Scaling Reproducibility: An AI-Assisted Workflow for Large-Scale Replication and Reanalysis
Computational reproducibility is central to scientific credibility, yet verifying published results at scale remains costly. We develop an AI-assisted workflow for automated full-paper replication -- retrieving materials, reconstructing environments,…
Authors: Yiqing Xu, Leo Yang Yang
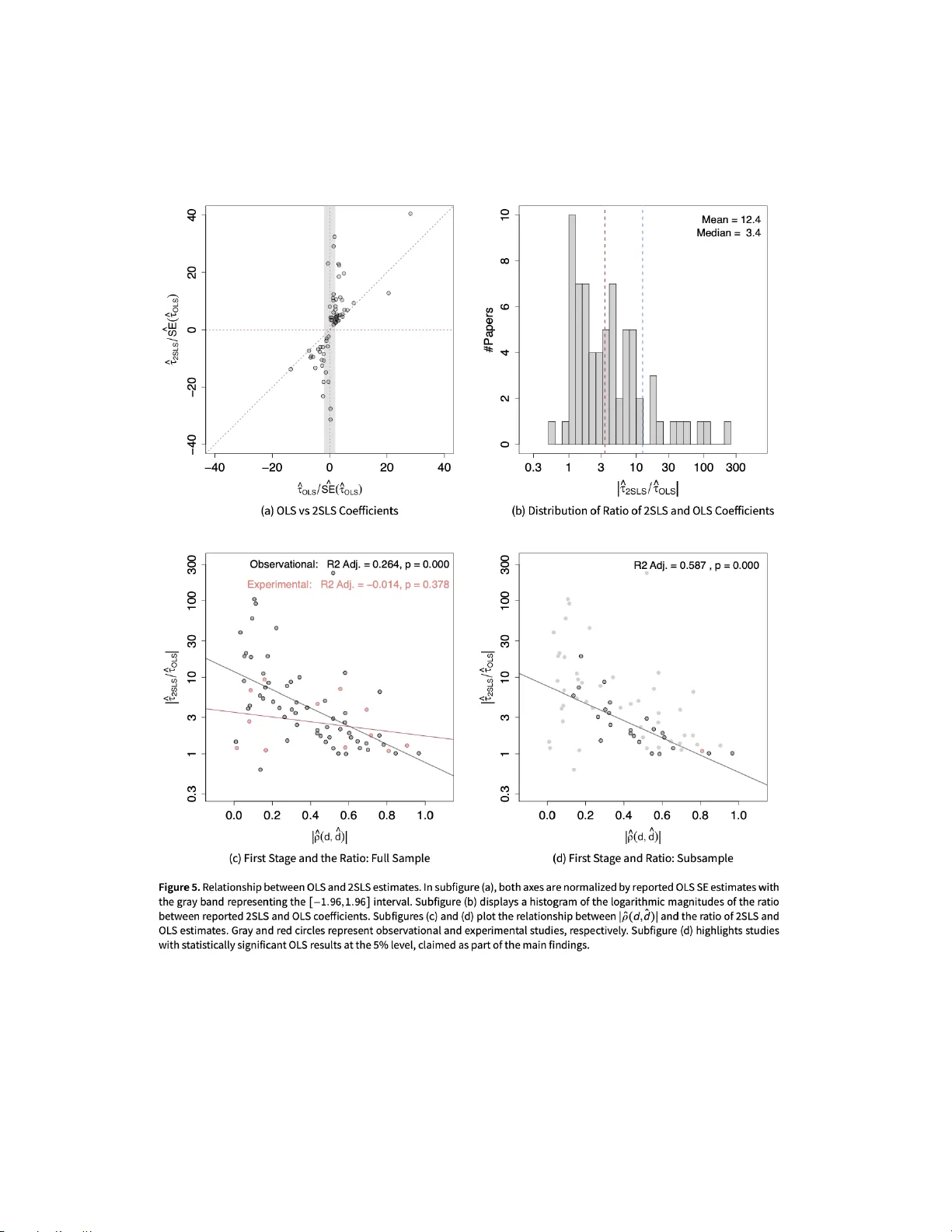
Scaling Repro ducibilit y: An AI-Assisted W orkflo w for Large-Scale Reanalysis ∗ Yiqing Xu † (Stanford) Leo Y ang Y ang ‡ (HKBU) F ebruary 20, 2026 Abstract Repro ducibilit y is cen tral to research credibilit y , y et large-scale reanalysis of empricial data remains costly b ecause replication pac kages v ary widely in structure, soft ware en vironment, and documentation. W e develop and ev aluate an agentic AI workflo w that addresses this execution b ottlenec k while preserving scientific rigor. The system separates scien tific reasoning from computational execution: researc hers design fixed diagnostic templates, and the workflo w automates the acquisition, harmonization, and execution of replication materials using pre-sp ecified, version-con trolled co de. A struc- tured knowledge la yer records resolv ed failure patterns, enabling adaptation across heterogeneous studies while k eeping eac h pip eline version transparent and stable. W e ev aluate this workflo w on 92 instrumental v ariable (IV) studies, including 67 with man- ually verified repro ducible 2SLS estimates and 25 newly published IV studies under iden tical criteria. F or each pap er, we analyze up to three tw o-stage least squares (2SLS) sp ecifications, totaling 215. A cross the 92 pap ers, the system achiev es 87% end-to-end success ov erall. Conditional on accessible data and co de, reproducibility is 100% at b oth the pap er and sp ecification levels. The f ramew ork substan tially lo wers the cost of executing established empirical proto cols and can b e adapted in empirical settings where analytic templates and norms of transparency are w ell established. Keyw ords: repro ducibility , replication, research transparency , op en science, AI-assisted w orkflows, agentic AI, Claude Skills, causal inference ∗ The authors used Claude Co de and ChatGPT as researc h and writing assistan ts in preparing this man uscript. All interpretations, conclusions, and any errors remain solely the responsibility of the authors. † Yiqing Xu, Assistan t Professor, Department of Political Science, Stanford Universit y . Email: yiqingxu@ stanford.edu . ‡ Leo Y ang Y ang, Researc h Assistant Professor, Department of A ccountancy , Economics and Finance, Sc ho ol of Business, Hong Kong Baptist Univ ersit y , Ko wlo on, Hong Kong SAR. Email: leoyang@hkbu.edu. hk . 1. In tro duction Repro ducibilit y is fundamen tal to researc h credibilit y and cum ulative scientific progress. In empirical so cial science, repro ducible analyses allow researc hers to v erify published claims, scrutinize identifying assumptions, and assess the practical relev ance of new metho dological dev elopments. As empirical metho ds ev olv e rapidly , access to real-w orld data and code has b ecome increasingly imp ortan t not only for assessing researc h credibility , but also for adv ancing metho dology through systematic reanalysis of existing studies. Institutional norms ha v e expanded the a v ailability of replication materials. Leading journals in economics and p olitical science no w require authors to p ost data and co de, and some conduct in-house replication c hec ks b efore publication. Y et a v ailabilit y alone do es not ensure repro ducibilit y at scale. Replication pac kages v ary widely in softw are en vironment, directory structure, naming conv en tions, do cumen tation qualit y , and execution logic. Ev en when materials are public, repro ducing results across man y pap ers remains costly and fragile. The b ottlenec k is op erational: executing idiosyncratic replication materials in a standardized and auditable manner requires substan tial researc her time. This pap er dev elops and ev aluates an agentic AI workflo w to address this execution b ottlenec k. The w orkflow combines adaptiv e co ordination with deterministic computation. A large language mo del (LLM) routes tasks across mo dular agents that ingest replication materials, iden tify sp ecifications, reconstruct computational en vironments, execute mo dels, and generate standardized diagnostic reports. A structured kno wledge lay er records previ- ously resolv ed failure patterns and clarifies stage-level responsibilities, allowing the system to accumulate exp erience across studies while k eeping each pip eline version transparent and stable. All numerical op erations—data preparation, estimation, and diagnostic computa- tion—are carried out b y version-con trolled program co de. F or a fixed pip eline v ersion and fixed inputs, reruns pro duce identical numerical outputs and retain a complete audit trail of in termediate artifacts and logs. The pap er do es not propose new estimators or diagnostics. 1 Instead, we ask whether established empirical proto cols can b e executed reliably and at scale under real-w orld conditions. Our evidence suggests that they can. A cen tral design principle of this workflo w is the separation of scientific reasoning from computational execution. Human researchers design diagnostic templates that sp ecify es- timands, estimators, robustness chec ks, and summary measures appropriate for a given re- searc h design. Once these templates are fixed, repro duction largely consists of execution- orien ted tasks: acquiring replication packages, reconstructing computational environmen ts, lo cating and running presp ecified specifications, extracting analysis datasets, and harmo- nizing outputs. A t the current stage of dev elopmen t, AI systems can not design diagnostic to ols that meet the precision standards implied by econometric and statistical theory . W e therefore treat diagnostics as h uman-designed inputs and ev aluate whether AI can execute them reliably and repro ducibly at scale. This division of lab or ma y ev olve as AI systems impro ve, but it aligns with current research needs. W e ev aluate the workflo w on a corpus of 92 studies with instrumen tal v ariable (IV) de- signs. Of these, 67 w ere previously analyzed in Lal et al. ( 2024 ), where the authors man ually v erified the repro ducibilit y of at least one the tw o-stage least squares (2SLS) co efficien t in eac h study . W e extend the analysis to 25 additional IV studies published after the origi- nal sample, applying identical inclusion criteria and the same diagnostic template. A cross the com bined corpus, the w orkflow targets up to three 2SLS sp ecifications p er pap er. Eac h sp ecification corresp onds to a mo del defined by an outcome, a single treatment v ariable, one or more instrumen ts, and a set of cov ariates, estimated on a particular sample. In the ex- panded set of 92 studies, the system ac hiev es a 87% end-to-end repro ducibilit y success. The unsuccessful cases are caused b y incomplete replication materials rather than computational instabilit y . Conditional on accessible materials, the pip eline repro duces the benchmark 2SLS estimates exactly and completes all the diagnostic tests. It is important to note that this lev el of reliabilit y was not ac hiev ed in a single en- gineering pass. The corpus spans m ultiple programming languages (mostly Stata and R), 2 estimation commands, directory structures, and idiosyncratic co ding practices. Man y failure mo des arise only when new replication pac kages are encountered. W e therefore adopt an adaptiv e, h uman-in-the-lo op pro cess. When a recurring failure pattern is iden tified, it is enco ded as a generalized rule in the execution lay er and v ersion-controlled b etw een runs. Co verage expands across v ersions, while n umerical b ehavior remains fixed within each ver- sion. The app endix do cuments the classes of v ariabilit y encountered and the corresp onding adjustmen ts that resolved them. This adaptiv e process reflects the challenges we encountered in our prior large-scale reanalysis projects. In earlier work, we man ually reconstructed and reanalyzed dozens of published studies using interaction mo dels, IV designs, and parallel trends designs using panel data ( Hainm ueller, Mummolo and Xu , 2019 ; Lal et al. , 2024 ; Chiu et al. , 2023 ). Eac h pro ject required years of coordinated effort. Much of that time w as dev oted not to metho d- ological dev elopment, but to deciphering authors’ co debases, repairing path dep endencies, reconstructing en vironments, and harmonizing heterogeneous replication materials. Those exp eriences rev ealed that once a diagnostic template is sp ecified, most remaining w ork is pro cedural—and therefore, in principle, automatable. They also pro duced structured b enc h- mark corp ora that enable systematic ev aluation of an automated executor. View ed more broadly , this pro ject connects to long-standing concerns ab out researc h credibilit y . Calls to improv e empirical practice—ranging from Leamer’s app eal to “tak e the con out of econometrics” ( Leamer , 1983 ) to the credibilit y rev olution in economics ( An- grist and Pischk e , 2010 ) and p olitical science ( T orreblanca et al. , 2026 )—ha v e emphasized transparency , auditability , and disciplined empirical w orkflows alongside adv ances in causal iden tification. More recen t discussions of the replication crisis, particularly in psychology ( Op en Science Collaboration , 2015 ), highligh t the consequences of fragile research pip elines. In this pap er, we adopt the no w-standard distinction betw een repro ducibilit y—recov ering rep orted results using the original data and code—and replicabilit y—obtaining similar find- ings in new studies. Our fo cus is explicitly on repro ducibilit y . It is not a substitute for 3 replication, but a necessary first step tow ard credible inference and cum ulative research. The contributions of this paper are threefold. First, w e design and implemen t an adap- tiv e yet version-con trolled agen tic AI workflo w that executes fixed empirical templates across heterogeneous replication materials. Second, we provide systematic ev aluation against a man ually verified benchmark and a forw ard extension to newly published studies, do cumen t- ing a 100% end-to-end success rate in the expanded corpus. Third, w e mak e transparent the v ariability inherent in real-world replication pac kages and the engineering adjustmen ts re- quired to accommo date it, offering a disciplined template for similar efforts in other research designs. The scop e of this study is curren tly limited to empirical so cial science, particularly causal inference, with data dra wn primarily from political science, where norms for sharing replication materials are relatively strong. The w orkflow dep ends on the av ailability of usable co de and data and is not designed to reco ver results when replication materials are missing, incomplete, or fundamentally flaw ed. The findings therefore sp eak to what is feasible under curren t b est practices rather than to settings without accessible materials. A t the same time, the framework itself is not discipline-sp ecific. Wherev er empirical fields hav e established analytic templates and norms of transparency , the same template–executor approach can b e adapted to support large-scale repro ducibility and systematic reanalysis. 2. Empirical Corpus and Ev aluation Design This section defines the empirical corpus and ev aluation framework used to assess the AI- assisted w orkflow. The demonstration in this pap er fo cuses exclusively on IV designs. W e b egin from a man ually curated b enchmark corpus and then ev aluate whether the w orkflow can (i) repro duce those studies end to end and (ii) extend the analysis to newly published IV studies in the same journals while increasing within-study cov erage. W e use “data” broadly to include replication packages, co de, computational en vironmen ts, diagnostic templates, and exp ected outputs. 4 2.1. Original Benc hmark Corpus The starting p oin t is the corpus of 67 IV studies analyzed in Lal et al. ( 2024 ). These studies w ere drawn from three leading p olitical science journals, The A meric an Politic al Scienc e R eview (APSR), A meric an Journal of Politic al Scienc e (AJPS), and The Journal of Poli- tics (JOP), published in 2010–2022 and satisfy a common set of design restrictions: linear IV mo dels with a single endogenous regressor (the treatmen t) and a clearly iden tified base- line sp ecification. In the original pro ject, we man ually selected each pap er, lo cated and do wnloaded replication materials, reconstructed computational environmen ts, repro duced the main results, and applied a prespecified diagnostic template comparing 2SLS and ordi- nary least squares (OLS) estimates. The key empirical finding is the cross-study 2SLS–OLS discrepancy and its negativ e correlation with IV strength in observ ational studies, summa- rized in Figure 5 of Lal et al. ( 2024 ), which is repro duced in Section B in the Supplementary Materials. The manual replication established b enchmar k 2SLS p oint estimates for eac h study and required substan tial harmonization of heterogeneous replication materials. These co efficients serv e as fixed ground truth for ev aluating execution reliabilit y on the original corpus. The AI-assisted w orkflow is first tested on its ability to repro duce the reanalysis of these 67 studies in Lal et al. ( 2024 ) from end to end. This includes extracting metadata from eac h pap er, do wnloading replication materials, reconstructing the analyses, and generating standardized diagnostic rep orts using the authors’ diagnostic template, which is implemen ted in the CRAN pac kage ivDiag ( Lal and Xu , 2024 ). 2.2. F orw ard Expansion and Within-Study Co v erage Bey ond repro ducing the original corpus, w e extend the analysis in t w o dimensions. First, w e incorp orate 25 additional IV studies published in the same journals b etw een 2023 and 2025 that satisfy the same inclusion criteria as the original corpus. The diagnostic template 5 remains unchanged. This forward expansion allo ws us to assess whether the 2SLS–OLS dis- crepancy and its negative correlation with IV strength p ersist in recent work. Because these journals no w condition acceptance on in-house verification—beginning with AJPS in 2015, follo wed by APSR and JOP around 2021—w e exp ect high reproducibility in the expanded sample. Second, rather than targeting a single sp ecification per pap er, the workflo w replicates up to three IV sp ecifications p er study , including the baseline and key robustness v arian ts. The unit of analysis is the IV sp ecification. Expanding within-study cov erage strengthens the execution test, as the w orkflow m ust iden tify and run distinct mo dels within heterogeneous co debases without man ual guidance. T able 1. Sample Size Comp arison: Original Study vs. This Stud y Lal et al. ( 2024 ) This Study Time Period Cov ered 2010–2022 2010–2025 Num b er of Studies 67 92 (67 original + 25 new) T arget Sp ecifications p er Study 1 baseline IV sp ecification Up to 3 IV sp ecifications p er study T otal T arget Sp ecifications 70 b enchmark sp ecifications 215 b enchmark sp ecifications Man ual V erification of Repro ducibility Y es Y es (original 67); No (new 25) Note: The unit of analysis in Lal et al. ( 2024 ) is IV designs (outcome-treatmen t-instrument combinations). Among the 67 pap ers, three contain t wo distinct IV designs, yielding 70 b enchmark specifications. A sp ecification means an outcome-treatment-instrumen t-cov ariate combination in a simple 2SLS regression. T able 1 summarizes the expansion. Relative to Lal et al. ( 2024 ), the corpus gro ws b oth across studies (from 67 to 92) and within studies (from one b enc hmark sp ecification p er design to up to three p er pap er). The maximum n umber of ev aluated sp ecifications therefore increases from 70 to 215. This larger corpus provides a stronger test of whether the w orkflow can harmonize heterogeneous replication materials at scale. 2.3. Repro ducibility Criterion and Ev aluation W e adopt an in tentionally minimal repro ducibilit y criterion. F or each IV sp ecification, re- pro duction is deemed successful if the workflo w exactly repro duces the rep orted 2SLS p oin t 6 estimate from the corresponding mo del using a harmonized system (which ma y differ from the one used b y the original authors), namely , Co efficien t in published w ork = Co efficient generated by the authors’ pip eline = Co efficient generated by the harmonized pip eline. F or the original 67-study corpus, exact agreemen t with the man ually replicated 2SLS co effi- cien t serves as the b enchmark for repro ducibilit y . In other words, for these 70 sp ecifications, the equality b et ween the published coefficient and the manually replicated co efficient (up to rounding error) has already b een established. Our ob jectiv e is therefore to v erify the second equalit y: that the harmonized pip eline repro duces the same 2SLS estimate. F or the newly incorp orated studies, repro ducibility has not been man ually verified. Although the journals from whic h these studies are drawn typically require exact n umerical replication as a condition of publication, w e do not indep endently v erify the equalit y betw een the published and authors’ pip eline outputs. Instead, we fo cus on achieving and do cumenting the second equality under our workflo w. V erifying the first equality w ould sometimes require access to detailed Supplemen tary Materials, which are not alwa ys av ailable, and is left for future w ork. Note that, as in Lal et al. ( 2024 ), reproducibility does not equal robustness or credibilit y , whic h requires additional diagnostics and kno wledge ab out the research design. F o cusing on the 2SLS p oin t estimate isolates the core execution b ottlenec k in large-scale repro ducibilit y . Successful repro duction implies that the w orkflo w has correctly iden tified the instrument set, endogenous regressor, control v ariables, fixed effects, sample restrictions, w eights, and data transformations required for the model. Because the 2SLS coefficient is join tly determined b y these comp onents, exact numerical agreement indicates that the sp ecification, data pro cessing, and execution ha ve b een correctly harmonized. Conditional on this success, do wnstream diagnostic statistics are mec hanically determined b y the template. Repro ducing the 2SLS point estimate therefore marks the critical breakp oint. 7 Ha ving defined this criterion, w e ev aluate performance at b oth the paper and sp ecifica- tion lev els. W e report ingestion success rates, sp ecification extraction rates for up to three IV mo dels p er study , co de execution rates, exact 2SLS replication rates at the sp ecification lev el, and diagnostic rep ort generation rates. Because the pip eline is adaptive and version-con trolled (see b elow), recurring execution failures are enco ded as generalized rules betw een runs. As a result, conditional on accessible replication materials, stage-lev el success conv erges to full cov erage under a fixed pip eline v ersion. The metrics therefore assess whether the finalized executor can reliably harmonize heterogeneous replication pac kages and scale the 2SLS–OLS diagnostic analysis b oth forw ard in time and within studies. 3. AI-Assisted Repro ducibility W orkflo w This section describ es the AI-assisted workflo w used to execute the reanalyses of IV cor- pus defined in Section 2 . The workflo w targets a practical b ottleneck in repro ducibility: executing established researc h proto cols reliably across heterogeneous replication pac kages while preserving numerical precision and auditability . This workflo w do es not automate metho dological reasoning or introduce new statistical pro cedures. Instead, it standardizes and accelerates execution when usable data and co de are av ailable. 3.1. Design Principles Large-scale reproducibility in v olves a basic tension b etw een heterogeneit y and determinacy . Replication materials v ary widely across studies. Ev en within the IV corpus, pap ers differ in programming language (Stata, R, and Python), directory structure, naming conv entions, and do cumentation quality . At the same time, reproducibility requires determinacy: for a fixed pip eline v ersion and fixed inputs, n umerical outputs must not dep end on ad ho c decisions, platform-sp ecific defaults, or stochastic behavior. The w orkflo w resolv es this tension b y separating adaptive co ordination from fixed com- 8 putation. Adaptation is used to route tasks, interpret failures, and select among predefined reco very steps. Numerical w ork—data preparation, model estimation, and diagnostic com- putation—is executed b y version-con trolled program code. F or a fixed pip eline version and fixed inputs, the workflo w pro duces identical numerical outputs and retains a complete audit trail of intermediate artifacts and logs. When new failure patterns are encountered, fixes are incorp orated b et ween runs and v ersion-con trolled, rather than allo wing n umerical b eha vior to drift within runs. Note that uncertaint y estimates, particularly those based on b o otstrap or jackknife procedures, make exact replication more challenging. This is b ecause random seed behavior is not alwa ys portable across platforms, and parallel computation can further complicate seed con trol. A second principle is the separation of scientific reasoning from execution. As describ ed in Section 2 , the diagnostic template—based on Lal et al. ( 2024 ) and ivDiag —is fixed in adv ance. Once this template is sp ecified, repro duction reduces to execution-oriented tasks: acquiring replication packages, reconstructing computational en vironments, iden tifying IV sp ecifications, running co de, extracting estimates, and compiling diagnostic outputs. The w orkflow ev aluates whether these tasks can b e automated without loss of precision. 3.2. Arc hitecture and Implemen tation W e implemen t the workflo w using Claude Co de Skil ls (hereafter, Skills), an agen tic sys- tem organized as a three-lay er arc hitecture. A t the top lay er, an LLM (Claude) serv es as an orchestrator that dispatc hes tasks, in terprets errors, and determines how the pip eline pro ceeds. The middle la y er consists of structured skill descriptions that define eac h stage’s input–output con tract and record previously resolv ed failure patterns. At the bottom la yer, rule-based agen t code and diagnostic scripts perform all file operations and statistical com- putation. The upp er lay ers gov ern co ordination and adaptation; the b ottom la y er go verns n umerical results. The orc hestrator reads task instructions, consults the relev an t skill descriptions, writes 9 and edits plain-text artifacts (primarily Markdo wn configuration files and small Python utilities), and inv ok es external to ols as needed. It do es not p erform statistical estimation. All estimation and diagnostics are executed by explicit co de in R, Stata, and Python. In particular, the full diagnostic suite is implemen ted in a standalone R script that op erates solely on exported analysis datasets. The LLM therefore controls task routing and structured in terpretation, but it is excluded from n umerical estimation and inference. Figure 1 illustrate the three-la yer arc hitecture. Repro duction is decomp osed in to mo dular stages b ecause replication pac kages v ary widely in softw are, directory structure, naming con v entions, and documentation. F ailures t ypically arise at distinct p oints—retriev al, parsing, code repair, execution, or rep orting—and require stage-sp ecific information. Each stage is assigned to a dedicated agen t. Agents comm unicate exclusiv ely through standardized in termediate files written to disk (e.g., JSON, CSV, logs) and share no hidden state. Each stage reads explicit inputs and writes explicit outputs, making every step insp ectable and rerunnable. When a failure o ccurs, execution can resume from the affected stage without restarting the en tire pip eline. The system w as developed iteratively through rep eated encoun ters with div erse replica- tion pac kages. When a new failure pattern is iden tified, the orc hestrator prop oses a diagnosis and candidate fix. After review, successful fixes are incorp orated as v ersion-controlled up- dates to the execution lay er and implemen ted b etw een runs rather than during execution. Eac h run is therefore tied to a fixed, inspectable pipeline v ersion, and expanded cov erage do es not alter the n umerical b eha vior of prior v ersions. 10 Input: diagnostics.json Action: Generate standardized markdown report, create visualizations Output: Final report & visualizations Journalist (T emplate-based Reporting) Input: analysis_data.csv Action: Run standalone R script, compute identification diagnostics, assign credibility rating Output: diagnostics.json, Rating (High to V ery Low) Skeptic (Deterministic Diagnostics) Input: Cleaned Code, metadata.json Action: Execute (Stata, R, Python), extract analysis dataset, cross- language validation (e.g., Stata to R) Output: analysis_data.csv ,exe cution_log.txt, V alidation Results Runner (Execution & Data Extraction) Input: Original Code Action: Path repair , Graphics suppression, Dependency handling, Format conversion Output: Cleaned Code, cleaning_log.json Janitor (Code Preparation) Input: .do, .R, .py scripts Action: Detect relevant commands or functions, handle multiple specs, LLM assistance for complex specs Output: metadata.json (Primary Specifications) Profiler (again) (Multi-Language Code Parsing) Input: Repository URL Action: Download from Dataverse, GitHub, OSF , or direct link (PDF-first strategy) Output: Local Replication Package (V ersioned) Librarian (Replication Package Retrieval) Input: PDF Action: Extract T itle, Authors, Y ear, Data URL Output: study_info.json Profiler (Metadata Extraction) SKILL.md Profiler CONTRACT (Interface): Inputs, Outputs, T ools, Constraints, Subtasks Accumulated Failure Patterns (Knowledge) : Contest, Root Cause, Resolution Rule (Version- Controlled) SKILL.md Librarian CONTRACT (Interface) Accumulated Failure Patterns (Knowledge) SKILL.md Janitor CONTRACT (Interface) Accumulated Failure Patterns (Knowledge) SKILL.md Runner CONTRACT (Interface) Accumulated Failure Patterns (Knowledge) SKILL.md Skeptic CONTRACT (Interface) Accumulated Failure Patterns (Knowledge) SKILL.md Journalist CONTRACT (Interface) Accumulated Failure Patterns (Knowledge) Dotted Arrows: Adaptation/Updates (Human-in-the-Loop) Solid Arrows: Control & Data Flow Generate Candidate Diagnosis & Fix Apply Documented Resolution Strategy Parse Failure T ype Any Failure? Inspects Logs & Artifacts (from Layer 3) Reads Project Instructions (Protocols) LA YER 3: Execution AGENT CODE & DIAGNOSTIC SCRIPTS - COMPUT A TION & EXECUTION LA YER 2: SKILL DESCRIPTIONS & KNOWLEDGE BASES (SKILL.md FILES) - INTERF ACE & MEMORY LA YER 1: THE LLM ORCHESTRA TOR (CLAUDE) - COORDINA TION & CONTROL SYSTEM ARCHITECTURE: THE LLM ORCHESTRA TOR, KNOWLEDGE BASES, AND AI AGENTS Consults Skill Descriptions (Layer 2) Invokes Execution Agents (Layer 3) Yes Match Known Pattern (in Layer 2)? No (Novel Failure) Yes HUMAN REVIEW Update Knowledge Base (Layer 2) Update Execution Code (Layer 3) Research Paper (PDF) Diagnostic Report (PDF) No Figure 1. Overview of the agentic AI w orkflow for repro ducibilit y . The ab ov e figure illustrates the three-lay er agentic arc hitecture enabled b y Skills. A top-la yer LLM orc hestrator routes tasks and interprets errors but do es not p erform estimation. The middle la yer defines structured input–output contracts and records resolv ed failure patterns. The b ottom lay er consists of rule-based agen t co de and diagnostic scripts in R, Stata, and Python that execute all file and statistical operations through a mo dular seven-stage pip eline, from material acquisition to standardized rep orts. 11 The pip eline comprises seven stages, also illustrated in Figure 1 . Given a paper in PDF format, an agen t called Profiler extracts metadata and replication links. The Librarian do wnloads asso ciated data and co de. Then, the same Profiler agent iden tifies IV sp ecifi- cations within the replication code, including up to three targeted sp ecifications p er study as defined in Section 2 . The Janitor prepares scripts for execution b y resolving path de- p endencies and environmen t assumptions. The R unner executes the mo dels and extracts 2SLS estimates. The Sk eptic applies the fixed diagnostic template for IV designs. The Journalist compiles standardized rep orts. Eac h stage writes inputs and outputs to disk and records run time, status, and error messages in structured logs, whic h form the basis for the stage-lev el p erformance metrics rep orted in Section 5 . 3.3. Challenges in a Skills-Based W orkflo w Using a Skills-based orchestration la yer in tro duces practical challenges that are easy to un- derstate if one only describ es the workflo w at a high level. W e highlight four c hallenges that arise sp ecifically b ecause task routing and failure handling are AI-assisted, and we summarize ho w our implementation constrains these risks. First, agent-based workflo ws can introduce run-to-run v ariation through branc hing logic. Ev en when n umerical co de is fixed, differences in routing or recov ery steps can change whic h scripts are executed, whic h in termediate datasets are exp orted, or whic h sp ecification is treated as primary . W e constrain routing decisions to explicit, insp ectable artifacts and fixed rules wherever p ossible. Agents define subsequen t inputs through standardized files, and the orc hestrator selects among do cumented options while recording all decisions in logs. F or a fixed pip eline v ersion and fixed inputs, reruns pro duce iden tical numerical outputs. Second, co verage can expand in wa ys that are difficult to audit. Without discipline, a w orkflow may accumulate undo cumen ted heuristics or pap er-sp ecific patches. W e address this by version-con trolling all deterministic co de and recurring resolution rules. When a new failure pattern is identified, the fix is implemented as a generalized up date b etw een 12 runs rather than as an ad ho c interv en tion within a single execution. Eac h run is therefore anc hored to a stable pip eline state. Third, execution v ariabilit y across replication packages generates complex failure mo des. Differences in soft ware environmen ts, directory structures, naming con ven tions, data enco d- ings, and multi-language co debases create errors that cannot b e fully an ticipated ex an te. Some failures do not pro duce explicit error messages but instead app ear as inconsistencies across intermediate artifacts, suc h as mismatc hed co efficien ts or incomplete exp orts. The w orkflow addresses these patterns through a structured resolut ion cycle. The orc hestra- tor inspects logs and cross-v alidates outputs, traces failures across stages to identify ro ot causes, and implemen ts fixes as generalized rules in deterministic co de. Resolv ed patterns are recorded in a structured knowledge base, allo wing solutions to persist across runs while preserving n umerical determinacy within eac h version. Finally , supp orting additional research designs creates pressure to em b ed design-sp ecific assumptions in the executor. W e av oid this b y k eeping the executor design-agnostic and treating diagnostic templates as inputs. Researchers sp ecify estimands, estimators, and sum- mary measures in the template. The executor p erforms the same execution tasks—acquisition, preparation, execution, extraction, and rep orting—while in voking the appropriate template. Extending to new designs therefore requires modifying templates rather than rewriting the underlying arc hitecture. 4. Demonstration The previous section describ ed eac h pip eline stage in abstract terms. Here w e trace a single AJPS study , R ueda ( 2017 ), through the full w orkflo w, from the input PDF to the final diagnostic rep ort. A t each stage, w e sho w the in termediate artifacts the system generates, illustrating ho w the mo dular, file-based arc hitecture supp orts auditability . This demonstration reflects the cum ulative kno wledge embedded through the adaptiv e mec hanism describ ed ab o ve. T o name a few nontrivial challenges the w orkflow has learned to 13 handle: parsing the ivreg2 syntax in the author’s Stata co de; resolving time-series op erators suc h as l. and l4. em b edded in v ariable names; enforcing the e(sample) post-estimation restriction; and executing a 13-script build chain of .do files. These capabilities w ere ac- quired from recurring patterns in earlier pap ers, indicating that the accumulated kno wledge generalizes b ey ond the initial dev elopmen t set. R ueda ( 2017 ) studies the relationship b etw een p olling station size and vote buying in Colom bia, instrumen ting a verage p olling station size with the maximum size set by election authorities. This case is well suited for demonstration for three reasons. First, the design is straigh tforward, with one endogenous regressor and a clearly defined instrumen t. Second, the pap er rep orts three IV sp ecifications with strong first stages and adequate p ow er, consistent with the diagnostics in our template. Third, the replication co de is written in Stata, the dominan t environmen t in our ev aluation corpus and comparativ ely difficult for AI systems to parse and execute due to its closed-source ecosystem and idiosyncratic syntax. W e now w alk through the pip eline step b y step. Stages 1–2: A cquire Materials The w orkflow b egins with the pap er’s PDF as the only input. In this first stage, the Profiler parses the PDF and extracts structured metadata, including the title, author, journal, and, critically , the data rep ository URL embedded in the data av ailabilit y statemen t. The output is a JSON file: 1 i v r e g 2 e _ v o t e _ b u y i n g l 4 . m a r g i n _ i n d e x 2 l . n b i _ i / / / 2 l . o w n _ r e s o u r c e s l p o p u l a t i o n l . a r m e d _ a c t o r / / / 3 l 4 . l s i z e l p o t e n c i a l / / / 4 ( l m _ p o b _ m e s a = l z _ p o b _ m e s a _ f ) i f e ( s a m p l e ) , / / / 5 f i r s t c l u s t e r ( m u n i _ c o d e ) In Stage 2, the Librarian resolv es the Data verse DOI, queries the Datav erse API for the full file listing, and do wnloads the complete replication pac kage. The materials include 14 m ultiple Stata data files ( .dta ), dataset-construction scripts, analysis scripts, and a master analysis file. All files are stored in a v ersioned w orkspace directory . The do wnload log confirms that both the article and the replication pac kage were retrieved without error. Stage 3: Determine Sp ecifications With the replication materials in place, the Profiler parses all Stata scripts to identify IV estimation commands. In the main analysis file ( main_results_aggregate_data.do ), it detects three ivreg2 calls—a user-contr ibuted t w o-stage least squares routine with syn tax distinct from the built-in ivregress 2sls . Supp ort for ivreg2 w as added incremen tally as similar patterns w ere encoun tered in earlier papers. The first command app ears as follo ws: 1 { 2 " t i t l e " : " S m a l l A g g r e g a t e s , B i g M a n i p u l a t i o n : V o t e B u y i n g E n f o r c e m e n t 3 a n d C o l l e c t i v e M o n i t o r i n g " , 4 " a u t h o r s " : " M i g u e l R . R u e d a " , 5 " y e a r " : " 2 0 1 7 " , 6 " j o u r n a l " : " A m e r i c a n J o u r n a l O f P o l i t i c a l S c i e n c e " , 7 " r e p l i c a t i o n _ u r l " : " h t t p : / / d x . d o i . o r g / 1 0 . 7 9 1 0 / D V N / K 6 Z O O W " 8 } A central feature of this sp ecification is the use of Stata time-series op erators. F or example, l.nbi_i denotes the first lag of nbi_i , and l4.margin_index2 denotes the fourth lag. These op erators must b e mapp ed to realized v ariable names in the constructed dataset. The Profiler and R unner resolve this mapping using translation rules accum ulated during prior executions. F or each ivreg2 call, the Profiler constructs a structured represen tation that records the outcome, endogenous regressor, instrumen t, con trols, sample restriction, and clustering v ariable. In this case, all three sp ecifications share the same treatment and instrument, cluster at the m unicipality level, and differ only in the outcome v ariable or the set of con trols. Rather than repro ducing the full table of v ariables, w e emphasize that the extracted structure captures only role assignmen ts and estimation options necessary for do wnstream execution 15 and diagnostics. All extracted fields are written to metadata.json , whic h serv es as the con tract b et ween the iden tification stage and subsequen t execution and ev aluation stages. Stages 4–5: Co de Preparation and Execution The original replication pac kage is organized as a m ulti-file Stata pro ject. Dataset-construction scripts generate intermediate .dta files, whic h are subsequen tly loaded b y analysis scripts to pro duce the rep orted tables. The IV sp ecifications are em b edded within this build c hain rather than implemen ted in a single script. Repro ducing the results therefore requires exe- cuting the scripts in the correct order and preserving dep endencies across files. Before execution, the workflo w harmonizes the co de for automated use. The Janitor redirects file paths to the lo cal w orkspace and remo ves interactiv e or side-effect commands suc h as graph export and log using , which w ould otherwise interrupt batc h execution. It also instruments each ivreg2 call so that co efficients and standard errors can b e program- matically extracted from the log. These adjustments do not alter the statistical conten t of the original co de; they standardize the environmen t for repro ducible execution. All mo difications are recorded in structured JSON logs, preserving a complete audit trail of the harmonization pro cess. A substan tive complication arises from the use of if e(sample) in the original Stata commands. This condition restricts the estimation sample to observ ations selected in a prior regression. Preserving the author’s intended sample requires resp ecting this sequencing: the conditioning regression m ust b e executed first, and data exp ort must o ccur b efore subsequen t commands o verwrite the sample indicator. Correct handling of this dep endency is essential for repro ducing the reported sp ecifications. The R unner then executes the harmonized build chain in batc h mo de. All scripts complete without error. The system extracts the IV estimates from the marked log output and exp orts the corresp onding analysis datasets for downstream diagnostics. As a cross- 16 language v alidation step, each sp ecification is re-estimated in R using iv_robust() from the estimatr package . The resulting co efficien ts matc h the Stata outputs within numerical tolerance, confirming that the harmonized execution preserves the original estimates. Stage 6: Diagnostic Analysis The Sk eptic reads metadata.json to recov er the mo del specification and loads the cor- resp onding analysis_data_spec_*.csv files. After matching v ariable names to dataset columns, it in vok es the R diagnostic script ( diagnostics_core.R ), whic h implements the full set of procedures describ ed in Section B in the Supplemen tary Materials. Because the original IV designs use a single instrumen t, the script also applies the tF pro cedure ( Lee et al. , 2022 ), which adjusts critical v alues for the conv entional t -test as a function of the first-stage F -statistic. T able 2 reports the results. All three sp ecifications displa y strong first stages. The effectiv e F -statistics range from 204 to 8,598, w ell ab ov e the conv en tional cutoff of 10, and no mo del is flagged for weak instrumen ts. Maxim um polling station size is therefore a strong predictor of a v erage station size in eac h sp ecification. F or Sp ecifications 1 and 3, the 2SLS estimates are statistically significant using the con ven tional t -test, b o otstrap metho ds, tF test, and Anderson-Rubin test, and the jackknife ranges are tight. The estimates from the full and reduced control sets are similar in sign and magnitude, pro viding an in ternal robustness comparison within the pap er’s design. F or Sp ecification 2, the instrumen t strength remains high, but inference is less robust. The p -v alue for the Anderson-Rubin test exceeds 0.05, the tF test do es not reject, and the b o otstrap- t interv al includes zero. The jackknife identifies m unicipality 11001 as influential; remo ving it shifts the estimate by 58%. Under the presp ecified rules, these t wo warnings yield a MODERA TE rating. The system do es not offer a substan tiv e interpretation. It applies the same criteria to each sp ecification and rep orts the results. Whether the weak er evidence reflects lo w er pow er in the smaller sample or a different relationship for the alternativ e 17 T able 2. Dia gnostic resul ts for R ueda ( 2017 ) Sp ecificaiton 1 Specificaiton 2 Specificaiton 3 Outcome v ariable e_vote_buying sum_vb e_vote_buying T reatmen t v ariable lm_pob_mesa lm_pob_mesa lm_pob_mesa Instrumen t lz_pob_mesa_f lz_pob_mesa_f lz_pob_mesa_f Clustering v araible munni_code munni_code munni_code #Co v ariates 7 7 2 Instrument str ength Effectiv e F 827.2 203.9 8,598.3 Bo otstrap F 925.5 202.6 8,989.5 2SLS estimate Co efficien t − 1.460 − 2.242 − 0.984 Std. error 0.463 1.300 0.142 p -v alue for t -stat 0.002 0.085 0.000 #Observ ations 4,352 1,069 4,352 #Clusters 1,098 632 1,098 R obust infer enc e AR p -v alue 0.002 0.075 0.000 tF p < 0 . 05 Y es No Y es Bo otstrap- c 95% CI [ − 2.42, − 0.62] [ − 4.66, − 0.07] [ − 1.32, − 0.73] Bo otstrap- t 95% CI [ − 2.37, − 0.55] [ − 5.74, 1.26] [ − 1.23, − 0.73] An y CI includes 0? No Y es: Bo ot- t No Sensitivity (jackknife) Range [ − 1.49, − 1.31] [ − 2.27, − 0.94] [ − 0.99, − 0.96] Most influential m uni 11001 ( ∆ =0.15) m uni 11001 ( ∆ =1.30) muni 11001 ( ∆ =0.02) OLS c omp arison OLS co efficient − 0.626 − 0.984 − 0.675 2SLS/OLS ratio 2.3 2.3 1.5 Robustness rating HIGH MODERA TE HIGH Notes: All b o otstrap tests use 1,000 iterations with cluster-level resampling. Jac kknife analysis remo v es one municipalit y cluster at a time. The effectiv e F -statistic ( Montiel Olea and Pflueger , 2013 ) is rep orted as the primary measure of instrument strength. Sp ec 2 triggers t wo w arnings: (1) the Anderson–R ubin p -v alue exceeds 0.05; (2) removing municipalit y 11001 (Bogotá) changes the estimate b y 58%, exceeding the 20% sensitivity threshold. outcome remains a question for the researcher. Note that the reanalysis do es not assess the credibilit y of the core identification assump- tions, namely unconfoundedness and the exclusion restriction of the instrumen t. When there 18 is a single instrumen t for a single endogenous regressor, these assumptions are not directly testable, and the diagnostics cannot adjudicate their v alidit y . Stage 7: Rep ort Findings The Journalist then assem bles the outputs from Stage 6 into a standardized rep ort, report.pdf , whic h is included in the Supplementary Materials (Section E ). The rep ort is organized by sp ecification. It b egins with an executive summary table that lists the trust worthiness rat- ings. It then do cumen ts the study design, v ariable definitions, replicated IV estimates, and the full set of diagnostics. F or each specification, four figures are generated automatically: follo wing Lal et al. ( 2024 ), a co efficient comparison plot displaying OLS and 2SLS estimates with multiple confidence in terv als, a comparison of first-stage F -statistics, b o otstrap con- fidence interv als, and jac kknife sensitivity . The format is iden tical across pap ers, which facilitates cross-study comparison. (a) Executive summary (b) Co efficien t plot for Sp ec 1 Figure 2. Selected figures from the diagnostic rep ort for R ueda ( 2017 ) generated b y the AI w orkflow. Left: the executive summary page summarizing ratings for all three sp ecifications (tw o HIGH, one MODERA TE). Right: the co efficient comparison plot for sp ecification 1, showing OLS and 2SLS p oint estimates with analytic, b o otstrap- c , b o otstrap- t , tF , and Anderson-Rubin confidence interv als. The full pip eline—from PDF ingestion and do wnloading the replication package to rep ort generation—completed in less than four min utes. Diagnostic computation in Stage 6 accoun ts for most of the runtime. No human interv ention was in volv ed. Clic k [ here ] for 19 a real-time demonstration, although the implemen tation itself do es not rely on a graphical in terface. 5. Main Findings This section rep orts the main findings from implemen ting the AI-assisted replication w ork- flo w at scale. W e first ev aluate the workflo w’s p erformance, including its success rate, binding constrain ts, and execution time. W e then presen t the empirical results from the extended IV corpus, sho wing that the automated pip eline repro duces the core patterns do cumen ted in Lal et al. ( 2024 ) under the same diagnostic template. 5.1. P erformance of the AI W orkflo w W e ev aluate the w orkflow on the 67 IV papers that form the b enc hmark corpus in Lal et al. ( 2024 ) and on 25 newly collected studies under identical inclusion criteria. T able 3 rep orts stage-lev el and end-to-end success rates at both the pap er and sp ecification levels. F or the original sample, end-to-end autonomous success is 55/67 (82%). All failures o ccur at the material retriev al stage, where replication arc hiv es are no longer publicly a v ail- able. These 12 pap ers—all published b efore 2020—cannot curren tly b e downloaded from public rep ositories. Using archiv ed materials retained from the earlier pro ject, how ever, w e execute the pip eline and reproduce their findings. Conditional on accessible data and co de, sp ecification extraction, execution, and diagnostic analysis succeed for all pap ers. Th us, among studies with a v ailable materials, the current pip eline achiev es full co verage. P erformance generalizes to the expanded sample. F or the 25 newly incorp orated pap ers, all stages succeed, yielding a 100% end-to-end rate. A t the sp ecification level, all 215 mo dels are successfully extracted, executed, and analyzed; the 90% o v erall rate reflects out-of-scop e designs rather than execution failures. A t first glance, this result may seem surprising. Three factors accoun t for it. First, the system is v ersion-con trolled and adaptive: recurring execution issues are enco ded as 20 T able 3. Success Replica tion Ra te (Original and Exp anded Samples) A. Original Sample (67 pap ers) Input Success F ailure Success rate Material retriev al (Librarian) 67 55 12 82% Sp ecification extraction (Profiler) 67 67 0 100% Co de execution (R unner) 67 67 0 100% Diagnostic analysis (Sk eptic) 67 67 0 100% End-to-end success rate 55 / 67 = 82% Success rate given data* 67 / 67 = 100% B. Exp ande d Sample (25 papers) Input Success F ailure Success rate Material retriev al (Librarian) 25 25 0 100% Sp ecification extraction (Profiler) 25 25 0 100% Co de execution (R unner) 25 25 0 100% Diagnostic analysis (Sk eptic) 25 25 0 100% End-to-end success rate 25 / 25 = 100% C. Al l 215 Sp e cific ations Input Success F ailure Success rate Sp ecification extraction (Profiler) 215 215 0 100% Co de execution (R unner) 215 215 0 100% Diagnostic analysis (Sk eptic) 215 215 0 100% End-to-end success rate 215 / 215 = 100% Notes. Panels A and B rep ort paper-level success: a pap er succeeds at a given stage if at least one sp ecification passes. Panel C reports sp ecification-level success. “F ailure” at the material retriev al stage reflects that, among the 67 original papers, replication materials for 12 are no longer publicly a v ailable online and were man ually supplied from archiv ed copies. repair rules and therefore do not recur under a fixed pip eline version. Second, as noted ab o v e, the pap ers in the expanded sample were published after 2023, when all three journals required in-house replication. Third, the diagnostic template is delib erately narro w and well defined. Once the b enchmark 2SLS p oin t estimate is repro duced, downstream diagnostics are mec hanically determined by the template. Conditional on correct sp ecification parsing and estimation, the remaining steps pro ceed deterministically . The w orkflow substantially reduces time and monetary cost relativ e to man ual replica- tion. F or pap ers with accessible materials, end-to-end pro cessing completes within min utes p er paper, ranging from under one minute to half an hour, and can b e fully parallelized. Most wall-clock time is sp en t do wnloading replication pac kages and running LLM diagnos- tics; only a small share of computation requires LLM calls. Once the co de is stabilized in the execution lay er, the marginal cost per additional pap er is low. Researc hers remain 21 resp onsible for in terpreting diagnostic rep orts, but core execution is automated. 5.2. Empirical Results from the Extended IV Corpus W e apply the automated workflo w to the extended IV corpus using the same diagnostic template as in Lal et al. ( 2024 ). The main empirical patterns, after the AI w orkflow applies the diagnostic template, remain similar to those rep orted in the original study . F or example, the most imp ortant empirical finding in Lal et al. ( 2024 ) is the discrepancy b et w een 2SLS and OLS estimates, and the negativ e relationship b etw een the 2SLS–OLS ra- tio and first-stage strength, but only in observ ational studies. W e find a similar pattern using estimates produced by the AI workflo w, no w with 215 sp ecifications (v ersus 70 in the original study). Figure 3 mirrors Figure 5 in Lal et al. ( 2024 ). Subfigure (a) plots nor- malized coefficients and shows that 2SLS and OLS estimates generally share the same sign, with 2SLS magnitudes often larger. Subfigure (b) rep orts the distribution of the absolute ratio | ˆ τ 2SLS / ˆ τ OLS | . In the extended sample, the mean of this ratio is 10.4 and the median is 3.0. In most of sp ecifications, the 2SLS estimate exceeds the OLS estimate in absolute v alue. Subfigure (c) relate | ˆ τ 2SLS / ˆ τ OLS | to first-stage strength, measured b y | ˆ ρ ( d, ˆ d ) | . Among observ ational designs, regressing the log ratio on first-stage strength yields a robust negative correlation ( p = 0 . 000 , with the standard error clustered at the study lev el). Among ex- p erimen tal designs, the relationship is statistically indistinguishable from zero ( p = 0 . 391 ). Subfigure (d) highlights observ ational studies in whic h the OLS estimates are statistically significan t at the 5% lev el and are presented as part of the pap er’s main findings; the same pattern remains. These findings reinforce the argument in Lal et al. ( 2024 ) that man y estimates from observ ational IV designs rest on fragile identification assumptions, including instrumen t un- confoundedness and the exclusion restriction. In practice, suc h designs are often introduced to strengthen the credibility of causal claims based on “naive” OLS; ho wev er, when these assumptions fail, esp ecially in the presence of publication bias tow ard statistically significant 22 Figure 3. Relationship b et w een OLS and 2SLS estimates. This figure replicates Figure 5 in Lal et al. ( 2024 ). Panel (a) rescales b oth co efficients b y the rep orted OLS standard errors; the shaded region corresp onds to the interv al [ − 1 . 96 , 1 . 96] . Panel (b) presents the distribution of the log absolute ratio b et ween the reported 2SLS and OLS co efficients. P anels (c) and (d) examine how first-stage strength, measured b y | ˆ ρ ( d, ˆ d ) | , relates to the magnitude of the 2SLS-to-OLS ratio. Gray mark ers denote observ ational designs and red mark ers denote exp eriment-based instruments. P anel (d) further distinguishes designs in which the OLS estimate is statistically significant at the 5% level and is presented as part of the pap er’s primary results. results, bias in 2SLS estimates may be substantially larger than in OLS. A key difference, how ev er, is the time required: whereas the original study inv olv ed appro ximately four y ears of manual data collection, processing, replication, and reanalysis, 23 the expanded corpus is processed within da ys under the automated pip eline. 6. Discussion This paper presen ts an AI-orc hestrated w orkflo w for systematic diagnostic ev aluation of empirical researc h with publicly av ailable data and co de. The system executes end to end and generates standardized rep orts at scale with minimal human in terv ention. It relies, how ev er, on diagnostic templates defined b y h uman experts. While extraction and execution are automated, b enchmark estimands, inclusion criteria, and w arning thresholds reflect prior metho dological judgment. The w orkflo w therefore scales ev aluation rather than defining ev aluative standards. Related evidence from Straus and Hall ( 2026 ) sho ws that frontier co ding mo dels can repro duce and extend published p olitical science analyses when given structured access to data and co de. Human-led replication initiativ es remain indispensable. Journal-based data editor pro- grams (e.g., the AEA Data Editor and Politic al A nalysis replicators), research transparency organizations such as OSF and BITSS, the Institute for Replication (I4R), and independent replication communities con tinue to play a cen tral role in credibility assessmen t. Ev aluat- ing iden tification strategies, measurement c hoices, data construction, and research design requires substantiv e judgmen t that cannot, at presen t, be delegated to automated systems. The w orkflow proposed here is complemen tary to these efforts, not a substitute. W e regard this separation b et w een exp ert judgment and automated execution as a feature. Once templates and standards are sp ecified, the pipeline applies them uniformly across studies, promoting consistency and transparency . As AI systems impro v e, elements of template design may b ecome more adaptive. Because the arc hitecture is mo dular, such c hanges can b e incorp orated without altering its core structure. W e outline extensions and discuss broader implications for empirical research. 24 6.1. F uture W ork W e consider three future extensions: expanding across researc h designs, deep ening the scop e of replication, and in tegrating the w orkflow in to researc h infrastructure. Extending to other designs. A natural extension applies the workflo w to additional re- searc h designs for whic h w e hav e previously constructed structured corp ora. One candidate is panel studies estimated using estimators tied to tw o-wa y fixed effects (TWFE) mo dels un- der v ariants of the parallel trends assumption. In earlier work, w e assembled and reanalyzed a corpus of 49 such studies ( Chiu et al. , 2023 ). There, the b enchmark ob ject is the base- line TWFE estimate, and the diagnostic objective is to assess robustness to heterogeneous treatmen t effects using mo dern difference-in-differences estimators. Because the corpus w as built under explicit inclusion criteria and a clearly defined estimand, it offers a disciplined template for automation. The w orkflow can replicate this corpus and extend it to newly pub- lished studies under the same criteria. A related extension concerns studies that estimate heterogeneous treatmen t effects using linear interaction mo dels. Hainmueller, Mummolo and Xu ( 2019 ) compiled a corpus of 22 suc h applications. T ogether with the up dated diagnostic template in Liu, Liu and Xu ( 2025 ), this corpus provides a structured foundation for scaling. F rom diagnostics to full replication. The curren t workflo w ev aluates b enchmark speci- fications. A natural next step is to reconstruct complete tables and figures and verify in ternal coherence across rep orted results. This w ould allo w systematic comparison betw een rep orted and regenerated outputs. F or example, the system could easily detect when t w o tables claim to use the same sample but report drastically different num b ers of observ ations, or when a robustness sp ecification silen tly changes clustering levels. More broadly , the w orkflow makes previously costly diagnostics more feasible. It can automate cluster jackknife and lea ve-one-out procedures, compute lev erage and Co ok’s dis- tance, apply alternative winsorization thresholds, and implemen t p ermutation or b o otstrap 25 inference under alternative resampling sc hemes. In most empirical settings, these analyses are tec hnically possible but rarely reported b ecause they require substantial time and com- putation. By standardizing and parallelizing these pro cedures, the system low ers the cost of applying them across many studies. Scaling from individual sp ecifications to integrated studies shifts attention from isolated co efficients to the stability of empirical claims as a whole. In tegration with the researc h pro cess. The w orkflow can also in tegrate into the re- searc h and publication pipeline. It can assist authors in preparing replication materials through standardized, machine-readable structures that clarify file organization and sp ec- ification definitions. A utomated v alidation can identify missing dep endencies, unresolv ed paths, or incomplete documentation at submission rather than after publication. If journals adopt suc h to ols, repro ducibilit y chec ks could b ecome more routine. Cen- tralized verification services or third-part y replication teams could rely on standardized di- agnostic outputs, reducing the burden on editors and shortening review cycles. In this role, the w orkflo w functions not only as a diagnostic instrumen t but as part of the infrastructure that supp orts more systematic v erification. 6.2. Implications for Empirical Researc h W e exp ect this or similar w orkflows to influence ho w empirical researc h is conducted, ev al- uated, and accum ulated in the coming y ears. W e outline several implications b elow. Lo wering the cost of v erification dramatically . The most immediate implication is a substan tial reduction in the marginal cost of verification. When replication materials are a v ailable, recomputing estimates and applying standardized diagnostics b ecomes con- siderably less exp ensiv e than under current practice. This do es not resolv e disputes ab out iden tification or theory , but it c hanges incen tives. A t presen t, systematic v erification is rare b ecause its cost often exceeds its exp ected b enefit. As that cost falls, more journals ma y 26 find it feasible to require in-house or third-part y repro ducibilit y chec ks as a condition for acceptance. A uthors, anticipating a higher likelihoo d of auditing, may adopt more disci- plined coding practices and address influence, clustering, and resampling concerns ex an te. V erification th us b ecomes more closely integrated in to the publication pro cess rather than applied only after con tro v ersies arise. Standardizing diagnostic rep orting. Uniform diagnostic protocols can also reshape rep orting norms. If weak-instrumen t tests, robust inference pro cedures, and sensitivit y anal- yses are implemented automatically and summarized in standardized formats, discretion in ho w robustness is selected and presented declines. Journals may require structured diag- nostic summaries alongside main results, m uch as data-av ailabilit y statements hav e b ecome routine. Referees may increasingly exp ect influence diagnostics and alternative clustering c hecks as part of the baseline empirical presentation. Over time, graduate training may adapt to treat such diagnostics as in tegral comp onents of empirical analysis rather than supplemen tary exercises. Enabling large-scale reanalysis and accelerating metho dological researc h. Har- monized analysis datasets and structured metadata enable large-scale reanalysis under con- sisten t criteria. Each of our previous large-scale reanalysis pro jects took three to four years of sustained effort. Much of that time was sp ent harmonizing replication materials, clarifying b enc hmark estimands, and standardizing robustness chec ks across heterogeneous applica- tions. With the present workflo w, many of these steps can b e automated, substan tially reducing the time required to conduct comparable large-scale reanalyses. In the near term, this infrastructure ma y supp ort more frequen t and systematic reassess- men t of empirical literatures. Research groups, professional asso ciations, or journals could p erio dically revisit published findings using up dated diagnostic standards without incurring m ulti-year co ordination costs. As harmonized corp ora accumulate, empirical claims may comp ete not only on substantiv e grounds but also on demonstrated stabilit y under shared 27 diagnostics. A large quan tit y of harmonized data will hav e profound implications for metho dological researc h. In computer science, b enc hmark datasets such as ImageNet ( Deng et al. , 2009 ), MS COCO ( Lin et al. , 2014 ), SQuAD ( Ra jpurkar et al. , 2016 ), and GLUE ( W ang et al. , 2018 ) structured progress by pro viding common ev aluation en vironmen ts. Researchers could compare algorithms under iden tical tasks and metrics, whic h facilitated cum ulativ e impro ve- men t. Analogously , a large collection of harmonized empirical datasets with standardized diagnostic outputs can serv e as a b enc hmark platform for causal and statistical methods. Metho dologists could ev aluate new estimators and inference pro cedures across diverse real- w orld applications rather than relying primarily on st ylized sim ulations. By low ering the cost of empirical v alidation, the workflo w may help shift metho dological researc h tow ard cum ulative comparison under shared empirical settings. T aken together, these implications suggest that agentic AI workflo ws for repro ducibil- it y , with h umans in the loop, can function as research infrastructure. They do not replace researc hers’ substan tive judgmen t, but make systematic ev aluation easier to conduct and harder to a void. By low ering the cost of verification, standardizing diagnostics, and acceler- ating metho dological dev elopment, they ma y help help mak e transparency and cum ulative scrutin y part of routine empirical practice. 28 References Angrist, Josh ua D and Jörn-Steffen Pischk e. 2010. “The credibilit y rev olution in empirical economics: Ho w b etter researc h design is taking the con out of econometrics. ” Journal of Ec onomic Persp e ctives 24(2):3–30. Berge, Lauren t. 2023. fixest: F ast Fixe d-Effe cts Estimation . R package version X.X.X. URL: https://CRAN.R-pr oje ct.or g/p ackage=fixest Blair, Graeme, Jasp er Co op er, Alexander Copp o ck, Macartan Humphreys and Luke Sonnet. 2024. estimatr: F ast Estimators for Design-Base d Infer enc e . R package v ersion 1.0.4. URL: https://CRAN.R-pr oje ct.or g/p ackage=estimatr Chiu, Alb ert, Xingc hen Lan, Ziyi Liu and Yiqing Xu. 2023. “Causal panel analysis under parallel trends: lessons from a large reanalysis study . ” A meric an Politic al Scienc e R eview pp. 1–22. Deng, Jia, W ei Dong, Richard So cher, Li-Jia Li, Kai Li and Li F ei-F ei. 2009. ImageNet: A Large-Scale Hierarchical Image Database. In Pr o c e e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) . IEEE pp. 248–255. Hainm ueller, Jens, Jonathan Mummolo and Yiqing Xu. 2019. “Ho w m uch should w e trust estimates from m ultiplicative interaction mo dels? Simple to ols to improv e empirical prac- tice. ” Politic al A nalysis 27(2):163–192. Lal, Ap o orv a, Mack enzie Lockhart, Yiqing Xu and Ziwen Zu. 2024. “Ho w muc h should w e trust instrumental v ariable estimates in p olitical science? Practical advice based on 67 replicated studies. ” Politic al A nalysis 32(4):521–540. Lal, Ap o orv a and Yiqing Xu. 2024. ivDiag: Estimation and Diagnostic T o ols for Instrumen- tal V ariables Designs . R package version 1.0.6. URL: https://CRAN.R-pr oje ct.or g/p ackage=ivDiag Leamer, Edw ard E. 1983. “Let’s tak e the con out of econometrics. ” The A meric an Ec onomic R eview 73(1):31–43. Lee, Da vid S., Justin McCrary , Marcelo J. Moreira and Jack P orter. 2022. “V alid t -Ratio Inference for IV. ” A meric an Ec onomic R eview 112(10):3260–3290. Lin, T sung-Yi, Michael Maire, Serge Belongie, James Ha ys, Pietro P erona, Dev a Ramanan, Piotr Dollár and C. Lawrence Zitnic k. 2014. Microsoft COCO: Common Objects in Con- text. In Eur op e an Confer enc e on Computer V ision (ECCV) . Springer pp. 740–755. 29 Liu, Jiehan, Ziyi Liu and Yiqing Xu. 2025. “A Practical Guide to Estimating Conditional Marginal Effects: Mo dern Approaches. ” arXiv pr eprint arXiv:2504.01355 . Mon tiel Olea, José Luis and Carolin Pflueger. 2013. “A Robust T est for W eak Instrumen ts. ” Journal of Business & Ec onomic Statistics 31(3):358–369. Op en Science Collab oration. 2015. “Estimating the repro ducibilit y of psychological science. ” Scienc e 349(6251):aac4716. Ra jpurkar, Pranav, Jian Zhang, Konstan tin Lop yrev and P ercy Liang. 2016. SQuAD: 100,000+ Questions for M ac hine Comprehension of T ext. In Pr o c e e dings of the 2016 Con- fer enc e on Empiric al Metho ds in Natur al L anguage Pr o c essing (EMNLP) . ACL pp. 2383– 2392. R ueda, Miguel R. 2017. “Small Aggregates, Big Manipulation: V ote Buying Enforcemen t and Collectiv e Monitoring. ” A meric an Journal of Politic al Scienc e 61(1):163–177. URL: https://doi.or g/10.1111/ajps.12260 Straus, Graham and Andrew B. Hall. 2026. “How A ccurately Did Claude Co de Replicate and Extend a Published P olitical Science P ap er?” Unpublished man uscript, January 9. URL: https://www.andr ewb enjaminhal l.c om/ S tr aus _ H al l _ C l aude _ Audit.pd f T orreblanca, Carolina, William Dinneen, Guy Grossman and Yiqing Xu. 2026. “The Credi- bilit y Revolution in Political Science. ” . URL: https://arxiv.or g/abs/2601.11542 W ang, Alex, Amanpreet Singh, Julian Michael, F elix Hill, Omer Levy and Sam uel R. Bo w- man. 2018. GLUE: A Multi-T ask Benchmark and Analysis Platform for Natural Lan- guage Understanding. In Pr o c e e dings of the 2018 EMNLP W orkshop Blackb oxNLP . A CL pp. 353–355. 30 Supplemen tary Materials Scaling Repro ducibility: An AI-Assisted W orkflo w for Large-Scale Reanalysis A. System Arc hitecture and W orkflow A.1. Three-La yer Arc hitecture A.2. Agen ts and Stage-Lev el Implemen tation B. IV Diagnostic T emplate C. A daptive Execution Mec hanism C.1. The Resolution Cycle C.2. A daptation in Practice D. Empirical In ven tory and P erformance D.1. Classes of Implementation V ariation D.2. Pip eline Performance D.3. Detailed In ven tory of Resolv ed Issues S-1 A. System Arc hitecture and W orkflo w This section describes the three-lay er system arc hitecture and details of the AI w orkflo w. A.1. Three-La y er Arc hitecture The AI w orkflow describ ed in the main text, whic h is adaptiv e in orc hestration and de- terministic in computation, is implemen ted through a three-lay er system. The la y ers are ordered b y control flow: the LLM orc hestrator gov erns co ordination, skill descriptions me- diate task specification and accumulated kno wledge, and deterministic agent co de executes all op erations whose outputs m ust b e n umerically repro ducible. La yer 1: The LLM Orchestrator. The orchestrator is an LLM (Claude) that manages the pip eline lifecycle. It reads a project-level instruction file that sp ecifies global proto cols for stage ordering, error handling, logging, and knowledge up dates. F or eac h stage, it consults the relev an t skill description, prepares the required inputs, in vok es the corresponding agen t, and insp ects the resulting logs and artifacts. When a stage fails, the orc hestrator parses structured log output to determine the failure t yp e. If the error matches a previously recorded pattern in the relev ant kno wledge base, it applies the do cumente d resolution strategy by mo difying inputs or dispatching auxiliary steps. If the failure is nov el, it generates a candidate diagnosis and prop osed fix, which is sub ject to h uman review b efore b eing incorp orated in to the system. The orc hestrator do es not p erform statistical estimation, transform datasets, or mo dify n umerical routines. Its role is strictly coordinative: it decides which comp onent runs and how to resp ond to execution outcomes, but it nev er en ters the computational path that determines n umerical results. La yer 2: Skill descriptions and knowledge bases. Eac h agen t is asso ciated with a structured natural-language file ( SKILL.md ) that functions as b oth a formal interface speci- fication and a persistent kno wledge base. The first comp onen t of the file defines the agent’s contract: required inputs, exp ected outputs, p ermissible to ols, execution constrain ts, and the sequence of subtasks. This sp ecifi- cation ensures that the orc hestrator in teracts with the agen t in a con trolled and predictable manner. The second component records accumulated failure patterns encountered during devel- opmen t and ev aluation. Eac h entry do cumen ts the con text in whic h a failure o ccurred, the ro ot cause, and the generalized resolution rule. These en tries are written in structured form to promote consistency across up dates. When a new class of failure is resolved, the corre- S-2 sp onding rule is added to the relev an t skill file. This pro cess expands the system’s co v erage without mo difying deterministic computation within a giv en pip eline v ersion. Because skill files are v ersion-controlled, each run is asso ciated with a fixed and insp ectable kno wledge state. La yer 3: Deterministic agen t co de and diagnostic scripts. The b ottom la yer consists of deterministic program co de that executes all file op erations and statistical pro cedures. Eac h agent is implemented as an indep enden t Python class resp onsible for a sp ecific stage of the pipeline (e.g., metadata extraction, rep ository retriev al, sp ecification parsing, co de preparation, execution, or rep orting). Agen ts op erate only on explicit inputs and pro duce explicit outputs written to disk. They share no in ternal state. Statistical estimation and diagnostic pro cedures are executed b y explicit scripts in R , Stata , and Python . In particular, the full diagnostic suite is implemented in a standalone R script ( diagnostics_core.R ) that consumes exp orted analysis datasets and pro duces structured diagnostic outputs. This script calls established statistical pac kages, including estimatr ( Blair et al. , 2024 ), fixest ( Berge , 2023 ), boot , and ivDiag ( Lal and Xu , 2024 ). Giv en the same inputs and the same pip eline version, this la yer pro duces identical n umerical results across runs. Information flo ws do wn ward as instructions and dispatc h decisions (Lay er 1 to Lay er 3) and up ward as logs, in termediate artifacts, and error messages (Lay er 3 to Lay er 1). Adap- tation occurs only through con trolled up dates to La y er 2 (skill descriptions) and, when necessary , to deterministic agen t co de b etw een v ersions. Within a fixed version, n umerical outputs dep end exclusiv ely on deterministic co de and exp orted datasets. This separation allows the system to remain adaptive in co verage while preserving com- putational determinacy in eac h execution. Human o versigh t op erates at the b oundary b e- t ween Lay ers 1 and 2: prop osed up dates to kno wledge bases or deterministic routines are review ed b efore b eing committed. The result is an arc hitecture that evolv es across versions y et remains repro ducible within v ersion. S-3 A.2. Agen ts and Stage-Lev el Implemen tation This section describ es the AI agents that implemen t each stage of the workflo w. The fo cus is op erational: inputs, outputs, implemen tation details, and design decisions that shap ed the system through rep eated encounters with real replication packages. Statistical diagnostics are describ ed separately in Section B . A.2.1. Data Acquisition: Profiler and Librarian The first step in repro ducing an empirical study is obtaining the pap er itself and its ac- compan ying replication pac kage—typically comprising data files and analysis co de. These tasks are handled b y the Profiler and the Librarian. T ogether they illustrate the adaptive- orc hestration-with-deterministic-computation principle at the pip eline’s en try p oin t: the Profiler in terprets unstructured PDF text, while the Librarian executes deterministic re- triev al routines. Profiler (Metadata Extraction) Giv en a pap er in PDF format, Profiler con verts the PDF to plain text using pdftotext , then extracts structured metadata including title, au- thors, publication year, and journal. More critically , it searches for a “Data A v ailability Statemen t” (or equiv alen t section) and extracts the data rep ository URL—for example, links to Harv ard Data verse, GitHub, or the Op en Science F ramew ork (OSF). Extraction com bines deterministic parsing rules (e.g., URL detection, section matc hing) with limited language-mo del assistance when formatting is irregular or nonstandard. The extracted information is written to a standardized JSON file ( study_info.json ), which serv es as the input to the Librarian. Librarian (Replication P ac kage Retriev al) The Librarian reads the rep ository URL recorded in study_info.json and do wnloads the complete replication pac kage. It supp orts commonly used academic data hosting platforms: • Data verse : retrieves the dataset file list via the Data verse API and downloads each file individually . • GitHub : downloads the rep ository as a ZIP arc hiv e. • OSF : retriev es pro ject files via the OSF API. • Direct HTTP links : downloads files via standard HTTP requests. A key design choice is a PDF-first retriev al strategy: URLs embedded in the pap er are prioritized ov er keyw ord-based searc h. Title-based search frequently returns irrelev ant datasets for pap ers with common keyw ords. By con trast, URLs in the PDF t ypically p oint S-4 directly to the authors’ own rep ository . Keyw ord search is used only as a fallback when no URL is found. If automated retriev al fails en tirely , the user ma y man ually supply the replication pac kage so that do wnstream stages can pro ceed. The output is a v ersioned lo cal cop y of the full replication pac kage. A.2.2. Sp ecification Iden tification: Profiler (Again) With the replication pac kage a v ailable, Profiler (the same agent in charge of metadata ex- traction) identifies the 2SLS sp ecifications implemen ted in the co de. This is one of the most tec hnically challenging stages of the pip eline. Multi-Language Co de Parsing The Profiler parses all Stata ( .do ), R ( .R ), and Python ( .py ) scripts in the replication pac kage. It uses language-specific deterministic patterns to detect IV estimation commands. F or Stata, matched commands include ivreg2 , ivregress 2sls , reghdfe ... (D = Z) , and ivprobit . F or R, it detects ivreg() , iv_robust() , and feols() calls containing IV syn tax. F or Python, it detects IV2SLS() commands. F or each iden tified IV command, the Profiler extracts a structured represen tation of the sp ecification, including the outcome v ariable ( Y ), endogenous treatmen t ( D ), instrumen t(s) ( Z ), exogenous con trols ( X ), clustering v ariable, fixed effects, statistical softw are used, source script file, and, when a v ailable, the corresp onding table reference in the pap er. These fields are recorded in metadata.json , whic h is consumed b y the R unner and Sk eptic. Multiple Sp ecification Handling Empirical pap ers often rep ort m ultiple IV sp ecifica- tions. The Profiler extracts al l IV commands and then selects primary specifications through a m ulti-step pro cedure: 1. Deduplicate sp ecifications based on ( Y , D , Z, X ) com binations. 2. Rank candidates using heuristic rules (e.g., explicit table references, lo cation in main- results scripts, ric her con trol sets). 3. Retain up to three primary sp ecifications p er study . Language Mo del Assistance When deterministic parsing fails due to opaque v ariable names, sparse comments, or nonstandard syn tax, the Profiler selectiv ely inv ok es a light weigh t language mo del to interpret the command structure. F or example, given a complex Stata command, the mo del ma y iden tify whic h v ariable serv es as the endogenous regressor and whic h as the instrumen t. S-5 P atterns that initially require LLM interpretation are progressiv ely enco ded as deter- ministic parsing rules. Over time, this reduces reliance on model interpretation and increases repro ducibilit y across standard command formats. A.2.3. Execution Environmen t: Janitor and R unner Janitor (Co de Preparation) Replication pac kages are t ypically written under assump- tions ab out directory structure and soft ware en vironment. Direct execution in a differen t en vironment often fails due to path mismatc hes, una v ailable graphics devices, deprecated pac kages, or syntax conv entions. The Janitor p erforms automated repairs to enable execution in the curren t en vironmen t. These op erations include: • P ath repair : Replacing absolute paths (e.g., C:\Users\author\data ) with w orkspace- relativ e paths. F or Stata, this includes parsing v ariations in use syn tax and macro references. • Graphics suppression : Commenting out graphical commands (e.g., graph export , pdf() , png() ) that ma y fail in headless en vironments. • Dep endency handling : Substituting or commenting out deprecated R pac kages (e.g., rgdal , rgeos , maptools ). • Stata-sp ecific repairs : Handling #delimit syntax, macro substitution (e.g., $datadir ), and panel declarations. • Data format con v ersion : Conv erting nonstandard formats (e.g., .tab ) to formats readable b y Stata or R. Eac h op eration was added in resp onse to a real failure class encoun tered during dev el- opmen t. All mo difications are recorded in a structured cleaning log ( cleaning_log.json ). R unner (Execution and Data Extraction) The Runner executes the cleaned repli- cation co de in batc h mo de using the appropriate interpreter: stata -b do , Rscript , or python3 , dep ending on the soft w are t yp e recorded in metadata.json . The primary ob jectiv e is to extract the analysis dataset con taining all v ariables used in the rep orted sp ecification. Data exp ort commands are inserted at appropriate execution p oin ts, and the in-memory dataset is sav ed as CSV. F or Stata studies, .dta files are also con verted to CSV after execution. F or Stata-based studies, the Runner p erforms cross-language v alidation. It translates the Stata IV command into an equiv alen t R sp ecification and re-estimates the mo del on the same dataset. Co efficien ts are compared within a tolerance of max (0 . 01 × | ˆ β | , 10 − 6 ) . T ranslation must handle syn tactic differences, suc h as conv erting i.var to factor(var) and S-6 mapping absorb() to fixed-effects syntax in fixest . The catalog of translation mappings expanded iterativ ely as new Stata idioms w ere encoun tered. Outputs include the extracted dataset ( analysis_data.csv ), execution logs ( execution_log.txt ), and cross-language v alidation results. A.2.4. Diagnostic Execution: Sk eptic The Skeptic applies the h uman-designed diagnostic template to the extracted dataset b y in- v oking a standalone R script that implemen ts the IV diagnostics describ ed in Section B . The Sk eptic contains no language-mo del calls and no adaptiv e logic. All statistical pro cedures are deterministic and v ersion-con trolled. Diagnostic results, including all statistics and w arning indicators, are written to a file called diagnostics.json , whic h serv es as the input to the rep orting stage. After computing all diagnostics, the Sk eptic assigns a summary credibility rating based on the n umber of triggered w arning flags: T able S1. Credibility Ra ting Scheme Rating Condition In terpretation High No warnings Strong instruments and robust inference Mo derate 1–2 warnings Some concerns; in terpret with caution Lo w 3–4 warnings Substan tial v alidity concerns V ery Lo w ≥ 5 warnings Results lik ely unreliable This rating is an auxiliary summary indicator rather than a substitute for indep endent ev aluation. Individual diagnostics ma y differ in substantiv e imp ortance—for example, ex- tremely w eak instruments may b e more consequential than sev eral minor warnings. The rating is intended to facilitate screening and to highligh t specifications that merit closer scrutin y . A.2.5. Rep orting: Journalist The Journalist con verts diagnostics.json in to a standardized Markdown rep ort and visu- alizations. The rep ort includes mo del sp ecification details, diagnostic statistics, and w arning summaries. Standardized charts include first-stage F -statistics, b o otstrap confidence in ter- v als, and jackknife sensitivity distributions. Because rep orting is fully deterministic and template-based, identical inputs pro duce iden tical outputs, preserving cross-study comparabilit y . S-7 B. IV Diagnostic T emplate This section briefly summarizes the statistical diagnostics applied to eac h IV sp ecification. The full motiv ation and in terpretation are detailed in Lal et al. ( 2024 ). The pip eline imple- men ts the same diagnostic template. Instrumen t strength. Instrumen t strength is assessed using first-stage F -statistics. The effectiv e F -statistic ( Mon tiel Olea and Pflueger , 2013 ) serv es as the primary indicator. F ol- lo wing common practice, F < 10 triggers a w eak-instrument w arning. Robust inference. Inference robustness is ev aluated using: • The Anderson–R ubin (AR) test, whic h remains v alid under w eak instrumen ts. • Bo otstrap confidence in terv als (including cluster bo otstrap when clustering is used). • The tF pro cedure ( Lee et al. , 2022 ) in single-instrument cases, which adjusts critical v alues as a function of the first-stage F . Sensitivit y analysis. A leav e-one-out jac kknife pro cedure assesses the influence of indi- vidual observ ations or clusters on the IV estimate. Large c hanges relative to the baseline estimate trigger w arnings. 2SLS–OLS comparison. An OLS mo del (without instruments) with the same outcome- treatmen t-cov ariates sp ecification is estimated and compared to the 2SLS estimate. S-8 Original findings. F or comparison purp oses, w e reproduce Figure 5 of Lal et al. ( 2024 ), whic h is op en access, b elow. S-9 C. A daptiv e Execution Mechanism The preceding sections describ ed the self-improv emen t mechanism in arc hitectural terms. This section makes that mechanism concrete. W e do cument the recurring resolution cy- cle through whic h new classes of implementation v ariation were addressed, and the role of structured kno wledge accum ulation in preven ting recurrence. Representativ e examples are dra wn from the 92-pap er ev aluation corpus. A complete empirical in v en tory of resolved issue classes app ears in Appendix D . C.1. The Resolution Cycle The w orkflow expands cov erage through a recurring four-phase cycle. First, the system detects anomalies. These include execution failures, silen t data incon- sistencies, and mismatc hes b etw een exp ected and observ ed outputs. It iden tifies them by reading execution logs, comparing estimates across soft ware, and chec king intermediate files for in ternal consistency . Second, it iden tifies the root cause. Rather than retrying commands, it traces the failure across stages and programming languages to lo cate the source of the problem. Third, it implemen ts a general fix. The repair is written as a rule in the relev ant deterministic co de la yer, not as a patc h for a single pap er. F uture pap ers exhibiting the same pattern are handled automatically . F ourth, it records the resolution. The con text, problem, fix, and impact are do cumented in the agen t’s knowledge base ( SKILL.md ) in a standardized format so that the solution can b e retriev ed and reused. This cycle differs from manual replication and fixed scripts. Manual replication repeats these steps for each pap er, and lessons are rarely formalized. A fixed script applies predefined rules but cannot detect new failure classes or extend its rule set. Here, the same four steps are applied systematically , with h uman review limited to appro ving code up dates b efore they are committed. A daptation pro ceeds through tw o channels. When a failure class is well-defined and recurring, the fix is enco ded as a deterministic rule in the relev ant agent’s co de. When a pattern is b etter captured as contextual guidance, it is recorded in the agent’s knowledge base and used to guide future orc hestration. In both cases, up dates occur betw een runs and are v ersion-controlled. S-10 C.2. A daptation in Practice W e describ e every steps of the adaptation cycle b elow and illustrate them with examples from practice. C.2.1. Disco v ery Man y consequential failures pro duced no explicit error message. Detection therefore relied on cross-field consistency c hec ks. Example: Silen t co efficien t failure due to bac ktick quoting. When CSV column names b egin with an underscore (e.g., _log_providers ), R internally wraps them in bac k- tic ks. A call such as coef(fit)["_log_providers"] returns NA silently . The orc hestrator detected this anomaly b ecause first-stage statistics w ere computed correctly while down- stream estimates—2SLS coefficients, jac kknife results, b o otstrap in terv als—were missing. This pattern suggested a name-matc hing failure rather than a data or model error. The fix in tro duced a four-w a y lo okup function that attempts ra w, backtic k-quoted, stripp ed, and fuzzy matc hes, and w as applied across the diagnostic script. Example: Destructiv e safeguard in Stata. The pattern capture drop X; gen X = expr prev ents error r(110) when a v ariable already exists. Ho w ever, if expr references a missing v ariable, gen fails after drop has remo ved the original v ariable. The orchestrator iden tified this when a replication pac kage contained a precomputed v ariable that was inad- v ertently deleted. The fix replaced drop-and-recreate with a bac kup–restore pattern: rename the original v ariable, attempt generation, and restore if generation fails. C.2.2. Ro ot-Cause Diagnosis Complex failures often spanned m ultiple agen ts and programming en vironments. Example: Cross-language sign rev ersal. In one sp ecification, R cross-v alidation yielded +2 . 15 while Stata pro duced − 2 . 24 . The orchestrator traced the discrepancy across seven la yers: a dropped lagged con trol, v ariable-name abbreviation in Stata, incomplete panel ex- p ort, and interaction with e(sample) memory . Switching to a full-panel exp ort with an estimation-sample indicator resolved the discrepancy , pro ducing an exact co efficient match ( − 2 . 2420 ). Diagnosis required co ordinated reasoning across Python, Stata, and R comp o- nen ts. S-11 C.2.3. Generalized Co de Repair Fixes w ere implemented as general rules rather than pap er-sp ecific patc hes. First, when a single failure revealed a broader pattern, we generalized the rule. F or ex- ample, failure to recognize abbreviated #delimit commands led to expansion of the regular- expression cov erage to include all v alid abbreviations. The c hange applied to all subsequen t pap ers using an y shortened form. Second, when rep eated failures exp osed a structural weakness, w e redesigned the com- p onen t. Retriev al based on k eyword search frequen tly downloaded incorrect datasets. W e therefore adopted a PDF-first retriev al strategy that prioritizes rep ository links embedded in the paper. Third, when insertion errors arose during data exp ort, w e refined the co de-injection logic. Exp orting analysis data required detecting the active delimiter mo de, scanning multi- line commands b efore insertion, and using con tent-based anc hors rather than line n umbers to a void drift as earlier edits shifted subsequen t lines. C.2.4. Kno wledge Accum ulation Eac h resolved issue is recorded in structured form: [Date] capture drop + gen safeguard destroys variables Con text: P attern capture drop X; gen X = EXPR . Problem: gen failure deletes preexisting v ariable. Fix: Backup–restore strategy . Impact: Generalizable to all similar exports. En tries are standardized, retriev able, and v ersion-con trolled. Across agents, the knowl- edge base expanded to 64 entries, cov ering syn tax handling, name resolution, translation mappings, sp ecification extraction, and w orkflo w co ordination. S-12 D. Empirical In v en tory and P erformance This section do cumen ts the full set of implementation-lev el issues encountered and resolved during developmen t and ev aluation of the AI-assisted repro duction pip eline across 92 IV studies. Eac h entry records a distinct execution pattern, the agent(s) adjusted, and the corresp onding resolution. The detailed in ven tory is organized in to ten classes. T ogether, they provide a concrete account of the recurring irregularities that arise when replication materials are executed in a standardized, automated environmen t. D.1. Classes of Implemen tation V ariation A cross the 92 studies, we identified and resolved failures spanning ten broad classes. T able S2 summarizes these classes, affected stages, and typical issues of failure patterns. T able S2. Classes of v aria tion encountered and resol ved acr oss 92 p apers Class Stage(s) Represen tative pattern P ath and en vironmen t Janitor, Runner Absolute paths, global macros, sub-file mismatches Soft w are and language Profiler, Runner, Sk eptic Multi-language co debases, op- erator translation Data format and enco ding Janitor, Runner, Skeptic .tab am biguity , factor enco d- ing, quoting rules V ariable name mismatc h Sk eptic, Profiler T yp os, prefix matches, unre- solv ed macros Stata syntax dialect Janitor #delimit mo des, merge syn- tax, e(sample) handling Mo del sp ecification structure Sk eptic, Profiler P anel FE, subset conditions, bandwidth rules R un time resource constrain ts Sk eptic Memory limits, jac kknife time- outs Graphics and in teractivit y Janitor Graphics devices, output table pac kages Data acquisition Librarian Deprecated links, incorrect datasets Co de injection logic Janitor Delimiter mo de, line-num b er drift These classes span the full pip eline: data acquisition, co de parsing, en vironment prepa- ration, execution, cross-language v alidation, and diagnostic computation. Some patterns re- flect softw are dialect differences (e.g., Stata version changes); others reflect rep ository-sp ecific formats or naming con ven tions. Man y failures were silen t and detectable only through cross- stage consistency c hecks. The detailed in ven tory that follo ws lists each resolved issue, its manifestation, the deter- ministic repair implemen ted, and the resp onsible agent. The purp ose is transparency rather S-13 than exhaustiveness of narrative: readers can trace each capabilit y to a concrete failure pattern and code mo dification. D.2. Pip eline P erformance P erformance gains are substantial and empirically v erifiable. The end-to-end success rate increased from approximately 63% in the initial implementation to 92.5% in the current v ersion. These impro v ements were dev elop ed and ev aluated on the same b enc hmark cor- pus; p erformance on previously unseen corp ora ma y differ. Nev ertheless, the resolved failure mo des primarily reflect language-lev el and softw are-lev el conv en tions rather than idiosyn- cratic features of individual pap ers, suggesting that a meaningful p ortion of the gains should generalize. The single largest improv emen t follo wed the adoption of a “PDF-first retriev al arc hitec- ture,” in whic h the system first analyzes the published PDF to infer the lik ely lo cation of the replication pac kage before attempting data acquisition. This design substantially reduced incorrect dataset do wnloads and increased the success rate from 62.9% to 88.6%. Appro ximately 40% of resolv ed issue classes were first encoun tered during ev aluation rather than an ticipated ex an te. This pattern illustrates the limits of purely rule-based design. A fixed script can implement predefined rules, but it cannot account for patterns that w ere not foreseen. Here, new patterns w ere incorporated in to the deterministic co de base after diagnosis and review, expanding cov erage across subsequen t studies. D.3. Detailed In v en tory of Resolv ed Issues Belo w we presen t an class-b y-class in v entory of resolv ed implemen tation issues. Class 1: P ath and en vironmen t v ariability . Replication code is t ypically written for a sp ecific directory structure and op erating system. When executed in a standardized w orkspace, these assumptions often fail. The patterns b elo w record the path and en viron- men t issues encountered and the corresp onding repairs. P attern Manifestation Resolution Agen t Absolute paths cd "C:\Users\john\..." , setwd("/home/author/...") Regex detection; replace with relativ e paths or commen t out Janitor Global path macros Stata global datadir "C:\..." follo w ed b y $datadir references Inline macro substitution b e- fore commen ting out the global definition Janitor S-14 P attern Manifestation Resolution Agen t use command v arian ts Quoted paths, extensionless filenames, digit-prefixed names, macro-em b edded paths Multiple regex patterns co v- ering all observ ed v ariants Janitor Sub-file reference mis- matc hes do script.do when actual filename is script_rep.do F uzzy stem-matching: searc h for candidates when exact matc h fails Janitor Sub directory output files analysis_data.csv gener- ated in a sub directory , not the exp ected ro ot Recursiv e rglob() fallback searc h R unner Platform-sp ecific soft- w are paths macOS vs. Linux Stata instal- lation paths Platform-a w are path detec- tion R unner Class 2: Soft ware and language v ariabilit y . The pap ers in the corpus use Stata, R, and Python, and several com bine multiple languages within a single replication pac kage. Supp orting cross-language execution required systematic expansion of parsing and transla- tion rules. The table b elo w lists the softw are- and language-related issues resolved during dev elopment. P attern Manifestation Resolution Agen t Multi-language co de- bases Stata data preparation + R analysis in a single replication pac kage Profiler parses .do , .R , and .py files sim ultaneously Profiler Div erse IV commands ivreg2 , ivregress , reghdfe , ivprobit , ivtobit , rdrobust fuzzy , man ual 2SLS Expanding IV command pat- tern list; detecting man ual t w o-stage implementations Profiler Stata → R v ariable translation l4.margin_index2 b e- comes l4margin_index2 or l4_margin_index2 in CSV Three-tier resolution: ex- act → dot-stripp ed → underscore-separated → recompute from base R unner, Sk eptic, R core F actor v ariable expan- sion i.year → dumm y columns _Iyear_2000 , _Iyear_2001 , etc. Detect i. prefix; matc h ex- panded dummy patterns R unner, Sk eptic Time-series op erators L. , L4. , F2. , D. , comp ound L2D.var Dual-side parsing c hains in Python (R un- ner/Sk eptic) and R ( diagnostics_core.R ) R unner, Sk eptic, R core S-15 P attern Manifestation Resolution Agen t T runcated v ariable names Stata truncates to 32 c haracters with ˜ (e.g., incumbvotesmajor˜t ) Prefix-plus-tilde pattern matc hing R unner R formula ob jects with update() Base form ula f <- y ˜ x mo dified b y update(f, . ˜ . + z) Extract formula dictionary; apply update() rules to ex- pand Profiler R interaction shorthand A * B implying A + B + A:B Detect * patterns; add ex- plicit A:B to control list Profiler Class 3: Data format and enco ding v ariabilit y . Replication materials are distributed in m ultiple data formats and enco ding con ven tions. Differences in file types, string enco dings, and exp ort formats required explicit handling to ensure consisten t do wnstream computation. The follo wing entries summarize the issues encoun tered. P attern Manifestation Resolution Agen t .tab format am biguit y Data verse stores as .tab (TSV); Stata exp ects .dta (binary) Detect .tab files; con vert to CSV or rewrite use com- mands Janitor F actor-enco ded strings Column stored as "0: Not low-education" instead of n umeric 0/1 Python prepro cessing to con- v ert to numeric before R di- agnostics Sk eptic Lost v ariables in Data- v erse exp ort pctcath v ariable missing from .tab exp ort Detect and flag as data- source limitation Sk eptic R backtic k quoting Column _computed_outcome quoted as ‘_computed_outcome‘ b y R in ternals F our-w a y lo okup: raw → bac ktic k → strip → fuzzy (9 call sites) R core Destructiv e gen safe- guard capture drop X; gen X = expr deletes X when expr fails Bac kup-restore pattern: re- name → gen → restore on failure Janitor F ormat con version ( .dta → CSV) Stata binary format unread- able by R/Python A utomatic pandas-based con- v ersion R unner Class 4: V ariable name mismatc hes. V ariable names extracted from co de do not alw ays match column names in the exp orted analysis dataset. Discrepancies arise from t yp os, truncation, macro expansion, encoding differences, or computed expressions. The patterns b elo w record the matc hing rules added to reconcile these differences. S-16 P attern Manifestation Resolution Agen t Single-c haracter typos lcri_euac1_r vs. lcri_euc1_r F our-tier resolution: exact → case-insensitiv e → Leven- sh tein ≤ 2 → prefix matc h Sk eptic Missing suffixes serfperc vs. serfperc1 Lev enshtein distance match- ing Sk eptic Prefix matches incumbvotes vs. incumbvotesmajorpercent Bidirectional prefix detection Sk eptic Computed expressions zero1(infeels-outfeels) is a function expression, not a column name Expression detection + pre- computation (min-max nor- malize, log transform) Sk eptic Unresolv ed Stata macros Metadata con tains $controls_z2 or ‘controls_z2’ literally Scan command field for $xxx references; expand using macro dictionary Profiler Unsplit cluster v ariables "ccode year" → R’s make.names() pro duces "ccode.year" Space-based splitting normal- ization for cluster v ariables Sk eptic Unresolv ed macro passthrough $Z , $C passed to R as literal strings Guard: detect unresolv ed $macro patterns b efore inv ok- ing R Sk eptic Case inconsistencies V ariable names differ only in capitalization Case-insensitiv e matc hing (second tier of resolution c hain) Sk eptic Class 5: Stata syn tax v arian ts. Stata syn tax differs across v ersions and programming st yles. The pip eline encountered v ariations in delimiter mo des, legacy commands, macro con ven tions, and wrapp er structures. The follo wing en tries summarize the syntax-related adjustmen ts implemented in the Janitor and related agen ts. P attern Manifestation Resolution Agen t #delimit ; mo de Semicolons replace newlines as statemen t terminators; m ulti-line commands Delimiter state tracking; treat conten t b etw een semi- colons as one statement Janitor #delimit abbreviations #d , #delim , #delimi are all v alid Extended regex: #d(?:e(?:l(?:i(?:m(?:i(?:t)?)?)?)?)?)? Janitor Old merge syn tax merge cow year using "file.dta" (pre-Stata 11) A uto-detection and conv er- sion to merge m:1 ... Janitor W eigh t sp ecifications [aweight=w] , [pweight=w] em b edded in IV commands Separate weigh t parsing b e- fore v ariable-list extraction R unner S-17 P attern Manifestation Resolution Agen t e(sample) filtering ivreg2 ... if e(sample) references prior estimation’s sample F ull-panel exp ort with janitor_esample flag column; R filters post-lag- computation Janitor, R core capture noisily side effects W rapping failed commands corrupts e(sample) and e(b) Commen t out non-target IV commands entirely instead of wrapping Janitor e(sample) restoration After capture noisily fail- ure, e(sample) is inv alid Bac kw ard scan to find es- timation command that set e(sample) ; inject re- estimation Janitor User-defined commands edvreg as custom ivreg2 wrapp er Main tain list of known user- defined commands; detect program define blo cks Janitor W rapp er commands parmby "ivreg2 ...", ... , bootstrap , jackknife W rapp er exclusion list: pre- serv e IV commands inside wrapp ers from commen ting Janitor Multi-line command end detection In #delimit ; mode, com- mands span multiple lines un- til ; Extended _find_end_of_stata_cmd() to scan forw ard to semicolon in delimiter mo de Janitor Class 6: Statistical mo del sp ecification v ariability . The IV designs in the corpus differ in fixed effects, sub-sample conditions, clustering structures, weigh ts, and mo del types. Supp orting these v ariations required additional parsing and normalization rules. The table b elo w lists the specification-related issues resolv ed. P attern Manifestation Resolution Agen t P anel fixed effects xtivreg2, fe requires xtset panel time Detect xtset in metadata; add FE columns to IV for- m ula Sk eptic Stata if conditions if year >= 2000 & region == "east" Extract condition; pass through to R --if_condition param- eter Sk eptic R inline subsetting data = df[df$var == 0, ] Man ual addition of subset() to metadata data_prep Sk eptic RDD bandwidth subset- ting rdrobust computes band- width at run time Compute bandwidth from ex- ecution log; hardcode as nu- meric subset condition Sk eptic S-18 P attern Manifestation Resolution Agen t Endogenous v ariable in- teractions log(providers) * as.factor(year) Iden tified as structural lim- itation; Journalist flags as “Non-Linear Mo del Approxi- mation” Journalist Non-linear IV mo dels ivprobit , ivtobit Journalist generates informa- tion b ox noting linear approx- imation Journalist W eigh ted regression Stata [pweight=w] , R weights = sample.size Cross-soft w are w eights ex- traction with fallbac k regard- less of language Sk eptic Multi-equation output ivprobit / ivtobit pro duce t w o-line headers Multi-line header detection and merging help er functions R unner Class 7: R un time resource constrain ts. The datasets in the corpus range from small cross-sections to large panels exceeding one million observ ations. These differences create v ariation in memory use and run time. The follo wing en tries summarize the constraints encoun tered and the safeguards implemen ted. P attern Manifestation Resolution Agen t Large-dataset time- out/OOM 1.26M ro ws (Ritter 2016); 115K rows (Lelkes 2017) MAX_OBS = 100,000 sam- pling cap with fixed seed for repro ducibilit y R core Cluster jackknife mem- ory exhaustion Large cluster count causes OOM F allbac k to observ ation-lev el jac kknife (200 observ ations) Sk eptic Co de execution timeout Some scripts exceed 600s Configurable hard timeout ( --timeout ) R unner Pre-computed lag col- umn NAs F ull-panel exp ort has extra NAs in lag columns outside estimation sample Compare NA coun ts: if pre- computed has more NAs than base, recompute from base R core Class 8: Graphics and in teractive commands. Man y replication packages assume an in teractiv e en vironment with an av ailable graphics device and user input. In a batch execution setting, suc h commands cause in terruptions or failures. The table b elo w records the patterns iden tified and the corresp onding handling rules. S-19 P attern Manifestation Resolution Agen t Common graphics com- mands graph twoway , histogram , plot() , ggplot() , plt.show() Regex-based commenting Janitor Rare Stata graphics cibplot , marginsplot , binscatter , spmap Expanded graphics command list Janitor In teractiv e commands pause , View() , browser() , input() , breakpoint() Commen t out all in teractive commands Janitor Output table pac kages modelsummary() , stargazer() , texreg() Commen t out (unnecessary for data extraction; may fail in batch mo de) Janitor Ov er-commen ting false p ositiv es F unction named estimate_plot_data in- correctly flagged as graphics Matc h complete function call patterns, not substrings Janitor Class 9: Data acquisition v ariability . Replication materials are hosted on multiple platforms with differen t API formats, URL con ven tions, and a v ailabilit y guarantees. Sup- p orting these platforms required explicit handling of retriev al formats and error cases. The follo wing entries document the acquisition-related issues encoun tered. P attern Manifestation Resolution Agen t Multiple hosting plat- forms Harv ard Datav erse, GitHub, OSF, journal w ebsites Multi-platform API supp ort Librarian W rong dataset retriev al Keyw ord search returns unre- lated datasets with similar ti- tles PDF-first architecture: prior- itize URLs from pap er ov er searc h Librarian API format errors T railing slash in Datav erse API URL causes 404 Correct API URL formatting Librarian Deprecated R pac kages rgdal , rgeos , maptools re- tired from CRAN in 2023 Commen t out library() calls for known deprecated pac kages Janitor Incompatible R packages ri package incompatible with R 4.x Flagged as unfixable — Expired rep ository URLs Rep ository tak en offline or nev er publicly released Multi-tier retriev al with man ual-supply fallback Librarian Class 10: Co de injection logic v ariabilit y . T o extract analysis datasets, the Janitor inserts exp ort commands in to the original scripts. The correct insertion dep ends on delimiter mo des, multi-line commands, and surrounding con trol flow. The en tries b elo w summarize S-20 the injection-related patterns resolv ed during dev elopment. P attern Manifestation Resolution Agen t Injection in #delimit ; regions Injected co de uses newline terminators; surrounding co de uses semicolons Detect active delimiter mo de; wrap injection with #delimit cr / #delimit ; Janitor Multi-line command truncation Exp ort blo ck inserted be- t w een lines of a multi-line command Scan forward to complete command end b efore insert- ing Janitor Line-n um b er drift Insertions shift all subsequent line num b ers; index-based trac king breaks Con ten t-based detection (bac kw ard scan from marker) instead of index tracking Janitor F ull-panel vs. e(sample) exp ort Some specifications need full panel for lag computation; others need only the estima- tion sample Detect esample_mode ; choose exp ort strategy accordingly Janitor parmest blo ck handling Co de b etw een parmest and restore is in terdep enden t Commen t out entire blo c k as a unit Janitor E. Example of Diagnose Rep ort S-21 IV Diagnostics Report F ebruary 16, 2026 IV Diagnostics Report: Small Aggregates, Big Manipulation: V ote Buying Enforcement and Collective Monitoring Miguel R. Rueda — American Journal Of P olitical Science — (2017) Generated: 2026-02-16 15:30:49 Contents 1 Executive Summary 2 2 Study Design 2 2.1 The Causal Question . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2.2 V ariables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 3 Replication Results 3 4 Diagnostic Results 4 4.1 Specication 1: e_vote_buying (Primary) — The incidence of vote buy- ing reported by Colombian citizens. . . . . . . . . . . . . . . . . . . . . . 4 4.1.1 Instrument Strength . . . . . . . . . . . . . . . . . . . . . . . . . . 4 4.1.2 Robust Inference . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 4.1.3 Sensitivity Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 4.1.4 IV vs. OLS Comparison . . . . . . . . . . . . . . . . . . . . . . . . . 7 4.2 Specication 2: sum_vb — The total number of vote buying incidents reported across various contexts. . . . . . . . . . . . . . . . . . . . . . . 8 4.2.1 Instrument Strength . . . . . . . . . . . . . . . . . . . . . . . . . . 9 4.2.2 Robust Inference . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 4.2.3 Sensitivity Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 4.2.4 IV vs. OLS Comparison . . . . . . . . . . . . . . . . . . . . . . . . . 11 4.3 Specication 3: e_vote_buying — The incidence of vote buying re- ported by Colombian citizens. . . . . . . . . . . . . . . . . . . . . . . . . 11 4.3.1 Instrument Strength . . . . . . . . . . . . . . . . . . . . . . . . . . 13 4.3.2 Robust Inference . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 4.3.3 Sensitivity Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 4.3.4 IV vs. OLS Comparison . . . . . . . . . . . . . . . . . . . . . . . . . 15 5 Conclusions and Recommendations 15 6 T echnical Appendix 16 6.1 Methods Used in This Report . . . . . . . . . . . . . . . . . . . . . . . . . 16 6.2 Key References . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 1 IV Diagnostics Report F ebruary 16, 2026 This report evaluates the robustness of an instrumental variable (IV) analy- sis. Here, we focus on the strength of the IV and the robustness to dierent inferential methods. It is important to note that the credibility of an IV de- sign relies on the instrument’s unconfoundedness and exclusion restriction, which are often untestable. 1 Executive Summary Spec Outcome (Y) T reatment (D) Instrument (Z) E. F Rating spec_1 ⋆ e_vote_buying lm_pob_mesa lz_pob_mesa_f 827.2 HIGH spec_2 sum_vb lm_pob_mesa lz_pob_mesa_f 203.9 LOW spec_3 e_vote_buying lm_pob_mesa lz_pob_mesa_f 8598.3 HIGH Primary Specication (spec_1): HIGH - Results appear robust P ASS No major concerns detected. Main Finding: The 2SLS estimate is -1.4600 (p = 0.0016), which is statis- tically signicant at the 5% level. spec_2 (sum_vb): LOW - Signicant concerns about validity spec_3 (e_vote_buying): HIGH - Results appear robust 2 Study Design 2.1 The Causal Question This study uses instrumental variable (IV) analysis to answer a causal question. Here’s how to understand the key components: P aper: Small Aggregates, Big Manipulation: V ote Buying Enforcement and Collective Monitoring IV Strategy: The rules that determine maximum sizes of polling stations cre- ate exogenous variation in polling place size, allowing for the identication of the causal eect of polling place size on vote buying incidents. 2 IV Diagnostics Report F ebruary 16, 2026 2.2 V ariables Role V ariable Description Y1 ⋆ e_vote_buying The incidence of vote buying reported by Colombian citizens. Y2 sum_vb The total number of vote buying incidents reported across various contexts. Y3 e_vote_buying The incidence of vote buying reported by Colombian citizens. T reatment (D) lm_pob_mesa The average size of polling stations in terms of registered voters. Instrument (Z) lz_pob_mesa_f The disaggregated electoral results at the polling station level. Cluster muni_code Clustering unit for standard errors Controls: 7 variables ( l4.margin_index2 , l.nbi_i , l.own_resources , lpopulation , l.armed_actor …) 3 Replication Results Before running diagnostics, we rst replicate the original analysis by executing the authors’ code and extracting the IV coeicient. This conrms our diagnostics analyze the correct specication. Spec Outcome (Y) T reatment (D) 2SLS Est. Std. Err . Match ∆ % spec_1 ⋆ e_vote_ buying lm_pob_mesa -1.4600 0.4625 excellent 0.00% spec_2 sum_vb lm_pob_mesa -2.2420 1.2939 excellent 0.00% spec_3 e_vote_ buying lm_pob_mesa -0.9835 0.1423 excellent 0.00% ⋆ = primary specication Match & ∆ % columns: The 2SLS Est. column shows the coeicient pro- duced by running the authors’ original source code (e.g., Stata). Our diagnos- tic engine independently re-estimates the same 2SLS specication in R using the extracted analysis dataset. Match rates the agreement between these two estimates, and ∆ % reports the percentage dierence. A close match (“excellent”, ∆ < 1 %) conrms that the diagnostic results presented below are based on the correct specication. 3 IV Diagnostics Report F ebruary 16, 2026 4 Diagnostic Results 4.1 Specication 1: e_vote_buying (Primary) — The incidence of vote buying reported by Colombian citizens. Outcome (Y): e_vote_buying | T reatment (D): lm_pob_mesa | Instrument (Z): lz_pob_mesa_f V eried : This diagnostic specication was cross-validated against Stata and matches exactly . Figure 1: OLS and 2SLS estimates with 95% CIs for e_vote_buying (Primary) 4.1.1 Instrument Strength F or IV to work, the instrument must strongly predict the treatment. A “weak instrument” leads to unreliable estimates. 4 IV Diagnostics Report F ebruary 16, 2026 Figure 2: First-stage F -statistics for e_vote_buying (Primary) Statistic V alue Assessment F -eective 827.18 P AS S Strong F -standard 812.36 — F -cluster 827.18 Cluster-robust F -robust 711.30 HC-robust F -bootstrap 865.98 Bootstrap-robust First-Stage P arameter V alue First-stage coef ( ˆ π ) 0.6557 First-stage SE 0.0228 First-stage ρ (correlation coeicient) 0.3970 P ASS The instrument is strong (F = 827.18). Standard IV inference shoul d be reliable. 4.1.2 Robust Inference Here, we gauge the uncertainties of the 2SLS estimates. 5 IV Diagnostics Report F ebruary 16, 2026 Statistic V alue Coeicient -1.4600 Standard Error 0.4632 p-value 0.0016 95% CI [-2.3678, -0.5521] N 4352 N clusters 1098 A one-unit increase in treatment is associated with a 1.4600 decrease in the outcome (p = 0.0016). Statistically signicant at 5%. Anderson-Rubin T est (weak-IV robust): p = 0.0016 → P ASS Signicant AR 95% CI: [-2.3678, -0.5614] (bounded) tF Procedure (Lee et al. 2022): |t| = 3.15 vs critical t = 1.96 → P ASS Sig- nicant tF 95% CI: [-2.3678, -0.5521] Figure 3: Bootstrap condence intervals for e_vote_buying (Primary) Method 95% CI Includes Zero? Bootstrap-c [-2.3785, -0.6694] No Bootstrap-t [-2.3017, -0.6182] No P ASS Bootstrap CI excludes zero — eect is signicant. 6 IV Diagnostics Report F ebruary 16, 2026 4.1.3 Sensitivity Analysis The jackknife method removes each observation/cluster one at a time and re- estimates the eect. Stable results = robust ndings. Figure 4: Jackknife leave-one-out sensitivity for e_vote_buying (Primary) Statistic V alue Mean estimate -1.4589 Range [-1.4937, -1.3086] Std. deviation 0.0171 Most inuential unit 11001 (Δ = 0.1513) P ASS Robust — only 12.7% variation across leave-one-out samples. 4.1.4 IV vs. OLS Comparison Comparing 2SLS estimate to the naive OLS estimate. Method Coeicient R atio OLS -0.6255 — 2SLS -1.4600 2.3x The 2SLS estimate is 2.3x larger than the naive OLS estimate, suggesting mod- erate endogeneity correction. 7 IV Diagnostics Report F ebruary 16, 2026 4.2 Specication 2: sum_vb — The total number of vote buying in- cidents reported across various contexts. Outcome (Y): sum_vb | T reatment (D): lm_pob_mesa | Instrument (Z): lz_pob_mesa_f V eried : This diagnostic specication was cross-validated against Stata and matches exactly . Figure 5: OLS and 2SLS estimates with 95% CIs for sum_vb 8 IV Diagnostics Report F ebruary 16, 2026 4.2.1 Instrument Strength Figure 6: First-stage F -statistics for sum_vb Statistic V alue Assessment F -eective 203.90 P AS S Strong F -standard 322.07 — F -cluster 203.90 Cluster-robust F -robust 246.03 HC-robust F -bootstrap 189.60 Bootstrap-robust First-Stage P arameter V alue First-stage coef ( ˆ π ) 0.8526 First-stage SE 0.0597 First-stage ρ (correlation coeicient) 0.4827 P ASS The instrument is strong (F = 203.90). Standard IV inference shoul d be reliable. 4.2.2 Robust Inference 9 IV Diagnostics Report F ebruary 16, 2026 Statistic V alue Coeicient -2.2420 Standard Error 1.2998 p-value 0.0845 95% CI [-4.7895, 0.3055] N 1069 N clusters 632 The eect is not statistically signicant (p = 0.0845 > 0.05) . Anderson-Rubin T est (weak-IV robust): p = 0.0747 → F AIL Not signicant AR 95% CI: [-4.8935, 0.2015] (bounded) tF Procedure (Lee et al. 2022): |t| = 1.73 vs critical t = 1.96 → F AIL Not signicant tF 95% CI: [-4.7895, 0.3055] Figure 7: Bootstrap condence intervals for sum_vb Method 95% CI Includes Zero? Bootstrap-c [-4.6198, 0.0109] Y es Bootstrap-t [-5.9682, 1.4841] Y es W ARNING Bootstrap CI includes zero — eect may not be signicant. 10 IV Diagnostics Report F ebruary 16, 2026 4.2.3 Sensitivity Analysis Figure 8: Jackknife leave-one-out sensitivity for sum_vb Statistic V alue Mean estimate -2.2293 Range [-2.2674, -0.9393] Std. deviation 0.1312 Most inuential unit 11001 (Δ = 1.3027) W ARNING Sensitive — 59.2% variation across leave-one-out samples. 4.2.4 IV vs. OLS Comparison Method Coeicient R atio OLS -0.9841 — 2SLS -2.2420 2.3x The 2SLS estimate is 2.3x larger than the naive OLS estimate, suggesting mod- erate endogeneity correction. 4.3 Specication 3: e_vote_buying — The incidence of vote buying reported by Colombian citizens. Outcome (Y): e_vote_buying | T reatment (D): lm_pob_mesa | Instrument (Z): lz_pob_mesa_f 11 IV Diagnostics Report F ebruary 16, 2026 V eried : This diagnostic specication was cross-validated against Stata and matches exactly . Figure 9: OLS and 2SLS estimates with 95% CIs for e_vote_buying 12 IV Diagnostics Report F ebruary 16, 2026 4.3.1 Instrument Strength Figure 10: First-stage F -statistics for e_vote_buying Statistic V alue Assessment F -eective 8598.33 P AS S Strong F -standard 3106.39 — F -cluster 8598.33 Cluster-robust F -robust 3108.59 HC-robust F -bootstrap 9360.14 Bootstrap-robust First-Stage P arameter V alue First-stage coef ( ˆ π ) 0.7957 First-stage SE 0.0086 First-stage ρ (correlation coeicient) 0.6455 P ASS The instrument is strong (F = 8598.33). Standard IV inference should be reliable. 4.3.2 Robust Inference 13 IV Diagnostics Report F ebruary 16, 2026 Statistic V alue Coeicient -0.9835 Standard Error 0.1424 p-value 0.0000 95% CI [-1.2626, -0.7044] N 4352 N clusters 1098 A one-unit increase in treatment is associated with a 0.9835 decrease in the outcome (p = 0.0000). Statistically signicant at 5%. Anderson-Rubin T est (weak-IV robust): p = 0.0000 → P ASS Signicant AR 95% CI: [-1.2626, -0.7073] (bounded) tF Procedure (Lee et al. 2022): |t| = 6.91 vs critical t = 1.96 → P ASS Sig- nicant tF 95% CI: [-1.2626, -0.7044] Figure 11: Bootstrap condence intervals for e_vote_buying Method 95% CI Includes Zero? Bootstrap-c [-1.2680, -0.7339] No Bootstrap-t [-1.2256, -0.7414] No P ASS Bootstrap CI excludes zero — eect is signicant. 14 IV Diagnostics Report F ebruary 16, 2026 4.3.3 Sensitivity Analysis Figure 12: Jackknife leave-one-out sensitivity for e_vote_buying Statistic V alue Mean estimate -0.9830 Range [-0.9881, -0.9634] Std. deviation 0.0033 Most inuential unit 11001 (Δ = 0.0201) P ASS Robust — only 2.5% variation across leave-one-out samples. 4.3.4 IV vs. OLS Comparison Method Coeicient R atio OLS -0.6750 — 2SLS -0.9835 1.5x P ASS The 2SLS estimate and the naive OLS estimate are similar (ratio = 1.46) — little evidence of bias. 5 Conclusions and Recommendations This study was evaluated across 3 specications . R atings: 2 HIGH, 1 LOW . 15 IV Diagnostics Report F ebruary 16, 2026 P ASS The IV estimates appear robust to weak IV tests and robust inferential methods. The instrument is strong, results are signicant under robust tests, and there are no major red ags. If you believe the key identifying assumptions—namely , the instrument’s un- confoundedness and the exclusion restriction—are valid, you can interpret the 2SLS estimate as causal. 6 T echnical Appendix 6.1 Methods Used in This Report Method Purpose Reference F -statistic (eective) T est instrument strength Olea & Pueger (2013) Anderson-Rubin test W eak-IV robust inference Anderson & Rubin (1949) Bootstrap CI (percentile) Robust condence intervals Efron (1979) Bootstrap CI (studentized) More accurate small-sample CI Hall (1992) Jackknife Sensitivity to inuential obs Quenouille (1956) tF procedure W eak-IV robust critical values Lee et al. (2022) 6.2 Key References • Lal et al. (2024). “How Much Should W e Trust Instrumental V ariable Estimates in P olitical Science?” Comprehensive guide to IV diagnostics. • Stock & Y ogo (2005). “T esting for W eak Instruments.” Established the F ≥ 10 rule of thumb. • Olea & Pueger (2013). “ A Robust T est for W eak Instruments.” Eective F - statistic for heteroskedastic errors. • Lee et al. (2022). “V alid t-ratio Inference for IV .” tF procedure for weak in- strument inference. *Report generated by Journalist Agent (IV Replication W orkow)* 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment