfied. Similarly , we can write A M 1 p z 1 q p L q as D j P M 1 p z q X L s.t. v j ą 1 p w q ą ÿ ℓ P M p z 1 q ,ℓ ‰ j 1 v j 1 ą ℓ ´ ÿ ℓ P M p z q ,ℓ ‰ j v j ą ℓ , @ j 1 P M ´ 1 X L. No w, since v j ą 1 p w q ` v 1 p w q ą j “ s , we can equiv alently write A M 1 p z 1 q p L q as D j P M 1 p z q X L s.t. v 1 p w q ą j ă s ´ ÿ ℓ P M p z 1 q ,ℓ ‰ j 1 v j 1 ą ℓ ` ÿ ℓ P M p z q ,ℓ ‰ j v j ą ℓ , @ j 1 P M ´ 1 X L. Again, the LHS con tains terms in F and the RHS con tains terms determined by F C . Th us, the ev en t A M 1 p z 1 q is decreasing: If the inequality is satisfied for some j P M 1 p z q X L and w e decrease v 1 p w q ą j 1 for some j 1 P M 1 p z q X L , the inequalit y is still satisfied. Thus, by the Harris inequalit y , Equation (D.1) is satisfied and the result holds. E Pro of of Theorem 4.1 W e first restate the result: Theorem 4.1 (Appro ximate clonepro ofness) . F or al l ε ą 0 , ther e exists s 0 , m 0 such that for al l s ě s 0 and m ě m 0 , the fol lowing holds. Fix any π , z , and let z 1 “ p 1 , z ´ i q b e the pr ofile wher e i inste ad plays one c opy of e ach mo del. Then E σ „ Σ p yr wr p M p z 1 q ,π q r u i p σ qsq ě E σ „ Σ p yr wr p M p z q ,π qq r u i p σ qs ´ ε. In our pro of, we’ll apply the following tw o lemmas. The first says that all pro ducers appro ximately prefer to submit at least 1 copy of eac h mo del. Lemma E.1. F or al l ε ą 0 , ther e exists s 0 , m 0 such that for al l s ě s 0 and m ě m 0 , the fol lowing holds. Consider an action ve ctor z wher e z i,j “ 0 for some pr o duc er i and mo del j . L et z 1 “ p 1 , z ´p i,j q q b e the action wher e i submits one c opy of j . L et π 1 b e the same as π on al l p airs r anke d by π and let the new ly submitte d mo del b e pr o duc er-r anke d last. Then E σ „ Σ p yr wr ,z 1 ,π 1 q r u i p σ qs ě E σ „ Σ p yr wr ,z ,π q r u i p σ qs ´ ε. The second sa ys that, for any pro ducer i action z i where there is some z ij ą 1 , it holds the pro ducer approximately prefers to submit one copy of j . Lemma E.2. F or al l ε ą 0 , ther e exists s 0 , m 0 such that for al l s ě s 0 and m ě m 0 , the fol lowing holds. Consider an action ve ctor z wher e z i,j ą 1 for some pr o duc er i and mo del j . L et z 1 “ p 1 , z ´p i,j q q b e the action wher e i submits one c opy of j . L et π 1 b e e qual to the π when dr opping j p 2 q , . . . , j p z ij q , ke eping the or dering of r emaining c andidates the same. Then E σ „ Σ p yr wr ,z 1 ,π 1 q r u i p σ qs ě E σ „ Σ p yr wr ,z ,π q r u i p σ qs ´ ε. 39 W e will show that together, these lemmas imply the theorem: In tuitively , for any pro ducer i action z i , we can make a series of ε -appro ximately utilit y-improving changes to the action suc h that we end up with action 1 . And since eac h pro ducer only has at most a constant n umber of distinct candidates by assumption, there are only a constan t n umber of such c hanges. Setting ε appropriately then yields the theorem (i.e., if W is the maxim um n um b er of distinct mo dels, setting ε in the lemma equal to ε { W for ε in the theorem). F ormally , let z p 0 q “ z and π p 0 q “ π . F or u P k i , let z p u q “ p 1 , z p u ´ 1 q ´p i,u q q b e the action that sets the first u en tries of z to 1. Note that z p m i q i “ 1 so z p m i q “ z 1 . Similarly , define π p u q i to b e the ranking achiev ed by altering π p u ´ 1 q i b y 1. app ending entry u to the end of the ranking if z i,u “ 0 , 2. dropping j p 2 q , . . . , j p z i,u q from the ranking if z i,u ą 1 , and 3. k eeping the ranking as is if z i,u “ 1 . Note that π p m i q i “ 1 , so π p m i q “ π 1 . By telescoping, note that E σ „ Σ p yr wr ,z 1 ,π 1 q r u i p σ qs ´ E σ „ Σ p yr wr ,z ,π q r u i p σ qs “ m i ÿ u “ 1 E σ „ Σ p yr wr ,z p u q ,π p u q q r u i p σ qs ´ E σ „ Σ p yr wr ,z p u ´ 1 q ,π p u ´ 1 q q r u i p σ qs . (E.1) A t each step we apply either Lemma E.1 if z i,j “ 0 or Lemma E.2 if z i,j ą 1 and note that z p u ´ 1 q “ z p u q and π p u ´ 1 q “ π p u q otherwise, so the exp ectations are equal in that case. Thus, eac h term in the sum on the second line is no less than ´ ε { W and so the sum is no less than ´ ε . Rearranging the left-hand side of Equation (E.1) yields the inequality in the theorem. Without loss of generality , in the next pro ofs of the next t wo lemmas, let the fo cal pro ducer in each lemma b e indexed 1 so that w e ma y use i for generic pro ducers. Pr o of of L emma E.1. Let σ „ Σ p yr wr , z , π q and σ 1 „ Σ p yr wr , z 1 , π 1 q . Then E σ 1 r u 1 p σ 1 qs ´ E σ r u 1 p σ qs “ ÿ L P L ν 1 p L q ´ Pr σ 1 r σ 1 p 1 q P M 1 p z 1 1 qs ´ Pr σ r σ p 1 q P M 1 p z 1 qs ¯ (Definition of u 1 ) “ ÿ L P L ν 1 p L q ¨ ˝ ÿ ℓ P M 1 p z 1 1 q Pr σ 1 r σ 1 p 1 q “ ℓ s ´ ÿ ℓ P M 1 p z 1 q Pr σ r σ p 1 q “ ℓ s ˛ ‚ (Probabilities that a mo del ranks first are disjoin t.) “ ÿ L P L ν 1 p L q Pr σ 1 r σ 1 p 1 q “ j s ` ÿ L P L ν 1 p L q ÿ ℓ P M 1 p z 1 q Pr σ 1 r σ 1 p 1 q “ ℓ s ´ Pr σ r σ p 1 q “ ℓ s ( M 1 p z 1 1 q “ M 1 p z 1 q Y t j u .) Let ¯ m b e an upp er b ound on max i | M i p z i q| (since we hav e assumed that no pro ducer has more than a constan t num b er of mo dels). Finally , the first term is trivially nonnegativ e and eac h term in the second sum is no less than ´ ε { ¯ m b y Lemma C.1 (c ho osing ε in Lemma C.1 to b e ε { ¯ m ). Th us, eac h inner sum is no less than ´ ε and b y assumption on ν summing to no more than 1 , the outer sum must b e no less than ´ ε . 40 Pr o of of L emma E.2. Let σ „ Σ p yr wr , z , π q and σ 1 „ Σ p yr wr , z 1 , π 1 q . Then, E σ 1 r u 1 p σ 1 qs ´ E σ r u 1 p σ qs “ ÿ L P L ν 1 p L q ¨ ˝ z ij ÿ u “ 2 Pr σ 1 p σ 1 L p 1 q “ j p u q q ` ÿ ℓ P M 1 p z 1 q Pr σ 1 p σ 1 L p 1 q “ ℓ q ´ Pr σ p σ L p 1 q “ ℓ q ˛ ‚ , similar to Lemma E.2. Now, notice that ř z ij u “ 2 Pr σ 1 p σ 1 L p 1 q “ j p u q q “ 0 since WLOG we assumed that π p j p 1 q q ă π p j p u q q for u ą 1 , so the mec hanism ensures σ p j p 1 q q ă σ p j p u q q for u ą 1 . Moreo ver, each term in the second RHS inner sum is no less than ´ ε { W , since w e remo ved at most ¯ m ´ 1 candidates and so can apply Lemma C.1 (using parameter ε {p ¯ mW q ) ¯ m times for each term. Finally , there are W terms in the second RHS sum by assumption, so the whole sum is no less than ´ ε . F A dditional pro ofs Pr o of of Pr op osition 4.2. T o sho w the key inequality ab o ve, we will specifically pro ve the follo wing c hain of inequalities: } ˇ R s ´ R } 8 “ } T π p ˆ R s q ´ T π p R q} 8 ď } ˆ R s ´ R } 8 where the first step is b y definition and the fact that when π is truthful, T π p R q “ R (the rew ards are unc hanged by the correction). The second inequality is by the general lipsc hitzness of the correction, which w e will pro v e no w: Fix R 1 , R 2 P R m , fix a pro ducer i and j P M i . Let S i,j : “ t π i p k q : k ď π ´ 1 i p j qu b e the set of all candidates i rank ed in π i as b etter than j . Then |p T π p R 1 qq j ´ p T π p R 2 qq j | “ ˇ ˇ ˇ ˇ min j 1 P S i,j R 1 j 1 ´ min j 2 P S i,j R 2 j 2 ˇ ˇ ˇ ˇ ď max j 1 P S i,j | R 1 j 1 ´ R 2 j 1 | ď } R 1 ´ R 2 } 8 . The first inequalit y is by the fact that if the mins are v ery far apart, then either those mins corresp ond to the same j 1 (and it holds with equality), or they corresp ond to differen t j 1 , j 2 and if so, the distance b etw een the mins is a lo wer b ound on the distance b et ween the resp ectiv e rew ards for at least one of these candidates. The second inequalit y is just by the definition of the ℓ 8 norm (lefthand side is just max ov er a subset of candidates). Then, it follows that } T π p R 1 q ´ T π p R 2 q} 8 “ max j |p T π p R 1 qq j ´ p T π p R 2 qq j | ď } R 1 ´ R 2 } 8 . Pr o of Cor ol lary 4.3. By Prop osition 4.2, } ˇ R s ´ R } 8 ď } ˆ R s ´ R } 8 . This implies the claim b ecause if for all random realizations of ˆ R s this is true, then for an y M and an y s , Pr p} ˇ R s ´ R } 8 ą M { ? s q ď Pr p} ˆ R s ´ R } 8 ą M { ? s q , 41 And ? s consistency is sho wn. Correctness under γ -separated true rew ards is a direct implication of the fi rst part, since the probabilit y an y pair of mo dels is misrank ed go es to zero as s Ñ 8 . Pr o of of Pr op osition 4.5. W e b egin by assuming that all candidates ha ve distinct qualities. Under this assumption, there exists some γ ą 0 such that | R j ´ R j 1 | ą γ for all j, j 1 . Because MLE estimates for Bradley-T erry concentrate around their true v alues, ˆ R j ´ ˆ R j 1 concen trates around R j ´ R j 1 . Therefore, if R j ą R j 1 , then Pr r ˆ R j ´ ˆ R j 1 ă 0 s Ý Ý Ñ s Ò8 0 . Consider an y j, j 1 P K i suc h that R j ą R j 1 . Supp ose they are adjacently ranked in π i , but in the incorrect order (i.e., ¨ ¨ ¨ ą j 1 ą j ą . . . ). Sw apping their ranks (call this π 1 i ) can only reduce pro ducer i ’s utility in the case where ˆ R j 1 ą ˆ R j . As sho wn ab o ve, the probability that this o ccurs go es to 0 as s Ò 8 . Therefore, for any ε , there exists sufficiently large s suc h that Pr r ˆ R j ´ ˆ R j 1 ă 0 s ă ε . Sw apping from π i to π 1 i can only w eakly increase q R j and weakly decrease q R j 1 . W e ignore the effect of increasing q R j , since it can only increase utilit y . Decreasing q R j 1 can reduce utilit y b ecause j 1 ma y lose a leaderb oard it would hav e otherwise won, and o ccurs if and only if ˆ R j 1 ą ˆ R j . F ormally , E σ „ Σ p yr wr p M p z q ,π 1 i qq r u i p σ qs ´ E σ „ Σ p yr wr p M p z q ,π 1 i qq r u i p σ qs ď E σ „ Σ p yr wr p M p z q ,π 1 i qq r u i p σ q ¨ 1 p ˆ R j 1 ą ˆ R j qs ´ E σ „ Σ p yr wr p M p z q ,π 1 i qq r u i p σ q ¨ 1 p ˆ R j 1 ą ˆ R j qs ď Pr r ˆ R j 1 ą ˆ R j s ď ε for sufficiently large s . Applying this argumen t inductively (we need at most ` k i 2 ˘ sw aps) sho ws that the true ranking π ˚ i is an ε -appro ximate dominan t strategy for sufficiently large s . Finally , we can lift the assumption that all qualities are distinct b y allowing that either ranking of t wo candidates with identical qualities is considered truthful. Our argument applies to all pairs of candidates with distinct scores, which yields the result. Pr o of of Cor ol lary 4.6. Let A b e the even t that the confidence interv als cov er R . No w, on A , the analysis in the pro of of Theorem 4.1 holds: Since the confidence interv als cov er R , clones must hav e ov erlapping confidence interv als. Th us, the isotonic score correction will b e applied to all clones and the arguments for the appro ximate utility improv emen t induced b y remo ving clones apply as is (conditioning on A ). On A C , since utilities are bounded in r 0 , 1 s , the c hange in utility can b e at most one. And since the confidence in terv als are sim ultaneously v alid, A C holds with probability at most ε . Therefore: E σ „ Σ p ua-yr wr p M p z 1 q ,π ,α q r u i p σ qsq ´ E σ „ Σ p ua-yr wr p M p z q ,π ,α qq r u i p σ qs “ P p A qp E σ „ Σ p ua-yr wr p M p z 1 q ,π ,α q r u i p σ q | A sq ´ E σ „ Σ p ua-yr wr p M p z q ,π ,α qq r u i p σ q | A sq ` p 1 ´ P p A qqp E σ „ Σ p ua-yr wr p M p z 1 q ,π ,α q r u i p σ q | A C sq ´ E σ „ Σ p ua-yr wr p M p z q ,π ,α qq r u i p σ q | A C sq ě 1 ¨ p´ ε q ` α ¨ p´ 1 q 42 Pr o of of Pr op osition 4.7. F or ? s -consistency , note that since the confidence interv als are ? s consisten t and include ˆ R , for all j P M ˇ R UA j ´ ˆ R j “ O P p s ´ 1 { 2 q . Moreo ver, by the MLE theorem, ˆ R j ´ R j “ O P p s ´ 1 { 2 q . Th us, ˇ R UA j ´ R j “ p ˇ R UA j ´ ˆ R j q ´ p R j ´ ˆ R j q “ O P p s ´ 1 { 2 q . Correctness is a direct implication of the first part, since the probability any pair of mo dels is misranked go es to zero as s Ñ 8 . 43
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment