The Exponentially Weighted Signature
The signature is a canonical representation of a multidimensional path over an interval. However, it treats all historical information uniformly, offering no intrinsic mechanism for contextualising the relevance of the past. To address this, we intro…
Authors: Alex, re Bloch, Samuel N. Cohen
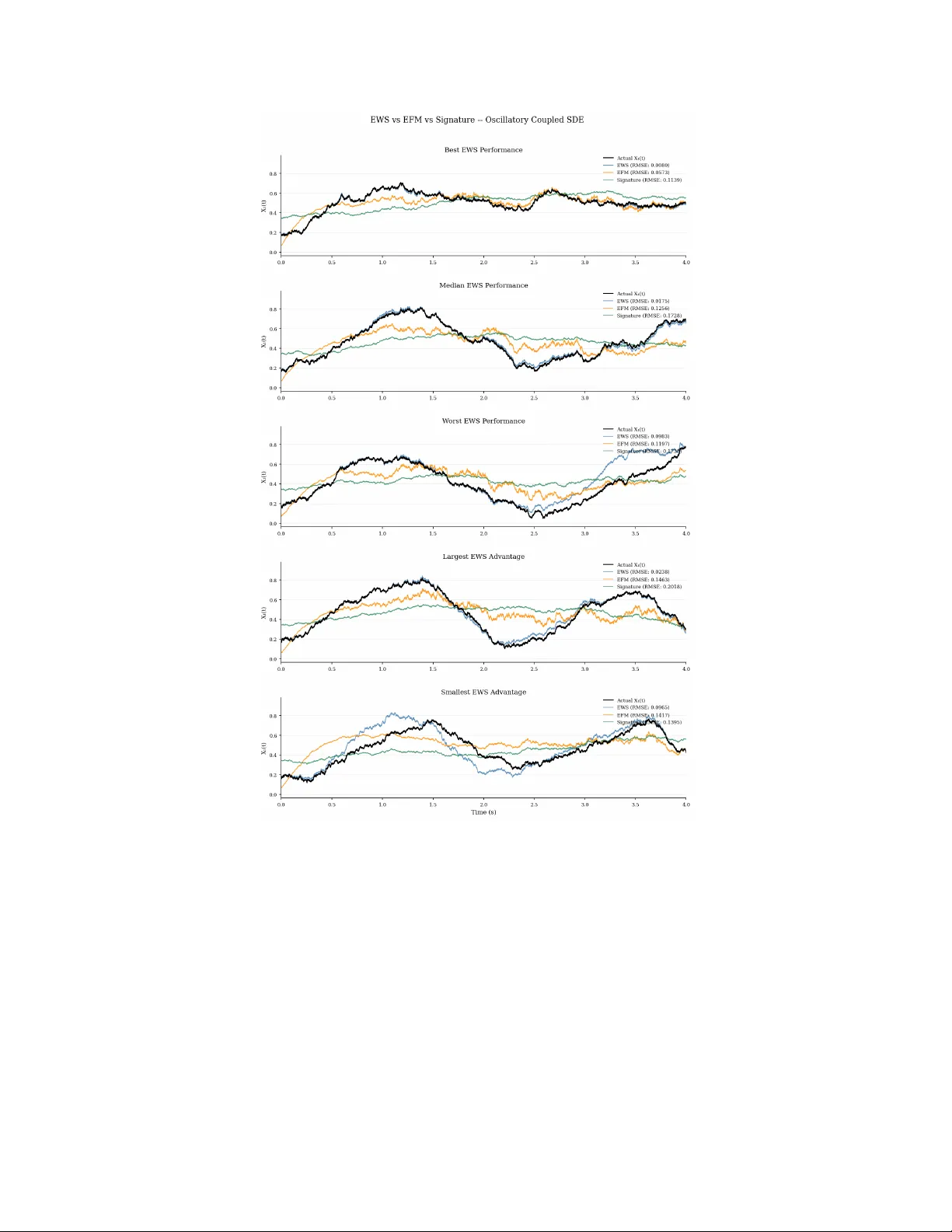
The Exp onen tially-W eigh ted Signature Alexandre Blo c h 1 Sam uel N. Cohen 1 T erry Ly ons 1 , 2 Jo ¨ el Mouterde 3 Benjamin W alk er 1 1 Mathematical Institute, Univ ersity of Oxford 2 Departmen t of Mathematics, Imp erial College London 3 SKF Abstract The signature is a canonical representation of a m ultidimensional path o ver an in terv al. Ho wev er, it treats all historical information uniformly , offering no intrinsic mec hanism for contextualising the relev ance of the past. T o address this, w e in tro duce the Exponentially W eighted Signature (EWS), generalising the Exponentially F ading Memory (EFM) signature from diagonal to general b ounded linear op erators. These operators enable cross-c hannel coupling at the lev el of temporal w eighting together with richer memory dynamics including oscillatory , gro wth, and regime-dep endent b ehaviour, while preserving the algebraic strengths of the classical signature. W e show that the EWS is the unique solution to a linear con trolled differential equation on the tensor algebra, and that it generalises b oth state-space mo dels and the Laplace and F ourier transforms of the path. The group-lik e structure of the EWS enables efficien t computation and mak es the framew ork amenable to gradien t-based learning, with the full semi- group action parametrised by and learned through its generator. W e use this framework to empirically demonstrate the expressivit y gap b et ween the EWS and b oth the signature and EFM on tw o SDE-based regression tasks. 1 In tro duction Man y real-w orld time-series, ranging from biological signals and physical systems to financial markets, are discrete observ ations of systems that ev olv e contin uously in time. In these settings, the apparent discreteness of the data reflects limitations of measuremen t rather than the nature of the underlying dynamics. Despite this, dominan t machine learning architectures, such as Recurrent Neural Netw orks (RNNs), T emporal Con- v olutional Net works (TCNs), and T ransformers, treat time-series as sequences of discrete observ ations, with time entering only implicitly through the sequence index. This p erspective identifies the evolution of the system with the discretisation used to observ e it and introduces assumptions not inherent to the data- generating process. Consequently , these mo dels suffer from limitations imp osed b y the discretisation itself. F or recurrent architectures, increasing the num ber of time steps exacerbates v anishing and exploding gra- dien t phenomena [Ho c hreiter et al. 2001], while in atten tion-based mo dels it leads to a quadratic increase in memory and computational costs [V asw ani et al. 2017]. Additionally , irregular sampling m ust often b e handled through ad ho c interpolation, imputation, or padding. Finally , the discrete viewp oint ties memory and temp oral scale to the observ ation grid rather than allowing them to b e determined by the underlying dynamics. These challenges suggest that the limitation lies in the discrete represen tation itself. A more principled approac h is to mo del the data as a con tinuous path X : [ t 0 , t N ] → V , where V is a Banach space. Ro oted in the theory of controlled differential equations [Lyons 1998], this p ersp ectiv e treats the underlying tra jectory as the primary ob ject of interest and decouples the mo del from the measurement schedule. Within this framework, 1 the problem becomes one of identifying a represen tation of the path that captures its essen tial information in a manner that is in trinsic to the underlying tra jectory , rather than dep enden t on the discretisation used to observ e it. A cen tral ob ject ac hieving this is the path signature, introduced by Chen [1954], which represen ts a path through its iterated integrals. The signature takes v alues in the tensor algebra T (( V )) = ∞ M n =0 V ⊗ n , (1) where V ⊗ 0 denotes R and w e assume that { V ⊗ n } ∞ n =0 is equipp ed with a family of admissible norms [McLeod et al. 2025]. F or more details on tensor pro ducts, admissible norms, and the integration framework, see App endix A & B. Definition 1.1 (Signature [Lyons et al. 2007]). L et X ∈ V p ([ t 0 , t N ] , V ) with p < 2 . The signatur e of X over the interval [ s, t ] ⊆ [ t 0 , t N ] is define d as S ( X ) s,t = (1 , S ( X ) (1) s,t , S ( X ) (2) s,t , . . . ) ∈ T (( V )) , wher e S ( X ) ( n ) s,t = Z t s Z t n s · · · Z t 2 s dX t 1 ⊗ · · · ⊗ dX t n ∈ V ⊗ n is define d in the Y oung sense [Y oung 1936]. ♢ The signature is a canonical representation of the path; as shown in Hambly et al. [2010], for paths X and Y of b ounded v ariation, the condition S ( X ) = S ( Y ) holds if and only if the tw o paths are tree-like equiv alent. This result was later extended to the p < 2 setting in Bo edihardjo et al. [2016]. In practice, when V is finite dimensional, this equiv alence can be remo ved b y augmen ting the path with a strictly monotone c hannel, suc h as time, whic h ensures that the signature is injective on the space of paths (up to a translation constant). Another key prop ert y of the signature is its univ ersal approximation capabilit y . Theorem 1.2 (Univ ersality). L et K ⊂ V p ([ a, b ] , V ) b e a c omp act set of p aths with p < 2 . L et F ⊂ C ( K , R ) b e the set of c ontinuous functions such that F ( X ) = F ( Y ) whenever S ( X ) = S ( Y ) . Then the set of line ar functionals of the signatur e is dense in F . That is, for any F ∈ F and ϵ > 0 , ther e exists a line ar functional l such that sup X ∈ K | F ( X ) − ⟨ l , S ( X ) ⟩| < ϵ. Recen t w ork extends universalit y results to sto c hastic settings. In particular, universal appro ximation by linear functionals of signatures has b een established for classes of non-geometric rough paths arising from sto c hastic processes, sho wing that signature-based mo dels retain their appro ximation pow er beyond the deterministic Y oung regime [Ceylan et al. 2026]. The signature also possesses a n um b er of additional algebraic and analytic prop erties, including multiplicativit y under concatenation and shuffle identities relating pro ducts of co ordinates. F or completeness, these and other foundational results are summarised in App endix C. T ogether, these prop erties make the signature a pow erful represen tation of sequential data, and they hav e led to its widespread use in time-series mo delling, both in shallow metho ds and in deep arc hitectures [Bonnier et al. 2019; Graham 2013; Gyurk´ o et al. 2014; Kir´ aly et al. 2019; Levin et al. 2016; Salvi et al. 2021]. How ever, signatures summarise the past uniformly , and therefore pro vide no intrinsic mechanism for contextualising history when the relev ance of past information v aries ov er time. While this is a strength from the persp ectiv e of representation, it becomes a limitation for man y temp oral mo delling tasks, where the relev ance of historical information is not uniform in time. In such settings, recent b eha viour may b e more informative than distant history , or the imp ortance of the past may v ary across regimes, while still requiring some form of long- term memory . How ev er, the signature treats all historical information identically and thus cannot adapt its represen tation to the temp oral context. A common remedy is to imp ose temp oral lo calit y by computing signatures on sliding or expanding windows, whereb y the representation at eac h time is constructed from a restricted sub-interv al of the past, either of 2 fixed length or gro wing with time [Bonnier et al. 2019; Cohen et al. 2023; Drobac et al. 2025; F ermanian 2021; Morrill et al. 2021]. Ho wev er, this makes the temporal horizon a fixed design choice: sliding windows discard all information before a prescribed cut-off, while expanding windo ws retain the entire past but weigh t distan t and recen t history identically . Moreov er, sliding-window signatures do not admit a simple contin uous-time dynamical description, while for expanding windo ws, signature terms may grow unbounded as the interv al length increases. T o address these limitations, Abi Jab er et al. [2025] prop osed the Exp onen tially F ading Memory Signature (EFM) as a contin uous-time alternative, replacing hard temp oral cut-offs with exp onen tial weigh ting of the past, while preserving many of the algebraic and analytical prop erties of the classical signature. Definition 1.3 (Exp onen tially F ading Memory Signature [Abi Jab er et al. 2025]). L et X ∈ V p loc (( −∞ , t N ] , R d ) for p < 2 . Assume further that ther e exists ρ ∈ R d such that 0 ≺ ρ ≺ λ and sup u ≤ t N e ρ ( t N − u ) | X u | < ∞ . L et λ ∈ R d with λ ≻ 0 . The λ -exp onential ly fading memory signatur e of X is define d as X λ s,t = (1 , X λ, 1 s,t , X λ, 2 s,t , . . . ) ∈ T (( R d )) , wher e X λ,n s,t = Z t s Z t n s · · · Z t 2 s e − λ ( t − t 1 ) ⊙ dX t 1 ⊗ · · · ⊗ e − λ ( t − t n ) ⊙ dX t n ∈ ( R d ) ⊗ n , (2) wher e e λ denotes the element-wise exp onential ( e λ 1 , . . . , e λ d ) , and ⊙ denotes the Hadamar d (p ointwise) pr o d- uct on R d ; that is, for x, y ∈ R d , x ⊙ y := ( x 1 y 1 , . . . , x d y d ) . We also denote X λ t = X λ −∞ ,t . ♢ In contrast to sliding or expanding windows, the EFM yields a representation that incorp orates the entire past, while ensuring that older information is smo othly attenuated o ver time. How ev er, this construction imp oses strong structural restrictions on how memory can evolv e: First, the exponential w eighting acts comp onen t-wise through the Hadamard product. Eac h increment dX i t k is scaled by a factor e − λ i ( t − t k ) that dep ends only on the i -th co ordinate of λ and is indep enden t of all other comp onen ts of the path. As a result, the temp oral weigh ting is factorised across channels: eac h comp onen t ev olves with its o wn fixed decay rate, and there is no interaction b et ween c hannels at the level of time propagation. While cross-channel effects do app ear at higher lev els through the tensor structure of the iterated integrals, they do not arise from the temp oral weigh ting. The mec hanism gov erning how past information is retained or forgotten is therefore indep enden t for eac h component. Second, the definition is formulated on the infinite time horizon ( −∞ , t ], and th us the existence of the resulting improp er integrals relies crucially on the exp onen tial decay of the memory kernel. This is enforced b y restricting the decay parameters λ i to b e strictly p ositiv e, ensuring that contributions from the distan t past are exp onentially attenuated. Ho wev er, the p ositivit y of the λ i constrains the temp oral w eighting to monotone exp onen tial decay , so that each c hannel is asso ciated with a single decaying mo de. In particular, the EFM cannot capture oscillatory b eha viour, growth, or more general temp oral dynamics in which the influence of the past do es not simply diminish ov er time. This limitation is significant in applications where the effect of past inputs is not well describ ed by uniform decay . F or example, in systems with inertia or resonance, past b eha viour may p ersist in an oscillatory or phase-dep enden t manner, while in financial time- series the relev ance of past information may v ary across regimes. Suc h phenomena require richer temp oral dynamics, in which the influence of the past can ev olve in a non-monotone or coupled wa y . A concurrent line of work, the V olterra signature of [Harang et al. 2022; Harang et al. 2021a,b], extended to matrix-v alued k ernels in [Hager et al. 2026], shares the motiv ation of expanding beyond channel-separable w eighting to increase expressivity , though it contextualises memory through a fundamentally differen t frame- w ork to both the EFM and the approach prop osed here. By lifting a linear V olterra CDE directly into the 3 tensor algebra via Picard iteration, this approach accommo dates a broad class of memory structures includ- ing fractional and p o wer-la w kernels. How ever, the V olterra signature do es not inherit the strong algebraic prop erties of the classical signature: it is not group-lik e and thus do es not satisfy the sh uffle pro duct iden tity , and requires a more in volv ed Chen identit y based on a conv olutional tensor pro duct. This renders it more computationally difficult to compute and calibrate than the approac h we prop ose here. W e therefore introduce the Exp onentially W eighted Signature (EWS), which adopts a different mo delling p erspective: rather than enforcing fading memory , w e aim to learn a general notion of temp oral context. Concretely , w e replace the comp onen t-wise exponential weigh ting in the EFM with a more general mec hanism go verned by bounded linear op erators. This allows for richer temp oral dynamics, including oscillatory and non-deca ying mo des, as well as coupling b etw een channels, so that the influence of past observ ations can ev olve in a non-monotone and state-dep enden t manner. Suc h flexibility is incompatible with the infinite- history formulation of the EFM without imp osing additional stabilit y constrain ts on the sp ectrum. Instead, the EWS is defined on finite horizons, allowing the temp oral weigh ting to b e learned without restricting it to purely decaying b ehaviour. 2 The Exp onen tially W eigh ted Signature In this section we introduce the EWS as a collection of iterated integrals. Let X ∈ V p ([ t 0 , t N ] , V )) for p < 2, and supp ose that the path carries one or more intrinsic notions of time. That is, there exist b ounded linear functionals ℓ : V → R whose ev aluation along the path pro duces a scalar, strictly monotone pro cess θ t := ℓ ( X t ) , t ∈ [ t 0 , t N ] . Suc h functionals define v alid clocks with respect to whic h the ev olution of the system can be parametrised. In principle, a single path may admit multiple admissible clo c k functionals, corresp onding to different intrinsic temp oral scales encoded in the data. A canonical example is the standard time-augmentation used in the signature literature [Chevyrev et al. 2016], where X t = ( t, b X t ) and ℓ extracts the first coordinate, yielding θ t = t . Another example of an intrinsic clock could b e the quadratic v ariation of the path θ t = ⟨ X ⟩ t . W e now fix a single clo c k functional ℓ and work with the associated intrinsic time θ . This c hoice is sufficient to ensure w ell-p osed contin uous-time dynamics and, when combined with time augmentation, guarantees uniqueness of the exp onen tially-weigh ted signature. Extensions to m ultiple clo c ks can b e treated analogously but are not pursued here for clarit y of exposition. W e no w define the EWS using iterated integrals in a similar manner to the classical signature; we leav e existence and uniqueness to Sections 5 & 7. Definition 2.1. L et V , W b e Banach sp ac es and c onsider X ∈ V p ([ t 0 , t N ] , V ) with intrinsic clo ck θ t = ℓ ( X t ) . L et A = ( A, B ) denote a p air of b ounde d line ar op er ators with A ∈ L ( W, W ) and B ∈ L ( V , W ) . Then, the exp onential ly weighte d signatur e of X over [ s, t ] ⊆ [ t 0 , t N ] is S A ( X ) s,t = 1 , S A ( X ) (1) s,t , S A ( X ) (2) s,t , . . . ∈ T (( W )) , (3) whose n -th level c omp onent S A ( X ) ( n ) s,t ∈ W ⊗ n is define d r e cursively by the iter ate d Y oung inte gr als S A ( X ) ( n ) s,t = Z t s Z t n s · · · Z t 2 s e − ( θ t − θ t 1 ) A B dX t 1 ⊗ · · · ⊗ e − ( θ t − θ t n ) A B dX t n . (4) ♢ When dim( W ) = w , using the basis B W = { e i } w i =1 w e can expand S A ( X ) ( n ) s,t as S A ( X ) ( n ) s,t = X i 1 ,...,i n ∈{ 1 ,...,w } S A ( X ) i 1 ,...,i n s,t e i 1 ⊗ · · · ⊗ e i n , 4 where with E ( h ) := e − hA and E i,j ( h ) denoting the ij -th entry , the co efficien t for w ord ( i 1 , . . . , i n ) is S A ( X ) i 1 ,...,i n s,t = Z t s Z t n s · · · Z t 2 s X j 1 ,...,j n ∈{ 1 ,...,w } n Y k =1 E i k ,j k ( θ t − θ t k ) ! d b X j 1 t 1 · · · d b X j n t n , (5) with b X t ∈ W b eing the lifted path defined b y b X t = B X t . W e can also express the co efficien t for word ( i 1 , . . . , i n ) in terms of the co efficien t for word ( i 1 , . . . , i n − 1 ) as follows: S A ( X ) i 1 ,...,i n s,t = X m 1 ,...,m n − 1 ∈{ 1 ,...,w } Z t s w X j =1 n − 1 Y k =1 E i k ,m k θ t − θ u S A ( X ) m 1 ,...,m n − 1 s,u E i n ,j ( θ t − θ u ) d b X j u . (6) F or an explicit example of the comp onen t-wise iterated integral definition of the EWS, see App endix E. In the sp ecial case B = Id and A = diag( λ 1 , . . . , λ d ) with λ i > 0, the EWS reduces exactly to the EFM- signature of Equation (2). In this setting, the temp oral weigh ting is entirely c hannel-wise: eac h comp onen t X i is propagated through a single scalar kernel e − λ i h , and while cross-channel terms do app ear at higher signature levels through the tensor structure of the iterated integrals, the mechanism gov erning how past information is retained or forgotten remains indep enden t for each c hannel. Allowing a general op erator A fundamen tally changes this picture: cross-channel coupling now en ters at the level of the temp oral weigh ting itself, since the full matrix exp onen tial E ( h ) = e − hA mixes channels as it propagates the past. This p ermits ric her b eha viour such as oscillatory or regime-dep enden t memory effects that are structurally inaccessible to an y diagonal op erator, regardless of truncation depth. Remark 2.2. At depth one, the EWS c oincides with the first level of the V olterr a signatur e of Hager et al. [2026] for the kernel K ( t, s ) = e − ( t − s ) A : b oth r e duc e to R t s e − ( t − u ) A dX u (under the c onvention τ = t n +1 = t in Hager et al. 2026, Definition 2.14). However, b eyond depth one, the two obje cts diver ge. R ewriting [Hager et al. 2026, Definition 2.14] c omp onent-wise, the n -th level term of the V olterr a signatur e for the wor d i 1 · · · i n is VSig( x ; K ) i 1 ··· i n s,t = Z t s Z t n s · · · Z t 2 s X j 1 ,...,j n ∈{ 1 ,...,w } n Y k =1 K i k ,j k ( t k +1 , t k ) ! dX j 1 t 1 · · · dX j n t n , (7) wher e the inte gr ation is over the simplex ∆ n s,t = { s ≤ t 1 ≤ · · · ≤ t n ≤ t } . In the EWS, the incr ement dX t k at e ach vertex t k of the simplex is weighte d by e − ( θ t − θ t k ) A , which dep ends on the distanc e fr om t k to the ap ex t . In the V olterr a signatur e, the same incr ement is weighte d by K ( t k +1 , t k ) , which dep ends on the gap to the next vertex t k +1 . This is the distinction b etwe en a glob al weighting scheme, in which every incr ement is disc ounte d r elative to a fixe d terminal time, and a lo c al one, in which e ach incr ement is disc ounte d r elative to its imme diate neighb our. While b oth the EWS and the V olterr a signatur e extend the diagonal op er ator of the EFM to a gener al matrix-value d op er ator, it is pr e cisely the glob al anchoring to a fixe d terminal time that makes the EWS the signatur e of a r e-weighte d p ath evaluate d at that time (Pr op osition 4.1), ensuring that the EWS is gr oup-like while the V olterr a signatur e is not [Hager et al. 2026, R emark 2.17]. The EWS ther efor e gener alises the EFM to arbitr ary b ounde d op er ators A ∈ L ( V , V ) while pr eserving the algebr aic str engths that make the EFM a natur al extension of the classic al signatur e. ♢ F or the remainder of this pap er, we adopt the follo wing simplifying con ven tion. The op erator B ∈ L ( V , W ) em b eds the input path into the space where exp onen tial weigh ting acts, often duplicating channels so that differen t mo des of A can act on them. Since B enters the iterated in tegrals only through the lifted path b X = B X , it amounts to a linear re-em b edding of the signal, and all results carry ov er unchanged up to constan ts dep ending on ∥ B ∥ . W e therefore take W = V and B = Id, noting that all definitions and results extend directly to general b ounded B by replacing X with b X . Under this conv en tion, the EWS takes v alues in T (( V )). 5 3 Dynamics of the EWS The iterated integrals defining the EWS inv olve rep eated applications of the matrix exp onen tial e − hA to individual incremen ts of the path. T o express these op erations coherently across all tensor lev els, it is con venien t to extend the action of e − hA from the base space V to the entire tensor algebra T (( V )) in a w ay that resp ects the algebraic structure. 3.1 The Flo w Op erator Recall that T (( V )) is the free unital asso ciativ e algebra generated b y V . In particular, any linear map f : V → V admits a unique extension to an algebra homomorphism on T (( V )), a consequence of the universal prop ert y of the tensor algebra [Lang 2002]. W e apply this construction to the linear map v 7→ e − hA v where, since A ∈ L ( V , V ) is b ounded, the op erator exp onen tial e − hA is w ell-defined for all h ∈ R and defines a uniformly contin uous one-parameter semigroup on V [Rudin 1991]. Definition 3.1. L et A ∈ L ( V , V ) b e a b ounde d line ar op er ator and h ∈ R . The flow op er ator D h A : T (( V )) → T (( V )) is define d as the unique algebr a homomorphism extending the line ar map L e − hA : V → V . That is, D h A | V = e − hA . (8) Equivalently, for any elementary tensor v 1 ⊗ · · · ⊗ v n ∈ V ⊗ n , D h A ( v 1 ⊗ · · · ⊗ v n ) = ( e − hA v 1 ) ⊗ · · · ⊗ ( e − hA v n ) . (9) ♢ The operator D h A propagates the exponential w eigh ting across tensor lev els in a m ultiplicative manner, acting indep enden tly on each tensor factor while preserving the concatenation structure of the algebra. This construction is precisely what is required to rewrite the EWS iterated integrals in a compact recursive form and to formulate their con tinuous-time dynamics. Lemma 3.2. The family { D h A : h ∈ R } is a one-p ar ameter sub gr oup of Aut T (( V )) , the gr oup of algebr a automorphisms of T (( V )) . Pr o of. Since Aut T (( V )) is a group, it suffices to show that G is closed under multiplication and inv erses. F or any h 1 , h 2 ∈ R and an y generator v ∈ V , D h 1 A D h 2 A ( v ) = e − h 1 A e − h 2 A v = e − ( h 1 + h 2 ) A v = D h 1 + h 2 A ( v ) . Both D h 1 A D h 2 A and D h 1 + h 2 A are algebra homomorphisms on T (( V )) that agree on the generators V ; by the univ ersal prop erty of the tensor algebra, they therefore coincide on all of T (( V )). Hence D h 1 A D h 2 A = D h 1 + h 2 A ∈ G . Moreo ver, D h A D − h A = D 0 A = id , so ( D h A ) − 1 = D − h A ∈ G . The claim follows by the subgroup test. When V is finite dimensional, the automorphism group Aut( T (( V ))) admits a natural Lie group structure, and the family ( D h A ) h ∈ R can b e view ed as a smo oth one-parameter Lie subgroup. In this setting, the op erator Λ A in tro duced in the next sub-section coincides with the corresp onding element of the Lie algebra. Nev ertheless, no Lie group structure is required for the constructions and results that follow, and th us they hold even when V is infinite dimensional. 6 3.2 The deriv ation op erator W e define the deriv ation operator Λ A as the infinitesimal generator of the contin uous one-parameter subgroup of automorphisms G = { D h A : h ∈ R } . More precisely , since the map h 7→ D h A is differentiable as a curve in the ambien t space of linear op erators acting on the tensor algebra, we set Λ A := − d dh h =0 D h A . Definition 3.3. L et A ∈ L ( V , V ) . The op er ator Λ A : T (( V )) → T (( V )) define d by Λ A := − d dh h =0 D h A (10) is c al le d the deriv ation induced b y A . ♢ W e now show that Λ A is a deriv ation on the tensor algebra, i.e. that it satisfies the Leibniz rule. Since eac h D h A is an algebra homomorphism, D h A ( x ⊗ y ) = D h A ( x ) ⊗ D h A ( y ) for all x, y ∈ T (( V )) . Using this, we get Λ A ( u 1 ⊗ u 2 ) = − d dh D h A ( u 1 ⊗ u 2 ) h =0 = − d dh D h A ( u 1 ) ⊗ D h A ( u 2 ) h =0 = − d dh D h A ( u 1 ) h =0 ⊗ D 0 A ( u 2 ) + D 0 A ( u 1 ) ⊗ − d dh D h A ( u 2 ) h =0 = Λ A ( u 1 ) ⊗ u 2 + u 1 ⊗ Λ A ( u 2 ) . Th us, Λ A is indeed a deriv ation. The deriv ation is uniquely defined b y its action on the generators V . F or u ∈ V we hav e Λ A ( u ) = − d dh h =0 D h A ( u ) = − d dh h =0 e − hA u = − ( − Ae − hA ) | h =0 u = Au where we used differen tiability of the op erator exp onential. Consequently , for any elementary tensor u 1 ⊗ · · · ⊗ u n ∈ V ⊗ n , Λ A ( u 1 ⊗ · · · ⊗ u n ) = n X k =1 u 1 ⊗ · · · ⊗ ( Au k ) ⊗ · · · ⊗ u n . (11) This explicit formula shows that Λ A is the unique contin uous deriv ation on T (( V )) induced by the op erator A . Since Λ A is a deriv ation on the unital algebra T (( V )), it v anishes on the unit element; that is, Λ A ( 1 ) = 0. 3.3 The EWS is the Solution of a Linear CDE W e no w combine the iterated integral definition of the EWS with the op erators D h A and Λ A to derive a compact recursive representation and the asso ciated linear CDE. Lemma 3.4. F or any [ s, t ] ⊆ [ t 0 , t N ] , the EWS satisfies S A ( X ) s,t = 1 + Z t s D θ t − θ u A ( S A ( X ) s,u ⊗ dX u ) , (12) wher e 1 = (1 , 0 , 0 , . . . ) is the identity element in T (( V )) . 7 Pr o of. Since trivially S A ( X ) (0) s,t = 1, we just need to sho w that the depth n term of the integral in the claim equals the depth n term of the EWS. Z t s D θ t − θ u A ( S A ( X ) s,u ⊗ dX u ) ( n ) = Z t s D θ t − θ u A ( S A ( X ) s,u ) ⊗ D θ t − θ u A ( dX u ) ( n ) = Z t s D θ t − θ u A ( S A ( X ) s,u ) ⊗ D θ t − θ u A ( dX u ) ( n ) = Z t s n X k =1 D θ t − θ u A ( S A ( X ) s,u ) ( k ) ⊗ D θ t − θ u A ( dX u ) ( n − k ) = Z t s D θ t − θ u A ( S A ( X ) s,u ) ( n − 1) ⊗ D θ t − θ u A ( dX u ) (1) = Z t s D θ t − θ u A ( S A ( X ) ( n − 1) s,u ) ⊗ ( e − ( θ t − θ u ) A dX u ) , where the second equality uses the algebra homomorphism prop ert y of the flow op erator, and the fourth equalit y uses the fact that dX u is only non zero at depth 1. W e can then plug in the iterated integral expression for the EWS to get Z t s D θ t − θ u A ( S A ( X ) s,u ⊗ dX u ) ( n ) = Z t s D θ t − θ u A Z u s Z t n − 1 u · · · Z t 2 s e − ( θ u − θ t 1 ) A dX t 1 ⊗ · · · ⊗ e − ( θ u − θ t n − 1 ) A dX t n − 1 ⊗ e − ( θ t − θ u ) A dX u = Z t s Z u s Z t n − 1 u · · · Z t 2 s e − ( θ t − θ t 1 ) A dX t 1 ⊗ · · · ⊗ e − ( θ t − θ t n − 1 ) A dX t n − 1 ⊗ e − ( θ t − θ u ) A dX u . Changing notation from u to t n giv es us exactly S A ( X ) ( n ) s,t , as required. This integral form now lets us write the EWS as the solution to a linear CDE in the following lemma. Lemma 3.5. The EWS is the unique solution of the line ar c ontr ol le d differ ential e quation dS A ( X ) s,t = − Λ A S A ( X ) s,t dθ t + S A ( X ) s,t ⊗ dX t , S A ( X ) s,s = 1 . (13) Equivalently, in Y oung inte gr al form, S A ( X ) s,t = 1 + Z t s − Λ A S A ( X ) s,u dθ u + Z t s S A ( X ) s,u ⊗ dX u . (14) Pr o of. Fix t 0 ≤ s < t < t ′ with t ′ := t + ∆ t for ∆ t > 0 and define δ θ := θ t ′ − θ t . Applying Equation (12) at times t ′ and t and subtracting giv es S A ( X ) s,t ′ − S A ( X ) s,t = Z t ′ s D θ t ′ − θ u A S A ( X ) s,u ⊗ dX u − Z t s D θ t − θ u A S A ( X ) s,u ⊗ dX u = Z t ′ t D θ t ′ − θ u A S A ( X ) s,u ⊗ dX u | {z } ( I ) + Z t s D θ t ′ − θ u A − D θ t − θ u A S A ( X ) s,u ⊗ dX u | {z } ( I I ) . W e now consider the con tribution of term ( I ). W e work at the arbitrary tensor lev el n . Using the semi-group prop ert y of D A h , we may rewrite ( I ) ( n ) = Z t ′ t D θ t ′ − θ u A S A ( X ) s,u ( n − 1) ⊗ e − ( θ t ′ − θ u ) A dX u , 8 whic h is a Y oung in tegral with respect to X taking v alues in V ⊗ n . W e therefore define the integrand F t ′ ( u ) := D θ t ′ − θ u A S A ( X ) ( n − 1) s,u ⊗ e − ( θ t ′ − θ u ) A , u ∈ [ t, t ′ ] , so that ( I ) is the Y oung integral of F t ′ against X . W e first observ e that F t ′ con verges uniformly on [ t, t ′ ] to the constan t tensor S A ( X ) ( n − 1) s,t ⊗ I as t ′ ↓ t . Indeed, u 7→ S A ( X ) ( n − 1) s,u is con tinuous, hence sup u ∈ [ t,t ′ ] ∥ S A ( X ) ( n − 1) s,u − S A ( X ) ( n − 1) s,t ∥ V ⊗ ( n − 1) → 0, and since θ is contin uous and h 7→ D A h (equiv alently h 7→ e − hA ) is contin uous at h = 0, we also hav e sup u ∈ [ t,t ′ ] e − ( θ t ′ − θ u ) A − I op → 0 , sup u ∈ [ t,t ′ ] D θ t ′ − θ u A − Id op → 0 . Com bining these giv es sup u ∈ [ t,t ′ ] ∥ F t ′ ( u ) − S A ( X ) ( n − 1) s,t ⊗ I ∥ V ⊗ n − − → t ′ ↓ t 0 , where the op erator norms are ov er L ( V , V ) and L ( V ⊗ n , V ⊗ n ) resp ectiv ely . Since uniform con vergence on a short interv al implies small q -v ariation for any q ≥ 1, we may choose q with 1 p + 1 q > 1 and apply the lo cal Y oung estimate [F riz et al. 2009, Prop osition 6.4] to obtain Z t ′ t F t ′ ( u ) dX u = F t ′ ( t ) ( X t ′ − X t ) + o | X | p, [ t,t ′ ] . Finally , F t ′ ( t ) = D θ t ′ − θ t A S A ( X ) ( n − 1) s,t ⊗ e − ( θ t ′ − θ t ) A − → S A ( X ) ( n − 1) s,t ⊗ I as t ′ ↓ t, and therefore ( I ) = S A ( X ) ( n − 1) s,t ⊗ ( X t ′ − X t ) + o | X | p, [ t,t ′ ] . In differential notation, the con tribution of T erm ( I ) is th us S A ( X ) ( n − 1) s,t ⊗ dX t . W e now consider the contribution of term ( I I ). Before doing so w e recall that on eac h tensor lev el, the family h 7→ D h A is C 1 in op erator norm and its generator is Λ A . Hence, for every h , w e hav e the operator equalit y d dh D h A = − Λ A D h A . Consequen tly , for any h ∈ R and ϵ > 0, we ha ve the first order T a ylor expansion (in op erator norm) D h + ϵ A = D h A − ϵ Λ A D h A + R ( ϵ, h ) , where the remainder R ( ϵ, h ) satisfies the uniform b ound sup h ∈ H || R ( ϵ, h ) || op = o ( ϵ ) , for any compact set H ⊂ R . Applying this to term ( I I ) gives us D θ t ′ − θ u A − D θ t − θ u A = D ( θ t − θ u )+ δ θ A − D θ t − θ u A = − δ θ Λ A D θ t − θ u A + R ( δθ , u ) . Substituting this into ( I I ) gives us ( I I ) ( n ) = Z t s − δ θ Λ A D θ t − θ u A + R ( δθ , u ) ( S A ( X ) ( n − 1) s,u ⊗ dX u ) = − δ θ Λ A Z t s D θ t − θ u A ( S A ( X ) ( n − 1) s,u ⊗ dX u ) + Z t s R ( δ θ , u )( S A ( X ) ( n − 1) s,u ⊗ dX u ) = − δ θ Λ A ( S A ( X ) ( n ) s,t − 1 ) + Z t s R ( δ θ , u )( S A ( X ) ( n − 1) s,u ⊗ dX u ) = − δ θ Λ A S A ( X ) ( n ) s,t + Z t s R ( δ θ , u )( S A ( X ) ( n − 1) s,u ⊗ dX u ) , 9 where w e can pull Λ A out of the in tegral as it is a b ounded linear op erator. The remainder integral has the op erator norm bound Z t s R ( δ θ , u )( S A ( X ) ( n − 1) s,u ⊗ dX u ) V ⊗ n ≤ sup u ∈ [ s,t ] || R ( δ θ , u ) || op Z t s ( S A ( X ) ( n − 1) s,u ⊗ dX u ) V ⊗ n = o ( δ θ ) , since the Y oung integral R t s ( S A ( X ) ( n − 1) s,u ⊗ dX u ) is a fixed bounded tensor. This leav es us with ( I I ) = − δθ Λ A S A ( X ) ( n ) s,t + o ( δ θ ) . Letting δ θ → 0 (i.e. t ′ ↓ t ) yields that the con tribution of ( I I ) to the increment is the differential − Λ A S A ( X ) ( n ) s,t dθ t . Finally , combining the contributions from ( I ) and ( I I ), and reassembling the level-wise equations, we get dS A ( X ) s,t = S A ( X ) s,t ⊗ dX t − Λ A S A ( X ) s,t dθ t , with S s,s = 1 . Uniqueness follows from standard theory for linear Y oung-controlled differen tial equations on [ s, t N ]. 4 F urther In terpretations of the EWS In addition to its definition via weigh ted iterated integrals, the EWS admits several useful interpretations that connect it to existing mo dels in time-series analysis and signal pro cessing. In this section we explore these p erspectives, showing in particular that o ver a fixed interv al, the EWS is the signature of a suitably re-w eighted path (although this path is interv al dep enden t), and that its first tensor level relates naturally to state space mo dels and sp ectral filtering metho ds. Moreov er, in a learning setting the EWS corresp onds to a structured linear neural controlled differential equation (SLiCE) [W alk er et al. 2025], with a sp ecific structure that provides an inductiv e bias for contextualising memory . 4.1 Equiv alence to the Signature of an Exponentially W eigh ted Path W e no w show that, ov er a fixed interv al, EWS admits an equiv alent representation as the classical signature of a linearly transformed path. W e consider X ∈ V p ([ t 0 , t N ] , V ) and the b ounded linear op erator A ∈ L ( V , V ) as b efore. W e define the exponentially re-weigh ted path o ver [ s, t ] ⊆ [ t 0 , t N ] by Z [ t ] r := Z r s e − ( θ t − θ u ) A dX u , r ∈ [ s, t ] , (15) where the integral is understo od in the Y oung sense. Note that we must select a horizon denoted by [ · ]. This construction defines a causal linear memory transform of the driving path X , with op erator-v alued kernel h 7→ e − hA . The main observ ation of this subsection is that the EWS of X o ver the interv al [ s, t ] coincides exactly with the classical signature of the weigh ted path Z [ t ] o ver the same interv al. Prop osition 4.1. L et [ s, t ] ⊆ [ t 0 , t N ] and let Z [ t ] b e define d as ab ove. Then, S A ( X ) s,t = S ( Z [ t ] ) s,t (16) as elements of the tensor algebr a. Pr o of. W e sho w that this holds for the depth n term by substituting d Z [ t ] u = e − ( θ t − θ u ) A dX u in to the classical 10 definition of the signature: S ( Z [ t ] ) ( n ) s,t = Z t s Z t n s · · · Z t 2 s d Z [ t ] t 1 ⊗ · · · ⊗ d Z [ t ] t n = Z t s Z t n s · · · Z t 2 s e − ( θ t − θ t 1 ) A dX t 1 ⊗ e − ( θ t − θ t n ) A dX t n = S A ( X ) ( n ) s,t . Remark 4.2. The identity S A ( X ) s,t = S ( Z [ t ] ) s,t holds for e ach fixe d terminal time t . It is ther efor e a p ointwise-in-time statement. It do es not assert that the map t 7→ S A ( X ) s,t c an b e written as t 7→ S ( Z ) s,t for some single p ath Z . Thus, the EWS tr aje ctory t 7→ S A ( X ) s,t is not the classic al signatur e of a single evolving p ath, but r ather a family of classic al signatur es taken over a family of time-dep endent r e-weightings. This observation explains why the EWS do es not satisfy the classic al Chen identity in its usual form, and why a r e-weighting term app e ars in the mo difie d Chen identity establishe d in L emma 6.1. ♢ The identit y S A ( X ) s,t = S ( Z [ t ] ) s,t is useful in analysis as it reduces some structural prop erties of the EWS to the corresp onding classical signature results applied to the single path Z [ t ] . Despite this theoretical reduction, the Z [ t ] viewp oin t is of limited direct use for time-evolving implemen tations: the ob ject computed at time t is the signature of the path Z [ t ] , while at time t + h is is the signature of a different path Z [ t + h ] . There is no simple algebraic relation b et ween S ( Z [ t ] ) s,t and S ( Z [ t ] ) s,t + h that av oids the flow op erator. 4.2 Relationship to Neural Controlled Differential Equations W e no w sho w that the EWS fits within the structured linear neural con trolled differen tial equation (SLiCE) framew ork of W alker et al. [2025]. A CDE describ es how a solution path ev olves in resp onse to incremen ts of a driving control path, with the relationship gov erned by a vector field. The solution evolv es contin uously in time and dep ends on changes in the control rather than its v alues (see D). Neural controlled differential equations (NCDEs) are contin uous-time time-series mo dels that interpret observed data streams as samples from a control path, which in turn drives a CDE with a neural-netw ork-parametrised vector field [Kidger 2022; Kidger et al. 2020]. Definition 4.3 (Linear Neural Con trolled Differen tial Equations [Kidger et al. 2020; W alk er et al. 2025]). L et { ( t i , x i ) } N i =0 denote a set of observations fr om a multivariate time-series and X : [ t 0 , t N ] → R d X b e a c ontinuous p ath r epr esentation of the observations such that X t i = ( t i , x i ) . NCDEs ar e define d as h t 0 = ξ ϕ ( t 0 , x 0 ) , h t = h t 0 + Z t t 0 g θ ( h s ) dX s , z t = l ψ ( h t ) , (17) wher e ξ ϕ : R d x → R d h and g θ : R d h → R d h × d X ar e neur al networks, and l ψ : R d h → R d z is a line ar map. F urther, line ar NCDEs (LNCDEs) take the form h t = h t 0 + Z t t 0 d w X i =1 A i θ h s dw X,i s = h t 0 + Z t t 0 d w X i =1 A i θ dw X,i s h s , (18) wher e w X : [ t 0 , t N ] → R d w is a p ath which dep ends on the input and the A i θ ar e tr ainable matric es. ♢ Lemma 3.5 shows that, just lik e the signature, the EWS is the solution to a linear CDE which takes v alues in the tensor algebra. Ho wev er, to make con tact with standard finite-dimensional mo dels, w e truncate the tensor algebra at depth n and work with the truncated EWS. Applying the canonical grade–lexicographic flattening Φ : T n ( R d ) ∼ = − − → R D , D = n X k =0 d k , (19) 11 the tensor-v alued linear CDE satisfied by the EWS b ecomes a finite-dimensional linear CDE in R D . W riting dX t = P D i =1 e i dX i t , one obtains the flattened CDE dS A ( X ) ≤ n s,t = − L S A ( X ) ≤ n s,t dθ t + d X i =1 ρ ( e i ) S A ( X ) ≤ n s,t dX i t , (20) where L = blo c kdiag L (0) , L (1) , . . . , L ( n ) , L (0) = [0] , (21) is the matrix represen tation of Λ A , and each ρ ( e i ) ∈ R D × D is the sparse lo wer-triangular matrix representing righ t tensor-multiplication b y e i . Equiv alen tly , writing M i for the co efficien t matrices, the system can b e cast in standard linear CDE form as dS A ( X ) ≤ n s,t = d X i =1 M i S A ( X ) ≤ n s,t dX i t , M i = ( − L + ρ ( e 1 ) , i = 1 ρ ( e i ) , i ∈ { 2 , . . . , d } . (22) This representation makes explicit that the truncated EWS evolv es according to a linear CDE with a highly structured collection of co efficien t matrices. Hence when the parameters of A = ( A, B ) are learnable, the truncated EWS defines a structured linear NCDE within the SLiCE framework that enco des a sp ecific inductiv e bias. In particular, its hidden state has dimension D whic h is determined by the truncation depth n and the dimension of the transformed input path. W e illustrate this structure with a simple example. Example 4.4. We c onsider the c ase of a p ath X ∈ R 2 and c ompute explicitly the CDE matric es for the EWS trunc ate d at depth n = 2 with B the identity. L et A = a b c d . The trunc ate d tensor algebr a has dimension D = 1 + 2 + 4 = 7 , with gr ade–lexic o gr aphic b asis { 1 , e 1 , e 2 , e 1 ⊗ e 1 , e 1 ⊗ e 2 , e 2 ⊗ e 1 , e 2 ⊗ e 2 } . The derivation matrix L = blo c kdiag ( L (0) , L (1) , L (2) ) has gr ade d blo cks L (0) = [0] , L (1) = a b c d , L (2) = 2 a b b 0 c a + d 0 b c 0 a + d b 0 c c 2 d . R ight tensor multiplic ation by e 1 and e 2 is r epr esente d by ρ ( e 1 ) = 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 , ρ ( e 2 ) = 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 . The instantane ous line ar op er ator app e aring in the flattene d EWS CDE, dS A ( X ) ≤ 2 s,t = M t S A ( X ) ≤ 2 s,t , is ther efor e M t = − L dθ t + ρ ( e 1 ) dX 1 t + ρ ( e 2 ) dX 2 t , 12 which explicitly e quals 0 0 0 0 0 0 0 dX 1 t − a dθ t − b dθ t 0 0 0 0 dX 2 t − c dθ t − d dθ t 0 0 0 0 0 dX 1 t 0 − 2 a dθ t − b dθ t − b dθ t 0 0 dX 2 t 0 − c dθ t − ( a + d ) dθ t 0 − b dθ t 0 0 dX 1 t − c dθ t 0 − ( a + d ) dθ t − b dθ t 0 0 dX 2 t 0 − c dθ t − c dθ t − 2 d dθ t . ♢ 4.3 Relationship to State Space Models W e now demonstrate that the EWS provides a principled extension of State Space Mo dels (SSMs) to the rough path setting, while also introducing intrinsic non-linearity through its higher-order terms. Let x ∈ C 0 ([ t 0 , t N ] , V ) and consider the SSM defined b y the ev olution dh t = − Ah t dt + B x t dt, h t 0 = 0 , (23) where A ∈ L ( W, W ) and B ∈ L ( V , W ) are b ounded linear op erators and h t ∈ W is the laten t state at time t ∈ [ t 0 , t N ] [Kalman 1960]. Note that in the literature, SSMs are usually defined using + A ; our choice of − A is purely a notational difference. The solution to this system at time t is giv en by h t = Z t t 0 e − A ( t − s ) B x s ds. (24) T o compare this solution to the definition of the re-w eigh ted path in Section 4.1, we define X ∈ V 1 ([ t 0 , t N ] , V ) as the integral path of the signal x , such that X t = R t t 0 x s ds . With the intrinsic clo c k θ t = t , the re-weigh ted path is given by Z [ t ] r = R r t 0 e − A ( t − s ) dX s . It is imp ortan t to note that for r < t , the re-weigh ted path Z [ t ] r do es not coincide with the latent state tra jectory h r , as the latter decays relative to the moving time r . Ho wev er, at the terminal time r = t , these tw o paths in tersect. Sp ecifically , the terminal state of the SSM is identically the endp oint of the re-w eighted path: h t = Z [ t ] t . (25) Giv en that Z [ t ] and h are distinct paths, it follows that the depth one term of the EWS is not the signature of the latent state tra jectory of an SSM. How ever, since b oth paths hav e the same start and end p oin ts, they ha ve the same increment and thus the same depth one signature term. Therefore, although S A ( X ) t 0 ,t = S ( Z [ t ] ) t 0 ,t = S ( h ) t 0 ,t , the equality holds at depth one. This can b e seen more directly via definition 2.1 whic h immediately iden tifies the depth one term of the EWS of X with the latent state of the SSM with the path’s deriv ative as input: S A ( X ) (1) t 0 ,t = Z t t 0 e − ( t − s ) A dX s = Z t t 0 e − ( t − s ) A x s ds = h t . (26) Hence, the paths t 7→ S A ( X ) (1) t 0 ,t and t 7→ h t are equal. This, identification confirms th at the EWS framework naturally encapsulates the linear dynamics of traditional SSMs within its first level. The EWS then extends 13 b ey ond SSMs in sev eral wa ys. While mo dern SSM architectures often pro cess input channels indep enden tly [Gu et al. 2024, 2022], the EWS is natively multi-dimensional, allowing higher-order terms to capture cross- c hannel b ehaviour. Additionally , while the latent state of an SSM is b y definition a linear function of its input history , the EWS in tro duces non-linearity at higher depths through its iterated integrals. Beyond expressivit y , the EWS generalizes the SSM to the rough path setting; whereas the ODE formulation in Equation (23) requires a well-defined deriv ative x t = d dt X t , the EWS remains mathematically rigorous for an y path X with finite p -v ariation for p < 2, without requiring X to b e differentiable. 4.4 The EWS Generalises the F ourier & Laplace T ransforms of the P ath The EWS admits a natural interpretation in terms of sp ectral filtering and its non-linear extensions. At the first tensor level, the EWS reduces to a collection of exp onen tially weigh ted linear functionals of the path, determined by the sp ectrum of the weigh ting op erator A . When the eigenv alues of A are real, these functionals correspond to Laplace mo des; when they are complex, whic h is only ac hiev able when A is non- diagonal, they corresp ond to F ourier-t yp e mo des. In this sense, depth one term of the EWS realises a finite- windo w, causal Laplace or F ourier transform of the path increments, ev aluated at a finite collection of sp ectral parameters. The structure of A gov erns ho w these sp ectral mo des are shap ed and mixed across channels, while the em b edding B determines how many such mo des are present. Higher tensor levels then depart from purely sp ectral analysis: rather than introducing new frequencies, they enco de multilinear interactions b et w een the filtered comp onen ts, extending linear time–frequency representations into a structured non- linear pathwise framework. W e now make these connections precise, b eginning with the first tensor level. As b efore, letting X ∈ V p ([ t 0 , t N ] , V ) for p < 2 and A = ( A, B ) with A ∈ L ( W , W ) and B ∈ L ( V , W ), we get that the depth one term of the EWS o ver [ t 0 , t ] is S A ( X ) (1) t 0 ,t = Z t t 0 e − ( θ t − θ u ) A d b X u ∈ W, (27) where b X ∈ V p ([ t 0 , t N ] , W ) is the lifted path given by b X t := B X t . F or fixed t ∈ [ t 0 , t N ], the assignment X 7→ S A ( X ) (1) t 0 ,t defines a linear functional of the path increments, and the sp ectral structure of the op erator exp onen tial of A gov erns the type of filtering p erformed. W e now detail how different structures of A yield differen t families of filters, b eginning with the diagonal case (EFM when the entries are in R + ). T o simplify the analysis, w e let V = R d and W = R m (although with a bit more rigour the following arguments can be made for general Banach spaces V and W ). Supp ose that A = diag ( λ 1 , · · · λ m ) for λ i ∈ R . Then the depth one term of the EWS b ecomes S A ( X ) (1) t 0 ,t = Z t t 0 e − λ k ( θ t − θ u ) d b X u m k =1 , (28) with the k − th co ordinate denoted b y S A ( X ) (1) ,k t 0 ,t . Th us, eac h co ordinate may be interpreted as a fi- nite–windo w Laplace transform ev aluation of the lifted path. When b X has b ounded v ariation, the Y oung in tegral coincides with in tegration against the signed measure determined by its increments, and the ab o ve expression is the Laplace transform of that measure ev aluated at λ k . More generally , for paths of finite p –v ariation with p < 2, the co ordinates resemble ev aluations of the Laplace transform of a distribution in the sense of Sch wartz [Sch wartz 1950, 1951]. F or this reason, w e refer to R t t 0 e − λ ( θ t − θ u ) dX u as the (finite windo w) Laplace transform of the path X ev aluated at λ . This terminology is natural in our rough path framew ork where paths are characterised not by p oin twise densities but through the CDEs that they drive, and where integration against the path is the fundamental op eration. Thus, the depth one term of the EWS in the diagonal case is a bank of Laplace modes of the path. Increasing the dimension of the latent space W via the lift B increases the num b er of such sp ectral prob es, corresponding to ev aluating the transform at additional parameter v alues λ k . 14 W e now consider the case in which A is diagonalisable but not necessarily diagonal in the chosen basis. F or the sp ectral analysis, we work ov er the complexification of W , in whic h A admits a decomp osition A = P Γ P − 1 , where Γ = diag ( λ 1 , . . . , λ m ) with λ k ∈ C . Then the depth one term of the EWS can b e written as S A ( X ) (1) t 0 ,t = P Z t t 0 e − ( θ t − θ u )Γ d ( P − 1 b X u ) . Th us, in the diagonalisable case, the depth one term is obtained by first applying a diagonal bank of Laplace or F ourier mo des—corresponding to the sp ectral parameters λ k —to the transformed path P − 1 b X , and then mixing the resulting comp onen ts via the linear map P . In particular, each output coordinate is a fixed linear com bination of scalar transform ev aluations at the spectral parameters λ k . Consequen tly , at depth one, a diagonalisable op erator A do es not increase the class of linear functionals represen table b ey ond those obtainable from a diagonal bank follow ed b y a linear lay er, provided the diagonal bank is allow ed arbitrary (p ossibly complex) sp ectral parameters. Ho wev er, allo wing general A strictly enlarges the admissible class of sp ectral filters b ey ond the purely decaying mo des of the diagonal case (EFM), since complex eigen v alues introduce oscillatory b eha viour. The eigenv ector structure further enables m ultiple sp ectral mo des to contribute to each output coordinate, producing ric her frequency resp onses per laten t dimension than strictly c hannel–separable filtering. The mixing is built directly into the dynamical represen tation, rather than b eing imp osed as a separate p ost-processing step. W e finally consider the case in which A is not diagonalisable. W orking again ov er the complexification of W , the op erator admits a Jordan decomp osition A = P J P − 1 , where J is blo ck diagonal with Jordan blo c ks corresp onding to eigen v alues λ k ∈ C . F or a Jordan blo c k of size r associated with eigen v alue λ , the matrix exp onen tial takes the form e − hJ = e − λh I + hN + h 2 2! N 2 + · · · + h r − 1 ( r − 1)! N r − 1 , where N is nilp oten t. Substituting into the depth one term yields S A ( X ) (1) t 0 ,t = P Z t t 0 e − ( θ t − θ u ) J d ( P − 1 b X u ) . In this case, the kernels are no longer purely exp onen tial. Instead, eac h spectral mo de e − λ ( θ t − θ u ) is accom- panied by p olynomial factors in ( θ t − θ u ). Consequently , the depth one term consists of linear combinations of integrals against p olynomial–exp onen tial kernels of the form ( θ t − θ u ) k e − λ ( θ t − θ u ) . (29) While the representation remains linear in the path, the admissible class of filters is strictly enlarged b ey ond purely exp onential mo des. In particular, non-diagonalisable operators allo w polynomially modulated Laplace or F ourier modes, thereb y increasing the expressivity of the depth one term of the EWS. W e now compare the depth one term of the EWS with the classical short-time F ourier transform (STFT). Recall that, for a real-v alued signal x , the STFT at time t and frequency ω is given by STFT x ( t, ω ) = Z R x ( u ) w ( u − t ) e − iω u du, (30) where w is a window function [Mallat 2009]. In practice, this corresp onds to sliding a window along the signal and computing F ourier co efficien ts on each windo w, yielding a time–frequency representation. The depth one term of the EWS may b e viewed as a contin uous-time, causal analogue of the STFT. When A has purely imaginary eigenv alues, the integrand consists of oscillatory F ourier-type mo des; when the eigenv alues ha ve negativ e real parts, these mo des are exponentially damped. Unlik e the classical STFT, whic h employs a sliding compact window, the EWS integrates o ver the entire past [ t 0 , t ] with exp onen tial temp oral w eighting. 15 In this sense, depth one term of the EWS defines a causal short-time F ourier transform of the path, with memory determined dynamically b y A rather than b y an externally imposed windo w. Viewing t 7→ S A ( X ) (1) t 0 ,t as a path in W , the depth one EWS pro duces a time-indexed family of sp ectral co efficien ts analogous to a sp ectrogram, but evolving contin uously and without rep eated windowing [Mallat 2009]. Increasing the dimension of the latent space via B corresp onds to enlarging the frequency bank, exactly as in classical time–frequency analysis. Ho wev er, the analogy with the STFT holds only at depth one. Higher tensor levels of the EWS take the form Z t t 0 Z t 2 t 0 e − ( θ t − θ t 1 ) A d b X t 1 ⊗ e − ( θ t − θ t 2 ) A d b X t 2 , (31) and higher-order analogues. These terms enco de multilinear interactions b etw een the exp onen tially filtered comp onen ts of the path. They do not introduce new sp ectral frequencies; rather, they enco de pro ducts and cross-in teractions b et w een sp ectral mo des across time and across channels. In particular, for a d –dimensional path, a classical vector-v alued STFT treats each channel indep endently and any cross-channel in teraction m ust b e introduced by a subsequent mixing la yer. By contrast, the EWS incorporates c hannel mixing in trinsically through b oth the op erator A and the tensor algebra structure at higher depths. Th us, the EWS generalises the STFT in t wo senses: temp orally , b y replacing sliding windows with contin uous exp onen tial memory , and structurally , by extending linear time–frequency analysis to include multilinear interactions b et w een spectral components. 4.4.1 Benefits of Non-Diagonal Op erators: A Duffing Oscillator Example In the previous section, w e observed that the Jordan structure of A generates p olynomial-exp onen tial memory k ernels at depth one, extending the class of temp oral filters b ey ond the purely exp onen tial mo des of the EFM. Here we make this adv antage precise through a concrete prediction task: giv en observ ations of a path ( s, u s , x s ) s ∈ [ t 0 ,t ] , predict the future state x t + h using a linear map on a truncated signature transform. W e sho w that representing the non-linear forcing terms app earing in the in tegral formulation of the Duffing oscillator requires constan t truncation depth 3 for the EWS with Jordan-structured A , compared to depth 3( K + 1) for the EFM, for the same factorial-in- K approximation accuracy . This saving grows linearly with the desired accuracy and arises directly from the Jordan structure enco ding p olynomial memory at depth one rather than through iterated integration. Let u ∈ C 0 ([ t 0 , t N ] , R ) b e a scalar forcing signal and consider the Duffing oscillator ¨ x t + α ˙ x t + β x t + γ x 3 t = δ u t , (32) with parameters ( α, β , γ , δ ) ∈ R and initial conditions ( x t 0 , ˙ x t 0 ) [Ko v acic et al. 2011]. Setting X t := ( t, u t , x t ) and introducing v = ˙ x , the v elo cit y admits the in tegral form ulation v t = e − α ( t − t 0 ) v t 0 + Z t t 0 e − α ( t − s ) − β x s − γ x 3 s + δ u s ds. (33) T o construct the EWS representation, fix K ≥ 0 and define B ∈ R (2 K +3) × 3 b y b X t := B X t = ( t, x t , 0 , . . . , 0 , u t , 0 , . . . , 0) ∈ R 2 K +3 , (34) where x t o ccupies the first slot of the x -block and u t o ccupies the first slot of the u -block, with the remaining K slots in each blo c k set to zero. W e tak e A = diag ( λ t , e A x , e A u ) where λ t > 0 and e A x , e A u ∈ R ( K +1) × ( K +1) are Jordan blo c ks of the form e A = λ 0 · · · 0 − 1 λ · · · 0 . . . . . . . . . . . . 0 · · · − 1 λ ∈ R ( K +1) × ( K +1) , λ > 0 , (35) 16 with parameters λ x , λ u > 0 respectively . Prop osition 4.5. L et S A ( X ) t 0 ,t ∈ T (( R 2 K +3 )) b e the EWS of X with p ar ameters A = ( A, B ) and clo ck θ t = t , with first-level c o or dinates S A ( X ) (1) t 0 ,t = ( S t t , S x, 0 t , . . . , S x,K t , S u, 0 t , . . . , S u,K t ) . Then for e ach m = 0 , . . . , K , S x,m t = Z t t 0 e − λ x ( t − s ) ( t − s ) m m ! dx s , S u,m t = Z t t 0 e − λ u ( t − s ) ( t − s ) m m ! u s ds, (36) wher e the inte gr al is understo o d in the Riemann–Stieltjes sense. This follows by pro jecting the EWS CDE on to the first tensor level, using the Jordan structure of e A , and solving via integrating factors; pro ofs are given in App endices F.1 and F.2. The co ordinates ( S x,m t ) K m =0 th us provide a family of p olynomial-exp onen tial memory functionals of the path. Using the expansion 1 = e − λ ( t − s ) P ∞ m =0 λ m ( t − s ) m m ! , one obtains the follo wing approximation result. Prop osition 4.6. L et x ∈ V 1 ([ t 0 , t N ] , R ) and let ( S x,m t ) K m =0 b e define d as ab ove. Then for al l t ∈ [ t 0 , t N ] , x t − x t 0 = K X m =0 λ m x S x,m t + R K +1 t , |R K +1 t | ≤ ∥ x ∥ 1 , [ t 0 ,t ] ( λ x ( t − t 0 )) K +1 ( K + 1)! . (37) The pro of is giv en in App endix F.3. Hence there exists a linear functional ℓ x supp orted on level one such that x t ≈ ⟨ ℓ x , S A ( X ) t 0 ,t ⟩ . By the shuffle identit y (Lemma 6.7), x 3 t ≈ ⟨ ℓ 3 x , S A ( X ) t 0 ,t ⟩ , (38) where ℓ 3 x is supp orted on tensor levels at most three. The same construction applied to the u -blo c k yields ℓ u at depth one. Setting λ t = α , the initial condition term e − α ( t − t 0 ) v t 0 is captured by a functional ℓ 0 at depths 0 and 1. Combining, and writing ℓ := − β ℓ x − γ ℓ 3 x + δ ℓ u , Equation (33) gives v t ≈ ⟨ ℓ 0 , S A ( X ) t 0 ,t ⟩ + Z t t 0 e − α ( t − s ) ⟨ ℓ, S A ( X ) t 0 ,s ⟩ ds. (39) The depth comparison b et ween EWS and EFM of the integrand term is established at this stage, b efore accoun ting for the conv olution. In the EWS case, the Jordan structure yields ℓ supp orted at depth ≤ 3 indep enden tly of K . In the EFM case, the depth-one co ordinates consist only of purely exp onen tial kernels R e − λ ( t − s ) dx s , whic h do not generate p olynomial factors in ( t − s ); such factors can only arise from iterated in tegrations against the x -c hannel, requiring depth m + 1 for degree m . Hence approximating x t with p olynomial degree K requires depth K + 1, and x 3 t requires depth 3( K + 1). The EWS therefore represents the in tegrand at constant depth 3, compared to depth 3( K + 1) for the EFM — a saving of 3 K lev els. The remaining conv olution against e − α ( t − s ) ds introduces additional representational cost equally to b oth settings, so this saving p ersists in the full representation of v t . Then, given an approximation of v t , one reco vers x t + h b y s olving v t = ⟨ l 0 , S A ( X ) t 0 ,t ⟩ + z t , ˙ z t = − αz t + ⟨ ℓ, S A ( X ) t 0 ,t ⟩ , z t 0 = 0 , ˙ x t = v t . (40) More broadly , this construction extends to any dynamical system whose v ector field is p olynomial in the state: the Jordan structure enco des p olynomial memory at depth one, and the sh uffle identit y lifts degree- p non-linearities to depth p , yielding a representation of constant depth indep enden t of the approximation accuracy K . 17 5 Analytic W ell-p osedness W e now establish analytic well-posedness of the EWS for paths X ∈ V p ([ t 0 , t N ] , V ) with p < 2, meaning that the defining tensor series conv erges. Since the EWS coincides with the classical signature of a suitably re-w eighted path, well-posedness for general p < 2 follows directly from standard signature theory . F or completeness, we demonstrate the factorial decay b ound explicitly in the finite v ariation case, which makes the conv ergence mec hanism and the dep endence on the op erator A transparen t. Lemma 5.1. F or X ∈ V 1 ([ t 0 , t N ]) , the EWS is wel l-define d, and for al l [ s, t ] ⊆ [ t 0 , t N ] , the fol lowing b ound holds || S A ( X ) ( n ) s,t || V ⊗ n ≤ ( C A,t N || X || 1 , [ s,t ] ) n n ! , (41) wher e E ( h ) = e − hA as b efor e and C A,t N = sup 0 ≤ h ≤ t N − t 0 || E ( h ) || op < ∞ sinc e A is b ounde d. Pr o of. Since X is of finite v ariation on [ t 0 , t N ], the level- n iterated integral defining the E W S on [ s, t ] can b e written as S A ( X ) ( n ) s,t = Z t s Z t n s · · · Z t 2 s n O k =1 ( E ( θ t − θ u k ) ˙ X u k ) du 1 · · · du n . Via the sub-multiplicativ e prop ert y of admissible norms on V ⊗ n , we get || S A ( X ) ( n ) s,t || V ⊗ n ≤ Z t s Z t n s · · · Z t 2 s n Y k =1 || E ( θ t − θ u k ) ˙ X u k || V du 1 · · · du k . F or each k we hav e || E ( θ t − θ u k ) ˙ X u k || V ≤ || E ( θ t − θ u k ) || op || ˙ X u k || V . Since θ t − θ u k ∈ [0 , t N − t 0 ] for all u k ∈ [ s, t ], w e hav e || E ( θ t − θ u k ) || op ≤ C A,t N . Therefore, || S A ( X ) ( n ) s,t || V ⊗ n ≤ C n A,t N Z t s Z t n s · · · Z t 2 s n Y k =1 || ˙ X u k || du 1 · · · du k . The remaining in tegral o ver the simplex can b e ev aluated explicitly just as in the pro of for the classical signature setting. By F ubini’s theorem, Z t s Z t n s · · · Z t 2 s n Y k =1 || ˙ X u k || du 1 · · · du k = 1 n ! Z [ s,t ] n n Y k =1 || ˙ X u k || du 1 · · · du k = Z t s || ˙ X || V du n = || X || n 1 , [ s,t ] . Com bining the ab o v e estimates yields the result. A t present, the factorial decay argument pro vided in Lemma 5.1 establishes the existence of the EWS for paths of finite v ariation (p=1). T o extend this result to the case of 1 < p < 2, we adopt an approach based on the equiv alence b et ween the EWS and the classical signature of the re-weigh ted path Z [ t ] r = R r t 0 e − ( θ t − θ u ) A dX u , where the in tegral is understoo d in the Y oung sense and t ∈ [ t 0 , t N ] is fixed. Assuming that the contin uous map u 7→ e − ( θ t − θ u ) A is of finite q -v ariation such that 1 p + 1 q > 1, the existence of Z [ t ] is guaran teed by the Y oung estimate || Z [ t ] || p, [ t 0 ,t ] ≤ C θ,A || X || p, [ t 0 ,t ] , where the constant C θ,A dep ends on sup 0 ≤ h ≤ t N − t 0 || e − hA || op and on the q -v ariation of the map u 7→ e − ( θ t − θ u ) A . Since the EWS satisfies S A ( X ) t 0 ,t = S ( Z [ t ] ) t 0 ,t , the existence of the EWS for p < 2 follows directly from the existence of the signature of Y oung paths. Note that when B ∈ L ( V , W ) is non-trivial, the statement b ecomes || S A ( X ) ( n ) s,t || W ⊗ n ≤ ( C A,t N || B || op || X || 1 , [ s,t ] ) n n ! . 18 6 Algebraic Prop erties of the EWS W e no w sho w that the EWS satisfies the k ey algebraic properties of the classical path signature. In particular, it is multiplicativ e with resp ect to path concatenation (Chen’s iden tity), and linear functionals of the EWS are closed under multiplication, forming a commutativ e algebra via the shuffle pro duct. 6.1 Chen’s Iden tity Chen’s iden tity expresses the fact that the signature of a path ov er an interv al can b e constructed as the pro duct of the signature ov er a set of sub-interv als. In the EWS setting, we satisfy an altered version of Chen’s identit y that reflects the action of the linear flow D A . The pro of for this mirrors the structure of the proof in the classical signature setting from Lyons et al. [2007] in that we first establish the claim for X ∈ V 1 ([ t 0 , t N ] , V ) and then extend it to the p ∈ (1 , 2) regime. Lemma 6.1. L et X ∈ V p ([ t 0 , t N ] , V ) for p = 1 . Then for any t 0 ≤ s ≤ u ≤ t ≤ t N , the exp onential ly- weighte d signatur e satisfies S A ( X ) s,t = D θ t − θ u A S A ( X ) s,u ⊗ S A ( X ) u,t . (42) Pr o of. W e will show that the statemen t holds at an arbitrary depth n . F or all s ≤ u ≤ t , w e can split the region of integration as S A ( X ) ( n ) s,t = Z t s Z t n s · · · Z t 2 s e − ( θ t − θ t 1 ) A dX t 1 ⊗ · · · ⊗ e − ( θ t − θ t n ) A dX t n = Z u s Z t n s · · · Z t 2 s e − ( θ t − θ t 1 ) A dX t 1 ⊗ · · · ⊗ e − ( θ t − θ t n ) A dX t n | {z } ( I ) + Z t u Z t n u · · · Z t 2 u e − ( θ t − θ t 1 ) A dX t 1 ⊗ · · · ⊗ e − ( θ t − θ t n ) A dX t n | {z } ( I I ) + n − 1 X k =1 Z t s Z t n s · · · Z t k +1 s Z u s Z t k − 1 s · · · Z t 2 s e − ( θ t − θ t 1 ) A dX t 1 ⊗ · · · ⊗ e − ( θ t − θ t n ) A dX t n | {z } ( I I I ) where ( I ) = D A θ t − θ u S A ( X ) ( n ) s,u and ( I I ) = S A ( X ) ( n ) u,t . W e then expand ( I II ) as ( I II ) = n − 1 X k =1 Z u s Z t k s · · · Z t 2 s e − ( θ t − θ t 1 ) A dX t 1 ⊗ · · · ⊗ e − ( θ t − θ t k ) A dX t k | {z } ( IV ) ⊗ Z t u Z t n u · · · Z t k +1 u e − ( θ t − θ t k +1 ) A dX t 1 ⊗ · · · ⊗ e − ( θ t − θ t n ) A dX t n | {z } ( V ) , 19 where ( V ) = S A ( X ) ( n − k ) u,t . F or ( IV ), it remains to introduce the correct factors inv olving u : ( IV ) = Z u s Z t k s · · · Z t 2 s e − ( θ t − θ u ) A e − ( θ u − θ t 1 ) A dX t 1 ⊗ · · · ⊗ e − ( θ t − θ u ) A e − ( θ u − θ t k ) A dX t k = ( e − ( θ t − θ u ) A ) ⊗ k Z u s Z t k s · · · Z t 2 s e − ( θ u − θ t 1 ) A dX t 1 ⊗ · · · ⊗ e − ( θ u − θ t k ) A dX t k = D A θ t − θ u S A ( X ) ( k ) s,u . Putting everything together, we get S A ( X ) ( n ) s,t = n X k =0 D A θ t − θ u S A ( X ) ( k ) s,u ⊗ S A ( X ) ( n − k ) u,t . The ab o ve pro of will not hold for p ∈ (1 , 2) since it mak es use of F ubini’s theorem. W e will extend the statemen t by using the fact that the truncated EWS is the solution to a con trolled differential equation, whic h provides contin uity in the p -v ariation top ology and allo ws us to pass to the limit from bounded v ariation approximations. Lemma 6.2. L et X ∈ V p ([ t 0 , t N ] , V ) for p < 2 and fix an inte ger n ≥ 1 . Define f : T ( n ) ( V ) → L ( V , T ( n ) ) by f ( a ) v = − Λ A ( a ) · ℓ ( v ) + π n ( a ⊗ v ) , wher e ℓ : V → R is the clo ck functional and π n : T (( V )) → T ( n ) ( V ) denotes pr oje ction onto the first n + 1 levels (including the 0 -th level). Then the unique solution to the CDE dS t = f ( S t ) dX t , S s = (1 , 0 , . . . , 0) , is the trunc ate d EWS S t = π n ( S A ( X ) s,t ) . Pr o of. Since p < 2 by Theorem D.3, existence and uniqueness hold. T o verify that π n ( S A ( X ) s,t ) solves this equation, we pro ject the EWS dynamics from Lemma 3.5. Applying π n to b oth sides and using dθ t = ℓ ( dX t ) giv es dπ n ( S A ( X ) s,t ) = − Λ A π n ( S A ( X ) s,t ) ℓ ( dX t ) + π n ( S A ( X ) s,t ⊗ dX t ) . As the tensor pro duct S A ( X ) s,t ⊗ dX t only affects levels up to n through comp onen ts of S A ( X ) s,t at lev els up to n − 1, and Λ A preserv es tensor degrees (it acts level-wise), w e ha ve π n ( S A ( X ) s,t ⊗ dX t ) = π n ( π n ( S A ( X ) s,t ) ⊗ dX t ) . Th us, π n ( S A ( X ) s,t ) satisfies the CDE with vector field f and initial condition π n ( S A ( X ) s,s ) = π n ((1 , 0 , . . . , 0)) = (1 , 0 , . . . , 0). By uniqueness, it is the solution. Remark 6.3. We now denote the trunc ate d EWS analo gously to the trunc ate d signatur e by S A ( X ) ≤ n s,t := π n ( S A ( X ) s,t ) . ♢ Corollary 6.4. F or e ach p ∈ [1 , 2) , and e ach inte ger n ≥ 0 , the trunc ate d EWS defines a c ontinuous mapping π n ◦ S A : V p ([ t 0 , t N ] , V ) → T ( n ) ( V ) with r esp e ct to the p -variation top olo gy on the domain. Pr o of. By Lemma 6.2, the truncated EWS π n ( S A ( X ) s,t ) is the unique solution of the linear CDE d Y t = f ( Y t ) dX t , Y s = 1 , 20 where f : T ( n ) ( V ) → L ( V , T ( n ) ( V )) is the linear vector field f ( a ) v = − Λ A a · ℓ ( v ) + π n ( a ⊗ v ). W e denote the solution b y Y t = π n ( S A ( X ) s,t ), and equip T ( n ) ( V ) with the norm ∥ a ∥ = P n k =0 ∥ a k ∥ V ⊗ k induced by the admissible norms on each tensor lev el. Let X ( k ) → X in p -v ariation. W e must show Y ( k ) t → Y t , where Y ( k ) t = π n ( S A ( X ( k ) ) s,t ) denotes the solution driv en by X ( k ) . By Theorem D.3, the solution is constructed via Picard iteration. F or driv er X , define Y (0) t = 1 and Y ( m +1) t = 1 + Z t s f ( Y ( m ) u ) dX u , with Y ( m ) t → Y t as m → ∞ . Similarly , for driver X ( k ) , define Y ( k, 0) t = 1 and Y ( k,m +1) t = 1 + Z t s f ( Y ( k,m ) u ) dX ( k ) u , with Y ( k,m ) t → Y ( k ) t as m → ∞ . W e claim that for each fixed m , we hav e Y ( k,m ) t → Y ( m ) t as k → ∞ . W e pro ve this b y induction on m . F or the base case, Y ( k, 0) t = 1 = Y (0) t for all k , so con vergence holds trivially . F or the inductive step, supp ose Y ( k,m ) t → Y ( m ) t as k → ∞ . W e write Y ( k,m +1) t − Y ( m +1) t = Z t s f ( Y ( k,m ) u ) dX ( k ) u − Z t s f ( Y ( m ) u ) dX u = Z t s f ( Y ( m ) u ) d ( X ( k ) − X ) u | {z } ( I ) + Z t s f ( Y ( k,m ) u ) − f ( Y ( m ) u ) dX ( k ) u | {z } ( I I ) . F or term ( I ), the integrand f ( Y ( m ) u ) is fixed and has finite q -v ariation for some q with 1 p + 1 q > 1. By the Y oung estimate [Ly ons et al. 2007], ∥ ( I ) ∥ ≤ ∥ f ( Y ( m ) s ) ∥ op · ∥ X ( k ) − X ∥ p, [ s,t ] + C ∥ X ( k ) − X ∥ p, [ s,t ] ∥ f ( Y ( m ) ) ∥ q , [ s,t ] . Since X ( k ) → X in p -v ariation (which implies uniform conv ergence), ( I ) → 0 as k → ∞ . F or term ( I I ), by the Y oung estimate [Lyons et al. 2007], ∥ ( I I ) ∥ ≤ ∥ f ( Y ( k,m ) s ) − f ( Y ( m ) s ) ∥ op · ∥ X ( k ) ∥ p, [ s,t ] + C ∥ X ( k ) ∥ p, [ s,t ] ∥ f ( Y ( k,m ) ) − f ( Y ( m ) ) ∥ q , [ s,t ] . Since X ( k ) → X in p -v ariation, the norms ∥ X ( k ) ∥ p, [ s,t ] are b ounded. Since f is linear, ∥ f ( Y ( k,m ) s ) − f ( Y ( m ) s ) ∥ op → 0 by the inductive hypothesis. F or the q -v ariation term, we use that f is linear and that the inductiv e hypothesis gives p oin twise conv ergence Y ( k,m ) u → Y ( m ) u for eac h u , which combined with uni- form b oundedness from the Picard b ounds yields ∥ f ( Y ( k,m ) ) − f ( Y ( m ) ) ∥ q , [ s,t ] → 0. Therefore ( I I ) → 0 as k → ∞ , completing the induction. T o conclude, let ε > 0 and estimate ∥ Y ( k ) t − Y t ∥ ≤ ∥ Y ( k ) t − Y ( k,m ) t ∥ + ∥ Y ( k,m ) t − Y ( m ) t ∥ + ∥ Y ( m ) t − Y t ∥ . By Theorem D.3, the Picard iterates conv erge with the b ound ∥ Y ( m ) t − Y t ∥ ≤ C ∞ X j = m +1 ( C A ∥ X ∥ p, [ s,t ] ) j Γ(1 + j /p ) , and similarly for ∥ Y ( k,m ) t − Y ( k ) t ∥ with ∥ X ( k ) ∥ p, [ s,t ] in place of ∥ X ∥ p, [ s,t ] . Since X ( k ) → X in p -v ariation, there exists M > 0 suc h that ∥ X ( k ) ∥ p, [ s,t ] ≤ M for all k . Cho ose m large enough that ∥ Y ( m ) t − Y t ∥ < ε/ 3 and ∥ Y ( k,m ) t − Y ( k ) t ∥ < ε/ 3 for all k . F or this fixed m , choose k large enough that ∥ Y ( k,m ) t − Y ( m ) t ∥ < ε/ 3. Then ∥ Y ( k ) t − Y t ∥ < ε . 21 W e now ha ve the necessary ingredients to extend Chen’s identit y to paths of finite p -v ariation with p < 2. Corollary 6.5. L et X ∈ V p ([ t 0 , t N ] , V ) for p < 2 . Then for any t 0 ≤ s ≤ u ≤ t ≤ t N , the exp onential ly- weighte d signatur e satisfies S A ( X ) s,t = D θ t − θ u A S A ( X ) s,u ⊗ S A ( X ) u,t . Pr o of. Fix s ≤ u ≤ t and let p < 2 b e giv en. Choose p ′ suc h that p < p ′ < 2. By the density of smo oth (hence finite v ariation) paths in V p ′ ([ t 0 , t N ] , V ), there exists a sequence ( X ( m ) ) m ≥ 0 of finite v ariation paths suc h that X ( m ) → X in p ′ -v ariation as m → ∞ . By Lemma 6.1, Chen’s iden tity holds for each finite v ariation path X ( m ) : S A ( X ( m ) ) s,t = D θ ( m ) t − θ ( m ) u A S A ( X ( m ) ) s,u ⊗ S A ( X ( m ) ) u,t , where θ ( m ) r := ℓ ( X ( m ) r ) denotes the clock ev aluated along X ( m ) . Fix an arbitrary level n ≥ 0. Pro jecting Chen’s identit y to level n gives π n ( S A ( X ( m ) ) s,t ) = n X k =0 D θ ( m ) t − θ ( m ) u A S A ( X ( m ) ) s,u ( k ) ⊗ S A ( X ( m ) ) u,t ( n − k ) . W e no w pass to the limit as m → ∞ . By Corollary 6.4, the truncated EWS is contin uous in the p ′ -v ariation top ology , so π n ( S A ( X ( m ) ) s,t ) → π n ( S A ( X ) s,t ) , π k ( S A ( X ( m ) ) s,u ) → π k ( S A ( X ) s,u ) for each k ≤ n, π n − k ( S A ( X ( m ) ) u,t ) → π n − k ( S A ( X ) u,t ) for each k ≤ n. Since ℓ : V → R is a con tinuous linear functional, the clo c k con verges uniformly: θ ( m ) r → θ r for all r ∈ [ t 0 , t N ]. In particular, θ ( m ) t − θ ( m ) u → θ t − θ u . The flo w op erator D h A dep ends contin uously on h : for any fixed a ∈ T ( n ) ( V ), the map h 7→ D h A a is contin uous since h 7→ e − hA is contin uous in op erator norm. Combined with contin uity in the tensor algebra argumen t, we hav e D θ ( m ) t − θ ( m ) u A π k ( S A ( X ( m ) ) s,u ) → D θ t − θ u A π k ( S A ( X ) s,u ) for each k ≤ n . Since the tensor pro duct ⊗ : T ( k ) ( V ) × T ( n − k ) ( V ) → T ( n ) ( V ) is con tinuous, taking limits in the pro jected Chen iden tity yields π n ( S A ( X ) s,t ) = n X k =0 D θ t − θ u A S A ( X ) s,u ( k ) ⊗ ( S A ( X ) u,t ) ( n − k ) = π n D θ t − θ u A S A ( X ) s,u ⊗ S A ( X ) u,t . Since S A ( X ) s,t and ( D θ t − θ u A S A ( X ) s,u ) ⊗ S A ( X ) u,t agree at ev ery lev el n ≥ 0, they are equal as elements of T (( V )). Remark 6.6. Beyond its algebr aic signific anc e, the mo difie d Chen identity is c entr al to the efficient nu- meric al c omputation of the EWS. It pr ovides the asso ciative binary op er ation underlying the p ar al lel sc an algorithm describ e d in Se ction 8, enabling aggr e gation of lo c al EWS incr ements in O (log N ) p ar al lel steps r ather than O ( N ) se quential ones. ♢ 6.2 Linearisation of Shuffle Pro duct W e no w establish the fact that pro ducts of linear functionals of the EWS can be linearised via the shuffle pro duct. This prop ert y can b e obtained simply by reducing the EWS to the classical signature, but instead w e give a direct pro of that works entirely within the CDE framework. This pro of would also extend to the infinite time framework whenever that existence and uniqueness hold in that setting. 22 Lemma 6.7. L et X ∈ V p ([ t 0 , t N ] , V ) for p < 2 and A ∈ L ( V , V ) b ounde d. Then for al l [ s, t ] ⊆ [ t 0 , t N ] and l 1 , l 2 ∈ T ( V ⋆ ) , ⟨ l 1 , S A ( X ) s,t ⟩⟨ l 2 , S A ( X ) s,t ⟩ = ⟨ l 1 l 2 , S A ( X ) s,t ⟩ . (43) Pr o of. Throughout this pro of, we write ⊠ for the external tensor pro duct, distinguishing it from the internal tensor product ⊗ whic h denotes m ultiplication in T (( V )). The external tensor product app ears in the co domain of the copro duct ∆ : T (( V )) → T (( V )) ⊠ T (( V )) and in the corresp onding dual space T ( V ⋆ ) ⊠ T ( V ⋆ ). Recall that the shuffle pro duct and the de-concatenation copro duct are dual in the sense that for all l 1 , l 2 ∈ T ( V ⋆ ) and s ∈ T (( V )), ⟨ l 1 l 2 , s ⟩ = ⟨ l 1 ⊠ l 2 , ∆( s ) ⟩ , where the pairing on the RHS is given b y ⟨ a ⊠ b, c ⊠ d ⟩ = ⟨ a, c ⟩⟨ b, d ⟩ [Lyons et al. 2024]. An elemen t s ∈ T (( V )) is group-like if ∆( s ) = s ⊠ s , in whic h case ⟨ l 1 l 2 , s ⟩ = ⟨ l 1 ⊠ l 2 , s ⊠ s ⟩ = ⟨ l 1 , s ⟩⟨ l 2 , s ⟩ . Th us, pro ving the claim reduces to showing that S A ( X ) s,t is group-like. That is, we m ust sho w that ∆( S A ( X ) s,t ) = S A ( X ) s,t ⊠ S A ( X ) s,t . W e establish this by sho wing that b oth sides, viewed as processes in t , satisfy the same controlled differen tial equation with the same initial condition. Define G t := ∆( S A ( X ) s,t ) , H t := S A ( X ) s,t ⊠ S A ( X ) s,t . F or the initial conditions at t = s , we hav e G s = ∆( S A ( X ) s,s ) = ∆( 1 ) = 1 ⊠ 1 , H s = S A ( X ) s,s ⊠ S A ( X ) s,s = 1 ⊠ 1 . Since ∆ is linear, w e may apply it to the EWS dynamic to obtain dG t = ∆( dS A ( X ) s,t ) = − ∆(Λ A S A ( X ) s,t ) dθ t + ∆( S A ( X ) s,t ⊗ dX t ) . F or the first term, we use the fact that Λ A is a deriv ation, which implies the compatibilit y condition ∆ ◦ Λ A = (Λ A ⊠ id + id ⊠ Λ A ) ◦ ∆ , where id is the iden tity map on T (( V )). T o verify this, note that b oth sides are deriv ations from T (( V )) to T (( V )) ⊠ T (( V )), so it suffices to chec k equality on the generators v ∈ V . The LHS gives ∆(Λ A ( v )) = 1 ⊠ Av + Av ⊠ 1 and the RHS gives (Λ A ⊠ id + id ⊠ Λ A )(∆( v )) = (Λ A ⊠ id + id ⊠ Λ A )( 1 ⊠ v + v ⊠ 1 ) = Λ A ( 1 ) ⊠ v + 1 ⊠ Λ A ( v ) + Λ A ( v ) ⊠ 1 + v ⊠ Λ A ( 1 ) = 1 ⊠ Av + Av ⊠ 1 , since Λ A ( 1 ) = 0. Th us, the first term in the dynamic of G t is − ∆(Λ A S A ( X ) s,t ) dθ t = − (Λ A ⊠ id + id ⊠ Λ A )( G t ) dθ t . F or the second term, we use the fact that ∆ is an algebra homomorphism, meaning ∆( x ⊗ y ) = ∆( x )∆( y ). ∆( S A ( X ) s,t ⊗ dX t ) = ∆( S A ( X ) s,t )∆( dX t ) = G t ( 1 ⊠ dX t + dX t ⊠ 1 ) . 23 Com bining b oth terms, the dynamics of G t are given by dG t = − (Λ A ⊠ id + id ⊠ Λ A )( G t ) dθ t + G t ( 1 ⊠ dX t + dX t ⊠ 1 ) . No w for the dynamics of H t , by the pro duct rule for the external tensor pro duct, dH t = dS A ( X ) s,t ⊠ S A ( X ) s,t + S A ( X ) s,t ⊠ dS A ( X ) s,t . Substituting in the EWS dynamics and collecting the dθ t terms gives − Λ A S A ( X ) s,t ⊠ S A ( X ) s,t dθ t − S A ( X ) s,t ⊠ Λ A S A ( X ) s,t dθ t = − (Λ A ⊠ id + id ⊠ Λ A )( H t ) dθ t , and collecting the dX t terms gives ( S A ( X ) s,t ⊗ dX t ) ⊠ S A ( X ) s,t + S A ( X ) s,t ⊠ ( S A ( X ) s,t ⊗ dX t ) = H t ( dX t ⊠ 1 + 1 ⊠ dX t ) . Th us, the dynamics of H t are dH t = − (Λ A ⊠ id + id ⊠ Λ A )( H t ) dθ t + H t ( 1 ⊠ dX t + dX t ⊠ 1 ) . Hence b oth G t and H t satisfy the same linear CDE with the same initial condition. On eac h finite tensor lev el, this is a finite-dimensional linear CDE, which admits a unique solution by Y oung integration theory . Therefore G t = H t for all t ∈ [ s, t N ], completing the pro of. 7 Uniqueness of the EWS & Univ ersal Appro ximation Under mild conditions, the signature of a path uniquely determines the path up to tree-like equiv alence, and when the path includes a strictly monotone component this reduces to uniqueness [Bo edihardjo et al. 2016; Ham bly et al. 2010]. This makes the signature a faithful representation of path information. F or the EWS, uniqueness is more subtle. While the EWS is the signature of a re-weigh ted path, uniqueness do es not follow immediately . In order to apply standard signature uniqueness results to distinguish tw o re-weigh ted paths, w e require them to not b e tree-like equiv alent, for instance by ha ving monotone components. Ho wev er, it is not ob vious that this prop ert y is inherited from the input paths through re-w eighting: for example, even if a path has a monotone comp onent, its re-weigh ted coun terpart ma y not due to mixing b et ween channels induced by A . This section characterises when t wo paths yield the same EWS for a given A , establishes uniqueness under structural assumptions on A , and prov es universal approximation in full generality . Throughout this section we work with paths b X ∈ V p ([ t 0 , t N ] , b V ) for p < 2 that hav e a clo c k functional θ t = ℓ ( X t ). W e then consider the clo ck-augmen ted path X ∈ V p ([ t 0 , t N ] , V ) defined by X t = ( θ t , b X t ) where V ∼ = R × b V . This guarantees that our paths hav e a strictly monotone channel. W e now verify that the re-w eighting map preserv es the information conten t of the path. 7.1 Characterisation of EWS Equiv alence W e b egin by characterising the equiv alence relation induced by the EWS. Two paths are A -equiv alent if they hav e the same EWS for a given A . Since the EWS of a path can viewed as the classical signature of its corresp onding re-w eighted path, this equiv alence is precisely the pull-back of tree-like equiv alence through the re-weigh ting map. Definition 7.1. L et X 1 , X 2 ∈ V p ([ t 0 , t N ] , V ) for p < 2 , and let A ∈ L ( V , V ) b e a b ounde d line ar op er ator. We say X 1 and X 2 ar e A -e quivalent over [ s, t ] ⊆ [ t 0 , t N ] , denote d X 1 ∼ A X 2 , if S A ( X 1 ) s,t = S A ( X 2 ) s,t . ♢ 24 Prop osition 7.2. L et X 1 , X 2 ∈ V p ([ t 0 , t N ] , V ) for p < 2 and define the r e-weighte d p aths Z i, [ t ] r = Z r s e − ( θ r − θ u ) A dX i r over [ s, t ] ⊆ [ t 0 , t N ] for i = 1 , 2 . Then the fol lowing ar e e quivalent: • X 1 ∼ A X 2 over [ s, t ] . • Z 1 , [ t ] and Z 2 , [ t ] ar e tr e e-like e quivalent over [ s, t ] . Pr o of. This is a trivial but nece ssary prop osition. If X 1 ∼ A X 2 , then S ( Z 1 , [ t ] ) s,t = S A ( X 1 ) s,t = S A ( X 2 ) s,t = S ( Z 2 , [ t ] ) s,t . Since Z 1 , [ t ] and Z 2 , [ t ] ha ve equal signatures, they are tree-like equiv alent. This c haracterisation is only implicit in the sense that it describes A -equiv alence via the re-weigh ted paths Z i rather than directly in terms of the original paths X i . F or the classical signature ( A = 0), the re-w eighting is trivial, and the characterisation reduces to tree-like equiv alence of the paths. F or general A , w e hav e not y et sho wn that tree-like equiv alence of the Z i ’s corresp ond to any prop erties of the X i ’s. If w e could show that tree-lik e equiv alence of the Z i ’s implied tree-lik e equiv alence of the X i ’s then w e would immediately hav e uniqueness of the EWS via uniqueness of the signature. While we hav e not yet b een able to show this for general A , we hav e had success with structured A . 7.2 Uniqueness of the EWS for Structured A In the literature, it is common to augment a path with a time channel to ensure uniqueness: the monotone comp onen t rules out tree-lik e equiv alence, so the signature fully c haracterises the path. The analogous approac h for the EWS is to guarantee that the re-weigh ted path inherits a monotone channel from the input path. If this holds, uniqueness follows from standard signature results. While this is not the case for general A , we can imp ose structure on A to satisfy this. Note that monotonicity is merely a sufficient condition for ruling out tree-like equiv alence, not a necessary one. Thus, for general A , even though the re-weigh ted path ma y not inherit a monotone channel from the input path, uniqueness of the EWS ma y still hold. Lemma 7.3. L et X ∈ V p ([ t 0 , t N ] , V ) for p < 2 such that X r = ( θ r , b X r ) with θ strictly monotone and V = R × b V . L et [ s, t ] ⊆ [ t 0 , t N ] and supp ose A ∈ L ( V , V ) satisfies π 1 ◦ e − hA = e − αh · π 1 ∀ h ∈ R , (44) wher e π 1 : V → R denotes the pr oje ction onto the first c omp onent and α ∈ R . Define the r e-weighte d p ath Z [ t ] r = R r s e − ( θ t − θ u ) A dX u , and write Z [ t ] r = ( ζ r , b Z [ t ] r ) wher e ζ = π 1 ( Z [ t ] ) . Then ζ is strictly monotone in r . Pr o of. F or any v ∈ V , the condition π 1 ◦ e − hA = e − αh · π 1 sa ys that the clo c k comp onen t of e − hA v dep ends only on the clo ck comp onen t of v : π 1 ( e − hA v ) = e − αh · π 1 ( v ) . Applying this to the re-w eighted path giv es ζ r = π 1 ( Z [ t ] r ) = π 1 Z r s e − ( θ t − θ u ) A dX u = Z r s π 1 ( e − ( θ t − θ u ) A dX u ) = Z r s e − α ( θ t − θ u ) dθ u . Since e − α ( θ t − θ u ) > 0 for all u ∈ [ s, r ] and θ is strictly monotone, ζ is strictly monotone in r . 25 Remark 7.4. A sufficient c ondition for π 1 ◦ e − hA = e − αh · π 1 is that π 1 ◦ A = α · π 1 . In the finite dimensional setting wher e V = R d +1 and A ∈ R ( d +1) × ( d +1) , this c orr esp onds to A = α 0 b b A wher e α ∈ R , b ∈ R d and b A ∈ R d × d . That is, the first r ow of A is ( α, 0 , . . . , 0) . ♢ Corollary 7.5. L et X 1 , X 2 ∈ V p ([ t 0 , t N ] , V ) for p < 2 b e clo ck-augmente d p aths and A ∈ L ( V , V ) satisfy the c ondition in L emma 7.3. Then S A ( X 1 ) s,t = S A ( X 2 ) s,t implies that X 1 = X 2 + c on [ s, t ] ⊆ [ t 0 , t N ] for some c onstant c ∈ V . Pr o of. By Prop osition 4.1, S A ( X 1 ) s,t = S A ( X 2 ) s,t implies that S ( Z 1 , [ t ] ) s,t = S ( Z 2 , [ t ] ) s,t . By Lemma 7.3, b oth Z 1 , [ t ] and Z 2 , [ t ] ha ve strictly monotone c hannel and thus, Z 1 , [ t ] = Z 2 , [ t ] + ˜ c . It follows that X 1 = X 2 + c o ver [ s, t ]. This structure assumption is mild in practice. It requires only that the clo c k channel is not influenced b y other c hannels; the con verse, other c hannels being influenced by the clock, is p ermitted. All features motiv ating the EWS o ver the EFM suc h as oscillatory mo des (via complex eigenv alues of b A ), coupled decay b et ween data c hannels (via off-diagonal entries in b A ), and even clo c k-dep enden t decay of data channels remain a v ailable. One could ev en introduce a second clo c k channel into X ; the first would guarantee uniqueness while the second participates freely in the dynamics of A . 7.3 Univ ersal Approximation Theorem Despite the subtleties of uniqueness, universal approximation holds in full generalit y . The EWS is alwa ys a univ ersal feature map for the class of functions it can distinguish; that is, functions constan t on A -equiv alence classes. When uniqueness holds, this class is all contin uous functions. Lemma 7.6. L et K ⊂ V p ([ t 0 , t N ] , V ) for p < 2 b e a c omp act set of p aths. F or any c ontinuous F : K → R satisfying X ∼ A Y ⇒ F ( X ) = F ( Y ) , and any ϵ > 0 , ther e exists an l ∈ T ( V ⋆ ) such that sup X ∈ K | F ( X ) − ⟨ l , S A ( X ) t 0 ,t N ⟩| < ϵ. (45) Pr o of. Define the algebra of linear signature functionals: A := { X 7→ ⟨ l, S A ( X ) s,t ⟩ : l ∈ T ( V ∗ ) } ⊂ C ( K , R ) . W e show that A satisfies the h yp otheses of the Stone–W eierstrass theorem on K/ ∼ A . First, w e show con tin uity . By Corollary 6.4, the truncated EWS π n ◦ S A : V p ([ s, t ] , V ) → T ( n ) ( V ) is con tinuous in the p -v ariation top ology for each n ≥ 0. F or any l ∈ T ( V ∗ ), the pairing ⟨ l , ·⟩ inv olves only finitely many tensor levels, so the map X 7→ ⟨ l, S A ( X ) s,t ⟩ is contin uous. Thus A ⊂ C ( K, R ). Second, we show that A con tains constant functions. F or any signature, the level-zero term is S A ( X ) (0) s,t = 1. Letting ∅ denote the empt y word, we hav e ⟨ ∅ , S A ( X ) s,t ⟩ = 1 for all X ∈ K . Hence for any c ∈ R , the functional l = c · ∅ satisfies ⟨ l , S A ( X ) s,t ⟩ = c , so A contains all constant functions. Third, w e sho w that A is closed under multiplication. By the shuffle pro duct linearisation, Lemma 6.7, for an y l 1 , l 2 ∈ T ( V ∗ ), ⟨ l 1 , S A ( X ) s,t ⟩ · ⟨ l 2 , S A ( X ) s,t ⟩ = ⟨ l 1 l 2 , S A ( X ) s,t ⟩ . 26 Since l 1 l 2 ∈ T ( V ∗ ), pro ducts of functions in A remain in A . T ogether with closure under addition and scalar multiplication, A is a subalgebra of C ( K , R ). F ourth, w e show that A separates p oin ts of K / ∼ A . Let X , Y ∈ K with, S A ( X ) s,t = S A ( Y ) s,t . Then there exists n ≥ 1 such that S A ( X ) ( n ) s,t = S A ( Y ) ( n ) s,t as elements of V ⊗ n . Since V ⊗ n is a Banach space, the Hahn–Banac h theorem (see e.g. Rudin [1991]) guarantees the existence of a contin uous linear functional ϕ ∈ ( V ⊗ n ) ∗ suc h that ϕ S A ( X ) ( n ) s,t = ϕ S A ( Y ) ( n ) s,t . Em b edding ϕ into T ( V ∗ ) by placing it at level n and zero elsewhere yields l ϕ ∈ T ( V ∗ ) with ⟨ l ϕ , S A ( X ) s,t ⟩ = ⟨ l ϕ , S A ( Y ) s,t ⟩ . Th us, A separates p oin ts. By the Stone–W eierstrass theorem, A is dense in C ( K/ ∼ A , R ) with resp ect to the uniform top ology . In particular, for any contin uous F : K → R and any ϵ > 0, there exists l ∈ T ( V ∗ ) such that sup X ∈ K | F ( X ) − ⟨ l, S A ( X ) s,t ⟩| < ϵ . Corollary 7.7. L et A ∈ L ( V , V ) satisfy the c ondition in L emma 7.3 and let K ⊂ V p ([ t 0 , t N ] , V ) b e a c omp act set of clo ck-augmente d p aths. F or any c ontinuous F : K → R and any ϵ > 0 , th er e exists l ∈ T ( V ⋆ ) such that sup X ∈ K | F ( X ) − ⟨ l , S A ( X ) t 0 ,t N ⟩| < ϵ. Pr o of. Let X , Y ∈ K with S A ( X ) t 0 ,t N = S ( Y ) t 0 ,t N . By Corollary 7.5, X = Y + c for some constant c ∈ V . F or paths with a fixed starting p oin t, or after quotienting b y translations, the EWS is injective on K . Hence, ev ery contin uous function on K satisfies X ∼ A Y ⇒ F ( X ) = F ( Y ), and the re sult follo ws from Lemma 7.6. The EWS thus provides a complete feature representation for any function that resp ects A -equiv alence, and linear functionals suffice to approximate such functions arbitrarily w ell. Uniqueness results, suc h as the blo c k diagonal case established abov e, iden tify when this appro ximation prop erty extends to all con tinuous functions on path space. The EWS framework acts as a natural generalisation of the classical path signature. When the op erator A is set to zero, the EWS reduces exactly to the classical signature. Consequen tly , the general EWS framework inherits the theoretical universalit y of the signature: since any con tinuous real-v alued function on a compact set of paths can b e approximated by linear functionals of the signature, the same m ust hold for the EWS framew ork when A is treated as a learnable parameter. In a deep learning context, this is significant b ecause NCDEs derive their p o wer from the fact that their v ector fields can represent the signature. By adopting this generalised structure, the EWS pro vides an in terpretable inductive bias while main taining the same fundamen tal guarantee of universal approximation. 8 Numerical Computation In practice, the EWS of the path X : [ t 0 , t N ] → R d is computed at finite truncation depth, S A ( X ) ≤ n ∈ T n ( R d ). A direct approach direct approach is to use the finite-dimensional linear CDE form ulation from Section 4.2, identifying T n ( R d ) ∼ = R D for D = P n k =0 d k , and to solv e resulting system using standard linear CDE solvers. T ypically , one computes the flow ov er each increment via a matrix exp onen tial, and then comp oses them via a parallel asso ciativ e scan (see Cirone et al. [2024]); this is precisely the depth-one log-ODE metho d of W alk er et al. [2025]. While this metho d is conceptually straightforw ard, it b ecomes impractical as the truncation depth increases. Indeed, the dimension D grows exp onen tially in n , and the computation requires exp onen tiating D × D matrices. This approach treats the EWS as a generic linear 27 CDE in R D and applies standard solution tec hniques, similar to the approach taken b y the V olterra signature [Hager et al. 2026, Prop osition 2.42], which reduces to a system of ODEs in the truncated tensor algebra. Ho wev er, the EWS is group-like, enabling a reduction to the classical signature of a re-weigh ted path that can b e lev eraged for more efficient computation. W e therefore adopt a metho d that exploits this structure. Giv en a piecewise linear path X with knots at { t 0 , . . . , t N } , our goal is to compute the EWS ov er the entire path, S A ( X ) t 0 ,t N . W e do so b y ev aluating the EWS on each sub-interv al [ t i , t i +1 ] (in parallel) and then aggregating these lo cal results via the mo dified Chen’s iden tity from Lemma 6.1 (in a parallel asso ciativ e scan). The computational challenge is th us shifted to the efficient ev aluation of the EWS on a single linear segmen t [ t i , t i +1 ]. By Prop osition 4.1, this is equiv alent to computing the classical signature of a re-weigh ted path Z [ t i +1 ] defined as Z [ t i +1 ] r = Z r t i e − ( θ t i +1 − θ u ) A dX u , r ∈ ( t i , t i +1 ] . Ov er the interv al [ t i , t i +1 ], the path and intrinsic clo ck evolv e with constant velocities v i = ∆ X i ∆ t i and κ i = ∆ θ i ∆ t i , where ∆ X i = X t i +1 − X t i , ∆ θ i = θ t i +1 − θ t i and ∆ t i = t i +1 − t i . Applying the change of v ariables s = u − t i , w e get Z [ t i +1 ] r = e − ∆ θ i A Z r − t i 0 e κ i sA v i ds. (46) The integral I ( τ ) = R τ 0 e κ i sA v i ds can b e can be ev aluated exactly using the V an Loan identit y [V an Loan 1978]. W e define an augmented blo c k matrix M i ∈ R ( d +1) × ( d +1) giv en b y M i = κ i A v i 0 0 , (47) where the solution to the integral is con tained in the upper-right blo c k of the matrix exp onen tial. Sp ecifically , exp( τ M i ) = e τ κ i A R τ 0 e ( τ − s ) κ i A v i ds 0 1 . (48) By the change of v ariables u = τ − s , it is easily v erified that the top-right blo ck is iden tical to I ( τ ). Ho wev er, Equation (47) is numerically ill-conditioned as ∆ t i → 0, since b oth κ i and v i in volv e a division by ∆ t i . T o resolv e the numerical instability as ∆ t i → 0, w e instead exp onen tiate Ψ i = δ M i and as such, the factors of ∆ t i cancel exactly: Ψ i = ∆ t i M ∆ θ i ∆ t i A ∆ X i ∆ t i 0 0 = ∆ θ i M A ∆ X i M 0 0 . (49) While the original path is linear on [ t i , t i +1 ], the re-weigh ted Z [ t i +1 ] is not. Thus, in practice, in order to compute its signature accurately , we must ev aluate Z [ t i +1 ] at M sub-discretised p oin ts r j = t i + j δ for j = 1 , . . . , M . Letting E i = exp(Ψ i ), the state of the augmented system after j sub-steps is given by the j -th p ow er of this op erator: E j i = exp( j Ψ i ) = exp( j δ M i ) = e j δκ i A R j δ 0 e ( j δ − s ) κ i A v i ds 0 1 . (50) The in tegral I ( j δ ) required for the re-weigh ted path is precisely the top-right blo ck of E j i . Consequen tly , the knots of the discretised re-weigh ted path are obtained by: Z [ t i +1 ] r j = e − ∆ θ i A h E j i i 1: d,d +1 , j = 1 , . . . , M , (51) where [ · ] 1: d,d +1 denotes the upp er-righ t d × 1 blo c k. T o compute the full sequence of p ow ers { E 1 i , . . . , E M i } efficien tly , we employ a parallel asso ciativ e scan. 28 9 Numerical Exp erimen ts W e now presen t preliminary numerical experiments designed to v alidate the theoretical adv antages of the EWS ov er both the classical signature and the EFM-signature. The exp erimen ts are structured around t wo ob jectives. First, we establish that the EWS framework is strictly more expressiv e than EFM b y demonstrating that no c hoice of diagonal decay rates can approximate temp oral w eighting structures with complex eigenv alues or growth mo des. Second, w e examine whether the EWS provides impro ved regression p erformance when the underlying dynamics are oscillatory or exhibit coupling b etw een c hannels. 9.1 Expressivit y Gap b etw een EWS & EFM T o establish that the EWS, EFM, and classical signature represent strictly different mo del classes at a fixed truncation depth, we design a con trolled exp erimen t in which each learning target is itself a depth-2 signature transform with kno wn parameters. By fixing the depth across all learners and targets, an y p erformance gap is attributable to representational capacity rather than to differences in the num b er of features or mo del parameters. W e consider time-augmen ted 2D Bro wnian motion X t = ( t, W 1 t , W 2 t ). F or each of the three target classes, w e fix a generating op erator A ⋆ (w e let B be the identit y in all cases), and define the scalar regression target as the comp onen t of the corresp onding depth-2 truncated signature transform asso ciated with the pair ( W 1 , W 2 ). That is, the target is the cross channel iterated integral S A ⋆ ( X ) 2 , 3 0 ,t = Z t 0 Z s 0 e − ( t − u ) A ⋆ dW 2 u ⊗ e − ( t − s ) A ⋆ dW 1 s , (52) whic h dep ends join tly on b oth Brownian channels. The learning task is same-time regression: at each time t , given the path X [0 ,t ] , the ob jective is to output the v alue of the target functional S A ⋆ ( X ) 2 , 3 0 ,t . Concretely , eac h mo del computes a truncated signature transform of the observed path, parameterised by a learnable op erator A and pro duces a scalar output via a linear readout. Both the op erator A (where applicable) and the readout are trained join tly from data. The three target op erators are: • EWS T arget: a full 3 × 3 matrix constructed from eigenv alues {− 0 . 5 ± 5 . 2 i, 0 . 8 } . The complex conjugate pair introduces oscillatory memory dynamics, and the p ositive real eigen v alue in tro duces a gro wth mo de; b oth are structurally inaccessible to any diagonal op erator, so this target lies strictly outside the hypothesis class of the EFM. • EFM T arget: the diagonal matrix A ⋆ = diag(0 . 5 , 0 . 3 , 0 . 8), representing the fading memory sp ecial case of the EWS. • Signature T arget: A ⋆ = 0 corresp onding to the classical signature. Against each target class we train the parameters of three learner classes via gradient descen t using AdamW [Loshc hilov et al. 2019] with a linear w armup follow ed b y cosine decay [Loshchilo v et al. 2017] at the same truncation depth: the EWS learner (an unconstrained 3 × 3 matrix initialised randomly), the EFM learner (a 3 × 3 diagonal matrix constrained to p ositiv e v alues initialised randomly) and the classical signature (no learning as A = 0 is fixed). Each combination receives an indep enden t Optuna hyperparameter searc h [Akiba et al. 2019] (up to 50 trials, 15 , 000 steps each), after whic h the b est configuration is retrained across 10 indep enden t seeds for 30 , 000 steps. W e use 750 Brownian tra jectories ov er [0 , 5] with 10 , 000 discretisation steps, a 70 : 15 : 15 train/v alidation/test split, and report the RMSE (mean ± std) using the b est v alidation c heckpoint. 29 T arget Learner EWS EFM Signature EWS 4 . 96 × 10 − 4 ± 1 . 53 × 10 − 4 2 . 43 × 10 − 2 ± 2 . 57 × 10 − 3 2 . 42 × 10 − 2 ± 2 . 52 × 10 − 3 EFM 6 . 52 × 10 − 5 ± 2 . 54 × 10 − 5 4 . 84 × 10 − 5 ± 1 . 60 × 10 − 5 4 . 25 × 10 − 2 ± 5 . 45 × 10 − 3 Signature 4 . 55 × 10 − 5 ± 2 . 08 × 10 − 5 5 . 11 × 10 − 5 ± 2 . 97 × 10 − 5 3 . 39 × 10 − 5 ± 1 . 10 × 10 − 5 T able 1: T est RMSE (mean ± std across 10 seeds) for each (target, learner) pair. All learners use depth-2 truncation; raw Brownian paths; targets normalised to unit v ariance ov er the training set. The results are consistent with the exp ected representational distinctions b et ween the three mo del classes at depth 2. F or the EWS target, the EWS learner achiev es substantially low er error (4 . 96 × 10 − 4 ) than b oth the EFM (2 . 43 × 10 − 2 ) and the classical signature (2 . 42 × 10 − 2 ), which perform nearly identically to eac h other. Since the target was constructed to hav e oscillatory and growth mo des that no diagonal op erator can represent at any depth, the failure of the EFM and classical signature learners is not a consequence of optimisation difficulty but of a fundamental structural limitation: no choice of diagonal deca y rates can generate the required temp oral w eighting. Both constrained learners conv erge stably to the b est hypothesis in their class, whic h is simply insufficient to approximate the target. W e note that the EWS learner’s error on this target is somewhat larger than on the EFM and classical signature targets; this reflects the harder optimisation landscap e asso ciated with reco vering a matrix with complex eigenv alues from gradient-based searc h, rather than any deficiency in expressivity . F or the EFM target, b oth the EWS and EFM learners ac hieve comparable low error, while the classical signature learner fails. The slight adv antage of the EFM learner is consisten t with its ha ving the correct inductiv e bias: restricting A to b e diagonal eliminates unnecessary degrees of freedom and simplifies the optimisation landscap e. Finally , with regards to the signature target, all three learners succeed with errors of similar order of magnitude. The EWS and EFM learners b oth reco ver A ≈ 0, consisten t with the targets. 9.2 Coupled Oscillatory SDE Regression W e consider a tw o-dimensional stochastic system gov erned by the coupled SDE with oscillatory dynamics: dX 1 t = ( α sin( ω X 2 t ) − β X 1 t ) dt + σ dW 1 t , (53) dX 2 t = ( α cos( ω X 1 t ) − β X 2 t ) dt + σ dW 2 t , (54) where W 1 , W 2 are indep endent Bro wnian motions. Throughout, w e fix α = 3 . 0, ω = 1 . 0, β = 0 . 5 and σ = 0 . 4, with initial condition X 0 = (0 . 5 , 0 . 5). The system exhibits non-linear coupling through the trigonometric in teraction terms, together with mean-reverting drift and additive noise. The learning task is again same- time regression: for each time t , giv en the driving path ( t, W 1 , W 2 ) [0 ,t ] , the ob jective is to output the curren t state X 1 t . W e train the parameters of the three mo del classes via gradient descen t using AdamW [Loshchilo v et al. 2019] with a linear w armup follo wed by cosine deca y [Loshc hilov et al. 2017] at fixed truncation depth: the EWS model (full 3 × 3 matrix A ), the EFM mo del (diagonal A ), and the classical signature (fixed A = 0). Eac h mo del is trained on 750 simulated tra jectories ov er [0 , 4] generated via the Euler–Maruyama scheme with 10 , 000 discretisation steps, using a 70 : 15 : 15 train/v alidation/test split. F or eac h model class, h yp erparameters are tuned indep enden tly using Optuna [Akiba et al. 2019] (up to 100 trials, 15 , 000 training steps p er trial), after which the b est configuration is retrained across 10 indep enden t seeds. Inputs are given b y the driving path ( t, W 1 , W 2 ), with all channels normalised to [0 , 1] using training-set statistics and a base-p oin t of (0 , 0 , 0) prep ended; targets X 1 t are normalised indep enden tly . W e rep ort RMSE (mean ± std) in normalised space using the b est v alidation chec kp oin t. T able 2 rep orts the regression p erformance of eac h mo del class. The EWS achiev es a mean test RMSE of 2 . 63 × 10 − 2 , substantially outp erforming b oth the EFM (9 . 45 × 10 − 2 ) and the classical signature 1 . 28 × 30 Metho d V al RMSE T est RMSE EWS 2 . 63 × 10 − 2 ± 2 . 10 × 10 − 3 2 . 61 × 10 − 2 ± 2 . 60 × 10 − 3 EFM 9 . 45 × 10 − 2 ± 5 . 30 × 10 − 3 9 . 39 × 10 − 2 ± 4 . 80 × 10 − 3 Signature 1 . 275 × 10 − 1 ± 4 . 90 × 10 − 3 1 . 268 × 10 − 1 ± 5 . 10 × 10 − 3 T able 2: V alidation and test RMSE (mean ± std across 10 seeds) for each mo del class on the SDE task. All mo dels use depth-2 truncation; inputs are time-augmented Brownian paths; targets are normalised to [0 , 1]. 10 − 1 , with well-separated uncertaint y in terv als. The same ordering holds on the v alidation set, indicating stable generalisation across all metho ds. This magnitude in the performance gap reflects the nature of the underlying dynamics. The system exhibits strongly coupled and oscillatory behaviour through the trigonometric interaction terms, whic h cannot b e captured by represen tations restricted to c hannel-wise deca ying memory or fixed temp oral w eighting. As a result, b oth the EFM and the classical signature incur a substantial approximation error in this setting. T o further understand this behaviour, w e examine the learned op erators A ; summary statistics of the learned sp ectra are rep orted in T able 3. Across all runs, the EWS learns matrices whose sp ectra contain a dominant complex conjugate pair together with a single real mo de. Aggregating across runs, the complex pair has mean real part 1 . 76 ± 0 . 24 and imaginary magnitude 9 . 53 ± 1 . 42, while the remaining real eigenv alue is small, 0 . 31 ± 0 . 41. This indicates that the mo del consistently captures oscillatory temp oral dynamics, with frequency determined by the imaginary comp onen t and growth/deca y by the real comp onen t. In addition, the learned matrices exhibit substantial off-diagonal structure, confirming that cross-channel interactions b etw een the driving signals play a key role. In con trast, the EFM is restricted to diagonal A and therefore admits only real eigenv alues corresp onding to purely deca ying mo des. Across all runs, the learned sp ectra consist of p ositiv e real v alues of v arying magnitude together with a small or near-zero mo de. Aggregating across runs, the eigenv alues are approximately λ 1 = 8 . 45 ± 0 . 43, λ 2 = 2 . 82 ± 0 . 21, and λ 3 = 0 . 15 ± 0 . 31. This reflects that the mo del assigns differen t decay rates to eac h channel, but cannot represen t oscillatory b ehaviour or cross-c hannel coupling. Consequently , while the EFM can capture some lo cal temp oral structure, it fails to mo del the coupled oscillatory dynamics of the system, consisten t with its substan tially higher error. Figure 1 shows representativ e test tra jectories, illustrating that the EWS tracks the underlying dynamics closely , while the EFM and classical signature exhibit systematic deviations, consistent with the quantitativ e results. EWS EFM Real part (complex pair) 1 . 76 ± 0 . 24 – Imaginary magnitude 9 . 53 ± 1 . 42 – Real eigenv alues 0 . 31 ± 0 . 41 8 . 45 ± 0 . 43 , 2 . 82 ± 0 . 21 , 0 . 15 ± 0 . 31 T able 3: Summary statistics of learned eigenv alues across runs for the EWS and EFM mo dels. 31 Figure 1: Five representativ e test tra jectories for the coupled oscillatory SDE task. Ground truth (black) is sho wn alongside predictions from the EWS (blue), EFM (orange), and classical signature (green). Ac kno wledgemen ts The authors would like to thank Sam Morley and J ´ erˆ ome T omezyk for engaging and insightful discussions regarding efficient numerical metho ds. The authors ac knowledge supp ort from His Ma jest y’s Gov ernmen t in the developmen t of this research. Sam uel N. Cohen ac knowledges the support of the UKRI Prosp erity P artnership Sc heme (F AIR) under EPSR C Grant EP/V056883/1, and EPSRC Gran t EP/Y028872/1 (Mathematical F oundations of Intelli- gence: An Erlangen Programme for AI). T erry Ly ons is supp orted by UK Researc h and Innov ation (UKRI) 32 through the Engineering and Ph ysical Sciences Research Council (EPSR C) via Programme Grants [Grant No. UKRI1010: High order mathematical and computational infrastructure for streamed data that enhance con- temp orary generativ e and large language mo dels], [Grant No. EP/S026347/1: Unparameterised multi-model data, high order signatures and the mathematics of data science], [Grant No. EP/Y028872/1: Mathematical F oundations of In telligence: An Erlangen Programme for AI], and the UKRI AI for Science aw ard [Grant No. UKRI2385: Creating F oundational Benchmarks for AI in Physical and Biological Complexity]. T erry Ly ons is also supp orted b y The Alan T uring Institute under the Defence and Security Programme (funded b y the UK Gov ernment) and through the pro vision of researc h facilities; by the UK Gov ernmen t; and through CIMD A@Oxford, part of the AIR@Inn oHK initiative funded b y the Inno v ation and T echnology Commission, HKSAR Gov ernment. Benjamin W alker is supp orted by UK Research and Innov ation (UKRI) through the Engineering and Physical Sciences Researc h Council (EPSRC) via Programme Gran t [Grant No. UKRI1010: High order mathematical and computational infrastructure for streamed data that enhance contemporary generativ e and large language models] and CIMDA@Oxford, part of the AIR@InnoHK initiativ e funded by the Innov ation and T echnology Commission, HKSAR Gov ernment. 33 References [1] Abi Jab er, Eduardo and Sotnik ov, Dimitri. Exp onential ly F ading Memory Signatur e . 2025. arXiv: 2507.03700 [math.PR] . url : https://arxiv.org/abs/2507.03700 . [2] Akiba, T akuya, Sano, Shotaro, Y anase, T oshihiko, Ohta, T ak eru, and Koy ama, Masanori. “Optuna: A Next-generation Hyp erparameter Optimization F ramework”. In: Pr o c e e dings of the 25th ACM SIGKDD International Confer enc e on Know le dge Disc overy and Data Mining . 2019, pp. 2623–2631. doi : 10 . 1145/3292500.3330701 . [3] Bo edihardjo, Horatio, Geng, Xi, Ly ons, T erry, and Y ang, Danyu. “The signature of a rough path: Uniqueness”. In: A dvanc es in Mathematics 293 [2016], pp. 720–737. [4] Bonnier, Patric, Kidger, Patric k, Arribas, Imanol Perez, Salvi, Cristopher, and Ly ons, T erry. “Deep Signature T ransforms”. In: Neur al Information Pr o c essing Systems (NeurIPS) . 2019. [5] Ceylan, Mihriban, Kw ossek, Anna P ., and Pr¨ omel, David J. Universal appr oximation with signatur es of non-ge ometric r ough p aths . 2026. arXiv: 2602 . 05898 [math.PR] . url : https : / / arxiv . org/ abs / 2602.05898 . [6] Chen, Kuo Tsai. “Iterated Integrals and Exp onential Homomorphisms”. In: Pr o c e e dings of the L ondon Mathematic al So ciety s3-4.1 [1954], pp. 502–512. [7] Chevyrev, Ily a and Kormilitzin, Andrey. “A Primer on the Signature Metho d in Machine Learning”. In: arXiv pr eprint arXiv:1603.03788 [2016]. [8] Cirone, Nicola Muca, Orvieto, An tonio, W alker, Benjamin, Salvi, Cristopher, and Ly ons, T erry. “The- oretical F oundations of Deep Selective State-Space Mo dels”. In: Pr o c e e dings of the 38th Confer enc e on Neur al Information Pr o c essing Systems (NeurIPS) . 2024. [9] Cohen, Samuel N., Lui, Silvia, Malpass, Will, Man toan, Giulia, Nesheim, Lars, Paula, ´ Aureo de, Reeves, Andrew, Scott, Craig, Small, Emma, and Y ang, Lingyi. “Now casting with signature metho ds”. In: arXiv pr eprint arXiv:2305.10256 [2023]. [10] Drobac, Nina, Br´ eg ` ere, Margaux, Vilmarest, Joseph de, and Winten b erger, Olivier. Sliding-Window Signatur es for Time Series: Applic ation to Ele ctricity Demand F or e c asting . 2025. arXiv: 2510 .12337 [stat.ME] . url : https://arxiv.org/abs/2510.12337 . [11] F ermanian, Adeline. “Learning Time-Dep endent Data with the Signature T ransform”. PhD thesis. Sorb onne Universit ´ e, 2021. [12] F riz, Peter K. and Victoir, Nicolas B. Multidimensional Sto chastic Pr o c esses as R ough Paths: The ory and Applic ations . Cambridge Studies in Adv anced Mathematics. Cambridge Universit y Press, 2009. isbn : 9780521876070. [13] Graham, Benjamin. Sp arse arr ays of signatur es for online char acter r e c o gnition . 2013. arXiv: 1308 . 0371 [cs.CV] . url : https://arxiv.org/abs/1308.0371 . [14] Gu, Alb ert and Dao, T ri. “Mamba: Linear-Time Sequence Mo deling with Selectiv e State Spaces”. In: Pr o c e e dings of the First Confer enc e on L anguage Mo deling . 2024. [15] Gu, Albert, Go el, Karan, and R´ e, Christopher. “Efficiently Mo deling Long Sequences with Struc- tured State Spaces”. In: Pr o c e e dings of The 10th International Confer enc e on L e arning R epr esentations (ICLR) . 2022. [16] Gyurk´ o, La jos Gergely, Ly ons, T erry, Kontk o wski, Mark, and Field, Jonathan. “Extracting information from the signature of a financial data stream”. In: arXiv pr eprint arXiv:1307.7244 [2014]. [17] Hager, Paul P ., Harang, F abian N., P elizzari, Luca, and Tindel, Samy. The V olterr a signatur e . 2026. arXiv: 2603.04525 [stat.ML] . url : . [18] Hambly , B. and Lyons, T. “Uniqueness for the signature of a path of bounded v ariation and the reduced path group”. In: Annals of Mathematics 171 [2010], pp. 109–167. [19] Harang, F abian, Tindel, Sam y, and W ang, Xiaoh ua. V olterr a e quations driven by r ough signals 3: Pr ob abilistic c onstruction of the V olterr a r ough p ath for fr actional Br ownian motions . 2022. arXiv: 2202.05076 [math.PR] . url : https://arxiv.org/abs/2202.05076 . 34 [20] Harang, F abian A. and Tindel, Samy. V olterr a Equations Driven by R ough Signals . 2021. arXiv: 1912. 02064 [math.PR] . url : https://arxiv.org/abs/1912.02064 . [21] Harang, F abian A., Tindel, Sam y, and W ang, Xiaohua. V olterr a e quations driven by r ough signals 2: higher or der exp ansions . 2021. arXiv: 2102. 10119 [math.PR] . url : https: // arxiv.org /abs /2102 . 10119 . [22] Ho c hreiter, Sepp, Bengio, Y oshua, F rasconi, P aolo, and Sc hmidhuber, J ¨ urgen. “Gradien t Flo w in Re- curren t Nets: The Difficult y of Learning Long-T erm Dep endencies”. In: A Field Guide to Dynamic al R e curr ent Neur al Networks . Ed. by Kremer, Stefan C. and Kolen, John F. IEEE Press, 2001. isbn : 0-7803-5369-2. doi : 10.1109/9780470544037.ch14 . [23] Kalman, Rudolf E. “A New Approac h to Linear Filtering and Prediction Problems”. In: ASME Journal of Basic Engine ering 82 [1960], pp. 35–45. [24] Kidger, Patric k. “On Neural Differential Equations”. PhD thesis. Univ ersity of Oxford, 2022. [25] Kidger, Patric k, Morrill, James, F oster, James, and Ly ons, T erry. “Neural Con trolled Differen tial Equa- tions for Irregular Time Series”. In: Pr o c e e dings of the 34th Confer enc e on Neur al Information Pr o- c essing System (NeurIPS) . 2020. [26] Kir´ aly , F ranz J. and Ob erhauser, Harald. “Kernels for sequentially ordered data”. In: Journal of Ma- chine L e arning R ese ar ch 20.31 [2019], pp. 1–45. [27] Kov acic, Iv ana and Brennan, Michael J. The Duffing Equation: Nonline ar Oscil lators and their Be- haviour . Chichester: Wiley , 2011. isbn : 978- 0-470-71549-9. [28] Lang, Serge. A lgebr a . 3rd. V ol. 211. Graduate T exts in Mathematics. Springer, 2002. isbn : 978-0-387- 95385-4. [29] Levin, Daniel, Ly ons, T erry, and Ni, Hao. “Learning from the past, predicting the statistics for the future, learning an evolving system”. In: arXiv pr eprint arXiv:1309.0260 [2016]. [30] Loshchilo v, Ilya and Hutter, F rank. “Decoupled W eight Decay Regularization”. In: International Con- fer enc e on L e arning R epr esentations . 2019. url : https://openreview.net/forum?id=Bkg6RiCqY7 . [31] Loshchilo v, Ilya and Hutter, F rank. “SGDR: Sto c hastic Gradient Descent with W arm Restarts”. In: International Confer enc e on L e arning R epr esentations . 2017. url : https://openreview.net/forum? id=Skq89Scxx . [32] Lyons, T., Caruana, M., and L´ evy , T. Differ ential Equations Driven by R ough Paths: ´ Ec ole D’´ et ´ e de Pr ob abilit´ es de Saint-Flour XXXIV-2004 . no. 1908. Springer, 2007. [33] Lyons, T erry, Ni, Hao, W u, Y ue, and Y ang, Danyu. The le ctur e notes for the the ory of r ough p aths . 2024. [34] Lyons, T erry J. “Differential Equations Driven by Rough Signals”. In: R evista Matem´ atic a Ib er o amer- ic ana 14.2 [1998], pp. 215–310. issn : 0213-2230. [35] Mallat, St´ ephane. A Wavelet T our of Signal Pr o c essing: The Sp arse Way . 3rd. Burlington, MA: Aca- demic Press, 2009. isbn : 978-0-12-374370-1. [36] McLeo d, Andrew and Lyons, T erry. “Signature metho ds in machine learning”. In: EMS Surveys in Mathematic al Scienc es [2025]. [37] Morrill, James, F ermanian, Adeline, Kidger, Patric k, and Lyons, T erry. A Gener alise d Signatur e Metho d for Multivariate Time Series F e atur e Extr action . 2021. arXiv: 2006 . 00873 [cs.LG] . url : https : //arxiv.org/abs/2006.00873 . [38] Ree, Rimhak. “Lie Elements and an Algebra Asso ciated With Shuffles”. In: Annals of Mathematics 68.2 [1958]. [39] Rudin, W alter. F unctional A nalysis . 2nd. New Y ork: McGra w-Hill, 1991. [40] Salvi, Cristopher, Cass, Thomas, F oster, James, Ly ons, T erry, and Y ang, W eixin. “The Signature Kernel Is the Solution of a Goursat PDE”. In: SIAM Journal on Mathematics of Data Scienc e 3.3 [Jan. 2021], pp. 873–899. issn : 2577-0187. doi : 10.1137 /20m1366794 . url : http:/ /dx.doi. org/10. 1137/20M1366794 . 35 [41] Sch wartz, Lauren t. Th´ eorie des Distributions . V ol. 1. P aris: Hermann, 1950. [42] Sch wartz, Lauren t. Th´ eorie des Distributions . V ol. 2. P aris: Hermann, 1951. [43] V an Loan, Charles F. “Computing integrals inv olving the matrix exp onen tial”. In: IEEE T r ansactions on A utomatic Contr ol 23.3 [1978], pp. 395–404. doi : 10.1109/TAC.1978.1101743 . [44] V aswani, Ashish, Shazeer, Noam, P armar, Niki, Uszk oreit, Jak ob, Jones, Llion, Gomez, Aidan N., Kaiser, Luk asz, and P olosukhin, Illia. “Atten tion Is All Y ou Need”. In: Pr o c e e dings of the 31st Con- fer enc e on Neur al Information Pr o c essing Systems (NeurIPS) . 2017. [45] W alker, Benjamin, Y ang, Lingyi, Cirone, Nicola Muca, Salvi, Cristopher, and Lyons, T erry. “Structured Linear CDEs: Maximally Expressive and Parallel-in-Time Sequence Mo dels”. In: Pr o c e e dings of the 39th Confer enc e on Neur al Information Pr o c essing Systems (NeurIPS) . 2025. [46] Y oung, L. C. “An inequalit y of the H¨ older type, connected with Stieltjes integration”. In: A cta Math- ematic a 67 [1936], pp. 251–282. A T ensor Algebra W e first define the tensor algebra, the space in whic h the signature is defined. This requires recalling the definition of the tensor pro duct of t wo vector spaces and establishing what norms are considered ‘admissible” on these spaces. Definition A.1 (T ensor Pro duct [Lang 2002]). L et U and V b e ve ctor sp ac es over a field F . A tensor pr o duct of U and V is define d as a ve ctor sp ac e U ⊗ V e quipp e d with a biline ar map τ : U × V → U ⊗ V . This sp ac e is uniquely char acterise d (up to isomorphism) by the fol lowing universal pr op erty: for any F -ve ctor sp ac e W and any biline ar map κ : U × V 7→ W , ther e exists a unique line ar map ι : U ⊗ V → W such that κ = ι ◦ τ . ♢ The tensor pro duct allo ws us to treat bilinear op erators as linear ones. W e denote the image of the pair ( u, v ) under τ as u ⊗ v . Example A.2. Consider U = R 3 and V = R 2 with their r esp e ctive standar d b ases { e 1 , e 2 , e 3 } and { f 1 , f 2 } . The tensor pr o duct U ⊗ V is a 6 -dimensional sp ac e sp anne d by the b asis set: B U ⊗ V = { e i ⊗ f j | 1 ≤ i ≤ 3 , 1 ≤ j ≤ 2 } . T o se e how the universal pr op erty functions, let u = [ u 1 , u 2 , u 3 ] ⊤ and v = [ v 1 , v 2 ] ⊤ . Their tensor pr o duct is the formal sum of al l p ossible c omp onent pr o ducts: u ⊗ v = 3 X i =1 2 X j =1 u i v j ( e i ⊗ f j ) This c onstruction ensur es that every de gr e e-2 inter action b etwe en the c omp onents of U and V is r epr esente d as a single c o or dinate in U ⊗ V . Conse quently, any biline ar function κ ( u, v ) —which by definition must b e a line ar c ombination of these u i v j terms—c an b e evaluate d by a unique line ar op er ator τ acting on the tensor u ⊗ v . While this sp ac e is isomorphic to the sp ac e of 3 × 2 matric es, its fundamental purp ose is to serve as the domain wher e biline arity b e c omes line arity. ♢ Throughout this work, w e let V be a real Banach space and denote by V ⊗ n the completion of the n -fold tensor product of V with respect to a norm || · || V ⊗ n , which w e assume satisfies the prop erties in the follo wing definition for all n ≥ 1. Definition A.3 (Admissible T ensor Norms [McLeod et al. 2025]). Given a Banach sp ac e V , a family of norms on { V ⊗ n } ∞ n =1 is said to b e admissible if for al l inte gers n ≥ 1 we have chosen a norm on V ⊗ n such that the fol lowing c onditions ar e satisfie d: 36 1. F or al l n ≥ 1 , the norm || · || V ⊗ n is invariant under the action of the symmetric gr oup S n on V ⊗ n . That is, || ρv || V ⊗ n = || v || V ⊗ n , ∀ v ∈ V ⊗ n , ∀ ρ ∈ S n , wher e ρ ( v 1 ⊗ · · · ⊗ v n ) = v ρ (1) ⊗ · · · ⊗ v ρ ( n ) for v i ∈ V . 2. F or al l n, m ≥ 1 , || v ⊗ w || V ⊗ ( n + m ) ≤ || v || V ⊗ n || w || V ⊗ m , ∀ v ∈ V ⊗ n , w ∈ V ⊗ m . That is, the norm is sub-multiplic ative. 3. F or al l n, m ≥ 1 and for any dual elements ϕ ∈ ( V ⊗ n ) ⋆ and σ ∈ ( V ⊗ m ) ⋆ , we have || ϕ ⊗ σ || ( V ⊗ ( n + m ) ) ⋆ ≤ || ϕ || ( V ⊗ n ) ⋆ || σ || ( V ⊗ m ) ⋆ . ♢ W e are no w able to define the tensor algebra, the space in which path signatures live. Definition A.4 (T ensor Algebra [Lyons et al. 2007]). L et { V ⊗ n } ∞ n =0 b e e quipp e d with admissible norms in the sense of the ab ove definition, and let V ⊗ 0 = R by c onvention. The tensor algebr a is the sp ac e T (( V )) = { a = ( a 0 , a 1 , . . . ) |∀ n ≥ 0 , a n ∈ V ⊗ n } , F or two elements of T (( V )) , a = ( a 0 , a 1 , . . . ) and b = ( b 0 , b 1 , . . . ) , addition is define d as a + b = ( a 0 + b 0 , a 1 + b 1 , . . . ) , and pr o duct define d as a ⊗ b = ( c 0 , c 1 , . . . ) , wher e for e ach n ≥ 0 c n = n X k =0 a k ⊗ b n − k . ♢ Giv en the natural action of R by λ a = ( λa 0 , λa 1 , . . . ), the space T (( V )) is a real non-comm utative algebra with unit 1 = (1 , 0 , 0 , . . . ). W e denote by ˜ T (( V )) the space of elemen ts a with a 0 = 1; this space is a group with a − 1 = 1 − ( a − 1) + ( a − 1) ⊗ 2 − · · · . Finally , T n ( V ) is the truncated tensor algebra whose elements are of the form a = ( a 0 , . . . , a n ). B Y oung In tegration With the tensor algebra established, we can now define the suitable framework for integration to b e used in the definition of the signature. Definition B.1 ( p -V ariation [Ly ons et al. 2007; Y oung 1936]). L et V b e a r e al Banach sp ac e and X : [ a, b ] → V b e a p ath. F or p ≥ 1 , the p -variation of X is define d as || X || p, [ a,b ] = sup P n − 1 X i =0 || X t i +1 − X t i || p V 1 p , wher e P is the set of al l finite p artitions { t i } n i =0 such that a = t 0 < · · · < t n = b . ♢ W e denote by V p ([ a, b ] , V ) the set of all paths X : [ a, b ] → V with finite p -v ariation. Note that if X is of finite p -v ariation, then it is of finite q -v ariation for an y q > p . W e refer to paths of finite 1-v ariation simply as paths of b ounded v ariation. 37 Definition B.2 (Y oung Integral [Lyons et al. 2007; Y oung 1936]). L et p, q ∈ (0 , 1] such that 1 p + 1 q > 1 . L et X ∈ V p ([ a, b ] , V ) and Y ∈ V p ([ a, b ] , L ( V , W )) , wher e L ( V , W ) denotes the sp ac e of al l b ounde d line ar maps fr om V to W . Consider the se quenc e of finite p artitions of [ a, b ] , denote d { π n } ∞ n =0 , wher e π n = ( t n 0 , · · · t n N n ) with sup i | t n i − t n i − 1 | → 0 as n → ∞ and e ach u n i ∈ [ t n i , t n i +1 ] an arbitr ary p oint. Then the Y oung inte gr al of Y against X , define d as Z b a Y s dX s = lim n →∞ N n − 1 X i =0 Y u n i ( X t n i +1 − X t n i ) , exists indep endently of the se quenc e of p artitions and arbitr ary p oint u n i ∈ [ t n i , t n i +1 ] . ♢ Pr o of. See Theorem 1 . 16 in Lyons et al. 2007. C Signatures W e defined the signature in Section 1 along with a couple of imp ortan t prop erties. Note that we restricted our paths to having finite p -v ariation for p < 2 in order for the integrals to b e w ell-defined as Y oung in tegrals. F or paths of lo wer regularity (finite p -v ariation for p > 2), rough path theory provides a generalisation to the signature; see Lyons et al. [2007] for an introduction. W e no w briefly outline a few more significant prop erties of the signature. W e omit pro ofs as as many of these results are established in the more general setting of the EWS. Theorem C.1 (Chen Identit y [Chen 1954]). L et X ∈ V p ([ s, t ] , V ) with p < 2 . Then for u ∈ [ s, t ] S ( X ) s,t = S ( X ) s,u ⊗ S ( X ) u,t . This tells us that the signature of a path ov er an interv al can b e decomp osed as the pro duct of signatures of sub-interv als. Definition C.2 (Sh uffle Pro duct [Ree 1958]). L et V b e a Banach sp ac e, ϕ ∈ ( V ⊗ n ) ⋆ and σ ∈ ( V ⊗ m ) ⋆ for m, n ≥ 1 . The shuffle of the b ounde d line ar functionals ϕ and σ is the b ounde d line ar functional ϕ σ ∈ ( V ⊗ ( n + m ) ) ⋆ define d by ⟨ ϕ σ, w ⟩ = X ρ ∈ Sh( m,n ) ⟨ ϕ ⊗ σ, ρ ( w ) ⟩ , w ∈ V ⊗ ( m + n ) , wher e Sh( n, m ) = { ρ ∈ S n + m | ρ (1) < · · · < ρ ( n ) and ρ ( n + 1) < · · · < ρ ( n + m ) } . ♢ Theorem C.3 (Sh uffle Pro duct Identit y [Ree 1958]). L et X ∈ V p ([ s, t ] , V ) for p < 2 , and n, m ≥ 0 inte gers. Then for al l b ounde d ϕ ∈ ( V ⊗ n ) ⋆ and σ ∈ ( V ⊗ m ) ⋆ , we have ⟨ ϕ, S ( X ) ( n ) s,t ⟩⟨ σ, S ( X ) ( m ) s,.t ⟩ = ⟨ ϕ σ, S ( X ) ( n + m ) s,t ⟩ . This tells us that p olynomial functions in the lo wer order terms of the signature can b e expressed as linear functions of the higher order terms. D Con trolled Differen tial Equations Definition D.1 (Con trolled Differential Equation [Ly ons et al. 2007]). L et V , W b e Banach sp ac es and f : W → L ( V , W ) b e a ve ctor field. F or a c ontr ol p ath X ∈ V p ([ a, b ] , V ) and an initial c ondition Y a ∈ W , 38 a p ath Y : [ a, b ] → W is said to satisfy a CDE if for al l t ∈ [ a, b ] : Y t = Y a + Z t a f ( Y s ) dX s , wher e the inte gr al is understo o d in the Y oung sense for p < 2 . ♢ In this definition, f is view ed as taking v alues in the space of linear maps L ( V , W ), so that for each Y s , the ob ject f ( Y s ) is a linear op erator that acts on the control increment dX s . Equiv alently , one can view f ( · ) v as a linear map from v ∈ V to the space of vector fields on W . The imp ortance of the signature in this context is that it can b e viewed as the solution to a specific linear CDE. Sp ecifically , for a path X , the signature S ( X ) s, · : [ s, t ] → T (( V )) is the unique solution to the follo wing tensor-v alued equation: dS t = S t ⊗ dX t , S a = 1 . (55) The existence and uniqueness of solutions to a CDE are determined b y the regularity of the control path X and the smo othness of the v ector field f , typically measured in terms of p -v ariation and Lip ( γ ) contin uit y , resp ectiv ely . While the technical definition of Lip ( γ ) is b ey ond the scop e of this background section, we state the fundamental results for the Y oung regime: Theorem D.2 (CDE Existence and Uniqueness [Lyons et al. 2007]). L et X ∈ V p ([ a, b ] , V ) with 1 ≤ p < 2 . 1. Existenc e: If W is finite-dimensional and f is Lip ( γ ) with γ > p − 1 , then the CDE admits a solution. 2. Uniqueness: If f is Lip ( γ ) with γ > p , then the solution is unique. While w e do not define Lip( γ ) contin uity , it is imp ortan t to note that linear vector fields, suc h as the one defining the signature, do not generally satisfy the Lip ( γ ) global boundedness conditions required for these standard theorems. Consequently , existence and uniqueness for the linear case must be established separately , often through the conv ergence of Picard iterations. A CDE is said to b e linear if the vector field dep ends linearly on the state. That is, there exists a b ounded linear op erator A ∈ L ( W, L ( V , W )) such that f ( w ) = A ( w ). Since A defines a bilinear map ( w , v ) 7→ A ( w )( v ), there is a canonical isomorphism L ( W , L ( V , W )) ∼ = L ( V , L ( W, W )). Via this identification, we ma y equiv alently regard A as an elemen t of L ( V , L ( W, W ). W e adopt this viewp oin t when defining A ⊗ n . In this case, the CDE takes the form d Y t = A ( Y t ) dX t . Theorem D.3 (Linear CDE Solution). L et X ∈ V p ([ a, b ] , V ) with p < 2 . The unique solution to the line ar CDE d Y t = A ( Y t ) dX t is given by: Y t = ∞ X n =0 A ⊗ n S ( X ) ( n ) a,t ! Y a . wher e A ⊗ n ∈ L ( V ⊗ n , L ( W , W )) is define d on simple tensors by A ⊗ n ( v 1 ⊗ · · · ⊗ v n ) = A ( v n ) · · · A ( v 1 ) , extende d by line arity and c ontinuity, with A ⊗ 0 = Id W . Pr o of. See F riz et al. [2009] Theorem 3 . 8 for the finite-dimensional version of this theorem. The extension to a general Banach space V follows by the same standard Picard iteration argument. E EWS Illustrativ e Example Example E.1. T o il lustr ate the structur e of the weighte d iter ate d inte gr als, let us c onsider the simple setting wher e V = R d , and the clo ck is standar d c o or dinate time, θ t = t . F or clarity, we take d = 2 so that A ∈ R 2 × 2 . 39 L evel 1. F or a single-letter wor d ( i 1 ) , we have S A ( X ) i 1 s,t = 2 X j 1 =1 Z t s E i 1 ,j 1 ( t − t 1 ) dX j 1 t 1 , i 1 ∈ { 1 , 2 } . That is, S A ( X ) 1 s,t = Z t s E 11 ( t − u ) dX 1 u + E 12 ( t − u ) dX 2 u , S A ( X ) 2 s,t = Z t s E 21 ( t − u ) dX 1 u + E 22 ( t − u ) dX 2 u . L evel 2. F or a two-letter wor d ( i 1 , i 2 ) , we obtain S A ( X ) i 1 ,i 2 s,t = 2 X j 1 ,j 2 =1 Z t s Z t 2 s E i 1 ,j 1 ( t − t 1 ) E i 2 ,j 2 ( t − t 2 ) dX j 1 t 1 dX j 2 t 2 . Exp anding the indic es explicitly gives S A ( X ) 1 , 1 s,t = Z t s Z t 2 s E 11 ( t − t 1 ) E 11 ( t − t 2 ) dX 1 t 1 dX 1 t 2 + E 11 ( t − t 1 ) E 12 ( t − t 2 ) dX 1 t 1 dX 2 t 2 + E 12 ( t − t 1 ) E 21 ( t − t 2 ) dX 2 t 1 dX 1 t 2 + E 12 ( t − t 1 ) E 22 ( t − t 2 ) dX 2 t 1 dX 2 t 2 , S A ( X ) 1 , 2 s,t = Z t s Z t 2 s E 11 ( t − t 1 ) E 21 ( t − t 2 ) dX 1 t 1 dX 1 t 2 + E 11 ( t − t 1 ) E 22 ( t − t 2 ) dX 1 t 1 dX 2 t 2 + E 12 ( t − t 1 ) E 21 ( t − t 2 ) dX 2 t 1 dX 1 t 2 + E 12 ( t − t 1 ) E 22 ( t − t 2 ) dX 2 t 1 dX 2 t 2 , and analo gous formulas for ( i 1 , i 2 ) = (2 , 1) and (2 , 2) . ♢ In this example, when A = diag( λ 1 , . . . , λ n ), E ij ( h ) = e − λ i h δ ij , and all cross-terms v anish. W e therefore reco ver the diagonal EFM-signature integrals from Equation (2): S A ( X ) i 1 ,...,i n s,t = Z t s · · · Z t 2 s n Y k =1 e − λ i k ( t − t k ) dX i k t k . F Duffing Oscillator Example Pro ofs Prop osition F.1. L et S A ( X ) t 0 ,t ∈ T (( R K +3 )) b e the EWS of X with p ar ameters A = ( A, B ) define d ab ove and clo ck θ t = t . Write the c o or dinates as S A ( X ) (1) t 0 ,t = S t t , S u t , S x, 0 t . . . , S x,K t ∈ R K +3 . (56) Then the first two c o or dinates (c orr esp onding to the time and for cing channels) satisfy dS t t = − λ t S t t dt + dt, (57) dS u t = − λ u S u t dt + du t . (58) The r emaining K + 1 c o or dinates satisfy the system dS x, 0 t = − λS x, 0 t dt + dx t , (59) dS x, 1 t = − λS x, 1 t dt + S x, 0 t dt, (60) . . . dS x,K t = − λS x,K t dt + S x,K − 1 t dt. (61) 40 Pr o of. Consider the EWS of the path X = ( t, u, x ) with parameters A = ( A, B ) defined as in Equation (35), and with clo c k θ t = t . By Lemma 3.5, the EWS satisfies the linear CDE dS A ( X ) t 0 ,t = − Λ A S A ( X ) t 0 ,t dt + S A ( X ) t 0 ,t ⊗ dX t . Applying the pro jection π 1 : T (( R d )) → R d on to the first lev el, and noting that Λ A acts as A on level one, w e obtain dS A ( X ) (1) t 0 ,t = − AS A ( X ) (1) t 0 ,t dt + dX t . W riting S A ( X ) (1) t 0 ,t = S t t , S u t , S x, 0 t , . . . , S x,K t , dX t = ( dt, du t , dx t , 0 , . . . , 0) , and using that A = diag( λ t , λ u , ˜ A ) is blo ck diagonal, w e can decomp ose the equation comp onen t-wise. The first tw o co ordinates corresp ond to scalar blo cks, hence dS t t = − λ t S t t dt + dt, dS u t = − λ u S u t dt + du t . F or the x -coordinates, using the Jordan blo ck structure of ˜ A , we obtain dS x, 0 t = − λS x, 0 t dt + dx t , dS x, 1 t = − λS x, 1 t dt + S x, 0 t dt, . . . dS x,K t = − λS x,K t dt + S x,K − 1 t dt. This gives the stated system. Prop osition F.2. F or e ach m = 0 , . . . , K , the c o or dinates ( S x,m t ) admit the r epr esentation S x,m t = Z t t 0 e − λ ( t − s ) ( t − s ) m m ! dx s , (62) wher e the inte gr al is understo o d in the Riemann–Stieltjes sense. Pr o of. Recall that S x,m t 0 = 0 since the EWS ov er [ t 0 , t 0 ] is trivial. All integrals b elow are understo od in the Riemann–Stieltjes sense, and are well-defined since x has b ounded v ariation. W e pro ceed by induction on m . F or the base case m = 0, m ultiply the defining equation by the in tegrating factor e λt to obtain d dt e λt S x, 0 t = e λt dx t . In tegrating from t 0 to t gives e λt S x, 0 t = Z t t 0 e λs dx s , and hence S x, 0 t = Z t t 0 e − λ ( t − s ) dx s . F or the inductive hypothesis, assume the result holds for m − 1. Multiplying the defining equation for S x,m t b y e λt and integrating yields e λt S x,m t = Z t t 0 e λr S x,m − 1 r dr . 41 Substituting the inductive hypothesis, e λt S x,m t = Z t t 0 e λr Z r t 0 e − λ ( r − s ) ( r − s ) m − 1 ( m − 1)! dx s dr . In terchanging the order of integration (justified by F ubini’s Theorem since x has b ounded v ariation and the in tegrand is con tinuous on a compact domain), we obtain e λt S x,m t = Z t t 0 Z t s e λr e − λ ( r − s ) ( r − s ) m − 1 ( m − 1)! dr dx s . Simplifying the integral, Z t s e λr e − λ ( r − s ) ( r − s ) m − 1 ( m − 1)! dr = e λs Z t s ( r − s ) m − 1 ( m − 1)! dr = e λs ( t − s ) m m ! . Th us, e λt S x,m t = e λt Z t t 0 ( t − s ) m m ! dx s , and cancelling e λt giv es S x,m t = Z t t 0 e − λ ( t − s ) ( t − s ) m m ! dx s . This completes the induction. Prop osition F.3. L et x ∈ V 1 ([ t 0 , t N ] , R ) b e of b ounde d variation, and let ( S x,m t ) K m =0 b e define d as ab ove. Then for al l t ∈ [ t 0 , t N ] , x t − x t 0 = K X m =0 λ m S x,m t + R K +1 t , (63) wher e the r emainder term admits the b ound |R K +1 t | ≤ ∥ x ∥ 1 , [ t 0 ,t ] ( λ ( t − t 0 )) K +1 ( K + 1)! . (64) Pr o of. Since x ∈ V 1 ([ t 0 , t N ] , R ), all in tegrals b elo w are well-defined in the Riemann–Stieltjes sense. Using the identit y 1 = e − λ ( t − s ) e λ ( t − s ) , w e write x t − x t 0 = Z t t 0 1 dx s = Z t t 0 e − λ ( t − s ) e λ ( t − s ) dx s . T aylor expanding the exp onen tial to order K gives e λ ( t − s ) = K X m =0 ( λ ( t − s )) m m ! + R K +1 λ ( t − s ) , where R K +1 y = ∞ X m = K +1 y m m ! . Substituting into the integral yields x t − x t 0 = K X m =0 Z t t 0 e − λ ( t − s ) ( λ ( t − s )) m m ! dx s + Z t t 0 e − λ ( t − s ) R K +1 λ ( t − s ) dx s . 42 By the definition of S x,m t , this gives x t − x t 0 = K X m =0 λ m S x,m t + R k +1 t , where R K +1 t = Z t t 0 e − λ ( t − s ) R K +1 λ ( t − s ) dx s . T o b ound this remainder, note that for y ≥ 0, e − y R K +1 y ≤ y K +1 ( K + 1)! . Hence, for s ∈ [ t 0 , t ] e − λ ( t − s ) R K +1 λ ( t − s ) ≤ ( λ ( t − t 0 )) K +1 ( K + 1)! . Using the standard b ound for Riemann–Stieltjes integrals R t t 0 g ( s ) dx s ≤ sup s ∈ [ t 0 ,t ] | g ( s ) |∥ x ∥ 1 , [ t 0 ,t ] [Y oung 1936], we obtain Z t t 0 g ( s ) dx s ≤ sup s ∈ [ t 0 ,t ] | g ( s ) |∥ x ∥ 1 , [ t 0 ,t ] . 43
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment