Is Mathematical Problem-Solving Expertise in Large Language Models Associated with Assessment Performance?
Large Language Models (LLMs) are increasingly used in math education not only as problem solvers but also as assessors of learners' reasoning. However, it remains unclear whether stronger math problem-solving ability is associated with stronger step-…
Authors: Liang Zhang, Yu Fu, Xinyi Jin
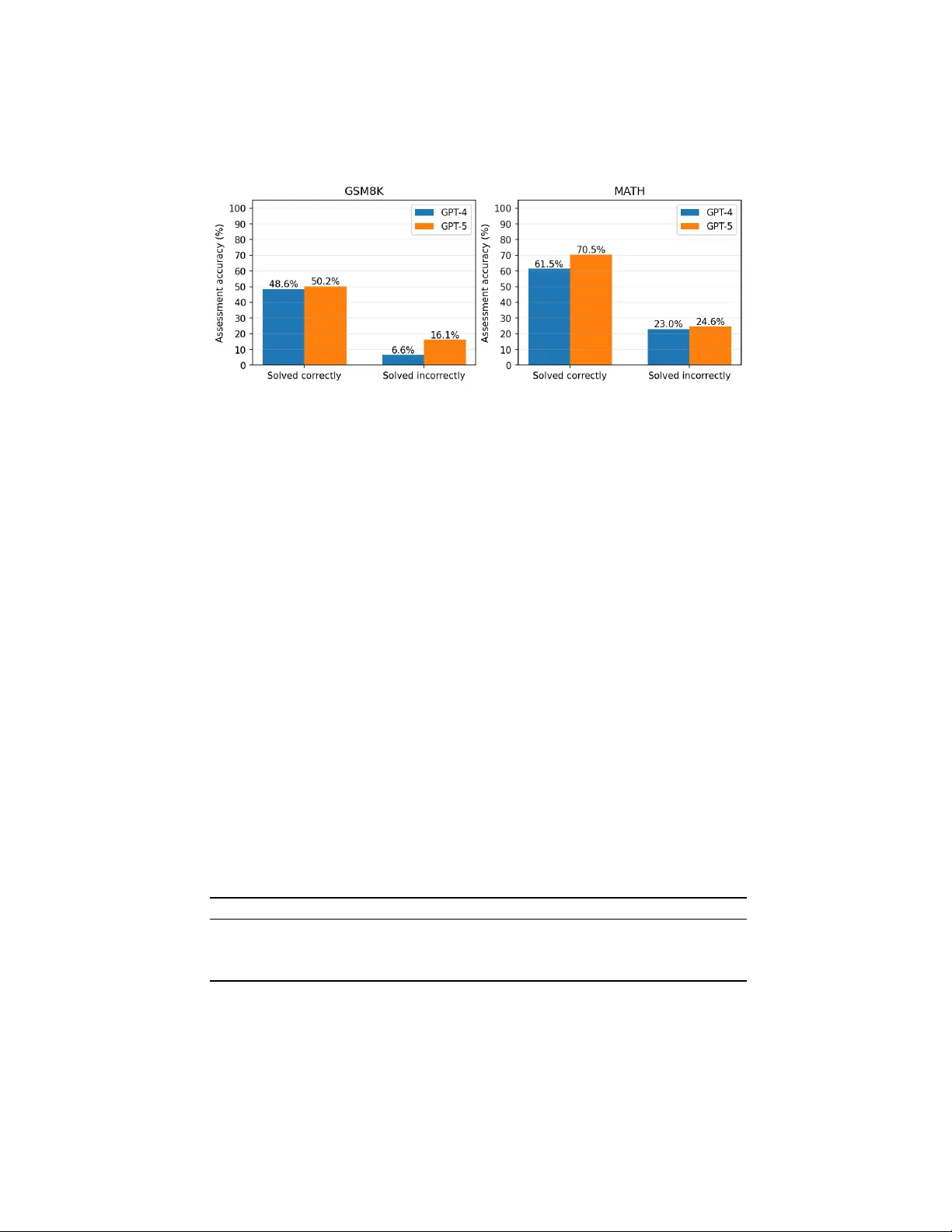
Is Mathematical Problem-Solving Exp ertise in Large Language Mo dels Asso ciated with Assessmen t P erformance? ∗ Liang Zhang 1 , Y u F u 2 and Xin yi Jin 3 1 Univ ersity of Michigan, Ann Arb or, MI, USA zhlian@umich.edu 2 New Y ork, NY, USA claireyufu@gmail.com 3 The High School Affiliated to Minzu Universit y of China, Beijing, China jinxichenzi@gmail.com Abstract. Large Language Models (LLMs) are increasingly used in math education not only as problem solvers but also as assessors of learners’ reasoning. How ev er, it remains unclear whether stronger math problem-solving ability is associated with stronger step-level assessmen t p erformance. This study examines that relationship using the GSM8K and MA TH subsets of PROCESSBENCH, a human-annotated b enc h- mark for identifying the earliest erroneous step in mathematical reason- ing. W e ev aluate tw o LLM-based math tutor agent settings, instan ti- ated with GPT-4 and GPT-5, in tw o indep enden t tasks on the same math problems: solving the original problem and assessing a b enc hmark- pro vided solution b y predicting the earliest erroneous step. Results show a consistent within-mo del pattern: assessment accuracy is substantially higher on math problem items the same model solv ed correctly than on items it solved incorrectly , with statistically significant asso ciations across both mo dels and datasets. At the same time, assessment remains more difficult than direct problem solving, esp ecially on error-presen t solutions. These findings suggest that math problem-solving exp ertise supp orts stronger assessment p erformance, but reliable step-level diag- nosis also requires additional capabilities suc h as step tracking, monitor- ing, and precise error lo calization. The results hav e implications for the design and ev aluation of AI-supp orted A daptive Instructional Systems (AISs) for formative assessmen t in math education. Keyw ords: Large Language Mo dels · Math Education · Problem Solv- ing · Step-level Assessmen t · Reasoning Error Detection. ∗ This man uscript has been accepted for presen tation at the 28th International Con- ference on Human-Computer In teraction, to b e held at the Montréal Con ven tion Centre in Montréal, Canada, from 26 to 31 July 2026. 2 L. Zhang et al. 1 In tro duction Large Language Models (LLMs) are increasingly b eing explored in math educa- tion for b oth instructional supp ort and assessment [1, 2]. Recent w ork suggests that LLMs are extending Adaptiv e Instructional Systems (AISs) b ey ond rule- based supp ort tow ard richer dialogue, generative instructional assistance, and more flexible assessment workflo ws [3, 4]. In math-related settings, LLMs hav e b een studied for dialog-based tutoring [5], hin t generation [6], personalized feed- bac k and error diagnosis [7], automated scoring of constructed responses [8], pro of grading [9], and step-level v erification of student reasoning [10]. These dev elopments p osition LLMs not only as math problem solvers, but also as p o- ten tial assessors of students’ reasoning, making it imp ortant to understand how these t wo capabilities are related. In h uman math education, assessing students’ reasoning dep ends not only on pedagogical skill, but also on sufficient understanding of the underlying math task and the diagnostic exp ertise needed to interpret students’ thinking [11, 12]. W e use this in tuition as an analogy , rather than a direct equiv alence, to motiv ate a similar question for LLMs: do es stronger math problem-solving ability supp ort stronger assessmen t of math reasoning? Drawing on Nelson and Narens’ distinction b et w een ob ject-lev el cognition and meta-level monitoring, we view problem solving as an ob ject-lev el reasoning task, whereas iden tifying the earliest erroneous step in a provided solution is a meta-level monitoring task [13]. F rom this p erspective, the tw o capabilities should be related but not iden tical, b ecause assessmen t requires more than solving alone, including trac king in termediate steps, chec king consistency , and lo calizing where reasoning first breaks down. Although prior w ork has examined LLMs b oth as math problem solvers [14, 15, 16] and as assessment to ols for grading student resp onses, identifying reasoning errors, and generating feedback or remediation [17], these tw o capabilities ha ve largely b een studied separately . Building on this distinction, we examine whether an LLM’s math problem- solving success is asso ciated with its step-level assessment performance. This question is esp ecially imp ortant for step-lev el assessmen t, b ecause identifying the earliest error in a m ulti-step solution is not merely an outcome judgment; it requires understanding the original problem and determining where the reason- ing first departs from a v alid path. In educational settings, such diagnosis can supp ort more interpretable and instructionally useful feedback than outcome- only scoring. Using the GSM8K and MA TH subsets of PROCESSBENCH, a h uman-annotated b enc hmark for earliest-error iden tification in math reasoning [18], we ev aluate the same LLM-based math tutor agent on t wo indep enden t tasks defined ov er the same underlying problems. In the problem-solving task, the tutor agen t answ ers the original problem; in the assessment task, it identifies the earliest erroneous step in a b enchmark-pro vided solution. More broadly , this study reframes LLM-based math assessment as a relationship b et ween t wo re- lated capabilities and informs the design of AI-supported assessmen t tools that can pro vide more interpretable and p edagogically useful feedback. Problem-Solving Exp ertise in LLMs Asso ciated with Assessment Performance 3 2 Metho ds Dataset. W e use the GSM8K and MA TH subsets of PROCESSBENCH [18] (h ttps://huggingface.co/datasets/Qw en/Pro cessBenc h), a human-annotated b enc h- mark for identifying the earliest erroneous step in math reasoning. Eac h item includes an original math problem, a b enchmark step-by-step solution trace, and a gold lab el indicating the earliest incorrect step using 0-based indexing, or − 1 if the solution is fully correct. T o create a balanced ev aluation setting, we use all 400 GSM8K items and a randomly sampled 400-item subset of MA TH, resulting in 800 ev aluation problem items in total. See all pro cessed data and exp erimen tal results at h ttps://github.com/LiangZhang2017/math-assessmen t-transfer. Mo dels and task setup. In b oth tasks, the system is instantiated as a sin- gle exp ert math tutor through a shared system prompt that frames the mo del as skilled in solving math problems and ev aluating step-b y-step solutions for er- rors. W e ev aluate tw o LLM-based math tutor configurations, using GPT-4 and GPT-5, on the same set of items in tw o indep enden t tasks: problem solving and assessmen t. In the problem-solving task, the mo del receives only the original problem and is ask ed to generate a solution and final answer. In the assessment task, the mo del receives the same original problem together with the b enc h- mark solution trace and is asked to iden tify the earliest erroneous step. F or eac h configuration, the same mo del deploymen t is used across b oth tasks. Ev aluation and analysis. Both tasks under each LLM mo del w ere rep eated three times, and the mean results w ere reported to reduce run-to-run v ariability . Problem-solving p erformance was measured by final-answer accuracy , and assess- men t performance b y exact-matc h accuracy on earliest-error prediction; follo w- ing PROCESSBENCH, we also report assessment accuracy for error-present and no-error items and their harmonic mean (F1). W e further compute a solve–assess gap as problem-solving accuracy minus assessment F1. T o test the within-mo del asso ciation b et ween solving and assessing, we compare assessment accuracy b e- t ween solved-correct and solved-incorrect items using 2 × 2 contingency tables with χ 2 and Fisher’s exact tests, together w ith assessmen t-accuracy differences and 95% confidence interv als. Finally , we conduct a brief qualitative analysis of represen tative agreement and mismatc h cases to examine common failure mo des and partial o verlap b etw een the t wo capabilities. 3 Results and Discussion 3.1 Ov erall T ask Performance Fig. 1 presents the p erformance of the LLM-based exp ert math tutor on the problem-solving task (left) and the step-level assessment task (right), av eraged o ver three runs. On the problem-solving task, b oth mo dels p erform very strongly on GSM8K, with GPT-4 achieving 94.9% accuracy and GPT-5 ac hieving 97.4%, whereas performance drops sharply on MA TH, where GPT-4 reaches 29.8% and GPT-5 reac hes 30.5%. This contrast highlights the substantially greater difficulty of the MA TH subset. On the step-level assessmen t task, p erformance is notably 4 L. Zhang et al. lo wer on GSM8K, with GPT-4 achieving 46.4% and GPT-5 49.3%, and remains mo derate on MA TH, where GPT-4 reaches 34.5% and GPT-5 38.6%. A cross b oth tasks, GPT-5 consistently outp erforms GPT-4, and this shared ordering is consistent with the hypothesis that stronger math problem-solving ability is asso ciated with stronger assessment performance. Fig. 1. A ccuracy on problem-solving (final answer vs. gold answer) and step-level as- sessmen t (predicted earliest error step vs. human lab el), by dataset and mo del (mean o ver 3 runs). 3.2 Item-Lev el Association Betw een Problem-solving and Assessmen t Fig. 2 shows step-lev el assessmen t accuracy group ed b y whether the same mo del solv ed the item correctly or incorrectly , av eraged o ver three runs. A consistent pattern emerges across b oth mo dels and b oth datasets: assessment accuracy is substan tially higher on items the model solved correctly than on items it solved incorrectly . On GSM8K, GPT-4 ac hieves 48.6% assessment accuracy on solved- correct items but only 6.6% on solved-incorrect items, while GPT-5 reac hes 50.2% v ersus 16.1%. A similar trend app ears on MA TH, where GPT-4 ac hieves 61.5% on solv ed-correct items and 23.0% on solved-incorrect items, and GPT-5 ac hieves 70.5% versus 24.6%. These results provide direct within-mo del evidence that successful problem solving on an item is asso ciated with stronger step-level assessmen t on that same item. In other w ords, when the mo del is able to solve the problem correctly , it is muc h more likely to identify the earliest erroneous step in a b enc hmark solution. W e then tested the statistical significance of the asso ciation b etw een solve outcome and assessmen t correctness using Fisher’s exact test on the correspond- ing 2 × 2 contingency table, and rep ort the difference in prop ortions with 95% confidence in terv als as an effect-size estimate. T able 1 rep orts the within-mo del asso ciation b et w een item-lev el solve outcome and step-lev el assessment accu- racy . F or each model and dataset, items were divided into solv ed-correct and Problem-Solving Exp ertise in LLMs Asso ciated with Assessment Performance 5 Fig. 2. Step-level assessment accuracy group ed by whether the same LLM mo del solved the item correctly or incorrectly , by dataset and mo del (mean ov er 3 runs). solv ed-incorrect groups, and assessment accuracy wa s compared across these tw o groups. The χ 2 statistics and Fisher’s exact test results b oth indicate a strong asso ciation b et ween solve outcome and assessment correctness in ev ery mo del– dataset condition. F or GPT-4, the asso ciation was significant on b oth GSM8K ( χ 2 = 39 . 38 , p < 0 . 001 ) and MA TH ( χ 2 = 162 . 32 , p < 0 . 001 ); for GPT-5, it was also significant on GSM8K ( χ 2 = 12 . 71 , p < 0 . 001 ) and MA TH ( χ 2 = 224 . 33 , p < 0 . 001 ). The effect sizes, rep orted as the difference in assessmen t accuracy b et w een solved-correct and solved-incorrect items, were consistently large, rang- ing from 34.1 to 45.9 p ercen tage p oin ts. Sp ecifically , GPT-4 show ed differences of 42.0 p oin ts on GSM8K and 38.4 points on MA TH, while GPT-5 sho w ed differ- ences of 34.1 p oin ts on GSM8K and 45.9 p oin ts on MA TH. All 95% confidence in terv als excluded zero, indicating that these p ositiv e differences were robust across all settings. T aken together, these results show that, within the same LLM, successful problem solving on an item is strongly asso ciated with b etter step-lev el assessment of that same item. T able 1. Within-mo del association betw een item-lev el problem-solving success and step-lev el assessmen t accuracy . The table rep orts χ 2 statistics, Fisher’s exact test p v alues, and differences in assessmen t accuracy (solved correct − solv ed incorrect) with 95% confidence interv als (CI), p ooled ov er three runs. Model Dataset χ 2 p (Fisher) Diff (%) 95% CI GPT-4 GSM8K 39.38 5 . 35 × 10 − 12 42.0 [35.1, 48.9] MA TH 162.32 1 . 82 × 10 − 36 38.4 [32.6, 44.2] GPT-5 GSM8K 12.71 1 . 66 × 10 − 4 34.1 [20.8, 47.4] MA TH 224.33 8 . 28 × 10 − 51 45.9 [40.4, 51.4] 6 L. Zhang et al. 3.3 Error-Sensitiv e Assessmen t P erformance T able 2 rep orts step-level assessmen t metrics separated by whether the b ench- mark solution contains an error. Sp ecifically , we rep ort accuracy on error-present samples, accuracy on no-error samples, and their harmonic mean (F1), following the b enchmark ev aluation proto col [18]. Across b oth models and b oth datasets, accuracy is consistently high on no-error samples (72.9%–97.1%) but remains v ery lo w on error-presen t samples (4.7%–10.0%), resulting in low F1 v alues o v er- all (8.9%–17.5%). GPT-5 ac hieves higher no-error accuracy than GPT-4 on b oth datasets, whereas error-present accuracy remains similarly limited across mo dels and app ears to b e the main b ottlenec k. F1 is particularly informative here b e- cause it balances t wo differen t failure modes: incorrectly flagging errors in fully correct solutions and failing to detect the earliest erroneous step when an error is presen t. The results show that b oth mo dels are muc h b etter at recognizing that a solution is fully correct than at lo calizing where a reasoning pro cess first go es wrong. This helps explain why ov erall assessment accuracy can appear moderate while error-sensitiv e step-level assessment performance remains weak. T able 2. Step -lev el assessment metrics by error presence: accuracy on error-present samples (human lab el = − 1 ), accuracy on no-error samples (human lab el = − 1 ), and their harmonic mean (F1), p ooled ov er three runs. Model Dataset Accuracy (error presen t) Accuracy (no error) F1 GPT-4 GSM8K 4.7 91.2 8.9 MA TH 10.0 72.9 17.5 GPT-5 GSM8K 4.8 97.1 9.2 MA TH 7.4 87.4 13.6 3.4 Assessmen t Difficult y Relativ e to Problem Solving T able 3 complements the baseline results in Fig. 1 by summarizing t wo deriv ed indicators of assessmen t difficult y: assessmen t F1 and the solve–assess gap. As- sessmen t F1 captures step-lev el p erformance while balancing accuracy on error- presen t and no-error cases, and the gap shows ho w far assessment p erformance lags b ehind direct problem solving. On GSM8K, b oth mo dels ac hieve v ery large gaps, with GPT-4 and GPT-5 reac hing 86.0 and 88.2 percentage p oin ts, resp ec- tiv ely , while assessment F1 remains b elo w 10% for b oth mo dels. On MA TH, the gaps are smaller but still substantial, at 12.3 p oin ts for GPT-4 and 16.9 p oin ts for GPT-5, with assessment F1 ranging from 13.6% to 17.5%. These results rein- force that step-lev el assessmen t is not simply solving in another form: even when a mo del p erforms well at pro ducing correct final answ ers, its abilit y to detect and lo calize the earliest erroneous step remains muc h more limited. Problem-Solving Exp ertise in LLMs Asso ciated with Assessment Performance 7 T able 3. Derived summary of step-level assessment difficult y , complementing Fig. 1. The table rep orts assessment F1 and the solve–assess gap, computed as solving accuracy min us assessmen t F1, po oled ov er three runs. Model Dataset Assess F1 (%) Gap (Solve − F1) GPT-4 GSM8K 8.9 86.0 MA TH 17.5 12.3 GPT-5 GSM8K 9.2 88.2 MA TH 13.6 16.9 3.5 Qualitativ e Analysis of Divergen t Cases The qualitative cases help explain why the relationship b et ween problem solving and step-level assessment is strong but incomplete. W e examine the four possible outcome combinations formed b y solving correctness and assessment correctness, with particular attention to the tw o most informative patterns: solve correct, assess incorrect and solve incorrect, assess correct . T o mak e these con- trasts concrete, w e present representativ e examples together with the full prob- lem statemen t, the b enc hmark lab el, and the mo del’s asse ssmen t rationale. Solv e correct, assess incorrect. In these cases, the mo del pro duces the correct final answ er when solving the problem itself but fails to iden tify the earliest erroneous step in the benchmark solution. That is, it recognizes that something is wrong, but mislo calizes where the reasoning first breaks down. F or example: – GSM8K item (gsm8k-192) . The problem states: “Over 30 days, Christina had 12 go o d days initial ly; the first 24 days ar e given (8 go o d, 8 b ad, 8 neutr al); the next thr e e days ar e go o d, neutr al, go o d; how many go o d days wer e left in the month?” The b enc hmark solution concludes that there are 0 goo d da ys left. The h uman annotator marks the first error at step 2, where the solution states “the numb er of days left in the month is 30 − 24 = 6 days” and then builds the remainder of the reasoning on that mistaken structure. GPT-4-based math tutor in stead predicted the first error at step 5. Its rationale was “Step 5 inc orr e ctly states that the next thr e e days add 3 mor e go o d days to the c ount, but only two of the next thr e e days ar e go o d (go o d, neutr al, go o d), so it should add 2, not 3.” Thus, the mo del iden tified a genuine coun ting error, but attributed the first error to a later step rather than to the earlier point at which the solution first wen t off trac k. This example shows that solving the problem correctly do es not guaran tee precise lo calization of the earliest error in another solution. – MA TH item (math-509) . The problem states: “Compute tan 315 ◦ .” The b enc hmark solution uses the reference angle 45 ◦ and states that in the fourth quadran t “the sine is p ositive and the c osine is ne gative,” then concludes that tan 315 ◦ = − 1 . The human lab el marks the first error at step 2, where this quadran t-sign claim app ears. GPT-4-based math tutor predicted the first error at step 3 and gav e the rationale “Step 3 c ontains a c onc eptual err or: it inc orr e ctly states that in the fourth quadr ant, ‘the sine is p ositive and the 8 L. Zhang et al. c osine is ne gative.’ In fact, in the fourth quadr ant, sine is ne gative and c osine is p ositive.” Here, the mo del iden tified the same conceptual mistake as the annotator, but assigned it to the wrong step index. The critique is therefore seman tically correct but still fails the b enc hmark’s exact-matc h criterion for earliest-error lo calization. Solv e incorrect, assess correct. In these cases, the mo del fails to solve the original problem correctly , but still assesses the b enc hmark solution accu- rately , either by correctly predicting -1 for a fully correct solution or b y correctly iden tifying the earliest erroneous step. F or example: – GSM8K item (gsm8k-238) . The problem states: “Charisma me ditates 15 minutes twic e p er day and do es 1 hour of yo ga 5 days p er we ek; how much time on me ditation and yo ga in 4 we eks?” The b enc hmark solution com- putes 0 . 5 hours/day of meditation × 7 days × 4 w eeks = 14 hours, plus 5 hours/w eek of yoga × 4 weeks = 20 hours, for a total of 34 hours. All steps are correct, so the h uman lab el is -1 . GPT-4-based math tutor’s o wn solu- tion to this problem was incorrect, but when asked to assess the benchmark solution, it correctly predicted -1 and stated “Al l steps ar e c orr e ct. Each c al- culation ac cur ately r efle cts the pr oblem c onditions, and the r e asoning is valid thr oughout.” This case shows that the model can recognize a v alid reasoning pro cess even when it cannot generate the correct solution on its o wn. – MA TH item (math-572) . The problem states: “Given a + b = 7 and a 3 + b 3 = 42 , find 1 /a + 1 /b as a c ommon fr action.” The benchmark so- lution applies the sum-of-cub es iden tity , deriv es ab = 43 / 3 , and computes 1 /a + 1 /b = ( a + b ) / ( ab ) = 7 / (43 / 3) = 21 / 43 . The human lab el is -1 , indi- cating that all steps are correct. GPT-4-based math tutor failed to solve this problem in the solving task, but when assessing the b enc hmark solution, it correctly predicted -1 and gav e the rationale “A l l steps ar e mathly c orr e ct: the sum of cub es identity is applie d pr op erly, the expr essions ar e manipulate d c orr e ctly, and the final answer is c ompute d ac cur ately using the given val- ues.” Again, the mo del’s generative solution was incorrect while its step-lev el assessmen t was correct, suggesting that critique dra ws on capabilities that partially o verlap with, but are not identical to, those required for solving. Summary . These cases rev eal t w o important asymmetries. First, solving correctly do es not necessarily imply assessing correctly , as shown by gsm8k-192 and math-509 , where the mo del reached the correct final answer but mislo calized the earliest error in the b enc hmark solution. Second, solving incorrectly do es not necessarily imply assessing incorrectly , as sho wn by gsm8k-238 and math-572 , where the model failed to solv e the problem itself but still correctly judged the b enc hmark solution as error-free. T aken together, these examples supp ort the claim that transfer from math problem solving to step-level assessment is real but incomplete, and that assessment relies in part on capabilities that are not fully redundan t with generative solving. Problem-Solving Exp ertise in LLMs Asso ciated with Assessment Performance 9 4 Discussion Our results provide conv erging evidence that mathematical problem-solving ex- p ertise in an LLM-based math tutor is asso ciated with stronger step-lev el as- sessmen t p erformance, although the relationship is conditional rather than deter- ministic. Across b oth mo dels and datasets, assessment accuracy was consistently higher on items the same mo del solved correctly than on items it solv ed incor- rectly . At the aggregate level, the GPT-5-based math tutor also outp erformed the GPT-4-based math tutor on b oth problem-solving and step-level assessment tasks. These findings directly support the cen tral question of this study and are consistent with the framing introduced in the pap er: problem solving and step-lev el assessment rely on ov erlapping capabilities, but assessment addition- ally inv olv es monitoring a provided reasoning pro cess rather than generating an answ er alone [13]. A t the same time, the relationship is clearly not one-to-one. Solving success increases the lik eliho od of accurate assessmen t, but does not guaran tee it. The results also sho w that step-level assessment remains substantially more difficult than problem solving, esp ecially when the b enc hmark solution actually con tains an error. The large solv e–assess gaps, low F1 v alues, and m uch stronger p erformance on no-error than error-present items suggest that the core challenge is not simply deciding whether a solution lo oks acceptable, but identifying where the reasoning first b ecomes in v alid. This distinction is educationally imp ortan t. In practice, confirming that a solution is correct is less useful than diagnosing the step at whic h reasoning breaks down, b ecause targeted feedback, remedia- tion, and adaptive scaffolding dep end on precise error lo calization rather than outcome judgment alone [18, 10, 8]. Our findings therefore suggest that ev alua- tions of LLM-based math assessmen t should prioritize error-sensitive, step-level metrics, rather than relying only on ov erall accuracy or final-answer agreement. The qualitative mismatch cases further clarify why solving and assessmen t should be view ed as related but partially distinct capabilities. In some cases, the mo del solved the original problem correctly but still misiden tified the earliest erroneous step in the benchmark trace, suggesting that generating a v alid solu- tion can b e easier than monitoring another solution at fine granularit y . In other cases, the mo del failed to solv e the original problem but still correctly judged the benchmark solution, especially when the provided trace w as coheren t or fully correct. These asymmetries indicate that assessment draws on additional capabilities b eyond answer generation, including step alignmen t, lo cal consis- tency chec king, and precise error lo calization. More broadly , the findings imply that stronger math solvers are not automatically reliable assessors, and that impro ving AI-supp orted math tutors ma y require targeted supp ort for critique, v erification, and pro cess sup ervision in addition to stronger generation [19, 20, 18]. Sev eral limitations qualify these conclusions. W e ev aluate only tw o LLM de- plo yments and tw o PROCESSBENCH subsets, and the b enchmark consists of curated reasoning traces rather than authentic student work. The exact-matc h earliest-error metric is also strict and may undercoun t partially correct critiques 10 L. Zhang et al. that identify the correct issue but assign it to a nearby step. In addition, b e- cause solving and assessment were measured on the same items, the observ ed asso ciation should not be interpreted as a purely causal transfer effect, since shared item difficulty may influence both outcomes. F uture work should test more mo dels, use authen tic studen t reasoning data, incorporate graded mea- sures of critique qualit y , and examine in teractive tutoring settings that in tegrate solving, assessmen t, feedback, and revision ov er time. 5 Conclusion This study examined whether math problem-solving expertise in LLM-based math tutor agents is asso ciated with stronger step-level assessment p erformance. Using GPT-4 and GPT-5 on the GSM8K and MA TH subsets of PROCESS- BENCH, we found a consistent within-model pattern: assessmen t p erformance w as substan tially higher on items the same mo del solv ed correctly than on items it solved incorrectly . This suggests that solving and assessing rely on o v erlapping reasoning capabilities. At the same time, large solve–assess gaps, lo w p erfor- mance on error-presen t solutions, and qualitativ e mismatc h cases show that the t wo are not equiv alent. Reliable earliest-error diagnosis requires more than gen- erating a correct final answ er; it also requires step trac king, consistency monitor- ing, and precise error lo calization. Overall, our findings sho w that stronger math problem-solving abilit y supp orts, but do es not fully determine, step-level assess- men t performance. These results highlight the need to ev aluate AI-supp orted math tutors not only as problem solvers, but also as reasoning-pro cess assessors that can pro vide more interpretable and instructionally useful feedback. References [1] Birgit P epin, Nils Buc hholtz, and Ulises Salinas-Hernández. “ A scoping surv ey of ChatGPT in mathematics education”. In: Digital Exp erienc es in Mathematics Educ ation 11.1 (2025), pp. 9–41. [2] Liang Zhang and Edith Graf. “ Mathematical Computation and Reason- ing Errors by Large Language Mo dels”. In: Pr o c e e dings of the Artificial Intel ligenc e in Me asur ement and Educ ation Confer enc e (AIME-Con): F ul l Pap ers . 2025, pp. 417–424. [3] Carol M F orsyth et al. “ Complex Con versations: LLM vs. Knowledge En- gineering Con versation-based Assessment”. In: Journal of e duc ational data mining (2024). [4] Liang Zhang et al. “ SPL: A So cratic Pla yground for Learning Po w ered b y Large Language Mo del”. In: Educ ational Data Mining 2024 W orkshop: L ever aging L ar ge L anguage Mo dels for Next Gener ation Educ ational T e ch- nolo gies (2024). [5] A dit Gupta et al. “ Bey ond final answ ers: Ev aluating large language mo dels for math tutoring”. In: International Confer enc e on Artificial Intel ligenc e in Educ ation . Springer. 2025, pp. 323–337. Problem-Solving Exp ertise in LLMs Asso ciated with Assessment Performance 11 [6] Changy ong Qi et al. “ TMA TH a dataset for ev aluating large language mo d- els in generating educational hints for math word problems”. In: Pr o c e e d- ings of the 31st International Confer enc e on Computational Linguistics . 2025, pp. 5082–5093. [7] Jennifer M Reddig, Arav Arora, and Christopher J MacLellan. “ Generating in-con text, p ersonalized feedbac k for in telligen t tutors with large language mo dels”. In: International Journal of Artificial Intel ligenc e in Educ ation (2025), pp. 1–42. [8] W esley Morris et al. “ Automated scoring of constructed response items in math assessment using large language mo dels”. In: International journal of artificial intel ligenc e in e duc ation 35.2 (2025), pp. 559–586. [9] Chen yan Zhao, Mariana Silv a, and Seth Poulsen. “ Autograding mathemat- ical induction pro ofs with natural language pro cessing”. In: International Journal of Artificial Intel ligenc e in Educ ation (2025), pp. 1–31. [10] Nico Daheim et al. “ Stepwise v erification and remediation of student rea- soning errors with large language mo del tutors”. In: Pr o c e e dings of the 2024 Confer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing . 2024, pp. 8386–8411. [11] Lee S Shulman. “ Those who understand: Knowledge gro wth in teaching”. In: Educ ational r ese ar cher 15.2 (1986), pp. 4–14. [12] Deb orah Lo ew enberg Ball, Mark Ho o ver Thames, and Geoffrey Phelps. “ Conten t kno wledge for teaching: What mak es it sp ecial?” In: (2008). [13] Thomas O Nelson. “ Metamemory: A theoretical framew ork and new find- ings”. In: Psycholo gy of le arning and motivation . V ol. 26. Elsevier, 1990, pp. 125–173. [14] Jason W ei et al. “ Chain-of-thought prompting elicits reasoning in large language mo dels”. In: A dvanc es in neur al information pr o c essing systems 35 (2022), pp. 24824–24837. [15] Xuezhi W ang et al. “ Self-consistency impro ves chain of thought reasoning in language mo dels”. In: arXiv pr eprint arXiv:2203.11171 (2022). [16] W enh u Chen et al. “ Program of though ts prompting: Disen tangling com- putation from reasoning for n umerical reasoning tasks”. In: arXiv pr eprint arXiv:2211.12588 (2022). [17] A driana Caraeni, Alexander Scarlatos, and Andrew Lan. “ Ev aluating GPT- 4 at grading handwritten solutions in math exams”. In: arXiv pr eprint arXiv:2411.05231 (2024). [18] Ch ujie Zheng et al. “ Pro cessbench: Iden tifying pro cess errors in mathe- matical reasoning”. In: Pr o c e e dings of the 63r d A nnual Me eting of the As- so ciation for Computational Linguistics (V olume 1: L ong Pap ers) . 2025, pp. 1009–1024. [19] Karl Cobb e et al. “ T raining verifiers to solve math word problem s”. In: arXiv pr eprint arXiv:2110.14168 (2021). [20] Hun ter Lightman et al. “ Let’s verify step by step”. In: The twelfth inter- national c onfer enc e on le arning r epr esentations . 2023.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment