Linear Attention for Joint Power Optimization and User-Centric Clustering in Cell-Free Networks
Optimal AP clustering and power allocation are critical in user-centric cell-free massive MIMO systems. Existing deep learning models lack flexibility to handle dynamic network configurations. Furthermore, many approaches overlook pilot contamination…
Authors: Irched Chafaa, Giacomo Bacci, Luca Sanguinetti
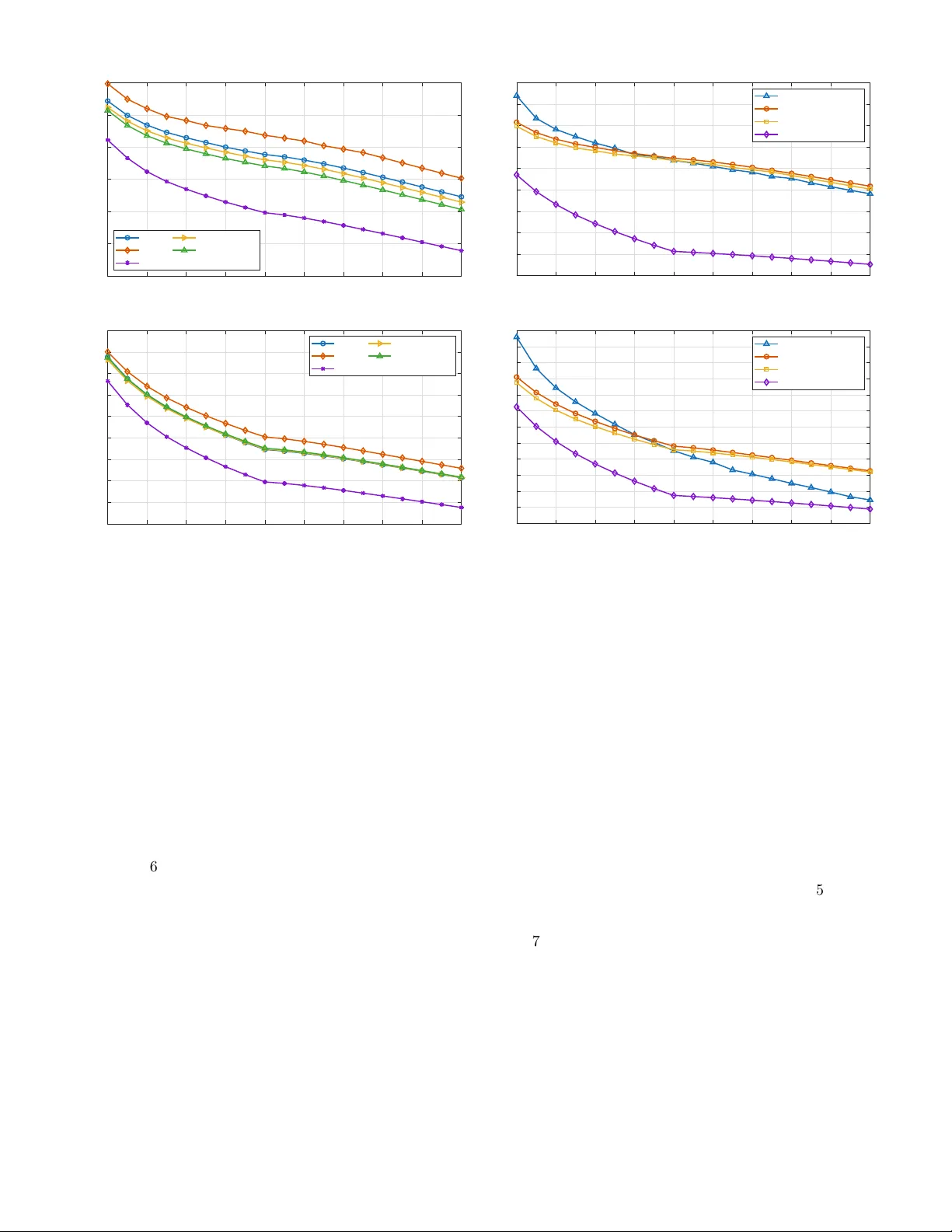
Linear A tten tion for Join t P o w er Optimization and User-Cen tric Clustering in Cell-F ree Net w orks Irc hed Chafaa, Giacomo Bacci, Senior Member, IEEE, Luca Sanguinetti, F ello w, IEEE Abstract—Optimal access p oin t (AP) clustering and p ow er allo cation are essen tial in user-centric cell-free massive MIMO systems. Ho wev er, existing solutions, whether based on deep learning or traditional optimization, lac k exibilit y to adapt to dynamic net work congurations, neglect pilot contamination eects and incur signicant computational complexit y . In this pap er, we prop ose a light w eigh t T ransformer mo del that o vercomes these limitations by join tly predicting AP clusters and p ow ers solely from the knowledge of spatial co ordinates of user devices and APs. Our mo del is architecture-agnostic to users load, handles b oth clustering and p ow er allo cation without c hannel estimation ov erhead, and eliminates pilot con tamination b y assigning users to APs within a pilot reuse constrain t. W e also incorp orate a customized linear attention mec hanism to capture user-AP interactions ecien tly and enable linear scalability with resp ect to the num ber of users. Numerical results conrm the mo del’s eectiv eness in maximiz- ing the minim um spectral eciency and providing near-optimal p erformance while ensuring adaptabilit y and scalabilit y in dynamic scenarios. Index T erms—CosF ormer, T ransformer, linear attention, sup ervised learning, pow er optimization, user-cen tric cell-free massiv e MIMO. I. In tro duction Cell-free (CF) massiv e MIMO (mMIMO) has emerged as a promising architecture to ov ercome the limitations of con v entional cellular net w orks [1]–[ 4 ]. Unlik e traditional cellular systems, where eac h user equipment (UE) is asso ciated with a single base station, CF mMIMO deploys a large num b er of distributed access p oints (APs) that coheren tly and jointly serv e all UEs within the cov erage area. This high level of co op eration oers uniform service qualit y , mitigates inter-cell interference, and enhances sp ectral eciency (SE), particularly in dense or hetero- geneous en vironmen ts. How ev er, realizing these b enets in practice remains c hallenging. If every AP serves ev ery UE, the resulting system demands substantial fronthaul The authors are with the Dipartimento di Ingegneria dell’Informazione, Universit y of Pisa, Via Caruso 16, 56122, Pisa, Italy (e-mail: irched.c hafaa@ing.unipi.it, {giacomo.bacci, luca.sanguinetti}@unipi.it). This work was supp orted by the Smart Networks and Services Joint Undertaking (SNS JU) under the European Union’s Horizon Europ e research and innov ation program under Grant Agreement No 101192369 (6G-MIRAI), and by the project F oReLab (Departments of Excellence), funded by the Italian Ministry of Education and Researc h (MUR). L. Sanguinetti was also supp orted by the Pro ject GARDEN funded by EU in NextGenerationEU Plan through Italian “Bando Prin 2022-D.D.1409 del 14-09-2022” . signaling, creates unnecessary interference from weak AP- UE links, and leads to inecient use of p ow er and pilot resources [ 5 ]. T o address these challenges, the user-cen tric (UC) paradigm has b een introduced in CF mMIMO [ 6 ]–[ 9 ]. In this approac h, each UE is served by a subset of the most relev ant APs, selected based on spatial proximit y or c hannel qualit y . By restricting co op eration to the most b enecial APs, the UC strategy reduces in terference and enhances scalability by low ering the computational and signaling burden. Nev ertheless, the performance of UC CF mMIMO depends critically on the prop er selection of AP clusters and transmission p ow ers, whic h m ust adapt dynamically to v ariations in c hannel conditions, UE mobility , and net w ork congurations. This makes clustering and p ow er control crucial c hallenges in realizing the full potential of UC CF mMIMO. A. Related w ork Giv en the imp ortance of clustering and p ow er optimiza- tion in UC CF mMIMO, a wide range of solutions hav e b een prop osed in the literature [ 6 ], [10]–[18]. These ap- proac hes dier in whether they treat clustering and p ow er allo cation separately or jointly , and in the metho dologies emplo y ed, ranging from classical optimization to mo dern mac hine learning. Classical optimization-based methods ha v e long b een applied to p ow er allocation, often through iterativ e al- gorithms [ 6 ], [10] or closed-form solutions for specic ob jectiv es such as the max-min fairness (MMF) problem [11]. While these approac hes can achiev e near-optimal p erformance, they t ypically require multiple iterations to con v erge, resulting in high computational complexity and p o or scalabilit y in dynamic net w orks. In parallel, clustering strategies hav e b een studied extensiv ely . Heuristic approac hes [12], [13] provide simple rules for grouping users and APs, while optimization-based form ulations [14] aim for more principled solutions. More recen tly , deep learning mo dels [15] ha ve b een introduced to automate clustering decisions. Despite their adv antages, these metho ds often lack adaptability: heuristic rules may o v ersimplify , optimization approac hes remain computa- tionally demanding, and deep learning solutions require retraining whenev er the n um b er of UEs or APs c hanges. Join t clustering and p ow er allo cation has also b een in v estigated [16]–[18], with the goal of simultaneously determining the serving AP subset and transmission p o wers. These metho ds generally outp erform separate treatmen ts, but they still suer from scalability issues and often neglect critical aspects suc h as pilot con tamination. Ov erall, whether treated separately or jointly , existing solutions remain limited in their abilit y to adapt eciently to dynamic net w ork conditions. B. T ransformer-based p ow er allo cation Recen tly , T ransformers [19] hav e b een explored to ad- dress exibility in dynamic wireless net works. In [20], the authors prop ose a T ransformer-based mo del only for do wn-link (DL) pow er allocation to handle v arying n um b ers of UEs via unsup ervised learning. Ho w ev er, the prop osed metho d requires p ost-pro cessing and padding, whic h introduces excessive padding when UE loads v ary widely , p otentially diluting meaningful information, and increases computational load without contributing useful information [21], [22], thereb y slowing training and af- fecting conv ergence. In [23], w e addressed the exibilit y issue in CF mMIMO by leveraging a T ransformer-based mo del capable of handling v arying user densities without padding or retraining. Unlik e [20], which employs large- scale fading co ecients as input, our mo del uses only spa- tial information (AP/UE co ordinates) to jointly predict up-link (UL) and DL p ow ers. This design enables ecien t adaptation to c hanges in the num b er of UEs and APs, while maintaining near-optimal performance for the MMF problem. Nevertheless, the solution did not address AP clustering or pilot contamination, and its complexity still scaled quadratically with the num b er of users similarly to [20]. In summary , the key question motiv ating this w ork is: Ho w can we o v ercome these limitations while preserving the adv antages of T ransformer-based mo dels in dynamic CF mMIMO? C. Main con tributions Building on our earlier work in [23], this pap er develops a scalable geometry-driv en optimization framework for UC CF mMIMO systems. The proposed model learns to approximate c hannel-a w are max-min SE optimization p olicies while signicantly reducing computational and signaling o v erhead. The main con tributions are summarized as follo ws: • Scalable joint clustering and pow er control: W e pro- p ose a single end-to-end learning framework that join tly predicts AP clusters and UL/DL p ow er under a max-min fairness ob jective. Unlike prior metho ds that rely on rep eated c hannel information for resource allo cation, the prop osed approac h pro duces near- optimal decisions using only spatial co ordinates as input, reducing o v erhead and decoupling clustering and p ow er control from c hannel estimation and data detection. Since UE p ositions capture key propaga- tion and interference c haracteristics, the mo del learns this mapping while naturally adapting to v arying UE loads. • Linear-complexit y attention for large-scale CF net- w orks: The prop osed mo del employs a customized linear attention mechanism whose complexity scales linearly with the num ber of UEs. This mak es the framework suitable for dense UC deploymen ts where quadratic-attention T ransformers or optimiza- tion metho ds become computationally prohibitive. In addition, the exp onential linear unit (ELU)-based mapping impro ves numerical conditioning and helps preserving weak er but fairness-relev ant AP-UE inter- actions in large heterogeneous net works. • A daptation to v arying UE loads without arc hitectural redesign: The arc hitecture is p ermutation-in v ariant and op erates with dierent num bers of UEs without arc hitecture mo dication or retraining, addressing a k ey limitation of existing deep learning-based resource allo cation sc hemes. • Pilot-a w are arc hitectural constraint: A pilot-related clustering constraint is embedded directly within the enco der, ensuring that eac h AP serves no more UEs than the av ailable orthogonal pilots. This mitigates pilot con tamination eects without requiring addi- tional pilot assignmen t procedures. • Robustness to imp erfect spatial information: W e ex- plicitly ev aluate robustness to co ordinate estimation errors by injecting Gaussian p erturbations into UE p ositions during training and testing. The results demonstrate stable p erformance under input uncer- tain t y , enhancing practical deploymen t feasibility . D. P ap er outline and notation The remainder of the pap er is organized as follows. Sects. I I and I I I describe the wireless net w ork mo del and the problem formulation. Sect. IV in tro duces the proposed ELU-CosF ormer architecture for AP clustering and p o w er optimization, while Sect. V details the training pro cedure. Sect. VI presen ts an extensiv e p erformance ev aluation, and Sect. VI I provides a computational complexit y analysis. Conclusions and p otential future extensions are discussed in Sect. VII I. W e denote the sets of real and complex num b ers b y R and C . Matrices and vectors are written in boldface upper- and low ercase letters, resp ectively . The sup erscripts ( · ) T and ( · ) H denote the transpose and the conjugate transpose op erations, respectively , and ⊙ indicates element-wise m ultiplication. Elemen t indices are written as a i for the i th en try of vector a and a i,j for the ( i, j ) th entry of a matrix. The notation N C ( µ , C ) refers to a circularly symmetric complex Gaussian v ariable with mean µ and cov ariance matrix C . The norm ∥·∥ denotes the ℓ 2 v ector norm, and E [ · ] the expectation op erator. The notation 1 ( · ) refers to the indicator function. The N × N iden tity matrix and the all-zero vector with N elements are denoted by I N and 0 N , resp ectiv ely . CPU AP 1 AP 4 AP 5 AP 6 AP 7 AP L =8 UE 1 UE K =3 AP cluster for UE 3 AP 2 AP 3 UE 2 AP cluster for UE 1 AP cluster for UE 2 Fig. 1: Illustration of a UC CF mMIMO net w ork, with L = 8 APs and K = 3 UEs. Each UE is served b y its o wn cluster of APs. I I. Wireless Net work Mo del W e consider a UC CF mMIMO netw ork, lik e the one sho wn in Fig. 1 , with K single-antenna UEs and L APs, eac h ha ving N antennas (in this example, w e use K = 3 , L = 8 , and N = 4 ). Eac h UE is served b y a subset of APs, called cluster and indicated by the dierent colors in Fig. 1 , and each AP can serve at most τ p UEs to preven t pilot con tamination. The net w ork op erates under a standard time division duplexing (TDD) proto col [ 6 ], where the τ c sym b ols of each coherence blo ck are allo cated to UL training ( τ p ), UL data ( τ u ), and DL data ( τ d ), with τ c ≥ τ p + τ u + τ d . W e adopt a narrowband c hannel mo del and assume that channels remain constant ov er a coherence blo c k. The c hannel v ector b etw een AP l and UE k is denoted b y h lk and mo deled as [ 6 ]: h lk = p β lk R 1 / 2 lk g lk , (1) where β lk is the large-scale fading, accounting for path loss and shado wing, R lk ∈ C N × N is the spatial correlation matrix at AP l , and g lk ∼ N C ( 0 , I N ) is an i.i.d. complex Gaussian v ector represen ting the small-scale fading, where I N is the N × N identit y matrix. W e assume that the c hannels { h lk ; l = 1 , . . . , L } are indep endent and call h k = h T 1 k , . . . , h T Lk T ∈ C LN the collective channel from all APs to UE k . The cen tral processing unit (CPU), also shown in Fig. 1 , computes the estimate of h k on the basis of received pilot sequences transmitted during the training phase [ 6 ]. The minim um mean square error (MMSE) estimate is b h k = [ b h T 1 k , . . . , b h T Lk ] T with [6, Sect. IV] b h lk = R lk Q − 1 lk h lk + 1 τ p ρ n lk ∼ N C ( 0 N , Φ lk ) , (2) where ρ is the UL pilot p ow er of each UE, n lk ∼ N C ( 0 N , σ 2 I N ) is the thermal noise, and Φ lk = R lk Q − 1 lk R lk , where Q lk = R lk + σ 2 τ p ρ I N . Hence, b h k ∼ N C ( 0 LN , Φ k ) , with Φ k = diag ( Φ 1 k , . . . , Φ Lk ) . Note that the metho d prop osed in this paper can b e applied to other c hannel estimation sc hemes. A. Uplink and do wnlink spectral eciency An achiev able UL SE of UE k is giv en b y the use-and- then-forget bound [ 6 , Sect. V]: SE UL k = τ u τ c log 2 1 + SINR UL k , (3) with UE k ’s eectiv e signal-to-interference-plus-noise ratio (SINR) dened as p UL k E v H k D k h k 2 K P i =1 p UL i E n v H k D k h i 2 o − p UL k E v H k D k h k 2 + σ 2 E { ∥ D k v k ∥ 2 } . (4) Here, p UL k is the UL transmit p ow er of user k , v k ∈ C N is the combining vector, and D k = diag( D k 1 , . . . , D kL ) is a block-diagonal matrix with D kl = I N if AP l serves UE k , and diag ( 0 N ) otherwise. The exp ectation is taken with resp ect to all sources of randomness. Although the b ound in ( 3 ) is v alid for any combiner v k , w e consider the MMSE, giv en b y [ 6 , Sect. V]: v k = K X k =1 p UL k b h k b h H k + Z ! − 1 b h k , (5) where Z = K X k =1 p UL k [diag( R 1 k , . . . , R Lk ) − Φ k ] + σ 2 I LN . (6) Similarly , the DL SE of user k is [6, Sect. VI] SE DL k = τ d τ c log 2 1 + SINR DL k , (7) where UE k ’s eectiv e SINR is p DL k E h H k D k w k 2 K P i =1 p DL i E n h H k D i w i 2 o − p DL k E h H k D k w k 2 + σ 2 . (8) Here, p DL k is the total DL p ow er allo cated to serve UE k such that p DL k = P L l =1 p DL k,l , with p DL k,l ∈ [0 , P DL l ] b eing AP l ’s transmit p ow er allo cated for user k ; P DL l is the maxim um p ow er p er AP (when user k is not served b y AP l , p DL k,l = 0 ); and w k ∈ C LN is the asso ciated unit- norm preco ding v ector. The MMSE precoder is used [ 6 ], whic h is given by w k = v k / ∥ v k ∥ . The channel estimation and preco ding/combining mo dels adopted ab ov e are used to generate channel-a ware training data as explained later in Sect. V-A. The prop osed learning framew ork itself do es not require instan taneous channel information at the CPU during inference, as it predicts clustering and p ow er deci- sions directly from UE/ AP spatial information, although c hannel v ariations are implicitly em b edded during training (see Sect. V-B for further details). I I I. Problem F ormulation T o ensure fairness among UEs, we adopt the MMF problem, widely used in UC CF mMIMO systems [ 6 ], [11], [24]. In the UL, the problem takes the form [ 6 , Sect. VI I]: max { p UL k ≥ 0 } min k SE UL k sub ject to p UL k ≤ P UL k ∀ k (9) where P UL k is the maxim um UL p ow er for UE k . Similarly , in the DL w e ha v e that: max { p DL k,l ≥ 0 } min k SE DL k sub ject to K X k =1 p DL k,l ≤ P DL l ∀ l. (10) The optimization problems in ( 9 ) and (10) can b e solv ed using a closed-form solution [11], iterative solvers (e.g., [ 6 ], [10]), or deep learning models (e.g., [20], [25], [26]) follo wing these common steps: 1) Estimate the large-scale fading coecients; 2) Assign serving AP clusters to the UEs using a clustering algorithm (e.g., the dynamic co op eration clustering (DCC) sc heme in [ 9 ]); 3) Estimate the channel v ectors b h l,k b et ween APs and UEs; 4) Compute the combining and preco ding vectors ( v k and w k ); 5) Ev aluate the SE using ( 3 ) or ( 7 ); 6) Compute the UL and DL transmit p ow ers b y solving ( 9 ) and (10). Irresp ectiv e of the adopted metho dology , the solution m ust b e obtained in real time, i.e., fast enough to b e deplo y ed b efore the UEs’ p ositions, load, and spatial distribution c hange and the clustering and pow er allo- cation problems need to be solv ed again. This stringent latency requiremen t limits the exibilit y of the system with respect to v arying UE loads and results in im- practical computational ov erhead in large and dynamic net w orks, since a new solution m ust b e computed at every coherence blo ck. In particular, the closed-form solution in [11] provides the optimal solution to ( 9 ) and (10) for a giv en xed clustering conguration. How ever, it do es not address the join t clustering and p ow er allo cation problem, and its computational complexit y scales cubically with the n um b er of UEs. T o address these limitations, we propose a learning mo del based on CosF ormer [27]. W e show that the geographical lo cations of UEs and APs provide sucien t information to serve as a proxy for jointly determining the clusters and computing the optimal pow er allo cation. W e advocate using the UEs’ positions since they capture the key characteristics of propagation c hannels and in- terference patterns in the net w ork. The prop osed mo del learns this mapping while naturally handling v arying UE loads. Once trained, the mo del b ypasses the rep eated execution of the full optimization pip eline (i.e., the six steps listed ab ov e) and pro duces near-optimal decisions through a single forward pass, enabling scalable and real- time adaptation to v arying UE loads while preserving fairness. F urthermore, this framework enables a separation be- t w een resource allo cation – p oten tially p erformed at the CPU – and data detection, carried out at the APs, thereb y further impro ving system scalabilit y . Finally , the prop osed approac h can also serv e as an eective system design to ol, as it relies only on coarse information (i.e., the UE lo cations). A. Ov erview of CosF ormer The standard T ransformer [19] relies on an attention mec hanism that captures dependencies among tokens (UEs in our case), but its quadratic complexity limits scalabilit y . CosF ormer [27] o v ercomes this issue by in tro- ducing a linearized atten tion mec hanism that preserv es accuracy while signican tly reducing computational cost. Among linear T ransformer v ariants [28]–[30], CosF ormer is particularly w ell suited to our setting due to the following prop erties: 1) A ccurate and stable attention: While many linear v ariants appro ximate the softmax attention and thus incur approximation errors, CosF ormer replaces soft- max with a cosine-based reweigh ting, improving nu- merical stabilit y and a v oiding suc h errors. 2) Implicit spatial bias: The cosine rew eighting naturally emphasizes lo cal relationships, whic h aligns with the imp ortance of nearby AP-UE pairs for clustering and p o wer allo cation. 3) Computational eciency: CosF ormer attains linear complexit y , reducing memory use and accelerating training, an essential feature for scalabilit y in large CF net w orks. Building on this foundation, we introduce our mo di- ed architecture, ELU-CosF ormer, which augments Cos- F ormer [27] with pilot-a w are constraints and mo died ac- tiv ation functions. These enhancements enable the model to join tly predict AP clusters and p o wers while eliminat- ing pilot contamination and ensuring SE fairness. Once trained with data that include channel mo deling and estimation, ELU-CosF ormer pro duces clusters and UL/DL p o wer levels directly from the spatial p ositions of the UEs and APs, allo wing seamless adaptation to v arying user loads. IV. Prop osed Learning Mo del for Clustering and P o w er Optimization In this section, w e in tro duce the proposed learning mo del, ELU-CosF ormer, whic h p erforms join t AP clus- tering and UL/DL pow er allo cation. W e rst describ e the o verall mo del architecture, and subsequen tly detail MHA + FFN MHA + FFN positions of UEs and APs input layer encoder output predictions Fig. 2: Architecture diagram of the prop osed mo del to predict jointly AP clusters, UL and DL p ow ers leveraging spatial information at the input. the linearized attention mechanism based on the mo died CosF ormer formulation. A. Mo del arc hitecture The prop osed mo del is a CosF ormer-based neural net- w ork composed of three main comp onents: a dynamic input la yer, a stack of enco der lay ers, and parallel output heads for clustering and p ow er prediction (see Fig. 2 ). These three components are described next in detail. 1) Input lay er: The input tensor is X ∈ R K × (2 L +2) , where eac h UE is represen ted b y 2 L + 2 spatial features (co ordinates of all L APs and the UE itself ). This tensor is pro jected into an em bedding space of dimension d mod via a linear la y er: Z in = XW ⊤ in + b in , (11) with trainable parameters W in and b in . The input is a sequence of K tok ens, where each token corresponds to one UE. Since the same projection is applied indep endently to ev ery tok en, the operation does not assume a xed n umber of UEs. Consequen tly , c hanges in K only mo dify the sequence length, while the mo del parameters remain unchanged. The sub- sequen t enco der processes this sequence using shared w eigh ts among UEs and preserv es the sequence token- structure, enabling the learning mo del to handle v arying user loads seamlessly without requiring ar- c hitectural mo dications. 2) Enco der lay ers: The embedded tensor Z (0) = Z in ∈ R K × d mod is pro cessed through M enco der la yers. Each la y er consists of a mo died CosF ormer m ulti-head atten tion (MHA), denoted by A ( · ) , follo wed by a feed- forw ard netw ork (FFN). Moreov er, the enco der lay ers apply lay er normalization and residual connections to stabilize training and preserv e information across la y ers [27]. Specically , the m -th enco der la yer applies the follo wing operations (see Fig. 3 ): Z ( m ) 1 = Z ( m − 1) + A ˜ Z ( m − 1) , (12) H ( m ) = ReLU ˜ Z ( m ) 1 W ( m ) ⊤ 1 + b ( m ) 1 , (13) Z ( m ) = ˜ Z ( m ) 1 + H ( m ) W ( m ) ⊤ 2 + b ( m ) 2 , (14) where ˜ Z denotes a lay er-normalized version of a tensor Z ; W ( m ) 1 , b ( m ) 1 , W ( m ) 2 , and b ( m ) 2 are trainable parameters; ReLU refers to an activ ation function [31] in tro ducing a non-linearit y . All M la yers share the same structure, and the output of each enco der lay er preserves the dimension R K × d mod , serving as input to the next la y er. After M la y ers, the nal tensor Z ( M ) = Z out represen ts the enco der output that will b e pro cessed next by the output heads. The attention mec hanism in (12)-(14) is detailed in Sect. IV-B. 3) Output heads: Three parallel heads op erate on the nal encoder output Z out ∈ R K × d mod : • UC clustering mask: A fully-connected lay er with sigmoid activ ation [31] pro duces an initial mask tensor M ∈ R K × L , where each entry represents the asso ciation strength b etw een a UE and an AP: M = sigmoid ( Z out W mask + b mask ) , (15) with trainable parameters W mask and b mask . T o mitigate pilot contamination, a t wo-step pro ce- dure is applied. First, for eac h AP, only the top τ p UEs with the highest mask scores are retained via T op τ p ( M ) . Then, a thresholding op eration assigns the AP to serv e the UE if the retained score exceeds a threshold ξ , yielding the nal binary clustering mask: M τ p = 1 T op τ p ( M ) ⊙ M > ξ . (16) The threshold ξ is a hyperparameter tuned during training to balance connectivity and interference. Prop er selection of ξ ensures strong UE-AP asso- ciations while main taining high SE. • Uplink p ow er prediction: A fully-connected la yer with sigmoid activ ation predicts normalized UL p o wers: ˜ p UL k = (sigmoid ( Z out W UL + b UL )) k , (17) where W UL and b UL are trainable parameters. The denormalized UL pow ers are obtained as ˆ p UL k = ∆ UL ˜ p UL k + P UL , (18) where ∆ UL = P UL − P UL denotes the UL pow er range. Here, P UL and P UL are the maximum and minim um allo w able UL transmit pow ers. layer normalization layer input layer output attention computation sum and layer normalization FFN sum and layer normalization Fig. 3: Illustration diagram of operations in one enco der lay er. • Do wnlink pow er prediction: A fully-connected lay er with sigmoid activ ation outputs normalized per-AP DL pow er w eigh ts: ˜ p DL k,l = (sigmoid( Z out W DL + b DL )) k,l , (19) where W DL and b DL are trainable parameters, and ˜ p DL k,l ∈ [0 , 1] represen ts the relative p ow er w eight assigned b y AP l to UE k . T o enforce the p er-AP p o w er constraint in (10), the predicted w eigh ts are scaled b y the AP pow er budget: ˆ p DL k,l = ˜ p DL k,l P K i =1 ˜ p DL i,l P DL l . (20) Since the av ailable DL p ow er lab els are dened p er UE, the total predicted DL p ow er allo cated to UE k is computed as ˆ p DL k = P L l =1 ˆ p DL k,l . These v alues are then normalized using the min-max scaling criterion in tro duced in Sect. V-A (Step 3) to obtain the pre- dicted lab els used for training. This ensures that the learning model resp ects the p er-AP p ow er constraints while remaining consistent with the av ailable optimal lab els used in the loss function dened in Sect. V-B. B. A tten tion mec hanism W e now detail the attention mechanism used in ( 12)- (14). The queries ( Q ), keys ( K ), and v alues ( V ) [19] are sim ultaneously computed from the lay er-normalized input ˜ Z in using a single linear transformation: Ω = ˜ Z in W Ω + b Ω , (21) where W Ω ∈ R d mod × 3 d mod and b Ω ∈ R 3 d mod are trainable parameters. The resulting tensor Ω ∈ R B × K × 3 d mod is split along the last dimension into three parts, yielding Q , K , V ∈ R B × K × d mod . These are then reshap ed into N h atten tion heads of dimension d head = d mod / N h , giving Q , K , V ∈ R B × N h × K × d head . (22) A k ernel feature mapping ϕ ( · ) is applied to the queries and k eys: Q ′ = ϕ ( Q ) , (23) K ′ = ϕ ( K ) , (24) with ϕ ( · ) b eing an activ ation function chosen to approxi- mate the softmax k ernel [31] of the original T ransformer while enabling linearized atten tion. The attention is then computed via a linearized opera- tion: A = Q ′ · K ′⊤ · V · W , (25) where W ∈ R K × K is a xed cosine rew eigh ting matrix with en tries w ij = cos( π ( i − j ) / (2 K )) . This mo dulation biases atten tion tow ard nearb y tok ens, mimicking the lo calit y bias of softmax without computing full pairwise in teractions, thereby av oiding the quadratic complexit y . In our context, this allows the model to distinguish b et ween nearby and distan t UEs/APs without in tro ducing additional trainable parameters. Finally , A is pro jected bac k into the mo del dimension, yielding the nal atten tion w eigh ts used in (12): A ˜ Z ( m − 1) = A W ⊤ out + b out , (26) with W out ∈ R d mod × d mod and b out ∈ R d mod b eing trainable parameters. Our choice of activ ation function. In the original Cos- F ormer [27], the k ernel feature mapping function ϕ ( · ) is implemen ted using rectied linear unit (ReLU). In this w ork, w e prop ose a simple y et ecien t mo dication: replacing ReLU with the ELU [31]. This choice is moti- v ated by b oth physical insights and empirical evidence. F ormally , the tw o activ ations are dened as [31]: ReLU( x ) = max(0 , x ) , ELU( x ) = ( x if x > 0 , α ( e x − 1) if x ≤ 0 , (27) where α is a h yp erparameter, t ypically set to 1 . ELU provides smo other gradien ts and nonzero outputs for negative inputs, preserving ric her feature interactions and impro ving gradien t ow and numerical stability dur- ing training. This is particularly imp ortant in our setting, where spatial coordinates require the attention mechanism to capture subtle UE-AP v ariations. In contrast, ReLU zero es out all negative inputs, p otentially discarding useful spatial information and leading to sparse gradients that hinder conv ergence. By delib erately allowing negativ e v alues, ELU maintains con tinuit y across the input do- main and prev en ts inactiv e atten tion heads, enabling the atten tion mechanism to exploit w eak but meaningful AP- UE asso ciations that would otherwise b e suppressed. Such asso ciations are critical under MMF criterion, where low- gain links can inuence the p erformance of the worst-case UE. Moreo v er, the exponential tail of ELU pro duces a smo oth and fully dieren tiable activ ation, which in teracts naturally with the cosine modulation in (25) (through W ). This combination yields a dieren tiable kernel that results in smo other and more stable attention distribu- tions, reducing abrupt v ariations in the attention weigh ts. This b ehavior is consistent with the inherently smo oth spatial v ariations observ ed in wireless propagation, where signal strengths c hange gradually rather than abruptly . Consequen tly , the learned attention patterns better reect realistic relationships b etw een UEs and APs, leading to more ph ysically meaningful clustering boundaries and a more balanced p o w er allo cation across the net work. The eectiv eness of this activ ation function is ev aluated in Sect. VI via an ablation experiment. V. T raining Setup The mo del is trained oine to predict the AP clusters and UE p ow ers. Next, we explain the structure of the generated dataset and provide details ab out the training pro cess. A. Dataset Construction T o train and ev aluate the learning mo del, we construct, based on the mo del in Sect. I I, a synthetic dataset that captures diverse cell-free netw ork congurations and realistic deploymen t conditions. The dataset construction follo ws four main steps: Step 1) Data generation: F or each conguration dened b y a pair ( K, L ) , w e generate: • random 2D p ositions within a b ounded area for K single-an tenna UEs, denoted as { u k } K k =1 , with u k ∈ R 2 , and L uniformly distributed APs, denoted as { a l } L l =1 , with a l ∈ R 2 ; • large-scale fading co ecients β lk , correlation matrices R lk , MMSE estimated channels b h lk , MMSE preco ders w k and combiners v k com- puted as detailed in Sect. II, which are required later by the closed-form solution to solve the max-min SE optimization problems in ( 9 ) and (10) for eac h set of clusters. Step 2) Noise injection: T o sim ulate localization errors and improv e robustness, Gaussian noise is added to UE positions: u ′ k = u k + δ k , δ k ∼ N (0 , σ 2 e ) , (28) where σ e = 1 m , follo wing [32]. This p erturbation accoun ts for p osition estimation errors. Step 3) Normalization: All features are normalized to the range [0 , 1] using min-max scaling. F or a feature v ector ξ , w e use ˜ ξ = ξ − min( ξ ) max( ξ ) − min( ξ ) + ε , (29) where ε is a small constan t to a v oid division b y zero. Co ordinates are normalized separately for x Algorithm 1 T raining with Dynamic Sup ervision Require: T raining dataset { X i } S i =1 , batch size S , trade-o parameter λ 1: for eac h ep o ch do 2: for each batc h do 3: Compute atten tion scores from the input X i 4: Generate AP clusters for eac h UE 5: Compute p o wers by solving ( 9 ) and (10) [11] 6: Ev aluate the loss function (30) 7: Up date mo del parameters via bac kpropagation 8: end for 9: end for and y , preserving geometric relationships, while UL and DL p ow ers are normalized globally to ensure consisten t scaling. Step 4) Dataset ov erview: A total of 8000 training sam- ples are generated for eac h v alue of K ∈ { 5 , 10 } and L = 16 . Each sample consists of normalized noisy UE and AP co ordinates, with corresp onding optimal p ow ers computed on the y during train- ing. T o ev aluate generalization, additional sam- ples are generated for other user counts b eyond the training v alues of K , enabling assessment of the mo del’s ability to adapt to unseen net w ork congurations. Overall, the dataset includes di- v erse congurations by v arying the num b er of UEs, their spatial distributions, and channel re- alizations, ensuring robust learning and eective generalization. B. T raining approach Unlik e conv en tional sup ervised learning [33], the opti- mal p o w er lab els cannot b e precomputed prior to training b ecause the clusters of APs serving each UE are deter- mined dynamically by the mo del itself. Consequently , the optimal p ow er labels dep end on the clustering decisions pro duced during the forw ard pass and are computed on-the-y during training. This results in a sup ervised learning framework with dynamic lab el generation, also referred to as dynamic sup ervision [34], [35], where the sup ervision signals are obtained by solving the p ow er con trol problems for the clusters predicted by the model. The ov erall training pro cedure is summarized in Algo- rithm 1 . During the forward pass, the model ev aluates atten tion scores betw een the input features, which dene the AP clusters b y assigning a set of serving APs to eac h UE. Given these predicted clusters, the UL and DL p ow er con trol problems are solved using the closed- form expressions in [11]. Then, the predicted p o wers ˜ p are compared with the normalized optimal ones ˜ p ⋆ , and the loss function updates the mo del parameters: L = 1 S S X i =1 ∥ ˜ p ⋆ i − ˜ p i ∥ 2 − λ min k SE UL k + min k SE DL k , (30) T able I: Mo del architecture parameters. Parameter V alue Encoder lay ers M 2 Atten tion heads N h 4 Model dimension d mod 64 Clustering threshold ξ 0 . 3 T able I I: Mo del training hyperparameters. Parameter V alue T rade-o parameter λ 10 − 2 Dropout rate 0 . 1 Optimizer Adam W [37] Learning rate 10 − 3 Epo chs 20 Batch size 64 where S is the batch size. The loss combines the mean- squared error b et ween predicted and optimal pow ers with a clustering-aw are p enalty that promotes fairness across users. The hyperparameter λ controls the trade- o betw een minimizing prediction error and improving the w orst-case SE. In practice, λ is tuned empirically via cross-v alidation. The mo del is implemented in PyT orch [36] and con- gured with the parameters listed in T ables I and I I, whic h are empirically tuned to balance accuracy and computational eciency . Notably , the mo del do es not take channel co ecients as input; instead, their eect is captured through the optimal p ow er lab els. By learning from these lab els, the net w ork maps UE-AP spatial congurations to clustering and pow er allo cation decisions across dierent net work congurations and user loads, eectively approximating the max-min SE policy at inference time without requiring instan taneous c hannel information. VI. Numerical results In this section, we assess the p erformance of the prop osed learning-based framework for solving the MMF problem in the UC CF mMIMO system describ ed in Sect. II. The main sim ulation parameters are reported in T able I I I. All numerical results are av eraged ov er the test set. The proposed solution is compared against the follo wing clustering and pow er allocation schemes: • Optimal CF: A fully co op erative baseline in which all APs serve all UEs, and transmit p ow ers are obtained via the closed-form expression in [11]. • DCC: A xed-clustering benchmark based on the DCC scheme [ 9 ], where eac h UE is asso ciated with its Q = 8 strongest APs. Po wer control follo ws the closed-form solution. • Optimal UC-CF: A h ybrid strategy in whic h AP-UE clusters are inferred by the proposed model, while transmit p o wers are still computed using the closed- form solution. T able I I I: CF mMIMO netw ork parameters. Parameter V alue Netw ork area 500 m × 500 m Number of APs ( L ) 16 (uniformly deploy ed) Antennas per AP ( N ) 4 Carrier frequency 2 GHz Path-loss exponent 3 . 67 UE-AP height dierence 10 m Shadow fading F kl N C (0 , α 2 ) , α 2 = 4 dB Noise p ow er σ 2 − 94 dB Noise gure η 7 dB Bandwidth B 20 MHz Max UL transmit power P UL 100 mW Max DL transmit power per AP P DL l 200 mW Coherence blo ck length τ c 200 Pilot length τ p 10 UL data symbols τ u 90 DL data symbols τ d 100 • Predicted UC-CF: The fully data-driven approach, where b oth clustering decisions and p ow er lev els are directly predicted by the prop osed learning arc hitec- ture. A. A ctiv ation function p erformance T o v alidate the choice of the ELU activ ation function detailed in Sect. IV-B, we ev aluate the p er-UE SE achiev ed b y a CosF ormer using sev eral activ ation functions [31] for the atten tion computation with the sim ulation parameters in T able I I I. The results rep orted in Fig. 4 demonstrate that ELU consisten tly yields higher SE across all user coun ts K for b oth UL and DL scenarios, conrming that ELU pro vides a more eective attention computation for our problem. B. Sp ectral eciency ev aluation Fig. 5 rep orts the av erage p er-UE SE as a function of the num b er of users K for b oth UL and DL transmission. As exp ected, the p er-UE SE decreases with increasing K in b oth links, since a larger num b er of users must share a xed amoun t of AP resources and is sub ject to higher in terference. Nev ertheless, the rate at which p erformance degrades v aries signicantly across the considered strate- gies. In the UL (Fig. 5a), Optimal CF pro vides the highest SE for small v alues of K due to full AP co op eration. Ho w ever, its performance deteriorates more rapidly as K increases. Beyond K ≈ 10 , Optimal UC-CF surpasses the fully coop erative baseline, as limiting co op eration to the most relev ant APs reduces interference and enables a more eectiv e allocation of transmit p o wer. A similar b ehavior is observed in the DL (Fig. 5b): while full CF remains sup erior at low user densities, Optimal UC-CF achiev es higher SE for larger K , with the b enets of clustering b eing ev en more pronounced in DL due to impro ved p ow er concen tration and reduced inter-user interference. The Predicted UC-CF closely tracks the optimal UC-CF in b oth UL and DL, conrming the generalization capability of the trained mo del across unseen user loads. In contrast, the classical DCC consistently yields the low est SE, as n umber of users K 2 4 6 8 10 12 14 16 18 20 p er-UE SE (bps/Hz) 2 2.2 2.4 2.6 2.8 3 3.2 ReLU ELU tanh LeakyReLU sigmoid (a) UL n umber of users K 2 4 6 8 10 12 14 16 18 20 p er-UE SE (bps/Hz) 2 2.2 2.4 2.6 2.8 3 3.2 3.4 3.6 3.8 ReLU ELU tanh LeakyReLU sigmoid (b) DL Fig. 4: Comparison of p er-UE SE using dieren t activ ation functions in CosF ormer for UL and DL. ELU yields the highest SE across all UE coun ts. its xed clustering cannot adapt to v arying interference conditions. Ov erall, these results sho w that while fully CF op- eration is adv antageous at low UE densities, UC clus- tering b ecomes increasingly b enecial as the netw ork gro ws congested. The prop osed learning mo del adapts to this transition, sustaining near-optimal p erformance with reduced computational and signaling o verhead. C. AP-UE clustering performance In Fig. 6 , w e ev aluate the total n umber of UE/AP connections (when UE is served by AP) of optimal CF, predicted UC-CF and DCC schemes for dierent user loads. In addition, we plot, in the secondary Y-axis, the a v erage num b er of connections p er UE of the predicted UC-CF. The results show that the UC-CF scheme exhibits few er total connections compared to CF, reecting the selectiv e asso ciation of users to a subset of APs based on the learned clustering. This indicates an ecient usage of netw ork resources since less connections implies less signaling and p o wer consumption while still pro viding near-optimal SE as illustrated earlier in Fig. 5. Moreo ver, it can b e seen that the total AP-UE connections saturates for higher n umber of users K 2 4 6 8 10 12 14 16 18 20 p er-UE SE (bps/Hz) 1.8 2 2.2 2.4 2.6 2.8 3 3.2 3.4 3.6 optimal CF optimal UC-CF predicted UC-CF DCC (a) UL n umber of users K 2 4 6 8 10 12 14 16 18 20 p er-UE SE (bps/Hz) 1.8 2 2.2 2.4 2.6 2.8 3 3.2 3.4 3.6 3.8 4 4.2 optimal CF optimal UC-CF predicted UC-CF DCC (b) DL Fig. 5: A verage p er-UE SE in UL and DL for dierent K v alues on the test set. The prop osed mo del adapts b etter to increasing user load compared to b enc hmark p olicies. user loads as the APs reach their τ p -serv ed UE constraint unlik e other p olicies that keep increasing, aecting their scalabilit y . Corresp ondingly , the av erage num b er of APs p er UE (red curve) gradually decreases as K increases. This b ehavior conrms the mo del’s ability to dynamically recongure clusters and allo cate AP ecien tly under v arying user densities to ac hieve b etter scalabilit y . In con trast, the DCC, whic h alwa ys connects the UE to Q = 8 APs, yields the low total connections at rst, but at the expense of a p o or SE p erformance (Fig. 5 ) and a linear gro wth of AP-UE connections with K . Fig. 7 represents an example of the clustering b ehavior of the model for K = 20 and L = 16 for a given sample of the testing set. Eac h UE is annotated with the n um b er of APs it is connected to, revealing the mo del’s adaptiv e clustering. Dashed lines highligh t the AP-UE links, showing selective asso ciation to only the most relev an t APs. This visualization conrms that UC- CF forms compact, user-sp ecic clusters that v ary across users, enabling ecient resource allo cation and reduced signaling o v erhead. n umber of users K 2 4 6 8 10 12 14 16 18 20 22 total AP-UE connections 0 50 100 150 200 250 300 350 400 a verage connections p er UE 7 8 9 10 11 12 13 14 15 16 optimal CF predicted UC-CF DCC Fig. 6: T otal AP-UE connections (left axis) and a v erage connections p er UE (right axis) as functions of dierent user loads. Our model in UC-CF strategy adapts the clusters dynamically to handle the increasing user load. D. P o wer prediction accuracy T o further ev aluate the eectiv eness of the prop osed learning mo del, w e compare the cumulativ e distribution functions (CDFs) of UL and DL p ow ers obtained from the optimal closed-form solution [11] and those predicted b y the trained mo del on the test set. As shown in Fig. 8 , the resulting curves are nearly ov erlapping in b oth cases, indicating that the mo del successfully learns the underly- ing p o wer allo cation strategy for the predicted clusters. This close agreemen t demonstrates that the predicted p o wers not only approximate the optimal allo cation with high delit y but also preserv e the statistical distribution of transmit p ow ers across UEs. Consequently , the pro- p osed approac h achiev es reliable p ow er prediction while a v oiding the computational burden of solving the closed- form optimization problem. This b eha vior is explained by the fact that the optimal p ow er allo cation is a mapping of large-scale channel statistics which highly dep end on UE-AP geometry , and th us the trained mo del learns to appro ximate this mapping accurately even for unseen UE deplo ymen ts of the test set. E. Robustness to input errors In Fig. 9 , we analyze the robustness of the prop osed learning model against input uncertaint y . During training, as stated in (28), the mo del is exp osed to user p osition in- puts corrupted by random Gaussian noise with a standard deviation of 1 m . T o assess generalization and robustness, the mo del is ev aluated under three test conditions: i) input with a xed standard deviation error of 3 m , ii) input with a xed standard deviation error of 5 m , and iii) an ideal scenario with error-free input. The results show that the p er-UE SE decreases only sligh tly as the input error level increases, for b oth UL and DL. Sp ecically , the maximum gap betw een the error- free and 5 m error cases is appro ximately 0 . 29 b / s / Hz in UL and 0 . 24 b / s / Hz in DL across all user coun ts, ˜ x 0 0.1 0.2 0.3 0.4 0 0.6 0.7 0.8 0.9 1 ˜ y 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 5 4 7 7 6 5 7 4 8 5 5 8 8 9 10 11 9 10 10 11 AP UE Fig. 7: Netw ork lay out of APs and UEs for K = 20 users. User-sp ecic clusters are predicted by the mo del for ecien t resource allocation. p er-UE p ow e r (W) 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 CDF 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 optimal predicted (a) CDF of UL transmit p ow ers. p er-UE p ow e r (W) 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2 CDF 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 optimal predicted (b) CDF of DL transmit p ow ers. Fig. 8: CDF comparison of optimal and predicted p ow ers in UL and DL. The close ov erlap conrms the accuracy of the prop osed learning mo del in repro ducing the optimal p o wer statistics. demonstrating the resilience of the proposed mo del. More- o v er, the relative trends across dierent user loads are preserv ed, indicating that the mo del can generalize its n umber of users K 2 4 6 8 10 12 14 16 18 20 p er-UE SE (bps/Hz) 2.2 2.4 2.6 2.8 3 3.2 3.4 3.6 withour errors with errors ± 3 m with errors ± 5 m (a) UL n umber of users K 2 4 6 8 10 12 14 16 18 20 p er-UE SE (bps/Hz) 2.2 2.4 2.6 2.8 3 3.2 3.4 3.6 withour errors with errors ± 3 m with errors ± 5 m (b) DL Fig. 9: A verage p er-UE SE for dierent UE counts and input error levels. The trained mo del remains robust to input errors. learned spatial relationships even when the inputs are aected by lo calization errors, th us ensuring practical robustness for real-world deploymen ts where user p osition estimates are inheren tly imperfect. F. Comparison with other T ransformer v ariants Fig. 10 presents a comparative analysis of UL and DL p er-UE SE achiev ed by the T ransformer and four linear atten tion v arian ts. Linformer is excluded b ecause it can- not accommo date v ariable UE counts without additional prepro cessing or arc hitectural mo dications [29]. In b oth UL and DL scenarios, ELU-CosF ormer consis- ten tly achiev es the highest SE across all user counts. This result highlights the b enet of integrating the ELU acti- v ation into the CosF ormer atten tion k ernel. As discussed in Sect. IV, the com bination of ELU with the cosine- based attention mechanism improv es the mo del’s ability to capture the spatial in teractions b etw een UEs and APs. Consequen tly , ELU-CosF ormer pro duces more eective AP clustering and p ow er allo cation decisions, maintaining strong p erformance ev en as the n umber of users increases under the considered fairness-driv en objective. In addition to SE, T able IV compares the mo dels in terms of complexity and eciency metrics. All models n umber of users K 2 4 6 8 10 12 14 16 18 20 p er-UE SE (bps/Hz) 2.2 2.4 2.6 2.8 3 3.2 3.4 3.6 Longformer T ransformer Cosformer ELU-Cosformer Performer (a) UL n umber of users K 2 4 6 8 10 12 14 16 18 20 p er-UE SE (bps/Hz) 2.2 2.4 2.6 2.8 3 3.2 3.4 3.6 Longformer T ransformer Cosformer ELU-Cosformer Performer (b) DL Fig. 10: Comparison of per-UE SE across dierent T rans- former v ariants for UL and DL scenarios. Our modied CosF ormer maintains higher SE. w ere ev aluated under consistent conditions to ensure fair comparison, with latency and training time rep orted for K = 10 UEs. • P arameters: T otal num b er of trainable weigh ts in the mo del. • Memory (MB): Estimated memory fo otprint during inference, reecting graphics pro cessing unit (GPU) usage. • FLOPs: Floating-p oint operations p er forward pass, indicating computational complexit y . • Latency (ms): A verage inference time, measuring real- time responsiveness. • T raining Time (s/ep o ch): Time p er training ep o ch, capturing training eciency . ELU-CosF ormer and CosF ormer share the same archi- tecture and parameter coun t, diering only in their acti- v ation functions-ELU and ReLU, resp ectiv ely . Although ELU is computationally more intensiv e, ELU-CosF ormer ac hiev es slightly low er training time per epo ch, due to smo other gradient o w that enables more ecient bac k- propagation and faster conv ergence. In contrast, ReLU’s simplicit y gives CosF ormer a marginal adv an tage in in- ference latency , as ReLU operations are highly optimized T able IV: Performance comparison of T ransformer v arian ts in terms of complexity and eciency metrics. Model Parameters Memory (MB) FLOPs Latency (ms) T raining Time (s/ep o ch) ELU-CosF ormer 103 , 378 0 . 39 1 , 056 , 820 3 . 42 858 . 27 CosF ormer 103 , 378 0 . 39 1 , 056 , 820 3 . 40 915 . 82 T ransformer 846 , 866 3 . 23 5 , 682 , 260 4 . 42 1447 . 69 Longformer 7 , 102 , 738 27 . 09 635 , 398 , 900 680 . 99 1866 . 63 Performer 103 , 378 0 . 39 1 , 041 , 460 4 . 40 1076 . 56 for GPU execution. Performer maintains a low parameter coun t and memory fo otprint comparable to CosF ormer, but exhibits higher training and inference times due to the computational ov erhead of random feature pro jections and exp onentiation in its k ernel mapping [28], which are less GPU-ecien t than CosF ormer’s cosine reweigh ting. The standard T ransformer exhibits substantially higher FLOPs and memory requirements, owing to its quadratic atten tion mec hanism and larger parameter count, re- sulting in increased latency and longer training time. Longformer shows the highest latency and training time o v erall, reecting its signican tly larger parameter coun t relativ e to the other models. In summary , the results in Fig. 10 and T able IV indicate that the prop osed ELU-CosF ormer achiev es the most balanced and scalable p erformance, v alidating its design for fairness-a w are resource optimization. VI I. Computational Complexit y Analysis When the num b er of users K increases, the p er-sample computational complexity of our mo del is dominated by the linearized atten tion term O ( M · d mod · K ) , which scales linearly with K . This linear scaling represen ts a clear adv an tage compared to prior T ransformer-based approac hes [20], [23], where the complexit y gro ws quadrat- ically as O ( M · d mod · K 2 ) , and iterative optimization metho ds [10], which scale as O ( T · L · K 2 ) with T iterations. It is also fav orable compared to the optimal closed-form solution that require cubic scaling O ( K 3 ) , which quickly b ecome prohibitiv e in dense net w orks. F or illustration, w e b enchmark the runtime on a CPU for K = 40 , computing b oth AP-UE clusters and UL/DL p o wers using our predicted UC-CF sc heme v ersus DCC (with closed-form solution for pow er computation). The prop osed UC-CF model requires only 9 . 2 ms , whereas DCC takes 31 . 6 s . This orders-of-magnitude sp eedup, ac hiev ed through linearized attention, highlights the sig- nican t eciency gain of our approach and makes it more suitable for large-scale deplo ymen ts. Bey ond asymptotic complexity , several practical as- p ects reinforce the adv an tage of our mo del. The linear atten tion mechanism reduces memory usage compared to quadratic approaches, enabling scalability to larger user counts and deploymen t on resource-constrained edge devices. This eciency also translates into low er energy consumption, aligning with sustainability goals in next- generation wireless netw orks. Moreov er, the one-shot in- ference design a voids iterative ov erhead, ensuring real-time resp onsiv eness to dynamic user distributions and mobilit y . Imp ortan tly , the model main tains near-optimal SE despite its reduced complexity , conrming that eciency do es not compromise accuracy . Finally , linear attention benets more from parallelization on graphics pro cessing unit and tensor pro cessing unit [38], [39], further widening the p erformance gap with quadratic and iterativ e metho ds. VI I I. Conclusion This pap er prop osed a scalable and exible deep learn- ing mo del for joint AP clustering and p ow er allo cation in UC CF mMIMO systems. The metho d follows a dynamic sup ervised learning paradigm in whic h optimal p ow er la- b els are generated on the y for the predicted AP clusters to train a CosF ormer-based mo del that maps UE-AP spatial congurations to the corresp onding resource allo ca- tion decisions. By relying primarily on spatial information and leveraging a customized attention mechanism, the prop osed framework a v oids pilot con tamination, adapts seamlessly to v arying user loads, and enables resource al- lo cation decisions without requiring instantaneous c hannel information as input. This allo ws the joint clustering and p o wer con trol to be decoupled from the data detection stage. Numerical ev aluations demonstrated that the proposed framew ork achiev es near-optimal SE while reducing com- putational complexity and signaling ov erhead. In partic- ular, while the complexity of the optimal solution scales as O ( K 3 ) with the num b er of UEs, the prop osed mo del p erforms resource allo cation through a single inference step and scales linearly with K . F urthermore, since the mo del relies only on spatial information during inference, it eliminates the need for exc hanging instan taneous chan- nels for resource optimization, thereb y reducing signaling o v erhead. In addition, the clustering learned by the mo del limits the num b er of APs serving each UE to the most relev ant ones, whic h further reduces coordination and signaling requiremen ts betw een APs and the CPU. F uture research directions include in v estigating dis- tributed learning strategies among APs or clusters to fur- ther reduce cen tralization requirements. Another promis- ing direction is the in tegration of temp oral information, enabling the mo del to capture user mobility , trac v ari- ations, and time-dep enden t channel dynamics. Extending the architecture with temp oral attention mec hanisms may enable proactive resource allo cation and enhance robust- ness in highly dynamic op erating conditions. Additionally , further v alidation could use ra y-tracing datasets or real measuremen t campaigns. References [1] H. Q. Ngo, A. Ashikhmin, H. Y ang, E. G. Larsson, and T. L. Marzetta, “Cell-free massiv e MIMO versus small cells,” vol. 16, no. 3, pp. 1834–1850, 2017. [2] ——, “Cell-free massive MIMO: Uniformly great service for every one,” in Pro c. IEEE Intl. W ork. Signal Pro cess. Adv ances in Wireless Commun. (SP A WC), Sto ckholm, Sweden, 2015, pp. 201–205. [3] E. Nay ebi, A. Ashikhmin, T. L. Marzetta, and H. Y ang, “Cell- free massive MIMO systems,” in Pro c. Asilomar Conf. Signals, systems, and computers, Pacic Gro v e, CA, USA, 2015, pp. 695–699. [4] E. Björnson and L. Sanguinetti, “Making cell-free massive MIMO comp etitive with MMSE pro cessing and centralized implementation,” v ol. 19, no. 1, pp. 77–90, 2019. [5] H. Q. Ngo, G. Interdonato, E. G. Larsson, G. Caire, and J. G. Andrews, “Ultradense cell-free massive MIMO for 6G: technical ov erview and op en questions,” vol. 112, no. 7, pp. 805–831, 2024. [6] Ö. T. Demir, E. Björnson, and L. Sanguinetti, “F oundations of user-centric cell-free massiv e MIMO,” F oundations and T rends® in Signal Pro cessing, vol. 14, no. 3-4, pp. 162–472, 2021. [7] S. Buzzi and C. D’Andrea, “Cell-free massive MIMO: User- centric approac h,” vol. 6, no. 6, pp. 706–709, 2017. [8] S. Buzzi, F. Linsalata, E. Moro, and G. Interdonato, “Why user- centric cell-free distributed MIMO systems will b e the disruptiv e 6G technology ,” 2026, to app ear. [9] E. Björnson and L. Sanguinetti, “A new look at cell-free massiv e MIMO: Making it practical with dynamic coop eration,” in Pro c. IEEE Intl. Symp. Personal, Indo or and Mobile Radio Commun. (PIMRC), Istan bul, T urkey , 2019. [10] M. F aroo q, H. Q. Ngo, and L.-N. T ran, “Accelerated projected gradient metho d for the optimization of cell-free massiv e MIMO downlink,” in Pro c. IEEE In tl. Symp. Personal, Indo or and Mobile Radio Commun. (PIMRC), London, UK, 2020. [11] L. Miretti, R. L. G. Cav alcante, S. Stańczak, M. Sch ubert, R. Böhnke, and W. Xu, “Closed-form max-min pow er con trol for some cellular and cell-free massiv e MIMO netw orks,” in Pro c. IEEE V eh. T echnol. Conf. (VTC), Helsinki, Finland, 2022. [12] E. Shi, J. Zhang, J. An, G. Zhang, Z. Liu, C. Y uen, and B. Ai, “Joint AP-UE asso ciation and preco ding for SIM-aided cell-free massive MIMO systems,” vol. 24, no. 6, pp. 5352–5367, 2025. [13] E. Björnson and E. Jorswieck, “Optimal resource allo cation in coordinated multi-cell systems,” F oundations and T rends® in Communications and Information Theory , v ol. 9, no. 2-3, pp. 113–381, 2013. [14] H. A. Ammar, R. Adv e, S. Shah bazpanahi, G. Boudreau, and K. V. Sriniv as, “User-centric cell-free massive MIMO netw orks: A survey of opp ortunities, challenges and solutions,” v ol. 24, no. 1, pp. 611–652, 2021. [15] G. Di Gennaro, A. Buonanno, G. Romano, S. Buzzi, and F. A. Palmieri, “A deep learning approach for user-centric clustering in cell-free massiv e MIMO systems,” in Pro c. IEEE Intl. W ork. Signal Pro cess. Adv ances in Wireless Commun. (SP A WC), Lucca, Italy , 2024, pp. 661–665. [16] A. Liu and V. K. Lau, “Joint BS-user asso ciation, p ow er allocation, and user-side interference cancellation in cell-free heterogeneous netw orks,” vol. 65, no. 2, pp. 335–345, 2016. [17] H. A. Ammar, R. Adv e, S. Shah bazpanahi, G. Boudreau, and K. V. Sriniv as, “Do wnlink resource allocation in multiuser cell- free MIMO netw orks with user-cen tric clustering,” v ol. 21, no. 3, pp. 1482–1497, 2021. [18] Z. Liu, J. Zhang, Z. Liu, D. W. K. Ng, and B. Ai, “Joint coop erative clustering and pow er control for energy-ecient cell-free XL-MIMO with multi-agent reinforcemen t learning,” vol. 72, no. 12, pp. 7772–7786, 2024. [19] A. V aswani, N. Shazeer, N. P armar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Atten tion is all you need,” in Pro c. Conf. Neural Inf. Process. Systems (NIPS), Long Beac h, CA, USA, 2017. [20] A. K. K o charlak ota, S. A. V oroby ov, and R. W. Heath Jr, “Pilot contamination aw are transformer for do wnlink p ow er con trol in cell-free massiv e MIMO net works,” v ol. 25, pp. 9656–9671, 2026. [21] M. Dwarampudi and N. Reddy , “Eects of padding on LSTMs and CNNs,” arXiv preprint arXiv:1903.07288, 2019. [22] F. Alrasheedi, X. Zhong, and P .-C. Huang, “Padding module: Learning the padding in deep neural netw orks,” v ol. 11, pp. 7348–7357, 2023. [23] I. Chafaa, G. Bacci, and L. Sanguinetti, “T ransformer-based power optimization for max-min fairness in cell-free massive MIMO,” vol. 14, no. 8, pp. 2316–2320, 2025. [24] S. Chakrab orty , E. Björnson, and L. Sanguinetti, “Centralized and distributed pow er allo cation for max-min fairness in cell- free massive MIMO,” in Pro c. Asilomar Conf. Signals, systems, and computers, Pacic Grov e, CA, USA, 2019, pp. 576–580. [25] D. Kim, H. Jung, and I.-H. Lee, “A surv ey on deep learning- based resource allocation sc hemes,” in Proc. Intl. Conf. Informa- tion and Commun. T ec hnol. Conv ergence (ICTC), Jeju Island, South Korea, 2023. [26] Q. Mao, F. Hu, and Q. Hao, “Deep learning for intelligen t wireless netw orks: A comprehensive survey ,” vol. 20, no. 4, pp. 2595–2621, 2018. [27] Z. Qin, W. Sun, H. Deng, D. Li, Y. W ei, B. Lv, J. Y an, L. Kong, and Y. Zhong, “cosF ormer: Rethinking softmax in atten tion,” arXiv preprint arXiv:2202.08791, 2022. [28] K. Choromanski, V. Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P . Hawkins, J. Davis, A. Mohiuddin, L. Kaiser, D. Belanger, L. Colwell, and A. W eller, “Rethinking attention with p erformers,” arXiv preprint 2020. [29] S. W ang, B. Z. Li, M. Khabsa, H. F ang, and H. Ma, “Lin- former: Self-attention with linear complexity ,” arXiv preprint arXiv:2006.04768, 2020. [30] I. Beltagy , M. E. Peters, and A. Cohan, “Longformer: The long- document transformer,” arXiv preprint arXiv:2004.05150, 2020. [31] A. D. Rasamo elina, F. Adjailia, and P . Sinčák, “A review of activ ation function for articial neural netw ork,” in Pro c. IEEE W orld Symp. Applied Machine In tell. & Informatics (SAMI), Herlany , Slov akia, 2020. [32] C. Xue, P . Psimoulis, Q. Zhang, and X. Meng, “Analysis of the performance of closely spaced low-cost multi-gnss receivers,” Applied Geomatics, vol. 13, no. 3, pp. 415–435, 2021. [33] V. Nasteski, “An ov erview of the sup ervised mac hine learning methods,” Horizons. b, vol. 4, no. 51-62, p. 56, 2017. [34] H. Pham, Z. Dai, Q. Xie, and Q. V. Le, “Meta pseudo labels,” in Proc. IEEE/CVF Conf. Computer Vision and Pattern Recog- nition, Nashville, TN, USA, 2021, pp. 11 557–11 568. [35] X. W ang, Z. Xu, D. Y ang, L. T am, H. Roth, and D. Xu, “Learning image labels on-the-y for training robust classi- cation mo dels,” arXiv preprint arXiv:2009.10325, 2020. [36] A. P . et al., “PyT orc h: An imp erative style, high-p erformance deep learning library ,” in Pro c. Conf. Neural Inf. Pro cess. Systems (NIPS), V ancouv er, Canada, 2019. [37] P . Zhou, X. Xie, Z. Lin, and S. Y an, “T o wards understanding conv ergence and generalization of Adam W,” vol. 46d, no. 9, pp. 6486–6493, 2024. [38] S. Pal, V. Zhang, E. Ebrahimi, S. Migacz, A. Zulqar, Y. F u, D. Nellans, and P . Gupta, “Optimizing m ulti-GPU paral- lelization strategies for deep learning training,” arXiv preprint arXiv:1907.13257, 2019. [39] N. P . Jouppi et al., “In-datacenter performance analysis of a tensor processing unit,” in Pro c. Annual Intl. Symp. Computer Architecture, T oronto, Canada, 2017, pp. 1–12.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment