Beyond Outliers: A Data-Free Layer-wise Mixed-Precision Quantization Approach Driven by Numerical and Structural Dual-Sensitivity
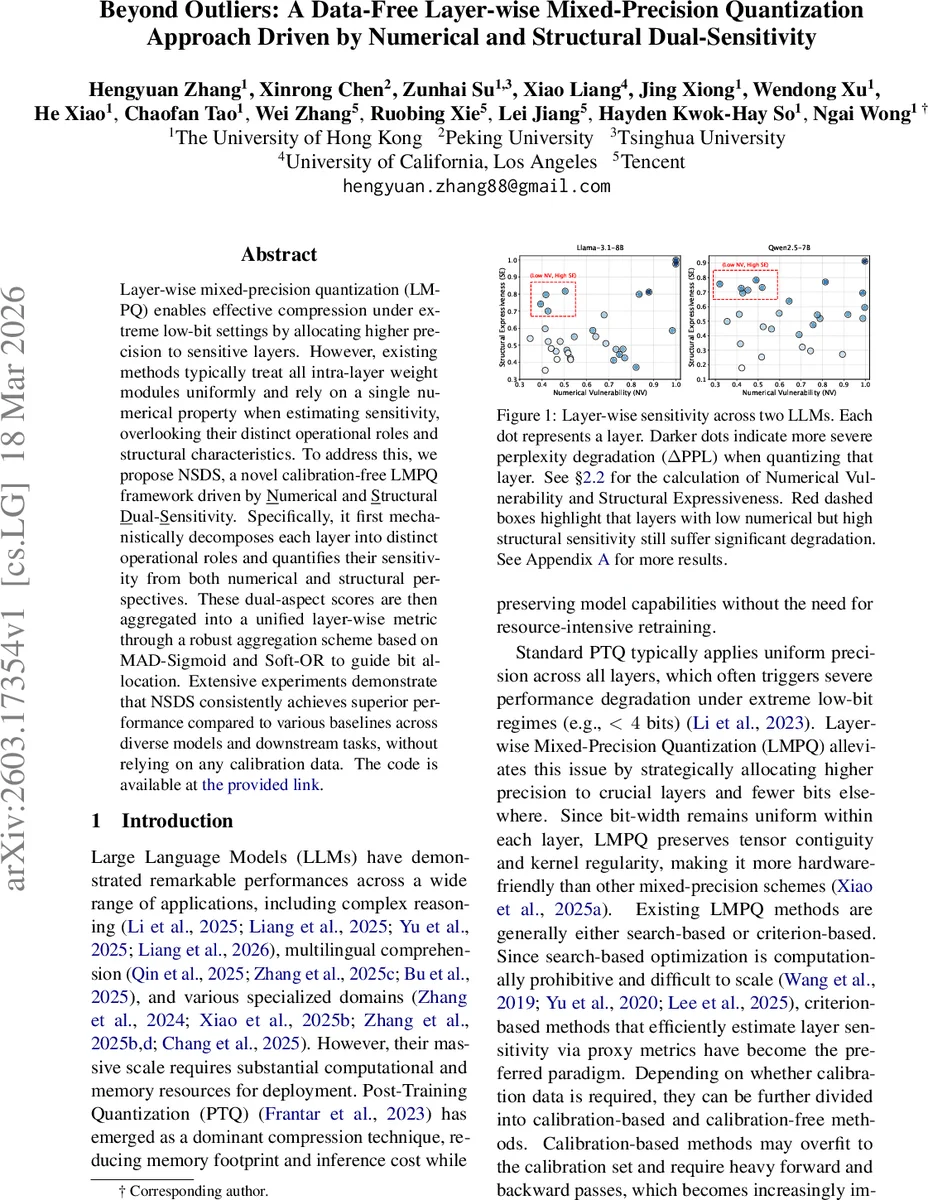
Layer-wise mixed-precision quantization (LMPQ) enables effective compression under extreme low-bit settings by allocating higher precision to sensitive layers. However, existing methods typically treat all intra-layer weight modules uniformly and rely on a single numerical property when estimating sensitivity, overlooking their distinct operational roles and structural characteristics. To address this, we propose NSDS, a novel calibration-free LMPQ framework driven by Numerical and Structural Dual-Sensitivity. Specifically, it first mechanistically decomposes each layer into distinct operational roles and quantifies their sensitivity from both numerical and structural perspectives. These dual-aspect scores are then aggregated into a unified layer-wise metric through a robust aggregation scheme based on MAD-Sigmoid and Soft-OR to guide bit allocation. Extensive experiments demonstrate that NSDS consistently achieves superior performance compared to various baselines across diverse models and downstream tasks, without relying on any calibration data.
💡 Research Summary
The paper introduces NSDS, a novel data‑free layer‑wise mixed‑precision quantization (LMPQ) framework designed for large language models (LLMs) operating under extreme low‑bit regimes (2–4 bits). Existing LMPQ approaches fall into two categories: search‑based methods that are computationally prohibitive for very large models, and criterion‑based methods that estimate layer sensitivity using a single numerical property (e.g., outlier statistics, Hessian information). Both categories share two critical shortcomings: (1) they treat all weight modules inside a layer uniformly, ignoring the distinct functional roles of different sub‑components, and (2) they rely on a single numerical metric, overlooking structural characteristics of the weight matrices.
NSDS addresses these gaps through three key innovations. First, it mechanistically decomposes each Transformer layer into its constituent operational components and classifies them into two functional roles: Detectors (which compute attention or activation patterns to detect relevant tokens or neuron features) and Writers (which write the detected information back into the residual stream). In a multi‑head attention (MHA) block, the query‑key product (W^{QK}) acts as a Detector, while the output projection (W^{OV}) acts as a Writer. In the feed‑forward network (FFN), the input projection (W^{in}) is a Detector and the output projection (W^{out}) is a Writer. This role‑aware decomposition provides a finer granularity for sensitivity analysis.
Second, NSDS quantifies sensitivity from two complementary perspectives:
- Numerical Vulnerability (NV) – measured by the excess kurtosis (\kappa) of the flattened weight vector. High kurtosis indicates heavy‑tailed distributions with many extreme outliers, which expand the quantization range and cause severe degradation when low‑bit quantization is applied.
- Structural Expressiveness (SE) – derived from singular‑value decomposition (SVD) of each weight matrix. The raw structural score combines the L1 norm of singular values (spectral magnitude) and the Shannon entropy of the normalized singular spectrum, capturing total energy and representational richness. To make SE role‑aware, NSDS introduces two re‑weighting factors: Detection Specificity ((\beta_{DS})) for Detectors, computed as the excess kurtosis of the input singular vectors (columns of (V)), and Writing Density ((\beta_{WD})) for Writers, computed as the L1 norm of the projection of output singular vectors (columns of (U)) onto the vocabulary unembedding matrix (W_U). The re‑weighted singular values are then fed back into the SE formula, yielding a role‑specific structural expressiveness (E_{role}).
Third, NSDS robustly normalizes and aggregates the NV and SE scores. Because the two metrics have different scales and variances, each raw score set is transformed into a robust Z‑score using Median Absolute Deviation (MAD) and then passed through a sigmoid to map it into (
Comments & Academic Discussion
Loading comments...
Leave a Comment