From Content to Audience: A Multimodal Annotation Framework for Broadcast Television Analytics
Automated semantic annotation of broadcast television content presents distinctive challenges, combining structured audiovisual composition, domain-specific editorial patterns, and strict operational constraints. While multimodal large language model…
Authors: Paolo Cupini, Francesco Pierri
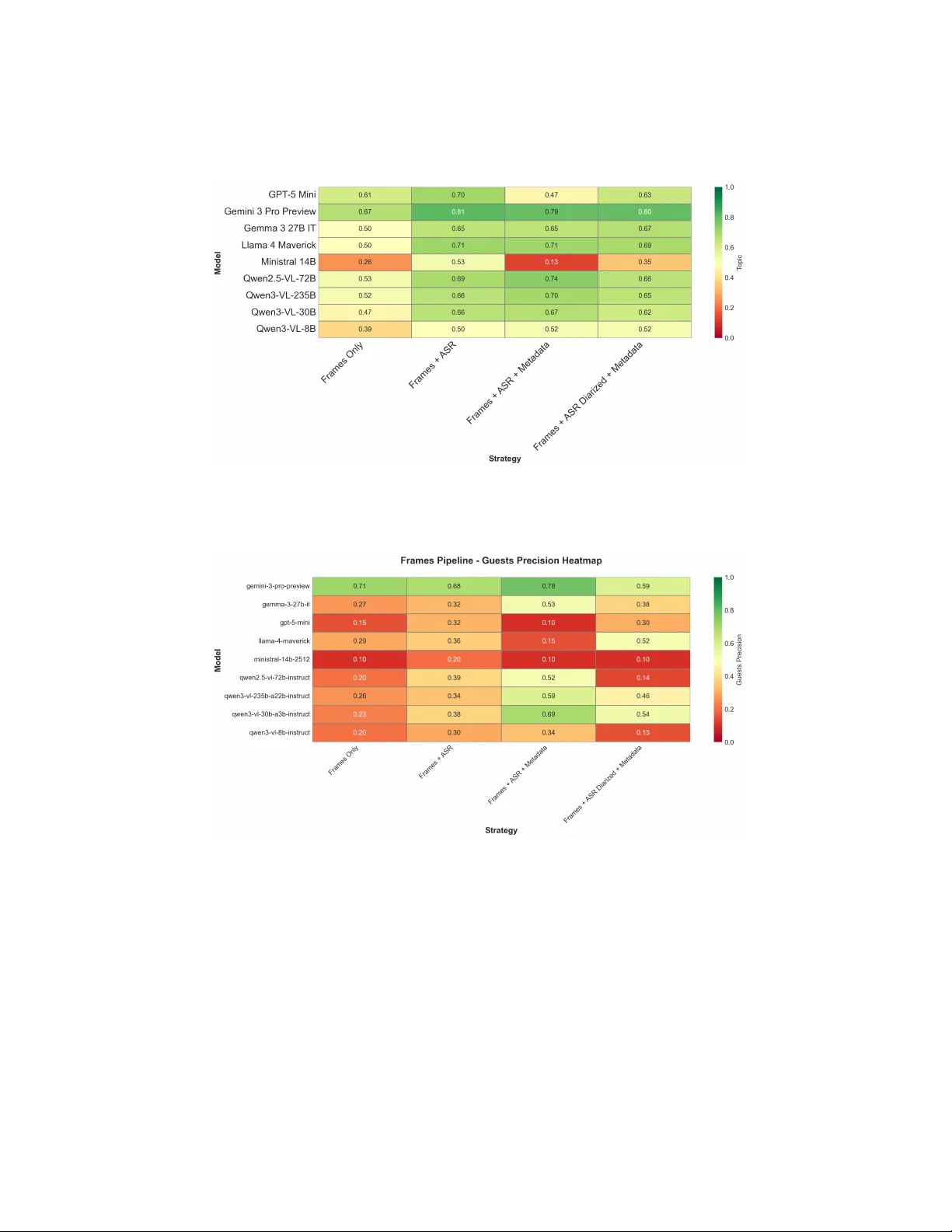
F rom Con ten t to Audience: A Multimo dal Annotation F ramew ork for Broadcast T elevision Analytics P aolo Cupini 1 and F rancesco Pierri 1 ( ) Dipartimen to di Elettronica, Informazione e Bioingegneria, Politecnico di Milano, Italy {paolo.cupini}@mail.polimi.it Abstract. Automated seman tic annotation of broadcast television con- ten t presen ts distinctive challenges, com bining structured audiovisual comp osition, domain-sp ecific editorial patterns, and strict operational constrain ts. Wh ile m ultimo dal large language mo dels (MLLMs) hav e demonstrated strong general-purp ose video understanding capabilities, their comparative effectiveness across pip eline architectures and input configurations in broadcast-sp ecific settings remains empirically under- c haracterized. This pap er presen ts a systematic ev aluation of multimodal annotation pipelines applied to broadcast television news in the Italian setting. W e construct a domain-sp ecific b enc hmark of clips lab eled across four semantic dimensions: visual en vironment classification, topic classi- fication, sensitiv e conten t detection, and named entit y recognition. T wo differen t pip eline architectures are ev aluated across nine frontier mo dels, including Gemini 3.0 Pro, LLaMA 4 Mav erick, Qwen-VL v ariants, and Gemma 3, under progressively enric hed input strategies combining visual signals, automatic speech recognition, speaker diarization, and metadata. Exp erimen tal results demonstrate that video-based inputs do not system- atically outp erform configurations based on image frames. Performance gains from video input are strongly mo del-dependent: larger mo dels ef- fectiv ely leverage temporal contin uity , while smaller mo dels sho w p erfor- mance degradation under extended multimodal context, likely due to to- k en ov erload. Beyond benchmarking, the selected pip eline is deploy ed on 14 full broadcast episodes (o ver 3,000 min utes), with minute-lev el anno- tations integrated with normalized audience measurement data pro vided b y an Italian media compan y . This integration enables correlational anal- ysis of topic-level audience sensitivit y and generational engagement di- v ergence, demonstrating the op erational viabilit y of the prop osed frame- w ork for con tent-based audience analytics. Keyw ords: Video Understanding · Multimo dal Large Language Mo dels · Audience Analytics · Pip eline Ev aluation · Applied Data Science. 1 In tro duction Broadcast television relies on min ute-level audience measuremen t systems to monitor p erformance and demographic comp osition [12, 13]. Metrics such as A v- erage Minute Rating (AMR) provide fine-grained information ab out ho w many 2 P . Cupini et al. view ers are w atc hing at each momen t of a program. How ever, while these in- dicators quan tify engagemen t, they do not explain why audience fluctuations o ccur. Connecting minute-lev el v ariations to the semantic structure of broad- cast conten t remains largely man ual and difficult to scale [14, 15]. Recent ad- v ances in multimodal large language mo dels (MLLMs) enable joint reasoning o ver visual frames, sp eec h transcripts, and structured metadata, offering new opp ortunities for automated video annotation [16–18]. In principle, suc h mo dels could supp ort min ute-lev el semantic labeling of broadcast programs and allow direct alignment with audience data [19]. Y et deploying multimodal systems in real broadcast environmen ts in tro duces practical constraints: broadcast con tent is temp orally structured and heterogeneous; sp eech recognition ma y in tro duce noise [20]; and large-scale annotation m ust remain computationally sustainable. Moreo ver, it is not eviden t whether richer multimodal inputs — such as full video represen tations — consistently impro ve p erformance under operational latency and tok en constraints [21, 22], or whether simpler image-frames-based config- urations offer a more practical trade-off [23].This paper presen ts a real-world case study conducted in collab oration with a national broadcast media group. W e develop and ev aluate a multimodal semantic annotation framew ork designed to supp ort professional TV audience analysis, and v alidate its deploymen t on o ver 3,000 minutes of broadcast conten t in tegrated with disaggregated audience measuremen t data. T w o researc h questions guide the work: – R Q1. Do video-based pip elines consistently outp erform image-based pip elines for broadcast video annotation, when jointly considering task p erformance and computational efficiency? – R Q2. Can semantic annotations generated by multimodal pipelines be in te- grated with minute-lev el audience data to identify demographic engagement patterns in broadcast television? Our w ork proceeds in t wo stages. First, we construct a domain-sp ecific b enc h- mark of 100 annotated broadcast clips and conduct a controlled ev aluation of image-based and video-based pip eline configurations across nine MLLM s and four semantic tasks. The comparison explicitly considers b oth predictive p er- formance and tok en consumption to iden tify a pro duction-ready solution. Sec- ond, the selected configuration is deploy ed on 14 full broadcast episo des aired in Italy in 2025 (o ver 3,000 minutes). Min ute-level seman tic annotations are aligned with normalized AMR data disaggregated by age cohort, enabling fine- grained analysis of demographic engagement patterns. The results sho w that video-based inputs do not systematically outp erform image-based configura- tions: performance gains are mo del-dep enden t and task-specific, with speech- deriv ed context and metadata enrichmen t represen ting more robust p erformance driv ers than temp oral visual con tinuit y [23, 24]. The deplo ymen t demonstrates that semantic annotation can meaningfully contextualize audience fluctuations: while high-frequency editorial topics sustain a stable senior audience backbone, lo wer-frequency thematic segments generate lo calized engagemen t deviations with v arying intensit y across age cohorts [14, 15]. A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 3 Con tributions – A domain-sp ecific b enc hmark for m ultimo dal broadcast video annotation, co vering four semantic tasks under a structured taxonom y adapted to Italian prime-time television. – A systematic empirical comparison of image-based and video-based MLLM pip elines, with evidence that temp oral video input do es not univ ersally im- pro ve p erformance and that metadata enrichmen t dominates transcription qualit y as a p erformance driver. – An op erational deplo yment in tegrating automated semantic annotation with min ute-level audience measurement data, demonstrating the applicability of m ultimo dal video understanding to conten t-based demographic analytics. 2 Related W ork The automated seman tic analysis of broadcast television resides at the in ter- section of three distinct research domains: domain-sp ecific video understanding, vision–language mo deling, and conten t-driven audience analytics. Broadcast programming introduces distinctive challenges for automated anal- ysis. Unlik e short-form w eb videos, television programs exhibit stable pro duction formats, recurring guest participation ecosystems, and a strong semantic cou- pling b etw een sp ok en disc ourse and visual con text [2]. Extant literature predomi- nan tly addresses these comp onent tasks in isolation: sp eaker recognition b enefits from the in tegration of face representations with audio em b eddings [3]; en vi- ronmen t classification demonstrates that coarse scene lab els provide meaning- ful contextual grounding; and topic classification relies primarily on Automatic Sp eec h Recognition (ASR) transcripts, where error propagation to do wnstream tasks necessitates careful configuration ev aluation [1]. These studies, how ev er, optimize individual components rather than ev aluating end-to-end pip elines un- der the pressure of heterogeneous seman tic tasks and constrained computational budgets. Vision-Language Large Mo dels (VLLMs) offer a unified reasoning frame- w ork for processing b oth visual and textual conten t [19, 4], and are increas- ingly deplo yed for structured video annotation and m ultimo dal question an- sw ering. Despite their robust general-purp ose capabilities, empirical ev aluations highligh t p ersisten t limitations in fine-grained spatiotemp oral reasoning. Sp ecifi- cally , merely extending the context window is insufficient without rigorous input structuring, and frame sampling strategies critically dictate do wnstream out- comes [5]. F urthermore, most benchmarks are calibrated on web-scale data; con trolled comparative studies across v arious VLLMs concerning heterogeneous seman tic tasks and broadcast-specific editorial structures remain scarce. The metho dological challenge of systematically comparing LLM configurations has recen tly gained traction in applied settings: [10] emphasize the inadequacy of iso- lated metric ev aluations when mo dels exhibit inconsistent relative p erformance across different dimensions. Similarly , [11] demonstrate that LLM p erformance 4 P . Cupini et al. on domain-sp ecific tasks is acutely sensitive to input structure, rev ealing sub- stan tial performance gaps betw een models that deviate from uniform scaling la ws. Constructing domain-specific benchmarks is a fundamental prerequisite for this calib er of ev aluation: [9] illustrate how the annotation c hallenges inher- en t in structured, real-w orld conten t diverge significan tly from those in generic b enc hmarks, thereb y informing the dataset construction metho dology adopted in the present work. The third foundational area inv estigates the interpla y b etw een audiovisual con tent and audience b ehavior. Early metho dologies relied on coarse metadata, suc h as programmatic schedules and broad genre labels; more contemporary re- searc h adopts signal-driven approaches at finer temp oral resolutions. [6] demon- strate that the large-scale visual analysis of televised news unco vers system- atic editorial exp osure patterns strongly correlated with screen-time allo cation. Concurren tly , [7] establish that automated subtitle analysis can b e effectively link ed to segment-lev el audience dynamics across v aried demographic groups. Both approaches, how ever, remain fundamentally unimo dal and hea vily reliant on pre-existing subtitles or manually curated metadata. The implemen tation of fully automated, multimodal pip elines capable of gen- erating seman tic annotations directly from raw broadcast video—and subse- quen tly in tegrating these annotations with minute-lev el, disaggregated audience data—remains a largely underexplored frontier. This is precisely the critical gap that the present work aims to bridge. 3 Metho dology: Dataset Construction and Pip eline Design The experimental ev aluation relies on a domain-sp ecific b enc hmark constructed to supp ort controlled comparison of multimodal annotation pip elines under re- alistic broadcast conditions.The dataset is used exclusively as a test set. 3.1 Source Material and Clip Extraction The dataset consists of 100 one-minute clips extracted from Italian broadcast television programs aired in 2025, spanning four editorial macro-categories: cur- ren t affairs talk shows, inv estigativ e programs, cultural programs, and lifestyle programs. Program identities are anonymized; 25 episo des were randomly sam- pled per category , with one 60-second clip extracted p er episo de. The one-min ute gran ularity aligns with AMR rep orting resolution and reflects op erational anno- tation conditions: clips are extracted without enforcing scene b oundaries and ma y span multiple shots, sp eak er turns, and topic transitions. 3.2 Annotation T axonom y and T asks Eac h clip is annotated along four semantic dimensions, inspired by the IAB Con- ten t T axonomy [8] and adapted to Italian prime-time television. The num b er and A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 5 Dimension Lab el T opic In ternational p olitics En vironment Studio – 1-to-1 in terview Named entities Person A, P erson B Sensitiv e W ar/armed conflicts Fig. 1. Represen tative annotation: studio interview on inte rnational politics with sen- sitiv e conten t signal. gran ularity of lab els within eac h dimension w ere determined through an itera- tiv e pro cess grounded in domain exp ertise: a preliminary taxonom y was v alidated against a represen tative sample of the corpus and refined in consultation with broadcast media professionals to ensure b oth cov erage and practical annotator reliabilit y . F ull taxonomies are provided as supplementary material. T opic clas- sification assigns one mandatory lab el from a 28-lab el taxonomy co vering 14 macro-areas (p olitics, econom y , justice, entertainmen t, culture, lifestyle, health, sp orts, and others). En vironment classification assigns one mandatory lab el for the visually dominant setting from 22 lab els across 7 macro-environmen ts. Named en tit y recognition produces a list of individuals visual ly pr esent in the clip; names are recorded as FirstName L astName and the list is empty if no identifiable p erson app ears. Sensitive con ten t detection identifies p oten- tially sensitiv e material across nine categories (violence, crime, sexual conten t, substance use, health emergencies, disasters, hate speech, self-harm, minors), dra wn from established conten t mo deration framew orks and broadcast regula- tory guidelines; the field is empty when absen t. Figure 1 shows a representativ e annotation. 3.3 Annotation Protocol and Dataset Characterization Annotation was p erformed indep endently by t wo annotators with backgrounds in computer science and prior exp erience in television conten t analysis. Inter- annotator agreemen t (Cohen’s κ ) reac hed 0.70 for topic, 0.67 for environmen t, and 0.67 for named en tities; sensitive conten t achiev ed p erfect agreemen t ( κ = 1 . 0 , interpreted cautiously given only 12 p ositiv e clips). All disagreemen ts were resolv ed b y consensus: annotators discussed conflicting lab els and jointly selected the most appropriate one. The topic distribution (Figure 2) exhibits a long-tail: Crime and justic e (17 clips), International p olitics (16), History and ar chae olo gy (14), and Domestic p olitics (13) are the most frequent categories, while several lab els app ear in fewer than five clips. Environmen t lab els are dominated by studio-based settings — Studio – Guest p anel (26) and Studio – 1-to-1 interview (22) account for nearly half the dataset. Se nsitiv e conten t is present in only 12% of clips, introducing pronounced class imbalance on the safet y task. 6 P . Cupini et al. Fig. 2. T opic label distribution. The long-tail structure introduces p er-class sparsity as a non-trivial classification challenge. 3.4 Pip eline Design Both pip elines share a common mo dular architecture (Figure 3) consisting of a visual branch, an audio-textual branch, and a multimodal reasoning stage. They differ exclusively in how the visual branch is instantiated. In the image-based pip eline , the visual branch extracts 12 frames via uniform sampling at 0.2 fps (fixed across all configurations), providing explicit control ov er visual representa- tion and enabling con trolled ablation of textual inputs while k eeping visual input constan t. In the video-based pip eline , the full 60-second clip is passed directly to the mo del’s native video enco der; internal frame sampling, temp oral attention, and visual tok enization are architecture-specific and not externally con trolled. The audio-textual branch is identical across b oth pip elines: the audio track is transcrib ed with F aster-Whisp er Medium, optionally augmen ted with sp eak er diarization via pyannote , and optionally enric hed with episo de-lev el metadata. This shared design yields four symmetric input configurations p er pip eline — Visual only , Visual + ASR , Visual + ASR + Metadata , and Visual + ASR + Diarization + Metadata — enabling direct cross-pip eline compari- son under equiv alent textual conditions. A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 7 Fig. 3. Unified pip eline architecture. Dashed comp onen ts are optional; the visual branc h is instantiated as static frames (image-frames pip eline) or full video clip (video- based pip eline). The audio-textual branch is identical across both configurations. Comp onen t Selection. F rame sampling and ASR systems w ere selected through preliminary studies prior to the main pipeline ev aluation; full results are rep orted in Section 4. F or image fr aming , a fixed budget of 18 frames p er clip was adopted to bal- ance visual co verage with vision–language API input limits and large-scale infer- ence costs. Seven strategies w ere ev aluated: uniform s ampling (0.1, 0.2, 0.3 fps), stratified sampling (1–3 frames per 10-second segment), and shot-based sam- pling. F or ASR , F aster-Whisp er (Small/Medium/Large), P arakeet, W av2V ec 2.0 (Italian fine-tuned), and V osk were compared, co vering arc hitectures from m ulti- lingual transformer mo dels to ligh tw eight language-sp ecific solutions. Ev aluation considered downstream topic classification and p erson recognition under three input settings: ASR only; ASR + diarization, where transcripts are segmen ted and sp eak er-attributed; and ASR + diarization + metadata, where metadata denotes episo de-lev el information (e.g., programme title, broadcast date, genre) pro vided with the clip. 3.5 Ev aluation Proto col Mo dels. Nine mo dels are ev aluated in the image-frames setting: gemini-3-pro , gpt-5-mini , qwen3-vl-235b , qwen2.5-vl-72b , qwen3-vl-30b , qwen3-vl-8b , llama-4-maverick , ministral-14b , and gemma-3-27b-it . Six mo dels supp ort- ing nativ e video ingestion are ev aluated in the video-based setting: gemini-3-pro , qwen3-vl-235b , qwen3-vl-30b , qwen-omni , molmo-2-8b , and seed-1.6 . Cross- pip eline comparisons are restricted to the four architectures presen t in b oth set- tings. Ev aluation Metrics. All T asks are ev aluated with accuracy , precision, recall, F1; full results are pro vided as supplementary material. 8 P . Cupini et al. Prompting and P arsing. All experiments use a zero-shot setting with a sin- gle prompt template that dynamically adapts to the active input configuration. The full lab el taxonom y is included in ev ery prompt; models are instructed to select exclusiv ely from the predefined set. Outputs are automatically parsed; predictions not matching any v alid lab el are coun ted as incorrect. F or person recognition, minimal p ost-pro cessing normalizes name formatting prior to ev al- uation. T ok en A ccounting. Input tok en coun ts are obtained from mo del APIs and include all pro cessed comp onen ts: prompt instructions, textual augmentations, and the internal representation of visual inputs. T oken consumption is rep orted alongside task p erformance as an explicit pro xy for computational cost. 4 Exp erimen tal Results This section rep orts consistent b eha vioral patterns across mo dels and input con- figurations; complete p er-configuration results are provided in the Appendix. P erformance differences are shap ed by three interacting factors: task structure, input mo dalit y , and mo del capacit y . Image F raming. As shown in Figure 4, accuracy plateaus b et ween 12 and 18 frames across all mo dels; shot-based sampling exhibits higher v ariance due to inaccurate b oundary detection on broadcast material. Uniform sampling at 0.2 fps (12 frames) reduces token consumption by ∼ 40% relative to the 18-frame budget at comparable accuracy , confirming it as the optimal configuration under join t p erformance and efficiency constraints. ASR Configuration. T wo consistent findings emerge: episo de-level metadata dominates transcription quality as a p erformance driver, and ASR systems align along a clear latency–p erformance curv e (Figure 5). F aster-Whisper Medium offers competitive performance across tasks without the o verhead of larger v ari- an ts, making it suitable for large-scale deplo yment. T opic Classification: requires inferring a high-level seman tic theme across a 28-label taxonom y . As shown in Figure 6, sp eec h-derived text is the domi- nan t performance driv er: visual-only conditions yield limited and v ariable ac- curacy (ranging from 0.26 to 0.67 across mo dels), while ASR transcripts pro- duce the most substantial and consistent improv emen t across architectures (e.g., gemini-3-pro-preview impro ves from 0.67 to 0.81, llama-4-maverick from 0.50 to 0.71), diarization alone provides no systematic b enefit. The exception is ministral-14b-2512 , whic h degrades sharply to 0.13 under F rames + ASR + Meta- data, suggesting sensitivit y to metadata noise rather than a capacity limitation. The primary b ottleneck is lab el gran ularity and conceptual o verlap rather than visual insufficiency . P erson Recognition is the most structurally demanding task. As sho wn in Fig- ure 7, visual-only configurations pro duce limited and unstable precision (rang- ing from 0.10 to 0.71 across mo dels, with most b elo w 0.30); transcripts alone pro vide mo dest gains, while metadata is the dominant driver for most architec- tures (e.g., gemini-3-pro-preview p eaks at 0.78, qwen3-vl-30b-a3b-instruct A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 9 Fig. 4. Environmen t classification accuracy vs. frame count. Performance plateaus b e- y ond 12 frames across all mo dels. Fig. 5. Downstream p erformance vs. transcription latency (ASR + diarization + meta- data). Left: topic accuracy . Right: p erson recognition precision. jumps from 0.23 to 0.69, and qwen3-vl-235b-a22b-instruct reac hes 0.59 under F rames + ASR + Metadata). Ho wev er, metadata enric hment is not uniformly b eneficial: gemini-3-pro-preview drops from 0.78 to 0.59 under diarization, qwen2.5-vl-72b-instruct collapses from 0.52 to 0.14, and llama-4-maverick degrades from 0.15 to 0.52 only via the diarized path, suggesting that diarization noise disrupts rather than assists identit y resolution for several architectures. ministral-14b-2512 remains flat at 0.10 across all configurations, confirming 10 P . Cupini et al. Fig. 6. T opic classification accuracy across input configurations (image-based pip eline). ASR transcripts are the primary driver; video input provides marginal b enefit once textual context is av ailable. Fig. 7. Person recognition precision across input configurations (image-based pip eline). Metadata enrichmen t dominates; video input pro vides no systematic improv ement for iden tity resolution. that performance dep ends on pretraining represen tations rather than p ercep- tual inference. Smaller mo dels frequently hallucinate identities in the absence of textual grounding, and video input offers no systematic adv antage ov er static frames. A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 11 En vironment Classification is primarily perceptual. Static frame sampling already provides strong discriminative p ow er for visually distinctiv e studio set- tings; adding transcripts or metadata yields inconsistent gains. The video-based pip eline consisten tly outp erforms frames for motion-dep enden t or spatially am- biguous environmen ts (v ehicles, dynamic outdo or scenes), with improv ements visible across mo del scales. Fine-grained indoor categories with similar com- p ositional structure remain c hallenging across both pipelines, indicating that p erceptual similarity — not lack of temp oral information — defines the main b ottlenec k. Sensitiv e conten t detection is characterized by class im balance (12% p osi- tiv e observ ations). Visual input alone yields relatively stable accuracy , as most sensitiv e categories are grounded in p erceptual cues. T extual augmen tation in- tro duces mixed effects: transcripts o ccasionally con textualize ambiguous scenes but increase the risk of spurious activ ations from lexical shortcuts, particularly in smaller mo dels. The primary challenge is false p ositiv e control under noisy m ultimo dal conditions rather than evidence extraction. 4.1 Cross-T ask Summary and Error Patterns Man ual error insp ection reveals recurring failure modes across tasks. T opic clas- sification shows systematic collapses betw een adjacent lab els (e.g., International p olitics → Domestic p olitics ), driven b y shared lexical fields in the transcript rather than genuine semantic am biguity . En vironment errors clus ter within per- ceptually similar settings (e.g., Home – Ap artment vs. Corp or ate offic e ), indicat- ing that visually similar spaces blur the signal, while comp ositionally distinctive studio environmen ts remain stable. Sensitiv e-conten t errors mainly arise from threshold instability: under weak visual evidence, lexical triggers in transcripts ma y induce spurious activ ations, turning textual input into a liabilit y . Person-recognition failures instead concen- trate in smaller mo dels and in clips lacking textual anc hors (e.g., lo wer-thirds or sp ok en names), where mo dels tend to hallucinate identities. These patterns are summarized in T able 1: no single input configuration dominates across tasks, and each task is primarily shaped b y a different modal- it y together with a c haracteristic failure mo de. Mo del capacit y mo derates these T ask Driv er Video Benefit F ailure Mo de T opic Sp eec h Mo derate Seman tic ov erlap En vironment Visual High Spatial ambiguit y Sensitiv e Visual Mo derate Spurious activ ation P erson Metadata Lo w Iden tit y hallucination T able 1. Mo dality dep endence and failure mo des across tasks relative to the image- frames baseline. effects but does not remo ve the underlying bottlenecks. The resulting trade-off 12 P . Cupini et al. Fig. 8. Distribution of annotated minutes p er topic (3,104 total, advertising excluded). P olitical conten t dominates with a long-tail across remaining categories. suggests com bining strong visual grounding for environmen t, reliable transcripts for topic, and controlled text exp osure for sensitive con tent. gemini-3-pro with Video + Metadata b est satisfies these conditions, achieving consistent p erfor- mance across tasks within acceptable token budgets, and is therefore selected for deploymen t. 5 Op erational Deplo yment and Audience Analytics Mo ving b ey ond con trolled b enc hmarking, this section presen ts the deploymen t of the selected pip eline on real broadcast episo des and its in tegration with audience measuremen t data. The video-based gemini-3-pro pip eline with metadata in- tegration is deploy ed on 14 full episo des of the same program (fixed w eekly time slot), annotating 3,104 minutes at one-minute granularit y (advertising excluded). Audience metrics are provided b y an Italian media company in aggregated and normalized form; no p ersonally identifiable information was accessed. 5.1 Con tent Characterization The editorial structu re is highly concentrated (Figure 8): Domestic p olitics (40.8%) and International p olitics (21.7%) account for ov er 60% of airtime, with a sec- ondary tier comprising Ec onomy and financ e (11.7%), Humor and satir e (9.2%), and Crime and justic e (6.0%). Remaining c ategories follo w a long-tail distribu- tion, several appearing in fewer than tw o episo des. The person recognition mo dule identifies 143 unique guests (hosts excluded) with 3,717 min ute-level o ccurrences. Participation is structurally asymmetric: male guests account for 81.1% of o ccurrences (3,017 out of 3,717), drawn from 89 A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 13 Fig. 9. Normalized AMR p er episo de by age cohort. The senior audience (55+) is the most stable segment; younger viewers exhibit higher in ter-episo de v ariability . unique individuals at an av erage recurrence of 33.9 app earances per guest, com- pared to 700 o ccurrences across 54 female guests (13.0 app earances p er guest). F urthermore, 80.2% of broadcast min utes feature exclusively male guests, a pat- tern consistently replicated across episo des. 5.2 Audience In tegration and Demographic Analysis Baseline Audience Comp osition. Figure 9 rep orts normalized AMR p er episo de disaggregated by age cohort (Y oung: 15–34, Adults: 35–54, Seniors: 55+). The senior segment consistently represents the largest and most stable demo- graphic comp onen t across all episo des. Y ounger viewers display markedly higher in ter-episo de v ariability , suggesting that episo de-lev el performance fluctuations are primarily driven b y c hanges in y ounger demographic participation rather than in the senior base. T opic-Lev el Sensitivity . Audience v alues are normalized in tra-episo de via z- score for each cohort and episo de. Positiv e v alues indicate ab o ve-a verage intra- episo de engagemen t, con trolling for episo de p opularit y and seasonal effects. In ter-Cohort Divergence. Figure 10 rep orts the ten topics with the largest z- score gap across cohorts. Art and liter atur e pro duces a p ositive deviation among Y oung view ers while remaining negative for A dults and Seniors — the clearest case of cohort-selectiv e engagemen t. A gradien t pattern c haracterizes Music , Fitness and tr aining , and Sp ort - so c c er : deviations are negativ e across all cohorts but the magnitude of decline increases with age. F amily and r elationships and Envir onment and climate are asso ciated with disengagement across all groups. F o o d and c o oking and Sp ort - others act as shared thematic attractors, with generational differences in amplitude rather than direction. In terpretation. High-frequency structural topics sustain baseline engagement, while lo w-frequency episodic segments generate localized deviations that dif- feren tially affect age cohorts. Minute-lev el semantic annotation integrated with 14 P . Cupini et al. Fig. 10. T opics with the largest inter-cohort z-score gap. Divergence reflects amplitude differences and, in selected cases, sign rev ersal betw een age groups. disaggregated audience data enables a shift from static aggregate measurement to ward dynamic audience sensitivity modeling — a practically relev ant capability for editorial strategy and conten t planning. All rep orted patterns are observ a- tional; no causal relationships are established. 6 Lessons Learned This section distills practical insights from b oth the controlled ev aluation and the op erational deploymen t for practitioners building similar broadcast annotation systems. Video input is not univ ersally b eneficial. Video-based pipelines do not systematically outp erform image-frames configurations. Performance gains are strongly model-dep endent: capable arc hitectures exploit temp oral contin uity ef- fectiv ely for spatially ambiguous en vironments, while mid-sized mo dels degrade under extended multimo dal context due to token ov erload. Video ingestion should b e treated as a conditional design choice, v alidated p er-task and p er-arc hitecture b efore accepting the asso ciated computational cost. T axonom y design is a first-order engineering decision. Recurring error patterns — semantic collapse in topic classification, p erceptual confusion in en- vironmen t recognition — were attributable to lab el structure rather than mo del limitations. Overlapping or undersp ecified categories introduce systematic am bi- guit y that additional mo dality or model capacit y cannot resolve. Lab el taxonomy A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 15 should b e treated as a core engineering artifact sub ject to iterative refinement, not a fixed annotation schema. Automated annotation pip elines enable scalable computational stud- ies of television conten t. The deploymen t shows that LLM-based annotation can support large-scale computational analysis of broadcast programming. T asks that would b e impractical to p erform manually — such as longitudinal conten t audits, cross-channel comparisons, or genre ev olution studies — b ecome feasible when annotation op erates at inference sp eed. Ho wev er, research designs m ust account for the pip eline’s error profile. Sys- tematic biases in label assignment (e.g., environmen t misclassification or topic conflation) propagate in to downstream analyses and may distort aggregate re- sults if left unmo deled. Computational studies based on automated annotations should therefore include uncertaint y estimates or reliability proxies, and findings deriv ed from b orderline categories should b e interpreted as indicativ e rather than definitiv e. 7 Conclusion This paper presen ted a systematic empirical study of m ultimo dal annotation pip elines for broadcast television, combining controlled b enc hmarking with de- plo yment in a real media analytics setting. Three contributions emerge. First, we construct a domain-specific b enc hmark of 100 man ually annotated one-minute clips co vering four semantic tasks under a taxonom y adapted to Italian prime-time television. Second, we ev aluate image- based and video-based pipelines across nine MLLMs, sho wing that temp oral video input do es not consisten tly improv e p erformance: gains are model- and task-dep enden t, while metadata enric hment provides the most reliable improv e- men t. Third, the selected pipeline is deplo yed on 3,104 min utes of broadcast con tent, pro ducing minute-lev el annotations in tegrated with normalized audi- ence data, demonstrating the op erational viability of automated seman tic anno- tation for audience analytics. Ov erall, the results p osition MLLMs not only as video understanding to ols but as comp onents of a broader framework for audience-orien ted broadcast ana- lytics, enabling join t analysis of conten t structure and demographic engagemen t within a unified data-driven w orkflow. Limitations. The 100-clip b enchmark limits statistical robustness and general- izabilit y and should therefore b e considered a diagnostic benchmark rather than a large-scale corpus. The adopted taxonomies are tailored to a sp ecific broad- cast format and may require adaptation in other contexts. Audience analyses are observ ational and do not establish causal relationships. The ev aluation is monolingual (Italian), leaving p erformance on other languages or multilingual con tent untested. Moreo ver, the study fo cuses on a single program t yp e, and its applicabilit y to other genres remains unv erified. Finally , all exp erimen ts rely on zero-shot or few-shot prompting of a general-purp ose model; no task-sp ecific fine-tuning was performed. 16 P . Cupini et al. Repro ducibilit y . The annotation taxonomy , ev aluation results, and prompting templates are rep orted in the App endix together with the anonymous co de rep os- itory: h ttps://anonymous.4open.science/r/F rom-Conten t-to-Audience-A-Multimo dal- Annotation-F ramework-for-Broadcast-T elevision-Analytics-5C88. References 1. A. Radford, J. W. Kim, T. Xu, G. Bro ckman, C. McLeav ey , and I. Sutskev er, R obust Sp e e ch R e c o gnition via Lar ge-Sc ale W e ak Sup ervision , in Pr o c. 40th Int. Conf. on Machine L earning (ICML) , pp. 28492–28518, 2023. 2. X. Li, Y. Zhang, and Z. W ang, A Survey on Multimo dal Vide o Understanding for Br o adcast Me dia , IEEE T ransactions on Multime dia , vol. 26, pp. 1234–1248, 2024. 3. J. S. Chung et al., V oxCeleb2: Deep Sp e aker Re c o gnition , in Interspeech, 2018. in Pr o c. IEEE/CVF Winter Conf. on Applic ations of Computer Vision (W ACV) , 2025. 4. Qw en T eam, Qwen-VL: A V ersatile Vision-Language Model for Understanding, L o calization, T ext R e ading, and Beyond , arXiv preprint arXiv:2308.12966, 2023. 5. W. Chen, X. Liu, and Y. W ang, Long-F orm Vide o Understanding with Vision– L anguage Mo dels: Limits and Opp ortunities , arXiv:2501.11345 , 2026. 6. J. Hong, W. Crich ton, H. Zhang, D. Y. F u, J. Ritchie, J. Barenholtz, B. Han- nel, X. Y ao, M. Murray , G. Moriba, M. Agraw ala, and K. F atahalian, Analysis of F ac es in a De c ade of US Cable TV News , in Pr o c. 27th ACM SIGKDD Conf. on Know le dge Disc overy and Data Mining (KDD) , 2021. 7. S. A. M. V ermeer, D. T rilling, and K. Hess, Who’s W atching What? Linking Au- tomate d Content Analysis of T elevision Subtitles to Audienc e Me asur ement Data , Journal of Communic ation , 2025. 8. In teractive A dvertising Bureau (IAB), Content T axonomy 3.0 , T echnical Sp ecifi- cation, IAB T ech Lab, 2022. A v ailable: https://iabtec hlab.com/standards/con tent- taxonom y/ 9. J. Ding, A. Lformally , and others, PDF-VQA: A New Dataset for R eal-W orld VQA on PDF Do cuments , in Pr o c. Eur op e an Conf. on Machine L e arning and Principles and Pr actic e of Know le dge Disc overy in Datab ases (ECML PKDD) , T urin, Italy , 2023. 10. L. Chenchen, and others, A Mer ge Sort Base d R anking System for the Evaluation of L ar ge L anguage Mo dels , in Pr o c. Eur op e an Conf. on Machine Le arning and Principles and Pr actic e of Know le dge Disc overy in Datab ases (ECML PKDD) , Vilnius, Lithuania, 2024. 11. M.Geerts, and others, On the Performanc e of LLMs for R e al Estate Appr aisal , in Pr o c. Europ e an Conf. on Machine L e arning and Principles and Pr actic e of Know l- e dge Disc overy in Datab ases (ECML PKDD) , P orto, P ortugal, 2025. 12. Auditel, “Metho dology ,” W eb page. A ccessed 2026-03-10. 13. T AM Ireland, “Understanding TV Data 2025,” PDF, 2025. A ccessed 2026-03-10. 14. M. Gambaro et al., “The Revealed Demand for Hard vs. Soft News: Evidence from Italian TV Viewership,” NBER W orking Paper, 2021. 15. R. Hinami and S. Satoh, “Audience Beha vior Mining by In tegrating TV Rat- ings with Multimedia Conten ts,” in Pr oc. International Symp osium on Multime dia , 2016. 16. S. Yin et al., “A survey on multimodal large language mo dels,” National Scienc e R eview , 2024. A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 17 17. J.-B. Ala yrac et al., “Flamingo: a Visual Language Mo del for F ew-Shot Learning,” arXiv preprint, 2022. 18. H. Liu, C. Li, Q. W u, and Y. J. Lee, “Visual Instruction T uning,” arXiv preprint, 2023. 19. Y. Y. T ang et al., “Video Understanding with Large Language Mo dels: A Survey ,” arXiv preprint, 2023. 20. C. Li et al., “Useful blunders: Can automated sp eec h recognition errors impro ve do wnstream dementia classification?” Journal of Biome dic al Informatics , 2024. 21. R. Qian et al., “Streaming Long Video Understanding with Large Language Mod- els,” in NeurIPS , 2024. 22. J. Jiang et al., “STORM: T oken-Efficien t Long Video Understanding for Multi- mo dal LLMs,” arXiv preprint, 2025. 23. M. Brkic et al., “F rame Sampling Strategies Matter: A Benchmark for small vision language mo dels,” arXiv preprint, 2025. 24. D. Cores et al., “Lost in Time: A New T emp oral Benchmark for VideoLLMs,” in BMVC , 2025. 8 App endix 8.1 Rep ository and Repro ducibilit y Resources T o supp ort reproducibility and facilitate further research, we provide an anonymized rep ository containing the full implementation of the pip elines developed in this w ork, together with the resources required to replicate the exp erimen tal ev alu- ation and the audience analytics use case. The rep ository contains four integrated pro cessing pip elines: – Video pip eline , whic h performs direct multi-modal analysis of video seg- men ts using VLM-based mo dels. – Images pip eline , which p erforms frame-based analysis with configurable frame extraction strategies. – T ext pip eline , whic h supp orts m ulti-engine ASR transcription, optional sp eak er diarization, and LLM-based topic classification. – F raming strategy b enc hmarking , which ev aluates alternative frame ex- traction approaches for visual classification tasks. In addition, the rep ository includes a complete audience analytics use case based on min ute-level television audience data, enabling the analysis of relationships b etw een broadcast conten t (topics, guests, and segments) and au- dience dynamics across demographic groups. The anonymized repository is av ailable at: h ttps://anonymous.4open.science/r/F rom-Conten t-to-Audience-A-Multimo dal- Annotation-F ramework-for-Broadcast-T elevision-Analytics-5C88 The rep ository will b e made publicly accessible upon acceptance of the pap er. 18 P . Cupini et al. 8.2 Complete Annotation T axonom y T able 2 reports the complete set of labels used for the semantic annotation of broadcast television segments across the three dimensions considered in this w ork: topic , envir onment , and sensitive c ontent . T opic Lab el Environmen t Label Sensitive Content Lab el Domestic p olitics Studio – Single host Violence International politics Studio – 1-to-1 interview Bloo d Crime and justice Studio – Guest panel W ar / armed conflicts Environmen t and climate Studio – Remote split screen Organized crime Society and so cial phenomena Studio – Video segment Humanitarian / migration crises F amily and relationship s Home – Apartment Self-harm / suicide Cinema, TV and entertainmen t Home – Kitchen Music Corporate office Humor and satire Commercial/public venue Art and literature Spa/wellness center History and archaeology V ehicle/transp ort Religion and spirituality Generic urban outdo or Science and technology Nature – Outdo ors Education and training Nature – Mountain F o od and co oking Identified tourist site F ashion and b eauty T rav el and tourism Health and wellness Motors and vehicles Sports – F o otball Sports – Other T able 2. T axonomies used for seman tic conten t annotation: topic labels (left), en vi- ronmen t lab els (centre), and sensitiv e con tent categories (right). A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 19 8.3 Prompt Strategies Both pip elines share the same annotation tasks, output sc hema, and a common set of hard constraints: select exactly one lab el for topic and envir onment , at most one label for br and_safety_flag , include a guest name only if the person is visually recognised or explicitly named in the transcript, and return a JSON ob ject only with no extra text. What v aries across configurations is which sources of information are provided and ho w their relative authorit y is defined. Video Pipeline Vide o only. The baseline configuration. The mo del is restricted to visual and audio evidence present in the ra w video stream, with no textual context. Vide o + metadata. Episo de-lev el metadata (programme name, category , de- scription, exp ected guests) is added as a secondary source. The k ey instruction in tro duced here is the explicit sub ordination of metadata to visual evidence: Use the metadata ONLY to confirm or correct identities already recognised visually. Do NOT assume guests are present based solely on the metadata. Vide o + ASR + metadata. An ASR transcript is added, and a three-level source hierarc hy is established: 1. VIDEO – primary for visual elements (environment, faces, brand safety); 2. ASR – primary for spoken content (topic, named entities); 3. METADATA – correction layer (fix ASR proper nouns, validate context). Vide o + diarize d ASR + metadata. Speaker diarization lab els ( SPEAKER_00 , SPEAKER_01 , . . . ) are added to the transcript. The nov el instruction in tro duced in this configuration ties diarization to environmen t classification and to speaker- to-iden tity resolution: Use diarization to estimate the number of speakers: 1 → single-host studio ; 2 → 1-to-1 interview ; 3+ → guest panel . Cross-reference speaker turns with metadata to associate names to speakers and correct ASR errors on proper nouns. F rames Pip eline The frames pip eline shares the video-only , ASR + meta- data, and diarized ASR + metadata configurations, adapted to use keyframe lists instead of a video stream. It additionally introduces t wo intermediate con- figurations – frames + ASR and frames + diarized ASR – that decouple the con tribution of transcription from that of metadata, an ablation that was not ev aluated in the video pip eline. F r ames only. Iden tical in spirit to the video-only prompt, restricted to visual evidence in the provided k eyframes. 20 P . Cupini et al. F r ames + ASR. A plain ASR transcript is added. Unlik e the video pip eline, no metadata is provided and no source hierarch y is enforced: images and transcript are treated as equally authoritative, with images gov erning en vironment and the transcript gov erning topic and named entities. F r ames + diarize d ASR. Diarization lab els are added without metadata. The en vironment classification heuristic based on sp eak er count (in tro duced in the video pip eline) is retained, but sp eak er-to-identit y resolution is limited to names explicitly mentioned in the transcript since no metadata is a v ailable to confirm or correct them. F r ames + ASR + metadata and F r ames + diarize d ASR + metadata. These t wo configurations mirror their video pip eline counterparts exactly , with the sole difference that the visual input consists of keyframes rather than a contin uous video stream. A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 21 8.4 F ull Exp erimen tal Results This app endix rep orts the complete ev aluation results for b oth pip elines exam- ined in this work: the fr ames-b ase d pip eline , which pro cesses videos as sequences of extracted k eyframes, and the vide o-b ase d pip eline , whic h ingests the video stream directly . Results are organized b y seman tic task and presented in eigh t tables in total. F or the frames-based pip eline , T ables 7, 8, 9, and 10 rep ort the results for Environmen t Recognition, T opic Classification, Sensitive Conten t Detection, and Person Recognition, respectively . F or the video-based pip eline , the cor- resp onding results are provided in T ables 3, 4, 5, and 6. Eac h table cov ers all tested mo dels and input configurations. The input con- figurations v ary the amoun t of supplemen tary textual context pro vided along- side the visual input: only denotes visual-only inference, while asr , asr_diar , asr_meta , and asr_diar_meta progressively augment the input with automatic sp eec h recognition transcripts, speaker diarization, and video metadata. F or eac h configuration we rep ort A ccuracy , Precision, Recall, and F1-score, together with the n umber of input tokens ( T ok ) and the av erage API latency in milliseconds ( Lat ). Entries marked – indicate metrics that are undefined due to the absence of p ositiv e predictions for the relev ant class. Model Input Acc Prec Rec F1 T ok Lat gemini-3-pro asr_diar_meta 0.74 0.79 0.74 0.75 6856 31932 gemini-3-pro asr_meta 0.66 0.76 0.66 0.68 6732 29595 gemini-3-pro meta 0.73 0.79 0.73 0.75 6443 31008 gemini-3-pro only 0.66 0.73 0.66 0.68 6224 35729 molmo-2-8b asr_diar_meta 0.33 0.42 0.33 0.29 12197 22064 molmo-2-8b asr_meta 0.14 0.06 0.14 0.06 11846 26757 molmo-2-8b meta 0.26 0.68 0.26 0.24 11608 24596 molmo-2-8b only 0.18 0.60 0.18 0.14 11361 21761 qwen3-omni asr_diar_meta 0.54 0.49 0.54 0.49 15346 9525 qwen3-omni asr_meta 0.56 0.56 0.56 0.53 15207 9735 qwen3-omni meta 0.55 0.63 0.55 0.54 14861 9879 qwen3-omni only 0.55 0.55 0.55 0.53 14615 9913 qwen3-235b asr_diar_meta 0.65 0.65 0.65 0.62 14614 7178 qwen3-235b asr_meta 0.71 0.73 0.71 0.71 14475 7237 qwen3-235b meta 0.70 0.72 0.70 0.69 14129 7091 qwen3-235b only 0.71 0.74 0.71 0.71 13884 9023 qwen3-30b asr_diar_meta 0.62 0.58 0.62 0.57 14614 22218 qwen3-30b asr_meta 0.66 0.60 0.66 0.62 14475 13720 qwen3-30b meta 0.71 0.77 0.71 0.69 14130 20742 qwen3-30b only 0.70 0.78 0.70 0.69 13884 18405 seed-1.6 asr_diar_meta 0.42 0.48 0.42 0.40 19506 40369 seed-1.6 asr_meta 0.54 0.65 0.54 0.56 19361 34226 seed-1.6 meta 0.61 0.64 0.61 0.61 19036 33848 seed-1.6 only 0.58 0.56 0.58 0.56 18799 57734 T able 3. Environmen t Recognition – full results. Input abbreviations: asr_diar_meta = video+ASR+diarization+metadata, asr_meta = video+ASR+metadata, meta = video+metadata, only = video only . T ok = input tokens; Lat = API latency (ms). 22 P . Cupini et al. Model Input Acc Prec Rec F1 T ok Lat gemini-3-pro asr_diar_meta 0.81 0.82 0.81 0.80 6856 31932 gemini-3-pro asr_meta 0.80 0.82 0.80 0.79 6732 29595 gemini-3-pro meta 0.83 0.82 0.83 0.81 6443 31008 gemini-3-pro only 0.79 0.79 0.79 0.77 6224 35729 molmo-2-8b asr_diar_meta 0.53 0.68 0.53 0.53 12197 22064 molmo-2-8b asr_meta 0.60 0.73 0.60 0.62 11846 26757 molmo-2-8b meta 0.50 0.67 0.50 0.52 11608 24596 molmo-2-8b only 0.34 0.62 0.34 0.36 11361 21761 qwen3-omni asr_diar_meta 0.76 0.75 0.76 0.74 15346 9525 qwen3-omni asr_meta 0.77 0.79 0.77 0.77 15207 9735 qwen3-omni meta 0.78 0.80 0.78 0.77 14861 9879 qwen3-omni only 0.78 0.82 0.78 0.78 14615 9913 qwen3-235b asr_diar_meta 0.69 0.74 0.69 0.69 14614 7178 qwen3-235b asr_meta 0.70 0.73 0.70 0.69 14475 7237 qwen3-235b meta 0.63 0.70 0.63 0.64 14129 7091 qwen3-235b only 0.55 0.68 0.55 0.57 13884 9023 qwen3-30b asr_diar_meta 0.69 0.77 0.69 0.70 14614 22218 qwen3-30b asr_meta 0.71 0.78 0.71 0.72 14475 13720 qwen3-30b meta 0.65 0.69 0.65 0.65 14130 20742 qwen3-30b only 0.60 0.68 0.60 0.60 13884 18405 seed-1.6 asr_diar_meta 0.75 0.79 0.75 0.76 19506 40369 seed-1.6 asr_meta 0.71 0.70 0.71 0.70 19361 34226 seed-1.6 meta 0.60 0.73 0.60 0.63 19036 33848 seed-1.6 only 0.45 0.68 0.45 0.50 18799 57734 T able 4. T opic Classification – full results. See T able 3 for abbreviation legend. Model Input Acc Prec Rec F1 T ok Lat gemini-3-pro asr_diar_meta 0.89 0.50 0.82 0.62 6856 31932 gemini-3-pro asr_meta 0.85 0.41 0.82 0.55 6732 29595 gemini-3-pro meta 0.88 0.47 0.64 0.54 6443 31008 gemini-3-pro only 0.88 0.47 0.73 0.57 6224 35729 molmo-2-8b asr_diar_meta 0.90 0.43 0.33 0.38 12197 22064 molmo-2-8b asr_meta 0.84 0.27 0.44 0.33 11846 26757 molmo-2-8b meta 0.82 0.24 0.44 0.31 11608 24596 molmo-2-8b only 0.88 0.25 0.10 0.14 11361 21761 qwen3-omni asr_diar_meta 0.69 0.22 0.89 0.35 15346 9525 qwen3-omni asr_meta 0.68 0.21 0.89 0.34 15207 9735 qwen3-omni meta 0.73 0.24 0.89 0.38 14861 9879 qwen3-omni only 0.91 0.57 0.40 0.47 14615 9913 qwen3-235b asr_diar_meta 0.77 0.23 0.67 0.34 14614 7178 qwen3-235b asr_meta 0.74 0.19 0.63 0.29 14475 7237 qwen3-235b meta 0.79 0.23 0.56 0.32 14129 7091 qwen3-235b only 0.84 0.29 0.56 0.38 13884 9023 qwen3-30b asr_diar_meta 0.77 0.25 0.78 0.38 14614 22218 qwen3-30b asr_meta 0.78 0.29 0.80 0.42 14475 13720 qwen3-30b meta 0.73 0.18 0.56 0.27 14130 20742 qwen3-30b only 0.71 0.17 0.63 0.26 13884 18405 seed-1.6 asr_diar_meta 0.88 0.33 0.09 0.14 19506 40369 seed-1.6 asr_meta 0.89 0.50 0.36 0.42 19361 34226 seed-1.6 meta 0.87 0.00 0.00 – 19036 33848 seed-1.6 only 0.89 1.00 0.08 0.15 18799 57734 T able 5. Sensitive Conten t Detection – full results. See T able 3 for abbreviation legend. A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 23 Mo del Input Acc Prec Rec F1 T ok Lat gemini-3-pro asr_diar_meta 0.60 0.62 0.60 0.61 6856 31932 gemini-3-pro asr_meta 0.50 0.56 0.50 0.52 6732 29595 gemini-3-pro meta 0.60 0.63 0.60 0.60 6443 31008 gemini-3-pro only 0.50 0.54 0.50 0.50 6224 35729 molmo-2-8b asr_diar_meta 0.14 0.18 0.14 0.10 12197 22064 molmo-2-8b asr_meta 0.13 0.11 0.13 0.07 11846 26757 molmo-2-8b meta 0.10 0.01 0.10 0.02 11608 24596 molmo-2-8b only 0.10 0.01 0.10 0.02 11361 21761 qw en3-omni asr_diar_meta 0.10 0.01 0.10 0.02 15346 9525 qw en3-omni asr_meta 0.10 0.01 0.10 0.02 15207 9735 qw en3-omni meta 0.10 0.01 0.10 0.02 14861 9879 qw en3-omni only 0.10 0.01 0.10 0.02 14615 9913 qw en3-235b asr_diar_meta 0.13 0.14 0.13 0.06 14614 7178 qw en3-235b asr_meta 0.18 0.17 0.18 0.12 14475 7237 qw en3-235b meta 0.13 0.09 0.13 0.06 14129 7091 qw en3-235b only 0.15 0.06 0.15 0.07 13884 9023 qw en3-30b asr_diar_meta 0.10 0.01 0.10 0.02 14614 22218 qw en3-30b asr_meta 0.10 0.01 0.10 0.02 14475 13720 qw en3-30b meta 0.10 0.01 0.10 0.02 14130 20742 qw en3-30b only 0.18 0.10 0.18 0.12 13884 18405 seed-1.6 asr_diar_meta 0.42 0.40 0.42 0.38 19506 40369 seed-1.6 asr_meta 0.39 0.38 0.39 0.37 19361 34226 seed-1.6 meta 0.31 0.31 0.31 0.26 19036 33848 seed-1.6 only 0.10 0.01 0.10 0.02 18799 57734 T able 6. Person Recognition – full results. See T able 3 for abbreviation legend. 24 P . Cupini et al. Mo del Input A cc Prec Rec F1 T ok Lat gemini-3-pro asr 0.68 0.72 0.68 0.68 14294 35028 gemini-3-pro asr_diar 0.72 0.77 0.72 0.72 14456 33811 gemini-3-pro asr_diar_meta 0.73 0.79 0.73 0.74 14666 34378 gemini-3-pro asr_meta 0.76 0.81 0.76 0.77 14572 32011 gemini-3-pro only 0.70 0.75 0.70 0.71 13996 34865 gemma-3-27b asr 0.46 0.51 0.46 0.43 4212 25520 gemma-3-27b asr_diar 0.47 0.29 0.47 0.36 4376 28385 gemma-3-27b asr_diar_meta 0.44 0.30 0.44 0.34 4586 8738 gemma-3-27b asr_meta 0.37 0.47 0.37 0.34 4491 29150 gemma-3-27b only 0.49 0.45 0.49 0.45 3917 8167 gpt-5-mini asr 0.55 0.50 0.55 0.52 4551 37385 gpt-5-mini asr_diar 0.27 0.51 0.27 0.34 4705 55330 gpt-5-mini asr_diar_meta 0.56 0.62 0.56 0.58 4945 28378 gpt-5-mini asr_meta 0.46 0.72 0.46 0.54 4849 45219 gpt-5-mini only 0.59 0.64 0.59 0.59 4234 15836 llama-4-ma v asr 0.57 0.64 0.57 0.59 9753 20462 llama-4-ma v asr_diar 0.58 0.56 0.58 0.54 9906 24420 llama-4-ma v asr_diar_meta 0.60 0.68 0.60 0.57 10135 8195 llama-4-ma v asr_meta 0.54 0.62 0.54 0.56 10056 19666 llama-4-ma v only 0.55 0.60 0.55 0.56 9461 4710 ministral-14b asr 0.28 0.30 0.28 0.25 5441 19854 ministral-14b asr_diar 0.21 0.37 0.21 0.15 5620 21727 ministral-14b asr_diar_meta 0.20 0.35 0.20 0.22 5868 10670 ministral-14b asr_meta 0.08 0.22 0.08 0.10 5742 26039 ministral-14b only 0.25 0.27 0.25 0.22 5124 7118 qw en2.5-72b asr 0.60 0.62 0.60 0.58 4821 19667 qw en2.5-72b asr_diar 0.53 0.47 0.53 0.46 4983 23429 qw en2.5-72b asr_diar_meta 0.59 0.47 0.59 0.50 5241 6494 qw en2.5-72b asr_meta 0.56 0.51 0.56 0.52 5150 19650 qw en2.5-72b only 0.63 0.67 0.63 0.62 4460 7222 qw en3-235b asr 0.65 0.63 0.65 0.62 3863 21662 qw en3-235b asr_diar 0.57 0.58 0.57 0.54 4024 21450 qw en3-235b asr_diar_meta 0.62 0.58 0.62 0.57 4283 6062 qw en3-235b asr_meta 0.67 0.70 0.67 0.67 4192 20654 qw en3-235b only 0.65 0.62 0.65 0.63 3501 3617 qw en3-30b asr 0.56 0.55 0.56 0.53 3863 19758 qw en3-30b asr_diar 0.44 0.36 0.44 0.35 4024 16779 qw en3-30b asr_diar_meta 0.41 0.41 0.41 0.34 4283 5855 qw en3-30b asr_meta 0.30 0.49 0.30 0.28 4192 16132 qw en3-30b only 0.50 0.52 0.50 0.47 3501 4657 qw en3-8b asr 0.34 0.53 0.34 0.32 9308 24031 qw en3-8b asr_diar 0.43 0.34 0.43 0.34 7690 18707 qw en3-8b asr_diar_meta 0.43 0.36 0.43 0.37 4283 7789 qw en3-8b asr_meta 0.36 0.40 0.36 0.33 7835 23203 qw en3-8b only 0.49 0.61 0.49 0.48 3501 7308 T able 7. En vironment Recognition (frames pipeline) – full results. Input abbrevi- ations: asr = frames+ASR, asr_diar = frames+ASR+diarization, asr_diar_meta = frames+ASR+diarization+metadata, asr_meta = frames+ASR+metadata, only = frames only . T ok = input tokens; Lat = API latency (ms). A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 25 Mo del Input A cc Prec Rec F1 T ok Lat gemini-3-pro asr 0.81 0.82 0.81 0.80 14294 35028 gemini-3-pro asr_diar 0.81 0.84 0.81 0.80 14456 33811 gemini-3-pro asr_diar_meta 0.80 0.81 0.80 0.78 14666 34378 gemini-3-pro asr_meta 0.79 0.81 0.79 0.78 14572 32011 gemini-3-pro only 0.67 0.73 0.67 0.65 13996 34865 gemma-3-27b asr 0.65 0.72 0.65 0.67 4212 25520 gemma-3-27b asr_diar 0.68 0.75 0.68 0.69 4376 28385 gemma-3-27b asr_diar_meta 0.67 0.73 0.67 0.68 4586 8738 gemma-3-27b asr_meta 0.65 0.74 0.65 0.66 4491 29150 gemma-3-27b only 0.50 0.62 0.50 0.50 3917 8167 gpt-5-mini asr 0.70 0.71 0.70 0.69 4551 37385 gpt-5-mini asr_diar 0.39 0.74 0.39 0.49 4705 55330 gpt-5-mini asr_diar_meta 0.63 0.80 0.63 0.68 4945 28378 gpt-5-mini asr_meta 0.47 0.75 0.47 0.55 4849 45219 gpt-5-mini only 0.61 0.73 0.61 0.63 4234 15836 llama-4-ma v asr 0.71 0.76 0.71 0.71 9753 20462 llama-4-ma v asr_diar 0.71 0.76 0.71 0.70 9906 24420 llama-4-ma v asr_diar_meta 0.69 0.72 0.69 0.67 10135 8195 llama-4-ma v asr_meta 0.71 0.75 0.71 0.71 10056 19666 llama-4-ma v only 0.50 0.65 0.50 0.52 9461 4710 ministral-14b asr 0.53 0.66 0.53 0.54 5441 19854 ministral-14b asr_diar 0.53 0.69 0.53 0.57 5620 21727 ministral-14b asr_diar_meta 0.35 0.71 0.35 0.46 5868 10670 ministral-14b asr_meta 0.13 0.54 0.13 0.20 5742 26039 ministral-14b only 0.26 0.47 0.26 0.31 5124 7118 qw en2.5-72b asr 0.69 0.84 0.69 0.72 4821 19667 qw en2.5-72b asr_diar 0.63 0.78 0.63 0.66 4983 23429 qw en2.5-72b asr_diar_meta 0.66 0.75 0.66 0.67 5241 6494 qw en2.5-72b asr_meta 0.74 0.78 0.74 0.74 5150 19650 qw en2.5-72b only 0.53 0.70 0.53 0.55 4460 7222 qw en3-235b asr 0.66 0.75 0.66 0.68 3863 21662 qw en3-235b asr_diar 0.65 0.76 0.65 0.67 4024 21450 qw en3-235b asr_diar_meta 0.65 0.72 0.65 0.64 4283 6062 qw en3-235b asr_meta 0.70 0.72 0.70 0.69 4192 20654 qw en3-235b only 0.52 0.66 0.52 0.55 3501 3617 qw en3-30b asr 0.66 0.78 0.66 0.68 3863 19758 qw en3-30b asr_diar 0.59 0.75 0.59 0.61 4024 16779 qw en3-30b asr_diar_meta 0.62 0.68 0.62 0.61 4283 5855 qw en3-30b asr_meta 0.67 0.76 0.67 0.67 4192 16132 qw en3-30b only 0.47 0.69 0.47 0.49 3501 4657 qw en3-8b asr 0.50 0.67 0.50 0.52 9308 24031 qw en3-8b asr_diar 0.49 0.63 0.49 0.49 7690 18707 qw en3-8b asr_diar_meta 0.52 0.69 0.52 0.51 4283 7789 qw en3-8b asr_meta 0.52 0.60 0.52 0.52 7835 23203 qw en3-8b only 0.39 0.62 0.39 0.38 3501 7308 T able 8. T opic Classification (frames pip eline) – full results. See T able 7 for abbrevi- ation legend. 26 P . Cupini et al. Mo del Input A cc Prec Rec F1 T ok Lat gemini-3-pro asr 0.83 0.38 0.82 0.51 14294 35028 gemini-3-pro asr_diar 0.86 0.43 0.82 0.56 14456 33811 gemini-3-pro asr_diar_meta 0.77 0.27 0.64 0.38 14666 34378 gemini-3-pro asr_meta 0.86 0.40 0.80 0.53 14572 32011 gemini-3-pro only 0.87 0.43 0.55 0.48 13996 34865 gemma-3-27b asr 0.87 0.40 0.60 0.48 4212 25520 gemma-3-27b asr_diar 0.89 0.40 0.20 0.27 4376 28385 gemma-3-27b asr_diar_meta 0.43 0.05 0.43 0.10 4586 8738 gemma-3-27b asr_meta 0.89 0.43 0.30 0.35 4491 29150 gemma-3-27b only 0.90 0.44 0.44 0.44 3917 8167 gpt-5-mini asr 0.70 0.22 0.89 0.35 4551 37385 gpt-5-mini asr_diar 0.84 0.20 0.20 0.20 4705 55330 gpt-5-mini asr_diar_meta 0.76 0.23 0.60 0.33 4945 28378 gpt-5-mini asr_meta 0.85 0.36 0.33 0.35 4849 45219 gpt-5-mini only 0.81 0.25 0.36 0.30 4234 15836 llama-4-ma v asr 0.65 0.17 0.88 0.29 9753 20462 llama-4-ma v asr_diar 0.91 0.57 0.40 0.47 9906 24420 llama-4-ma v asr_diar_meta 0.13 0.00 – – 10135 8195 llama-4-ma v asr_meta 0.33 0.00 0.00 – 10056 19666 llama-4-ma v only 0.72 0.19 0.67 0.30 9461 4710 ministral-14b asr 0.88 – 0.00 – 5441 19854 ministral-14b asr_diar 0.88 – 0.00 – 5620 21727 ministral-14b asr_diar_meta 0.88 – 0.00 – 5868 10670 ministral-14b asr_meta 0.87 0.00 0.00 – 5742 26039 ministral-14b only 0.88 – 0.00 – 5124 7118 qw en2.5-72b asr 0.87 0.43 0.25 0.32 4821 19667 qw en2.5-72b asr_diar 0.84 0.25 0.30 0.27 4983 23429 qw en2.5-72b asr_diar_meta 0.88 0.00 0.00 – 5241 6494 qw en2.5-72b asr_meta 0.89 0.50 0.09 0.15 5150 19650 qw en2.5-72b only 0.91 0.80 0.33 0.47 4460 7222 qw en3-235b asr 0.84 0.14 0.33 0.20 3863 21662 qw en3-235b asr_diar 0.82 0.26 0.86 0.40 4024 21450 qw en3-235b asr_diar_meta 0.84 0.15 0.29 0.20 4283 6062 qw en3-235b asr_meta 0.81 0.12 0.33 0.17 4192 20654 qw en3-235b only 0.89 0.40 0.20 0.27 3501 3617 qw en3-30b asr 0.82 0.32 0.70 0.44 3863 19758 qw en3-30b asr_diar 0.63 0.20 1.00 0.33 4024 16779 qw en3-30b asr_diar_meta 0.86 0.25 0.20 0.22 4283 5855 qw en3-30b asr_meta 0.88 0.41 0.78 0.54 4192 16132 qw en3-30b only 0.81 0.13 0.29 0.17 3501 4657 qw en3-8b asr 0.86 0.25 0.20 0.22 9308 24031 qw en3-8b asr_diar 0.80 0.17 0.38 0.23 7690 18707 qw en3-8b asr_diar_meta 0.01 0.01 1.00 0.02 4283 7789 qw en3-8b asr_meta 0.19 0.02 1.00 0.05 7835 23203 qw en3-8b only 0.87 0.40 0.17 0.24 3501 7308 T able 9. Sensitive Conten t Detection (frames pip eline) – full results. See T able 7 for abbreviation legend. A Multimo dal Annotation F ramework for Broadcast T elevision Analytics 27 Mo del Input A cc Prec Rec F1 T ok Lat gemini-3-pro asr 0.39 0.42 0.39 0.38 14294 35028 gemini-3-pro asr_diar 0.27 0.29 0.27 0.24 14456 33811 gemini-3-pro asr_diar_meta 0.30 0.27 0.30 0.26 14666 34378 gemini-3-pro asr_meta 0.59 0.60 0.59 0.58 14572 32011 gemini-3-pro only 0.43 0.39 0.43 0.40 13996 34865 gemma-3-27b asr 0.15 0.08 0.15 0.09 4212 25520 gemma-3-27b asr_diar 0.16 0.09 0.16 0.10 4376 28385 gemma-3-27b asr_diar_meta 0.20 0.14 0.20 0.16 4586 8738 gemma-3-27b asr_meta 0.36 0.38 0.36 0.36 4491 29150 gemma-3-27b only 0.15 0.06 0.15 0.07 3917 8167 gpt-5-mini asr 0.09 0.06 0.09 0.07 4551 37385 gpt-5-mini asr_diar 0.11 0.05 0.11 0.06 4705 55330 gpt-5-mini asr_diar_meta 0.21 0.26 0.21 0.20 4945 28378 gpt-5-mini asr_meta 0.11 0.04 0.11 0.04 4849 45219 gpt-5-mini only 0.10 0.01 0.10 0.02 4234 15836 llama-4-ma v asr 0.13 0.07 0.13 0.08 9753 20462 llama-4-ma v asr_diar 0.12 0.10 0.12 0.09 9906 24420 llama-4-ma v asr_diar_meta 0.26 0.36 0.26 0.28 10135 8195 llama-4-ma v asr_meta 0.11 0.05 0.11 0.04 10056 19666 llama-4-ma v only 0.16 0.08 0.16 0.09 9461 4710 ministral-14b asr 0.09 0.01 0.09 0.02 5441 19854 ministral-14b asr_diar 0.09 0.02 0.09 0.03 5620 21727 ministral-14b asr_diar_meta 0.14 0.09 0.14 0.09 5868 10670 ministral-14b asr_meta 0.14 0.12 0.14 0.08 5742 26039 ministral-14b only 0.09 0.01 0.09 0.02 5124 7118 qw en2.5-72b asr 0.13 0.05 0.13 0.06 4821 19667 qw en2.5-72b asr_diar 0.12 0.05 0.12 0.06 4983 23429 qw en2.5-72b asr_diar_meta 0.21 0.25 0.21 0.20 5241 6494 qw en2.5-72b asr_meta 0.48 0.45 0.48 0.45 5150 19650 qw en2.5-72b only 0.13 0.04 0.13 0.05 4460 7222 qw en3-235b asr 0.17 0.08 0.17 0.10 3863 21662 qw en3-235b asr_diar 0.13 0.07 0.13 0.08 4024 21450 qw en3-235b asr_diar_meta 0.22 0.16 0.22 0.17 4283 6062 qw en3-235b asr_meta 0.48 0.52 0.48 0.49 4192 20654 qw en3-235b only 0.15 0.06 0.15 0.07 3501 3617 qw en3-30b asr 0.15 0.08 0.15 0.10 3863 19758 qw en3-30b asr_diar 0.13 0.08 0.13 0.09 4024 16779 qw en3-30b asr_diar_meta 0.23 0.29 0.23 0.23 4283 5855 qw en3-30b asr_meta 0.41 0.52 0.41 0.43 4192 16132 qw en3-30b only 0.12 0.04 0.12 0.05 3501 4657 qw en3-8b asr 0.14 0.06 0.14 0.07 9308 24031 qw en3-8b asr_diar 0.14 0.07 0.14 0.08 7690 18707 qw en3-8b asr_diar_meta 0.24 0.27 0.24 0.25 4283 7789 qw en3-8b asr_meta 0.29 0.30 0.29 0.28 7835 23203 qw en3-8b only 0.11 0.03 0.11 0.04 3501 7308 T able 10. Person Recognition (frames pipeline) – full results. See T able 7 for abbre- viation legend.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment