Natural-Language Agent Harnesses
Agent performance increasingly depends on \emph{harness engineering}, yet harness design is usually buried in controller code and runtime-specific conventions, making it hard to transfer, compare, and study as a scientific object. We ask whether the …
Authors: Linyue Pan, Lexiao Zou, Shuo Guo
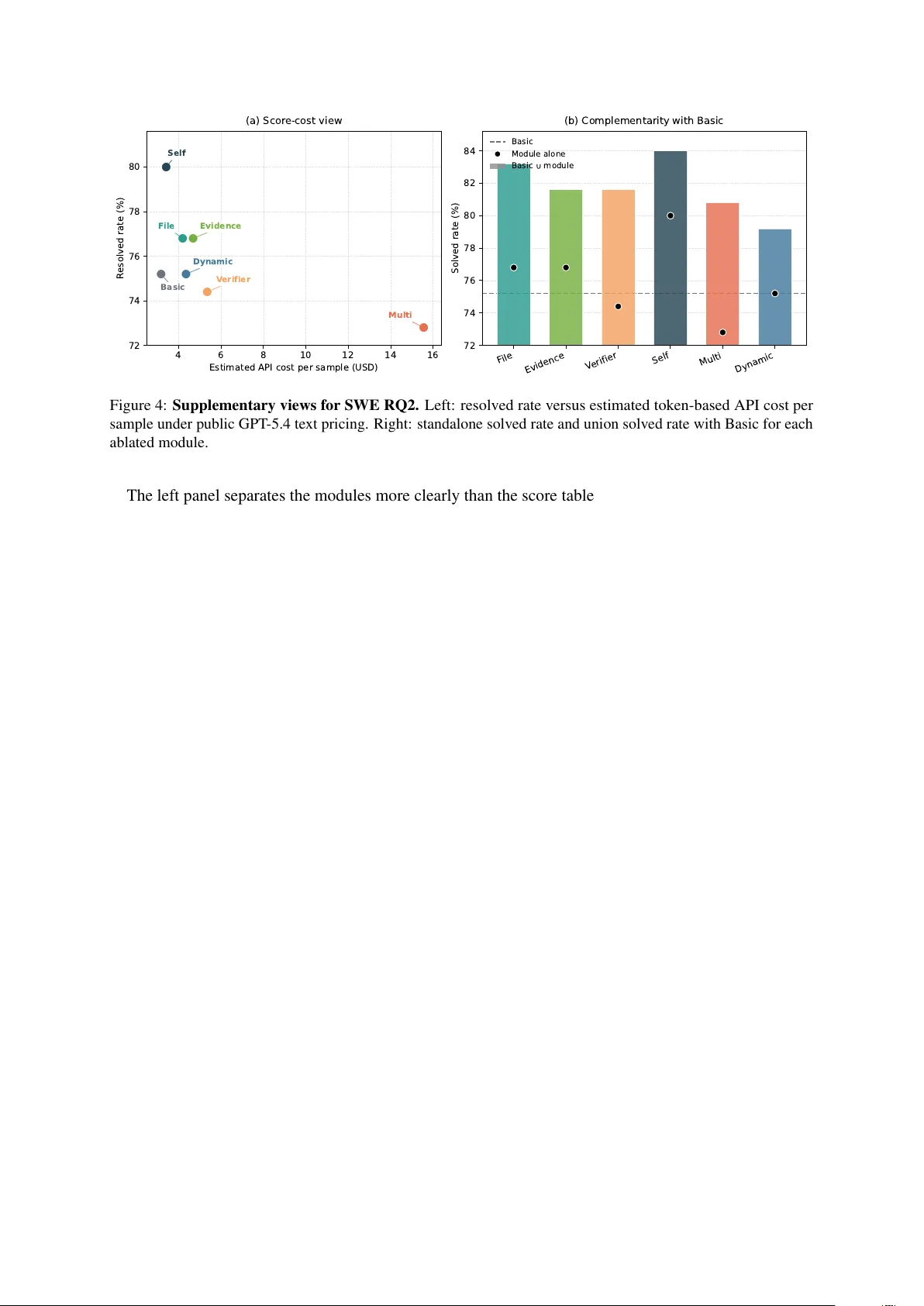
Natural-Language Agent Harnesses Linyue Pan 1 Lexiao Zou 2 Shuo Guo 1 Jingchen Ni 1 Hai-T ao Zheng 1 * 1 Shenzhen International Graduate School, Tsinghua Uni versity 2 Harbin Institute of T echnology (Shenzhen) ply24@mails.tsinghua.edu.cn zheng.haitao@sz.tsinghua.edu.cn Abstract Agent performance increasingly depends on harness engineering , yet harness design is usu- ally buried in controller code and runtime- specific con ventions, making it hard to trans- fer , compare, and study as a scientific ob- ject. W e ask whether the high-lev el control logic of an agent harness can instead be e x- ternalized as a portable ex ecutable artifact. W e introduce Natural-Language Agent Har - nesses (NLAHs), which e xpress harness beha v- ior in editable natural language, and Intelligent Harness Runtime (IHR), a shared runtime that ex ecutes these harnesses through e xplicit contracts, durable artifacts, and lightweight adapters. Across coding and computer-use benchmarks, we conduct controlled e v aluations of operational viability , module ablation, and code-to-text harness migration. 1 Introduction Modern agents increasingly succeed or fail because of the surrounding harness : the control stack that structures multi-step reasoning, tool use, memory , delegation, and stopping be yond an y single model call. A large body of research sho ws that exter - nalized control patterns can be decisiv e, includ- ing reason–act loops ( Y ao et al. , 2023 ), retrie v al- augmented generation ( Lewis et al. , 2021 ), and explicit self-feedback ( Shinn et al. , 2023 ). Re- cent work has e xpanded this space tow ard explicit memory and self-ev olution ( Zhang et al. , 2026 ), workflo w generation ( Li et al. , 2024 ; Zheng et al. , 2025 ), multi-agent orchestration ( Fourney et al. , 2024 ; W ang et al. , 2025b ; K e et al. , 2026 ; Costa , 2026 ; Xia et al. , 2026 ), and interface-lev el test-time scaling and nati ve tool execution ( Muennighof f et al. , 2025 ; W ang et al. , 2024b ; HKUDS , 2026 ). In parallel, long-context and long-horizon settings hav e exposed that the control stack—including state management, context curation, and context * Corresponding author . Figure 1: Examples of harness design patterns used by modern agents (reason–act, retrie v al, reflection, v erifi- cation, memory , search, orchestration). folding—can bottleneck performance ev en when the base model is fixed ( Liu et al. , 2024 ; Chroma Research , 2025 ; T ang et al. , 2025 , 2026a , b ; Sun et al. , 2025 ; Su et al. , 2026 ). The same pressure ap- pears in scaf fold-aw are e v aluation and increasingly demanding reasoning settings, where differences in scaf folds and harnesses can dominate outcomes e ven under fixed base models ( Ding et al. , 2026 ; An et al. , 2025 ; Zhan et al. , 2026b , a ). This shift reframes “prompt engineering” into the broader practice of context engineering : de- ciding what instructions, evidence, intermediate artifacts, and state should be made av ailable at each step of a long run. Practitioner accounts emphasize that as tasks span many context win- do ws, robust progress depends less on one-shot phrasing and more on durable state surfaces, val- idation gates, and clear responsibility boundaries ( Anthropic , 2024 , 2025a , b ; Bui , 2026 ). In the same spirit, recent discussions of harness engineering 1 treat the harness as a first-class systems object, not a thin wrapper around a model ( OpenAI , 2026a ; LangChain , 2026a , b , 2025 ). Problem. Despite the growing importance of har - ness design, harness logic is rarely exposed as a coherent, portable artifact. In most agent systems, the ef fecti ve harness is scattered across controller code, hidden frame work defaults, tool adapters, verifier scripts, and runtime-specific assumptions ( Lou et al. , 2026 ; Shi et al. , 2025 ; Chivukula et al. , 2025 ; W ang et al. , 2025a ; Zhang et al. , 2025 ). As a result, harnesses are difficult to transfer across runtimes, hard to compare fairly , and hard to ab- late cleanly: two systems that nominally differ by one design choice often differ simultaneously in prompts, tool mediation, artifact con v entions, ver - ification gates, and state semantics ( Liang et al. , 2025 ; Cheng et al. , 2025 ). This collapses e valua- tion into controller-b undle comparisons rather than module-le vel e vidence. Motivation. Natural-language artifacts such as AGENTS.md and skill bundles show that practi- cal systems can package repository-local con ven- tions and reusable procedures in portable text ( A GENTS.md , 2026 ; AgentSkills , 2026 ). Recent work further treats these artifacts as learnable and benchmarkable objects through experience-dri v en skill creation, context-engineering skill evolution, reusable procedural memory , and cross-task skill e valuation ( Hao et al. , 2026 ; Y e et al. , 2026 ; Mi et al. , 2026 ; Zhang et al. , 2026 ; Li et al. , 2026b ). What they establish, ho we ver , is feasibility at the le vel of reusable control knowledge, not an ex- plicit ex ecutable harness representation. They typi- cally attach local instructions or reusable routines, but the y do not mak e harness-wide contracts, role boundaries, state semantics, failure handling, and runtime-facing adapters first-class and jointly e xe- cutable under a shared runtime. This gap moti vates our setting rather than closing it: we lift natural language from a carrier of reusable procedures to an explicit, e xecutable harness object. Thesis and approach. W e ask whether the design-pattern layer inside agent harnesses can be made explicit as an executable natural-language object under shared runtime assumptions. W e pro- pose: (i) Natural-Language Agent Harnesses (NLAHs), a structured natural-language representa- tion of harness control bound to e xplicit contracts and artifact carriers; and (ii) an Intelligent Har - ness Runtime (IHR), which interprets NLAHs di- rectly and separates shared runtime charter from task-family harness logic . Contributions. • F ormulation. W e formalize the harness design-pattern layer as an explicit representa- tion object distinct from runtime policy and lo w-lev el e xecution hooks. • Representation ingr edients. W e specify the components a natural-language harness must expose to be executable: contracts, roles, stage structure, adapters, scripts, state seman- tics, and a failure taxonomy . • Shared intelligent runtime. W e introduce Intelligent Harness Runtime (IHR), an in-loop LLM runtime that interprets harness logic di- rectly while cleanly separating the runtime charter from harness logic. • Controlled e vidence. W e conduct controlled experiments on shared-runtime behavioral ef fect (RQ1), module composition/ablation (RQ2), and paired code-to-text migration fi- delity (RQ3) on coding and computer-use benchmarks. 2 Methodology 2.1 Harnesses and the patter n layer W e use harness to denote the orchestration layer that gov erns multiple model or agent calls for a task family . A harness specifies (i) control: how work is decomposed and scheduled; (ii) contracts: what artifacts must be produced, what gates must be satisfied, and when the run should stop; and (iii) state: what must persist across steps, branches, and dele gated workers. By conte xt engineering we mean designing the immediate prompt and re- trie ved context for a single call; a harness subsumes this, b ut also manages multi-step structure, tool me- diation, verification, and durable state ( Anthropic , 2025a , b ). The boundary between harness and runtime is analytical rather than absolute. In practice, some generic services (tool adapters, sandboxing, child lifecycle) may liv e in the runtime, while task-family policy (stages, artifact contracts, verifiers) liv es in the harness. W e mak e this boundary explicit for study: our goal is to compare, migrate, and ablate harness pattern logic under shared runtime assumptions. 2 Natural-Language Agent Harness Intelligent Harness Runtime (IHR) Control & Prompts Contracts & Gates Runtime Charter / Policy State & Artifacts Workspaces, Manifests, Semantics Orchestration Child Agent Permission Boundaries Prompts, Tool Adapters, Harness Logic, Role In-loop LLM Input/Output Requirement, Path-Addressable Failure Taxonomy Agent Calls Tool Interface Stopping Rules, interpreter Backend Objects Natural Language Harness Portable Traditional Code-Coupled Harness Framework-Locked Complex Explicit Opaque Logic Composable def run_task(task): # Stage 1: plan plan = llm_call(prompt= f"Write a Python function for: {task}" ) # Stage 2: execute (generate code) code = extract_code(plan) write_file("solution.py", code) # Stage 3: verify result = run_tests("solution.py") # Stage 4: repair loop retries = 0 while not result.passed and retries < 3: fix_prompt = f""" The following code failed tests: {code} Error: {result.error} Fix it. """ code = llm_call(prompt=fix_prompt) write_file("solution.py", code) result = run_tests("solution.py") retries += 1 return code Task: Implement a function and ensure it passes tests. Stages: 1. PLAN - Role: Planner - Produce a plan for solving the task. 2. EXECUTE - Role: Solver - Generate the code file: solution.py - Contract: must output valid Python code 3. VERIFY - Run tests on solution.py - If tests pass → STOP 4. REPAIR (if failure) - Role: Debugger - Input: failing code + error message - Fix the code - Overwrite solution.py - Retry VERIFY (max 3 attempts) Failure taxonomy: - format_error → regenerate code - test_failure → go to REPAIR - tool_error → retry once A. Comparison of Harness Designs B. Details of Natural Language Harness&Intelligent Harness Runtime File-Backed State Module Path-Addressable, Compaction-Stable, Persistent across Steps task_state.json task_state.json response.txt response.txt Workspace/ Artifacts/ Ledgers/ Figure 2: Framework ov erview . Intelligent Harness Runtime (IHR), with an in-loop LLM, a back end with tool access and child-agent support, and a runtime charter that specifies policy and semantics, ex ecutes a Natural- Language Agent Harness (NLAH), which exposes harness logic, roles, contracts, adapters, and state con ventions, ov er task instances. 2.2 Intelligent Harness Runtime Because NLAHs are written in natural language, ex ecuting them requires interpretation. IHR there- fore places an LLM inside the runtime loop: at each step it reads (i) the harness, (ii) current state and en vironment, and (iii) the runtime charter , and then selects the ne xt action consistent with contracts and budgets. W e decompose IHR into three components (Fig- ure 2 ): (1) an in-loop LLM that interprets harness logic; (2) a backend that provides terminal tools and a first-class multi-agent interface (e.g., spa wn- ing and supervising child agents, ingesting returned artifacts); and (3) a runtime charter that defines the semantics of contracts, state, orchestration, and child lifecycle. In our experiments, child man- agement uses the backend’ s multi-agent tool sur - face (e.g., spawn_agent , wait_agent ) ( OpenAI , 2026c ). From model calls to agent calls. W e lift a sin- gle completion into an agent call bounded by an explicit e xecution contract: required outputs, b ud- gets, permission scope, completion conditions, and designated output paths. Appendix A gi ves the contract-based formalization used by the runtime. 2.3 Natural-Language Agent Harnesses An NLAH is a structured natural-language repre- sentation of harness control intended to be e xecuted by IHR. Natural language does not replace low- le vel deterministic code. Instead, it carries editable , inspectable or chestration logic , while adapters and scripts provide deterministic hooks (tests, linters, scrapers, verifiers). Our formulation makes the follo wing core com- ponents explicit: • Contracts: required inputs and outputs, for- mat constraints, v alidation gates, permission boundaries, retry and stop rules. • Roles: role prompts (solver , verifier , re- searcher , orchestrator) with non-ov erlapping responsibilities. • Stage structure: an explicit workload topol- ogy (e.g., plan → ex ecute → verify → repair). • Adapters and scripts: named hooks for de- terministic actions (tests, verifiers, retriev al, parsing). • State semantics: what persists across steps (artifacts, ledgers, child workspaces) and how it is reopened (paths, manifests). 3 • F ailure taxonomy: named failure modes that dri ve reco very (missing artif act, wrong path, verifier f ailure, tool error , timeout). 2.4 File-backed state as an explicit module Long-horizon autonomy fails in practice when crit- ical state remains implicit or ephemeral. Recent context-folding w ork similarly treats e xplicit con- text management as essential, compressing com- pleted sub-trajectories or dialogue history into reusable summaries and logs ( Sun et al. , 2025 ; Su et al. , 2026 ). W e therefore study an optional file- back ed state module that externalizes durable state into path-addressable artifacts, improving stability under conte xt truncation and branching ( Anthropic , 2025b ; Liu et al. , 2024 ; Chroma Research , 2025 ). Operationally , the module enforces three prop- erties: externalized (state is written to artifacts rather than held only in transient context), path- addressable (later stages reopen the exact object by path), and compaction-stable (state surviv es truncation, restart, and delegation). Appendix B gi ves a canonical workspace and file-role mapping used in our experiments. 3 Experimental Design 3.1 Research questions W e ev aluate whether harness pattern logic can be- come an ex ecutable and analyzable object under shared runtime assumptions. • RQ1 (Behavioral Effect). Under fixed bud- gets, how do the shared runtime charter and benchmark-specific harness logic change agent behavior and task outcomes? • RQ2 (Composability). Once patterns are ex- plicit, can modules be composed and ablated at the pattern le vel? • RQ3 (Migration). What dif ferences remain between native code harnesses and recon- structed natural-language harnesses under a shared runtime? 3.2 Instantiation In our instantiation, the backend is realized by Codex with terminal tools and a multi-agent inter - face; the shared runtime charter is carried by a fix ed runtime skill; and benchmark-specific harness logic is carried by harness skills ( OpenAI , 2025 , 2026b ). This factorization allows controlled ablations of Figure 3: Realization mapping: backend + runtime skill (charter) + harness skill (task-family logic). shared runtime policy versus benchmark-specific harness logic. Appendix C summarizes the shared runtime skill used in all IHR runs. 3.3 Benchmarks and harness families W e e valuate on tw o representati ve benchmark fami- lies that require multi-step control, tool use, durable state accumulation, and verification or evidence management. Coding. SWE-bench V erified e valuates repository-grounded issue resolution; the main metric is issue resolution rate ( Jimenez et al. , 2024 ; Cho wdhury et al. , 2024 ). W e study coding harness families including TRAE-style multi-candidate search ( T eam et al. , 2025 ) and Live-SWE-Agent ( Xia et al. , 2025 ). Computer use. OSW orld ev aluates computer- use behavior grounded in real desktop en viron- ments; the main metric is task success rate ( Xie et al. , 2024 ). W e study OS-Symphony as a holis- tic harness for computer-use agents ( Y ang et al. , 2026 ). 3.4 Experimental setup All experiments use the same IHR instantiation: Codex CLI version 0.114.0 , model GPT -5.4 ( Ope- nAI , 2026b ), and reasoning effort xhigh . Runs ex- ecute on Ubuntu 24.04 serv ers with 64 CPU cores and 251 GiB of memory . T o improve reproducibil- ity and sandbox safety , all runs are executed in Docker containers. Per-task container caps are 32 vCPUs, 84 GiB memory , and 40 GiB storage. Due to budget limits, the current paper reports results on benchmark subsets sampled once with a fixed random seed rather than on the full bench- mark suites. The current subsets contain 125 SWE- bench V erified samples and 36 OSW orld samples. 4 T able 1: RQ1: Outcome and process metrics under Full IHR and ablations. The runtime skill carries shared charter; the harness skill carries benchmark-specific harness logic. Here, w/o RTS and w/o HS denote remo ving the runtime skill and harness skill, respectiv ely . Benchmark Harness Setting Perf. Prompt T okens Completion T okens T ool Calls LLM Calls Runtime (min) SWE V erified TRAE Full IHR 74.4 16.3M 211k 642.6 414.3 32.5 w/o R TS 76.0 11.1M 137k 451.9 260.5 16.6 w/o HS 75.2 1.2M 13.6k 51.1 34.0 6.7 Li ve-SWE Full IHR 72.8 1.4M 17.0k 58.4 41.4 7.6 w/o R TS 76.0 1.1M 11.7k 41.0 28.2 5.5 w/o HS 75.2 1.2M 13.6k 51.1 34.0 6.7 T able 2: RQ1 paired flips on SWE-bench V erified. Counts compare Full IHR against each ablation on the same 125 stitched samples. F means only Full resolv es, A means only the ablation resolv es, and S means both settings agree. vs. w/o R TS vs. w/o HS Harness F A S F A S TRAE 4 6 115 7 8 110 Li ve-SWE 4 8 113 4 7 114 W e plan to rerun the full benchmarks with GPT - 5.4-mini and update the reported results in a future re vision. 4 Results 4.1 RQ1: Beha vioral effect RQ1 tests whether the shared runtime charter and benchmark-specific harness logic materially change agent behavior and task outcomes under fixed b udgets. The first result is that process met- rics mov e much more than resolved rate. On SWE- bench V erified, the TRAE and Liv e-SWE ro ws stay within a narrow performance band, but Full IHR produces much larger changes in tokens, calls, and runtime than either ablation. RQ1 should therefore be read first as evidence that the shared runtime and harness logic change system behavior , not as a monotonic gain story . The trajectory-lev el evidence shows that Full IHR is not a prompt wrapper . For TRAE, Full IHR sharply increases tool calls, LLM calls, and run- time, and T able 4 shows that about 90% of prompt tokens, completion tokens, tool calls, and LLM calls occur in delegated child agents rather than in the runtime-owned parent thread. The added budget therefore reflects multi-stage exploration, candidate comparison, artifact handoff, and extra verification. Li ve-SWE is the lighter regime of the same mechanism: it raises process cost more mod- erately , but it still pushes the run toward a more ex- plicit staged workflo w than either ablation. T aken together , the runtime charter plus harness logic are behaviorally real controls rather than prompt deco- ration. The next result is that most SWE instances do not flip. Across both TRAE and Li ve-SWE, more than 110 of 125 stitched SWE samples agree be- tween Full IHR and each ablation (T able 2 ). The meaningful dif ferences are therefore concentrated in a small frontier of component-sensitive cases. Full IHR behav es more like a solved-set replacer than a uniform frontier expander: it creates some Full-only wins, but it also loses some direct-path repairs that lighter settings retain. Appendix D sum- marizes representati ve component-sensiti ve SWE cases. The most informative failures are align- ment failures rather than random misses. On matplotlib__matplotlib-24570 , TRAE Full expands into a lar ge candidate search, runs multiple selector and re validation stages, and still ends with a locally plausible patch that misses the official ev aluator . Li ve-SWE ex- poses the lighter analogue on cases such as django__django-14404 , sympy__sympy-23950 , and django__django-13406 , where extra struc- ture makes the run more organized and more expensi ve while drifting aw ay from the shortest benchmark-aligned repair path or from the ev alua- tor’ s final acceptance object. These failures matter because they sho w not that the harness is inert, but that it can reshape local success signals in ways that do not always align with benchmark acceptance. 5 T able 3: RQ2: Module composition and ablation. W ithin each benchmark, we begin from a benchmark-specific Basic starting point and add one module at a time. Benchmark Basic File- Backed State Evidence- Backed Answering V erifier Self- Evolution Multi- Candidate Search Dynamic Orchestration SWE V erified 75.2 76.8 +1 . 6 76.8 +1 . 6 74.4 − 0 . 8 80.0 +4 . 8 72.8 − 2 . 4 75.2 0 . 0 OSW orld 41.7 47.2 +5 . 5 41.7 0 . 0 33.3 − 8 . 4 44.4 +2 . 7 36.1 − 5 . 6 44.4 +2 . 7 T able 4: TRAE NLAH usage split. Approximate share of total usage attrib utable to the runtime-o wned parent thread vs. delegated child agents (per-sample a verages). Metric Runtime-o wned parent Delegated child agents Prompt tokens 8.5% 91.5% Completion tokens 8.1% 91.9% T ool calls 9.8% 90.2% LLM calls 9.4% 90.6% 4.2 RQ2: Harness patter n ablations RQ2 asks whether , once harness patterns are made explicit, the y can be composed and ablated as mod- ules under a shared substrate. For clarity , Basic is benchmark-specific in this table. On SWE, Basic is a bare Codex baseline with shell plus file reading, writing, and editing tools. On OSW orld, Basic is the NLAH realiza- tion of OS-Symphony before adding the extra RQ2 modules. W e then add one module at a time: file- backed state, evidence-back ed answering, a verifier stage, self-ev olution, multi-candidate search, and dynamic orchestration. This makes the SWE ro ws close to tool-and-workflo w ablations ov er a mini- mal coding agent, whereas the OSW orld ro ws are ablations ov er an already structured computer-use harness. The first pattern is that module effects concen- trate on a small solved frontier rather than shifting the whole benchmark uniformly . Most tasks are either solved robustly by nearly all conditions or remain unsolved across conditions, so the informa- ti ve dif ferences come from boundary cases that flip under changed control logic. RQ2 should there- fore be read as a study of ho w modules reshape the frontier of difficult cases, not just as a ranking ov er mean scores. The second pattern is that the modules f all into two qualitati vely different f amilies. Self-e volution is the clearest e xample of a module that impro ves the solve loop itself. The trajectory e vidence sug- gests that its main benefit is not open-ended re- flection, but a more disciplined acceptance-gated attempt loop that keeps the search narrow until failure signals justify another pass. Cases such as scikit-learn__scikit-learn-25747 fit this interpretation: the module succeeds by forcing a cleaner success criterion around an ordinary re- pair attempt, not by expanding into an expensiv e tree of candidates. By contrast, file-backed state and evidence-backed answering mainly improv e process structure. They lea ve durable e xternal sig- natures such as task histories, manifests, and analy- sis sidecars, which is strong e vidence that they re- ally externalize state and e vidence handling. Their gains remain mild, which suggests that they im- prov e auditability , handof f discipline, and trace quality more directly than semantic repair ability . The third pattern is that more explicit structure does not automatically mean better end-task perfor - mance. Dynamic orchestration is behaviorally real rather than inert because it changes which SWE in- stances are solv ed, but it mostly acts as a solv ed-set replacer instead of expanding the frontier . V er- ifier and multi-candidate search show a harsher version of the same principle. V erifier adds a gen- uine independent checking layer , yet failures such as sympy__sympy-23950 sho w that verifier -level acceptance can still di ver ge from benchmark-level acceptance. Multi-candidate search mak es search behavior more visible, but under the current run- time and budget it appears too overhead-hea vy and infrastructure-sensiti ve to con vert that richer beha v- ior into better aggregate outcomes. OSW orld points in the same direction from a dif ferent starting point: because its Basic condition is already a structured harness, the most useful ad- ditions are again the lighter modules that tighten local organization without adding a hea vy extra acceptance layer . Overall, RQ2 does not support a simple “more structure is always better” story . The stronger interpretation is that e xplicit modules help when they tighten the path from intermediate be- 6 T able 5: RQ3: Paired code-to-text harness comparison. Each harness is e valuated as original source code vs. reconstructed NLAH under IHR. Here, Code denotes the original source implementation. Benchmark Harness Realization Perf. Prompt T okens Completion T okens Agent Calls T ool Calls LLM Calls Runtime (min) OSW orld OS-Symphony Code 30.4 11.4M 147.2k 99 651 1.2k 361.5 NLAH 47.2 15.7M 228.5k 72 683 34 140.8 havior to the e valuator’ s acceptance condition, and help less when the y mainly add local process lay- ers whose notion of success is only weakly aligned with the final benchmark. Appendix E adds token- cost and Basic-union views together with represen- tati ve case studies that make the same mechanism- le vel pattern more concrete. 4.3 RQ3: Code-to-text harness migration RQ3 is a paired migration study: each harness appears in two realizations (source code vs. re- constructed NLAH), ev aluated under a shared re- porting schema (T able 5 ). The target is task-le vel equi v alence—comparable exposed logic, contracts, and benchmark-facing artifacts—not identical in- ternal traces. On OSW orld, the migrated OS- Symphony realization reaches 47.2 versus 30.4 for the nativ e code harness. The more important dif- ference, ho wever , is behavioral rather than purely numerical. Nativ e OS-Symphony e xternalizes con- trol as a screenshot-grounded repair loop: verify the pre vious step, inspect the current screen, choose the next GUI action, and retry locally when focus or selection errors occur . Under IHR, the same task family tends to re-center around file-backed state and artifact-back ed verification. Runs materialize task files, ledgers, and explicit artifacts, and they switch more readily from brittle GUI repair to file, shell, or package-lev el operations when those oper- ations provide a stronger completion certificate. The retained RQ3 archiv es make this reloca- tion concrete. The nati ve side e xposes 36 main traces plus 7 short nested search_1 traces, whereas the migrated side e xposes 34 retained inner e vent streams and 2 missing-inner-stream stubs. This means the nativ e topology is a desktop control loop with occasional detachable tutorial detours, while the migrated topology is a contract-first runtime flo w whose state liv es in task files, ledgers, and artifacts. Search is preserved functionally , but relocated topologically . Among the 6 nativ e-search samples whose migrated inner streams are retained, only 3 also contain explicit web_search , and 1 additional migrated sample uses web_search without a na- ti ve search_1 branch. Search therefore surviv es less as an auxiliary sub-agent branch and more as in-band runtime support for substrate choice and deterministic repair . V erification shifts ev en more strongly . Nativ e traces often stop on screen plausibility , whereas mi- grated runs more often close on path-addressable e vidence such as a written file, a reopened docu- ment, a package-lev el object, or a system query . This shift matters because OSW orld tasks often fail not at first-pass intent, but at reco very and closure. Retained migrated traces are also denser , but that density should not be read as a raw action multiplier . Across paired retained samples, nativ e main traces av erage 18.1 steps, while migrated traces a verage about 18.2 unique command starts but 58.5 total logged e vents because the runtime also preserves started/completed pairs, bookkeeping, and explicit artifact handling. The extra density is therefore better interpreted as observ ability plus recov ery scaf folding than as dramatically more task actions. These tendencies are consistent with the OSW orld module results in RQ2, where file-backed state is the strongest positi ve addition, and they help ex- plain why the NLAH realization obtains a modest performance gain rather than a penalty . Case sketches. Representative cases make the same mechanism concrete. In a system- configuration task, the nati ve run stays trapped in GUI focus repair, whereas the NLAH realization shifts to shell-side configuration and closes only after explicit sshd v alidation. In a spreadsheet task, the nativ e run reaches apparent visual progress yet fails to close robustly , whereas the migrated har- ness writes the target artifact deterministically and reopens it before completion. In a presentation task, the nativ e harness can retriev e the right tu- torial path yet still struggle with object binding and drag control, whereas the migrated harness edits the .pptx package directly and verifies the resulting slide artifact. T aken together , these cases suggest that the main migration ef fect is not loss of 7 high-le vel orchestration, b ut relocation of reliabil- ity mechanisms from local screen repair to durable runtime state and artifact-backed closure. 5 Discussion Code v ersus natural language. W e do not ar gue that natural language should replace code. Instead, natural language carries editable high-le vel harness logic, while code remains responsible for deter- ministic operations, tool interfaces, and sandbox enforcement. The scientific claim is about the unit of comparison: externalizing harness pattern logic as a readable, e xecutable object under shared run- time semantics. Why natural language still matters. A natu- ral concern is whether stronger foundation mod- els reduce the v alue of natural-language control. Empirically , gains from complex prompt engineer- ing can diminish or become brittle in some set- tings ( W ang et al. , 2024a ; Cao et al. , 2024 ). How- e ver , our results support a diff erent interpretation for agent systems: natural language remains im- portant when used to specify harness-le vel con- tr ol —roles, contracts, verification gates, durable state semantics, and delegation boundaries—rather than only one-shot prompt phrasing. This framing is consistent with practitioner accounts that em- phasize context engineering and long-running har - ness design ( Anthropic , 2025a , b ; OpenAI , 2026a ; LangChain , 2026a ). It is also compatible with emerging scaffold-a ware e v aluation and harness- synthesis research that treat the surrounding control stack as part of the system under ev aluation ( Ding et al. , 2026 ; Lou et al. , 2026 ; Chen et al. , 2026b ). Searching har ness representations. Once har- nesses are explicit objects, they become a search space. Explicit harness modules can be manually designed, retriev ed, migrated, recombined, and systematically ablated under shared assumptions. Longer term, this suggests automated search and optimization o ver harness representations rather than opaque b undle engineering, enabling harness engineering to become a more controlled scientific object. 6 Related W ork Prompts as programs and LLM pr ogramming systems. Sev eral lines of work treat prompts and LLM calls as programmable objects. Liang et al. argue that some prompts are programs and study ho w dev elopers engineer prompt-enabled software systems ( Liang et al. , 2025 ). Promptware engi- neering further frames prompt-enabled systems as a software-engineering object with concerns of maintainability , testing, and integration ( Chen et al. , 2026b ). At the language and systems lev el, LMQL adds constraints and control flo w to prompt- ing ( Beurer-K ellner et al. , 2023 ), DSPy compiles declarati ve LM pipelines ( Khattab et al. , 2024 ), APPL integrates prompts and Python programs ( Dong et al. , 2025 ), and SGLang provides an ex e- cution system for structured language-model pro- grams ( Zheng et al. , 2024 ). Cheng et al. study mechanisms for sharing state between prompts and programs ( Cheng et al. , 2025 ). These works primar- ily program calls or pipelines; our focus is the har- ness layer that gov erns multi-step agent calls , arti- fact contracts, delegation, v erification, and durable state. Agent control patterns and orchestration. Core agent control patterns include reason–act loops ( Y ao et al. , 2023 ), retriev al augmentation ( Le wis et al. , 2021 ), and reflection/self-feedback ( Shinn et al. , 2023 ). Subsequent work expands this space toward memory and self-ev olution ( Zhang et al. , 2026 ; Xia et al. , 2025 ), multi-agent general- ists ( F ourney et al. , 2024 ), workflo w generation ( Li et al. , 2024 ; Zheng et al. , 2025 ), and dynamic topol- ogy/routing ( W ang et al. , 2025b , c ; Y ue et al. , 2025 ; K e et al. , 2026 ; Costa , 2026 ). Our work is comple- mentary: we do not propose a new orchestration algorithm, b ut instead externalize the harness pat- tern logic as an e xecutable representation under a shared runtime. Natural language to workflows, constraints, and enf orcement. Se veral systems translate nat- ural language into workflo ws or executable con- straints. AutoFlo w generates workflo ws from natural-language descriptions ( Li et al. , 2024 ), Flo wAgent studies compliance vs. fle xibility ( Shi et al. , 2025 ), and Agint compiles softw are- engineering agents into agentic graphs ( Chi vukula et al. , 2025 ). AgentSpec focuses on runtime en- forcement mechanisms ( W ang et al. , 2025a ), and ContextCo v derives executable constraints from agent instruction files ( Sharma , 2026 ). OpenProse and Lobster expose workflow/specification systems close to natural-language authoring ( OpenProse , 2026 ; OpenClaw , 2026 ). In contrast to compiling to a runtime-owned IR, IHR interprets harness logic directly , relying on explicit contracts and durable 8 artifacts for auditability . Harness engineering in practice and automatic harness synthesis. Recent conte xt-folding work tackles a nearby systems problem by compressing long interaction histories for long-horizon agents ( Sun et al. , 2025 ; Su et al. , 2026 ). Recent public engineering accounts describe harness engineering as a primary driv er of robustness in long-running agents ( Anthropic , 2024 , 2025a , b , c , 2026b , a ; Ope- nAI , 2026a ; LangChain , 2026b , a ; Bui , 2026 ). On the research side, AutoHarness explicitly treats har- ness synthesis as an optimization tar get, automati- cally producing code harnesses that improve agent behavior ( Lou et al. , 2026 ). General Modular Har- ness studies modular harness structure in multi-turn en vironments ( Zhang et al. , 2025 ). Our work dif- fers by focusing on the harness design-pattern layer as a natural-language representation object that can be ex ecuted under a shared intelligent runtime. Reusable instruction carriers and skills. Natural-language carriers such as AGENTS.md , AgentSkills, and related skill b undles demonstrate that portable, attachable operational knowledge can be packaged as te xt and reused across en vironments ( A GENTS.md , 2026 ; AgentSkills , 2026 ). Recent skill work pushes this further by treating skills as objects that can be created from experience, ev olved for context engineering, or maintained as reusable procedural memory rather than fixed one-off prompts ( Hao et al. , 2026 ; Y e et al. , 2026 ; Mi et al. , 2026 ; Zhang et al. , 2026 ). Skills also provide an alternati ve modularity substrate: a single agent equipped with a skill library can sometimes replace explicit multi-agent communication, although this substitution breaks when tasks require genuine parallelism, priv ate state, or adversarial role structure ( Li , 2026 ). At the ecosystem le vel, AgentSkillOS studies org anizing and orchestrating large skill collections, while SkillsBench, SkillCraft, and PinchBench e valuate cross-task transfer , higher-le vel tool composition, and practical skill in vocation under di verse tasks ( Li et al. , 2026a , b ; Chen et al. , 2026a ; PinchBench , 2026 ). W e extend this idea from reusable local guidance to executable harness-le vel control. 7 Conclusion W e study whether the harness design-pattern layer can be externalized as an executable, compara- ble, and ablatable object. W e propose Natural- Language Agent Harnesses and an Intelligent Har- ness Runtime that interprets harness logic directly under shared runtime semantics. Across the current coding and computer-use benchmarks, we pro vide controlled e vidence that this stack is operationally viable, enables module-lev el composition and abla- tion, and supports meaningful code-to-text harness migration studies. These results suggest a path to- ward harness representation science, where harness modules become first-class research artif acts rather than incidental glue around models. Limitations Natural language is less precise than code, and some harness mechanisms cannot be recovered faithfully from text, especially when they rely on hidden service-side state, proprietary schedulers, or training-induced behaviors not observ able from released artifacts. Runtime contamination remains a real risk: a strong shared runtime charter may ab- sorb part of the beha vior that one might otherwise attribute to harness text. Module-lev el ablation is not strict causal identification; textual representa- tions can introduce confounds such as instruction salience and prompt length. Broader impact and risks Externalizing harness modules can reduce dev el- opment cost, improve comparability , and encour- age reuse of rob ust workflo ws. Howe ver , portable harness logic and scripts may also lo wer the bar - rier to spreading risky workflo ws. Because har - nesses mediate tool use, artifact handling, and del- egation, they can introduce ne w attack surfaces for prompt injection, malicious tool grafting, or supply-chain contamination. Deployments should combine prov enance tracking, revie w , permission control, and sandbox isolation. References AgentSkills. 2026. Agentskills . W ebsite home page. Accessed: 2026-03-13. A GENTS.md. 2026. Agents.md . Community specifica- tion website. Accessed: 2026-03-13. Shengnan An, Xunliang Cai, Xuezhi Cao, Xiaoyu Li, Y ehao Lin, Junlin Liu, Xinxuan Lv , Dan Ma, Xuanlin W ang, Ziwen W ang, and Shuang Zhou. 2025. Amo-bench: Large language models still struggle in high school math competitions . Pr eprint , 9 Anthropic. 2024. Building effecti ve agents . Engineer- ing blog. Published: 2024-12-19. Accessed: 2026- 03-12. Anthropic. 2025a. Effecti ve conte xt engineering for ai agents . Engineering blog. Published: 2025-09-29. Accessed: 2026-03-12. Anthropic. 2025b. Effecti ve harnesses for long-running agents . Engineering blog. Published: 2025-11-26. Accessed: 2026-03-12. Anthropic. 2025c. How we built our multi-agent re- search system . Engineering blog. Published: 2025- 06-13. Accessed: 2026-03-12. Anthropic. 2026a. Claude code subagents . Documenta- tion page. Accessed: 2026-03-06. Anthropic. 2026b. How claude remembers your project . Documentation page. Accessed: 2026-03-12. Luca Beurer-K ellner, Marc Fischer , and Martin V echev . 2023. Prompting is programming: A query language for large language models . Pr oc. ACM Pro gram. Lang. , 7(PLDI). Nghi D. Q. Bui. 2026. Building effecti ve ai coding agents for the terminal: Scaffolding, harness, con- text engineering, and lessons learned . Pr eprint , Bowen Cao, Deng Cai, Zhisong Zhang, Y uexian Zou, and W ai Lam. 2024. On the worst prompt per- formance of large language models . Pr eprint , Shiqi Chen, Jingze Gai, Ruochen Zhou, Jinghan Zhang, T ongyao Zhu, Junlong Li, Kangrui W ang, Zihan W ang, Zhengyu Chen, Klara Kaleb, Ning Miao, Siyang Gao, Cong Lu, Manling Li, Junxian He, and Y ee Whye T eh. 2026a. Skillcraft: Can llm agents learn to use tools skillfully? Pr eprint , Zhenpeng Chen, Chong W ang, W eisong Sun, Xuanzhe Liu, Jie M. Zhang, and Y ang Liu. 2026b. Prompt- ware engineering: Software engineering for prompt- enabled systems . Preprint , arXi v:2503.02400. Ellie Y . Cheng, Logan W eber, Tian Jin, and Michael Carbin. 2025. Sharing state between prompts and programs . Preprint , arXi v:2512.14805. Abhi Chi vukula, Jay Somasundaram, and V ijay So- masundaram. 2025. Agint: Agentic graph compi- lation for software engineering agents . Preprint , Neil Cho wdhury , James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Y ang, Leyton Ho, T ejal Patwardhan, Ke vin Liu, and Aleksander Madry . 2024. Introducing SWE-bench verified . Chroma Research. 2025. Context rot: How increasing input tokens impacts llm performance . Research article. Accessed: 2026-03-06. Igor Costa. 2026. Agentspawn: Adaptive multi- agent collaboration through dynamic spawning for long-horizon code generation . Pr eprint , Deming Ding, Shichun Liu, Enhui Y ang, Jiahang Lin, Ziying Chen, Shihan Dou, Honglin Guo, W eiyu Cheng, Pengyu Zhao, Chengjun Xiao, Qunhong Zeng, Qi Zhang, Xuanjing Huang, Qidi Xu, and T ao Gui. 2026. Octobench: Benchmarking scaffold- aware instruction following in repository-grounded agentic coding . Preprint , arXi v:2601.10343. Honghua Dong, Qidong Su, Y ubo Gao, Zhaoyu Li, Y angjun Ruan, Gennady Pekhimenko, Chris J. Mad- dison, and Xujie Si. 2025. APPL: A prompt pro- gramming language for harmonious integration of programs and large language model prompts . In Pr oceedings of the 63rd Annual Meeting of the As- sociation for Computational Linguistics (V olume 1: Long P apers) , pages 1243–1266, V ienna, Austria. Association for Computational Linguistics. Adam Fourne y , Gagan Bansal, Hussein Mozannar, Cheng T an, Eduardo Salinas, Erkang, Zhu, Friederike Niedtner , Grace Proebsting, Griffin Bassman, Jack Gerrits, Jacob Alber, Peter Chang, Ricky Loynd, Robert W est, V ictor Dibia, Ahmed A wadallah, Ece Kamar , Rafah Hosn, and Saleema Amershi. 2024. Magentic-one: A generalist multi-agent system for solving complex tasks . Pr eprint , Zhezheng Hao, Hong W ang, Jian Luo, Jianqing Zhang, Y uyan Zhou, Qiang Lin, Can W ang, Hande Dong, and Jia wei Chen. 2026. Recreate: Reasoning and cre- ating domain agents dri ven by e xperience . Preprint , HKUDS. 2026. CLI-Anything: Making ALL Software Agent-Nativ e . GitHub repository . Repository cre- ated: 2026-03-08. Accessed: 2026-03-23. Carlos E Jimenez, John Y ang, Alexander W ettig, Shunyu Y ao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can language mod- els resolve real-w orld github issues? In The T welfth International Conference on Learning Representa- tions . Zixuan Ke, Y ifei Ming, Austin Xu, Ryan Chin, Xuan- Phi Nguyen, Prathyusha Jwalapuram, Jiayu W ang, Semih Y avuz, Caiming Xiong, and Shafiq Joty . 2026. Mas-orchestra: Understanding and improving multi- agent reasoning through holistic orchestration and controlled benchmarks . Pr eprint , Omar Khattab, Arnav Singhvi, Paridhi Maheshw ari, Zhiyuan Zhang, Kesha v Santhanam, Sri V ard- hamanan A, Saiful Haq, Ashutosh Sharma, Thomas Joshi, Hanna Moazam, Heather Miller , Matei Za- haria, and Christopher Potts. 2024. Dspy: Compiling declarativ e language model calls into state-of-the-art 10 pipelines . In International Confer ence on Learning Repr esentations , volume 2024, pages 54928–54958. LangChain. 2025. Deep agents . Engineering blog. Pub- lished: 2025-07-30. Accessed: 2026-03-12. LangChain. 2026a. The anatomy of an agent harness . Engineering blog. Published: 2026-03-10. Accessed: 2026-03-12. LangChain. 2026b. Impro ving deep agents with harness engineering . Engineering blog. Published: 2026-02- 17. Accessed: 2026-03-12. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, W en tau Y ih, T im Rock- täschel, Sebastian Riedel, and Douwe Kiela. 2021. Retriev al-augmented generation for knowledge- intensiv e nlp tasks . Pr eprint , Hao Li, Chunjiang Mu, Jianhao Chen, Siyue Ren, Zhiyao Cui, Y iqun Zhang, Lei Bai, and Shuyue Hu. 2026a. Organizing, orchestrating, and bench- marking agent skills at ecosystem scale . Preprint , Xiangyi Li, W enbo Chen, Y imin Liu, Shenghan Zheng, Xiaokun Chen, Y ifeng He, Y ubo Li, Bingran Y ou, Haotian Shen, Jiankai Sun, Shuyi W ang, Qunhong Zeng, Di W ang, Xuandong Zhao, Y uanli W ang, Roey Ben Chaim, Zonglin Di, Y ipeng Gao, Junwei He, and 21 others. 2026b. Skillsbench: Benchmark- ing ho w well agent skills w ork across di verse tasks . Pr eprint , Xiaoxiao Li. 2026. When single-agent with skills replace multi-agent systems and when they fail . Pr eprint , Zelong Li, Shuyuan Xu, Kai Mei, W enyue Hua, Bal- aji Rama, Om Raheja, Hao W ang, He Zhu, and Y ongfeng Zhang. 2024. Autoflow: Automated work- flow generation for large language model agents . Pr eprint , Jenny T . Liang, Melissa Lin, Nikitha Rao, and Brad A. Myers. 2025. Prompts are programs too! under - standing how dev elopers build software containing prompts . Proc. A CM Softw . Eng. , 2(FSE). Nelson F . Liu, K evin Lin, John Hewitt, Ashwin P aran- jape, Michele Be vilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language mod- els use long conte xts . T ransactions of the Association for Computational Linguistics , 12:157–173. Xinghua Lou, Miguel Lázaro-Gredilla, Antoine Dedieu, Carter W endelken, W olfgang Lehrach, and K evin P . Murphy . 2026. Autoharness: improving llm agents by automatically synthesizing a code harness . Pr eprint , Qirui Mi, Zhijian Ma, Mengyue Y ang, Haoxuan Li, Y isen W ang, Haifeng Zhang, and Jun W ang. 2026. Procmem: Learning reusable procedural memory from experience via non-parametric ppo for llm agents . Preprint , arXi v:2602.01869. Niklas Muennighoff, Zitong Y ang, W eijia Shi, Xi- ang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer , Percy Liang, Emmanuel Candès, and T atsunori Hashimoto. 2025. s1: Simple test-time scaling . Preprint , arXi v:2501.19393. OpenAI. 2025. Introducing codex . Product announce- ment. Published: 2025-05-16. Accessed: 2026-03- 13. OpenAI. 2026a. Harness engineering: leveraging code x in an agent-first world . Engineering blog. Published: 2026-02-11. Accessed: 2026-03-13. OpenAI. 2026b. Introducing gpt-5.4 . Product an- nouncement. Published: 2026-03-05. Accessed: 2026-03-13. OpenAI. 2026c. Multi-agents . Documentation page. Accessed: 2026-03-10. OpenClaw. 2026. Lobster . GitHub repository . First public repository commit: 2026-01-17; Accessed: 2026-03-11. OpenProse. 2026. Openprose . GitHub repository . First public repository commit: 2026-01-03; Accessed: 2026-03-11. PinchBench. 2026. Pinchbench . GitHub repository . Accessed: 2026-03-08. Reshabh K Sharma. 2026. Contextcov: Deriving and en- forcing executable constraints from agent instruction files . Preprint , arXi v:2603.00822. Y uchen Shi, Siqi Cai, Zihan Xu, Y uei Qin, Gang Li, Hang Shao, Jiawei Chen, Deqing Y ang, Ke Li, and Xing Sun. 2025. Flow agent: Achieving compli- ance and flexibility for workflow agents . Pr eprint , Noah Shinn, Federico Cassano, Edward Berman, Ash- win Gopinath, Karthik Narasimhan, and Shunyu Y ao. 2023. Reflexion: Language agents with verbal rein- forcement learning . Preprint , arXi v:2303.11366. Jin Su, Runnan Fang, Y eqiu Li, Xiaobin W ang, Shihao Cai, Pengjun Xie, Ningyu Zhang, and Fajie Y uan. 2026. U-fold: Dynamic intent-aware context folding for user-centric agents . Pr eprint , W eiwei Sun, Miao Lu, Zhan Ling, Kang Liu, Xuesong Y ao, Y iming Y ang, and Jiecao Chen. 2025. Scaling long-horizon llm agent via context-folding . Pr eprint , Jiwei T ang, Shilei Liu, Zhicheng Zhang, Qingsong Lv , Runsong Zhao, T ingwei Lu, Langming Liu, Haibin Chen, Y ujin Y uan, Hai-T ao Zheng, W enbo Su, and Bo Zheng. 2026a. Read as human: Compressing con- text via parallelizable close reading and skimming . Pr eprint , 11 Jiwei T ang, Jin Xu, Tingwei Lu, Zhicheng Zhang, Y im- ing Zhao, Lin Hai, and Hai-T ao Zheng. 2025. Per- ception compressor: A training-free prompt compres- sion frame work in long conte xt scenarios . Preprint , Jiwei T ang, Zhicheng Zhang, Shunlong W u, Jingheng Y e, Lichen Bai, Zitai W ang, T ingwei Lu, Lin Hai, Y iming Zhao, Hai-T ao Zheng, and Hong-Gee Kim. 2026b. Gmsa: Enhancing context compression via group merging and layer semantic alignment . Pr eprint , T rae Research T eam, Pengfei Gao, Zhao Tian, Xi- angxin Meng, Xinchen W ang, Ruida Hu, Y uanan Xiao, Y izhou Liu, Zhao Zhang, Junjie Chen, Cuiyun Gao, Y un Lin, Y ingfei Xiong, Chao Peng, and Xia Liu. 2025. Trae agent: An llm-based agent for soft- ware engineering with test-time scaling . Preprint , Guoqing W ang, Zeyu Sun, Zhihao Gong, Sixiang Y e, Y izhou Chen, Y ifan Zhao, Qingyuan Liang, and Dan Hao. 2024a. Do advanced language models elim- inate the need for prompt engineering in software engineering? Pr eprint , Haoyu W ang, Christopher M. Poskitt, and Jun Sun. 2025a. Agentspec: Customizable runtime enforce- ment for safe and reliable llm agents . Pr eprint , Song W ang, Zhen T an, Zihan Chen, Shuang Zhou, T ian- long Chen, and Jundong Li. 2025b. AnyMA C: Cas- cading flexible multi-agent collaboration via next- agent prediction . In Pr oceedings of the 2025 Con- fer ence on Empirical Methods in Natural Languag e Pr ocessing , pages 11555–11567, Suzhou, China. As- sociation for Computational Linguistics. Xingyao W ang, Y angyi Chen, Lifan Y uan, Y izhe Zhang, Y unzhu Li, Hao Peng, and Heng Ji. 2024b. Exe- cutable code actions elicit better llm agents . Pr eprint , Zhexuan W ang, Y utong W ang, Xuebo Liu, Liang Ding, Miao Zhang, Jie Liu, and Min Zhang. 2025c. Agent- Dropout: Dynamic agent elimination for token- efficient and high-performance LLM-based multi- agent collaboration . In Pr oceedings of the 63rd An- nual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 24013– 24035, V ienna, Austria. Association for Computa- tional Linguistics. Chunqiu Steven Xia, Zhe W ang, Y an Y ang, Y uxiang W ei, and Lingming Zhang. 2025. Live-swe-agent: Can software engineering agents self-e volve on the fly? Pr eprint , Peng Xia, Jianwen Chen, Hanyang W ang, Jiaqi Liu, Kaide Zeng, Y u W ang, Siwei Han, Y iyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Y ao. 2026. Skillrl: Evolving agents via recursiv e skill-augmented reinforcement learning . Pr eprint , T ianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, T oh Jing Hua, Zhou- jun Cheng, Dongchan Shin, Fangyu Lei, Y itao Liu, Y iheng Xu, Shuyan Zhou, Silvio Sav arese, Caiming Xiong, V ictor Zhong, and T ao Y u. 2024. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer en vironments . In Advances in Neural Information Pr ocessing Systems , volume 37, pages 52040–52094. Curran Associates, Inc. Bowen Y ang, Kaiming Jin, Zhenyu W u, Zhaoyang Liu, Qiushi Sun, Zehao Li, JingJing Xie, Zhoumi- anze Liu, Fangzhi Xu, Kanzhi Cheng, Qingyun Li, Y ian W ang, Y u Qiao, Zun W ang, and Zichen Ding. 2026. Os-symphony: A holistic framew ork for ro- bust and generalist computer-using agent . Pr eprint , Shunyu Y ao, Jef frey Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Y uan Cao. 2023. React: Synergizing reasoning and acting in language models . In The Eleventh International Conference on Learning Repr esentations . Haoran Y e, Xuning He, V incent Arak, Haonan Dong, and Guojie Song. 2026. Meta conte xt engineering via agentic skill ev olution . Pr eprint , arXi v:2601.21557. Y anwei Y ue, Guibin Zhang, Boyang Liu, Guancheng W an, Kun W ang, Dawei Cheng, and Y iyan Qi. 2025. MasRouter: Learning to route LLMs for multi-agent systems . In Pr oceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V ol- ume 1: Long P apers) , pages 15549–15572, V ienna, Austria. Association for Computational Linguistics. Shaoxiong Zhan, Y anlin Lai, Zheng Liu, Hai Lin, Shen Li, Xiaodong Cai, Zijian Lin, W en Huang, and Hai-T ao Zheng. 2026a. 3viewsense: Spa- tial and mental perspective reasoning from ortho- graphic vie ws in vision-language models . Pr eprint , Shaoxiong Zhan, Y anlin Lai, Ziyu Lu, Dahua Lin, Ziqing Y ang, and Fei T an. 2026b. Mathsmith: T o- wards extremely hard mathematical reasoning by forging synthetic problems with a reinforced polic y . Pr eprint , Haozhen Zhang, Quanyu Long, Jianzhu Bao, T ao Feng, W eizhi Zhang, Haodong Y ue, and W enya W ang. 2026. Memskill: Learning and ev olving memory skills for self-ev olving agents . Pr eprint , arXi v:2602.02474. Y uxuan Zhang, Haoyang Y u, Lanxiang Hu, Haojian Jin, and Hao Zhang. 2025. General modular harness for llm agents in multi-turn gaming en vironments . Pr eprint , Chengqi Zheng, Jianda Chen, Y ueming L yu, W en Zheng T erence Ng, Haopeng Zhang, Y ew-Soon Ong, Ivor Tsang, and Haiyan Y in. 2025. Mermaidflow: Redefining agentic workflo w generation via safety- constrained e volutionary programming . Preprint , 12 Lianmin Zheng, Liangsheng Y in, Zhiqiang Xie, Chuyue Sun, Jef f Huang, Cody Hao Y u, Shiyi Cao, Christos K ozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Y ing Sheng. 2024. Sglang: efficient ex ecution of structured language model programs. In Pr oceedings of the 38th International Confer ence on Neural Information Pr ocessing Systems , NIPS ’24, Red Hook, NY , USA. Curran Associates Inc. 13 A From model calls to agent calls A multimodal LLM can be vie wed as a mapping from context c to output y , where the conte xt may include text, images, or video: y = LM m ( c ) . T o support tool use, we assume a structured action format that can inv oke external tools. W e lift a base model call into an agent call . W e define a task as T = ( p, F in , κ ) , where p is the task prompt, F in is the set of input files or linked resources, and κ is an ex ecution contract (required outputs, budget, permission scope, completion conditions, designated output paths). An agent call is Agen tCall( T , Ω in t ) = ( A t , ∆Ω t , y t ) , where Ω in t is the visible en vironment and file state at call start, A t is the designated artifact set, ∆Ω t are en vironment modifications, and y t is a normalized final response pointing to artifacts and stating success or failure. A single model call is a degenerate special case where κ enforces one-shot answering with no external action. B Canonical workspace f or file-backed state The file-backed module treats a canonical workspace as the authoritativ e carrier of durable cross-step state. Canonical workspace run/ TASK.md harness-skill/ SKILL.md references/ scripts/ state/ task_history.jsonl children/ 001/ TASK.md SKILL.md inputs/ scripts/ scratch/ RESPONSE.md artifacts/ RESPONSE.md artifacts/ Abstract object Example carrier Role T ask object TASK.md Run-local task statement, linked inputs, designated outputs Run-lev el final re- sponse RESPONSE.md , children/*/RESPONSE.md Normalized outcome together with success or failure status and artifact pointers Harness skill harness-skill/SKILL.md , harness-skill/references/ , harness-skill/scripts/ T ask-family control logic together with reusable references and scripts T ask history state/ task_history.jsonl Append-only record of child in vocations and state promotions used to recov er activ e runtime state Child workspace children/*/TASK.md , children/*/SKILL.md , children/*/inputs/ , children/*/scripts/ , children/*/scratch/ , children/*/artifacts/ Child-local task packet, copied inputs, tools, scratch space, and local artifacts Final artifacts artifacts/ Benchmark-facing outputs and designated deliv erables T able 6: Canonical workspace layout and file-role mapping for file-backed state. C Outline of the shared runtime skill The fixed runtime skill used in IHR is not a benchmark-specific harness. It encodes the shared runtime charter that makes dif ferent harness skills executable under a common substrate. In operational terms, the charter enforces fi ve ideas: • Runtime-only parent r ole. The top-lev el agent is an orchestrator rather than the direct w orker , so e ven a nominally single-agent harness is realized as “parent runtime + one task child. ” This keeps substanti ve workspace w ork inside child agents and makes delegation boundaries inspectable. 14 T able 7: Representative component-sensiti ve SWE cases for RQ1. Sample Outcome pattern Main lesson matplotlib__ matplotlib-24570 Liv e-SWE Full resolves, but Li ve-SWE without the runtime skill, the shared baseline, and TRAE Full all fail. A moderate delegated topology can help on some boundary cases, but the same sample also sho ws that a much heavier candidate-search topology can o vershoot the task. django__ django-14404 Liv e-SWE Full fails, while lighter coding conditions resolve the task. Some local repository repairs fa vor the shortest direct patch path, so extra workflo w structure can add friction instead of robustness. sympy__ sympy-23950 The heavier Full conditions f ail, while lighter structured conditions resolve. Component value is task-dependent: additional orchestration is not uniformly helpful when the bug mainly requires a tight local repair loop. django__ django-13406 Structured runs report successful local rev alidation, yet the official e valuator still fails. Local acceptance layers can div erge from the benchmark’ s final acceptance object, so extra v erification structure is only useful when it stays aligned with ev aluator behavior . • Minimal delegated baseline. If no harness skill is loaded, or if the loaded skills are incomplete, the runtime first constructs the thinnest runnable baseline from the benchmark contract and then treats extra skills as ov erlays on that baseline. This is the shared substrate behind the RQ1 “w/o harness skill” condition. • Call-graph reco very with explicit context semantics. The runtime reconstructs roles, stages, repetition structure, and independence requirements from the skill text, and then realizes them as child-agent launches. fork_context=true means that a child forks and inherits the parent’ s accumulated con versational context. fork_context=false means that a child starts from a fresh, independent, clean context and recei ves only the minimal task packet explicitly handed to it. T ogether with disposable one-shot children and fresh children for independent branches, this preserves the original harness’ s model-call boundaries instead of collapsing everything into one long dialogue. • Separated runtime state and final artifacts. Durable intermediate state is written under STATE_ROOT (default /sa-output/runtime ) only when needed for reuse or auditability , while judgeable deli verables go to /sa-output/artifacts . This lets the runtime expose stable e vidence surfaces without mirroring the entire task workspace. • Contract-first completion and auditability . Benchmark outputs and completion gates remain the primary contract, but the runtime must lea ve inspectable e vidence when a harness claims staged or multi-role ex ecution. As a result, removing the runtime skill in RQ1 remov es a shared layer of orchestration, context, artifact, and reporting discipline rather than merely deleting extra prompt text. D Supplementary RQ1 case notes T able 7 lists representative SWE cases that shape our RQ1 interpretation. The goal is not exhaustiv e error taxonomy . Instead, the table isolates a few component-sensiti ve samples that expose the main mechanisms behind the paired flips: moderate structure helping, over -expanded search hurting, direct-path ov er-structuring, and local-verifier mismatch. E Supplementary RQ2 analysis Figure 4 adds two complementary views for SWE RQ2. Estimated API cost uses the public GPT -5.4 text-tok en rates on OpenAI’ s API pricing page as accessed on March 26, 2026 ( 2 . 50 / M inputand 15.00/M output). 1 Because our logs only expose aggregate prompt and completion totals, we exclude cached-input discounts, context-length surchar ges above 270K, and tool or container fees. 1 https://openai.com/api/pricing/ 15 4 6 8 10 12 14 16 Estimated API cost per sample (USD) 72 74 76 78 80 R esolved rate (%) Basic File Evidence V erifier Self Multi Dynamic (a) Scor e-cost view F ile Evidence V erifier Self Multi Dynamic 72 74 76 78 80 82 84 Solved rate (%) (b) Complementarity with Basic Basic Module alone Basic module Figure 4: Supplementary views for SWE RQ2. Left: resolved rate versus estimated token-based API cost per sample under public GPT -5.4 text pricing. Right: standalone solved rate and union solved rate with Basic for each ablated module. The left panel separates the modules more clearly than the score table alone. Self-ev olution is the only module that mov es upward without moving f ar right, which matches the claim that it tightens the solv e loop rather than simply buying a larger search tree. File-backed state and evidence-back ed answering mov e moderately right for only mild score gains, which is consistent with process-structure benefits rather than large correctness gains. V erifier and especially multi-candidate search are dominated in this vie w , while dynamic orchestration stays near Basic in score but not in cost. The right panel explains why some score-neutral or slightly negati ve modules are still behaviorally interesting. Dynamic orchestration and v erifier still enlarge the Basic union solved set e ven when their standalone score is weak, so they change which boundary cases are recov erable rather than merely lea ving behavior unchanged. Self-ev olution positive case: scikit-learn__scikit-learn-25747 . Basic fails this sample, but self- e volution resolves it. The trajectory organizes the run around an e xplicit attempt contract in which Attempt 1 is treated as successful only if the task acceptance gate is satisfied. In this case, the system closes the run after Attempt 1 rather than expanding into a larger retry tree, and the e valuator confirms that the final patch fixes the tar get F AIL_TO_P ASS tests. This is the fa vorable re gime for self-ev olution: the extra structure makes the first repair attempt more disciplined and better aligned with the benchmark gate. File/evidence positi ve case: mwaskom__seaborn-3069 . Basic fails this sample, while both file-backed state and e vidence-backed answering resolv e it. Under file-backed state, the w orkspace leav es a durable spine consisting of a parent response, append-only task history , and manifest entries for the promoted patch artifact, which makes the child handoff and artifact lineage e xplicit. Under evidence-back ed answering, the run produces a standalone analysis artifact that ties the patch to direct observ ations, root-cause reasoning, and focused validation on the nominal-axis regressions. T aken together , the pair shows that these modules are strongest when cleaner state handoff and release discipline help the solver keep one patch surface and one verification story . V erifier positive case: django__django-11734 . V erifier helps when the central claim can be checked independently and narro wly . In this sample, the verifier stage does more than restate the patch: it reruns targeted Django tests around OuterRef behavior , checks the resulting correlated-query beha vior , and inspects whether the generated SQL binds against the outer-model columns that define the bug. The benchmark then agrees with that judgment and marks the sample resolved. This is the re gime in which verifier adds v alue: the verifier’ s local acceptance object is close to the benchmark’ s final acceptance gate. Shared counter example: sympy__sympy-23950 . This sample is resolved by Basic and self-e volution, but file-backed state, e vidence-backed answering, verifier , dynamic orchestration, and multi-candidate 16 search all fail it. The verifier run is especially informativ e because the final response explicitly says that a separate verifier reported “solv ed, ” while the official e v aluator still fails test_as_set . This is a compact example of the broader RQ2 warning sign: extra process layers can make a run more structured and locally con vincing while still drifting away from the benchmark’ s actual acceptance object. That is why RQ2 is better read as a study of alignment between intermediate control structure and final e valuator beha vior , not as a monotonic story about adding more structure. F Shared modules used in RQ2 The module boxes belo w are concise paraphrastic summaries of the shared behaviors used in RQ2 rather than verbatim copies of the original skill te xt. file-backed state ROOT: Choose STATE_ROOT under /sa-output, keep it separate from the original task workspace, and maintain STATE_ROOT/RESPONSE.md as the stable runtime-level status file. HANDOFF: No prompt, role instruction, reply, or promoted artifact counts as transferred until it exists as TASK.md, SKILL.md, RESPONSE.md, or another named file under STATE_ROOT. CHILD PACKET: Each launched child receives children//TASK.md, optional children//SKILL.md , and writes back children//RESPONSE.md. BOOKKEEPING: Keep append-only launch and promotion history in state/task_history.jsonl, index promoted outputs in artifacts/manifest.json, and reopen files by path for reuse and recovery. evidence-backed answering ARTIFACT: Before any final answer, final patch, or solved claim, write one standalone evidence document as the designated evidence artifact for the current task or stage. STRUCTURE: Cover the problem statement, relevant materials, observed symptoms, root cause, candidate resolution, validation, and residual uncertainty. CLAIM DISCIPLINE: Each major claim must state its provenance, whether it is direct observation or inference, and the minimal supporting span or output segment when available. GATE: Do not release a complete answer while release-critical claims remain uncited, contradicted , or materially incomplete in that evidence document. verifier separation ROLE: Verifier inspects one candidate answer against the original problem and the lightest sufficient task materials needed to check it. PROCEDURE: Identify the candidate ' s claim, break it into checkable subclaims, audit completeness, factual correctness, and logical correctness, and run at least one central independent check when feasible. OUTPUT: Return exactly one primary verdict label plus a report that explains the verdict, names the checks run or blocked, and does not repair the candidate on its behalf. self-evolution LOOP: Run an explicit retry loop with a real baseline attempt first and a default cap of five attempts unless the task specifies otherwise. TRIGGER: After every non-successful, partially successful, unstable, or stalled attempt, reflect on concrete failure signals before planning the next attempt. AXES: Redesign the next attempt along prompt, tool, and workflow evolution, and make attempt 2 materially reflect the reflection from attempt 1. STOP: Continue until judged success or the attempt cap is reached, and report incomplete rather than pretending the last attempt passed. multi-candidate search BUDGET: Use an explicit candidate budget K, defaulting to K=5 when unspecified, and restore lost budget if a branch crashes before returning comparable evidence. DIVERSITY: Vary the core hypothesis, decomposition, evidence route, tool plan, or risk preference so candidates are not near-duplicates. SELECTION: Prune duplicates, unsupported, dominated, or overly risky branches, then compare survivors on task fit, evidence quality, coherence, and repair cost. ESCALATION: If no candidate is good enough, expand or redesign the search instead of forcing a fragile winner. 17 dynamic orchestration AUTONOMY: Beyond the mandatory task-owning child, add extra subagents only when delegation materially improves coverage, latency, specialist focus, or quality control, and prefer the smallest adequate topology. TOPOLOGY: Classify the task shape, assign each child a non-overlapping responsibility and success condition, and parallelize only genuinely independent branches. PARENT ROLE: Once a delegated topology is chosen, the parent should narrate launches, waits, comparisons, and integration rather than child-owned substantive actions. BOUNDARY: Direct task-workspace familiarization or repository probing belongs to child roles after commitment to delegated execution, not to the parent. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment