Multi-view Graph Convolutional Network with Fully Leveraging Consistency via Granular-ball-based Topology Construction, Feature Enhancement and Interactive Fusion
The effective utilization of consistency is crucial for multi-view learning. GCNs leverage node connections to propagate information across the graph, facilitating the exploitation of consistency in multi-view data. However, most existing GCN-based m…
Authors: Chengjie Cui, Taihua Xua, Shuyin Xia
Multi-view Graph Con v olutional Net w ork with F ully Lev eraging Consistency via Gran ular-ball-based T op ology Construction, F eature Enhancemen t and In teractiv e F usion Cheng jie Cui a , T aih ua Xu a, ∗ , Shuyin Xia b , Qinghua Zhang b , Y un Cui a , Shiping W ang c a Scho ol of Computer, Jiangsu University of Science and T e chnology, Zhenjiang, 212100, China b Chongqing Key L ab oratory of Computational Intel ligenc e, Chongqing University of Posts and T ele communic ations, Chongqing, 400065, China c Col lege of Computer and Data Scienc e, F uzhou University, F uzhou 350116, China Abstract The effective utilization of consistency is crucial for m ulti-view learning. Graph con volutional net works (GCNs) leverage no de connections to propagate infor- mation across the graph, facilitating the exploitation of consistency in multi- view data. How ev er, most existing GCN-based multi-view metho ds suffer from sev eral limitations. First, curren t approac hes predominan tly rely on k -Nearest Neigh b ors ( k NN) for top ology construction, where the artificial selection of the k v alue significantly constrains the effectiv e exploitation of in ter-no de consis- tency . Second, the inter-feature consistency within individual views is often o verlooked, whic h adv ersely affects the qualit y of the final embedding rep- resen tations. Moreo ver, these metho ds fail to fully utilize inter-view consis- tency as the fusion of embedded representations from multiple views is often implemen ted after the in tra-view graph conv olutional op eration. Collectiv ely , these issues limit the mo del’s capacit y to fully capture inter-node, inter-feature and inter-view consistency . T o address these issues, this pap er prop oses the m ulti-view graph conv olutional net work with fully leveraging consistency via gran ular-ball-based top ology construction, feature enhancemen t and interactiv e fusion (MGCN-FLC). MGCN-FLC can fully utilize three types of consistency via the follo wing three modules to enhance learning abilit y: (1) The topol- ogy construction module based on the granular ball algorithm, whic h clusters no des into granular balls with high in ternal similarity to capture in ter-no de consistency; (2) The feature enhancement mo dule that improv es feature rep- ∗ Corresponding author. E-mail addr ess: 231210703107@stu.just.edu.cn (Chengjie Cui), xutaihua2019@just.edu.cn (T aih ua Xu), xiasy@cqupt.edu.cn (Shuyin Xia), zhangqh@cqupt.edu.cn (Qinghua Zhang), ycui@just.edu.cn (Y un Cui), shipingw angphd@163.com (Shiping W ang). resen tations by capturing inter-feature consistency; (3) The interactiv e fusion mo dule that enables each view to deeply interact with all other views, thereby obtaining more comprehensive inter-view consistency . Experimental results on nine datasets show that the proposed MGCN-FLC outperforms state-of-the-art semi-sup ervised no de classification metho ds. K eywor ds: Multi-view learning, Granular ball computing, Graph con volutional net work, Semi-supervised classification 1. Introduction Multi-view data refers to data obtained from multiple p ersp ectiv es, sources, or feature extraction metho ds that describ e the same set of ob jects. While the feature sets of different views may v ary , the ob jects across all views maintain a one-to-one correspondence. Multi-view learning can comprehensiv ely utilize in- formation from m ultiple views to ac hieve b etter representational capability , and has spark ed extensive research across multiple fields including computer vision [ 1 , 2 , 3 ] and mac hine learning [ 4 , 5 , 6 ]. The effective utilization of consistency is crucial for multi-view learning [ 7 ]. By using the consistency in multi-view data [ 8 , 9 ], m ulti-view learning can ac hieve high-qualit y embedding representations. Graph neural net works (GNNs) hav e demonstrated strong expressiv e p o w er in v arious learning tasks [10, 11, 12, 13], driving significant atten tion in the field of multi-view learning. In particular, graph con volutional net works (GCNs) [14], a widely used GNN mo del, extend conv olutional op erations to non-Euclidean graph data, enabling node features to in teract through top ology structure. GCNs hav e b een applied successfully in do wnstream tasks suc h as no de classifi- cation [15, 16, 17] and link prediction [18, 19]. Recently , numerous GCN-based m ulti-view learning approac hes [ 9 , 20, 21, 22] hav e incorporated GCNs into m ulti-view data. These metho ds can effectively leverage the consistency [ 8 , 9 ] in multi-view data through message passing mechanisms on graphs, achieving sup erior learning capabilities [21, 23]. Since multi-view data do es not provide the top ology information, the con- struction of high-quality top ology structures is a necessary step in GCN-based m ulti-view learning. Some studies [24, 25] adopted k -Nearest Neighbors ( k NN) as the foundational algorithm for top ology construction. Giv en that k NN ma y in tro duce k -v alue noise [26, 27, 28] in to the constructed top ology , some re- searc h [ 9 , 20, 25] has made v arious improv ements to the k NN-based top ology construction. Ho wev er, a fixed global k v alue is destined to not adapt to the data distribution of different views simultaneously . Then some latest studies [21, 23, 29] mov ed aw a y from the k NN and instead fo cus on exploring nov el metho ds for constructing topologies. Among them, GBCM-GCN [23] first in- tro duces the unsup ervised granular ball algorithm [30] to cluster the data into sev eral granular balls (GBs), then the top ology are constructed by p erforming no de-lev el full connection b et ween the GBs pairs according to the b oundary distances. As is well kno wn, the lab el consistency assumption [31, 32] under- pins the message passing mechanism in GNNs, and the quality of the learned 2 em b eddings strongly dep ends on ho w well the data satisfy this assumption. A commonly used metric to quan tify this prop ert y is the homophily ratio [31, 32], defined as the prop ortion of edges whose endp oints share the same lab el rela- tiv e to the total num b er of edges; this metric can also serves as an indicator of top ology quality . Our analysis rev eals that the homophily ratio of the GBCM- GCN [23] metho d is not very high, which inevitably impacts the quality of the constructed top ology . Therefore, the first issue fo cused on in this pap er is: how to construct the high-quality top ologies with the high homophily ratio. In recent years, lev eraging feature in teraction to enhance inter-feature con- sistency has emerged as a key researc h direction in GNNs [ 33, 34]. DFI-GCN [33] employs Newton’s iden tities to extract high-order interactiv e features, while Cross-GCN [34] introduces a "cross-feature graph conv olution" op erator to effi- cien tly and explicitly capture interactiv e features of arbitrary orders. Although there is already research [9] successfully integrates feature interaction into multi- view data, it concentrates solely on inter-view feature interactions, ov erlooking in tra-view feature interactions. This fails to fully leverage the in ter-feature con- sistency within individual views, and degrades the qualit y of the final em b ed- dings. Therefore, the second issue fo cused on in this pap er is: how to effectively em b ed the inter-feature consistency within each view into the final represen ta- tion. In ter-view information interaction directly affects the effectiveness of multi- view learning [9, 35]. Therefore, the utilization of inter-view consistency has alw ays b een a key research in multi-view learning [ 20, 21, 23, 25]. In the GCN- based multi-view learning, the most traditional approach [ 22, 36, 37, 38] to in ter-view feature interaction is to directly concatenate feature representations from all views. How ever, this strategy neither enables deep interaction among views nor explicitly exploits in ter-view consistency . Recen tly , GBCM-GCN [23] prop osed constructing the la yer-specific collaboration matrices using the view with the richest feature information and sharing them across conv olutional la y- ers of other views. Although this approach explicitly leverages inter-view con- sistency , the collab oration matrices are deriv ed solely from information-richest view, which limits information exchange across arbitrary views. As a result, GBCM-GCN [23] do es not fully utilize in ter-view consistency . Therefore, the third issue fo cused on in this pap er is: how to explicitly and fully leverage the in ter-view consistency by the information in teraction across arbitrary views. T o address the ab ov e three issues, this pap er prop oses a m ulti-view graph con volutional net work with fully leveraging consistency via granular-ball-based top ology construction, feature enhancemen t and interactiv e fusion (MGCN- FLC). The MGCN-FLC consists of three mo dules: top ology construction, fea- ture enhancement and interactiv e fusion. T op ology construction mo dule. The top ology construction mo dule em- plo ys an unsupervised gran ular ball clustering algorithm[30] to cluster nodes in to granular balls (GBs). The no des within the same GB demonstrate a high- lev el similarit y , leading to strong categorical consistency . Moreov er, nodes from t wo closely p ositioned GBs also display similarity to some extent. Based on GBs, this mo dule p erforms no de connections at t wo levels: intra-GB connec- 3 tions and inter-GB connections, which yields the high-qualit y top ologies with the high homophily ratio. F eature Enhancement Mo dule. The feature enhancemen t mo dule in- tro duces feature interaction within each individual view. Sp ecifically , for each view, the inter-feature similarity matrix is computed and then is multiplied by the original features matrix to generate similarity-based features matrix. T o extract more comprehensive information, mixed p ooling that combines a v erage p ooling and max p ooling is applied to the stac ked original and similarity-based feature matrices, producing an enhanced feature matrix. This enhanced feature matrix con tains the results of intra-view feature interaction, effectively enhanc- ing inter-feature consistency representation. In teractiv e F usion Mo dule. The interactiv e fusion mo dule is designed to deeply explore the inter-view interaction information to explicitly and fully exploit in ter-view consistency . Specifically , the interaction matrix b et w een any t wo views is computed, and then the in teraction matrices corresp onding to each view are aggregated together, which can explicitly express the inter-view con- sistency . F urthermore, all views share a common weigh t matrix to generate the final feature represen tation, which can fully exploit the inter-view consistency . The main con tributions of this pap er are summarized as follows: • An adaptive top ology construction metho d is prop osed, whic h constructs t wo-lev el no de connections (intra-GB and inter-GB) via unsup ervised GB clustering, yielding high-homophily top ologies. • A feature enhancement metho d is designed, enhancing in tra-view feature in teraction and inter-feature consistency representation by computing the feature similarity matrix and applying mixed p ooling. • An interactiv e fusion mo dule is used to explicitly express and fully exploit the inter-view consistency . • In the do wnstream semi-sup ervised no de classification task, exp erimen tal results demonstrate the effectiveness of the prop osed MGCN-FLC. 2. Related work W e will introduce the granular ball, graph conv olutional netw orks, and GCN- based multi-view learning. 2.1. Gr anular b al ls Most GCN-based multi-view learning [26, 27] employ ed k -Nearest Neighbors ( k NN) for top ology construction. How ever, the use of k NN inevitably introduces noise asso ciated with the selection of the k v alue, which can degrade the qualit y of the constructed top ology . T o address this issue, Xia et al. [39] prop osed a clustering algorithm that av oids k -v alue noise by partitioning data into granular balls (GBs). This partitioning is based on the premise that spatially proximate 4 ob jects tend to exhibit similar distributions and are therefore lik ely to belong to the same category . This premise naturally leads to the need for ev aluating GB’s quality . In other words, an optimal GB should contain as many ob jects of the same category as p ossible. F or this issue, the concept of "purity" w as prop osed [40] and adopted as the termination criterion for GB partitioning. Ho wev er, the computation of purity hea vily relies on the av ailability of lab el information. T o ov ercome this limitation, Cheng et al. [30] developed an unsu- p ervised GB clustering algorithm that adopts √ N as the termination criterion for GB partitioning, thereb y eliminating the reliance on lab el information. In this w ork, we adopt this unsup ervised GB clustering metho d to generate GBs, whic h av oids can av oid k -v alue noise and do es not require lab el information. As a result, it pro vides reliable no de category information for subsequent topology construction. 2.2. Gr aph c onvolutional network Graph Con volutional Netw orks (GCNs) [14] are an imp ortan t branc h of Graph Neural Netw orks (GNNs), which extended the con v olution op eration from regular Euclidean data to non-Euclidean graph-structured data. The core idea of GCNs is to use the top ology to guide the propagation and aggregation of no de features, enabling each no de to gather information from its neighbors, thereb y generating no de embeddings that encapsulate rich contextual relation- ships. GCN employ ed the follo wing propagation formula (Eq. 1 ), whic h incorp o- rates top ology information (i.e., the adjacency matrix) to propagate and aggre- gate no de features: H ( l +1) = σ ˜ D − 1 2 ˜ A ˜ D − 1 2 H ( l ) W ( l +1) , (1) where H ( l +1) represen ts the embedding at the ( l + 1) -th lay er of the GCN. T o retain the node’s own information after feature information integration, GCN in tro duces self-lo ops to the adjacency matrix A , resulting in ˜ A = A + I . ˜ D represen ts the degree matrix of ˜ A . H ( l ) is the embedding at the l -th lay er. W ( l +1) represen ts the weigh t matrix at the ( l + 1) -th lay er and σ ( · ) is the activ ation function. Based on GCN, many extension algorithms [33, 41, 42, 43, 44] hav e b een dev elop ed that demonstrate sup erior p erformance in semi-supervised node clas- sification tasks. DFI-GCN [33] utilizes Newton’s identit y to extract across fea- tures of differen t orders from the original features and designs an attention mec hanism to fuse these features, enhancing feature represen tation capability . HDGCN [41] in tro duces a dual-channel architecture that effectiv ely captures high-order topological information while preserving original features, address- ing the lack of robustness in single-channel GCNs when pro cessing high-order information. AM-GCN [42] adaptively fuses multi-c hannel conv olution results via an attention mechanism, effectively mitigating insufficien t integration of no de feature and top ology information in GCN. MOGCN [43] constructs mul- tiple learners using multi-order adjacency matrices and introduces an ensemble 5 mo dule to fuse the results of these learners, alleviating the ov er-smo othing is- sue. LPD-GCN [44] utilizes an enco der-decoder mechanism to sup ervise eac h con volutional la y er, enabling b etter preserv ation of lo cal features in the hidden represen tations of each la yer. Figure 1: MGCN-FLC consists of three mo dules: the top ology construction mo dule (TC), the feature enhancement mo dule (FE) and the interactiv e fusion mo dule (IF). Sp ecifically , the TC module constructs the top ology by establishing the inter-GB and intra-GB full connections between no des, providing an effective path wa y for information propagation in the GCN. The FE mo dule applies mixed po oling to the stacking result of the similarit y feature matrix and the original feature matrix, generating the enhanced feature representations. Subsequently , the enhanced feature representations generated by FE mo dule from multiple views are en- coding into the same dimension. Based on the enco der’s output, the IF module computes and aggregates interactiv e features b et ween tw o distinct views to ultimately generate no de embeddings. Finally , the topology constructed by the TC mo dule and the no de embeddings generated by the IF mo dule are jointly fed as input into a standard GCN for no de prediction. 2.3. GCN-b ase d multi-view le arning The core of multi-view learning is to capture the consistency and comple- men tarity b et w een m ultiple views, thereby enhancing the mo del’s performance. A multi-view dataset can b e represen ted as X = { X v } V v =1 . F or the v -th view, X v = [ x 1 , x 2 , . . . , x N ] T ∈ R N × d v , where N is the num b er of no des, and d v is the num b er of features in the v -th view. F rom the persp ective of feature, the m ultiple-view data can also b e denoted as X = { F v } V v =1 . F or the v -th view, F v = [ f 1 , f 2 , . . . , f d v ] ∈ R N × d v . Researc hers [20, 21, 23, 24, 25, 38] ha ve b een prop osed v arious GCN-based metho ds for handling multi-view data. LGCN-FF [20] implements collab orativ e optimization b et ween features and top ologies in multi-view data by join tly train- ing the feature fusion netw ork and the adaptive top ology fusion mo dule. JF GCN 6 [25] learns consistent feature representations through the auto encoder, and in- tro duces the adaptive fusion mec hanism that combines k -Nearest Neighbors ( k NN) and k -F arthest Neighbors ( k FN), achieving collab orative optimization b et w een features and top ologies. Co-GCN [24] constructs k NN-based top olo- gies from the features of each view as a foundation, and provides each view with top ology information derived from a weigh ted combination of all views’ Lapla- cian matrices, thereby ac hieving implicit collab oration of inter-view top ologies. CGCN-FMF [21] emplo ys b oth k NN and limited lab el information to obtain the optimal top ology for each view, dynamically fusing them via trainable weigh ts π , and in tro duces the 1D con volutional neural net work to fuse multi-view features learned by sparse auto encoders into the unified representation. MSGG [38] con- structs the top ology by employing edge sampling and path sampling strategies to collect top ology information, and utilizes maxim um likelihoo d estimation to directly learn the in tegrated top ology that captures cross-view consistency . Sub- sequen tly , the MSGG mo del uses MLP to extract multi-view features separately , and then concatenates these features to obtain the fused feature represen tation. GBCM-GCN [23] introduces an unsup ervised GB algorithm [30] to construct top ologies b y fully connecting no des b et w een GB pairs based on b oundary dis- tances. In addition, it computes lay er-sp ecific collab orative matrices from the most feature-rich view and shares them across all views to enhance cross-view consistency . Although these metho ds hav e achiev ed promising p erformance in multi-view learning, several limitations remain. These metho ds either fail to hinder the k - v alue noise from the k NN applied in top ology construction, or do not to fully exploit the inter-view consistency through the feature fusion strategies. In this pap er, we contin ue to adopt the unsup ervised GB algorithm used in previous w ork [23] to generate GBs, in which no des b elonging to the same GB naturally exhibit consistency . The difference lies in that the topology constructed in this pap er includes b oth intra-GB and inter-GB connections, exhibiting a high homophily ratio. F urthermore, we introduce the feature enhancement mo dule and the in teractive fusion mo dule. The feature enhancemen t module refines in tra-view feature representation within each view by lev eraging inter-feature in teractions, while the interactiv e fusion mo dule explicitly and fully explores the inter-view consistency . 3. The prop osed metho d In this section, we prop ose the MGCN-FLC mo del, which is designed to explore inter-node, inter-feature, and inter-view consistency in multi-view data. The mo del consists of three main mo dules: top ology construction, feature en- hancemen t, and interactiv e fusion. The ov erall framework of MGCN-FLC is illustrated in Fig. 1 . 3.1. T op olo gy c onstruction via GBs W e employ an unsup ervised GB clustering algorithm [30] to generate GBs. The sp ecific pro cess is as follows: all no des in each view are initially assigned to 7 Algorithm 1 Generate-GBs Input: X v = [ x 1 , x 2 , . . . , x N ] T ∈ R N × d v . Output: GB s ={ GB 1 , GB 2 , . . . , GB m }. Initialize: GB = [ x 1 , x 2 , . . . , x N ] T ∈ R N × d v , GB s = ∅ . A dd GB to an empt y queue Q . While Q is not empty do Get the first GB from Q and delete it from Q . if the GB contains more than √ N no des then Split the GB into t wo sub-GBs using the 2-means algorithm. Enqueue the t wo sub-GBs into Q . end if the GB contains no more than √ N no des then A dd the GB to GB s . end End Return: GB s a single GB. T o ensure high in ter-no de similarity within each GB while main- taining computational efficiency , the balance must b e struck b et ween the size and the quan tity of GB. In [30], √ N is used as the termination condition for GB splitting. GB is split if the num b er of no des it contains exceeds √ N ; oth- erwise, the splitting pro cess terminates. This pro cedure is rep eated iteratively un til all GBs satisfy the termination condition. Upon completion, the resulting set of GBs is denoted as GB s ={ GB 1 , GB 2 , . . . , GB m }. Algorithm 1 sho ws the detailed pro cedure for generating GB s in the v -th view. F or intra-GB top ology construction, we apply a full connection op eration within each GB I ( I ∈ [1 , m ] ), resulting in intra-GB top ology A intra . The element at the i -th ro w and j -th column of A intra ( i, j ) , denoted A intra ( i, j ) , is defined as follo ws: A intra ( i, j ) = ( 1 if x i , x j ∈ GB I , 0 otherwise , (2) where x i and x j are tw o different nodes. T o enable no des to learn global information, the inter-GB connections also need to b e established. W e prop ose connecting the t wo most similar GBs. Sp ecifically , for eac h GB, a representativ e no de is selected, whic h is the no de within the GB that minimizes the sum of Euclidean distances to all other no des. F ormally , the representativ e no de r I of GB I is chosen as follows: r I = arg min x i ∈ GB I X x j ∈ GB I D ist ( x i , x j ) , (3) where D ist ( x i , x j ) = ∥ x i − x j ∥ 2 . The Euclidiean distance b et ween tw o represen- tativ e no des r I and r J , D ist ( r I , r J ) = ∥ r I − r J ∥ 2 , is then used to measure the similarit y b et ween tw o GBs GB I and GB J . W e use full connection op eration b et w een GB I and its nearest neighbor GB J to construct the inter-GB top ology 8 A inter . The element at the i -th row and j -th column of A inter ( i, j ) , denoted A inter ( i, j ) is defined as follows: A inter ( i, j ) = ( 1 if x i ∈ GB I , x j ∈ GB J , 0 otherwise , (4) where x i and x j are tw o different nodes. F or the v -th view, the top ology A v is constructed by fusing A v intra and A v inter . The fusion is controlled by the hyperparameter α , which is learnable from the data distribution through end-to-end training using a cross-entrop y loss func- tion, eliminating the need for manual tuning. The form ula is as follows: A v = α A v inter + (1 − α ) A v intra . (5) The differences b et ween views can lead to v ariations in the top ologies. T o obtain a unified top ology A that aligns with all views, w e introduce an adaptive w eighting metho d to in tegrate the top ologies from all views, as shown in Eq. 6 . A = V X v =1 π v A v , (6) where π v is the w eight of the v -th view, reflecting the importance of each view. T o av oid an y view from dominating the fusion of top ologies, the w eights of π v are normalized as follows: π v ← exp( π v ) V P v =1 exp( π v ) . (7) 3.2. F e atur e enhanc ement mo dule T o explore the inter-feature consistency within eac h view, the intra-view feature interaction is essential. Firstly , w e design the similarit y matrix S v ∈ R d v × d v for the v -th view by computing the similarities b etw een all feature, characterizing the inter-feature consistency . The calculation formula is as follows: S v = ( F v ) T F v ∥ ( F v ) T ∥ 2 ∥ ( F v ) ∥ 2 , (8) where F v ∈ R N × d v is the feature matrix of the v -th view, and ∥ · ∥ 2 represen ts L -2 norm. T o enable the original features to acquire inter-feature consistency informa- tion, the feature matrix X v is transformed into the similarity feature matrix X v s via multiplication with S v : X v s = X v S v . (9) T o obtain the comprehensive feature representation H v for the v -th view, w e adopt the mixed p ooling strategy . This strategy leverages max p o oling to 9 extract salient lo cal details from the original feature matrix and a verage po oling to preserve global con textual information from the similarity feature matrix, thereb y integrating b oth information sources. The formula is as follo ws: H v = β MP ( X v input ) + (1 − β ) AP ( X v input ) , (10) where X v input ∈ R N × d v × 2 is the stacking of X v and X v s , and MP and AP repre- sen t max p ooling and a verage po oling resp ectively . β is the hypeparameter. 3.3. Inter active fusion mo dule Most existing approaches do not explicitly or fully exploit inter-view consis- tency , which can result in sub optimal no de em b edding. In this work, we leverage in ter-view consistency through interactiv e fusion to generate feature representa- tions that yield more p o werful no de em b eddings. Before p erforming the fusion, it is necessary to align feature dimensions across all views. T o achiev e this, w e emplo y the sparse autoenco der [20] to map features of different dimensions into the same dimension d . The sparse auto enco der is formulated as follows: O ( l,v ) = σ O ( l − 1 ,v ) W ( l,v ) sa + b ( l,v ) sa , (11) where O ( l,v ) ∈ R N × d l represen ts the output of the l -th la y er in the sparse auto encoder for v -th view. d l denotes the output feature dimensionalit y of the decoder in the sparse auto enco der. W ( l,v ) sa ∈ R d l − 1 × d l , b ( l,v ) sa ∈ R d l and σ represen t the weigh ts, the biases and the activ ation function, resp ectively . The loss function of the sparse auto enco der for the v -th view is defined as follo ws: L v sa = 1 2 O ( l,v ) − X v 2 2 + γ D K L ( ρ ∥ ˆ ρ ) , (12) where ∥ · ∥ 2 represen ts L -2 norm, D K L ( ρ ∥ ˆ ρ ) quantifies the divergence b et w een the target sparsity ρ and the actual sparsit y ˆ ρ distributions, thereby guiding the sparse auto encoder to learn meaningful features. The parameter γ controls the strength of the sparsity . The sparse auto enco der, consisting of the total of L la yers, has tw o main comp onen ts: the encoder and the deco der. Because the enco der pro duces di- mensionally aligned feature represen tations, we adopt its output as the feature represen tation for the v -th view: H v = O ( L 2 ,v ) . T o explicitly and fully lev erage inter-view consistency , we explore the in- teractiv e information b etw een an y tw o different views. F or the node x i , the no de-lev el in teractiv e information c ( v,v ′ ) i ∈ R N × d is calculated b y using the fea- ture information of x i from v -th and v ′ -th views, i.e. H v i and H v ′ i . Sp ecifically , c ( v,v ′ ) i = H v i ⊙ H v ′ i , (13) where ⊙ is the element-wise pro duct. The interactiv e information in volving N no des is as follo ws: c ( v,v ′ ) = h c ( v,v ′ ) 1 ; c ( v,v ′ ) 2 ; . . . ; c ( v,v ′ ) N i . (14) 10 The feature represen tation of the v -th view, C v ∈ R N × d , is generated by aggregating the interactiv e information betw een the v -th view and all other views. C v = V X v ′ =1 c ( v,v ′ ) − c ( v,v ) . (15) Finally , the output of the interactiv e fusion mo dule, H ∈ R N × d , is computed b y fusing the feature representations of all views using shared w eights matrix whic h is trained end-to-end with the cross-entrop y loss function: H = V X v =1 σ ( C v ⊙ W share + b share ) , (16) where W share ∈ R N × d and b share ∈ R N × d are the share weigh ts and biases, resp ectiv ely . 3.4. Semi-sup ervise d no de classific ation F or the do wnstream semi-sup ervised no de classification task, the constructed top ology A (Eq. 6 ) and the fused feature representations H (Eq. 16) are input in to the GCN for information propagation. The propagation mec hanism of features across GCN lay ers is defined by the forward propagation formula, which iterativ ely up dates no de features based on the top ology: H l = σ AH l − 1 W l , (17) where H l − 1 is the up dated feature representation from the ( l − 1) -th la yer, W l is the trainable weigh t matrix of the l -th lay er and σ is the non-linear activ ation function. In particular, H 1 = σ ( AH 0 W 1 ) , with H 0 = H . The traditional shallow GCN consists of tw o lay ers, then the no de embedding Z is shown as follows: Z = softmax Aσ AH W 1 W 2 , (18) where sof tmax ( · ) computes the probabilit y distribution ov er no de categories. F or semi-sup ervised no de classification tasks, the cross-entrop y loss function is used to measure the discrepancy b et w een the mo del’s predicted probability distribution and the actual lab els. Minimizing this loss ensures optimal classi- fication p erformance. The loss function L gcn is shown as follows: L gcn = − X i ∈ X L C X c =1 Y ic log( Z ic ) , (19) where X L represen ts the set of lab eled samples, C is the num b er of categories, Y ic is the true label and Z ic represen ts the predicted probability for no de i b elonging to class c . Algorithm 2 sho ws the detailed pro cedure of MGCN-FLC. 11 Algorithm 2 MGCN-FLC Input: X = { X 1 , X 2 , . . . , X v } . Output: No de embedding Z . F or v = 1 → V do Generate GB s ={ GB 1 , GB 2 , . . . , GB m } by the Algorithm 1. Construct the in tra-GB top ology A v intra b y Eq. 2 . Construct the in ter-GB top ology A v inter b y Eq. 4 . Generate A v through A v intra and A v inter b y Eq. 5 . Generate the feature representation H v based on X v s b y Eq. 10. End for Compute the unified top ology A b y Eq. 6. While not con verging do for v = 1 → V do Compute O ( L/ 2 ,v ) for the sparse auto enco der b y Eq. 11. Calculate the feature representation C v b y Eq. 15. end for Compute the output H of interactiv e fusion mo dule by Eq. 16. Compute H l of the GCN by Eq. 17. End while Return: No de embedding Z . 3.5. Complexity analysis This section analyzes the computational complexity of the prop osed MGCN- FLC mo del. F or the v -th view, the topology construction mo dule first employs the unsu- p ervised GB algorithm [30] to generate GBs. Its time complexity is O ( N log m ) ( m ≪ N ) in whic h N and m represen t the num b er of no des and GBs, resp ec- tiv ely . Then, the mo dule establishes no de connections based on the GBs. On a verage, each GB contains approximately N m no des, so the time complexity for establishing intra-GB or in ter-GB connections is O ( N 2 m ) . F or establishing inter- GB connections, represen tative no des must b e selected from each GB and the distances b et ween each pair of GBs computed. Selecting representativ e nodes has the time complexity of O ( N 2 m ) , while computing distances b etw een GB pairs requires O ( m 2 ) . In summary , the total time complexity of the top ology con- struction mo dule is O ( N log m + N 2 m + m 2 ) . F or the v -th view, the feature enhancement mo dule first computes the sim- ilarit y matrix with complexity O ( N ( d v ) 2 ) , and then multiplies the original fea- ture matrix with the similarity matrix, also O ( N ( d v ) 2 ) . Stac king the original and similarit y feature matrices and applying mixed p ooling to pro duce the fea- ture representation H v has complexity O ( N d v ) . Th us, the total complexity of the feature enhancemen t mo dule is O ( N ( d v ) + N ( d v ) 2 ) . F or the v -th view, the interactiv e fusion mo dule first aligns feature dimen- sions using the sparse auto enco der, with time complexity O ( N d v d 1 + N d 1 d ) , where d 1 and d represent the hidden lay er dimensions of the sparse auto en- 12 co der. Computing the interactiv e information b et w een the v -th view and all other views is O (( V − 1) N d ) , and aggregating the interactiv e information also requires O (( V − 1) N d ) . Therefore, the total complexity of the interactiv e fusion mo dule is O ( N d v d 1 + N d 1 d + ( V − 1) N d ) . F or the v -th view, these three mo dules hav e the total time complexity of O ( N d v d 1 + N d 1 d + ( V − 1) N d + N ( d v ) + N ( d v ) 2 + N log m + N 2 m + m 2 ) . F or a m ulti-view dataset with V views, assuming D = P V v =1 d v , then the total time complexit y of the three mo dules will b e O ( N D d 1 + N V d 1 d + N V ( V − 1) d + N D + N D 2 + N V log m + V N 2 m + V m 2 ) . In addition, thereafter the graph conv olution op eration is adopted by MGCN- FLC, which requires the time complexit y of O ( N 2 d ) . Thus, the time complexity of MGCN-FLC is: O ( N V ( D d 1 + d 1 d + ( V − 1) d + D + D 2 + log m + N m ) + V m 2 + N 2 d ) . Generally , there are N ≫ V , N ≫ m and D ≫ d 1 , d , then the time complexit y of MGCN-FLC can b e simplified to: O ( N D 2 + N 2 ) . 4. Exp erimen t In this section, w e conduct extensive exp erimen ts on semi-sup ervised no de classification tasks, including comparative exp erimen ts, parametric sensitivit y analysis, ablation exp erimen ts, exp eriments with v arying lab el rates, visual- ization analysis, con vergence analysis, runtime comparison, and exp erimental discussion. 4.1. Datasets T able 1: A brief description of multi-view datasets Datasets # samples # views # features # classes # data types BBCnews 685 4 4,659/4,633/4,665/4,684 5 T extual documents Caltech101-7 1474 6 48/40/254/1984/512/928 7 Object images MNIST 10000 3 30/9/9 10 Digit images NUS-WIDE 2400 6 64/73/128/144/225/500 8 Object images W ebKB 203 3 1,703/230/230 4 T extual documents BBCsports 544 2 3183/3203 5 T extual documents NGs 500 3 2000/2000/2000 5 T extual documents ProteinF old 694 12 27/27/27/.../27 27 Protein documents Reuters 1500 5 21531/24893/34279/.../11547 6 T extual documents T able 1 . presents detailed information ab out multi-view datasets used in our exp eriments, including the num ber of samples, the num b er of views, the n umber of features of each view, the n umber of categories, and the data types. 4.2. A lgorithm and p ar ameter setup The prop osed MGCN-FLC is compared with nine algorithms, including tw o classical multi-view learning algorithms (MLAN [45] and MV AR [46]), fiv e GCN- based m ulti-view algorithms fo cusing on top ology construction (Co-GCN [24], DSRL [47], LGCN-FF [20], JFGCN [25], and HGCN-MVSC [36]), and tw o 13 GCN-based multi-view algorithms simultaneously lev erage top ology construc- tion and cross-view interactiv e fusion (MvRL-DP [22] and GBCM-GCN [23]). The dataset is split into training, v alidation, and testing sets with ratios of 10%, 10%, and 80% of the total dataset size, resp ectiv ely . The parameters of the nine baseline are set according to the configurations reported in their original pap ers. F or the prop osed MGCN-FLC mo del, we employ a 2-lay er graph con volutional architecture with the dropout rate of 0.5 and the learning rate of 0.01. The ReLU and Softmax functions are used as activ ation functions in the hidden and output lay ers, resp ectively . The sparse auto enco der is structured with lay er sizes [1024 , 256] , trained with a learning rate of 0.001 and weigh t deca y of 0.01. The prop osed MGCN-FLC mo del is implemented in PyT orch platform and executed on the machine equipp ed with the In tel i9-12400F CPU, Nvidia R TX 4070 GPU and 12 GB RAM. 4.3. Classific ation ac cur acy and F1-sc or e T able 2: The classification p erformance of all compared semi-sup ervised classification methods uses 10% lab eled samples as sup ervision, where the b est p erformance is highlighted in b old and the second-best results are underlined. Methods/Datasets BBCnews Caltech101-7 MNIST NUS-WIDE W ebKB BBCSp orts NGs ProteinF old Reuters MLAN (2017) 74.1 73.5 76.3 75.6 87.7 86.1 34.1 33.2 73.9 41.2 80.5 80.1 85.5 83.3 35.6 31.2 64.6 63.2 MV AR (2017) 75.3 76.6 79.1 78.5 84.9 81.7 29.3 28.5 76.9 46.3 82.1 82.8 86.6 85.7 39.6 35.1 83.5 81.8 Co-GCN (2020) 81.9 78.1 83.1 80.2 90.2 90.1 27.5 28.1 72.6 39.3 86.3 84.9 84.2 83.6 41.2 37.8 78.4 73.7 DSRL (2022) 84.5 83.1 85.3 84.6 88.9 87.1 43.6 43.2 82.5 58.2 90.9 93.7 88.7 84.5 46.5 39.5 36.5 25.3 LGCN-FF (2023) 86.1 85.8 86.5 85.5 88.8 86.4 32.4 28.6 83.1 52.6 94.7 94.7 92.4 92.4 41.3 35.0 64.9 60.9 JFGCN (2023) 85.6 85.4 92.2 86.3 91.5 90.5 48.4 45.5 80.1 58.3 92.9 92.8 90.2 90.5 38.7 29.7 57.9 39.7 HGCN-MVSC (2024) 90.7 90.2 92.5 91.2 92.5 92.2 49.2 46.3 82.3 59.5 96.9 97.0 93.1 92.8 51.2 47.6 77.4 73.7 MVRL-DP (2025) 94.2 94.3 93.1 93.0 94.1 94.1 54.3 52.1 83.8 62.2 97.1 97.1 93.5 83.1 54.0 47.8 64.4 55.4 GBCM-GCN (2026) 98.0 97.1 94.2 87.3 98.0 98.1 96.5 96.5 85.3 55.2 96.7 95.2 94.5 94.0 58.3 48.0 97.6 96.5 MGCN-FLC 98.4 97.9 97.5 91.3 96.4 95.8 99.0 99.0 91.8 67.2 97.4 97.3 97.8 97.8 60.0 48.3 99.1 98.9 The accuracy (A CC) and F1-score of all algorithms on the nine datasets are presented in T able 2 . On the Caltec h101-7, NUS-WIDE, W ebKB, NGs, ProteinF old, and Reuters datasets, MGCN-FLC outp erforms the second-b est metho d GBCM-GCN [ 23], improving the ACC v alues b y 3.3%, 2.5%, 6.5%, 3.3%, 1.7%, and 1.5%, respectively . These impro vemen ts are attributed to that the proposed MGCN-FLC simultaneously utilizes b oth in tra-ball and in ter-ball connections, whereas GBCM-GCN [23] fo cuses only on the inter-ball connec- 14 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label ratios 0.5 0.6 0.7 0.8 0.9 1.0 A CC ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (a) BBCnews 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label rati s 0.7 0.8 0.9 1.0 A CC ML AN MV AR C - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (b) Caltech101-7 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label rati s 0.7 0.8 0.9 1.0 A CC ML AN MV AR C - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (c) MNIST 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label ratios 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 A CC ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (d) NUS-WIDE 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label rati s 0.7 0.8 0.9 1.0 A CC ML AN MV AR C - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (e) W ebKB 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label ratios 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 A CC ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (f) BBCsp orts 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label rati s 0.7 0.8 0.9 1.0 A CC ML AN MV AR C - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (g) NGs 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label ratios 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 A CC ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (h) ProteinF old 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label ratios 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 A CC ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (i) Reuters Figure 2: ACC of all methods as the ratio of lab eled data ranges in {0.05, 0.10, . . . , 0.5} on the nine datasets. tions, whic h facilitates feature propagation, thereb y generating more expressiv e no de em b eddings. By leveraging feature in teractions, MGCN-FLC captures inter-feature con- sistency and generates feature representations that incorp orate such consistency . Compared with MvRL-DP [22] and the GBCM-GCN [23], which b oth utilize top ology construction and cross-view in teractive fusion, MGCN-FLC ac hieves further ACC improv ements on most datasets. F urthermore, b y explicitly and fully leveraging inter-view consistency , MGCN-FLC consistently outp erforms that fo cus solely on top ology construction, such as Co-GCN [24], DSRL [47], LGCN-FF [20], JFGCN [25], and HGCN-MVSC [36], demonstrating significant gains in A CC across all datasets. 15 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label rat os 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 F1-scor e ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (a) BBCnews 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label ratios 0.7 0.8 0.9 1.0 F1-scor e ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (b) Caltech101-7 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label ratios 0.7 0.8 0.9 1.0 F1-scor e ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (c) MNIST 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label rat os 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 F1-scor e ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (d) NUS-WIDE 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label rat os 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 F1-scor e ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (e) W ebKB 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label rat os 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 F1-scor e ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (f) BBCsp orts 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label ratios 0.7 0.8 0.9 1.0 F1-scor e ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (g) NGs 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label rat os 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 F1-scor e ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (h) ProteinF old 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0.50 Label rat os 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 F1-scor e ML AN MV AR Co - GCN DSRL LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC (i) Reuters Figure 3: F1-score of all metho ds as the ratio of lab eled data ranges in {0.05, 0.10, . . . , 0.5} on the nine datasets. 4.4. Classific ation p erformanc e with varying lab el r atios Figs. 2 and 3 show the ACC and F1-score of each algorithm under v arying lab el ratios. Here, the lab el ratio refers to the prop ortion of lab eled training sam- ples relative to the total num b er of samples, ranging 5% to 50% in increments of 5%. As shown in Fig. 2 and Fig. 3 , across all datasets, the ACC and F1-score of the v arious algorithms generally increase as the lab el ratio rises. MGCN-FLC p erforms stably and demonstrates a significant adv antage ov er other metho ds, particularly at lo w lab el ratios. 4.5. Par ameter ne c essity analysis The learnable hyperparameter weigh ting α is used to control the fusion of in tra-GB and inter-GB connections for constructing view-sp ecific top ology . The p erformance of MGCN-FLC under different v alues of α is shown in Fig. 4 . It can b e observ ed that the optimal ACC is achiev ed when α is neither 0 nor 1, 16 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 P arameter 0.4 0.5 0.6 0.7 0.8 0.9 1.0 A CC BB Cnews Caltech101-7 MNIST NUS- WIDE W ebKB BB Csports NGs P r oteinF old R euters (a) ACC 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 P arameter α 0.4 0.5 0.6 0.7 0.8 0.9 1.0 A CC BB Cnews C altech101 -7 MNIST NUS- WIDE W eb KB BB Cspor-s NGs P r o-einF old R eu-ers (b) F1-score Figure 4: The ACC and F1-score of MGCN-FLC w.r.t. hyperparameter α on datasets. 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 P arameter β 0.4 0.5 0.6 0.7 0.8 0.9 1.0 A CC BB Cnews Caltech101 -7 MNIST NUS- WIDE W eb KB BB Cspor-s NGs P r o-einF old R eu-ers (a) ACC 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 P arameter β 0.4 0.5 0.6 0.7 0.8 0.9 1.0 F1-s or e BB Cne.s Calte h101-7 MNIST NUS- WIDE W e bKB BB Csports NGs P r oteinF old R euters (b) F1-score Figure 5: The A CC and F1-score of MGCN-FLC w.r.t. hyperparameter β on datasets. whereas relativ ely low er p erformance o ccurs when α is set to 0 or 1. This obser- v ation indicates that the adaptive fusion of intra-GB and inter-GB connections is necessary . The hyperparameter β in the feature enhancement mo dule is analyzed. Fig. 5 shows the p erformance of MGCN-FLC under different v alues of β , with a range of [0 , 1] and a step size of 0.1. when β = 1, the feature enhancemen t mo dule relies solely on max p ooling, fo cusing exclusively on the salient information from the original feature matrix. Conv ersely , when β = 1, only av erage p ooling is applied, emphasizing global information from the similarit y feature matrix. As sho wn in Fig. 5, the ACC reaches its b est p erformance on the v ast ma jorit y of datasets when β = 0.6, suggesting that the mixed p o oling strategy effectively balances the information b et ween the original feature matrix and similarit y feature matrix. 17 Loss A CC F1-score 0 100 200 300 400 500 The number of epo ch s 0.5 1.0 1.5 2.0 L oss 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy and F 1- s c or e (a) BBCnews 0 100 200 300 400 500 The number of epo ch s 0.5 1.0 1.5 2.0 2.5 3.0 L oss 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy and F 1- s c or e (b) Caltech101-7 0 100 200 300 400 500 The number of epo ch s 0.5 1.0 1.5 2.0 2.5 L oss 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy and F 1- s c or e (c) MNIST 0 100 200 300 400 500 The number o f epoch s 1 2 3 4 5 L oss 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy and F 1- s c or e (d) NUS-WIDE 0 100 200 300 400 500 The number o f epoch s 0.25 0.50 0.75 1.00 1.25 1.50 1.75 L oss 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy and F 1- s c or e (e) W ebKB 0 100 200 300 400 500 The number of epochs 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 L oss 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy and F1-scor e (f) BBCsp orts 0 100 200 300 400 500 The number of epo ch s 0.5 1.0 1.5 2.0 2.5 L oss 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy and F 1- s c or e (g) NGs 0 100 200 300 400 500 The number of epochs 10 20 30 40 50 60 70 80 L oss 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy and F1-scor e (h) ProteinF old 0 100 200 300 400 500 The number of epochs 1 2 3 4 5 6 7 L oss 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy and F1-scor e (i) Reuters Figure 6: The curves of MGCN-FLCs loss v alues, ACC and F1-score on the selected datasets. 4.6. Conver genc e analysis Fig. 6 illustrates the con vergence pro cess of MGCN-FLC across all datasets. The loss v alue decreases while the ACC textcolorredand F1-score increase until stabilization. The conv ergence pro cess can b e divided into t wo distinct phases: (1) the rapid conv ergence phase within the first 300 ep o chs, indicating effective learning, and (2) the stable conv ergence phase, demonstrating that the mo del parameters hav e b een effectively optimized. 4.7. V isualization analysis Fig. 7 visualizes the node embeddings pro jected on to a t wo-dimensional plane using the tSNE metho d, show casing the effectiveness of no de classification. W e present the visualization results of node embeddings obtained by JFGCN, LGCN-FF, and MGCN-FLC on the BBCnews and NUS-WIDE datasets, re- sp ectiv ely . Our MGCN-FLC algorithm makes the no des of the same category to cluster together, while no des of different categories are effectiv ely separated. 18 −40 −20 0 20 40 −20 −10 0 10 20 0 1 2 3 4 (a) JFGCN −30 −20 −10 0 10 20 −40 −20 0 20 40 0 1 2 3 4 (b) LGCN-FF −30 −20 −10 0 10 20 30 40 −40 −20 0 20 40 0 1 2 3 4 (c) MGCN-FLC −40 −20 0 20 40 60 −40 −20 0 20 40 0 1 2 3 4 5 6 7 (d) JFGCN −60 −40 −20 0 20 40 60 −40 −20 0 20 0 1 2 3 4 5 6 7 (e) LGCN-FF −60 −40 −20 0 20 40 60 −40 −20 0 20 40 60 0 1 2 3 4 5 6 7 (f) MGCN-FLC Figure 7: t-SNE visualizations of the features from JFGCN, LGCN-FF, and MGCN- FLC on the (a-c) BBCnews and (d-f ) NUS-WIDE datasets, with colors denoting dif- feren t classes. Although some outlier no des remain, the num b er of them is decreased compared to other metho ds. The visualization results can also demonstrate that MGCN- FLC outp erforms other algorithms in semi-sup ervised no de classification tasks. 4.8. A blation exp eriment 4.8.1. Contribution of main mo dules Ablation exp erimen ts are conducted to assess the contribution of each of the three mo dules in MGCN-FLC mo del. F or clarity , the top ology construc- tion mo dule is denoted as tc , the feature enhancement module as f e , and the in teractive fusion mo dule as ( if ). The sp ecific ablation settings are as follows: • tc : The k NN algorithm replaces the unsup ervised GB algorithm to ev al- uate the contribution of the GB-based top ology construction mo dule to the classification p erformance. • f e : The original feature is used to replace the enhanced feature to assess the contribution of the feature enhancement mo dule. • if : T raditional m ulti-view fusion metho d (i.e. weigh ted sum) replaces the in teractive fusion metho d to ev aluate its contribution to interactiv e fusion mo dule to the classification p erformance. The results of the ablation exp erimen ts, including the classification p erfor- mance (A CC and F1-scores) with each mo dule ablated, are presented in T able 3 . 19 T able 3: Ablation study results of the prop osed MGCN-FLC on all datasets. Datasets/Methods MGCN-FLC tc MGCN-FLC fe MGCN-FLC if MGCN-FLC BBCnews ACC F1 91.1 90.2 95.3 94.3 98.4 97.9 98.4 97.9 Caltech101-7 ACC F1 83.8 73.1 92.0 83.3 97.4 90.7 97.5 91.3 MNIST ACC F1 90.6 88.6 95.0 94.3 82.9 76.9 96.4 95.8 NUS-WIDE ACC F1 40.9 38.9 98.1 98.1 98.1 98.1 99.0 99.0 W ebKB ACC F1 82.0 44.6 86.9 66.3 91.8 67.4 91.8 67.4 BBCsports ACC F1 88.6 89.6 93.5 93.6 96.3 95.8 97.3 97.2 NGs ACC F1 94.2 94.3 93.8 93.8 97.8 97.8 97.8 97.8 ProteinF old ACC F1 31.0 15.4 39.6 20.0 29.4 11.9 60.0 48.3 Reuters ACC F1 72.7 68.8 87.0 63.2 98.1 96.6 99.1 98.9 Ablating the tc mo dule leads to v arying degrees of classification p erformance degradation across all datasets for the MGCN-FLC metho d, with a particularly notable ACC drop of 58.1% on the NUS-WIDE dataset. This ablation highlights the contribution of the GB-based top ology construction mo dule whic h not only a voids the inheren t k -v alue noise in k NN but also achiev es the high homophily ratio (as shown in Fig. 8 ), enabling MGCN-FLC to construct high-quality top ology . Ablating the f e mo dule also results in decreased classification p erformance across all datasets for the MGCN-FLC metho d, with significan t ACC drop of 5.5% on the Caltech101-7 dataset. This demonstrates the imp ortance of the feature enhancement mo dule, whic h leverages inter-feature consistency to enable MGCN-FLC to generate feature represen tations. Ablating the if mo dule, the ablation of it leads to degraded classification p erformance of the MGCN-FLC metho d on some datasets, notably with A CC drop of 13.5% on the MNIST dataset. This confirms the imp ortance of the in- teractiv e fusion mo dule in explicitly and fully exploiting inter-view consistency . It is w orth noting, ho wev er, that on the BBCnews, W ebKB, and NGs datasets, the ACC remains largely unchanged after ablating the if mo dule. This o ccurs b ecause the feature representations of different views in these datasets are highly similar in terms of classification ability , resulting in feature represen tations pro- duced by the interactiv e fusion mo dule that conv erge with those from a single view. F or instance, on the W ebKB dataset, the individual views ha ve achiev e accuracies of 91.2%, 91.2%, and 91.7%, resp ectiv ely . Regardless of whether the if mo dule is used, MGCN-FLC ac hieves the ACC of 91.8%. This indicates that the p ow erful classification capability of the feature representations from the individual views leav es limited ro om for the if mo dule to demonstrate its 20 1 2 3 1 2 3 4 1 2 3 4 5 6 Figure 8: The homophily ratios of the top ologies generated by the four algorithmsJFGCN, GBCM-GCN, LGCN-FF, and MGCN-FLCacross the W ebKB, BBCnews, and Caltech101-7 datasets. adv antages. But there’s no need to worry , b ecause the p ow erful classification capabilit y of the feature representations from the individual views actually orig- inates from the other t wo modules of the MGCN-FLC metho d, i.e. tc and f e . 4.8.2. The sup eriority of r epr esentative no de sele ction T able 4: The classification results of MGCN-FLC based on representativ e node and its v ariants (center no de and density p eak no de) on all datasets. Datasets/Methods MGCN-FLC center no de density peak no de representativ e no de (our) BBCnews ACC F1 98.4 97.9 98.4 97.9 98.4 97.9 Caltech101-7 ACC F1 97.5 91.3 97.5 91.3 97.5 91.3 MNIST ACC F1 95.4 94.8 95.9 94.9 96.4 95.8 NUS-WIDE ACC F1 99.0 99.0 98.5 98.5 99.0 99.0 W ebKB ACC F1 91.8 67.4 91.8 67.4 91.8 67.4 BBCsports ACC F1 97.3 97.2 97.3 97.2 97.3 97.2 NGs ACC F1 97.4 97.4 97.8 97.8 97.8 97.8 ProteinF old ACC F1 58.7 47.8 58.3 46.0 60.0 48.3 Reuters ACC F1 99.1 98.9 99.1 98.9 99.1 98.9 In top ology construction, we select represen tative no des by minimizing the sum of Euclidean distances to other no des. T o v alidate the sup eriorit y of the selection approach, we replaced the original represen tativ e no de with center no de and density p eak no de, resp ectiv ely . In detail, the center no de is selected 21 via the mean v ector of no des within the GB, and the densit y p eak no de is se- lected according to the highest density within the GB. T able 4 presents the classification p erformance of the three metho ds based on different represen ta- tiv e no de selection strategies on all datasets. Compared with the v arian t based on center no de, our MGCN-FLC improv es ACC by 1%, 0.4%, and 1.3% on the MNIST, NGs, and ProteinF old datasets, resp ectiv ely . These improv ements are attributed to MGCN-FLC’s strategy of selecting actual no des and focusing more on the node itself, while the virtual nature of the center no de ma y in tro duce noise. Compared with the v ariant based on densit y p eak no de, MGCN-FLC impro ves ACC b y 0.5%, 0.5%, and 1.7% on the MNIST, NUS-WIDE, and Pro- teinF old datasets, resp ectiv ely . This is b ecause MGCN-FLC do es not require parameter tuning, whereas adjustments to parameters may affect the selection of density p eak no des, potentially leading to connections b et ween dissimilar no des. The iden tical classification results observed on datasets such as BBC- news and Caltech101-7 can b e attributed to the similar features of the selected no des, whic h consequently do not affect the connections b et w een similar GBs. 4.8.3. A dvangtage of inter active fusion mo dule T able 5: The classification results of MGCN-FLC and its v ariants on all datasets. ’V A- based’ denotes the MGCN-FLC v ariant based on view-level attention. ’VSF-based’ denotes the MGCN-FLC v ariant based on view-shared underlying features. ’IF-based’ denotes the original MGCN-FLC model. Datasets/Methods MGCN-FLC V A-based VSF-based IF-based (our) BBCnews ACC F1 98.0 97.2 96.6 95.5 98.4 97.9 Caltech101-7 ACC F1 79.0 55.2 69.8 40.2 97.5 91.3 MNIST ACC F1 95.6 93.5 81.2 78.5 96.4 95.8 NUS-WIDE ACC F1 79.0 78.9 77.6 77.6 99.0 99.0 W ebKB ACC F1 90.2 65.4 88.0 64.0 91.8 67.4 BBCsports ACC F1 96.9 96.7 96.9 96.5 97.3 97.2 NGs ACC F1 97.4 97.4 96.0 96.0 97.8 97.8 ProteinF old ACC F1 27.8 15.6 42.5 28.5 60.0 48.3 Reuters ACC F1 97.8 96.4 91.0 87.7 99.1 98.9 T o further v alidate the differences b et w een the proposed in teractive fusion mo dule and existing in teraction mec hanisms, we introduced tw o v arian ts of MGCN-FLC, replacing the interactiv e fusion mo dule with view-level atten- tion and view-shared underlying feature, resp ectiv ely . The details of these tw o MGCN-FLC v ariants are as follo ws: (1) the v ariant based on view-lev el atten- 22 tion assigns learnable weigh ts to each view; (2) the v ariant based on view-shared underlying feature integrates multi-view features in to a shared feature matrix through a trainable fully connected netw ork which is optimized b y a reconstruc- tion loss function. T able 5 presents the classification p erformance of MGCN- FLC and its tw o v ariants on all datasets. Ob viously , the prop osed in teractive fusion mo dule outp erforms the other tw o interaction mechanisms on all datasets. Compared to the MGCN-FLC v ariant based on view-lev el attention, the orig- inal MGCN-FLC based on interactiv e fusion mo dule improv es A CC by 18.5%, 20%, and 32.2% on the Caltech101-7, NUS-WIDE, and ProteinF old datasets, resp ectiv ely . These impro vemen ts stem from the fine-grained feature-lev el in- teractions b et w een views conducted in the interactiv e fusion mo dule, allowing for a deep er exploration of inter-view consistency . Compared to the MGCN- FLC v ariant based on view-shared underlying feature, the original MGCN-FLC based on interactiv e fusion mo dule improv es ACC b y 27.7%, 15.2%, 21.4%, 17.5%, and 8.1% on the Caltech101-7, MNIST, NUS-WIDE, ProteinF old, and Reuters datasets, resp ectiv ely . These improv emen ts stem from the more com- prehensiv e pairwise inter-view consistency ac hieved by the interactiv e fusion mo dule, rather than the narrow er consistency among all views obtained by the view-shared underlying feature. 4.9. Runtime c omp arison BB Cnews Caltec h101-7 MNIST NUS- WIDE W ebKB BB Csports NGs P r oteinF old R e-ters 10 1 10 2 10 3 10 4 R -ntime (se (nds) C( -CGN LGCN-FF JFGCN HGCN-MVSC MvRL -DP GB CM- GCN MGCN-FLC Figure 9: Running time of MGCN-FLC and other GCN-based mo dels on all datasets. W e compared the training time of MGCN-FLC and other GCN-based algo- rithms in Figure 9 . Due to the introduction of the GB algorithm [30] during top ology construction, MGCN-FLC needs additional computational time; ho w- ev er, its ov erall training time remains within an acceptable range. Compared with GBCM-GCN [23], which also employ ed the GB algorithm [30], MGCN-FLC demonstrates higher training efficiency . Although MvRL-DP [ 22] is the fastest among all algorithms, it suffers from severe p erformance degradation compared to our MGCN-FLC, particularly on the NUS-WIDE dataset, where its accu- racy drops by 44.7%. LGCN-FF [20] ranks as the second fastest algorithm, it 23 also encounters a significant accuracy gap when compared to MGCN-FLC, with particularly sev ere drops of 66.6% and 34.2% on the NUS-WIDE and Reuters datasets, resp ectiv ely . 4.10. Exp erimental discussion Our MGCN-FLC employs an unsup ervised GB algorithm [30], enabling it to ac hieve excellent p erformance on low-dimensional datasets, yet the mo del’s p erformance ma y b e constrained by the GB algorithm’s [30] ability to handle high-dimensional sparse data. The results in T able 3 show that on the high- dimensional sparse Reuters dataset, our MGCN-FLC outp erforms the M GC N − F LC tc using the k NN algorithm, achieving a 26.4% impro vemen t in A CC. This impro vemen t is primarily attributed to the feature enhancement mo dule and the interactiv e fusion module within MGCN-FLC, which effectively comp ensate for the GB algorithm’s [30] limitations, enabling the mo del to outp erform other algorithms. The complexit y of the in teractive fusion mo dule in MGCN-FLC exhibits quadratic growth with resp ect to the n umber of views. How ever, the num b er of views is typically not high in practice, th us having limited impact on the o verall complexity . T o ev aluate the efficiency of the interactiv e fusion mo dule, w e compare MGCN-FLC with its v ariant based on view-shared underlying fea- ture. T able 5 presents the classification p erformance of our MGCN-FLC and the v ariant on all datasets. F or the ProteinF old dataset, the MGCN-FLC improv es A CC by 17.5% compared to the v ariant. Both the interactiv e fusion mo dule and the view-shared underlying feature mo dule emplo y a sparse enco der for feature alignmen t to facilitate subsequent feature fusion. The computational complex- ities of the interactiv e fusion mo dule and the view-shared underlying feature mo dule are O ( N d v d 1 + N d 1 d + ( V − 1) N d ) and O ( N d v d 1 + N d 1 d + N d 2 ) , resp ectiv ely . T aking the ProteinF old dataset ( N =694, V =12, d v =27) as an example, after incorporating its parameters and those of the sparse enco der ( d 1 =1024, d =256) into the complexity form ula, the complexity of the interac- tiv e fusion mo dule is approximately 82% of that of the view-shared underlying feature mo dule, while achieving a 17.5% A CC improv ement, demonstrating the effectiv eness of the mo dule. 5. Conclusion This pap er prop oses the multi-view graph conv olutional netw ork with fully lev eraging consistency via granular-ball-based top ology construction, feature enhancemen t and interactiv e fusion (MGCN-FLC), which explores inter-node consistency , inter-feature consistency , and in ter-view consistency . The metho d emplo ys the unsup ervised GB algorithm to construct the high-qualit y top olo- gies that leverages both the in tra-GB high similarity and the inter-GB global information. This top ology effectively captures inter-node consistency . The fea- ture enhancemen t mo dule generates enriched feature representations through in tra-view feature interactions, fully utilizing the inter-feature consistency . The 24 in teractive fusion mo dule explicitly and fully exploits in ter-view consistency to further improv e the feature represen tations. Exp erimen ts demonstrate the ef- fectiv eness of the prop osed MGCN-FLC mo del and v alidate the importance of in ter-no de consistency , in ter-feature consistency , and in ter-view consistency in m ulti-view learning. In the future, given that the feature enhancement mo dule uses full-range feature similarit y , low er similarit y may introduce lo w-relev ance information in to the enhanced features, affecting their quality . T o address this, w e will attempt to cluster the features of each view and compute the similarit y b et w een features only within the cluster, which may help mitigate the impact of low-relev ance information. A c knowledgmen t This work was supp orted b y National Science F oundation (Grant num b er 62466063, Grant n umber 61936001). References [1] Hamidreza F azlali, Yixuan Xu, Y uan Ren, and Bingbing Liu. A versatile m ulti-view framework for lidar-based 3d ob ject detection with guidance from panoptic segmentation. In IEEE/CVF Confer enc e on Computer V i- sion and Pattern R e c o gnition, CVPR 2022, New Orle ans, LA, USA, June 18-24, 2022 , pages 17171–17180. IEEE, 2022. [2] Marcos Lupión, A urora Polo Ro dríguez, Javier Medina Quero, Juan F. Sanjuan, and Pilar M. Ortigosa. 3d human pose estimation from multi- view thermal vision sensors. Inf. F usion , 104:102154, 2024. [3] Xing W ei, T aizhang Hu, Di W u, F an Y ang, Chong Zhao, and Y ang Lu. ECCT: efficient contrastiv e clustering via pseudo-siamese vision trans- former and m ulti-view augmentation. Neur al Networks , 180:106684, 2024. [4] Sheng Huang, Y unhe Zhang, Lele F u, and Shiping W ang. Learnable multi- view matrix factorization with graph embedding and flexible loss. IEEE T r ans. Multim. , 25:3259–3272, 2023. [5] W ei Zhang, Zhaohong Deng, Qiongdan Lou, T e Zhang, Kup-Sze Choi, and Shitong W ang. T akagi-sugeno-kang fuzzy system tow ards lab el-scarce in- complete multi-view data classification. Inf. Sci. , 647:119466, 2023. [6] Cai Xu, Jia jun Si, Ziyu Guan, W ei Zhao, Y ue W u, and Xiyue Gao. Reli- able conflictiv e multi-view learning. In Michael J. W o oldridge, Jennifer G. Dy , and Sriraam Natara jan, editors, Thirty-Eighth AAAI Confer enc e on A rtificial Intel ligenc e, AAAI 2024, Thirty-Sixth Confer enc e on Innovative A pplic ations of A rtificial Intel ligenc e, IAAI 2024, F ourte enth Symp osium on Educ ational A dvanc es in A rtificial Intel ligenc e, EAAI 2014, F ebruary 20-27, 2024, V anc ouver, Canada , pages 16129–16137. AAAI Press, 2024. 25 [7] Jiafeng Cheng, Qianqian W ang, Zhiqiang T ao, Deyan Xie, and Quanxue Gao. Multi-view attribute graph conv olution netw orks for clustering. In Pr o c e e dings of the twenty-ninth international c onfer enc e on international joint c onfer enc es on artificial intel ligenc e , pages 2973–2979, 2021. [8] Xin Huang, Ranqiao Zhang, Y uanyuan Li, F an Y ang, Zhiqin Zhu, and Zhihao Zhou. MFC-A CL: multi-view fusion clustering with attentiv e con- trastiv e learning. Neur al Networks , 184:107055, 2025. [9] Luying Zhong, Jielong Lu, Zhaoliang Chen, Na Song, and Shiping W ang. A daptive multi-c hannel contrastiv e graph conv olutional netw ork with graph and feature fusion. Inf. Sci. , 658:120012, 2024. [10] Zhihao W u, Zhao Zhang, and Jicong F an. Graph conv olutional kernel ma- c hine versus graph conv olutional netw orks. In Alice Oh, T ristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, A dvanc es in Neur al Information Pr o c essing Systems 36: A nnual Confer- enc e on Neur al Information Pr o c essing Systems 2023, NeurIPS 2023, New Orle ans, LA, USA, De c emb er 10 - 16, 2023 , 2023. [11] Lijuan W ang, Lin Zhang, Ming Yin, Zhifeng Hao, Ruic hu Cai, and W en W en. Double em b edding-transfer-based m ulti-view sp ectral clustering. Ex- p ert Syst. A ppl. , 210:118374, 2022. [12] Zixiao W ang and Jicong F an. Graph classification via reference distribution learning: theory and practice. A dvanc es in Neur al Information Pr o c essing Systems , 37:137698–137740, 2024. [13] Bin Y u, Heng jie Xie, Jingxuan Chen, Ming jie Cai, Hamido F ujita, and W eiping Ding. Sdhgcn: A heterogeneous graph conv olutional neural net- w ork combined with shado wed set. IEEE T r ansactions on F uzzy Systems , 2024. [14] Thomas N. Kipf and Max W elling. Semi-sup ervised classification with graph conv olutional netw orks. In 5th International Confer enc e on Le arning R epr esentations, ICLR 2017, T oulon, F r anc e, A pril 24-26, 2017, Confer- enc e T r ack Pr o c e e dings . Op enReview.net, 2017. [15] Zixing Song, Yifei Zhang, and Irwin King. T o wards an optimal asymmetric graph structure for robust semi-sup ervised no de classification. In Aidong Zhang and Huzefa Rangwala, editors, KDD ’22: The 28th A CM SIGKDD Confer enc e on K now le dge Disc overy and Data Mining, W ashington, DC, USA, A ugust 14 - 18, 2022 , pages 1656–1665. A CM, 2022. [16] Qin Y ue, Jiye Liang, Junbiao Cui, and Liang Bai. Dual bidirectional graph con volutional netw orks for zero-shot no de classification. In Aidong Zhang and Huzefa Rangwala, editors, KDD ’22: The 28th A CM SIGKDD Con- fer enc e on K now le dge Disc overy and Data Mining, W ashington, DC, USA, A ugust 14 - 18, 2022 , pages 2408–2417. ACM, 2022. 26 [17] Jielong Lu, Zhihao W u, Luying Zhong, Zhaoliang Chen, Hong Zhao, and Shiping W ang. Generative essential graph conv olutional netw ork for multi- view semi-sup ervised classification. IEEE T r ans. Multim. , 26:7987–7999, 2024. [18] Sezin Kircali Ata, Y uan F ang, Min W u, Jiaqi Shi, Chee Keong K woh, and Xiaoli Li. Multi-view collab orativ e netw ork embedding. A CM T r ans. K now l. Disc ov. Data , 15(3):39:1–39:18, 2021. [19] Seongjun Y un, Seoy o on Kim, Junh yun Lee, Jaew o o Kang, and Hyunw o o J. Kim. Neo-gnns: Neighborho o d ov erlap-aw are graph neural netw orks for link prediction. CoRR , abs/2206.04216, 2022. [20] Zhaoliang Chen, Lele F u, Jie Y ao, W enzhong Guo, Claudia Plan t, and Shiping W ang. Learnable graph conv olutional netw ork and feature fusion for multi-view learning. Inf. F usion , 95:109–119, 2023. [21] Guo wen Peng, F adi Dornaika, and Jinan Charafeddine. CGCN-FMF:1D con volutional neural netw ork based feature fusion and multi graph fusion for semi-sup ervised learning. Exp ert Syst. A ppl. , 277:127194, 2025. [22] Xuzheng W ang, Shiy ang Lan, Zhihao W u, W enzhong Guo, and Shiping W ang. Multi-view represen tation learning with decoupled priv ate and shared propagation. K now l. Base d Syst. , 310:112956, 2025. [23] W eijun W ang, Xib ei Y ang, Qinghua Zhang, Sh uyin Xia, Jie Y ang, and T aihua Xu. Capturing lo cal and global information: Multi-view graph con- v olutional netw ork via granular-ball computing and collab orativ e matrix. Exp ert Syst. A ppl. , 296:129057, 2026. [24] Sh u Li, W en-T ao Li, and W ei W ang. Co-gcn for multi-view semi-sup ervised learning. In The Thirty-F ourth AAAI Confer enc e on A rtificial Intel ligenc e, AAAI 2020, The Thirty-Se c ond Innovative A pplic ations of A rtificial In- tel ligenc e Confer enc e, IAAI 2020, The T enth AAAI Symp osium on Edu- c ational A dvanc es in A rtificial Intel ligenc e, EAAI 2020, New Y ork, NY, USA, F ebruary 7-12, 2020 , pages 4691–4698. AAAI Press, 2020. [25] Y uhong Chen, Zhihao W u, Zhaoliang Chen, Mianxiong Dong, and Ship- ing W ang. Joint learning of feature and top ology for multi-view graph con volutional net work. Neur al Networks , 168:161–170, 2023. [26] Yiming W ang, Dongxia Chang, Zhiqiang F u, Jie W en, and Y ao Zhao. In- complete m ultiview clustering via cross-view relation transfer. IEEE T r ans. Cir cuits Syst. V ide o T e chnol. , 33(1):367–378, 2023. [27] Xiaocheng Y ang, Mingyu Y an, Shirui Pan, Xiao ch un Y e, and Dongrui F an. Simple and efficient heterogeneous graph neural netw ork. In Brian Williams, Yiling Chen, and Jennifer Neville, editors, Thirty-Seventh AAAI Confer enc e on A rtificial Intel ligenc e, AAAI 2023, Thirty-Fifth Confer enc e 27 on Innovative Applic ations of A rtificial Intel ligenc e, IAAI 2023, Thirte enth Symp osium on Educ ational A dvanc es in A rtificial Intel ligenc e, EAAI 2023, W ashington, DC, USA, F ebruary 7-14, 2023 , pages 10816–10824. AAAI Press, 2023. [28] Zhihao W u, Xincan Lin, Zhenghong Lin, Zhaoliang Chen, Y ang Bai, and Shiping W ang. Interpretable graph conv olutional netw ork for multi-view semi-sup ervised learning. IEEE T r ans. Multim. , 25:8593–8606, 2023. [29] F adi Dornaika, Jing jun Bi, Jinan Charafeddine, and H. Xiao. Semi- sup ervised learning for multi-view and non-graph data using graph con- v olutional netw orks. Neur al Networks , 185:107218, 2025. [30] Dongdong Cheng, Y a Li, Shuyin Xia, Guoyin W ang, Jinlong Huang, and Sulan Zhang. A fast gran ular-ball-based density p eaks clustering algo- rithm for large-scale data. IEEE T r ans. Neur al Networks L e arn. Syst. , 35(12):17202–17215, 2024. [31] W endong Bi, Lun Du, Qiang F u, Y anlin W ang, Shi Han, and Dongmei Zhang. Make heterophilic graphs b etter fit GNN: A graph rewiring ap- proac h. IEEE T r ans. K now l. Data Eng. , 36(12):8744–8757, 2024. [32] Lun Du, Xiaozhou Shi, Qiang F u, Xiao jun Ma, Hengyu Liu, Shi Han, and Dongmei Zhang. GBK-GNN: gated bi-kernel graph neural net works for mo deling b oth homophily and heterophily . In F rédérique Laforest, Raphaël T roncy , Elena Simp erl, Deepak Agarwal, Aristides Gionis, Iv an Herman, and Lionel Médini, editors, WWW ’22: The A CM W eb Confer enc e 2022, V irtual Event, Lyon, F r anc e, A pril 25 - 29, 2022 , pages 1550–1558. ACM, 2022. [33] Zhongying Zhao, Zhan Y ang, Chao Li, Qingtian Zeng, W eili Guan, and MengCh u Zhou. Dual feature interaction-based graph conv olutional net- w ork. IEEE T r ans. K now l. Data Eng. , 35(9):9019–9030, 2023. [34] F uli F eng, Xiangnan He, Hanw ang Zhang, and T at-Seng Ch ua. Cross-gcn: Enhancing graph conv olutional netw ork with k-order feature in teractions. CoRR , abs/2003.02587, 2020. [35] Jinglin Xu, W en bin Li, Xinw ang Liu, Dingwen Zhang, Ji Liu, and Jun wei Han. Deep embedded complementary and interactiv e information for multi- view classification. In Pr o c e e dings of the AAAI c onfer enc e on artificial intel ligenc e , v olume 34, pages 6494–6501, 2020. [36] Shiping W ang, Sujia Huang, Zhihao W u, Rui Liu, Y ong Chen, and Dell Zhang. Heterogeneous graph conv olutional netw ork for multi-view semi- sup ervised classification. Neur al Networks , 178:106438, 2024. [37] Shiping W ang, Jiac heng Li, Y uhong Chen, Zhihao W u, Aiping Huang, and Le Zhang. Multi-scale graph diffusion con volutional net work for multi-view learning. A rtif. Intel l. R ev. , 58(6):184, 2025. 28 [38] Yilin W u, Zhaoliang Chen, Ying Zou, Shiping W ang, and W enzhong Guo. Multi-scale structure-guided graph generation for multi-view semi- sup ervised classification. Exp ert Syst. Appl. , 263:125677, 2025. [39] Sh uyin Xia, Y unsheng Liu, Xin Ding, Guoyin W ang, Hong Y u, and Y uoguo Luo. Granular ball computing classifiers for efficient, scalable and robust learning. Inf. Sci. , 483:136–152, 2019. [40] Sh uyin Xia, Xiao ch uan Dai, Guoyin W ang, Xinbo Gao, and Elisab eth Giem. An efficien t and adaptiv e gran ular-ball generation method in classi- fication problem. IEEE T r ans. Neur al Networks L e arn. Syst. , 35(4):5319– 5331, 2024. [41] Meixia He, Jianrui Chen, Maoguo Gong, and Zhongshi Shao. HDGCN: dual-c hannel graph conv olutional net work with higher-order information for robust feature learning. IEEE T r ans. Emer g. T op. Comput. , 12(1):126– 138, 2024. [42] Xiao W ang, Meiqi Zhu, Deyu Bo, Peng Cui, Ch uan Shi, and Jian Pei. AM- GCN: adaptiv e m ulti-c hannel graph con v olutional net works. In Ra jesh Gupta, Y an Liu, Jiliang T ang, and B. Adit y a Prakash, editors, KDD ’20: The 26th A CM SIGKDD Confer enc e on K now le dge Disc overy and Data Mining, V irtual Event, CA, USA, A ugust 23-27, 2020 , pages 1243–1253. A CM, 2020. [43] Jie W ang, Jianqing Liang, Jun biao Cui, and Jiye Liang. Semi-sup ervised learning with mixed-order graph conv olutional netw orks. Inf. Sci. , 573:171– 181, 2021. [44] W enfeng Liu, Maoguo Gong, Zedong T ang, A. Kai Qin, Kai Sheng, and Mingliang Xu. Lo cality preserving dense graph con volutional netw orks with graph context-a ware no de representations. Neur al Networks , 143:108–120, 2021. [45] F eiping Nie, Guohao Cai, and Xuelong Li. Multi-view clustering and semi- sup ervised classification with adaptiv e neighbours. In Satinder Singh and Shaul Marko vitch, editors, Pr o c e e dings of the Thirty-First AAAI Confer- enc e on A rtificial Intel ligenc e, F ebruary 4-9, 2017, San F r ancisc o, Califor- nia, USA , pages 2408–2414. AAAI Press, 2017. [46] Hong T ao, Chenping Hou, F eiping Nie, Jub o Zhu, and Dongyun Yi. Scal- able multi-view semi-sup ervised classification via adaptive regression. IEEE T r ans. Image Pr o c ess. , 26(9):4283–4296, 2017. [47] Shiping W ang, Zhaoliang Chen, Shide Du, and Zhouchen Lin. Learning deep sparse regularizers with applications to multi-view clustering and semi-sup ervised classification. IEEE T r ans. Pattern A nal. Mach. Intel l. , 44(9):5042–5055, 2022. 29
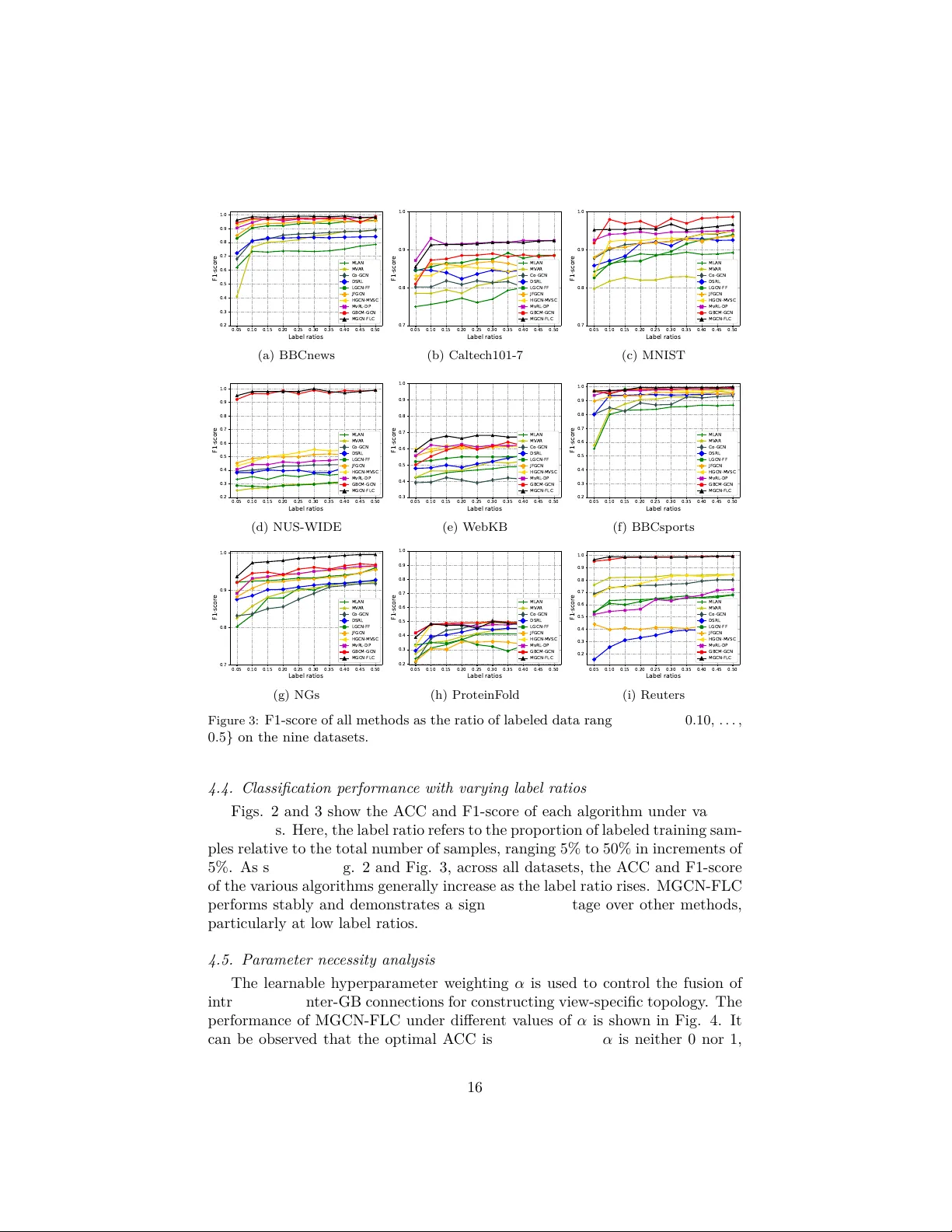
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment