GISclaw: An Open-Source LLM-Powered Agent System for Full-Stack Geospatial Analysis
The convergence of Large Language Models (LLMs) and Geographic Information Science has opened new avenues for automating complex geospatial analysis. However, existing LLM-powered GIS agents are constrained by limited data-type coverage (vector-only)…
Authors: Jinzhen Han, JinByeong Lee, Yuri Shim
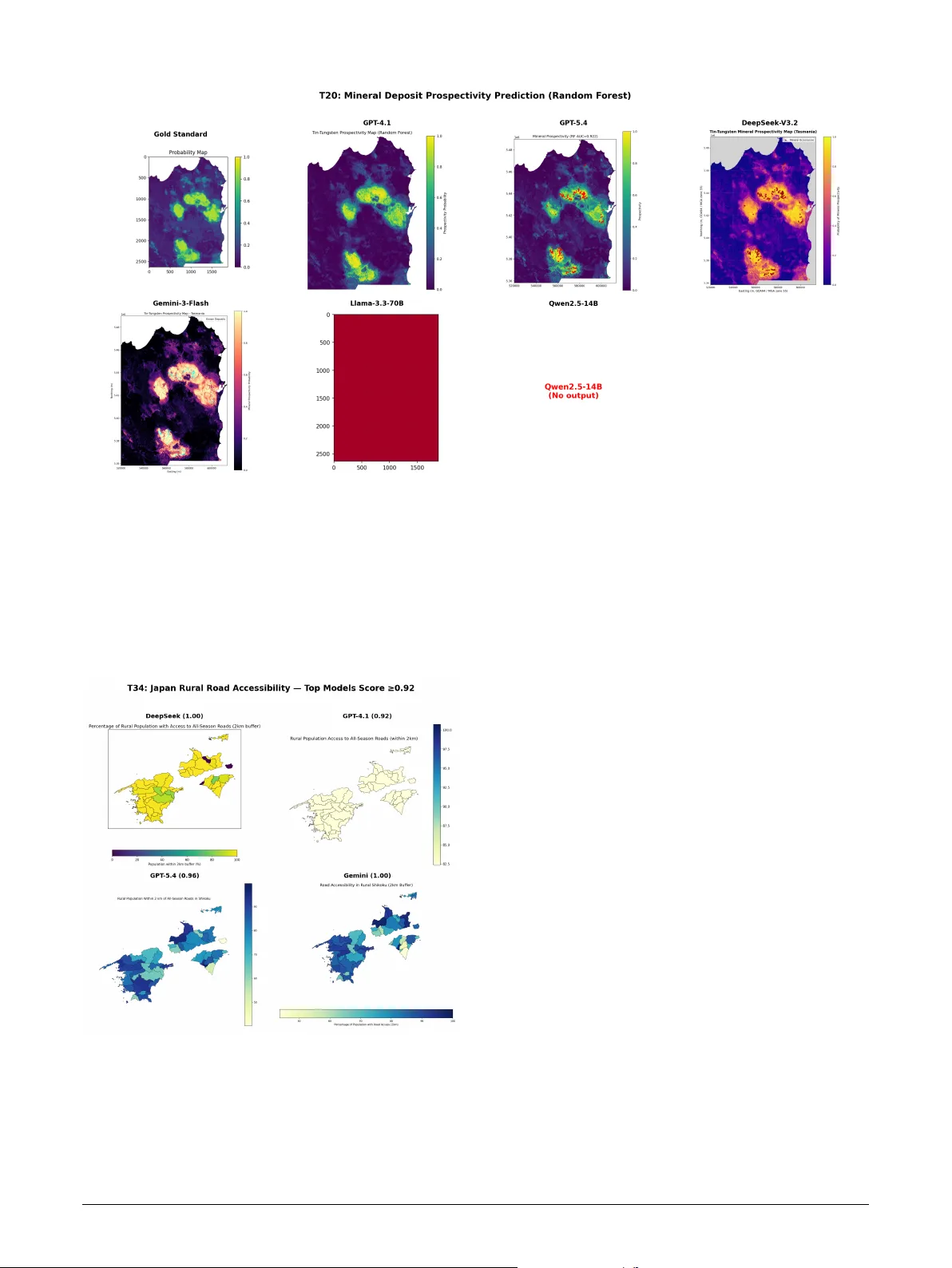
Highlights GIScla w: An Open-Source LLM-P o wer ed Agent Sy stem f or Full-Stack Geospatial Anal ysis Jinzhen Han, JinByeong Lee, Y uri Shim, Jisung Kim, Jae-Joon Lee • An open-source LLM-pow ered agent sy stem suppor ting full-stack (v ector , raster, tabular) g eospatial analysis • Systematic comparison of 6 LLMs × 2 architectures acr oss 600 experiment r uns achie ving up to 96% task success • Multi-agent architecture degrades strong models but mar ginally benefits weak ones—architectural comple xity should match model capability • A three-lay er ev aluation protocol addressing the functional equiv alence problem in GIS code assessment GIScla w: An Open-Sour ce LLM-P o wered Ag ent System f or Full-Stack Geospatial Analy sis Jinzhen Han a , JinBy eong Lee a , Y ur i Shim b , Jisung Kim c , ∗ and Jae-Joon Lee d , ∗∗ a Department of Civil, Ar chitectur al & En vironment Engineering, Sungkyunkw an Univ ersity, Suw on, South K orea b Ministry of the Interior and Safe ty, South Korea c School of Geogr aphy, Univer sity of Leeds, United Kingdom d Department of Fir e Safety Engineering, Jeonju Univer sity, Jeonju-si, Republic of Korea A R T I C L E I N F O Keyw ords : GIS agent system Large language models Geospatial analysis automation Multi-agent architecture Code generation Open-source A B S T R A C T The conv ergence of Lar ge Language Models (LLMs) and Geographic Inf or mation Science has opened new a v enues for aut omating complex g eospatial analysis. How ever , existing LLM-powered GIS agents are constrained by limited data-type cov erage (vector -only), reliance on proprietary GIS platforms, and single-model architectures that preclude systematic compar isons. W e present GIScla w , an open- source agent system that integrates an LLM reasoning core wit h a persistent Python sandbox, a comprehensive suite of open-source GIS libraries (GeoPandas, r aster io, scipy , scikit-lear n), and a web-based interactive interface for full-stack geospatial analysis spanning v ector, raster, and t abular data. GISclaw implements two pluggable agent architectures—a Single Agent ReAct loop and a Dual Agent Plan-Ex ecute-Replan pipeline—and supports six heterogeneous LLM back ends ranging from cloud-hosted flagship models (GPT -5.4) to locally deploy ed 14B models on consumer GPUs. Through three ke y engineer ing innov ations—Schema Analysis br idging the task –dat a information gap, Domain Know ledge injection f or domain-specific wor kflows, and an Error Memor y mechanism for intelligent self-correction—GISclaw achie ves up to 96% task success on t he 50-task G EO A N ALYST B E NC H benchmark. Systematic ev aluation across 600 model–architecture–task combinations rev eals that the Dual Agent architecture consistentl y degrades strong models while pro viding marginal gains f or w eaker ones. W e fur ther propose a three-la yer ev aluation protocol incor porating code str ucture analy sis, reasoning process assessment, and type-specific output v er ification for comprehensiv e GIS agent assessment. The system and all evaluation code are publicly available. 1. Introduction Geographic Information Systems (GIS) under pin spatial decision-making in domains ranging from urban planning and environmental monitoring to disaster response and pub- lic health ( SUN et al. , 2025 ). Modern geospatial analysis de- mands proficiency across multiple data modalities—vect or geometries for boundar ies and infrastructure, raster grids for satellite imagery and elev ation models, and t abular attributes f or census and sensor data—using specialized t oolchains such as ArcGIS, QGIS, and programmatic libraries includ- ing GeoPandas, rasterio, and scipy . This steep technical bar- rier limits accessibility for domain scientists who understand what anal ysis is needed but lack the programming skills to implement how , creating a persistent bottlenec k be tween geospatial q uestions and actionable answers. The rapid advancement of Lar ge Languag e Models (LLMs) with strong code generation and reasoning ca- pabilities has opened a pr omising pat hw ay to bridge this gap through autonomous GIS ag ents —systems that trans- late natural-language instr uctions into ex ecutable spatial analy sis workflo ws ( Li et al. , 2025 ). Li and Ning ( 2023 ) f or malized this vision as “ Autonomous GIS, ” demonstrating that GPT-4 could generate and execute spatial analysis code with approximatel y 80% success. Subsequent systems ∗ Corresponding author ∗ ∗ Corresponding author OR CI D (s): advanced different axes of this vision: GIS Copilot ( Akin- boy ew a et al. , 2025 ) integrates LLM-guided tool selection within QGIS (86% success on 110 t asks); GeoGPT ( Zhang et al. , 2023 ) integrates GPT-3.5 with a GIS tool pool f or autonomous spatial data collection and analy sis; GeoJ- SON Agents ( Luo et al. , 2026 ) compare code-generation vs. function-calling paradigms (97% on 70 tasks); Geo- Colab ( W u et al. , 2025 ) introduces a t hree-role multi- agent framew ork with RA G (+7–26% ov er single-agent baselines); and G TChain ( Zhang et al. , 2025b ) fine-tunes LLaMA-2-7B on synthetic tool-use c hains. On the e val- uation side, G EO A NA LY ST B E N C H ( Zhang et al. , 2025a ) pro vides the most comprehensive GIS benchmark to date (50 expert tasks), complemented by GeoBenchX ( Kreche tov a and K ochedyk ov , 2025 ) f or multi-s tep g eospatial reasoning and cloud-based benchmarks ( Cardille et al. , 2025 ), while metrics research has produced CodeBLEU ( Ren et al. , 2020 ), LLM-as-a-Judge ( Zheng et al. , 2023 ), and embedding-based similarity ( Reimers and Gurevyc h , 2019 )—each capturing complementar y aspects of agent quality . Despite t hese advances, t hree cr itical limit ations persis t across existing systems, all rooted in system design rat her than model capability: (1) N arrow data-type cov erage. Although some sy s- tems incorporate basic raster suppor t (e.g., GIS Copilot via QGIS raster tools, GTChain via Kr iging/density operators), none provides an integrated w orkflow that spans vector ov erla ys, raster inter polation, spectral inde x computation, Han et al.: Preprint submitted to Elsevier Page 1 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis and mac hine learning (clus ter ing, classification) within a single agent execution. (2) Platform dependency and limited model diversity . Most systems are tightly coupled to a single LLM (typically GPT -4) and often depend on proprietar y GIS platforms ( Li and Ning , 2023 ; Akinboy ew a et al. , 2025 ). This coupling prev ents sys tematic comparison across model families and precludes deployment in air -gapped or resource-constrained en vironments where API access is una vailable. (3) Fragmented ev aluation methodology . Existing metr ics— binary task success, CodeBLEU , or single-dimension LLM judging—each capture only one facet of agent quality ( Hou et al. , 2025 ; Gramacki et al. , 2024 ), and no prior w ork unifies them into a coherent multi-lay er protocol. The func- tional equivalence problem in GIS code—where a buffer analy sis can be cor rectly implemented via gpd.overlay() , shapely.buffer() , or gpd.sjoin() , all producing identical outputs—furt her renders lexical metr ics unreliable. T o address these system-le vel gaps, we present GISclaw , an open-source LLM-po wered agent system designed for full-stack geospatial analy sis. GIScla w integrates a persis- tent Python sandbo x wit h comprehensive open-source GIS libraries, three engineered prompt r ules that bridge t he infor - mation gap betw een task descriptions and data realities, and tw o pluggable agent architectures t hat can be paired wit h any LLM backend—fr om cloud APIs to fully offline 14B models on consumer GPUs. Our contributions are as follo ws: • Full-stack, model-agnostic agent syst em. W e design and implement GIScla w , an end-to-end agent sys tem supporting v ector, raster , and tabular g eospatial anal- ysis t hrough a persistent Python sandbo x, pre-loaded open-source GIS libraries, and t hree domain-specific prompt engineering rules (Sc hema Anal ysis, Pac k - age Constraint, Domain Know ledge Injection). Unlike prior systems tied to specific platforms or models, GIScla w suppor ts six heterog eneous LLM back ends, enabling deployment ranging from cloud APIs to fully offline 14B models on consumer hardw are. • Architectur e–capability matching principle. Through controlled compar ison of Single Agent (ReAct) and Dual Agent (Plan-Execute-Replan) architectures within identical infrastructure, we establish that ar chitec- tur al complexity should be inver sely pr opor tional to model capability —multi-agent ov erhead degrades strong models while providing marginal benefits only f or weaker ones. • Three-la yer ev aluation protocol. W e propose a uni- fied ev aluation protocol combining code str ucture analy sis (CodeBLEU + API Operation F1), reasoning process assessment (embedding similarity + LLM- as-Judge), and type-specific output verification, ad- dressing the fragmentation of e xisting single-metric approaches. • Empirical design lessons from 600 experiments. Systematic ev aluation on G E O A N A L YST B E N CH ( Zhang et al. , 2025a ) across 600 model–architecture–task combinations yields actionable engineering insights: infrastructure-lev el fixes (dat a pathing, API state man- agement) impr ov e task success by 400% on interme- diate tasks; code-specialized fine-tuning outperforms ra w parameter scaling; and cost-effectiv e open-source models achie ve parity with flagship APIs at substan- tially lower cost. T able 1 summar izes ho w GIScla w compares wit h e x- isting GIS agent systems. The remainder of this paper is org anized as f ollow s: Section 2 details the sys tem architec- ture and methodology; Section 3 introduces the ev aluation framew ork and benchmark; Section 4 presents experimental results and design analy sis; Section 5 concludes wit h future directions. 2. Methodology GIScla w is designed around three pr inciples: (1) Plat- form independence : no dependency on propr ietar y GIS sof t- w are, relying ex clusivel y on open-source Python libraries; (2) Model agnosticism : a pluggable LLM interface support- ing cloud APIs and locally deplo yed models with identi- cal w orkflow s; (3) Domain-aw are pr ompting : engineered prompt r ules that inject GIS-specific know ledge to compen- sate f or LLMs’ limited geospatial training data. Fig. 1 illustrates the o verall sys tem design. 2.1. Sys tem Design A fundamental design decision in GIScla w is its com- plete independence from proprietary GIS platforms . Unlik e systems that embed LLMs wit hin existing GIS software— e.g. , GIS Copilot ( Akinboy ew a et al. , 2025 ) couples with QGIS processing tools, and GeoGPT ( Zhang et al. , 2023 ) relies on an e xter nal GIS tool pool—GISclaw constructs its anal ytical capabilities entirel y from open- source Python libraries. This design c hoice is motivated by the obser vation t hat platf orm-dependent agents inherit the limitations and licensing constraints of t heir host soft- w are, restricting reproducibility and deplo yment flexibility . Moreov er , pilot experiments wit h non-agent, single-pass LLM code generation rev ealed critical deficiencies—models frequentl y produced syntactically valid but semantically incor rect GIS code ( e.g. , wrong CRS transforms, in verted raster band indices) that could not self-correct without iterativ e e xecution f eedbac k, confirming the necessity of an agent-based architecture wit h sandbox integ ration. By building on a self-contained Python ecosystem (Table 2 ), GIScla w ensures t hat any anal ysis expressible in Python— from basic v ector ov erla ys to mac hine lear ning-based spa- tial prediction—can be e xecuted wit hout external software dependencies. The execution core of GISclaw is a persistent Python sandbox that pro vides an interactive, Jupyter -like envir on- ment where variables and imported librar ies persist across ex ecution rounds within a single task. U nlike stateless code- generation approaches that ex ecute monolithic scr ipts, the Han et al.: Preprint submitted to Elsevier P age 2 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis T able 1 Compa rison of GIScla w with existing LLM-p o wered GIS agent systems. System Data T ypes Models Architectures Open-Source T asks Best Success LLM-Geo ( Li and Ning , 2023 ) Vecto r 1 (GPT-4) Single ✓ Case study ∼ 80% GIS Copilot ( Akinb oy ewa et al. , 2025 ) Vecto r+Raster 2 (GPT-4/3.5) Single ✓ 110 86.4% GeoGPT ( Zhang et al. , 2023 ) Vecto r 1 (GPT-3.5) Single No Case study — GeoJSON Agents ( Luo et al. , 2026 ) GeoJSON Multiple Multi (2-role) No 70 97.1% GeoColab ( Wu et al. , 2025 ) Vecto r 7 Multi (3-role) ✓ 50 +26.1% GTChain ( Zhang et al. , 2025b ) Vecto r+Raster 2 (LLaMA/GPT-4) Single (Fine-tuned) ✓ Custom +32.5% ‡ GISclaw (ours) Vec+Ras+T ab 6 SA + D A ✓ 50 96% ‡ Relative imp rovement over GPT-4 on the GTChain b enchmark, not an absolute success rate. Figure 1: Overview of the GISclaw system architecture. The system accepts natural-language tasks with GIS data (vector, raster, tabula r) as input, routes them through a pluggable LLM backend, and executes analysis in a p ersistent Python sandb ox. T wo agent a rchitectures—Single Agent (ReAct) and Dual Agent (Plan-Execute-Replan)—a re supported, with outputs evaluated via a three-la yer p roto col. sandbox enables t he agent to ex ecute incremental code snip- pets, inspect intermediate results, and iterativel y refine its approach—a capability critical f or e xploratory GIS w ork - flow s where each analytical step depends on t he results of the previous one. The sandbo x pre-loads a comprehensiv e GIS librar y stack (GeoPandas, rasterio, numpy , scipy , matplotlib, shapely , scikit-learn) upon initialization, eliminating common ImportError f ailures. A key design c hoice is an asymmetric output truncation policy : standard output is truncated from the fr ont (preser ving the most recent dat a inspection results), while er ror output is truncated fr om the tail (preser ving the root-cause er ror message). This strategy is informed b y the observation t hat GIS agents primar ily need the latest in- termediate results f or decision-making, whereas debugging requires t he or iginal er ror traceback. The sandbo x fur ther tracks new variables created in each ex ecution round and enf orces a 10-minute per-task timeout to prev ent r unaw a y computations. T able 3 summar izes t he key design f eatures of the sandbox and their rationale. A central design goal of GIScla w is model agnosti- cism . The system abstracts all LLM interaction through a unified LLMEngine interface, decoupling the agent logic from any specific model pro vider . This interface suppor ts cloud-hosted APIs, locally served open-weight models, and ev en quantized models running on a single consumer GPU , enabling deployment scenar ios ranging from full cloud to fully air-gapped en vironments. In practice, w e found that different model families exhibit substantial variation in out- put f or matting conv entions— e.g. , some models wrap code in markdo wn f ences while others emit raw code, and reasoning- specialized models allocate internal “thinking tokens ” that Han et al.: Preprint submitted to Elsevier P age 3 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis T able 2 Pre-loaded op en-source lib rary stack organized by analytical capabilit y . This ecosystem replaces the need fo r prop rieta ry GIS platforms. Catego ry Libra ries Capabilities V ector GeoPandas, shap ely , fiona, p yproj Spatial joins, buffer, overla y , CRS transforms Raster rasterio, xa rray , rasterstats Band algebra, interp o- lation, zonal statistics Analysis scip y , scikit-lea rn, libp ysal Kriging, clustering, re- gression, spatial auto- co rrelation Visualization matplotlib, seab o rn, geoplot, ca rtopy Cho ropleth, heatmaps, multi-panel cartography T able 3 Key design features of the p ersistent Python sandb ox. F eature Design Rationale State p ersistence V ariables and imp orts survi ve across rounds, enabling incremental explo ratory analysis Asymmetric truncation stdout: front-truncated (latest results); stderr: tail-truncated (ro ot-cause er- ro r) V ariable track- ing New variables logged per round, p ro- viding the agent with execution con- text 10-min timeout Prevents runaw ay computations ( e.g. , la rge-scale Kriging on consumer GPUs) reduce the effective output budget. GISclaw addresses these incompatibilities through provider -specific adapters within the unified inter face, allowing any conf or ming LLM back - end to be plugged in wit hout modifying the agent logic. 2.2. Domain-Specific Prompt Engineering Through iterative dev elopment and f ailure anal ysis, we identified three prompt engineering rules that are critical for reliable GIS agent per formance. The first rule, Schema Analysis , addresses a fundamen- tal inf ormation gap between t ask descriptions and actual data schemas. GIS datasets frequentl y use abbreviated or domain-specific column names ( e.g. , “ A CSHHBPO V” f or pov erty rate) that LLMs cannot inf er from task descr iptions alone. T o br idge this gap, the system prompt mandates that the agent ’ s first action must be a data inspection step— printing column names, data types, coordinate refer ence systems, and sample row s—bef ore generating any analytical code. In ablation experiments, this single r ule eliminated column-name guessing er rors and significantl y improv ed output quality f or the locally deplo yed 14B model. The second r ule, Packag e Constraint , prev ents the agent from g enerating code that depends on proprietary or una vailable librar ies. LLMs trained on GIS corpora frequentl y produce arcpy code (requiring an ArcGIS license) or ref erence packag es no t installed in the sandbo x ( e.g. , pykrige , skimage ). The pr ompt explicitl y redirects the agent to open-source equivalents such as geopandas , rasterio , and scipy.interpolate . The t hird r ule, High-lev el W orkflow & Domain Knowl- edge Injection , supplies task -specific procedural know ledge that lies beyond the LLM’ s parametr ic capabilities. As noted in the Introduction, domain scientists often understand the logical steps required to solv e a problem ( what anal ysis to perform) but lack t he prog ramming proficiency to handle complex spatial dat a formats ( ho w to code it). GISclaw accepts a user-pr ovided high-lev el w orkflow or domain know ledg e as an optional input field and injects it directl y into the agent prompt. This positions the Agent as a faithful ex ecutor , empo wering t he human e xper t to guide the anal yt- ical direction while the Agent bridges t he implementation gap from conceptual steps to specific GIS librar y function calls, mitigating s tep omissions or hallucinations caused by relying solely on the LLM’ s intrinsic know ledge. Fig. 1 illustrates a simplified excerpt of the system prompt, sho wing how these three r ules are operationalized. 2.3. Ag ent Arc hitectures GIScla w implements tw o pluggable agent architectures that operate on the same sandbox and prompt infrastr ucture, enabling controlled compar ison of their effectiveness across different model capabilities. Fig. 2 illustrates the tw o archi- tectures. Single Agent (SA) f ollow s t he ReAct ( Y ao e t al. , 2022 ) paradigm, iterativ ely g enerating Thought (natural-languag e reasoning), Action (Python code f or t he sandbox), and re- ceiving Obser vation (ex ecution output or er ror messages). An ErrorMemory module records er ror patterns encountered across rounds, pre venting the agent from repeating failed ap- proaches and promoting progressive refinement. The agent accumulates all generated code into a consolidated script upon task completion. Dual Agent (DA) adopts a Plan-Execute-Replan pipeline with explicit task decomposition. A Planner receives the task instruction, domain know ledge, and data schema (ob- tained via Schema Anal ysis), then decomposes the task into 3–7 ordered analytical steps. A W orker executes each step within the shared persistent sandbox, with up to 10 self-cor rection rounds per step. When t he W ork er fails on a step, the Planner is re-inv oked as a Replanner with the f ailure context to generate a simplified alter native plan that av oids the f ailed operations; up to 2 replanning cycles are per mitted. Both roles share t he same underlying LLM and sandbox namespace, ensur ing inf or mation continuity . Notabl y , the Replanner is not a separate module but the same Planner in v oked with f ailure-a ware context—this keeps the architecture lightweight while enabling adaptive recov er y . Han et al.: Preprint submitted to Elsevier P age 4 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis 3. Evaluation F ramew ork and Benc hmark 3.1. Benchmark Dataset W e ev aluate GISclaw on G E O A NA LY ST B E N C H ( Zhang et al. , 2025a ), the most comprehensiv e publicly a vailable benchmark f or GIS agent systems. G E O A N A L YST B E NC H comprises 50 expert-designed t asks organized into six an- alytical categor ies (T able 4 ), spanning three data modalities (vect or, raster, t abular) with an av erage of 5.8 wor kflow steps per task. Each t ask is modeled af ter a real-w orld GIS analy sis scenario—including flood r isk assessment, mineral prospec- tivity mapping, urban heat island analy sis, and wildlif e cor- ridor optimization—requiring multi-step spatial reasoning, cross-f or mat data integ ration, and domain-specific parame- ter calibration. This design prior itizes anal ytical depth over task count: the 50 t asks collectivel y cover the full spectr um of geospatial operations (ov erlay , buffer , inter polation, raster algebra, machine lear ning, netw ork analysis) at a complexity lev el r epresentative of prof essional GIS wor kflow s, making the benchmark a r igorous testbed for agent capability despite its moderate size. Across all e valuation e xperiments, w e unif or mly inject the “Human Designed W orkflo w” provided by the benchmark as domain know ledge (see Section 2.2 ) di- rectly into the evaluation prompt. This setup not only ensures f air comparability among models under identical problem- solving logic but also effectiv ely isolates the vast variance introduced b y unconstrained free e xploration, thereby truly reflecting t he A gent ’ s ability to comprehend and e xecute precise prof essional instructions. Gold standard adaptation. A critical contribution of our w ork is the systematic adaptation of G EO A NA L YST - B E NC H ’ s gold-standard solutions. The original benchmark pro vides e xper t-authored reference code wr itten in ArcPy — a Pyt hon API tightly coupled wit h t he propr ietar y ArcGIS platf or m. Since GISclaw operates entirely on open-source libraries, we manually rewro te all 50 gold-standard solutions using the open-source GIS ecosystem (GeoPandas, rasterio, scipy , scikit-learn), ensuring functional equivalence while eliminating propr ietar y dependencies. These rewritten solu- tions ser ve as the ref erence f or all evaluation la yers (L1–L3). 3.2. LLM Backends T o validate model agnosticism, w e ev aluate GIScla w with six heterogeneous LLM bac kends spanning cloud APIs and local deplo yments (T able 5 ). Cloud models include two OpenAI models (GPT -5.4 and GPT -4.1), DeepSeek - V3.2 (a cost-effectiv e alternative at significantl y lo wer pr ice), and Google’ s Gemini-3-Flash. For offline deployment, we test Llama-3.3-70B on a multi-GPU server and Qwen2.5-Coder - 14B on a single consumer RTX 3090 GPU . This selec- tion cov ers the spectrum from flagship reasoning models to lightweight code-specialized models, enabling systematic comparison of how model capability interacts with system design. T able 4 GeoAnal ystBench task categories with representative ex- amples. Each task includes natural-language instructions, heterogeneous input data, optional domain kno wledge, and exp ert-autho red gold-standard co de. Catego ry 𝑁 Rep resentative T ask Understanding spatial distributions 19 T1: Urban heat island & elderly risk mapping via Kriging interpo- lation Making p redictions 8 T20: Mineral dep osit prediction using Random Fo rest with raster features Detecting patterns 7 T42: Airbnb price clustering via lo cal Moran’s I spatial autocorre- lation Measuring shap e & distribution 7 T36: V egetation change detec- tion using SA VI sp ectral index Determining spa- tial relationships 6 T38: T ravel-time iso chrone com- putation on road netw orks Optimal lo cations & paths 3 T32: Wildlife co rridor optimiza- tion via weighted cost-surface overla y T able 5 LLM back ends evaluated. Cost is p er million tokens (input/out- put). Open-weight models are deploy ed on local servers at zero ma rginal cost. Mo del Back end Cost ($/M) Context Cloud API (pay-per-use) GPT-5.4 Op enAI 2.50 / 15.00 1M GPT-4.1 Op enAI 2.00 / 8.00 1M DeepSeek-V3.2 DeepSeek 0.28 / 0.42 128K Gemini-3-Flash Google AI 0.50 / 3.00 1M Lo cal deployment (zero ma rginal cost) Llama-3.3-70B Lo cal server F ree 128K Qw en2.5-14B Local GPU F ree 32K 3.3. Multi-Lay er Evaluation Protocol T o comprehensiv ely assess agent per formance beyond binary success rates, we propose a multi-lay er ev alua- tion pro tocol that captures complement ary aspects of ag ent quality —from surface-le vel code fidelity to deep reasoning process and final output cor rectness (Fig. 3 ). Individual lay er scores are combined into a composite score: 𝑆 comp = 0 . 4 ⋅ 𝑅 succ + 0 . 3 ⋅ 𝑄 out + 0 . 15 ⋅ 𝐹 api + 0 . 15 ⋅ 𝐶 emb (1) where 𝑄 out a verag es only o ver successful tasks to av oid double-penalizing f ailures already captured by 𝑅 succ . L1: Code Structure. W e e valuate syntactic and struc- tural similar ity between generated and gold code using f our metrics. BLEU-4 ( Papineni et al. , 2002 ) computes geometric-mean 𝑛 -gram precision ( 𝑛 = 1…4 ) with brevity Han et al.: Preprint submitted to Elsevier P age 5 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis penalty: BLEU-4 = BP ⋅ e xp 1 4 4 𝑛 =1 log 𝑝 𝑛 (2) where 𝑝 𝑛 denotes clipped 𝑛 -gram precision and BP = min(1 , 𝑒 1− 𝑟 ∕ 𝑐 ) . ROUGE-L measures the longest common subsequence (LCS): 𝑅 lcs = LCS 𝑟 , 𝑃 lcs = LCS 𝑐 , 𝐹 lcs = 2 𝑅 lcs 𝑃 lcs 𝑅 lcs + 𝑃 lcs (3) CodeBLEU ( Ren et al. , 2020 ) extends BLEU with code- a ware components: CodeBLEU = 1 4 𝛼 ngram + 𝛼 wt + 𝛼 syn + 𝛼 df (4) where 𝛼 ngram is standard BLEU-4, 𝛼 wt is ke yword-w eighted 𝑛 -gram matc h (Python ke yw ords receiv e double weight), 𝛼 syn is AST subtree match F1, and 𝛼 df is dat a-flow match F1 based on variable define–use c hains. W e additionall y compute Edit Similarity as 1 − 𝑑 Lev ∕ max( 𝑟 , 𝑐 ) . Critically , we introduce API Operation F1 : extracting GIS-specific operations ( e.g. , spatial_join , buffer , overlay , kriging ) from both generated and ref erence code via pattern matching, and computing set-le vel precision, recall, and F1. This metric is robust to the functional equiv alence problem, where semanticall y correct implementations share minimal lexical ov erlap. L2: Reasoning Process. This lay er e valuates whether the agent ’ s analytical reasoning pr ocess aligns wit h e xper t expectations, using two complementary methods. First, we encode cleaned e xecution logs and gold ref erences using OpenAI’ s text-embedding-3-large model (3072-d) and com- pute cosine similarity: 𝐶 emb = 𝐞 agent ⋅ 𝐞 gold 𝐞 agent ⋅ 𝐞 gold (5) This pro vides a continuous, ref erence-aligned measure of process quality . Second, we employ an LLM-as-Judge pro- tocol ( Zheng et al. , 2023 ): GPT -4o—deliberately ex cluded from the set of ev aluated models to av oid self-assessment bias—scores each ex ecution log on five dimensions (1–5 scale): (i) T ask Understanding : correct interpretation and planning; (ii) Data Handling : loading, CRS management, f or mat handling; (iii) Methodology : appropr iateness of GIS analy sis methods; (iv) Self-Corr ection : er ror detection and recov ery efficiency; (v) Result Comple teness : completeness of final deliv erables. The judge receives the task instruc- tion, expert-aut hored gold code, and the complete execution log, producing per -dimension scores wit h natural-language justifications. This dual assessment captures both statistical process alignment (embedding) and nuanced qualitative rea- soning ev aluation (LLM-as-Judge). Of t he two, onl y 𝐶 emb enters the composite score (Eq. 1 ); the LLM-as-Judge scores serve as a qualitativ e diagnostic tool for the case-study analy sis in Section 4 . L3: Output Accuracy . Generated outputs are ev aluated against gold standards using type-specific methods t ailored to the heterogeneous output formats of GIS tasks: Visualization outputs (PNG): GPT -4o vision receiv es both t he gold and agent images alongside the task instr uc- tion, scor ing fiv e cartographic dimensions: Task Comple- tion, Spatial Accuracy , Visual Readability , Cartog raphic Quality , and Dat a Integrity (each 1–5), explicitl y accepting alternative-but-correct visualization styles. Raster outputs (Geo TIFF): e valuated prog rammatically via CRS match, shape match, pixel-lev el Pearson cor rela- tion, and mean relative error against the gold raster , yielding a weighted composite: 𝑠 raster = 0 . 2 ⋅ 1 shape + 0 . 2 ⋅ 1 CRS + 0 . 3 ⋅ 𝑓 ( 𝜌 ) + 0 . 3 ⋅ 𝑔 ( MRE ) , where 𝑓 and 𝑔 are piecewise thresholding functions. T abular outputs (CSV): assessed through column ov er- lap ratio, row -count match, and av erage Pearson cor relation across shared numeric columns. V ector outputs (Shapefile, GeoJSON, GeoPac kage): com- pared via f eature count match, CRS consistency , and column ov erlap ratio agains t the gold reference. All type-specific scores are nor malized to [0 , 1] (vision scores are divided b y t he maximum scale of 5) and av eraged across output files to yield a per -task output accuracy score 𝑄 out . 4. Experimental Results and Analy sis W e evaluate GISclaw acr oss all 6 LLM bac kends (Sec- tion 3.2 ) × 2 architectures (S A, D A) = 600 experiment runs on G E O A NA L YST B E N C H . Each t ask is allocated a 10- minute timeout and a maximum of 50 interaction rounds. The sandbo x envir onment r uns Ubuntu with Python 3.12 and the pre-loaded GIS library st ack descr ibed in Section 2.1 . T able 6 presents the comprehensive e valuation results. DeepSeek - V3.2 ac hiev es the highes t S A composite score (0.759) with a str iking 96% success rate at onl y $0.50 total cost, while GPT -5.4 leads D A mode (0.685, 88% success) at significantl y higher cost. Notably , Qwen-14B and Llama- 70B are the onl y models where D A mar ginally outperforms S A, v alidating the pr inciple t hat arc hitectur al complexity should be inver sely proportional to model capability . The f ollowing subsections analyze each evaluation lay er in det ail. 4.1. Quantitative Evaluation Results 4.1.1. T ask success r ate and arc hitecture compar ison Fig. 4 visualizes the S A–D A gap acr oss all models. Strong models suffer general deg radation in D A mode (DeepSeek drops from 96% to 32 4.1.2. Code quality analysis (L1) A notable finding from T able 7 : Llama-70B achiev es the low est CodeBLEU (0.099) but a very high API F1 (0.593) in D A mode. This exposes the systematic bias of CodeBLEU f or GIS code—a single task ( e.g. , buffer analysis) can be cor- rectly implemented via gpd.overlay() , shapely.buffer() , or gpd.sjoin() with manual geometry operations, all yielding equiv alent results but sharing minimal lexical over lap. W e recommend API F1 as a more reliable metr ic for GIS code ev aluation. Han et al.: Preprint submitted to Elsevier P age 6 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis T able 6 Comp rehensive evaluation across all six LLM backends and tw o architectures. 𝑅 𝑠 : task success rate; 𝑄 out : output accuracy (L3, successful tasks only); 𝐹 api : API operation F1 (L1); 𝐶 emb : embedding cosine similarit y (L2); 𝑆 comp : composite score (Eq. 1 ). Cost is total API exp enditure fo r 50 tasks. Bold = b est p er architecture. Single Agent Dual Agent Mo del 𝑅 𝑠 𝑄 out 𝐹 api 𝐶 emb 𝑺 comp Cost 𝑅 𝑠 𝑄 out 𝐹 api 𝐶 emb 𝑺 comp Cost DeepSeek-V3.2 96% 0.615 0.633 0.638 0.759 $0.50 32% 0.551 0.410 0.603 0.445 $0.80 Gemini-3-Flash 88% 0.632 0.652 0.646 0.736 $0.80 76% 0.506 0.517 0.559 0.617 $1.50 GPT-5.4 90% 0.581 0.603 0.540 0.705 $8.50 88% 0.544 0.515 0.616 0.685 $12.3 GPT-4.1 82% 0.618 0.663 0.560 0.697 $1.20 74% 0.503 0.578 0.628 0.628 $3.40 Llama-3.3-70B 56% 0.406 0.573 0.619 0.525 $0 † 58% 0.371 0.593 0.634 0.527 $0 † Qw en2.5-14B 52% 0.590 0.535 0.518 0.543 $0 † 61% 0.458 0.602 0.591 0.561 $0 † † Open-weight models deplo yed lo cally; zero ma rginal cost. T able 7 Co de quality metrics across architectures. Mo del Co deBLEU API F1 ROUGE-L Dual Agent Gemini Flash 0.182 0.517 0.140 GPT-4.1 0.169 0.578 0.132 Llama-70B 0.099 0.593 0.100 Single Agent GPT-4.1 0.171 0.663 0.143 Gemini Flash 0.166 0.652 0.138 DeepSeek 0.124 0.633 0.097 Fig. 5 presents the per -task API F1 distribution, rev eal- ing that code similarity is highl y task -dependent: simple ov erla y t asks (T24, T40) score consistentl y above 0.7 across models, while complex multi-step analy ses (T27, T39) show near -zero ov erlap ev en f or successful completions. 4.1.3. Reasoning process assessment (L2) Fig. 6 presents the e xecution log embedding similar - ity for each task –model pair . In SA mode, DeepSeek and Gemini Flash maintain consistentl y high cosine similar- ity ( > 0 . 6 ) across most tasks, while in DA mode, the planner –work er decomposition introduces greater pr ocess variance—reflected in the wider scatter dispersion. T o complement the embedding-based assessment, a GPT -4o LLM-as-Judg e evaluates each ex ecution log across five qualitative dimensions (T able 8 ). DeepSeek dominates all S A dimensions, achie ving the highest aggregate score (4.04/5), while GPT -4.1 leads in DA mode (3.36/5). Notably , the Output Quality dimension exhibits the largest S A–D A gap: DeepSeek drops from 4.18 to 1.38 ( Δ = 2 . 80 ), con- firming that Dual Agent ’ s replanning mechanism disr upts successful ex ecution f or strong models. 4.1.4. Output accuracy and composite scores (L3) Fig. 7 pro vides a per-task breakdo wn of L3 output accu- racy scores across SA mode. The heatmap rev eals a bimodal distribution: most t asks cluster near 0.5–1.0 or near 0.0, T able 8 LLM-as-Judge reasoning assessment (1–5 scale). Bold = best p er a rchitecture. The five dimensions capture task understand- ing, data handling, methodology , self-correction, and result completeness. Model T ask Data Method Self-Co rr. Result Avg. Single Agent DeepSeek 4.14 4.48 3.98 3.44 4.18 4.04 Gemini Flash 3.78 4.10 3.42 3.16 3.46 3.58 GPT-5.4 3.28 3.98 3.14 3.12 3.12 3.33 GPT-4.1 3.26 3.62 3.02 2.48 2.76 3.03 Llama-70B 3.04 3.42 2.52 2.64 1.86 2.70 Qwen-14B 2.81 2.94 2.23 2.30 1.66 2.39 Dual Agent GPT-4.1 3.66 3.48 3.18 3.46 3.04 3.36 GPT-5.4 3.34 3.00 2.96 3.64 2.76 3.14 Gemini Flash 2.94 3.22 2.54 3.10 2.44 2.85 Llama-70B 3.10 2.54 2.40 3.08 1.92 2.61 DeepSeek 3.10 2.76 2.40 3.04 1.38 2.54 Qwen-14B 2.92 2.31 2.24 2.86 1.53 2.37 with fe w intermediate values, indicating that t ask success is larg ely binary once t hreshold quality is achie ved. This binary patter n itself motivates the multi-lay er protocol: man y “f ailed” t asks completed ov er 70% of t he required pipeline (cor rect spatial joins, Moran’ s I computation, or GWR fit- ting), ye t binar y pass/fail scoring cannot capture this par tial progress. The composite scores in T able 6 integ rate all ev alua- tion la yers. DeepSeek achie ves t he highest SA composite (0.759), but undergoes the largest D A degradation ( Δ = +0 . 314 ). 4.2. Case Studies W e present three categories of case studies that illu- minate the interaction between model capability , domain know ledg e, and system design. 4.2.1. Exceptional performance on complex t asks T20 — Mineral deposit prospectivity prediction. This task req uires a complete machine lear ning pipeline: load- ing 11 geological raster lay ers (geochemistry , geophy sics, lithology , structure), extracting pixel-lev el f eatures, training Han et al.: Preprint submitted to Elsevier P age 7 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis a Random Forest classifier on known tin-tungsten dep osit locations, generating a full-resolution pr obability map, and visualizing the prospectivity surf ace. The pipeline spans raster I/O, nodata handling, feature matrix construction, scikit-learn model fitting, pixel-wise prediction, and geo- ref erenced output—a representativ e end-to-end ML-dr iven geospatial w orkflo w . As shown in Fig. 9 , f our models (GPT -4.1, GPT-5.4, DeepSeek, Gemini Flash) produce prospectivity maps that f ait hfull y reproduce the spatial patter n of the gold stan- dard, with high-probability zones correctly localized around known deposit clusters. GPT-5.4 additionally reports a model A UC of 0.922 and over lay s known deposit points, while DeepSeek annotates the coordinate ref erence system (GD A94 / MGA zone 55). In contrast, Llama-70B g ener- ates a unif orm single-color raster , indicating a complete f ailure in the ML pipeline, and Qwen-14B produces no visualization output. This case demonstrates that strong models can autonomously orches trate complex multi-step ML w orkflow s—from ra w raster data to calibrated predic- tion sur faces—without explicit procedural guidance, while weak er models fail at fundamental stages of t he pipeline. T34 — Japan rural road accessibility analy sis. This multi-step GIS pipeline requires r ural area e xtraction, road buffer constr uction, population ratio computation, and choro- pleth visualization. Four models score abov e 0.92, with DeepSeek and Gemini achie ving perfect scores (1.00). Fig. 10 show s that successful outputs faithfull y reconstr uct the spatial accessibility pattern across Japan’ s pref ectures. 4.2.2. Parametric domain knowledg e gaps T07 — Land subsidence flood analy sis. This task ex- poses a cr itical limitation: the gold s t andard uses a flood depth threshold of ≤ −200 cm, which encodes domain know ledg e about pr ojected future sea lev el rise. All six models instead use the naive threshold elevation < 0 , producing outputs that appear correct but significantly ov er - estimate flood e xtent. Moreo ver , several models incor rectly hardcode the CRS as EPSG:4326 instead of t he data ’ s nativ e EPSG:28992, causing the ov erla y operation to fail silently and producing near -blank visualizations (Fig. 11 ). T08 — Fire station cov erage gap analy sis. Similarl y , the gold standard specifies a 2,500 m service buffer based on fire response time st andards, while models select arbitrar y values (500–1,000 m), producing “no-ser vice” areas that are 3–5 × larg er than t he ref erence (Fig. 12 ). These cases re veal a qualitativ e distinction that RAG- based systems cannot resolv e: while RAG can supply librar y documentation, it cannot impar t fundamental conceptual domain know ledge (e.g., flood depth = sea lev el − ter rain el- ev ation) or parame tric thresholds (e.g., fire-response buffer distances) that human analysts acq uire t hrough prof essional experience. This “conceptual know ledge gap” represents a distinct f ailure mode from the “ API kno wledg e gap” that retriev al-augmented systems w ere designed to address. T able 9 Infrastructure-level fixes and their impact on task success. These engineering lessons reveal that system design, not mo del capabilit y , is the prima ry b ottleneck for GIS agent p erfo rmance. Catego ry F ailure Symptom Fix Applied Data P athing Nested SHP files cause FileNotFoundError Flatten dataset structure API State rasterio.open() returns a reader object; agent calls .astype() Return raw ndarray + metadata dict Memo ry City-wide grids exceed 10 4 cells; overlay OOM Enfo rce grid-size templates T yp e Co er- cion String-enco ded nu- merics fail during in- terp olation Auto-cast with pd.to_numeric 4.2.3. Infrastr ucture vs. model capability T18 — Quadtree density visualization. All models cor rectl y ide ntify geoplot.quadtree() as t he appropriate function, but a compatibility issue betw een geoplot 0.5.1 and the installed pyproj v ersion causes univ ersal failure. This case demonstrates that some “model failures ” are actually envir onmental limitations , underscor ing the import ance of infrastructure design descr ibed in the next section. 4.3. Design Lessons Our 600-experiment ev aluation and iterative dev elop- ment process yield sev eral engineering pr inciples t hat extend bey ond benchmark scores. 4.3.1. Infrastr ucture dominates model capability A key empirical finding is that t he pr imar y bottleneck f or GIS ag ent success is not model reasoning ability but infrastructure-le vel system design . Through iterative fail- ure diagnosis across dev elopment versions, we identified and resolv ed f our categor ies of infrastructure bugs that domi- nated f ailure cases: After resolving these infrastructure issues, task success on inter mediate-difficulty tasks (requiring multi-step spa- tial analy sis with raster–v ector integration) impro ved from 20% to 80%—a 400% increase—while simple and comple x task categor ies remained lar gely unchang ed. This dispro- portionate impact demonstrates that the GIS agent design bottleneck lies in t he interface betw een model output and execution en vironment , not in the model’ s reasoning capacity . A complement ary finding concerns tool abstraction: tool la yers can introduce silent semantic mismatches —errors t hat produce no e xceptions but fundamentally corr upt do wn- stream computations. In multi-band remote sensing tasks (e.g., T36 SA VI computation), a load_raster helper that internally calls src.read(1) returns onl y Band 1 as a 2D Han et al.: Preprint submitted to Elsevier P age 8 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis ar ra y ( H , W ) . The agent inter prets data[3] as the f ourth spectral band, but actually retriev es the fourth pixel ro w— yielding systematically wrong values wit hout any er ror mes- sage. GPT -5.4 spent 35 rounds cor rectly diagnosing “wrong values ” but could not identify the root cause hidden in the tool la yer . After returning a full 3D ar ra y ( Bands , H , W ) alongside band metadata, the same model produced a valid Geo TIFF in round 3. This underscores t hat agent robust- ness critically depends on transparent, semantically un- ambiguous tool interfaces . T w o fur ther infrastr ucture-lev el f ailure modes illustrate how behavior al and information constraints operate at the system lay er rather than the model la y er . First, a visualiza- tion output constraint : in T06 (elk mov ement analy sis), Qwen-14B completed the full pipeline—Con ve x Hull, KDE, and DBSCAN clustering—but called plt.show() instead of plt.savefig() , causing all outputs t o be sa ved as empty emerg ency plots and the t ask to fail. Adding a single prompt line— NEVER use plt.show(); always use plt.savefig(..., dpi=150, bbox_inches=‘tight’) —reduced the r ound count from 20 (ceiling) to 12 and ele vated the output from an empty file to a cor rectly rendered car tographic product (ev al- uation score: 3.5 → 7.8). This demonstrates that output- format beha vioral constraints are as cr itical as analytical correctness constraints in GIS agent prompting. Second, a file-name guessing failur e : across 50 task s, 8 failures (16%) w ere attributable solel y t o incorrect file access—models “auto-cor rected” capitalization ( e.g. , Before_Storm.tif → Before_storm.tif ) or inferred names from task seman- tics ( e.g. , instruction mentions “Census Bloc k” → model queries CensusBlock.geojson , actual file is block.geojson ). This beha vior reflects models trained on Window s filesys- tems where paths are case-insensitive, causing systematic misjudgment when deployed on case-sensitive Linux en vi- ronments. The Schema Analysis rule—mandating list_files() as the agent ’ s first action—eliminates this class of f ailures by grounding file access in observed reality rather than semantic inf erence. 4.3.2. Hard cons traints outper form prompt-level constraints Small models exhibit a f ailure patter n we ter m frustration- induced constraint collapse : after repeated failures, the model abandons system-prompt constraints and falls back on pre-training def aults. In T26 (g roundw ater vulnerability mapping), Qwen-14B encountered persistent rasterio errors and, by round 17, attempted import arcpy —despite t he system prompt explicitl y marking it as unav ailable. This represents a deg radation of instr uction-f ollowing under fr us- tration: the model’ s parametric kno wledg e encodes ArcPy as the correct solution f or t his task type, and af ter alter native routes repeatedl y failed, it abandoned prompt compliance. Comparing three configurations rev eals the sev erity: (1) Prompt-only : the model attempts import arcpy at round 17, blocking the workflo w; (2) Pr ompt + deduplication : six consecutive import arcpy attempts (rounds 10–15), blocking earlier; (3) Promp t + sandbo x-level impor t inter ception : zero forbidden impor ts, 5 self-cor rection cycles, full pipeline completion. Implementing a sandbox-le vel impor t block er— raising an informative ImportError with sugges ted alter- natives at e xecution time—resolv es the issue completel y . The broader lesson: for resource-constr ained models, sandbox-le vel enforcement is a necessary com plement to prom pt-lev el constraints . A related mechanism—code deduplication—rev eals a precision–recall tradeoff in agent loop control. Dedupli- cation guards effectivel y pre vent “progress amnesia ” loops, where the model f org ets completed steps and resubmits identical code. In T25 (CO VID-19 r isk anal ysis), Qwen- 14B resubmitted handle_nan() eight consecutive times; a deduplication aler t at round 2 brok e t he loop and t he model successfully advanced to t he clustering anal ysis at round 19. How ev er, deduplication can also prematurely ter minate le- gitimate retry attempts. In T28, three consecutive submis- sions of identical GridSearchCV code were ter minated as a loop—but these were actually valid ex ecution retries for a computationally expensiv e hyperparameter search that had timed out. Distinguishing between “stuc k in a loop” and “retrying a slow operation ” requires semantic understanding of the code’ s intent, which simple hash-based deduplication cannot provide. This tradeoff suggests that context-a war e deduplication —a ware of e xecution timeout signals—is a w or thwhile direction for future agent engineer ing. 4.3.3. T wo failur e modes of self-correction The LLM-as-Judge Self-Cor rection dimension (T able 8 ) captures aggregate self-cor rection quality , but our qualita- tive analysis rev eals two distinct failure mechanisms with different remediation strategies. T ype A — Conceptual failur e (correct diagnosis impossi- ble): In T33 (flood depth analy sis), the model does not under - stand t he hydrological formula flood_depth = -(elevation + 200) . Self-cor rection loops produce the same conceptually wrong formula in ev ery round because the er ror is at t he domain-know ledg e level, not the code lev el. No amount of iterativ e e xecution can resol ve a conceptual misunderstand- ing. T ype B — Attentional f ailure (diagnosis available, cor - r ection not applied): In T34, Qw en-14B successfull y di- agnosed the problem— print(gdf[’landuse’].unique()) re- vealed the value ’RURAL’ in the execution log—but the ne xt code generation submitted == ’Rural’ (wrong capitalization) again. The correct diagnosis w as present in the conte xt window but w as not utilized dur ing code generation. This represents limited context utilization efficiency in smaller models: the answ er resided in the ag ent’ s o wn ex ecution history , ye t was not referenced. These tw o failure types call f or different interventions: T ype A requires richer domain know ledge injection at the t ask level; Type B ma y benefit from explicit memor y prompting t hat foregrounds key extracted values bef ore each code-generation step. Han et al.: Preprint submitted to Elsevier P age 9 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis T ype A f ailures further re veal a conceptual know ledge gap that retriev al-augmented generation (RA G) cannot re- solv e. In T33 (flood depth anal ysis), models consistentl y applied flood_depth = elevation - rasterized_buildings , producing outputs numer ically close to raw elev ation rather than the hydrologicall y cor rect flood_depth = -(elevation + 200) . RAG sys tems can supply librar y document ation (t he “ API kno w ledge g ap”), but the y cannot impar t the ph ysical understanding that flood depth equals the difference between sea level and terrain elevation —a domain insight t hat hu- man GIS analys ts acquire through prof essional experience, not from code repositories. A related failure mode is task instruction ambiguity : in T25 (COVID-19 risk mapping), a strong model completed the full spatial clustering pipeline but inter preted “create r isk maps” as a data output task (sa ving GeoJSON la y ers), while the gold standard expected PNG c horopleth visualizations. In GIS, the ter m “map” simultaneously denotes a visual cartographic product and a geospatial data la yer —an ambiguity that domain practition- ers resolv e implicitl y but that models cannot infer wit hout explicit output-format specification. These cases collectively argue for extending Domain Kno wledg e Injection beyond procedural wor kflow steps to include output format con- tracts and domain-calibrated phy sical parameter specifi- cations that ground agent beha vior in field-specific conv en- tions. 4.3.4. Local deplo yment viability and model selection Our results demons trate that fully offline GIS agent de- ployment on consumer har dware is viable, but model selec- tion is a critical and non-obvious design decision. Qw en2.5- Coder -14B running on a single RTX 3090 GPU achie ves a 52% end-to-end t ask success rate—a figure t hat under- states the model’ s actual GIS capability . More diagnosti- cally , Qwen-14B achie ves an output quality of 0.590 among successful t asks, comparable to GPT -4.1 (0.618) and sub- stantially abov e Llama-3.3-70B (0.406). This indicates t hat when Qwen-14B succeeds, its outputs ar e of comparable pr ofessional quality to those of much lar ger models . Counter -intuitivel y , Llama-3.3-70B—wit h 5 × more parameters— does not outper form Qwen2.5-Coder -14B on composite scores (0.525 vs. 0.543). Llama-70B achie ves high em- bedding similar ity (0.619 in S A), indicating strong seman- tic understanding of GIS concepts and t ask requirements; ye t it produces the lowes t output quality (0.406), rev eal- ing a pronounced comprehension–ex ecution gap. This lack of selective information e xtraction —printing only what is needed f or the ne xt decision step rather than the entire data structure—is a qualitativel y different skill from seman- tic comprehension, and is precisely what code-specialized training pro vides. F or local GIS ag ent deplo yment, code- specialized fine-tuning is mor e im pactful than ra w pa- rameter scaling. The 52% end-to-end success rate, how ev er, should not be interpreted as the ceiling of what a 14B model can contribute in practice. Qualitative anal ysis of Qwen-14B’ s f ailed e xe- cutions rev eals that failures are frequently concentrated in the final output assembly stag e rather than in the analytical reasoning or spatial computation steps. In T34 (r ural road accessibility), Qwen-14B correctly loaded the data, con- structed t he road buffer, e xtracted r ural polygons using the cor rect spatial join sequence, and computed per -prefecture ratios—but produced an incor rectly styled visualization in the final step, causing evaluation failure. In T01 (heat island & elderly r isk mapping via Kriging), the model successfully performed data inspection, CRS alignment, and point data preparation, but encountered a numer ical precision issue in the Kr iging grid resolution step. In T20 (mineral deposit prospectivity), Qw en-14B cor rectl y configured the Random Forest training pipeline and predicted class probabilities; how ev er, it failed to correctly reassemble t he prediction ar- ra y into a georef erenced Geo TIFF , yielding an empty output file. In each case, the core GIS reasoning—selecting t he right analytical method, calling t he cor rect library functions, and inter preting spatial data str uctures—w as demonstrabl y cor rect. These observations suggest an alter native deplo yment paradigm for resource-constrained environments: rather than fully autonomous end-to-end ex ecution, a human-in-the- loop GIS pipeline in which the agent handles s tr uctured analytical steps while the user validates and guides the w ork - flow at key transition points. Under this paradigm, Qwen2.5- Coder -14B on a single consumer GPU functions as a capable GIS coding par tner—tr anslating domain-expert kno wledg e into ex ecut able geospatial code, iterativel y refining analy ses based on execution f eedbac k, and handling the librar y-le vel complexity that constitutes the primar y technical bar r ier f or domain scientists. This collaborative mode transf orms t he 52% end-to-end metric into a more relevant measure: the proportion of pipeline stages the model can autonomously complete, which our anal ysis sugg ests substantially ex ceeds 80% f or the major ity of tasks. 5. Conclusion W e presented GIScla w, an open-source, model-agnostic LLM agent system f or full-stack geospatial analy sis. By grounding agent beha vior in a persis tent Python sandbo x pre-loaded with open-source GIS libraries—and by engi- neering three domain-a ware prompt r ules (Schema Anal- ysis, Package Constraint, Domain Know ledge Injection)— GIScla w achiev es up to 96% task success on G E O A N A - L YST B E NC H , spanning v ector, raster , and tabular geospatial w orkflow s that existing sy stems cannot support. Architectur al findings. Controlled comparison of Sin- gle Agent (ReAct) and Dual Agent (Plan-Ex ecute-Replan) architectures across 600 model–arc hitecture–task combina- tions rev eals a consistent pattern: multi-agent o verhead de- grades all strong cloud models (DeepSeek - V3.2 drops fr om 96% to 32% success), while providing marginal gains only f or w eaker local models. The root causes are mec hanical— unnecessary replanning that disrupts working solutions, variable name loss across planning boundaries, and a 2.4 × round inflation t hat amplifies failure oppor tunities. This Han et al.: Preprint submitted to Elsevier P age 10 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis establishes a concrete design pr inciple: arc hitectur al com- plexity should be inv ersely proportional to model capability . Infrastructure as the primar y bottleneck. Our iter- ative failure diagnosis re veals that the performance ceil- ing f or GIS agents is set not b y model reasoning qual- ity but by infrastr ucture design. Resolving four categories of en vironment-lev el bugs—data pathing, API state man- agement, memory limits, and type coercion—produced a 400% impro vement in inter mediate-task success. Additional f ailure modes at the behavioral lay er —visualization output f or mat, file-name guessing, and code deduplication side effects—furt her demonstrate that a sy stem’ s engineering quality is a first-class determinant of agent per f or mance, independent of the underlying model. The know ledge gap hierarch y . Our evaluation identi- fies a hierarch y of kno w ledge gaps that GIS agents face. The API know ledg e g ap —unfamiliarity with specific li- brary calls—is addressable through prompt engineer ing and retriev al augmentation. The par ametric kno wledg e g ap — domain-calibrated thresholds such as flood depth cutoffs and fire-station buffer radii—is not recov erable from code cor- pora and produces “false positive” outputs that appear plau- sible but are anal ytically incorrect. The conceptual knowl- edg e g ap —phy sical relationships suc h as flood dept h = −( elev ation + 200) , and GIS-specific semantic con ventions such as “create maps ” implying PN G visualization and not GeoJSON export—lies beyond what any retriev al system can supply and calls for expert-in-the-loop validation or out- put format contracts baked into domain know ledge injectio n. Local deployment and human-in-the-loop pathw ay s. Qwen2.5-Coder -14B on a single consumer RTX 3090 achiev es 52% end-to-end task success at zero marginal cost, with output quality among successful t asks (0.590) comparable to GPT-4.1 (0.618). Qualit ative analy sis sho ws that f ailures concentrate in final output assembl y rather than in core GIS reasoning or spatial comput ation—indicating t hat t he gap betw een 14B models and full autonomy is narrower than aggregate me tr ics sugg est. For deployments where cloud APIs are unav ailable, a human-in-the-loop collaborative mode—agent handles pipeline stages autonomously while the domain expert validates at ke y transitions—offers a pragmatic pat h to capable g eospatial AI wit hout propr ietar y infrastructure. Future directions. Near-term pr iorities include e xtend- ing GISclaw tow ard real-time g eospatial dat a streams, in- corporating context-a ware deduplication, and adapting agent framew orks f or r easoning-specialized models that require expanded token budgets. Longer-term, t he conceptual and parametric kno w ledge gaps identified in t his work motivate hybrid arc hitectures coupling LLM code g eneration with domain know ledge bases that encode field-specific phy sical models and calibrated parameter ranges—advancing GIS agents from syntactic proficiency to ward genuine geoscien- tific reasoning. A ckno wledgements This study was supported by a grant from the National Researc h Foundation, Korea (NRF), funded by the Ko- rean gov er nment (MSIT) (RS-2026-25474388). This re- search was suppor ted by the 2023-MOIS36-004 (RS-2023- 00248092) of the T echnology De velopment Program on Disaster Restoration Capacity Building and Strengthening funded b y the Ministr y of Inter ior and Saf ety (MOIS, Korea). Data A vailability GIScla w, including all source code, ev aluation scr ipts, and benchmark results, is publicl y av ailable at: https:// github.com/geumjin99/GISclaw . CRedi T authorship contribution statement Jinzhen Han: Conceptualization, Methodology , Soft- w are, V alidation, Formal analysis, In vestig ation, Data cura- tion, W r iting – or iginal draft, Visualization. JinByeong Le e: In vestig ation, Dat a curation, Writing – review & editing. Y uri Shim: Resources, W r iting – re view & editing. Jisung Kim: Supervision, Writing – re view & editing, Pr oject ad- ministration. Jae-Joon Lee: Supervision, W r iting – revie w & editing, Funding acquisition. Ref erences Akinboy ew a, T ., Li, Z., Ning, H., Lessani, M.N., 2025. Gis copilot: To wards an autonomous gis agent f or spatial anal ysis. Inter national Jour nal of Digital Earth 18, 2497489. Cardille, J.A ., Johnston, R., Ilyushc henko, S., Kartiwa, J., Shamsi, Z., Abraham, M., Azad, K., Ahmed, K., Quic k, E.B., Caughie, N ., et al., 2025. The cloud-based geospatial benc hmark: Challeng es and llm ev aluation, in: T erraBytes-ICML 2025 workshop. Gramacki, P ., Mar tins, B., Szymański, P ., 2024. Evaluation of code llms on geospatial code generation , 54–62. Hou, S., Shen, Z., Liang, J., Jiao, H., Zhao, A., Qing, Y ., Peng, D., Gui, Z., Guan, X., Xiang, L., et al., 2025. Can larg e language models generate geospatial code? Geo-Spatial Information Science , 1–35. Krecheto va, V ., Kochedyk ov , D., 2025. Geobenc hx: Benchmarking llms in agent solving multistep geospatial tasks , 27–35. Li, Z., Ning, H., 2023. Autonomous gis: the ne xt-generation ai-pow ered gis. International Journal of Digital Ear th 16, 4668–4686. Li, Z., Ning, H., Gao, S., Janowicz, K., Li, W ., Ar undel, S.T ., Y ang, C., Bhaduri, B., W ang, S., Zhu, A.X., et al., 2025. Giscience in the era of ar tificial intelligence: A research agenda tow ards autonomous gis. Annals of GIS 31, 501–536. Luo, Q., Lin, Q., X u, L., Wu, S., Mao, R., W ang, C., Feng, H., Huang, B., Du, Z., 2026. Geojson agents: a multi-agent llm arc hitecture for geospatial analy sis—function calling vs. code generation. Big Earth Data , 1–55. Papineni, K., Rouk os, S., W ard, T ., Zhu, W .J., 2002. Bleu: a method f or automatic ev aluation of machine translation, in: Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pp. 311–318. Reimers, N., Gurevy ch, I., 2019. Sentence-BER T: Sentence embeddings using Siamese BERT-netw orks. arXiv prepr int arXiv:1908.10084 . Ren, S., Guo, D., Lu, S., Zhou, L., Liu, S., T ang, D., Sundaresan, N., Zhou, M., Blanco, A., Ma, S., 2020. CodeBLEU: a method f or automatic ev aluation of code synthesis. arXiv preprint arXiv:2009.10297 . Han et al.: Preprint submitted to Elsevier P age 11 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis SUN, C., L AN, T ., WU, Z., SHI, X., CHENG, D., JIANG, S., 2025. Generative artificial intelligence and its applications in cartog raphy and gis: An e xploratory review . Jour nal of Geodesy and Geoinformation Science 8, 74–89. Wu, H., Jiao, H., Hou, S., Liang, J., Shen, Z., Zhao, A., Qing, Y ., Jin, F ., Guan, X., Gui, Z., 2025. Geocolab: an llm-based multi-ag ent collaborative framew ork for geospatial code gener ation. Inter national Journal of Digital Earth 18, 2569405. Y ao, S., Zhao, J., Y u, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y ., 2022. React: Synergizing reasoning and acting in language models, in: The eleventh inter national conf erence on lear ning representations. Zhang, Q., Gao, S., W ei, C., Zhao, Y ., Nie, Y ., Chen, Z., Chen, S., Su, Y ., Sun, H., 2025a. Geoanaly stbench: A geoai benchmark for assessing large language models for spatial analysis workflo w and code generation. Transactions in GIS 29, e70135. Zhang, Y ., Li, J., W ang, Z., He, Z., Guan, Q., Lin, J., Y u, W ., 2025b. Geospatial large language model trained with a simulated en vironment f or gener ating tool-use chains autonomously . Inter national Journal of Applied Ear th Observation and Geoinformation 136, 104312. Zhang, Y ., W ei, C., Wu, S., He, Z., Y u, W ., 2023. Geogpt: U nderstanding and processing geospatial tasks through an autonomous gpt. arXiv preprint arXiv:2307.07930 . Zheng, L., Chiang, W .L., Sheng, Y ., Zhuang, S., Wu, Z., Zhuang, Y ., Lin, Z., Li, Z., Li, D., Xing, E., et al., 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems 36, 46595–46623. You are a GIS analyst agent. Solve geospatial analysis tasks step-by-step using tools. ## Basic Guidelines 1. Start by calling list_files to see available data. 2. Load and inspect data (print columns, CRS, shape, head) BEFORE writing analysis code. 3. If unsure about a library API or GIS method, call search_docs to look it up. 4. Save outputs to pred_results/ before finish. 5. NEVER use plt.show(). Always use plt.savefig(..., dpi=150, bbox_inches= ' tight ' ) ## Available Packages (ONLY use these) geopandas, rasterio, shapely, numpy, pandas, scipy, matplotlib, sklearn, xarray, ... NOT available (do NOT import): pykrige, arcpy Alternatives: pykrige -> scipy.interpolate Listing 1: Simplified excerpt of the GISclaw system p rompt (Single Agent mo de). Figure 2: Compa rison of the tw o agent a rchitectures. (a) Single Agent follows a ReAct lo op with Error Memo ry for self- co rrection. (b) Dual Agent decomposes tasks via a Planner, executes steps through a W ork er, and adaptively replans upon failure. L1: Code CodeBLEU API Op. F1 L2: Process Embedding Sim. LLM-as-Judge L3: Output PNG: Vision TIF: Rasterio CSV/SHP 𝑆 comp qualitative Figure 3: Multi-lay er evaluation pip eline. Three complementary la yers assess co de-level fidelity (L1), reasoning process quality (L2), and output correctness (L3), combined into a weighted comp osite score 𝑆 comp (Eq. 1 ). Han et al.: Preprint submitted to Elsevier P age 12 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis Figure 4: T ask success rate comparison: Single Agent (solid) vs. Dual Agent (hatched). Strong models degrade significantly in DA mode; weak er mo dels sho w minimal change. Figure 5: P er-task API F1 scores (D A a rchitecture). W arm colo rs indicate higher code-level agreement with gold stan- da rds. The task-dep endent va riance highlights the limitation of aggregate metrics. Figure 6: L2: Execution log emb edding cosine similarit y p er task. Each dot represents one mo del’s reasoning process sim- ila rity to the gold standard. SA (left) shows tighter clustering than D A (right), confirming that strong mo dels follow more gold-aligned reasoning paths without planner overhead. Figure 7: L3: Per-task output accuracy sco res (SA). Green = high accuracy; red = failure. DeepSeek sho ws the most unifo rmly green column. T asks T18, T27 remain red across most mo dels, indicating intrinsic difficult y . Figure 8: Multi-dimensional performance p rofiles for SA (left) and DA (right) a rchitectures. In SA mo de, DeepSeek domi- nates all dimensions; in D A mo de, GPT-class models lead but with compressed performance ranges. Han et al.: Preprint submitted to Elsevier P age 13 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis Figure 9: T20: Mineral deposit prospectivity p rediction outputs (SA mo de). Four strong mo dels accurately reproduce the spatial distribution of tin-tungsten prospectivity , while Llama-70B generates a uniform raster and Qw en-14B fails to p ro duce any visualization. This task requires a complete ML pip eline spanning raster feature extraction, Random F orest training, and geo referenced p robability mapping. Figure 10: T34: Road accessibility visualization outputs. T op mo dels accurately identify and render p refecture-level accessi- bilit y patterns across Japan. Han et al.: Preprint submitted to Elsevier P age 14 of 12 GIScla w: LLM-Po wered Agent for Geospatial Analysis Figure 11: T07: Flo o d analysis outputs illustrating domain kno wledge gaps. The Gold Standard (left) uses a domain-calibrated −200 cm threshold, while all models default to 0 cm. Some mo dels further suffer CRS misalignment, p roducing blank maps. This demonstrates that parametric domain knowledge cannot b e acquired from co de patterns alone. Figure 12: T08: Fire station coverage gap analysis. The Gold Standa rd (top-left) uses a 2,500 m buffer; all mo dels select smaller radii (500–1,000 m), dramatically overestimating the uncovered area. This illustrates the pa rametric domain kno wledge gap . Han et al.: Preprint submitted to Elsevier P age 15 of 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment