Aesthetic Assessment of Chinese Handwritings Based on Vision Language Models
The handwriting of Chinese characters is a fundamental aspect of learning the Chinese language. Previous automated assessment methods often framed scoring as a regression problem. However, this score-only feedback lacks actionable guidance, which lim…
Authors: Chen Zheng, Yuxuan Lai, Haoyang Lu
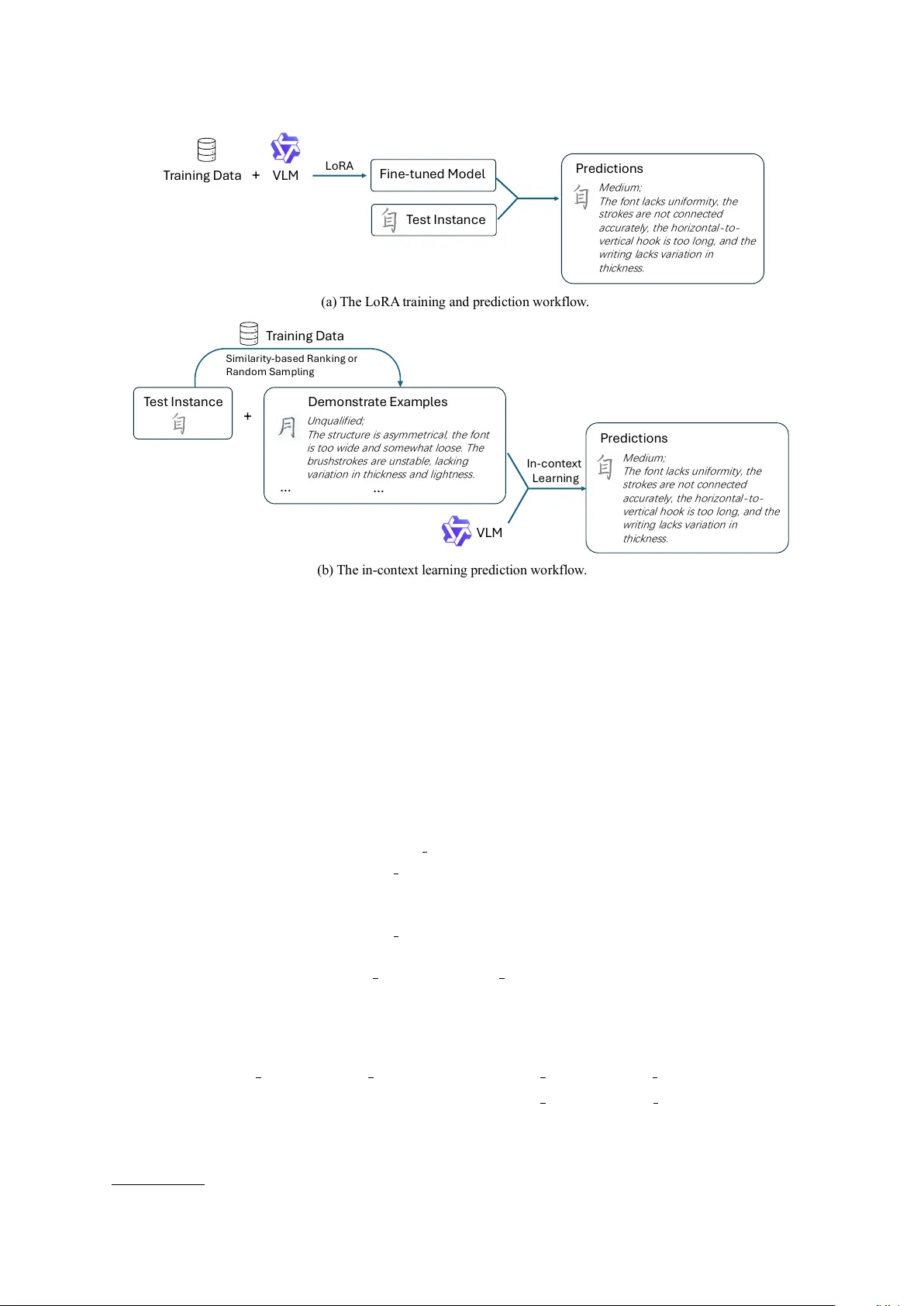
System Report f or CCL25-Eval T ask 11: Aesthetic Assessment of Chinese Handwritings Based on V ision Language Models Chen Zheng 1,2 , Y uxuan Lai 1,2 , Haoyang Lu 3 , W entao Ma 3 , Jitao Y ang 3 , and Jian W ang 3 1 The Open Uni versity of China, Beijing, China 2 Engineering Research Center of Integration and Application of Digital Learning T echnology , Ministry of Education, Beijing, China 3 OUC-online, Beijing, China zhengchen@ouchn.edu.cn Abstract The handwriting of Chinese characters is a fundamental aspect of learning the Chinese language. Pre vious automated assessment methods often framed scoring as a regression problem. Ho w- e ver , this score-only feedback lacks actionable guidance, which limits its effecti veness in helping learners improve their handwriting skills. In this paper , we le v erage vision-language models (VLMs) to analyze the quality of handwritten Chinese characters and generate multi-level feed- back. Specifically , we in vestigate two feedback generation tasks: simple grade feedback (T ask 1) and enriched, descripti ve feedback (T ask 2). W e explore both lo w-rank adaptation (LoRA)-based fine-tuning strategies and in-context learning methods to integrate aesthetic assessment knowl- edge into VLMs. Experimental results sho w that our approach achiev es state-of-the-art perfor- mances across multiple e v aluation tracks in the CCL 2025 workshop on ev aluation of handwritten Chinese character quality . K eywords: Handwritten Chinese Characters , Aesthetic Assessment , V ision-Language Models , Lo w-rank Adaptation , In-context Learning 1 Introduction The automated assessment of Chinese handwriting is a critical research area in language education and intelligent ev aluation systems ( Xiao et al., 2022 ; Chen et al., 2024 ). Chinese handwritten characters, characterized by their linguistic accuracy and structural comple xity , serve as a cornerstone of cultural and educational expression. Howe ver , existing systems typically provide only score-based feedback ( Han et al., 2008 ; Gao et al., 2011 ; Li et al., 2014 ; Sun et al., 2015 ; W ang et al., 2016 ; Zhou et al., 2017 ; W ang and Lv , 2021 ; Sun et al., 2023 ; W ang et al., 2023 ; Y an et al., 2024 ; W u et al., 2024 ), which limits their ef fectiv eness in supporting learners’ skill development. This highlights the need for advanced methods to deli ver detailed, constructi ve feedback, thereby enhancing educational practices and supporting Chinese handwriting in digital learning en vironments. Recent adv ancements in computer vision have facilitated the dev elopment of automated systems for e valuating Chinese handwriting, enabling standardized assessments while preserving the artistic qualities of calligraphy . Howe ver , constructing e valuation models that effecti vely balance standardization with aesthetic merit remains a