Improving RCT-Based CATE Estimation Under Covariate Mismatch via Double Calibration
We develop estimators that improve precision of heterogeneous treatment effect estimates that allow borrowing information from observational studies when the available covariates in each data source do not perfectly match. Standard data-borrowing met…
Authors: Samhita Pal, Jared D. Huling, Amir Asiaee
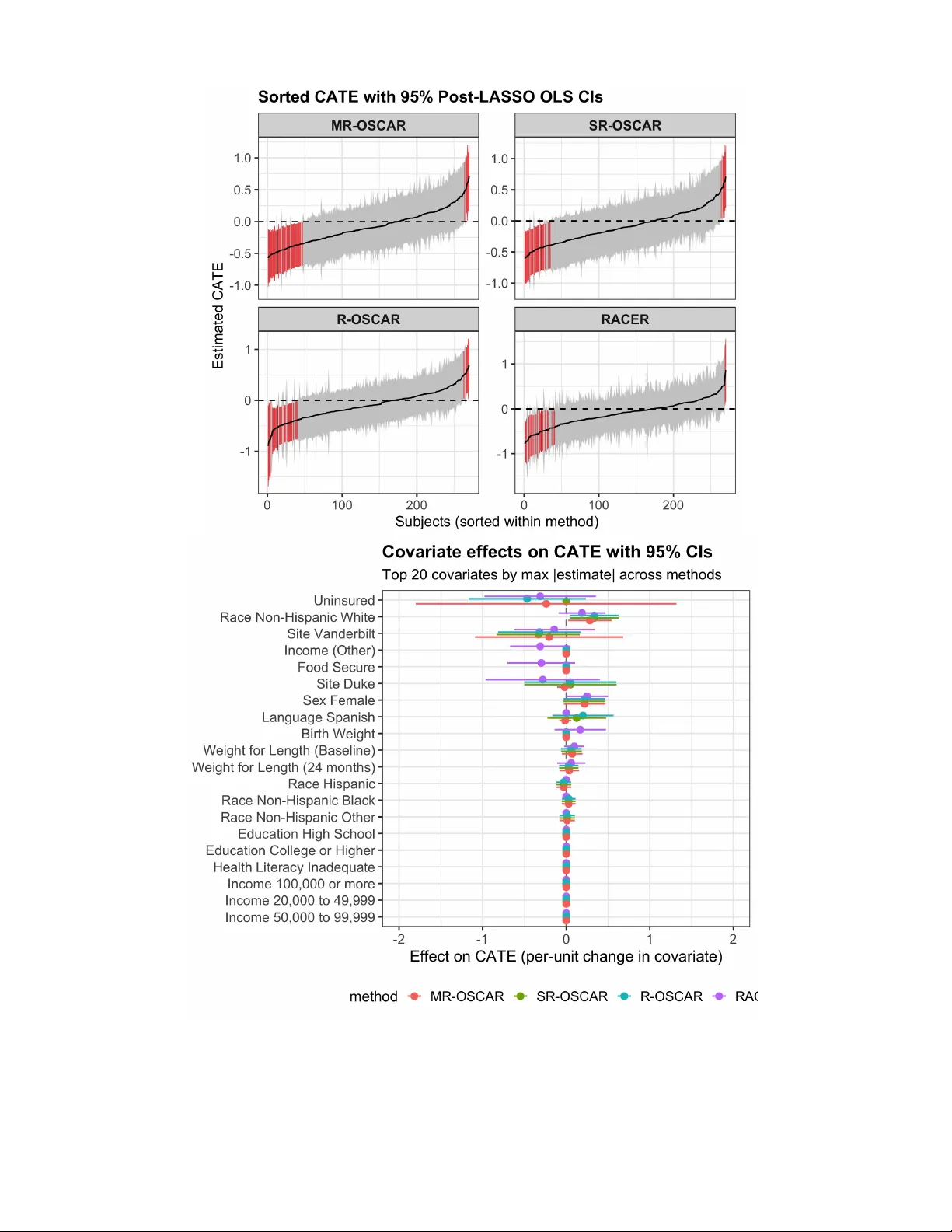
Impro ving R CT-Based CA TE Estimation Under Co v ariate Mismatc h via Double Calibration Samhita P al, ∗ Departmen t of Biostatistics, V anderbilt Universit y Medical Cen ter Jared D. Huling Division of Biostatistics and Health Data Science, Univ ersit y of Minnesota and Amir Asiaee Departmen t of Biostatistics, V anderbilt Universit y Medical Cen ter Marc h 19, 2026 Abstract W e dev elop estimators that improv e precision of heterogeneous treatment effect estimates that allo w b orro wing information from observ ational studies when the av ail- able cov ariates in each data source do not p erfectly match. Standard data-b orrowing metho ds often assume perfectly matched co v ariates. W e prop ose MR-OSCAR, an R CT-calibrated, tw o-stage estimation approach that first predicts the trial-missing v ariables using the observ ational data via imputation and then calibrates observ a- tional outcome predictions to the randomized trial, preserving the causal contrast, unlik e the results for generalization, where imputation do es not impro ve p erformance. Our theory giv es finite-sample guaran tees with a transparen t error decomp osition in- cluding an imputation error that shrinks as the observ ational mapping b ecomes more predictable. Sim ulations sho w that imputation almost alw ays outperforms naiv ely us- ing only the shared cov ariates and clarifies when b orro wing helps (strong predictabil- it y of the missing blo c k, mo derate trial size) and when it doe s not (po or predictabilit y or dominan t trial-only mo derators). W e motiv ate the approac h with the Greenlight Plus trial on early childhoo d ob esity and outline a forthcoming EHR analysis at V an- derbilt, highlighting the use of our metho d in common scenarios where data do not p erfectly align. Keywor ds: causal inference, data integration, imputation, conditional a verage treatmen t effect, randomized trials ∗ samhita.pal@vumc.org 1 1 In tro duction Heterogeneous treatment effects (HTEs) are central to precision preven tion and care. Ran- domized con trolled trials (RCTs) remain the gold standard for causal inference, y et most trials are p o wered for av erage effects rather than the fine-grained heterogeneity that guides individualized decisions (W ang et al., 2007; Ken t et al., 2018). Large observ ational studies (OS) con tain rich cov ariates and massive sample sizes, but are vulnerable to confounding and design biases. This asymmetry motiv ates b orro wing information from observ ational data to impro ve within-trial precision for conditional a verage treatmen t effects (CA TEs), pro vided the b orro wing is conducted such that observ ational confounding cannot distort the randomized contrast. A growing metho dological literature has made this idea concrete b y sho wing how to combine trials with large observ ational cohorts while preserving, or ev en sharp ening, the randomized contrast Cheng and Cai (2021); Ob erst et al. (2022); Ra- man et al. (2023). Recen t causal fusion framew orks use w eigh ting, outcome mo deling, or double-robust estimators to integrate an R CT with an external cohort under formal trans- p ortabilit y assumptions, and theory and simulations sho w that, when those assumptions hold, borrowing can substan tially reduce v ariance for HTE estimands relativ e to trial-only analyses Asiaee et al. (2025); W u and Y ang (2022). In this pap er, we aim to improv e the precision of RCT-based CA TE estimation b y b orro wing outcome-prediction structure from a large observ ational database while ensuring that the causal identification remains anc hored in the randomized contrast. Several existing approac hes follow this principle. Represen tation-learning metho ds (Johansson et al., 2016; Y ao et al., 2018; Hatt et al., 2022) use large OS datasets to learn prognostic scores or balanced embeddings that stabilize effect estimation in small RCTs. Most directly related, Asiaee et al. (2025) prop ose R-OSCAR, a t wo-stage estimator that learns outcome mo dels from OS data, calibrates them to the RCT via a discrepancy function estimated on the trial, and uses the calibrated predictions as v ariance-reducing pseudo-outcomes. Because the final CA TE is iden tified solely through the randomized con trast, OS confounding do es not bias the estimate. In parallel, Karlsson et al. (2025) in tro duce the QR-learner, a mo del- agnostic learner that leverages external data for CA TE estimation in the trial p opulation while guaran teeing that using external data cannot w orsen the risk relative to a trial-only learner. F or a broader o verview of metho ds that in tegrate trials and non-experimental data 2 for HTE, see Bran tner et al. (2023). A ma jor barrier to such in tegration is that the co v ariates collected in trials and ob- serv ational sources rarely align. W e refer to this as co v ariate mismatch: the RCT may con tain b ehavioral or surv ey-based v ariables absen t from the OS, while the OS may con- tain lab oratory or utilization features not recorded in the trial (R¨ assler, 2002). This differs fundamen tally from co v ariate shift (Sugiy ama and Ka w anab e, 2012; Ghosh et al., 2026), where the same cov ariates are observed in b oth sources but follow different distributions. Under mismatc h, standard fusion strategies including regression adjustmen t, rew eighting, and man y recen t trial-OS generalizabilit y estimators (Ack erman et al., 2019; Josey et al., 2022; Li et al., 2022; Colnet et al., 2021) can fail b ecause key effect mo difiers or prognostic v ariables are unobserv ed in one of the sources. Indeed, Colnet et al. (2021) show that when transp orting trial effects to a target p opulation, imputing co v ariates that w ere never mea- sured in the trial cannot recov er the required iden tification, even under p erfectly specified linear mo dels. Under co v ariate mismatch, a few transfer-learning approac hes address partial ov erlap in co v ariate sets (Bica and v an der Schaar, 2022; Chang et al., 2024; Xu and Qu, 2025), but typically rely on learned latent represen tations optimized for predictive fit. While only Bica and v an der Schaar (2022) fo cuses on a causal setting, in general, suc h end-to-end pro cedures may not preserv e the randomization structure and therefore provide limited guaran tees that observ ational confounding will not leak into the CA TE, a phenomenon kno wn as ne gative tr ansfer . More broadly , p o w er-likelihoo d and b orro wing framew orks (Lin et al., 2025; Rahman et al., 2021) combine exp erimental and observ ational data for treatmen t effect estimation, but do not explicitly address cov ariate mismatch or pro vide CMO-based negativ e-transfer guarantees. This pap er extends R-OSCAR to settings with cov ariate mismatc h. W e partition base- line cov ariates into RCT-only , OS-only , and shared blo c ks and in tro duce discrepancy func- tions calibrated on the randomized data, explicitly accommo dating outcome shift without assuming transp ortabilit y of outcome means or CA TEs (Dahabreh et al., 2020). W e con- sider tw o b orrowing strategies: SR-OSCAR, whic h applies R-OSCAR to the shared co- v ariates only , and our main prop osal MR-OSCAR, which uses the OS to predict OS-only co v ariates from the shared blo c k, imputes them in the R CT, fits OS outcome mo dels on the full co v ariate set, calibrates to the R CT, and estimates CA TEs via augmented pseudo- 3 outcome regression. In the calibration step, b oth shared and R CT-only cov ariates can en ter, so strong RCT-only predictors are retained. On the theoretical side, we derive finite-sample risk b ounds that decomp ose into an appro ximation term, a complexit y term for the OS-trained n uisance functions, and an imputation term quantifying uncertaint y from predicting OS-only co v ariates in the RCT. These b ounds sho w that MR-OSCAR con trols negative transfer: when imputation error is large, the risk is driv en b y the R CT calibration step and do es not substantially deteriorate relativ e to R CT-only estimation. Sp ecializing to sparse linear mo dels yields concrete con- ditions c haracterizing when each strategy is beneficial. Simulations confirm these trade-offs across a range of co v ariate-mismatch configurations. W e illustrate these ideas using the Greenligh t Plus early c hildho o d ob esity preven tion trial (Heerman et al., 2022, 2024), comparing standard counseling (Sanders et al., 2014) with an enhanced digital program. The trial w as underpow ered for fine-grained heterogene- it y (W ang et al., 2007; Ken t et al., 2018), but link ed EHR data from non-enrolled children pro vide ric h auxiliary information. Behavioral co v ariates in the R CT and utilization data in the EHR create a canonical co v ariate-mismatch setting in whic h MR-OSCAR sharp ens CA TE estimates while retaining protection against observ ational confounding. The rest of the pap er is organized as follo ws. Section 2 presents the setup, causal assumptions, and the prop osed metho ds. Section 3 deriv es the error b ounds and their sparse linear sp ecialization. Section 4 rep orts simulation studies, and Section 5 applies MR-OSCAR to the Greenligh t Plus study . Section 6 concludes. 2 Metho ds for data b orro wing from an R CT under co v ariate mismatc h In this section w e formalize the co v ariate-mismatch setting, review the coun terfactual mean outcome (CMO) and pseudo-outcome representation from Asiaee et al. (2025), and then dev elop tw o estimat ors that leverage observ ational information under misaligned cov ariates. 4 2.1 Setup, bac kground, and causal assumptions W e consider t w o data sources: a randomized trial and a large observ ational study . Let S ∈ { r , o } denote mem b ership in the R CT and OS resp ectively , Y the outcome of in terest, and treatment A ∈ {− 1 , 1 } . F or each unit w e p osit p oten tial outcomes Y (1) , Y ( − 1), the p oten tial outcome under treatmen t and that under control, resp ectively . Eac h source observ es a differen t subset of baseline cov ariates: the R CT records X r and the OS records X o . W e denote the co v ariates measured in b oth sources as Z ∈ R p z (the shared blo ck), those exclusiv e to the RCT as U := X r \ Z ∈ R p u , and those exclusive to the OS by V := X o \ Z ∈ R p v , so that X r = ( U , Z ) ∈ R p u + p z and X o = ( Z , V ) ∈ R p z + p v . W e write X = ( U , Z , V ) ∈ R p with p = p u + p z + p v for the complete co v ariate v ector. F or generic realizations we write x = ( u , z , v ), x r = ( u , z ), and x o = ( z , v ). Because co v ariate distributions can differ across sources, we retain the source indicator S = s in conditional distributions and exp ectations as needed. Since Z is a sub vector of b oth X r and X o , functions of Z may app ear alongside functions of X r or X o in the same expression; in suc h cases Z denotes the shared component extracted from the source-sp ecific vector. A complete glossary of notation is provided in T able 3 in the Supplement. The RCT sample is { ( X r i , A i , Y i , S i = r } n r i =1 , and the OS sample is { ( X o i , A i , Y i , S i = o } n o i =1 . Let n s a denote the num b er of units in arm a under source s . F or each study s ∈ { r , o } and treatment arm a ∈ {− 1 , 1 } , w e write µ s a ( x s ) : = E [ Y | A = a, X s = x s , S = s ] for the mean outcome that w ould be observ ed in p opulation s for individuals with observed cov ariates x s if they all receiv ed treatment a , and π r a ( x r ) for the randomization probabilit y of arm a in the RCT at co v ariate v alue x r . F or source S = s , w e write the p er-arm ful l c onditional me an outc ome as µ s a ( x ) = E Y | X = x , A = a, S = s . Our target is the CA TE in the RCT p opulation, whic h dep ends on the con trast b et ween the t wo arm-specific mean outcomes µ r 1 ( x r ) and µ r − 1 ( x r ). Mathematically , this target R CT CA TE is giv en by τ r ( x r ) : = E Y (1) − Y ( − 1) | X r = x r , S = r = µ r 1 ( x r ) − µ r − 1 ( x r ) . (2.1) This quan tity marginalizes the full CA TE on X ov er the unobserv ed V in the trial. Simi- larly , the R CT prop ensit y score as π r a ( x r ) = P { A = a | X r = x r , S = r } . (2.2) Next, we in tro duce the c ounterfactual me an outc ome (CMO) whic h is a v ariance mini- mizing c hoice of the augmen tation function used to construct a pseudo-outcome (2.4) for 5 CA TE estimation through pseudo-outcome regression that w e discuss later in (2.5). The CMO can b e defined for an y source, but here we focus on the RCT and define µ r ( x r ) = X a ∈{− 1 , 1 } π r − a ( x r ) µ r a ( x r ) . (2.3) This quantit y is the main building blo ck for R-OSCAR: in our estimator, µ r serv es as a p ersonalized baseline outcome that w e subtract from Y to construct pseudo-outcomes for CA TE regression (Asiaee et al., 2025). T o build in tuition, note that for an y fixed individual x r , the CMO is a particular weigh ted a v erage of the arm-sp ecific predicted outcomes, where eac h arm is w eighted b y the RCT randomization probability of the opp osite arm. Informally , for treatmen ts 1 and − 1, the CMO tak es the predicted outcome under treatmen t 1 and w eights it by the probabilit y of b eing assigned − 1, and vice v ersa, then sums these t w o components. This swapped-weigh t construction is chosen so that the CMO is highly predictiv e of the outcome but nearly uncorrelated with the treatment indicator under the R CT randomization scheme. Op erationally , the CMO acts as a p ersonalized baseline outcome: it captures the part of an individual’s resp onse that can be predicted from co v ariates alone, before using the actual treatmen t they received. In the R-OSCAR framew ork, one subtracts this baseline from the observ ed outcome to form a transformed outcome (a pseudo-outcome) and then regresses this transformed outcome on co v ariates. This remo ves noise due to treatmen t-free effects of cov ariates and leav es a cleaner signal for the CA TE, while the causal iden tification still comes entirely from randomization in the RCT. It should b e noted that the OS enters only through improv ed prediction of the arm-sp ecific mean outcomes { µ s a } and hence through a b etter estimate of the CMO. F ollo wing Asiaee et al. (2025), w e construct the pseudo- outcomes τ m ( X r , A, Y ) = A { Y − m ( X r ) } π r A ( X r ) , (2.4) for a generic augmen tation function m : R p u + p z → R . A natural wa y to view this construction is as a sp ecific instance of the broader class of transformed-outcome and pseudo-outcome metho ds for CA TE estimation. These ap- proac hes recast CA TE estimation as a standard prediction problem by constructing a deriv ed outcome whose conditional mean equals the CA TE. F or example, A they and Im- b ens (2016) and W ager and Athey (2018) use “transformed outcomes” and orthogonalized 6 pseudo-outcomes within tree- and forest-based learners so that flexible prediction methods can directly target heterogeneous effects. Building on this idea, Nie and W ager (2021) and Kennedy (2023) develop residualized and doubly robust pseudo-outcomes whose con- ditional exp ectation is the CA TE, yielding estimators with strong robustness and efficiency guaran tees while allowing the use of arbitrary mac hine-learning regressors. W e no w view the pseudo-outcome regression as an empirical risk minimization (ERM) problem in the RCT. Define the p opulation squared-error loss L ( f ) := E n τ m ( X r , A, Y ) − f ( X r ) 2 | S = r o , where the exp ectation is ov er the R CT distribution ( X r , A, Y ) ∼ P ( · | S = r ). Under the RCT identification assumptions in Assumption 1 stated b elo w, the pseudo-outcome is conditionally un biased for the CA TE: E τ m ( X r , A, Y ) | X r , S = r = τ r ( X r ) . Consequen tly , τ r is the unconstrained minimizer of the population loss, τ r ∈ arg min f L ( f ). In practice, we restrict optimization to a function class D on X r , so the empirical risk minimizer ˆ τ ∈ arg min f ∈D 1 n r X i : S i = r τ m ( X r i , A i , Y i ) − f ( X r i ) 2 (2.5) targets the best appro ximation to τ r within D , with excess risk go v erned b y the approxima- tion error ∆ 2 2 ( D , τ r ) and the complexit y of D (see T able 3 for formal definitions). Moreov er, Y u et al. (2021) and Asiaee et al. (2025) sho w that the conditional v ariance of τ m giv en X r is minimized b y m = ˜ µ r , where ˜ µ r is the marginalized R CT CMO given b y ˜ µ r ( x r ) = E µ r ( X ) | X r = x r , S = r . (2.6) Th us the CA TE estimator obtained b y regressing pseudo-outcomes on X r is most precise when the augmentation is the marginalized RCT CMO, yielding an augmented in v erse probabilit y weigh ting (AIPW) form (Robins et al., 1994; Zhang et al., 2012). This observ a- tion motiv ates using OS data to obtain a b etter estimator of ˜ µ r , while keeping the causal iden tification in the RCT. W e imp ose the following assumptions. Assumption 1 (In ternal v alidity of the RCT) . SUTV A holds; ( Y (1) , Y ( − 1)) ⊥ ⊥ A | ( X r , S = r ) (RCT ignor ability); and ther e exists ρ > 0 such that 0 < ρ ≤ π r a ( X r ) ≤ 1 − ρ almost sur ely for e ach a ∈ {− 1 , 1 } . 7 Assumption 2 (T ransp ortability of V giv en Z ) . The c onditional distribution of V given Z is the same in RCT and OS, and V is c onditional ly indep endent of U given Z in the R CT: P ( V | U , Z , S = r ) = P ( V | Z , S = r ) = P ( V | Z , S = o ) . Assumption 1 ensures that the pseudo-outcome regression in the RCT truly targets the CA TE in (2.1), so that b orrowing from the OS is used purely for v ariance reduction rather than to correct for unmeasured confounding or violations of randomization. Assumption 2 formalizes our co v ariate-mismatc h setting: OS-only cov ariates V are conditionally trans- p ortable giv en the shared blo c k Z , and Z renders U and V conditionally indep endent in the RCT, i.e. U ⊥ ⊥ V | Z , S = r . In particular, this assumption justifies fitting a prediction function g : R p z → R p v for V given Z in the OS and then using ˆ g to impute b V = ˆ g ( Z ) in the R CT. Under Assumption 2, this imputation do es not in tro duce bias in the RCT; the discrepancy b et ween b V and the unobserved V manifests only as additional imputation noise, whic h we track explicitly in our risk b ounds. Throughout, our target of inference is the CA TE in the R CT population. The observ a- tional source is used purely as an auxiliary data source, not as a second target p opulation. In particular, w e do not assume that arm-specific outcome regressions agree betw een the t w o sources; in general, µ r a ( x ) = µ o a ( x ). All causal identifica tion and p opulation interpreta- tion are anc hored in the R CT; the OS sample is only used to improv e prediction of outcomes or cov ariates that are missing or sparse in the trial, and all of these OS-based predictions are alw ays calibrated bac k to the R CT. T able 3 (Supplemen t) collects the principal symbols used throughout. 2.1.1 Baseline Methods under Cov ariate Mismatc h Under co v ariate mismatc h, a natural baseline is to ignore the OS data en tirely and estimate the CA TE using only the R CT. T o do so, one can fit arm-wise outcome mo dels in the R CT, ˆ µ r a ( x r ) ∈ arg min f 1 n r a X i : A i = a, S i = r Y i − f ( X r i ) 2 + P r a ( f ) , with a p enalty P r a con trolling the complexit y of the arm-sp ecific regression class. These n uisance estimates are then plugged in to the coun terfactual mean outcome and the pseudo- outcome to construct a purely RCT-based CA TE estimator. Plugging it into the CMO as 8 ˆ ˜ µ r ( x r ) = P a ∈{− 1 , 1 } π r − a ( x r ) ˆ µ r a ( x r ) , w e obtain the RA CER estimator ˆ τ RACER b y regressing the pseudo-outcome (2.4) for each RCT unit i on X r i within the R CT. Under Assump- tion 1 and correct sp ecification of the propensity scores π r a ( X r ) and arm-wise outcome mo dels µ r a ( X r ), the pseudo-outcome satisfies that its exp ectation giv en { X r i , S i = r } equals τ r ( X r i ), so ˆ τ RACER is cen tered on the target CA TE and an y remaining error is due to es- timation v ariance rather than bias. When n r is mo dest, how ever, this purely R CT-based strategy can hav e relatively high v ariance, motiv ating the use of OS data to stabilize the n uisance estimators and improv e CA TE precision. W e no w in tro duce a naiv e b orrowing strategy under cov ariate mismatch that follows the R-OSCAR logic of fitting outcome mo dels in the OS, calibrating them to the RCT via discrepancy functions, and then using the calibrated mo dels to construct v ariance- reducing CMOs for pseudo-outcome regression. Here, we can restrict our attention to the shared cov ariates Z . W e can fit OS outcome mo dels using only the shared co v ariates Z , calibrate these mo dels to the R CT using discrepancy functions on X r , and then use the calibrated predictions to construct the CMO and pseudo-outcomes. This b orrows outcome information from the large OS without ev er knowing ab out the OS-only blo c k V . When outcomes dep end strongly on V , ho w ever, restricting to Z can in tro duce an irreducible pro jection error that limits the b enefit of b orro wing. Mathematically , for eac h arm a , we fit an OS outcome mo del that ignores V : ˆ µ o, sh a ( z ) ∈ arg min f 1 n o a X i : A i = a,S = o Y i − f ( Z i ) 2 + P o, sh a ( f ) , (2.7) where P o, sh a ( f ) regularizes the OS mo del fitted on the shared space. W e then calibrate these predictions to the R CT using a discrepancy function on X r : ˆ δ sh a ( x r ) ∈ arg min d 1 n r a X i : A i = a,S = r n Y i − ˆ µ o, sh a ( Z i ) − d ( X r i ) o 2 + P sh a ( d ) , (2.8) with a p enalt y P sh a ( d ) con trolling the calibration complexity . Here d ( x r ) is a discrepancy function that corrects for differences in the relationship betw een X r and Y in the OS v ersus the R CT: if the OS outcome model ˆ µ o, sh a w ere p erfectly transportable, the ideal discrepancy w ould b e close to zero. The penalty P r U Z ,a ( d ) regularizes the magnitude and complexit y of this correction. Larger p enalization shrinks d to ward zero, effectively b orrowing more strength from the OS mo del, while smaller penalization allo ws a larger correction and hence 9 relies more hea vily on the RCT data. Th us, when the OS and RCT share a similar cov ariate- outcome relationship, the calibration step remains small and substantial information can b e b orro wed; when there is more mismatch, the p enalt y preven ts ov er-correction and limits the influence of the OS. The calibrated arm-specific prediction on X r is ˆ µ sh a ( x r ) = ˆ µ o, sh a ( z ) + ˆ δ sh a ( x r ) , whic h w e aggregate in to a shared-only CMO and an induced preliminary CA TE resp ectiv ely as ˆ ˜ µ sh ( x r ) = X a ∈{− 1 , 1 } π r − a ( x r ) ˆ µ sh a ( x r ) , and ˆ ˜ τ sh ( x r ) = X a ∈{− 1 , 1 } a ˆ µ sh a ( x r ) . As in R-OSCAR, we then p erform a second-stage CA TE calibration on the RCT, using the shared-only CMO as augmen tation. This second-stage calibration targets p oten tial miscalibration of the OS-deriv ed CA TE itself. The first calibration la y er adjusts the OS outcome mo del so that, after shrink age, its arm-sp ecific mean predictions align with the R CT outcomes. Ho wev er, this shrink age can still induce bias in the resulting CA TE con- trasts, since the CA TE is a nonlinear functional of the outcome mo dels and ma y ha v e a differen t smo othness structure. The second calibration stage therefore directly regresses the pseudo-outcomes on X r , treating the OS-estimated CA TE as an initial plug-in estimate and learning an additional correction term. This separates calibration and regularization for the outcome mo dels from calibration and regularization for the CA TE surface, allowing the latter to adapt to its own complexity even when the underlying outcome mo dels are hea vily smo othed. W e then get ˆ δ sh = arg min d ∈D 1 n r X i : S = r ( A i Y i − ˆ ˜ µ sh ( X r i ) π r A i ( X r i ) − ˆ ˜ τ sh ( X r i ) + d ( X r i ) ) 2 + P ( d ) , (2.9) and define the shared-only b orro wing SR-OSCAR CA TE estimator, writing ˆ τ SR and ˆ τ MR for the SR-OSCAR and MR-OSCAR estimators in subscripts, as ˆ τ SR ( x r ) = ˆ ˜ τ sh ( x r ) + ˆ δ sh ( x r ) . This strategy lev erages outcome structure estimated with high precision in the large OS sample and then uses the RCT to correct systematic differences that are explainable b y X r . It is safe in the sense that it never imputes V in the RCT and therefore do es not rely on Assumption 2. How ever, when outcomes dep end strongly on OS-only cov ariates V , the map z 7→ E [ µ o ( z , V ; a ) | Z = z , S = o ] may lie far from the chosen function class on 10 Z alone, and SR-OSCAR can incur an irreducible pro jection bias that w e will quantify in Section 3. 2.1.2 Prop osed Metho d: MR-OSCAR A more robust w ay to handle cov ariate mismatch is to b e explicit ab out the fact that the RCT is missing the whole blo c k of co v ariates V and then try to recreate this blo ck in the trial using information from the OS. This mismatch-a ware, imputation-augmen ted b orro wing, whic h w e call MR-OSCAR (Mismatc h-aw are Robust Observ ational Studies for CMO-Augmen ted RCT), uses the OS to learn how OS-only co v ariates V relate to the shared blo c k Z , then transports the predictable part of V in to the R CT via imputation. Supp ose the imputed pro xy for RCT units is b V . W e then fit OS outcome mo dels on X o , calibrate them to the R CT on ( X r , b V ), and use the resulting calibrated predictions to build the CMO and pseudo-outcomes. Under a transp ortabilit y condition for V given Z , the extra uncertain ty introduced b y this step is captured b y an explicit imputation error term in our risk b ounds, whic h w e analyze in Section 3. Under Assumption 2, this additional term reflects only imputation noise rather than bias. Mathematically , w e first estimate a mapping g : R p z → R p v in the OS: ˆ g ∈ arg min g 1 n o X i : S = o V i − g ( Z i ) 2 + P im ( g ) , where P ( g ) is a p enalt y appropriate for the chosen regression class (e.g., ridge or LASSO). In other w ords, ˆ g is trained to appro ximate the conditional mean E ( V | Z ) within the chosen function class, so that for an y RCT unit with co v ariates Z i , ˆ g ( Z i ) provides a regularized prediction of its OS-only cov ariates V i . W e then impute b V i = ˆ g ( Z i ) , for i = 1 , . . . , n r , for R CT units, and treat b V as a pro xy for the predictable comp onent of V . Next, for eac h arm a , w e fit OS outcome mo dels on the full OS feature set X o : ˆ µ o, im a ( x o ) ∈ arg min f 1 n o a X i : A i = a,S = o Y i − f ( X o i ) 2 + P o, im a ( f ) , (2.10) and calibrate these mo dels to the R CT in the augmented co v ariate space ( X r , b V ): ˆ δ im a ( x r , b v ) ∈ arg min d 1 n r a X i : A i = a,S = r n Y i − ˆ µ o, im a ( Z i , b V i ) − d ( X r i , b V i ) o 2 + P im a ( d ) . (2.11) Without regularization, the discrepancy would simply recov er the estimate one would ob- tain from the R CT outcomes; the p enalt y P im a ( d ) instead forces the calibration step to k eep 11 most of the OS prediction and add only a mo dest R CT correction, allo wing for b orro wing of information from the OS. The calibrated arm-sp ecific prediction in the augmented space is ˆ µ im a ( x r , b v ) = ˆ µ o, im a ( z , b v ) + ˆ δ im a ( x r , b v ) . W e define the imputation-augmented CMO and preliminary CA TE as ˆ ˜ µ im ( x r ) = X a ∈{− 1 , 1 } π r − a ( x r ) ˆ µ im a ( x r , b v ) and ˆ ˜ τ im ( x r ) = X a ∈{− 1 , 1 } a ˆ µ im a ( x r , b v ) . (2.12) Finally , we p erform the same second-stage CA TE calibration as in (2.9), now using the imputation-augmen ted CMO: ˆ δ im = arg min d ∈D 1 n r X i : S = r ( A i Y i − ˆ ˜ µ im ( X r i ) π r A i ( X r i ) − ˆ ˜ τ im ( X r i ) + d ( X r i ) ) 2 + P ( d ) , (2.13) where, this second-stage calibration tak es the OS-derived CA TE as an initial plug-in esti- mate and then fits an additional regression of the pseudo-outcomes on X r to correct an y remaining bias. W e define the MR-OSCAR CA TE estimator as ˆ τ MR ( x r ) = ˆ ˜ τ im ( x r ) + ˆ δ im ( x r ) . (2.14) In practice w e employ sample-splitting or cross-fitting across the nuisance stages (OS outcome mo deling, imputation, and RCT calibrations) to av oid o verfitting. Intuitiv ely , MR-OSCAR uses a single imputation to exp ose the predictable component of V to the R- OSCAR calibrator, thereb y shrinking the residual structure that must b e learned from the R CT. When V carries substan tial predictive signal that is partially reco verable from Z , we sho w that MR-OSCAR can reduce CA TE risk relativ e to b oth RA CER and SR-OSCAR. When V is w eakly predictiv e or p o orly imputable, our finite-sample theory in Section 3 sho ws that MR-OSCAR effectively falls bac k to ward RCT-only estimation, thereb y guard- ing against negative transfer. Recall that w e do not imp ose an y transp ortabilit y of outcome regressions or CA TEs betw een sources; MR-OSCAR uses the OS only to impro ve prediction and then calibrates all b orro w ed structure back to the R CT. T able 1 summarizes the estimation pip eline for eac h metho d. 2.1.3 Example: Sparse Linear Mo del F or implemen tation, we first fo cus on a sparse linear sp ecification of the MR-OSCAR n ui- sance mo dels. Let p r := p u + p z = dim( X r ) and p o := p z + p v = dim( X o ). Define the 12 T able 1: Summary of arm-sp ecific mean, CMO, and CA TE estimators across metho ds. A dash (–) indicates the comp onen t is not used. Comp onen t RA CER SR-OSCAR MR-OSCAR OS outcome – ˆ µ o, sh a ( z ) ˆ µ o, im a ( x o ) Imputation – – b V = ˆ g ( Z ) Discrepancy – ˆ δ sh a ( x r ) ˆ δ im a ( x r , b v ) (Calibrated) Arm mean ˆ µ a ˆ µ r a ( x r ) ˆ µ sh a = ˆ µ o, sh a + ˆ δ sh a ˆ µ im a = ˆ µ o, im a + ˆ δ im a CMO ˆ ˜ µ r = P a π r − a ˆ µ r a ˆ ˜ µ sh = P a π r − a ˆ µ sh a ˆ ˜ µ im = P a π r − a ˆ µ im a Preliminary CA TE – ˆ ˜ τ sh = P a a ˆ µ sh a ˆ ˜ τ im = P a a ˆ µ im a (Calibrated) CA TE ˆ τ ˆ τ RACER ( x r ) ˆ τ SR = ˆ ˜ τ sh + ˆ δ sh ˆ τ MR = ˆ ˜ τ im + ˆ δ im in tercept-augmen ted design v ectors ˜ X o i := (1 , Z ⊤ i , V ⊤ i ) ⊤ ∈ R p o +1 , ˜ X r, im i := (1 , U ⊤ i , Z ⊤ i , b V ⊤ i ) ⊤ ∈ R p r + p v +1 , and ˜ X r i := (1 , U ⊤ i , Z ⊤ i ) ⊤ ∈ R p r +1 for the OS, the R CT with imputed b V , and the R CT with observed ( U , Z ), resp ectiv ely . W e assume that for each arm a ∈ {− 1 , 1 } , the OS outcome mo del is µ o, im a ( ˜ X o i ) = ( ˜ x o i ) ⊤ β o a , , where β o a is s -sparse. In this sparse linear set- ting, eac h outcome mo del and calibration step is a LASSO regression on the corresp onding design matrix, and w e estimate the sparse co efficient vector β o a via b β o a ∈ arg min β ∈ R p o +1 1 n o a X i : A i = a,S = o Y i − ( ˜ X o i ) ⊤ β 2 + λ o a ∥ β ∥ 1 , (2.15) where λ o a ≥ 0 is a LASSO tuning parameter. The fitted OS prediction is ˆ µ o, im a ( X o i ) = ( ˜ X o i ) ⊤ b β o a . Given the OS fit, we form residuals for R CT units in arm a , ˜ Y i ( a ) = Y i − ˆ µ o, im a ( Z i , b V i ) , for i : A i = a, S = r, and mo del the arm-sp ecific discrepancy as d a ( X r i , b V i ) = ( ˜ X r, im i ) ⊤ γ r a . W e estimate γ r a via a second LASSO regression, b γ r a ∈ arg min γ ∈ R p r + p v +1 1 n r a X i : A i = a,S = r ˜ Y i ( a ) − ( ˜ X r, im i ) ⊤ γ 2 + λ r a ∥ γ ∥ 1 . (2.16) The calibrated arm-sp ecific prediction in the augmen ted space ( X r , b V ) is then ˆ µ im a ( X r i , b V i ) = ˆ µ o, im a ( Z i , b V i ) + ( ˜ X r, im i ) ⊤ b γ r a . Using the calibrated predictions, w e define the imputation- augmen ted CMO and preliminary CA TE in the RCT as (2.12). W e then form pseudo- outcomes ψ i as in Equation 2.4 and fit a final linear correction d ( X r i ) = ( ˜ X r i ) ⊤ η via b η ∈ arg min η ∈ R p r +1 1 n r X i : S = r ψ i − [ ˆ ˜ τ im ( X r i ) + ( ˜ X r i ) ⊤ η ] 2 + λ δ ∥ η ∥ 1 . (2.17) 13 The MR-OSCAR CA TE estimator in the sparse linear regime is finally ˆ τ MR ( X r ) = ˆ ˜ τ im ( X r )+ ( ˜ X r ) ⊤ b η . In practice, we employ sample-splitting or cross-fitting across (2.15)-(2.17) to a v oid ov erfitting. Moreov er, the tuning parameters λ o a , λ r a , and λ δ are selected separately for each nuisance stage by cross-v alidation, using the squared-error criterion asso ciated with that stage’s own regression problem. Sp ecifically , for the OS arm-sp ecific outcome mo dels in (2.15), cross-v alidation is p erformed using the original outcome Y i as the re- sp onse and the prediction loss P i ∈ V , A i = a,S = o ( Y i − ( ˜ X o i ) ⊤ ˆ β o a, − V ) 2 on eac h v alidation fold V . F or the RCT arm-specific discrepancy regressions in (2.16), cross-v alidation uses the residualized outcome ˜ Y i ( a ) = Y i − ˆ µ o, im a ( Z i , b V i ) as the resp onse and minimizes the cor- resp onding v alidation loss P i ∈ V , A i = a,S = r ( ˜ Y i ( a ) − ( ˜ X r, im i ) ⊤ ˆ γ r a, − V ) 2 . Finally , for the CA TE correction step in (2.17), cross-v alidation is p erformed using the pseudo-outcome regres- sion criterion itself. Equiv alently , since ˆ ˜ τ im ( X r i ) is an offset, one may view the resp onse as either the pseudo-outcome ψ i with offset ˆ ˜ τ im ( X r i ), or as the residualized pseudo-outcome ψ i − ˆ ˜ τ im ( X r i ); both formulations give the same optimization problem. Th us the v alidation loss for λ δ is P i ∈ V , S = r ( ψ i − [ ˆ ˜ τ im ( X r i ) + ( ˜ X r i ) ⊤ ˆ η − V ]) 2 . Because MR-OSCAR in volv es mul- tiple nuisance stages (imputation, OS outcome, R CT discrepancy , and CA TE regression), w e emplo y K -fold cross-fitting: for eac h fold I k , all nuisance functions— ˆ g ( − k ) , ˆ µ o, ( − k ) a , ˆ δ ( − k ) a , and the preliminary CMO ˆ ˜ µ ( − k ) —are estimated on the complemen t I c k , and the final CA TE ˆ τ ( − k ) MR is ev aluated on I k . Aggregating ov er folds ensures that pseudo-outcomes and CA TE regressions use disjoin t data, av oiding ov erfitting. 3 Theory W e now study the finite-sample p erformance of the CA TE estimators ˆ τ SR and ˆ τ MR . Through- out this section w e fo cus on the p opulation risk in the RCT distribution, ∆ 2 2 ( ˆ τ , τ r ) := E ˆ τ ( X r ) − τ r ( X r ) 2 | S = r , where the expectation is taken ov er an indep enden t R CT dra w ( X r , A, Y ) ∼ P ( · | S = r ). Since all of our results are in squared L 2 loss under the R CT distribution, this notation is meaningful in this con text. Our goal is to characterize ho w m uch eac h estimator can reduce this risk relativ e to the RCT-only RA CER benchmark b y borrowing information from the OS, and ho w cov ariate mismatc h and imputation error impact the rate. 14 3.1 F unction classes, complexit y measures, and shift structure W e first introduce the function classes and complexity measures that enter our b ounds. Let D ⊂ L 2 ( P r ) b e the function class used for the final CA TE calibration d in (2.9) and (2.13), and for eac h arm a ∈ {− 1 , 1 } define M o, sh a and M o, im a as the function classes used for the OS outcome mo dels ˆ µ o, sh a ( z ) in (2.7) and ˆ µ o, im a ( x o ) in (2.10), M r a as the arm- sp ecific RCT outcome classes used b y RA CER on ( U , Z ) = X r , and D sh a and D im a as the calibration classes used for ˆ δ sh a in (2.8) and (2.11) resp ectiv ely . Let G be the class used for the imputation map g : Z 7→ V in MR-OSCAR. W e write R n ( H ) for the empirical Rademac her complexit y of a class H based on n samples (Bartlett and Mendelson, 2006) (see T able 3 for its formal definition), and we use ≲ to suppress universal constants. F or any function class H ⊂ L 2 ( P r ), define the approximation error as ∆ 2 2 ( H , τ r ) := inf h ∈H E ( h ( X r ) − τ r ( X r )) 2 | S = r . This term captures the irreducible bias induced by restricting attention to a giv en class (for example, linear or sparse linear functions), while all remaining terms in our b ounds arise from estimation error and from co v ariate mismatc h. T o quantify the effect of ignoring OS-only cov ariates V , w e in tro duce a shared-only mismatch p enalt y (3.18). F or eac h arm a ∈ {− 1 , 1 } , define the arm-sp ecific marginalized R CT mean (the per-arm coun terpart of the CMO (2.6)) ˜ µ r a ( x r ) := E µ r a ( x r , V ) | X r = x r , S = r . Under SR-OSCAR, the armwise calibrated predictor has the form m ( Z ) + d ( X r ) with m ∈ M o, sh a and d ∈ D sh a . Define the corresp onding SR-represen table class H sh a := n x r 7→ m ( z ) + d ( x r ) : m ∈ M o, sh a , d ∈ D sh a o . W e define the squared mismatch p enalt y for shared-only b orrowing as the residual approx- imation error of ˜ µ r a in H sh a : B 2 sh := X a ∈{− 1 , 1 } inf h ∈H sh a E h h ( X r ) − ˜ µ r a ( X r ) 2 | S = r i . (3.18) In tuitiv ely , B 2 sh is the irreducible p enalt y from restricting SR-OSCAR’s arm wise calibration to functions of X r : it is small when OS-only co v ariates V do not materially affect outcomes b ey ond what X r can represent, and it is large when important effect mo difiers reside in V and cannot be summarized by X r . F or MR-OSCAR, we trac k the qualit y of imputation 15 via r 2 im := E ∥ V − g ⋆ ( Z ) ∥ 2 | S = r , where g ⋆ ∈ G denotes an ideal imputation map in the chosen class and the exp ectation is tak en under the R CT distribution. In practice r 2 im can b e though t of as the prediction risk of the b est imputation mo del. One ma y also consider the OS-av eraged version E [ ∥ V − g ⋆ ( Z ) ∥ 2 | S = o ]; under transp ortabilit y of V | Z and mild ov erlap b etw een P ( Z | S = r ) and P ( Z | S = o ), the OS- and RCT-a veraged imputation risks are of the same order. Finally , for some parts of the theory it is conv enient to use lo calized complexity param- eters in the sense of Asiaee et al. (2025) follo wing Bartlett and Mendelson (2006). Giv en a function class H and rate exp onen t η > 0, w e write c ( H ) for a lo calized complexity of H suc h that ∆ 2 2 ( ˆ h n , h ⋆ ) ≲ c ( H ) n η for ERM in H based on n samples, (3.19) under correct sp ecification h ⋆ ∈ H and standard regularit y . F or instance, for sparse linear mo dels (LASSO) with sparsit y s among p features one has c ( H ) ≍ s log p and η = 1; for H¨ older-smo oth nonparametric classes one obtains η = 2 α/ (2 α + p ), etc. The Rademac her- based statements b elow and the localized forms (3.19) are equiv alent up to constants. The follo wing assumptions formalize the outcome-shift structure and smo othness conditions needed for our analysis. Assumption 3 (Outcome shift in the full space) . F or e ach arm a ∈ {− 1 , 1 } ther e exists a function δ a : R p → R such that µ r a ( x ) = µ o a ( x ) + δ a ( x ) , and δ a b elongs to a function class D a of c ontr ol le d c omplexity (e.g., having b ounde d R ademacher c omplexity). Assumption 4 (Lipsc hitzness in the OS-only block) . Ther e exists L > 0 such that for al l s ∈ { r, o } and for al l ( x r , v , v ′ , a, s ) , we have µ s a ( x r , v ) − µ s a ( x r , v ′ ) ≤ L ∥ v − v ′ ∥ and δ a ( x r , v ) − δ a ( x r , v ′ ) ≤ L ∥ v − v ′ ∥ . Assumption 5 (Rates for n uisance estimation) . The estimators ˆ µ o, sh a , ˆ µ o, im a , ˆ δ sh a , ˆ δ im a , ˆ g , and the final-stage c alibr ators ˆ δ sh , ˆ δ im ar e obtaine d by empiric al risk minimization (or p enalize d ERM) in their r esp e ctive function classes, with sample splitting or cr oss-fitting acr oss nuisanc e stages. Their estimation err ors admit b ounds of the form E h ˆ h − h ⋆ 2 2 i ≲ R 2 n ( H ) for e ach nuisanc e c omp onent h ⋆ ∈ H , with n = n r or n o as appr opriate. 16 Assumption 3 allo ws the arm-sp ecific mean outcomes to differ arbitrarily b etw een the R CT and OS, enco ded b y the shift functions δ a . Crucially , we do not assume that the outcome means or CA TEs transp ort b etw een p opulations in the sense that w e allo w µ r a = µ o a and τ r = τ o . The OS is used only as a high-quality predictor of outcomes, with the shift structure captured and corrected on the R CT via the calibration steps. Assumption 4 ensures that small c hanges in the OS-only co v ariates V lead to small, predictable c hanges in b oth the outcome mo del and the discrepancy function, whic h is crucial when w e impute V into the trial. Assumption 5 (combined with (3.19)) ensures that the n uisance estimators are sufficiently accurate for standard Rademac her/lo calized-complexit y arguments to apply . 3.2 Baseline risk b ound for RACER As a b enchmark, we recall the risk b ound for the R CT-only estimator RACER in our curren t notation. RACER fits arm-sp ecific outcome mo dels ˆ µ r a ( X r ) in the R CT only and then constructs CMOs and pseudo-outcomes using these mo dels, follo wed b y a final CA TE calibration in the class D . The following result is a straigh tforward adaptation of the main R-OSCAR risk b ound in Asiaee et al. (2025) to the cov ariate blo c k X r . Theorem 1 (Baseline risk b ound for RA CER, adapted from Asiaee et al. (2025)) . Supp ose Assumptions 1 and 5 hold, and that RACER uses arm-sp e cific outc ome classes M r a and final CA TE class D , with nuisanc e estimators obtaine d via cr oss-fitting. Then ther e exists a c onstant C > 0 such that, with pr ob ability at le ast 1 − γ for al l γ ∈ (0 , 1) , ∆ 2 2 ( ˆ τ RACER , τ r ) c an b e b ounde d by ∆ 2 2 ( D , τ r ) + C " R 2 n r ( D ) + X a ∈{− 1 , 1 } R 2 n r M r a # + C log(1 /γ ) n r . (3.20) Equivalently, in the lo c alize d-c omplexity notation of Asiae e et al. (2025), if c ( M r a ) denotes a lo c alize d c omplexity of the arm-sp e cific R CT outc ome class on X r , then under the same c onditions ther e exists C < ∞ and η r > 0 such that ∆ 2 2 ˆ τ RACER , τ r ≲ X a ∈{− 1 , 1 } c M r a ( n r ) η r . (3.21) The b ound (3.20) will serve as our baseline for comparison with SR-OSCAR and MR- OSCAR: all three estimators share the same approximation error ∆ 2 2 ( D , τ r ), but RACER 17 do es not incur mismatch or imputation p enalties and relies solely on RCT-based outcome mo dels whose complexit y scales with n r . 3.3 Error b ounds for MR-OSCAR and imputation p enalties W e now turn to the mismatch-a ware estimator MR-OSCAR, which augmen ts the RCT co v ariates with imputed OS-only cov ariates b V . Under Assumption 2, the distribution of V giv en Z is transp ortable across R CT and OS, and Z screens off the dep endence b etw een U and V in the RCT. Com bined with the Lipschitz condition in Assumption 4, this lets us relate the error due to imputation to the prediction error of the outcome models. Let ˆ τ MR denote the CA TE estimator constructed in (2.14), using an imputation class G with oracle risk r 2 im and final calibration class D . Let m aug ,a ( X r ) denote the arm-specific augmentation function implicitly defined b y MR-OSCAR after imputation and calibration, and define the corresp onding augmen tation error ∆ 2 2 ( m aug ,a , ˜ µ r a | X r ) := E h m aug ,a ( X r ) − ˜ µ r a ( X r ) 2 | S = r i . Theorem 2 (Risk b ound for MR-OSCAR) . Supp ose Assumptions 1-2 and 3-5 hold, and the nuisanc es ar e estimate d with cr oss-fitting. Then ther e exists a c onstant C > 0 such that, with pr ob ability at le ast 1 − γ for al l γ ∈ (0 , 1) , we c an b ound ∆ 2 2 ( ˆ τ MR , τ r ) by ∆ 2 2 ( D , τ r ) + C " L 2 r 2 im + R 2 n r ( D ) + X a ∈{− 1 , 1 } R 2 n o ( M o, im a ) + R 2 n r ( D im a ) + R 2 n o ( G ) # + C log(1 /γ ) n r . (3.22) The b ound (3.22) closely parallels the SR-OSCAR b ound (8.25) deriv ed in the sup- plemen t, but with three key differences. First, whereas the SR-OSCAR b ound contains the shared-only mismatch penalty B 2 sh arising from discarding V , the MR-OSCAR b ound replaces this structural p enalt y b y an explicit imputation term. In particular, the Lipsc hitz- imputation factor L 2 r 2 im quan tifies the additional error incurred by working with imputed or predicted OS-only co v ariates b V rather than observing V directly . When V is highly predictable from Z , the oracle imputation risk r 2 im is small and the MR-OSCAR b ound approac hes the ideal case in whic h the full co v ariate v ector is a v ailable in the R CT. Sec- ond, MR-OSCAR op erates in the full X o space, so the OS outcome and R CT discrepancy complexities enter through R 2 n o ( M o, im a ) and R 2 n r ( D im a ), reflecting the cost of using richer mo dels that exploit V . Finally , the complexit y of the imputation class G appears via 18 R 2 n o ( G ), capturing the estimation error in fitting the map g : Z 7→ b V . T ogether, these terms make explicit how MR-OSCAR trades the shared-only mismatc h p enalt y in SR- OSCAR for a combination of imputation error and additional modeling flexibility in the enlarged co v ariate space. T ogether, Theorem 2 and Theorem 4 in the Supplement pro vide transparen t conditions under which b orrowing from the OS is b eneficial. F or example, MR-OSCAR improv es on SR-OSCAR when (i) the OS-only co v ariates V carry substan tial predictiv e signal for the outcome; (ii) V can b e imputed from Z with small oracle risk r 2 im ; and (iii) the classes M o, im a , D im a , and G hav e manageable complexity so that their Rademacher penalties deca y reasonably with n o and n r . At the same time, the b ound (3.22) makes explicit how negativ e transfer is controlled. If V is p o orly predictable from Z (so that r 2 im is large) or if the outcome mo dels on X o are highly complex, the additional penalties in (3.22) may out w eigh the gains from accessing V . In suc h arrangemen ts, one can tune the p enalties in (2.10)-(2.11) to shrink the influence of OS-only co v ariates, effectiv ely reverting MR-OSCAR to w ard RA CER and recov ering the robust R CT-only behavior. Th us the theory highligh ts ho w MR-OSCAR can b e deploy ed in a “safe b orrowing” mo de: exploiting informative V when imputation is reliable, while automatically damp ening their effect when it is not. Augmen tation-error decomp osition for MR-OSCAR. Analogously to (8.26), the analysis of MR-OSCAR yields an intermediate b ound in terms of augmentation errors: ∆ 2 2 ( ˆ τ MR , τ r ) ≲ ∆ 2 2 ( D , τ r ) + 1 + X a ∈{− 1 , 1 } ∆ 2 2 ( m aug ,a , ˜ µ r a | X r ) ! R n r ( D ) , up to negligible residual terms. The next prop osition sho ws ho w the augmen tation errors decomp ose in to complexit y and imputation terms. Prop osition 1 (Augmen tation error for MR-OSCAR) . Under the c onditions of The or em 2, ther e exist c onstants C < ∞ , η o > 0 , and η r > 0 such that, for e ach arm a , ∆ 2 2 ( m aug ,a , ˜ µ r a | X r ) ≲ c ( M o, im a ) ( n o ) η o + c ( D im a ) ( n r ) η r + L 2 r 2 im . (3.23) Com bining this with the generic lo calized b ound (3.19) yields a lo calized v ersion of (3.22): ∆ 2 2 ( ˆ τ MR , τ r ) ≲ ∆ 2 2 ( D , τ r ) + L 2 r 2 im + c ( D ) ( n r ) η r + X a ∈{− 1 , 1 } c ( M o, im a ) ( n o ) η o + c ( D im a ) ( n r ) η r + c ( G ) ( n o ) η o . (3.24) 19 Similar bounds for SR-OSCAR hav e b een deriv ed in the Supplemen t. The localized b ounds (8.28) and (3.24) also yield conditions under whic h MR-OSCAR can strictly dominate SR- OSCAR. MR-OSCAR improv es on SR-OSCAR when the additional complexit y of mo deling X o and the imputatio n error r 2 im are more than offset by the reduction in mismatc h p enalt y obtained from accessing V . This is concretely formalized in the following Corollary . Corollary 2.1 (MR-OSCAR can dominate SR-OSCAR) . Under the assumptions of The- or ems 4 in the Supplement and The or em 2 with the same CA TE class D and RCT size n r , we have that for al l sufficiently lar ge n r , n o , ∆ 2 2 ( ˆ τ MR , τ r ) ≤ ∆ 2 2 ( ˆ τ SR , τ r ) whenever X a ∈{− 1 , 1 } ( c ( M o, im a ) ( n o ) η o + c ( D im a ) ( n r ) η r + L 2 r 2 im ) + c ( G ) ( n o ) η o < X a ∈{− 1 , 1 } ( c ( M o, sh a ) ( n o ) η o + c ( D sh a ) ( n r ) η r + B 2 sh ) . 3.4 Sp ecialization of risk b ounds to sparse linear mo dels The general b ounds ab o v e apply to a wide range of nonparametric learners. T o provide more concrete guidance, w e no w sp ecialize to sparse linear mo dels, which yield explicit sample-size and signal-strength thresholds. Assume that all cov ariates are centered and b ounded, and that the true CA TE b elongs to a sparse linear class, τ r ( x r ) = β ⊤ x r , ∥ β ∥ 0 ≤ s τ , for some sparsit y level s τ . Similarly , the OS outcome mo dels, discrepancy mo dels, and imputation map are assumed to lie in sparse linear classes o ver their resp ectiv e co v ariates. Because the SR- and MR-OSCAR pip elines op erate on different co v ariate spaces, each class carries its own sparsit y: M o, sh a on Z ∈ R p z with sparsity s sh µ , M o, im a on X o ∈ R p o with sparsity s im µ , D sh a on X r ∈ R p r with sparsity s sh δ , D im a on ( X r , b V ) ∈ R p with sparsity s im δ , and G on Z ∈ R p z . Since Z ⊂ X o and X r ⊂ ( X r , b V ), any sparse mo del on the smaller space embeds in to the larger one (b y zeroing the extra co ordinates), so s sh µ ≤ s im µ and s sh δ ≤ s im δ . The imputation map g : Z → V predicts each co ordinate V j indep enden tly from Z via a sparse regression with sparsity s j := ∥ λ o,j ∥ 0 , where λ o,j is the j -th row of the co efficien t matrix Λ o ∈ R p v × p z . P enalties are chosen to implemen t (group) LASSO-type estimators. Standard high-dimensional linear theory then giv es R 2 n r ( D ) ≲ s τ log p r n r , R 2 n o ( M o, sh a ) ≲ s sh µ log p z n o , R 2 n o ( M o, im a ) ≲ s im µ log p o n o , 20 R 2 n r ( D sh a ) ≲ s sh δ log p r n r , R 2 n r ( D im a ) ≲ s im δ log p n r , R 2 n o ( G ) ≲ ( P j s j ) log p z n o . Plugging these in to (8.25)–(3.22) yields ∆ 2 2 ˆ τ SR , τ r ≲ ∆ 2 2 ( D , τ r ) + B 2 sh + ( s τ + s sh δ ) log p r n r + s sh µ log p z n o , and ∆ 2 2 ˆ τ MR , τ r ≲ ∆ 2 2 ( D , τ r ) + L 2 r 2 im + s τ log p r n r + s im δ log p n r + s im µ log p o n o + ( P j s j ) log p z n o , up to constants and lo wer-order logarithmic factors. The ordering s sh µ ≤ s im µ and s sh δ ≤ s im δ together with p z ≤ p o and p r ≤ p show that MR-OSCAR incurs a strictly larger statistical cost than SR-OSCAR in ev ery Rademac her term, and it pa ys an additional imputation estimation cost ( P j s j ) log p z /n o that SR-OSCAR a v oids entirely . MR-OSCAR’s sole ad- v an tage is replacing the shared-only mismatch p enalt y B 2 sh with the imputation risk L 2 r 2 im , whic h can be substan tially smaller when V is predictable from Z . Because the extra statis- tical and imputation costs are all O (1 /n o ) or O (1 /n r ), they v anish with sample size, whereas B 2 sh and r 2 im are p opulation-level quan tities that p ersist regardless of sample size. Th us, with sufficiently large n o and n r , the comparison reduces to B 2 sh v ersus L 2 r 2 im . When V is w eakly predictive of Y so that including it in the OS outcome mo del do es not meaningfully reduce the mismatch B 2 sh , then L 2 r 2 im is comparable to or larger than B 2 sh , and the extra statistical costs of MR-OSCAR offer no compensating gain; in this regime SR-OSCAR is preferable. When V is difficult to impute from Z (lo w R 2 ( V | Z )), the imputation risk r 2 im is large and in tro duces noise that further inflates the MR-OSCAR bound, again fav oring SR-OSCAR or ev en the RCT-only RACER. T o further interpret r 2 im , consider the linear-Gaussian imputation mo del V = Λ s Z + ε s , s ∈ { o, r } , with ε s ⊥ Z , Co v( ε s ) = Σ s V | Z , and Co v s ( Z ) = Σ s Z Z . In the p opulation (oracle) case where the true map Λ o is kno wn and used for imputation in b oth sources, one obtains r 2 im = tr ( Λ o − Λ r ) Σ r Z Z ( Λ o − Λ r ) ⊤ + tr Σ r V | Z , which cleanly separates an OS → R CT mean-relation shift term and an irreducible R CT noise term. Under Assump- tion 2, the conditional la w P ( V | Z , S = o ) = P ( V | Z , S = r ) implies Λ o = Λ r in this linear mo del (so the shift trace term is 0), and the oracle imputation risk reduces to r 2 im = tr Σ r V | Z . If instead Λ o is learned in the OS via a row-sparse LASSO with p er- co ordinate sparsity s j := ∥ λ o,j ∥ 0 (as in tro duced ab o ve), then one can establish the b ound stated in the follo wing theorem. 21 Theorem 3 (MR-OSCAR risk b ound in the sparse linear setting) . Assume X is sub- Gaussian and the p opulation Gr am matric es on the r elevant supp orts satisfy r estricte d eigenvalue (RE) c onditions (van de Ge er and B¨ uhlmann, 2009). Under Assumptions 2 and 4, the imputation err or satisfies r 2 im ≲ tr ( Λ ⋆ o − Λ r ) Σ r Z Z ( Λ ⋆ o − Λ r ) ⊤ + κ log p z n o p v X j =1 s j σ 2 o,j + tr Σ r V | Z , wher e σ 2 o,j := ( Σ o V | Z ) j j is the j -th c onditional varianc e, Λ ⋆ o is the b est r ow-sp arse appr oxi- mation to Λ o , and κ = Σ r Z Z ( Σ o Z Z ) − 1 op . Th us the only extra price of bringing in V is the imputation error r 2 im , whic h is small precisely when V is predictable from Z (high R 2 ( V | Z )) and the OS → RCT map for V | Z is stable. Altogether, when n o is large, R 2 ( V | Z ) is mo derate to high, and the calibration class on X is reasonably sparse, the augmentation-driv en factor in the MR-OSCAR b ound b ecomes small, yielding strictly tigh ter rates than the RCT-only RA CER and the shared- only SR-OSCAR. Con versely , if V | Z is p o orly predictable or undergoes strong cross-source shifts in conditional distribution, the r 2 im term can dominate, w arning that mismatc h-aw are b orro wing ma y not impro ve up on the simpler baseline estimators, exactly the trade-off the theory is designed to mak e explicit. 4 Finite sample exp erimen ts W e consider tw o data sources with partially ov erlapping cov ariates: the randomized trial observ es X r = ( U , Z ) and the observ ational study observ es X o = ( Z , V ). The total dimension is fixed at p = 100, with the blo ck dimensions p u , p v , and p z = p − p u − p v . Co v ariates are generated from an equicorrelated Gaussian distribution ( ρ = 0 . 4) with a mean shift applied to U in the R CT to induce mild domain shift. The observ ational sample size is n o = 1000 and the RCT size is n r = 300, unless men tioned otherwise. T reatmen t is assigned at random in the R CT (Pr( A = 1) = 0 . 5) and by a logistic mo del in the OS using a subset of Z so that the treated prop ortion is approximately 1 / 3. P otential outcomes are linear in the cov ariates with sparse co efficien ts: a prop ortion (= 0 . 05) of the X r co ordinates carry signal of magnitude ab out 2 / 3, and the V co efficien ts ha ve magnitude ab out 1; a small fraction (= 0 . 02) of the X r co efficien ts are p erturb ed in the 22 R CT to induce an outcome shift. The outcome dep ends sparsely on all of X = ( U , Z , V ), but w e observe only X r in the R CT and X o in the OS. Homoscedastic Gaussian noise is added to both arms. More details can b e found in the supplement. W e compare three R CT-anc hored CA TE pro cedures: RA CER, whic h uses only RCT data with predictors X r ; SR-OSCAR, which b orro ws from OS using only the shared co v ariates Z on b oth sources; and MR-OSCAR, whic h augmen ts R CT predictors with an imputed b V = ˆ g ( Z ), where the imputation map g : R p z → R p v is estimated in the OS and applied to the R CT; OS outcome predictions are then calibrated to the RCT. All OS-anc hored pro cedures are implemen ted with sample splitting to a void ov erfitting. 4.1 V arying the Effect of OS-only Co v ariates W e fix ( p u , p z , p v ) = (30 , 40 , 30) and v ary the signal strength of V in the outcome mo del from w eak (0 . 3) to strong (1 . 3). The left panel of Figure 1 sho ws that RMSE increases with the V effect for all metho ds. Across the entire grid, MR-OSCAR has the low est RMSE, RA CER is intermediate, and SR-OSCAR is uniformly worst. MR-OSCAR improv es ov er RA CER by 0 . 03–0 . 10 RMSE units, with the separation widest at mid-range effects ( ≈ 0 . 6– 1 . 0). As the V signal strengthens, SR-OSCAR degrades while MR-OSCAR maintain s b oth lo w er error and greater stability b y leveraging OS information. 4.2 V arying the R CT Sample Size W e v ary n r from 200 to 1000 with all else fixed. The righ t panel of Figure 1 sho ws three patterns. First, RMSE decreases for all metho ds as n r gro ws. Second, MR-OSCAR attains the low est RMSE throughout, with the adv antage most pronounced at small-to- mo derate trial sizes and gradually attenuating as n r increases, consistent with the ( n r ) − 1 / 2 scaling of the complexity term. A t sufficiently large n r , the RACER and MR-OSCAR curv es essentially sup erimp ose. Third, SR-OSCAR is uniformly w orst due to the irreducible pro jection error from restricting to the shared blo c k Z . In summary , MR-OSCAR is most b eneficial when R CT enrollment is limited; as n r increases the gains diminish but do not rev erse. 23 Figure 1: L eft: Me an RMSE (p oints) with ± 1 SD (b ars) versus the effe ct size of the OS-only c ovariates V (OS size fixe d at n o = 1000 , R CT size at n r = 300 ). R ight: Me an RMSE versus R CT sample size n r (OS fixe d at n o = 1000 ). 4.3 V arying the Prop ortion of Shared F eatures W e set p u = ⌊ f 1 p ⌋ , p v = ⌊ f 2 p ⌋ for f 1 , f 2 ∈ { 0 , 0 . 1 , . . . , 0 . 5 } with f 1 + f 2 ≤ 0 . 8, and displa y heatmaps of RMSE(MR-OSCAR) − RMSE(RA CER) and RMSE(MR-OSCAR) − RMSE(SR-OSCAR) in Figure 2. MR-OSCAR outp erforms RA CER (left panel, blue) when the OS contains many un- a v ailable v ariables (large f 2 ) and the trial has few exclusive ones (small f 1 ). As f 1 in- creases, imputation cannot recov er U -sp ecific structure and RACER becomes preferable (red). MR-OSCAR uniformly dominates SR-OSCAR (righ t panel), confirming that aug- men ting b eyond Z through imputation and calibration is alwa ys preferable to restricting to the shared in tersection alone. Additionally , to assess ho w the b enefit of imputation-augmented b orro wing dep ends on the predictability of the OS-only cov ariates, we carried out a sensitivity study that v aries the p opulation R 2 ( V | Z ) from 0.1 to 0.9 (see Supplemen t, Figure S4). As R 2 ( V | Z ) increases, RMSE decreases for all metho ds, with MR-OSCAR sligh tly worse than RA CER when V is p oorly predictable but o v ertaking RACER once R 2 ( V | Z ) ≳ 0 . 6, while the SR-OSCAR b enc hmark is uniformly w orst. 24 Figure 2: He atmaps of RMSE gaps over the grid of c ovariate-mismatch fr actions ( f 1 , f 2 ) , wher e f 1 is the shar e exclusive to the RCT ( U ) and f 2 the shar e exclusive to the OS ( V ). 5 Analysis of Greenligh t Plus Study 5.1 Data Description and Pre-pro cessing The trial sample comprises n r = 860 complete-case c hildren from the Greenligh t Plus Study (Heerman et al., 2022, 2024), a m ulti-site RCT that ev aluated whether augmenting stan- dard w ell-c hild counseling with a literacy-sensitiv e digital program—including tailored text messages, goal-setting supports, and a caregiv er dashboard—could help paren ts main tain health y w eight tra jectories in early childhoo d. Children w ere randomized appro ximately 1:1 to clinic-only care ( n = 431) or clinic plus digital interv ention ( n = 429) across six sites (Duk e, UNC, V anderbilt, NYU, Stanford, and Miami). Baseline co v ariates recorded in the R CT include c hild sex, birth w eigh t, caregiv er race/ethnicity , education, household income, preferred language (English or Spanish), foo d securit y , health literacy , and base- line weigh t-for-length z -score (WFLz). The observ ational sample is drawn from electronic health records at three of the six trial sites with accessible systems—Duk e ( n = 27 , 679), V anderbilt ( n = 10 , 498), and UNC ( n = 1 , 147)—yielding n o = 39 , 324 non-enrolled children who received routine w ell-child care during the trial window and thus represent the control condition only . EHR cov ariates include site, sex, race/ethnicity , language, insurance type, and baseline WFLz. In the notation of Section 2.1, the shared blo ck Z comprises site, sex, race/ethnicit y , language, and baseline WFLz; the RCT-only block U includes birth weigh t, education, income, fo o d security , and health literacy; and insurance, which is delib erately 25 mask ed in the R CT to construct a co v ariate-mismatch scenario, serves as the OS-sp ecific v ariable V . F or eac h child in both sources, WFLz outcomes at target ages w ere obtained b y lo cal linear interpolation of observ ed gro wth measuremen ts within age-sp ecific windo ws ( ± 1 mon th at the 12- and 24-month endp oin ts), using the WHO Child Growth Standards. The EHR cohort was assembled by linking patient demographic files with clinical encoun ter records con taining anthropometric measurements from w ell-c hild and other visits. Patien ts w ere excluded from the EHR analytic sample if they lac ked a reliable weigh t measuremen t in the first 21 days of life at or ab o v e the third WHO p ercen tile (71% of exclusions), sp ok e a language other than English or Spanish (24%), or had no co ded w ell-child visit in their first year (4%). Insurance status for R CT participan ts at the three linked sites w as extracted from the corresp onding EHR billing records, and all v ariable names were harmonized across sources to ensure consistency b efore analysis. The raw insurance field in the EHR contains sev eral categories, including a large “Una v ailable/No Pa yer” group comprising roughly 58% of EHR patien ts. During binarization, this group was com bined with the uninsured category ( V = 0), yielding a binary indicator V ∈ { 0 , 1 } (insured vs. uninsured/una v ailable). This co ding inflates the prop ortion of V = 0 observ ations and in tro duces site-sp ecific sparsity in the insured category , which contributes to the v ariance inflation seen when the ra w indicator is used directly in R-OSCAR (see Section 5.3). 5.2 Metho d Implemen tations In our Greenlight Plus analysis w e delib erately imp ose a co v ariate-mismatc h scenario b y masking the binary insurance v ariable (that we call V ) in the R CT and treating it as una v ailable for primary CA TE estimation so that we can assess ho w well metho ds can p erform with real world data relative to the gold standard when all cov ariates are av ailable in b oth data sources. The EHR data contain V only for con trol patients (there are no treated children in the external EHR), so an y b orrowing m ust resp ect this restriction and cannot rely on external information ab out the treatmen t arm. In this scenario, SR-OSCAR implemen ts the R-OSCAR framew ork using only the shared cov ariates Z : an outcome mo del for the control arm is first trained in the EHR on ( Z, Y ) for A = 0 and transported to the R CT, a discrepancy function is learned on R CT con trols to correct for outcome shift, and finally a treatment-arm model and CA TE calibration are fit using RCT data. F or MR- 26 OSCAR, in the first step, we use the EHR con trol sample to learn a prediction mo del for insurance based on the shared cov ariates, fitting a logistic LASSO for Pr( V = 1 | Z ) using only individuals with A = 0 in the EHR. W e then apply this fitted mo del to the R CT con trols and treated c hildren to obtain sub ject-sp ecific probabilities b V = Pr( V = 1 | Z ). Next, w e fit the EHR con trol outcome mo del on ( Z, V ), i.e., using b oth the shared co v ariates and the observed insurance in the large EHR control sample. In the R CT, by contrast, all outcome, discrepancy , and CA TE calibration mo dels use ( Z , b V ), replacing the unobserv ed V with its logistic-LASSO prediction. In this w ay , MR-OSCAR b orrows external information only from the control arm and only through the shared co v ariates Z and the imputed insurance b V , while the randomized treatmen t con trast in the trial remains the sole source of causal identification. W e compare against three baselines. SR-OSCAR is describ ed ab o v e (shared cov ariates only). R-OSCAR (Asiaee et al., 2025) uses ( Z , V ) in b oth the EHR and the R CT, representing an “oracle” scenario in which insurance is fully a v ailable in the trial (it is masked only to show case MR-OSCAR’s utility). RA CER (Asiaee et al., 2025) is an RCT-only b enc hmark that fits separate outcome mo dels for A = 0 and A = 1 using all trial co v ariates and calibrates the CA TE via pseudo-outcome regression. 5.3 Results Figure 3 (upp er panel) displa ys the sorted individual CA TE estimates and their 95% confi- dence interv als for all four methods. All approaches rev eal substantial heterogeneity in the in terv ention effect across c hildren, with estimated CA TEs ranging from mo derately nega- tiv e to clearly p ositiv e. The width of the bands, how ever, differs markedly: MR-OSCAR pro duces the tigh test in terv als, follow ed b y SR-OSCAR, then R-OSCAR, with RACER sho wing the widest interv als. These visual impressions are confirmed by T able 2. Rela- tiv e to the R CT-only RACER b enchmark, MR-OSCAR reduces the mean CI width from 1.03 to 0.83 (roughly a 20% reduction) and the mean radius from 0.283 to 0.178, with SR-OSCAR and R-OSCAR yielding intermediate gains. An interesting feature of T able 2 is that R-OSCAR, which has access to the true insurance indicator V in the R CT, yields sligh tly wider CA TE interv als than MR-OSCAR, whic h uses an imputed b V . This does not necessarily con tradict the in tuition that more co v ariate information should help; rather, it ma y reflect how that information enters the estimation pip eline. In the Greenlight Plus data, our co v ariate-balance diagnostics (Figure 5, Supplement) sho w that the collapsed 27 insurance indicator is not only a little im balanced across treatment arms, but it is also relativ ely rare and exhibits site-sp ecific sparsit y in the uninsured category . Including the ra w insurance factor V directly in the regression steps therefore forces the RCT mo dels to estimate several small cell means and in teractions, whic h can substantiall y inflate v ariance with little corresp onding reduction in bias. By contrast, MR-OSCAR first learns a smooth prediction b V = Pr( V = 1 | Z ) in the large EHR control sample and then uses this de- noised surrogate in the R CT outcome and calibration mo dels, stabilizing the contribution of insurance. As noted in the data description, the “Unav ailable/No P a y er” category was merged with uninsured during binarization, inflating the V = 0 coun ts and exacerbating the sparsit y that driv es R-OSCAR’s v ariance. MR-OSCAR sidesteps this issue b y replacing the noisy binary indicator with a smo oth imputed probabilit y , effectiv ely regularizing the insurance signal. As a result, MR-OSCAR can ac hiev e shorter interv als than the oracle R-OSCAR in this particular co v ariate-mismatch setting, while still relying solely on the randomized trial for causal iden tification. Metho d Mean width Median width 25th pct. width 75th pct. width Mean radius MR-OSCAR 0.831 0.786 0.716 0.901 0.178 SR-OSCAR 0.872 0.830 0.764 0.936 0.195 R-OSCAR 0.909 0.846 0.770 0.962 0.217 RA CER 1.030 0.970 0.832 1.190 0.283 T able 2: Summary of individual CA TE uncertaint y across metho ds. F or eac h metho d, w e rep ort the mean, median, 25th and 75th p ercentiles of the 95% CI widths, and the mean radius r i = 0 . 25 · (width i ) 2 a v eraged ov er trial participants. Figure 3 (lo w er panel) examines how key co v ariates affect the CA TE. Across metho ds, b eing uninsured is asso ciated with lo w er predicted treatmen t benefit, whereas non-Hispanic White race, V anderbilt site, and higher-income categories are asso ciated with larger CA TEs. Baseline an throp ometrics (birth w eigh t, baseline weigh t-for-length, and 24-month weigh t- for-length), language, and health literacy also exhibit non-negligible asso ciations. The four estimators largely agree on the direction and relative magnitude of these effects; the b orro wing-based metho ds (MR-OSCAR and SR-OSCAR) tend to produce slightly shrunk and more stable co efficien t estimates than RACER, consisten t with their narrow er CA TE in terv als. 28 Figure 3: Upp er Panel: Sorted individual CA TE estimates with 95% p ost-LASSO OLS confidence in terv als; grey in terv als cov er 0, while red in terv als corresp ond to sub jects whose CIs exclude 0. L ower Panel: Cov ariate-sp ecific effects on the CA TE with 95% confidence interv als for the top 20 cov ariates (b y maximum absolute effect size). 29 6 Discussion W e ha ve proposed MR-OSCAR, a framework for impro ving CA TE estimation in random- ized trials by b orro wing strength from observ ational sources that record additional, p o- ten tially effect-mo difying cov ariates not a v ailable in the trial. Rather than discarding the mismatc hed cov ariates, MR-OSCAR imputes them in the trial using a prediction mo del trained in the observ ational sample, then calibrates all outcome and CA TE mo dels bac k to the RCT, preserving the randomized treatment con trast as the sole source of causal iden tification. Our error b ounds decomp ose the CA TE risk in to the complexit y of the final CA TE re- gression, the qualit y of OS-to-R CT outcome mo del transp ort, and the accuracy of co v ariate imputation. When OS-only co v ariates are strongly related to the outcome and moderately predictable from shared v ariables, MR-OSCAR strictly dominates b oth an RCT-only esti- mator and a shared-only b orrowing strategy . When the missing blo ck is weakly predictive or hard to impute, MR-OSCAR gracefully shrinks bac k to ward R CT-only estimation with- out substan tial additional error. These theoretical predictions are confirmed b y sim ulations across a range of co v ariate-mismatch configurations. In the Greenligh t Plus application, MR-OSCAR deliv ers the narro west individual con- fidence interv als—roughly a 20% reduction in mean CI width relative to the RCT-only b enc hmark—ev en outp erforming an “oracle” estimator that observes the true insurance v ariable in the trial. This coun terin tuitiv e result arises b ecause a smooth imputed prob- abilit y regularizes a sparse, noisy binary co v ariate more effectively than using the ra w indicator directly . The co v ariate-effect analysis further shows that insurance status is a k ey driv er of treatment response, underscoring the cost of ignoring mismatched v ariables and the v alue of imputation-based in tegration for iden tifying which children b enefit most from ob esit y prev ention programs. 7 Ac kno wledgemen t This research w as funded b y the Patien t-Centered Outcomes Research Institute (PCORI) a w ard ME-2023C1-32148, “Improving Metho ds for Conducting Patien t-Centered Compar- ativ e Clinical Effectiveness Research.” All authors are supp orted by this a ward. 30 8 Data Av ailabilit y Statemen t This authors are unable to share the data due to patient priv acy concerns. How ever, users ma y request access from V anderbilt Univ ersity Medical Cen ter up on reasonable request. References Ac k erman, B., Schmid, I., Rudolph, K. E., Seamans, M. J., Susukida, R., Mo jtabai, R., and Stuart, E. A. (2019). Implementing statistical metho ds for generalizing randomized trial findings to a target p opulation. A ddictive b ehaviors , 94:124–132. Asiaee, A., Gravio, C. D., Beck, C., Mei, Y., Pal, S., and Huling, J. D. (2025). Impro ving precision of RCT-based CA TE estimation using data borrowing with double calibration. A they , S. and Im b ens, G. (2016). Recursiv e partitioning for heterogeneous causal effects. Pr o c e e dings of the National A c ademy of Scienc es , 113(27):7353–7360. Bartlett, P . L. and Mendelson, S. (2006). Lo cal rademacher complexities and empirical minimization. Annals of Statistics , 34. Bica, I. and v an der Schaar, M. (2022). T ransfer learning on heterogeneous feature spaces for treatment effects estimation. A dvanc es in Neur al Information Pr o c essing Systems , 35:37184–37198. Bran tner, C. L., Chang, T.-H., Nguy en, T. Q., Hong, H ., Di Stefano, L., and Stuart, E. A. (2023). Metho ds for integrating trials and non-exp erimental data to examine treatment effect heterogeneit y . Statistic al Scienc e , 38(4):640–654. Chang, J. H., Russo, M., and Paul, S. (2024). Heterogeneous transfer learning for high dimensional regression with feature mismatc h. arXiv pr eprint arXiv:2412.18081 . Cheng, D. and Cai, T. (2021). Adaptive combination of randomized and observ ational data. arXiv pr eprint arXiv:2111.15012 . Colnet, B., Josse, J., Scornet, E., and V aro quaux, G. (2021). Generalizing a causal effect: sensitivit y analysis and missing cov ariates. arXiv pr eprint arXiv:2105.06435 . 31 Dahabreh, I. J., Rob ertson, S. E., Steingrimsson, J. A., Stuart, E. A., and Hernan, M. A. (2020). Extending inferences from a randomized trial to a new target p opulation. Statis- tics in me dicine , 39(14):1999–2014. Ghosh, D., T ushar, F., Dahal, L., V ancoillie, L., Lafata, K. J., Samei, E., Lo, J. Y., and Luo, S. (2026). Demographic distribution matc hing b et ween real-world and virtual phan tom p opulation. Me dic al Physics , 53(3):e70364. Hatt, T., Berrev o ets, J., Curth, A., F euerriegel, S., and v an der Sc haar, M. (2022). Combin- ing observ ational and randomized data for estimating heterogeneous treatmen t effects. arXiv pr eprint arXiv:2202.12891 . Heerman, W. J., P errin, E. M., Yin, H. S., Sc hildcrout, J. S., Delamater, A. M., Flo wer, K. B., Sanders, L., W o o d, C., Ka y , M. C., Adams, L. E., et al. (2022). The greenligh t plus trial: Comparativ e effectiv eness of a health information technology interv ention vs. health communication in terven tion in primary care offices to prev en t childhoo d ob esity . Contemp or ary clinic al trials , 123:106987. Heerman, W. J., Rothman, R. L., Sanders, L. M., Schildcrout, J. S., Flo wer, K. B., De- lamater, A. M., Kay , M. C., W o o d, C. T., Gross, R. S., Bian, A., et al. (2024). A digital health b eha vior in terv ention to preven t childhoo d ob esit y: the greenligh t plus randomized clinical trial. JAMA , 332(24):2068–2080. Johansson, F., Shalit, U., and Sontag, D. (2016). Learning represen tations for counter- factual inference. In International c onfer enc e on machine le arning , pages 3020–3029. PMLR. Josey , K. P ., Y ang, F., Ghosh, D., and Raghav an, S. (2022). A calibration approach to trans- p ortabilit y and data-fusion with observ ational data. Statistics in me dicine , 41(23):4511– 4531. Karlsson, R., De Bartolomeis, P ., Dahabreh, I. J., and Krijthe, J. H. (2025). Robust estimation of heterogeneous treatmen t effects in randomized trials leveraging external data. arXiv pr eprint arXiv:2507.03681 . Kennedy , E. H. (2023). T o wards optimal doubly robust estimation of heterogeneous causal effects. Ele ctr onic Journal of Statistics , 17(2):3008–3049. 32 Ken t, D. M., Steyerberg, E., and V an Kla veren, D. (2018). Personalized evidence based medicine: predictiv e approac hes to heterogeneous treatmen t effects. Bmj , 363. Li, F., Buc hanan, A. L., and Cole, S. R. (2022). Generalizing trial evidence to target p opulations in non-nested designs: Applications to aids clinical trials. Journal of the R oyal Statistic al So ciety Series C: Applie d Statistics , 71(3):669–697. Lin, X., T arp, J. M., and Ev ans, R. J. (2025). Combining exp erimen tal and observ ational data through a p o w er likelihoo d. Biometrics , 81(1):ujaf008. Nie, X. and W ager, S. (2021). Quasi-oracle estimation of heterogeneous treatment effects. Biometrika , 108(2):299–319. Ob erst, M., D’Amour, A., Chen, M., W ang, Y., Sontag, D., and Y adlowsky , S. (2022). Un- derstanding the risks and rewards of com bining unbiased and p ossibly biased estimators, with applications to causal inference. arXiv pr eprint arXiv:2205.10467 . Rahman, R., V en tz, S., Redd, R., Cloughesy , T., W en, P . Y., T rippa, L., and Alexander, B. M. (2021). Lev eraging external data in the design and analysis of clinical trials in neuro-oncology . The L anc et Onc olo gy , 22(10):e456–e465. Raman, S. R., Qualls, L. G., Hammill, B. G., Nelson, A. J., Nilles, E. K., Marsolo, K., and O’Brien, E. C. (2023). Optimizing data in tegration in trials that use ehr data: lessons learned from a m ulti-center randomized clinical trial. T rials , 24(1):566. R¨ assler, S. (2002). F r e quentist The ory of Statistic al Matching , pages 15–43. Springer New Y ork, New Y ork, NY. Robins, J. M., Rotnitzky , A., and Zhao, L. P . (1994). Estimation of regression co effi- cien ts when some regressors are not alwa ys observed. Journal of the Americ an Statistic al Asso ciation , 89(427):846–866. Sanders, L. M., P errin, E. M., Yin, H. S., Bronaugh, A., and Rothman, R. L. (2014). “greenligh t study”: a con trolled trial of low-literacy , early c hildho o d obesity preven tion. Pe diatrics , 133(6):e1724–e1737. Sugiy ama, M. and Kaw anab e, M. (2012). Machine le arning in non-stationary envir onments: Intr o duction to c ovariate shift adaptation . MIT press. 33 v an de Geer, S. and B ¨ uhlmann, P . (2009). On the conditions used to prov e oracle results for the lasso. Ele ctr onic Journal of Statistics , 3:1360–1392. W ager, S. and Athey , S. (2018). Estimation and inference of heterogeneous treatment effects using random forests. Journal of the Americ an Statistic al Asso ciation , 113(523):1228– 1242. W ang, R., Lagak os, S. W., W are, J. H., Hunter, D. J., and Drazen, J. M. (2007). Statistics in medicine—rep orting of subgroup analyses in clinical trials. New England Journal of Me dicine , 357(21):2189–2194. W u, L. and Y ang, S. (2022). In tegrative r -learner of heterogeneous treatment effects com- bining experimental and observ ational studies. In Confer enc e on Causal L e arning and R e asoning , pages 904–926. PMLR. Xu, Q. and Qu, A. (2025). Represen tation retriev al learning for heterogeneous data inte- gration. arXiv pr eprint arXiv:2503.09494 . Y ao, L., Li, S., Li, Y., Huai, M., Gao, J., and Zhang, A. (2018). Representation learning for treatment effect estimation from observ ational data. A dvanc es in neur al information pr o c essing systems , 31. Y u, M., Kuang, C., Huling, J. D., and Smith, M. (2021). Diagnosis-group-sp ecific transi- tional care program recommendations for 30-da y rehospitalization reduction. The A nnals of Applie d Statistics , 15(3):1478–1498. Zhang, B., Tsiatis, A. A., Da vidian, M., Zhang, M., and Lab er, E. (2012). Estimating optimal treatmen t regimes from a classification p ersp ectiv e. Stat , 1(1):103–114. 34 SUPPLEMENT AR Y MA TERIAL T able 3: Comprehensive glossary of notation. Sym b ol Definition / description Data S ∈ { r, o } Source indicator (RCT or OS) Y ; Y (1) , Y ( − 1) Observed / p oten tial outcomes A ∈ {− 1 , 1 } T reatment indicator n s ; n s a T otal and arm-sp ecific sample sizes for source s Covariates X = ( U , Z , V ) ∈ R p Complete cov ariate v ector; p = p u + p z + p v X r = ( U , Z ) ∈ R p r RCT-observ ed cov ariates; p r = p u + p z X o = ( Z , V ) ∈ R p o OS-observed cov ariates; p o = p z + p v U , Z , V RCT-exclusiv e, shared, OS-exclusive blo cks b V = ˆ g ( Z ) Imputed OS-only cov ariates in the RCT Cor e quantities µ s a ( x ) E [ Y | X = x , A = a, S = s ]: conditional mean outcome, arm a , source s δ a ( x ) µ r a ( x ) − µ o a ( x ): outcome shift b etw een RCT and OS τ r ( x r ) E [ Y (1) − Y ( − 1) | X r = x r , S = r ]: target CA TE (2.1) π r a ( x r ) P ( A = a | X r = x r , S = r ): RCT prop ensity (2.2) µ r ( x r ) P a π r − a µ r a : coun terfactual mean outcome (CMO) (2.3) ˜ µ r ( x r ) E [ µ r ( X ) | X r = x r , S = r ]: marginalized CMO (2.6) τ m ( X r , A, Y ) A { Y − m ( X r ) } /π r A ( X r ): pseudo-outcome (2.4) ˆ τ SR , ˆ τ MR SR-OSCAR and MR-OSCAR CA TE estimators (see T able 1) Estimators ˆ ˜ µ r , ˆ ˜ µ sh , ˆ ˜ µ im CMO estimators: RACER, SR-OSCAR, MR-OSCAR (T able 1) ˆ µ o, sh a , ˆ µ o, im a OS outcome mo dels (shared-only Z ; full X o ) ˆ δ sh a , ˆ δ im a Discrepancy: (2.8), (2.11) ˆ µ sh a , ˆ µ im a Calibrated arm means: ˆ µ o, ( · ) a + ˆ δ ( · ) a ˆ g Imputation map Z → V ˆ µ r a RACER arm-sp ecific R CT outcome mo del Classes M o, sh a , M o, im a OS outcome classes on Z ( p z -dim) and X o ( p o -dim) D sh a , D im a ; D Discrepancy on X r ( p r -dim) / ( X r , b V ) ( p -dim); CA TE class on X r M r a ; G RA CER outcome class on X r ; imputation class on Z P ( · ) a ( · ) Penalt y term matching the corresponding class Risk terms ∆ 2 2 ( H , τ r ) inf h ∈H E { ( h ( X r ) − τ r ( X r )) 2 | S = r } : approximation error R n ( H ) E ϵ sup h ∈H 1 n P n i =1 ϵ i h ( X r i ) : empirical Rademacher complexity ( ϵ i iid ∼ Unif {− 1 , 1 } ) c ( H ) Localized complexit y parameter (Bartlett and Mendelson, 2006) B 2 sh P a inf h ∈H sh a E [( h ( X r ) − ˜ µ r a ( X r )) 2 | S = r ]: mismatch p enalt y (3.18) r 2 im E [ ∥ V − g ⋆ ( Z ) ∥ 2 | S = r ]: imputation risk L Lipschitz constant of µ o a in V Sp arsity s τ Sparsity of the CA TE model on X r ( § 3.4) s sh µ , s im µ OS outcome sparsity on Z (SR) and X o (MR); s sh µ ≤ s im µ s sh δ , s im δ Discrepancy sparsity on X r (SR) and ( X r , b V ) (MR); s sh δ ≤ s im δ s j Per-coordinate imputation sparsity: s j := ∥ λ o,j ∥ 0 35 Algorithm 1 summarizes the common structure of these pro cedures. Algorithm 1 High-level structure of R-OSCAR-t yp e estimators under co v ariate mismatc h 1: Input: R CT data { ( X r i , A r i , Y r i ) } n r i =1 , OS data { ( X o i , A o i , Y o i ) } n o i =1 , choice of estimator in { RA CER, SR-OSCAR, MR-OSCAR } . 2: If using MR-OSCAR then estimate g : Z 7→ V in the OS and impute b V i = ˆ g ( Z r i ) for RCT units. 3: for a ∈ {− 1 , 1 } do 4: OS outcome modeling: • RACER: no OS outcome mo del is used. • SR-OSCAR: fit an OS model ˆ µ o, sh a ( Z ) on ( Z o , Y o ). • MR-OSCAR: fit an OS model ˆ µ o, im a ( X o ) on ( Z o , V o , Y o ). 5: Calibration to the RCT: • RACER: fit ˆ µ r a ( X r ) directly on the R CT. • SR-OSCAR: fit a discrepancy ˆ δ sh a ( X r ) so that Y r ≈ ˆ µ o, sh a ( Z r ) + ˆ δ sh a ( X r ). • MR-OSCAR: fit a discrepancy ˆ δ im a ( X r , b V ) so that Y r ≈ ˆ µ o, im a ( Z r , b V ) + ˆ δ im a ( X r , b V ). 6: end for 7: Construct arm-sp ecific calibrated predictions ˆ µ sh a (SR-OSCAR) or ˆ µ im a (MR-OSCAR) and the asso ciated CMO for eac h individual by com bining the t wo arm-specific calibrated predictions with sw app ed R CT randomization w eights (as in Asiaee et al. (2025)). 8: F orm transformed outcomes by subtracting the CMO from the observed outcome in the R CT and multiplying by a kno wn function of ( A, X r ) (the pseudo-outcome), and regress these transformed outcomes on X r to obtain the final CA TE estimator ˆ τ ( X r ). 9: Output: CA TE estimator ˆ τ ( · ) corresp onding to RACER, SR-OSCAR, or MR-OSCAR. Sim ulation Setup Details W e generate a latent baseline v ector X = ( U , Z , V ) ∈ R p from an equicorrelated Gaus- sian distribution with correlation ρ = 0 . 4 and unit marginal v ariances. T o induce a mild co v ariate (domain) shift betw een sources, w e set E [ X | S = o ] = 0 and E [ X | S = r ] = ( δ u , 0 z , 0 v ), where the co ordinates of δ u ∈ R p u are dra wn indep endently with random sign and magnitude in a small range (e.g., | δ u,j | ∈ [0 . 25 , 0 . 5]). T reatment is randomized in the RCT with Pr( A = 1) = 0 . 5, whereas in the OS it follo ws a sparse logistic prop ensity mo del dep ending only on a subset of shared co v ariates, Pr( A = 1 | Z ) = expit( α 0 + Z ⊤ S γ ), where S ⊂ { 1 , . . . , p z } is a fixed index set (e.g., | S | = 10), γ has nonzero entries on S (e.g., 36 γ j ∈ [0 . 25 , 0 . 5] with random sign), and α 0 is c hosen so that the marginal treated proportion is appro ximately 1 / 3. P oten tial outcomes are linear with sparse coefficients: for a ∈ { 0 , 1 } w e set Y ( a ) = X ⊤ β a + ε a , where a small prop ortion of coordinates in X r = ( U , Z ) carry signal (e.g., 5% with magnitude about 2 / 3) and coefficients on V hav e larger magnitude (ab out 1), reflecting outcome-relev ant information observed only in the OS. T o induce an outcome-mo del shift, w e p erturb a small fraction (e.g., 2%) of the X r co efficien ts in the RCT relativ e to the OS. Finally , we add homoskedastic Gaussian noise indep enden tly across units (and arms), ε a ∼ N (0 , σ 2 ε ); in our implemen tation the noise standard deviation is 0 . 5 σ , so σ 2 ε = σ 2 / 4. Additional Sim ulation: V arying the predictabilit y of OS-only co- v ariates Here, in order to study the effect of imputability of V from Z , w e v ary the p opulation predictabilit y R 2 ( V | Z ) b y sampling V | Z = Λ Z + ε with ε ∼ N (0 , σ 2 V | Z I ) and c ho osing σ 2 V | Z to ac hieve target v alues R 2 ∈ { 0 . 10 , 0 . 20 , . . . , 0 . 90 } , while keeping Λ fixed and the rest of the study design same as b efore. Figure 4 displa ys RMSE versus R 2 ( V | Figure 4: RMSE (me an ± 1 SD) for CA TE estimation in the R CT p opulation as a function of R 2 ( V | Z ) , which c ontr ols how wel l the OS-only c ovariates V c an b e pr e dicte d fr om Z . MR-OSCAR (r e d) is slightly worse than RACER (gr e en) when imputability is low, ties ar ound mo der ate values, and dominates onc e R 2 ( V | Z ) is sufficiently lar ge; SR-OSCAR (blue) is uniformly worst. 37 Z ). Three qualitative features emerge: (i) monotone impro v ement with imputabilit y . All metho ds enjoy decreasing RMSE as R 2 ( V | Z ) increases, reflecting the fact that the problem b ecomes easier when V is more predictable from Z ; (ii) threshold b ehavior for MR-OSCAR. At low levels of imputabilit y ( R 2 ≈ 0 . 10-0 . 30), MR-OSCAR is slightly worse than RACER: the noise in tro duced by imputing a p o orly predictable V offsets the b enefit of b orro wing from the OS. In the mid-range ( R 2 ≈ 0 . 40-0 . 60), the t w o metho ds are essen tially indistinguishable. Beyond a clear threshold ( R 2 ≳ 0 . 60), MR-OSCAR ov ertakes RA CER and the gap widens as R 2 increases; this aligns with our theory in which the MR-OSCAR risk improv es as the imputation error r 2 im shrinks; (iii) dominance o v er Z -only b orro wing. SR-OSCAR is uniformly w orse across the en tire range, b ecause it ignores the V signal en tirely; it nev er crosses the other curv es. Error bars shrink mo destly with R 2 , indicating greater stabilit y when b V is reliable. Co v ariate Balance in the Greenligh t Plus R CT A t first glance it may seem surprising that MR-OSCAR, which treats insurance as unob- serv ed in the R CT and instead uses an imputed b V , can outp erform an “oracle” R-OSCAR that conditions on the true insurance indicator V . The co v ariate-balance diagnostics help clarify this phenomenon. T o assess whether an y gains from our borrowing strategies could b e attributed to residual im balances in baseline co v ariates, w e examined co v ariate balance b et w een treatmen t arms in the Greenligh t Plus RCT. F or eac h baseline cov ariate W , we computed the absolute standardized mean difference (SMD) b etw een A = 1 and A = 0, defined as SMD( W ) = ¯ W 1 − ¯ W 0 p { s 2 1 + s 2 0 } / 2 , where ¯ W a and s 2 a denote the sample mean and v ariance of W in arm A = a ; for binary co v ariates we used the analogous standardization based on the p o oled binomial v ariance. Figure 5 displa ys the resulting “lov e plot” of absolute SMDs. Ov erall, cov ariate balance w as excellent. The v ast ma jority of baseline cov ariates had absolute SMDs well b elo w 0 . 10, a common b enc hmark for negligible im balance. The only clearly pronounced difference w as for the income category “ $ 50,000- $ 99,999”, whic h exhib- ited an absolute SMD of appro ximately 0 . 30; most remaining co v ariates were b elow 0 . 15. In particular, the collapsed insurance indicator (Uninsured vs. Insured) sho wed a modest 38 Figure 5: Lo v eplot of Cov ariate Balance 39 absolute SMD sligh tly abov e 0 . 15. This indicates that randomization achiev ed a mo derate balance on insurance and, and that any efficiency gains from MR-OSCAR may b e driv en b y correcting a sizable treatmen t-arm imbalance in insurance. Rather, as discussed b e- lo w, the imputation step in MR-OSCAR acts primarily to stabilize a relativ ely sparse and site-heterogeneous insurance signal when incorp orating EHR information in to the CA TE estimation. Moreo v er, insurance is a relativ ely sparse and heterogeneous cov ariate: only a small fraction of children are uninsured, and the uninsured counts are unev enly distributed across sites (e.g., v ery few uninsured c hildren at Duke and UNC). When R-OSCAR includes the full insurance factor V (and its asso ciated basis functions) in the R CT outcome and calibration regressions, the p ost-LASSO OLS steps m ust estimate co efficients for sev eral small cells, leading to unstable estimates and inflated sampling v ariance. MR-OSCAR handles insurance differently . It first fits an imputation mo del g ( Z ) ≈ E [ V | Z ] in the large EHR control sample and then propagates only the smo othed pre- diction b V = g ( Z ) into the RCT outcome and calibration models. This construction p o ols information across sites and shrinks aw ay idiosyncratic noise and co ding irregularities in the observed insurance v ariable, effectively replacing a sparse binary factor b y a stable, con tin uous risk score. The bias incurred b y using b V instead of V is negligible, whereas the v ariance reduction from smo othing can b e substantial. This v ariance-bias tradeoff explains wh y , in the GPS application, MR-OSCAR attains shorter CA TE in terv als than oracle R-OSCAR despite not observing V directly in the R CT. Error b ounds for SR-OSCAR on the shared cov ariate space W e first consider the shared-only estimator SR-OSCAR. Let ˆ τ SR b e the CA TE estimator constructed in Section 2.1.1, and supp ose the last-stage calibrator ˆ δ sh in (2.9) is fit in a class D with complexit y measured b y R n r ( D ). Define the arm-sp ecific marginalized RCT CMOs ˜ µ r a ( x r ) := E µ r a ( x r , V ) | X r = x r , S = r , and let m Z ,a ( X r ) denote the augmentation comp onen t used by SR-OSCAR for arm a (the calibrated OS prediction en tering the CMO). W e measure the augmentation error b y ∆ 2 2 ( m Z ,a , ˜ µ r a | X r ) := E h m Z ,a ( X r ) − ˜ µ r a ( X r ) 2 | S = r i . 40 Theorem 4 (Risk b ound for SR-OSCAR) . Supp ose Assumptions 1 and 3-5 hold, and the nuisanc e estimators ar e obtaine d with cr oss-fitting acr oss folds. Then ther e exists a c onstant C > 0 such that, with pr ob ability at le ast 1 − γ for al l γ ∈ (0 , 1) , ∆ 2 2 ( ˆ τ SR , τ r ) ≤ ∆ 2 2 ( D , τ r ) + C " B 2 sh + R 2 n r ( D ) (8.25) + X a ∈{− 1 , 1 } R 2 n o ( M o, sh a ) + R 2 n r ( D sh a ) # + C log(1 /γ ) n r . The first term in (8.25) is the appro ximation error of the CA TE calibration class D , whic h is shared across RACER, SR-OSCAR, and MR-OSCAR. The second group of terms is purely statistical: it dep ends on the complexities of the RCT calibration class D , the OS outcome classes M o, sh a , and the arm-wise R CT discrepancy classes D sh a . The mismatch p enalt y B 2 sh in (3.18) captures the irreducible error induced b y restricting to the shared space Z : ev en with infinite data and p erfect optimization, SR-OSCAR cannot improv e b ey ond this term if imp ortan t effect mo difiers reside in V that cannot b e pro jected onto Z . Finally , the log(1 /γ ) /n r term is a standard residual due to concentration. Augmen tation-error decomp osition and lo calized rates. The pro of of Theorem 4 pro ceeds in t wo conceptually separate steps, mirroring the analysis in Asiaee et al. (2025). First, one sho ws that the CA TE risk of SR-OSCAR can b e b ounded in terms of the aug- men tation errors: ∆ 2 2 ( ˆ τ SR , τ r ) ≲ ∆ 2 2 ( D , τ r ) + 1 + X a ∈{− 1 , 1 } ∆ 2 2 ( m Z ,a , ˜ µ r a | X r ) ! R n r ( D ) , (8.26) up to negligible residual terms. Second, one b ounds the augmen tation errors themselv es in terms of the OS/R CT nuisance complexities and the mismatc h p enalt y B 2 sh . Prop osition 2 (Augmentation error for shared-only b orro wing) . Under the c onditions of The or em 4, ther e exist c onstants C < ∞ , η o > 0 , and η r > 0 such that, for e ach arm a , ∆ 2 2 ( m Z ,a , ˜ µ r a | X r ) ≲ c ( M o, sh a ) ( n o ) η o + c ( D sh a ) ( n r ) η r + B 2 sh , (8.27) wher e c ( M o, sh a ) and c ( D sh a ) ar e lo c alize d c omplexities of the OS outc ome and R CT discr ep- ancy classes, r esp e ctively. 41 Com bining (8.26) with (8.27) and the generic lo calized-complexity b ound (3.19) yields a lo calized v ersion of (8.25): ∆ 2 2 ( ˆ τ SR , τ r ) ≲ ∆ 2 2 ( D , τ r ) + B 2 sh + c ( D ) ( n r ) η r + X a ∈{− 1 , 1 } c ( M o, sh a ) ( n o ) η o + c ( D sh a ) ( n r ) η r . (8.28) This form closely parallels the RACER b ound (3.21) but makes explicit the additional mismatc h p enalt y B 2 sh and the role of the OS outcome and calibration complexities. In particular, when the outcome dep ends w eakly on OS-only co v ariates (so that B 2 sh is small) and the OS outcome mo dels are well-behav ed (small c ( M o, sh a )), SR-OSCAR can strictly re- duce the CA TE risk relative to RA CER by reducing the estimation error without incurring appreciable mismatc h p enalt y . Conv ersely , when B 2 sh is large, the b ound makes explicit that restriction to the shared space can dominate the p otential gain from b orrowing. Pro ofs of Theorems Pr o of of Pr op osition 1. Fix an arm a . Let g ⋆ ∈ G b e an oracle imputation map achieving r 2 im = E [ ∥ V − g ⋆ ( Z ) ∥ 2 | S = r ], and write b V := g ⋆ ( Z ). The MR-OSCAR arm-sp ecific calibrated predictor ev aluated at the imputed cov ariates is m aug ,a ( X r ) := ˆ µ o, im a ( Z , b V ) + ˆ δ im a ( X r , b V ) . Let µ o, im ,⋆ a ∈ M o, im a and δ im ,⋆ a ∈ D im a denote oracle targets for the t wo ERM steps (so that, under correct specification, µ r a ( x ) = µ o, im ,⋆ a ( x o ) + δ im ,⋆ a ( x )). Add and subtract the oracle predictor at b V : m aug ,a ( X r ) − ˜ µ r a ( X r ) = { ˆ µ o, im a − µ o, im ,⋆ a } ( Z , b V ) + { ˆ δ im a − δ im ,⋆ a } ( X r , b V ) + { µ r a ( X r , b V ) − ˜ µ r a ( X r ) } . By ( x + y + z ) 2 ≤ 3( x 2 + y 2 + z 2 ) and Assumption 5, the first t wo terms contribute at most ≲ c ( M o, im a ) / ( n o ) η o and ≲ c ( D im a ) / ( n r ) η r to ∆ 2 2 ( m aug ,a , ˜ µ r a | X r ). F or the last term, use Jensen’s inequalit y and Lipschitzness of µ r a in the V blo ck (Assumption 4): µ r a ( X r , b V ) − ˜ µ r a ( X r ) = E µ r a ( X r , b V ) − µ r a ( X r , V ) | X r , S = r ≤ L E [ ∥ b V − V ∥ | X r , S = r ] , whic h implies E [ { µ r a ( X r , b V ) − ˜ µ r a ( X r ) } 2 | S = r ] ≤ L 2 E [ ∥ b V − V ∥ 2 | S = r ] = L 2 r 2 im . Com bining b ounds yields (3.23). 42 Pr o of of Pr op osition 2. Fix an arm a . In SR-OSCAR the arm-specific calibrated predictor is m Z ,a ( X r ) = ˆ µ o, sh a ( Z ) + ˆ δ sh a ( X r ) . Let h ⋆ a ∈ H sh a b e an oracle elemen t attaining (or nearly attaining) the infimum in the definition of B 2 sh , and write h ⋆ a ( X r ) = µ o, sh ,⋆ a ( Z ) + δ sh ,⋆ a ( X r ) with µ o, sh ,⋆ a ∈ M o, sh a and δ sh ,⋆ a ∈ D sh a . Then ∆ 2 2 ( m Z ,a , ˜ µ r a | X r ) ≤ 2 E ( m Z ,a ( X r ) − h ⋆ a ( X r )) 2 | S = r + 2 E ( h ⋆ a ( X r ) − ˜ µ r a ( X r )) 2 | S = r . The second term is b ounded b y the (single-arm) approximation residual defining B 2 sh , and hence b y B 2 sh itself. F or the first term, ( x + y ) 2 ≤ 2 x 2 + 2 y 2 giv es E [( m Z ,a − h ⋆ a ) 2 | S = r ] ≤ 2 E [( ˆ µ o, sh a ( Z ) − µ o, sh ,⋆ a ( Z )) 2 | S = r ]+2 E [( ˆ δ sh a ( X r ) − δ sh ,⋆ a ( X r )) 2 | S = r ] . By Assumption 5 (equiv alen tly (3.19)), these t w o estimation errors are ≲ c ( M o, sh a ) / ( n o ) η o and ≲ c ( D sh a ) / ( n r ) η r . Com bining the pieces yields (8.27). Pr o of of The or em 2. W e define ˆ ϕ i as the doubly-robust pseudo-outcome for eac h R CT unit i as describ ed in (2.4). Recall that the MR-OSCAR estimator ˆ τ MR is obtained as the empirical risk minimizer o ver D of a squared-loss regression of cross-fitted pseudo-outcomes ˆ ϕ i on X r i in the RCT. Throughout the pro of we condition on the splits used for cross-fitting. Step 1: Oracle pseudo-outcomes and generic CA TE b ound. Let ϕ ⋆ i denote the or acle pseudo-outcome that w ould b e constructed if all nuisance comp onents (outcome regressions, discrepancies, imputation map) w ere known. By Assumption 1, the oracle CA TE τ r minimizes the p opulation squared error L ( f ) := E ( ϕ ⋆ − f ( X r )) 2 | S = r o v er f ∈ L 2 ( P r ), and the excess CA TE risk ∆ 2 2 ( ˆ τ MR , τ r ) coincides (up to constan ts) with the excess risk of regressing ϕ ⋆ on X r ; see Asiaee et al. (2025) for a detailed deriv ation. Let ˆ τ or b e the empirical risk minimizer in D when regressing the oracle pseudo-outcomes ( ϕ ⋆ i ) on the cross-fitted R CT sample. Standard ERM arguments with squared loss and Rademac her complexity (Bartlett and Mendelson, 2006) then yield, for some constant C > 0 and all γ ∈ (0 , 1), ∆ 2 2 ( ˆ τ or , τ r ) ≤ ∆ 2 2 ( D , τ r ) + C h R 2 n r ( D ) + log(1 /γ ) n r i , (8.29) with probability at least 1 − γ / 2. Here ∆ 2 2 ( D , τ r ) is the approximation error of D and R n r ( D ) is the empirical Rademac her complexity of D under the R CT distribution. 43 Step 2: Decomp osing the effect of estimated pseudo-outcomes. The actual esti- mator ˆ τ MR minimizes the empirical risk based on estimate d pseudo-outcomes ˆ ϕ i , obtained b y plugging cross-fitted nuisance estimators into the oracle construction. Let ℓ ( f , ϕ ) := ( ϕ − f ( X r )) 2 denote the squared loss. By a standard p erturbation argument for plug-in pseudo-outcome regressions, w e hav e ∆ 2 2 ( ˆ τ MR , τ r ) ≤ 2 ∆ 2 2 ( ˆ τ or , τ r ) + C E h ˆ ϕ − ϕ ⋆ 2 | S = r i , (8.30) for some univ ersal constan t C > 0. Intuitiv ely , the first term is the excess risk due to restricting to the class D (already con trolled in (8.29)), whereas the second term quantifies the extra noise in tro duced b y using estimated, rather than oracle, pseudo-outcomes. The error b et ween ˆ ϕ and ϕ ⋆ can b e expressed in terms of the arm-sp ecific augmentation functions that MR-OSCAR estimates. W riting m aug ,a ( X r ) for the implicit augmen tation function for arm a (as defined in the statement of Prop osition 1) and using the algebra of the pseudo-outcome represen tation (exactly as in Equation (7.23) of Asiaee et al., 2025), one obtains E h ˆ ϕ − ϕ ⋆ 2 | S = r i ≲ X a ∈{− 1 , 1 } ∆ 2 2 m aug ,a , ˜ µ r a | X r , (8.31) where ˜ µ r a is the arm-specific target app earing in the augmen tation lay er. Combining (8.30), (8.29), and (8.31), and absorbing constants, yields ∆ 2 2 ( ˆ τ MR , τ r ) ≤ C " ∆ 2 2 ( D , τ r ) + R 2 n r ( D ) + log(1 /γ ) n r + X a ∈{− 1 , 1 } ∆ 2 2 m aug ,a , ˜ µ r a | X r # , (8.32) with probabilit y at least 1 − γ (after a union b ound o ver the oracle and plug-in steps). Step 3: Bounding the augmen tation errors via Prop osition 1. Under the condi- tions of Theorem 2, Prop osition 1 guaran tees that, for each arm a , ∆ 2 2 m aug ,a , ˜ µ r a | X r ≲ c ( M o, im a ) ( n o ) η o + c ( D im a ) ( n r ) η r + L 2 r 2 im , where c ( · ) and η o , η r > 0 are lo calized complexit y constants asso ciated with the corre- sp onding function classes, and r 2 im is the oracle imputation risk defined in Section 3.3. 44 Assumption 5 states that the localized complexities can b e dominated (up to constan ts) b y the squared Rademacher complexities of the same classes, so that c ( M o, im a ) ( n o ) η o ≲ R 2 n o ( M o, im a ) , c ( D im a ) ( n r ) η r ≲ R 2 n r ( D im a ) . Summing the b ound in Prop osition 1 o v er a ∈ {− 1 , 1 } and substituting in to (8.32) yields ∆ 2 2 ( ˆ τ MR , τ r ) ≤ C " ∆ 2 2 ( D , τ r ) + R 2 n r ( D ) + log(1 /γ ) n r + L 2 r 2 im + X a ∈{− 1 , 1 } n R 2 n o ( M o, im a ) + R 2 n r ( D im a ) o # , (8.33) again up to univ ersal constants. Step 4: Error from estimating the imputation map. So far r 2 im has b een defined relativ e to the oracle imputation map g ⋆ ∈ G . In practice, MR-OSCAR uses ˆ g , obtained b y ERM (or p enalized ERM) in the same class G on the OS sample with cross-fitting. Assumption 5 implies E ∥ ˆ g ( Z ) − g ⋆ ( Z ) ∥ 2 | S = o ≲ R 2 n o ( G ) . By the Lipsc hitz condition in Assumption 4, replacing g ⋆ b y ˆ g in the construction of the pseudo-outcomes and augmen tation functions p erturbs the latter by at most a constant m ultiple of ∥ ˆ g ( Z ) − g ⋆ ( Z ) ∥ . Therefore the imputation-induced part of the augmen tation error pic ks up an additional term of order R 2 n o ( G ), whic h can b e absorb ed additively in to the righ t-hand side of (8.33). Collecting terms and re-absorbing univ ersal constants in to a single C gives exactly the b ound in (3.22): ∆ 2 2 ( ˆ τ MR , τ r ) ≤ ∆ 2 2 ( D , τ r )+ C " L 2 r 2 im + R 2 n r ( D )+ X a ∈{− 1 , 1 } R 2 n o ( M o, im a )+ R 2 n r ( D im a ) + R 2 n o ( G ) # + C log(1 /γ ) n r , with probabilit y at least 1 − γ . This completes the pro of. Pr o of of The or em 3. W e ha v e cov ariates Z ∈ R p z , target to impute V ∈ R p v . Linear- Gaussian relations in eac h source s ∈ { o, r } : V s = Λ s Z s + ε s , E [ ε s | Z s ] = 0 , Cov( ε s ) = Σ s V | Z , Co v( Z s ) = Σ s Z Z . W e estimate Λ o ro w-wise by LASSO on OS data and then impute in RCT as b V ( Z r ) = b Λ o Z r . The RCT mean-squared imputation error is r 2 V := E r ∥ b V ( Z r ) − V r ∥ 2 2 . Let 45 Λ ⋆ o b e the best ro w-sparse appro ximation to Λ o (defined precisely b elo w), and define the co v ariance transfer factor κ r ← o := Σ r Z Z (Σ o Z Z ) − 1 op = ( Σ o Z Z ) − 1 / 2 Σ r Z Z ( Σ o Z Z ) − 1 / 2 op . W rite V r = Λ r Z r + ε r and b V ( Z r ) = b Λ o Z r . Then, b V ( Z r ) − V r = ( b Λ o − Λ r ) Z r − ε r . Hence r 2 im = E h ∥ ( b Λ o − Λ r ) Z r − ε r ∥ 2 2 | S = r i = E h ∥ ( b Λ o − Λ r ) Z r ∥ 2 2 | S = r i − 2 E h ⟨ ( b Λ o − Λ r ) Z r , ε r ⟩ | S = r i + E ∥ ε r ∥ 2 2 | S = r . Since E [ ε r | Z r , S = r ] = 0 and ε r ⊥ Z r , the cross term is zero: E h ⟨ ( b Λ o − Λ r ) Z r , ε r ⟩ | S = r i = E r h E r ⟨ ( b Λ o − Λ r ) Z r , ε r ⟩ | Z r i = 0 . Also E [ ∥ ε r ∥ 2 2 | S = r ] = tr( Σ r V | Z ). Therefore r 2 im = tr ( b Λ o − Λ r ) Σ r Z Z ( b Λ o − Λ r ) T + tr( Σ r V | Z ) . Next, we fix any ro w-sparse Λ ⋆ o (w e will choose it as the b est s -sparse approximation to Λ o in OS prediction norm). Define ∆ := b Λ o − Λ ⋆ o , B := Λ ⋆ o − Λ r . Then b Λ o − Λ r = ∆ + B . Plugging it in to the quadratic form, we get tr ( b Λ o − Λ r ) Σ r Z Z ( b Λ o − Λ r ) T = tr ( ∆ + B ) Σ r Z Z ( ∆ + B ) T = tr ∆Σ r ∆ T + tr B Σ r B T + 2 tr ∆Σ r B T , where Σ r := Σ r Z Z . Now applying Cauc hy-Sc hw arz for the F rob enius inner product with the PSD w eight Σ r , w e get for any conformable matrices A 1 , A 2 , tr( A 1 Σ r A T 2 ) = ⟨ A 1 Σ 1 / 2 r , A 2 Σ 1 / 2 r ⟩ F ≤ ∥ A 1 Σ 1 / 2 r ∥ F ∥ A 2 Σ 1 / 2 r ∥ F = tr( A 1 Σ r A T 1 ) tr( A 2 Σ r A T 2 ) 1 / 2 . Therefore 2 tr( ∆Σ r B T ) ≤ 2 p tr( ∆Σ r ∆ T ) tr( B Σ r B T ) ≤ tr( ∆Σ r ∆ T ) + tr( B Σ r B T ) , using 2 ab ≤ a 2 + b 2 . Hence tr ( b Λ o − Λ r ) Σ r ( b Λ o − Λ r ) T ≤ 2 tr( B Σ r B T ) + 2 tr( ∆Σ r ∆ T ) . Com bining, we hav e r 2 im ≤ 2 tr B Σ r B T | {z } T shift + 2 tr ∆Σ r ∆ T | {z } T est + tr( Σ r V | Z ) , 46 where T shift = tr ( Λ ⋆ o − Λ r ) Σ r Z Z ( Λ ⋆ o − Λ r ) T , and T est is the OS estimation con tribution measured under the R CT cov ariance. No w, for any vector x = 0, x T Σ r Z Z x x T Σ o Z Z x = y T ( Σ o Z Z ) − 1 / 2 Σ r Z Z ( Σ o Z Z ) − 1 / 2 y y T y ≤ ( Σ o Z Z ) − 1 / 2 Σ r Z Z ( Σ o Z Z ) − 1 / 2 op = κ r ← o , with y = ( Σ o Z Z ) 1 / 2 x . Th us Σ r Z Z ⪯ κ r ← o Σ o Z Z (PSD order), whic h implies, tr( ∆Σ r Z Z ∆ T ) ≤ κ r ← o tr( ∆ Σ o Z Z ∆ T ) . Supp ose, w e estimate eac h row of Λ o b y LASSO on OS. F or the j -th resp onse co ordinate V j , v o j = Z o λ o,j + ε o j , b λ o,j ∈ arg min β ∈ R p z n 1 2 n o ∥ v o j − Z o β ∥ 2 2 + λ j ∥ β ∥ 1 o . Let λ ⋆ o,j b e the b est s j -sparse appro ximation to λ o,j in the OS prediction norm: λ ⋆ o,j ∈ arg min ∥ β ∥ 0 ≤ s j ( β − λ o,j ) T Σ o Z Z ( β − λ o,j ) . Set ∆ j := b λ o,j − λ ⋆ o,j . Under the usual restricted eigen v alue (RE) condition holds on the supp ort S j = supp( λ ⋆ o,j ) with constant ϕ 0 > 0, and for λ j ≍ σ o,j p (2 log p z ) /n o , where σ 2 o,j := (Σ o V | Z ) j j , the standard LASSO theory (KKT + RE + Gaussian/sub-Gaussian tails) yields, with probabilit y at least 1 − c 1 p − c 2 z , ∆ T j Σ o Z Z ∆ j ≤ C 0 λ 2 j s j ϕ 2 0 ≤ C 1 s j log p z n o σ 2 o,j , where we used λ 2 j ≍ σ 2 o,j (log p z ) /n o in the last step. No w stacking all rows such that ∆ has ro ws ∆ T j , w e hav e tr ∆Σ o Z Z ∆ T = p v X j =1 ∆ T j Σ o Z Z ∆ j ≤ C 1 log p z n o p v X j =1 s j σ 2 o,j . Renaming C := 2 C 1 and com bining all pieces, we finally ha ve r 2 im ≤ 2 tr ( Λ ⋆ o − Λ r ) Σ r Z Z ( Λ ⋆ o − Λ r ) ⊤ | {z } OS → RCT mean-relation shift + sparsity approximation + C κ r ← o log p z n o p v X j =1 s j σ 2 o,j | {z } OS estimation error (sparse LASSO) + tr( Σ r V | Z ) | {z } irreducible RCT noise 47
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment