A two-step sequential approach for hyperparameter selection in finite context models
Finite-context models (FCMs) are widely used for compressing symbolic sequences such as DNA, where predictive performance depends critically on the context length k and smoothing parameter α. In practice, these hyperparameters are typically selected …
Authors: José Contente, Ana Martins, Arm
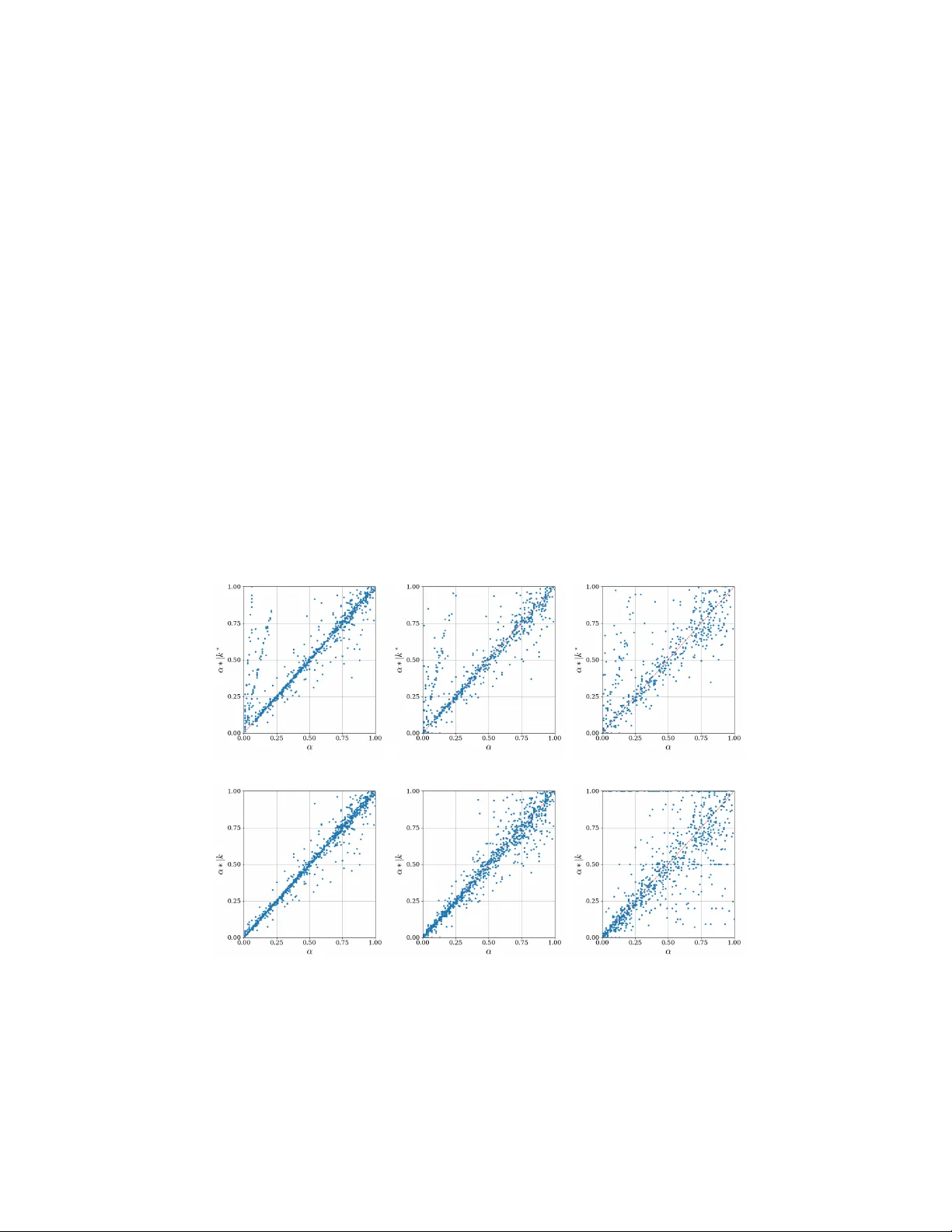
A t w o-step sequen tial approac h for h yp erparameter selection in finite con text mo dels José Con tente 1 [0009 − 0001 − 9354 − 4546] , Ana Martins 1 , 2 [0000 − 0003 − 4860 − 7795] , Armando J. Pinho 1 , 2 [0000 − 0002 − 9164 − 0016] , and Sónia Gouv eia 1 , 2 [0000 − 0002 − 0375 − 7610] 1 Institute of Electronics and Informatics En gineering of A v eiro (IEET A), Departmen t of Electronics, T elecomm unications and Informatics (DETI), Univ ersity of A veiro (UA), A veiro, Portugal {jfcc11, a.r.martins, ap, sonia.gouveia}@ua.pt 2 In telligent Systems Associate Laboratory (LASI), Portugal Abstract. Finite-context mo dels (F CMs) are widely used for compress- ing sym b olic sequences such as DNA, where predictiv e performance de- p ends critically on the con text length k and smoothing parameter α . In practice, these h yp erparameters are typically selected through exhaus- tiv e search, which is computationally exp ensiv e and scales p oorly with mo del complexity . This pap er prop oses a statistically grounded t wo-step sequential ap- proac h for efficient h yp erparameter selection in F CMs. The key idea is to decomp ose the join t optimization problem into t wo indep enden t stages. First, the con text length k is estimated using categorical serial depen- dence measures, including Cramér’s ν , Cohen’s κ and partial mutual information (pami). Second, the smoothing parameter α is estimated via maximum lik eliho od conditional on the selected con text length k . Sim ulation experiments were conducted on syn thetic symbolic sequences generated by FCMs across multiple ( k , α ) configurations, considering a four-letter alphab et and differen t sample sizes. Results sho w that the dep endence measures are substan tially more sensitiv e to v ariations in k than in α , supporting the sequential estimation strategy . As exp ected, the accuracy of the hyperparameter estimation impro ves with increasing sample size. F urthermore, the proposed method ac hieves compression p erformance comparable to exhaustiv e grid search in terms of av erage bitrate (bits per sym b ol), while substantially reducing computational cost. Overall, the results on simulated data sho w that the prop osed se- quen tial approac h is a practical and computationally efficien t alternative to exhausti v e hyperparameter tuning in F CMs. Keyw ords: Finite con text models · Hyperparameter tuning · Maxim um lik eliho o d · Serial dep endence 1 In tro duction Data compression, that is, reducing data digital size by enco ding information using few er bits, is an increasingly imp ortan t task for efficien t storage of infor- 2 J. Con ten te et al. mation in a fast-moving data-driven w orld. F urthermore, compression tec hniques ha ve underlying mo dels that attempt to repro duce as closely as p ossible the in- formation source to be compressed. Th us, these models are interesting on their o wn as they can provide insight into the statistical prop erties of the data. One suc h mo del are finite context mo dels (FCMs), widely used in the compression of finite alphab et sequences, suc h as DNA or proteins [11,14,15]. Finite context mo dels describe sequences from a finite alphab et, where the probability of ob- serving the next sym b ol s dep ends only on the k previous sym b ols, i.e., the con text. This probabilit y is calculated for a fixed k context using the Lidstone estimator [8], where α is a smo othing factor. As suc h, F CMs are describ ed by h yp erparameters con text ( k ) and smo othing factor ( α ) . Curren t approac hes to set these hyperparameters in compressors are based on exhaustiv e trial and error pro cedures (grid searc h), whic h implies that the compression technique must b e emplo yed at every trial, so that the “b est” com bination of hyperparameters in the searc h space is iden tified. Thus, the wide use of FCMs advocates for a timely manner to find the “b est” set of hyperparameters, impro ving compressors time efficiency . Finite context models are, in fact, discrete-time Mark ov mo dels, whic h, from a time series analysis p erspective, hav e a close relation to autoregressive mo dels, i.e., an observ ation at time t relies on the previous p observ ations. Thus, concepts commonly used in time series analysis to describe serial dep endence are of high relev ance in this setting. F or real-v alued time series, the auto correlation function (acf ) and partial auto correlation (pacf ) pla y an important role in the study of structural serial dep endence [13]. The acf provides information on the correlation b et w een t w o time p oin ts, whereas pacf pro vides this information, conditional on in termediate time p oin ts, meaning that, it pro vides a more accurate represen- tation of the serial dep endence [13]. In fact, pacf is used to identify the order p of autoregressive mo dels [13]. Thus, giv en the categorical nature of F CMs, to bridge this kno wledge into its domain requires the use of counterpart measures adequate for this t ype of data. The dev elopmen t of serial metrics for categorical time series faces sev eral c hallenges, but contin uous correlation measures suc h as Cohen’s κ and Cramer’s ν hav e b een adapted for categorical time series [17]. Another in teresting measure, is the partial auto mutual information (pami, for short) proposed by Biswas and Gua (2009) [3] to deal with categorical data. The authors hav e sho wn that this measure b eha v es in a similar fashion to the pacf, whic h supp orts its use for mo del order iden tification. Although, this measure w as prop osed under a time series p erspective, it makes use of the concept of m utual information, thus, relating to information theory and compressors. As suc h, pami is a very strong con tester to aid identifying the h yp erparameter k . The previous metrics allow only the selection of k , how ev er, it is also nec- essary to set α in the Lidstone estimator. This estimator requires that the size of the context ( k ) is previously fixed, whic h advocates for a sequential strategy where the v alue of α is chosen after k has b een set. Thus, the selection of α can b e framed within a principled probabilistic modelling persp ectiv e. Sp ecifically , un- der the Lidstone formulation, the smoothed predictive probabilit y corresp onds F CM h yp erparameter selection 3 to the posterior exp ectation of a m ultinomial distribution with a symmetric Diric hlet prior. Consequently , estimating α b ecomes a hyperparameter inference problem. A natural approac h is to adopt an empirical Bay es strategy , whereb y the multinomial probabilit y vectors associated with each con text are treated as laten t v ariables and in tegrated out, yielding a Diric hlet - m ultinomial marginal lik eliho o d for the observed count vectors. Pooling information across all con texts of fixed order k enables the estimation, as eac h context pro vides an independent m ultinomial observ ation contributing to the likelihoo d of α . The resulting es- timator is obtained by maximizing the joint marginal likelihoo d o ver α . This approac h yields a data-driv en estimate of α , coherent with the probabilistic in- terpretation of Lidstone smo othing factor, and naturally adapts to the amount of information a v ailable in the collection of contexts. Therefore, the goal of this work is to in troduce a tw o-step sequen tial ap- proac h for the selection of F CM hyperparameters ( k , α ) . The first step of the approac h consists in fixing k using categorical serial dep endence measures as features. Then, α is estimated via maxim um lik eliho od conditional on the v alue of k . By separating the context length from the smo othing factor, the proposed approac h reduces the dimensionality of the optimization problem and av oids the com binatorial search typically required for join t h yp erparameter tuning. Hence, this approach will contribute to largely reduce the computational burden and time cost of compression tasks. The remaining of the pap er is outlined as follows: section 2 pro vides bac k- ground information finite context models and their h yp erparameters, section 3 presen ts the metho ds used to dev elop the tw o-step sequential approac h, including the sim ulation study design and p erformance ev aluation. Section 4 presen ts the results of the exp erimen tal study and its discussion. Lastly , section 5 is dev oted to the main conclusions and future w ork. 2 Finite context mo dels an d h yp erparameters Finite con text models are Marko v models used in the mo deling of serial de- p endence. In this particular case, the in terest lies in modeling the serial depen- dence of a categorical pro cess Y t describ ed by a finite alphab et A with range { a 1 , a 2 , . . . , a r } . In this t yp e of model, the o ccurrence of an observ ation of a categorical time series y t , where t = 1 , . . . , T , at a time step t , dep ends only on the previous k observ ations, i.e., the con text length. Th us, the hyperparameter k can b e referred to as order, context, or even depth of the mo del [1,12]. Fig- ure 1 displays an example of ho w an FCM w orks in the compression paradigm. The data sequence is generated from a four-symbol alphab et A = { A, B , C , D } . The observ ation in the time instance t + 1 relies on the previous k = 5 obser- v ations. Thus, the set of observ ations y t − 4 , ..., y t , is the conditioning con text c t that allo ws to calculate the probabilit y of observing a given symbol s at t + 1 . Remark that the n umber of conditioning states of the mo del is |A| k , dictating its complexit y . Thus, the h yp erparameter k exp onen tially increases the num b er of conditioning states for a giv en alphab et. 4 J. Con ten te et al. C ... A A D A C A B B D C ... y t − 4 y t +1 F CM Enco der c t P ( y t +1 = s | c t ) Output bit-stream Fig. 1: Illustration of the usage of a finite con text m odel in a compression task, sho wing how the probability of the next outcome, y t +1 , is conditioned by the last k outcomes ( k = 5 , in this example). Adapted from [10]. The probabilit y that the next outcome equals a giv en symbol, y t +1 = s is obtained using the Lidstone estimator [8] P ( y t +1 = s | c t ) = n t s + α P a ∈A n t a + |A| α , (1) where n t s represen ts the num b er of times that, in the past, the symbol s was generated having c t as the conditioning context, and |A| is the cardinality of the alphab et (the cardinality is 4 in Fig. 1 example). In equation (1), the factor α con trols how muc h probability is assigned to unseen (but p ossible) even ts, playing a key role in the case of high-order mo dels [9]. The Lidstone estimator reduces to Laplace’s estimator for α = 1 [7], and to the Jeffreys/ Krichevsky and T rofimov estimator for α = 1 / 2 [5,6]. The smo othing factor α > 0 , but often v alues in the range [0 , 1] are considered where α = 0 is the no smoothing case. Thus, full sp ecification of a finite context mo del is ac hieved with the hyperparameters k and α . A dditionally , in Fig. 1 is also represented an arithmetic enco der, whic h gen- erates an output of bit-streams with av erage bitrates almost identical to the en tropy of the mo del [1,12,16]. The theoretical av erage bitrate (en tropy) of the finite-con text mo del after enco ding T symbols is given b y [10] H T = − 1 T T − 1 X t =0 log 2 P x t +1 = s | c t bps, (2) where bps stands for bits p er sym b ol. Note that the entrop y of an y four sym b ol alphab et is, at most, t wo bps, which is achiev ed when the sym b ols are indep en- F CM h yp erparameter selection 5 den t and equally likely . Supp ose that for the example in Fig. 1, with a fixed v alue for α , P ( y t +1 = C | c t ) = 0 . 1 and P ( y t +1 = A | c t ) = 0 . 4 , then the theoretically a verage bitrate w ould b e H 1 = 3 . 32 and H 1 = 1 . 32 , resp ectiv ely . This shows that for sym b ol C, given that it is less probable, more than tw o bits are need for compression. In contrast, for symbol A, less bits would b e required. Thus, the arithmetic compressor pro vides insigh t on how well the F CM describes the underlying data. 3 Metho ds Figure 2 outlines the t wo-step sequen tial framew ork emplo yed to obtain the pair of optimal hyperparameters ( k ∗ , α ∗ ). First, from an observ ed categorical time series, y t , feature extraction is p erformed based on pami and other serial dep endence metrics. Then k ∗ is chosen b y identificat ying the lag at which the maxim um serial dep endence o ccurs. This step identifies the order of the FCM that b est captures the serial dep endence structure of the sequence, indep enden tly of an y smoothing assumptions. The second-step of the strategy is fed with both y t and k ∗ , and the smo othing parameter α ∗ is estimated via maxim um lik eliho od conditional on k ∗ . At the end of the pro cedure ,a pair of optimal h yp erparameters is obtained. Thus, rather than relying on exhaustiv e join t search procedures, the prop osed approach decomposes the problem into t wo stages guaran teeing its computational efficiency . k ∗ Selection F eature Extration Compute k ∗ y t k ∗ ML Estimation Compute α ∗ | k ∗ ( k ∗ , α ∗ ) Fig. 2: Outline of the tw o-step sequential strategy for hyperparameter con text ( k ∗ ) and smo othing factor ( α ∗ ) selection. In the following subsections, the selection of k ∗ via pami, and the computa- tion of α ∗ conditionally on k ∗ are described. Moreov er, other categorical time- series features employ ed for context length selection are also discussed. Then, the sim ulation study design and p erformance metrics are presented. 3.1 Determination of k ∗ via pami The partial auto m utual information (pami) is a sp ecial case of the conditional m utual information ( I ). The latter measures how muc h information t w o random 6 J. Con ten te et al. v ariables share, when accoun ting for the effect of a third one, i.e., I( X 1 , X 2 | Z ) = E log P( X 1 , X 2 | Z ) P( X 1 | Z ) P ( X 2 | Z ) , (3) where P( . | Z ) are conditional probabilities. The deriv ation of a time-lagged v er- sion of (3), results in pami, where X 1 and X 2 are replaced b y Y t and Y t + h , and Z are now the time lags b et w een in b etw een these these time-p oin ts, i.e., F t = Y t +1 , . . . , Y t + h − 1 [3]. Therefore, pami( h ) = E log P( Y t , Y t + h |F t ) P( Y t |F t ) P( Y t + h |F t ) (4) The similarit y of pami expression to the pacf one is striking, in fact, [3] show ed that for a discrete AR( p ) pro cess, pami( h ) = 0 for h > p supp orting its use for mo del order selection. After computing the pami for a data sequence, a criterion is needed to select the optimal v alue k ∗ . A maximum-based criteria is defined, i.e., the lag at whic h the maxim um pami v alue is observed is set as the optimal k ∗ . 3.2 Determination of α ∗ | k ∗ The Lidstone estimator (1) corresp onds to the p osterior exp ectation of the multi- nomial probabilities under a symmetric Diric hlet prior Diric hlet ( α, . . . , α ) [2,4]. Consequen tly , the estimation of α can b e formulated as a hyperparameter infer- ence problem. Let C k ∗ denote the set of contexts of order k ∗ extracted from the sequence. F or eac h context c ∈ C k ∗ , let n c = ( n c, 1 , . . . , n c, |A| ) (5) denote the multinomial count vector asso ciated with that context, w ith total coun t N c = P s ∈A n c,s . Under the symmetric Dirichlet prior, integrating out the m ultinomial parameters yields the Dirichlet–m ultinomial marginal likelihoo d p ( n c | α ) = Γ ( |A| α ) Γ ( N c + |A| α ) Y s ∈A Γ ( n c,s + α ) Γ ( α ) . (6) Assuming conditional indep endence across contexts, the joint log-marginal lik eliho o d o v er all contexts of order k ∗ is giv en by ℓ ( α ) = log G Y g =1 p n ( g ) | α , (7) and the empirical Ba yes estimate of α is defined b y α ∗ = arg max α> 0 ℓ ( α ) . (8) Because this optimisation problem is one-dimensional, the maxim um can b e obtained efficiently using n umerical optimisation metho ds suc h as Newton– Raphson or gradien t-based search. F CM h yp erparameter selection 7 3.3 Other candidate features The additional features explored for the hyperparameter k ∗ are con ven tional categorical time series dep endence measures, namely Cramer’s υ and Cohen’s κ . These serial dependence metrics w ere adapted from con tinuous data, to han- dle the discrete nature of categorical time series [17]. Let p i = P( Y t = i ) b e the marginal probability of the i th category of Y t , obtained with the relative frequencies estimator ˆ p i = 1 T T X t =1 1 i ( Y t ) , (9) where 1 i () is the indicator function with 1 i ( Y t ) = 1 if Y t = i and 0 other- wise. Moreov er, consider the notation for the joint probability p ij ( h ) = P( Y t = i, Y t − h = j ) , with i, j ∈ A , estimated by ˆ p ij ( h ) = 1 T − k T X t = h +1 1 i ( Y t ) 1 j ( Y t − h ) . (10) Then, Cramer’s υ , a measure of unsigned serial dep endence, i.e. unorientated asso ciation, can be defined as [17] υ ( h ) = r 1 r − 1 r X i,j =1 ( p ij ( h ) − p i p j ) 2 p i p j , (11) In con trast, Cohen’s κ is a signed (orientated) association measure [17] κ ( h ) = r P i =1 p ii ( h ) − p 2 i 1 − r P i =1 p 2 i . (12) 3.4 Sim ulation Study & Performance Ev aluation T o ev aluate the prop osed sequential hyperparameter selection strategy , a sim- ulation study w as conducted. Synthetic categorical time series were generated from finite-context mo dels (FCMs) defined o ver a four-symbol alphabet A = { A, B , C , D } , k ∈ { 1 , · · · , 10 } and α defined on a grid of 201 equally spaced v alues in the interv al [0 , 1] . Thus, a total of 2010 com binations of ( k , α ) were used as the true data-generating pro cess. F or each com bination, 100 sequences of length T = 100 , 000 were generated. Then, pami and the other serial depen- dence measures were computed for each one of the 201,000 data sequences, to assess their abilit y in identifying k ∗ . In a second exp erimen t, random pairs of ( k , α ) w ere randomly selected from the 2010 p ossible combinations to generate 1000 sequences of length T = { 1 , 000; 10 , 000; 100 , 000 } , resulting in 622 unique pairs of ( k, α ). F or eac h sequence, the 8 J. Con ten te et al. prop osed tw o-step approach was applied, i.e., k ∗ selection based on pami, fol- lo wed by estimation of α ∗ via maximum likelihoo d conditional on k ∗ . The se- quences were generated from differen t lengths to ev aluate whether the pro cedure degrades when limits information is a v ailable. F or the second experiments with 1,000 instances, p erformance w as ev aluated from tw o complementary p erspectives. First, the predictive abilit y of pami was assessed b y comparing the proportion of correctly estimated k ∗ with the data- generating k . In addition, the estimation of α ∗ w as ev aluated conditional on k and k ∗ , to assess how the estimation of α ∗ is impacted by k ∗ . T o assess how α ∗ | k and α ∗ | k ∗ are related to α , the Pearson correlation w as computed, r ( z i , α ) = P n i =1 ( z i − ¯ z ) ( α i − ¯ α ) q P n i =1 ( z i − ¯ z ) 2 q P n i =1 ( α i − ¯ α ) 2 , (13) where α i is the data generating parameter, ¯ α is its av erage and, z i can b e replaced b y α ∗ i | k i or α ∗ i | k ∗ i , for i = 1 . . . , 1 , 000 sequences. Second, the practical impact of the estimated hyperparameters on compres- sion p erformance was ev aluated using the theoretical av erage bitrate (bits p er sym b ol) defined in equation (2). F or eac h sequence, the bitrate obtained us- ing the pair of estimated hyperparameters ( k ∗ , α ∗ ) was compared with the bi- trate obtained via exhaustive grid searc h. This pro cedure was carried out for k ∈ { 1 , . . . , 10 } and α ∈ { 0 , 0 . 1 , . . . , 1 } , yielding a total of 1,010 com binations. Then, the pair ( k, α ) , achieving the minim um bitrate was selected as the optimal grid searc h configuration. Thus, a fairer comparison is rendered since, in prac- tice, the h yp erparameters ( k , α ) are not known and this is the usual pro cedure to find them. 4 Results Figure 3 shows the distribution of pami for the syn thetic sequences of length T = 100 , 000 for different combinations of ( k , α ) . T wo representativ e context lengths ( k = 3 and k = 8 ) are shown for sev eral v alues of α . The results show a clear and consisten t pattern, with pami exhibiting a pronounced p eak at the lag corresponding to k , follo wed by a rapid decay for higher lags. This b eha vior is similar to that of the pacf of autoregressive models. Although some v ariation can b e observed as a result of α , the pami pattern presents similar shap e for k . The shape found for k = 3 for α > 0 . 5 is noteworth y . Larger v alues of α mean that more w eight is giv en in the Lidstone estimator (1) to the uniform distribution. Th us, this curve maybe explained by giving more weigh t to less frequen t ev ents. This effect is somewhat observ ed for k = 8 , but o verlapped b y an effect asso ciated with the serial dep endence. Also, remark that pami considers the relative frequency estimator of probabilities, i.e. α = 0 . Ov erall, the results suggests that pami is driven mainly b y k , rather than the smo othing factor ( α ), th us supp orting its use in iden tifying k ∗ . F CM h yp erparameter selection 9 ( k , α ) = (3 , 0) ( k , α ) = (8 , 0) ( k , α ) = (3 , 0 . 1) ( k , α ) = (8 , 0 . 1) ( k , α ) = (3 , 0 . 5) ( k , α ) = (8 , 0 . 5) ( k , α ) = (3 , 0 . 8) ( k , α ) = (8 , 0 . 8) ( k , α ) = (3 , 1) ( k , α ) = (8 , 1) Fig. 3: Boxplots of the distribution of pami for synthetic time series of length 100,000, generated with k ∈ { 3 , 8 } and α ∈ { 0 , 0 . 1 , 0 . 5 , 0 . 8 , 1 } . 10 J. Conten te et al. Figure 4 shows the behavior of Cramér’s ν (blue) and Cohen’s κ (red), for sequences generated with k = 3 and several smo othing factors. F or Cramér’s, ν sligh tly higher v alues for k up to lag 3, decreasing from there on, can b e detected. Ho wev er, for larger v alues of k , the observed Cramér’s ν pattern rapidly v anishes, with v alues close to zero for all lags (data not shown). Th us, Cramér’s ν is not a goo d option as feature to describe k , since for larger k it loses its (small) discriminativ e ability . Regarding, Cohen’s κ no pattern is iden tified. Th us, these metrics are not helpful for aiding in k selection. ( k , α ) = (3 , 0 . 1) ( k , α ) = (3 , 0 . 1) ( k , α ) = (3 , 0 . 5) ( k , α ) = (3 , 0 . 5) ( k , α ) = (3 , 0 . 8) ( k , α ) = (3 , 0 . 8) Fig. 4: Bo xplots of the distribution of Cramér’s ν (blue) and Cohen’s κ (red) for the syn thetic time series of length 100,000, with k = 3 and α ∈ { 0 . 1 , 0 . 5 , 0 . 8 } . Figure 5 highlights the use of the maxim um-based pami criteria computed for t wo data sequences with differen t v alues of ( k , α ) . The optimal k ∗ is chosen as the lag at which the maximum pami v alue is observed. In b oth cases, k ∗ corresp onds to the true k , although the peak is more evident for k = 8 (highlighted in red), since for k = 3 a similar pami v alue can b e found at lag 10. F CM h yp erparameter selection 11 ( k , α ) = (3 , 0 . 96) ( k , α ) = (8 , 0 . 22) Fig. 5: Partial auto mutual information for tw o data sequences with T = 100 , 000 . Maxim um v alue highlighted in red. After ev aluating pami for an exhaustiv e num b er of ( k , α ) v alues, the assess- men t of the prop osed pro cedure is performed for the second experiment setting with 1,000 data sequences for the 622 unique pairs of ( k , α ) and for v arying T lengths. First, confusion matrices were built using the maxim um-based pami criterion to select k ∗ . The matrix compares the true context ( k ) with the v al- ues obtained by the prop osed metho d ( k ∗ ) for T = { = 1 , 000; 10 , 000; 100 , 000 } (Fig. 6). The diagonal identifies the num b er of correctly predicted k ∗ v alues. F or T = 100 , 000 nearly 70% of the series had k ∗ correctly predicted. This v alue is limited as a result of the large miss-classification for k = 9 , 10 , whic h are mainly predicted as k ∗ = 8 . F or smaller sample sizes, the correctly predicted k ∗ v alues decrease to ab out 50% for T = 10 , 000 and just 40% for T = 1 , 000 . Moreov er, the miss-classification no w occurs mostly for v alues of k ∗ = 6 , 7 and k ∗ = 5 for T = 10 , 000 and T = 1 , 000 , resp ectively . Thus, this suggests, that the abilit y of this criteria in identifying k decreases for smaller T and, ma y b e limited by a relation b et w een the context length k and the sample size T . Fig. 6: Confusion matrix comparing the context k used to generate the synthetic sequences and the optimal context k ∗ obtained using the pami-based selection rule for differen t v alues of T . 12 J. Conten te et al. Figure 7 displa ys the disp ersion plots of ( α ∗ | k ∗ ) and ( α ∗ | k ) , against α used in the data-generating pro cess for different sample sizes T , where the red line indicates p erfect correlation ( r = 1 ). The optimization pro cedure allows α > 1 , but, for readabilit y , plots are sho wn for the in terv al [0 , 1] . When α ∗ is estimated conditionally on k ∗ , although a considerable amount of points is o ver the line of p erfect correlation, there is still some v ariabilit y for T = 100 , 000 . As T decreases, v aribilit y increases and the n umber of p oints o ver the r = 1 line visibly diminish. Moreo ver, a pattern stands out for all T , on the left side of the disp ersion plot, whic h may suggest a comp ensatory effect o ver k ∗ on the estimation of α ∗ . T o ev aluate the qualit y of the estimation procedure, ( α ∗ | k ) w as computed. The v ariabilit y in estimates is substantially lo wer compared to the case of k ∗ , except for T = 1 , 000 , whic h appears to lose qualit y considerably . Th us, suggesting that this sample size is indeed to o small to get an accurate α ∗ . Overall, results for T > 1 , 000 , indicate that, if a reliable estimate of k is provided, then α is accurately estimated. ( α ∗ | k ∗ ) T = 100 , 000 ( α ∗ | k ∗ ) T = 10 , 000 ( α ∗ | k ∗ ) T = 1 , 000 ( α ∗ | k ) T = 100 , 000 ( α ∗ | k ) T = 10 , 000 ( α ∗ | k ) T = 1 , 000 Fig. 7: Dispersion plots of the estimated smoothing factor conditioned to the optimal context ( α ∗ | k ∗ ) , and conditioned to the data-generating context ( α ∗ | k ) , against the smo othing factor ( α ) for differen t sample sizes T . Red line is r = 1 . F CM h yp erparameter selection 13 T able 1 shows summary statistics for ( α ∗ | k ∗ ) and ( α ∗ | k ) for several sample sizes, and aids in clarifying the previous results. The correlation b et ween ( α ∗ | k ) for the largest sample size is 0.93, while for ( α ∗ | k ∗ ) is ab out a third. This can be largely explained by the amount of instances where α > 1 , which are less than 5% for ( α ∗ | k ), but ov er 20% for ( α ∗ | k ∗ ). Also, for ( α ∗ | k ∗ ) about 7% instances return α > 5 , which further impacts r . These extreme lead to more biased estimated of ( α ∗ | k ∗ ) , compared to ( α ∗ | k ) . The correlation for T = 10 , 000 drops to 0.37 for ( α ∗ | k ) , thus, it is not surprising that for the case ( α ∗ | k ∗ ) this is less than 0.10. F or T = 1 , 000 both cas es hav e a similar correlation, and estimates are extremely biased, further supp orting the fact that this sample size is too small to generate accurate estimates of α . T able 1: Summary statistics for the estimation procedure of the smo othing fac- tor conditioned to the optimal context ( α ∗ | k ∗ ) , and conditioned to the data- generating con text ( α ∗ | k ) for differen t sample sizes T . Statistic T = 100 , 000 T = 10 , 000 T = 1 , 000 r ( α ∗ | k ∗ , α ) 0.32 0.08 0.07 r ( α ∗ | k , α ) 0.93 0.37 0.07 Bias α ∗ | k ∗ 1.06 7 . 6 × 10 9 1 . 44 × 10 11 Bias α ∗ | k 0.01 0.06 2 . 1 × 10 10 % ( α ∗ | k ∗ ) > 1 22.5 41.5 52.3 % ( α ∗ | k ) > 1 4.3 8.4 26.1 % ( α ∗ | k ∗ ) > 5 7.7 23.1 33.6 % ( α ∗ | k ) > 5 0 0.2 6.1 Figure 8 ev aluates the impact of the proposed sequen tial hyperparameter selection pro cedure on compression performance. The disp ersion plots compare the bitrate obtained from the optimal ( k ∗ , α ∗ ) , bps ∗ , and bitrate obtained using grid search, bps g s with the bps obtained from the data-generating parameters ( k , α ) .Most p oin ts lie close to the diagonal line, indicating that the bitrate ob- tained with ( k ∗ , α ∗ ) is generally v ery similar to the bitrate computed with the data-generating pro cess ( k , α ) (Fig. 8a). When the con text length is correctly iden tified, i.e., k ∗ = k , (blue points), the achiev ed bps ∗ is indistinguishable from bps . In con trast, when the context is misidentified, i.e., k ∗ = k , (blac k points), the resulting compression performance is consistently worse than the optimal one, highlighting the importance of accurately estimating k . Ho wev er, p oints o ver the line account for 5% of the misclassified k ∗ . Th us, suggesting that α ∗ can, to some exten t, comp ensate for inaccuracies in the estimation of k . The bitrate obtained from the grid searc h ( bps g s ) closely matc hes the bps obtained with ( k, α ), with the p oin ts concen trated along the diagonal. It is eviden t that there is a p erfect correlation b et w een bps g s and bps (Fig. 8b). Ho wev er, while bps ∗ is computed with a simple t wo-step procedure and only needs to compress 14 J. Conten te et al. the data once, bps g s is the result of an exhaustive searc h pro cedure ov er 1,010 p oin ts, th us requiring the compressor to b e executed 1,010 times. (a) (b) Fig. 8: Disp ersion diagrams of bps versus the estimated bps . (a) bps ∗ obtained when compressing with optimal ( k ∗ , α ∗ ) using the prop osed approac h, distin- guishing k ∗ = k (blue) or k ∗ = k (black). (b) bps g s obtained when compressing with the optimal ( k , α ) found via grid search. Red line is r = 1 . 5 Conclusion This w ork introduced a t wo-step sequen tial approac h for the selection of F CM h yp erparameters ( k , α ) . The prop osed framework decomp oses the joint optimiza- tion of the con text length k and smo othing parameter α in to t wo independent stages. First, k is estimated using the serial dep endence categorical features. Then, conditional on the selected k ∗ , α ∗ is estimated via maxim um likelihoo d. The simulation results pro vide several important insigh ts. First, the exp er- imen ts show that pami exhibits a clear and consisten t pattern that allows to iden tify k , through a maximum v alue criteria. Thus, pami is clearly superior to the other metrics ev aluated, and was capable to successfully iden tify k in ab out 70% of cases for T = 100 , 000 . Secondly , the estimation of α via maxi- m um lik eliho od pro ved effective when k is correctly iden tified. The accuracy of the estimates increases with the sample size, while small sample sizes lead to larger v ariability in the estimates. The results also suggest that misidentifying k can propagate to the estimation of α , highligh ting the importance of a reliable k detection. Lastly , the proposed strategy was ev aluated in terms of compression p erformance. Results sho w that the bitrate obtained using the estimated hyper- F CM h yp erparameter selection 15 parameter ( k ∗ , α ∗ ) is comparable to that obtained through grid search. More imp ortan tly , the prop osed approac h achiev es this p erformance while requiring only a single compression run, whereas grid search requires multiple compres- sions with a large n umber of hyperparameter combinations. Ov erall these results suggest that the con text length k is the dominant h y- p erparameter in compression efficiency . Th us, next stages of the work should fo cus on developing other criteria that impro ve the classification success of k . F urthermore, more extensiv e studies for other alphab et sizes and deep er contexts are also necessary . A ckno wledgmen ts. This w ork was supp orted by the F oundation for Science and T echnology (F CT) through Institute of Electronics and Informatics Engineering of A veiro (IEET A) contract doi.org/10.54499/UID/00127/2025 and Pro ject “Agenda IL- LIANCE” [C644919832-00000035 | Pro ject n º 46], PRR – Plano de Recuperação e Resiliência u nder the Next Generation EU from the Europ ean Union. Disclosure of In terests. The authors ha ve no in terests to disclose. References 1. Bell, T.C., Cleary , J.G., Witten, I.H.: T ext compression. Prentice-Hall, Inc. (1990) 2. Bishop, C.M.: P attern Recognition and Mac hine Learning. Springer, New Y ork (2006) 3. Biswas, A., Guha, A.: Time series analysis of categorical data using auto-m utual in- formation. Journal of Statistical Planning and Inference 139 (9), 3076–3087 (2009) 4. Gelman, A., Carlin, J.B., Stern, H.S., Dunson, D.B., V ehtari, A., Rubin, D.B.: Ba yesian Data Analysis. CRC Press, Boca Raton, 3 edn. (2013) 5. Jeffreys, H.: An in v ariant form for the prior probabilit y in estimation problems. Pro ceedings of the Roy al So ciet y of London. Series A. Mathematical and Ph ysical Sciences 186 (100 7), 453–461 (1946) 6. Krichevsky , R., T rofimov, V.: The p erformance of universal enco ding. IEEE T rans- actions o n Information Theory 27 (2), 199–207 (1981) 7. Laplace, P .S.: Essai philosophique sur les probabilités (a philosophical essay on probabilities). P aris, F rance: V euve Courcier (1814) 8. Lidstone, G.J.: Note on the general case of the bay es-laplace formula for inductive or a p osteriori probabilities. T ransactions of the F aculty of A ctuaries 8 (182-192), 13 (1920) 9. Pinho, A.J., F erreira, P .J., Neves, A.J., Bastos, C.A.: On the representabilit y of complete genomes by multiple comp eting finite-context (marko v) mo dels. PloS one 6 (6), e 21588 (2011) 10. Pinho, A.J., Neves, A.J., Martins, D.A., Bastos, C.A., F erreira, P .: Finite-context mo dels for DNA co ding. Signal Processing pp. 117–130 (2010) 11. Pratas, D., Hosseini, M., Pinho, A.J.: Geco2: An optimized to ol for lossless com- pression and analysis of dna sequences. In: International Conference on Practical Applications of Computational Biology & Bioinformatics. pp. 137–145. Springer (2019) 12. Say o od, K.: Introduction to data compression. Morgan Kaufmann (2017) 16 J. Conten te et al. 13. Shum wa y , R.H., Stoffer, D.S.: Time series analysis and its applications: with R examples. Springer (2006) 14. Silv a, M., Pratas, D., Pinho, A.J.: Efficient dna sequence compression with neural net works. GigaScience 9 (11), giaa119 (2020) 15. Silv a, M., Pratas, D., Pinho, A.J.: A C2: an efficient protein sequence compression to ol using artificial neural net works and cache-hash mo dels. Entrop y 23 (5), 530 (2021) 16. Solomon, D.: Data compression: The complete reference. Springer-V erlag, London (2007) 17. W eiß, C.H., Göb, R.: Measuring serial dep endence in categorical time series. AStA A dv ances in Statistical Analysis 92 , 71–89 (2008)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment