The Nature of Technical Debt in Research Software
Research software (also called scientific software) is essential for advancing scientific endeavours. Research software encapsulates complex algorithms and domain-specific knowledge and is a fundamental component of all science. A pervasive challenge…
Authors: Neil A. Ernst, Ahmed Musa Awon, Swapnil Hingmire
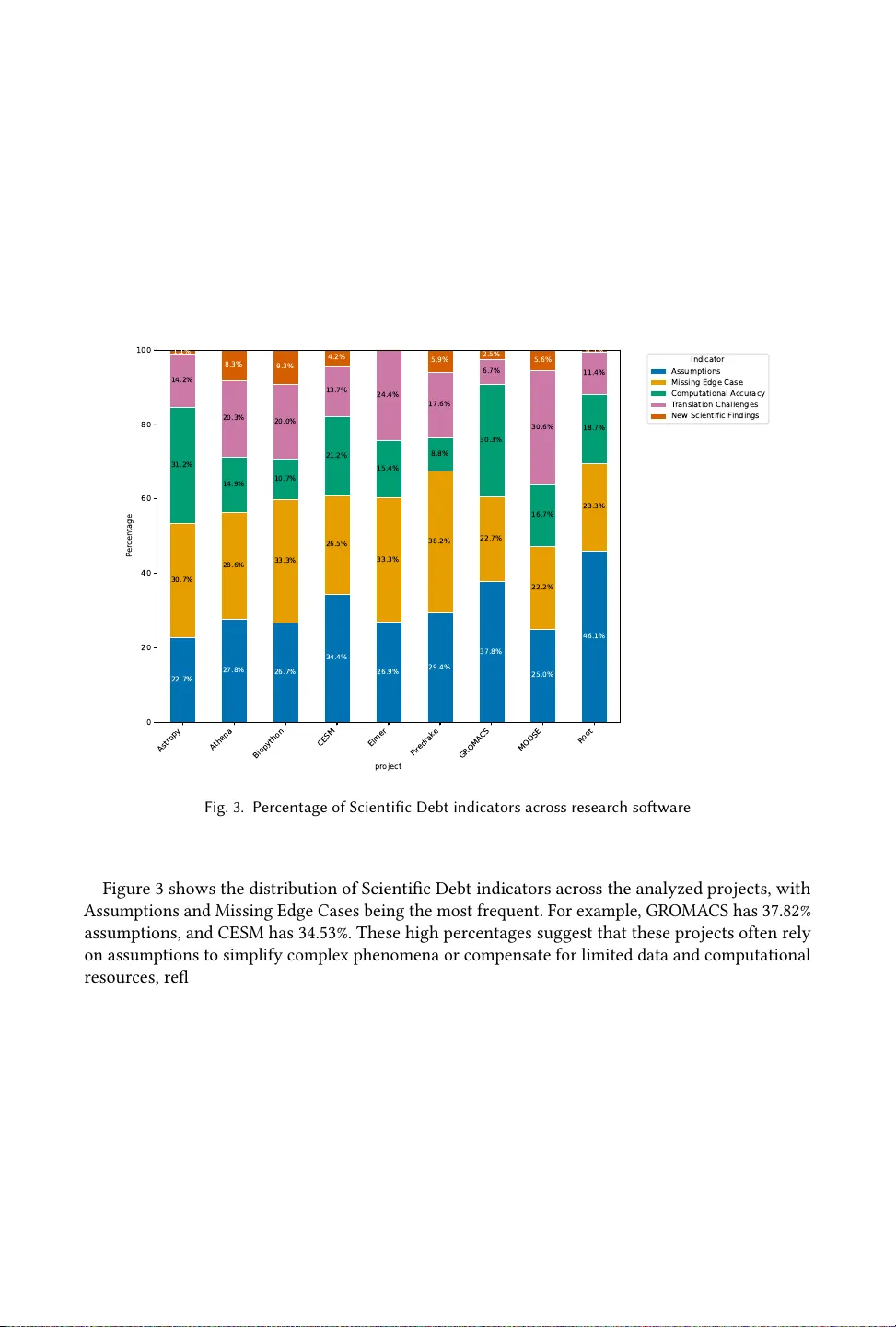
The Nature of T echnical Debt in Research Soware NEIL A. ERNST, University of Victoria, Canada AHMED MUSA A W ON, University of Victoria, Canada SW APNIL HINGMIRE, IIT Palakkad, India ZE SHI LI, University of Oklahoma, United States Research software ( also called scientic software) is essential for advancing scientic endeavours. Resear ch software encapsulates complex algorithms and domain-specic knowledge and is a fundamental comp onent of all science. A pervasive challenge in developing research software is technical debt, which can adversely aect reliability , maintainability , and scientic validity . Research software often relies on the initiative of the scientic community for maintenance, requiring diverse expertise in both scientic and software engineering domains. The extent and natur e of technical debt in research software are little studied, in particular , what forms it takes, and what the science teams developing this software think about their technical debt. In this paper we describe our multi-method study examining technical debt in research software . W e begin by examining instances of self-reported technical debt in research code, examining 28k code comments across nine research software projects. Then, building on our ndings, we interview r esearch software engineers and scientists about how this technical debt manifests itself in their experience, and what costs it has for research software and research outputs mor e generally . W e identify nine types of self-admitted technical debt unique to research software , and four themes impacting this technical debt. Additional K ey W ords and P hrases: technical debt, research software, domain kno wledge A CM Reference Format: Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmir e, and Ze Shi Li. 2018. The Nature of T echnical Debt in Research Software. J. A CM 37, 4, Article 111 (A ugust 2018), 36 pages. https://doi.org/XXXXXXX.XXXXXXX 1 Introduction Research software, also known as scientic software , is essential for modern science, providing crucial tools for complex calculations, simulations, and data analysis across nearly all scientic disciplines. It is integral to the formulation, testing, and validation of scientic hypotheses, with its accuracy and robustness directly impacting the validity of research ndings. This makes the dev el- opment of research softwar e a critical aspect of contemporary science, necessitating exceptional levels of precision and reliability [Carver et al. 2007; Hook and K elly 2009b]. For example, in 2006, undetected software errors le d to the retraction of ve high-prole pa- pers [Miller 2006]. These unintentional errors were not sophisticated: “a homemade data-analysis program had ipped two columns of data, inverting the electron-density map ” yet w ent undetected for years, and were partially due to time pressure . This type of problem suggests that accumu- lated shortcuts—insucient testing, inadequate code review , and missing validation of scientic assumptions—allowed the defects to persist. The signicant “interest” paid in compromised accuracy A uthors’ Contact Information: Neil A. Ernst, nernst@uvic.ca, University of Victoria, Victoria, BC, Canada; Ahmed Musa A won, its.ahmed.musa@gmail.com, University of Victoria, Victoria, BC, Canada; Swapnil Hingmire, swapnilh@iitpkd.ac.in, II T Palakkad, Palakkad, India; Ze Shi Li, zeshili@ou.edu, University of Oklahoma, Norman, United States. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. T o copy other wise, or republish, to post on servers or to redistribute to lists, requires prior specic permission and /or a fee. Request permissions from permissions@acm.org. © 2018 Copyright held by the owner/author(s). Publication rights licensed to A CM. A CM 1557-735X/2018/8- ART111 https://doi.org/XXXXXXX.XXXXXXX J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:2 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li and credibility illustrates how te chnical debt in research software can have consequences beyond the co debase itself , threatening the integrity of published scientic ndings. Much like conventional software systems, resear ch software requires active monitoring and management of technical debt. One challenge in research software development is that building research to ols requires command of a diverse set of knowledge domains, each contributing to the overall precision and reliability of the software. A ccording to Kelly [2015], these domains include 1) Real- W orld Knowledge, which involves understanding the scientic problems and data; 2) Theor y-Based Knowledge, which encompasses the scientic principles and mo dels underlying the software; 3) Software Knowledge, which involves programming and softwar e engine ering skills; 4) Execution Knowledge, related to running and testing the software; 5) Op erational Knowledge, which pertains to the deployment and practical use of the software in real-world scenarios. The intersection of these domains poses signicant challenges. T o cross domains requires col- laboration between scientists and software engineers (as well as other experts, e.g., in operating compute clusters), each bringing their expertise to ensure the software’s quality , such as scientic accuracy and robustness. Such cross-domain challenges e xist in most, if not all forms of software, as explored in research into social-technical congruence [Damian et al. 2013], so the implications of this research ar e broad. W e focus on research software as one software discipline with r eadily apparent Real- W orld and The ory-Based knowledge domains. Our goal is to explore the nature of technical debt in research software, including its extent, its characteristics, and how it is per- ceived by research softwar e developers. T echnical debt provides a useful lens for understanding these cross-domain challenges b ecause it captures not just individual defects, but the systemic accumulation of shortcuts and deferred decisions that erode software quality over time . Understanding research software and te chnical debt is a multi-faceted, and socio-te chnical, research pr oblem [Lamprecht et al. 2022]. Softwar e technical debt combines aspects of business and management, human motivations, and technical questions around mitigation and removal [N. Ernst, Kazman, et al. 2021]. The study of such pr oblems lends itself to a mixed-methods research approach (MMR) [Storey, Hoda, et al. 2025]. W e approach the question using a quantitative study of self-admitted technical debt, and a qualitative study inter viewing research software de velopers. Self- Admitted T echnical Debt (SA TD) provides a unique quantitative signal we can use to examine the challenges arising from the intersection of diverse knowledge domains ne cessary for developing robust software. SA TD occurs when developers explicitly acknowledge, through code comments, that certain parts of the code are incomplete, need rework, contain errors, or are temporar y solutions [Potdar and Shihab 2014]. In particular , these comments often reveal areas where the interplay between domain-specic knowledge and software engineering practices may compromise the reliability and correctness of the software . In the context of research software , SA TD is particularly valuable as it highlights cross-domain challenges faced by developers in integrating complex scientic the ories and mo dels with software implementations of those mo dels . These challenges are signaled by explicit indicators within SA TD comments, pointing to underlying issues, complexities, or deciencies in the co de related to scientic accuracy , assumptions, or computational methods. Such signals provide direct insights into where and why the software might fail to meet scientic and engineering standards. Addressing these debts would not only enhance the maintainability of the software, but also ensure the accuracy and robustness of scientic computations, thereby safeguarding the integrity of research ndings. J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:3 1.1 A Mixed Methods Approach Our paper rst introduces important background for our work, discussing technical debt and research softwar e. T o inv estigate the nature of technical debt in r esearch software, we follo w an Convergent Parallel mixed metho ds approach [Storey, Hoda, et al. 2025] highlighted in Fig. 1. W e gather quantitative insights (quaN) from large-scale analysis of research software code comments on self-admitted technical debt, reported in Section 3. This study is motivated by our rst research question: RQ1: How do es SA TD signal cross-domain challenges in Research Software? T o answer this question, we collect a set of 28,680 self-admitted te chnical debt (SA TD) comments from representative scientic projects, including high energy physics, astronomy , molecu- lar dynamics, mole cular biology , climate modeling, and applied mathematics. W e then systematically label these comments using a combination of predened and emergent lab els. W e then lo ok to explain the results from that analysis using conv ergent analysis of our second study , an inter view study of research software developers (Section 4). This study builds on the insights we gain into research software and Scientic Debt to answer our second research question: RQ2: How do practitioners in research software projects perceive T echnical Debt? T o answer this question, we interviewed 11 contributors to long-lived resear ch software projects about technical debt, conducted thematic analysis on their answers, and derived four themes to characterize the nature of technical debt. W e present each research question as two separate se ctions in this paper , each with self-contained details on method, analysis, and ndings. A separate Discussion section (Se ction 5) then integrates our ndings from each method to synthesize insights. High-quality MMR studies follow four guiding principles: a) methodological rationale; b) novel integrated insights; c) procedural rigor , d) ethical research Storey, Hoda, et al. [2025]. Rationale . W e chose a mixed metho ds approach since the socio-technical nature of the problem, a complex interplay of human and organizational challenges occurring in the context of often highly complex and technical software projects, suggested that merely interviewing or mining would not be able to capture the complete picture . Inter viewees may not be able to articulate the challenges with the code since it is so familiar to them; mining studies, esp ecially for self-admitted technical debt, cannot capture the complete picture of te chnical debt in a project, just as it cannot for software bugs [Aranda and V enolia 2009]. In particular , our appr oach emphasizes Complementarity , Triangulation, and Explainability . Integration and Rigor . What did we gain from using a MMR approach? How well did we conduct the mixed studies? W e comment on this in Section 5. Ethical Research. W e sought and wer e granted review and approval for our study fr om our institution’s IRB. In addition, our mining study follow ed ethical guidelines from Gold and Krinke [2022]. 1.2 Contributions Emerging from our mixed methods study we contribute: (1) Dening a new typ e of technical debt, termed Scientic Debt , which highlights issues within the codebase acknowledged by contributors that could potentially compromise the validity , accuracy , and reliability of scientic results. (2) A characterization of Scientic Debt across nine research software projects, including its distribution, sub-indicators (assumptions, translation challenges, missing edge cases, compu- tational accuracy , and new scientic ndings), and cross-project pr evalence. J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:4 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li Fig. 1. Overview of our Convergent Parallel Mixed Methods research approach. Aer Storey, Hoda, et al. [2025] (3) A comprehensive dataset comprising 28,680 labeled SA TD comments from various program- ming languages, marking the rst instance of a SA TD dataset that encompasses multiple programming languages. (4) A repeatable coding guide to identify and categorize Scientic Debt. (5) Empirically grounded themes and theory characterizing the nature, causes, and perception of technical debt in research software . 2 Background and Related W ork What even is research software? T aken broadly , the term suggests any use of software for research endeavours, and indeed software supp orts research in nearly every discipline, from humanities (text analysis) to engine ering ( building energy models) and social sciences (economic models). More recently , and more narrowly , research softwar e has referred to any software written to supp ort researchers, often by roles r eferred to as research software engine ers [Pinto et al. 2018]. W e focus on research that pertains largely to natural science and engineering domains, e.g., math, physics, astronomy , climatology . Focusing on these domains emphasizes long-lived programs, which tended to originate in these elds before others, and tend to be large and complex. W e comment on generality of our results later in the paper . W e characterize software more strictly . W e delib erately exclude both software that plays an infrastructure role (operating systems, programming languages, message passing) and software that supp orts other software as helper libraries (such as matrix operations or supporting workows). This denition mirrors the one chosen by K elly [2015] and used in the construction of a recent representative dataset, SciCat [Malviya- Thakur et al. 2023]. 2.1 Scientists and Research Soware Dev elopment It is tempting to characterize research software developers as amateurs building tools as an ancillary task to their real interest, the domain science. T o be sure, a large number of projects represent one-os and paper/project-specic code that is never used by others (such as notebooks [Pertseva et al. 2024]). However , many research software projects are long-lived and developed by large teams, such as the software use d to process astronomical obser vations at the a radio telescope [N. A. Ernst, Klein, et al. 2023]. In these projects, contributors ar e a mix of domain specialists (e .g., astronomy PhD students) and software experts (e.g., high performance computing programmers) [Glendenning et al. 2014]. It is these projects we focus on in this paper , and where technical debt is more likely to be an issue. J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:5 Characterizing how research software is developed requires disentangling how the project operates, i.e., its software development process. Often scientists nd that traditional software development methodologies, such as agile methodologies, do not fully addr ess the unique needs of research software projects [Kelly 2011]. However , identifying a more suitable approach is challenging due to the lack of formal software development training among the scientists who typically lead these projects, and who often prioritize the correctness of scientic computations over software de velopment processes. This prioritization results in an aversion to process-oriented approaches [Car ver et al. 2007], leading them to adopt an "ametho dical" approach [K elly, Thorsteinson, et al. 2011]. Many scientists learn software development thr ough self-study and peer learning rather than formal education, which can result in poorly structured code and inadequate testing practices [Hannay et al. 2009; Pinto et al. 2018; Wilson 2006]. Consequently , scientists tend to use programming languages, paradigms, and development environments they are familiar with, such as Fortran, which may not always align with best practices in software engineering [Kelly and Sanders 2008; Segal 2008]. Accuracy is a critical quality attribute for research softwar e, as errors can sev erely compromise the validity and credibility of scientic ndings [Meng et al. 2011]. However , achieving this accuracy is challenging for several reasons. Research software needs to integrate knowledge across multiple domains, such as software knowledge , operations kno wledge, and science/the ory knowledge [K elly 2015]. These multiple domains are often the r esponsibility of dier ent people, leading to fragmented team structures [Aranda, S. Easterbrook, et al. 2008]. Gathering requirements for r esearch software projects is particularly dicult due to the evolving and poorly dened nature of scientic inquiries [Carver et al. 2007; K elly 2007]. This uncertainty complicates the process of ensuring that the software meets its intended requirements. Determining whether these requirements are met requires rigor ous testing and validation, which are inherently complex in the context of research software. The intricate nature of scientic algorithms and the nee d to accurately model underlying scientic phenomena demand specialize d testing methodologies tailored to the scientic domain [Carver et al. 2007; Kelly and Sanders 2008]. The oracle problem, where it is dicult to determine the correct output due to complex compu- tations, further complicates testing [Hook and Kelly 2009b]. Moreov er , these issues ar e exacerbated by the necessity of deep domain knowledge for b oth requirements gathering and validation [Kelly, Smith, et al. 2011]. Even with this knowledge, scientists often build software to understand require- ments better , and the lack of formal softwar e development training can result in overlooked test cases. The high stakes involv ed are underscored by instances wher e software err ors have led to the retraction of scientic papers, highlighting the critical importance of maintaining software accuracy [Miller 2006]. 2.1.1 Knowledge Domains. Developing resear ch software necessitates a profound integration of diverse knowledge domains to ensure accuracy and reliability . Kelly [2015]’s knowledge acquisition model highlights the importance of Real- W orld Knowledge , Theory-Base d Knowledge, Software Knowledge, Execution Knowledge, and Operational Knowledge. For instance, constructing a climate model demands Real- W orld Knowledge about meteorological phenomena, such as understanding the dynamics of hurricanes. Theory-Base d Knowledge is r equired to apply scientic principles and e quations that gov ern atmospheric behavior . Software Knowledge is essential for programming these models eciently . Execution Knowledge involves running and testing the software to ensure it produces accurate simulations, while Operational Knowledge pertains to deploying and using the softwar e in real- world scenarios. This interdisciplinary approach is crucial for the successful development of research J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:6 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li software, bridging theoretical concepts with practical implementations and ensuring the r obustness of scientic ndings. Another primary challenge in the development of research software is ensuring long-term usability , as it must remain functional for many years and adapt to new scientic discoveries and technological advancements [N. A. Ernst, Klein, et al. 2023; Kelly 2009]. The "amethodical" development process, driven by the immediacy of publication and research needs, complicates long-term maintainability [Kelly 2013]. Resear ch software tends to b e highly customized for specic scientic questions, limiting its reuse and generalization [Arnold and Dongarra 2000; Koteska et al. 2018]. This customization requires scientists to possess extensive software knowledge to maintain and update the software eectively , ensuring scalability and adaptability across dierent scientic domains. 2.2 T echnical Debt and Self- Admied T echnical Debt T echnical Debt (TD) refers to the metaphorical “b orrowing" of shortcuts or suboptimal solutions in software development to achiev e immediate gains, with the understanding that these de cisions will incur “interest" in the form of additional work required in the future if left unaddressed [Cunningham 1992]. The “principal" in this context is the initial work deferred, which represents the tasks or improv ements that were postponed. As time passes, inter est accumulates, leading to increased maintenance costs and reduced system reliability . Since W ard Cunningham intr oduced the concept in 1992, it has evolved to encompass various software development trade-os with long-term impacts [Kruchten et al. 2012]. Lim et al. [2012] found that while practitioners may not always recognize the term “technical debt, " they understand its implications, such as increased maintenance costs and reduced system reliability . TD includes dierent types such as code, design, architecture, and requirements debt, each posing unique challenges and requiring specic management strategies [N. S. R. Alves et al. 2014]. Design and architectural debts ar e particularly impactful, as they can lead to signicant rework if not addr essed early [N. A. Ernst, Bellomo, et al. 2015]. Vidoni and co-authors have studied te chnical debt in mathematical computing [M. C. Vidoni and Cunico 2022] and the R ecosystem [M. Vidoni 2021]. They found that programmers in these domains w ere familiar with the ideas b ehind technical debt, if not the sp ecic terminology , and that these programmers were usually quite deliberate and prudent in incurring technical debt. Vidoni coined the term Algorithm Debt , which we use later in the paper , to capture the comple x algorithms present in scientic code. Graetsch et al. [Graetsch et al. 2025] conduct a study of data-intensive teams and determine new types of technical debt. The team they examine does not cross knowledge domains, focusing on data engineering, and does less software development. Howev er , they note se veral data-focused types of technical debt, such as pip eline debt. W e did not identify this as a form of SSA TD , although most of our applications do feature data pipelines. Future exploration of the role of data-intensive technical debt in research software is important. Self- Admitted T echnical Debt (SA TD) ser ves as a valuable signal to the various challenges and issues developers encounter in software development. Thr ough intentional acknowledgment of technical debt in co de comments, commit messages, or do cumentation, developers highlight areas of concern that need further attention. Storey, Ryall, et al. [2008] found that annotations such as TODO and FIXME are widely used by developers to mark incomplete features, signal bugs, and indicate the ne ed for refactoring. These annotations are prevalent, with 97% of sur veyed developers regularly employing them. Examples of SA TD comments include statements like “TODO - Move the next two subroutines to a new module called glad_setup?" . or "FIXME(bja, 2016 − 10 ) do these need to be strings, or can they b e integer enumerations?" J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:7 Potdar and Shihab [2014] formally dened SA TD and identied that developers introduce it due to time pressure, the ne ed for quick xes, and the complexity of problems requiring temporar y solutions. Their study re vealed that SA TD often remains unresolved for long periods, with only 26.3% to 63.5% of SA TD being addr essed across multiple releases. They identied 62 r ecurring patterns of SA TD , which helps in recognizing the various forms of SA TD across software projects. Research software also contains SA TD . Sharma et al. [2022] highlighted the gap in studying SA TD within research software , particularly in dynamically-typed languages like R. They discovered that SA TD in R packages often remains unaddressed, negativ ely impacting software quality and reliability . Similarly , Liu et al. [2021] examined SA TD in deep learning frameworks, nding that design debt is the most fr equently introduced type, followed by requirement and algorithm debt. Their ndings indicate d that while requirement debt tends to b e addressed promptly , documentation debt is frequently neglected. These studies underscore the p otential of SA TD to reveal underlying issues, such as bugs, incomplete features, and other challenges within a codebase , providing critical insights into the software development pr ocess. Research software is critical for reliable and accurate scientic results, yet the cross-domain nature of r esearch softwar e makes its construction dicult. While SA TD exists in resear ch software, it is not clear how its presence inuences cross-domain challenges. W e therefore investigate how technical debt inuences research software. W e begin with a quantitative exploration of SA TD in research software , and then expand on those results with practitioner interviews. 3 Study 1 - antitative Evaluation of SA TD Our rst research question is RQ1: How does SA TD signal cross-domain challenges in Re- search Software? In this section we describe the quantitative method we used to answer this question, and discuss ndings. 3.1 Methodology 3.1.1 Project Selection. The selection of software projects for our analysis was guided by criteria aimed at capturing diverse practices and challenges across dierent scientic domains. W e priori- tized inuential research software within their r espective communities to ensure the relevance and impact of our ndings. Ke y selection criteria included: • Renown : Recognition and reputation within the scientic community . • Community Engagement : Active, long-term discussions in project-specic forums, reect- ing ongoing relevance and dev elopment. • Codebase Size : Projects with at least 50,000 lines of code, as measur ed by the SLOCCount tool, ensuring medium to large scale. • Development Activity : Regular updates and maintenance indicated by GitHub commit frequency . • Longevity : Projects active for a minimum of 10 years, suggesting stability and enduring utility . • Popularity Metrics : GitHub stars and forks, along with the number of dependent packages (DP) and dependent repositories (DR) for libraries. Using these criteria, we purposively sampled nine exemplary projects that reect the diversity and dynamism of advanced op en-source software development in various scientic elds. Projects were selected to span diverse scientic domains (astronomy , high-energy physics, molecular biology , climate modeling, molecular dynamics, applied mathematics), programming languages (Python, J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:8 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li C++, Fortran), and organizational structures. All nine projects met the minimum thresholds for code- base size, longevity , and dev elopment activity liste d above. W e did not systematically enumerate all candidate projects; rather , we drew on domain e xpertise and community recommendations to iden- tify well-known, actively maintained projects in each eld. T able 1 pro vides detailed descriptions of each selected project. T able 1. Overview of case study projects. Note: Due to accessibility restrictions fr om GitLab, w e could not extract the exact number of contributors and users for Athena. Name Domain Lang. Contr . SLOC Stars Forks Age (Y ears) Astrop y Astronomy Python 453 1,308,577 3.84K 1.6K 15 Athena High En- ergy Physics C++ 100+ 5,207,555 – – 21 Biopython Molecular Biol- ogy Python 331 620,437 3.61K 1.63K 27 CESM Climate Model Fortran 134 2,799,805 265 154 43 GROMA CS Molecular Dy- nam- ics C++ 85 2,102,045 552 285 29 Moose Physics C++ 221 847,602 1.5K 979 18 Elmer Applied Mathe- matics Fortran/C++ 45 954,420 1.1K 292 12 Firedrake Applied Mathe- matics Python 96 63,013 451 156 13 Root High En- ergy Physics C++ 387 5,080,496 2.4K 1.2K 26 3.1.2 Extracting Comments. Inspired by Maldonado et al. [2017] and Liu et al. [2021], we cloned the repositories of the selected projects and examined each le in the main or master branch. T o handle the unique challenges of languages like C++ and Fortran, we created custom Python scripts using the GitPython library to explore the version control history . For each le, we retrie ved the initial commit using GitPython and extracted all comments from that point onward, recording metadata such as commit date, le name, and line number . T o track comment removal, we r ecorded the date of the rst commit in which the comment was no longer present. In line with Freitas et al. [2012], we treated multi-line comments as single, continuous comments in our analysis. Errors could arise if les were renamed, relocated, or if SA TD comments were modied. T o minimize inaccuracies, we thoroughly reviewed comments and their context, cross-referencing J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:9 commit histories and le changes to account for renaming or relocation and documenting instances where comments were alter ed rather than removed. 3.1.3 Identifying SA TD Instances. Manually identifying SA TD from a large v olume of comments is challenging and time-consuming. Maldonado et al. [2017] sp ent 185 hours classifying 62,556 comments. Our detection strategy draws inspiration from recent research by Guo et al. [2021], conrming the eectiveness of keyword searches for identifying SA TD instances. W e used 64 established keywords identied by Potdar and Shihab [2014], known for agging “easy-to-nd" instances of SA TD , and an additional 597 key words from Sridharan et al. [2023] for detecting more subtle forms of technical debt. All comments were preprocessed to normalize text, including tokenizing, converting text to low- ercase, and stripping special characters. This ensured uniformity and improved keyword detection, recognizing variations like “TODO , " “todo, " or “T oDo, " and compound terms like “pleasexme. " A comprehensive keyword sear ch reduced the number of comments to 39,697. However , this process also agged non-relevant comments. For example , an Astropy comment: “Description: Generates a vector of length n containing the integers 0, ... , n-1 in random order . W e do not use a new see d. " This was agged due to the phrase do not use . The second author (a graduate student with 2 years of experience in SA TD resear ch and software engineering) manually revie wed each of the 39,697 agged comments, reading the comment text and its surrounding code context to determine whether the comment genuinely reected a developer’s acknowledgment of technical debt. Comments that matched keywords incidentally (as in the example above) were marked as non-relevant. This process took approximately 150 hours over 5 months, eliminating 11,017 non-relevant comments and resulting in 28,680 comments for further analysis. Our keyword-based approach prioritizes precision over recall: while we removed false positives through manual review , we did not conduct a systematic false negative analysis (i.e., sampling comments not agge d by keywords to estimate how many SA TD instances wer e missed). Prior work suggests keyword-based detection captures the majority of explicit SA TD [Potdar and Shihab 2014], but more implicit or unusually phrased instances may be absent from our dataset. 3.1.4 Categorizing SA TD Instances. Given the dominance of Java in previous SA TD research, automatic SA TD categorization methods have primarily been developed for Java code comments, resulting in a high rate of false positives and limited detection of SA TD types in our multi-language corpus. For example , [Li et al. 2022] only dete cts four types of SA TD . T o identify a broader range of SA TD types, including newer categories like “On Hold Debt" and “ Algorithm Debt, " and to uncover any new types of debt, we opted for a manual categorization approach. W e employed the op en card sorting technique [Spencer 2009], focusing on identifying the types of technical debt prevalent in the research software pr ojects under study . Our categorization included Code Debt, Design Debt, Architectural Debt, Build Debt, Documentation Debt, Re quirements Debt, T est Debt, and Defect Debt, as originally outlined in [N. S. R. Alves et al. 2014]. Additionally , we added categories for On Hold Debt and Algorithm Debt as describ ed by Maipradit et al. [2019] and M. Vidoni [2021] respectively . W e frequently encountered blurred distinctions between dierent types of debt, aligning with ndings from other studies [Li et al. 2022; Maldonado et al. 2017]. In response, we developed operational denitions to clarify these distinctions, guiding our labeling of SA TD comments. After reecting on the data, w e added a new category , termed Scientic Debt , reecting debt specic to the scientic nature of the software. T o mitigate personal bias in the manual classi- cation of code comments, we implemented a systematic verication process. The second author J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:10 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li randomly sampled a statistically representativ e subset of 1,000 SA TD instances from the 28,680 identied instances, using a 95% condence level with a 10% condence interval. This sample was independently classied by the third author , a post-do ctoral researcher . Inter-rater reliability was +0.79 (Cohen’s kappa coecient), indicating substantial inter-rater reliability . The kappa was computed on single-label classications, following the approach of Maldonado et al. [2017]. Subsequently , during disagreement resolution, we observed that many comments could reason- ably fall under multiple categories; we then added those additional lab els but did not conduct a second round of inter-rater agreement on the multi-label assignments. W e included all relevant categories for each comment. For example, the comment TODO - Change which_call to an integer? Modify for Glissade? (dissip has smaller vertical dimension) was labele d as both Code Debt and Design Debt, because it indicates a need for changes in the code implementation (Code Debt) and suggests a potential alteration in the software ’s design or architecture to accommodate new requirements or improvements (Design Debt). This approach provides a nuanced and accurate representation of the self-admitted technical debt present in the code. The denitions of dierent categories of debt with examples are dened in T able 2. T able 2. SA TD types used in the co ding. Debt T ype Denition Example Source Architectural Issues in project architecture, such as the vio- lation of modularity , which can impact archi- tectural requirements like performance and robustness. CESM : “TODO - Move the higher-order stu to the HO driver , leaving only the old Glide code. " [N. S. R. Alves et al. 2014] Build Problems in dependency management and build processes, such as disorganized compile ags or problematic build targets, which com- plicate the build environment. Root : “FIXME! This function is a workaround on OSX b ecause it is impossible to link against libzmq.so" [N. S. R. Alves et al. 2014] Code Complex, obsolete, or redundant code that compromises code quality or fails to adhere to best coding practices. Moose : “TODO: Rename this metho d to get- Name; the normal name (ID) should b e get- Path. " [N. S. R. Alves et al. 2014] Defect Known bugs or issues within the software that are acknowledged but not yet corrected. Elmer : “For some reason this is not always active. If not set, parallel interpolation could fail. " [N. S. R. Alves et al. 2014] Design Suboptimal design decisions that lead to in- consistent practices or insucient modular- ization, complicating future modications. Biopython : “TODO - How to handle the ver- sion eld? At the moment, the consumer will try to use this for the ID which isn’t ideal for EMBL les. " [N. S. R. Alves et al. 2014] T est Issues related to the testing process, including costly or complex tests, lack of cov erage, or inconsistent test results. CESM : “NOTE ( bja, 2018-03) ignoring for now ... Not clear under what conditions the test is needed. " Requirements Unmet or partially implemented require- ments, including non-functional ones (e.g., security , performance), aecting system func- tionality . Astropy : “Binary FI TS tables support TN ULL *only* for integer data columns. TODO: De- termine a schema for handling non-integer masked columns in FI TS. " [N. S. R. Alves et al. 2014] Docs Missing, inadequate, or inaccurate documen- tation that fails to properly guide the user or developer . Biopython : “TODO: add information about what is in the aligned sp ecies DNA b efore and after the immediately preceding ’s’ line. " [N. S. R. Alves et al. 2014] Algorithm Use of algorithms that are suboptimal or inad- equately address the intended problem, result- ing in inecient performance or scalability issues. Root : “TODO: W e could optimize based on the knowledge that when splitting a failed partition into two, if one side checks out okay then the other must be a failure. " [Maipradit et al. 2019; M. Vidoni 2021] On Hold Development delays caused by waiting for other functionalities to complete or for spe- cic events to occur . MOOSE : “TODO: Add a sync time; Remove af- ter old output system is removed; sync times are handled by OutputW arehouse. " [Maipradit et al. 2019; M. Vidoni 2021] Scientic Accumulation of suboptimal scientic prac- tices, assumptions, and inaccuracies within scientic software that potentially compro- mise the validity , accuracy, and r eliability of scientic results. Detailed examples provided in the following sections. this study Throughout the categorization process, we thoroughly reviewed the do cumentation of the research software projects involv ed. Leveraging the reliability of large language models (LLMs) J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:11 [Chiang and Lee 2023], we used ChatGPT and GitHub Copilot to aid in our analysis. ChatGPT help ed us understand comments with complex scientic terms and jargon by providing explanations and context for domain-specic terminology , particularly in comments related to scientic algorithms and methods. GitHub Copilot assisted in navigating dierent programming languages, understanding co de structures, and identifying the intent behind code changes, especially in polyglot codebases. Impor- tantly , LLMs were used solely as comprehension aids—to understand unfamiliar domain terminology and navigate unfamiliar code—and not to make or inuence categorization decisions. All label- ing judgments were made by the human coders. Additionally , for each identied SA TD instance, we cross-r eferenced the associated documentation and user manuals to verify context and accu- racy . This careful extraction pr ocess resulted in a comprehensive dataset of 28,680 labeled SA TD comments, which we provide in our r eplication package 1 . 3.2 Findings RQ1: Cross-Domain Challenges Ref lected in SA TD in Research Soware T o analyze the distribution of SA TD categories and identify cross-domain challenges in research software, we rst counted all instances of each SA TD category . Comments with multiple labels were counte d separately for each relevant categor y to accurately capture their prevalence . For instance, a comment categorized as b oth design debt and code debt was included in the counts for both categories. This approach allowed us to determine the repr esentation of each SA TD type within the projects. W e then calculated the percentages for each category across all projects and visualized these distributions in a bar chart, as shown in Figure 2. Astr opy A thena Biopython CESM Elmer F ir edrak e GROMA CS MOOSE R oot pr oject 0 20 40 60 80 100 P er centage 34.7% 32.0% 31.4% 29.5% 27.6% 31.0% 29.3% 30.5% 33.0% 11.3% 17.9% 15.9% 20.5% 15.1% 13.6% 25.2% 23.9% 20.0% 10.8% 10.6% 11.8% 6.6% 11.6% 6.1% 6.3% 8.7% 11.4% 7.5% 4.1% 6.0% 7.8% 15.5% 16.0% 7.5% 5.3% 13.1% 4.8% 8.7% 10.6% 7.0% 8.0% 6.1% 6.3% 4.5% 6.9% 4.2% 6.9% 4.1% 5.5% 3.9% 8.0% 9.4% 6.3% 5.3% 9.0% 4.4% 5.9% 15.0% 11.6% 9.9% 3.4% 5.1% 1.8% 4.0% 8.0% 1.8% 4.0% 3.3% 4.0% 4.4% 5.0% 3.2% 8.6% 1.5% 5.7% 2.3% 1.6% 1.6% 4.7% 5.6% 1.2% 3.4% 4.0% 4.4% 1.2% 1.0% 2.6% 1.6% 3.1% 1.5% 1.7% 2.1% 2.3% 0.7% 0.7% 1.2% 1.8% 2.1% 2.6% Debt Category Code Debt Design Debt Defect Debt Algorithm Debt R equir ements Debt Ar chitectural Debt Scientific Debt (Highlighted) On Hold Debt T est Debt Documentation Debt Build Debt Fig. 2. Percentage of SA TD types across selected research projects, scientific debt highlighted. Figure 2 illustrates the distribution of various types of technical debt across the analyzed projects, with Co de Debt being the most frequently self-admitted, followed by Design Debt and Defe ct 1 https://github.com/AwonSomeSauce/ScienticSATD J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:12 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li Debt. The prevalence of Code and Design Debt aligns with previous research ndings on research software practices [Hannay et al. 2009; Hook and Kelly 2009a; K elly 2011, 2013; Pinto et al. 2018]. This supports the reports from those studies indicating that the resear ch software community typically prioritizes scientic objectives over robust coding and design practices. This prioritization results in compromised code quality and suboptimal design decisions, driven by the urgent need for immediate scientic results. W e provide further support for this in §4. Scientic Debt. A smaller p ortion of the self-admitted technical debt in resear ch software projects is due to Scientic Debt . These signal underlying issues at the intersection of scientic the ories and software engineering practices, complicating the integration of scientic models into computational systems. This type of debt is notably pre valent across all projects, with CESM (14.43%), Elmer (11.16%), and Firedrake (9.21%) showing the highest percentages. Unlike traditional forms of technical debt, which primarily concern software engineering issues such as code quality and design practices, Scientic Debt specically arises from the challenges inherent in translating complex scientic methodologies into computational mo dels. W e dene this novel category as the accumulation of suboptimal scientic practices, assumptions, and inaccuracies within research software that potentially compromise the validity , accuracy , and reliability of scientic results. Our use of the word ‘science’ here refers to softwar e projects that deal with “systematic and critical investigations aimed at acquiring the best possible understanding of the workings of nature, people, and human society [Hansson 2025]" . Scientic Debt highlights the unique complexities in resear ch software development, where domain-specic intricacies and the need to align scientic knowledge with robust software engi- neering practices often lead to technical debt, potentially compromising the accuracy and reliability of scientic outcomes. Scientic Debt is distinct from Algorithm Debt. Algorithm Debt, as dene d by M. Vidoni [2021], concerns algorithms that are suboptimal in terms of p erformance or scalability —the algorithm works but could be faster or more ecient. Scientic Debt, by contrast, concerns the scientic correctness of the implementation: whether the software faithfully represents the underlying science. A numerically stable but scientically incorrect assumption is Scientic Debt, not Algorithm Debt. In practice, some comments may carry both labels (e.g., an algorithm that is both inecient and scientically approximate), but the distinction lies in the nature of the concern: computational eciency versus scientic delity . In our labeling, we found that Scientic Debt can manifest in various forms, which we refer to as indicators: • Translation Challenges: Diculties in accurately representing scientic concepts and theories within computational frameworks. This can lead to oversimplications or incorrect implementations that do not fully capture the intricacies of the original scientic models. – Example from Astr opy: “W e are going to share 𝑛 𝑒 𝑓 𝑓 between the neutrinos equally . In detail, this is not correct, but it is a standard assumption because properly calculating it is (a) complicated (b) depends on the details of the massive neutrinos (e.g., their weak interactions, which could b e unusual if one is considering sterile neutrinos). " In this example, the comment highlights the challenge of simplifying complex interactions between neutrinos for practical implementation in the co de. The standard assumption used, though common, is acknowledged as not entirely accurate, demonstrating the trade-o between scientic precision and computational feasibility . – Example from Elmer: “The computation of the dierential of the Hencky strain function is based on its truncated series expansion. TO DO: The following involves the dierential of the Hencky strain function. For some reason it doesn’t app ear to give convergence. Therefore, we J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:13 still omit this and replace the Hencky strain dierential by the dierential of the Lagrangian strain. This is expe cted to work for reasonably small straining. Find a remedy!" This comment p oints out an unresolved issue with the convergence of a sp ecic math- ematical function used in the software. The temporary solution, while working under certain conditions, highlights the ongoing struggle to achieve an accurate and reliable representation of the scientic model. • Assumptions: The necessity to embed assumptions within the code due to limitations in data, understanding, or computational resources. These assumptions, while necessary for initial model development, may introduce inaccuracies or biases that aect the outcomes of simulations and analyses. – Example from CESM: “W e assume here that new ice arrives at the surface with the same temperature as the surface. TODO: Make sure this assumption is consistent with energy conservation for coupled simulations. " This example show cases an assumption made to simplify the modeling of ice formation. The need to verify this assumption underscores the potential risk of it aecting the accuracy of energy conser vation in couple d simulations, reecting the impact of embedded scientic assumptions. • New Scientic Findings: The need to continually update software to reect the latest scientic discoveries and advancements. Failure to incorp orate new ndings can result in outdated models that do not leverage the most current scientic knowledge, thereby diminishing the relevance and accuracy of the software . – Example from Astropy: “This frame is dene d as a velocity of 220 km/s in the direction of l=270, b=0. The rotation velocity is dened in: Kerr and Lynden-Bell 1986, Review of galactic constants. NOTE: should this b e l=90 or 270? (WCS paper says 90). " This comment indicates a discrepancy in the scientic constants use d, with references to diering values in literature. It highlights the necessity to revie w and update the code to incorporate the most accurate and current scientic ndings. • Missing Edge Cases: Limitations in the software’s ability to handle all relevant scenarios or edge cases. This can lead to incomplete or erroneous r esults, particularly in complex scientic domains where edge cases may have signicant implications. – Example from ROOT: “This do es not work for large molecules that span > half of the b ox!" The comment points out a limitation in the software ’s capability to handle large molecules, which could lead to signicant inaccuracies in simulations involving such cases. It under- scores the importance of ensuring comprehensive coverage of all possible scenarios to maintain the reliability of the software . • Computational Accuracy: Instances where the mathematical or scientic accuracy within the software is compromised. This can occur due to simplications, numerical precision issues, or incorrect implementation of scientic algorithms, leading to unreliable or incorr ect results. – Example from GROMACS: “TODO: For large systems, a oat may not have enough precision. " This comment highlights a concern with numerical precision in large systems. The use of oat data types may lead to signicant inaccuracies, indicating a need for better precision management in scientic computations. – Example from GROMACS: “Since the energy and not forces are interpolated, the net force might not be exactly zero. This can be solved by also interp olating F, but that comes at a cost. A better hack is to remove the net force every step, but that must be done at a higher level J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:14 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li since this routine doesn’t see all atoms if running in parallel. Don’t know how important it is? EL 990726. " This comment describes a potential issue with force calculations due to interpolation methods used. The proposed hack to address the issue indicates a temporary workaround, highlighting the compr omise in scientic accuracy and the need for a mor e robust solution. Astr opy A thena Biopython CESM Elmer F ir edrak e GROMA CS MOOSE R oot pr oject 0 20 40 60 80 100 P er centage 22.7% 27.8% 26.7% 34.4% 26.9% 29.4% 37.8% 25.0% 46.1% 30.7% 28.6% 33.3% 26.5% 33.3% 38.2% 22.7% 22.2% 23.3% 31.2% 14.9% 10.7% 21.2% 15.4% 8.8% 30.3% 16.7% 18.7% 14.2% 20.3% 20.0% 13.7% 24.4% 17.6% 6.7% 30.6% 11.4% 1.1% 8.3% 9.3% 4.2% 5.9% 2.5% 5.6% 0.5% Indicator Assumptions Missing Edge Case Computational A ccuracy T ranslation Challenges New Scientific F indings Fig. 3. Percentage of Scientific Debt indicators across resear ch soware Figure 3 shows the distribution of Scientic Debt indicators acr oss the analyzed projects, with Assumptions and Missing Edge Cases being the most frequent. For example, GROMA CS has 37.82% assumptions, and CESM has 34.53%. These high p ercentages suggest that these projects often rely on assumptions to simplify complex phenomena or compensate for limited data and computational resources, reecting a pragmatic approach to advancing scientic inquiry . Similarly , missing edge cases are prevalent, particularly in Firedrake (38.24%) and Elmer (33.33%). This indicates signicant challenges in handling all possible scenarios within these projects, high- lighting the diculties in comprehensively testing and validating resear ch software, which often deals with highly variable data and complex phenomena. Computational accuracy issues are particularly prominent in projects like Astr opy (31.25%) and GROMA CS (30.25%), underscoring the continuous challenge of maintaining numerical pr ecision and reliability in scientic computations. Translation challenges are signicant in projects such as MOOSE (30.56%) and Athena (20.33%), highlighting the complexity of converting theoretical scientic models into practical computational algorithms, which reects the intricate nature of research software de velopment. J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:15 Summary While Code Debt and Design Debt are the most prevalent types of SA TD in research software, we identied a novel category called Scientic Debt. This categor y , signicant across all projects, includes indicators such as assumptions, missing edge cases, computational accuracy , translation challenges, and new scientic ndings. 4 Study 2: Perceptions of T echnical Debt W e now look to explain the results from the results in Study 1 using our next method, an interview study of research software developers. This second phase builds on the insights we gain into research softwar e and the occurrence of a new form of self-admitte d technical debt, Scientic Debt, to answer our second research question: RQ2: How do practitioners in research software projects p erceive T echnical Debt? 4.1 Research Method 4.1.1 Participant Selection and Interview Process. W e used personal connections and purp osive sampling from cold calling [Baltes and Ralph 2022] to create an initial sample of participants, shown in T able 3. Our sample was drawn from a selection of projects with some overlap with projects in the RQ1 portion of the paper . Five participants contribute to projects from RQ1. Cold calling has the drawback of not being representative of all researchers inv olved in research software, but the advantage of being tailored to p eople with meaningful inv olvement in the project, as well as mapp ed to the project domains covered in RQ1. The exploratory nature of the interviews and our constructivist philosophy align well with these tradeos. Note that due to the potential for identication, and p er our ethics board, we have not included project names but only the science domain. T able 3. Interview Participants. * - most common language. Ref Domain Role Language* Context Training P1 Climate Developer Fortran prod CS P2 Climate Developer Fortran prod CS P3 Climate PostDoc Fortran/R explore Domain P4 Climate Developer Fortran prod CS P5 Climate PI Fortran explore Domain P6 Astronomy Maintainer Python prod Domain P7 Molecular Dynamics Developer Python/C++ prod Domain P8 Climate PI Fortran/C++ prod Domain P9 Physics Maintainer C++ prod Domain P10 Mathematics Maintainer C++ prod/explore Domain P11 Climate De veloper Fortran/C++ prod Domain The inter view follow ed a semi-structured approach using the questions outline d in T able 4. Although we designed an inter view guide, its purpose was to guide the conversation while allowing uidity by prompting the interviewee to elaborate and explain further base d on their responses. As interviews proceeded, we added some questions (bottom of table) to cover emerging themes of interest. In particular , the questions about sp ecic examples of te chnical debt (“What caused J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:16 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li T able 4. Key Parts of the Interview Guide Experiences and personal histor y What does the project do? What are its goals? Amount of time dedicated to programming vs science.? What mentorship or learning is provided for newcomers? T echnical debt Looking at the software you maintain, but also other code you use , what would you say are the main challenges? Have you heard of technical debt? If yes, can y ou give me your denition? Do you see examples of technical debt in the code you work on? What caused this specic example? What were the consequences of this example? How do you remediate problems with y our code? What tools, if any , do you nd helpful? Incorporating domain knowledge and scientic models Scientic software often has a heavy domain component (e.g., climate modeling). How well is that integrated with your code? Do you take any particular steps to manage this? Added questions after P6 How does your project use Github or other tools for maintenance? How has the design changed/- would it be changed? What is that process like? this specic example?” , “What were the consequences?”) and the se ction on incorporating domain knowledge and scientic models were designe d to elicit the kinds of cross-domain challenges identied as Scientic Debt in Study 1. 4.1.2 Data A nalysis and Coding. All interviews were conducted using Zoom and lasted 40-75 minutes. The rst author conducte d the inter views over the months from October 2023 to June 2024. W e used Otter .AI to transcribe the interviews, and the rst author then went through the transcripts to correct the AI’s errors and to anonymize the transcripts, which we release in the replication package. W e adopted a constructivist stance [S. M. Easterbrook et al. 2008], which aligns with our obje ctive to understand research software engineers and their perceptions and experiences with technical debt. By adopting this stance, we recognize that knowledge and meaning are actively constructed by individuals through their experiences and interactions. T echnical debt is a well-established construct in the research literature, but the nature of technical debt in the context of r esearch softwar e is not. W e thus conducte d a combined de ductive and induc- tive coding exercise. W e began with a de ductive codeb ook derived fr om the literatur e (Section 4.2.1); during coding, when a passage did not t an existing deductive code, we created a new de novo code to capture the idea. Both deductive and inductive codes were applied simultaneously in a single pass through each transcript. The four themes reported below emerged from collating all codes—both deductive and inductive—into higher-level groupings during the thematic analysis. J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:17 T able 5. Sample quotes, codes, and themes showing traceability to original data. Complete examples available in replication package. Quote Code Denition Theme "I had the same program run on 2 dier- ent workstations, b oth Silicon graphics ma- chines. Just one year dierence . And I get dierent numbers out. And there wer e 5% dierences. And the metho d was supposed to be exact to 0.5%. interest- science scientic accuracy suers as a result of TD Science & Org. Goals "I brought some piece of Fortran code and I sent together with my oce neighbors who was working [on] slightly dierent program writing his own Fortran code, and we exchanged and checked each other" process- code- review team does code re- views Boundary Obj. “Is this like a critical change that we really need for this upcoming simulation? Or is this ... would be nice to have ... and where does this fall on the priority list? cause- business- priority priority of features over maintenance - refactoring less im- portant Science & Org. Goals “[where] w ere the emissions were happen- ing within the code, but once you nd that, nd out where it’s computing the ux" context- code- structure Statements about how the code is architected/designed that are not quality judgments Complexity “ All my Git knowledge is very limited. I just learned it on the on the go" rse- training the RSE is doing the work or starte d the work as part of edu- cation T eam & Peo- ple T able 5 highlights a few examples of each type, with the complete code book available as a supplement. For e xample, the notion of technical debt interest , that is, the ongoing payments caused by technical debt, was introduced in Kruchten et al. [2012]. As we coded the inter views, howev er , patterns emerged that were not cover e d by the existing codes. These de novo codes are agged as such in our codebook. Coding. W e follo wed the thematic analysis guidelines of Braun and Clarke [2006]. That method consists of (1) Familiarization: re-reading transcripts and audio to deeply engage with the data. Some initial ideas noted. (2) Initial Coding: Systematic lo w-level coding across all transcripts, expanding the code book as necessary . (3) Searching for Themes: Collate codes into potential themes, alongside relevant data. (4) Theme Review: “Checking if the themes work in relation to the coded extracts (Level 1) and the entire data set (Level 2), generating a thematic ‘map’ of the analysis. " [Braun and Clarke 2006, p. 87] (5) Dene and Name Themes: Rene specics of each theme and overall narrative, ensuring clear theme labels. J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:18 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li (6) Report Production: Extract representative quotes and r elate back to the relevant literature . W e used the op en source tool T aguette [R. Rampin and V . Rampin 2021] to organize the transcripts and co ding for the data. W e provide T aguette’s exporte d SQLite DB in our replication package. This database contains the transcripts and our codes. Upon the completion of the analysis, w e organized memb er checking [Miles et al. 2014] to collect feedback from our interviewees on our ndings, reported in Se c 6.2.4. 4.2 Findings RQ2 W e report ndings in two ways. For our deductive coding exercise , based on pre-existing theories about technical debt, we present a simple descriptive summar y of code frequency , alongside those codes which were theorized but not seen. Then we present a more detailed, inductive assessment of our interviews by showing a thematic analysis of the data, grounded in the source material. 4.2.1 Deductive Coding Results. W e applie d deductive coding using predened theor y constructs from the papers of N. S. Alves et al. [2016], N. Ernst, Kazman, et al. [2021], Martini et al. [2014], Pinto et al. [2018], and Rios et al. [2018]. Our r eplication package contains a table mapping all of our codes to this existing work for traceability . T able 6 reports on the codes we deductively coded that had more than 10 occurrences. Additionally , the below codes which were pre-e xisting, i.e., described in other research publica- tions, had fewer than two occurrences. • rse-pain-user [Pinto et al. 2018]: the pain from dealing with users. This might reect that users may not be as relevant if you are the user . • rse-pain-interruptions [Pinto et al. 2018]: w e did not see examples wher e interruptions cause d pain, perhaps reecting a less user-driven process. • interest-financial loss [Rios et al. 2018]: interest payments on debt may be causing nancial loss. W e did not obser ve this, but it is perhaps less relevant when the focus is the science. • interest-indicator-static [N. S. Alves et al. 2016]: static analysis issues as another source of interest costs; in our respondents, few use static analysis tools. • cause-incompleteref [Martini et al. 2014]: incomplete refactoring as a cause of TD. W e found little evidence of refactoring. • cause-reuse [Martini et al. 2014]: reuse as a cause of TD. While this theme did not occur , we posit it is so common it was not even mentioned in our interviews. 4.2.2 Inductive A nalysis. W e identie d four overarching themes from our inductive analysis. These are Artifacts A s Boundary Objects , Science/Organization Goals Drive TD Management , People As Drivers of Success (In Spite of Barriers) , and nally , Complexity Complicates . W e elab orate on these with reference to specic quotes and low-level co des below . Figure 4 highlights how our codes and themes evolved. In the initial map (4a), co des clustered around broad groupings such as causes of TD, inter est on TD, and human/social factors. As we iterated, we consolidated these into four themes: for example, codes related to scientic outcomes, organizational priorities, and time pressure coalesced into Science/Organization Goals Drive TD Management , while codes about team structure, domain complexity , and code size merged into Complexity Complicates . Sev eral initial groupings (e .g., “repayment of TD, ” “tools and techniques”) were absorbe d into other themes rather than standing alone. Theme 1: Artifacts As Boundar y Objects Artifacts are boundary objects that facilitate col- laboration. Boundar y object theor y [Star and Griesemer 1989; W ohlrab et al. 2019] posits that inter-team communication often revolv es around artifacts, “a means of enabling collab oration between dierent groups of actors” . These boundary objects “inhabit several intersecting social J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:19 T able 6. Co des from literature with 10 or more occurrences. Part.: number of distinct participants (out of 11) who contributed the code. RSE: research soware engineer . T ag Description Freq. Part. Source cause- business- priority Priority of features over mainte- nance 32 11 [Martini et al. 2014] cause-social- silos Silos in org 24 8 [N. Ernst, Kazman, et al. 2021] cause-social Social factors cause TD 23 9 [Martini et al. 2014] cause- techevo Reliance on legacy hardware or soft- ware 23 5 [Martini et al. 2014] rse-pain- reward Lack of formal reward (publica- tions) 23 6 [Pinto et al. 2018] rse-pain-lack of time RSE has no time 21 8 [Pinto et al. 2018] interest- rework Rework has to be done due to TD 20 8 [Rios et al. 2018] rse-pain- mismatch Mismatch between co ding and do- main skills 19 9 [Pinto et al. 2018] cause- business-time Time pressure 17 7 [Martini et al. 2014] cause-docs Incomplete or poor docs 17 5 [Martini et al. 2014] cause-design- arch Shortcuts in design and arch choices from before cause TD 16 7 [N. Ernst, Kazman, et al. 2021] cause-lack of knowledge Didn’t know enough (that we should have known) 16 6 [Rios et al. 2018] interest- indicator-doc issues TD is causing documentation prob- lems 15 6 [N. S. Alves et al. 2016] cause-req Ignorance of requirements, poor re- quirement, no elicitation done, bad user stories 14 7 [Martini et al. 2014] interest-low quality Software has low quality 12 8 [Rios et al. 2018] rse-pain- collaborate Hard to collaborate on software project 12 6 [Pinto et al. 2018] cause-test Poor or incomplete tests 12 4 [N. Ernst, Kazman, et al. 2021] interest-low maintainabil- ity Software hard to maintain 11 5 [Rios et al. 2018] rse-pain-docs Poor docs bother RSE 10 6 [Pinto et al. 2018] worlds and satisfy the informational requirements of each of them" [Star and Griesemer 1989]. In addition to formal communication artifacts such as emails and meeting notes, boundar y objects are artifacts which these dierent groups shape together , often in what Star and Griesemer [1989] J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:20 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li human/social factors complexity quality assurance tools and techniques scientific outcomes interest on TD causes of TD repayment of TD training mentoring shared-accountability team code process domain testing maintainabiility usability goal model or predict validity of results refactor RSE Pain - code Pain - Time Pain - Reward Pain - Mismatch rework low quality docs need fixed maintain harder delayed social silos social other prioritization time pressure docs flawed arch probls tech evolves lack of knowledge requirements tests flakey (a) Initial thematic map. T e sting/tests flakey cause process- testing Maintenance and maintainability harder Usability Docs (all) (rse-pain-docs, interest-doc, cause-doc) Refactor T ools in general (context-tools) Cause - arch, interest-arch-issues Process-Code-Review Process-T esting x RSE - code skill-* RSE Pain - Reward Training Shared-accountability Mentoring Social other rse-pain-collab cause-social RSE-Pain - Mismatch complexity Context - team structure code-size process-incremental process-bigbang domain-complex social silos Code/Artifact Factors T eam and People Factors Science and Org. Goals xRSE-Pain - T ime Cause-Prioritization Cause-Time Pressure Cause-T ech Evolves Cause-Lack of Knowledge X Cause-Business Priority Cause-Requirements Interest - delayed Interest- rework Interest - low quality X project-goal Science-model or predict Science-validity of results (b) Revised thematic map, aer coalescing around key themes. Fig. 4. Thematic maps showing how our analysis evolved. called standardized forms . In our study , these obje cts include source code, code management items such as pull requests, specications, standards, and design documents. Each group understands the artifacts, but specializes it for their spe cic purposes. A b oundary object view is important in these teams, which are inherently cross-disciplinary according to the domains of Kelly [2015]. For example, “dealing with scientists and software engineers who both think they’re talking about the same thing, but haven’t troubled to nd out J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:21 whether they are and wondering why they’r e talking past each other (P8 27 minutes)" . Artifacts make this communication easier , as there is a single source of truth (e.g., the code). Across pr ojects, the artifact is imp ortant because it is tangible and what people do or talk about. “I can hand someb ody a PDF and say , This is the spec for that data le format (P6 57m)" . For a lot of interviewees, the code is the main b oundary object , and code review is ke y to forming understanding across teams: "instead of writing the formulas and Latex, it’s actually faster for me to write them in Python, and then have it as a pull request, as opp osed to have someb ody else type it o again (P6 57m)" . Code artifacts act as a visible manifestation of te chnical debt, both pain and cause: "we ’ve got to nd the right scientists to talk to and we ’ll sit down together and see what we can to puzzle out about how this is working. (P6 46m)" The overall architecture is a key interaction shaper: "we have split out things out of the core and separate into separate packages to be installe d, separate and to be up dated on other [teams’s] schedules. (P6 62m)" . Architecture is an artifact directly inuencing the way science is done, e .g. with grid models: "we get to a point where we can do changes to small pieces without accidentally breaking other parts of it because of the more isolated and more you hav e cleaner interfaces. (P6)" One unique artifact was the scientic pap er , with venues to accept publications focusing speci- cally on the software driving the discoveries (e .g., Journal of Open Source Software .): "I should actually write that paper , I mean, [I hav e] given talks about it (P8)" . Dierent teams acr oss organizations then read these experience reports to learn more about design choices. Boundary objects likely play a dual role with respect to technical debt. They make any debt visible and actionable (e.g., thr ough code review of Scientic Debt comments, such as those described in §3.2). Ho wev er , when these artifacts are po orly maintained or misunderstood, the y can also become sources of debt themselves. In sev eral interviews participants referenced code that was essentially unmaintainable since the author had left the project: “w e lost our main font of knowledge about how we reconstructed electrons (P9, 25m)” . Theme 2: Science/Organization Goals Drive TD Management W e found that most of the challenges with managing technical debt in research software are cause d by a combination of science and organizational goal setting . These goals often conict with the ne ed to manage technical debt and make the software maintainable. W e did not se e a lot of evidence in the interviews that individual actions ar e the problem, such as bad coding practices. Instead, changing priorities inuence the code/artifacts: "there’s a lot which we want to do, which is not done because the highest priority and the really critical stu is what gets done (P9 43m)" . Science projects are discovery oriented, and work that does not support new discoveries is not a priority for the leadership or funders. "National Science Foundation grants, you know , they target some particular de velopment. And then they just expe ct that, Okay , that’s done. (P1 16m)" . Most projects are lead by domain experts who may not know much about software: "we had a period of time when a signicant fraction of the leadership couldn’t write a single line of Python code" (P6 6m); the "mo del has a scientic steering committee that, you know , basically makes decisions about what what’s going to be worked on and that p ercolates down. (P1 23m)" . This mimics nancial pressures driving technical debt in commercial settings [N. A. Ernst, Bellomo, et al. 2015]. Projects have goals and mandates from within and from without/above : "the physics per- formance is ultimately what people care about (P9 42m)" . Howev er , these goals typically do not include long-term maintenance, despite the team understanding this to be a signicant challenge. P2: "lots of te chnical debt and that we want to come back and clean up and and so staying on top of those issues is its own challenge (P2 49m). " "Often, I think in scientic, like co de development, we J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:22 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li do not take into the account the overhead of optimum optimizing that code or like, improving like the software engineering aspect of that code (P11 10m). " . As a r esult of misunderstanding software , "[leadership] don’t se e that software is a dynamic artifact that it changes over time, and the results change over time. Ev en the metho ds implemented change over time (P7)" . The project cadence is also science driven, e.g., to align with worldwide collaborations such as the Climate Model Intercomparison Project (CMIP) or start up of costly major instruments, like the CERN Large Hadron Collider: "It’s be en a bit close really for data taking this year , especially as the trigger is complicated and we use it in a very advanced way (P9 13m). " The lack of software awareness means projects are often r eactive: "So we can’t r eally leave it because because they’ll be deplo ying them with the latest Pytor ch or whatever , alongside it. And so if we get too far away from the bleeding edge, we’ d be in trouble (P8 12m)" . As a result, pr oje cts face interest payments in the form of delayed releases or dicult to change co de . "I think we know when it’s [tech debt] happening, b ecause just the, there’s mor e friction when you work on a piece of software and kind of run into things, problems (P4 21m)" , and "in the process of adding stu we are for ced essentially to, to addr ess some of the underlying technical debt pr oblems, because otherwise we can’t implement the new stu because it just won’t work (P6 35m). " The project then needs to sp end time reworking the code: "there ’s at least a dozen spectroscopy reduction pipelines that fundamentally do the same thing, but implemented by dierent people for dierent instruments (P6 45m)" , which impacts science goals: "we kind of got left with this thing that was thrown together really hastily , but everyone was really anticipating the output from it (P4 16m)" . Ideally , the interest in the form of bugs are at least visible when they impact science goals: "Our best bugs are the ones that the model just blows up and crashes. And it’s really obvious. But you know , what we really work hard to avoid, are the bugs that like , the scary bugs, or the bugs where everything runs ne. It looks like it’s working, right. But it’s the things are working wrong (P2 61m)" . Notably , while our Study 1 ndings show that Scientic Debt is pr esent across all projects, our interviews reveal that it is rar ely prioritized for remediation. Scientic Debt is paradoxically driven by the same science goals that deprioritize its r emoval: the pressur e to produce scientic results creates the debt, while the pressure to pr oduce the next result defers its repayment. Theme 3: People As Drivers of Success (In Spite of Barriers) In spite of the challenges to project success from Theme 2, our inter views found that the individuals developing research software exhibit high technical and domain skills . Individuals are the most dominant signal in project success: "we ’ve be en fortunate to have sta that are here for longer term and take a long term view and are able to design things to be sustainable (P4 15m)" and have deep knowledge of the code: "I’ve seen every sub module I’ve seen ev ery every major import (P6 65m)" . For science-dominant careers, coding is not always complicate d, if the project lives a long time: "there’s a module in the community atmosphere model, that uxes sea salt intake atmosphere... And so we just add a term (P3 16m)" . There are some skill gaps, around user experience design: "we kind of just don’t do user experience design (P4 13m)" , and high performance sp ecic co de parallelization: "I have been interested at some point in like, parallel pr ogramming, like using MPI and stu like that, be cause I didn’t feel like I know much about it (P5)" or platform specic optimizations (e.g., for GP U programming). A big challenge is turnover and recruitment, be cause te chnical debt only matters in the context of the social system building it (skills, structures, incentiv es): "a couple of super experts move on to dier ent elds in the last couple of y ears. And also [in 2015], I can think of at least a few people who left who took with them huge amounts of domain knowledge (P9 25m)" . Collaboration is essential since "no one is anyone ’s direct b oss (P9 20m)" and "we ’ve gone past the point where any one group can own a climate model and all the components and we have J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:23 to depend on each other , a lot more(P8 45m)" , and a career in research software is now less of a penalty: "they allowed people to move between science track and software engine ering track without being penalized in terms of career terms (P8 39m)" . The people on these pr ojects typically are trained on the job : "the biggest things that I probably had to pick up were just how to w ork with a large code base, and how to understand a large code base (P2 21m)" , which pose challenges for managing the essential complexity we do cument in Theme 4. Theme 4: Complexity Complicates . This theme captures the technical debt issues in r esearch software that arise due to complexity of various kinds (such as process, domain, the code itself ). Some of the technical debt that happens is unavoidable , cause d by what Brooks called “ essential complexity" [Fred P. Brooks 1986]. Essential complexity varies by domain, and reects the challenges of working at advanced levels in modern science, be it in physics, math, biology , to name a few . It also reects the complexity of the underlying legacy code, often decades old. This theme also captures what Brooks called accidental complexity , ‘o wn goals’ if you will, for example, around how teams are structured, or the portability of super computers. None of that complexity is inherent, but tends to emerge over time, like biofouling, the sea life and barnacles agglomerating onto the bottom of a ship. W e found essential complexity existed primarily when the domain is complex : "I don’t think documentation alone is going to save us because this is a really v ery complicate d domain specic problem, which we need people to learn over many years, I don’t think there ’s any any other way of doing it other than having people operating the [ high energy physics] trigger . (P9 31m)" Respondents also identie d complexity that arose when code is enormous : "These are like, really big codes, like more than million lines of code and, like, not easy to maintain, longer term. (P11 25m)"; for new contributors, "There’s a huge amount of technical overhead (P9 7m)" . Some of this complexity can be reduced with modern tools: "never been easier in that sense also for fewer people to maintain the code base, given that the to oling (P9 23m)" , and therefore , accidental, but complex domains seem to require larger and more complex codebases. Other complexity issues came from organizational factors, such as how they fund the project "So that’s part of why , in addition to internal change, the whole funding is shifted between groups (P6 58m)" or the process of collaborating on the software: "we operate as a collaboration of 5000, technically independent scientists (P9 52m)" . From the operational knowledge domain, a lot of complexity exists at the hardware/softwar e interface for supercomputing, as p ortability is complex : "you know , the problems are more Cray , and Intel’s compilers are as aky as hell. MPI is aky on new platforms we ’re always dealing with with the the next version, the compiler won’t w ork out, why why not? (P8 12m)" . Another complexity was testing : "test passing is relative to some baseline. And so you need to be careful about how you dene that baseline and ... whether we expect that large suite of tests to pass and which ones we expect to pass (P2 32m)" Finally , complexity impacts science and shared understanding "so if we rewrite the whole thing, it will be easier than guring out like, what’s going on here? (P11 37m), r eecting complexity from legacy code and poor documentation. 5 Discussion In our quantitative study (RQ1), we analyzed 28,680 SA TD comments drawn from nine long-liv ed research software projects spanning astronomy , climate mo deling, mole cular dynamics, high-energy physics, and applied mathematics. Beyond the expected pre valence of Code Debt and Design Debt, we identied and dened a novel category , Scientic Debt : the accumulation of suboptimal scientic practices, assumptions, and inaccuracies that can compromise the validity and reliability of scientic J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:24 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li results. Scientic Debt manifests as unvalidated assumptions, missing edge cases, computational accuracy trade-os, translation challenges between theor y and implementation, and outdated scientic knowledge embedded in co de. In our qualitative study (RQ2), interviews with 11 contributors to long-lived research software projects revealed four themes characterizing how technical debt arises and p ersists. Artifacts such as source code and pull r equests serve as boundary objects bridging domain scientists and software engineers. Science and organizational goal-setting, driven by publication pressure and grant cycles, routinely subordinate long-term maintainability to immediate scientic results. Despite these structural barriers, the high technical and domain skill of individual contributors is the primary driver of project success, though turnover creates fragility . Finally , b oth essential complexity inherent in advanced science and accidental complexity from team structure, legacy code, and platform portability continuously compound the debt burden. The rationale for sele cting a mixe d methods research (MMR) design is to be able to conduct second-order inferences from both the quantitative and qualitative studies. Although we reported our ndings in each of Sections 3 and 4, we now report a results-based integration [Storey, Hoda, et al. 2025] of these ndings into second order inferences about technical debt in research software. W e identify thr e e key aspects: the human and socio-technical nature of research software; managing scientic technical debt; and dealing with resear ch artifacts in technical debt eorts. Neither study alone could produce these inferences: the quantitative study revealed what types of debt exist and their relative pre valence, but not why they persist or how practitioners e xperience them; the qualitative study surfaced the organizational, social, and comple xity-driven forces behind technical debt, but could not quantify its extent or distribution across projects. T ogether , they show that Scientic Debt is not merely an artifact of comment-mining—it reects real tensions b etween scientic goals and software quality that practitioners actively navigate . 5.1 Knowledge Domains in Domain Knowledge-Intensive Soware Our ndings on Scientic Debt (§3.1.4) in research software complement the K elly knowledge acquisition model [Kelly 2015]. K elly’s model emphasizes continuous knowledge acquisition and integration, highlighting the nee d for deep domain-sp ecic knowledge and systematic approaches in research software de velopment. Fig. 5 illustrates a hyp othetical application of the K elly domains to two hypothesized team members. “Scientist” would represent an individual holding an advanced degree in a science domain, who learns software development on the job. This is most research softwar e developers [Hannay et al. 2009]. “Developer” represents team members with training in software engineering, e.g., through a CS degree. The spider diagram captures the amount of knowledge and skill on the dierent domains. Developer is more skilled at Software and Execution of that software; Scientist is skilled in the science (Theor y) and Operation of the software (e .g., in making climate predictions). While the diagram suggests these are two individuals, our interviews in RQ2 found that these roles can be uid, with people moving b etween domain and software roles periodically . Both our study and K elly’s model emphasize the importance of domain-specic knowledge in research software de velopment. W e identied a novel categor y of technical debt, termed Scientic Debt , with indicators like assumptions, missing edge cases, computational accuracy , translation challenges, and new scientic ndings. This aligns with Kelly’s emphasis on Real- W orld and Theor y- Based Knowledge, highlighting the necessity for developers to deeply understand the scientic problems and principles behind the software . In RQ2, we found that it is the human developers that drive the project along, and the loss of any one can b e problematic as the project loses their “huge amounts of domain kno wledge (P9 25m)" . The r elevance of domain knowledge is also ackno wledged in other work, such as attracting new project participants [Fang et al. 2023], building eective J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:25 Fig. 5. Illustrative knowledge profiles for two hypothesized team member archetypes, based on Kelly’s domains [Kelly 2015]. These ar e not empirical measurements. cross-disciplinary projects [Damian et al. 2013], and requirements engineering [Niknafs and Berr y 2016] (though knowing too much can sometimes be unhelpful [Sharp 1991]). Our observation of increased Scientic Debt during early software development stages r eects the challenges of integrating scientic kno wledge into co de. Inter views from §4 support this nding, as they highlight diculties in, for example, translating mathematical algorithms into ecient Python code , underscoring the alignment between Kelly’s work, our data, and practitioner experiences. The interviews revealed a theme surr ounding complexity . A s Kelly’s model captur es, there is essential complexity in research computing, often due to the Theory- and Real- W orld Knowledge domains, but not exclusively . Capturing real world phenomena (such as the presence of rocky planets in front of a distant star) is dicult and r equires knowledge of astrophysics and advanced J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:26 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li math. But this is not e xclusive to these domains. Softwar e itself has essential complexity to manage, for example, in building to ols to handle exascale data volumes [N. A. Ernst, Klein, et al. 2023]. Thus eective research software requires expertise across all domains. In Aranda et al. [Aranda, S. Easterbrook, et al. 2008], the paper reports similar diuse sets of knowledge across the team members. What seems to have change d since the Aranda pap er in 2008 is that coordination mechanisms, particularly for the larger projects we study , have gr eatly improv ed communication and teamwork. All of our projects used social platforms for managing the b oundary objects of source code and project management artifacts. 5.2 Managing Research Related T echnical Debt One constant in the TD literature is that having some technical debt is important. If technical debt is incurred in order to learn how it should be done [Cunningham 1992], then cutting edge, novel software projects, which feature prominently in scientic research, should have a reasonable amount of technical debt (perhaps 8-15% of the codebase [N. Ernst, Delange, et al. 2021; Graetsch et al. 2025]). The main question for research software projects is which types of te chnical debt are present. If the technical debt is part of the discovery process inherent to research, then it is advancing project knowledge and the team’s shared the ory of the program (in the Naur sense of theor y [Naur 1985]). Inadvertent technical debt by contrast is undesirable, as it reects p ortions of the codebase that do not expand our understanding of the pr ogram’s theory , but are rather attributable to external pressures. As Ramasubbu and Kemer er note, well managed organizations understand technical debt as part of moving towards an improved end state for their products [Ramasubbu and Kemer er 2018]. From our interviews, we saw that removing the less desirable technical debt is often dicult due to stakeholder focus on developing new features. This is common across software projects, and has been long-established: maintenance in general is less appealing, and often deferred [Lientz et al. 1978]. In research software, these pressures emerge as a focus on scientic priorities (e.g., new discoveries such as pulsars), often driven by domain expert led scientic advisor y committees (such as the Astropy Strategic Planning Committee 2 ). This is in addition to typical funding and operational pressures (captured deductively as ca use-business-priority , our most common deduc- tive code). The challenge for research softwar e projects is to allow for nov el software approaches and algorithms, while ensuring that, as projects mature and grow , long-term maintainability is not sacriced. 5.3 Levels of Analysis and the Inevitability of A ssumptions Scientic software must bridge multiple levels of abstraction. Marr’s levels of analysis [Marr 1982], originally proposed for understanding complex information-processing systems, provide a useful lens. At the computational level , the software encodes what scientic problem is b eing solved and why (e.g., modeling ice formation in couple d climate simulations). At the algorithmic level , it species how scientic theories are translated into computational procedures ( e.g., choosing a truncated series e xpansion for the Hencky strain function). At the implementational level , it realizes those procedures in code (e.g., choosing oat vs. double precision for force calculations). Our Scientic Debt indicators map naturally onto these levels. Assumptions and New Scientic Findings ar e primarily computational-level concerns: they reect what the software takes to be true about the world. Translation Challenges and Computational A ccuracy op erate at the algorithmic level: they concern how faithfully the scientic model is rendered as a procedure. Missing Edge Cases 2 https://www .astropy.org/team.html J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:27 and precision issues arise at the implementational level. Because Marr’s levels are hierarchical—each level is a realization of the one above—assumptions at a higher level cascade into constraints and complications at lower le vels. An assumption made to simplify the physics (computational level) forces algorithmic choices that in turn constrain the implementation, comp ounding debt across all three levels. This cascade helps explain why our interviewees reporte d that complexity complicates : the entanglement of scientic theory with software implementation across multiple levels makes technical debt in research software structurally dierent from debt in conventional systems, where the “domain” is typically conned to one level of abstraction. A ssumptions are inevitable at every level of a complex scientic system; understanding their cross-level dependencies is key to managing Scientic Debt eectively . 5.4 The Rise of GenAI: T echnical Debt and Cognitive Debt Cognitive debt is a neologism to explain the lack of understanding of a software system that arises when Generative AI to ols take responsibility for a large amount of thinking ( e.g., writing or programming) [Kosmyna et al. 2025; Shen and T amkin 2026]. It refers to a poorly developed internal theor y of how the system works ( or should work), as expressed by Naur [Naur 1985]. Maintaining a well-grounded theory of how the system does work, and should work, is critical. From our interviews we found that this theory is developed and rened in the rich interplay between people with dierent knowledge domains (the ory , real-world, software, execution, operations), collaborating using boundar y objects such as source code and issues. Use of LLMs Increased Cognitive Debt More TD More Code Created Poorer Theory of System Fig. 6. A p ossible LLM-induced cognitive/technical debt spiral. With the rise of generative AI tools, we hypothesize—based on our ndings ab out the importance of deep domain knowledge (Theme 3) and the cascading complexity across levels of analysis— that there is a risk of a negative feedback spiral with negative implications for long-term health of research software projects. One respondent in our member-che cking survey (Section 6.2.4) independently identied LLMs as a frequent cause of accidental complexity , lending preliminary support to this concern. Figure 6 illustrates this. Ev en before generative AI, as more code is written, more technical debt accrues [Curtis et al. 2012], making the the ory of the system harder to maintain (dashed lines). The system must be refactored to prev ent entropy and degradation. This has been understood since the w ork of Lehman and Belady [Lehman 1979]. In the generative AI era, this cycle accelerates (solid lines). Use of LLMs both creates more code, and reduces cognitive understanding of the system and its theory . This in turn seems likely to lead to more use of LLMs, and the cycle repeats. Pertseva et al. [Pertseva et al. 2024] also studie d scientic teams. They postulated a theory of scientic programming ecacy that suggests gradual learning cur ves, strong technical training, and good software engineering practice were essential to being eective in coding research softwar e. J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:28 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li Extending this idea of ecacy to the Naurian concept of the ory [Naur 1985], generative AI tools seem to hold potential to atten the learning curve, but at the expense of technical skills and (possibly) software engineering practices. W e emphasize that this feedback loop remains a hypothesis. Our interviews were conducted between October 2023 and June 2024, prior to widespread adoption of LLM-base d coding to ols in scientic computing, and participants were not asked directly about LLM usage. Systematic investigation of how generative AI aects technical debt in resear ch software is an important direction for future work. 5.5 Implications for Soware Researchers While collaboration between diverse kno wledge domains is crucial, the exact natur e of this collab o- ration remains ambiguous. For instance, studies hav e shown that pairing scientists with software engineers can lead to challenges, as seen when a software engineer and an astronomer struggled to align unit testing with scientic goals, and another case where a software engine er faced di- culties applying standard testing practices with nuclear scientists [Cote 2005; K elly, Thorsteinson, et al. 2011]. These examples suggest that simply putting dierent skills together may not suce. This reinforces resear ch results in socio-technical congruence [Aranda, S. Easterbrook, et al. 2008; Damian et al. 2013]. While our research shows the dierent knowledge types necessary , it is not clear which of these is harder to acquire, or better supported in LLMs. For example, is Real- W orld Knowledge, which requires deep domain-specic understanding of (for example) complex mathematics and scientic principles, mor e challenging to gain than Software Kno wledge? W e found that complexity complicates , but what type of complexity dominates? An imp ortant corollary here is that scientic projects often cannot pay skilled software professionals what they might expe ct, even as those individuals drive the successes of the research software projects. This results in more scientic developers starting rst from scientic domains, rather than software developers acquiring science knowledge [Pertseva et al. 2024; Pinto et al. 2018]. Understanding these dynamics can inform the design of training programs and team structures, enhancing the eectiveness of research software de velopment. Researchers should dev elop strate- gies that integrate diverse knowledge domains, ensuring both robustness and eciency in r esearch software projects. 5.6 Implications for Research Soware Projects The projects we studied make use of so cial coding platforms such as GitHub to manage code, issue tracking, and project artifacts. The code is the main source of truth, and Scientic Debt comments in the code reect this role as boundary obje ct between experts in the Real- W orld and Theory domains, and experts in Software or Operations. The Elmer project’s example of the “ dierential of the Hencky strain function" illustrates this, as the implementation choices and the science combine in a single shared artifact. The identication and categorization of Scientic Debt indicators (incorrect assumptions, missing edge cases) oer a framew ork for practitioners to prioritize technical debt. Understanding that new scientic ndings and computational accuracy ar e more fr equently addressed, while translation challenges and assumptions are often neglected, allows for targeted strategies. For example , a project may wish to treat novel results that ought to be incorporated into (say) a climate model dierently than tradeos of simulation accuracy over performance. Using LLMs like Claude Co de shows promise in managing technical debt by identifying domain- specic issues. However , these tools also bring the risk of reduced understanding of the complexity inherent in research software . Integrating LLMs into the development workow might help detect J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:29 potential scientic impacts early , enabling timely inter ventions, although human verication, and human cognitive awareness, is necessary to improve precision and r educe false positives. Finally , the complexity of acquiring Real- W orld Kno wledge versus Software Knowledge suggests careful team composition. Interdisciplinary teams of scientists and software engineers can bridge knowledge gaps and enhance softwar e reliability and accuracy . T raining programs focused on both domain-specic knowledge and software engine ering principles can further support collab oration. 6 Limitations and Tradeos A mixed methods study like this one has limitations and tradeos from each method to report on. 6.1 Study 1 Limitations For the quaN study of Section 3, we e xamine the internal, external, and construct validity in the study . Internally , there is potential bias from the manual lab eling of SA TD comments. The primary categorization of 28,680 comments was conducted by the second author , with the novel category of Scientic Debt emerging during this process. Because the coder proposing the category was also the primary labeler , their evolving understanding of Scientic Debt may have shaped what was included. T o mitigate this, we conducte d a post-hoc inter-rater reliability check: the third author independently classied a statistically representativ e sample of 1,000 comments, achieving a Cohen’s kappa of 0.79 (substantial agreement) computed on single-lab el classications following Maldonado et al. [2017]. Multi-label assignments were added during subsequent disagreement resolution but were not subject to a second round of inter-rater agreement. While a concurrent independent coding process would have been stronger , the scale of the dataset (28,680 comments across multiple programming languages) made fully independent dual-coding impractical. W e note that in our constructivist epistemology , novel interpretiv e categories are expected to emerge from close engagement with the data; the validity of Scientic Debt as a categor y will ultimately b e conrmed or refuted through replication by subsequent studies. Our construct of Scientic Debt is novel, and raises ontological questions ab out how it is dened. One may ask whether such Scientic Debt comments reect technical debt in the software engineering sense, or simply scientic uncertainty and provisional modeling. Perhaps our denition merely identied deciencies in scientic methodology or epistemic assumptions. Our position is that these uncertainties, when embedded in the software itself—e.g., in implementing the science of ‘Smith and Jones 2025’—constitute technical debt b ecause they directly aect the correctness of the software ’s outputs. As K elly [Kelly 2015] writes, science, and the software implementing that science, are usually inextricable . The ontology and taxonomies of self-admitted te chnical debt are not well-dened. For example, what we call scientic technical debt might be labeled as test debt by other researchers. W e acknowledge our explicit lens of scientically rele vant self-admitted technical debt. This overlap to us points to a need for a clearer ontology of terms representing these debt types. Finally , one might ask whether Scientic Debt is unique to research software . Any software that encodes complex domain knowledge—nancial modeling, medical devices, game physics—likely exhibits analogous forms of domain-knowledge debt. W e would expect similar debt indicators (unvalidated assumptions, translation challenges, missing edge cases) to appear wherever software must cross b oundaries between levels of abstraction, from domain the ory through algorithmic realization to implementation. What distinguishes research softwar e is the depth and explicitness of this multi-level entanglement (as discussed in Section 5): the explicit goal of advancing scientic understanding, the need to faithfully enco de evolving theories, and the high stakes of scientic J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:30 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li validity make the cascade of assumptions across levels particularly acute. Our denition is in- tentionally scoped to scientic software, but future work could investigate whether analogous categories emerge in other knowledge-intensive domains. Our external validity for Study 1 is reliant on our sampling and its generalizability . Our sample selection was limited to projects with publicly available source code and active r epositories. This focus might exclude insights from less pr ominent, less active , or private pr ojects, potentially biasing our understanding toward practices in more visible and activ ely maintained research software . Assessing whether Scientic Debt is a reliable signal for scientic issues within software is challenging. Our categorization aime d to capture potential scientic issues, but validating whether these comments truly reect signicant scientic concerns or are routine developer notes remains dicult. T o address this, we conducted a thor ough review process with multiple labelers and sought insights from project contributors to ensure accurate interpretations. Additionally , we cross- referenced identied Scientic Debt with actual issues and errors in the software ’s history to gauge the correlation between SA TD and real-world scientic pr oblems. Finally , the reliability of our ndings is inuenced by the complexities of mining data from Git repositories. The decentralized nature of Git allows commits to be reordered, deleted, or e dited, which can lead to inconsistencies in development history . Practices like rebasing can obscure the true se quence of events, complicating the tracking of technical debt origins and resolution. These factors necessitate cautious interpretation of our results, acknowledging p otential gaps and inaccuracies in the data. 6.2 Study 2 Limitations For the quaL resear ch in Section 4, we use the quality framework from Small and Calarco [2022] which denes the following categories for quality and study validity: empathy , heterogeneity , palpability , follow-up, and self-awareness. W e explain and reect on each in turn. Then we explore some inherent tradeos we made in conducting the study . 6.2.1 Empathy . Empathy is about asking enough probing questions or observing enough detail to understand motivations and depth of circumstance. 6.2.2 Heter ogeneity . A study without heterogeneity in the ndings will b e a limite d one that did not probe deeply . But reporting limitations often demand homogeneity to lead to actionable , generalizable insights. The suggestion in [Small and Calarco 2022] is to reect carefully on the theory and use the heterogeneity to support the the ory , while acknowledging that it might not cover all the variation. In both the quantitative and qualitative portions of the study we conducte d opportunistic samples. This is partially driv en by practical considerations around time and cost: scientists on these projects are usually quite busy and nding time to talk about software is dicult. But we also feel that in an exploratory study such as this one that getting a cr oss section of projects is more useful than a wide-net random sample that may or may not captur e the interesting aspects we require (such as size, domain, openness). Another way to conceptualize this is via Yin’s notion of ‘analytical inference ’ . As we select a range of cases on our dimensions of r elevance, w e expand the scope of potential inferences, as we may encounter a project or participant which diers from the others (e .g., as counterexample). In particular , our inter view sample skews to ward climate science (6 of 11 participants), with only one participant each from astronomy , molecular dynamics, physics, and mathematics. Our themes may therefore disproportionately reect the culture of climate modeling projects (e.g., Fortran J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:31 legacy codebases, CMIP-driven release cadences, large government-funded collaborations), and may not fully capture practices in other research softwar e domains. A common critique of qualitative r esearch in particular is the notion of saturation. Saturation refers to stopping conditions on the data collection process, and saturation is usually achieved only when the data analysis re veals no new insights. Our philosophical approach is at o dds with this assessment. W e believe it is probably impossible to saturate, particularly on rich qualitative data sources. There is still more to be learned from these interviews and research questions. What we present here is a single interpr etation subject to our biases, sample bias. Further testing of the theory can only b e achieved by replication. Data saturation refers to a positivist concept of justifying when it is acceptable to "stop " the data collection process. Saturation is often measured with empirical counts of how often a given code or theme recurs, and the theory has emerge d when some (typically post-hoc) threshold is met. In our case we stopped the interviews when the data collected was sucient to begin analysis, and nding further interviewees was becoming dicult. A critique of this study ther efore is that the themes that emerged below may change should we conduct further data collection. Our response is to admit that this is true, but likely true of any constructivist study . As Braun and Clarke [2021, p.201] state, it is important to be able “to dwell with uncertainty and recognise that meaning is generated through interpretation of, not excavated from, data, and ther efore judgments about ‘how many’ data items, and when to stop data collection, are inescapably situated and subjective” 6.2.3 Palpability . Palpability refers to the sense that the data are specic and concrete, acting as data points rather than generic sur vey questions. In this study we were careful to ask participants to reect on a specic example of technical debt or project characteristics. The transcript reects the specic nature of the questions and answers. At the same time we were careful not to stray too far o topic which might limit generality . 6.2.4 Follow-up. Follow-up requires the research project to validate themes and insights with the respondents and subjects of the study , as well as the broader community , including those who may not have participated in the study . W e sent a summary of the themes and insights to our original eleven interviewees as a short survey . They wer e asked whether they agreed with the theme, to oer additional comments, and then asked for additional comments. Five of elev en people responded (non-response may reect disagreement, disinterest, or simply time constraints), and all ve agreed the themes repr esented the problem of technical debt in r esearch software , save for one "neither agree nor disagree" for the last theme. For the open-ended answers, one comment indicated that a reason for accidental complexity may be “uncritical adoption of practices from the software industry , whose obje ctives and context are very dierent. ” Another pointed out that new technology , in this case LLMs, was a frequent cause of accidental complexity . Finally , we posted a two page summar y to the US-RSE Slack channel, a virtual watercooler for the community of resear ch software engineers in the US, but received no feedback. 6.2.5 Self-awar eness. More conventionally known as ree xivity , a best practice in qualitative research is to reect on one’s positionality and bias [Sousa et al. 2025]. This is because the researcher is the ‘data collection instrument’ . W e are a team of researchers in a Canadian university , in a computer science department. None of us have de ep knowledge of the scientic domains we studie d. The lead interviewer is a white tenured male to whom interviewees may r espond in a particular way , e.g., by inferring certain inuence and power r elations. Finally , we believed prior to the study that research software plays a vital role in science and society and that this role is underappreciated. J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:32 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li 6.3 Tradeos Tradeos are inevitable in designing a study [Robillard et al. 2024]. Using inter views as opposed to eld studies reects our choice to focus on a detailed yet broad set of insights over realistic environments [Storey, N. A. Ernst, et al. 2020]. Interviews are usually cheaper to conduct (no eld visit required) and collate (no risk of lost recordings). How ever , we lose insight into the non-verbal approaches our participants might reveal, for example, in how they allocate tasks or how they browse source code . W e fo cus explicitly on larger co de bases, that have been active for a long time , and constitute many de velopers. This is quite a dierent than other scenarios that researchers e xamine in research software. The other end of the scale is the small, single developer project, perhaps a PhD student thesis project. The lessons fr om this paper may not apply to these projects, excepting that these projects o ccasionally turn into bigger , mor e complex team projects. The German aerospace r esearch center , DLR (Deutsche Zentrum für Luft- und Raumfahrt) categorizes research software according to application class [Hasselbring et al. 2025]. This study focuse d on application classes 2 and 3, and not 0 or 1, which are "personal use" projects and not directly supported for external users. Navigating existing technical debt, e.g., due to changes in expe cted usage context, are a big part of the problem Lawrence et al. [2018] refer to in the challenge of “cr ossing the chasm" to production software projects. 7 Conclusion Research software underpins mo dern science, yet the so cio-technical challenges of its dev elopment make it fertile ground for technical debt. Using a Convergent Parallel mixed methods design, we analyzed 28,680 SA TD comments across nine research software projects and interviewed 11 practitioners. Our central contribution is Scientic Debt , a novel category capturing the accumulation of suboptimal scientic assumptions and inaccuracies in code that can compromise the validity of results. Our inter views revealed that Scientic Debt is paradoxically driven by the same science goals that deprioritize its removal, and that managing it requires navigating the interplay of boundary objects, organizational incentives, individual expertise, and multi-layer ed complexity . T ogether , these ndings conrm that te chnical debt in research software is shape d by forces largely absent in commercial contexts. W e contribute a new conceptual category , a labeled dataset of 28,680 comments, a r eusable coding guide, and empirically grounded theory to help practitioners and funders recognize and address this challenge. 8 CRediT Statement NE : Conceptualization, Funding acquisition, Methodology , Project administration, Supervision, W riting – original draft, W riting – review & editing, Resources. AA : Data curation, Formal analysis, Investigation, Software, Visualization, W riting – original draft, W riting – revie w & editing. SH : W riting – original draft, Writing – revie w & editing, Software, Methodology . ZL : Methodology , Formal analysis, Data curation, V alidation, W riting – original draft. Acknowledgments Thanks to the anonymous interview participants, and reviewers of earlier v ersions of this work. This work was funded under Sloan grant G-2022-19443. LLMs were leveraged to critique the paper , improve the presentation of plots, and with minor scripting for data analysis. J. ACM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:33 References Nicolli S.R. Alves, Thiago S. Mendes, Mano el G. de Mendonça, Rodrigo O. Spínola, Forrest Shull, and Carolyn Seaman. Feb. 2016. “Identication and management of technical debt: A systematic mapping study. ” Information and Software T echnology , 70, (Feb. 2016), 100–121. Publisher: Elsevier BV. doi:10.1016/j.inf sof .2015.10.008. Nicolli Souza Rios Alves, Leilane Ferreira Ribeiro, Vivyane Caires, Thiago Souto Mendes, and Rodrigo Oliveira Spínola. 2014. “T owards an Ontology of T erms on T echnical Debt. ” 2014 Sixth International W orkshop on Managing T echnical Debt , 1–7. Jorge Aranda, Steve Easterbrook, and Greg Wilson. May 2008. “Observations on Conway’s Law in Scientic Computing. ” In: (May 2008). Jorge Aranda and Gina V enolia. 2009. “The Se cret Life of Bugs: Going Past the Errors and Omissions in Software Repositories. ” In: 2009 IEEE 31st International Conference on Software Engineering . IEEE, V ancouver , BC, Canada, 298–308. isbn : 978-1- 4244-3453-4. doi:10.1109/ICSE.2009.5070530. Dorian C. Arnold and Jack J. Dongarra. 2000. “De veloping an Architecture to Support the Implementation and Development of Scientic computing Applications. ” In: The A rchitecture of Scientic Software . Sebastian Baltes and Paul Ralph. July 2022. “Sampling in software engineering research: a critical re view and guidelines. ” en. Empirical Software Engine ering , 27, 4, (July 2022), 94. doi:10.1007/s10664- 021- 10072- 8. Virginia Braun and Victoria Clarke. Mar . 2021. “T o Saturate or Not to Saturate? Questioning Data Saturation as a Useful Concept for Thematic Analysis and Sample-Size Rationales. ” Qualitative Research in Sp ort, Exercise and Health , 13, 2, (Mar . 2021), 201–216. doi:10.1080/2159676X.2019.1704846. Virginia Braun and Victoria Clarke. Jan. 2006. “Using thematic analysis in psy chology. ” Qualitative Research in Psychology , 3, 2, (Jan. 2006), 77–101. Publisher: Informa UK Limited. doi:10.1191/1478088706qp063oa. Jerey C. Carver, Richard P . Kendall, Susan E. Squires, and Douglass E. Post. 2007. “Software Dev elopment Environments for Scientic and Engineering Software: A Series of Case Studies. ” 29th International Conference on Software Engine ering (ICSE’07) , 550–559. Cheng-Han Chiang and Hung-yi Lee. July 2023. “Can Large Language Models Be an Alternative to Human Evaluations?” In: Proceedings of the 61st A nnual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) . Association for Computational Linguistics, T oronto, Canada, (July 2023), 15607–15631. N. Cote. 2005. “An Exploration of a T esting Strategy to Support Refactoring. ” Master’s Thesis. Royal Military College of Canada, Kingston, Canada. W ard Cunningham. 1992. “The W yCash portfolio management system. ” In: Conference on Object-Oriented Programming Systems, Languages, and A pplications . Bill Curtis, Jay Sappidi, and Alexandra Szynkarski. June 2012. “Estimating the size, cost, and types of T echnical Debt. ” In: 2012 Third International W orkshop on Managing T echnical Debt (MTD) . IEEE, (June 2012), 49–53. doi:10.1109/mtd.2012.6226000. Daniela Damian, Remko Helms, Irwin K wan, Sabrina Marczak, and Benjamin Koelewijn. May 2013. “The role of domain knowledge and cross-functional communication in socio-technical coordination. ” In: 2013 35th International Conference on Software Engine ering (ICSE) . IEEE, (May 2013). doi:10.1109/icse.2013.6606590. Steve M. Easterbrook, Janice Singer, Margaret- Anne D. Storey, and Daniela E. Damian. 2008. “Selecting Empirical Methods for Software Engineering Research. ” In: Guide to Advanced Empirical Software Engineering . Neil Ernst, Julien Delange, and Rick Kazman. 2021. T echnical Debt in Practice: How to Find It and Fix It . MI T Press. https://w ww.amazon.ca/Technical- Debt- Practice- How- Find/dp/0262542110/. Neil Ernst, Rick Kazman, and Julien Delange. A ug. 2021. T echnical Debt in Practice: How to Find It and Fix It . English. The MI T Press, Cambridge, Massachusetts, (A ug. 2021). isbn : 978-0-262-54211-1. Neil A. Ernst, Stephany Bellomo, Ipek Ozkaya, Rob ert L. Nord, and Ian Gorton. 2015. “Measure it? Manage it? Ignore it? software practitioners and technical debt. ” Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering . Neil A. Ernst, John Klein, Marco Bartolini, Jeremy Coles, and Nick Rees. Oct. 2023. “Architecting complex, long-lived scientic software. ” Journal of Systems and Software , 204, (Oct. 2023), 111732. doi:10.1016/j.jss.2023.111732. Hongbo Fang, James Herbsleb, and Bogdan V asilescu. Nov . 2023. “Matching Skills, Past Collaboration, and Limited Com- petition: Modeling When Open-Source Projects Attract Contributors. ” In: Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering . ACM, (Nov . 2023). doi:10.114 5/3611643.3616282. Fred P. Brooks. 1986. “No Silver Bullet—Essence and Accident in Softwar e Engineering. ” In: Proceedings of the IFIP T enth W orld Computing Conference , 1069–1076. Jose Freitas, Daniela Cruz, and Pedro Rangel Henriques. Oct. 2012. “A Comment Analysis Approach for Program Compre- hension. ” In: Proceedings of the 2012 IEEE 35th Software Engineering W orkshop . (Oct. 2012), 11–20. isbn : 978-1-4673-5574-2. doi:10.1109/SEW.2012.8. J. ACM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:34 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li B. E. Glendenning, Erich Schmid, George Kosugi, Je Kern, Jorge Ibsen, Manabu W atanab e, Maurizio Chavan, Morgan Grith, and Rubén Soto. 2014. “T en things we would do dierently today: r eections on a decade of ALMA software development. ” In: Astronomical T elescopes and Instrumentation . https://api.semanticscholar.org/CorpusID:54546919. Nicolas E. Gold and Jens Krinke. Jan. 2022. “Ethics in the Mining of Software Repositories. ” Empirical Software Engineering , 27, 1, (Jan. 2022), 17. doi:10.1007/s10664- 021- 10057- 7. Ulrike M. Graetsch, Rashina Hoda, Hourieh Khalajzadeh, Mojtaba Shahin, and John Grundy. Dec. 2025. “Managing technical debt in a multidisciplinary data intensive software team: An observational case study. ” Journal of Systems and Software , 230, (Dec. 2025), 112546. doi:10.1016/j.jss.2025.112546. Zhaoqiang Guo, Shiran Liu, Jinping Liu, Y anhui Li, Lin Chen, Hongmin Lu, and Y uming Zhou. 2021. “How Far Have W e Progressed in Identifying Self-admitted T echnical Debts? A Comprehensive Empirical Study. ” ACM Transactions on Software Engine ering and Methodology (TOSEM) , 30, 1–56. Jo Erskine Hannay, Hans Petter Langtangen, Carolyn MacLeod, Dietmar Pfahl, Janice Singer, and Greg Wilson. 2009. “How do scientists develop and use scientic software?” 2009 ICSE W orkshop on Software Engineering for Computational Science and Engineering , 1–8. Sven Ove Hansson. 2025. “Science and Pseudo-Science. ” In: The Stanford Encyclopedia of Philosophy . (Fall 2025 e d.). Ed. by Edward N. Zalta and Uri Nodelman. Metaphysics Research Lab, Stanfor d University. Wilhelm Hasselbring et al.. 2025. “Multi-Dimensional Resear ch Software Categorization. ” Computing in Science & Engineering , 1–10. doi:10.1109/MCSE.2025.3555023. Dan V an Hook and Diane Kelly. 2009a. “Mutation Sensitivity T esting. ” Computing in Science & Engineering , 11, 40–47. Dan V an Hook and Diane Kelly. 2009b. “T esting for trustworthiness in scientic software. ” 2009 ICSE W orkshop on Software Engineering for Computational Science and Engineering , 59–64. Diane Kelly. 2007. “A Software Chasm: Softwar e Engineering and Scientic Computing. ” IEEE Software , 24. Diane Kelly. 2011. “An Analysis of Process Characteristics for Developing Scientic Software. ” J. Organ. End User Comput. , 23, 64–79. Diane Kelly. 2009. “Determining factors that aect long-term evolution in scientic application software. ” J. Syst. Softw . , 82, 851–861. Diane Kelly. 2013. “Industrial scientic software: a set of interviews on software development. ” In: Conference of the Centre for Advanced Studies on Collaborative Research . Diane Kelly. 2015. “Scientic software development vie wed as knowledge acquisition: T owards understanding the develop- ment of risk-averse scientic software. ” J. Syst. Softw . , 109, 50–61. Diane Kelly and Rebecca Sanders. 2008. “Assessing the Quality of Scientic Software. ” In: First International W orkshop on Software Engine ering for Computational Science and Engineering . Leipzig, Germany. Diane Kelly, Spencer Smith, and Nicholas Meng. 2011. “Software Engineering for Scientists. ” Comput. Sci. Eng. , 13, 7–11. Diane Kelly, S. Thorsteinson, and Dan V an Hook. 2011. “Scientic Software T esting: Analysis with Four Dimensions. ” IEEE Software , 28, 84–90. Nataliya Kosmyna, Eugene Hauptmann, Y e T ong Y uan, Jessica Situ, Xian-Hao Liao, Ashly Vivian Beresnitzky, Iris Braunstein, and Pattie Maes. 2025. Y our Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay W riting Task . (2025). doi:10.48550/ARXIV.2506.08872. Bojana K oteska, Anastas Mishev, and Ljupco Pejov. 2018. “Quantitative Measurement of Scientic Software Quality: Denition of a Novel Quality Model. ” International Journal of Software Engineering and Knowledge Engineering , 28, 03, 407–425. Philippe B. Kruchten, Rob ert L. Nord, and Ipek Ozkaya. 2012. “T e chnical Debt: From Metaphor to Theory and Practice. ” IEEE Software , 29, 18–21. Anna-Lena Lamprecht et al.. 2022. “What Do W e (Not) Know Ab out Research Software Engineering?” Journal of Open Research Software . Bryan N. Lawrence et al.. May 2018. “Cr ossing the Chasm: How to Develop W eather and Climate Models for next Generation Computers?” Geoscientic Model Development , 11, 5, (May 2018), 1799–1821. doi:10.5194/gmd- 11- 1799- 2018. M.M. Lehman. Jan. 1979. “On understanding laws, evolution, and conservation in the large-program life cycle. ” Journal of Systems and Software , 1, (Jan. 1979), 213–221. doi:10.1016/0164- 1212(79)90022- 0. Yikun Li, Mohamed Soliman, and Paris A vgeriou. 2022. “Automatic identication of self-admitted technical debt from four dierent sources. ” Empirical Software Engineering , 28, 1–38. Bennet P. Lientz, E. Burton Swanson, and G. E. T ompkins. 1978. “Characteristics of application software maintenance. ” Commun. A CM , 21, 466–471. https://api.semanticscholar.org/CorpusID:14950091. Erin Lim, Nitin T aksande, and Carolyn Budinger Seaman. 2012. “A Balancing Act: What Software Practitioners Have to Say about T echnical Debt. ” IEEE Softw . , 29, 22–27. J. ACM, V ol. 37, No. 4, Article 111. Publication date: August 2018. The Nature of T echnical Debt in Research Soware 111:35 Jiakun Liu, Qiao Huang, Xin Xia, Emad Shihab, David Lo, and Shanping Li. Feb . 2021. A n exploratory study on the introduction and removal of dierent types of te chnical debt in deep learning frameworks . 2. V ol. 26. ISSN: 1573-7616 Publication Title: Empirical Software Engineering. Springer Science and Business Me dia LLC, (Feb. 2021). doi:10.1007/s10664- 020- 09917- 5. Rungroj Maipradit, Christoph Treude, Hideaki Hata, and Kenichi Matsumoto. 2019. “W ait for it: identifying “On-Hold” self-admitted technical debt. ” Empirical Software Engineering , 25, 3770–3798. Everton da S. Maldonado, Emad Shihab, and Nikolaos T santalis. 2017. “Using Natural Language Processing to A utomatically Detect Self-Admitted T echnical Debt. ” IEEE Transactions on Software Engineering , 43, 1044–1062. Addi Malviya- Thakur, Reed Milewicz, Lav’inia Paganini, Ahmed Samir Imam Mahmoud, and Audris Mockus. 2023. “SciCat: A Curated Dataset of Scientic Software Repositories. ” ArXiv , abs/2312.06382. https://api.semanticscholar.org/CorpusID: 266162809. David Marr. 1982. Vision: A Computational Investigation into the Human Representation and Processing of Visual Information . W .H. Freeman, San Francisco. Antonio Martini, Jan Bosch, and Michel Chaudron. Aug. 2014. “Ar chitecture T echnical Debt: Understanding Causes and a Qualitative Model. ” In: 2014 40th EUROMICRO Conference on Software Engine ering and Advanced Applications . IEEE, (A ug. 2014). doi:10.1109/seaa.2014.65. Nicholas Meng, Diane Kelly, and Thomas R. Dean. 2011. “T owards the proling of scientic software for accuracy. ” In: Conference of the Centre for Advanced Studies on Collab orative Research . Matthew B. Miles, A. M. Huberman, and Johnny Saldaña. 2014. Qualitative Data Analysis: A Methods Sourcebook . (Third edition ed.). SAGE Publications, Inc, Thousand Oaks, Califorinia. isbn : 978-1-4522-5787-7. Greg Miller. 2006. “A Scientist’s Nightmare: Software Pr oblem Leads to Five Retractions. ” Science , 314, 1856–1857. Peter Naur. 1985. “Programming as theor y building. ” Microprocessing and Microprogramming , 15, 253–261. https://api.seman ticscholar.org/CorpusID:62150543. Ali Niknafs and Daniel Berry. Apr . 2016. “The impact of domain knowledge on the ee ctiveness of r equirements engineering activities. ” Empirical Software Engineering , 22, 1, (Apr . 2016), 80–133. doi:10.1007/s10664- 015- 9416- 2. Elizaveta Pertseva, Melinda Chang, Ulia Zaman, and Michael Coblenz. Apr. 2024. “A Theory of Scientic Programming Ecacy. ” In: Proceedings of the IEEE/A CM 46th International Conference on Software Engineering . ACM, Lisbon Portugal, (Apr . 2024), 1–12. isbn : 9798400702174. doi:10.1145/3597503.3639139. Gustavo Henrique Lima Pinto, Igor Scaliante Wiese, and Luiz Felipe Dias. 2018. “How do scientists develop scientic software? An external replication. ” 2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER) , 582–591. Aniket Potdar and Emad Shihab. De c. 2014. “An Exploratory Study on Self-Admitted T echnical Debt. ” In: Proceedings - 30th International Conference on Software Maintenance and Evolution, ICSME 2014 . (De c. 2014), 91–100. doi:10.1109/ICSME.201 4.31. Narayan Ramasubbu and Chris Kemerer. 2018. “Integrating technical debt management and software quality management processes: a framework and eld tests. ” In: Procee dings of the 40th International Conference on Software Engine ering (ICSE ’18). A ssociation for Computing Machinery, Gothenburg, Sweden, 883. isbn : 9781450356381. doi:10.1145/3180155.3182529. Rémi Rampin and Vicky Rampin. 2021. “Taguette: open-source qualitative data analysis. ” Journal of Open Source Software , 6, 68, 3522. doi:10.21105/joss.03522. Nicolli Rios, Rodrigo Oliveira Spínola, Manoel Mendonça, and Carolyn Seaman. Oct. 2018. “The most common causes and eects of technical debt: rst results fr om a global family of industrial surveys. ” In: Proceedings of the 12th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM ’18). ACM, (Oct. 2018). doi:10.1145 /3239235.3268917. Martin P Robillard et al.. 2024. “Communicating study design trade-os in software engineering. ” A CM T ransactions on Software Engineering and Methodology . Publisher: A CM New Y ork, N Y tex.date-added: 2025-01-13 15:32:26 -0800 tex.date-modied: 2025-01-13 15:33:52 -0800. Judith Segal. 2008. “Scientists and Software Engineers: A T ale of T wo Cultures. ” In: A nnual W orkshop of the Psychology of Programming Interest Group . Rishab Sharma, Ramin Shahbazi, Fatemeh Hendijani Fard, Zadia Codabux, and Melina C. Vidoni. 2022. “Self-admitted technical debt in R: detection and causes. ” Automated Software Engineering , 29. Helen Sharp. Sept. 1991. “The role of domain knowledge in software design. ” Behaviour & Information T e chnology , 10, 5, (Sept. 1991), 383–401. doi:10.1080/01449299108924298. Judy Hanwen Shen and Alex T amkin. 2026. How AI Impacts Skill Formation . (2026). doi:10.48550/ARXIV.2601.20245. Mario Luis Small and Jessica McCrory Calarco. 2022. Qualitative literacy: a guide to evaluating ethnographic and inter view research . University of California Pr ess, Oakland, California. isbn : 978-0-520-39067-6. Breno Felix de Sousa, Ronnie de Souza Santos, and Kiev Gama. 2025. “Integrating Positionality Statements in Empirical Software Engineering Research. ” 2025 IEEE/ACM International W orkshop on Metho dological Issues with Empirical Studies in Software Engine ering (WSESE) , 28–35. https://api.semanticscholar.org/CorpusID:280003358. J. ACM, V ol. 37, No. 4, Article 111. Publication date: August 2018. 111:36 Neil A. Ernst, Ahmed Musa A won, Swapnil Hingmire, and Ze Shi Li Donna Spencer. 2009. Card sorting: Designing usable categories . Rosenfeld Media. Murali Sridharan, Leevi Rantala, and Mika Mäntylä. 2023. “PENTA CET data - 23 Million Contextual Code Comments and 250,000 SA TD comments. ” 2023 IEEE/ACM 20th International Conference on Mining Software Rep ositories (MSR) , 412–416. Susan Leigh Star and James R. Griesemer. A ug. 1989. “Institutional Ecology, ‘Translations’ and Boundary Objects: Amateurs and Professionals in Berkeley’s Museum of V ertebrate Zoology, 1907-39. ” So cial Studies of Science , 19, 3, (Aug. 1989), 387–420. doi:10.1177/030631289019003001. Margaret- Anne Storey, Neil A. Ernst, Courtney Williams, and Eirini Kalliamvakou. Aug. 2020. “The who, what, how of software engineering r esearch: a socio-technical framework. ” Empirical Software Engineering , 25, 5, (A ug. 2020), 4097–4129. Publisher: Springer Science and Business Media LLC. doi:10.1007/s10664- 020- 09858- z. Margaret- Anne Storey, Rashina Hoda, Alessandra Maciel Paz Milani, and Maria T eresa Baldassarr e. 2025. “Guiding Principles for Mixed Methods Research in Software Engineering. ” Empirical Software Engineering , 30. doi:10.1007/s10664- 025- 10629 - x. Margaret- Anne Storey, Jody Ryall, R. Bull, Del Myers, and Janice Singer. Jan. 2008. “TODO or to bug: exploring how task annotations play a role in the w ork practices of software dev elopers. ” In: Proceedings - International Conference on Software Engineering . (Jan. 2008), 251–260. doi:10.1145/1368088.1368123. M. Vidoni. 2021. “Self-Admitted T echnical Debt in R Packages: An Exploratory Study. ” 2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR) , 179–189. Melina C. Vidoni and Maria Laura Cunico. 2022. “On technical debt in mathematical programming: An exploratory study. ” Mathematical Programming Computation , 14, 781–818. G. J. Wilson. 2006. “Where ’s the Real Bottleneck in Scientic Computing?” A merican Scientist , 94, 5. Rebekka W ohlrab, Patrizio Pelliccione, Eric Knauss, and Mats Larsson. 2019. “Boundar y Objects and Their Use in Agile Systems Engineering. ” Journal of Software: Evolution and Process , 31, 5, e2166. doi:10.1002/smr.2166. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009 J. A CM, V ol. 37, No. 4, Article 111. Publication date: August 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment