Mixture of Experts with Soft Nearest Neighbor Loss: Resolving Expert Collapse via Representation Disentanglement
The Mixture-of-Experts (MoE) model uses a set of expert networks that specialize on subsets of a dataset under the supervision of a gating network. A common issue in MoE architectures is ``expert collapse'' where overlapping class boundaries in the r…
Authors: Abien Fred Agarap, Arnulfo P. Azcarraga
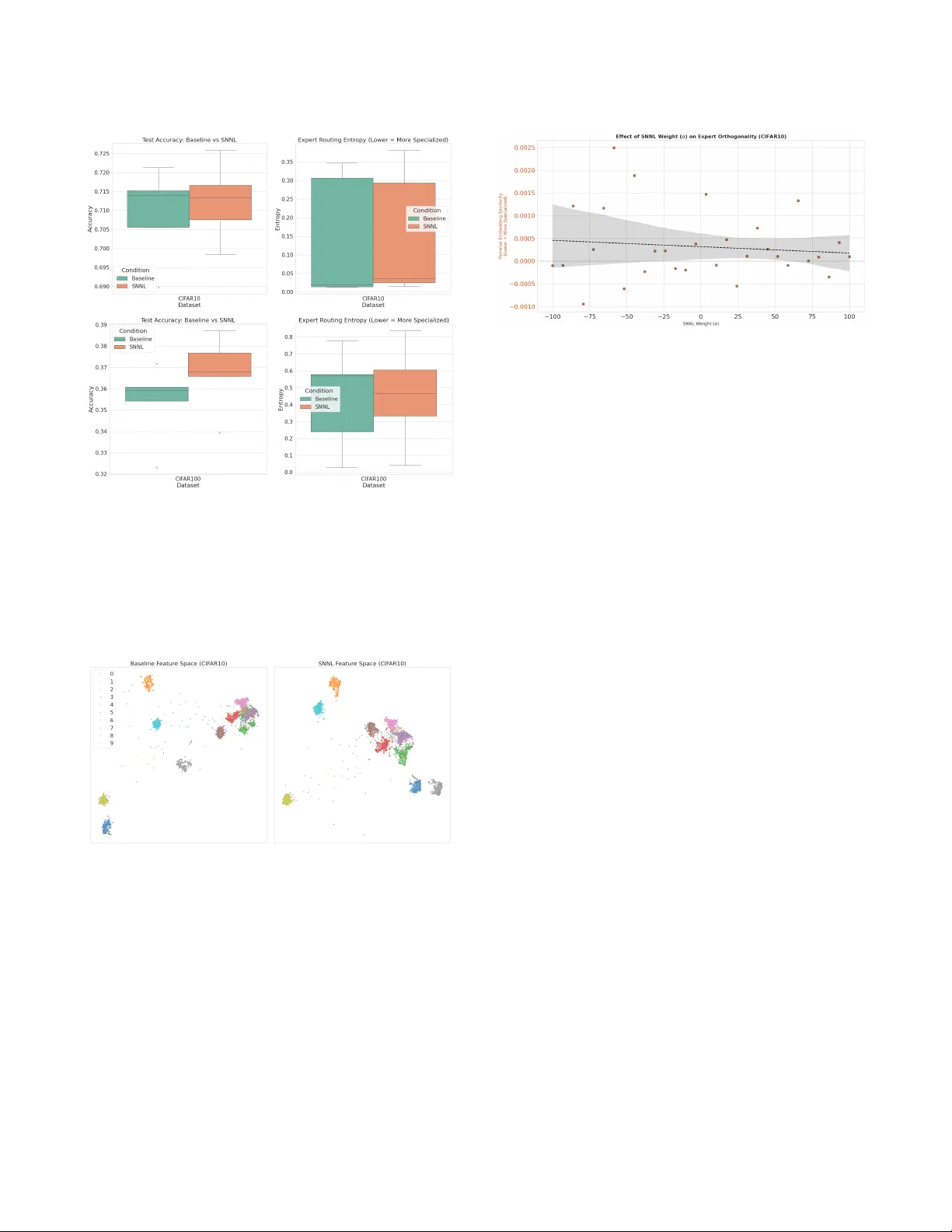
Mixture of Experts with So Nearest Neighbor Loss: Resolving Expert Collapse via Representation Disentanglement Abien Fred Agarap abien.agarap@dlsu.edu.ph De La Salle University Manila, Philippines Arnulfo Azcarraga arnulfo.azcarraga@dlsu.edu.ph De La Salle University Manila, Philippines ABSTRA CT The Mixture-of-Experts (MoE) model uses a set of expert networks that specialize on subsets of a dataset under the super vision of a gating network. A common issue in MoE architectures is “ex- pert collapse” where ov erlapping class b oundaries in the raw input feature space cause multiple e xperts to learn redundant represen- tations, thus forcing the gating network into rigid routing to com- pensate. W e propose an enhanced MoE architecture that utilizes a feature extractor network optimized using Soft Near est Neighbor Loss (SNNL) prior to fee ding input features to the gating and ex- pert networks. By pre-conditioning the latent space to minimize distances among class-similar data points, we resolve structural expert collapse which r esults to experts learning highly orthogonal weights. W e employ Exp ert Specialization Entropy and Pairwise Embedding Similarity to quantify this dynamic. W e evaluate our experimental approach across four benchmark image classication datasets (MNIST , FashionMNIST , CIF AR10, and CIF AR100), and we show our SNNL-augmented MoE models demonstrate structurally diverse experts which allow the gating network to adopt a more exible routing strategy . This paradigm signicantly improves clas- sication accuracy on the FashionMNIST , CIF AR10, and CIF AR100 datasets. CCS CONCEPTS • Computing methodologies → Learning latent representa- tions ; Ensemble methods ; Semi-sup ervised learning settings ; KEY W ORDS contrastive learning, ensemble learning, mixture-of-experts, repre- sentation learning 1 IN TRODUCTION AND RELA TED W ORKS An articial neural network solves a given problem by learning to approximate the function that describes the relationship between dataset features 𝑥 and labels 𝑦 in a given training data. This is accomplished by training with r etro-propagation of its output errors [ 21 ] and then adjusting its weights based on such error signals. Neural networks can be used for a plethora of tasks such as image classication [ 15 ], language translation [ 6 ], and speech recognition [ 10 ]. It learns to solve these problems by breaking them down to learn the best representations for the input features, and then performing the given task on the resulting learned representations. This representation learning capability is among the advantages of neural networks over other machine learning algorithms. 1.1 Class Neighb orhood Structure A number of methods have been used to further improve the per- formance of neural networks on subsequent problem-specic tasks, such as expressing high-dimensional data in low-dimensional space, in which capturing the structure of a given dataset may be pur- posely learned. This structure contains the class information of a given dataset which indicates how the class-similar data points cluster together in a projected space. Several techniques have be en introduced and are popularly used for this purp ose such as princi- pal components analysis (PCA), t-stochastic neighbor embedding (t-SNE) [ 17 ], triplet loss [ 5 ], and the soft nearest neighbor loss [1, 7, 22] to transform the input features to contain attributes that are primed for classication. The aforementioned techniques capture the underlying class neighborhood structure of an input data. However , each technique has their respective drawbacks. If the most salient features of the data can be found in a nonlinear manifold, then a linear technique like PCA will not be able to fully learn the underlying structure of the data. On the other hand, nonlinear techniques like t-SNE, soft nearest neighbor loss, and triplet loss require relativ ely expensive computational cost. Not to mention that t-SNE discovers dierent representations of an input data as a function of its hyperparameters. Meanwhile, the soft nearest neighbor loss and triplet loss can b e relatively much slow er to compute even when compared to t-SNE, depending on the available compute resources. Despite the known drawbacks, it is still desirable to learn the underlying structure of a data as it implies how the input features form clusters, and consequently , these clusters imply the class mem- bership of the input features as per the clustering assumption in the semi-supervise d learning literature [ 3 ]. Although it is established that nonlinear techniques are relatively slower and more computa- tionally expensive to use, the evolution of computational har dware has provided drastic advancements that compute issues might be negligible for those with the necessary resources. 1.2 Ensemble Learning Aside from learning the class neighborhoo d structure of a given data, we can improve the performance of neural networks by com- bining their outputs through averaging or summation [ 2 ]. This technique is known as ensemble learning, which enfor ces coop- eration among neural networks to solve a common goal. In this context, we dene cooperation as the phenomenon where the neu- ral networks in an ensemble contribute to the overall success of the group. The neural netw orks in an ensemble cooperate among themselves by compensating for the performance of one another , thereby decreasing the error correlation of the gr oup. PCSC2026, April 2026, Davao, Philippines Agarap and Azcarraga In contrast, if a training data can be naturally divided into sub- sets, the group of neural networks can be inspired to specialize on their own subsets rather than to cooperate among themselves. This approach is known as the mixture-of-experts mo del [ 13 ] which uses a gating netw ork as a supervisor to choose which sub-network must b e assigned on a subset of the dataset based on their predictive performance on such subsets. Howev er , if the raw input features fed to the gating network con- tain highly entangled class boundaries, the gating network struggles to condently partition the space . This often leads to “ expert col- lapse” where a single expert dominates the task or multiple experts learn redundant representations. In such a case, the gating network often results to hard-routing strategies that fail to generalize w ell on complex datasets. 1.3 Contributions T o address the issue of expert collapse, we propose an architectural pipeline that primes the input features to the MoE model using SNNL. Our core contributions are: (1) Architectural Enhancement . W e employ a feature extrac- tor regularized with SNNL b efore the MoE routing phase, thus minimizing intra-class distances to simplify the gating network’s partition task. (2) Quantitative Specialization Metrics . W e address the need for detailed analysis by introducing Expert Specialization Entropy and Pairwise Embedding Similarity to empirically measure expert divergence and routing e xibility . (3) Statistical Rigor and Visual Proof . W e conduct robust non-parametric statistical testing (Wilcoxon signed-rank test) and provide compr ehensive manifold and embedding visualizations to denitively prove that SNNL prevents struc- tural collapse, thus allowing experts to be utilized more col- laboratively on complex benchmark datasets. 2 BA CK GROUND 2.1 Feed-For ward Neural Network The feed-forward neural network is the quintessential deep learning model that is used to approximate the function mapping between the dataset input and output, i.e. 𝑦 ≈ 𝑓 ( ® 𝑥 ; 𝜃 ) . Its 𝜃 parameters are then optimized to learn the b est approximation for the input targets, which may either be a class label (classication) or a real value (regression). 𝑓 ( ® 𝑥 ) = 𝑓 ( 𝑛 ) 𝑓 ( . . . ) 𝑓 ( 1 ) ( ® 𝑥 ) (1) ℓ ce ( 𝑦, 𝑓 ( 𝑥 ) ) = − 𝑖 𝑦 𝑖 log [ 𝑓 ( 𝑥 𝑖 ) ] (2) T o accomplish this, the model comp oses a number of nonlinear functions in the form of hidden layers, each of which learns a representation of the input features (see Eq. 1). Afterwards, the similarities between the approximation and the input targets are measured by using an error function such as cross entropy (see Eq. 2), which shall b e the basis for optimization usually through gradient-based learning. For our experiments, we use a fee d-forward neural network with a single hidden layer containing 128 units. The hidden layer weights were initialized with Kaiming initializer [ 12 ] and had ReLU [ 19 ] ac- tivation function while the output lay er was initialized with Xavier initializer [ 9 ]. W e use this architecture for the e xpert networks in our MoE models. For the gating network, we simply use a linear classier to select which expert to use for particular input features. 2.2 Convolutional Neural Network The convolutional neural network (or CNN) is a neural network architecture that uses the convolution operator as its feature extrac- tor in its hidden layers [ 8 , 16 ]. Like feed-for ward neural networks, they also compose hidden layer representations for a downstream task. However , with its use of the conv olution operator in its hidden layers, it learns better representations of an input data. Figure 1: Architecture of the CNN-based Feature Extractor . This mo dule computes disentangled representations that are subsequently routed to the MoE gating network and experts. In Figure 1, we illustrate the CNN-based feature extractor we use to prime the input features for the gating and expert networks across all our e xperiments. The network processes raw input fea- tures through a sequence of two distinct feature blocks to construct a disentangled latent representation. Each block consists of a 2D convolutional layer utilizing a 3 × 3 kernel with 32 lters in the rst block and 64 lters in the second, then immediately followed by 2D batch normalization, a ReLU activation function to intro- duce non-linearity , and a 2 × 2 max pooling layer to progressively downsample the spatial dimensions. After the second block, the resulting multi-channel feature maps are attened into a concise 1D vector . This nal embedding ser ves as the topologically struc- tured, SNNL-optimized input fed directly into the downstream MoE gating network and expert modules. 2.3 Mixture-of-Experts The Mixture-of-Experts (MoE) model consists of a set of 𝑛 “e xpert” neural networks 𝐸 1 , . . . , 𝐸 𝑛 and a “gating” neural network 𝐺 . Figure 2 is an illustration of the MoE mo del. The experts are chosen by the gating network to handle a subset of the entire dataset, wherein each subset is tantamount to a sub-region of the data space. The output of this model is given by the following equation, ˆ 𝑦 = 𝑛 𝑖 = 1 𝐺 ( 𝑥 ) 𝑖 𝐸 𝑖 ( 𝑥 ) (3) Mixture of Experts with So Nearest Neighbor Loss: Resolving Expert Collapse via Representation Disentanglement PCSC2026, April 2026, Davao, Philippines Figure 2: The mixture-of-experts model is a system of experts and gating networks where each expert be come a function of a subset of the input environment. These expert networks receive the same inputs and produce the same numb er of outputs. The gating network also receives the same input as the expert networks, but its output is the probability of choosing a particular expert on a given input. where 𝐺 ( 𝑥 ) 𝑖 is the probability output of the gating network to choose expert 𝐸 𝑖 for a given input 𝑥 . The gating network and the experts have their dier ent set of parameters 𝜃 . In our classication experiments, we modied the inference function above as follows, ˆ 𝑦 = 𝑛 𝑖 = 1 arg max 𝐺 ( 𝑥 ) 𝑖 𝐸 𝑖 ( 𝑥 ) (4) This modied inference function allows the selection of the b est expert network 𝐸 𝑖 as indicated by the highest gating network output arg max 𝐺 ( 𝑥 ) 𝑖 . Without this modication, the model only results to a model akin to a traditional ensemble model alb eit outputs a weighted summation as its output instead of a simple summation of expert outputs. Subsequently , we optimize the MoE model based on the following error function, L moe ( 𝑥 , 𝑦 ) = 1 𝑏 𝑛 𝑖 = 1 𝐺 ( 𝑥 ) 𝑖 × ℓ 𝑐𝑒 ( 𝑦, 𝐸 𝑖 ( 𝑥 ) ) (5) where ℓ ce is the cross entropy function measuring the dierence between the target 𝑦 and the output of e xpert 𝐸 𝑖 , while 𝐺 ( 𝑥 ) 𝑖 is the probability output for choosing expert 𝑖 . Then, the loss is averaged over the number of batch samples 𝑏 . In this system, each expert learns to specialize on the cases where they perform well, and they are impose d to ignore the cases on which they do not perform well. With this learning paradigm, the experts become a function of a subregion of the data space, and thus their set of learned weights highly dier from each other as opposed to traditional ensemble models that result to having almost identical weights for their learners. 3 RESOLVING EXPERT COLLAPSE WI TH DISEN T ANGLEMEN T 3.1 Soft Nearest Neighbor Loss W e dene disentanglement as how close pairs of class-similar data points from each other are, r elative to pairs of class-dierent data points, and we can measure this by using the soft nearest neighbor loss (SNNL) function [7, 22]. This loss function is an expansion on the original nonlinear neighborhood comp onents analysis objective which minimizes the distances among class-similar data points in the latent code of an autoencoder network [ 22 ]. On the other hand, the SNNL function minimizes the distances among class-similar data points in each hidden layer of a neural network [ 7 ]. The SNNL function is dened for a batch of 𝑏 samples ( 𝑥 , 𝑦 ) as follows, ℓ snn ( 𝑥 , 𝑦, 𝑇 ) = − 1 𝑏 𝑖 ∈ 1 .. .𝑏 log © « Í 𝑗 ∈ 1 . . .𝑏 𝑗 ≠ 𝑖 𝑦 𝑖 = 𝑦 𝑗 exp − 𝑑 𝑖 𝑗 𝑇 Í 𝑘 ∈ 1 .. .𝑏 𝑘 ≠ 𝑖 exp − 𝑑 𝑖𝑘 𝑇 ª ® ® ® ® ® ® ® ® ® ¬ (6) where 𝑑 is a distance metric on either raw input features or learned hidden layer representations 𝑥 of a neural network, and 𝑇 is a temperature parameter that can be used to inuence the value of the loss function. That is, at high temperatures, the distances among widely separated data points can inuence the loss value. 3.2 Our approach W e pr opose to use a feature extractor network 𝑓 for the MoE model instead of using the raw input featur es for the expert and gating net- works (see Figure 3). Using our featur e extractor network optimized with SNNL, we prime the input features via disentanglement w .r .t. their class labels. Our proposal thus leads to the optimization of a composite loss (see Eq. 7) of the cross entropy as the classication loss and the SNNL as the regularizer . L ( 𝑓 , 𝑥 , 𝑦 ) = L moe ( 𝑥 , 𝑦 ) + 𝛼 · min ℓ snn ℓ snn ( 𝑓 𝑖 ( 𝑥 ) , 𝑦 , 𝑇 ) (7) W e found more stable and better optimization of the SNNL when we take its minimum value across the hidden layers 𝑓 𝑖 of the feature extractor network. 3.3 Theoretical Analysis T o formalize the contribution of the soft nearest neighb or loss (SNNL) to expert specialization, w e analyze the interaction between the feature extractor 𝑓 and the Mixture-of-Experts (MoE) gating mechanism. 3.3.1 Latent Space Partitioning via SNNL. The SNNL objective 𝑙 𝑠𝑛𝑛 serves as a topological regularizer on the feature extractor’s hid- den layers. By minimizing the distance between class-similar data points relative to class-dier ent ones, the feature extractor 𝑓 ( ® 𝑥 ) maps the high-dimensional input ® 𝑥 into a lo wer-dimensional latent manifold where class clusters are highly localized. Mathematically , the SNNL gradient w .r .t. the weights of 𝑓 minimizes the pairwise PCSC2026, April 2026, Davao, Philippines Agarap and Azcarraga Figure 3: W e optimize the soft nearest neighbor loss over the hidden layers found in the feature extractor network before the MoE mo del. In doing so, the input features to the expert and gating networks are transformed to a set of representations with the classication information ingrained in them, thereby helping improve the overall classication performance of the MoE mo del. distance 𝑑 𝑖 𝑗 for all 𝑦 𝑖 = 𝑦 𝑗 . This results in a latent representation 𝑧 = 𝑓 ( ® 𝑥 ) where the intra-class variance is minimized. 3.3.2 Gating Dynamics and Exp ert Selection. In a traditional MoE model, the gating network 𝐺 ( ® 𝑥 ) often suers from “expert collapse” where a single expert dominates the gradients due to a disorganize d input space. In our approach, the gating network operates on the transformed representation 𝐺 ( 𝑓 ( ® 𝑥 ) ) . Since 𝑓 ( ® 𝑥 ) essentially clusters inputs by class, the gating function 𝐺 ( 𝑧 ) encounters a “pre-partitioned” environment. Let 𝑧 𝑐 be the centroid of class 𝑐 in the latent space. The gating network learns a mapping 𝜙 : 𝑧 𝑐 → { 1 , . . . , 𝑛 } , eectively assigning a specic expert 𝐸 𝑖 to a specic class cluster . As the inference function utilizes arg max 𝐺 ( 𝑧 ) 𝑖 , the model selects the "best" expert for a given sub- region of the data space. 3.3.3 Formalizing the Sp ecialization. Specialization is achieved when the variance of the input distribution seen by expert 𝐸 𝑖 is signicantly lower than the global distribution variance: V ar ( 𝑓 ( ® 𝑥 ) | 𝐺 ( 𝑓 ( ® 𝑥 ) ) 𝑖 ≈ 1 ) ≪ V ar ( 𝑓 ( ® 𝑥 ) ) By ensuring that the input to the gating network is already disentangled by class, our approach forces each expert 𝐸 𝑖 to learn a localized function 𝑓 ( 𝐸 𝑖 ) specically tuned to the nuances of the assigned class cluster . This reduces the interference between experts and facilitates higher classication accuracy , as evidenced by the empirical results on the classication datasets used in the study . 4 EXPERIMEN TS W e use four benchmark image classication datasets to evaluate our proposed model: MNIST , FashionMNIST , CIF AR10, and CIF AR100. W e ran each model ve times, and computed their average perfor- mance across those runs. W e report both the average classication performance and the best classication performance for each of our model. For reproducibility , we used the following set of seeds for the random number generator: 1, 2, 3, 4, and 5. No hyperparameter tuning was done as tr ying to achieve state-of-the-art performance is beyond the scope of this study , w e only intend to show that using a feature extractor optimized with SNNL helps resolve the issue of expert collapse in a mixture-of-experts model. In addition, no other regularizers were used in order to better demonstrate the benets of SNNL for our feature extractor . 4.1 Evaluation Metrics T o thoroughly evaluate the impact of SNNL and address the limita- tions of purely accuracy-based metrics, we employed the following analytical framework: (1) Expert Specialization Entropy (EN T) . W e calculate the Shannon entropy of the average routing distribution per class. Lower entrop y indicates “hard-routing” while higher entropy indicates a more exible routing distribution across the experts. (2) Pairwise Embe dding Similarity (SIM) . W e extract the rst-layer weight matrices of each expert network and com- pute their pairwise cosine similarity . Lower similarity indi- cates that the experts hav e learned orthogonal and divergent internal representations, thus escaping expert collapse. (3) Statistical Analysis . T o verify if the improvements were robust, all mo dels were trained across multiple random seeds. The dierences in metrics were evaluated using the non- parametric Wilcoxon signed-rank test. (4) Manifold Visualization . W e project the high-dimensional feature representations in the feature extractor into 2D space using UMAP [ 18 ] to qualitatively assess cluster homogeneity and conrm the prevention of structural collapse . 4.2 Experimental Setup T o ensure our ndings are applicable in resource-constrained re- search environments, all models wer e trained locally using PyT orch Lightning on an RTX 3060 GP U . Since the SNNL computation is only required during the training phase to shape the feature e xtrac- tor’s weights, our pr oposed architectural enhancement adds zero computational overhead during inference . W e trained all our models for 15,000 steps on a mini-batch size of 100 using SGD with momentum (0.9) and weight decay (1e-4) [ 20 ] with a learning rate of 1e-1, and we used OneCycleLR to anneal the learning rate [23]. 4.3 Classication Performance T able 1 summarizes the performance across all three core metrics. The experimental models demonstrate signicant b ehavioral shifts compared to the baselines, i.e. trading rigid routing for structural diversity which particularly beneted the more complex datasets. Mixture of Experts with So Nearest Neighbor Loss: Resolving Expert Collapse via Representation Disentanglement PCSC2026, April 2026, Davao, Philippines A CC (MEAN (SD) in %) SIM (MEAN (SD) in x100) EN T (MEAN (SD) in x100) Dataset Baseline Experimental Baseline Experimental Baseline Experimental MNIST 99.36 (0.03) * 99.25 (0.08) 0.03 (0.03) 0.04 (0.06) 0.58 (0.06) 1.94 (0.14) FMNIST 91.33 (0.13) 91.61 (0.23) * 0.03 (0.07) -0.01 (0.05) 16.82 (10.88) 16.00 (11.03) CIF AR10 70.91 (1.09) 71.23 (0.91) (ns) 0.05 (0.11) 0.03 (0.06) 14.00 (15.28) 15.01 (15.52) CIF AR100 35.75 (1.64) 36.74 (1.59) * 0.20 (0.24) 0.10 (0.15) 43.92 (26.88) 45.74 (26.60) T able 1: Classication Accuracy (A CC), Embe dding Similarity (SIM), and Routing Entropy (EN T) across Baseline and Experimen- tal MoE models. V alues represent MEAN (SD). Asterisks (*) denote statistical signicance at 𝑝 < 0 . 05 via Wilcoxon signed-rank test; (ns) denotes not signicant. The Complex Datasets (FashionMNIST and CIF AR100) . The experimental model shows a statistically signicant improv ement over the Baseline in classication accuracy . This conrms that for more dicult and highly entangled feature spaces, priming the latent space with SNNL genuinely aids downstream classication. The Simple Dataset (MNIST) . The baseline model signicantly outperforms the experimental model. Since MNIST is an extremely simple and highly separable dataset (baseline accuracy approaches 99.4%), we suspect forcing SNNL clustering likely introduces over- regularization or unnecessary constraints that marginally degrade performance. 4.4 Ablation and Specialization Analysis Our specialization metrics potentially reveals why the performance on complex datasets improved with our experimental approach. The quantitative data contradicts the assumption that SNNL merely enforces harder routing; instead, SNNL fundamentally pre vents structural expert collapse. Orthogonal Embeddings (Resolving Expert Collapse) . On FashionMNIST , CIF AR10, and CIF AR100, the SNNL model achie ved noticeably lower emb edding similarities. This is profoundly pro- nounced on CIF AR100, where the baseline experts suered from high similarity (0.20), indicating structural redundancy and collapse. SNNL halved this redundancy (0.10). On FashionMNIST , it pushed the similarity into the negative ( -0.01). As visualized in Figure 4, the baseline condition exhibits redun- dancy among experts. By feeding disentangled representations to the MoE, the experts are forced to learn highly distinct and non- overlapping weights, thus cutting the highest o-diagonal similarity by more than half. Routing Entropy (Flexible Collaboration) . Our results show that aside from FashionMNIST , the SNNL model actually increased routing entropy . The SNNL feature extractor makes the latent clus- ters so well-dened that the gating network does not nee d to hard route input features. Instead, it employs a more distributed routing strategy (higher entropy) while relying on the structurally diverse, orthogonal experts to handle classication nuances. Figure 5 visualizes our “exible collaboration” narrative. On the highly complex CIF AR100 dataset, the SNNL condition elevates the entire interquartile range for accuracy , proving a robust p er- formance boost while simultaneously raising the median entropy . On the intermediate CIF AR10 dataset, the SNNL boxplot reaches a higher maximum accuracy , but the heavily overlapping boxes Figure 4: Pair wise cosine similarity between expert weight matrices on CIF AR10. (Left) The Baseline shows distinct patches of redundancy (e.g. b etween Expert 0 and 3). (Right) The SNNL condition visibly suppresses these redundancies, thus forcing experts to learn highly distinct and orthogonal features. contextualize why the overall gain was not statistically signicant. Nevertheless, the underlying behavioral shift towards higher en- tropy remains intact acr oss both complexity levels. Manifold Visualization (V alidating Disentanglement). The UMAP projections in Figure 6 qualitatively conrm the mechanism driving our quantitative metrics. The baseline feature space (Left) exhibits highly entangle d class boundaries, which explains why baseline MoE models suer from higher embe dding similarity: the gating network is forced to send ov erlapping distributions of data to multiple experts. Conversely , the SNNL feature space (Right) demonstrates that intra-class variance has eectively collapsed, resulting in dense and distinct clusters. This proves that SNNL eectively disentangles the feature representations, thus trivializing the gating network’s routing task and enforcing strict structural specialization. 4.5 SNNL W eight Ablation: T uning Expert Diversity T o further understand the continuous eect of the SNNL weighting factor ( 𝛼 ) on expert orthogonality , we conducted an ablation study using a 25k subset of the CIF AR10 training set. W e evaluated 30 models with 𝛼 values linearly spaced from -100 to 100. As illustrated in Figure 7, the trend line conrms a negative correlation between the SNNL weight and pairwise embedding PCSC2026, April 2026, Davao, Philippines Agarap and Azcarraga Figure 5: Distribution of T est Accuracy and Routing Entropy across random se eds. (T op/CIF AR100) SNNL provides a ro- bust, highly stable bo ost to both accuracy and entropy , elevat- ing the entire interquartile range. (Bottom/CIF AR10) While median entropy slightly increases, the wider variance and overlapping accuracy boxes explain the non-signicant ac- curacy gain on this intermediate dataset. Figure 6: UMAP projection of the latent feature space imme- diately prior to the MoE gating network on CIF AR10. (Left) The baseline featur e extractor produces highly entangled class boundaries. (Right) The SNNL-regularized feature ex- tractor minimizes intra-class distance, producing dense and homogeneous class clusters. similarity among the experts. While MoE routing exhibits inherent variance across runs, progressiv ely increasing 𝛼 actively pulls the expected similarity closer to 0. This demonstrates that the SNNL weight acts as a tunable control parameter , i.e. a stronger topologi- cal penalty directly forces the downstream experts to learn more distinct, non-overlapping repr esentations. Figure 7: The ee ct of the SNNL weight ( 𝛼 ) on the pairwise embedding similarity of the experts. The dashed regression line shows a negative correlation, indicating that stronger SNNL penalties actively suppress expert redundancy . 5 RECOMMEND A TIONS While our ndings demonstrate the signicant advantages of SNNL in resolving expert collapse, several avenues for future research remain to fully realize the potential of topology-aware MoE archi- tectures: (1) Dynamic Parameter T uning . Our ablation study high- lighted the sensitivity of expert orthogonality to the SNNL weighting factor ( 𝛼 ). Future work should explore dynami- cally adjusting b oth 𝛼 and the temp erature parameter ( 𝑇 ) during training. Utilizing learning rate schedulers to grad- ually decay or warm up these values could better optimize the transition from global repr esentation clustering to ne- grained cross-entropy classication. (2) Architectural Scaling . The current experiments were con- strained to lightw eight CNN variants to accommodate lo- cal computing limits. Future investigations should scale this methodology to Vision Transformers (ViT s) and higher-resolution, large-scale datasets (e.g. ImageNet) to verify if the disentan- glement benets scale linearly with model size and extreme class diversity . (3) Comparative Representation Learning . Direct bench- marking against other modern contrastive learning tech- niques such as Super vised Contrastive Learning (SupCon) [ 14 ] or SimCLR [ 4 ] is necessar y . This will isolate whether SNNL’s specic layer-wise distance minimization is uniquely suited for MoE gating or if any class neighborhoo d structure- preserving clustering objective yields similar structural di- versity and routing exibility . Mixture of Experts with So Nearest Neighbor Loss: Resolving Expert Collapse via Representation Disentanglement PCSC2026, April 2026, Davao, Philippines 6 CONCLUSION W e proposed and evaluated an architectural modication to the Mixture-of-Experts (MoE) model by integrating a feature extractor optimized via Soft Nearest Neighbor Loss (SNNL). By expanding our evaluation to include specialization metrics like Pairwise Em- bedding Similarity and Expert Sp ecialization Entropy , and including UMAP manifold visualization, we uncovered a nuanced mechanism of action that addresses the limitations of standard MoE architec- tures. Our empirical ndings demonstrate that baseline MoE architec- tures often suer from structural expert collapse, where experts learn redundant representations which r esults to rigid routing by the gating network. Disentangling the feature r epresentations with SNNL solves this structural collapse by forcing the experts to learn highly orthogonal and diverse features. Conse quently , this lib erates the gating network to utilize a more collaborative routing strategy . While disentanglement may have the tendency to “ov er-regularize” models on simple datasets like MNIST , it yields statistically sig- nicant accuracy improv ements on complex or highly entangled datasets such as FashionMNIST , CIF AR10, and CIF AR100, thus ef- fectively bridging the gap between representation learning and ensemble specialization. REFERENCES [1] Agarap, Abien Fred, and Arnulfo P . Azcarraga. “Improving k-means clustering performance with disentangled internal representations. ” 2020 International Joint Conference on Neural Networks (IJCNN). IEEE, 2020. [2] Breiman, Leo. “Stacked regressions. ” Machine learning 24.1 (1996): 49-64. [3] Chapelle, Olivier , Bernhard Scholkopf, and Alexander Zien. “Semi-super vised learning (chapelle, o. et al., e ds.; 2006)[ book reviews]. ” IEEE Transactions on Neural Networks 20.3 (2009): 542-542. [4] Chen, Ting, et al. “ A simple framework for contrastiv e learning of visual repre- sentations. ” International conference on machine learning. PmLR, 2020. [5] Chechik, Gal, et al. “Large Scale Online Learning of Image Similarity Through Ranking. ” Journal of Machine Learning Research 11.3 (2010). [6] Cho, Kyunghyun, et al. “Learning phrase representations using RNN en- coder–decoder for statistical machine translation. ” Proceedings of the 2014 con- ference on empirical methods in natural language processing (EMNLP). 2014. [7] Frosst, Nicholas, Nicolas Papernot, and Geore y Hinton. “ Analyzing and improv- ing representations with the soft nearest neighbor loss. ” International conference on machine learning. PMLR, 2019. [8] Fukushima, Kunihiko. “Neural network model for a me chanism of pattern recog- nition unaected by shift in position-Ne ocognitron. ” IEICE Technical Report, A 62.10 (1979): 658-665. [9] Glorot, X avier , and Y oshua Bengio. “Understanding the diculty of training deep feedforward neural networks. ” Proceedings of the thirteenth international con- ference on articial intelligence and statistics. JMLR W orkshop and Conference Proceedings, 2010. [10] Graves, Alex, Abdel-rahman Mohamed, and Georey Hinton. “Spee ch recognition with deep recurrent neural networks. ” 2013 IEEE international conference on acoustics, speech and signal processing. Ieee, 2013. [11] He, Kaiming, et al. “Deep residual learning for image recognition. ” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. [12] He, Kaiming, et al. “Delving deep into rectiers: Surpassing human-level p er- formance on imagenet classication. ” Proceedings of the IEEE international conference on computer vision. 2015. [13] Jacobs, Robert A., et al. “A daptive mixtures of local experts. ” Neural computation 3.1 (1991): 79-87. [14] Khosla, Prannay , et al. “Supervised contrastive learning. ” Advances in neural information processing systems 33 (2020): 18661-18673. [15] Krizhevsky , Alex, Ilya Sutske ver , and Georey E. Hinton. “Imagenet classica- tion with deep convolutional neural networks. ” Advances in neural information processing systems 25 (2012). [16] LeCun, Y ann, et al. “Gradient-based learning applied to document recognition. ” Proceedings of the IEEE 86.11 (1998): 2278-2324. [17] V an der Maaten, Laurens, and Georey Hinton. “Visualizing data using t-SNE. ” Journal of machine learning research 9.11 (2008). [18] McInnes, Leland, et al. “UMAP: Uniform Manifold Approximation and Projection. ” Journal of Open Source Software 3.29 (2018). [19] Nair , Vinod, and Georey E. Hinton. “Rectied linear units impr ove restricted boltzmann machines. ” ICML. 2010. [20] Polyak, Boris T . “Some metho ds of speeding up the convergence of iteration methods. ” Ussr computational mathematics and mathematical physics 4.5 (1964): 1-17. [21] Rumelhart, David E., Georey E. Hinton, and Ronald J. Williams. Learning inter- nal representations by error propagation. California Univ San Diego La Jolla Inst for Cognitive Science, 1985. [22] Salakhutdinov , Ruslan, and Geo Hinton. “Learning a nonlinear embedding by preserving class neighbourhood structure. ” Articial intelligence and statistics. PMLR, 2007. [23] Smith, Leslie N., and Nicholay T opin. “Super-convergence: V er y fast training of residual networks using large learning rates. ” arXiv preprint arXiv:1708.07120 5 (2017): 4.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment