PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference
Autoregressive video diffusion models have demonstrated remarkable progress, yet they remain bottlenecked by intractable linear KV-cache growth, temporal repetition, and compounding errors during long-video generation. To address these challenges, we…
Authors: Xiaofeng Mao, Shaohao Rui, Kaining Ying
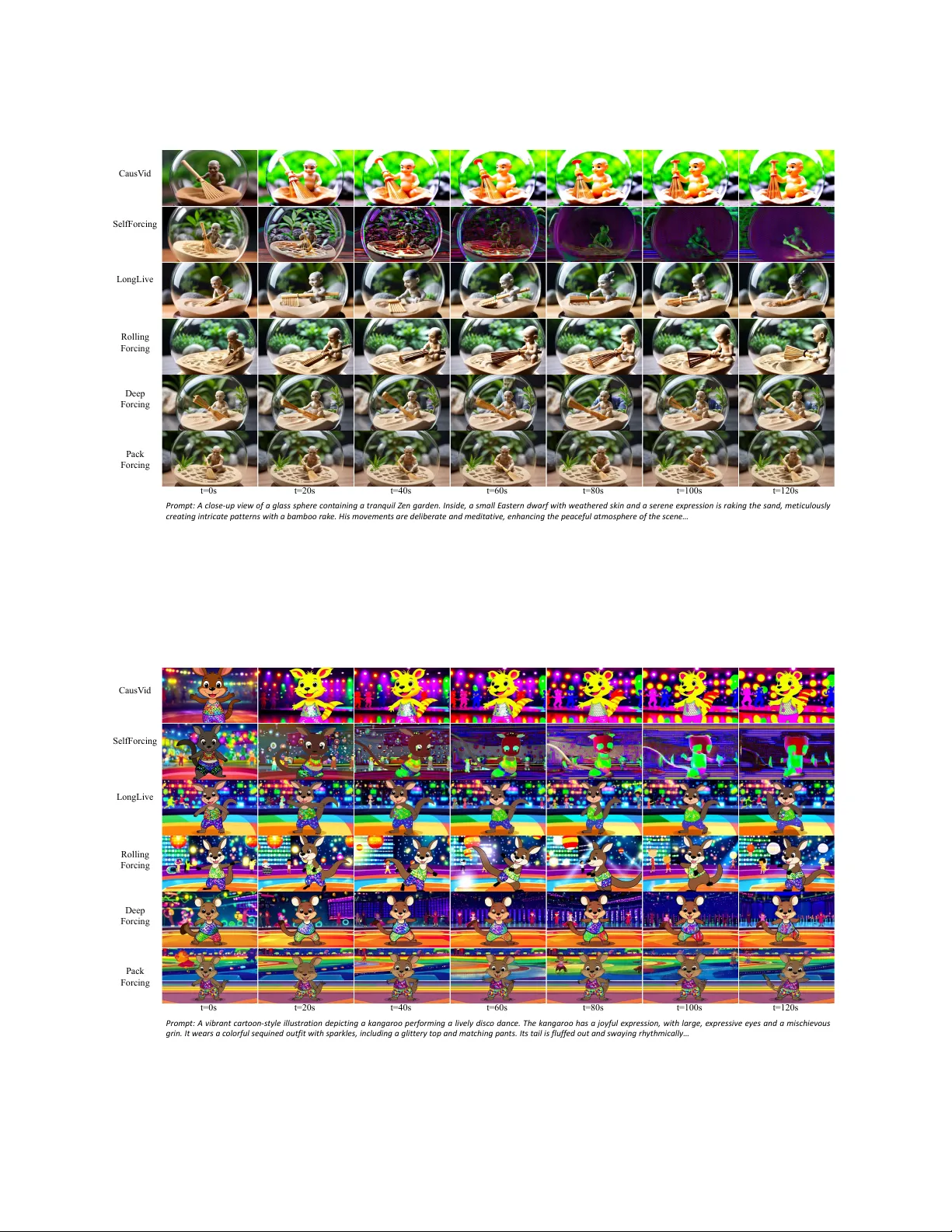
PackF orcing: Short Video T raining Suffices for L ong Video Sampling and L ong Conte xt Inference Xiaofeng Mao 1,2, ∗ , § , Shaohao R ui 1,3, ∗ , § , Kaining Ying 1,2 , Bo Zheng 1 , Chuanhao Li 1 , Mingmin Chi 2,† , Kaipeng Zhang 1,3† 1 Ala ya Studio, Shanda AI Research T oky o 2 Fudan Univ ersity 3 Shanghai Innov ation Institute A utoregressiv e video diffusion models ha v e demonstrated remarkable progress, y et they remain bottlenecked b y intractable linear KV -cache growth, temporal repetition, and compounding errors during long-video generation. T o address these challenges, w e present PackF orcing , a unified framew ork that efficiently manages the generation history through a nov el three-partition KV -cache strategy . Specifically , we categorize the historical context into three distinct types: (1) Sink tok ens , which preserv e early anchor frames at full resolution to maintain global semantics; (2) Mid tok ens , which achiev e a massiv e spatiotemporal compression ( ∼ 32 × token reduction) via a dual-branch netw ork fusing progressiv e 3D convolutions with low-resolution V AE re-encoding; and (3) Recent tok ens , kept at full resolution to ensure local temporal coherence. T o strictly bound the memor y footprint without sacrificing quality , w e introduce a dynamic top- k context selection mechanism for the mid tokens, coupled with a continuous T emporal RoPE Adjustment that seamlessly re-aligns position gaps caused by dropped tokens with negligible ov er head. Empo w ered by this principled hierarchical context compression, PackForcing can generate coherent 2-minute, 832 × 480 videos at 16 FPS on a single H200 GPU. It achiev es a bounded KV cache of just ∼ 4 GB and enables a remarkable 24 × temporal extrapolation (5 s → 120 s ), operating effectiv ely either zero-shot or trained on merely 5-second clips. Extensiv e results on VBench demonstrate state-of-the-art temporal consistency (26.07) and dynamic degree (56.25), proving that short-video supervision is sufficient for high-quality , long-video synthesis. Project pag e: https://github.com/ShandaAI/PackForcing Date: March 27, 2026 Self Forcing Roll ing Forci ng C ausV id LongLive Pack Forcing Promp t : A ch a rmin g 3 D d i g it a l re n d e r a rt s tyl e imag e s ho wc a si n g an a d or a b l e and h a p p y ot t e r c on f i d e n tl y s t a n d i n g on a s u r f b o a r d , w e a ri n g a b ri g h t y e l lo w li f e j a ck e t . Th e ot t e r is d e p icte d with a jo y fu l e xp ressio n , it s fur sof t and d e t a iled , and it a p p e a rs to g lide g rac e fu lly t hroug h t u rqu oise t rop ic a l wa t e rs … t=0s t=20s t=40s t=60s t=80s t=100s t=120s Deep Forci ng Figure 1 Our framew ork enables the generation of high-quality , temporally coherent videos up to 120 seconds. § This w ork was done during Xiaofeng and Shaohao’s internship at Shanda AI Research T okyo * Equal contribution. † Corresponding authors: mmchi@fudan.edu.cn; kaipeng.zhang@shanda.com 1 1 Introduction Recent video diffusion models Ho et al. ( 2022 ); Blattmann et al. ( 2023 ); Polyak et al. ( 2024 ); W an et al. ( 2025 ); V alevski et al. ( 2024 ); Chen et al. ( 2025 , 2024b ); Ce ylan et al. ( 2023 ); Harv ey et al. ( 2022 ); W ang et al. ( 2024 ); He et al. ( 2025 , 2024 ) ha v e demonstrated significant progress in high-fidelity and complex motion synthesis for short clips (5–15 s). How ev er , their bidirectional architectures typically require the simultaneous processing of all frames within a spatiotemporal volume. This computationally intensiv e paradigm hinders the dev elopment of streaming or real-time generation. A utoregressiv e video generation Y in et al. ( 2025 ); Huang et al. ( 2025a ); Chen et al. ( 2024a ) addresses this limitation by employing a block-b y-block generation strategy . Instead of computing the entire sequence jointly , these methods sequentially cache key-v alue (KV) pairs from previously generated blocks to provide continuous contextual conditioning. While this approach theoretically mitigates the memory bottlenecks of joint processing and enables unbounded-length video generation, its practical application for minute-scale generation is limited by two primar y challenges: (1) Error accumulation. Small prediction errors compound iterativ ely during the autoregressiv e denoising process, leading to progressiv e quality degradation and semantic drift. Although S elf-Forcing Huang et al. ( 2025a ) attempts to mitigate this by training on self-generated historical frames, it still suffers from sev ere error accumulation beyond its training horizon. Consequently , it exhibits a significant decline in text-video alignment: within 60 s, the model gradually loses the prompt’s semantics, with its CLIP score dropping from 33.89 to 27.12 (T able 2 ). (2) Unbounded memory growth. The KV cache scales linearly with the length of the generated video. For a 2-minute, 832 × 480 video at 16 FPS, the full attention context gro ws to ∼ 749K tokens, requiring ∼ 138 GB of KV storage across 30 transfor mer la y ers, well bey ond the memory budget of a single commodity GPU. Standard w orkarounds, such as histor y truncation Y in et al. ( 2025 ) or sliding windows Liu et al. ( 2025 ), sev erely compromise long-range coherence. Ev en recent advanced baselines struggle with this bottleneck. For instance, DeepForcing introduces attention sinks and participativ e compression to retain infor mativ e tokens based on query importance. How ev er , to prev ent unbounded KV cache expansion, it ultimately relies on aggressiv e buffer truncation, leading to the irrev ersible loss of intermediate historical memor y . A fundamental dilemma thus emerges in autoregressiv e video generation: mitigating error accumulation requires an extensiv e contextual history , y et unbounded KV cache growth inevitably forces the discarding of critical memory under hardw are constraints. Maintaining a large effectiv e context windo w while strictly bounding the KV cache size remains a critical open problem. Building upon DeepForcing’s insights, we recognize the effectiv eness of its deep sink and participative compression mechanisms in identifying and retaining crucial historical context. How ev er , rather than irrev ersibly dropping unselected inter mediate tokens to sa v e memor y , w e propose efficiently compressing them. T o this end, w e introduce PackF orcing , a unified framew ork comprehensively addressing both challenges via a principled three-partition KV cache design. T o this end, we introduce PackF orcing , a unified framew ork that comprehensiv ely addresses both error accumulation and memor y bottlenecks via a principled three-partition KV cache design. Specifically , our framew ork categorizes the historical context into: (1) Sink tokens , which preserv e early anchor frames at full resolution to maintain global semantics and prev ent drift; (2) Compressed mid tokens , which undergo a 128 × spatiotemporal v olume compression (via a dual-branch netw ork) to efficiently retain the bulk of the historical memory; and (3) Recent and current tok ens , which are kept at full resolution to ensure fine-grained local coherence. This hierarchical design successfully bounds memor y requirements while preserving critical infor mation. T o strictly limit the capacity of the compressed mid-buffer , we adapt dynamic context selection as an advanced top- k selection strategy , retrieving only the most informative mid tokens during generation. T o resolv e the ensuing positional discontinuities caused b y managing unselected tokens, w e introduce a no v el incremental RoPE rotation that gracefully corrects temporal positions without requiring a full cache recomputation. In a nutshell, our primar y contributions are summarized as follows: 2 • Three-partition KV cache . W e propose PackF orcing , which partitions generation history into sink, com- pressed, and recent tokens, bounding per-la yer attention to ∼ 27,872 tokens for any video length. • Dual-branch compression. W e design a hybrid compression la y er fusing progressiv e 3D convolutions with lo w-resolution re-encoding. This achiev e a 128 × spatiotemporal compression ( ∼ 32 × token reduction) for intermediate histor y , increasing effectiv e memor y capacity b y ov er 27 × . • Incremental RoPE rotation & Dynamic Context Selection. W e introduce a temporal-only RoPE adjustment to seamlessly correct position gaps during memory management. Alongside an importance-scored top- k token selection strategy , this ensures highly stable generation o v er extended horizons. • 24 × temporal extrapolation. T rained exclusiv ely on 5-second clips (or operating zero-shot without any training), PackForcing successfully generates coherent 2-minute videos. It achiev es state-of-the-art VBench scores and demonstrates the most stable CLIP trajectory among all compared methods. 2 R elated W ork Video Diffusion Models. Early video models inflated 2D U-Nets with pseudo-3D modules Ho et al. ( 2020 ); Rombach et al. ( 2022 ); Ho et al. ( 2022 ); Singer et al. ( 2022 ); Blattmann et al. ( 2023 ). Recently , Diffusion T ransfor mers (DiT s) Peebles & Xie ( 2023 ); Brooks et al. ( 2024 ) ha v e emerged as the dominant architecture, treating videos as spatiotemporal patches to enable scalable 3D attention in state-of-the-art models (e.g., CogV ideoX Y ang et al. ( 2024 ), Movie Gen Poly ak et al. ( 2024 ), W an W an et al. ( 2025 ), Open-S ora Zheng et al. ( 2024 )). Concurrently , Flow Matching Lipman et al. ( 2022 ); Liu et al. ( 2022 ) has largely replaced standard diffusion to offer faster conv ergence. Despite these advances, current models primarily generate short clips (5–10 s). Joint spatiotemporal modeling for minute-lev el videos remains computationally intractable, as full 3D attention incurs a quadratic O ( ( T H W ) 2 ) memory cost. This bottleneck directly motivates the need for memory-efficient, autoregressiv e long-video generation strategies. Autoregressiv e Video Generation. A utoregressiv e video generation ov ercomes the fixed-length limitations of joint spatiotemporal modeling b y synthesizing frames block-by-block and maintaining historical context via key-v alue (KV) caching. Recent methods hav e rapidly ev olved this paradigm, exploring ODE-based initialization Y in et al. ( 2025 ), self-generated frame conditioning Huang et al. ( 2025a ), rolling temporal windo ws Liu et al. ( 2025 ), long-short context guidance Y ang et al. ( 2025 ), and enlarged attention sinks Y i et al. ( 2025 ). Despite these inno vations, existing approaches univ ersally lack a mechanism to explicitly compress the KV cache. Consequently , they face a rigid trade-off: retaining the full history inevitably causes out-of-memory failures for videos exceeding roughly 80 seconds, whereas truncating the context buffer results in an irrev ersible loss of long-range coherence. PackForcing explicitly breaks this memory-coherence trade-off by introducing lear ned spatiotemporal token compression tailored for causal video generation. KV Cache Management. KV cache management has been extensiv ely studied in Large Language Models (LLMs) to enable long-context understanding. Representativ e techniques include retaining initial attention sinks Xiao et al. ( 2023 ), selecting heavy-hitter keys based on attention scores Zhang et al. ( 2023 ), and extending context via RoPE interpolation Peng et al. ( 2023 ). How ev er , these methods primarily focus on token selection or eviction rather than explicit compression, as text representations are already highly compact. V ideo tokens, conversely , encode dense spatiotemporal grids characterized by massiv e inter-frame redundancy . Exploiting this unique structural redundancy motivates our lear ned 128 × v olume compression, achieving a memor y reduction far bey ond what token selection alone can provide. L ong Video Generation. Bey ond purely autoregressiv e caching, traditional long video generation strategies often rely on modifying the inference noise scheduling Qiu et al. ( 2023 ); Ge et al. ( 2023 ), designing hierarchical planning framew orks Hong et al. ( 2023 ), or utilizing complex multi-stage extensions Henschel et al. ( 2025 ). While effectiv e, these methods typically require multi-stage pipelines or alter the fundamental diffusion process. In contrast , PackForcing operates within a unified, single-stage causal framew ork. By managing the historical context through hierarchical compression and position-corrected eviction, our method achiev es the generation of arbitrarily long videos with strictly bounded memory footprint and constant-time attention cost. 3 3 Method W e first introduce the background on flow matching and causal KV caching (S ec. 3.1 ), then present the core components of PackForcing: the three-partition KV cache (Sec. 3.2 ), dual-branch compression (S ec. 3.3 ), Dual-Resolution Shifting with incremental RoPE adjustment (S ec. 3.4 ), and Dynamic Context Selection (Sec. 3.5 ). 3.1 Preliminaries Flow Matching. Our base model builds upon the flo w matching framew ork Lipman et al. ( 2022 ). Giv en a clean video latent x 0 and standard Gaussian noise ϵ ∼ N ( 0 , I ) , the noisy latent at noise lev el σ ∈ [ 0, 1 ] is constructed as: x σ = ( 1 − σ ) x 0 + σ ϵ . (1) A neural netw ork f θ is trained to predict the v elocity field v θ ( x σ , σ ) ≈ ϵ − x 0 . KV Caching. A video sequence of T latent frames is partitioned into non-ov erlapping blocks, each containing B f frames. Each block i , denoted as z i ∈ R B f × C × H × W (where C , H , and W represent the channel, height, and width dimensions, respectiv ely), is generated autoregressiv ely . After spatial patchification, each block yields n = B f hw tokens, where h and w represent the spatial height and width after patchification. During the generation of block i , each transformer la y er l attends to the Key-V alue (KV) pairs cached from all previously generated blocks: C l = ( K l j , V l j ) i − 1 j = 1 , (2) where K l j , V l j ∈ R n × N h × d h , with N h representing the number of attention heads and d h denoting the head dimension. The attention operation for the current block i concatenates these historical keys and values with its own: Attn ( Q i , C l ) = softmax Q i K | 1: i √ d h V 1: i , (3) where Q i is the query matrix for block i , while K 1: i and V 1: i represent the concatenated keys and v alues from block 1 to i . As generation proceeds, the KV cache grows linearly . For a 2-minute, 832 × 480 video at 16 FPS ( h = 30, w = 52, B f = 4), the context size at the final block sw ells to ∼ 749K tokens—consuming an intractable amount of GPU memory . This fundamental scaling bottleneck directly motivates our three-partition design. 3.2 Three-Partition KV Cache The core idea of PackForcing is to decouple the monotonically gro wing generation history into three distinct functional partitions. Rather than applying a one-size-fits-all eviction or compression strategy , w e apply a tailored policy to each partition based on its temporal role and infor mation density (Fig. 2 ). Sink T ok ens (Full resolution, nev er evicted) . Inspired b y the attention-sink phenomenon in StreamingLLM Xiao et al. ( 2023 ), we hypothesize that the earliest generated frames serve as critical semantic anchors. Let N sink denote the number of these initial frames, corresponding to the first N sink / B f generation blocks. For a giv en transfor mer la y er l , the sink cache is defined as: C l sink = ( K l j , V l j ) N sink / B f j = 1 , |C l sink | = N sink B f n , (4) where j is the block index, and K l j , V l j are the original, uncompressed key and value. These tokens lock in the scene la y out, subject identity , and global style. Because they are vital for prev enting semantic drift, they are never compressed or evicted . W e set N sink = 8 (tw o blocks), which consumes < 2% of the total token budget for a 2-minute video, y et pro vides a robust and stable global reference throughout the entire generation process. 4 Keep Resolution Rope Adjustment 𝑆 ! ... 𝑆 "#$% 𝑀 ! ... 𝑀 &#' 𝑅 ! ... 𝑅 ()* 𝑅 *+( ... ... ... Denois ing Co ntext Denois ing Bl ock (a) Three - Partition KV managem ent of PackForcing (b) Dual - Branch Compr ession Mid Tokens HR: 4 - stage 3D CNN LR: Pool>VAE>Patc h + Compre ssed To kens Sink T okens Mid T okens Recent and Current T okens (i ) Before Dynamic Co ntext Selec tion S0 p=0 S1 p=1 M2 p=2 M3 p=3 M4 p=4 M5 p=5 M6 p=6 M7 p=7 R p=8 R p=9 ( ii ) After Select Top -K candidate tokens ( position gap! ) S0 p=0 S1 p=1 X M3 M4 p=4 M5 p=5 X M7 p=7 R p=8 R p=9 ( iii ) After RoPE Adjust ment (continuous) S0 p=2 S1 p=3 M3 p=4 M4 p=5 M5 p=6 M7 p=7 R p=8 R p=9 p=3 (c) Te m p o r a l RoPE A djustme nt of Historical Contexts (d ) H R c o m p r e s s i o n l a y e r s Dual Branch Compression Dynamic Context Selection Rope Adjustment Keep Resolution Full< - >Reduced Exchange Input: 16,T ,H,W 16 ,T,H,W Conv3D 16->32, s=(2,1,1) 32 ,T/2,H,W Conv3D 32->128, s=(1,2,2) 128 ,T/2,H/2,W/2 Conv3D 128->512, s=(1,2,2) 512 ,T/2,H/4,W/4 Conv3D 512->2048, s=(1,2,2) 204 8,T/2,H/8,W /8 Conv3D 2048->D, s=(1,1,1) D, T/2,H/8,W/8 Figure 2 Overview of PackF orcing. (a) The three-partition KV management organizes the denoising context into sink tokens (full resolution), mid tokens (compressed and dynamically selected), and recent / current tokens (full resolution with full-to-reduced exchange). (b) & (d) The dual-branch compression module fuses a High-Resolution (HR) branch (a progressiv e 4-stage 3D CNN) with a Low-Resolution (LR) branch (pooling follow ed by V AE re-encoding) via element- wise addition to minimize token count. (c) T o efficiently bound the memory footprint, dynamic context selection is applied to retain only the top- K informative mid tokens. T o resolv e the ensuing position gaps caused by dropped tokens, a T emporal RoPE Adjustment is utilized to re-align and enforce continuous positional indices across the historical contexts. Compressed Mid T ok ens ( ∼ 32 × tok en reduction & dynamically routed). The vast majority of the video history falls betw een the initial sink frames and the most recent window . W e define this region as the mid partition. Retaining this partition at full resolution is computationally prohibitiv e and highly redundant. Instead, tokens populating this region are represented by highly compressed KV pairs ( ˜ K l j , ˜ V l j ) produced via our dual-branch module (S ec. 3.3 ). Furthermore, as this compressed buffer accumulates ov er time, w e do not attend to the entire pool indiscriminately . W e employ Dynamic Context Selection (S ec. 3.5 ) to dynamically ev aluate quer y-key affinities, activ ely routing only the N mid most informativ e blocks to form the activ e set S mid for the current computation: C l mid = ( ˜ K l j , ˜ V l j ) j ∈ S mid , |C l mid | ≤ N mid · N c , (5) where the tilde ( ∼ ) denotes compressed part and N mid limits the activ e computational budget. N c is the token count per compressed block, calculated as N c = ⌊ B f / 2 ⌋ × ⌊ h / 4 ⌋ × ⌊ w / 4 ⌋ . Here, the factors 1 / 2 and 1 / 4 correspond to the do wnsampling strides of the compression module along the temporal and spatial dimensions. W ith default settings ( B f = 4, h = 30, w = 52), each block is compressed to N c = 182 tokens—a dramatic ∼ 32 × reduction from the original n = 6,240 tokens. Recent & Current T ok ens (Dual-resolution shifting). T o maintain high-fidelity local temporal dynamics when generating new video frames, the most recently generated frames must be kept pristine. Let i denote the index of the block currently being generated and N recent be the number of preceding recent frames. The context for this partition comprises the intact KV pairs from these recent blocks, alongside the current block 5 i itself: C l rc = ( K l j , V l j ) i j = i − N recent / B f , |C l rc | = N recent B f + 1 n . (6) Preserving these recent tokens at uncompressed resolution guarantees smooth temporal transitions. Cru- cially , to bridge this partition with the mid-buffer without incurring sequential latency , w e concurrently compute a low-resolution backup for these tokens. As detailed in S ec. 3.4 , this dual-resolution shifting pipeline perfectly hides the compression ov er head and ensures a seamless transition of aging recent tokens into long-term mid memory . Bounded A ttention Context. During the generation of block i , the transformer la y er l concatenates the three partitions to form the activ e attention context: C l = C l sink ∥ C l mid ∥ C l rc , (7) which enforces a constant token count for the attention computation: |C l | = N sink B f n + N mid · N c + N recent B f + 1 n . Crucially , while the entire generation history is persistently maintained within the memory buffers (either at full resolution or in a highly compressed state), the actual context input for generating the block i is strictly bounded and independent of the total video length T . Rather than attending to the full growing sequence, this fixed-size input context is dynamically retriev ed from the comprehensiv e historical partitions, ensuring O ( 1 ) attention complexity without discarding any past memor y . 3.3 Dual-Branch HR Compression The mid partition requires a massiv e token reduction ( ∼ 32 × ) while retaining sufficient structural and semantic information for coherent attention patter ns (see Fig. 3 ). A single-pathwa y compressor faces a steep trade-off: aggressiv e spatial downsampling preser v es lay out but loses texture, whereas semantic pooling preserv es meaning but destro ys spatial structure. T o resolv e this, w e propose a dual-branch compression module (Fig. 2 (b)) that aggregates fine-grained structure (HR branch) and coarse semantics (LR branch). HR Branch: Progressive 3D Convolution. The HR branch operates directly on the V AE latent z ∈ R B × C × T × H × W to preserv e local, fine-grained details. It applies a cascade of strided 3D conv olutions with SiLU activ ations. Specifically , it first perfor ms a 2 × temporal compression, follo w ed by three stages of 2 × spatial compression, and a final 1 × 1 × 1 projection to the model’s hidden dimension d = 1536. This yields a structurally rich representation h HR with a total 128 × v olume reduction (2 × 8 × 8) in the latent space. LR Branch: Pix el-Space Re-encoding. T o capture complementary global context, the LR branch operates via a distinct pixel-space pathwa y . W e decode the latent z back into pixel frames, apply a 3D a v erage pooling (2 × temporally , 4 × spatially), and then re-encode the pooled frames back into the latent space using the frozen V AE encoder , follow ed by standard patch embedding to obtain h LR . This decoding-pooling-encoding pipeline preserv es the perceptual la yout far better than direct pooling in the latent space. F eature F usion. The outputs from both branches share the same dimensional space and are fused via element-wise addition: ˜ h = h HR + h LR ∈ R B × N c × d , (8) where the compressed token count is N c = ⌊ T / 2 ⌋ × ⌊ H / 8 ⌋ × ⌊ W / 8 ⌋ . Giv en that the original patch embedding already performs a 1 × 2 × 2 spatial reduction, our dual-branch module effectiv ely achiev es a net token reduction of ∼ 32 × per block (e.g., from 6 , 240 to 182 tokens). This simple y et effectiv e fusion ensures comprehensiv e infor mation retention under extreme compression. 3.4 Dual-R esolution Shifting and Incremental RoPE adjustment Dual-Resolution Shifting Mechanism. Unlike FIFO methods that permanently discard tokens, w e preserv e long-term memory via a seamless dual-resolution pipeline. During chunk generation, w e concurrently compute a full-resolution KV cache for immediate prediction and a reduced-resolution backup. Once the next chunk is generated, new full-resolution tokens replace the old ones, while the pre-computed compressed tokens smoothly slide into the mid partition. This retains comprehensiv e histor y while hiding compression latency . 6 The P osition Misalignment Problem. Although this dual-track pipeline efficiently populates the compressed mid-buffer , strictly bounding the total memor y capacity ( N mid ) ev entually necessitates evicting the absolute oldest compressed blocks from the mid partition. Our backbone uses 3D Rotary Position Embeddings (RoPE) Su et al. ( 2024 ) with separate temporal, height, and width frequencies θ = [ θ t , θ h , θ w ] , allocated as 44 + 42 + 42 = 128 dimensions per head. When a key is cached, it already carries the rotation for its absolute position p : k ( p ) cached = k ra w ⊙ e i θ p . (9) After evicting ∆ blocks ( δ = ∆ B f frames) to maintain the capacity budget, the sink keys still encode positions 0, . . . , N sink − 1, yet the earliest sur viving mid key no w encodes position N sink + δ . The resulting position gap breaks the positional continuity that the transformer attention relies on. Incremental RoPE adjustment. W e exploit tw o properties to resolv e this without a full recomputation: (i) RoPE adjustments are multiplicative : e i θ p · e i θ δ = e i θ p + δ ; and (ii) eviction shifts only the temporal axis. W e therefore apply a highly efficient, temporal-only RoPE adjustment to the sink keys: k ′ sink = k sink ⊙ e i θ t ( δ ) , 1 h , 1 w , (10) where 1 h , 1 w are identity (unit-magnitude) rotations that lea ve spatial positions unchanged. After adjustment, the sink positions become δ , δ + 1, . . . , seamlessly preceding the mid positions. This operation is applied once per eviction ev ent across all lay ers, costing < 0.1% of total inference time (T able 9 in Appendix). 3.5 Dynamic Conte xt Selection T reating all compressed blocks equally ignores their v arying semantic importance. T o prioritize visually critical keyframes, w e introduce a dynamic context selection mechanism based on query-key affinity . Unlike DeepForcing Y i et al. ( 2025 ), which per manently prunes unselected tokens, w e employ a non-destructiv e soft-selection. W e retriev e only the top- K most relev ant mid-blocks for attention, keeping unselected tokens safely archiv ed for potential future reactiv ation as the scene ev olves. T o ensure negligible o v erhead ( < 1%), affinity scoring occurs only at the first denoising step of each block, caching the indices for subsequent steps. W e further accelerate this by subsampling quer y tokens and using half the attention heads. This soft-routing impro v es subject consistency by +0.8 and the CLIP score b y +0.12 o v er strict FIFO eviction (T able 5 ). 3.6 Empirical Analy sis of T emporal Attention Patterns T o motivate our KV cache design, w e empirically investigate the attention distribution of the denoising netw ork during a 480-frame generation (Fig. 3 ). Our analysis rev eals two critical insights (detailed in the Appendix): (1) Attention demand persists across the entire video history , invalidating naive FIFO eviction strategies; and (2) Highly attended tokens are sparsely and dynamically distributed, exhibiting a high Jaccard distance (0.75) betw een consecutiv e selection steps. These observations fundamentally justify our three-partition cache architecture (sink, mid, and recent). By aggressiv ely compressing the sporadically queried y et globally essential mid-range tokens, we successfully preserve comprehensiv e spatiotemporal context within a strictly bounded memor y footprint. . 4 Experiments 4.1 Experimental Settings Implementation Details. PackForcing emplo ys the W an2.1-T2V -1.3B W an et al. ( 2025 ) backbone to generate 832 × 480 videos at 16 FPS. T ext conditioning relies on the UMT5-XXL encoder , where text key-v alue pairs are computed once and cached globally to reduce ov er head. Consistent with recent causal generativ e framew orks Y in et al. ( 2025 ); Huang et al. ( 2025a ); Liu et al. ( 2025 ); Y i et al. ( 2025 ), the causal student is initialized via ODE trajector y alignment. T raining prompts are sourced from V idProM and augmented via large language models following the S elf-Forcing paradigm. For the cache partitions, w e set N sink = 8, 7 0.0 0.2 0.4 0.6 0.8 1.0 R elative P osition in KV Cache 5 10 15 20 25 V ideo T ime (s) Sink Recent (a) Block Selection Density 0.00 0.02 0.04 0.06 0.08 0.10 0.12 Density 0 20 40 60 80 100 Block Inde x (temporal) 5 8 10 12 15 18 20 22 25 28 V ideo T ime (s) (b) Continuous Importance Scores 0.0 0.2 0.4 0.6 0.8 1.0 Nor m. Importance 0.0 0.2 0.4 0.6 0.8 1.0 R elative P osition (0=earliest, 1=most r ecent) 0.35 0.40 0.45 0.50 0.55 0.60 0.65 0.70 Nor malized Importance Scor e Attention demand persists across ALL positions must retain historical tokens (c) Importance vs History Position (Late generation, frame 200) Mean = 0.499 5 10 15 20 25 30 V ideo T ime (seconds) 0.0 0.2 0.4 0.6 0.8 1.0 Scor e Scattered, changing selection high redundancy in mid-tokens motivates compression (d) Selection Dynamics (High = diverse/changing needs) P osition diversity (window=10) Jaccar d dist (mean=0.75) Attention P attern Analysis: Why W e Need KV Cache Compression for Long-form Causal V ideo Generation Figure 3 Attention patterns in causal video generation. (a) Density map shows attention distributed across the entire histor y . (b) Importance scores ϕ j = ∑ i q ⊤ i k j / √ d rev eal sparse infor mation. (c) Near-flat late-stage importance (mean = 0.499) rules out FIFO eviction. (d) High Jaccard distance (0.75) and position div ersity ( > 0.85) show rapid, div erse block retriev al, motivating compression. N recent = 4, and N top = 16. Chunk-wise generation operates with B f = 4 latent frames per block and S = 4 distilled denoising steps. The model is trained for 3,000 iterations with a batch size of 8 on a 20-latent-frame temporal window ( ˜ 5 seconds). W e use AdamW Loshchilov & Hutter ( 2017 ) ( β 1 = 0, β 2 = 0.999), setting learning rates to 2.0 × 10 − 6 for the generator G θ and 1.0 × 10 − 6 for the fake score estimator s fake , with a 1:5 update ratio. During inference, w e utilize a classifier-fr ee guidance scale of 3.0 and a timestep shift of 5.0. Ev aluation Protocols. T o rigorously assess long video generation perfor mance, w e adopt the ev aluation setting of VBench-Long Huang et al. ( 2025b ). Specifically , w e utilize 128 text prompts sourced from Mo vieGen Polyak et al. ( 2024 ), adhering strictly to the prompt selection protocol established in S elf- Forcing++ Cui et al. ( 2025 ). Consistent with the standard S elf-Forcing Cui et al. ( 2025 ) paradigm, each prompt is refined and expanded using Qw en2.5-7B-Instruct Qwen et al. ( 2025 ) prior to generation. Under this standardized setup, w e generate videos at both 60 s and 120 s durations. W e quantitativ ely ev al- uate the results using sev en core metrics from the VBench framew ork Huang et al. ( 2024 ): Dynamic Degree (Dyn. Deg.), Motion Smoothness (Mot. Smth.), Ov erall Consistency (Ov er . Cons.), Imaging Quality (Img. Qual.), Aesthetic Quality (Aest. Qual.), Subject Consistency (Subj. Cons.), and Background Consistency (Back. Cons.). Further more, to measure the temporal stability of text-video alignment o v er extended durations, w e compute and report CLIP scores at 10-second inter v als throughout the generated sequences. 8 T able 1 Quantitative comparison on 60 s and 120 s benchmarks (7 VBench Huang et al. ( 2024 ) metrics). Best results are highlighted in bold . Method Dyn. Deg. ↑ Mot. Smth. ↑ Ov er . Cons. ↑ Img. Qual. ↑ Aest. Qual. ↑ Subj. Cons. ↑ Back. Cons. ↑ 60 s generation CausV id Y in et al. ( 2025 ) 48.43 98.04 23.36 65.69 60.63 84.53 89.84 LongLiv e Y ang et al. ( 2025 ) 44.53 98.70 25.73 69.06 63.30 92.00 92.97 Self-Forcing Huang et al. ( 2025a ) 35.93 98.26 24.92 66.62 57.15 80.41 86.95 Rolling Forcing Liu et al. ( 2025 ) 33.59 98.70 25.73 71.06 61.43 91.62 93.00 Deep Forcing Y i et al. ( 2025 ) 53.67 98.56 21.75 67.75 58.88 92.55 93.80 PackF orcing (ours) 56.25 98.29 26.07 69.36 62.56 90.49 93.46 120 s generation CausV id Y in et al. ( 2025 ) 50.00 98.11 23.13 65.41 60.11 83.24 87.83 LongLiv e Y ang et al. ( 2025 ) 44.53 98.72 25.95 69.59 63.00 91.54 93.73 Self-Forcing Huang et al. ( 2025a ) 30.46 98.12 23.42 62.49 51.68 74.40 83.57 Rolling Forcing Liu et al. ( 2025 ) 35.15 98.65 25.45 70.58 60.62 90.14 92.40 Deep Forcing Y i et al. ( 2025 ) 52.84 98.22 21.38 68.21 57.96 91.95 92.55 PackF orcing (ours) 54.12 98.35 26.05 69.67 61.98 92.84 91.88 4.2 Main R esults Quantitative Comparison. T able 1 ev aluates 60 s and 120 s video generation across sev en VBench metrics. PackForcing excels in motion synthesis, achieving the highest Dynamic Degree at both durations (56.25 and 54.12) and outperfor ming the strongest baseline, CausV id, by +7.82 and +4.12. This confirms that our persistent memor y mechanism provides reliable temporal grounding, enabling the model to confidently synthesize extensiv e motion. Furthermore, PackForcing demonstrates superior stability ov er extended horizons. While baselines like S elf-Forcing degrade significantly from 60 s to 120 s (e.g., Subject Consistency drops by 6.01, Aesthetic Quality b y 5.47), our performance declines are marginal (-1.01 and -0.49, respec- tiv ely). This robustness highlights the effectiv eness of sink tokens in anchoring global semantics and the dynamically routed mid-buffer in preser ving inter mediate context. Finally , despite an aggressiv e ∼ 32 × token reduction, PackForcing maintains highly competitive Image and Aesthetic Quality , pro ving that our dual-branch architecture successfully retains perceptually critical spatiotemporal details. L ong-Range Consistency . T able 2 evaluates the temporal stability of text-video alignment via CLIP scores at 10-second intervals. PackForcing maintains the highest alignment throughout the 60-second generation, with a marginal decline of only 1.14 points (from 34.04 to 32.90). Conv ersely , baselines suffer from compounding errors: Self-Forcing exhibits a sev ere 6.77-point drop, while CausV id declines by 1.86 points. This sustained temporal coherence directly validates our sink token mechanism’s ability to anchor global semantics across extended horizons. T able 2 CLIP Score comparison on long video generation (60s). Method 0–10 s 10–20 s 20–30 s 30–40 s 40–50 s 50–60 s Overall CausV id Y in et al. ( 2025 ) 32.65 31.78 31.47 31.13 30.81 30.79 31.44 LongLiv e Y ang et al. ( 2025 ) 33.95 33.38 33.14 33.51 33.45 33.36 33.46 Self-Forcing Huang et al. ( 2025a ) 33.89 33.23 31.66 29.99 28.37 27.12 30.71 Rolling Forcing Liu et al. ( 2025 ) 33.85 33.39 32.94 32.78 32.49 32.25 32.95 Deep Forcing Y i et al. ( 2025 ) 33.47 33.29 32.38 32.28 32.26 32.27 32.33 PackF orcing (ours) 34.04 33.99 33.70 33.37 33.24 32.90 33.54 Qualitative Comparison. Fig. 4 presents sampled frames from a 120-second generation for all methods under 9 Self Forci ng Roll ing Forci ng C ausV id LongLive Pack Forcing Promp t : A 3 D a n i ma tion of a small , rou n d , f l u f f y crea t u re w ith b i g , e x p re ssive e ye s e x p l oring a vi b ra n t, e n ch a n t e d f or e s t . The cre a t u re, a w h imsic a l b l e n d of a r a b b it and a s q u irr e l, has sof t b lue fur and a b u sh y , s t ripe d t a il . It h op s a lon g a sp a rkling s t rea m, it s e ye s wid e with wonder … t=0s t=20s t=40s t=60s t=80s t=100s t= 12 0s Deep Forci ng Figure 4 Qualitative comparison of 120 s generation. Sampled frames across sev en timestamps under the same prompt. PackForcing consistently maintains strict subject identity and high visual fidelity throughout the entire sequence. In contrast, baseline methods suffer from progressiv e degradation ov er time: S elf-Forcing exhibits color shifts by 60 s and ev entual collapse, CausV id loses background details, and LongLive generates sev erely restricted motion. Further more, Rolling-Forcing struggles with significant subject inconsistencies, while DeepForcing loses the main subject at 100s. the same text prompt. At 0 s all methods produce comparable quality . By 60 s, S elf-Forcing exhibits visible color shift and object duplication; CausV id loses fine details in the background. At 120 s, only PackForcing and LongLiv e maintain coherent subjects, but LongLive shows noticeably less camera and subject motion. PackForcing preser v es both subject identity and dynamic motion throughout the full tw o minutes, thanks to the persistent sink tokens and compressed history . 4.3 Ablation S tudies W e perfor m systematic ablations on the 60 s benchmark to ev aluate each critical component of PackForcing. Qualitativ e comparisons are shown in Fig. 5 . T able 3 Quantitative ablation results of sink size. W e consolidate ov erall CLIP scores and VBench metrics across varying sink sizes. Setting N sink = 8 achiev es the optimal balance betw een dynamic motion and semantic consistency . Sink Size Ov erall CLIP x Dyn. Deg. x Mot. Smth. x Ov er . Cons. x Img. Qual. x Aest. Qual. x Subj. Cons. x Back. Cons. x 0 31.24 20.31 98.89 23.11 72.87 59.37 74.72 86.37 2 34.85 49.69 98.57 26.78 72.59 65.85 91.37 93.68 4 34.85 50.16 98.57 26.99 72.59 65.84 91.37 93.73 8 35.09 49.84 98.68 26.29 73.18 66.46 93.11 94.53 16 35.39 35.16 98.82 26.71 73.05 66.34 93.84 94.92 Effect of Sink T ok ens. T o ev aluate the impact of sink size ( N sink ) on long-term stability , we conduct an ablation study on 60 randomly selected samples (T able 3 ). Remo ving attention sinks entirely ( N sink = 0) causes sev ere semantic drift, evidenced b y sharp drops in the Ov erall CLIP score (35.09 to 31.24) and Subject Consistency (93.11 to 74.72), confir ming their role as critical global anchors (Fig. 5 ). Conv ersely , an excessively large sink ( N sink = 16) maximizes consistency but stifles motion, plummeting the Dynamic 10 w/o Sink T oke ns w/o RoPE Adjus tm ent PackForcing (F ull) w/o Conte xt Selection Pr om p t : A 3 D a nima t i on of a sm all , rou n d, f l uff y cre at ure wit h big, e x pre ss i ve e y e s e x plori ng a vibr an t , e ncha n t e d f ore s t . The cr e ature , a wh i msi c al ble nd of a ra b bit and a s q uir re l , has sof t blue f ur and a bu sh y , s t ri ped t ail . It ho p s alon g a spa rkli ng s t re am , its e y e s wide wit h won der … t=0s t=10s t=20s t=30s t=40s t=50s t=60s R ese t t o or i gi n R ese t t o or i gi n Figure 5 Qualitative ablation results on 60 s generation. Remo ving sink tokens leads to progressiv e semantic drift, whereas disabling either the RoPE adjustment or dynamic context selection introduces sev ere frame reset artifacts. T able 4 Ablation on compress. branches. Branch Img. Qual. x Ov er . Cons. x CLIP x 60 s HR only 68.12 25.41 32.97 ✓ LR only 67.45 25.18 33.11 ✓ HR + LR 69.36 26.07 33.54 ✓ T able 5 Ablation on eviction strategy . Strategy Subj. Cons. x Ov er . Cons. x CLIP x Random 86.31 25.42 33.01 FIFO 87.82 25.91 33.42 Dynamic Select 88.62 26.07 33.54 Degree to 35.16 as the model ov er-conditions on static early frames. S etting N sink = 8 achiev es the optimal balance. It preserv es dynamic richness (49.84) and yields the best Image (73.18) and Aesthetic (66.46) Quality , with Subject Consistency within 1% of the N sink = 16 setting—all while consuming strictly bounded memor y ( < 2% of the total token budget). T emporal CLIP details can be found in the Appendix. Effect of Compression Branches. T able 4 isolates each compression branch, ev aluated at 60 s where all variants fit in memory . The HR branch alone provides strong spatial compression but misses coarse semantic cues; the LR branch alone preser v es semantics but lacks spatial precision. FIF O vs. Dynamic Context Selection. T able 5 compares memor y management strategies within the compressed mid-buffer . Dynamic context selection outperforms standard FIFO, yielding notable improv ements in Subject Consistency (+0.8) and the ov erall CLIP score (+0.12). This advantage stems from its affinity-driv en approach, which prioritizes the retention of highly attended historical blocks rather than relying on a rigid chronological eviction. 4.4 Discussion Generalization from Short- Video Supervision. The remarkable 24 × temporal extrapolation capability of PackForcing (from 5 s training clips to 120 s generated videos) can be attributed to two primar y mechanisms. First, the framew ork enforces context size invariance. By systematically compressing and managing the KV cache, the attention context remains strictly bounded (e.g., ∼ 27 , 872 tokens) during both training and inference. This effectiv ely pre v ents out-of-distribution sequence length shifts that typically trigger error accumulation in standard autoregressiv e models. S econd, the architecture ensures representational compatibility. Jointly training the dual-branch compression lay er aligns the compressed tokens with the full-resolution tokens within the same latent subspace, enabling the transfor mer to seamlessly attend to the highly compressed historical features. Motion Richness and Dynamic Degree . As indicated b y the VBench ev aluations, PackForcing consistently achiev es superior dynamic degree scores. Existing autoregressiv e baselines, which often lack persistent long-range memory , tend to degenerate into producing low-v ariance, near-static frames as a conser v ativ e 11 strategy to av oid compounding temporal errors. In contrast, by preser ving the global lay out through sink tokens and the intermediate motion trajectory through the compressed mid-buffer , our framew ork provides a reliable, uninterrupted spatiotemporal reference. This comprehensive contextual grounding encourages the model to confidently synthesize complex, continuous motion without collapsing into static artifacts. Limitations and F uture Work. While PackForcing excels in generating dynamic content, w e obser v e a nuanced trade-off. Baselines such as LongLiv e achiev e marginally higher Subject Consistency (92.00 v ersus our 90.49) at the sev ere expense of motion richness, yielding a Dynamic Degree of only 44.53 compared to our 56.25. Closing this consistency gap b y further enhancing strict subject preser v ation without compromising the high dynamic div ersity enabled by our compressed history remains a primary direction for future work. 5 Conclusion In this paper , w e introduce PackF orcing , a unified framew ork that fundamentally resolv es the dual bot- tlenecks of error accumulation and unbounded memor y growth in autoregressiv e video generation. By strategically partitioning the KV cache into sink , compressed mid , and recent tokens, our approach strictly bounds the memory footprint to ∼ 4 GB and ensures constant-time attention complexity without discarding essential historical context. Empow ered b y a 128 × dual-branch compression module ( ∼ 32 × token reduc- tion), incremental RoPE adjustments, and dynamic context selection, PackForcing achiev es a remarkable 24 × temporal extrapolation (5 s → 120 s). This demonstrates that short-video supervision is entirely sufficient for high-quality , long-video synthesis. Ultimately , it generates highly coherent 2-minute videos, establishing state-of-the-art VBench scores and the most robust text-video alignment among existing baselines, pa ving the w a y for efficient, unbounded video generation on standard hardw are. R eferences Andreas Blattmann, Robin Rombach, Huan Ling, T im Dockhor n, Seung W ook Kim, Sanja Fidler , and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 22563–22575, 2023. T im Brooks, Bill Peebles, Connor Holmes, W ill DePue, Y ufei Guo, Li Jing, Da v id Schnurr , Joe T a ylor , T ro y Luh- man, Eric Luhman, Clarence Ng, Ricky W ang, and Aditya Ramesh. V ideo generation models as w orld sim- ulators. 2024. URL https://openai.com/research/video- generation- models- as- world- simulators . Duy gu Ceylan, Chun-Hao P Huang, and Niloy J Mitra. Pix2video: V ideo editing using image diffusion. In Proceedings of the IEEE/CVF international conference on computer vision , pp. 23206–23217, 2023. Bo yuan Chen, Diego Martí Monsó, Y ilun Du, Max Simcho witz, Russ T edrake, and V incent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. Advances in Neural Information Processing Systems , 37:24081–24125, 2024a. Haoxin Chen, Y ong Zhang, Xiaodong Cun, Menghan Xia, Xintao W ang, Chao W eng, and Y ing Shan. V ideocrafter2: Over coming data limitations for high-quality video diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 7310–7320, 2024b. Junsong Chen, Y uyang Zhao, Jincheng Y u, Ruihang Chu, Junyu Chen, Shuai Y ang, Xianbang W ang, Y icheng Pan, Daquan Zhou, Huan Ling, et al. Sana-video: Efficient video generation with block linear diffusion transformer . arXiv preprint , 2025. Justin Cui, Jie W u, Ming Li, T ao Y ang, Xiaojie Li, Rui W ang, Andrew Bai, Y uanhao Ban, and Cho-Jui Hsieh. Self-forcing++: T o w ards minute-scale high-quality video generation. arXiv preprint , 2025. Songwei Ge, S eung jun Nah, Guilin Liu, T yler Poon, Andrew T ao, Br yan Catanzaro, Da vid Jacobs, Jia-Bin Huang, Ming-Y u Liu, and Y ogesh Balaji. Preser v e y our own correlation: A noise prior for video diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer V ision , pp. 22930–22941, 2023. W illiam Har v ey , Saeid Naderiparizi, V aden Masrani, Christian W eilbach, and Frank W ood. Flexible diffusion modeling of long videos. Advances in neural information processing systems , 35:27953–27965, 2022. 12 Hao He, Y inghao Xu, Y uw ei Guo, Gordon W etzstein, Bo Dai, Hongsheng Li, and Ceyuan Y ang. CameraCtrl: Enabling camera control for text-to-video generation, 2024. Hao He, Ceyuan Y ang, Shanchuan Lin, Y inghao Xu, Meng W ei, Liangke Gui, Qi Zhao, Gordon W etzstein, Lu Jiang, and Hongsheng Li. Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer V ision , pp. 13416– 13426, 2025. Roberto Henschel, Lev on Khachatryan, Ha yk Poghosyan, Daniil Hayrapety an, V ahram T adev osy an, Zhangyang W ang, Shant Nav asardyan, and Humphrey Shi. Streamingt2v: Consistent, dynamic, and extendable long video generation from text. In Proceedings of the Computer V ision and Pattern Recognition Conference , pp. 2568–2577, 2025. Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems , 33:6840–6851, 2020. Jonathan Ho, T im Salimans, Alexey Gritsenko, W illiam Chan, Mohammad Norouzi, and Da vid J Fleet. V ideo diffusion models. Advances in neural information processing systems , 35:8633–8646, 2022. Susung Hong, Junyoung S eo, Heeseong Shin, Sunghw an Hong, and S eungr y ong Kim. Large language models are frame-lev el directors for zero-shot text-to-video generation. In First Workshop on Controllable V ideo Generation@ ICML24 , 2023. Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. S elf forcing: Bridging the train-test gap in autoregressiv e video diffusion. arXiv preprint , 2025a. Ziqi Huang, Y inan He, Jiashuo Y u, Fan Zhang, Chenyang Si, Y uming Jiang, Y uanhan Zhang, T ianxing W u, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Compr ehensiv e benchmark suite for video generativ e models. In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition , pp. 21807–21818, 2024. Ziqi Huang, Fan Zhang, Xiaojie Xu, Y inan He, Jiashuo Y u, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Y uming Jiang, et al. Vbench++: Comprehensiv e and versatile benchmark suite for video generativ e models. IEEE T ransactions on Pattern Analysis and Machine Intelligence , 2025b. Y aron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flo w matching for generativ e modeling. arXiv preprint , 2022. Kunhao Liu, W enbo Hu, Jiale Xu, Y ing Shan, and Shijian Lu. Rolling forcing: Autoregr essiv e long video diffusion in real time. arXiv preprint , 2025. Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow . arXiv preprint , 2022. Ilya Loshchilov and Frank Hutter . Decoupled w eight deca y regularization. arXiv preprint , 2017. W illiam Peebles and Saining Xie. Scalable diffusion models with transfor mers. In Proceedings of the IEEE/CVF international conference on computer vision , pp. 4195–4205, 2023. Bo w en Peng, Jeffre y Quesnelle, Honglu Fan, and Enrico Shippole. Y ar n: Efficient context window extension of large language models. arXiv preprint , 2023. Adam Polyak, Amit Zohar , Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv V yas, Bow en Shi, Chih-Y ao Ma, Ching-Y ao Chuang, et al. Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720 , 2024. Haonan Qiu, Menghan Xia, Y ong Zhang, Y ingqing He, Xintao W ang, Y ing Shan, and Ziwei Liu. Freenoise: T uning-free longer video diffusion via noise rescheduling. arXiv preprint , 2023. Qw en, :, An Y ang, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bo w en Y u, Chengyuan Li, Da yiheng Liu, Fei Huang, Haoran W ei, Huan Lin, Jian Y ang, Jianhong T u, Jianwei Zhang, Jianxin Y ang, Jiaxi Y ang, Jingren Zhou, Juny ang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Y ang, Le Y u, Mei Li, 13 Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, T ianhao Li, T ianyi T ang, T ingyu Xia, Xingzhang Ren, Xuancheng Ren, Y ang Fan, Y ang Su, Y ichang Zhang, Y u W an, Y uqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. Qw en2.5 technical report, 2025. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser , and Björ n Ommer . High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 10684–10695, 2022. Uriel Singer , Adam Poly ak, Thomas Ha y es, Xi Y in, Jie An, S ongyang Zhang, Qiyuan Hu, Harr y Y ang, Oron Ashual, Oran Gafni, et al. Make-a-video: T ext-to-video generation without text-video data. arXiv preprint arXiv:2209.14792 , 2022. Jianlin Su, Murtadha Ahmed, Y u Lu, Shengfeng Pan, W en Bo, and Y unfeng Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing , 568:127063, 2024. Dani V alevski, Y aniv Leviathan, Moab Arar , and Shlomi Fruchter . Diffusion models are real-time game engines. arXiv preprint , 2024. T eam W an, Ang W ang, Baole Ai, Bin W en, Chaojie Mao, Chen-W ei Xie, Di Chen, Feiwu Y u, Haiming Zhao, Jianxiao Y ang, et al. W an: Open and advanced large-scale video generativ e models. arXiv preprint arXiv:2503.20314 , 2025. Zhouxia W ang, Ziy ang Y uan, Xintao W ang, Y ao w ei Li, T ianshui Chen, Menghan Xia, Ping Luo, and Y ing Shan. Motionctrl: A unified and flexible motion controller for video generation. In ACM SIGGRAPH 2024 Conference Papers , pp. 1–11, 2024. Guangxuan Xiao, Y uandong T ian, Beidi Chen, Song Han, and Mike Lewis. Ef ficient streaming language models with attention sinks. arXiv preprint , 2023. Shuai Y ang, W ei Huang, Ruihang Chu, Y icheng Xiao, Y uyang Zhao, Xianbang W ang, Muyang Li, Enze Xie, Y ingcong Chen, Y ao Lu, et al. Longliv e: Real-time interactiv e long video generation. arXiv preprint arXiv:2509.22622 , 2025. Zhuo yi Y ang, Jia yan T eng, W endi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Y uanming Y ang, W enyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: T ext-to-video diffusion models with an expert transformer . arXiv preprint , 2024. Jung Y i, W ooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Y oon, and S eungryong Kim. Deep forc- ing: T raining-free long video generation with deep sink and participativ e compression. arXiv preprint arXiv:2512.05081 , 2025. T ianwei Y in, Qiang Zhang, Richard Zhang, W illiam T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slo w bidirectional to fast autoregressiv e video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition , pp. 22963–22974, 2025. Zhenyu Zhang, Y ing Sheng, T ianyi Zhou, T ianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao S ong, Y uandong T ian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generativ e inference of large language models. Advances in Neural Information Processing Systems , 36:34661–34710, 2023. Zangw ei Zheng, Xiangyu Peng, T ianji Y ang, Chenhui Shen, Shenggui Li, Hongxin Liu, Y ukun Zhou, T ianyi Li, and Y ang Y ou. Open-sora: Democratizing efficient video pr oduction for all. arXiv preprint arXiv:2412.20404 , 2024. 14 Appendix Contents A Extended Discussion on Limitations 16 B Design Comparison of Causal V ideo Generation Methods 16 C T raining Strategy 16 D Streaming V AE Decode 16 E Additional Exper imental Results 17 E.1 Detailed T emporal CLIP S cores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 F Inference Algorithm 17 G Detailed Mechanism of Dynamic Context Selection 17 H Further Analysis 18 H.1 Empirical Analysis of T emporal Attention Patterns . . . . . . . . . . . . . . . . . . . . . . . . 18 H.2 Effect of RoPE Adjustment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 H.3 Computational Efficiency Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 I More Qualitativ e Results 20 15 A Extended Discussion on Limitations S ev eral directions remain open: (i) the fixed compression ratio (128 × v olume / ∼ 32 × token) could be made adaptive to scene complexity; (ii) attention-based importance scoring ma y not capture all aspects of visual saliency—learned importance predictors could help; (iii) scaling to higher resolutions (e.g., 1920 × 1080) requires inv estigating the interaction betw een spatial compression and quality . W e believ e the three-partition principle is general and can be applied to other autoregressiv e domains bey ond video. B Design Comparison of Causal Video Generation Methods T able 6 Design comparison of causal video generation methods. PackForcing uniquely integrates learned compression, bounded memory , and RoPE adjustment to ensure persistent long-range memor y during extended generation. Method KV Compress Bounded Memory RoPE Adjustment Long-range Memory CausV id Y in et al. ( 2025 ) ✗ ✗ — ✗ Self-Forcing Huang et al. ( 2025a ) ✗ ✗ — ✗ Rolling-F . Liu et al. ( 2025 ) ✗ ✓ ✓ ✗ LongLiv e Y ang et al. ( 2025 ) ✗ ✓ N/A partial DeepForcing Y i et al. ( 2025 ) ✗ ✓ ✓ partial PackF orcing (Ours) ✓ ✓ ✓ ✓ C T raining S trategy Our training procedure closely follows the two-phase S elf-forcing paradigm Huang et al. ( 2025a ). First, the causal student model G θ is initialized from a pretrained bidirectional prior (e.g., W an2.1-T2V -1.3B W an et al. ( 2025 )) via ODE trajectory alignment. S econd, the student perfor ms block-wise rollout and is optimized via score distillation against a frozen bidirectional teacher . Since the o v erarching loss for mulation and gradient normalization techniques remain identical to standard self-forcing, we omit the standard score-matching equations for brevity . The critical distinction in our training pipeline is the end-to-end optimization of the HR compression la y er (Sec. 3.3 ). During the rollout phase, the compression module is integrated directly into the computational graph. This joint optimization ensures that the compressed mid tokens are explicitly tailored to preserv e essential semantic and structural cues for do wnstream causal attention, rather than merely minimizing a generic pixel-lev el reconstruction loss. Short-to-L ong Generalization. T raining uses only 20 latent frames ( ∼ 5 s after 4 × V AE temporal decompres- sion), y et the model generalizes to 2-minute generation—a 24 × temporal extrapolation. This transfer is enabled by the three-partition design: the attention context seen by each transfor mer la y er is bounded at ∼ 27 , 872 tokens during both training and inference , since compression maintains a constant-size window regardless of the actual video length. The model therefore nev er encounters a context distribution it was not trained on. D S treaming V AE Decode T o reduce latency , PackForcing supports streaming V AE decoding: each block is decoded incrementally as it is generated rather than accumulated for joint decoding. The V AE decoder maintains a temporal cache to ensure seamless frame boundaries—the first block produces 13 pixel frames (due to the initial receptiv e field), while subsequent blocks produce 16 each via cache-assisted decoding. This reduces the time-to-first-frame and enables progressiv e displa y . 16 E A dditional Experimental Results E.1 Detailed T emporal CLIP Scores In T able 7 , w e pro vide the fine-grained, temporal breakdown of the CLIP scores ov er 20-second intervals for different sink sizes. Consistent with the main text, N sink = 0 exhibits a continuous degradation ov er time (dropping to 28.51 b y 120 s), while N sink ≥ 8 successfully maintains a stable score trajectory throughout the entire minute-scale generation. T able 7 Detailed temporal CLIP Score breakdo wn. Ev aluated across 20-second intervals for different sink sizes. N sink ≥ 8 demonstrates robust prev ention of temporal degradation. Sink Size 0–20s 20–40s 40–60s 60–80s 80–100s 100–120s Ov erall 0 34.72 33.24 31.51 30.44 29.01 28.51 31.24 2 35.32 35.45 34.64 34.24 34.63 34.80 34.85 4 35.33 35.45 34.64 34.24 34.63 34.79 34.85 8 35.59 35.16 35.04 35.14 34.81 34.81 35.09 16 35.54 35.34 35.21 35.42 35.40 35.46 35.39 F Inference Algorithm Algorithm 1 summarizes the complete PackForcing inference procedure. The key operations inv olve: (1) block-wise causal generation with multi-step denoising, (2) KV cache updates after each block, (3) periodic dual-branch compression of mid-range frames, and (4) incremental RoPE adjustment for capacity management coupled with streaming V AE decoding for immediate frame output. G Detailed Mechanism of Dynamic Context Selection In this section, w e pro vide the detailed for mulation and engineering optimizations of the Dynamic Context S election introduced in S ec. 3.5 . Our goal is to dynamically identify the top- K most informativ e compressed mid-blocks without introducing noticeable latency to the autoregressiv e generation pipeline. Giv en the recent and current blocks acting as queries Q ∈ R B × L q × N h × d h , and the candidate mid-blocks acting as keys K ∈ R M × B × L k × N h × d h (where M is the number of candidate blocks), w e compute an aggregated importance score s m for each candidate block m ∈ { 1, . . . , M } . T o minimize the computational o v erhead of the dot-product attention, w e introduce three structural optimizations: (1) Deterministic Query Subsampling: W e unifor mly sample a subset of quer y tokens S q from the L q sequence using a target sampling ratio γ (e.g., yielding max ( 32, ⌊ γ L q ⌋ ) tokens), preserving the spatial-temporal distribution without evaluating the full grid. (2) Half-Head Evaluation: Since importance is highly correlated across attention heads, w e compute the affinity using only the first N o pt = N h / 2 heads. (3) Step-wise Caching: The affinity distribution shifts minimally within the internal denoising loop of a single generated chunk. Therefore, w e strictly compute s m only at the first denoising timestep t = T , caching the sorted indices for all subsequent t < T . Furthermore, an optional inter v al hyperparameter allows reusing the same indices across multiple adjacent video blocks. Formally , the importance score s m for block m is defined as the a v eraged multi-head affinity o v er the batch and selected heads, summed across the subsampled queries and full block keys: s m = L k ∑ j = 1 ∑ i ∈ S q 1 B · N o pt B ∑ b = 1 N o pt ∑ h = 1 Q b , h , i K ⊤ m , b , h , j √ d h ! (11) Once s m is computed for all M candidates, w e select the indices of the top- K scores. T o maintain the causal temporal structure essential for the Rotary Position Embedding (RoPE) and temporal consistency , 17 Algorithm 1: PackForcing Inference Input: Noise ϵ , text prompt c , initial frames z 0 Output: Generated video frames V 1 Initialize KV cache C = { C sink , C mid , C recent } ; 2 Cache initial frames into C sink ; 3 t gen ← N sink ; 4 for each block i = 1, . . . , N blocks do 5 z i ← ϵ i ; // Initialize from noise 6 for s = 1, . . . , S do ; // S = 4 denoising steps 7 if s = 1 then 8 S mid ← Affinity_Routing ( C mid , z i , N top ) ; // Dynamic context selection 9 C activ e ← { C sink , C mid [ S mid ] , C recent } ; // Sparse attention context 10 v ← f θ ( z i , σ s , c , C activ e ) ; // Attend to active partitions 11 ˆ z i ← z i − σ s · v ; 12 z i ← ( 1 − σ s + 1 ) ˆ z i + σ s + 1 ϵ ′ ; 13 Update C recent with denoised z i ; 14 V i ← Streaming_V AE_Decode ( z i ) ; // Decode incrementally 15 if t gen ≥ N sink + N mid + N rc then ; // Context window is full 16 ˜ h ← HR ( z i − 1 ) + LR ( V i − 1 ) ; // LR uses streaming decoded output 17 Append compressed tokens to C mid ; 18 if | C mid | > N mid then 19 Shift C mid windo w b y ∆ blocks ; // Maintain capacity budget 20 Apply incremental RoPE adjustment (Eq. 10 ) to C sink ; 21 t gen ← t gen + B f ; 22 return Concatenated frames V the selected indices are sorted in ascending order before retrieving the corresponding Key-V alue tensors from the mid-buffer . The selected compact KV caches are then concatenated with the recent blocks for the standard flash-attention for w ard pass. H F urther Analy sis H.1 Empirical Analy sis of T emporal Attention Patterns A central question in designing KV cache compression for causal video generation is: which historical tokens does the denoising network actually attend to? If attention w ere concentrated on a small, predictable subset of the histor y—sa y , only the initial frames and the most recent context—a simple sliding-window or FIFO eviction policy w ould suffice. How ev er , our empirical analysis rev eals a fundamentally differ ent picture. Setup. W e generate a 30-second video (480 latent frames, decoded at 16 fps) using our causal inference pipeline with participatory compression enabled (sink size = 8, budget = 16 mid-blocks, block size = 4 frames). At each compression step, w e record the per-block importance score ϕ j = ∑ i q ⊤ i k j / √ d , where queries q i are drawn from the recent and current blocks and keys k j from each candidate mid-block. W e also record which blocks are selected (top- k b y importance) for retention. Results are visualized in figure 3 . Observation 1: Attention demand spans the full history. figure 3 (a) shows the block selection density as a function of relativ e position in the KV cache. If only sink and recent tokens mattered, we w ould observe activity exclusively at the left ( position ≈ 0) and right ( position ≈ 1) edges. Instead, selected blocks are distributed across the entire temporal range, with persistent demand in the mid-range (0.2–0.8). This is further confirmed b y figure 3 (c), where the av erage importance score is plotted against relativ e position 18 T able 8 Ablation on RoPE Corr . RoPE Corr . CLIP (0–20 s) ↑ CLIP (40–60 s) ↑ ∆ ↓ ✗ 33.95 31.42 2.53 ✓ 34.02 33.07 0.95 T able 9 Memory and speed for 120 s generation (832 × 480, 16 FPS, single A100-80GB). Method KV Cache Peak GPU Speed Full cache ∼ 138 GB OOM — W indow-only 3.1 GB 24 GB 18 FPS PackForcing (FIFO) 4.0 GB 26 GB 16 FPS PackForcing (Part.) 4.2 GB 27 GB 15 FPS for late-stage generation (frame ≥ 200). The cur v e is remarkably flat with a mean of 0.499, indicating near-uniform attention demand o v er all historical positions. This observation rules out FIFO-based eviction, which w ould systematically discard early tokens that remain equally relev ant. Observation 2: Important tokens are sparsely and unpredictably distributed. figure 3 (b) displays the continuous importance scores for each candidate block across the generation process. High-importance blocks (bright spots) appear at scattered, non-contiguous positions rather than forming coherent temporal clusters. Moreo v er , figure 3 (d) quantifies the selection dynamics: the Jac card distance betw een consecutiv e selection sets a v erages 0.75, meaning 75% of the retained blocks change at ev ery step. The position div ersity metric— the fraction of distinct cache positions visited within a sliding windo w of 10 steps—stabilizes abov e 0.85, confirming that the model rapidly cy cles through diverse temporal locations. Implications for compression design. These tw o observations jointly motivate our compression strategy . First, since attention demand persists across all historical positions, w e must retain a representativ e summar y of the entire past rather than only recent context—hence the three-region cache structure (sink + mid + recent). Second, since individual mid-range tokens are each only sporadically needed while the aggregate demand co v ers the full histor y , there is high temporal redundancy among mid-tokens. This makes them ideal candidates for aggressiv e compression: a compact representation can preser v e the distributed infor mation without retaining ev er y individual token. Our dual-shift compression network exploits this redundancy by compressing mid-range KV blocks at a high ratio, achieving constant memory usage regardless of video length while maintaining generation quality . H.2 Effect of R oPE Adjustment. T able 8 isolates the impact of incremental RoPE rotation. W ithout Adjustment, the CLIP gap between early (0–20 s) and late (40–60 s) segments is 2.53—indicating progressiv e semantic drift after FIFO eviction begins around the 20 s mark. W ith Adjustment, the gap shrinks to 0.95 (a 62% reduction), confirming that position continuity is essential for stable long-horizon generation. The cost is negligible: one complex multiplication per eviction ev ent, amounting to < 0.1% of total FLOPs. H.3 Computational Efficiency Analy sis T able 9 compares memory footprint and speed for 120 s generation. W ithout compression, the KV cache alone requires ∼ 138 GB (748 , 800 × 30 × 2 × 12 × 128 × 2 bytes), exceeding single-GPU capacity . PackForcing bounds KV cache memory to ∼ 4.2 GB regardless of video length, while maintaining competitive speed through the reduced attention context. 19 Self Forcing Roll ing Forci ng C ausV id LongLive Pack Forcing Promp t : A ch a rmin g 3 D d i g it a l re n d e r a rt s tyl e imag e s ho wc a si n g an a d or a b l e and h a p p y ot t e r c on f i d e n tl y s t a n d i n g on a s u r f b o a r d , w e a ri n g a b ri g h t y e l lo w li f e j a ck e t . Th e ot t e r is d e p icte d with a jo y fu l e xp ressio n , it s fur sof t and d e t a iled , and it a p p e a rs to g lide g rac e fu lly t hroug h t u rqu oise t rop ic a l wa t e rs … t=0s t=20s t=40s t=60s t=80s t=100s t=120s Deep Forci ng Figure 6 Qualitativ e Results (1) In this section, we present extended 120-second qualitativ e comparisons to further demonstrate the robust long-range consistency and dynamic generation capabilities of PackForcing against state-of-the-art baselines. I More Qualitativ e Results Analysis for Figure 1: Figure 6 illustrates the generation of a highly dynamic scene featuring an "adorable and happ y otter confidently standing on a surfboard". PackForcing successfully maintains strict subject identity , preser ving fine details such as the "bright yello w lifejacket" and the "turquoise tropical waters" seamlessly across the entire tw o-minute duration. In stark contrast, baseline methods struggle with error accumulation o v er the extended horizon: Self-Forcing exhibits sev ere color degradation and visual collapse b y t = 60 s , while CausV id and Rolling Forcing suffer from noticeable background blurring and subject inconsistency , respectiv ely . Analysis for Figure 2: Figure 7 ev aluates the models’ ability to maintain complex structural boundaries and intricate details, specifically a "glass sphere containing a tranquil Zen garden" and a dwarf holding a "bamboo rake". PackForcing consistently preserves the transparent properties of the glass sphere and the precise identity of the dw arf throughout the 120-second sequence. Baselines fail to sustain this coherence: Self-Forcing completely collapses into dark purple artifacts early in the generation, and DeepForcing gradually loses the structural integrity of the rake and the sphere. While LongLive maintains the subject, it does so at the cost of freezing the motion, whereas our method sustains continuous, deliberate raking mo v ements. Analysis for Figure 3: Figure 8 tests the generation of vibrant, stylized content with complex, continuous motion—a "kangaroo performing a liv ely disco dance" in a "colorful sequined outfit". PackForcing excels in preserving both the high-frequency visual details (the sparkles and vibrant colors) and the highly dynamic rhythmic motion o v er the extended timeframe. Competing methods typically face a trade-off, either collapsing under the complexity of the prolonged motion or rev erting to near-static frames to a v oid drift. PackForcing’s three-partition memory efficiently prev ents these artifacts, ensuring the character remains energetic and visually consistent. 20 Self Forcing Roll ing Forci ng C ausV id LongLive Pack Forcing Promp t : A clos e - up vie w of a g l a ss sph e re c on t a i n in g a tr a n quil Z e n g a rden . I n si d e , a sm a ll E a s t e r n d w a r f w ith w e a t h e re d s ki n and a s e r e n e e x p r e ssion is r a ki n g t h e s a n d , m e ti cu lo u s ly cr e a t ing in t ric a t e pa t t e rns with a b a mbo o rak e . Hi s mo ve men t s a re d e libe rat e and med it a t ive, e n h a n cin g t h e p e a c e fu l a t mosp h e re of t h e sc e n e … t= 0 s t= 20 s t=40s t= 60 s t= 80 s t= 100 s t= 120 s Deep Forci ng Figure 7 Qualitativ e Results (2) Self Forcing Roll ing Forci ng C ausV id LongLive Pack Forcing Promp t : A vi b ra n t c a rt oo n - s t yl e il lu s tr a tio n d e p ict in g a k a n g a roo p e r f ormin g a live l y d is c o danc e . T h e k a n g a roo h a s a jo y f u l e x p r e ss io n , w it h l a r g e , e x p r e ssiv e e y e s and a misch i e v ou s g rin . It we a rs a c olorfu l se q u ined ou t fit with sp a rkles, includ ing a g lit t e r y t op and mat chin g p a n t s . Its t a il is flu ff e d ou t and s wa yin g rh y t hmic ally … t=0s t=20s t=40s t= 60 s t=80s t= 100 s t= 120 s Deep Forci ng Figure 8 Qualitativ e Results (3) 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment