Vega: Learning to Drive with Natural Language Instructions
Vision-language-action models have reshaped autonomous driving to incorporate languages into the decision-making process. However, most existing pipelines only utilize the language modality for scene descriptions or reasoning and lack the flexibility…
Authors: Sicheng Zuo, Yuxuan Li, Wenzhao Zheng
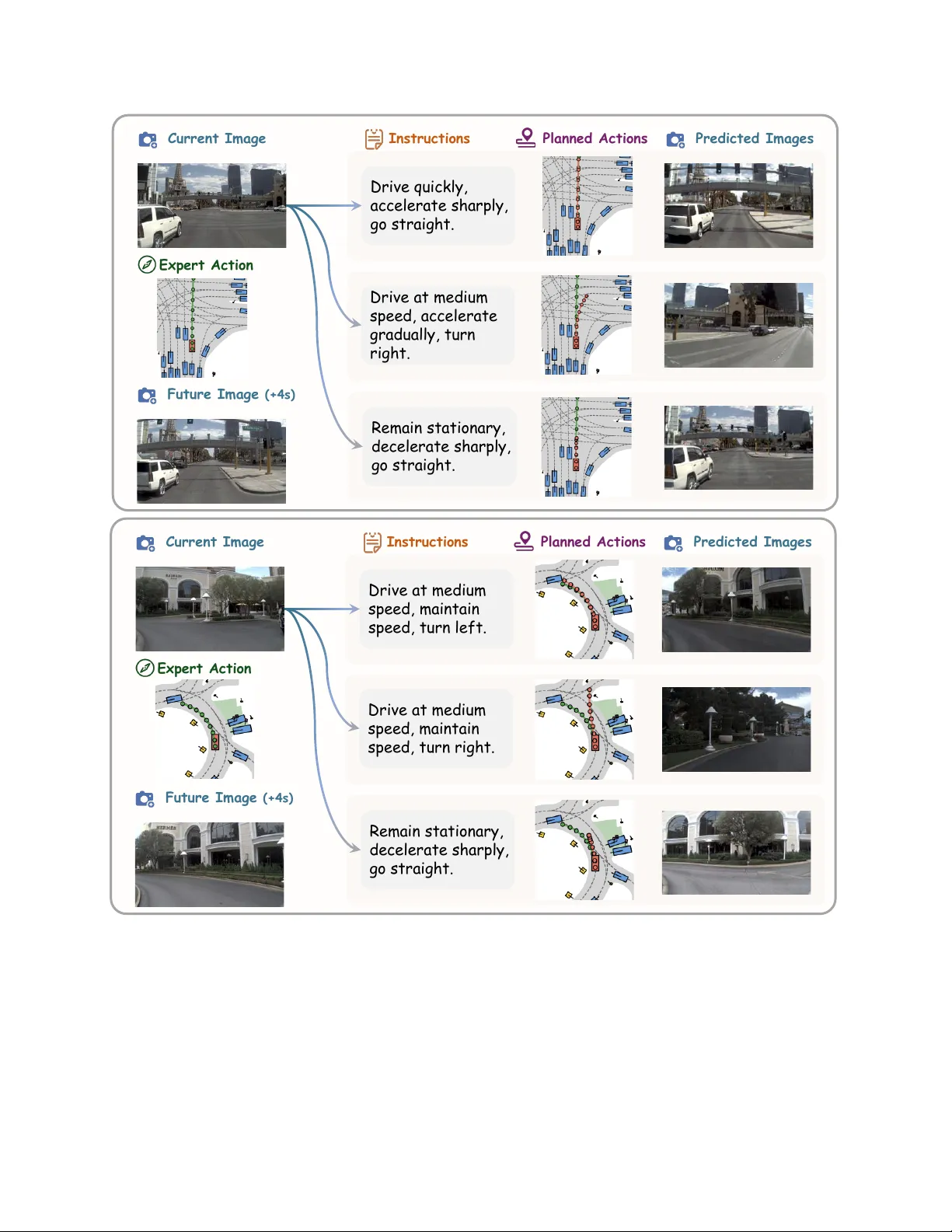
V ega: Learning to Dri ve with Natural Language Instructions Sicheng Zuo 1 , ∗ Y uxuan Li 1 , ∗ W enzhao Zheng 1 , ∗ , † Zheng Zhu 2 Jie Zhou 1 Jiwen Lu 1 1 Tsinghua Uni versity 2 GigaAI Project Page: https://zuosc19.github.io/Vega Large Dri ving Models: https://github.com/wzzheng/LDM St op imm ed iat ely an d r emain st il l . In struct ion A In struct ion B Pu l l up to th e side. In struct ion A In struct ion B In struct ion A In struct ion B Pu l l up to th e side. Foll ow th e ca r, go st raight th roug h t he int ers ection. G o along t he road and pass th e oran ge t raf f ic barrier. Stop at th e crosswalk, wait f or th e l ight t o turn g reen . Figure 1. V isualizations of our model f or instructional driving . W e propose a unified vision-language-world-action model, V ega, for instruction-based generation and planning. V ega can predict multiple trajectories in the same scenario follo wing di verse instructions. Abstract V ision-language-action models have reshaped autonomous driving to incorporate languages into the decision-making pr ocess. However , most existing pipelines only utilize the language modality for scene descriptions or reason- ing and lac k the flexibility to follow diverse user instruc- tions for personalized driving. T o address this, we first construct a lar ge-scale driving dataset ( InstructScene ) containing ar ound 100,000 scenes annotated with diverse driving instructions with the corr esponding trajectories. W e then pr opose a unified vision-language-world-action model, V ega , for instruction-based generation and plan- ning. W e employ the autore gr essive paradigm to pr o- cess visual inputs ( vision ) and language instructions ( lan- guage ) and the dif fusion paradigm to g enerate futur e pre- dictions ( world modeling) and trajectories ( action ). W e perform joint attention to enable inter actions between the ∗ Equal contributions. † Project leader . modalities and use individual pr ojection layers for differ - ent modalities for mor e capabilities. Extensive experiments demonstrate that our method not only achieves superior planning performance but also exhibits str ong instruction- following abilities, paving the way for more intelligent and personalized driving systems. Code is available at https://github.com/zuosc19/Vega . 1. Introduction V ision-centric autonomous driving is a promising direction due to its economic advantages and scalability [ 19 , 21 , 27 , 37 , 60 , 67 ]. Con ventional methods typically follow a mod- ular pipeline of perception [ 20 , 22 , 23 , 41 , 86 ], predic- tion [ 66 , 79 , 82 , 87 ], and planning [ 2 , 19 , 27 , 80 , 81 ], which heavily relies on expensiv e 3D annotations and thus faces limitations in real-world applications. Recently , vision- language-action (VLA) models ha ve emerged to lev erage rich world knowledge from large language models to map visual inputs to dri ving actions [ 13 , 25 , 62 , 72 ], demonstrat- 1 ing remarkable generalization across driving scenarios. Despite their good generalization across dri ving scenar- ios, most existing VLA models only use languages for scene descriptions or decision reasoning and lack flexible instruction-following capabilities [ 13 , 35 , 75 , 84 , 85 ]. They are either trained to imitate an av eraged expert policy , or are confined to a closed set of simple navigational com- mands like “turn left” or “go straight”, failing to generalize to open-ended and flexible natural language instructions. In contrast, a general driving agent should not only na vigate autonomously but also comprehend and execute diverse, user-specified natural language instructions. For instance, a user in a hurry might instruct the vehicle to “overtak e the front car to catch the next green light” rather than adhere to the conservati ve policy learned from the training data. T o facilitate the shift from imitation driving to in- structional driving, we construct a large-scale driving dataset, InstructScene , with around 100,000 instruction- annotated scenes and the corresponding trajectories b uilt on N A VSIM [ 5 ]. While a direct w ay is to train a VLA model on our dri ving dataset containing rich instructions, we find that it struggles to generate feasible trajectories and follow in- structions accurately . W e think this is due to the significant information disparity between the high-dimensional visual- instruction inputs and the low-dimensional action predic- tion, making it difficult for the model to learn a generaliz- able mapping from high-level instructions to lo w-le vel ac- tions in complex and dynamic en vironments. T o address this, we propose a unified vision-language- world-action model, V ega , for joint instruction-based gen- eration and planning. W e train the model to jointly perform future image generation and action planning conditioned on past observ ations and language instructions. This task provides a dense and pixel-le vel supervision signal, com- pelling the model to learn the causal relationships among instructions, actions, and visual predictions. The joint mod- eling enforces consistency between predictions, enabling mutual supervision and refinement. Our model adopts a mixed autoregressiv e-diffusion transformer architecture [ 6 , 38 , 44 , 56 ] to achieve unified vision - language understand- ing, world modeling, and action planning. Specifically , we use the autoregressi ve pipeline for visual and instruction understanding, and the diffusion pipeline [ 10 , 40 ] for im- age and action generation. W e use joint attention to enable interactions across all modalities and employ a Mixture- of-T ransformers (MoT) design [ 38 ] to effecti vely decouple the parameters associated with different modalities and en- hance the model capacity for joint generation and planning. Extensiv e experiments on the N A VSIM [ 1 , 5 ] benchmark show that our model not only achiev es superior planning performance but also demonstrates a remarkable ability to generate high-fidelity and instruction-compliant future im- ages and plausible trajectories. 2. Related W ork 2.1. VLM and VLA f or A utonomous Driving The extensi ve world knowledge and reasoning capabilities of vision-language models (VLMs) have dri ven their ap- plications in autonomous driving [ 24 , 45 , 55 , 73 ]. Early works primarily lev eraged VLMs for high-level driving scene understanding and reasoning, but could not output driv able trajectories [ 8 , 24 , 29 , 43 , 46 , 48 , 50 , 57 ]. Sub- sequent methods attempted to hav e VLMs directly pre- dict textual waypoints [ 7 , 25 , 62 , 72 ], but they struggled due to the inherent limitations of LLMs in precise numer- ical reasoning [ 12 , 49 ]. This led to the development of VLA models, which integrate a planning module for end- to-end trajectory prediction [ 13 , 28 , 84 ]. Common plan- ning approaches include autoregressi ve prediction of dis- cretized waypoints [ 26 , 84 , 85 ], diffusion-based trajectory generation [ 13 , 35 , 75 ], and direct regression via an MLP head [ 53 ]. Howe ver , these models suffer from sparse action supervision and often rely on auxiliary understanding and reasoning tasks to guide the learning process [ 13 , 84 , 85 ]. In contrast, V ega employs world modeling to provide a dense signal to enhance instruction-based planning. 2.2. W orld Models for A utonomous Driving W orld models are typically defined as generative models that predict future states conditioned on past observ ations and current actions [ 16 ]. In autonomous driving, applica- tions of world models can be categorized into three main ap- proaches: image-based, occupancy-based, and VLA-based methods. Image-based methods leverage powerful genera- tiv e architectures to synthesize high-fidelity driving videos, primarily for data generation and scene simulation [ 14 , 18 , 54 , 64 , 65 , 78 ]. Occupanc y-based methods model scene ev olution in 3D occupancy space to enhance scene under - standing [ 47 , 66 , 87 ] and planning [ 31 , 66 , 74 , 79 ], b ut their reliance on dense 3D labels limits scalability . Re- cently , VLA-based methods hav e emerged with Doe-1 [ 82 ] first proposing a closed-loop driving model that unifies scene understanding, prediction, and planning. Dri veVLA- W0 [ 33 ] integrated world modeling into a VLA framework to provide dense supervision and enhance planning. Ho w- ev er, they can not perform instruction-based prediction and planning. Our work enables this capability , allowing the model to predict corresponding future scenes and driving trajectories conditioned on flexible language instructions. 2.3. Unified V isual Understanding and Generation Unified visual understanding and generation methods can be categorized into three main pipelines: quantized autore- gressiv e (AR), external diffusion, and integrated transform- ers. Quantized AR models quantize images into discrete tokens [ 30 , 77 ], enabling generation within the nati ve au- 2 toregressi ve frame work [ 3 , 42 , 51 , 59 , 63 , 69 – 71 ]. While this design is straightforward, its visual quality typically lags behind that of dif fusion-based methods. The External Diffuser approach pairs a VLM with an external diffusion model [ 9 , 15 , 58 , 61 ]. The VLM provides a high-level un- derstanding by generating a fe w latent tokens that condi- tion the diffusion generator . Ho wever , this narrow interface between understanding and generation can restrict informa- tion flow [ 6 ]. Integrated transformer models merge autore- gressiv e and diffusion mechanisms into a single transformer [ 6 , 38 , 44 , 56 , 83 ], enabling a deep integration of po wer- ful understanding and generation capabilities. In this paper , we adopt the integrated transformer to achie ve instruction- based joint visual generation and action planning. 3. Proposed A pproach 3.1. Imitation Driving to Instructional Driving An autonomous dri ving model M usually tak es as input the past T and current image observations [ I t − T , . . . , I t ] and past T actions [ A t − T , . . . , A t − 1 ] , and predicts the current action A t for the ego car , which can be formulated as: A t = M ([ I t − T , . . . , I t ] , [ A t − T , . . . , A t − 1 ]) . (1) Con ventional methods often adopt a perception- prediction-planning pipeline. The perception module P er extracts the scene representation z from observations [ I t − T , . . . , I t ] . Then the prediction module P re forecasts the future motion v of agents based on z . Finally , the planning module P lan uses z , v , and historical ego actions [ A t − T , . . . , A t − 1 ] to plan the current ego action A t . This multi-step pipeline can be expressed as: z = P er ( I t − T , . . . , I t ]) , (2) v = P re ( z ) , (3) A t = P lan ( z , v , [ A t − T , . . . , A t − 1 ]) . (4) Howe ver , such methods heavily rely on costly high-quality 3D annotations, which greatly limits their scalability . Recently , vision-language-action (VLA) models hav e been applied to autonomous driving, leveraging their rich world kno wledge and demonstrating strong generaliza- tion across div erse scenarios. Based on past observations [ I t − T , . . . , I t ] and historical actions [ A t − T , . . . , A t − 1 ] , cur - rent VLA models W often predict both the textual descrip- tion of the scene D and the current ego action A t . This end-to-end planning process can be formulated as: A t , D t = W ([ I t − T , . . . , I t ] , [ A t − T , . . . , A t − 1 ]) . (5) Although existing VLA models show remarkable gen- eralization, they fall short in flexible instruction-following. Most VLA models are trained to imitate an av eraged ex- pert policy or process a closed set of simple navigational commands, failing to handle open-ended natural language instructions. T o address this, we introduce an instruction- based driving model V , which predicts the current ego ac- tion A t based on observations [ I t − T , . . . , I t ] , historical ac- tions [ A t − T , . . . , A t − 1 ] and the current user instruction L t . This process can be expressed as: A t = V ([ I t − T , . . . , I t ] , [ A t − T , . . . , A t − 1 ] , L t ) . (6) T o enable instruction-based driving, we constructed a large-scale driving dataset with around 100,000 instruction- annotated scenes based on NA VSIM [ 5 ], where we gen- erated instructions automatically using VLM, supple- mented by rule-based methods. For each timestep t, we prompt a powerful VLM [ 52 ] with future observations [ I t +1 , . . . , I t + N ] and actions [ A t +1 , . . . , A t + N ] to produce a high-lev el instruction L t describing the driving intent of the current ego-vehicle. This process yields a se- quence of image, instruction, and action triplets: D = {⟨ I t , L t , a t ⟩} T max t =1 . W e then train our model on this dataset, equipping it with instruction-follo wing driving capabilities. 3.2. Unified Generation and Planning While a direct way to achie ve instruction-based driving is to train a VLA model on our driving dataset containing rich instructions, we find that it struggles to generate fea- sible trajectories and accurately follo w instructions, due to the sparse action supervision. T o address the supervision gap, we introduce the vision-language-world-action model, a nov el frame work that jointly learns instruction-based ac- tion planning and future image generation. Our core insight is that future image generation provides a dense, pixel-le vel supervision signal, which helps the model learn the under- lying dynamics of the world. By joint modeling generation and planning, the model is compelled to learn the causal relationships among instructions, actions, and visual out- comes, which is critical for instruction-based planning. The framew ork is formulated as a generative model trained on triplets of images, instructions, and actions, which models the fundamental causal chain of driving: An agent perceiv es the world I t , receives the instruction L t , de- cides on an action A t , and observes the next outcome I t +1 . At each timestep t , the model receiv es the current observa- tion I t and instruction L t , and the historical observations [ I t − T , . . . , I t − 1 ] . It then jointly predicts the action A t to be ex ecuted and the resulting next step I t +1 . W e apply causal attention modeling to the model’ s architecture, ensuring that it learns the correct reasoning pathway from instruction to action and then to visual outcome, providing a solid foun- dation for resolving the supervision gap. 3.3. Joint A utoregressi ve-Diffusion Architectur e Unified generation and planning requires our model to not only possess significant visual-text understanding, visual 3 d e c e l e r a t e g ra d ua l l y I m i t a t i o n D r i vi n g Mo d e l s N a v i g a t i o n C o m m a n d V i s i o n I n p u t Ma in t a in s p e e d a n d g o s t ra ig h t I n st r u ct i o n - Ba se d D r i vi n g Mo d e l I n s t r u c t i o n A De c e l e ra t e g ra d ua l l y S i n g l e E x pe r t T r a j e c t o r y Pe r s o n a l i z e d Pl a n n i n g Fu t u r e Ge n e r a t i o n I n s t r u c t i o n B Figure 2. Overview of our model. Compared to traditional imitation driving models, which can only predict the single expert trajectory , V ega can follow natural language instructions to generate di verse planning trajectories and future image predictions. generation, and action planning capabilities, but also in- tegrates them to solve complex driving scenarios. Cur- rent research mainly follows three approaches to bridge the gap between visual-text-understanding, which primar- ily uses auto-regressi ve VLM, and image generation, which often adopts diffusion models. Howe ver , most methods fall short of our requirements. Autoregressiv e visual generation models with discrete visual tokenizers struggle to match dif- fusion models in image quality and also suffer from high latency due to their sequential generation pipeline. LLMs combined with external diffusers yield competiti ve results, but are constrained by an information bottleneck caused by the limited number of latent tokens passed from LLMs to generation modules. T o address these, we adopt the In- tegrated T ransformer architecture [ 6 ], which fuses auto- regressi ve VLM and diffusion transformer into a single model, enabling the generation module to interact with the understanding module without information loss and result- ing in unified understanding and generation capabilities. Our integrated model employs a unified paradigm to pre- dict images and actions. It first encodes multi-modal in- puts, including text, images, and actions, and concatenates them to the noises of target images or actions, forming a unified sequence. The model then processes the sequence as a whole, calculating causal attention across modalities to ensure full information flow among text, image, and action latents. Finally , the denoised latents are decoded by their respectiv e decoders into images or actions. Encoding Inputs . T o prepare the multi-modal inputs for the forward pass, we first encode them with corresponding tokenizers. For text, we tokenize natural language inputs L t with the Qwen2.5 tokenizer . For visual understanding, we only use the forw ard-view camera images as visual obser - vations, which are encoded by a V AE encoder into latents F V t . T o enrich the visual context, we also encode input im- ages with a SigLIP2 V iT encoder , and append the latents to the corresponding image’ s V AE latents. For action, we first con vert the 2D absolute trajectory tr aj = [( x, y , θ ) , . . . ] into relati ve movements between consecutiv e steps A = (∆ x, ∆ y , ∆ θ ) , so that actions from different steps share a distribution and can be easily normalized. W e project the normalized relative action sequence into the latent dimen- sion of the model with a linear head. Constructing Input Sequence . W e then combine the multi-modal segments in an interleaving manner . The his- torical images [ I t − T , ..., I t ] and actions [ A t − T , ..., A t − 1 ] are placed at the beginning, followed by natural language instructions L t . When performing the action planning task, we then append a noisy tar get action A noisy t . Oth- erwise, we first add the ground truth current action A t , 4 “Catch up wi th t he front c ar” VLM Tokenizer VAE Nor m Ca usal Attention Und . Ge n. Act. 𝑰 𝒕 𝑳 𝒕 𝑨 𝒕 𝑨 𝒕 𝑰 𝒕 + 𝟏 Pla nnin g … … Ge nera tion Tim e Vi sio n Te xt Ac tion Noise d Action Noise d Image Figure 3. Framework of our Unified Vision-Language-W orld- Action Model. W e jointly model action planning and image gen- eration using multi-modal inputs and a MoT architecture [ 38 ]. then append a noisy future image I noisy t + K for visual gen- eration. Due to the strictly causal nature of our sequence S = [ I 0 , L 0 , A 0 , ..., I n , L n , A n ] , we set the attention mask as a blocked lo wer triangular matrix, so that each block, rep- resenting an image, action, or instruction, can only attend to previous blocks. In the text block, we adopt a strictly lo wer triangular mask for causal self-attention and allocates con- secutiv e RoPE indices to textual tokens. In the image or action block, we adopt a full attention mask and share the same RoPE inde x for all tok ens, using sinusoidal positional embedding to encode relativ e position instead. During inference, the model denoises the action and fu- ture image sequentially , where future image prediction is conditioned on a fully denoised action. While during train- ing, the two tasks are optimized jointly for training effi- ciency . A direct concatenation of noisy action and image inputs would cause later tokens to attend to noisy preced- ing latents, creating a mismatch with inference and degrad- ing training. T o resolve this, we duplicate each latent that serves both as a prediction target and as a condition for subsequent predictions. Specifically , we add noise to the first copy F noisy t and use it for denoising supervision, while keeping the second copy F clean t as the condition input. W e further mask F noisy t from all subsequent tokens, ensuring that they attend only to the clean latents. This design al- lows us to train multiple dif fusion processes within a single autoregressi ve sequence efficiently . Integrated T ransformer . T o enhance the performance of our integrated transformer, we decouple the modules and weights in charge of each capability so that they can be optimized individually . Unlike the Mixture of Expert (MoE) technique, which only uses separate weights for FFN, we employ the Mixture of Transformers (MoT) ar- chitecture [ 38 , 56 ], where all trainable parameters of the transformer , including attention and FFN layers, are du- plicated for each module. This design has been shown to not only conv erge faster , but also maintain higher model capacity [ 6 ]. Specifically , we process visual and text un- derstanding tokens with a understanding transformer based on Qwen2.5 LLM [ 52 ], which has a hidden size of 3584 and a depth of 28 layers. Image generation tokens are pro- cessed by a generation transformer of the same design. The weights of both transformers are initialized from Bagel- 7B [ 6 ]. Due to the relati vely low dimensionality of the ac- tion space, we reduce the hidden size of the action module to 256, thus reducing action-related computation without significantly degrading model performance. During the forward process, the interleaving multi- modal sequence is split into segments and passed onto their respective modules in each attention and FFN lay- ers. T o calculate global causal attention, the sequence is re-assembled to be processed as a whole. T okens for image generation and action planning are then extracted from the output sequence for final prediction. 3.4. T raining and Inference W e implement a single-stage training paradigm to cover both action planning and world modeling. For action planning, we train the model to predict the action plan A ( N ) t = [ A t , ..., A t + N − 1 ] based on past observ ations I ( − T ) t = [ I t − T , ..., I t ] and current driving instruction L t . For world modeling, we train the model to predict future image observation I t + K based on past images I ( − T ) t , cur- rent dri ving instruction L t and action plan A ( N ) t . W e use the MSE of the normalized relativ e action A as action loss: L A = E A ( N ) t ,ϵ,m [ || ϵ − ˆ ϵ ( A ( N ) t , ϵ, m, I ( − T ) t , L t ) || 2 ] , (7) where ϵ ∼ N (0 , I ) is sampled Gaussian noise and m is a random timestep, and MSE of the V AE latents F V as image loss: L V = E F V t + K ,ϵ,n [ || ϵ − ˆ ϵ ( F V t + K , ϵ, n, I ( − T ) t , L t , A ( N ) t ) || 2 ] , (8) where ϵ ∼ N (0 , I ) is sampled Gaussian noise and n is a random timestep. T o enable classifier-free guidance (CFG) [ 17 ] in inference, we randomly drop text, V iT , clean V AE, and clean action tok ens during training. T okens of the same modality that belong to dif ferent images or actions are dropped or kept jointly . In the training stage, we optimize a joint objective with loss L pretr ain = λ A · L A + λ V · L V . This allows the model to learn world kno wledge alongside planning capabilities. In the inference stage, we use Classifier-Free Guidance Dif- fusion [ 17 ] to generate actions, with both image guidance and text guidance enabled. While we primarily focus on the action planning task during inference, the model retains its image generation capabilities from the training stage. 5 T able 1. Comparison with state-of-the-art methods on the NA VSIM v2 with extended metrics. NC: No at-fault Collision. D A C: Driv able Area Compliance. DDC: Driving Direction Compliance. TLC: T raffic Light Compliance. EP: Ego Progress. TTC: Time to Collision. LK: Lane Keeping. HC: History Comfort. EC: Extended Comfort. EPDMS: Extended Predicti ve Dri ver Model Score. †: Using the best-of-N (N=6) strategy follo wing [ 85 ]. Method NC ↑ D A C ↑ DDC ↑ TLC ↑ EP ↑ TTC ↑ LK ↑ HC ↑ EC ↑ EPDMS ↑ Ego Status 93.1 77.9 92.7 99.6 86.0 91.5 89.4 98.3 85.4 64.0 T ransFuser [ 4 ] 96.9 89.9 97.8 99.7 87.1 95.4 92.7 98.3 87.2 76.7 HydraMDP++ [ 36 ] 97.2 97.5 99.4 99.6 83.1 96.5 94.4 98.2 70.9 81.4 Driv eSuprim [ 76 ] 97.5 96.5 99.4 99.6 88.4 96.6 95.5 98.3 77.0 83.1 AR TEMIS [ 11 ] 98.3 95.1 98.6 99.8 81.5 97.4 96.5 98.3 - 83.1 DiffusionDri ve [ 39 ] 98.2 95.9 99.4 99.8 87.5 97.3 96.8 98.3 87.7 84.5 Driv eVLA-W0 98.5 99.1 98.0 99.7 86.4 98.1 93.2 97.9 58.9 86.1 V ega 98.9 95.3 99.4 99.9 87.0 98.4 96.5 98.3 76.3 86.9 V ega † 99.2 96.6 99.5 99.9 87.5 98.7 97.4 98.4 84.5 89.4 4. Experiments 4.1. Datasets and Benchmarks • NA VSIM v1 [ 5 ] filters OpenScene to remove near -trivial and erroneous scenes, reducing the train split size to 85k. During ev aluation, N A VSIM v1 runs a non-reactiv e sim- ulation at 10Hz for future 4 seconds, then scores the driv- ing agent with metrics including No at-fault Collision (NC), Driv able Area Compliance (D AC), T ime T o Col- lision (TTC), Comfort (Comf.), and Ego Progress (EP). These metrics are aggregated into the Predictiv e Driv er Model Score (PDMS). W e use the train split for finetun- ing and the test split for ev aluation. • NA VSIM v2 [ 1 ] impro ves simulation realism by enabling reactiv e traffic. It ev aluates agents with the Extended Predictiv e Driver Model Score (EPDMS), adding metrics including Dri ving Direction Compliance (DDC), T raffic Light Compliance (TLC), Lane Keeping (LK), History Comfort (HC) and Extended Comfort (EC). 4.2. Implementation Details Instruction Annotation . The driving instructions in our InstructScene dataset were generated by a fully-automated two-stage annotation pipeline. W e select Qwen2.5-VL- 72B-Instruct [ 52 ] as our annotation model for its powerful visual understanding capabilities. The inputs of each scene are 14 consecutiv e frames captured by the front-vie w cam- era at 2Hz, with a resolution of (1920 , 1080) . The first 4 frames are considered past and current observations, and the last 10 frames are future observ ations that will not be av ailable to the driving agent in the inference stage. • Stage One: Scene Understanding . In stage one, we prompt the model with two requests, designed to conv ert the visual inputs and expected actions of the driving agent into natural language descriptions. W e first instruct the model to describe the scene in the first 4 frames and to identify the traffic participants as well as the static ob- jects. W e then instruct it to describe the vehicle’ s driving behavior in the next 10 frames and its interaction with previously observ ed traffic participants. • Stage T wo: Instruction Formulation . In stage two, we combine the visual inputs with the scene descriptions generated in stage one, and prompt the model to create concise driving instructions that would guide the driving agent to predict the actions described in stage one. Since VLMs struggle to accurately perceiv e e go-vehicle motion, we generate supplementary rule-based instructions. W e classify scenes using speed, acceleration, and turn rate thresholds, con verting them into natural language. While these closed-set instructions lack div ersity , they provide precise ego-motion cues. W e then use them as auxiliary prompts for the VLM, combining both to generate accu- rate and div erse driving instructions. W ith this pipeline, we annotated 85109 scenes from the N A VSIM train split and 12144 scenes from the N A VSIM test split. T raining. The model is trained on the N A VSIM train split for 200k steps using 8 H20 GPUs. W e set the number of historical images to 4, and predict 8 future actions as well as the future image at the end of the actions. W e set the learning rate to 2e-5 with 2500 w armup steps, and use a per-de vice batch size of 1. The weights of action and image loss are λ A = λ V = 1 . 0 . W e also maintain an EMA model with a decay rate of 0.9999, which is sav ed as checkpoints. 4.3. Main Results As shown in T ables 1 and 2 , our model demonstrates com- petitiv e performance on both NA VSIM benchmarks. On N A VSIM v2, it scores 86.9 EPDMS without any additional performance-enhancing techniques, which is comparable to SO T A. Using the best-of-N strate gy as prior works [ 33 , 85 ], it achiev es top performance on NA VSIM v2, surpassing state-of-the-art methods on se veral metrics, including Driv- ing Direction Compliance, T raffic Light Compliance, Lane Keeping, and History Comfort. These results suggest that V ega has learned robust instruction following capabilities and benefited from future image prediction training. On 6 T able 2. Comparison with state-of-the-art methods on the NA VSIM v1. NC: no at-fault collision. D A C: driv able area compliance. TTC: time-to-collision. C.: comfort. EP: ego progress. PDMS: the predicti ve driv er model score. Abbre viations: 1x Cam (single front-view camera), Nx Cam (surround-view cameras), L (LiD AR). †: Using the best-of-N (N=6) strategy follo wing [ 85 ]. Method Ref Sensors NC ↑ D A C ↑ TTC ↑ C. ↑ EP ↑ PDMS ↑ Human - - 100 100 100 99.9 87.5 94.8 BEV -based Methods UniAD [ 19 ] CVPR’23 6x Cam 97.8 91.9 92.9 100.0 78.8 83.4 T ransFuser [ 4 ] TP AMI’23 3x Cam + L 97.7 92.8 92.8 100.0 79.2 84.0 P ARA-Drive [ 68 ] CVPR’24 6x Cam 97.9 92.4 93.0 99.8 79.3 84.0 LA W [ 32 ] ICLR’25 1x Cam 96.4 95.4 88.7 99.9 81.7 84.6 Hydra-MDP [ 36 ] arXiv’24 3x Cam + L 98.3 96.0 94.6 100.0 78.7 86.5 DiffusionDri ve [ 39 ] CVPR’25 3x Cam + L 98.2 96.2 94.7 100.0 82.2 88.1 W oTE [ 34 ] ICCV’25 3x Cam + L 98.5 96.8 94.4 99.9 81.9 88.3 VLA-based Methods AutoVLA [ 85 ] NeurIPS’25 3x Cam 98.4 95.6 98.0 99.9 81.9 89.1 ReCogDriv e [ 35 ] arXi v’25 3x Cam 98.2 textbf97.8 95.2 99.8 83.5 89.6 AutoVLA† [ 85 ] NeurIPS’25 3x Cam 99.1 97.1 97.1 100.0 87.6 92.1 Driv eVLA-W0† arXiv’25 1x Cam 99.3 97.4 97.0 99.9 88.3 93.0 V ega - 1x Cam 98.9 95.3 96.1 100.0 81.6 87.9 V ega † - 1x Cam 99.2 96.6 96.9 100.0 83.4 89.8 T able 3. Ablation of future image prediction. PDMS: NA VSIM v1 [ 5 ] benchmark, EPDMS: N A VSIM v2 [ 1 ] benchmark. Setting PDMS ↑ EPDMS ↑ Random Frame 77.3 75.2 Action Only 51.8 48.9 Next Frame 77.9 76.0 T able 4. Ablation of action expert. PDMS: NA VSIM v1 [ 5 ] benchmark, EPDMS: N A VSIM v2 [ 1 ] benchmark. Setting PDMS ↑ EPDMS ↑ Use Diffusion 19.7 19.6 Use VLM 77.6 75.7 Action Expert 77.9 76.0 N A VSIM v1, our model achie ves 87.9 PDMS, matching multi-modal BEV methods, and improv es to 89.8 with the best-of-N strategy . W e note that V ega achiev es lower per - formance compared to state-of-the-art VLA-based methods on N A VSIM v1. This discrepancy is partially attributed to N A VSIM v1’ s inbalanced metrics, which disproportionately fa vor risk-av erse policies over alternativ e, equally valid strategies learned by our model. Furthermore, competing VLA-based methods either require supplementary inputs such as multi-vie w images with high resolutions, or inte- grate CoT reasoning via additional RL training. Critically , these performance-enhancing mechanisms operate indepen- dently of our model’ s core architecture and may be modu- larly incorporated without modifying the primary design. 4.4. Experimental Analysis Future Frame Pr ediction . During pretraining, the model is trained to predict the first future frame. W e ablate future - original - 2 VA - 4 VA - 6 VA St eps (fin e tune ) log(loss) Figure 4. Ablation of interleaving image-action sequences . W e compare the finetuning losses of models trained on non- interleaving sequences (original) and interleaving sequences of different lengths. frame prediction with two additional configurations. First, we randomly sample one of the 8 future frames and spec- ify the chosen index in the text prompt. Second, we re- mov e the future frame prediction task altogether . All three configurations are trained on 8 H20 GPUs, with other hy- perparameters identical to pretraining in Section 4.2 . The results, shown in T able 3 , indicate that the task of future frame prediction indeed improves the planning capabilities of the model, but the exact choice of future frame has lim- ited impact on performance. Interleaving Observation and Action . In our original design, only past images are provided to the model as refer- ence. W e argue that interleaving image and action helps the model learn their dynamics, resulting in faster conv ergence and lower loss during training. Following [ 33 ], we pretrain the model with interleaving image-action sequences. W e ablate the pretraining image-action sequence length with 7 Ac c el erate im m edi atel y to c atc h up with th e ca r in f ron t. In struct ion A R emai n s te ady an d f ol l ow t he ca r in fron t. In struct ion B Proc eed al on g th e l ane at cons tan t speed. In struct ion A G radual l y slow t o a st op and remai n st ation ary. In struct ion B Figure 5. Instruction-based planning examples . W e visualize the ef fects of language instructions on action planning with front-view camera images and BEV maps. 2, 4 and 6. During finetuning, we interleave the origi- nal 4 past images with 3 past actions. Figure 4 rev eals that although models pretrained on interleaving sequences suffer from higher loss in the initial stages of finetuning, which can be attributed to the discrepancy between their pretraining and finetuning designs, they conv erge signifi- cantly faster than models without interleaving sequences, ev entually surpassing the latter . In addition, although all interleaving models use the same sequence length during finetuning, those with longer image-action sequences dur- ing pretraining show lo wer losses. Independent Action Module . T o validate our design of an additional action expert, we ablate it against using the existing VLM or diffusion modules for action plan- ning. Although these alternativ es reduce model size, they increase computational cost because of the high dimensions of these modules. As sho wn in T able 4 , our action expert model slightly outperforms the VLM-module-based plan- ner and significantly surpasses the diffusion-module-based one, confirming the effecti veness of our architecture. V isualizations . In addition to Figure 1 , we provide two more examples to visualize the effect of instructions on V ega ’ s ability to adjust the vehicle’ s speed according to user instructions in Figure 5 . W e test two instructions in each scene and plot the predicted trajectories for the next 8 frames on the front-view-camera image as well as the Bird’ s-Eye-V iew (BEV) map. In both scenes, our model successfully increased, decreased, or maintained speed to follow the instructions. W e also offer a qualitative ev alua- tion of our pretrained model’ s ability to align both its action planning and image generation with user instructions in Fig- ure 6 . W e select critical scenes where there can be multiple possible courses of action, e.g. approaching the intersec- tion, encountering another vehicle. For each scene, we gi ve the model different sets of instructions, then generate future actions and images sequentially . W e observe that V ega is able to generate future actions and images that are consis- tent with the instructions, indicating that our world model- ing framew ork has successfully helped the model learn the dynamics of the driving en vironment. VLA Baseline . As a straightforward baseline for in- structional driving, we extend Qwen-2.5-VL [ 52 ] with a planning head to predict future actions based on language instructions. Despite being trained on the same dataset with instruction annotations as V ega , this VLA model per- forms poorly , achieving only ∼ 60 PDMS and often failing to generate instruction-consistent trajectories. W e attrib ute this limitation to the sparse low-dimensional action su- pervision, which is insufficient to bridge high-dimensional visual-language inputs and low-le vel driving actions. This motiv ates us to explore dense visual supervision from future prediction to improv e instruction-based planning. 5. Conclusion In this paper , we hav e aimed to address current driving mod- els’ inability to follo w di verse driving instructions. W e hav e 8 Dri ve qui ckly, a cceler a te s h a rp ly, go s traight. D rive at medi um spe ed, accelerate g radually , t urn rig ht. Rema in stationa ry, de cele r a te s h a rp ly, go s traight. In struct ion s Plann ed Act ion s Predicte d Im ages Cu rre n t Im age Future Im age (+4s) Ex pert Act ion Dri ve at medium sp e e d, mainta in sp e e d, tu rn left. D rive at medi um spe ed, maint ain spe ed, t urn rig ht. Rema in stationa ry, de cele r a te s h a rp ly, go s traight . In struct ion s Predicte d Im ages Cu rre n t Im age Future Im age (+4s) Ex pert Act ion Plann ed Act ion s Figure 6. Future image generation conditioned on instructions and actions. In the same scenario, giv en two sets of instructions, the model plans two action sequences and generates their respectiv e future images. Both action sequences follow their instructions and both images are consistent with their actions. introduced V ega , a unified vision-language-world-action model that bridges this gap by leveraging future visual gen- eration as a dense supervision signal. W e hav e b uilt a large- scale driving dataset with instruction annotations to enable the training for instructional dri ving. By jointly generat- ing instruction-compliant future images and planning ac- tions, the model learns the causal relationships among in- structions, actions, and the visual outcomes. Built upon an integrated transformer architecture and an instruction- annotated dataset, our model achiev es SOT A planning per- formance while demonstrating strong instruction-following capabilities in both visual generation and action planning. 9 References [1] W ei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun W ang, Y akov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, et al. Pseudo-simulation for autonomous driving. arXiv pr eprint arXiv:2506.04218 , 2025. 2 , 6 , 7 [2] Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, W enyu Liu, and Xinggang W ang. V adv2: End-to-end vectorized autonomous dri ving via probabilistic planning. arXiv pr eprint arXiv:2402.13243 , 2024. 1 [3] Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, W en Liu, Zhenda Xie, Xingkai Y u, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint , 2025. 3 [4] Kashyap Chitta, Aditya Prakash, Bernhard Jaeger , Zehao Y u, Katrin Renz, and Andreas Geiger . Transfuser: Imitation with transformer-based sensor fusion for autonomous driv- ing. TP AMI , 45(11):12878–12895, 2022. 6 , 7 [5] Daniel Dauner, Marcel Hallgarten, Tian yu Li, Xinshuo W eng, Zhiyu Huang, Zetong Y ang, Hongyang Li, Igor Gilitschenski, Boris Ivano vic, Marco Pav one, et al. Navsim: Data-driv en non-reactiv e autonomous v ehicle simulation and benchmarking. NeurIPS , 37:28706–28719, 2024. 2 , 3 , 6 , 7 [6] Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu W ang, Shu Zhong, W eihao Y u, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining. arXiv preprint , 2025. 2 , 3 , 4 , 5 [7] Kairui Ding, Boyuan Chen, Y uchen Su, Huan-ang Gao, Bu Jin, Chonghao Sima, W uqiang Zhang, Xiaohui Li, Paul Barsch, Hongyang Li, et al. Hint-ad: Holistically aligned interpretability in end-to-end autonomous dri ving. arXiv pr eprint arXiv:2409.06702 , 2024. 2 [8] Xinpeng Ding, Jianhua Han, Hang Xu, Xiaodan Liang, W ei Zhang, and Xiaomeng Li. Holistic autonomous driving un- derstanding by bird’ s-eye-vie w injected multi-modal large models. In CVPR , pages 13668–13677, 2024. 2 [9] Runpei Dong, Chunrui Han, Y uang Peng, Zekun Qi, Zheng Ge, Jinrong Y ang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran W ei, et al. Dreamllm: Synergistic multimodal com- prehension and creation. arXiv preprint , 2023. 3 [10] Patrick Esser , Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨ uller , Harry Saini, Y am Levi, Dominik Lorenz, Axel Sauer , Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. In ICML , 2024. 2 [11] Renju Feng, Ning Xi, Duanfeng Chu, Rukang W ang, Zejian Deng, Anzheng W ang, Liping Lu, Jinxiang W ang, and Y an- jun Huang. Artemis: Autoregressiv e end-to-end trajectory planning with mixture of experts for autonomous driving. arXiv pr eprint arXiv:2504.19580 , 2025. 6 [12] Simon Frieder . Mathematical capabilities of chatgpt. arXiv pr eprint arXiv:2301.13867 , 2023. 2 [13] Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing W ang, and Xiang Bai. Orion: A holistic end-to- end autonomous driving framework by vision-language in- structed action generation. arXiv preprint , 2025. 1 , 2 [14] Shenyuan Gao, Jiazhi Y ang, Li Chen, Kashyap Chitta, Y i- hang Qiu, Andreas Geiger , Jun Zhang, and Hongyang Li. V ista: A generalizable driving world model with high fi- delity and versatile controllability . NeurIPS , 37:91560– 91596, 2024. 2 [15] Y uying Ge, Sijie Zhao, Jinguo Zhu, Y ixiao Ge, Kun Y i, Lin Song, Chen Li, Xiaohan Ding, and Y ing Shan. Seed-x: Mul- timodal models with unified multi-granularity comprehen- sion and generation. arXiv preprint , 2024. 3 [16] David Ha and J ¨ urgen Schmidhuber . W orld models. arXiv pr eprint arXiv:1803.10122 , 2(3), 2018. 2 [17] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint , 2022. 5 [18] Anthony Hu, Lloyd Russell, Hudson Y eo, Zak Murez, George Fedosee v , Alex Kendall, Jamie Shotton, and Gian- luca Corrado. Gaia-1: A generativ e world model for au- tonomous driving. arXiv preprint , 2023. 2 [19] Y ihan Hu, Jiazhi Y ang, Li Chen, Ke yu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, T ianwei Lin, W enhai W ang, et al. Planning-oriented autonomous driving. In CVPR , pages 17853–17862, 2023. 1 , 7 [20] Junjie Huang, Guan Huang, Zheng Zhu, Y un Y e, and Dalong Du. Bevdet: High-performance multi-camera 3d object de- tection in bird-eye-view . arXiv preprint , 2021. 1 [21] Y uanhui Huang, W enzhao Zheng, Y unpeng Zhang, Jie Zhou, and Jiwen Lu. Tri-perspecti ve view for vision-based 3d se- mantic occupancy prediction. In CVPR , pages 9223–9232, 2023. 1 [22] Y uanhui Huang, W enzhao Zheng, Y unpeng Zhang, Jie Zhou, and Jiwen Lu. Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction. In ECCV , pages 376–393. Springer , 2024. 1 [23] Y uanhui Huang, Amonnut Thammatadatrakoon, W enzhao Zheng, Y unpeng Zhang, Dalong Du, and Jiwen Lu. Gaussianformer-2: Probabilistic gaussian superposition for efficient 3d occupancy prediction. In CVPR , pages 27477– 27486, 2025. 1 [24] Zhijian Huang, Chengjian Feng, Feng Y an, Baihui Xiao, Ze- qun Jie, Y ujie Zhong, Xiaodan Liang, and Lin Ma. Drivemm: All-in-one large multimodal model for autonomous driving. arXiv pr eprint arXiv:2412.07689 , 2024. 2 [25] Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, W ei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, T ong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving. arXiv pr eprint arXiv:2410.23262 , 2024. 1 , 2 [26] Anqing Jiang, Y u Gao, Zhigang Sun, Y iru W ang, Jijun W ang, Jinghao Chai, Qian Cao, Y uweng Heng, Hao Jiang, 10 Y unda Dong, et al. Diffvla: V ision-language guided dif- fusion planning for autonomous driving. arXiv pr eprint arXiv:2505.19381 , 2025. 2 [27] Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, W enyu Liu, Chang Huang, and Xinggang W ang. V ad: V ectorized scene representation for efficient autonomous driving. In ICCV , pages 8340– 8350, 2023. 1 [28] Bo Jiang, Shaoyu Chen, Bencheng Liao, Xingyu Zhang, W ei Y in, Qian Zhang, Chang Huang, W enyu Liu, and Xing- gang W ang. Senna: Bridging lar ge vision-language mod- els and end-to-end autonomous driving. arXiv preprint arXiv:2410.22313 , 2024. 2 [29] Bo Jiang, Shaoyu Chen, Qian Zhang, W enyu Liu, and Xing- gang W ang. Alphadriv e: Unleashing the power of vlms in autonomous driving via reinforcement learning and reason- ing. arXiv preprint , 2025. 2 [30] Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and W ook-Shin Han. Autoregressi ve image generation using residual quantization. In CVPR , pages 11523–11532, 2022. 2 [31] Xiang Li, Pengfei Li, Y upeng Zheng, W ei Sun, Y an W ang, and Y ilun Chen. Semi-supervised vision-centric 3d occu- pancy world model for autonomous driving. arXiv preprint arXiv:2502.07309 , 2025. 2 [32] Y ingyan Li, Lue Fan, Jiawei He, Y uqi W ang, Y untao Chen, Zhaoxiang Zhang, and T ieniu T an. Enhancing end-to-end autonomous dri ving with latent world model. arXiv pr eprint arXiv:2406.08481 , 2024. 7 [33] Y ingyan Li, Shuyao Shang, W eisong Liu, Bing Zhan, Haochen W ang, Y uqi W ang, Y untao Chen, Xiaoman W ang, Y asong An, Chufeng T ang, et al. Dri ve vla-w0: W orld mod- els amplify data scaling law in autonomous dri ving. arXiv pr eprint arXiv:2510.12796 , 2025. 2 , 6 , 7 [34] Y ingyan Li, Y uqi W ang, Y ang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end dri ving with online tra- jectory ev aluation via bev world model. arXiv preprint arXiv:2504.01941 , 2025. 7 [35] Y ongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Y an, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing W ang, et al. Recogdriv e: A reinforced cognitive frame- work for end-to-end autonomous driving. arXiv pr eprint arXiv:2506.08052 , 2025. 2 , 7 [36] Zhenxin Li, Kailin Li, Shihao W ang, Shiyi Lan, Zhiding Y u, Y ishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan W u, et al. Hydra-mdp: End-to-end multimodal planning with multi- target hydra-distillation. arXiv preprint , 2024. 6 , 7 [37] Zhiqi Li, W enhai W ang, Hongyang Li, Enze Xie, Chong- hao Sima, T ong Lu, Qiao Y u, and Jifeng Dai. Bevformer: learning bird’ s-eye-vie w representation from lidar-camera via spatiotemporal transformers. TP AMI , 2024. 1 [38] W eixin Liang, Lili Y u, Liang Luo, Sriniv asan Iyer , Ning Dong, Chunting Zhou, Gargi Ghosh, Mike Lewis, W en-tau Y ih, Luke Zettlemoyer , et al. Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models. arXiv preprint , 2024. 2 , 3 , 5 [39] Bencheng Liao, Shaoyu Chen, Haoran Y in, Bo Jiang, Cheng W ang, Sixu Y an, Xinbang Zhang, Xiangyu Li, Y ing Zhang, Qian Zhang, et al. Diffusiondri ve: Truncated diffusion model for end-to-end autonomous driving. In CVPR , pages 12037– 12047, 2025. 6 , 7 [40] Y aron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generativ e mod- eling. arXiv preprint , 2022. 2 [41] Zhijian Liu, Haotian T ang, Alexander Amini, Xinyu Y ang, Huizi Mao, Daniela L Rus, and Song Han. Bevfusion: Multi- task multi-sensor fusion with unified bird’ s-eye view repre- sentation. In 2023 IEEE international conference on r obotics and automation (ICRA) , pages 2774–2781. IEEE, 2023. 1 [42] Jiasen Lu, Christopher Clark, Sangho Lee, Zichen Zhang, Savya Khosla, Ryan Marten, Derek Hoiem, and Aniruddha Kembha vi. Unified-io 2: Scaling autoregressiv e multimodal models with vision language audio and action. In CVPR , pages 26439–26455, 2024. 3 [43] Y ingzi Ma, Y ulong Cao, Jiachen Sun, Marco Pav one, and Chaowei Xiao. Dolphins: Multimodal language model for driving. In ECCV , pages 403–420. Springer , 2024. 2 [44] Y iyang Ma, Xingchao Liu, Xiaokang Chen, W en Liu, Chengyue W u, Zhiyu W u, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Y u, et al. Janusflow: Harmonizing autore- gression and rectified flo w for unified multimodal under - standing and generation. In CVPR , pages 7739–7751, 2025. 2 , 3 [45] Jiageng Mao, Y uxi Qian, Junjie Y e, Hang Zhao, and Y ue W ang. Gpt-driv er: Learning to drive with gpt. arXiv pr eprint arXiv:2310.01415 , 2023. 2 [46] Ana-Maria Marcu, Long Chen, Jan H ¨ unermann, Alice Karn- sund, Benoit Hanotte, Prajwal Chidananda, Saurabh Nair, V ijay Badrinarayanan, Alex Kendall, Jamie Shotton, et al. Lingoqa: V isual question answering for autonomous driving. In ECCV , pages 252–269. Springer , 2024. 2 [47] Chen Min, Dawei Zhao, Liang Xiao, Jian Zhao, Xinli Xu, Zheng Zhu, Lei Jin, Jianshu Li, Y ulan Guo, Junliang Xing, et al. Driv ew orld: 4d pre-trained scene understanding via world models for autonomous driving. In CVPR , pages 15522–15533, 2024. 2 [48] Sung-Y eon Park, Can Cui, Y unsheng Ma, Ahmadreza Moradipari, Rohit Gupta, Kyungtae Han, and Ziran W ang. Nuplanqa: A lar ge-scale dataset and benchmark for multi- view driving scene understanding in multi-modal large lan- guage models. arXiv preprint , 2025. 2 [49] Shuai Peng, K e Y uan, Liangcai Gao, and Zhi T ang. Math- bert: A pre-trained model for mathematical formula under- standing. arXiv preprint , 2021. 2 [50] Tianwen Qian, Jingjing Chen, Linhai Zhuo, Y ang Jiao, and Y u-Gang Jiang. Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. In AAAI , pages 4542–4550, 2024. 2 [51] Liao Qu, Huichao Zhang, Y iheng Liu, Xu W ang, Y i Jiang, Y iming Gao, Hu Y e, Daniel K Du, Zehuan Y uan, and Xin- glong W u. T okenflo w: Unified image tok enizer for multi- modal understanding and generation. In CVPR , pages 2545– 2555, 2025. 3 11 [52] Qwen, :, An Y ang, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran W ei, Huan Lin, Jian Y ang, Jianhong Tu, Jianwei Zhang, Jianxin Y ang, Jiaxi Y ang, Jingren Zhou, Jun- yang Lin, Kai Dang, K eming Lu, Keqin Bao, K exin Y ang, Le Y u, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tian yi T ang, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Y ang Fan, Y ang Su, Y ichang Zhang, Y u W an, Y uqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. Qwen2.5 technical report, 2025. 3 , 5 , 6 , 8 [53] Katrin Renz, Long Chen, Elahe Arani, and Oleg Sina vski. Simlingo: V ision-only closed-loop autonomous dri ving with language-action alignment. In CVPR , pages 11993–12003, 2025. 2 [54] Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fe- doseev , Jamie Shotton, Elahe Arani, and Gianluca Corrado. Gaia-2: A controllable multi-view generativ e world model for autonomous driving. arXiv pr eprint arXiv:2503.20523 , 2025. 2 [55] Hao Shao, Y uxuan Hu, Letian W ang, Guanglu Song, Stev en L W aslander, Y u Liu, and Hongsheng Li. Lmdrive: Closed-loop end-to-end driving with large language models. In CVPR , pages 15120–15130, 2024. 2 [56] W eijia Shi, Xiaochuang Han, Chunting Zhou, W eixin Liang, Xi V ictoria Lin, Luke Zettlemoyer , and Lili Y u. Lmfusion: Adapting pretrained language models for multimodal gener- ation. arXiv preprint , 2024. 2 , 3 , 5 [57] Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger , Ping Luo, Andreas Geiger, and Hongyang Li. Driv elm: Driving with graph visual question answering. In ECCV , pages 256–274. Springer , 2024. 2 [58] Quan Sun, Y ufeng Cui, Xiaosong Zhang, F an Zhang, Qiy- ing Y u, Y ueze W ang, Y ongming Rao, Jingjing Liu, T iejun Huang, and Xinlong W ang. Generativ e multimodal models are in-context learners. In CVPR , pages 14398–14409, 2024. 3 [59] Chameleon T eam. Chameleon: Mixed-modal early-fusion foundation models. arXiv pr eprint arXiv:2405.09818 , 2024. 3 [60] Xiaoyu T ian, T ao Jiang, Longfei Y un, Y ucheng Mao, Huitong Y ang, Y ue W ang, Y ilun W ang, and Hang Zhao. Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving. NeurIPS , 36:64318–64330, 2023. 1 [61] Shengbang T ong, David Fan, Jiachen Li, Y unyang Xiong, Xinlei Chen, Koustuv Sinha, Michael Rabbat, Y ann LeCun, Saining Xie, and Zhuang Liu. Metamorph: Multimodal un- derstanding and generation via instruction tuning. In ICCV , pages 17001–17012, 2025. 3 [62] Shihao W ang, Zhiding Y u, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Y ing Li, and Jose M Al- varez. Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. In Pr o- ceedings of the computer vision and pattern r ecognition con- fer ence , pages 22442–22452, 2025. 1 , 2 [63] Xinlong W ang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Y ufeng Cui, Jinsheng W ang, Fan Zhang, Y ueze W ang, Zhen Li, Qiying Y u, et al. Emu3: Next-tok en prediction is all you need. arXiv preprint , 2024. 3 [64] Xiaofeng W ang, Zheng Zhu, Guan Huang, Xinze Chen, Jia- gang Zhu, and Jiwen Lu. Drivedreamer: T owards real-world- driv e world models for autonomous dri ving. In ECCV , pages 55–72. Springer , 2024. 2 [65] Y uqi W ang, Jiawei He, Lue Fan, Hongxin Li, Y untao Chen, and Zhaoxiang Zhang. Dri ving into the future: Multivie w visual forecasting and planning with world model for au- tonomous driving. In CVPR , pages 14749–14759, 2024. 2 [66] Julong W ei, Shanshuai Y uan, Pengfei Li, Qingda Hu, Zhongxue Gan, and W enchao Ding. Occllama: An occupancy-language-action generati ve world model for au- tonomous driving. arXiv preprint , 2024. 1 , 2 [67] Y i W ei, Linqing Zhao, W enzhao Zheng, Zheng Zhu, Jie Zhou, and Jiwen Lu. Surroundocc: Multi-camera 3d occu- pancy prediction for autonomous driving. In ICCV , pages 21729–21740, 2023. 1 [68] Xinshuo W eng, Boris Ivanovic, Y an W ang, Y ue W ang, and Marco P av one. Para-dri ve: Parallelized architecture for real- time autonomous dri ving. In CVPR , pages 15449–15458, 2024. 7 [69] Chengyue W u, Xiaokang Chen, Zhiyu W u, Y iyang Ma, Xingchao Liu, Zizheng Pan, W en Liu, Zhenda Xie, Xingkai Y u, Chong Ruan, et al. Janus: Decoupling visual encod- ing for unified multimodal understanding and generation. In CVPR , pages 12966–12977, 2025. 3 [70] Junfeng Wu, Y i Jiang, Chuofan Ma, Y uliang Liu, Heng- shuang Zhao, Zehuan Y uan, Song Bai, and Xiang Bai. Liq- uid: Language models are scalable multi-modal generators. arXiv e-prints , pages arXiv–2412, 2024. [71] Y echeng W u, Zhuoyang Zhang, Junyu Chen, Haotian T ang, Dacheng Li, Y unhao Fang, Ligeng Zhu, Enze Xie, Hongxu Y in, Li Y i, et al. V ila-u: a unified foundation model inte- grating visual understanding and generation. arXiv preprint arXiv:2409.04429 , 2024. 3 [72] Shuo Xing, Chengyuan Qian, Y uping W ang, Hongyuan Hua, Ke xin Tian, Y ang Zhou, and Zhengzhong Tu. Openemma: Open-source multimodal model for end-to-end autonomous driving. In W ACV , pages 1001–1009, 2025. 1 , 2 [73] Zhenhua Xu, Y ujia Zhang, Enze Xie, Zhen Zhao, Y ong Guo, Kwan-Y ee K W ong, Zhenguo Li, and Hengshuang Zhao. Driv egpt4: Interpretable end-to-end autonomous driving via large language model. RA-L , 2024. 2 [74] Y u Y ang, Jianbiao Mei, Y ukai Ma, Siliang Du, W enqing Chen, Y ijie Qian, Y uxiang Feng, and Y ong Liu. Dri ving in the occupancy world: V ision-centric 4d occupancy forecast- ing and planning via world models for autonomous driving. In AAAI , pages 9327–9335, 2025. 2 [75] Zhenjie Y ang, Y ilin Chai, Xiaosong Jia, Qifeng Li, Y uqian Shao, Xuekai Zhu, Haisheng Su, and Junchi Y an. Driv emoe: Mixture-of-experts for vision-language-action model in end-to-end autonomous driving. arXiv preprint arXiv:2505.16278 , 2025. 2 [76] W enhao Y ao, Zhenxin Li, Shiyi Lan, Zi W ang, Xinglong Sun, Jose M Alv arez, and Zuxuan W u. Drivesuprim: T o- 12 wards precise trajectory selection for end-to-end planning. arXiv pr eprint arXiv:2506.06659 , 2025. 6 [77] Jiahui Y u, Xin Li, Jing Y u Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Y uanzhong Xu, Jason Baldridge, and Y onghui W u. V ector-quantized image modeling with improv ed vqgan. arXiv preprint , 2021. 2 [78] Guosheng Zhao, Xiaofeng W ang, Zheng Zhu, Xinze Chen, Guan Huang, Xiaoyi Bao, and Xingang W ang. Driv edreamer-2: Llm-enhanced world models for diverse driving video generation. In AAAI , pages 10412–10420, 2025. 2 [79] W enzhao Zheng, W eiliang Chen, Y uanhui Huang, Borui Zhang, Y ueqi Duan, and Jiwen Lu. Occworld: Learning a 3d occupancy world model for autonomous driving. In ECCV , pages 55–72. Springer , 2024. 1 , 2 [80] W enzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. Genad: Generative end-to-end au- tonomous driving. In ECCV , pages 87–104. Springer , 2024. 1 [81] W enzhao Zheng, Junjie W u, Y ao Zheng, Sicheng Zuo, Zixun Xie, Longchao Y ang, Y ong Pan, Zhihui Hao, Peng Jia, Xi- anpeng Lang, et al. Gaussianad: Gaussian-centric end-to- end autonomous driving. arXiv preprint , 2024. 1 [82] W enzhao Zheng, Zetian Xia, Y uanhui Huang, Sicheng Zuo, Jie Zhou, and Jiwen Lu. Doe-1: Closed-loop au- tonomous dri ving with large world model. arXiv pr eprint arXiv:2412.09627 , 2024. 1 , 2 [83] Chunting Zhou, Lili Y u, Arun Babu, Kushal Tirumala, Michihiro Y asunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Le vy . T ransfusion: Pre- dict the next token and dif fuse images with one multi-modal model. arXiv preprint , 2024. 3 [84] Xingcheng Zhou, Xuyuan Han, Feng Y ang, Y unpu Ma, and Alois C Knoll. Opendriv evla: T ow ards end-to-end au- tonomous driving with large vision language action model. arXiv pr eprint arXiv:2503.23463 , 2025. 2 [85] Zewei Zhou, Tianhui Cai, Seth Z Zhao, Y un Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision- language-action model for end-to-end autonomous driving with adaptiv e reasoning and reinforcement fine-tuning. arXiv pr eprint arXiv:2506.13757 , 2025. 2 , 6 , 7 [86] Sicheng Zuo, W enzhao Zheng, Xiaoyong Han, Longchao Y ang, Y ong Pan, and Jiwen Lu. Quadricformer: Scene as superquadrics for 3d semantic occupancy prediction. arXiv pr eprint arXiv:2506.10977 , 2025. 1 [87] Sicheng Zuo, W enzhao Zheng, Y uanhui Huang, Jie Zhou, and Jiwen Lu. Gaussianworld: Gaussian world model for streaming 3d occupancy prediction. In CVPR , pages 6772– 6781, 2025. 1 , 2 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment