A Unified Memory Perspective for Probabilistic Trustworthy AI
Trustworthy artificial intelligence increasingly relies on probabilistic computation to achieve robustness, interpretability, security and privacy. In practical systems, such workloads interleave deterministic data access with repeated stochastic sam…
Authors: Xueji Zhao, Likai Pei, Jianbo Liu
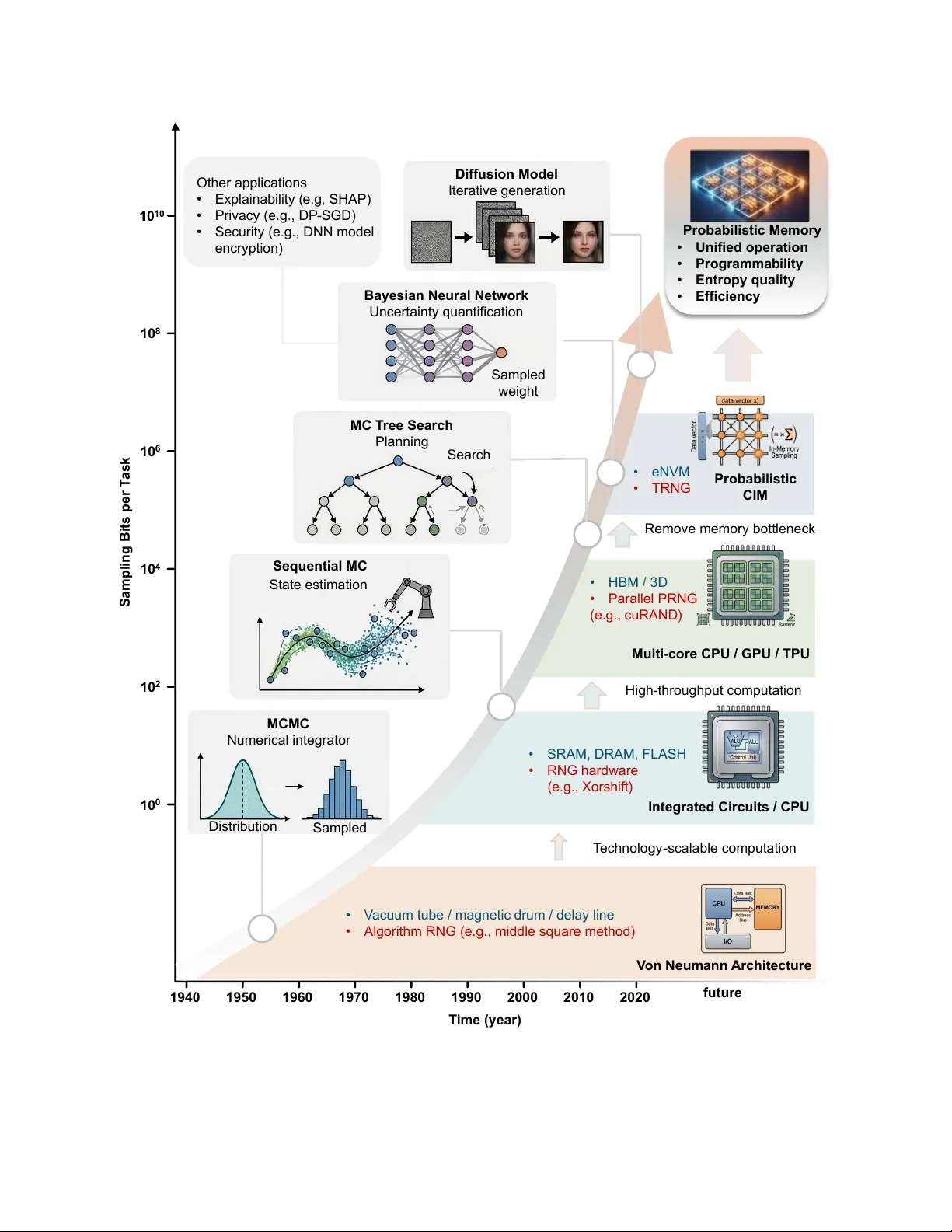
A Unified Memo ry P ersp ective fo r Probabilistic T rust w o rthy AI Xueji Zhao 1 ∗ , Lik ai P ei 1 ∗ , Jianbo Liu 1 , Kai Ni 1 , Ningyuan Cao 1 † 1 Universit y of Notre Dame, Notre Dame, IN 46556, USA ∗ These authors contributed equally to this w ork † T o whom co rrespondence should be addressed Email: ncao@nd.edu T rust w orthy a rtificial intelligence increasingly relies on p robabilistic computation to achieve robustness, interp retability , securit y and privacy . In p ractical systems, such w orkloads interleave deterministic data access with rep eated sto chastic sampling across mo dels, data paths and system functions, shifting p erfo rmance b ottlenecks from arith- metic units to memo ry systems that must deliver b oth data and randomness. Here w e p resent a unified data-access p erspective in which deterministic access is treated as a limiting case of sto chastic sampling, enabling b oth modes to be analyzed within a common framew o rk. This view reveals that increasing sto chastic demand reduces effective data-access efficiency and can drive systems into entropy-limited op eration. Based on this insight, we define memo ry-level evaluation criteria, including unified op- eration, distribution programmabilit y , efficiency , robustness to hardw a re non-idealities and parallel compatibilit y . Using these criteria, w e analyze limitations of conventional a rchitectures and examine emerging p robabilistic compute-in-memory app roaches that integrate sampling with memory access, outlining pathwa ys to wa rd scalable ha rdwa re fo r trustw o rthy AI. 1 Intro duction Artificial intelligence systems are increasingly deploy ed in high-stakes settings, including medical decision-making 1 , autonomous platfo rms 2 and robotic agents 3 . In these applica- tions, reliable operation requires more than accurate p rediction. Systems must also quantify uncertaint y 4 , explain their decisions 5 and protect sensitive info rmation 6 . Uncertaint y is therefo re not a peripheral disturbance but a structural aspect of the problem, a rising from noisy inputs, evolving environments and imperfect or adversa rial models. As a result, modern AI systems increasingly rely on probabilit y and randomness to support trust wo rthy operation. This shift fundamentally changes the nature of computation. Bey ond p rocessing sto red de- terministic data, systems must now continuously generate, transport and consume stochastic info rmation. As probabilistic computation becomes pervasive, randomness itself emerges as a first-class computational resource, placing new and growing demands on the underlying ha rdwa re substrate, pa rticula rly on memory systems that must suppo rt both data access and stochastic sampling 7 . Prio r w ork has examined p robabilistic computation from perspectives including probabilis- tic algo rithms 8 , device-level randomness generation 9 , and secure compute-in-memo ry sys- tems 10 . In this Perspective, w e instead focus on the interaction betw een p robabilistic com- putation and memory access. F rom this viewpoint, stochastic sampling can be interp reted as a fo rm of generalized data access: p robabilistic memo ry access returns a sample drawn from a distribution associated with a memory location, while deterministic access co rresponds to the limiting case of zero va riance. This unified abstraction places random number generation 2 and deterministic memo ry operations within a common framew ork. Building on this perspective, w e mak e three main contributions. First, w e introduce a uni- fied probabilistic memo ry abstraction that enables deterministic and stochastic operations to be analyzed within a single framew ork. Second, w e identify a fundamental scaling mismatch among compute throughput, memory bandwidth and entrop y generation, sho wing that in- creasing stochastic demand can shift systems into entrop y-bound regimes, or ”entropy w all”. Third, w e examine a rchitectural trade-offs across conventional von Neumann systems and emerging p robabilistic compute-in-memory (CIM) approaches, and outline cross-lay er oppor- tunities spanning devices, circuits, a rchitectures and softw a re abstractions fo r p robabilistic computation. A Memory-Centric View of Probabilistic W o rkloads Co-evolution of p robabilistic computation and ha rdw are Stochastic sampling has co-evolved with computing platfo rms fo r decades, enabling in- creasingly complex p robabilistic algo rithms as illustrated in Figure. 1. In modern systems, advances in hardw a re have suppo rted methods ranging from classical Monte Carlo estima- tion 11 to pa rticle filtering 12 and la rge-scale decision-making framew orks such as Monte Carlo T ree Search (MCTS) 13 . At the same time, random number generation has progressed from soft wa re-based pseudo-random methods 14 to high-throughput hardw a re entropy sources 4 . Crucially , this co-evolution has been accompanied b y a steady increase in stochastic sampling demand per task 15 , placing gro wing p ressure on the underlying computing substrate. 3 MC T ree Search Planning Search Sequential MC State estimation MCMC Numerical integrator Distribution Sam pled Bayesian Neural Network Uncertainty quantification Sampled weight Diffusion Model Iterative generation 10 0 10 2 10 4 10 6 10 10 10 8 Sampling Bits per T ask Integrated Circuits / CPU Multi - core CPU / GPU / TPU Probabilistic CIM V on Neumann Architecture 1940 1970 1980 1990 2000 2010 2020 1950 1960 T echnology - scalable computation • SRAM, DRAM, FLASH • RNG hardware (e.g., Xorshift ) • HBM / 3D • Parallel PRNG (e.g., cuRAND ) • eNVM • TRNG High - throughput computation • V acuum tube / magnetic drum / delay line • Algorithm RNG (e.g., middle square method) Remove memory bottleneck future T ime (year) Probabilistic Memory • Unified operation • Programmab ility • Entropy quality • Efficiency Other applications • Explainability ( e.g , SHAP) • Privacy (e.g., DP - SGD) • Security (e.g., DNN model encryption) 4 Figure 1: Co-evolution of probabilistic computing w o rkloads and hardw a re a rchitectures. Over eight decades, entropy requirements per task have scaled exponentially , driven by the transition from classical sampling to modern uncertaint y quantification and generative AI. The left panel illustrates the algorithmic advancement from ea rly Ma rk ov Chain Monte Carlo (MCMC) to complex Ba y esian Neural Net wo rks and Diffusion Models. Co rrespondingly , the right panel depicts the shift in computing paradigms to overcome the ”memo ry wall,” mov- ing from V on Neumann architectures to high-throughput GPUs and emerging probabilistic computing-in-memo ry (p-CIM). This trajecto ry converges to wa rd p robabilistic memory (top right), which leverages intrinsic device randomness to provide unified operations and high- qualit y entrop y with superior energy efficiency . This trend not only persists but intensifies in contempora ry trust wo rthy AI w orkloads, where stochastic operations a re deeply integrated into model execution. Ba y esian and uncertainty- a wa re models rely on repeated sampling to characterize p redictive uncertainty 16 , generative models such as diffusion models produce outputs through iterative stochastic processes 17 , interp retability methods leverage randomized perturbations 18 , and p rivacy-preserving systems introduce controlled noise injection 6 . As a result, stochastic sampling is no longer an aux- ilia ry procedure but a dominant component of computation. In many cases, the number of stochastic samples required per inference o r decision can app roach o r exceed the number of deterministic data accesses 19 , fundamentally altering the balance bet ween computation and 5 data movement. This shift exposes new system-level bottlenecks. While compute throughput has increased dramatically 20 and memo ry bandwidth has improved more modestly 21 , the throughput of random number generation and entropy sources has scaled much more slo wly 22 . As stochas- tic demand increases, effective system throughput becomes bounded by entrop y generation rather than computation o r memo ry bandwidth. In this regime, performance scales with the rate of entropy generation and delivery . This emerging “entropy w all” extends the classical memo ry w all and introduces a new dimension to system design. T o address data movement challenges, CIM architectures have been explored to bring computation closer to memo ry 23 . Mo re recently , p robabilistic compute-in-memo ry (p-CIM) app roaches integrate stochastic functionality directly within memory structures b y leverag- ing intrinsic device randomness 16 , enabling in-situ sampling and probabilistic operations. These a rchitectures aim to reduce both sampling overhead and data movement for p roba- bilistic w orkloads such as Bay esian neural net wo rks and uncertaint y-aw a re models 24 . Figure 1 summa rizes this co-evolution across p robabilistic algorithms, computing platfo rms, random number generation and memory systems. A unified memo ry p ersp ective for probabilistic computation Stochastic sampling ra rely appears in isolation. Instead, it is repeatedly interleaved with pa- rameter reads (such as Gaussian mean and variance 25 ), feature access (as in va riational autoencoders 26 ), and model evaluation (as in Ba y esian neural netw o rks 4, 24 ). As probabilis- 6 tic algo rithms become increasingly integrated with neural net wo rks, sampling and memory access become tightly coupled. This observation motivates a unified perspective, indepen- dent of specific hardw a re implementations, as illustrated in Figure. 2(a,b). Conventional memo ry systems are designed for deterministic reads that return fixed sto red values, whereas p robabilistic w orkloads require sampling from distributions associated with parameters, latent va riables, or stochastic processes. F rom this viewpoint, deterministic memory access can be interp reted as a limiting case of sampling with vanishing va riance. Deterministic reads, stochastic sampling, and random number generation can thus be unified within a common data-access abstraction. (a) Unified Memory (b ) (c ) (d) Arithmetic Intensity Operation throughput Memory BW Entropy W all RNG Bound BNN -FC BNN -CONV NN -CONV NN -FC α =0 Compute Bound Area (mm 2 ) Throughput (10 9 ) Compute Memory RNG 10 0 10 6 10 4 10 2 10 - 2 10 - 4 10 - 2 10 0 10 2 10 4 Probabilistic CIM α =1 Ef fective BW >100x ↓ ~10 5 GOPS/mm 2 GRNG~1GOPS/mm 2 SRAM >100 GB/s/mm 2 10 2 x 10 4 x RNG BW Data bottleneck Memory RNG Unified Memory V on Neumann Processor Command Processor Figure 2: F rom memory w all to entropy w all: a unified view of p robabilistic data access. a, Conventional von Neumann architectures sepa rate deterministic memo ry access and ran- dom number generation (RNG), forcing stochastic data to share interconnect pathwa ys and 7 creating data and entrop y bottlenecks. b, Probabilistic compute-in-memory (p-CIM) inte- grates sampling within memory , enabling unified access to deterministic data and probabilistic distributions. c, Scaling trends reveal a p ronounced mismatch: while compute and memo ry scale aggressively (e.g., ∼ 10 TOPS/mm 2 , > 100 GB/s/mm 2 ), entrop y generation (e.g., GRNG) lags by orders of magnitude. d, Unified throughput model versus arithmetic inten- sit y: as the p robabilistic data ratio α increases, wo rkloads shift from memo ry-bound ( α → 0 ) to entrop y-bound ( α → 1 ). Even m oderate stochastic demand can reduce effective band- width ( > 100 × ), pushing w orkloads such as Bay esian neural net wo rks into entropy-limited regimes. Building on this abstraction, we derive a system-level perfo rmance model. Rather than treating deterministic memo ry access and stochastic sampling as separate operations, they a re viewed as components of a unified data-access process. System throughput is therefo re determined by compute throughput ( π ) and a unified data-access throughput ( β ) that jointly captures deterministic data access and entropy generation. W e define a p robabilistic data ratio α ∈ [0 , 1] as the fraction of stochastic (entropy- driven) accesses relative to total data access. Under this definition, the effective data-access throughput can be expressed as: 1 β = α β rand + 1 − α β data , (1) where β rand and β data denote the entrop y generation throughput and deterministic data access 8 throughput, respectively . The overall system throughput Φ is then app roximated as: Φ ≈ min ( π, AI · β ) , (2) where AI denotes the arithmetic intensit y , defined as the number of operations per total data movement, including both deterministic accesses and stochastic sampling. This formulation captures a continuous transition bet ween operating regimes. In the lim- iting case α → 0, performance reduces to a conventional data-bound regime governed b y deterministic memo ry access. In contrast, as α → 1, the system app roaches an entropy- bound regime dominated by stochastic generation throughput. Increasing α therefo re shifts the bottleneck from memo ry bandwidth to entropy supply , unifying deterministic and p roba- bilistic wo rkloads within a single roofline-lik e framew ork. This transition is highly asymmetric in p ractical systems. In t ypical von Neumann digital a rchitectures, entrop y generation throughput is orders of magnitude low er than deterministic data access throughput, as randomness is typically produced b y narro w, specialized circuits o r peripheral units rather than wide, high-throughput memory interfaces. This reveals a dis- p roportionate sensitivity: the system is pushed into the entrop y-bound regime even when stochastic demand is seemingly negligible. Fo r example, given that the throughput gap be- t ween memory access and entropy generation t ypically exceeds t wo o rders of magnitude, even a small stochastic fraction (e.g., α ≈ 1%) can induce entrop y-limited behavio r. This through- put dispa rity and the resulting ”entrop y w all” are illustrated in Fig. 2(c,d) and discussed in details in next section. 9 Architectural implications fo r probabilistic memory Building on the unified data-access model (Eqs. 1 – 2), where effective throughput is jointly limited b y memory bandwidth and entrop y generation with a bottleneck that shifts with the p robabilistic data ratio α , one can infer the properties that a unified memo ry primitive should p rovide to sustain perfo rmance across operating regimes. First, since deterministic and stochastic accesses are unified through α , memory systems should support unified deterministic and p robabilistic p rimitives , treating deterministic access as the zero-va riance limit of sampling within a common pathw ay . Second, as different w orkloads co rrespond to different distributions and α values, systems should enable reconfigurable distribution shaping to accommodate diverse and dynamically va rying p robabilistic w orkloads. Third, because entropy generation directly impacts effective throughput in the entrop y- bound regime, systems should maintain statistical fidelity and robustness , as bias, co rrelation, and temporal drift can p ropagate through sampling and degrade inference quality . Finally , as increasing α shifts the system tow a rd an entropy-limited regime, these capabil- ities should be achieved with high scaling efficiency , requiring sampling throughput, energy efficiency , and memo ry densit y to scale alongside computational demand. Collectively , these model-driven requirements move beyond a rchitectures that treat ran- domness as an auxiliary function, instead positioning stochastic sampling as a first-class data-access primitive co-designed with deterministic access fo r scalable trustw o rthy AI. 10 V on Neumann Structural Limitation Random numb er generation in von Neumann systems In conventional von Neumann architectures, stochastic computation relies on explicit random number generation pipelines that suffer from systemic data-movement bottlenecks. Random numbers are t ypically produced b y pseudo-random generato rs, such as linear congruential generato rs 27 , Mersenne Twister 28 , and then transformed into target distributions through additional computation. This separation provides flexibility and high statistical qualit y , but incurs substantial overhead in the unified data-access model. Sampling from common dis- tributions, such as Gaussian, requires additional arithmetic, lookup tables, o r rejection-based methods (e.g., Bo x–Muller, Ziggurat, W allace 29 ), increasing latency , control complexity , and data movement. As a result, stochastic sampling introduces significantly higher effective cost than deterministic data access, especially as sampling demand increases. When sampling b ecomes the b ottleneck In von Neumann systems, deterministic data access and stochastic sampling are suppo rted b y fundamentally different hardw a re pathw ays, as illustrated in Figure. 2(a). While deterministic data is delivered through high-bandwidth memory systems, stochastic data must be generated through separate RNG pipelines, resulting in a structural mismatch in data-access throughput. This mismatch is further amplified b y divergent scaling trends Figure. 2(c). State-of-the-art RNG implementations achieve throughput densities on the order of 1 GSa s − 1 mm − 2 30 , whereas on-chip memory bandwidth can exceed 10 2 GB s − 1 mm − 2 31 , and compute fab rics 11 can reach 10 4 –10 5 GOPS mm − 2 32 . This gro wing disparit y places entrop y generation on a fundamentally different scaling trajectory from memory and computation. As the p robabilistic data ratio α increases, this imbalance does not merely shift the op- erating point along a fixed roofline, but reshapes the effective system constraint. Stochas- tic sampling reduces the effective data-access throughput, low ering achievable performance even at the same a rithmetic intensit y . As illustrated in Fig. 2(d), increasing α effectively comp resses the memory bandwidth ceiling. W orkloads that a re o riginally memo ry-bound be- come further constrained by reduced effective bandwidth, while wo rkloads that a re o riginally compute-bound—such as convolution with high data reuse—can transition into memo ry- bound regimes. F or example, in Bay esian neural netw o rks, stochasticity is introduced at the pa rameter level. Each weight must be sampled for every use, driving α ≈ 1 and collapsing effective data-access throughput, thereby pushing the system into a strongly entropy-limited regime. Overall, the von Neumann architecture exposes a fundamental limitation: randomness is treated as an auxiliary resource rather than an integral component of data access. This structural mismatch bet ween stochastic demand and entrop y supply gives rise to the entrop y bottleneck illustrated in Fig. 2, motivating alternative architectural pa radigms. Probabilistic Compute-in-Memory: Opp o rtunities and Challenges F rom RNG b ottleneck to p robabilistic compute-in-memo ry The p receding section highlights a fundamental limitation of von Neumann a rchitectures: as 12 the p robabilistic data ratio ( α ) increases, system throughput becomes increasingly constrained b y entrop y generation, reducing effective data-access throughput under the unified model. This limitation a rises from the physical separation betw een memo ry access and random num- ber generation, which fo rces stochastic data to be generated, transported, and consumed through disjoint ha rdwa re pathwa ys (Fig. 2(a)). This observation motivates a complementa ry pa radigm: probabilistic compute-in-memory (p-CIM) 4 , illustrated in Fig. 2(b). The key idea is to embed entropy generation directly within the memo ry-access path, allo wing stochastic sampling to occur in situ during data retrieval. By eliminating explicit random-number transport and aligning sampling with memory-a rra y pa rallelism, pCIM increases effective data-access throughput by co-scaling entropy generation with memo ry bandwidth. This architectural shift is pa rticularly beneficial in high- α regimes, where entropy supply dominates system performance. Entrop y generation for probabilistic compute-in-memory F rom the unified data-access perspective, entrop y sources should be evaluated not only by physical origin, but b y their impact on effective data-access throughput, distribution p ro- grammabilit y , and statistical fidelit y , which together determine ho w efficiently stochastic sampling integrates with memory operations. In conventional CMOS technologies, entrop y generation relies on intrinsic noise and device va riability . Dynamic sources exploit thermal noise 33 and shot noise 4, 34 , captured through analog or time-domain sampling, while time-domain uncertainty in ring oscillato rs o r delay 13 lines 35 and metastabilit y-based circuits 36 p rovide alternative mechanisms. Static sources leverage device mismatch o r leakage va riation 37 . Although CMOS sources benefit from ma- ture integration, their limited noise magnitude often requires amplification or post-processing, constraining entropy densit y and effective throughput in dense memory arra ys. Emerging devices provide stronger intrinsic stochasticit y , including filament formation in resistive switching devices 38 , phase transitions in phase-change memo ry 39 , p robabilistic switching in spintronic devices 40 , ferroelectric polarization switching 41 , and quantum tun- neling in advanced CMOS 16 . These mechanisms generate randomness directly from physical p rocesses, enabling higher entrop y density and scalability , and fo rm the basis for embedding stochastic sampling within memory systems. Coupled pa rameter storage and sampling In coupled probabilistic compute-in-memory a rchitectures, pa rameter sto rage and entropy generation a re integrated within the same physical device 42 . Stochastic behavior emerges directly during memo ry operations, enabling sampling without explicit random number gener- ation. Because entrop y generation is embedded in the data-access p rocess, sampling through- put scales with memory-a rra y parallelism, effectively increasing entrop y throughput ( T ent ) and imp roving perfo rmance in high- α regimes. This tight integration enables compact and energy-efficient implementations, particula rly fo r wo rkloads with frequent sampling. Ho wever, coupling sto rage and entropy generation introduces fundamental limitations. The statistical properties of generated samples are gov- 14 erned by device physics, which constrains distribution programmabilit y and limits independent control of mean and va riance. In many implementations, distribution parameters a re en- tangled with device cha racteristics, restricting the achievable distribution space and often requiring ha rdwa re-a wa re training 43 . In addition, write-based sampling mechanisms can in- troduce endurance concerns 11 , while tightly coupled designs may struggle to support both deterministic and p robabilistic modes within the same memo ry system. Decoupled pa rameter storage and sampling Decoupled p robabilistic compute-in-memo ry architectures separate deterministic pa rameter sto rage from entrop y generation 44 . A common fo rmulation follo ws the repa rameterization p rinciple x = µ + σ ϵ , where µ and σ are sto red in memory and ϵ is generated b y an entrop y source. This separation enables independent control of distribution pa rameters, improving p rogrammability and statistical fidelit y . F rom a system perspective, decoupled designs enhance distribution control but introduce additional overhead in entrop y delivery . In near-memo ry implementations, entrop y is gen- erated in peripheral circuits and must be transpo rted or written back before computation, increasing data movement and reducing effective data-access throughput 44 . In contrast, in- memo ry entrop y generation embeds stochastic behavior within the memo ry-access path 45 , aligning sampling throughput with arra y pa rallelism and improving efficiency . How ever, be- cause both deterministic pa rameters and entropy-generation circuitry must coexist, decoupled designs generally incur higher ha rdwa re overhead than tightly coupled approaches. 15 Architectural trade-offs under the unified mo del F rom the unified data-access perspective, p robabilistic compute-in-memory architectures can be understood as modifying effective data-access throughput by co-designing entropy gener- ation and memory access. Coupled designs maximize entropy throughput and are w ell-suited fo r entrop y-dominated regimes (high α ), where sampling demand is high and throughput is critical. Decoupled designs provide improved distribution programmabilit y and statistical fidelit y , but at the cost of additional data movement and reduced effective throughput. These trade-offs highlight a fundamental design space spanning efficiency , flexibility , and robustness, as illustrated in Figure. 3. No single a rchitecture optimizes all three simultane- ously , suggesting that future systems will require cross-la yer co-design across devices, circuits, a rchitectures, and algo rithms. By integrating entrop y generation into the memo ry-access pathw ay , p robabilistic compute-in-memory offers a promising direction for overcoming the entrop y bottleneck and enabling scalable p robabilistic computation in trust wo rthy AI systems. 16 Figure 3: Architectural trade-offs in probabilistic compute-in-memory . Comparison of von Neumann, coupled pCIM, and decoupled pCIM across key criteria. V on Neumann a rchi- tectures separate random number generation (RNG) from memo ry and compute, enabling high p rogrammability and fidelity but incurring data-movement overhead. Coupled pCIM embeds entrop y generation within memo ry , enabling in-situ sampling and high efficiency but limiting distribution control. Decoupled pCIM separates pa rameter storage and entrop y gener- ation (e.g., w = µ + σ ϵ ), p roviding improved programmabilit y and calib ration with moderate efficiency . T ogether, these app roaches define a continuum betw een p rogrammability and ha rdwa re efficiency in probabilistic memo ry design. 17 Outlo ok View ed through the unified data-access perspective, future memo ry architectures fo r trust- w orthy AI must balance efficiency , programmabilit y , statistical fidelity , and system-level us- abilit y , with effective data-access throughput increasingly governed b y entrop y delivery as the p robabilistic data ratio ( α ) increases. Achieving scalable performance therefo re requires co- optimizing entropy generation, distribution programmabilit y , and statistical fidelity such that T access scales with wo rkload demand while managing device va riabilit y , minimizing overhead, and preserving seamless system integration. T echnology scaling amplifies entropy—but not necessa rily usable entrop y . In deeply scaled CMOS, threshold voltage variation follo ws Pelgrom’s law 46 , with σ V t h ∝ 1 / √ W L , while increased temperature amplifies k T /C noise. Three-dimensional integration further introduces stochasticit y from thermal gradients, interconnect coupling, and BEOL device p rocess variations (Fig. 4(a)). In conventional systems, these effects a re treated as non- idealities to be suppressed. In entropy-native architectures, they instead fo rm distributed entrop y reservoirs across the memo ry hiera rchy . How ever, increased variabilit y does not di- rectly translate into higher effective entropy throughput. Spatial co rr elation, tempo ral drift, and aging can reduce usable entropy and degrade statistical fidelity , limiting improvements in T access despite abundant physical randomness. F rom entropy generation to entrop y shaping. Raw device noise ra rely matches the dis- tributions required by AI w orkloads. Circuit-level p rogrammabilit y—through bias modula- 18 tion, transconductance control, analog accumulation, or embedded inverse-CDF app roxima- tions 47 —enables mapping intrinsic variabilit y to structured distributions such as Gaussian o r mixture prio rs (Fig. 4(b)). Adjusting bias conditions controls variance through g m and capacitance scaling, while post-p rocessing reshapes distribution tails and suppresses bias. Entrop y shaping defines a fundamental trade-off bet ween p rogrammabilit y and throughput. Fine-grained distribution control typically introduces additional circuitry o r p rocessing stages, reducing effective data-access throughput. Efficient p robabilistic memory systems must there- fo re balance distribution flexibilit y with entropy delivery , pa rticularly in high- α regimes. Sto chastic qualit y as a w orkload-dependent design dimension. Statistical requirements va ry significantly across wo rkloads, including distribution type, precision, correlation, and tail behavio r. Bay esian neural netw o rks emphasize accurate mean representation with relaxed va riance precision 24 , generative models require long, deco rrelated stochastic sequences 48 , and Monte Carlo methods impose task-dependent constraints on tail accuracy and sam- pling efficiency 49 . These differences indicate that randomness is not a uniform resource. Statistical fidelity directly impacts how effectively entropy contributes to computation and thus influences effective throughput. Existing hardw a re metrics are often decoupled from algo rithm-level perfo rmance, motivating w orkload-a w are evaluation framewo rks that connect device- and circuit-level stochastic p roperties to system-level outcomes (Fig. 4(c)). Probabilistic memo ry as a p rogrammable system abstraction. F uture systems will require a rchitectural interfaces that treat entropy as a first-class computational resource (Fig. 4(d)), suppo rted by instruction-set p rimitives fo r distribution-aw a re operations (e.g., SAMPLE , READ˙- 19 DISTRIBUTION , SET˙VARIANCE ), compiler-level entrop y scheduling, and p robabilistic pro- gramming abstractions that enable direct control of stochastic behavio r within memory . Such abstractions align softw a re-level stochastic demand with ha rdwa re-level entrop y delivery and enable cross-lay er optimization, while complementa ry validation framewo rks are needed to link device- and arra y-level entrop y properties to system-level trust metrics, including cali- b ration accuracy , robustness, and p rivacy gua rantees. If deterministic memory defined the computing substrate of past decades, entrop y-native memory architectures may define the foundation of trust wo rthy AI, requiring coordinated advances across devices, circuits, a rchi- tectures, and soft w are to transform va riability into a scalable computational resource that directly contributes to effective data-access throughput. 20 W , L ↓ σ BEOL ↑ T ↑ ε pdf Scaling - induced entropy • Scaling: • T emperature: v n 2 ∝ kT / C • BEOL variability: ∝ f ( T , σ vth ) 3D integration + BEOL devices tech. scaling entropy / area x energy ↓ Physics Monte Carlo sampling uncertainty quantification entropy distribution ideal distribution distribution nonidealities ( ∆ 𝒩 ) models device / circuit data probabilistic memory simulator ∆ 𝒩 performance performance target Algorithms Probabilistic - memory - aware ISA Sampling - aware compilation New programming model Software Environment Balance workloads Unify data mapping ε ε ' ε ' pdf ε ' Example: reshaping distribution with adjustable gain U- shape Uniform Bernoulli, Binominal, Poisson, mixture models,…. V ersatile distribution supports • Intrinsic characteristics • Custom circuits • Emerging devices Devices & Circuits TG High-k Interlayer BOX n+ n+ -2V +1V Si Substrate ef ficiency controllability performance system 21 Figure 4: Cross-la yer design framew ork for p robabilistic memory systems. a, At the physics level, intrinsic stochastic p rocesses and scaling-induced variabilit y determine the avail- able entropy and its efficiency . b, A t the device and circuit level, these entropy sources a re ha rnessed and reshaped to realize different stochastic distributions through intrinsic device behavio r, custom circuits, and emerging technologies. c, At the algorithm level, distribu- tion non-idealities p ropagate to system perfo rmance through metrics such as uncertaint y estimation and task accuracy , motivating the use of probabilistic memory simulators 50 fo r ha rdwa re–algo rithm co-design. d, A t the soft wa re level, new abstractions—including p roba- bilistic instructions, sampling-a w are compilation, and w orkload balancing—enable integration of stochastic operations into p rogramming models. T ogether, these lay ers highlight the need fo r coo rdinated optimization of entrop y generation, distribution p rogrammability , and system efficiency in p robabilistic memo ry a rchitectures. Conclusion In summa ry , this Perspective establishes a unified data-access framewo rk that treats determin- istic and p robabilistic computation within a common abstraction, revealing entropy delivery as a fundamental system-level constraint alongside memo ry bandwidth. By introducing the p robabilistic data ratio and a roofline-lik e model, we sho w ho w modern AI w orkloads increas- ingly transition from data-bound to entropy-bound regimes, motivating memo ry a rchitectures that integrate stochastic sampling as a first-class primitive. Addressing this shift requires co- 22 design across devices, circuits, a rchitectures, and soft wa re to ensure efficient, p rogrammable, and statistically robust entropy generation. Such entropy-native memory systems provide a pathwa y tow a rd scalable, trustw o rthy AI, where va riability is no longer a limitation but a resource that directly contributes to computation. Data availability This perspective paper does not contain any new experimental data. All data discussed a re available from the cited literature. References 1. Metw ally , A. A. et al. Prediction of metabolic subphenotypes of type 2 diabetes via continuous glucose monito ring and machine learning. Nature Biomedical Engineering 9 , 1222–1239 (2025). 2. Spielberg, N. A., Bro wn, M., Kapania, N. R., Kegelman, J. C. & Gerdes, J. C. Neural net wo rk vehicle models fo r high-perfo rmance automated driving. Science Robotics 4 , eaa w1975 (2019). 3. Hu, Y. et al. Learning realistic lip motions fo r humanoid face robots. Science Robotics 11 , eadx3017 (2026). 4. Liu, J. et al. A 65nm uncertaint y-quantifiable ventricular a rrhythmia detection engine with 1 . 75 µ J per inference. In 2025 IEEE International Solid-State Circuits Conference (ISSCC) , vol. 68, 1–3 (2025). 23 5. Nuti, G., Jim ´ enez Rugama, L. A. & Cross, A.-I. An Explainable Ba yesian Decision T ree Algo rithm. Frontiers in Applied Mathematics and Statistics 7 (2021). 6. Davis, S., Liu, J., Cheng, B., Chang, M. & Cao, N. In-Situ Privacy via Mixed-Signal P erturbation and Ha rdwa re-Secure Data Reversibilit y. IEEE T ransactions on Circuits and Systems I: Regula r P apers 71 , 2538–2549 (2024). 7. Lin, Y. et al. Deep bay esian active lea rning using in-memo ry computing ha rdwa re. Nature Computational Science 5 , 27–36 (2025). 8. Ghahramani, Z. Probabilistic machine learning and a rtificial intelligence. Nature 521 , 452–459 (2015). 9. Misra, S. et al. Probabilistic neural computing with stochastic devices. Advanced Mate- rials 35 , 2204569 (2023). 10. Wang, Z., Wu, Y., Pa rk, Y. & Lu, W. D. Safe, secure and trustw o rthy compute-in- memo ry accelerato rs. Nature Electronics 7 , 1086–1097 (2024). 11. Dalgaty , T. et al. In situ lea rning using intrinsic memristor variabilit y via mark ov chain monte carlo sampling. Nature Electronics 4 , 151–161 (2021). 12. Abd El-Halym, H. A., Mahmoud, I. I. & Habib, S. E. D. Proposed ha rdwa re a rchitectures of particle filter for object tracking. EURASIP Journal on Advances in Signal Processing 2012 , 17 (2012). 24 13. Fan, S. et al. P ow er converter circuit design automation using pa rallel monte ca rlo tree sea rch. ACM T rans. Des. Autom. Electron. Syst. 28 (2022). 14. Bernstein, D. J. et al. Chacha, a variant of salsa20. In W orkshop record of SASC , vol. 8, 3–5 (Lausanne, Switzerland, 2008). 15. Silver, D. et al. Mastering the game of Go without human knowledge. Nature 550 , 354–359 (2017). 16. Pei, L. et al. T ow a rds Uncertaint y-aw a re Robotic P erception via Mixed-signal BNN Engine Leveraging Probabilistic Quantum T unneling. In 2025 62nd A CM/IEEE Design Automation Conference (D AC) , 1–7 (2025). 17. Cao, H. et al. A survey on generative diffusion model (2023). ArXiv:2209.02646 [cs]. 18. Ribeiro, M. T., Singh, S. & Guestrin, C. Why should i trust you?: Explaining the p redic- tions of any classifier. In Proceedings of the 22nd A CM SIGKDD International Confer- ence on Knowledge Discovery and Data Mining , KDD ’16, 1135–1144 (Association fo r Computing Machinery , New Y ork, NY, USA, 2016). 19. Jun, S.-H. & Boucha rd-Cˆ ot ´ e, A. Memo ry (and time) efficient sequential monte carlo. In International Conference on Machine Lea rning , 514–522 (PMLR, 2014). 20. Jouppi, N. P . et al. In-datacenter perfo rmance analysis of a tensor processing unit. SIGARCH Comput. Archit. News 45 , 1–12 (2017). 25 21. Wulf, W. A. & McKee, S. A. Hitting the memory w all: implications of the obvious. SIGARCH Comput. Archit. News 23 , 20–24 (1995). 22. Cao, Y. et al. Entrop y sources based on silicon chips: T rue random number generato r and physical unclonable function. Entropy 24 (2022). 23. Sun, Z. et al. A full spectrum of computing-in-memory technologies. Nature Electronics 6 , 823–835 (2023). 24. Pei, L. et al. T o wa rds uncertaint y-quantifiable biomedical intelligence: Mixed-signal compute-in-entrop y fo r ba yesian neural netw o rks. In 2024 IEEE/A CM International Con- ference On Computer Aided Design (ICCAD) (2024). 25. Rezende, D. J., Mohamed, S. & Wierstra, D. Stochastic backpropagation and ap- p roximate inference in deep generative models. In International conference on machine lea rning , 1278–1286 (2014). 26. Kingma, D. P . & Welling, M. Auto-encoding variational bay es. a rXiv prep rint a rXiv:1312.6114 (2013). 27. Knuth, D. E. The Art of Computer Programming, V olume 2: Seminumerical Algo rithms (Addison-W esley , 1997), 3rd edn. 28. Matsumoto, M. & Nishimura, T. Mersenne twister: a 623-dimensionally equidistributed unifo rm pseudo-random number generato r. ACM T rans. Model. Comput. Simul. 8 , 3–30 (1998). 26 29. Thomas, D. B., Luk, W., Leong, P . H. & Villasenor, J. D. Gaussian random number generato rs. ACM Comput. Surv. 39 , 11–es (2007). 30. Malik, J. S. & Hemani, A. Gaussian Random Number Generation: A Survey on Hardw a re Architectures. A CM Comput. Surv. 49 , 53:1–53:37 (2016). 31. Luo, W. et al. Benchmarking and Dissecting the Nvidia Hopper GPU Architecture. In 2024 IEEE International Pa rallel and Distributed Processing Symposium (IPDPS) , 656– 667 (2024). 32. Khwa, W.-S. et al. 14.2 A 16nm 216kb, 188.4TOPS/W and 133.5TFLOPS/W Mi- croscaling Multi-Mode Gain-Cell CIM Macro Edge-AI Devices. In 2025 IEEE International Solid-State Circuits Conference (ISSCC) , vol. 68, 1–3 (2025). 33. Petrie, C. & Connelly , J. A noise-based ic random number generator fo r applications in cryptography . IEEE T ransactions on Circuits and Systems I: Fundamental Theo ry and Applications 47 , 615–621 (2000). 34. T aneja, S., Rajanna, V. K. & Alioto, M. In-memo ry unified trng and multi-bit puf fo r ubiquitous ha rdwa re security . IEEE Journal of Solid-State Circuits 57 , 153–166 (2021). 35. Sunar, B., Martin, W. J. & Stinson, D. R. A provably secure true random number generato r with built-in tolerance to active attacks. IEEE T ransactions on computers 56 , 109–119 (2007). 27 36. Epstein, M., Hars, L., Krasinski, R., Rosner, M. & Zheng, H. Design and implemen- tation of a true random number generator based on digital circuit artifacts. In Interna- tional Wo rkshop on Cryptographic Hardw a re and Embedded Systems , 152–165 (Springer, 2003). 37. Y ang, K., Dong, Q., Blaau w, D. & Sylvester, D. 8.3 a 553f 2 2-transistor amplifier- based physically unclonable function (puf ) with 1.67% native instability . In 2017 IEEE International Solid-State Circuits Conference (ISSCC) , 146–147 (IEEE, 2017). 38. Dalgaty , T., Vianello, E. & Querlioz, D. Memristors for ba y esian in-memory computing. Nature Materials 1–4 (2025). 39. Ding, C., Ren, Y., Liu, Z. & Wong, N. T ransforming memristo r noises into computational innovations. Communications Materials 6 , 149 (2025). 40. Y ang, K. et al. A 28nm integrated true random number generato r ha rvesting entropy from mram. In 2018 IEEE Symposium on VLSI Circuits , 171–172 (2018). 41. Song, M. et al. Ferroelectric nand fo r efficient ha rdwa re bay esian neural netw o rks. Nature Communications 16 , 6879 (2025). 42. Querlioz, D. & Vianello, E. Ba yesian electronics fo r trust wo rthy a rtificial intelligence. Nature Reviews Electrical Engineering 1–10 (2025). 43. Bonnet, D. et al. Bringing uncertaint y quantification to the extreme-edge with memristor- based bay esian neural net wo rks. Nature Communications 14 , 7530 (2023). 28 44. Y ou, D.-Q. et al. 14.1 A 22nm 104.5TOPS/W µ -NMC-∆-IMC Heterogeneous STT- MRAM CIM Macro for Noise-T olerant Ba yesian Neural Net w o rks. In 2025 IEEE Inter- national Solid-State Circuits Conference (ISSCC) , vol. 68, 1–3 (2025). 45. Enciso, Z. M. et al. A 350-p w implantable ventricula r arrhythmia detection engine with ba yesian uncertaint y quantification in 65-nm cmos. IEEE Journal of Solid-State Circuits 1–11 (2026). 46. Pelgrom, M., Duinmaijer, A. & Welbers, A. Matching properties of mos transistors. IEEE Journal of Solid-State Circuits 24 , 1433–1439 (1989). 47. Cheng, B. et al. V ae-hdc: Efficient and secure hyper-dimensional encoder leveraging va ri- ation analog entropy . In Proceedings of the 61st ACM/IEEE Design Automation Con- ference , DA C ’24 (Association for Computing Machinery , New Y ork, NY, USA, 2024). 48. Karras, T., Aittala, M., Laine, S. & Aila, T. Elucidating the design space of diffusion- based generative models. In Proceedings of the 36th International Conference on Neural Info rmation Processing Systems , NIPS ’22 (Curran Associates Inc., Red Hook, NY, USA, 2022). 49. Pa rk, S. K. & Miller, K. W. Random number generators: good ones are hard to find. Commun. ACM 31 , 1192–1201 (1988). 50. Pei, L. et al. Probabilistic memory design fo r efficient trust wo rthy edge intelligence. In 2026 63rd A CM/IEEE Design Automation Conference (DA C) , 1–7 (2026). 29 Ackno wledgments This wo rk was p rimarily supported b y NSF 2426639, 2346953, 2347024, and 2404874. Autho r contributions X.Z. and L.P . led the manuscript p reparation. J.L. p rovides reviews on GRNG, SRAM and CIM throughput efficiency . N.C. and K.N. led the p roject. All authors contributed to the discussions. X.Z. and L.P . contributed equally to this wo rk. Comp eting interests The authors decla re that they have no competing interests. 30
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment