Beyond Via: Analysis and Estimation of the Impact of Large Language Models in Academic Papers
Through an analysis of arXiv papers, we report several shifts in word usage that are likely driven by large language models (LLMs) but have not previously received sufficient attention, such as the increased frequency of "beyond" and "via" in titles …
Authors: Mingmeng Geng, Yuhang Dong, Thierry Poibeau
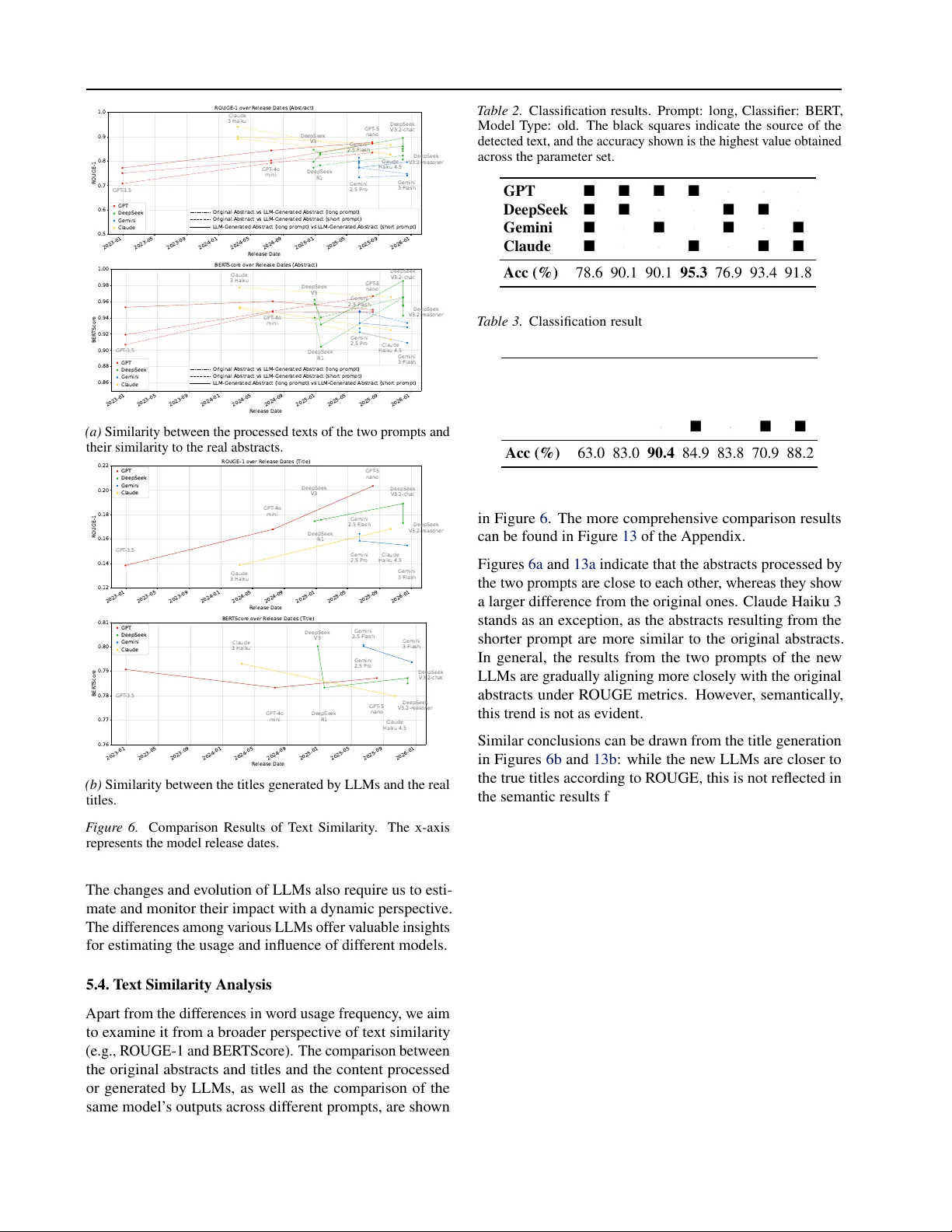
Bey ond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers Mingmeng Geng * 1 2 Y uhang Dong * 3 Thierry Poibeau 1 2 Abstract Through an analysis of arXiv papers, we report sev eral shifts in word usage that are likely dri ven by large language models (LLMs) but hav e not previously receiv ed sufficient attention, such as the increased frequenc y of “ bey ond ” and “ via ” in titles and the decreased frequency of “ the ” and “ of ” in abstracts. Due to the similarities among different LLMs, experiments sho w that current classifiers struggle to accurately determine which specific model generated a gi ven text in multi- class classification tasks. Meanwhile, variations across LLMs also result in ev olving patterns of word usage in academic papers. By adopting a di- rect and highly interpretable linear approach and accounting for differences between models and prompts, we quantitatively assess these effects and show that real-w orld LLM usage is heteroge- neous and dynamic. 1 1. Introduction The increasing impact of large language models (LLMs) in academic publications has been observed ( Liang et al. , 2024 ; Geng & T rotta , 2024 ; K obak et al. , 2024 ). As LLMs continue to de velop, has their impact ev olved more recently? For e xample, some researchers might have be gun to reduce their use of certain LLM-style (more precisely , ChatGPT - style) expressions, such as “ delve ”, around late 2023 and early 2024 ( Geng & Trotta , 2025 ). Different LLMs possess their o wn idiosyncrasies, which can be used to classify the text they generate ( W u et al. , 2023 ; Antoun et al. , 2024 ; Sun et al. , 2025 ). Considering the multiple updates to Chat- GPT and the emergence of other models, this paper aims 1 ´ Ecole Normale Sup ´ erieure (ENS) – Univ ersit ´ e Paris Sci- ences et Lettres (PSL) 2 Laboratoire Lattice 3 Friedrich-Alexander - Univ ersit ¨ at Erlangen-N ¨ urnberg (F A U). Correspondence to: Ming- meng Geng < mingmeng.geng@ens.psl.eu > . Pr eprint. Mar ch 27, 2026. 1 V isualization of w ord usage patterns in arXiv abstracts: https:// llm- impact.g ithub.i o /word- usage - arx iv- abstract/ 0 100 200 300 W or d F r equency R eal abstracts GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek via 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 200 300 400 500 600 700 F r equency (per 10,000 T itles) via R eal Data Linear T r end F it P eriod (a) In arXiv paper titles. 0 20 40 60 80 W or d F r equency R eal abstracts GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude together 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 200 250 300 350 400 F r equency (per 10,000 abstracts) together R eal Data Linear T r end F it P eriod 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 80000 85000 90000 95000 100000 105000 F r equency (per 10,000 abstracts) the R eal Data Linear T r end F it P eriod 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 45000 50000 55000 60000 65000 of (b) In arXiv paper abstracts. F igure 1. T op-left & Middle-left : W ord frequenc y comparison for titles or rewritten abstracts produced by different LLMs from 2,000 real arXiv abstracts; error bars denote v ariance across models and prompts. Remaining panels : T emporal trends of w ord frequencies in real arXiv data, with the yellow dashed line fitted on data from 2015 to 2021 and extended to early 2026. to analyze and estimate the impact of LLMs on academic publications in relation to these dev elopments. As depicted in Figure 1a , certain LLMs hav e a preference for the word “ via ” when generating titles from real arXi v abstracts, whose frequency is also becoming more com- mon in real arXi v paper titles from 2025. Meanwhile, Fig- ure 1b shows that the frequency of “ together ” first declines markedly and is then followed by a rapid increase, likely reflecting the contrasting preferences between newer and older LLMs regarding this term. Moreover , “ the ” and “ of ”, 1 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers two of the most commonly used words in many English cor- pora, hav e experienced a clear decline in frequenc y within arXiv abstracts. The use of words and expressions in academic writing has always been ev olving ( Bizzoni et al. , 2020 ; W ang et al. , 2023 ; Cheng et al. , 2024 ). Researchers are also continuously monitoring the use of specific indicati ve words to estimate the usage of LLMs in academic writing ( Gray , 2025 ; He & Bu , 2025 ). Comparisons between texts generated by LLMs and those written by humans can no w be carried out using different techniques ( W u et al. , 2025 ). In this work, we first collect arXiv papers based on a publicly av ailable dataset and use dif ferent LLMs to simulate parts of the abstracts submitted before the emer gence of ChatGPT , either by re writing the abstracts or generating titles. W e then compare the similarities and differences between the texts produced by LLMs and those written by humans from different perspectiv es, as well as the variations between texts generated by dif ferent LLMs. Although models ha ve been advanci ng, their outputs still dif fer in some way from human- written texts. Finally , we choose to analyze and estimate the impact of LLMs in academic publications through word usage, since different LLMs fa vor dif ferent words and word frequency is a relati vely interpretable measure. Our findings suggest that the influence of LLMs on aca- demic publications is growing, and the v ariety and the de- velopment of LLMs has led to further v ariations. The tools and metrics for analyzing and monitoring their impact need to ev olve as well. Although more sophisticated methods may provide numerically more accurate estimates, direct ap- proaches can also offer ne w insights into the understanding and visualizing of the societal impact of LLMs. 2. Data 2.1. arXiv Data This paper analyzes abstracts of arXiv papers, based on a dataset that is updated weekly on Kaggle ( arXiv .org sub- mitters , 2024 ) 2 . These data include more than 2.9 million arXiv papers across different fields. Considering the quan- tity and rapid update rate of arXiv papers, they may well be the best av enue for timely monitoring of LLM influence on academic writing. As our study requires analyzing how ef fects vary o ver time, we need to incorporate timestamps into the analysis. In this dataset, two such timestamps are av ailable: the paper ID id (indicating the initial submission) and the last update time update date (indicating the most recent revision). 2 h t t p s : / / w w w . k a g g l e . c o m / d a t a s e t s / C o r n e l l- University/arxiv 2.2. Data Preparation Dataset versions from v ersion 1 (released in August 2020) to version 277 (released in March 2026) were collected, with only ne wly added papers retained in each version. This means that the time implied by the arXiv ID is essentially the submission time, and even with re visions, the delay will not exceed a week. In this way , we can reduce the temporal delay introduced by paper updates. W e categorize papers based on arXi v categories, consid- ering only the first category for papers with multiple cat- egories. W e also apply re.findall(r’ \ b \ w+ \ b’, x.lower()) in Python to strip punctuation and conv ert all text to lo wercase. Based on their update dates in version 265, we randomly selected 2,000 papers from January to October 2022 for simulation using LLMs, i.e., prior to the release of ChatGPT . 2.3. Other Data Only frequent words are considered to estimate the impact of LLMs. In addition to word frequencies in the arXiv dataset, we also used data from the Google Books Ngram dataset to establish a threshold for selecting common words. W e are also interested in how stopwords are used in LLMs, with ref- erence to the list in Natural Language T oolkit (NL TK) ( Bird , 2006 ). 3. Methods 3.1. T rend of W ord Frequency Over T ime W e denote the observed frequency of word w in the dataset at time t by f d w ( t ) , which is defined by the follo wing equa- tion: f d w ( t ) = f w ( t ) + ε w ( t ) (1) where f w ( t ) refers to the pattern of ho w word frequency changes over time, while ε w ( t ) represents random v aria- tions. Even without considering randomness, the frequency of words can be influenced by multiple factors, such as changes in research topics or writing con ventions. In the follo wing, we assume that the baseline word frequency changes linearly ov er time and then model the ef fect of LLM usage as a factor that modifies this established linear trend, as shown in the formula below: f w ( t ) = a w + b w t + c w ( t ) (2) where a w and b w are word-specific coef ficients, while c w ( t ) represents the effect introduced by LLMs. Based on observ ational data from the pre-LLM period t ∈ T 1 , we estimate the parameters a w and b w and ˆ a w and ˆ b w . 2 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers These estimates are then used to predict the word frequency f pred w ( t ) ov er the later time interval t ∈ T 2 as follow: f pred w ( t ) = ˆ a w + ˆ b w t . (3) As shown in Figures 1 , the linear regression results based on data from 2021 and earlier can also reasonably predict the word frequencies for the first ten months of 2022, i.e., before the emergence of ChatGPT . Therefore, we can use the linear regression described above to predict how w ord frequencies w ould change over time as if LLMs did not exist. 3.2. Impact Estimation For dif ferent models m , they ha ve varying preferences for words, which also depend on the prompt. Let f 0 w represent the word frequency in human-written text. For model m under prompt p , the word frequenc y is f m,p w , and its mean across prompts is denoted by f m w . For the observ ed v alues in Equation 1 and the predicted values in Equation 3 , we can easily obtain the follo wing ratio: r w ( t ) = f d w ( t ) f pred w ( t ) . (4) If we further assume that η 0 ( t ) represents the proportion in human-written text at time t , and η m,p ( t ) represents the proportion in text generated by model x and prompt p . Then, under the assumption that the observed text is a mixture of these components, we can obtain the follo wing approximate relationship: r w ( t ) ≈ η 0 ( t ) + X m ∈M ,p ∈P η m,p ( t ) f m w f 0 w , (5) where M represents the set of all LLMs under consideration, and P represents the set of all prompts being considered. If we denote all the unknowns related to η as the vector η ( t ) , and define M ∗ and P ∗ to include both human and non-prompted cases to accommodate η 0 . Then for the set of all considered words W , η ( t ) can be determined using the following relation: min η ( t ) X w ∈W r w ( t ) − X m ∈M ∗ ,p ∈P ∗ η m,p ( t ) f m,p w f 0 w 2 s.t. η 0 ( t ) + X m ∈M ∗ ,p ∈P η m,p ( t ) = 1 , η m,p ( t ) ∈ [ ℓ m,p , u m,p ] , ∀ m ∈ M ∗ , p ∈ P ∗ . (6) It is important to note that the v alue of η 0 may be v ery close to 1, for example, before the emergence of ChatGPT . At the same time, other v alues of η may be close to 0. Therefore, although the loss function can be adjusted, it needs to be done with caution. 3.3. T ext Similarity Comparison and Distinction W e explore two different tasks: generating the title and modifying the abstract. T o examine the similarities and differences between human-authored texts and those gen- erated by LLMs, as well as across outputs from dif ferent LLMs, we initially assess textual similarity using multiple metrics. W e then attempt to train classifiers to categorize texts generated by dif ferent LLMs. For example, we consider three specific cases of R OUGE ( Lin , 2004 ) to compare the lexical similarity of te xts: R OUGE-1 (word-lev el comparison), R OUGE- 2 (bigram-le vel comparison), and R OUGE-L (comparison based on the longest common subsequence). W e also use BER TScore ( Zhang et al. , 2019 ), based on a pre-trained semantic neural network, to assess their semantic similarity between two pieces of text. Referring to the design and parameters of a previous study ( Sun et al. , 2025 ), we also train classifiers to dis- tinguish texts generated by dif ferent LLMs, based on three classical models: BER T ( Devlin et al. , 2019 ), GPT - 2 ( Radford et al. , 2019 ), T5 ( Raffel et al. , 2020 ), and LLM2V ec ( BehnamGhader et al. , 2024 ). The selection of parameters, such as the learning rate is consistent with that of the previous paper ( Sun et al. , 2025 ). Although adjusting the model and its parameters might yield better classification results, the purpose of this section is to validate our dataset using the current best open-source classifier , so no modifications were made. 3.4. W ord Frequency Comparison W ord frequency can also be analyzed from various perspec- tiv es. For example, we can define frequency change ratio as follows: r w,m = f m w − f 0 w f 0 w . (7) The variance of the frequenc y of a word w in the same texts giv en a prompt p across different models m is expressed as: V ar w,p = 1 |M ∗ | − 1 X m ∈M ∗ ( f m,p w − ¯ f p m ) 2 (8) where the av erage value ¯ f p m can be represented as ¯ f p m = 1 |M ∗ | X m ∈M ∗ f m,p w . (9) Subsequently , the coef ficient of variation is defined as CV w,p = p V ar w,p ¯ f p m . (10) 3 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers T able 1. Release timeline of the LLMs used in this paper. Dates indicate the initial public av ailability , verified by of ficial announce- ments. Model Name Release Date GPT -3.5 ( OpenAI , 2022 ) Dec 30, 2022 GPT -4o mini ( OpenAI , 2024 ) Jul 18, 2024 GPT -5 nano ( OpenAI , 2025 ) Aug 07, 2025 DeepSeek V3 ( DeepSeek-AI , 2024 ) Dec 26, 2024 DeepSeek R1 ( DeepSeek-AI , 2025a ) Jan 20, 2025 DeepSeek V3.2 ( DeepSeek-AI , 2025b ) Dec 01, 2025 Gemini 2.5 Flash ( Google , 2025a ) Jun 17, 2025 Gemini 2.5 Pro ( Google , 2025a ) Jun 17, 2025 Gemini 3 Flash ( Google , 2025b ) Dec 17, 2025 Claude 3 Haiku ( Anthropic , 2024 ) Mar 13, 2024 Claude Haiku 4.5 ( Anthropic , 2025 ) Oct 15, 2025 Therefore, we can identify which words beha ve dif ferently across different LLMs. 4. Simulation 4.1. Models Simulations were conducted using nine different models from the GPT , DeepSeek, Gemini, and Claude for simu- lation. Their release dates range from Nov ember 2022 to December 2025, as illustrated in T able 1 . More details on the simulation using the API can be found in Appendix Section A.2 . W e are aware that some LLMs are not covered in this study , and some versions of GPT and Claude are not included in the experiments. But the models we choose are expected to yield fairly stable estimation results. 4.2. Prompts Giv en the diversity of real-w orld application scenarios, we adopt two prompts of different lengths, one long and one short, for simulation. Short Prompt f or Abstract Rewriting : It is possible that authors restrict their use of LLM tools to light assistance, such as minor rewrites. Therefore, we consider the short prompt as follows. Revise the following sentences. Please only output the revised text in JSON format. Only one version. No explanations. Only plain text. EXAMPLE JSON OUTPUT: { "text": "Your revised version of the provided sentences goes here." } Other Pr ompts: W e can also provide more details in a longer prompt to simulate a researcher maximizing LLM capabilities for deep editing, like requesting the persona of a 0 5 10 W or d F r equency R eal abstracts GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek beyond 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 20 40 60 80 100 120 F r equency (per 10,000 T itles) beyond R eal Data Linear T r end F it P eriod (a) Left: the frequency of the word “be yond” in the titles of 2,000 simulated papers. Right: its frequency in actual arXi v titles (across all categories). 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 200 400 600 800 1000 F r equency (per 10,000 T itles) via (cs) R eal Data Linear T r end F it P eriod 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 150 200 250 300 350 400 via (non-cs) (b) T emporal change in the frequency of the word “via” in actual arXiv paper titles for CS and non-CS cate gories. F igure 2. Examples of word frequencies in paper titles. professional academic editor . The long prompt for abstract rewriting can be found in Appendix A.1 , along with the prompt used for title generation. 5. Results 5.1. W ord Choice in the Titles LLMs are asked to generate titles based on real abstracts. The word distrib utions of these titles also differ from those written by humans, which is not surprising. For example, as illustrated in Figures 1a and 2a , newer LLMs such as DeepSeek and GPT -5 tend to f av or the words “via” and “beyond” in paper titles, and their actual frequency only begins to significantly exceed the predicted v alues starting from 2025. W e also analyze the differences between CS (computer sci- ence) and non-CS papers. As shown in Figure 2b , the fre- quency of “via” in titles has increased noticeably in both categories. Giv en the relativ ely small number of words in titles, we focus primarily on the analysis of abstracts. 5.2. Commonly Used W ords LLMs have their own preferences for word usage. Some commonly used words are often regarded as stopw ords that carry little informational content, and are therefore remo ved in natural language processing ( Sarica & Luo , 2021 ), but there are differences between LLMs and humans in the usage of man y common words. For instance, for the 20 most common words in the abstracts, their w ord variation 4 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers the of and a to in we is for that with on this ar e by as an fr om which be GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 W or d F r equency Change R atio (P ost- vs. P r e-LLM P r ocessing) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 F igure 3. Frequency change ratios of the 20 most frequent w ords in 2,000 abstracts using multiple LLMs and the shorter prompt. 0 5000 10000 15000 20000 R eal abstracts GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude the 0 2500 5000 7500 10000 12500 of W or d F r equency F igure 4. W ord frequencies in 2,000 abstracts or in the corre- sponding LLM-processed content. Error bars denote the standard deviation of word frequencies across outputs produced by dif ferent LLMs and/or prompts. frequency defined in Equation 7 is illustrated in Figure 3 . Similar to pre vious results, although it is difficult to estimate LLM usage based on individual words, some correlations can still be observed. The earlier Figure 1b shows a decline in the frequencies of “the” and “of ”, and Figure 4 demon- strates that most LLMs may indeed av oid using these two words. T o better present word preferences across LLMs, we plot the frequency of the 20 words most f av ored and the frequenc y of the 20 words least fav ored by LLMs, based on the coef ficient of v ariation defined in Equation 10 , in Figures 5a and 5b . Thus, in theory , the changes in the frequencies of these common words can also be used to estimate the influence of LLMs on academic publications. 5.3. Changes and Evolution of LLMs LLMs are also continuously e volving, and dif ferent LLMs hav e distinct word preferences. The word “together” in Fig- ure 1b serves as a clear e xample. W ords previously consid- ered characteristic of ChatGPT , like “ delve ” and “ intricate ”, are being abandoned by ne wer LLMs, as seen in Figure 9 in the Appendix. There are also more examples of the change in word usage preferences, including e ven some more common words. For outcomes crucial utilized additionally methodology findings r egar ding characterized conducted advances utilize pr ecise focuses indicate inher ent further mor e e xamine illustrate ther eby characteristics R eal abstracts GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 W or d F r equency 100 200 300 400 500 600 700 800 (a) The 20 words with the highest change coefficients that LLMs prefer to use. usually besides etc give mainly gr eat done able comes behaviour gr eatly gives hence tak es uses enough together whole inter esting idea R eal abstracts GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 W or d F r equency 0 20 40 60 80 100 (b) The 20 words with the highest change coefficients that humans prefer to use. F igure 5. The frequencies of some words that appeared at least 20 times in the 2,000 abstracts used for the simulation. instance, as illustrated in Figure 10 in the appendix, the frequency of “ and ” has recently exceeded the predicted up- ward trend, whereas the frequenc y of “ this ” first decreased and then increased. These shifts may reflect differences in word preference between some recent models such as GPT -5 nano and earlier models, as shown in Figure 3 . In addition, Figure 5a indicates that, except for GPT -5 Nano, other models sho w a strong preference for the word “ furthermore ”. The frequency of this term rises sharply but returns to a le vel close to its previous gro wth trajectory recently , as illustrated in Figure 11 of the appendix. This pattern could also indicate that GPT -5 Nano or models like it are more widely used in academic writing. The changes in w ord frequency in abstracts discussed abov e are observed across the entire arXiv corpus. Similar patterns also emerge when CS and non-CS papers are examined sep- arately . For example, Figure 12 in the appendix shows the frequency changes of “the” and “of ” in these two groups. In- teracti ve results for more words and categories are av ailable on the website 3 . 3 ht t ps : // l lm- im p ac t .g i th u b .i o /w o rd - u s ag e - arxiv- abstract/ 5 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.5 0.6 0.7 0.8 0.9 1.0 ROUGE-1 GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash ROUGE-1 over R elease Dates (Abstract) Original Abstract vs LLM- Generated Abstract (long pr ompt) Original Abstract vs LLM- Generated Abstract (short pr ompt) LLM- Generated Abstract (long pr ompt) vs LLM- Generated Abstract (short pr ompt) GPT DeepSeek Gemini Claude 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.86 0.88 0.90 0.92 0.94 0.96 0.98 1.00 BER TScor e GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash BER TScor e over R elease Dates (Abstract) Original Abstract vs LLM- Generated Abstract (long pr ompt) Original Abstract vs LLM- Generated Abstract (short pr ompt) LLM- Generated Abstract (long pr ompt) vs LLM- Generated Abstract (short pr ompt) GPT DeepSeek Gemini Claude (a) Similarity between the processed texts of the two prompts and their similarity to the real abstracts. 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.12 0.14 0.16 0.18 0.20 0.22 ROUGE-1 GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash ROUGE-1 over R elease Dates (T itle) GPT DeepSeek Gemini Claude GPT DeepSeek Gemini Claude 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.76 0.77 0.78 0.79 0.80 0.81 BER TScor e GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash BER TScor e over R elease Dates (T itle) GPT DeepSeek Gemini Claude GPT DeepSeek Gemini Claude (b) Similarity between the titles generated by LLMs and the real titles. F igure 6. Comparison Results of T ext Similarity . The x-axis represents the model release dates. The changes and e volution of LLMs also require us to esti- mate and monitor their impact with a dynamic perspecti ve. The differences among v arious LLMs offer v aluable insights for estimating the usage and influence of different models. 5.4. T ext Similarity Analysis Apart from the dif ferences in word usage frequency , we aim to examine it from a broader perspecti ve of text similarity (e.g., R OUGE-1 and BER TScore). The comparison between the original abstracts and titles and the content processed or generated by LLMs, as well as the comparison of the same model’ s outputs across dif ferent prompts, are sho wn T able 2. Classification results. Prompt: long, Classifier: BER T , Model T ype: old. The black squares indicate the source of the detected text, and the accuracy sho wn is the highest v alue obtained across the parameter set. GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Acc (%) 78.6 90.1 90.1 95.3 76.9 93.4 91.8 T able 3. Classification results. Prompt: long, Classifier: BER T , Model T ype: new . GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Acc (%) 63.0 83.0 90.4 84.9 83.8 70.9 88.2 in Figure 6 . The more comprehensive comparison results can be found in Figure 13 of the Appendix. Figures 6a and 13a indicate that the abstracts processed by the two prompts are close to each other , whereas they sho w a larger dif ference from the original ones. Claude Haiku 3 stands as an exception, as the abstracts resulting from the shorter prompt are more similar to the original abstracts. In general, the results from the two prompts of the new LLMs are gradually aligning more closely with the original abstracts under ROUGE metrics. Ho wev er , semantically , this trend is not as evident. Similar conclusions can be drawn from the title generation in Figures 6b and 13b : while the new LLMs are closer to the true titles according to R OUGE, this is not reflected in the semantic results from BER TScore. The analysis in this part further highlights the differences between various LLMs, as well as the changes occurring within models of the same series. It is important to note that higher similarity does not necessarily mean stronger model performance, which may simply indicate that the model has made fewer modifications to the output te xt. 5.5. Classification W e consider two scenarios in classification tasks: distin- guishing between texts generated by different LLMs, and a multi-class classification that includes texts written by humans. The method and code we use here are based on the rare open-source work that in volv es classifying texts from different LLMs ( Sun et al. , 2025 ). In the first scenario, we consider binary and four-class clas- 6 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers R eal abstract GPT 3.5 GPT 4o mini GPT 5 nano DeepSeek Gemini Claude P r edicted Class R eal abstract GPT 3.5 GPT 4o mini GPT 5 nano DeepSeek Gemini Claude T rue Class 77.47% 1.10% 2.20% 9.34% 1.10% 2.20% 6.59% 2.75% 71.98% 14.84% 1.10% 1.65% 5.49% 2.20% 0.00% 18.13% 67.58% 0.00% 3.30% 9.34% 1.65% 6.59% 0.00% 1.65% 66.48% 6.04% 3.85% 15.38% 3.30% 7.69% 14.29% 8.79% 19.78% 31.87% 14.29% 1.10% 6.59% 9.89% 2.20% 12.09% 59.34% 8.79% 13.19% 2.75% 5.49% 8.24% 19.78% 18.13% 32.42% GPT -2 Confusion Matrix 0 10 20 30 40 50 60 70 R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude P r edicted Class R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude T rue Class 84.07% 0.00% 0.00% 3.85% 1.65% 0.00% 10.44% 0.55% 87.36% 6.59% 0.55% 2.20% 0.55% 2.20% 0.00% 8.79% 80.77% 0.00% 7.69% 1.65% 1.10% 1.65% 0.00% 0.00% 76.37% 6.59% 4.40% 10.99% 1.10% 3.30% 3.85% 2.75% 49.45% 18.13% 21.43% 0.00% 0.55% 5.49% 0.55% 13.74% 72.53% 7.14% 9.34% 1.10% 0.55% 6.59% 18.68% 6.04% 57.69% LLM2V ec Confusion Matrix 0 10 20 30 40 50 60 70 80 F igure 7. Confusion matrix of classification results from the de- tectors based on GPT -2 and LLM2V ec. In the training and test data, GPT -3.5, GPT -4o mini, and GPT -5-nano are mixtures of two prompts, while DeepSeek, Gemini, and Claude are mixtures of multiple versions and two prompts. After mixing, each class contains 2,000 abstracts. sification. An earlier v ersion (GPT -3.5, DeepSeek V3, Gem- ini 2.5 Flash, Claude 3 Haiku) and the most recent ver- sion (GPT -5 nano, DeepSeek V3.2, Gemini 3 Flash, Claude Haiku 4.5) from each of the four model families (GPT , DeepSeek, Gemini, and Claude) are chosen for comparison. T ables 2 and 3 present the classification results of the BER T - based classifier for texts generated with long prompt, while T able 4 to T able 13 in the Appendix provide more compari- son results. The v alues in the table represent the results with the highest accurac y in the test set with dif ferent parameters. In general, the results indicate that the abstracts polished by different LLMs sho w some differences, with binary classifi- cation accuracy reaching around 80%-90% and four-class classification accuracy at about 60%. In the old models, the long prompt generally achie ves higher classification accu- racy than the short prompt. In other words, the dif ferences between different LLMs are narro wing, which may indicate a homogenizing effect. For the second scenario, we directly perform a se ven-class or thirteen-class classification, including texts written by humans. The results of the se ven cate gories shown in Fig- ure 7 and Figure 14 of the appendix refer to three GPT models, along with DeepSeek, Gemini, and Claude (with mixed outputs from dif ferent models in each series), as well as human-written texts. In Figures 16 to 19 of the appendix, the thirteen categories correspond to the classification of each model separately . The table 15 in the Appendix sum- marizes some of the results. It can be observed from these results that the accuracy de- clines with the increase in categories. While the accuracy of classifying human-written texts and GPT -processed texts is quite high, it’ s also fairly common for human-written text to be mistak enly identified as LLM-generated. In real- world scenarios, the number of prompts is far greater than two, and there are more models in volv ed than those in our experiment. 5.6. Impact Estimation Giv en that real abstracts have about 20% or ev en more chance of being misclassified as LLM-generated with the classifier described abov e, we use the previously described word frequency-based estimation, which is easier to inter - pret. Based on Equation 6 , the estimated impact of LLMs vari es depending on the dif f erent w ords and parameters. For example, we can set η m,p ( t ) ∈ [0 , 1] , ∀ m ∈ M ∗ , p ∈ P ∗ (11) T o demonstrate the effecti veness of the simple method, we used SLSQP (Sequential Least Squares Programming) to solve this equation, with the initial value of η m,p ( t ) uni- formly distributed. Figure 8 presents the estimates deri ved from the models in T able 1 and the prompts in Section 4.2 . The results in Figure 8a are based on 2,741 words that are relativ ely common in both the Google Books Ngram dataset and arXiv abstracts, while the results in Figure 8b are deri ved from the stopw ords in NL TK that appear at least once in the 2,000 arXiv abstracts. These results are generally consistent with our expectations, such as the LLM impact estimates being close to zero before October 2022. W e can also observe in Figure 8a that the proportion of te xt similar to the GPT -3.5 style first increases and then decreases. The outputs of various LLMs sho w some similarities ( Jiang et al. , 2025 ), which could reduce the accuracy of predictions. The estimates based on stopwords in Figure 8b sho w larger fluctuations, likely due to the low differentiation of these 7 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers 2022-01 2023-01 2024-01 2025-01 2026-01 0.0 0.2 0.4 0.6 0.8 1.0 (t) Human-written GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude (a) The 2,741 words used for estimation are dra wn from the 10,000 most frequent words in the Google Books Ngram dataset that occur at least 10 times in the 2,000 preprocessed abstracts used for simulation. 2022-01 2023-01 2024-01 2025-01 2026-01 0.0 0.2 0.4 0.6 0.8 1.0 (t) Human-written GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude (b) The 126 words used for estimation are drawn from NL TK’ s English stopwords in the Google Books Ngram dataset that occur in the 2,000 cleaned abstracts used for simulation. F igure 8. Estimation of LLM impact in arXiv abstracts. words across different models, e ven though they differ from human-written text. 6. Related W ork LLM-Generated T ext Detection. Researchers have pro- posed many detectors for identifying text generated by LLMs, with a variety of approaches and techniques ( W u et al. , 2025 ). Howe ver , in real-world scenarios, such as academic writing, human modifications to LLM outputs can indeed affect the ef fectiv eness of detection ( Russell et al. , 2025 ). Considering the v ariety of models and use cases, it may be an impossible task to accurately estimate the numerical usage of LLMs ( Geng & Poibeau , 2025 ). LLM Fingerprint. Some LLMs each have their o wn lin- guistic fingerprints, such as in vocab ulary and lexical div er- sity , the frequency of certain lexical and morphosyntactic features ( Re viriego et al. , 2024 ; McGo vern et al. , 2025 ). These features can be used to trace their origins ( Nikolic et al. , 2025 ) as well as to detect LLM-generated text ( An- toun et al. , 2024 ; Sun et al. , 2025 ) and check API calls ( Gao et al. , 2024 ). Similar studies have also appeared in other languages, although some LLMs may be quite similar and difficult to distinguish ( Zaitsu et al. , 2025 ). LLMs for Scientific Writing. Many people are dis- cussing the use of LLMs in scientific research, and this has become an unstoppable trend ( Eger et al. , 2025 ). The disclosure of AI usage may impact ho w people perceive the article ( Hazra et al. , 2025 ). Despite the widespread use of AI in academic writing, there are fe w papers that disclose its usage ( He & Bu , 2025 ). The scope of LLMs’ use in sci- entific research goes be yond just writing, such as research fields ( Hao et al. , 2026 ), citations ( Algaba et al. , 2025 ), and more. Impact Estimation The influence of LLMs on academic publications is div erse ( K usumegi et al. , 2025 ). In addi- tion to the pre viously mentioned works, some papers at- tempt to quantify these impacts, such as through the use of words ( Liang et al. , 2025 ) and different linguistic shifts ( Bao et al. , 2025 ; Lin et al. , 2025 ). 7. Discussion The focus of this paper is on the impact of LLMs rather than on whether the text was generated by them. Classifiers are likely to perform well in binary classification, b ut their accuracy significantly decreases in multi-class tasks. In real-world scenarios, ho wev er , the latter situation is more common. Although the method of analyzing word frequency may sound simple, this intuiti ve approach pro ves to be quite ef- fectiv e in analyzing the impact of LLMs. F ocusing on more common words may pro vide better estimates, and our sim- ple method can fill the gap left by complex classifiers. Our estimates can also be improv ed, for example, by considering more models and prompts. In the era of LLMs, the way people use words is continually ev olving ( Geng & T rotta , 2025 ; Mak & W alasek , 2025 ). The effect of LLMs on te xt goes beyond academic publications. As similar impacts are likely to increase in the future, the methods and findings presented in this paper could serve as important references for subsequent research. The language style of LLMs, including their preference for certain words, requires further exploration ( Juzek & W ard , 2025 ). The opportunities these tools pro vide differ for authors from various regions (e.g., Eastern vs. W estern) ( Khan et al. , 2025 ), though our paper does not explore this aspect. The modification of content and information is more troubling than any change in wording ( Mohamed et al. , 2025 ; Ab- dulhai et al. , 2026 ). The generation of content may require more caution, such as hallucinated references ( Sakai et al. , 2026 ). 8 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers 8. Conclusion W e systematically analyze similarities and differences be- tween arXiv abstracts and titles processed by different LLMs. Compared to human-written texts, LLM-generated outputs exhibit distinct stylistic characteristics, with addi- tional variation observ ed across different models. While complex classifiers can be employed for detection, the application of such black-box methods in real-world scenarios raises concerns. Nev ertheless, it remains possible to estimate the influence of LLMs by examining the dif fer- ences between their outputs and human-written text. Our study also shows that LLMs, especially the GPT series, hav e a significant impact on the writing in arXiv abstracts, but other models likely ha ve considerable usage as well. Considering both similarity comparisons and detector out- comes, model outputs may indeed become progressively more human-like, raising more challenges for AI-generated text detection. Furthermore, humans could be subtly shaped by machines. Consequently , approaches for tracking and ev aluating their impact will need to be continuously refined as LLMs advance. Acknowledgments This work benefited from funding from the French State, managed by the Agence Nationale de la Recherche, under the France 2030 program (grant reference ANR-23-IA CL- 0008). This research also receiv ed support from the ENS- PSL BeYs Chair in Data Science and Cybersecurity . References Abdulhai, M., White, I., W an, Y ., Qureshi, I., Leibo, J., Kleiman-W einer , M., and Jaques, N. How llms distort our written language. arXiv pr eprint arXiv:2603.18161 , 2026. Algaba, A., Holst, V ., T ori, F ., Mobini, M., V erbeken, B., W enmackers, S., and Ginis, V . How deep do large lan- guage models internalize scientific literature and citation practices? arXiv pr eprint arXiv:2504.02767 , 2025. Anthropic. Claude 3 Haiku. https://www.anthropi c.co m/ne ws/c laud e- 3 - haiku , 2024. Accessed: 2026-01-25. Anthropic. Claude Haiku 4.5. h t t p s : / / w w w . a n t h r o p i c . c o m / n e w s / c l a u d e- h a i k u - 4 - 5 , 2025. Accessed: 2026-01-25. Antoun, W ., Sagot, B., and Seddah, D. From text to source: Results in detecting large language model-generated con- tent. In Pr oceedings of the 2024 Joint International Confer ence on Computational Linguistics, Language Re- sour ces and Evaluation (LREC-COLING 2024) , pp. 7531– 7543, 2024. arXiv .org submitters. arxiv dataset, 2024. URL ht t ps : //www.kaggle.com/dsv/7548853 . Bao, T ., Zhao, Y ., Mao, J., and Zhang, C. Examining linguis- tic shifts in academic writing before and after the launch of chatgpt: a study on preprint papers. Scientometrics , pp. 1–31, 2025. BehnamGhader , P ., Adlakha, V ., Mosbach, M., Bahdanau, D., Chapados, N., and Reddy , S. Llm2v ec: Large lan- guage models are secretly powerful te xt encoders. arXiv pr eprint arXiv:2404.05961 , 2024. Bird, S. Nltk: the natural language toolkit. In Pr oceedings of the COLING/ACL 2006 inter active presentation sessions , pp. 69–72, 2006. Bizzoni, Y ., Deg aetano-Ortlieb, S., Fankhauser , P ., and T e- ich, E. Linguistic v ariation and change in 250 years of english scientific writing: A data-dri ven approach. F r on- tiers in Artificial Intelligence , 3:73, 2020. Cheng, M., Gligori ´ c, K., Piccardi, T ., and Jurafsky , D. An- throscore: A computational linguistic measure of anthro- pomorphism. In Pr oceedings of the 18th Confer ence of the Eur opean Chapter of the Association for Computa- tional Linguistics (V olume 1: Long P apers) , pp. 807–825, 2024. DeepSeek-AI. DeepSeek V3 release ne ws. https://ap i- d o c s . de e p s e e k . c o m / z h- c n / n e w s / n e w s 1 226 , 2024. Accessed: 2026-01-20. DeepSeek-AI. DeepSeek R1 release ne ws. https://ap i- d o c s. d e e p s ee k . c o m /z h- cn / n e w s /n e w s 2 50120 , 2025a. Accessed: 2026-01-20. DeepSeek-AI. DeepSeek V3.2 release news. h t t p s : / / a p i- d oc s . d e e p s e e k . c o m / z h- cn / n e w s / n ews251201 , 2025b. Accessed: 2026-01-20. Devlin, J., Chang, M.-W ., Lee, K., and T outanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. In Pr oceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technolo gies, volume 1 (long and short papers) , pp. 4171–4186, 2019. Eger , S., Cao, Y ., D’Souza, J., Geiger, A., Greisinger , C., Gross, S., Hou, Y ., Krenn, B., Lauscher , A., Li, Y ., et al. T ransforming science with large language models: A surve y on ai-assisted scientific discovery , experimenta- tion, content generation, and e valuation. arXiv pr eprint arXiv:2502.05151 , 2025. 9 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers Gao, I., Liang, P ., and Guestrin, C. Model equality test- ing: Which model is this api serving? arXiv pr eprint arXiv:2410.20247 , 2024. Geng, M. and Poibeau, T . On the detectability of llm- generated te xt: What e xactly is llm-generated text? arXiv pr eprint arXiv:2510.20810 , 2025. Geng, M. and T rotta, R. Is chatgpt transforming academics’ writing style? arXiv pr eprint arXiv:2404.08627 , 2024. Geng, M. and T rotta, R. Human-llm coev olution: Evidence from academic writing. arXiv pr eprint arXiv:2502.09606 , 2025. Google. Gemini 2.5 model family expands. ht t p s : / / bl o g . go o g l e/ p r o d u c t s - a n d - p la t f o rm s / p roducts/gem ini/gemini- 2- 5- model- famil y- expands/ , 2025a. Accessed: 2026-01-20. Google. Gemini 3 Flash. https://blog.google/pr od u c t s- a n d - pl a t fo r m s /p r o d uc t s / g e m i n i /gemini- 3- flash/ , 2025b. Accessed: 2026-01-20. Gray , A. Estimating the pre valence of llm-assisted text in scholarly writing. arXiv preprint , 2025. Hao, Q., Xu, F ., Li, Y ., and Evans, J. Artificial intelligence tools expand scientists’ impact b ut contract science’ s fo- cus. Natur e , pp. 1–7, 2026. Hazra, S., Lee, D., Majumder , B. P ., and Kumar , S. Accepted with minor re visions: V alue of ai-assisted scientific writ- ing. arXiv pr eprint arXiv:2511.12529 , 2025. He, Y . and Bu, Y . Academic journals’ ai policies fail to curb the surge in ai-assisted academic writing. arXiv pr eprint arXiv:2512.06705 , 2025. Jiang, L., Chai, Y ., Li, M., Liu, M., Fok, R., Dziri, N., Tsvetk ov , Y ., Sap, M., Albalak, A., and Choi, Y . Artificial hiv emind: The open-ended homogeneity of language models (and beyond). arXiv preprint , 2025. Juzek, T . S. and W ard, Z. B. Why does chatgpt “delve” so much? exploring the sources of lexical overrepresentation in lar ge language models. In Pr oceedings of the 31st international confer ence on computational linguistics , pp. 6397–6411, 2025. Khan, F . K., Ibrahim, H., Aldahoul, N., Rahwan, T ., and Zaki, Y . Who gets seen in the age of ai? adoption patterns of lar ge language models in scholarly writing and citation outcomes. arXiv pr eprint arXiv:2509.08306 , 2025. K obak, D., Gonz ´ alez-M ´ arquez, R., Horv ´ at, E.- ´ A., and Lause, J. Delving into chatgpt usage in academic writing through excess vocab ulary . arXiv preprint arXiv:2406.07016 , 2024. Kusume gi, K., Y ang, X., Ginspar g, P ., de V aan, M., Stuart, T ., and Y in, Y . Scientific production in the era of large language models. Science , 390(6779):1240–1243, 2025. Liang, W ., Izzo, Z., Zhang, Y ., Lepp, H., Cao, H., Zhao, X., Chen, L., Y e, H., Liu, S., Huang, Z., et al. Monitoring ai-modified content at scale: A case study on the impact of chatgpt on ai conference peer re views. arXiv pr eprint arXiv:2403.07183 , 2024. Liang, W ., Zhang, Y ., W u, Z., Lepp, H., Ji, W ., Zhao, X., Cao, H., Liu, S., He, S., Huang, Z., et al. Quantifying large language model usage in scientific papers. Natur e Human Behaviour , pp. 1–11, 2025. Lin, C.-Y . Rouge: A package for automatic ev aluation of summaries. In T ext summarization branches out , pp. 74–81, 2004. Lin, D., Zhao, N., T ian, D., and Li, J. Chatgpt as linguistic equalizer? quantifying llm-driv en lexical shifts in aca- demic writing. arXiv pr eprint arXiv:2504.12317 , 2025. Mak, M. H. and W alasek, L. Style, sentiment, and quality of undergraduate writing in the ai era: A cross-sectional and longitudinal analysis of 4,820 authentic empirical reports. Computers and Education: Artificial Intelligence , pp. 100507, 2025. McGov ern, H. E., Sturebor g, R., Suhara, Y ., and Alikaniotis, D. Y our large language models are leaving fingerprints. In Proceedings of the 1stW orkshop on GenAI Content Detection (GenAIDetect) , pp. 85–95, 2025. Mohamed, A., Geng, M., V azirgiannis, M., and Shang, G. Llm as a broken telephone: Iterativ e generation distorts information. In Pr oceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pp. 7493–7509, 2025. Nikolic, I., Baluta, T ., and Saxena, P . Model prove- nance testing for lar ge language models. arXiv pr eprint arXiv:2502.00706 , 2025. OpenAI. Introducing ChatGPT. ht tp s: // op en ai .c om/index/chatgpt/ , 2022. Accessed: 2026-01-20. OpenAI. GPT -4o mini: Advancing cost-efficient intelli- gence. h t t p s : / / o p e n a i . c o m / i n d e x / g p t - 4 o- mi n i- adva n c ing- c o s t- effi c i ent- i n tel ligence/ , 2024. Accessed: 2026-01-20. 10 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers OpenAI. Introducing GPT -5. ht t ps :/ /o pe na i. c om /ind ex/ int r odu cin g - gpt - 5 / , 2025. Accessed: 2026-01-20. Radford, A., W u, J., Child, R., Luan, D., Amodei, D., Sutske ver , I., et al. Language models are unsupervised multitask learners. OpenAI blog , 1(8):9, 2019. Raffel, C., Shazeer , N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W ., and Liu, P . J. Exploring the limits of transfer learning with a unified text-to-text transformer . Journal of machine learning resear ch , 21 (140):1–67, 2020. Revirie go, P ., Conde, J., Merino-G ´ omez, E., Mart ´ ınez, G., and Hern ´ andez, J. A. Playing with words: Comparing the vocab ulary and lexical di versity of chatgpt and humans. Machine Learning with Applications , 18:100602, 2024. Russell, J., Karpinska, M., and Iyyer , M. People who fre- quently use chatgpt for writing tasks are accurate and robust detectors of ai-generated text. arXiv pr eprint arXiv:2501.15654 , 2025. Sakai, Y ., Kamigaito, H., and W atanabe, T . Hallucitation matters: Re vealing the impact of hallucinated references with 300 hallucinated papers in acl conferences. arXiv pr eprint arXiv:2601.18724 , 2026. Sarica, S. and Luo, J. Stopwords in technical language processing. Plos one , 16(8):e0254937, 2021. Sun, M., Y in, Y ., Xu, Z., K olter, J. Z., and Liu, Z. Id- iosyncrasies in large language models. arXiv preprint arXiv:2502.12150 , 2025. W ang, G., W ang, H., Sun, X., W ang, N., and W ang, L. Linguistic complexity in scientific writing: A large-scale diachronic study from 1821 to 1920. Scientometrics , 128 (1):441–460, 2023. W u, J., Y ang, S., Zhan, R., Y uan, Y ., Chao, L. S., and W ong, D. F . A surve y on llm-generated text detection: Necessity , methods, and future directions. Computational Linguistics , 51(1):275–338, 2025. W u, K., Pang, L., Shen, H., Cheng, X., and Chua, T .-S. Llmdet: A third party large language models generated text detection tool. In F indings of the association for computational linguistics: emnlp 2023 , pp. 2113–2133, 2023. Zaitsu, W ., Jin, M., Ishihara, S., Tsuge, S., and Inaba, M. Stylometry can reveal artificial intelligence authorship, but humans struggle: A comparison of human and sev en large language models in japanese. PLoS One , 20(10): e0335369, 2025. Zhang, T ., Kishore, V ., W u, F ., W einber ger , K. Q., and Artzi, Y . Bertscore: Evaluating te xt generation with bert. arXiv pr eprint arXiv:1904.09675 , 2019. 11 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers A. Simulation Details A.1. Other prompts Long prompt f or abstract rewriting: Role: Act as a professional academic editor and reviewer for top-tier scientific journals (e.g., Nature, IEEE Transactions, ACM). You have expertise in technical writing, grammar, and scientific logic. Task: Refine and polish the specific text provided below. Your goal is to improve clarity, coherence, and academic tone while strictly maintaining the original technical meaning. Constraints & Guidelines: 1. Grammar & Syntax: Correct all grammatical, spelling, and punctuation errors. 2. Academic Tone: Use formal, objective, and precise language. Avoid colloquialisms, contractions, or overly flowery language. 3. Clarity & Flow: Improve sentence structure to enhance readability. Break down overly complex sentences if necessary, but ensure the logical flow remains smooth. 4. Vocabulary: Replace weak or repetitive words with more precise academic vocabulary suited for a technical context. 5. Preservation: - Do NOT change the core scientific meaning or data. - Do NOT alter specific variable names, LaTeX formulas, citations (e.g., [1]), or technical terminology unless they are clearly incorrect. 6. Conciseness: Remove redundancy and fluff. Output Format: Please only output the polished text in JSON format. Only one version. No explanations. Only plain text. EXAMPLE JSON OUTPUT: { "text": "Your polished version of the provided text goes here." } Prompts f or title generation: Read the following abstract of a research paper. Generate a representative title that accurately reflects the main contribution of the work. Constraint: You must output ONLY a valid JSON object. Do not include any introductory or concluding text. Format: { "title": "Your generated title here" } A.2. API Usage All polished texts utilized in this study were generated via cloud-based LLM services rather than local ex ecution. T o ensure data consistency and mitigate potential disruptions caused by network instability , all LLM responses were ac- quired using Python-based batch API processing instead of interactiv e chat interfaces. The APIs were configured to output data in JSON format to strictly exclude e xtraneous explanatory text. All other settings were retained at their default v alues. The specific model APIs employed are listed belo w: 1. OpenAI Models: gpt-3.5-turbo , gpt-4o-mini , gpt-5-nano . Access period: January 13, 2025 – January 14, 2025. 2. DeepSeek Models: deepseek-chat , deepseek-reasoner . Note: DeepSeek provides only the latest model versions on its official website without specific version reference. According to the official documentation, the actual version that was executed during the access period was DeepSeek-V3.2. Access period: January 13, 2025 – January 15, 2025. 3. Alibaba Cloud Models: deepseek-v3 , deepseek-r1 . Note: These models utilized open-source code provided by DeepSeek and were hosted on servers operated by the Alibaba Cloud internet vendor . Access period: January 13, 2025 – January 16, 2025. 4. Google Models: gemini-2.5-flash , gemini-2.5-pro , gemini-3-flash-preview . Access period: January 13, 2025 – January 15, 2025. 5. Anthropic Models: claude-3-haiku-20240307 , claude-haiku-4-5-20251001 . Access period: January 21, 2026. B. Other Results 12 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers 0 20 40 60 R eal abstracts GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude delve 0 25 50 75 100 125 intricate W or d F r equency 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 0 10 20 30 40 50 F r equency (per 10,000 abstracts) delve R eal Data Linear T r end F it P eriod 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 0 25 50 75 100 125 150 intricate F igure 9. Supplementary comparison results. 0 2000 4000 6000 8000 R eal abstracts GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude and 0 1000 2000 3000 this W or d F r equency 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 35000 40000 45000 50000 F r equency (per 10,000 abstracts) and R eal Data Linear T r end F it P eriod 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 10000 11000 12000 13000 14000 this F igure 10. Supplementary comparison results. 0 200 400 600 R eal abstracts GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude further mor e 0 100 200 300 ther eby W or d F r equency 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 400 500 600 700 800 900 F r equency (per 10,000 abstracts) further mor e R eal Data Linear T r end F it P eriod 2015-01 2016-01 2017-01 2018-01 2019-01 2020-01 2021-01 2022-01 2023-01 2024-01 2025-01 2026-01 100 200 300 400 500 ther eby F igure 11. Supplementary comparison results. (a) W ord frequency in CS abstracts. (b) W ord frequency in non-CS abstracts. F igure 12. Comparison Results of T ext Similarity . The x-axis represents the model release dates. 13 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers T able 4. Classification results. Prompt: long, Classifier: GPT -2, Model T ype: old. GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Accuracy 78.2% 87.1% 89.0% 94.8 % 71.7% 90.1% 89.8% T able 5. Classification results. Prompt: long, Classifier: GPT -2, Model T ype: new . GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Accuracy 65.2% 84.6% 90.1 % 81.9% 77.7% 62.9% 82.7% T able 6. Classification results. Prompt: long, Classifier: T5, Model T ype: old. GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Accuracy 72.8% 90.7% 91.2% 94.8 % 73.4% 91.2% 91.8% T able 7. Classification results. Prompt: long, Classifier: T5, Model T ype: new . GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Accuracy 57.3% 88.5% 93.1 % 84.1% 83.8% 58.5% 82.4% T able 8. Classification results. Prompt: short, Classifier: BER T , Model T ype: old. GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Accuracy 73.1% 82.1% 89.3% 91.5% 71.2% 89.3% 93.4 % T able 9. Classification results. Prompt: short, Classifier: BER T , Model T ype: new . GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Accuracy 65.5% 80.8% 89.8 % 83.8% 87.6% 76.6% 86.8% 14 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers T able 10. Classification results. Prompt: short, Classifier: GPT -2, Model T ype: old. GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Accuracy 69.0% 80.2% 88.2% 89.6% 73.1% 85.7% 90.9 % T able 11. Classification results. Prompt: short, Classifier: GPT -2, Model T ype: new . GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Accuracy 58.2% 76.6% 89.6 % 83.0% 80.8% 70.6% 83.0% T able 12. Classification results. Prompt: short, Classifier: T5, Model T ype: old. GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Accuracy 70.9% 83.5% 91.2% 92.9 % 69.8% 86.3% 92.9 % T able 13. Classification results. Prompt: short, Classifier: T5, Model T ype: new . GPT ■ ■ ■ ■ · · · DeepSeek ■ ■ · · ■ ■ · Gemini ■ · ■ · ■ · ■ Claude ■ · · ■ · ■ ■ Accuracy 63.5% 82.7% 90.4 % 85.4% 83.2% 64.6% 84.3% T able 14. Summary of Binary Classification Accuracy (%) across dif ferent Model T ypes, Prompts, and Classifiers. Abbr eviations: G: GPT , D: DeepSeek, Ge: Gemini, C: Claude. Columns represent the ensemble combination. Model T ype Prompt Classifier All G + D G + Ge G + C D + Ge D + C Ge + C (G+D+Ge+C) New Long BER T 63.0 83.0 90.4 84.9 83.8 70.9 88.2 GPT -2 65.2 84.6 90.1 81.9 77.7 62.9 82.7 T5 57.3 88.5 93.1 84.1 83.8 58.5 82.4 Short BER T 65.5 80.8 89.8 83.8 87.6 76.6 86.8 GPT -2 58.2 76.6 89.6 83.0 80.8 70.6 83.0 T5 63.5 82.7 90.4 85.4 83.2 64.6 84.3 Old Long BER T 78.6 90.1 90.1 95.3 76.9 93.4 91.8 GPT -2 78.2 87.1 89.0 94.8 71.7 90.1 89.8 T5 72.8 90.7 91.2 94.8 73.4 91.2 91.8 Short BER T 73.1 82.1 89.3 91.5 71.2 89.3 93.4 GPT -2 69.0 80.2 88.2 89.6 73.1 85.7 90.9 T5 70.9 83.5 91.2 92.9 69.8 86.3 92.9 15 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.4 0.5 0.6 0.7 0.8 0.9 1.0 ROUGE-1 GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash ROUGE-1 over R elease Dates Original Abstract vs LLM- Generated Abstract (long pr ompt) Original Abstract vs LLM- Generated Abstract (short pr ompt) LLM- Generated Abstract (long pr ompt) vs LLM- Generated Abstract (short pr ompt) GPT DeepSeek Gemini Claude 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.4 0.5 0.6 0.7 0.8 0.9 1.0 ROUGE-2 GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash ROUGE-2 over R elease Dates Original Abstract vs LLM- Generated Abstract (long pr ompt) Original Abstract vs LLM- Generated Abstract (short pr ompt) LLM- Generated Abstract (long pr ompt) vs LLM- Generated Abstract (short pr ompt) GPT DeepSeek Gemini Claude 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.4 0.5 0.6 0.7 0.8 0.9 1.0 ROUGE-L GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash ROUGE-L over R elease Dates Original Abstract vs LLM- Generated Abstract (long pr ompt) Original Abstract vs LLM- Generated Abstract (short pr ompt) LLM- Generated Abstract (long pr ompt) vs LLM- Generated Abstract (short pr ompt) GPT DeepSeek Gemini Claude 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.800 0.825 0.850 0.875 0.900 0.925 0.950 0.975 1.000 BER TScor e GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash BER TScor e over R elease Dates Original Abstract vs LLM- Generated Abstract (long pr ompt) Original Abstract vs LLM- Generated Abstract (short pr ompt) LLM- Generated Abstract (long pr ompt) vs LLM- Generated Abstract (short pr ompt) GPT DeepSeek Gemini Claude (a) Similarity between the processed texts of the two prompts and their similarity to the real abstracts. 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.050 0.075 0.100 0.125 0.150 0.175 0.200 0.225 0.250 ROUGE-1 GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash ROUGE-1 over R elease Dates GPT DeepSeek Gemini Claude GPT DeepSeek Gemini Claude 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 0.200 ROUGE-2 GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash ROUGE-2 over R elease Dates GPT DeepSeek Gemini Claude GPT DeepSeek Gemini Claude 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.050 0.075 0.100 0.125 0.150 0.175 0.200 0.225 0.250 ROUGE-L GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash ROUGE-L over R elease Dates GPT DeepSeek Gemini Claude GPT DeepSeek Gemini Claude 2023-01 2023-05 2023-09 2024-01 2024-05 2024-09 2025-01 2025-05 2025-09 2026-01 R elease Date 0.700 0.725 0.750 0.775 0.800 0.825 0.850 0.875 0.900 BER TScor e GPT -3.5 Claude 3 Haik u GPT -4o mini DeepSeek V3 DeepSeek R1 Gemini 2.5 Flash Gemini 2.5 P r o GPT -5 nano Claude Haik u 4.5 DeepSeek V3.2-chat DeepSeek V3.2-r easoner Gemini 3 Flash BER TScor e over R elease Dates GPT DeepSeek Gemini Claude GPT DeepSeek Gemini Claude (b) Similarity between the titles generated by LLMs and the real titles. F igure 13. Comparison Results of T ext Similarity . The x-axis represents the model release dates. 16 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers T able 15. Comparison of 7-class classification performance across BER T , GPT -2, T5, and LLM2V ec models. Metrics are reported in percentage (%). P denotes Precision, R denotes Recall. Class BER T GPT -2 T5 LLM2V ec P R F1 P R F1 P R F1 P R F1 Real abstract 82.24 68.68 74.85 74.21 77.47 75.81 85.06 71.98 77.98 86.93 84.07 85.47 GPT 3.5 74.07 76.92 75.47 66.50 71.98 69.13 79.62 68.68 73.75 86.41 87.36 86.89 GPT 4o mini 64.71 72.53 68.39 58.29 67.58 62.60 60.68 78.02 68.27 83.05 80.77 81.89 GPT 5 nano 68.45 63.19 65.71 69.14 66.48 67.79 67.50 74.18 70.68 84.24 76.37 80.12 DeepSeek 36.18 30.22 32.93 31.03 19.78 24.16 38.71 26.37 31.37 49.45 49.45 49.45 Gemini 44.56 71.98 55.04 45.57 59.34 51.55 48.55 73.63 58.52 70.21 72.53 71.35 Claude 41.74 26.37 32.32 39.86 32.42 35.76 48.06 34.07 39.87 51.98 57.69 54.69 Overall Accuracy 58.56 56.44 60.99 72.61 17 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers R eal abstract GPT 3.5 GPT 4o mini GPT 5 nano DeepSeek Gemini Claude P r edicted Class R eal abstract GPT 3.5 GPT 4o mini GPT 5 nano DeepSeek Gemini Claude T rue Class 68.68% 0.00% 0.55% 12.09% 1.10% 1.65% 15.93% 1.65% 76.92% 9.89% 0.55% 3.85% 5.49% 1.65% 0.00% 13.74% 72.53% 0.00% 3.85% 9.34% 0.55% 4.40% 0.00% 0.55% 63.19% 14.29% 5.49% 12.09% 0.55% 4.40% 13.19% 5.49% 30.22% 40.66% 5.49% 0.00% 4.95% 9.89% 1.10% 10.99% 71.98% 1.10% 8.24% 3.85% 5.49% 9.89% 19.23% 26.92% 26.37% BER T Confusion Matrix 0 10 20 30 40 50 60 70 R eal abstract GPT 3.5 GPT 4o mini GPT 5 nano DeepSeek Gemini Claude P r edicted Class R eal abstract GPT 3.5 GPT 4o mini GPT 5 nano DeepSeek Gemini Claude T rue Class 71.98% 0.55% 0.00% 12.64% 2.75% 2.20% 9.89% 1.10% 68.68% 18.13% 1.10% 4.40% 4.95% 1.65% 0.00% 9.34% 78.02% 0.55% 3.30% 7.69% 1.10% 2.75% 1.10% 2.20% 74.18% 6.04% 6.04% 7.69% 1.10% 4.40% 14.29% 6.59% 26.37% 34.07% 13.19% 0.00% 1.10% 11.54% 1.65% 8.79% 73.63% 3.30% 7.69% 1.10% 4.40% 13.19% 16.48% 23.08% 34.07% T5 Confusion Matrix 0 10 20 30 40 50 60 70 F igure 14. Confusion matrix of classification results from the GPT -2-based detector and T5-based detector . 18 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude P r edicted Class R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek Gemini Claude T rue Class 84.07% 0.00% 0.00% 3.85% 1.65% 0.00% 10.44% 0.55% 87.36% 6.59% 0.55% 2.20% 0.55% 2.20% 0.00% 8.79% 80.77% 0.00% 7.69% 1.65% 1.10% 1.65% 0.00% 0.00% 76.37% 6.59% 4.40% 10.99% 1.10% 3.30% 3.85% 2.75% 49.45% 18.13% 21.43% 0.00% 0.55% 5.49% 0.55% 13.74% 72.53% 7.14% 9.34% 1.10% 0.55% 6.59% 18.68% 6.04% 57.69% LLM2V ec Confusion Matrix 0 10 20 30 40 50 60 70 80 F igure 15. Confusion matrix of classification results from the LLM2V ec-based detector . 19 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 P r edicted Class R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 T rue Class 71.43% 0.55% 0.55% 4.95% 0.00% 0.00% 1.10% 1.10% 0.55% 1.10% 0.00% 16.48% 2.20% 0.55% 71.43% 10.44% 0.00% 4.95% 0.55% 0.55% 1.65% 0.55% 1.65% 2.75% 4.95% 0.00% 0.00% 18.13% 64.84% 0.00% 5.49% 0.55% 1.10% 0.55% 1.65% 3.30% 2.75% 1.65% 0.00% 5.49% 0.00% 1.65% 54.95% 0.55% 0.55% 4.40% 2.20% 0.00% 3.85% 4.40% 7.14% 14.84% 0.00% 6.59% 14.84% 0.55% 24.73% 4.95% 7.14% 5.49% 9.34% 3.85% 14.29% 3.85% 4.40% 2.20% 1.10% 0.55% 1.65% 17.58% 17.03% 4.40% 8.24% 11.54% 9.34% 14.29% 3.30% 8.79% 1.65% 3.30% 8.24% 2.75% 15.93% 2.75% 22.53% 8.24% 3.85% 6.59% 7.14% 6.59% 10.44% 2.20% 3.30% 9.89% 3.85% 12.09% 4.40% 12.64% 12.09% 6.04% 6.59% 11.54% 7.69% 7.69% 0.00% 1.65% 6.59% 0.00% 8.24% 2.20% 3.30% 4.95% 39.56% 12.09% 18.13% 1.65% 1.65% 0.55% 0.55% 0.55% 1.65% 1.65% 2.20% 2.75% 0.00% 13.74% 53.85% 18.13% 1.65% 2.75% 0.00% 1.10% 1.65% 1.65% 6.04% 2.20% 0.55% 2.20% 7.14% 13.19% 61.54% 0.55% 2.20% 17.03% 1.10% 2.75% 5.49% 0.00% 1.10% 6.59% 4.95% 1.65% 4.40% 2.20% 47.25% 5.49% 1.10% 0.55% 1.10% 9.34% 8.79% 7.69% 7.14% 6.04% 2.20% 6.59% 9.89% 2.20% 37.36% bert (lr=1e-04, accuracy=44.51%) Confusion Matrix 0 10 20 30 40 50 60 70 F igure 16. Confusion matrix of BER T (lr=1e-04) 20 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 P r edicted Class R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 T rue Class 70.33% 0.00% 1.10% 8.79% 0.55% 0.55% 0.55% 3.30% 0.55% 2.20% 0.00% 11.54% 0.55% 2.20% 75.82% 6.04% 1.10% 4.40% 0.55% 1.10% 0.55% 2.20% 1.10% 1.65% 3.30% 0.00% 0.00% 16.48% 59.89% 0.55% 6.04% 0.00% 1.10% 1.10% 6.04% 1.10% 4.40% 3.30% 0.00% 8.24% 0.55% 0.55% 56.59% 0.55% 1.65% 2.75% 4.95% 0.55% 3.85% 3.30% 5.49% 10.99% 1.10% 10.44% 7.69% 3.30% 33.52% 3.85% 4.95% 4.40% 9.34% 4.95% 7.69% 3.85% 4.95% 4.40% 2.20% 2.20% 4.40% 10.99% 13.74% 3.85% 7.14% 15.38% 9.34% 12.09% 2.20% 12.09% 4.40% 3.30% 9.89% 6.59% 11.54% 4.95% 11.54% 10.44% 6.04% 11.54% 7.14% 5.49% 7.14% 7.14% 4.95% 4.95% 9.89% 10.44% 3.30% 7.14% 13.19% 5.49% 10.99% 9.34% 6.04% 7.14% 1.10% 5.49% 6.59% 3.30% 4.40% 5.49% 1.10% 4.95% 44.51% 12.09% 9.89% 0.00% 1.10% 1.65% 1.10% 2.20% 2.20% 4.95% 3.30% 1.65% 4.95% 13.74% 47.80% 8.24% 3.30% 4.95% 0.55% 2.20% 3.85% 5.49% 5.49% 2.75% 1.65% 2.20% 9.34% 14.29% 49.45% 1.10% 1.65% 21.43% 0.00% 2.20% 9.34% 1.10% 2.20% 3.85% 0.55% 2.75% 3.30% 2.20% 43.41% 7.69% 2.20% 0.00% 0.00% 14.29% 5.49% 10.99% 3.85% 6.04% 5.49% 9.34% 6.04% 2.20% 34.07% gpt2 (lr=3e-04, accuracy=42.60%) Confusion Matrix 0 10 20 30 40 50 60 70 F igure 17. Confusion matrix of GPT -2 (lr=3e-04) 21 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 P r edicted Class R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 T rue Class 72.53% 0.00% 0.00% 6.04% 0.00% 1.10% 0.00% 1.65% 0.00% 1.10% 0.00% 15.38% 2.20% 0.55% 65.38% 19.78% 0.55% 4.95% 0.00% 1.10% 1.10% 2.20% 0.00% 0.55% 2.75% 1.10% 0.00% 12.09% 74.73% 0.00% 2.20% 0.55% 0.55% 1.65% 2.75% 0.00% 2.75% 1.65% 1.10% 3.30% 0.00% 2.20% 63.19% 0.00% 0.55% 3.30% 4.40% 0.55% 3.30% 5.49% 4.40% 9.34% 0.55% 5.49% 12.64% 1.65% 29.12% 5.49% 4.40% 4.95% 10.99% 2.20% 15.38% 2.20% 4.95% 0.55% 1.10% 3.85% 3.30% 14.29% 12.09% 3.85% 7.14% 8.79% 9.34% 13.19% 6.04% 16.48% 2.75% 1.10% 12.64% 8.24% 9.89% 4.40% 14.29% 10.99% 5.49% 6.59% 6.59% 8.24% 8.79% 2.75% 1.10% 9.34% 5.49% 7.69% 2.75% 12.64% 14.29% 9.34% 10.99% 9.89% 6.59% 7.14% 0.00% 3.30% 9.89% 0.55% 3.30% 3.30% 3.30% 2.75% 37.91% 16.48% 15.38% 0.55% 3.30% 0.00% 0.55% 3.30% 1.10% 1.65% 1.10% 2.20% 1.10% 9.89% 53.85% 17.03% 1.65% 6.59% 0.00% 0.00% 3.85% 2.20% 4.40% 2.20% 0.00% 2.75% 8.79% 12.64% 59.34% 0.55% 3.30% 21.43% 0.55% 4.40% 8.79% 0.55% 1.65% 5.49% 4.95% 1.65% 1.65% 2.20% 40.66% 6.04% 2.20% 0.00% 1.10% 12.09% 8.24% 4.95% 4.95% 4.40% 2.20% 10.44% 7.69% 2.75% 39.01% t5 (lr=3e-04, accuracy=44.34%) Confusion Matrix 0 10 20 30 40 50 60 70 F igure 18. Confusion matrix of T5 (lr=3e-04) 22 Beyond V ia: Analysis and Estimation of the Impact of Large Language Models in Academic Papers R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 P r edicted Class R eal abstract GPT -3.5 GPT -4o mini GPT -5 nano DeepSeek V3 DeepSeek R1 DeepSeek V3.2 DeepSeek V3.2 Thinking Gemini 2.5 Flash Gemini 2.5 P r o Gemini 3 Flash Claude 3 Haik u Claude Haik u 4.5 T rue Class 81.87% 0.00% 0.00% 4.95% 0.00% 2.20% 0.00% 0.55% 0.00% 0.00% 0.00% 10.44% 0.00% 0.55% 81.87% 7.69% 0.55% 2.20% 0.55% 0.55% 1.10% 1.65% 0.00% 0.55% 2.75% 0.00% 0.00% 8.79% 74.73% 0.00% 3.85% 1.10% 2.20% 4.95% 1.65% 0.00% 0.55% 2.20% 0.00% 2.20% 0.00% 0.00% 75.82% 0.55% 1.65% 2.20% 3.85% 0.00% 2.20% 3.30% 4.40% 3.85% 0.00% 4.40% 4.40% 0.55% 47.80% 9.89% 3.85% 8.24% 5.49% 3.85% 6.04% 1.10% 4.40% 0.00% 2.75% 1.65% 2.20% 10.44% 36.81% 4.95% 9.89% 9.34% 4.40% 4.95% 3.30% 9.34% 1.65% 1.65% 3.85% 6.59% 13.74% 6.04% 19.23% 19.23% 3.85% 8.24% 2.75% 4.95% 8.24% 1.10% 2.20% 2.20% 4.95% 10.44% 5.49% 9.89% 35.71% 5.49% 4.95% 3.30% 6.59% 7.69% 0.00% 0.55% 2.20% 0.00% 6.04% 6.59% 2.20% 6.59% 59.89% 5.49% 4.95% 2.20% 3.30% 0.00% 0.55% 0.55% 1.10% 0.55% 0.55% 1.10% 3.30% 6.04% 71.98% 10.99% 1.10% 2.20% 0.00% 0.55% 0.55% 2.20% 3.85% 2.75% 0.55% 1.10% 2.75% 13.19% 70.88% 1.10% 0.55% 17.58% 1.10% 0.55% 4.95% 1.10% 2.20% 2.20% 4.95% 3.30% 0.55% 2.20% 56.04% 3.30% 0.55% 0.55% 0.00% 5.49% 3.30% 9.34% 7.14% 4.95% 2.20% 4.40% 2.20% 3.85% 56.04% llm2vec (lr=5e-05, accuracy=59.13%) Confusion Matrix 0 10 20 30 40 50 60 70 80 F igure 19. Confusion matrix of LLM2V ec (lr=5e-05) 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment