LLMServingSim 2.0: A Unified Simulator for Heterogeneous and Disaggregated LLM Serving Infrastructure
Large language model (LLM) serving infrastructures are undergoing a shift toward heterogeneity and disaggregation. Modern deployments increasingly integrate diverse accelerators and near-memory processing technologies, introducing significant hardware heterogeneity, while system software increasingly separates computation, memory, and model components across distributed resources to improve scalability and efficiency. As a result, LLM serving performance is no longer determined by hardware or software choices in isolation, but by their runtime interaction through scheduling, data movement, and interconnect behavior. However, understanding these interactions remains challenging, as existing simulators lack the ability to jointly model heterogeneous hardware and disaggregated serving techniques within a unified, runtime-driven framework. This paper presents LLMServingSim 2.0, a unified system-level simulator designed to make runtime-driven hardware-software interactions in heterogeneous and disaggregated LLM serving infrastructures explicit and analyzable. LLMServingSim 2.0 embeds serving decisions and hardware behavior into a single runtime loop, enabling interaction-aware modeling of batching, routing, offloading, memory, and power. The simulator supports extensible integration of emerging accelerators and memory systems through profile-based modeling, while capturing dynamic serving behavior and system-level effects. We validate LLMServingSim 2.0 against real deployments, showing that it reproduces key performance, memory, and power metrics with an average error of 0.95%, while maintaining simulation times of around 10 minutes even for complex configurations. These results demonstrate that LLMServingSim 2.0 provides a practical bridge between hardware innovation and serving-system design, enabling systematic exploration and co-design for next-generation LLM serving infrastructures.
💡 Research Summary
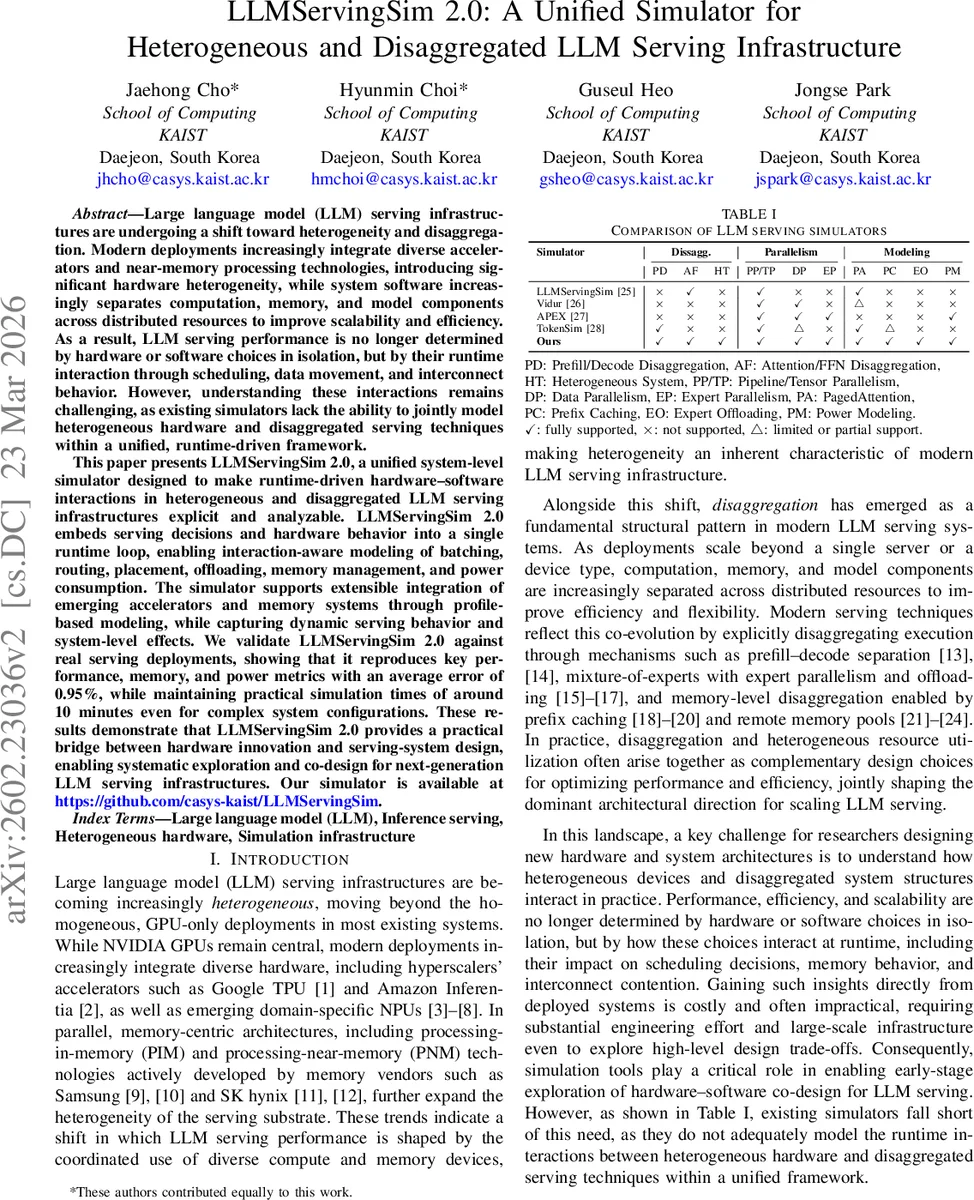
Large language model (LLM) serving is rapidly evolving from homogeneous GPU‑only deployments to highly heterogeneous and disaggregated infrastructures. Modern data‑center deployments now combine a variety of accelerators—NVIDIA GPUs, Google TPUs, Amazon Inferentia, domain‑specific NPUs—as well as emerging memory‑centric technologies such as processing‑in‑memory (PIM) and CXL‑based memory pools. At the same time, serving software increasingly separates computation, memory, and model components across distributed resources using techniques such as prefill‑decode (PD) disaggregation, mixture‑of‑experts (MoE) with expert offloading, and prefix caching for KV‑cache reuse. Consequently, performance, efficiency, and scalability are determined not by isolated hardware or software choices but by their runtime interactions: scheduling, data movement, interconnect contention, and dynamic memory management. Existing simulators either focus on low‑level accelerator behavior (e.g., LLMCompass, ADOR) without modeling request‑driven dynamics, or they model serving policies (e.g., Vidur, APEX) but lack detailed heterogeneous hardware and memory models. This gap motivates the development of LLMServingSim 2.0.
LLMServingSim 2.0 is a unified system‑level simulator that embeds serving decisions and hardware behavior within a single runtime loop. It accepts three inputs: (1) a workload specification (model, request arrival rates, per‑request execution traces), (2) a cluster configuration (node types, CPU settings, memory capacities, device placement, routing and parallelism policies, KV‑cache eviction and offloading rules), and (3) hardware performance profiles (operator‑level latency and power for each device). Profiles are generated by a lightweight PyTorch/HuggingFace profiler that runs a single decode block per model‑device pair; the profiling pass typically finishes within a few hours and the resulting data can be reused across experiments. External simulator‑generated profiles can also be imported, enabling evaluation of future accelerators such as PIM without physical hardware.
The simulator constructs a Model Serving Group (MSG) for each model. An MSG contains a heterogeneous device pool, a batch scheduler, an operation mapper, and integrated memory and power models. During initialization, the Execution Planner creates MSGs according to the cluster configuration, instantiates the serving engine, and sets up the system topology. At runtime, the Request Router assigns incoming requests to MSGs, which generate execution graphs for each batch. The System Simulator evaluates these graphs, accounting for compute, inter‑device communication, synchronization, and multi‑tier memory accesses (HBM, DRAM, CXL pools, storage). The loop repeats until all requests finish, producing online statistics (throughput, memory usage, energy) and per‑request metrics (time‑to‑first‑token, time‑per‑output‑token, queueing delay).
Key contributions include: (i) interaction‑awareness—explicit modeling of feedback between serving policies (batching, routing, offloading, caching) and hardware state (utilization, contention, power); (ii) unified representation of heterogeneous accelerators, multi‑tier memory, and disaggregated serving architectures; (iii) runtime‑driven dynamics that capture queue formation, batch size fluctuation, KV‑cache hit/miss patterns, and expert routing over time; (iv) extensibility through profile‑based operator modeling, allowing rapid inclusion of new devices; and (v) power‑aware modeling that ties compute, memory, and data‑movement activities to energy consumption.
Validation against real deployments across multiple models (e.g., Llama 3.1‑70B, GPT‑NeoX) and hardware mixes (NVIDIA H100, Google TPU, CXL memory pools) shows that LLMServingSim 2.0 reproduces throughput, TTFT, TPOT, memory usage, and power with an average error of 0.95 %. Even for complex configurations involving eight nodes and heterogeneous interconnect topologies, simulation time remains around ten minutes, demonstrating the efficiency of the profile‑based approach.
Case studies illustrate the simulator’s utility for co‑design: (a) evaluating how increased PIM bandwidth improves KV‑cache hit rates and reduces decode latency; (b) exploring expert offloading policies and their impact on token‑level load balancing; (c) quantifying the effect of different prefix‑caching sizes and eviction strategies on overall latency. These experiments highlight how LLMServingSim 2.0 enables rapid, quantitative exploration of the design space that would be prohibitively expensive to probe on physical hardware.
In summary, LLMServingSim 2.0 provides a high‑fidelity, extensible, and fast platform for studying the intertwined hardware‑software dynamics of heterogeneous, disaggregated LLM serving infrastructures. By accurately reproducing performance, memory, and energy metrics while supporting emerging accelerators and serving techniques, it bridges the gap between hardware innovation and serving‑system design, facilitating systematic co‑design and early‑stage exploration of next‑generation LLM serving ecosystems.
Comments & Academic Discussion
Loading comments...
Leave a Comment