complex challenge. Existing research has predominantly relied on hand-crafted features to assess structural and aesthetic quality . For instance, Gao et al. ( 2011 ) proposes a method for e valuating Chinese handwriting quality based on the recognition confidence of online handwriting analysis using a modified quadratic discriminant function classifier . Sun et al. ( 2015 ) utilize global shape features and component layout information to enhance aesthetic ev aluation. Zhou et al. ( 2017 ) use a possibility-probability distribution method to assess the quality of robotic Chinese handwriting. Despite these advances, such approaches often lack the flexibility to provide nuanced, context-aw are feedback that ef fectiv ely integrates both structural and strok e dimensions. ©2025 China National Conference on Computational Linguistics Published under Creativ e Commons Attribution 4.0 International License China National Conference on Computational Linguistics Recently , vision-language models (VLMs) hav e sho wn remarkable capabilities across various do- mains, including document understanding, visual perception, and multimodal reasoning ( Bai et al., 2023 ; W ang et al., 2024 ; Bai et al., 2025 ; Lu et al., 2024 ; Kimi T eam et al., 2025 ). Despite these advancements, their application in the aesthetic assessment of Chinese handwriting remains largely une xplored. T raditional computer vision methods often struggle to pro vide fine-grained and personalized feedback in aesthetic assessment tasks. VLMs, with their robust capabilities in image understanding and natural language generation, of fer a novel approach to address these limitations. This study explores the application of VLMs to generate detailed, context-sensiti ve feedback on Chi- nese handwriting quality , with a focus on both structural integrity and stroke aesthetics. T o effecti vely integrate domain-specific kno wledge into VLMs for this task, we in vestigate two data-ef ficient methods: Lo w-Rank Adaptation (LoRA) based fine-tuning for open-source VLMs ( Hu et al., 2022 ), and in-conte xt learning for closed-source large language models (LLMs) ( Bro wn et al., 2020 ). W e conducted experiments on the CCL 2025 ev aluation task for assessing the quality of handwrit- ten Chinese characters, which includes two subtasks: grading and comment generation. Our proposed method obtained scores of 0.76 and 0.52 on the respective subtasks, securing third place in the competi- tion and demonstrating its ef fectiv eness. 2 T ask F ormulation In the CCL 2025 e valuation of the quality of handwritten Chinese characters task, the objective is to assess the aesthetic quality of a giv en Chinese handwritten image. This task in v olves two distinct sub- tasks: T ask 1: Grading of handwritten Chinese characters: the goal is to classify the quality of handwritten characters into three discrete grades: excellent, medium, and unqualified. This classification is primarily based on the structural integrity and strok e aesthetics of the characters. T ask 2: Comment generation of handwritten Chinese characters: the goal is to provide targeted textual descriptions focusing on the two aforementioned dimensions: structure and stroke form. 3 Methods W e explore LoRA and in-context learning methods, with the o verall frame work depicted in Fig. 1. 3.1 T raining Format for LoRA For LoRA fine-tuning, training and testing data are structured as single-turn dialogues, follo wing the template provided below . In T ask 1, the model receiv es a raw image of a handwritten Chinese character as input, and its training objecti ve is to output the corresponding quality grade. [ { “role”: “user”, “content”: } , { “role”: “assistant”, “content”: } ] T ask 2 employs tw o dif ferent input-output formats. The first is similar to T ask 1, b ut the e xpected output is detailed feedback on handwriting quality , rather than just a grade. [ { “role”: “user”, “content”: } , { “role”: “assistant”, “content”: } ] The second format’ s input differs by including the raw image of the handwritten Chinese character and the grade predicted by the model trained on T ask 1. [ { “role”: “user”, “content”: The ev aluation for the abov e handwritten Chinese characters is , generate a comment. } , { “role”: “assistant”, “content”: } ] China National Conference on Computational Linguistics T r a i n i n g D a t a Lo R A F i n e - t u n e d M od e l V L M P re d i c t i on s T e s t In s t a n c e V L M T e s t Inst a n c e T r a i n i n g D a t a D e mon s t r a t e Exa m p le s S imi l a r it y - b a s e d R a n k in g or R a n d o m S a m p l in g In - c o n t e x t Le a rn i n g + + Un q u a l i f i e d ; T h e s t r u c t u r e is a s y m m e t r i c a l , t h e f o n t is t oo w i de a n d s om e w h a t l oo s e . T h e br u s h s t r ok e s a r e u n s t a bl e , l a c k i n g v a r i a t i on in t h i c k n e s s a n d l i gh t n e s s . … (a) T h e L o RA t rai n i n g an d p red i ct i o n w o rk fl o w . (b ) T h e in - co n t ex t l ea rn i n g p red i ct i o n w o rk fl o w . … M e d i u m ; T h e f on t l a c k s u n i f or m i t y , t h e s t r ok e s a r e n ot c on n e c t e d a c c u r a t e l y , t h e h or i z on t a l - to - v e r t i c a l h oo k i s t oo l on g, a n d t h e w r i t i n g l a c k s v a r i a t i on i n t h i c k n e s s . P re d i c t i on s M e d i u m ; T h e f on t l a c k s u n i f or m i t y , t h e s t r ok e s a r e n ot c on n e c t e d a c c u r a t e l y , t h e h or i z on t a l - to - v e r t i c a l h oo k i s t oo l on g, a n d t h e w r i t i n g l a c k s v a r i a t i on i n t h i c k n e s s . Figure 1: The LoRA and in-context learning frame works. 3.2 Example Demonstation f or In-context Learning W e in vestigated two in-context learning methods: a similarity-based method for selecting and ordering in-context examples, and random selection of in-context examples. In the first method, giv en a test instance, we select the k most similar instances from the training data to serve as demonstrations. A training instance is placed closer to the test instance as its similarity increases. In the second method, instances are randomly selected from the training data. The org anization of the query for in-context learning is illustrated belo w: [ { “role”: “system”, “content”: SYSTEM PROMPT } , { “role”: “user”, “content”: } , { “role”: “assistant”, “content”: or } , ..., { “role”: “user”, “content”: } , { “role”: “assistant”, “content”: or } , { “role”: “user”, “content”: TEST PROMPT , } ] In the similarity-based method, the input images are ordered based on their similarity to a test image, as follo ws: sim ( INPUT IMAGE 1 , TEST IMAGE ) ≤ sim ( INPUT IMAGE 2 , TEST IMAGE ) ≤ . . . ≤ sim ( INPUT IMAGE k , TEST IMAGE ) (1) Here, sim ( ˙ ) denotes the cosine similarity between the image embeddings of the instances. The system prompt for T ask 1 clearly outlined the ev aluation criteria for each grade, as shown belo w 1 . 1 All prompts were originally in Chinese and hav e been translated into English for presentation. China National Conference on Computational Linguistics SYSTEM PROMPT : Y ou are an e xpert in Chinese calligraph y who is familiar with the aesthetic features of Chinese characters. Y ou are capable of accurately ev aluating the quality of stu- dents’ handwriting. Follo wing the example provided, you are required to rate the gi ven samples of Chinese char- acter writing into three grades: A (Excellent), B (Medium), or C (Unqualified). The grading criteria are defined as follo ws: A (Excellent): The character structure and proportions are well-balanced, the center of gra vity is stable, and the overall appearance is symmetrical and aesthetically pleasing. The strokes are correctly shaped with proper coordination, clearly ex ecuted, and demonstrate variation in pressure and thickness. There are no significant flaws in the writing. B (Medium): The structure and proportions are generally reasonable, the center of gravity is mostly stable, and the character appears relativ ely balanced. The stroke forms are largely cor - rect, and the individual strok es are clear , but there is limited v ariation in pressure. The writing exhibits systematic deficiencies in one or more aspects. C (Unqualified): The structure is imbalanced or the center of gravity is unstable, resulting in an asymmetrical and unappealing appearance. The strok es are careless, unclear , or sloppy . The writing contains serious flaws that significantly af fect legibility or aesthetic quality . The SYSTEM PROMPT for T ask 2 outlined the key points for generating feedback, details of which can be found in Appendix A. The TEST PROMPT instructs the VLM to grade the test image or give feedback based on the instructions and examples. For T ask 1, TEST PROMPT : Y ou are required to assign a score of A (Excellent), B (Medium), or C (Un- qualified) to the gi ven image of Chinese character writing, based on the example and criteria provided above. Note: Y our response must consist of only a single uppercase letter corre- sponding to the score for this image. The details of the TEST PROMPT for task 2 can be found in appendix B. 4 Experiment 4.1 Experimental Setups W e conduct experiments on the CCL 2025 Ev aluation of the quality of handwritten Chinese characters dataset. For T ask 1, the dataset comprises 1500 training instances and 300 test instances. For T ask 2, it includes 600 training instances and 100 test instances. For T ask 1, e valuation metrics include precision, recall and the F1-score. For T ask 2, the metrics are R OUGE-1, R OUGE-2, and ROUGE-L. The final score is calculated as follo ws: FinalScore = 0 . 4 × R OUGE-L + 0 . 3 × R OUGE-2 + 0 . 3 × R OUGE-1 . (2) W e use the open-source VLMs Qwen2.5-VL-72B-Instruct 2 (QwenVL) (for both task 1 and 2) and QVQ-72B-Pr evie w 3 (QVQ) (for task 2) as the base models for LoRA training. The training was con- ducted for 3 epochs with a learning rate of 1 × 10 − 4 using the open-source fine-tuning tool LLaMA- Factory ( Zheng et al., 2024 ). In the LoRA training for T ask 1, we utilized an open-source dataset, CHAED ( Sun et al., 2015 ) to expand our training set. This dataset comprises 1000 Chinese handwriting images, each accompanied by aesthetic scores. Images were empirically classified into three categories based on their aesthetic scores: Excellent (scores > 80), Medium (scores 30 ∼ 80), and Unqualified (scores < 30). Separate models were then trained using only the task-specific dataset and with the combined CHAED data, respecti vely . For LoRA-based training in T ask 2, the first model was trained similarly to T ask 1, but it generated feedback text instead of grading scores. The second model utilized the model trained on the T ask 1- specific dataset to predict grading scores for each image in the training and test sets. Subsequently , the 2 https://huggingface.co/Qwen/Qwen2.5- VL- 72B- Instruct 3 https://huggingface.co/Qwen/QVQ- 72B- Preview China National Conference on Computational Linguistics Model Precision Recall F1 QwenVL LoRA 0.76 0.76 0.76 QwenVL LoRA w/ CHAED 0.61 0.61 0.61 In-Context Learning 0.69 0.69 0.69 T able 1: Summary of results of the task 1. Model R OUGE-1 R OUGE-2 ROUGE-L FinalScore QwenVL LoRA 0.43 0.24 0.41 0.36 QwenVL LoRA w/ grade 0.46 0.26 0.43 0.39 QVQ LoRA 0.47 0.26 0.44 0.39 In-Context Learning 0.63 0.34 0.56 0.52 T able 2: Summary of results of the task 2. handwriting images with their predicted grades were used as input, while the corresponding feedback text serv ed as the output to fine-tune the model. In the in-context learning strategy , we compared the performance of similarity-based ordering for in- context examples against random selection of in-context examples. The model used in the in-context learning is the closed-source VLM qwen-vl-max-2025-01-25 4 . For the selection and ordering of in- context examples, we use the multimodal-embedding-v1 5 provided by Alibaba Cloud for image embed- ding. V ector indexing w as implemented with ChromaDB 6 . For T ask 1, we separated 300 examples from the training set as a development set and found that similarity-based ordering of in-context examples performed better . In T ask 2, we separated 100 exam- ples from the training set as a dev elopment set and found that random selection of in-context examples performed better . 4.2 Results T able 1 and 2 presents the main results. The results for T ask 1 indicate that the model fine-tuned on the task-specific dataset achiev ed the best performance. Howe ver , the model fine-tuned on the ex- panded dataset exhibited suboptimal performance, likely because the aesthetic score classification was misaligned with the grading criteria of the task-specific dataset. The results for T ask 2 demonstrate that the in-context learning method achie ved the best performance. The fine-tuned QVQ model outperformed the QwenVL model. Additionally , the model trained with images paired with their predicted grades sho wed a marginal impro vement of 0.03 in final score. 5 Conclusion and Future W ork In this paper , we explore the application of VLMs to the e valuation of Chinese handwritten characters. Utilizing both open-source and closed-source VLMs, we in vestigate multiple strate gies, including LoRA and in-context learning. Our approach achieved third place on the final leaderboard, demonstrating the ef fectiv eness of the proposed methods. In practical applications, fine-tuning VLMs is more computationally efficient than in-conte xt learning, as the latter requires significantly higher token consumption and computational resources. Building on recent advancements in reinforcement learning (RL) for training LLMs and VLMs ( Guo et al., 2025 ; Kimi T eam et al., 2025 ), our future work will focus on adv ancing the aesthetic assessment 4 https://bailian.console.aliyun.com/?tab=model#/model- market/detail/qwen- vl- max? modelGroup=qwen- vl- max 5 https://bailian.console.aliyun.com/?tab=model#/model- market/detail/ multimodal- embedding- v1 6 https://www.trychroma.com China National Conference on Computational Linguistics capabilities of VLMs through two directions. First, we will design comparati ve ranking tasks and fine- grained classification tasks to enhance the precision of aesthetic assessments in handwritten Chinese characters. Second, we will explore RL ’ s potential in reasoning about complex aesthetic principles, while tackling challenges related to subjecti ve e v aluation and data scarcity . Acknowledgements This work is supported by the National Natural Science Foundation of China (NSFC) under Grant Nos. 82371397 and 62206070 and the Inno v ation Fund Project of the Engineering Research Center of Inte gra- tion and Application of Digital Learning T echnology , Ministry of Education via Grant No.1421012. W e thank the Open Uni versity of China for the computational resources provided by its AI infrastructure. References Rongju Sun, Zhouhui Lian, Y ingmin T ang, and Jianguo Xiao. 2015. Aesthetic V isual Quality Ev aluation of Chinese Handwritings. In Proceedings of the International Joint Confer ence on Artificial Intelligence (IJCAI) , volume 15, pages 2510–2516. Xue Xiao and Chengcheng Li. 2022. Research Progress on Evaluation Methods of Handwritten Chinese Charac- ters. Computer Engineering and Applications , 58(2):27-42. W eiran Chen, Jiaqi Su, W eitao Song, Jialiang Xu, Guiqian Zhu, Y ing Li, Y i Ji, and Chunping Liu. 2024. Qual- ity Evaluation Methods of Handwritten Chinese Characters: A Comprehensiv e Survey . Multimedia Systems , 30(4):194. Fei Y an, Xueping Lan, Hua Zhang, and Linjing Li. 2024. Intelligent Evaluation of Chinese Hard-Pen Calligraphy Using a Siamese T ransformer Network. Applied Sciences 14, no. 5: 2051. Chin-Chuan Han, Chih-Hsun Chou, and Chung-Shiou W u. 2008. An Interactiv e Grading and Learning System for Chinese Calligraphy . Machine V ision and Applications 19:43–55. Y an Gao, Lianwen Jin, and Nanxi Li. 2011. Chinese Handwriting Quality Evaluation Based on Analysis of Recognition Confidence. In 2011 IEEE International Confer ence on Information and Automation , 221–225. IEEE. W ei Li, Y uping Song, and Changle Zhou. 2014. Computationally Evaluating and Synthesizing Chinese Calligra- phy . Neur ocomputing 135: 299–305. Mengdi W ang, Qian Fu, Xingce W ang, Zhongke W u, and Mingquan Zhou. 2016. Evaluation of Chinese Cal- ligraphy by Using DBSC V ectorization and ICP Algorithm. Mathematical Problems in Engineering 2016, 1:4845092. Dajun Zhou, Jiamin Ge, Ruiqi W u, Fei Chao, Longzhi Y ang, and Changle Zhou. 2017. A Computational Eval- uation System of Chinese Calligraphy via Extended Possibility-Probability Distribution Method. In 2017 13th International Confer ence on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD) , pages 884–889. IEEE. Mingwei Sun, Xinyu Gong, Haitao Nie, Muhammad Minhas Iqbal, and Bin Xie. 2023. SRAFE: Siamese Regres- sion Aesthetic Fusion Evaluation for Chinese Calligraphic Copy . CAAI T ransactions on Intellig ence T echnology 8, no. 3: 1077-1086. Zhaoyi W ang and Ruimin Lv . 2021. Design of Calligraphy Aesthetic Evaluation Model Based on Deep Learning and Writing Action. In International Conference on Computing, Control and Industrial Engineering , pp. 620– 628. Singapore: Springer Nature Singapore. Min W ang, W an Ma, Chuang Zhu, Shanfei Shi, Jiangbo Shu, and Shuaicheng Lu. 2023. Research on Quantitati ve Evaluation of Standard Chinese Characters Written by Pen and Paper Based on Neural Network. Journal of Central China Normal University (Natur al Sciences) , 57(6): 813–820. Meng-Luen W u, Y i-Rong Du, and Dai-Hua Jiang. 2024. Aesthetic Evaluation System for Calligraphy Characters using Conv olutional Neural Networks. In 2024 International Confer ence on Machine Learning and Cybernetics (ICMLC) , pp. 547–552. IEEE. China National Conference on Computational Linguistics Jinze Bai, Shuai Bai, Shusheng Y ang, Shijie W ang, Sinan T an, Peng W ang, Jun yang Lin, Chang Zhou and Jingren Zhou. 2023. Qwen-VL: A V ersatile V ision-Language Model for Understanding, Localization, T e xt Reading, and Beyond. . Peng W ang, Shuai Bai, Sinan T an, Shijie W ang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, Y ang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-VL: Enhancing V ision-Language Model’ s Perception of the W orld at Any Resolution. . Shuai Bai, Keqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, Sibo Song, Kai Dang, Peng W ang, Shijie W ang, Jun T ang, Humen Zhong, Y uanzhi Zhu, Mingkun Y ang, Zhaohai Li, Jianqiang W an, Pengfei W ang, W ei Ding, Zheren Fu, Y iheng Xu, Jiabo Y e, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Y ang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL T echnical Report. . Kimi T eam, Angang Du, Bohong Y in, et al. 2025. Kimi-VL T echnical Report. . Haoyu Lu, W en Liu, Bo Zhang, Bingxuan W ang, Kai Dong, Bo Liu, Jingxiang Sun, T ongzheng Ren, Zhuoshu Li, Hao Y ang, Y aofeng Sun, Chengqi Deng, Hanwei Xu, Zhenda Xie, and Chong Ruan. 2024. DeepSeek-VL: T o wards Real-W orld V ision-Language Understanding. . Edward J. Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean W ang, Lu W ang, and W eizhu Chen. 2022. LoRA: Low-Rank Adaptation of Lar ge Language Models. ICLR 1(2): 3. T om Brown, Benjamin Mann, Nick Ryder , et al. 2020. Language Models are Few-Shot Learners. Advances in Neural Information Pr ocessing Systems , 33: 1877–1901. Y aowei Zheng, Richong Zhang, Junhao Zhang, Y anhan Y e, Zheyan Luo, Zhangchi Feng, and Y ongqiang Ma. 2024. LlamaFactory: Unified Efficient Fine-T uning of 100+ Language Models. In Pr oceedings of the 62nd An- nual Meeting of the Association for Computational Linguistics (V olume 3: System Demonstrations) , Bangkok, Thailand. Association for Computational Linguistics. DeepSeek-AI, Daya Guo, Dejian Y ang, et al. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. . Kimi T eam, Angang Du, Bofei Gao, et al. 2025. Kimi k1.5: Scaling Reinforcement Learning with LLMs. arXiv:2501.12599 . A System prompts For T ask 1, the original SYSTEM PROMPT in the in-context learning method was written in Chinese: 你 是 一 名 汉 字 书 法 专 家 , 你 对 汉 字 的 图 形 图 像 非 常 了 解 , 可 以 准 确 评 价 学 生 汉 字 书 写 的 质 量 。 你 需 要 仿 照 样 例 , 对 给 出 的 汉 字 书 写 图 片 按 A: 优 秀 , B: 中 等 , C: 不 合 格 三个 等 级 打 分 。 三个 等 级 的 评 价 标 准 如 下 : A. 优 秀 : 结 构 比 例 安 排 适 当 , 重 心 平 稳 , 字 体 匀 称 美 观 。 点 画 形 态 正 确 且 有 呼 应 , 笔 画 清 晰 到 位 , 用 笔 有 轻 重 变化 之 分 。 字 体 无 明显 缺 陷 。 B. 中 等 : 结 构 比 例 基 本 合 理 , 重 心 基 本 稳 定 , 字 体 较 匀 称 。 笔 画 形 态 基 本 正 确 , 点 画 清 晰 但 轻 重 变化 不 够 。 字 体 在 某 一 类 或 几 类 问 题 上 存 在 系 统 性 缺 陷 。 C. 不 合 格 : 结 构 比 例 失 衡 或 重 心 不 稳 , 字 体 不 匀 称 。 点 画 随 意 , 笔 画 不 清 晰 或 潦 草 。 字 体 存 在 较 严 重 缺 点 。 The English version used in experiments is provided in Section 3.2. For T ask 2, the SYSTEM PROMPT was: Y ou are an expert in Chinese calligraphy with a deep understanding of the graphical aspects of Chinese characters, capable of accurately ev aluating the quality of students’ handwriting. Y ou need to follow the examples and write comments for the giv en Chinese character images. The comments should provide targeted ev aluations and descriptions focusing on two main di- mensions: structure and stroke form. For structure, consider density , balance (such as the symmetry of top-bottom or left-right struc- tures), and the center of gravity . For strokes, consider the variation in stroke weight and the specific forms of indi vidual strokes. China National Conference on Computational Linguistics The original Chinese version: 你 是 一 名 汉 字 书 法 专 家 , 你 对 汉 字 的 图 形 图 像 非 常 了 解 , 可 以 准 确 评 价 学 生 汉 字 书 写 的 质 量 。 你 需 要 仿 照 样 例 , 对 给 定 的 汉 字 图 片 撰 写 评语 。 评 语 主 要 对 结 构 和 笔 画 形 态 两 大 维 度 , 进 行 有 针 对 性 的 评 价 和 描 述 。 结 构 上 , 考 虑 疏 密 、 匀 称 ( 如 上下 结 构 、 左 右 结 构 等 方 面 的 匀 称 性 ) 、 重 心 。 笔 画 上 , 考 虑 笔 画 的 轻 重 变化 , 以 及 具 体 笔 画 的 形 态 。 B T est prompts The TEST PROMPT for task 1 in the in-context learning method was: Y ou need to refer to the abov e image and scoring to grade the Chinese character writing in the image belo w as A: Excellent, B: Medium, C: Unqualified. Attention! Y our output must only contain one uppercase letter! Corresponding to the score of the Chinese character writing in this image. The original Chinese version: 你 需 要 参 照 上 面 的 图 片 及 打 分 , 对 下 面 这 张 汉 字 书 写 的 图 片 按 照 A: 优 秀 , B: 中 等 , C: 不 合 格 给 出 分 数 。 注 意 ! 你 的 输 出 只 能 有 一个 大 写 字 母 ! 对 应 这 张 图 上 汉 字 书 写 的 分 数 。 The TEST PROMPT for task 2 was: Y ou need to refer to the abov e image and the corresponding comments to write a critique for the follo wing Chinese handwriting image. Attention! Y our output format and content style must strictly follo w the reference comments. Write a passage of similar length and style. The original Chinese version: 你 需 要 参 照 上 面 的 图 片 及 对 应 的 评语 , 对 下 面 这 张 汉 字 书 写 的 图 片 撰 写 评语 。 注 意 ! 你 输 出 的 格 式 和 内 容 风 格 要 严 格 参 考 上 面 的 评 语 。 以 相 似 的 长 度 和 风 格 撰 写 一 段 话 。
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment