DAPA: Distribution Aware Piecewise Activation Functions for On-Device Transformer Inference and Training
Non-linear activation functions play a pivotal role in on-device inference and training, as they not only consume substantial hardware resources but also impose a significant impact on system performance and energy efficiency. In this work, we propos…
Authors: Maoyang Xiang, Bo Wang
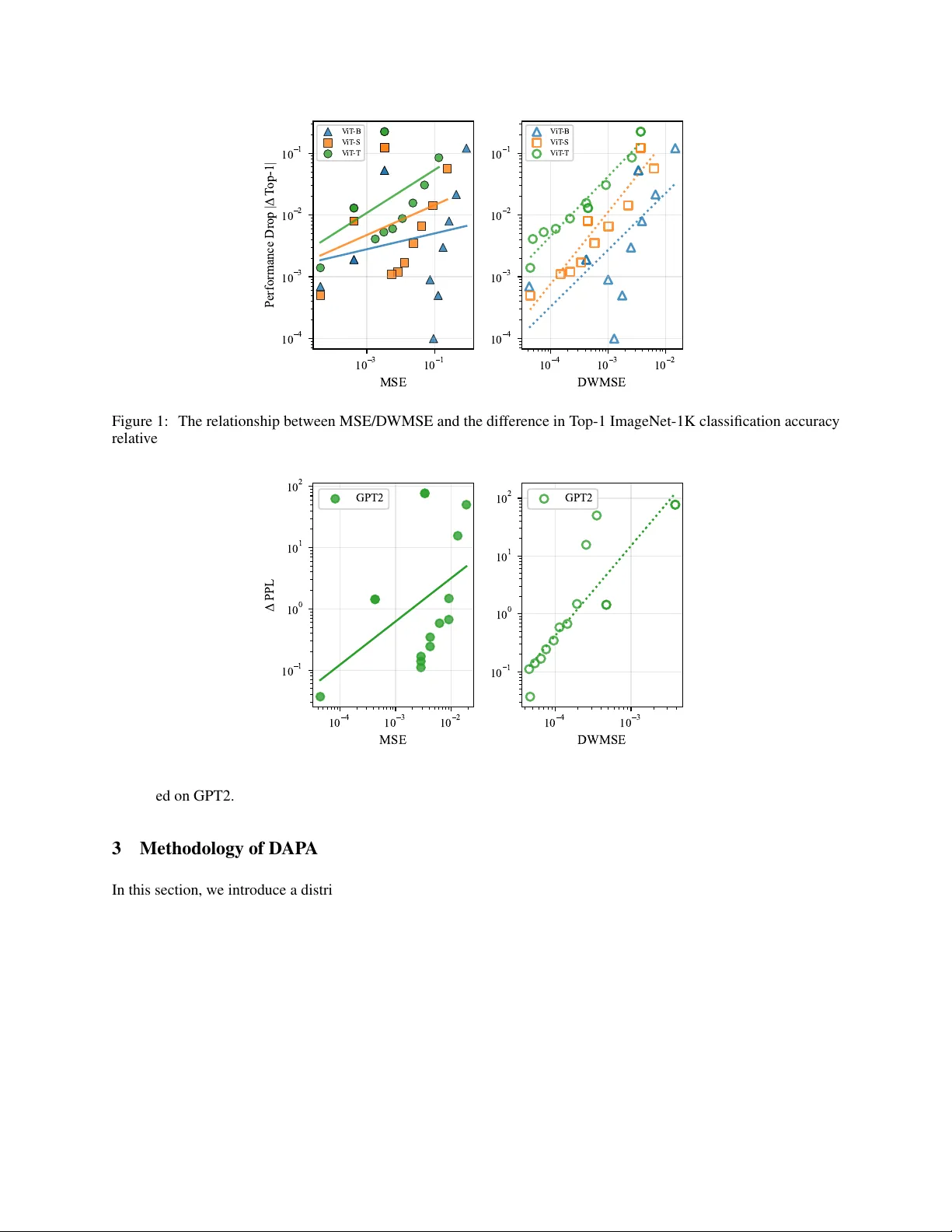
DA P A : D I S T R I B U T I O N A W A R E P I E C E W I S E A C T I V A T I O N F U N C T I O N S F O R O N - D E V I C E T R A N S F O R M E R I N F E R E N C E A N D T R A I N I N G ∗ Maoyang Xiang, Bo W ang Information Systems T echnology and Design Singapore Uni versity of T echnology and Design Singapore {maoyang_xiang, bo_wang}@sutd.edu.sg A B S T R AC T Non-linear acti vation functions play a pi v otal role in on-de vice inference and training, as the y not only consume substantial hardware resources but also impose a significant impact on system performance and energy ef ficienc y . In this work, we propose Distribution-A ware Piece wise Acti vation (D AP A), a differentiable and hardw are-friendly acti vation function for T ransformer architectures by exploiting the distribution of pre-acti vation data. D AP A employs a non-uniform piece wise approximation that allocates finer se gments to high-probability regions of the distrib ution, improving generalizability over prior piece wise linear methods. The resulting approximation is further quantized using Distrib ution- W eighted Mean Square Error to reduce latency and resource utilization for hardware deployment. Our HLS implementation demonstrates that D AP A speeds up GELU computation by 16 × and decreases DSP utilization by 16 × while maintaining comparable or better performance across vision T ransformers and GPT -2 models. K eywords Acti v ation Function · Distribution · Piecewise Linear Approximation 1 Introduction Acti vation functions are fundamental components of modern Deep Neural Networks (DNNs) as they introduce essential non-linearity for models to learn complex data patterns in the real world. T o enable efficient DNN acceleration at the edge, approximated activ ation functions are often adopted. As a result, the quality and efficienc y of these approximations become crucial for ov erall system performance and energy ef ficienc y . In particular , acti vation function approximation becomes a major bottleneck to accelerating T ransformer architectures. Although matrix multiplications in T ransformers are highly parallel, ov erall throughput is often constrained by the la- tency of non-linear acti v ation functions [ 1 ]. Ho we ver , approximating these functions typically in volv es computationally expensi ve operations such as higher -order polynomials that are inherently slo wer than simple arithmetic, which can stall parallel processing pipelines. Consequently , ho w to ef ficiently implement these non-linear operations becomes critical for enhancing the o verall efficienc y of on-de vice T ransformer e xecution. T o handle this challenge, strategies such as Look-Up T ables (LUTs), polynomial approximations, and piecewise linear functions ha ve been proposed. The y are all designed to minimize the Mean Squared Error (MSE) with respect to the original activ ation function for approximation. Ho wev er , a smaller MSE does not necessarily translate to better model performance when utilizing the approximated functions. This is because MSE implicitly assigns uniform weighting o ver all pre-acti v ation inputs, regardless of the actual data distrib ution. Consequently , approximations optimized for minimizing MSE may not generalize well and can lead to inef ficient hardware resource utilization as unnecessary precision can be allocated to statistically insignificant regions. T o address this limitation, we propose Distribution-A w are Piecewise Linear Approximation (D AP A) functions, a differ- entiable acti vation approximation for on-chip T ransformer inference and training. Our approach le v erages the actual ∗ Accepted for publication at the 63rd IEEE/A CM Design A utomation Confer ence (D A C 2026) input data distribution, allo wing the approximation to focus on high-probability re gions that pose a significant impact on performance. This leads to a more accurate and hardware-ef ficient approximation with improved generalizability for various T ransformer models. The main contributions of this paper are summarized as follo ws: • W e propose a novel approach that exploits the input probability density function to approximate both acti vation functions and their deri v ati ves, which can be generalized to a v ariety of V ision T ransformer and the GPT -2 models. Our e valuation demonstrates that it speeds up GELU computation by 16 × without compromising accuracy . • W e introduce Distribution-W eighted Mean Squared Error (DWMSE) as a new loss function for approximation. Our experiment sho ws that D WMSE e xhibits a stronger correlation with model performance v ariations than con ventional MSE, leading to impro ved netw ork performance with the resulting approximation. • W e propose a 16-bit fixed-point (Fix16) quantization scheme for D AP A that automatically selects integer and fractional precision under a D WMSE-guide error b udget, achie ving inference accuracy comparable to a non-quantized baseline. • W e demonstrate a 16 × reduction in DSP utilization for GELU and 48 × reduction for Softmax, both with significant savings in flip-flops and LUT resources compared to prior Fix16 implementations. • W e sho w that D AP A-based GELU functions can be successfully trained from scratch and con ver ge at the same rate as standard GELU, while achieving slightly higher accurac y in V ision T ransformer models. The remainder of this paper is organized as follo ws: Section 2 revie ws prior work on acti vation function approximation. Section 3 details the proposed D WMSE metric and the D AP A approach, while Section 4 presents the experiential results of D AP A across multiple tasks. Finally , Section 5 concludes this work. Our source code is av ailable at https://github.com/MayerUser/DAPA_Activation 2 Related W ork The complexity of modern acti v ation functions presents a significant challenge for ef ficient hardware implementation [ 2 ]. In particular , their non-linear operations, such as exponentials, are prohibiti vely e xpensiv e in terms of area, latency , and po wer , moti v ating the use of approximation techniques [ 3 ]. Among e xisting approaches, LUTs provide simplicity and relativ ely lo w latency , but their memory requirements gro w exponentially with precision [ 4 , 5 ]. Algorithmic approximations present an alternative. For instance, T aylor series-based methods can achieve high accuracy b ut require a substantial number of Multiply-Accumulate (MAC) operations [ 6 , 5 , 7 , 8 ]. In contrast, the CORDIC algorithm offers a more area-ef ficient solution by solely using shifts and additions, though its iterati v e nature results in higher latenc y [6, 9]. The limitations of these methods lead to the rise of hybrid piecewise approximation. This technique partitions the function into multiple segments and approximates each using a simple linear model or a lo w-degree polynomial [ 4 , 10 , 11 ]. By localizing the approximation, it achiev es higher accuracy with minimal hardware cost. Specifically , rather than storing full-precision function v alues, a piece wise approximation requires only a small LUT for se gment coefficients and a MA C unit to reconstruct the function output. This structure substantially reduces both memory footprint and logic utilization, providing an ef fecti ve balance between accurac y and hardware ef ficiency [12, 4, 3]. The piece wise approximation method has been widely adopted and e volv ed into multiple v ariants. For instance, the Internal Symmetry Piece wise Approximation (ISP A) [ 12 ] le verages the odd symmetry of the internal Gaussian error function to approximate GELU, ef fecti vely halving the size of the coef ficient memory . [ 13 ] has proposed a hardware- ef ficient piecewise linear acti v ation function as an alternativ e to GELU. Ho we ver , the performance is constrained by the configurability of the parameters, limiting the generalizability across dif ferent models and tasks. At the architectural lev el, the Fle x-SFU accelerator [ 10 ] employs non-uniform segmentation over a fixed input range, assigning finer intervals to high-curv ature regions. Consequently , it achiev es higher accuracy than uniform schemes. Ho we ver , for a giv en function and number of segments, these interv als are statically calculated of fline and remain unchanged at run time, without adapting to input-dependent data distributions. It is worth noting that most of these approaches merely focus on minimizing function-level error (e.g., MSE) between the approximated and the original activ ations [ 14 ]. Although ef fecti ve in some cases, this methodology is inherently data- agnostic. It treats all parts of the input range as equally important and ignores the actual distrib ution of pre-acti vation val ues. As a result, hardware resources are often misallocated, providing unnecessary precision to rarely visited regions while underserving high-probability inputs. This limitation motiv ates a shift from conv entional function-lev el error minimization to distribution-a ware error minimization. 2 1 0 3 1 0 1 MSE 1 0 4 1 0 3 1 0 2 1 0 1 Performance Drop | T op-1| V iT -B V iT -S V iT -T 1 0 4 1 0 3 1 0 2 DWMSE 1 0 4 1 0 3 1 0 2 1 0 1 V iT -B V iT -S V iT -T Figure 1: The relationship between MSE/D WMSE and the dif ference in T op-1 ImageNet-1K classification accuracy relativ e to the FP32 baseline, e v aluated across three V ision Transformer v ariants. 1 0 4 1 0 3 1 0 2 MSE 1 0 1 1 0 0 1 0 1 1 0 2 PPL GPT2 1 0 4 1 0 3 DWMSE 1 0 1 1 0 0 1 0 1 1 0 2 GPT2 Figure 2: The relationship between MSE/DWMSE and the dif ference in W ikiT ext2 PPL relati v e to the FP32 baseline, ev aluated on GPT2. 3 Methodology of D AP A In this section, we introduce a distribution-aw are error metric, Distribution-W eighted Mean Squared Error (DWMSE), together with a Distribution-A ware Piece wise Activ ation (DAP A) for on-device T ransformer inference and training. 3.1 Distribution-W eighted Mean Squar ed Error When designing hardware-friendly approximations, MSE is a commonly used error function to guide approximation optimization. Ho wev er , we observ e a remarkable discrepancy where approximations with lo w MSE v alues can still lead to substantial degradation in model accuracy , as Fig.1 illustrates. This indicates that MSE, by assigning equal importance to all input ranges, can not precisely capture the components most critical to network performance. Specifically , the inputs to an acti v ation function in a well-trained T ransformer model typically e xhibit a non-uniform probability distribution. Howe ver , the intrinsic distribution characteristics are ignored by MSE, which penalizes errors in low-probability and high-probability re gions equally . T o address this limitation, we propose D WMSE as a ne w metric for ev aluating performance v ariation arising from approximated acti vation functions. It e xtends the standard 3 MSE by incorporating the probability density function (PDF) of the input data, p ( x ) . The DWMSE within interval [ a, b ] is defined as: D WMSE = 1 b − a Z b a p ( x )( σ ( x ) − ˆ σ ( x )) 2 dx (1) where σ ( x ) denotes the original activ ation function, ˆ σ ( x ) denotes its approximation. The formula weights the squared error according to its probability of occurrence, highlighting the most frequently encountered inputs. T able 1: Comparison of correlation coefficients and 95% Fisher CIs. Model Metric Correlation Coefficients Fisher CI r ρ τ V iT -Base MSE 0.191 0.359 0.312 [-0.43, 0.69] D WMSE 0.646 0.754 0.562 [0.12, 0.89] V iT -Small MSE 0.323 0.169 0.250 [-0.31, 0.76] D WMSE 0.938 0.923 0.812 [0.79, 0.98] V iT -Tiny MSE 0.490 0.528 0.438 [-0.12, 0.83] D WMSE 0.973 0.979 0.938 [0.90, 0.99] GPT -2 MSE 0.230 0.490 0.449 [-0.32, 0.66] D WMSE 0.903 0.943 0.864 [0.73, 0.97] T o v alidate the ef ficacy , we in v estigate the model performance changes against MSE and D WMSE metrics, respectiv ely , and analyze ho w approximation error correlates with accuracy degradation. W e study this using V iT -Base/Small/T iny[ 15 , 16 ] models on the ImageNet-1K dataset[ 17 ], and the GPT -2 Base model[ 18 ] on the W ikiT ext-2 dataset. All MSE and D WMSE v alues are computed ov er the range of [ − 4 , 4] , follo wing a common approach [ 11 ]. As Fig. 1 sho ws, D WMSE exhibits a more linear correlation with the accurac y change compared to MSE. It is w orth noting that the correlation for V iT -Base is weaker than for the other models, primarily because many V iT -Base cases exhibit a tiny accuracy drop. Subsequently , we use Pearson coefficient r , Spearman coefficient ρ , Kendall coef ficient τ , and their 95% Fisher Confidence Intervals (CIs) to further quantify the correlation between the error metrics and performance changes. T able 1 sho ws that for all V iT models, D WMSE exhibits a consistently higher correlation with the performance change compared to MSE. Moreov er , the 95% Fisher CIs for D WMSE are always narro wer than those for MSE, indicating a more precise estimation across all tested models. For the GPT -2 Base model, D WMSE also exhibits higher coefficient values with respect to the perple xity change ( ∆ PPL ), indicating a stronger correlation. As further illustrated in Fig. 2, the ∆ PPL shows a more linear relationship with D WMSE, suggesting that D WMSE provides a more accurate measure to capture performance v ariations. 3.2 Design of Distribution-A ware Piecewise Activ ation The core principle of our D AP A function is to achie ve a highly accurate approximation by allocating precision according to the input data’ s probability distribution. Rather than dividing the input range into uniform segments, D AP A partitions the cumulativ e probability into N equal segments, ensuring that each segment represents an equal portion (i.e., 1 / N ) of the probability mass, as Figure 3 illustrates. As a result, this scheme generates finer granularity for pre-acti vation data with high probability density and coarser granularity for data with low probability density . The boundaries of these segments, or "knots," are determined using the in v erse of the Cumulati ve Distrib ution Function (CDF), F − 1 ( x ) . The CDF , F ( x ) , is defined as the integral of the probability density function p ( t ) : F ( x ) = Z x −∞ p ( t ) dt (2) where t denotes the pre-activ ation input of the non-linear function. In practice, p ( t ) is captured from the actual distribution of pre-acti v ation values collected by running the network on M real samples (images or tokens) and aggregating all occurrences across layers. Thus the n -th knot, k i , is calculated as: 4 0.0 0.2 0.4 P D F p ( x ) PDF 0.0 0.5 1.0 GELU GELU DAP A 4 3 2 1 0 I n p u t V a l u e ( x ) 0.0 0.5 1.0 d G E L U / d x GELU derivative DAP A Figure 3: The D AP A method approximates the GELU function and its deriv ati ve by partitioning the probability density function (PDF) into N quantile regions. k n = F − 1 n N for n = 1 , . . . , N − 1 (3) Once the knots [ k 0 , k 1 , . . . , k N − 1 ] are determined, we design the optimal linear approximation function, ˆ σ ( x ) , that best approximates the activ ation function, σ ( x ) within each interval [ k n , k n +1 ] . The coef ficients a n and b n for the linear approximation of the tar geted acti v ation function in the n -th se gment are obtained by solving the follo wing optimization problem: { a n , b n } = arg min a,b D WMSE ( σ ( x ) , ˆ σ ( x )) k n k n +1 (4) The continuous optimization problem can be discretized and solved efficiently as a W eighted Least Squares (WLS) problem[ 19 ]. The integral is approximated by a weighted summation ov er m samples, x i , drawn from the distrib ution p ( x ) within the interval [ k n , k n +1 ] . Therefore, the objecti ve function L to be minimized is: arg min a,b L ( a, b ) = m X i =1 p i ( σ ( x i ) − ( ax i + b )) 2 (5) where p i = p ( x i ) is the corresponding weight (probability) for each sample. As a ke y acti vation in T ransformer architectures, softmax differs from element-wise nonlinearities such as GELU in that it performs exponentiation and normalization o ver a v ector . W e adopt the standard shifted exp-sum formulation softmax( x i ) = exp( x i − x max ) P N j =1 exp( x j − x max ) (6) 5 Algorithm 1 Fixed-Point F ormat Selection Guided by D WMSE Require: ˆ σ fp32 ( x ) full precision D AP A, input range [ a, b ] , scaling factor θ , BIT _ MAX = 16 Ensure: Q ( m, n ) 1: threshold ← θ · DWMSE( ˆ σ f p 32 ) 2: m ← ⌈ log 2 (max( | a | , | b | )) ⌉ + 1 3: n ← 0 4: while m + n < BIT _ MAX and D WMSE( ˆ σ Q ( m,n ) ) > threshold do 5: n ← n + 1 6: end while 7: retur n ( m, n ) which guarantees that all exponential inputs are non-positi ve and the outputs are within the range of (0 , 1] , prev enting hardware ov erflow . In particular , D AP A is designed to compute the exponential operations in the softmax function, while the remaining computations are offloaded to a MA C unit for efficienc y . Similarly , the linear approximation of the deri v ati ve of the acti vation function, σ ′ ( x ) , within each interv al [ k s , k s +1 ] , can be defined as: { ¯ a n , ¯ b n } = arg min ¯ a, ¯ b Z k n +1 k n p ( x )( σ ′ ( x ) − (¯ ax + ¯ b )) 2 dx (7) which can be seamlessly integrated into the backpropagation process for training netw orks from scratch. Benefiting from D WMSE, we further quantize D AP A to a fix ed-point representation for the inference stage. W e first compute the D WMSE of D AP A under floating-point arithmetic. Then, we introduce a scaling factor θ and define the admissible error threshold as θ × DWMSE . Next, we determine the number of integer bits from the maximum absolute input v alue of the activ ation function from its distribution, and iterati vely increase the number of fractional bits while recomputing D WMSE until it falls belo w the threshold. In this work, we constrain the total bit-width to be no greater than 16 so that the subsequent hardware design can uniformly adopt a 16-bit fixed-point format. 4 Experimental Results In this section, we present a comprehensi ve ev aluation of D AP A, including network performance results and HLS-based hardware implementation. W e also report the training performance of V iT models with D AP A functions. 4.1 Impact of Number of Input Samples Since D AP A is based on real data distributions, determining the appropriate number of input samples to the network to obtain a reliable distribution is critical. W e thus design an experiment to in vestigate the relationship between the number of samples M used to generate D AP A and the resulting model accuracy . Using V iT -small, we randomly sample varying numbers of images from the ImageNet dataset to construct D AP A functions with different se gment counts. The pretrained V iT -Small model with these D AP A functions is then ev aluated to measure classification accurac y . As Figure 4 illustrates, the accuracy remains with v ery small variations and is largely insensitiv e to the number of input samples used for distribution modeling. In particular, for the configurations with more than 4 se gments, the final accuracy v aries by less than 0 . 36% across dif ferent numbers of input samples. For the V iT -Small model with DAP A(16), we observe only modest v ariations where the highest accuracy is 81.51% and the lo west is 81.46%, achie ving a mean accuracy of 81.47% with a v ariance of 4 . 8 × 10 − 8 . Overall, D AP A with 16 segments can le verage data distrib ution for approximation from a small number of input samples. 4.2 Perf ormance on Image Classification W e e v aluate the performance of the D AP A method with 16 se gments, D AP A(16), on a wide range of vision T ransformer models, including V iT -T iny/Small/Base, DeiT -Tin y/Small/Base, and Swin-Small/Base on the ImageNet-1K dataset[ 15 , 21 , 22 ]. W e e valuate D AP A(16) under fiv e configurations, including an MSE baseline where we use MSE as a loss function, D WMSE-guided softmax-only and GELU-only approximations, and a joint softmax+GELU approximation. As shown in T able 2, the DWMSE-based D AP A approximation for acti vation layers (i.e., (D, A, F)) attains comparable or slightly higher accuracy than the PyT orch baseline. It also exhibits superior accuracy across almost all the architectures compared to the MSE-based method. The only e xception is DeiT -Base, where the MSE-based approach sho ws a slightly 6 1 2 4 8 16 32 64 Number of Images 0.74 0.76 0.78 0.80 0.82 Performance Metric Config DAP A(4) DAP A(6) DAP A(8) DAP A(16) Figure 4: D AP A functions generated from distrib utions with dif ferent numbers of images are e valuated on the V iT - Small. T able 2: Performance of V ision and NLP T ransformer models with dif ferent approximation methods Model T or ch, a F b M, c A, F d D, A, F D, e S, F D, S&A, F D, S&A, f Q [11] [14] [20] [13] V iT -Tin y 75.51% 73.82% 75.51% 75.44% 75.42% 75.17% (Q9.7) g - - - - V iT -Small 81.40% 80.81% 81.41% 81.37% 81.40% 81.30% (Q8.8) - - - - V iT -Base 81.66% 81.35% 81.69% 81.69% 81.70% 81.61% (Q7.7) - - - - DeiT -T in y 74.53% 73.92% 74.55% 74.47% 74.43% 74.37% (Q6.9) - - 71.47% - DeiT -Small 81.17% 80.85% 81.11% 81.21% 81.16% 81.11% (Q6.8) 79.36% 79.11% 79.44% 80.34% DeiT -Base 83.32% 83.13% 82.90% 83.28% 82.88% 82.97% (Q7.5) - - 82.92% - Swin-Small 83.20% 82.96% 83.24% 83.20% 83.23% 83.24% (Q7.5) - - 82.91% - Swin-Base 85.12% 84.81% 85.08% 85.11% 85.05% 85.05% (Q7.5) - - 83.36% - GPT2 (PPL) 29.37 36.50 29.47 29.37 29.47 29.47 (Q7.9) - - 31.02 - a F : Data type configured as 32-bit floating point. b M : The approximation function deriv ed by minimizing MSE. c A : D AP A methodology implemented in acti v ation layer . d D : D AP A emplo ying 16-segment piece wise linear approximation. e S : D AP A methodology implemented in softmax layer . f Q : D AP A quantized using fix ed-point number with θ = 1 . 05 . g The activ ation input and output for the D AP A algorithm utilize Q notation. higher accuracy . Moreover , when applying D AP A(16) only to softmax (i.e., (D, S, F)), all models achie ve comparable accuracy to the PyT orch baseline, where the maximum drop is kept within 0 . 06% . Applying D AP A(16) only to GELU (i.e., (D, A, F)) also preserv es performance, with a maximum drop of 0 . 42% on DeiT -Base. When both softmax and GELU are approximated (i.e., (D, S&A, F)), the maximum accuracy drop remains as 0 . 44% on DeiT -Base. Under the DWMSE-guided quantization (i.e., 16-bit fixed-point data (Q9.7)), the additional loss is kept at most 0 . 23% on V iT -T in y . W e compare D AP A with state-of-the-art V ision T ransformer approximation approaches. As T able 2 shows, DAP A exceeds the accurac y of the benchmarks such as PEANO-V iT [ 11 ] and SwiftT ron[ 14 ], ev en after quantization, where our baseline and the prior work’ s baseline are very close. 4.3 Perf ormance on Natural Language Pr ocessing T asks W e also e v aluate D AP A(16) in natural language processing tasks by testing a GPT -2 Base model on the W ikiT ext-2 dataset and a BER T model on the GLUE benchmark v alidation set [ 23 ]. As sho wn in T able 2, DAP A(16) approaches perform well, achieving a maximum perplexity of 29.47 on W ikiT e xt-2 e ven after quantization, very close to the full-precision baseline. The y also exhibit a better performance than [ 20 ], where a perple xity of 31.02 is reported. Howe ver , the MSE-based approximation attains only a PPL of 36.50, indicating a substantial performance degradation compared to the D WMSE-guided design. 7 Method SST -2 MRPC (F1) STS-B QQP MNLI-m MNLI-mm QNLI A v erage Baseline in [3] 91.51 88.01 88.32 90.77 83.83 84.43 90.88 88.24 [3] 91.40 88.05 88.27 90.76 83.77 84.33 90.88 88.21 [24] 91.86 88.22 88.30 90.62 83.82 84.17 90.68 88.24 Baseline in [20] 92.08 85.66 - 91.35 84.23 - 91.49 88.96 [20] 91.96 86.27 - 91.12 84.10 - 91.23 88.94 PyT or ch, F 92.43 91.35 88.05 90.91 84.57 84.45 91.54 89.05 D(16), S&A, F 92.09 91.32 88.10 90.99 84.75 84.71 91.62 89.08 D(16), S&A, Q(9.4) 91.86 91.33 88.06 90.78 84.76 84.48 91.29 88.94 *Owing to variations in testing methodologies and model chec kpoints, BERT baseline r esults often dif fer . T o ensure a fair comparison, we evaluate methods based on the performance c hange r elative to their r espective r eported baselines. T able 4.3 summarizes the GLUE results. As different works report slightly varing baseline scores due to variations in checkpoints, fine-tuning and hyperparameters, we explicitly list the baselines used in prior work to ensure a fair comparison. Our PyT orch FP32 run (i.e., (PyT orch, F)) serves as our own reference baseline for all D AP A e xperiments. In this context, applying D AP A(16) to both softmax and GELU in full precision (i.e., (D(16), S&A, F)) deli vers good performance, yielding a higher average score of 89.06. After applying quantization (i.e., (D(16), S&A, Q9.4)), the av erage score remains at 88.94, sho wing a very small amount of dif ference from the baseline. It is worth noting that our approximation scheme, combined with quantization, is more hardware-friendly , significantly reducing po wer and latency while impro ving area efficienc y , which will be elaborated on later . 4.4 T raining T ransf ormers with D AP A The D AP A function is designed to approximate both activ ation functions in the forward process and their deriv atives in the backpropagation. Therefore, it can be applied for on-de vice fine-tuning as well as training from scratch. W e thereby train V iT -T in y , V iT -Small, and V iT -Base models from scratch using DAP A-based functions. As Figure 5 illustrates, the models exhibit con vergence speeds comparable to those of the baseline models. Moreover , as shown in T able 3, our method achiev es e ven higher final accurac y compared to the baseline. Specifically , V iT -Small trained with D AP A(16) obtains an accuracy of 68.35%, sho wing an accuracy impro vement of 0.65% ov er the GELU baseline. These results rev eal that D AP A is inherently efficient for T ransformer model training and fine-tuning. 0 20 40 60 80 100 120 Epoch 0 1 2 3 4 5 6 A verage Loss V iT -T D(16) V iT -S D(16) V iT -B D(16) V iT -T T orch V iT -S T orch V iT -B T orch 45 50 55 60 65 70 0.75 1.00 1.25 1.50 1.75 2.00 Figure 5: T raining loss curves for three V iT v ariants comparing standard PyT orch GELU acti v ation with the D AP A(16) approximation function across epochs. 8 T able 3: Classification results on ImageNet-1K: V iT models trained with GELU and D AP A activ ation functions V iT -Base ViT -Small V iT -T iny GELU (PyT orch) 69.76% 67.70% 66.27% D AP A(16) 69.90% 68.35% 66.47% > > > > > > X + Encoder > 1 0 0 0 n n III IV II I S Figure 6: Hardware architecture of the proposed D AP A with N =8 segments with four-stage pipeline. Stages I–III realize a pipelined comparator tree and encoder for segment identification, while stage IV performs the final linear computation with a single MA C unit using the selected ( a n , b n ) . T able 4: Comparison of FPGA Hardware Implementations for Acti v ation Functions. DT ype a L(ns) b B c DSP FF LUT Gelu (Ours) FP32 580 5 62 12158 7228 Gelu (Ours) Fix16 320 - 8 5858 6302 D(16) (Ours) d FP32 150 2 7 1304 1100 D(16) (Ours) d Fix16 20 - 1 100 401 DS(16) (Ours) e Fix16 155 - 1 2243 1614 Gelu [11] Fix16 - - 16 2951 2940 Softmax [11] Fix16 - - 48 3831 5595 Gelu [25] FP32 - - 0 2499 11314 Softmax [25] FP32 - - 0 13837 238569 G&S [24] d Fix16 - - 0 1024 4897 a Data T ype; b Latency; c BRAM; e Integrating D AP A into the Full Softmax Unit; d Reconfigurable to approximate GELU or Softmax Exp; 9 4.5 Hardwar e Implementation W e design an ef ficient D AP A hardware engine for edge deployment. Fig. 6 illustrates an 8-se gment (i.e., N = 8 ), four-stage pipeline, where a log 2 N -stage comparator tree selects the segment index n , and a LUT provides ( a n , b n ) to a single DSP to compute y = a n x + b n . By replacing the original nonlinearity with a fe w comparisons and one MA C unit, the architecture significantly reduces latency and resource utilization compared to con ventional acti vation blocks. Specifically , we implement tanh -based GELU, aligned with our PyT orch version, in both 32-bit Floating Point format (FP32) and 16-bit quantized fixed-point format (Fix16), and summarize the results in T able 4. Our FP32 Gelu is implemented using the PyT orch tanh approximation with HLS. Our DAP A(16) engine is synthesized with V itis HLS 2025.1 at 200MHz. It is aligned with the (D, S&A, Q) configuration and achiev es network performance comparable to the FP32 baseline. The FP32 reconfigurable D AP A(16) unit (for both GELU and Exponential computation) achiev es a latency of 150 ns using only 7 DSPs, 1304 FFs, and 1100 LUTs, while the Fix16 D AP A(16) core achie ves a lo wer latency of 20ns using a single DSP , 100 FFs and 401 LUTs. Compared with prior Fix16 GELU block [ 11 ], D AP A(16) reduces DSP usage by 16 × and achiev es one order of magnitude sa vings in flip-flops and LUT resources. For a fair comparison with the benchmark design, we enhance the D AP A unit by incorporating additional accumulators and a divisor -equi v alent unit to form a fully-functional Softmax module, denoted as D S (16) . Our D S (16) unit utilizes 2243 FFs and 1614 LUTs, both of which are lower than the figures reported in [ 11 ]. More importantly , it achie ves a 48-fold reduction in DSP usage compared to [11] with a latency of 155 ns. Conclusion W e ha ve introduced D AP A as an ef ficient, hardw are-friendly approach to approximate acti v ation functions for T rans- former models. By e xploiting input distrib utions, D AP A enables efficient approximation of acti v ation functions and their deri vati ves without compromising performance. T ogether with the proposed D WMSE loss function and the D WMSE-guided fixed-point quantization, our scheme provides a software-hardware co-design methodology that enhances approximation performance while reducing hardware cost. W e further show that D AP A is fully trainable with a comparable con ver gence rate and thus well-suited for both on-chip inference and training. These results highlight the promise of distribution-a ware acti v ation functions for future T ransformer accelerator design. References [1] Sehoon Kim, Amir Gholami, Zhewei Y ao, Michael W Mahoney , and Kurt Keutzer . I-bert: Integer-only bert quantization. In International confer ence on mac hine learning , pages 5506–5518. PMLR, 2021. [2] Jiho Park, Geon Shin, and Hoyoung Y oo. Implementation of activ ation functions using v arious approximation methods. In 2024 21st International SoC Design Confer ence (ISOCC) , pages 175–176. IEEE, 2024. [3] Christodoulos Peltekis, Kosmas Alexandridis, and Giorgos Dimitrakopoulos. Reusing softmax hardware unit for gelu computation in transformers. In 2024 IEEE 6th International Confer ence on AI Cir cuits and Systems (AICAS) , pages 159–163. IEEE, 2024. [4] Zhengang Li, Mengshu Sun, Alec Lu, Haoyu Ma, Geng Y uan, Y anyue Xie, Hao T ang, Y anyu Li, Miriam Leeser , Zhangyang W ang, et al. Auto-vit-acc: An fpga-a ware automatic acceleration frame w ork for vision transformer with mixed-scheme quantization. In 2022 32nd International Conference on F ield-Pr ogrammable Logic and Applications (FPL) , pages 109–116. IEEE, 2022. [5] Sara Bouraya and Abdessamad Belangour . A comparative analysis of activ ation functions in neural networks: un veiling cate gories. Bulletin of Electrical Engineering and Informatics , 13(5):3301–3308, 2024. [6] Qingyu Guo, Jiayong W an, Songqiang Xu, Meng Li, and Y uan W ang. Hg-pipe: V ision transformer acceleration with hybrid-grained pipeline. In Pr oceedings of the 43rd IEEE/A CM International Confer ence on Computer -Aided Design , pages 1–9, 2024. [7] Barry Lee and Neil Burgess. Some results on taylor-series function approximation on fpga. In The Thrity-Seventh Asilomar Confer ence on Signals, Systems & Computers, 2003 , v olume 2, pages 2198–2202. IEEE, 2003. [8] Fe vzullah T emurtas, Ali Gulbag, and Nejat Y umusak. A study on neural networks using taylor series expansion of sigmoid activ ation function. In International Conference on Computational Science and Its Applications , pages 389–397. Springer , 2004. [9] Omkar K okane, T anushree Dewangan, Akash Sankhe, Mukul Lokhande, Adam T eman, Linga Reddy Cenk era- maddi, and Santosh K umar V ishvakarma. Da-vinci: Dynamically-configurable acti v ation function for v ersatile neuron via cordic implementation. Author ea Pr eprints , 2025. 10 [10] Enrico Reggiani, Renzo Andri, and Lukas Ca vigelli. Flex-sfu: Accelerating dnn activ ation functions by non- uniform piece wise approximation. In 2023 60th A CM/IEEE Design Automation Confer ence (D AC) , pages 1–6. IEEE, 2023. [11] Mohammad Erfan Sade ghi, Arash Fayyazi, Se yedarmin Azizi, and Massoud Pedram. Peano-vit: Power-ef ficient approximations of non-linearities in vision transformers. In Pr oceedings of the 29th ACM/IEEE International Symposium on Low P ower Electr onics and Design , pages 1–6, 2024. [12] Jianxin Huang, Y uling W u, Mingyong Zhuang, and Jianyang Zhou. High-precision and efficiency hardware implementation for gelu via its internal symmetry . Electr onics , 14(9):1825, 2025. [13] Y u-Hsiang Huang, Pei-Hsuan Kuo, and Juinn-Dar Huang. Hardware-friendly acti v ation function designs and its efficient vlsi implementations for transformer -based applications. In 2023 IEEE 5th International Confer ence on Artificial Intelligence Cir cuits and Systems (AICAS) , pages 1–5. IEEE, 2023. [14] Alberto Marchisio, Da vide Dura, Maurizio Capra, Maurizio Martina, Guido Masera, and Muhammad Shafique. Swifttron: An ef ficient hardware accelerator for quantized transformers. In 2023 International Joint Confer ence on Neural Networks (IJCNN) , pages 1–9. IEEE, 2023. [15] Alex ey Doso vitskiy , Lucas Beyer , Ale xander K olesniko v , Dirk W eissenborn, Xiaohua Zhai, Thomas Unterthiner , Mostafa Dehghani, Matthias Minderer , Georg Heigold, Sylvain Gelly , et al. An image is worth 16x16 words: T ransformers for image recognition at scale. arXiv pr eprint arXiv:2010.11929 , 2020. [16] Ross W ightman. Pytorch image models. https://github.com/rwightman/pytorch- image- models , 2019. [17] Olga Russakovsky , Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy , Aditya Khosla, Michael Bernstein, Ale xander C. Berg, and Li Fei-Fei. ImageNet Lar ge Scale V isual Recognition Challenge. International J ournal of Computer V ision (IJCV) , 115(3):211–252, 2015. [18] Alec Radford, Jeff W u, Rew on Child, David Luan, Dario Amodei, and Ilya Sutskev er . Language models are unsupervised multitask learners. 2019. [19] Henk AL Kiers. W eighted least squares fitting using ordinary least squares algorithms. Psychometrika , 62(2):251– 266, 1997. [20] W enxun W ang, W enyu Sun, and Y ongpan Liu. Improving transformer inference through optimized non-linear operations with quantization-approximation-based strategy . IEEE T ransactions on Computer -Aided Design of Inte grated Cir cuits and Systems , 2024. [21] Hugo T ouvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Ale xandre Sablayrolles, and Hervé Jégou. T raining data-ef ficient image transformers & distillation through attention. In International confer ence on machine learning , pages 10347–10357. PMLR, 2021. [22] Ze Liu, Han Hu, Y utong Lin, Zhuliang Y ao, Zhenda Xie, Y ixuan W ei, Jia Ning, Y ue Cao, Zheng Zhang, Li Dong, et al. Swin transformer v2: Scaling up capacity and resolution. In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , pages 12009–12019, 2022. [23] Alex W ang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy , and Samuel Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. In Pr oceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpr eting neural networks for NLP , pages 353–355, 2018. [24] Qi-Xian W u, Shu-Sian T eng, Ming-Der Shieh, Chih-Tsun Huang, and Juin-Ming Lu. A low-comple xity and reconfigurable design for nonlinear function approximation in transformers. IEEE T ransactions on Cir cuits and Systems II: Expr ess Briefs , 2025. [25] Y ueyin Bai, Hao Zhou, K eqing Zhao, Manting Zhang, Jianli Chen, Jun Y u, and Kun W ang. Ltrans-opu: A low-latenc y fpga-based o verlay processor for transformer netw orks. In 2023 33r d International Confer ence on F ield-Pr ogrammable Logic and Applications (FPL) , pages 283–287. IEEE, 2023. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment