ASK: Adaptive Self-improving Knowledge Framework for Audio Text Retrieval
The dominant paradigm for Audio-Text Retrieval (ATR) relies on dual-encoder architectures optimized via mini-batch contrastive learning. However, restricting optimization to local in-batch samples creates a fundamental limitation we term the Gradient…
Authors: Siyuan Fu, Xuchen Guo, Mingjun Liu
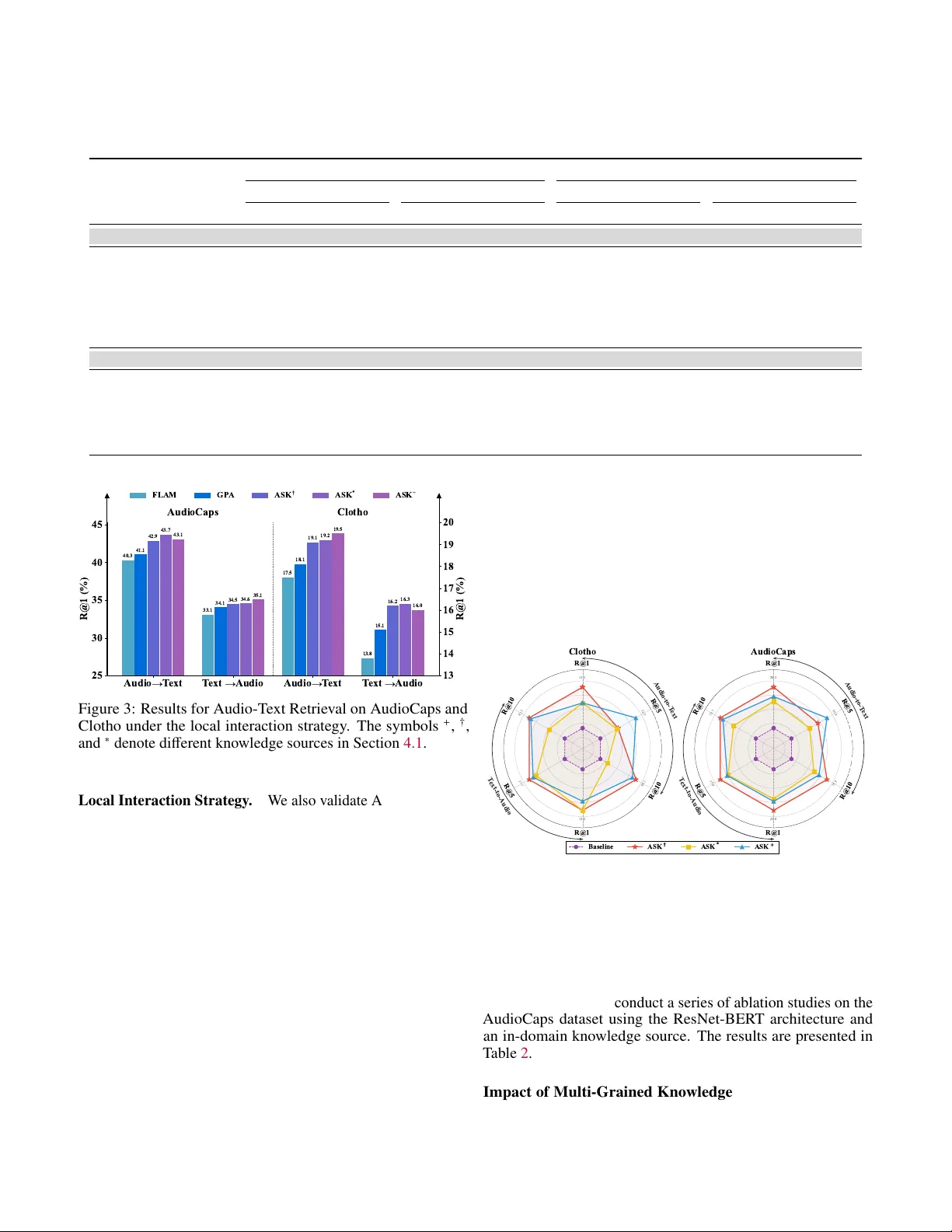
ASK: Adapti v e Self-improving Kno wledge Frame w ork for Audio T e xt Retrie v al Siyuan Fu 1 * Xuchen Guo 1 * Mingjun Liu 1 * Hongxiang Li 2 Boyin T an 3 Gongxi Zhu 5 Xianwei Zhuang 4 Jinghan Ru 4 Y uxin Xie 4 † Y uguo Y in 4 1 Uni versity of Electronic Science and T echnology of China 2 Hong K ong Uni versity of Science and T echnology 3 Mohamed Bin Zayed Uni versity of Artificial Intelligence 4 Peking Uni versity 5 Tsinghua Uni versity siyuanfu05@gmail.com, yuxinxie2001@gmail.com A bstra ct The dominant paradigm for Audio-T e xt Retriev al (A TR) relies on dual-encoder architectures optimized via mini- batch contrasti ve learning. Howev er , restricting optimization to local in-batch samples creates a fundamental limitation we term the Gradient Locality Bottleneck (GLB), which prevents the resolution of acoustic ambiguities and hinders the learning of rare long-tail concepts. While external kno wledge injection can break this bottleneck, it often triggers a problem called Representation-Drift Mismatch (RDM), where a static kno wledge base becomes misaligned with ev olving encoders, degrading guidance into noise. T o address these intertwined challenges, we propose the A dapti ve S elf-improving K nowledge ( ASK ) frame work. ASK breaks the GLB via multi-grained knowledge injection and mitig ates RDM through a dynamic refinement strategy that synchronizes the kno wledge base with the model. Additionally , an adaptiv e reliability weighting scheme is employed to filter retrie val noise based on cross-modal consistency . Extensi ve experiments across multiple benchmarks demonstrate that ASK consistently achiev es new state-of-the-art performance across v arious backbones. 1 Introduction Audio-T ext Retrie val (A TR) aims to establish a shared em- bedding space where acoustically and semantically correspond- ing audio and text pairs are aligned [ Mei et al. , 2022 , Y an et al. , 2024 ]. The dominant paradigm currently relies on dual-encoder architectures optimized via contrastive learning objecti ves, such as the NT -Xent loss [ Chen et al. , 2020 ]. As illustrated in Figure 1 (left), this approach refines representations by maximizing the similarity between matched pairs while contrasting them against other samples within the same mini-batch. While e ff ecti ve, this in-batch mechanism implicitly restricts the optimization land- scape to the local context. The limitations of such batch-constrained optimization hav e been extensiv ely discussed in broader representation learn- ing literature, particularly reg arding the necessity of large ne g- ativ e pools [ He et al. , 2020 , Xiong et al. ]. Building on these observations, we define this phenomenon in the context of A TR as the Gradient Locality Bottleneck (GLB). This term charac- terizes the specific di ffi culty of resolving fine-grained acoustic details that are often semantically sparse or ambiguous when the model is confined to a limited sample space. Lacking access to a broader global semantic context, the model struggles to form robust decision boundaries for long-tail e vents, lea ving a significant portion of the dataset’ s semantic potential untapped. * Equal contribution. † Corresponding author . T o break this bottleneck, one e ff ectiv e approach is to aug- ment training with an external knowledge base [ Dwibedi et al. , 2021 , Khandelwal et al. , 2019 , Guu et al. , 2020 ]. Howev er , uti- lizing external memory introduces synchronization latency be- tween the ev olving model and the stored representations [ Xiong et al. ]. W e formalize this temporal discrepanc y in our continu- T ext Encoder Audio Encoder Cross-Modality Loss T ext Encoder Audio Encoder Cross-Modality Loss Multi-Grained Knowledge Base Adaptive Loss Modulation Periodically Update Periodically Update In-batch T ext Samples Out-of-batch T ext Samples Retrieved Knowledge Samples for T ext In-batch Audio Samples Out-of-batch Audio Samples Retrieved Knowledge Samples for Audio T ypical Contrastive Learning The ASK Framework Figure 1: Comparison between typical contrasti ve learning (left) and our proposed ASK frame work (right) with a periodically up- dated knowledge base and an adapti ve loss modulation module. ous training frame work as the Representation-Drift Mismatch (RDM). RDM describes the ine vitable lag where audio and 2 text encoders update rapidly while the e xternal knowledge base remains static or updates slowly . Consequently , the retrieved knowledge risks de grading from a source of semantic guidance into representational noise, potentially destabilizing the training process. T o systematically address these formally defined chal- lenges, we propose the A dapti ve S elf-improving K nowledge (ASK) frame work. Uniquely designed as a model-agnostic en- hancement, ASK can be seamlessly integrated into various back- bones. As shown in Figure 1 (right), it serv es as a holistic solution to inject information from a dynamically maintained multi-grained knowledge base. T o handle the inherent noise and ambiguity described by the GLB, we introduce an adaptiv e reli- ability mechanism that modulates the learning signal based on cross-modal consistency . Simultaneously , to resolve the RDM, ASK employs a dynamic refinement strategy that periodically updates the knowledge base, ensuring that the external guidance co-ev olves with the model. This syner gistic design enables ASK to e ff ectiv ely le verage global semantic structures while maintaining training stabil- ity , independent of the specific underlying architecture. Exten- siv e experiments across multiple datasets and backbone models demonstrate that our approach consistently achiev es state-of-the- art performance, validating the uni versality and e ff ecti veness of our framew ork in handling global optimization challenges. Our main contributions are summarized as follo ws: • W e identify and define two fundamental challenges in Audio- T ext Retrie val: the Gradient Locality Bottleneck (GLB), and the Representation-Drift Mismatch (RDM). • W e propose the Adaptive Self-improving Kno wledge (ASK) framew ork, a model-agnostic solution. It breaks the GLB via multi-grained kno wledge injection and systematically mit- igates RDM through dynamic knowledge refinement. Fur- thermore, we introduce a novel adapti ve reliability weighting scheme to explicitly filter retrie v al noise based on cross-modal consistency . • Extensiv e experiments across multiple benchmarks demon- strate that ASK consistently achieves new state-of-the-art performance across diverse global and local interaction ar- chitectures. Comprehensive ablation and zero-shot studies further validate the rob ustness of our frame work. 2 Related W ork 2.1 Featur e Representations Feature representation serves as the cornerstone of audio- text retriev al. Early Audio-T ext Retriev al systems relied on pairing handcrafted acoustic features like MFCCs [ Huizen and Kurniati , 2021 ] with static word embeddings such as W ord2V ec [ Mikolov et al. , 2013 ]. The advent of deep learning has led to the adoption of po werful, pre-trained unimodal encoders. T ext representations are no w predominantly extracted from lar ge language models like BER T [ Devlin et al. , 2019 ], while audio features are deri ved from deep models pre-trained on large- scale audio datasets, such as P ANNs [ K ong et al. , 2020 ] and AST [ Gong et al. , 2021 ]. More recently , the field has shifted to wards large-scale cross-modal pre-training. Models like CLAP [ Zhao et al. , 2023 , Guzhov et al. , 2022 ] lev erage contrastiv e learning on vast audio-text datasets to directly learn a shared embedding space, significantly enhancing zero-shot capabilities. Our work builds upon these adv anced encoders, proposing a nov el mechanism to further enhance their representations during downstream fine-tuning. 2.2 Cross-Modal Interaction and Alignment Cross-modal interaction is key to achieving semantic align- ment in A TR. Early and prev alent approaches perform this at a global, sentence-le vel, using contrasti ve learning to align the final embeddings of entire audio clips and text descriptions [ Rad- ford et al. , 2021 , W u et al. , 2022 , Mei et al. , 2022 ]. T o capture more fine-grained relationships, recent w orks have focused on local, token-le vel interactions. These methods typically employ attention mechanisms or cross-modal T ransformers to model correspondences between audio frames and text tokens [ Lee et al. , 2018 , Lu et al. , 2019 , Xie et al. , 2024 , Y in et al. , 2025 ]. Our ASK framework is orthogonal to these design choices; it op- erates on the representations themselves and can be seamlessly integrated with both global and local interaction architectures. 2.3 Retrieval-A ugmented Contrastive Lear ning The challenges formalized as GLB and RDM parallel fun- damental bottlenecks in computer vision and information re- triev al. T o overcome limited in-batch negativ es, frameworks like MoCo He et al. [ 2020 ] and RocketQA Qu et al. [ 2021 ] expand the contrasti ve denominator via memory queues, while NNCLR Dwibedi et al. [ 2021 ] utilizes e xternal support sets. Fur- thermore, ANCE Xiong et al. proposes asynchronous updates to mitigate stale indices. Howe ver , these classical paradigms rely on unimodal queues or strict hard negativ e mining, making them highly susceptible to acoustic confusion in A TR. Unlike them, ASK structurally breaks the GLB by directly injecting out-of-batch knowledge into representations. Furthermore, to combat the subsequent representation drift, ASK introduces an adaptiv e reliability weighting scheme that explicitly e v aluates cross-modal consistency to filter out retrie val noise. 3 Problem F ormulation and Analysis 3.1 Preliminaries In a standard Audio-T ext Retrie val frame work, a dual- encoder architecture, comprising an audio encoder f θ ( · ) and a text encoder g ϕ ( · ), maps an audio-text pair ( a i , t i ) to L2- normalized embeddings u i and v i . The encoders are optimized via a symmetric NT -Xent loss [ Chen et al. , 2020 ] ov er a mini- batch B . For a single vie w , the loss is: L i = − log exp( u ⊤ i v i /τ ) P v j ∈ B exp( u ⊤ i v j /τ ) , (1) where τ is a temperature hyperparameter . Crucially , as shown in Eq. 1 , the contrastiv e denominator is computed exclusiv ely ov er samples within the mini-batch B . This inherent structural confinement is the direct cause of the bottleneck we analyze next. 3 3.2 The Gradient Locality Bottleneck The batch-centric nature of standard contrastiv e objectiv es creates a fundamental limitation in Audio-T ext Retriev al. T o formalize this, we introduce the concept of Out-of-Batch Influ- ence (OBI) , which measures the gradient contribution from data points outside the current mini-batch to the optimization process. Let D denote the entire training dataset and B ⊂ D represent a specific mini-batch. For a batch loss L B , the OBI is defined as the expected gradient norm with respect to all out-of-batch embeddings: OBI( L B ) = E k ∈D\ B " ∂ L B ∂ u k 2 + ∂ L B ∂ v k 2 # , (2) where u k and v k are the audio and text embeddings of an out-of- batch sample k ∈ D \ B . W e argue that a training paradigm su ff ers from a Gradi- ent Locality Bottleneck (GLB) if its OBI is identically zero, indicating that no gradient flow e xists from out-of-batch data to guide the current optimization step. In a standard A TR frame- work using the symmetric NT -Xent loss (Eq. 1 ), the objective L B is formulated exclusi vely as a function of the in-batch em- beddings { u j , v j } j ∈ B . Consequently , the partial deri vati ves with respect to any out-of-batch embedding u k or v k (where k < B ) are necessarily zero: ∀ k ∈ D \ B : ∂ L B ∂ u k = 0 , ∂ L B ∂ v k = 0 . (3) This directly results in OBI ( L B ) = 0, proving that standard A TR optimization is strictly constrained by the GLB and cannot lev erage the v ast semantic information present in out-of-batch data. This structural confinement prev ents the model from lev er- aging the vast semantic knowledge present in the majority of the dataset. This leads to two critical failures: (1) Semantic Ambiguity and Acoustic Hallucination, where the lack of di- verse out-of-batch context prev ents the model from learning fine-grained acoustic distinctions between similar b ut semanti- cally distinct ev ents; and (2) Long-tail Concept Collapse, as the reliance on limited in-batch ne gativ es hinders the formation of robust decision boundaries for rare e vents, causing the model to default to common concepts with shared tonal properties. 3.3 The Representation Drift Mismatch A direct approach to break the GLB is to perform knowl- edge injection, where out-of-batch samples are retriev ed and fused with the current samples. By employing a simple feature fusion such as u ′ i = (1 − ρ ) u i + ρ K , where u i is the embedding of the current sample, K is the retrie ved out-of-batch kno wledge and ρ represents the injection ratio, we establish a non-zero gradient pathway from the out-of-batch data to the model pa- rameters. This ensures that the Out-of-Batch Influence (OBI) is no longer zero, e ff ecti vely breaking the structural confinement of standard contrastiv e learning. While knowledge injection breaks the GLB by introducing out-of-batch samples D \ B , it inherently introduces a critical challenge: Representation Drift Mismatch (RDM) . Since the encoders f θ t and g ϕ t are non-stationary and e volv e during opti- mization, a static kno wledge base constructed at step t k becomes progressiv ely misaligned with the current model state at step t ( t > t k ). T o formalize this, taking the audio modality as an example, we define RDM as the expected K ullback-Leibler (KL) div ergence Kullback and Leibler [ 1951 ] between the ideal neigh- borhood distribution P ideal and the actual distribution P actual : RDM( t , t k ) = E a i ∈D [ D KL ( P ideal ( ·| i ) || P actual ( ·| i ) ) ] , P ideal ( j | i ) ∝ exp(sim( f θ t ( a i ) , f θ t ( a j ))) , P actual ( j | i ) ∝ exp(sim( f θ t ( a i ) , f θ t k ( a j ))) , (4) where a i denotes the current query sample, the distributions are normalized over all knowledge samples index ed by j , θ t and θ t k represent the model parameters at the current step t and the knowledge snapshot step t k respectiv ely , and sim ( · , · ) is the dot product similarity . Formally , the kno wledge vector K is computed as the expected representation over the neighborhood distribution: K = P j P ( j ) z j , where z j denotes the embedding of the j -th knowledge sample. As the training progresses, RDM accumu- lates and corrupts the optimization objective by inducing a de vi- ation in the fused knowledge v ectors K , ∆ K = K actual − K ideal . The impact of this drift on training stability can be quan- tified via the gradient deviation: ∆ ∇ = ∇ θ t L actual − ∇ θ t L ideal . Specifically , consider a simplified loss: L = L main ( u i , u ′ i ) that incorporates the knowledge-enhanced representation: u ′ i = (1 − ρ ) u i + ρ K . The gradient with respect to parameters θ t is: ∇ θ t L = ∂ L ∂ u i + (1 − ρ ) ∂ L ∂ u ′ i ∂ u i ∂θ t . By performing a first-order T aylor expansion of the loss deri vati ve around the ideal representation, we obtain: ∂ L actual ∂ u ′ i − ∂ L ideal ∂ u ′ i ≈ H L ( u ′ ideal ) · ρ ∆ K , (5) where H L is the Hessian matrix. This prov es that the gra- dient misalignment ∆ ∇ is approximately proportional to the knowledge de viation ∆ K . T o bound this deviation, we le verage Pinsker’ s inequality to relate the KL diver gence to the T otal V ariation Distance, yielding the relationship: ∥ ∆ K ∥ 2 ≤ C p 2 · RDM( t , t k ) , (6) where C = max j ∥ z j ∥ 2 is a bounded constant. Equation 6 es- tablishes a formal link between RDM and the potential error margin for the gradients. Higher RDM directly widens this margin, causing training instability and representational noise. This theoretical foundation necessitates our dynamic refinement mechanism, which periodically resets the RDM to zero to ensure stable co-ev olution between the model and its kno wledge. 4 The Adaptive Self-impr oving Kno wledge Framework In this section, we elaborate on each component of our pro- posed frame work ASK, whose architecture is shown in Figure 2 . 4.1 Formulation of Kno wledge Bases Our framework’ s first step is to construct multi-grained knowledge bases from a source dataset, D k . The choice of source is flexible; in our experiments, we explore three types 4 Similarity Matrix Input Initialization Knowledge Injection "Constant Rattling" Knowledge Bases Formulation OT Realignment Knowledge Source Fine-Grained Knowledge Base T ext Embeddings Audio Embeddings T ext Encoder Audio Encoder In-Domain Out-of-Domain Enriched In-Domain Coarse-Grained Knowledge Base K-means Clustering Max Pooling Multi-Grained Knowledge Base Retrieved Knowledge + + T ext Injection Audio Injection Augmented T ext Embeddings Augmented Audio Embeddings Optimal T ransportation Realigned Similarity Matrix Adaptive Reliability W eighting Knowledge Samples Knowledge Samples Compute Similarity Contrastive Loss Unified Optimization Objective Figure 2: The proposed ASK framew ork. A multi-grained knowledge base is periodically updated to mitigate RDM. During training, knowledge is injected into samples, and a cross-modal reliability weight is computed. A final loss is optimized using both an O T -realigned similarity matrix and the reliability weight. to demonstrate versatility: 1) In-Domain + : the training set itself, 2) Out-of-Domain † : W avCaps [ Mei et al. , 2024 ], and 3) Enriched In-Domain ∗ : training set re-annotated by Gemini 2.5 [ Comanici et al. , 2025 ]. From a chosen source, we construct two complementary bases. Fine-Grained Knowledge Base. The fine-grained base, K f , captures instance-le vel semantic details. It is formed by encod- ing all audio-text pairs in the source D k = { ( a k j , t k j ) } N k j = 1 using the current model encoders f θ ( · ) and g ϕ ( · ). The result is a collection of L2-normalized embedding pairs: K f = { ( u k j , v k j ) } N k j = 1 , (7) where u k j = f θ ( a k j ) , v k j = g ϕ ( t k j ). Coarse-Grained Knowledge Base. The coarse-grained base, K c , provides a global semantic prior by storing a set of learned prototypes. These prototypes are generated by first partitioning the fine-grained embeddings via K-Means clustering into N c groups, and then distilling the salient features from each group. For the m -th audio cluster C u m , which contains all member em- beddings { u k j } , its prototype c u m is computed via max-pooling: c u m = MaxPooling( { u k j | u k j ∈ C u m } ) . (8) An identical procedure is applied to the text embeddings to yield text prototypes { c v m } N c m = 1 . The final coarse-grained base is the set of these prototype pairs, K c = { ( c u m , c v m ) } N c m = 1 . 4.2 Multi-Grained Knowledge Injection W ith the knowledge bases established, we perform two parallel injection processes to create distinct fine-grained and coarse-grained enhanced embeddings for each training sample. For the fine-grained injection, we first retrie ve the T op-K nearest neighbors for a given embedding (e.g., audio u i ) from K f , yielding the neighborhood set N f ( u i ). The retrie ved embeddings are averaged to form a kno wledge vector ¯ u f i , which is then interpolated with the original embedding u i : u ′ i , f = (1 − ρ ) u i + ρ ¯ u f i , ¯ u f i = P ( u k j , v k j ) ∈N f ( u i ) u k j K , (9) where ρ is an interpolation hyperparameter . An identical, par- allel process is performed using the coarse-grained base K c to produce the coarse-grained enhanced representation, u ′ i , c . A sym- metric procedure is applied to the text embedding v i , ultimately yielding two distinct sets of enhanced embedding pairs for the final optimization: ( u ′ i , f , v ′ i , f ) and ( u ′ i , c , v ′ i , c ). Breaking the Gradient Locality Bottleneck. This injection mechanism breaks the GLB (Sec. 3.2 ) by creating a gradient pathway to out-of-batch kno wledge. For any out-of-batch knowl- edge item u k k retriev ed by an in-batch sample u i , its gradient is non-zero. Let S k = { i ∈ B | u k k ∈ N f ( u i ) } be the set of in-batch samples that retrie ved u k k . The gradient of the loss L ′ B w .r .t. u k k 5 is: ∂ L ′ B ∂ u k k = X i ∈S k ∂ L ′ B ∂ u ′ i , f ∂ u ′ i , f ∂ u k k . (10) From Eq. 9 , the second partial deriv ativ e is a non-zero constant ρ K . Giv en that one of its partial deriv ativ es is non-zero, the total gradient is therefore non-zero. Consequently , the OBI, defined in Eq. 2 , becomes strictly positiv e. This quantitati vely proves that our injection process breaks the GLB. 4.3 Adaptive Reliability W eighting T o mitigate the risk of injecting noisy knowledge from equally-weighted neighbors (Sec. 4.2 ), we introduce an adapti ve weighting mechanism. This mechanism is based on the principle of cross-modal consistency: for a well-aligned audio-text pair ( u i , v i ), the neighborhoods retrieved by u i and v i should them- selves be semantically consistent. W e quantify this consistency to compute a reliability score for each neighbor, which in turn modulates its contribution to the final objecti ve. Fine-Grained Reliability W eighting. For each pair ( u i , v i ), we consider two fine-grained neighborhoods: the audio-retrieved audio set U r = { u k l } K l = 1 and the te xt-retriev ed audio–te xt set N f ( v i ) = { ( u k ′ j , v k j ) } K j = 1 . W e first assign each neighbor in N f ( v i ) a consistency score ¯ s j , defined as its average similarity to the audio-retriev ed neighborhood: ¯ s j = 1 K K X l = 1 ( u k ′ j ) ⊤ u k l . (11) These scores are subsequently normalized via a softmax function to yield the reliability weights w f = { w j } K j = 1 : w j = exp( ¯ s j ) P K m = 1 exp( ¯ s m ) . (12) The reliability-aware knowledge potential is then computed as the weighted similarity between u i and the audio components of N f ( v i ): Ψ T → A i , f = K X j = 1 w j · exp( u ⊤ i u k ′ j ) . (13) A symmetric construction produces the text-side potential Ψ A → T i , f , based on the audio-retriev ed text neighborhood. Coarse-Grained Reliability W eighting. An identical proce- dure is applied to the coarse-grained neighborhoods to produce the coarse-grained potentials, Ψ T → A i , c and Ψ A → T i , c . These poten- tials represent the model’ s alignment with reliable, high-lev el semantic prototypes. The resulting four reliability-aw are potentials are core com- ponents that will be directly incorporated into our final optimiza- tion objectiv e, as detailed in Section 4.5 . 4.4 Dynamic Knowledge Refinement As sho wn in Section 3.3 , a static knowledge base leads to Representation Drift Mismatch (RDM), which induces in- creasing gradient misalignment during training. T o mitigate this, we employ a dynamic refinement mechanism that periodically reconstructs the knowledge bases K f and K c using the current encoders. The update period T specifies the number of epochs between successiv e reconstructions. This procedure directly controls the RDM. At each update step t , refinement sets the kno wledge-base timestamp to t k = t , making the ideal and actual neighborhood distributions identical, P ideal ≡ P actual . Thus, the RDM (Eq. 4 ) is reset to its minimum value: RDM( t , t ) = E [ D K L ( P ideal ∥ P ideal )] = 0 . (14) By periodically dri ving the RDM to zero, the mechanism also resets the upper bound on gradient de viation (Eq. 6 ), ensuring stable optimization and enabling the knowledge base to co- ev olve with the model. 4.5 Unified Optimization Objective The final optimization objective is constructed in two main stages. First, we compute NT -Xent losses on similarity matri- ces that hav e been realigned via Optimal T ransport. Second, these losses are modulated by our reliability-aw are knowledge potentials to form the final composite objectiv e. Loss on O T -Realigned Similarities. The process begins with the knowledge-enhanced embeddings from Section 4.2 . For a mini-batch, we compute a fine-grained similarity matrix S f and a coarse-grained one S c . Since the audio and text knowledge are retriev ed independently , the distributions of their nearest neighbors within the batch may di ff er . T o reconcile this potential discrepancy and find a globally optimal batch-lev el matching, we employ Optimal T ransport (O T) [ Cuturi , 2013 ] to learn an optimal transport plan Q ∗ . This plan is then used to produce the realigned similarity matrices S ∗ f and S ∗ c : S ∗ f = (1 − β ) I + β Q ∗ S f . (15) An identical process is applied to S c . Based on these realigned matrices, we define two NT -Xent loss components. The text- to-audio loss, L T → A , is the sum of the fine- and coarse-grained objectiv es: L T → A = − 1 B B X i = 1 log exp(( S ∗ f ) ii /τ ) P B j = 1 exp(( S ∗ f ) i j /τ ) − 1 B B X i = 1 log exp(( S ∗ c ) ii /τ ) P B j = 1 exp(( S ∗ c ) i j /τ ) . (16) The audio-to-text loss, L A → T , is formulated symmetrically . Reliability-A ware Objective. The O T -realigned losses abov e do not yet account for the cross-modal consistency of the re- triev ed kno wledge. T o incorporate this, we use the kno wledge potentials computed in Section 4.3 as reliability modulators. W e first define the reliability-aware terms, e.g., for the text-to-audio direction: F T → A f = 1 | B | | B | X i = 1 − log Ψ T → A i , f , F T → A c = 1 | B | | B | X i = 1 − log Ψ T → A i , c . (17) 6 The final text-to-audio loss, L ∗ T → A , is then the base O T -realigned loss, modulated by a weighted sum of these reliability terms: L ∗ T → A = (1 + λ f F T → A f + λ c F T → A c ) · L T → A , (18) where λ f and λ c are hyperparameters. The final audio-to-text loss, L ∗ A → T , is computed symmetrically . The ov erall loss for the ASK framework is the a verage of these two modulated objectiv es: L ASK = 1 2 ( L ∗ T → A + L ∗ A → T ) . (19) This composite objecti ve ensures the model learns from multi- grained knowledge that is both globally aligned at the batch lev el and weighted by its cross-modal reliability . 4.6 Theoretical Analysis W e provide a theoretical justification for ASK, framing the training as an alternating optimization to maximize the log- likelihood of observed audio-te xt pairs x i = ( a i , t i ). Probabilistic Formulation via ELBO Our goal is to maxi- mize the log-likelihood L ( θ ) = P i log p ( x i ; θ ). By introducing latent variables z i = ( z i , f , z i , c ) representing the optimal knowl- edge, and an auxiliary distrib ution Q ( z i ), we apply Jensen’ s In- equality to deriv e the Evidence Lower Bound (ELBO), F ( Q , θ ): L ( θ ) = X i log X z i p ( x i , z i ; θ ) Q ( z i ) Q ( z i ) ≥ X i E Q ( z i ) [log p ( x i , z i ; θ )] + H ( Q ) ≜ F ( Q , θ ) , (20) where H ( Q ) is the entropy and maximizing L ( θ ) is achiev ed by iterativ ely maximizing F ( Q , θ ). Alternating Optimization. Let θ t be the parameters at itera- tion t . The process alternates between two stages: Stage 1: Auxiliary Distribution Update. Fixing θ t , we approximate the optimal Q t ( z i ) using the retriev ed neighbors. W e define the probability mass of Q t ov er a neighbor z j directly via our reliability weights (Eq. 12 ): Q t , f ( z j ) : = w j , f ( θ t ) and Q t , c ( z j ) : = w j , c ( θ t ). Stage 2: Model P arameter Update. Fixing Q t , we max- imize the expectation E Q t [ log p ( x i , z i ; θ )]. W e model the joint log-probability as the negativ e sum of the alignment loss and the reliability potential: log p ( x i , z i ; θ ) ∝ − ( L OT ( θ ) + log Ψ i ( θ )). Substituting this into the ELBO, the maximization objectiv e becomes minimizing the negati ve e xpectation: min θ L m ≈ X i E Q t , f [ L OT , f + log Ψ i , f ] + E Q t , c [ L OT , c + log Ψ i , c ] . (21) This objectiv e L m mathematically aligns with our modulated loss L ∗ (Eq. 18 ), where the reliability term F = − log Ψ acts as a regularizer . Con vergence. Since each step monotonically increases the ELBO F ( Q , θ ), and L ASK is bounded below , the Monotone Con- ver gence Theorem guarantees that the sequence of loss v alues con ver ges to a stationary point. 5 Experiments 5.1 Experimental Setup Datasets and Metrics. W e ev aluate our method on two stan- dard benchmarks: AudioCaps [ Kim et al. , 2019 ] and Clotho [ Drossos et al. , 2020 ]. Follo wing prior work [ Mei et al. , 2022 , Xie et al. , 2024 , Y an et al. , 2024 ], we report audio-to-text (A2T) and text-to-audio (T2A) retrie val performance using Recall at K (R@K, for K = 1, 5, 10). Baselines. T o validate ASK’ s model-agnosticism, we ev aluate it across two interaction paradigms. 1) Global Interaction: W e build upon the ML-A CT baseline [ Mei et al. , 2022 ] (ResNet-38 [ K ong et al. , 2020 ] + BER T [ De vlin et al. , 2019 ]), compar- ing against BLA T [ Xu et al. , 2023 ] and Auto-A CD [ Sun et al. , 2024 ]. W e also adapt the English-only ML-CLAP setup [ Y an et al. , 2024 ] (CED-Base [ Dinkel et al. , 2024 ] + SONAR-TE [ Duquenne et al. , 2023 ]), comparing it with GLAP [ Dinkel et al. , 2025 ]. 2) Local Interaction: W e follow the setups of GP A [ Xie et al. , 2024 ] and FLAM [ W u et al. ], and adopt the same maximum number of tokens for the dataset. Implementation Details. All models are trained with the Adam optimizer [ Kingma and Ba , 2014 ]. The ResNet-BER T architecture is trained for 50 epochs on AudioCaps (batch size 32) and Clotho (batch size 24), with an initial learning rate of 5 × 10 − 5 , which is decayed by a factor of 10 ev ery 20 epochs. The CED-SONAR models are trained for 10 epochs with a decay step applied e very 4 epochs. W e use the Faiss library [ Douze et al. , 2025 ] for e ffi cient neighbor search. Unless specified oth- erwise, the hyperparameters for our ASK frame work are set as follows: we retriev e K = 10 neighbors, with a coarse-grained prototype set of size N c = 512. The knowledge injection ratio is ρ = 0 . 2, and the O T -realignment factor is β = 0 . 2. Empirical analyses confirm our framework’ s robustness across K ∈ [5 , 15] and ρ ∈ [0 . 15 , 0 . 25]. The reliability modulation weights are λ f = 0 . 2 and λ c = 0 . 3. The knowledge base is dynamically refined e very T = 15 epochs. All experiments were conducted on 2 NVIDIA A100 and 8 R TX 4090 GPUs. 5.2 Main Results W e ev aluate the e ff ectiveness of our proposed ASK frame- work by integrating it into v arious baseline models. The results are organized by the cross-modal interaction strate gy . Global Interaction Strategy . T able 1 presents the results for models using a global, sentence-lev el interaction strategy . ASK consistently outperforms competiti ve methods across all datasets and architectures. On AudioCaps (ResNet-BER T), ASK sur- passes the foundational ML-A CT by a remarkable 6.0% (A2T) and 3.2% (T2A) in absolute R@1. Crucially , it eclipses Auto- A CD, with further R@1 gains of up to 1.5% ( ASK † ) and 2.2% ( ASK + ). These improvements v alidate our core mechanisms in successfully breaking the GLB and mitigating RDM. Demon- strating its model-agnosticism, ASK also significantly enhances the transformer-based CED-SONAR architecture. On the Clotho dataset, it outperforms the GLAP baseline, boosting A2T R@1 to 19.7% ( + 1.3%) and T2A R@1 to 16.3% ( + 1.2%). Finally , the varying optimal v ariants across setups highlight ASK’ s flexi- bility in lev eraging div erse knowledge sources. 7 T able 1: Results for Audio-T ext-Retrie val on AudioCaps and Clotho under the global interaction strategy . The symbols † , ∗ , and + denote the use of knowledge from W avCaps, the Gemini-annotated training set and the original training set respecti vely . AudioCaps Clotho Method Audio-to-T ext T ext-to-Audio Audio-to-T ext T ext-to-Audio R@1 R@5 R@10 R@1 R@5 R@10 R@1 R@5 R@10 R@1 R@5 R@10 Architecture: ResNet-38 + BER T ML-A CT Mei et al. [ 2022 ] 36 . 3 ± 0 . 5 68 . 6 ± 0 . 3 81 . 5 ± 0 . 2 32 . 2 ± 0 . 4 68 . 2 ± 0 . 1 81 . 2 ± 0 . 2 16 . 3 ± 0 . 4 39 . 1 ± 0 . 3 51 . 5 ± 0 . 6 14 . 2 ± 0 . 4 37 . 3 ± 0 . 2 49 . 9 ± 0 . 3 BLA T Xu et al. [ 2023 ] 38 . 2 ± 0 . 2 70 . 4 ± 0 . 3 82 . 1 ± 0 . 2 32 . 9 ± 0 . 3 68 . 9 ± 0 . 1 81 . 8 ± 0 . 2 16 . 8 ± 0 . 2 39 . 6 ± 0 . 3 52 . 1 ± 0 . 3 14 . 1 ± 0 . 2 37 . 6 ± 0 . 2 50 . 2 ± 0 . 1 Auto-A CD Sun et al. [ 2024 ] 40 . 8 ± 0 . 2 71 . 3 ± 0 . 4 83 . 3 ± 0 . 2 33 . 2 ± 0 . 3 68 . 7 ± 0 . 2 82 . 1 ± 0 . 2 17 . 1 ± 0 . 2 39 . 3 ± 0 . 2 53 . 2 ± 0 . 3 14 . 4 ± 0 . 2 37 . 5 ± 0 . 2 50 . 1 ± 0 . 2 ASK † 42.3 ± 0 . 3 73 . 3 ± 0 . 8 84 . 2 ± 0 . 6 34 . 6 ± 0 . 5 69 . 6 ± 0 . 4 82 . 9 ± 0 . 9 17 . 3 ± 0 . 3 40 . 2 ± 0 . 6 54.1 ± 0 . 2 14 . 8 ± 0 . 4 38 . 1 ± 0 . 7 50 . 7 ± 0 . 6 ASK ∗ 39 . 5 ± 0 . 3 73 . 2 ± 0 . 4 85 . 3 ± 0 . 6 34 . 2 ± 0 . 6 69 . 1 ± 0 . 7 81 . 9 ± 0 . 3 18.5 ± 0 . 2 40 . 1 ± 0 . 4 53 . 6 ± 0 . 6 14 . 7 ± 0 . 5 38 . 3 ± 0 . 9 50 . 1 ± 0 . 3 ASK + 42 . 0 ± 0 . 2 74.2 ± 0 . 5 85.4 ± 0 . 6 35.4 ± 0 . 3 70.2 ± 0 . 3 83.1 ± 0 . 7 17 . 5 ± 0 . 2 40.3 ± 0 . 8 54.1 ± 0 . 6 15.2 ± 0 . 3 38.5 ± 0 . 6 51.1 ± 0 . 4 Architecture: CED-Base + SON AR-TE ML-CLAP Y an et al. [ 2024 ] 39 . 6 ± 0 . 2 69 . 8 ± 0 . 3 81 . 7 ± 0 . 6 31 . 9 ± 0 . 3 69 . 2 ± 0 . 5 82 . 8 ± 0 . 9 18 . 0 ± 0 . 2 39 . 5 ± 0 . 7 53 . 0 ± 0 . 6 14 . 9 ± 0 . 3 39 . 9 ± 0 . 6 53 . 1 ± 0 . 7 GLAP Dinkel et al. [ 2025 ] 41 . 2 ± 0 . 1 72 . 4 ± 0 . 3 83 . 7 ± 0 . 2 33 . 3 ± 0 . 3 68 . 9 ± 0 . 1 81 . 8 ± 0 . 4 18 . 4 ± 0 . 2 40 . 6 ± 0 . 3 54 . 1 ± 0 . 3 15 . 1 ± 0 . 2 40 . 2 ± 0 . 2 54 . 2 ± 0 . 1 ASK † 43.3 ± 0 . 3 73 . 7 ± 0 . 6 84 . 4 ± 0 . 8 34 . 8 ± 0 . 2 70 . 6 ± 0 . 5 84 . 0 ± 0 . 4 19 . 0 ± 0 . 1 41 . 5 ± 0 . 6 56 . 5 ± 0 . 7 16.3 ± 0 . 2 40 . 3 ± 0 . 6 55.4 ± 0 . 7 ASK ∗ 41 . 9 ± 0 . 3 74.1 ± 0 . 4 85.6 ± 0 . 6 34.9 ± 0 . 2 70.9 ± 0 . 5 84.1 ± 0 . 7 18 . 5 ± 0 . 2 41 . 6 ± 0 . 6 56 . 9 ± 0 . 7 16 . 0 ± 0 . 1 40 . 6 ± 0 . 5 55 . 1 ± 0 . 8 ASK + 40 . 9 ± 0 . 2 71 . 6 ± 0 . 6 84 . 3 ± 0 . 3 33 . 7 ± 0 . 2 70 . 3 ± 0 . 5 83 . 5 ± 0 . 6 19.7 ± 0 . 1 43.3 ± 0 . 5 57.3 ± 0 . 7 16 . 0 ± 0 . 2 41.5 ± 0 . 6 55.2 ± 0 . 7 Audio T ext T ext Audio Audio T ext T ext Audio 25 30 35 40 45 R@1 (%) 40.3 33.1 41.1 34.1 42.9 34.5 43.7 34.6 43.1 35.1 AudioCaps Clotho F L A M G P A A S K A S K * A S K + 13 14 15 16 17 18 19 20 R@1 (%) 17.5 13.8 18.1 15.1 19.1 16.2 19.2 16.3 19.5 16.0 Figure 3: Results for Audio-T ext Retrie val on AudioCaps and Clotho under the local interaction strategy . The symbols + , † , and ∗ denote di ff erent knowledge sources in Section 4.1 . Local Interaction Strategy . W e also validate ASK with local, token-le vel interaction strategies [ Xie et al. , 2024 , W u et al. ]. Fig- ure 3 presents the retriev al results for our local, token-le vel inter - action baselines. The results demonstrate consistent and signifi- cant gains across both retrie val directions, outperforming both the FLAM and GP A baselines. On AudioCaps, ASK achiev es substantial improvements over the strongest baseline (GP A), with ASK ∗ enhancing the Audio-to-T ext R@1 by 2.6% and ASK + boosting the T ext-to-Audio R@1 by 1.0%. On Clotho, ASK + deliv ers the top Audio-to-T ext R@1 performance, while ASK ∗ yields the best T ext-to-Audio R@1. Notably , our variants exceed FLAM by e ven larger mar gins across all metrics. These symmetric improvements confirm the univ ersal benefit of our framew ork. Zero-Shot Generalization. T o strictly ev aluate robustness, we conduct bidirectional zero-shot experiments: training on Au- dioCaps and testing on Clotho, and vice versa. As illustrated in Figure 4 , the ASK framework consistently expands the re- triev al performance env elope compared to the baseline across all metrics in both transfer directions. Specifically , when trans- ferring from AudioCaps to Clotho (left), le veraging the di verse W avCaps knowledge source (ASK † ) yields a notable 1.3% ab- solute gain in A2T R@1. Similarly , in the Clotho-to-AudioCaps transfer (right), ASK variants maintain superior performance, with ASK † achieving a significant improv ement over the base- line (e.g., + 2.6% in A2T R@1). These results confirm that our multi-grained knowledge injection e ff ecti vely mitigates domain shifts and prev ents ov erfitting to source-domain specifics. R@1 14.3 R@5 32.0 R@10 44.3 R@1 12.2 R@5 31.7 R@10 43.5 Audio-to-T ext T ext-to-Audio Clotho R@1 28.5 R@5 60.4 R@10 75.9 R@1 25.8 R@5 56.9 R@10 72.7 Audio-to-T ext T ext-to-Audio AudioCaps Baseline A S K A S K * A S K + Figure 4: Zero-shot performance on AudioCaps and Clotho. † , ∗ , and + denote di ff erent knowledge sources in Section 4.1 . 5.3 Ablation Study and Analysis T o validate the contribution of each component within our ASK framew ork, we conduct a series of ablation studies on the AudioCaps dataset using the ResNet-BER T architecture and an in-domain knowledge source. The results are presented in T able 2 . Impact of Multi-Grained Knowledge Bases. W e first ana- lyze the necessity of our multi-grained design. Remo ving the fine-grained knowledge base results in a substantial performance drop of 4.3% absolute in A2T R@1, confirming the critical 8 T able 2: Ablation experiments on AudioCaps dataset using the ResNet-38 + BER T architecture. + denotes the utilization of knowledge deri ved from AudioCaps training set. A2T T2A G. Method R@1 R@5 R@10 R@1 R@5 R@10 w / o ASK 36 . 3 ± 0 . 5 68 . 6 ± 0 . 3 81 . 5 ± 0 . 2 32 . 2 ± 0 . 4 68 . 2 ± 0 . 1 81 . 2 ± 0 . 2 1 w / o Fine-grained Kno wledge Base 37 . 7 ± 0 . 2 70 . 4 ± 0 . 4 81 . 8 ± 0 . 7 31 . 9 ± 0 . 2 67 . 3 ± 0 . 6 81 . 0 ± 0 . 7 w / o Coarse-grained Kno wledge Base 37 . 4 ± 0 . 1 67 . 6 ± 0 . 5 81 . 3 ± 0 . 7 31 . 2 ± 0 . 3 66 . 6 ± 0 . 4 81 . 0 ± 0 . 6 2 w / o the Kno wledge Injection Step 39 . 1 ± 0 . 3 72 . 7 ± 0 . 6 84 . 1 ± 0 . 7 34 . 5 ± 0 . 3 69 . 1 ± 0 . 6 82 . 6 ± 0 . 7 w / o O T Alignment Correction 41 . 1 ± 0 . 3 73 . 4 ± 0 . 5 85 . 2 ± 0 . 6 34 . 2 ± 0 . 2 69 . 4 ± 0 . 4 82 . 8 ± 0 . 6 3 w / o Adapti ve Reliability W eighting 39 . 3 ± 0 . 2 72 . 2 ± 0 . 4 83 . 6 ± 0 . 6 33 . 9 ± 0 . 3 68 . 9 ± 0 . 5 81 . 6 ± 0 . 7 4 w / o the Dynamic Kno wledge Refinement 39 . 2 ± 0 . 3 71 . 0 ± 0 . 6 83 . 8 ± 0 . 5 34 . 1 ± 0 . 2 68 . 7 ± 0 . 6 81 . 5 ± 0 . 5 Our Full ASK + 42.0 ± 0 . 2 74.2 ± 0 . 5 85.4 ± 0 . 6 35.4 ± 0 . 3 70.2 ± 0 . 3 83.1 ± 0 . 7 role of instance-le vel details for precise retrie val. Similarly , re- moving the coarse-grained base leads to a 4.6% drop in A2T R@1, which underscores the importance of the global semantic prior provided by the prototypes. The model, which lev erages both, significantly outperforms either single-granularity vari- ant, demonstrating that the fine- and coarse-grained knowledge sources are complementary . 5 10 15 20 25 30 Knowledge Update Fr equency 34 36 38 40 42 44 Audio-to-T ext R@1 ASK A2T Baseline A2T ASK T2A Baseline T2A 31 32 33 34 35 36 37 T ext-to-Audio R@1 Figure 5: E ff ect of the frequenc y T of Knowledge Update. Abla- tion experiment on ASK + under the global interaction strategy . Impact of Core ASK Mechanisms. W e then ablate the core mechanisms of ASK. 1) Kno wledge Injection: Disabling the knowledge injection step causes a notable drop of 2.9% in A2T R@1. This empirically validates that creating gradient path- ways to out-of-batch data is the primary dri ver for breaking the GLB and enhancing representations. 2) Reliability W eighting: Ablating our adapti ve reliability weighting mechanism results in a significant 2.7% drop in A2T R@1 and a 1.5% drop in T2A R@1. This provides strong e vidence that not all retrie ved knowledge is equally beneficial, and that modulating the loss based on cross-modal consistenc y is crucial for mitigating the impact of noises and achieving rob ust performance. Impact of Dynamic Knowledge Refinement. W e ev aluate the e ff ect of the knowledge-base update period T on mitigating RDM. As shown in T able 2 , disabling dynamic refinement leads to a 2.8% drop in A2T R1, empirically v alidating our theoretical claim in Section 3.3 that unchecked RDM introduces stale and misaligned knowledge. Figure 5 shows that performance improves as the update frequency increases, reaching an optimum at T = 15 epochs, which surpasses both the static knowledge base and the base- line. Howe ver , overly frequent updates degrade performance, indicating a trade-o ff : while frequent updates curtail RDM, they can also destabilize the knowledge representation before the model fully adapts. These findings highlight the necessity of a co-ev olving knowledge base and careful tuning of the update frequency . T able 3: Qualitative comparison of audio-text retriev al. GT represents Ground T ruth. A udio Query ML-A CT Mei et al. [ 2022 ] ASK (Ours) Scenario 1: Semantic Ambiguity GT : “Thunder r oars in the dis- tance as rain falls” (Confusing T ex- tur e) T op-1: “F ood siz- zling in a pan” ✗ (Audio Ambiguity) GT Rank: 21 T op-1: “Thunder r oars in the distance as rain falls” ✓ GT Rank: 1 Scenario 2: Long-tail Concept GT : “Chur ch bells ringing” (Rar e Event) T op-1: “T rain horn blowing” ✗ (T onal Similarity) GT Rank: 13 T op-1: “Church bells ringing” ✓ GT Rank: 1 Case Study. T able 3 qualitativ ely illustrates how the ASK framew ork overcomes the Gradient Locality Bottleneck (GLB). 9 In Scenario 1, the baseline model f ails to resolve semantic am- biguity between acoustically similar te xtures like thunder and sizzling food , whereas ASK distinguishes these fine-grained de- tails to achiev e Rank 1. Like wise, for the long-tail Churc h bells concept, ASK av oids the baseline’ s tendency to default to com- mon tonal relati ves like tr ain horns . These results demonstrate that lev eraging div erse out-of-batch knowledge during training allows ASK to learn a discriminati ve embedding space that gen- eralizes to rare and ambiguous ev ents without requiring explicit retriev al during inference. 6 Conclusion In this paper , we identified and formalized two funda- mental challenges in kno wledge-enhanced Audio-T ext Re- triev al: the Gradient Locality Bottleneck, which confines stan- dard contrastive learning to mini-batches, and the consequent Representation-Drift Mismatch, which arises from using static knowledge bases with ev olving models. T o address this dual challenge, we proposed the Adaptiv e Self-improving Knowledge framew ork. ASK is a model-agnostic, plug-and-play solution that breaks the GLB via multi-grained knowledge injection, miti- gates RDM through dynamic knowledge refinement, and ensures reliability with a novel adapti ve weighting scheme. Extensi ve experiments demonstrate that ASK consistently and significantly improv es performance across div erse architectures and datasets, achieving ne w state-of-the-art results. References T ing Chen, Simon K ornblith, Mohammad Norouzi, and Geo ff rey Hinton. A simple framework for contrastive learning of vi- sual representations. In International confer ence on machine learning , pages 1597–1607. PmLR, 2020. Gheorghe Comanici, Eric Bieber , Mike Schaekermann, Ice Pasu- pat, Nov een Sachdev a, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Ev an Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality , long con- text, and ne xt generation agentic capabilities. arXiv preprint arXiv:2507.06261 , 2025. Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. Advances in neural information pr ocessing systems , 26, 2013. Jacob Devlin, Ming-W ei Chang, Kenton Lee, and Kristina T outanova. Bert: Pre-training of deep bidirectional transform- ers for language understanding. In Pr oceedings of the 2019 confer ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages 4171–4186, 2019. Heinrich Dinkel, Y ongqing W ang, Zhiyong Y an, Junbo Zhang, and Y ujun W ang. Ced: Consistent ensemble distillation for audio tagging. In ICASSP 2024-2024 IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 291–295. IEEE, 2024. Heinrich Dinkel et al. Glap: General contrastive audio–text pretraining across domains and languages. arXiv pr eprint arXiv:2506.11350 , 2025. Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Je ff Johnson, Gergely Szilv asy , Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. The faiss library . IEEE T ransactions on Big Data , 2025. K onstantinos Drossos, Samuel Lipping, and T uomas V irtanen. Clotho: An audio captioning dataset. In ICASSP 2020-2020 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 736–740. IEEE, 2020. Paul-Ambroise Duquenne, Holger Schwenk, and Benoît Sagot. Sonar: sentence-lev el multimodal and language-agnostic rep- resentations. arXiv pr eprint arXiv:2308.11466 , 2023. Debidatta Dwibedi, Y usuf A ytar, Jonathan T ompson, Pierre Ser- manet, and Andrew Zisserman. W ith a little help from my friends: Nearest-neighbor contrasti ve learning of visual rep- resentations. In Proceedings of the IEEE / CVF international confer ence on computer vision , pages 9588–9597, 2021. Y uan Gong, Y u-An Chung, and James Glass. Ast: Audio spec- trogram transformer . arXiv pr eprint arXiv:2104.01778 , 2021. Kelvin Guu, Kenton Lee, Zora T ung, Panupong Pasupat, and Mingwei Chang. Retrie v al augmented language model pre- training. In International conference on machine learning , pages 3929–3938. PMLR, 2020. Andrey Guzho v , Federico Raue, Jörn Hees, and Andreas Den- gel. Audioclip: Extending clip to image, text and audio. In ICASSP 2022-2022 IEEE International Conference on Acous- tics, Speech and Signal Pr ocessing (ICASSP) , pages 976–980. IEEE, 2022. Kaiming He, Haoqi Fan, Y uxin W u, Saining Xie, and Ross Gir- shick. Momentum contrast for unsupervised visual representa- tion learning. In Pr oceedings of the IEEE / CVF conference on computer vision and pattern r ecognition , pages 9729–9738, 2020. Roy Rudolf Huizen and Florentina T atrin Kurniati. Feature extraction with mel scale separation method on noise audio recordings. arXiv pr eprint arXiv:2112.14930 , 2021. Urvashi Khandelwal, Omer Levy , Dan Jurafsky , Luke Zettle- moyer , and Mike Le wis. Generalization through memoriza- tion: Nearest neighbor language models. arXiv preprint arXiv:1911.00172 , 2019. Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. In Pr oceedings of the 2019 Confer ence of the North American Chapter of the Association for Computational Lin- guistics: Human Language T echnologies, V olume 1 (Long and Short P apers) , pages 119–132, 2019. Diederik P Kingma and Jimmy Ba. Adam: A method for stochas- tic optimization. arXiv pr eprint arXiv:1412.6980 , 2014. Qiuqiang K ong, Y in Cao, T urab Iqbal, Y uxuan W ang, W enwu W ang, and Mark D Plumbley . Panns: Large-scale pre- trained audio neural networks for audio pattern recognition. IEEE / A CM T ransactions on Audio, Speech, and Language Pr ocessing , 28:2880–2894, 2020. Solomon Kullback and Richard A Leibler . On information and su ffi ciency . The annals of mathematical statistics , 22(1): 79–86, 1951. 10 Kuang-Huei Lee, Xi Chen, Gang Hua, Houdong Hu, and Xi- aodong He. Stacked cross attention for image-text matching. In Pr oceedings of the Eur opean confer ence on computer vi- sion (ECCV) , pages 201–216, 2018. Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. V ilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Advances in neural information pr ocessing systems , 32, 2019. Xinhao Mei, Xubo Liu, Jianyuan Sun, Mark Plumbley , and W enwu W ang. On metric learning for audio-text cross-modal retriev al. In Pr oc. Interspeech 2022 , pages 4142–4146, 2022. Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang K ong, T om K o, Chengqi Zhao, Mark D Plumble y , Y uexian Zou, and W enwu W ang. W avcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal re- search. IEEE / A CM T ransactions on Audio, Speech, and Lan- guage Pr ocessing , 32:3339–3354, 2024. T omas Mikolov , Ilya Sutskev er, Kai Chen, Greg S Corrado, and Je ff Dean. Distributed representations of w ords and phrases and their compositionality . Advances in neural information pr ocessing systems , 26, 2013. Y ingqi Qu, Y uchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, W ayne Xin Zhao, Daxiang Dong, Hua W u, and Haifeng W ang. Rocketqa: An optimized training approach to dense passage retriev al for open-domain question answering. In Pr oceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies , pages 5835–5847, 2021. Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning trans- ferable visual models from natural language supervision. In International conference on machine learning , pages 8748– 8763. PmLR, 2021. Bing Su and Gang Hua. Order-preserving w asserstein distance for sequence matching. In Pr oceedings of the IEEE con- fer ence on computer vision and pattern r ecognition , pages 1049–1057, 2017. Luoyi Sun, Xuenan Xu, Mengyue W u, and W eidi Xie. Auto- acd: A large-scale dataset for audio-language representation learning. In Proceedings of the 32nd A CM International Confer ence on Multimedia , pages 5025–5034, 2024. Ho-Hsiang W u, Prem Seetharaman, Kundan Kumar , and Juan Pablo Bello. W av2clip: Learning robust audio repre- sentations from clip. In ICASSP 2022-2022 IEEE Interna- tional Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 4563–4567. IEEE, 2022. Y usong W u, Christos Tsirigotis, Ke Chen, Cheng-Zhi Anna Huang, Aaron Courville, Oriol Nieto, Prem Seetharaman, and Justin Salamon. Flam: Frame-wise language-audio model- ing. In F orty-second International Conference on Machine Learning . Y uxin Xie, Zhihong Zhu, Xianwei Zhuang, Liming Liang, Zhichang W ang, and Y uexian Zou. Gpa: Global and pro- totype alignment for audio-te xt retrie val. In Pr oc. Interspeech 2024 , pages 5078–5082, 2024. Lee Xiong, Chenyan Xiong, Y e Li, Kwok-Fung T ang, Jialin Liu, Paul N Bennett, Junaid Ahmed, and Arnold Overwijk. Ap- proximate nearest neighbor negati ve contrastiv e learning for dense text retrie val. In International Conference on Learning Repr esentations . Xuenan Xu, Zhiling Zhang, Zelin Zhou, Pingyue Zhang, Ze yu Xie, Mengyue W u, and Kenn y Q Zhu. Blat: Bootstrapping language-audio pre-training based on audioset tag-guided synthetic data. In Pr oceedings of the 31st ACM International Confer ence on Multimedia , pages 2756–2764, 2023. Zhiyong Y an, Heinrich Dinkel, Y ongqing W ang, Jizhong Liu, Junbo Zhang, Y ujun W ang, and Bin W ang. Bridging language gaps in audio-text retrie val. In Proc. Interspeech 2024 , pages 1675–1679, 2024. Y uguo Y in, Y uxin Xie, W enyuan Y ang, Dongchao Y ang, Jinghan Ru, Xianwei Zhuang, Liming Liang, and Y ue xian Zou. Atri: Mitigating multilingual audio text retriev al inconsistencies by reducing data distribution errors. In Proceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 5491–5504, 2025. T ianqi Zhao, Ming K ong, T ian Liang, Qiang Zhu, Kun K uang, and Fei W u. Clap: Contrastive language-audio pre-training model for multi-modal sentiment analysis. In Proceedings of the 2023 ACM international confer ence on multimedia r etrieval , pages 622–626, 2023. A Derivation and V isualization of RDM’ s Impact This appendix provides a detailed deri vation of the relation- ship between the Representation Drift Mismatch (RDM) and training stability . The core premise of RDM is that a model’ s representation space is non-stationary during training. W e first provide a visualization in Figure 6 that empirically demonstrates this phenomenon. It shows how the embeddings of the same audio clips, encoded by a model without dynamic updates, drift significantly as training progresses. Our goal in the following sections is to formally prove that this observ ed drift leads to a greater potential for gradient misalignment. Gradient Formulation. W e consider a simplified loss func- tion L = L main ( u i , u ′ i ) that incorporates a kno wledge-enhanced representation u ′ i = (1 − ρ ) u i + ρ K , where u i = f θ t ( a i ) and K is the expected representation of retrie ved kno wledge. Formally , K = P j P ( j ) z j , where z j denotes the embedding vector of the j -th sample in the kno wledge base, and P ( j ) is its corresponding probability weight. The gradient of the loss with respect to the model parameters θ t is: ∇ θ t L = ∂ L ∂ u i + (1 − ρ ) ∂ L ∂ u ′ i ! ∂ u i ∂θ t (22) Linking Gradient Deviation to Knowledge De viation. The di ff erence between the ideal gradient ( ∇ θ t L ideal ) and the actual gradient ( ∇ θ t L actual ) arises from the di ff erence in their respecti ve knowledge vectors, K ideal and K actual . Let the gradient di ff erence vector be ∆ ∇ = ∇ θ t L actual − ∇ θ t L ideal . This di ff erence is primarily driv en by the change in the loss deriv ati ve term ∂ L ∂ u ′ i . 11 Figure 6: t-SNE visualization of Representation Drift. Embed- dings of a fixed set of audio samples, encoded by the same model at di ff erent training epochs, are plotted. The progressive shift in embedding positions (from Epoch 1 [blue] to Epoch 50 [red]) empirically validates the core premise of RDM: a static knowledge base becomes misaligned with the non-stationary representation space ov er time. T o analyze this relationship, we use a first-order T aylor ex- pansion of the loss gradient term around the ideal representation u ′ ideal . The di ff erence can be approximated as: ∂ L actual ∂ u ′ i − ∂ L ideal ∂ u ′ i ≈ H L ( u ′ ideal ) · ( u ′ actual − u ′ ideal ) (23) where H L is the Hessian matrix of the loss function with respect to its input. Since u ′ actual − u ′ ideal = ρ ( K actual − K ideal ) = ρ ∆ K , we can see that the de viation in the loss gradient is approximately proportional to the deviation in the kno wledge vector: ∆ ∇ ∝ H L · ∆ K (24) This establishes a direct relationship: a larger deviation in the fused knowledge vector ∆ K leads to a larger deviation in the final parameter gradient ∆ ∇ . The next step is therefore to bound the magnitude of ∆ K using the RDM. Bounding the Knowledge Deviation via RDM W e now bound the norm of the deviation ∥ ∆ K ∥ 2 using the RDM. W e lev erage Pinsker’ s inequality , which relates the KL di vergence to the T otal V ariation Distance ( D T V ): D T V ( P 1 , P 2 ) = 1 2 X j | P 1 ( j ) − P 2 ( j ) | ≤ r 1 2 D K L ( P 1 || P 2 ) (25) Applying this to our distributions gi ves D T V ( P ideal , P actual ) ≤ q 1 2 RDM( t , t k ) . W e can then bound ∥ ∆ K ∥ 2 : ∥ ∆ K ∥ 2 = ∥ X j ( P actual ( j ) − P ideal ( j )) z j ∥ 2 ≤ X j | P actual ( j ) − P ideal ( j ) |∥ z j ∥ 2 ≤ max j ∥ z j ∥ 2 ! · 2 · D T V ( P ideal , P actual ) ≤ C p 2 · RDM( t , t k ) (26) where C = max j ∥ z j ∥ 2 is a bounded constant. Conclusion. Combining these steps, we have established a formal link: an increase in RDM widens the upper bound on the kno wledge vector de viation ∥ ∆ K ∥ 2 (Eq. 26 ), which in turn increases the potential magnitude of the gradient de viation ∆ ∇ (Eq. 23 ). This increases the risk of gradient misalignment, which can lead to training instability . Our dynamic knowledge refine- ment mechanism is designed to mitigate this risk by periodically resetting the RDM to zero. B Theoretical J ustification and Con ver gence of the ASK Objective In this section, we provide a complete theoretical justifica- tion for the ASK frame work. W e demonstrate that our training procedure can be viewed as a principled alternating optimiza- tion algorithm designed to maximize the log-likelihood of the observed data, which in turn guarantees the monotonic non- increase of our final loss function and thus ensures con vergence. Probabilistic F ormulation with Latent Knowledge. The pri- mary goal of Audio-T ext Retrie val is to find model parameters θ ∗ that maximize the log-lik elihood of observing matched audio- text pairs x i = ( a i , t i ): θ ∗ = max θ L ( θ ) = max θ X i log p ( x i ; θ ) (27) W e conceptualize our approach by introducing latent variables, z i = ( z i , f , z i , c ), representing the unobserved optimal kno wledge for each sample x i . The observed data likelihood is the marginal likelihood ov er these latent variables: p ( x i ; θ ) = X z i p ( x i , z i ; θ ) (28) Thus, the optimization objectiv e becomes: θ ∗ = max θ X i log X z i p ( x i , z i ; θ ) (29) The summation inside the logarithm makes direct optimization intractable. Deriving the Evidence Lo wer Bound. T o create a tractable objectiv e, we introduce an arbitrary distribution Q ( z i ) and ap- ply Jensen’ s Inequality to deri ve a lower bound on the log- likelihood, kno wn as the Evidence Lower Bound (ELBO), de- 12 noted as F ( Q , θ ): log p ( x i ; θ ) = log X z i Q ( z i ) p ( x i , z i ; θ ) Q ( z i ) ≥ X z i Q ( z i ) log p ( x i , z i ; θ ) Q ( z i ) (30) F ( Q , θ ) = E Q ( z i ) [log p ( x i , z i ; θ )] (31) − E Q ( z i ) [log Q ( z i )] Maximizing log p ( x i ; θ ) is achieved by iterati vely maximizing this lower bound F with respect to Q and θ . The ASK Framework as an Alternating Optimization Al- gorithm. Let θ t be the parameters at iteration t . The ASK training process alternates between two stages. Stage 1: A uxiliary Distribution Update. In this stage, we fix θ t and approximate the optimal auxiliary distribution Q t ( z i ) which should be the true posterior p ( z i | x i ; θ t ). W e as- sume independence between fine- and coarse-grained knowl- edge: Q t ( z i ) = Q t , f ( z i , f ) Q t , c ( z i , c ). • The retrie val of T op-K neighbors defines the support of Q t , f and Q t , c . • W e define the probability mass of these distributions ov er a specific neighbor z j using our reliability weights: Q t , f ( z i , f = z j ) : = w j , f ( θ t ) , Q t , c ( z i , c = z j ) : = w j , c ( θ t ) (32) Stage 2: Model Parameter Update. In this stage, we fix Q t and maximize the ELBO with respect to θ , which is equiv alent to maximizing E Q t [ log p ( x i , z i ; θ )]. W e model the joint log-probability as a sum of independent fine- and coarse- grained components, e.g., for the text-to-audio direction: log p ( x i , z i ; θ ) ≈ −L OT , f ( θ ) − log Ψ T ← A i , f ( θ ) + −L OT , c ( θ ) − log Ψ T ← A i , c ( θ ) + − log Z ( θ ) (33) where Z ( θ ) is a normalization constant. The maximization objectiv e is to minimize the negati ve expectation of this log- probability under Q t . Substituting Eq. 32 and Eq. 33 , this objec- tiv e becomes: L m = − X i E Q t ( z i ) [log p ( x i , z i ; θ )] ≈ X i ( E Q t , f [ L OT , f + log Ψ i , f ] + E Q t , c [ L OT , c + log Ψ i , c ]) (34) Our final modulated loss, L ∗ T → A = (1 + λ f F T → A f + λ c F T → A c ) · L T → A (35) where F = − log Ψ , is a principled and sophisticated imple- mentation of this maximization objective. Minimizing L ASK e ff ectiv ely performs this parameter update. Proof of Con vergence. This two-stage alternating optimiza- tion guarantees that the total objective is non-decreasing at each full iteration, L ( θ t + 1 ) ≥ L ( θ t ). Consequently , minimizing the negati ve log-lik elihood guarantees that the loss is monotonically non-increasing. Giv en that L ASK is bounded below by zero, the Monotone Con ver gence Theorem ensures that the sequence of loss values conv erges to a limit, and the parameters { θ t } con ver ge to a stationary point C Optimal T ransport for Batch-le vel Alignment This section details the entropy-regularized Optimal T rans- port (OT) formulation used to refine the batch-wise similarity matrices. Giv en a batch of knowledge-enhanced pairs, we com- pute a similarity matrix, e.g., the fine-grained matrix S f ∈ R B × B . W e then seek an optimal transport plan Q ∈ R B × B , where Q i j represents the soft-alignment probability between the i -th text and the j -th audio. The optimal plan Q ∗ is found by solving the following re gularized optimization problem: Q ∗ = max Q ∈C ⟨ Q , S f ⟩ + ε H ( Q ) s.t. C = { Q ∈ R B × B | Q1 B = µ , Q ⊤ 1 B = ν } , (36) where ⟨ Q , S f ⟩ = tr ( Q ⊤ S f ) is the total similarity score. H ( Q ) = − P i , j Q i j log Q i j is the entropy regularizer , controlled by ε > 0. The constraints enforce that the marginals of Q must sum to predefined distrib utions µ and ν , which represent the importance of each instance. Follo wing prior work [ Su and Hua , 2017 ], we set both µ and ν to a uniform distribution over the batch, i.e., 1 | B | 1 | B | . This problem is e ffi ciently solved for the optimal plan Q ∗ using the Sinkhorn-Knopp algorithm [ Cuturi , 2013 ]. D Full Results f or Local Interaction Strategy This section provides the complete retrie val results for our experiments on the local, tok en-lev el interaction baselines, including both Audio-to-T ext and T ext-to-Audio directions. T a- ble 4 presents the full comparison ag ainst both the FLAM and GP A architectures. As demonstrated in T able 4 , ASK consistently outpaces both baselines across all metrics in the T ext-to-Audio retrie val direction as well. When compared to the stronger GP A baseline, ASK + achiev es the highest R@1 score on AudioCaps, yielding a 1.0% absolute improv ement, which translates to a substantial 2.0% margin ov er FLAM. On Clotho, the ASK ∗ variant deli vers the strongest R@1 performance with a significant gain of 1.2% absolute over GP A, and a notable 2.5% absolute advantage ov er FLAM. These results confirm that the benefits of our proposed mechanisms are symmetric, enhancing both retriev al directions and v alidating the overall e ff ecti veness of the ASK frame work on fine-grained architectures. E Comparison with Alternati ve Retriev al-A ugmented Frameworks T o further validate the design choices of our ASK frame- work, we compare it ag ainst classical retriev al-augmented con- trastiv e learning paradigms adapted from computer vision and in- formation retriev al. Specifically , we benchmark against represen- tativ e retrie val-augmented and contrasti ve learning paradigms: 13 T able 4: Full results for Audio-T ext Retrie val on AudioCaps and Clotho under the local interaction strategy . The symbols + , † , and ∗ denote di ff erent knowledge sources. A udio-to-T ext AudioCaps Clotho Method R@1 R@5 R@10 R@1 R@5 R@10 FLAM W u et al. 40 . 3 ± 0 . 1 71 . 2 ± 0 . 3 83 . 6 ± 0 . 2 17 . 5 ± 0 . 1 38 . 8 ± 0 . 4 50 . 5 ± 0 . 4 GP A Xie et al. [ 2024 ] 41 . 1 ± 0 . 3 73 . 8 ± 0 . 4 85 . 2 ± 0 . 6 18 . 1 ± 0 . 2 40 . 2 ± 0 . 3 53 . 4 ± 0 . 4 ASK † 42 . 9 ± 0 . 3 75 . 1 ± 0 . 6 86 . 4 ± 0 . 5 19 . 1 ± 0 . 1 41.9 ± 0 . 4 53 . 9 ± 0 . 8 ASK ∗ 43.7 ± 0 . 2 75.8 ± 0 . 3 86 . 2 ± 0 . 7 19 . 2 ± 0 . 3 41 . 6 ± 0 . 7 54.5 ± 0 . 6 ASK + 43 . 1 ± 0 . 3 74 . 0 ± 0 . 6 86.9 ± 0 . 5 19.5 ± 0 . 3 41 . 4 ± 0 . 7 54.5 ± 0 . 6 T ext-to-A udio AudioCaps Clotho Method R@1 R@5 R@10 R@1 R@5 R@10 FLAM W u et al. 33 . 1 ± 0 . 1 67 . 5 ± 0 . 2 80 . 0 ± 0 . 2 13 . 8 ± 0 . 2 33 . 2 ± 0 . 3 45 . 1 ± 0 . 2 GP A Xie et al. [ 2024 ] 34 . 1 ± 0 . 2 70 . 0 ± 0 . 4 82 . 2 ± 0 . 6 15 . 1 ± 0 . 2 37 . 9 ± 0 . 6 50 . 2 ± 0 . 4 ASK † 34 . 5 ± 0 . 3 71.1 ± 0 . 5 83.1 ± 0 . 6 16 . 2 ± 0 . 1 38 . 5 ± 0 . 4 51 . 3 ± 0 . 5 ASK ∗ 34 . 6 ± 0 . 2 70 . 5 ± 0 . 5 82 . 7 ± 0 . 6 16.3 ± 0 . 2 38 . 4 ± 0 . 3 51 . 5 ± 0 . 4 ASK + 35.1 ± 0 . 3 70 . 8 ± 0 . 5 83.1 ± 0 . 4 16 . 0 ± 0 . 1 38.8 ± 0 . 3 52.1 ± 0 . 5 MoCo He et al. [ 2020 ], ANCE Xiong et al. , and NNCLR Dwibedi et al. [ 2021 ]. These baselines represent the classical strategies for e xpanding negati ve sample capacity , performing hard negati ve mining, and utilizing external support sets, re- spectiv ely . W e adapt their core mechanisms to the Audio-T ext Retriev al setting. All variants are built upon the identical ML- A CT Mei et al. [ 2022 ] backbone to ensure a fair and rigorous comparison. T able 5: Comparison with other retriev al-augmented methods on AudioCaps. The symbol + denotes using training set as the knowledge source Audio-to-T ext T ext-to-Audio Method R@1 R@5 R@10 R@1 R@5 R@10 ML-A CT Mei et al. [ 2022 ] 36 . 3 ± 0 . 5 68 . 6 ± 0 . 3 81 . 5 ± 0 . 2 32 . 2 ± 0 . 4 68 . 2 ± 0 . 1 81 . 2 ± 0 . 2 NNCLR Dwibedi et al. [ 2021 ] 32 . 5 ± 0 . 9 66 . 6 ± 0 . 5 80 . 9 ± 0 . 7 30 . 2 ± 0 . 3 64 . 9 ± 0 . 1 80 . 1 ± 0 . 1 ANCE Xiong et al. 35 . 9 ± 0 . 5 67 . 8 ± 0 . 3 83 . 6 ± 0 . 2 31 . 7 ± 0 . 1 65 . 4 ± 0 . 5 79 . 8 ± 0 . 1 MoCo He et al. [ 2020 ] 37 . 2 ± 0 . 3 68 . 5 ± 0 . 5 82 . 0 ± 0 . 3 32 . 9 ± 0 . 4 67 . 4 ± 0 . 6 80 . 9 ± 0 . 1 ASK + 42.0 ± 0 . 2 74.2 ± 0 . 5 85.4 ± 0 . 6 35.4 ± 0 . 3 70.2 ± 0 . 3 83.1 ± 0 . 7 As sho wn in T able 5 , our proposed ASK significantly out- performs all alternati ve strategies across all metrics, achie ving an R@1 of 42.0% in Audio-to-T ext retriev al. Conv ersely , di- rectly migrating classical contrastive methods to the Audio-T ext Retriev al (A TR) domain yields sub-optimal or degraded perfor- mance. While MoCo provides only marginal improvements, both ANCE and NNCLR lead to noticeable performance drops, with NNCLR causing the most sev ere degradation (e.g., Audio- to-T ext R@1 dropping from 36.3% to 32.5%). W e hypothesize that this performance degradation stems from the unique semantic ambiguities in A TR. Specifically , meth- ods relying on strict hard negati ve mining (ANCE) or unimodal nearest neighbors (NNCLR) are highly susceptible to acoustic confusion, which inadvertently introduces false negati ves or modality-specific noise into the contrastiv e objective. Addition- ally , the memory queues in MoCo may su ff er from represen- tation drift due to the continuous updating of the fine-grained audio encoder . Unlike these rigid mechanisms, ASK mitigates these domain-specific bottlenecks by employing an adapti ve re- liability weighting scheme that explicitly ev aluates cross-modal consistency , e ff ectiv ely filtering out the retrie val noise that limits standard baselines. F Hyperparameter Sensitivity Analysis T o comprehensively ev aluate the robustness of the proposed ASK framew ork, we conduct sensitivity analyses on two criti- cal hyperparameters: the retrieved knowledge size ( K ) and the knowledge injection ratio ( ρ ). The experiments are conducted on the AudioCaps dataset using the ASK + variant. The results are illustrated in Figure 7 . 5 10 15 20 25 30 The number of Knowledge Samples 34 36 38 40 42 44 Audio-to-T ext R@1 ASK A2T Baseline A2T ASK T2A Baseline T2A 31 32 33 34 35 36 37 T ext-to-Audio R@1 0.10 0.15 0.20 0.25 0.30 0.35 Knowledge Injection Ratio 34 36 38 40 42 44 Audio-to-T ext R@1 ASK A2T Baseline A2T ASK T2A Baseline T2A 31 32 33 34 35 36 37 T ext-to-Audio R@1 Figure 7: Hyperparameter sensiti vity analysis. Left: Impact of the retrie ved kno wledge size K . Right: Impact of the kno wledge injection ratio ρ . Impact of the Retrieved Knowledge Size ( K ). The left panel of Figure 7 illustrates the e ff ect of varying the number of re- triev ed knowledge samples K from 5 to 30. The framew ork achiev es its optimal performance in both Audio-to-T ext (A2T) and T ext-to-Audio (T2A) retriev al at K = 10, reaching a peak A2T R@1 of 42.0% and T2A R@1 of 35.4%. When K is set too small (e.g., K = 5), the limited neighborhood fails to provide su ffi cient semantic diversity , restricting the model’ s ability to generalize to ambiguous or long-tail concepts. Conv ersely , set- ting K too lar ge (e.g., K ≥ 15) ine vitably introduces acoustically similar but semantically irrelev ant noise into the kno wledge base. This excessi ve retrie val dilutes the v alid semantic guidance and consequently degrades the alignment performance. Impact of the Knowledge Injection Ratio ( ρ ). The right panel of Figure 7 presents the performance fluctuations across di ff erent kno wledge injection ratios ρ ∈ [0 . 10 , 0 . 35]. This hyper- parameter controls the crucial trade-o ff between retaining the original instance identity and incorporating the retrieved global semantic prior . As sho wn in the figure, the model attains its peak performance at ρ = 0 . 20. A lower injection ratio (e.g., ρ = 0 . 10) provides insu ffi cient global context, making it di ffi cult to fully break the Gradient Locality Bottleneck (GLB). Howe ver , an ex- cessiv ely high ratio ( ρ ≥ 0 . 25) o ver -dominates the feature fusion process. This leads to feature homogenization, where the unique acoustic or textual characteristics of the original sample are ov ershadowed by the aggregated neighborhood representations, ultimately resulting in a decline in retriev al accuracy . G V isualization of Adaptiv e Reliability W eighting T o explicitly address ho w the Adaptive Reliability W eight- ing mechanism mitigates Representation-Drift Mismatch (RDM) 14 and filters noise, we delve into the mathematical behavior of the reliability potential F = − log Ψ . W e provide an internal visual- ization of these assigned weights during the training process to demonstrate their dynamic modulation e ff ects. A critical but nuanced property of our framework is that F acts as a dynamic ne gativ e regularizer . Giv en the normalized em- bedding space, the cross-modal similarity generally maintains non-negati ve e xponential characteristics, leading to an expected similarity Ψ ≥ 1. Consequently , the reliability weight F con- sistently operates in the ne gativ e domain ( F ≤ 0). This design intrinsically serves as a rew ard mechanism that dynamically relaxes the standard in-batch contrasti ve penalty when reliable external kno wledge is injected. T able 6 illustrates this internal mechanism using two chal- lenging acoustic ambiguity scenarios. Query 1 in volv es confus- ing environmental textures ( “Thunder” vs. “Sizzling food” ). Query 2, dra wn directly from our e valuation set, in volves engine and wind noises where a “Motorboat” could be acoustically confused with a “Motor cycle” . T able 6: Internal visualization of the reliability potential Ψ and the negati ve re gularizer weight F . Neighborhood State Semantic Concept Ψ F Modulation Query 1: “Thunder roar s in the distance as rain falls” (Environmental T exture Ambiguity) Clean Neighborhood “Loud thunder claps” 1.60 - 0.47 0.91 Noise Neighborhood “F ood sizzling loudly” 1.05 - 0.05 0.99 Query 2: “A motorboat driving by as water splashes and wind blows” (V ehicle Engine Ambiguity) Clean Neighborhood “A speedboat traveling across water” 1.55 - 0.44 0.91 Noise Neighborhood “A motorcycle engine revving” 1.08 - 0.08 0.98 When the retriev ed neighborhood contains highly relev ant concepts (e.g., “Loud thunder claps” or “A speedboat travel- ing” ), the strong semantic alignment yields a larger Ψ ( > 1), forcing F to be a distincti vely negati ve v alue with a large mag- nitude (e.g., -0.47 and -0.44). This dynamically reduces the modulation multiplier (1 + λ F ) < 1, e ff ecti vely re warding the model by down-weighting the standard contrasti ve penalty and encouraging the absorption of this clean knowledge. Con versely , when the retrie ved kno wledge is corrupted by RDM drift—such as retrieving the acoustically similar but se- mantically incorrect “F ood sizzling loudly” or “A motor cycle engine re vving” —the weak cross-modal alignment results in a Ψ closer to 1. This causes the negati ve regularizer F to ap- proach zero (e.g., -0.05 and -0.08), which pulls the modulation multiplier back to near 1.0. By doing so, the framework with- holds the reward and maintains the strict original contrastiv e loss, seamlessly prev enting the model from ov er-relying on the drifted acoustic noise.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment