Neural Network Conversion of Machine Learning Pipelines
Transfer learning and knowledge distillation has recently gained a lot of attention in the deep learning community. One transfer approach, the student-teacher learning, has been shown to successfully create ``small'' student neural networks that mimi…
Authors: Man-Ling Sung, Jan Silovsky, Man-Hung Siu
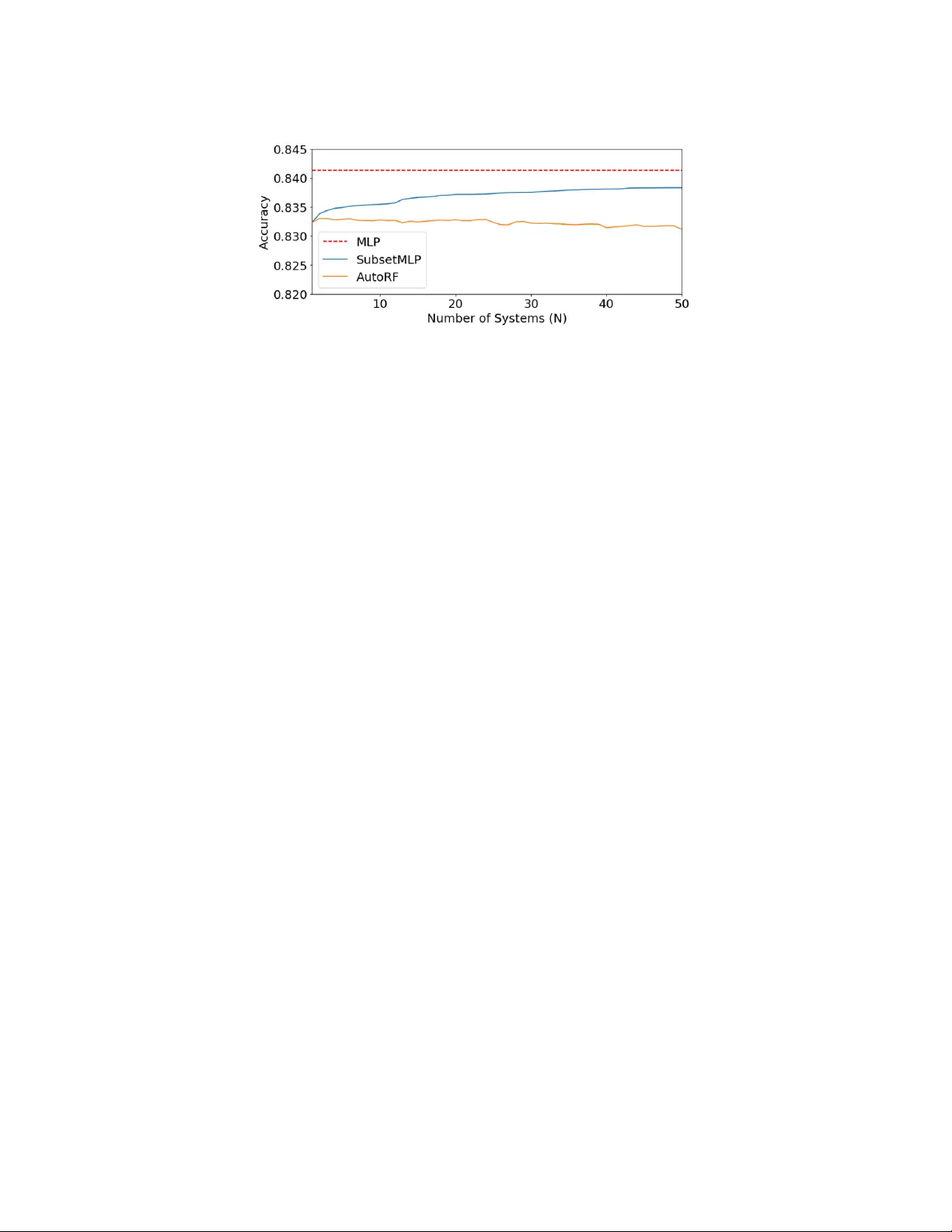
JMLR: W orkshop and Conference Proceedings 1: 1 – 7 , 2018 ICML 2018 AutoML W orkshop Neural Net w ork Con version of Mac hine Learning Pip elines Man-Ling Sung sammi.sung@ra ytheon.com Jan Silo vsky jan.silovsky@ra ytheon.com Man-h ung Siu man-hung.siu@ra ytheon.com Herb ert Gish herb.gish@ra ytheon.com Chinn u Pittapally chinnu.pitt ap all y@ra ytheon.com R aythe on BBN T e chnolo gies, 10 Moulton Str e et, Cambridge, MA 02138 Abstract T ransfer learning and kno wledge distillation has recently gained a lot of atten tion in the deep learning communit y . One transfer approach, the student-teac her learning, has been sho wn to successfully create “small” studen t neural net works that mimic the p erformance of a m uc h bigger and more complex “teac her” net works. In this pap er, w e in vestigate an extension to this approach and transfer from a non-neural-based mac hine learning pip eline as teac her to a neural netw ork (NN) student, which would allow for joint optimization of the v arious pip eline comp onen ts and a single unified inference engine for m ultiple ML tasks. In particular, we explore replacing the random forest classifier by transfer learning to a student NN. W e experimented with v arious NN topologies on 100 OpenML tasks in whic h random forest has b een one of the best solutions. Our results sho w that for the ma jority of the tasks, the student NN can indeed mimic the teacher if one can select the righ t NN h yp er-parameters. W e also inv estigated the use of random forest for selecting the righ t NN h yp er-parameters. Keyw ords: transfer learning, studen t-teacher learning, neural netw ork 1. In tro duction Our goal is to explore the use of neural netw orks as replacements for ML pip eline, or a p or- tion of these pip eline. W e will accomplish this replacemen t b y having the neural net w ork (NN) learning from the original pip eline. This go es beyond the more usual motiv ation in emplo ying the student teac her paradigm, which go es from large NN to smaller, more de- plo yable ones, e.g., Ba and Caruana ( 2014 ); Hinton et al. ( 2015 ). While smaller and more deplo yable are w elcome c haracteristics, w e ha v e additional considerations. One considera- tion is that our con verted components ma y be part of a larger net work, and c haining v arious con verted comp onen ts to form a larger neural net work will simplify the join t optimization of all parts of our system. Mapping v arious systems into neural net works can hav e several additional b enefits. Sp ecialized hardware, suc h as GPUs can enhance p erformance and a neural netw ork may ha ve b etter generalization p erformance than the original systems. Moreo ver, w e exp ect our systems to op erate in dynamic en vironments and ha ving a unified approac h to these c hanges can enhance the capabilities of these more deplo yable systems. In particular we can use standard metho ds for regularizing these netw orks, which ties in with generalization capabilities as w ell as methods for adapting the net works to changing conditions. In this w ork, our fo cus is on conv erting other classifiers in to NN classifiers. W e under- stand that a neural netw ork is not necessarily the best classifier in all situations, esp ecially © 2018 M.-L. Sung, J. Silovsky , M.-h. Siu, H. Gish & C. Pittapally . Sung Silovsky Siu Gish Pitt ap all y in small data problems. How ever, our goal is not to exceed the performance of the teac her but rather attempt to matc h it. In some situations it ma y be necessary to rely mainly on the function appro ximation capabilities of neural netw orks and at other times we may need to train the neural net w ork using metho ds of data augmen tation. By data augmentation w e en vision mo deling of the feature s p ace based on the original training data and generating new samples based on this mo del. The samples, coupled with the lab els pro vided by the teac her provide additional training for the neural net w ork. In some cases, the teacher brings more to the knowledge transfer problem than just generating classification resp onses. In some particular cases, w e can hav e kno wledge of the decision boundary in some form as well as metadata regarding the structure of the particular classifier. F or example, for random forest classifiers it has b een sho wn ( Sethi ( 1990 ), Biau et al. ( 2016 )) that they can be restructured as multi-la y ered neural netw orks. Additionally , W ang et al. ( 2017 ) sho ws ho w to create random forest inspired neural net work architectures. In our curren t w ork, these c haracteristics are not exploited. In the follo wing, w e discuss in greater detail the student-teac her approach, which for us is con version to a neural net work, follo wed b y a discussion of our experimental results. 2. Neural Net w ork Conv ersion 2.1. Studen t-T eacher Kno wledge Distillation Learning The goal of kno wledge distillation is to transfer knowledge acquired by ”teacher” to a ”studen t” such that the student can p erform as w ell or b etter than the teacher. T ypically , the teac her is a complex system either with large n umber of parameters and/or an ensem ble of classifiers while the student is relatively smaller to enable effic ien t inference, e.g. in Hin ton et al. ( 2015 ). F or Inductiv e T ransfer Learning defined in P an and Y ang ( 2010 ), consider training data T = { ( x 1 , y 1 ) , . . . , ( x n , y n ) } where x ’s are the input features with corresp onding labels y ’s. The teac her mo del M is trained using T . M can generate the lab els of a new training set T ′ = { ( x ′ 1 , ˆ y 1 ) , . . . , ( x ′ n , ˆ y n ) } where { ˆ y } is the set of lab el p osteriors generated by M . { x ′ } in T ′ and { x } in T can be differen t. In Li et al. ( 2014 ), { x ′ } includes additional unlabeled data and in Cui et al. ( 2017 ), { x ′ } and { x } are generated by different feature extractors. 2.2. Studen t-T eacher o ver Differen t System Types In typical distillation framework, b oth teac her and student are neural net w orks, or as in Tyukina et al. ( 2017 ), transfer across v ery sp ecific systems is p ossible by tapping into the internal states of the teacher systems. How ever, the student-teac her formulation in Sec- tion 2.1 can be generalized to distill b et ween t wo differen t system t yp es with the following considerations. 1. T rainability: The studen t system can be trained using lab el p osteriors ˆ y . 2. F eature Handling: The studen t system can process the t yp e of input feature x . 3. Student Complexit y: The studen t system should hav e enough capacity to learn the decision b oundaries of the teacher system. F or example, using a linear classifier as a 2 Neural Network Conversion of Machine Learning Pipelines studen t will not be able to mimic the classification decision of a deep neural netw ork classifier. Other than the particular type of studen t system (i.e. neural netw orks or random forests), the h yp er-parameters of the studen t and the amount of a v ailable training can ha ve signifi- can t impact on distillation effectiv eness. 2.3. T raining Data for Studen t The qualit y of the transfer dep ends hea vily on the amount of training data av ailable and the complexit y of the student mo del. As noted ab o v e, the student can b e trained with a different data set from those used for training the teacher. While it can b e difficult or exp ensiv e to obtain manually annotated data, the annotation needed for studen t training, { ˆ y } , can easily b e generated using the teacher mo del. Thus, extending T ′ only inv olv es obtaining more x ′ . This can b e accomplished by 1) collecting more unlabeled data whic h is feasible for man y problems; 2) Using T to estimate the input feature distribution, P ( x ), and then sampling from it. Where P ( x ) can be estimated using either parametric mo dels, suc h as GMM, or non-parametric mo dels, such as KNN or an y kernel-based distribution estimators; 3) Assuming P ( x ) to be a uniform distribution and sampling from it. Such P ( x ) can be suboptimal as discussed in Sc holkopf et al. ( 2012 ) but can b e useful as a smo othing function. 2.4. Initial Approac h In this pap er w e fo cus on a set of random forest teachers and our ability to match the random forest performance with NN classifiers. W e selected random forest classifiers based on their reputation for pro viding the b est performance on a wide range of problems and also their widespread use. W e perform this exploration on a standard set of problems pro vided b y Op enML. In addition to studen t-teac her p erformance comparisons, we also inv estigate w ays to determine the best choice of neural net work arc hitecture and h yp er-parameters to emplo y on particular problems. 3. Exp erimen ts 3.1. OpenML Op enML (Op en Machine Learning), founded b y V ansc horen et al. ( 2014 ), is a platform for sharing datasets, ready-to-use mo dels, and problems in mac hine learning. It provides cross-language APIs that facilitates the reproduction and comparison of differen t machine learning architectures. There are 4 main organization groups, 1. Data: collection of data sets a v ailable for definition of ML problems; 2. T ask: a formulation of a ML problem and sp ecification of ev aluation criteria; 3. Flo w: describ es a particular solution as a c omp osition of primitives/modules p erforming v arious tasks - e.g. feature extraction, normalization, classification, etc. 4. Run: describ es particular c onfigur ation of a flo w, most imp ortan tly , h yp erparameters of individual primitiv es. Hence, multiple Runs can b e asso ciated with iden tical Flow and yield different p erformance. 3 Sung Silovsky Siu Gish Pitt ap all y 3.2. Experimental setup First, we iden tified a Flow, Olson ( 2017 ), employing random forest as the back e n d clas- sifier, which was ev aluated for many tasks. The flo w we found w as comp osed of three sklearn primitives: prepro cessing.imputation.Imputer, decomposition.p ca.PCA and ensem- ble.forest.RandomF orestClassifier. Next, we selected 100 T asks based on best Runs. A Student system was built simply by substituting the random forest (RF) classifier b y Multi-La yer Perceptron (MLP) 1 . F or each T ask, w e used iden tical set of 600 differen t configurations of MLPs acting as differen t Studen ts. T able 1 tabulates the parameters mo dified in our configurations. F or parameters not listed, sklearn’s MLP defaults are used. By b ottlenec k, we refer to the middle lay er in systems having 3 or more la yers and the relativ e size presen ted in T able 1 is relativ e to the standard la yer size in the net works 2 . La yers No des in lay er Rel. b ottlenec k size Activ ation Init. learning rate 1,2,3,4,5 10,25,100,200,400 0.2, 0.5, 1.0 relu, tanh 1e-2,1e-3,1e-4,1e-5 T able 1: Overview of different configurations of MLP Students 3.3. Studen t-T eacher Kno wledge T ransfer In this study , we focused on knowledge transfer using the original training inputs. Thus, the Student mo del M ′ is trained with training data T ′ = { ( x 1 , ˆ y 1 ) , . . . , ( x n , ˆ y n ) } , where ˆ y = M ( x ). The OpenML exp erimen ts are designed as 10-fold cross-v alidation and we follow ed this exp erimen tal setup. This means that for each task, 10 differen t RF T eac hers w ere trained and the knowledge transfer applied indep enden tly for 10 MLP Studen ts with a particular configuration (one of the 600). The final task accuracy is then simply an av erage o v er the 10 folds. Fig. 1 illustrates the p erformance difference of the random forest T eac hers and the MLP Students. The b est p erforming MLP configuration is considered for each task. Over all tasks, 55% of Students p erform equally well or b etter than T eac her. On av erage, the p erformance of Studen ts is w orse by 2.66%. In terms of the median, the Studen ts p erform as well as the T eac hers (0.01% b etter). The shift b et ween the av erage and median is caused b y few outliers as shown in the right side of the figure. W e plan to further inv estigate wh y MLP performs so p oorly on the few outliers. F or some tasks, the Student surprisingly outp erforms the T eacher by a larger margin. W e attribute this partly to natural statistical v ariations, and partly to the fact that RF par- titions the feature space in rectangular regions while MLP has smo other decision boundary whic h may fit certain problems b etter. 1. W e relied on sklearn’s implementation of MLP classifier P edregosa et al. ( 2011 ) 2. A NN with 3 lay ers, 100 no des p er lay er and relative b ottlene ck size of 0.5, has (100,50,100) no des in its hidden lay ers 4 Neural Network Conversion of Machine Learning Pipelines Figure 1: Histogram on differences betw een RF and MLP accuracies on 100 tasks 3.4. Studen t V ersatility and Complemen tarity Ha ving large num b er of MLP studen t configurations (hereafter, we refer to these student configurations as Students ) is impractical and w e exp ect many to hav e similar p erformance across T asks. It is desirable to keep only a smaller set of complemen tary Students, i.e. studen t configurations with high performance across many T asks. Fig. 2 depicts ho w v arying the num b er of Student candidates affect the p erformance across T asks. Candidate sets of eac h size w ere formed b y removing the systems with least con tribution to the o verall p erformance. W e found that the single b est system 3 turns out to b e v ery v ersatile across T asks as it p erforms only 0.9% worse on a verage compared to the choice of the best Student out of the full inv entory of 600 Studen ts. How ev er, as shown in the figure, pic king from 20 Studen ts reduces the gap b y half to 0.45%. 3.5. Automatic Studen t Selection While w e can rely on cross-v alidation exp erimen ts to select the b est Studen t, it may still not b e feasible to train m ultiple Students in some practical applications. Ideally we w ould b e able to automatically select the best Studen t candidate based on c haracteristics of the Data, T ask and the T eacher. W e carried out a set of experiments using random forest for selecting the best studen t candidate. In tuitively , the complexity of selecting the b est Student grows with the num b er of Studen ts candidates and the complexity is further accen tuated by the limited num b er of training samples (100 samples corresp onding to the 100 T asks). The RF system for automatic Studen t selection w as trained with a 10-fold cross-v alidation o ver the T asks. As input features to this system, w e used metadata c haracterizing the datasets as pro- vided b y Op enML ( Op e ( 2018 )). W e excluded features corresp onding to p erformance of other reference classifiers, e.g. nearest neighbor. As a result, our input feature v ectors w ere formed by 74 co efficien ts reflecting v arious dataset qualities and quantities. Fig. 2 shows the comparison of choice of the b est candidate from the set of a particular size with the automatic choice done by the random forest. W e conclude that the automatic Studen t selection fails to select the b est Student candidates. Our reasoning is that the metadata pro vided by Op enML for dataset c haracterization are not suitable for automatic system selection and the performance is also affected b y the small n umber of samples av ailable. 3. A DNN with t wo hidden la yers (400,400), relu activ ation function and initial learning rate of 1e-2 5 Sung Silovsky Siu Gish Pitt ap all y Figure 2: All accuracies are computed using cross-v alidation. The top line ”MLP” is ob- tained b y selecting the b est (out of 600) Student p er task. The ”SubsetMLP” and ”AutoRF” curv es sho w the p erformance of selecting from a subset of size N. 4. Conclusions and F uture W ork There are multiple b enefits in b eing able to represent mac hine learning pip elines for v arious datasets and tasks in a unified framew ork based on neural netw orks. In this work, we first laid out a solution for conv ersion of generic machine learning pip elines in to neural net works. W e view the conv ersion as a m ulti-stage process where parts of the original pip eline are first conv erted separately b efore join t optimization can b e done. W e then fo cused on th e conv ersion of the bac k-end classifier represen ted by random forest in to a NN. W e sho wed that NNs learned emplo ying the studen t-teacher concept p erformed generally as w ell as the original random forests, with a few outliers. While NNs with man y different configurations w ere initially considered, we sho wed that the n umber of NN configurations can be significantly reduced without harming the p erformance. Finally , we inv estigated the p ossibilit y of using a random forest for automatic selection of the b est NN configuration based on the c haracteristics of the data. In contrast to using a single b est configuration, this automatic selection leads to only a marginal impro vemen t for very small sets of Students and the p erformance deteriorates as the num b er of Studen ts gro ws. W e attribute this mainly to the lack of relev ant information in the metadata which is used as input to the automatic selection system, and the lac k of training samples. Exp erimen tal work presen ted in this pap er represen ts just an initial step in our effort and man y asp ects of our prop osed solution will hav e to b e further inv estigated in the future, suc h as substitution of v arious parts of generic ML pip elines (including feature extraction or transformation), augmentation of training data, end-to-end join t optimization and automatic selection of the b est NN configuration for substitution. Ac kno wledgement This w ork is sp onsored by the Air F orce Researc h Lab oratory (AFRL) and DARP A. 6 Neural Network Conversion of Machine Learning Pipelines References List of op enml data attributes and measure, 2018. URL https://www.openml.org/search? type=measure . Accessed: 2018-05-21. Jimm y Ba and Ric h Caruana. Do deep nets really need to be deep? In A dvanc es in neur al information pr o c essing systems , pages 2654–2662, 2014. G. Biau, E. Scornet, and J. W elbl. Neural random forests. In arXiv pr eprint arXiv:1604.07143 , 2016. Jia Cui, Brian Kingsbury , Bhuv ana Ramabhadran, George Saon, T om Sercu, Kartik Au- dhkhasi, Abhina v Sethy and Markus Nussbaum-Thom, and Andrew Rosen b erg. Kno wl- edge distillation across ensem bles of m ultilingual mo dels for lo w-resource languages. In ICASSP , 2017. Geoffrey Hin ton, Oriol Viny als, and Jeff Dean. Distilling the kno wledge in a neural netw ork. In arXiv , 2015. Jin yu Li, Rui Zhao, Jui-Ting Huang, and Yifan Gong. Learning small-size dnn with output- distribution-based criteria. In Intersp e e ch , 2014. Randal Olson. Op enml flow id: 5909, 2017. URL https://www.openml.org/f/5909 . Sinno Jialin P an and Qiang Y ang. A survey on transfer learning. IEEE T r ansactions on know le dge and data engine ering , 22(10):1345–1359, 2010. F. P edregosa, G. V aro quaux, A. Gramfort, V. Mic hel, B. Thirion, O. Grisel, M. Blon- del, P . Prettenhofer, R. W eiss, V. Dub ourg, J. V anderplas, A. Passos, D. Cournap eau, M. Brucher, M. Perrot, and E. Duchesna y . Scikit-learn: Machine learning in Python. Journal of Machine L e arning R ese ar ch , 12:2825–2830, 2011. Bernhard Sc holkopf, Dominik Janzing, Jonas P eters, Eleni Sgouritsa, Kun Zhang, and Joris Mo oij. On causal and an ticausal learning. In ICML , 2012. I. K. Sethi. En tropy nets: from decision trees to neural netw orks. Pr o c e e dings of the IEEE , 78(10):1605–1613, 1990. Iv an Y u Tyukina, Alexander N. Gorbana, Konstan tin I. Sofeiko v a, and Ily a Romanenko. Kno wledge transfer b et ween artificial in telligence systems. In arXiv , 2017. Joaquin V ansc horen, Jan N V an Rijn, Bernd Bisc hl, and Luis T orgo. Op enml: netw orked science in mac hine learning. ACM SIGKDD Explor ations Newsletter , 15(2):49–60, 2014. Suhang W ang, Charu Aggaraw al, and Huan Liu. Using a random forest to inspire a neural net work and improving on it. In SIAM International Confer enc e on Data Mining , 2017. 7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment