Smoothness and other hyperparameter estimation for inverse problems related to data assimilation
We consider Bayesian inverse problems arising in data assimilation for dynamical systems governed by partial and stochastic partial differential equations. The space-time dependent field is inferred jointly with static parameters of the prior and lik…
Authors: Baptiste Sim, oux, Nikolas Kantas
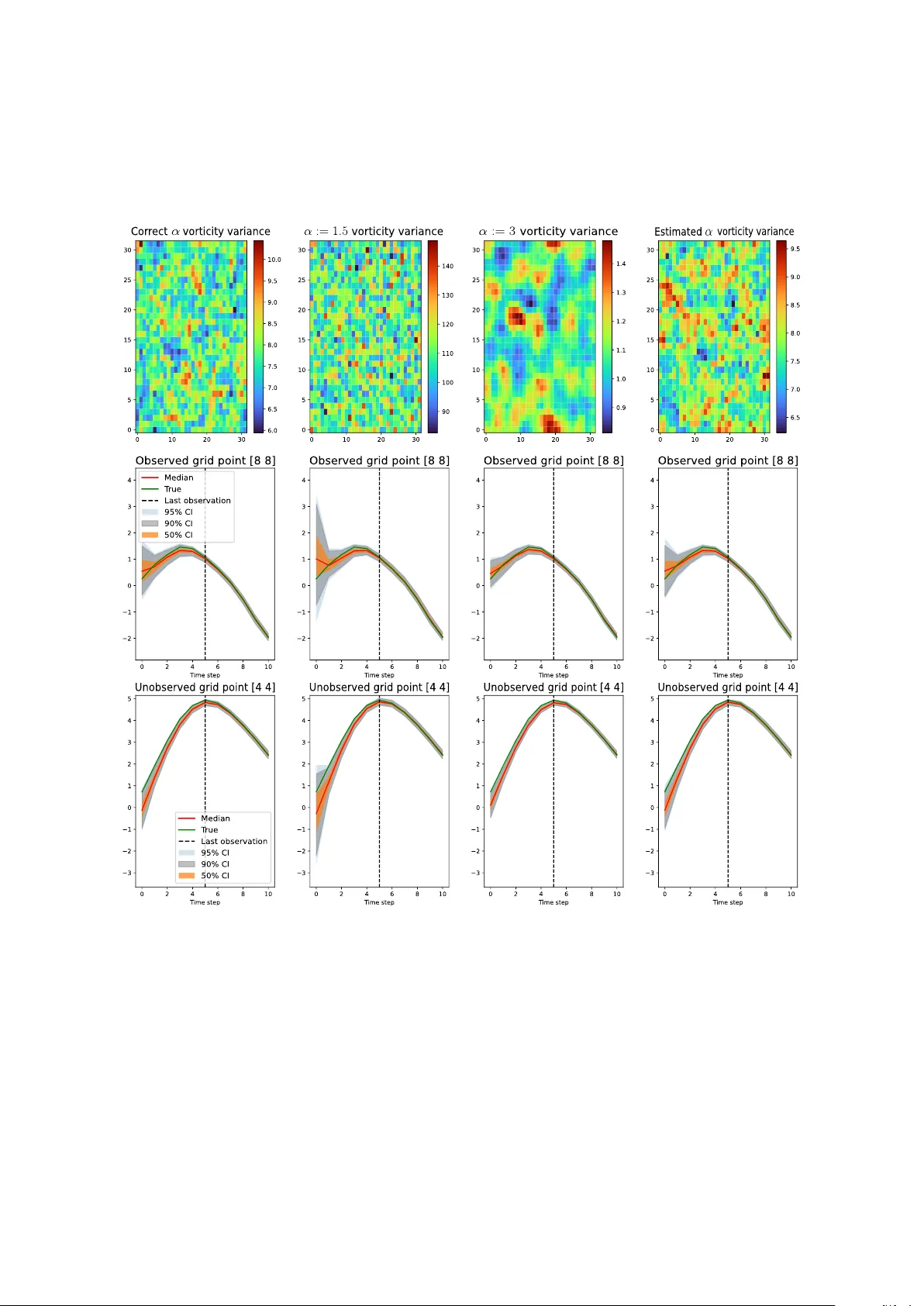
Smo othness and other h yp erparameter estimation for in v erse problems related to data assimilation Baptiste Simandoux 1 , Nik olas Kantas 1 , and Dan Crisan 1 1 Departmen t of Mathematics, Imp erial College, London, SW7 2AZ, UK. Abstract W e consider Ba y esian inv erse problems arising in data assimilation for dynamical sys- tems go verned b y partial and stochastic partial differen tial equations. The space–time dep enden t field is inferred join tly with static parameters of the prior and likelihoo d densities. P articular emphasis is placed on the hyperparameter controlling the prior smo othness and regularit y , which is critical in ensuring well-posedness, shaping p osterior structure, and determining predictive uncertain ty . Commonly it is assumed to b e kno wn and fixed a priori; how ev er in this pap er w e will adopt a hierarchical Ba yesian framew ork in whic h smo othness and other h yp erparameters are treated as unknown and assigned h yp erpriors. P osterior inference is performed using Metrop olis-within-Gibbs sampling suitable to high dimensions, for which hyperparameter estimation in volv es little com- putational ov erhead. The metho dology is demonstrated on inv erse problems for the Na vier–Stokes e quations and the sto chastic advection–diffusion equation, under sparse and dense observ ation regimes, using Gaussian priors with differen t cov ariance structure. Numerical results show that jointly estimating the smo othness substan tially reduces the errors in uncertain ty quantification and parameter estimation induced b y smoothness missp ecification, by achieving p erformance comparable to scenarios in which the true smo othness is known. 1 In tro duction In meteorology , o ceanograph y and atmospheric sciences, h ydrology , geophysics, v arious dy- namical space-time dep enden t quantities need to b e estimated and used for prediction; see [6, 20, 5, 4] for an o verview. They are typically mo delled with physical mo dels from fluid dynamics formulated as partial differen tial equations (PDEs) and more recently sto c hastic PDEs (SPDEs), describing the evolution of the atmospheric quantities suc h as v elo cit y , tem- p erature, pressure, turbulence of wind or o cean curren ts, salinit y and man y others [62, 3, 35]. In the last few dec ades, increasingly larger space–time data sets are obtained from remote sensing satellites or in situ sensors for example [24]. Satellites pro duce high-resolution im- ages of geophysical v ariables, suc h as stratospheric ozone, sea surface height winds, that are used for many tasks ranging from the estimation of seasonal cycles to the identifica- tion of long-term trends [54, 53]. Data assimilation pro vides a framew ork to combine this observ ational data with dynamical mo dels to estimate and predict accurately those states. F orecasting, one of the core aims of n umerical weather prediction, can b e achiev ed using an inferred initial condition of the state b y propagating its gov erning dynamics forw ard. As 1 these mo del tra jectories quic kly deviate from their true state, we incorp orate observ ations to correct this drift, see [46, 4, 6] for more details. In addition to states, referred to as dynamical v ariables, there are static parameters that determine the mo del equations and prop erties such as smo othness, noise amplitude, rotation angles among others. These also need to b e estimated from data and in this pap er we will consider joint Bay esian inference for dynamic and static v ariables [1, 7]. Data assimilation problems are naturally phrased as Bay esian inv erse problems: this has b een common notably in the fields of meteorology , atmospheric and o ceanic sciences, see [6, 20] for examples. Motiv ated b y these applications, w e adopt a Bay esian p erspective to infer from noisy observ ations a v ector field v = ( v ( t, x ); t ∈ [0 , T ] , x ∈ X ) in a suitable separable v ector space ( V , ∥ · ∥ V ). Bay esian in verse problems hav e gro wn significantly in p opularit y ov er the last decade, driv en by the av ailabilit y of simulation-based algorithms and large computational p o wer [25]. Within this framew ork, we aim to learn a p osterior distribution µ given data y via the abstract Ba yes rule: dµ dµ θ 0 ( v ) = l ( y , v , ϕ ) . (1) Here θ , ϕ denote sets of v arious constants used to sp ecify the prior µ 0 and the likelihoo d l resp ectiv ely . An estimate of v is given b y samples of this p osterior. The prior acts as regulariser and imp oses certain smo othness and regularity conditions on v so that µ is well p osed [17, 9, 30, 55]. Different regularisers can b e chosen dep ending on the approac h used, for example Gaussian priors corresp ond to a Tikhonov regulariser [23] or a T otal V ariation prior can b e used to preserve edges [31]. Here we will use Gaussian priors as in [29] but our metho dology is generic for other priors and regularisers, see [17] for an ov erview of different options. θ is usually a concatenation of several parameters: v ariance amplitude, spatial range, correlation le ngth or order of a differential op erator for example. In this pap er w e will pay particular atten tion to determining the smo othness/roughness of v , denoting the relev an t parameter as α . One requiremen t for the a priori spatial smo othness α is to ensure p osterior w ell-p osedness of the in v erse problem itself. Beyond this α is crucial in setting v arious spatial prop erties of the p osterior and subsequen t predictions. In many cases in data assimilation estimation of α is omitted and is assumed to b e fixed and known [16, 26, 45, 48, 52]. Similar c hallenges in setting these regularisation parameters also app ear in image pro cessing prob- lems, see [60, 37]. In this pap er w e prop ose to estimate α and demonstrate the b enefits of the added mo del flexibilit y brought by the h yp erpriors. The remaining parameters of θ and the ones of ϕ will also need to b e estimated. While in some cases these ma y b e kno wn a priori via some offline calibration metho ds, esp ecially for ϕ , they often require joint estimation with v , particularly when not physically measurable [1, 11]. T o that end, w e will adopt a hierarchical mo deling approach [1, 7, 19, 27, 43, 44], treating ( θ , ϕ ) as v ariables also to b e inferred and assigned with h yp er-prior π ( ϕ, θ ). This allo ws for a flexible and expressiv e w ay to specify priors and models. The resulting joint prior distribution on v , θ , ϕ is c hosen to lead to a well-posed p osterior distribution by conditioning on the observed data [55]. It is common in hierarc hical in verse problems for v to emplo y ensem ble Kalman techniques [27, 49]. Whilst fast and c heap to implement, the latter are not theoretically justified and are biased. They ha ve p erformed well in providing p oin t estimates like the maximum a p osteriori (MAP) estimator, ho wev er they do not capture the uncertain ty around these estimates [2]. This motiv ates our choice to use Mon te Carlo metho ds for parameter estimation and in particular Mark ov Chain Mon te Carlo (MCMC) as 2 in [7, 8, 9, 10, 32, 34, 40, 55]. T o estimate ϕ, θ along with v , we will use Metrop olis-within- Gibbs (MwG) sampling. F or v , w e will use appropriate MCMC algorithms that are efficient and robust to the high dimensionality of v , namely the preconditioned Crank–Nicolson (pCN) [10, 22, 32]. These are computationally intensiv e methods especially when used for n umerical discretisations of v and the relev an t (S)PDEs, but they are theoretically justified and robust under mesh refinement [22]. W e will demonstrate the merit of our approac h in t wo case studies. First, we will con- sider an in v erse problem using the Navier-Stok es equations, similar to [8, 9, 26, 55]. Secondly w e consider the sto c hastic advection-diffusion equation, p opular for environmen tal monitor- ing, for example in [54, 63, 52, 14, 36, 65]. F or µ 0 , we will use the p opular Gaussian pro cess prior used in many data assimilation settings [55, 25, 29, 42, 26]. F or the Navier-Stok es case, the co v ariance of µ 0 will b e set as β 2 A − α , where α and β c haracterise the smo othness and scaling resp ectiv ely and A is the Stok es op erator. In the sto c hastic advection-diffusion case w e consider as prior the Whittle-Mat´ ern cov ariance [61], widely used in spatial statistics [38, 52]. In b oth cases the p osterior is highly sensitive to choices of its hyperparameters [40, 41] and in particular α . 1.1 Relations with existing literature F rom a theoretical standp oin t a fixed α may yield sub-optimal contraction rates, unless the prior captures the fine prop erties of the truth like its regularit y [29]. As this is rarely known, determining the regularit y/smo othness of v systematically is necessary for accurate infer- ence of v . Alternativ ely to Hierarc hical Ba yesian metho ds, one could use empirical Bay es to estimate θ , including α from the data, t ypically by maximizing the marginal lik eliho o d of θ prior to p osterior inference [58, 28]. Whilst computationally cheaper, this is not a fully Ba yesian metho d and it ignores the parameters’ uncertain t y , p oten tially underestimating our p osterior uncertain ty . Hierarc hical Ba yesian metho ds considering smo othness were studied theoretically for the linear diagonalizable in verse problems in [28], obtaining adaptiv e op- timal conv ergence rates, under mild assumptions on α ’s hyper-prior. The sp ecific form of the parameterisation for θ can affect the mixing of MwG [1, 43, 64]. Non-centered parame- terisations of the laten t space and h yp erparameters allo w for faster mixing in MwG, and a non-cen tered parameterisation was also used for pCN algorithms, with [1] sho wing that it is robust to discretisation. W e note that to the b est of our kno wledge, there are no case studies related to nonlinear inv erse problems prior to this work inv estigating and demonstrating the efficiency of this approach when also estimating the smo othness parameter α . W e will b e using the MwG algorithm along with pCN as in [7]. Parameter learning for the Matern prior using MwG is studied in [48] but α := 3 − d/ 2 was fixed. F or linear mo dels the MAP estimate has b een well studied theoretically in [28, 15], but there is a lack of case studies on in verse problems with PDEs/SPDEs, esp ecially when learning the smo othness parameter. Our pap er addresses this gap and is intended to illustrate that one can recreate similar p erformance to knowing α . In parallel w ork, [41] provides a case study with a p oin t estimate (MAP) for fixed hyperparameters, without considering lik elihoo d parameters ϕ . W e will also demonstrate how learning α leads to b etter uncertain ty quantification. Finally our case studies include different mo dels and observ ation regimes. 1.2 Con tributions • W e prop ose an efficient MwG algorithm for in verse problems of PDEs and SPDEs. W e use pCN for the state and Gibbs sampling or Gibbs MCMC kernels for the h y- 3 p erparameters, as in [7]. W e remark that the computational ov erhead of considering h yp erparameters is minimal. • W e pay particular attention to the effect of the smo othness parameter on the state’s inference and prediction, often ov erlo ok ed in the literature as men tioned earlier. T o that end, w e demonstrate its impro vemen ts in uncertaint y quantification b oth in es- timation and prediction compared to standard metho ds relying on fixed smo othness assumptions. W e also lo ok into the smoothness’ influence on the rest of the parameters’ estimation. 1.3 Organisation The structure of this pap er is as follows: in section 2 w e presen t the problem form ulation, our notation along with the tw o different problems to b e studied. Section 3 describ es the Metrop olis-within-Gibbs algorithm we are considering in the high-dimensional setting and its implementation for eac h case study . Subsequently , section 4 contains n umerical results. Finally , in section 5 we will conclude and discuss future work. The App endix contains supplemen tary material and additional n umerical exp erimen ts. 2 Problem F orm ulation Adopting a Bay esian p ersp ectiv e, we will estimate v from y b y sampling from its p osterior distribution, introduced in (1). T o do so, we first sp ecify a prior for v conditional on param- eter θ , where α ∈ θ controls the spatial regularity of the prior realizations. W e will mo del the observ ations y as noisy measuremen ts of the latent field v at fixed lo cations and discrete in terv als for the observ ation times. As a result, the lik eliho o d function will dep end on the dynamics of v and the observ ation pro cess. F or simplicit y w e will only consider an Eule- rian observ ation setting with a regularly spaced grid for the observ ation lo cations and use Gaussian additive noise, but we p oin t out that our metho dology straightforw ardly extends to more general non-linear non Gaussian observ ation schemes and irregular grids as we are using MCMC. Recall that ϕ, θ are the parameters of the likelihoo d and prior resp ectiv ely . As men- tioned abov e, inference for θ and ϕ is performed join tly with v . T ypically , the parameters θ , ϕ are low dimensional whilst the dimension of v is high, so the latter dictates the algorithm’s computational cost. Below w e will in tro duce the observ ation equation and t wo different dy- namical mo dels we will consider in our n umerical study: the 2D Navier-Stok es equation and the sto c hastic advection-diffusion equation. 2.1 Observ ations W e mo del the data as noisy measurements of the v elo cit y field v on a fixed grid of p oints: x 1 , ..., x Υ , for Υ ≥ 1. W e assume that the observ ation noise is Gaussian and its standard deviation τ is known. These are obtained regularly at interv als δ time units apart. y n,υ = v ( x υ , nδ ) + τ ζ n,υ , ζ n,υ iid ∼ N (0 , 1) , 1 ≤ υ ≤ Υ , 1 ≤ n ≤ T . So the likelihoo d of this data conditioned on the initial condition v 0 tak es the form: l ( y ; v ) = 1 (2 π τ 2 ) T · Υ 2 T Y n =1 Υ Y υ =1 exp − 1 2 τ 2 ( y n,υ − v ( x υ , nδ )) 2 . (2) 4 2.2 Case study 1: Inferring the initial condition of deterministic Na vier- Stok es equations The domain we consider is a 2D T orus T = [0 , 2 π ] 2 with initial flow v 0 ∈ V and let v : T × [0 , ∞ ) → R 2 , v ( x, t ) = ( v 1 ( x, t ) , v 2 ( x, t )) T . One can write the incompressible Navier- Stok es PDE as lifted in a suitable Hilb ert space (see section A in the App endix for details) dv dt + η Av + B ( v , v ) = P ( f ) , v (0 , · ) = v 0 , (3) where η > 0 is a known viscosit y parameter, A is the Stok es op erator, B is the symmetric bilinear form and P ( f ) is the forcing term. Let Ψ( · , t ) : V → V t ≥ 0 denote the semigroup of solution op erators for the ODE (3) through t time units. Due to the nature of the obser- v ations we are interested in the discrete-time semigroup where v ( · , nδ ) = G ( n ) δ ( · ) = Ψ( · , nδ ) corresp onding to time instances t = nδ , of lag δ > 0 and n = 0 , ..., T , with conv entions G (0) δ = I , G (1) δ = G δ , G ( n ) δ = G δ ∗ G ( n − 1) δ . F or simplicity we will assume ϕ = { η , P ( f ) , τ } to b e known. Notice then that in this problem the Navier-Stok es dynamics enter in the p oste- rior only in the likelihoo d function, formulated abov e in (2). Also all the information for v is captured in v 0 as v ( x υ , nδ ) = G ( n ) δ ( v 0 )( x υ ) so w e will consider this as an inference problem for v 0 . T o clarify , since the dynamics are deterministic, forecasting can b e p erformed b y propagating them from samples of v 0 to the desired future time. An appropriate orthonormal basis for V is comprised of ψ k ( x ) = k ⊥ 2 π | k | exp( ik · x ) , k ∈ Z 2 \ { 0 } , where k ⊥ = ( − k 2 , k 1 ) T . Using this basis we obtain the F ourier decomp osition where v 0 ( x ) = P k ∈ Z 2 \{ 0 } u k ψ k ( x ) with u k = ⟨ v 0 , ψ k ⟩ . Since v 0 is real v alued, u k = − u − k so w e only need to consider half the F ourier co efficien ts. W e split the domain b y defining: Z 2 ↑ = { k = ( k 1 , k 2 ) ∈ Z 2 \ { 0 } : k 1 + k 2 > 0 } ∪ { k ∈ Z 2 \ { 0 } : k 1 + k 2 = 0 , k 1 > 0 } , and imp osing u k = − u − k for k ∈ { Z 2 \ { 0 }} \ Z 2 ↑ . W e represent the initial vector field v 0 b y its F ourier co efficien ts, and equiv alen tly: v 0 ↔ { u k } k ∈ Z 2 ↑ . v 0 will denote the concatenated v ector of the real and imaginary part of its F ourier co efficien ts. Since w e are only inferring v 0 , we set the prior on v 0 to b e µ 0 = N (0 , β 2 A − α ) with h yp erparameters θ := ( α > 1 / 2 , β > 0) as earlier. This prior, a Gaussian distribution on this Hilb ert space, is a conv enien t and flexible prior, see for details [13]. In the F ourier domain w e hav e: v 0 ∼ µ 0 ⇐ ⇒ Re( u k ) , Im( u k ) iid ∼ N (0 , 1 2 β 2 | k | − 2 α ) , k ∈ Z 2 ↑ . The prior admits a Karhunen–Lo ` eve expansion: µ θ 0 = Law X k ∈ Z 2 \{ 0 } β √ 2 | k | − α ξ k ψ k , (4) with θ = ( α, β 2 ) , Re( ξ k ) , Im( ξ k ) iid ∼ N (0 , 1) , k ∈ Z 2 ↑ ; ξ k = − ξ − k , k ∈ { Z 2 \ { 0 }} \ Z 2 ↑ , pro viding the Non-Centered Parameterisation ( θ , { ξ k } k ∈ Z 2 ↑ ). W e choose a zero-mean prior for simplicity; results will still hold for any mean function in the Cameron-Martin space of µ 0 [8, 9, 55]. Under this prior, u k are initially assumed 5 indep enden t normally distributed, with a particular rate of deca y for their v ariances as | k | increases so that the prior is trace class i.e. X k ∈ Z 2 \{ 0 } β √ 2 | k | − α < ∞ . This v ariance decay is particularly relev ant for the Na vier-Stokes mo del, for which the dissi- pation will transfer energy from high to low frequencies un til v 0 en ters the PDE’s attractor [47]. F or appropriate forcing and initialisation, the sp ectrum of v 0 tends to concen trate at lo w frequencies. This means higher frequencies will b e less informativ e in the posterior. Here the role of the smo othness parameter α is crucial: higher v alues w ould corresp ond to lo wer n umber of F ourier mo des capturing most of the prior and p osterior and since the viscosity constan t η is fixed and known, α sets the effectiv e dimension. Since ϕ is known, we use the following joint p osterior probability measure µ on V : µ ( v 0 , α, β 2 ) = 1 Z ( y ) l ( y ; v 0 ) µ α,β 2 0 ( v 0 ) π ( α ) π ( β 2 ) , (5) where the sup erscript in µ α,β 2 0 denotes conditioning with α , β 2 and π ( α ) , π ( β 2 ) are indep en- den t hyper-priors. The w ell-p osedness of µ is cov ered by the results in [8, 9, 55], which deal with the infinite dimensional v ariable v 0 , and has b een established with the requiremen t that α > 1 / 2 or equiv alently A − α b e a trace-class op erator. As long as the hyper-prior π ( α ) do es not violate this requiremen t and Z ( y ) is finite, the p osterior will b e well posed. F or this reason w e will use an in verse Gamma distribution for β 2 and an appropriate uniform for α . 2.3 Case study 2: Data assimilation with the Sto c hastic Adv ection Diffu- sion equation W e now study a mo del whereby the state’s dynamics follo w a linear SPDE on V := T 2 . d v ( t ) = ( − µ T ∇ v t + ∇ · Σ ∇ v t − ζ v t )d t + d ϵ t , where µ T ∇ v t mo dels transp ort effects, advection in weather applications, with drift µ , ∇ · Σ ∇ v t is a diffusion term that can incorp orate anisotropy and − ζ v t , ζ > 0 is a damping term. The sto c hastic noise ϵ t is a temp orally white and spatially correlated Gaussian pro cess, with Whittle-Mat ´ ern co v ariance. Σ − 1 = 1 ρ 2 1 cos( ψ ) sin( ψ ) − γ sin( ψ ) γ cos( ψ ) T cos( ψ ) sin( ψ ) − γ sin( ψ ) γ cos( ψ ) where ρ 1 > 0 , γ > 0 and ψ ∈ [0 , π / 2]. Here, ρ 1 acts as a range parameter and controls the amoun t of diffusion. γ and ψ control the amount and the direction of anisotropy; with γ = 1, isotropic diffusion is obtained. F or this problem: ϕ = ( ζ , ρ 1 , γ , ψ , µ 1 , µ 2 , τ ). Contrary to the previous setting, the noise in the dynamics means w e cannot easily recov er v t directly from v 0 . T o do this we need to simulate the whole path of v t . As a result, this is an inv erse problem on the whole path { v t } t ∈ [0 ,T ] . F orecasting b ey ond the time of the last observ ation T is p ossible after inferring { v t } T t ≥ 0 giv en observ ations defined as in section 2.1. This filtering setting and the prior are defined on the path space { v t } T t ≥ 0 . So we let our prior include the initial condition and the noise increments in the dynamics, whic h will dep end on θ . W e set v 0 P := ϵ 0 and describ e in detail the distribution of ϵ b elo w. 6 2.3.1 Whittle-Mat ´ ern prior The Mat ´ ern cov ariance b et w een lo cations u, v is r ( u, v ) = σ 2 Γ( ν )2 ν − 1 ( ρ 0 ∥ v − u ∥ ) ν K ν ( ρ 0 ∥ v − u ∥ ) , where K ν is the mo dified Bessel function of second kind and order ν > 0 , ρ 0 > 0 is a scaling parameter and σ 2 is the marginal v ariance. Using a Gaussian field with Whittle- Mat ´ ern co v ariance, the noise { ϵ t } T t =0 is quite a common choice in practice and applications [38, 52, 54, 36]. A Gaussian field x ( u ) with Mat´ ern cov ariance is a solution to ( ρ 2 0 − ∆) α/ 2 x ( u ) = σ W ( u ) , u ∈ R d , α = ν + d/ 2 , ρ 0 > 0 , ν > 0 where the inno v ation pro cess W is a spatial Gaussian white noise [33]. As in [52] we w ill infer σ 2 , ho wev er in our case we will also infer α ([52] has it set with ν = 1). ( ρ 2 0 − ∆) α/ 2 is a pseudo-differen tial op erator with F ourier transform: {F ( ρ 2 0 − ∆) α/ 2 Λ } ( k ) = ( ρ 2 0 + ∥ k ∥ 2 ) α 2 ( F Λ)( k ) (6) where Λ is a function on R d for which the right-hand side of (6) has a well-defined inv erse F ourier transform. ρ con trols the spatial correlation, a defining feature of the Mat ´ ern field. Here θ = ( α, σ 2 , ρ 0 ), so ( ρ 2 0 + ∥ k ∥ 2 ) α 2 cannot b e precomputed, and we consider indep enden t h yp erpriors for θ . As a result in this case every mo del parameter is b eing estimated. So the join t p osterior we sample from corresp onds to: µ ( v , ϕ, θ ) = 1 Z ( y ) l ϕ ( y ; v ) µ θ 0 ( v ) π ( θ ) π ( ϕ ) . (7) 3 Mon te Carlo Metho ds for filtering and in v erse problems 3.1 Mark o v Chain Mon te Carlo MCMC is an iterative pro cedure simulating a long run of an ergo dic time-homogeneous µ - in v arian t Marko v chain to sample from the target distribution µ . After a burn-in p erio d the samples of the chain form an empirical appro ximation of µ . Several Marko v chain metho ds are av ailable to sample from a given target p osterior distribution µ , suc h as the Gibbs sampler or the Metrop olis-Hastings algorithm; see [59] for an ov erview. Our setting requires sampling from distributions defined on a Hilb ert space and the p os- teriors lie in an infinite-dimensional state-space. F or inv erse problems on v , one cannot easily use conditional dep endence to develop Gibbs-type samplers to up date blo c ks of co efficien ts and improv e efficiency . In practice we use a high-dimensional discretisation, but our metho d still needs to b e robust to mesh refinement. Sampling directly from the full conditional of v giv en ϕ, θ , y is imp ossible so we use a MCMC suited to high dimensions. Random-W alk Metrop olis algorithms are not a v alid option for targets with Gaussian priors as their sp ec- tral gaps will prov ably collapse with increasing dimensions [22]. Autoregressiv e proposals that are inv arian t to the prior hav e b een prop osed in [59]. These were recen tly renamed as preconditioned Crank–Nicolson (pCN) and introduced for inference of high-dimensional in verse problems in [10, 55]. [22] establishes that in contrast to Random walk metho ds, the sp ectral gap of pCN and hence the mixing of the metho d do es not collapse as the dimension gro ws and o vercomes some of the slow mixing issues encountered b y standard MCMCs in high dimensions. W e fix ϕ, θ to the current estimates and run iterations of pCN on the full conditional of v . The pseudo-co de is presented in Algorithm 1. 7 Algorithm 1 pCN K pC N ( v 0 , · ): µ -inv ariant MCMC for High Dimensional In verse Prob- lems Inputs : • Prior µ 0 • step-size ρ close to 1 ( ∼ 1 − 1 / (n umber of v ariables to estimate) 2 ) • Data y , lik eliho o d and its parameters ϕ conditioned on initial condition v 0 : l ( y , v 0 , ϕ ) • Num b er of iterations T with burn-in p erio d bur n in Initialize : v 0 (0) ∼ µ 0 . F or t = 1 , . . . , T : 1. Prop ose: ˜ µ = ρ · v 0 ( t − 1) + p 1 − ρ 2 · ξ , ξ ∼ µ 0 2. Accept v 0 ( t ) = ˜ v 0 with probabilit y: 1 ∧ l ( y , ˜ v 0 , ϕ ) l ( y , v 0 ( t − 1) , ϕ ) otherwise v 0 ( t ) = v 0 ( t − 1). Output: ( v 0 ( t )) T t = burn in form estimates of v 0 as samples from K pC N ( v 0 (0)). 3.2 Metrop olis-within-Gibbs Giv en the hierarc hical structure of the mo del, we will use Metrop olis-within-Gibbs (MwG). Gibbs sampling alternates sampling from the full conditional distributions of each v , θ , ϕ , conditional on the curren t v alues of the remaining v ariables and y . Indep enden t hyperpriors for θ and ϕ will b e used so that up dates of v , ϕ, θ will b e simulating in sequence from the follo wing densities: π ( v | y , θ , ϕ ) ∝ l ( y | v , ϕ ) π ( v | θ ) (8) π ( ϕ | y , v , θ ) ∝ l ( y | v , ϕ ) π ( v | θ ) π ( ϕ ) (9) π ( θ | v ) ∝ π ( v | θ ) π ( θ ) (10) One could use either direct sampling from each conditional ab o v e or if this is not p ossible a small num b er of Metrop olis iterations targeting eac h of the ab o v e densities. 1 The latter is referred to as MwG. Sampling directly using conjugate relationships is recommended when a v ailable to accelerate sampling. W e now discuss the particular case of estimating the hyperparameters θ in the prior. Unlik e v and ϕ , θ is not informed by the data, only b y the estimate of v . So in its Gibbs up date of π ( v , θ , ϕ | v ) the costly likelihoo d do es not need to b e computed. 3.3 Sampling for Case study 1 W e pro ceed with the Navier-Stok es inv erse problem from section 2.2 and the observ ations in section 2.1. F or the hyperparameters, θ = ( α, β 2 ) and the join t prior is π ( v | α, β 2 ) π ( α ) π ( β 2 ). 1 One may even go further and implement MwG for each co ordinate or blo c ks of co ordinates of the v ariables in v , θ , ϕ ). 8 Algorithm 2 Metrop olis-within-Gibbs sampler K M w G ( v 0 , α, β 2 , · ) for Case study 1 A dditional inputs to Algorithm 1: • P arameter hyper-priors: P β = In v-Gamma( a, b ) , U α • prop ortion of steps p er parameter: p v 0 , p β 2 , p α (= 1 − p v 0 − p β 2 ) • additional learning rate: ρ α Initialize : v 0 (0) ∼ µ 0 , β 2 (0) ∼ P β , α (0) ∼ U α . F or t = 1 , . . . , T : 1. Sample p ∼ U ([0 , 1]). 2. IF p < p u , v 0 ( t ) ∼ K pC N ( v 0 ( t − 1) , · | α ( t − 1) , β 2 ( t − 1)), ELSE IF p < p u + p β 2 , β 2 ( t ) ∼ In v-Gamma( a + n 2 2 , b + v 0 ( t − 1) A α v 0 ( t − 1) 2 ), ELSE prop ose ˆ α = ρ α · α ( t − 1) + p 1 − ρ 2 α · u where u ∼ U α , and accept α ( t ) = ˆ α with probabilit y A , or reject and set α ( t ) = α ( t − 1). 3. Set the remaining parameters to their previous v alue e.g. α ( t ) = α ( t − 1) Output: ( v 0 , α, β 2 ) T t = burn in form estimates of ( v 0 , α, β 2 ) as samples from K M w G ( v 0 (0) , α (0) , β 2 (0) , · ). In Alg. 2 we present a random scan MwG where with probability p v , p β 2 , p α , w e choose one of the conditionals (or when appropriate the MCMC kernels targeting them) in (8)-(10) to iterate the corresp onding v ariable, see step 2 in Algorithm 2. F or up dating v , the full conditional is as follows: π ( v 0 | y , α, β 2 ) ∝ l ( y | v 0 ) π ( v 0 | α, β 2 ) ∝ 1 (2 π τ 2 ) T · Υ 2 T Y n =1 Υ Y υ =1 exp − 1 2 τ 2 ( y n,υ − G ( n ) δ ( v 0 )( x υ )) 2 × 1 √ 2 π d/ 2 | β | d | A − α | 1 2 exp( − 1 2 β 2 v 0 A α v 0 ) , so giv en α, β 2 w e will target this densit y using Alg. 1, where we adjust ρ for an a verage acceptance probabilit y ( ∼ 0 . 2 − 0 . 3). Each iteration requires running a PDE solver un til the time of the latest observ ation to compute l ( y | v , ϕ ), which is the most computationally exp ensiv e step in our algorithm. W e will set the h yp erprior π ( β 2 ) := IG( a, b ) (Inv erse Gamma distribution with shap e parameter a and scale parameter b ) to get a conjugate full conditional: π ( β 2 | y , α, v 0 ) ∝ π ( v 0 | α, β 2 ) π ( β 2 ) = IG(ˆ a, ˆ b ) with ˆ a = a + d 2 , ˆ b = b + 1 2 v 0 A α v 0 , where d corresp onds to the dimension of the mesh for v . This is equal to the n umber of random v ariables we are ev aluating: d = n ( n − 1) 2 b ecause of the restrictions ∇ · v = 0 and u k = − u − k . Deriv ations for this expression can b e found in the App endix in section B. 9 F or α we will use a uniform prior U α on compact domain and sample from pCN type MCMC k ernel targeting the follo wing full conditional: π ( α | y , β 2 , v 0 ) ∝ π ( v 0 | α, β 2 ) π ( α ) . The prop osal will b e ˆ α = ρ α α + (1 − ρ α ) P where P ∼ U α and hence is in v arian t to the uniform prior. As a result, the acceptance ratio A for this MCMC k ernel is given b y: A = 1 ∧ π ( v 0 | ˆ α, β 2 ) π ( v 0 | α, β 2 ) Q ( ˆ α, α ) Q ( α, ˆ α ) = µ 0 ( v 0 | ˆ α, β 2 ) µ 0 ( v 0 | α, β 2 ) = | A − α | 1 2 | A − ˆ α | 1 2 exp 1 2 β 2 ( v 0 A α v 0 − v 0 A ˆ α v 0 ) 3.4 Sampling for Case study 2 W e now lo ok to the problem in section 2.3. The underlying dynamics are linear and the noise is Gaussian, so Kalman filtering provides efficient and quic k estimates of v t giv en ( y n ) nδ ≤ t and ϕ, θ . How ever estimating the system’s parameters ( ϕ, θ ) is a c hallenging problem. This study extends the w ork in [52] by also inferring α and hence redesigning the hyperpriors. Compared to the previous case study , the use of a SPDE in the mo delling means that after discretising in time one has a higher dimensional Gaussian prior on { ϵ t } T t ≥ 0 . W e will follow [51] for sampling p ( v | y , ϕ, θ ) using the forward filtering bac kw ard sampling (FFBS) algorithm [18]. Whilst this is not the pCN algorithm, it uses Kalman filtering recursions and ac hieves sufficien tly fast mixing. In [51] smo othness was deterministically fixed to α = 2 and w as known. Also improp er priors were used, which w ould cause unidentifiabilit y issues for v arying α . Redesigning this requires the prior parameters for the remaining θ to b e rescaled according to v alues of α . So w e will set these priors instead to: ρ 0 ∼ U [0 . 01 , 5 · ( α − d/ 2) − 2 ] , σ 2 ∼ In vGamma(1 , 1) , γ ∼ In vGamma(5 , 5) , ζ ∼ InvGamma(1 , 1) , τ 2 ∼ U [0 , 100]. W e fo cused our efforts on the noise parameters since they are the most sensitive to c hanges in α . The b oundaries on the uniform prior of ρ 0 w ere chosen so that ρ 0 w ould b e identifiable from its corresp onding Mat ´ ern field. As for σ 2 w e chose an In verse Gamma h yp erprior as it could b e used in a conjugate relationship to sample directly from it. W e also chose In verse Gamma hyperpriors for γ and ζ to allow the whole state space to b e explored whilst p enalising large mov es. The rest are as in [52]: µ x , µ y ∼ U [ − 0 . 5 , 0 . 5] , ψ ∼ U [0 , π / 2] , ρ 1 ∼ U [0 , 100]. W e choose again a w eakly informative prior on α to highlight the adv antages of estimating it in a challenging case: U [1 , 4]. 4 Numerical results 2 4.1 Case study 1: inv erse problem for Na vier-Stok es W e are interested in comparing pCN and MwG for similar exp erimen ts to [26], where α is assumed to b e known and set to either 2 or 2 . 2. W e pro duce figures in the study to compare the p erformance in initial condition estimation of the MwG to pCN, assuming correct and incorrect v alues of α . F or the PDE solver, we will use a sp ectral Galerkin metho d. W e consider the finite dimensional pro jection onto the Hilb ert space spanned b y { ψ k } k ∈ L n where n ∈ N \ { 0 } and L n = { ( k 1 , k 2 ) ∈ Z 2 \ { 0 } : max( | k 1 | , | k 2 | ) < n/ 2 } . W e refer to the size of the implied mesh, d u , as the dimensionalit y of u. W e observ e that A is diagonalized in U with eigenv alues { λ k } k ∈ Z 2 \{ 0 } , where λ k = | k | 2 . Periodic b oundary conditions allow the use 2 The co de for the exp eriments can b e found in https://github.com/bs519/Hyperpar_est . 10 of sp ectral Galerkin methods when solving the Navier-Stok es PDE n umerically with F ast F ourier T ransforms (FFTs). When facing different b oundary conditions or forcing, w e would use Finite Elements tec hniques or other metho ds [21]. Conv olutions arising from pro ducts in the nonlinear term are computed via FFTs on our mesh with additional antialiasing using double-sized zero padding. In addition, exp onen tial time differencing is used as in [12] to deal with the resulting stiff system, whereby an analytical integration is used for the linear part, together with an explicit numerical Euler integration scheme for the nonlinear part. F or the mesh n = 32, the num b er of observ ations is set to T = 5 and for the observ ation grid Υ = 16. W e ha v e set f ( x ) = ∇ ⊥ cos((5 , 5) ′ · x ) , τ 2 = 0 . 2. W e consider N = 8 · 10 5 iterations and hav e found the optimal learning rate to b e around 0 . 999 and 0 . 998 in a stationary ( η = 0 . 1 , δ = 1) and ”chaotic” regime ( η = 0 . 02 , δ = 0 . 02) resp ectiv ely . F or the true initial condition and observ ations, we use a similar synthetic dataset, generated from a random sample of the prior with α = 2 . 2 , β 2 = 1 . 2. W e use π ( β 2 ) = IG(1 . 5 , 2 . 5). Stationary regime Figure 1: (Stationary regime) T race (left) and densit y (righ t) plots of prior parameters. The trace plots show the MCMC estimates (blue) captures the true v alue (green) in its distribution, with its cumulativ e av erage (red) con verging to a v alue close to the truth. Similarly the density plots display the p osterior’s estimate (blue) p eaking around the true v alue (red) of b oth parameters. The prior corresp onds to the blac k dashed line. F or b oth parameters, the true v alue lies in the supp ort of the densities of the estimates. The diagnostics plots for pCN and MwG are in the App endix in section C.1. Run times are shown in T able C.1. W e remark that as exp ected the runtimes are close to that of Algorithm 1, with α, β 2 kno wn. In Fig. 1 w e plot the trace plots and densities of our parameter estimation and the results pro ve the success of the parameter estimation even with uninformative priors. W e now study the algorithm’s uncertaint y quan tification of the initial condition. In Fig. 2 w e plot the v orticity of the initial condition’s estimates against the true v alue. W e observ e similar estimates from the algorithms knowing the correct α and 11 Figure 2: (Stationary regime) V orticity of the initial condition v 0 with the truth (far left) and MCMC estimates: knowing the true α = 2 . 2 v alue (cen tre left), underestimating with α = 1 . 5 (centre), o verestimating with α = 3 (cen tre right) and estimating α using MwG (far right). The crosses indicate the p ositions where the v ector field is observed. W e observe similar estimates from the algorithms kno wing the correct smo othness and estimating it, alb eit giving a smo other estimate. estimating it. The estimates reco ver the true initial condition relativ ely accurately , alb eit giving a smo other estimate. W e now plot in Fig. 3 the v ariance of the estimates’ vorticit y to fully ev aluate the algorithm’s uncertaint y quan tification. W e see from the scales that the v ariance is highly impacted by the choice of α . W e recov er the order of v ariance when the true α is kno wn only with the MwG. When α is ov er and underestimated the uncertaint y is under and o ver estimated, resp ectfully . Practitioners often choose to sac rifice uncertaint y quantification for impro ved p oin t estimates and vice-v ersa. This could b e used within our framework by adjusting the priors of α . Note how ev er we will use a high viscosit y and this low ers the system’s energy , and in doing so, this stationary regime renders our v ariance estimation less crucial and the predictive p o w er of all the algorithms similar after a few timesteps. W e repeat this b elo w for the ”c haotic” regime with low er viscosity and more frequen t and informative observ ations to in vestigate the differences. Chaotic regime W e obtain similarly go od results in parameter estimation as in the stationary case, see Fig. 9. This is also the case for the vorticit y p oint estimates sho wn in Fig. 10. These plots can b e found in the App endix in section C.2. In Fig. 4 w e presen t the results as in Fig. 3 previ- ously . The scale of the v ariance of the v orticit y estimates is as b efore at unobserv ed lo cations, ho wev er there is spatial correlation in tro duced b y the observ ations. The lik eliho o d is p eaky around the informative observ ation lo cations, which reduces the v ariance of the p osterior of the velocity at these lo cations, as w ell as the p osterior’s dep endence on the prior. F or higher v alues of α this spatial correlation is more pronounced as the corresp onding prior v ariance is smo othed. So a higher α leads to a less informative prior v ariance, additionally increasing the p osterior’s dep endence on the likelihoo d. This is why the v ariance is impacted by α as it w as in the stationary setting only at unobserved lo cations. This can b e additionally seen in the plots of the tra jectories of the velocity’s estimates at observed times. Due to the chaotic regime having high energy , the tra jectory plots sho w that the difference in v ariances do es not v anish in time and in turn impacts the estimate’s predictive p o wer. α = 3 leads to an underestimated v ariance at unobserv ed lo cations: the confidence interv al do es not capture the true v alue after v ery few time steps past the observ ations. At observed lo cations the forecast p erforms w ell, meaning the likelihoo d is enough to correct the missp ecified prior. As for α = 1 . 5, the v ariance is o verestimated leading to p oor uncertain ty quan tification at all times. At observed lo cations its forecast p erforms well un til the last observ ation, its pre- 12 Figure 3: (Stationary regime) Heat map of the v ariance of the vorticit y of v 0 vs α (top) in the stationary setting, as previously arranged, with: α = 2 . 2 v alue (far left), α = 1 . 5 (cen tre left), α = 3 (centre righ t) and estimating α using MwG (far righ t). Note the scale of the v ariance of v 0 ’s estimates b eing inv ersely prop ortional to α . W e also plot the tra jectory of the v elo cit y in the 2nd dimension of those estimates at obse rv ed (middle) and unobserved (b ottom) lo cations. The vertical dashed line indicates the time of the last observ ation. The algorithms kno wing the true α and estimating it via MwG exhibit similar b eha viour and uncertain ty quantification. 13 Figure 4: (Chaotic regime) Heat map of the v ariance of the velocity squared of v 0 vs α (top) in the c haotic setting, as previously arranged, with: α = 2 . 2 v alue (far left), α = 1 . 5 (cen tre left), α = 3 (centre righ t) and estimating α using MwG (far righ t). The white circles in the top panels indicate the p ositions where the vector field is observed. W e also plot the tra jectory of the velocity in the 2nd dimension of those estimates at observed (middle) and unobserved (b ottom) lo cations. The v ertical dashed line indicates the time of the last observ ation. Note the scale of the v ariance of the prediction estimates being in v ersely prop ortional to α . 14 Figure 5: T race (left) and density (righ t) plot of smo othness parameter estimates in case study 2. The dashed line corresp onds to the median estimate ≈ 1 . 1, close the true v alue generating the data α = ν + 1 = 2. dictiv e p o wer degrades quic kly as the v ariance explo des. Then pCN with α = 1 . 5 p erforms p oorly at uncertaint y quantification, particularly for unobserved states and prediction. This sho ws that even where the likelihoo d is most influen tial, the prior still influences the algo- rithm’s predictive pow er. Finally the MwG repro duces similar p erformance to the algorithm assuming the correct v alue of α and p erforms similarly w ell even in prediction. 4.2 Case study 2: advection-diffusion SPDE W e reuse the co de and example provided in [51] using the R pack age ’spate’. The dis- cretisation grid is of size n 2 with n = 32. W e set T = 20 observ ations, generated from the whole grid (Υ = n 2 ) with Gaussian noise τ 2 = 0 . 01. ξ is generated from parameters ρ 0 = 0 . 1 , σ 2 = 0 . 2 , ζ = 0 . 5 , ρ 1 = 0 . 1 , γ = 2 , α = π / 4 , µ 1 = 0 . 2 , µ 2 = − 0 . 2. W e pick N = 10 6 with 10% burn-in and 5000 to b e b oth the burn-in p eriod and the minimal num ber of MCMC samples after this burn-in to estimate the prop osal matrix. W e pic k as starting v alues ρ 0 = 0 . 2 , σ 2 = 0 . 1 , ζ = 0 . 25 , ρ 1 = 0 . 2 , γ = 1 , α = 0 . 3 , µ 1 = 0 , µ 2 = 0 , τ 2 = 0 . 005 and initiate α correctly . As before we compare the p erformance of the algorithm additionally estimating the smo othness to the standard algorithm assuming correct and incorrect v alues of α . Results on α and the remaining parameters are shown in Fig. 5 and Fig. 6 respec - tiv ely . The estimation of α as 2 . 1 is close to the true v alue 2 and the parameter space is w ell explored. Assuming the wrong v alue of α leads to very p o or parameter estimation with parameter samples for σ 2 , ζ , ρ 1 , γ , µ x , µ y , τ in non-represen tative v alues. How ev er es timating α allows for parameter estimation results very close to the accurate p erformance of the stan- dard algorithm kno wing the correct α , as the distributions of their estimates are cen tered or capture well the true v alue. This is additionally supp orted by the parameters’ trace plots in Fig. 11 in section D in the App endix. 5 Conclusion In this w ork, w e consider tw o case studies that share common c haracteristics with op erational data assimilation problems. In b oth cases, w e ha ve illustrated the merits of estimating the smo othness parameter together with other parameters of the prior and lik eliho o d as w ell as noticed p erformance similar to knowing the true v alue of α . At the same time, we 15 (a) α = 2 (b) Estimated α (c) α = 1 . 5 (d) α = 2 . 5 Figure 6: Histogram of the parameters estimated when the algorithm knows the true α = 2 v alue (top left), underestimates α = 1 . 5 (b ottom left), o verestimates α = 2 . 5 (b ottom right) and estimates α (top right). The dashed line indicates the true v alue and the full line represen ts the median of the samples. Assuming the wrong v alue of α leads to very p oor parameter estimation with parameter samples for σ 2 , ζ , ρ 1 , γ , µ x , µ y , τ in non-represen tative v alues. Samples for µ x , µ y are still distributed according to their prior meaning no informa- tion w as gained from the data for µ . How ev er estimating α and knowing the correct α allo ws for similar accurate parameter estimation results, as the distributions of their estimates are cen tered around or capture w ell the true v alue. 16 sho wed how missp ecifying α can lead to p o or uncertain ty quantification or estimation of other parameters in ϕ, θ . Our case studies co vered different Gaussian priors (Matern/Laplacian), differen t dynamics (linear, nonlinear stationary or c haotic), observ ation regimes (dense or sparse observ ation grids). So w e b eliev e using hierarchical mo delling for ϕ, θ together with MwG can b e very helpful in practice. Ev en when little is kno wn ab out the smo othness of the state, it can b e inferred and by exploring the parameter space it adds flexibility to the mo del. W e ha ve also established that in certain cases practitioners ma y c ho ose to sacrifice uncertaint y quantification for improv ed p oint estimates and vice-versa. In real NWP op erational problems the state dimension may reac h O (10 7 − 10 9 ), whereas our pro of of concept lo oks at O (10 3 ). Still we highlight that the ov erhead of estimating α as well as the rest of θ and ϕ can b e minimal. Finally , this approac h could b e generalized/extended to more elab orate priors: e.g. Matern with Cauc hy noise [56] or the more general α -stable distributions [57], with Studen t’s t priors as in [50] or sparsity-promoting priors as in [16, 39]. Ac kno wledgemen ts B.S. was supp orted by the Additional F unding Programme for Mathematical Sciences, de- liv ered b y EPSR C (EP/V521917/1) and the Heilbronn Institute for Mathematical Research. Conflict of in terest The authors state that none of the work describ ed in this publication app ears to hav e b een influenced b y any known conflicting financial motiv es or p ersonal ties. 17 References [1] S. Agapiou, J. M. Bardsley, O. P ap aspiliopoulos, and A. M. Stuar t , A nal- ysis of the Gibbs Sampler for Hier ar chic al Inverse Pr oblems , SIAM/ASA Journal on Uncertain ty Quantification, 2 (2014), pp. 511–544. [2] S. A gra w al, H. Kim, D. Sanz-Alonso, and A. Strang , A V ariational Infer enc e Appr o ach to Inverse Pr oblems with Gamma Hyp erpriors , SIAM/ASA Journal on Un- certain ty Quantification, 10 (2022), pp. 1533–1559. [3] D. Beletsky, D. J. Schw ab, P. J. Roebber, M. J. McCormick, G. S. Miller, and J. H. Sa ylor , Mo deling wind-driven cir culation during the Mar ch 1998 se diment r esusp ension event in L ake Michigan , Journal of Geoph ysical Researc h (Oceans), 108 (2003), p. 3038. [4] A. F. Bennett , Inverse Mo deling of the Oc e an and Atmospher e , Cambridge Univ ersity Press, Cam bridge, 2002. [5] M. Bocquet, C. A. Pires, and L. Wu , Beyond Gaussian Statistic al Mo deling in Ge ophysic al Data Assimilation , Monthly W eather Review, 138 (2010), pp. 2997–3023. [6] A. Carrassi, M. Bocquet, J. Demaeyer, C. Grudzien, P. Raanes, and S. V an- nitsem , Data assimilation for chaotic dynamics , Data Assimilation for Atmospheric, Oceanic and Hydrologic Applications (V ol. IV), (2022), pp. 1–42. [7] V. Chen, M. M. Dunlop, O. P ap aspiliopoulos, and A. M. Stuar t , Dimension- R obust MCMC in Bayesian Inverse Pr oblems , Mar. 2019. [8] S. L. Cotter, M. D ashti, J. C. R obinson, and A. M. Stuar t , Bayesian inverse pr oblems for functions and applic ations to fluid me chanics , In verse Problems, 25 (2009), p. 115008. [9] S. L. Cotter, M. D ashti, and A. M. Stuar t , Appr oximation of Bayesian Inverse Pr oblems for PDEs , SIAM Journal on Numerical Analysis, 48 (2010), pp. 322–345. [10] S. L. Cotter, G. Rober ts, A. Stuar t, and D. White , MCMC Metho ds for F unc- tions: Mo difying Old Algorithms to Make Them F aster , Statistical Science, 28 (2012). [11] J. Coullon and Y. Pokern , Markov chain Monte Carlo for a hyp erb olic Bayesian inverse pr oblem in tr affic flow mo deling , Data-Centric Engineering, 3 (2022). [12] S. Cox and P. Ma tthews , Exp onential Time Differ encing for Stiff Systems , Journal of Computational Physics, 176 (2002), pp. 430–455. [13] G. D a Pra to and J. Zabczyk , Sto chastic e quations in infinite dimensions , no. 152 in Encyclop edia of mathematics and its applications, Cambridge Univ ersity Press, Cam- bridge, United Kingdom, second edition ed., 2014. [14] J. A. Duan, A. E. Gelf and, and C. F. Sirmans , Mo deling sp ac e-time data using sto chastic differ ential e quations , Bay esian Analysis, 4 (2009). [15] M. M. Dunlop, T. Helin, and A. M. Stuar t , Hyp erp ar ameter Estimation in Bayesian MAP Estimation: Par ameterizations and Consistency , The SMAI Journal of computational mathematics, 6 (2020), pp. 69–100. 18 [16] M. Emzir, S. Lasanen, Z. Purisha, L. Roininen, and S. S ¨ arkk ¨ a , Non-stationary multi-layer e d Gaussian priors for Bayesian inversion , Inv erse Problems, 37 (2020), p. 15002. [17] H. W. Engl, M. Hanke, and A. Neubauer , R e gularization of inverse pr oblems , v ol. 375, Kluw er Academic Publishers Group, Dordrech t, mathematics and its applica- tions ed., 1996. [18] S. Fr ¨ uhwir th-Schna tter , Data Augmentation and Dynamic Line ar Mo dels , Journal of Time Series Analysis, 15 (1994), pp. 183–202. [19] A. Gelman, J. B. Carlin, H. S. Stern, D. B. Dunson, A. Veht ari, and D. B. R ubin , Bayesian Data A nalysis , Chapman and Hall/CR C, New Y ork, 3 ed., July 2015. [20] M. Ghil and P. Malanotte-Rizzoli , Data Assimilation in Mete or olo gy and Oc e ano gr aphy , Adv ances in geoph ysics, 33 (1991), pp. 141–266. [21] V. Giraul t and P.-A. Ra viar t , Finite Element Metho ds for Navier-Stokes Equa- tions , vol. 5 of Springer Series in Computational Mathematics, Springer, Berlin, Heidel- b erg, 1986. [22] M. Hairer, A. M. Stuar t, and S. J. Vollmer , Sp e ctr al gaps for a Metr op olis- Hastings algorithm in infinite dimensions , The Annals of Applied Probability , 24 (2014). [23] T. Hein , On Tikhonov r e gularization in Banach sp ac es – optimal c onver genc e r ates r esults , Applicable Analysis, 88 (2009), pp. 653–667. [24] T. Hey and A. Trefethen , The Data Deluge: An e-Scienc e Persp e ctive , in Grid Computing: Making the global infrastructure a reality , Wiley Online Library , 1 ed., Mar. 2003, pp. 809–824. [25] J. P. Kaipio and E. Somersalo , Statistic al and Computational Inverse Pr oblems , v ol. 160 of Applied Mathematical Sciences, Springer, New Y ork, NY, 2005. [26] N. Kant as, A. Beskos, and A. Jasra , Se quential Monte Carlo Metho ds for High-Dimensional Inverse Pr oblems: A Case Study for the Navier–Stokes Equations , SIAM/ASA Journal on Uncertaint y Quan tification, 2 (2014), pp. 464–489. [27] H. Kim, D. Sanz-Alonso, and A. Strang , Hier ar chic al ensemble Kalman metho ds with sp arsity-pr omoting gener alize d gamma hyp erpriors , F oundations of Data Science, 5 (2023), pp. 366–388. [28] B. T. Knapik, B. T. Szab ´ o, A. W. v an der V aar t, and J. H. v an Zanten , Bayes pr o c e dur es for adaptive infer enc e in inverse pr oblems for the white noise mo del , Probabilit y Theory and Related Fields, 164 (2016), pp. 771–813. [29] B. T. Knapik, A. W. v. d. V aar t, and J. H. v. Zanten , Bayesian inverse pr oblems with Gaussian priors , Annals of Statistics, (2012). [30] D. Konen and R. Nickl , Data assimilation with the 2D Navier-Stokes e quations: Optimal Gaussian asymptotics for the p osterior me asur e , July 2025. [31] M. Lassas and S. Sil t anen , Can one use total variation prior for e dge-pr eserving Bayesian inversion? , In verse Problems, 20 (2004), p. 1537. 19 [32] K. J. H. La w , Pr op osals which sp e e d-up function-sp ac e MCMC , Journal of Computa- tional and Applied Mathematics, 262 (2014), pp. 127–138. [33] F. Lindgren, H. R ue, and J. Lindstr ¨ om , An explicit link b etwe en Gaussian fields and Gaussian Markov r andom fields: the sto chastic p artial differ ential e quation ap- pr o ach , Journal of the Ro yal Statistical So ciet y: Series B (Statistical Metho dology), 73 (2011), pp. 423–498. [34] D. Luengo, L. Mar tino, M. Bugallo, V. El vira, and S. S ¨ arkk ¨ a , A survey of Monte Carlo metho ds for p ar ameter estimation , EURASIP Journal on Adv ances in Signal Pro cessing, 2020 (2020), p. 25. [35] A. J. Majda and J. Harlim , Filtering Complex T urbulent Systems , Cambridge Uni- v ersity Press, Cambridge, 2012. [36] A. Malmber g, A. Arellano, D. P. Ed w ards, N. Fl yer, D. Nychka, and C. Wikle , Interp olating fields of c arb on monoxide data using a hybrid statistic al- physic al mo del , The Annals of Applied Statistics, 2 (2008), pp. 1231–1248. [37] R. Molina, A. Ka tsa ggelos, and J. Ma teos , Bayesian and r e gularization meth- o ds for hyp erp ar ameter estimation in image r estor ation , IEEE T ransactions on Image Pro cessing, 8 (1999), pp. 231–246. [38] F. Monard, R. Nickl, and G. P. P a ternain , Statistic al Guar ante es for Bayesian Unc ertainty Quantific ation in Nonline ar Inverse Pr oblems with Gaussian Pr o c ess Pri- ors , The Annals of Statistics, 49 (2021), pp. 3255–3298. [39] K. Monterrubio-G ´ omez, L. R oininen, S. W ade, T. D amoulas, and M. Giro- lami , Posterior infer enc e for sp arse hier ar chic al non-stationary mo dels , Computational Statistics & Data Analysis, 148 (2020), p. 106954. [40] R. M. Neal , Monte Carlo Implementation of Gaussian Pr o c ess Mo dels for Bayesian R e gr ession and Classific ation , Jan. 1997. arXiv:ph ysics/9701026. [41] N. H. Nelsen, H. O whadi, A. M. Stuar t, X. Y ang, and Z. Zou , Bilevel optimiza- tion for le arning hyp erp ar ameters: Applic ation to solving PDEs and inverse pr oblems with Gaussian pr o c esses , Oct. 2025. [42] R. Nickl and E. S. Titi , On p osterior c onsistency of data assimilation with Gaussian pr o c ess priors: The 2D-Navier–Stokes e quations , The Annals of Statistics, 52 (2024). [43] O. P ap aspiliopoulos and G. Rober ts , Non-Center e d Par ameterisations for Hier- ar chic al Mo dels and Data Augmentation , Bay esian Statistics, 7 (2003), pp. 307–326. [44] O. P ap aspiliopoulos, G. O. R ober ts, and M. Sk ¨ old , A Gener al F r amework for the Par ametrization of Hier ar chic al Mo dels , Statistical Science, 22 (2007), pp. 59–73. [45] F. Pons Llopis, N. Kant as, A. Beskos, and A. Jasra , Particle Filtering for Sto chastic Navier–Stokes Signal Observe d with Line ar A dditive Noise , SIAM Journal on Scien tific Computing, 40 (2018), pp. A1544–A1565. [46] S. Reich and C. Cotter , Pr ob abilistic F or e c asting and Bayesian Data Assimilation , Cam bridge Universit y Press, Cambridge, 2015. 20 [47] J. C. R obinson , Infinite-Dimensional Dynamic al Systems: A n Intr o duction to Dissi- p ative Par ab olic PDEs and the The ory of Glob al A ttr actors. Cambridge T exts in Applie d Mathematics , Applied Mechanics Reviews, 56 (2003), pp. B54–B55. [48] L. Roininen, M. Girolami, S. Lasanen, and M. Markkanen , Hyp erpriors for Mat ´ ern fields with applic ations in Bayesian inversion , In verse Problems and Imaging, 13 (2018), pp. 1–29. [49] D. Sanz-Alonso and N. W aniorek , Hier ar chic al Bayesian inverse pr oblems: A high- dimensional statistics viewp oint , SIAM Review, 67 (2025), pp. 543–575. [50] A. Senchuko v a, F. Uribe, and L. Roininen , Bayesian inversion with Student’st priors b ase d on Gaussian sc ale mixtur es , In verse Problems, 40 (2024), p. 105013. [51] F. Sigrist, H. R. K ¨ unsch, and W. A. St ahel , sp ate: an R Package for Statistic al Mo deling with SPDE Base d Sp atio-T emp or al Gaussian Pr o c esses . [52] F. Sigrist, H. R. K ¨ unsch, and W. A. St ahel , Sto chastic Partial Differ ential Equa- tion Base d Mo del ling of L ar ge Sp ac e–Time Data Sets , Journal of the Ro yal Statistical So ciet y Series B: Statistical Metho dology , 77 (2015), pp. 3–33. [53] M. L. Stein , Sp atial V ariation of T otal Column Ozone on a Glob al Sc ale , The Annals of Applied Statistics, 1 (2007), pp. 191–210. [54] J. R. Stroud, M. L. Stein, B. M. Lesht, D. J. Schw ab, and D. Beletsky , An Ensemble Kalman Filter and Smo other for Satel lite Data Assimilation , Journal of the American Statistical Asso ciation, 105 (2010), pp. 978–990. [55] A. M. Stuar t , Inverse pr oblems: A Bayesian p ersp e ctive , Acta Numerica, 19 (2010), pp. 451–559. [56] J. Suuronen, N. K. Chada, and L. Roininen , Cauchy Markov r andom field priors for Bayesian inversion , Statistics and Computing, 32 (2022), p. 33. [57] J. Suur onen, T. Soto, N. K. Chada, and L. R oininen , Bayesian inversion with α -stable priors , Inv erse Problems, 39 (2023), p. 105007. [58] A. L. Teckentr up , Conver genc e of Gaussian Pr o c ess R e gr ession with Estimate d Hyp er-Par ameters and Applic ations in Bayesian Inverse Pr oblems , SIAM/ASA Journal on Uncertain ty Quantification, 8 (2020), pp. 1310–1337. [59] L. Tierney , Markov Chains for Exploring Posterior Distributions , The Annals of Statistics, 22 (1994), pp. 1701–1728. [60] A. F. Vidal, V. D. Bor toli, M. Pereyra, and A. Durmus , Maximum Likeliho o d Estimation of R e gularization Par ameters in High-Dimensional Inverse Pr oblems: An Empiric al Bayesian Appr o ach Part I: Metho dolo gy and Exp eriments , SIAM Journal on Imaging Sciences, (2020). [61] P. Whittle , On Stationary Pr o c esses in the Plane , Biometrik a, 41 (1954), pp. 434–449. [62] C. K. Wikle, R. F. Milliff, D. Nychka, and L. M. Berliner , Sp atiotemp or al Hier ar chic al Bayesian Mo deling T r opic al Oc e an Surfac e Winds , Journal of the American Statistical Asso ciation, 96 (2001), pp. 382–397. 21 [63] K. Xu and C. K. Wikle , Estimation of p ar ameterize d sp atio-temp or al dynamic mo dels , Journal of Statistical Planning and Inference, 137 (2007). [64] Y. Yu and X.-L. Meng , T o Center or Not to Center: That Is Not the Question—An A ncil larity–Sufficiency Interwe aving Str ate gy (ASIS) for Bo osting MCMC Efficiency , Journal of Computational and Graphical Statistics, 20 (2011), pp. 531–570. [65] Y. Zheng and B. H. Aukema , Hier ar chic al dynamic mo deling of outbr e aks of moun- tain pine b e etle using p artial differ ential e quations , En vironmetrics, 21 (2010), pp. 801– 816. 22 A The Na vier Stok es equation W e introduce here the Navier-Stok es equation for incompressible flo w. Let v ( x, t ) denote the velocity vector field at p oin t x and time t . The domain w e consider is a 2D T orus T = [0 , 2 π ] 2 with initial flow v 0 ∈ T and let v : T × [0 , ∞ ) → R 2 , v ( x, t ) = ( v 1 ( x, t ) , v 2 ( x, t )) T . The dynamics for v are as follo ws: ∂ t v − η ∆ v + ( v · ∇ ) v = f − ∇ p, v ( x, 0) = v 0 ( x ) (11) ∇ · v = 0 , Z T v j ( x, · ) dx = 0 , j = 1 , 2 , (12) where η > 0 is the viscosity parameter, p : T × [0 , ∞ ) → R is the pressure function, and f : T → R 2 is an exogenous time-homogeneous forcing. F or simplicity we consider the mean flo w to b e 0 and assume p erio dic b oundary conditions: v j ( · , 0 , t ) = v j ( · , 2 π , t ) , v j (0 , · , t ) = v j (2 π , · , t ) , j = 1 , 2 ∀ t ≥ 0. Here v 0 is the initial velocity field to b e estimated. W e no w define its domain as the following Hilb ert space V with closure V with resp ect to L 2 ( T ) 2 norm: V := 2 π -p eriodic trigonometric p olynomials u : T → R 2 | ∇ · u = 0 , Z T u ( x ) dx = 0 . Let P : ( L 2 ( T )) 2 → V denote the Leray–Helmholtz orthogonal pro jector. P pro jects f on to the space of incompressible functions. In our con text this means the pressure term in (11) is remov ed. W e obtain the equation as in (3), rep eated b elo w for conv enience: dv dt + η Av + B ( v , v ) = P ( f ) , v (0) = v 0 , (13) where B ( v , ˜ v ) = 1 2 P (( v · ∇ ) ˜ v ) + 1 2 P (( ˜ v · ∇ ) v ) and A = − P ∆ is the Stokes op erator. If this set of equations is pro jected on a finite dimensional subspace, then it is an ODE. B Conjugate prior deriv ation In this section we explicitly show the conjugate relationship of the parameter β 2 , in Case study 1 used in section 3.3, exploiting the conjugate prior with Inv erse Gamma distribution for the Gaussian likelihoo d. A similar conjugate relationship holds for σ 2 in case 2. π ( β 2 | y , α, v 0 ) ∝ √ 2 √ 2 π d | β | d | A − α | 1 2 exp( − 1 2 β 2 v 0 A α v 0 ) · b a Γ( a ) ( β 2 ) − a − 1 exp − b β 2 ∝ b a Γ( a ) ( β 2 ) − a − 1 ( β 2 ) − d 2 exp − b β 2 − 1 2 β 2 v 0 A α v 0 ∝ b a Γ( a ) ( β 2 ) − ( a + d 2 ) − 1 exp − b + 1 2 v 0 A α v 0 β 2 ! ∝ ( b + 1 2 v 0 A α v 0 ) a + d 2 Γ( a + d 2 ) ( β 2 ) − ( a + d 2 ) − 1 exp − b + 1 2 v 0 A α v 0 β 2 ! 23 C Case study 1: diagnostics and run times C.1 Diagnostics (a) Acceptance ratio (b) V elo cit y trace plot (c) Auto correlation plot Figure 7: pCN diagnostics: the cumulativ e a verage (red) of the acceptance ratio (left) is around 0 . 23 as desired. The acceptance ratio (blue) do es not alternate b et ween 0 and 1 despite the blue background, it is div erse as desired. The trace plot (middle) of the real part of the v elo cit y in the first dimension at the p oin t [2,0] of our grid shows the MCMC estimate (blue) oscillates around the true v alue (green), with its cumulativ e av erage (red) con verging to a v alue close to the truth. The auto correlation plot of this quantit y shows that the MCMC chain decorrelates after 1 . 5 · 10 5 iterations. Fig. 7 diagnostics for pCN show that N = 8 · 10 5 iterations are sufficien t for the MCMC to pro vide goo d estimates. In Fig. 7a we can observ e that the acceptance ratio is stable after the burn-in p erio d of 8 · 10 4 and b et ween the desired v alues of 0.2 and 0.3. F o cusing on the real v alue of a single F ourier coefficient, in Fig. 7b the MCMC estimate con verges to − 0 . 54 very close to the true v alue − 0 . 56. Additionally its auto correlation plot in Fig. 7c suggests that despite high decorrelation lags, the high num ber of MCMC iterations will lead to a reasonable effective sample size. F or MwG, we increase the n umber of MCMC mo ves to the traditional MCMC algorithm to take into accoun t the Gibbs sampler’s mov es on the h yp erparameters: N = 2 . 4 · 10 6 for p v = p β 2 = p α = 1 3 . T o fully observe the b eha viour of the parameter estimation, we use longer runs: N = 6 · 10 6 . This is solely for our study and w ould not b e needed in practice. W e found the optimal step-size for α to b e 0 . 96 for b oth regimes. T race plots of the v elo cit y estimates are sho wn in Fig. 8. 24 Figure 8: MwG diagnostics: the cum ulativ e av erage of the acceptance ratio of the initial condition and of α is around 0 . 23 as desired. The acceptance ratio is diverse as desired. The trace plot of the real part of the velocity in the first dimension at v arious p oin ts shows each MCMC estimate (blue) captures the true v alue (green) in its distribution, with its cum ulative a verage (red) conv erging to a v alue mostly close to the truth. 25 Run times Algorithm Regime Mo del Configuration Execution time PDE coun t pCN Stationary N-S N = 8 · 10 5 25 hours 8 · 10 7 MwG Stationary N-S N = 6 · 10 6 85 hours 2 · 10 8 pCN Chaotic N-S N = 8 · 10 5 12.5 hours 4 · 10 6 MwG Chaotic N-S N = 6 · 10 6 49 hours 5 · 10 6 MwG N/A Sto c h. AD α := 2 11 hours N/A MwG N/A Sto c h. AD U (1 , 4) 12.5 hours N/A T able 1: Run times of the MwG algorithm estimating θ , ϕ and of the pCN algorithm kno wing θ , ϕ . The MwG with p u = p β 2 = p α = 1 / 3 is sligh tly slow er than pCN due to additional mem- ory requiremen ts for storing h yp erparameter samples. T aking this into accoun t and lo oking at the n umber of times the PDE solver was ran, the run times highligh t that estimating θ do es not significan tly increase the run times ov er the known θ case. The computational run times are dominated b y the runs of the PDE solver when ev aluating the likelihoo d, which w as confirmed when profiling the co de. C.2 Chaotic regime plots Figure 9: T race (left) and densit y (righ t) plots of prior parameters. The trace plots show the MCMC estimates (blue) captures the true v alue (green) in its distribution, with its cum ulative av erage (red) conv erging to a v alue close to the truth. Similarly the densit y plots display the p osterior’s estimate (blue) p eaking around the true v alue (red) of b oth parameters. The prior corresp onds to the black dashed line. F or b oth parameters, the true v alue lies in the supp ort of the densities of the estimates. F or β , the challenging hea vy-tailed Gamma prior is shrunk around the true v alue to form the p osterior. 26 Figure 10: V orticit y of the initial condition v 0 with the truth (far left) and MCMC estimates: kno wing the true α = 2 . 2 v alue (centre left), underestimating α = 1 . 5 (centre), ov erestimat- ing α = 3 (cen tre right) and estimating α using MwG (far right). The crosses indicate the p ositions where the v ector field is observed. W e observe similar estimates from the algo- rithms kno wing the correct smo othness and estimating it, alb eit giving a smo oth estimate. 27 D Case Study 2: trace plots (a) α = 2 (b) Estimated α (c) α = 1 . 5 (d) α = 2 . 5 Figure 11: T race plots of the parameters estimated when the algorithm knows the true α = 2 v alue (top left), underestimates α = 1 . 5 (b ottom left), ov erestimates α = 2 . 5 (b ottom righ t) and estimates α (top right). The dashed line indicates the burn-in p eriod. Assuming the wrong v alue of α leads to very p o or parameter estimation with σ 2 , ζ , ρ 1 , γ , µ x , µ y , τ in non-represen tative v alues. Samples for µ x , µ y are still distributed according to their prior indicating no information was gained from the data for µ . How ev er estimating α and kno wing the correct α allows for similar accurate parameter estimation results, as the samples are cen tered around or capture w ell the true v alue. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment