When and Why Does Unsupervised RL Succeed in Mathematical Reasoning? A Manifold Envelopment Perspective
Although outcome-based reinforcement learning (RL) significantly advances the mathematical reasoning capabilities of Large Language Models (LLMs), its reliance on computationally expensive ground-truth annotations imposes a severe scalability bottlen…
Authors: Zelin Zhang, Fei Cheng, Chenhui Chu
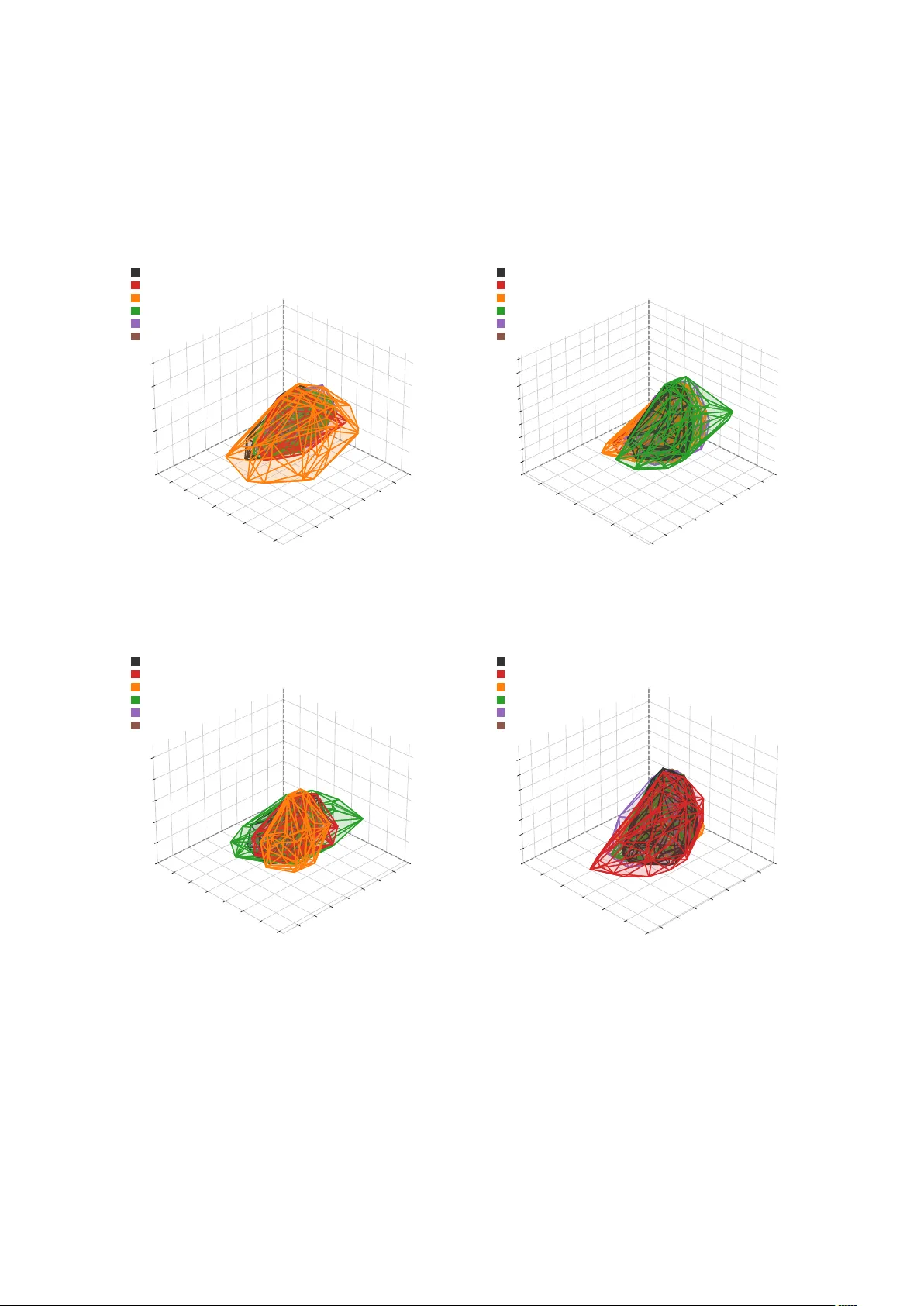
When and Why Does Unsuper vised RL Succeed in Mathematical Reasoning? A Manif old En v elopment P erspective Zelin Zhang F ei Cheng Chenhui Chu K yoto Univ ersity zelin@nlp.ist.i.kyoto-u.ac.jp , {feicheng, chu}@i.kyoto-u.ac.jp Abstract Although outcome-based reinforcement learn- ing (RL) significantly adv ances the mathemat- ical reasoning capabilities of Lar ge Language Models (LLMs), its reliance on computation- ally expensi ve ground-truth annotations im- poses a sev ere scalability bottleneck. Unsu- pervised RL guided by intrinsic rew ards offers a scalable alternati ve, yet it suffers from opaque training dynamics and catastrophic instability , such as policy collapse and reward hacking. In this paper , we first design and ev aluate a suite of intrinsic re wards that e xplicitly enforce concise and certain generation. Second , to dis- cov er the boundaries of this approach, we test base models across a spectrum of intrinsic rea- soning capabilities, re vealing ho w a model’ s foundational logical prior dictates its success or failure. Finally , to demystify why certain configurations stabilize while others collapse, we introduce a nov el geometric diagnostic lens, showing successful cases are en veloped by manifolds . Ultimately , our work goes beyond merely demonstrating that enforcing concise and certain responses successfully boosts math- ematical reasoning; we re veal when this unsu- pervised approach breaks do wn and geometri- cally diagnose why . 1 Introduction Recent adv ances in mathematical reasoning for Large Language Models (LLMs) rely on outcome- based reinforcement learning frame works, such as Group Relativ e Policy Optimization (GRPO; Shao et al. , 2024 ), often categorized as Reinforcement Learning with V erifiable Re wards (RL VR). These paradigms operate on verifiable supervision: mod- els are trained by generating multiple solution paths for a gi ven prompt, and polic y updates are guided by reward signals deri v ed from ground-truth la- bels. This dependence on ground truth imposes a scalability bottleneck, as verifiable answers are fre- quently una vailable or computationally expensi ve to obtain ( Lightman et al. , 2024 ). Unsupervised RL, which optimizes models us- ing intrinsic rew ards such as entropy minimization ( Prabhudesai et al. , 2025 ; Agarwal et al. , 2025 ) or self-consistency ( Zhang et al. , 2025 ; Zuo et al. , 2025 ) without ground-truth labels, provides a scal- able alternativ e. Ho wev er , deploying unsupervised RL for mathematical tasks presents challenges. T o pre vent optimization instability such as re ward hacking, a phenomenon where the model e xploits loopholes in the rew ard function to achiev e high scores without fulfilling the intended task ( Gao et al. , 2022 ), the design of rewards often requires adaptation to specific datasets or models. Studies on unsupervised RL generally treats the optimiza- tion process as a black box, omitting the e xplana- tion of why the policy succeeds or collapses during training. The internal mechanisms of unsupervised re wards require further in v estigation. Our primary research objecti ve is to uncover the underlying mechanisms and boundaries of un- supervised mathematical reasoning in LLMs. T o systematically unpack this, we try to answer the follo wing questions: (a) W ill penalizing a model for being verbose and uncertain natur ally for ce it to discover corr ect mathematical reasoning? (b) How do factors lik e the base model’ s inher ent ca- pacity define the boundaries wher e this unsuper- vised method inevitably fails? (c) What analytical lens can effectively captur e the underlying dynam- ics to distinguish successful unsupervised settings fr om failed ones? T o answer question (a) , as illustrated in Figure 1 (a), we systematically design and e valuate a se- ries of intrinsic rewards based on two penalty di- mensions: uncertainty and response length. W e compare fi ve specific methods: Shannon Entropy (Ent) ( Agarwal et al. , 2025 ), Cumulativ e Rényi Entropy (CH2), A v eraged Shannon Entropy (A v- gEnt) ( Prabhudesai et al. , 2025 ), Collision Proba- 1 (b) Boundary Con ditions W e a k P r i or M ode r a t e S t r ong (a) Intrinsic Rewards (c) Geometric Diagn ostic Lens Model Parameters i n Different T raining Steps Strong T raining State V erbose/Uncertain Concise/Cer tain W eak Model Moderate Figure 1: Overview of Resear ch Pipeline. (a) Design Re wards: enforce concise and certain. (b) Find Boundary Conditions: ev aluate across models with different reasoning abilities. (c) Find Diagnostic Lens: DTW clustering to 3D phase space. bility (CP), and Length Penalty (LP). Among them, CH2, CP , and LP are newly designed methods intro- duced to cover dif ferent penalties, demonstrating the generality of the subsequent mechanistic analy- sis. T o answer question (b) , as illustrated in Figure 1 (b), we e v aluate dif ferent model families across a spectrum of intrinsic logical reasoning priors from Llama to Qwen. W e establish a developmental pro- gression by systematically testing different config- urations across base models with weak, moderate, and high capabilities and their corresponding re- ward methods. This design allows us to observe ho w a model’ s ev olutionary stage dictates its train- ing stability , failure modes, and ultimate success. T o answer question (c) , as illustrated in Figure 1 (c), we introduce a nov el two-step analytical frame- work. (Step 1) W e cluster tokens based on ho w their av erage entropy e volv es throughout the train- ing process. W e apply Dynamic Time W arping (DTW) ( Berndt and Clifford , 1994 ) for this cluster- ing because these tok en-lev el entropy trajectories naturally v ary in length. (Step 2) W e project these high-dimensional trajectories into a measurable 3D phase space where each semantic cluster or entropy le vel corresponds to one dimension, providing a unified geometric lens to diagnose stability . The results of Step 1 indicate that across dif- ferent training configurations, the temporal trends of token entropy group into distinct entropy lev- els, each corresponds to a semantic cluster: a lo w-entropy “Execution State” (e.g., 1, +, by ), a medium-entropy “Logic State” (e.g., Let, So, Ther e- for e ), and a high-entropy “Thinking State” (e.g., perhaps, maybe, suppose ). In Step 2 , we apply a geometric diagnostic lens to analyze the training trajectories on the manifold within this projected space. W e observ e that successful training settings result in trajectories that are tightly env eloped on a well-defined manifold, demonstrating ordered and structured exploration. In contrast, failing settings are either loosely en veloped or display chaotic w an- dering across the geometric space. Our main contributions are summarized as fol- lo ws: • Systematic Evaluation of Unsupervised Re- wards: Addressing question (a) , we design and compare a suite of re wards including our nov el designs (LP , CH2 and CP) based on re- sponse length and predicti ve uncertainty . W e empirically demonstrate how e xplicitly penal- izing verbose and uncertain outputs can natu- rally force a model to discover correct mathe- matical reasoning without ground-truth labels. • Identification of Boundary Conditions: Ad- dressing question (b) , we establish a compar - ati ve e v aluation pipeline across base models with weak, moderate, and highly capable foun- dational reasoning skills. This dev elopmental progression rev eals how a model’ s intrinsic logical prior fundamentally dictates its train- ing stability , failure modes, and ultimate suc- cess under unsupervised RL. • Novel Diagnostic Lens for T raining Dy- namics: Addressing question (c) , we intro- 2 Method Uncertainty Length Ent Penalty Strong penalty A vgEnt Penalty None LP ∗ None Strong penalty CH2 ∗ Penalty W eak penalty CP ∗ Penalty Encourage (Confusing) T able 1: Formulation of the unsupervised r ewards. W e decompose each rew ard into two orthogonal dimen- sions: uncertainty penalization and length penalization. Methods marked with an asterisk ( ∗ ) are ne wly designed formulations introduced in this work to complete the design matrix across both dimensions. Ent ( Agarwal et al. , 2025 ) and A vgEnt ( Prabhudesai et al. , 2025 ) are previous methods. duce a two-step analytical framew ork using DTW clustering and 3D phase space projec- tion. This lens uncovers a consistent map- ping between temporal entropy and cogniti ve states (Execution, Logic, and Thinking), and identifies the “Manifold En velopment” phe- nomenon as a geometric metric to physically distinguish successful, stable reasoning from chaotic policy collapse. 2 T raining Methods During the RL training phase, the language model acts as a policy to generate a reasoning path token- by-token in an auto-regressi ve manner . This genera- tion process occurs during the rollout stage of train- ing, which practically functions as an inference step to collect trajectories. Once the full reasoning path is completed, a reward is assigned to update the model’ s parameters. Supervised RL for mathemati- cal reasoning ev aluates the final outcome against a ground-truth label. In contrast, unsupervised RL operates entirely without access to correct answers. Instead, the re ward R is calculated at the response sequence level, deriv ed purely from the intrinsic properties of the generated trajectory . Specifically , for a generated reasoning response of length T , let p t ( v ) denote the predicted probability of token v from the vocab ulary at generation step t . W e detail the mechanical intent behind each unsupervised formulation as follo ws. 2.1 Reward F ormulation Building on the ef fectiv eness of Ent identified by Agarwal et al. ( 2025 ), we decompose it into two core optimization factors: uncertainty penaliza- tion and length penalization . Accordingly , we pro- pose fiv e rew ard formulations that systematically isolate and vary these dimensions to pro vide a com- prehensi ve cov erage across the penalty spectrum, as detailed in T able 1 . These di verse formulations serve to verify the generalizability of our diagnostic frame work across v arious unsupervised objectiv es, while simultaneously allowing us to identify the most effecti ve penalty mechanisms for eliciting mathematical reasoning. Furthermore, this setup functions as an extensi ve ablation study , providing empirical insights into ho w rew ards across differ - ent dimensions and intensities impact the model’ s reasoning performance. Shannon Entr opy (Ent). Ent represents the most aggr essive joint optimization . The re ward employs the exact vocab ulary-lev el Shannon en- tropy: R Ent = − T X t =1 H ( p t ) = T X t =1 X v ∈V p t ( v ) log( p t ( v )) Because token entropy H ( p t ) is strictly non- negati ve, the cumulative sum monotonically de- creases as the sequence elongates. The model is pressured to become certain and concise at the same time. A veraged Shannon Entropy (A vgEnt). T o com- pletely remov e the implicit length penalty found in cumulati ve metrics, we formulate A vgEnt as R AvgEnt = − 1 T T X t =1 H ( p t ) By av eraging the entropy across the entire se- quence, the pressure to output short responses is eliminated. This formulation isolates uncertainty penalization . Length Penalty (LP). T o isolate the ef fect of sequence length from certainty , we establish LP as a pure length punishment. R LP = − T /T max where T max denotes the maximum response length. This metric applies an explicit penalty based solely on the token count, stripping away all feedback regarding the model’ s internal confidence. It serves to answer whether forcing bre vity alone can induce mathematical reasoning. 3 Cumulative Rényi Entropy (CH2). Represent- ing the formulation based on Second-order Rényi Entropy , CH2 is defined as R CH 2 = T X t =1 log X v ∈V p t ( v ) 2 ! Although the rew ard looks similar to Ent, its me- chanical effect div erges from Ent. It provides a weaker length penalty by annihilating the “long- tail tax. ” In Ent, Shannon entropy e v aluates − p log p ov er the entire vocab ulary ( |V | ≈ 10 5 ). The log arithmic term aggressiv ely amplifies the im- pact of the remaining probability mass distrib uted across the long tail ( lim p t ( v ) → 0 log p t ( v ) → −∞ ). In contrast, CH2’ s squaring operation mathemat- ically obliterates the infinitesimal probabilities in the long tail ( lim p t ( v ) → 0 p t ( v ) 2 → 0 ). Conse- quently , the term is dominated by the top-1 prob- ability . Collision Probability (CP). Representing Colli- sion Probability , CP introduces a mathematically in verted length dynamic formulated as R CP = T X t =1 X v ∈V p t ( v ) 2 The reward is strictly positi ve ( p 2 t > 0 ). Conse- quently , adding more tokens increases the total cumulati ve reward. This creates a tension: the model tends to maximize certainty , but is simulta- neously encouraged to generate verbose responses to accumulate more rew ard points. CP is designed to stress-test the training dynamics and observe which factor (certainty vs. verbosity) dominates when they are placed in conflict. Furthermore, it also represents a confusing situation to disentan- gle the impact of the reward signal from the base model’ s inherent capabilities. 2.2 Policy Optimization T o translate our unsupervised intrinsic rew ards into policy updates without the memory ov erhead of a separate critic network, we employ GRPO ( Shao et al. , 2024 ). GRPO estimates the baseline directly from the scores of multiple rollouts generated for the same prompt, making it particularly well-suited for our scalable unsupervised frame work. For a gi ven m athematical problem query q , we sample a group of G response token trajectories { o 1 , o 2 , . . . , o G } from the old polic y π θ old . For each trajectory o i , we compute its intrinsic scalar re ward r i using one of the formulations defined in Section 2.1 . The advantage A i for each rollout is then cal- culated by standardizing the rewards within the sampled group: A i = r i − µ r σ r + ϵ std where µ r and σ r are the mean and standard de- viation of the group re wards r = { r 1 , . . . , r G } , respecti vely , and ϵ std is a small constant to prevent di vision by zero. This relativ e advantage stabilizes the training by ensuring the model is re warded only when a trajectory outperforms its own av erage gen- eration for that specific query . The policy model π θ is then optimized by maxi- mizing the objecti ve function of GRPO: J ( θ ) = E " 1 G G X i =1 min ρ i ( θ ) A i , clip ϵ A i # where ρ i ( θ ) = π θ ( o i | q ) /π θ old ( o i | q ) is the im- portance sampling ratio, ϵ is the clipping hyperpa- rameter to prev ent destructiv ely large policy up- dates, and π ref is the reference model. Note that we explicitly exclude the KL diver gence term D K L across all settings. While typically used to anchor the policy to a reference model and pre- vent o ver -optimization ( Schulman et al. , 2017 ), the KL penalty functionally overlaps with our entropy- based rew ards. Because our primary objectiv e is to mechanistically elucidate the working principles of unsupervised RL, introducing this redundant con- straint w ould obscure the pure ef fects of the rew ard signals and hinder accurate theoretical analysis. 3 Experimental Settings 3.1 Models and Datasets T o identify the boundaries of this unsupervised ap- proach, we e v aluate a div erse set of open-weights LLMs across a spectrum of intrinsic reasoning ca- pabilities. This cross-model ev aluation allows us to observe how foundational model abilities dictate the transition from stable reasoning con vergence to catastrophic policy collapse. W e primarily utilize Qwen3-8B as our main testbed. Having undergone rigorous post-training, it represents a highly aligned state with robust foun- dational reasoning capabilities, striking an opti- mal balance between state-of-the-art performance 4 at its parameter scale and computational feasibil- ity ( Y ang et al. , 2025 ). T o ev aluate generalizabil- ity across parameter sizes, we also test Qwen3- 1.7B . Note that in all our experimental settings, the Qwen3 models are configured to use their native ‘think’ mode to ensure a fair ev aluation of their reasoning potential. Furthermore, to understand the ev olutionary tra- jectory of reasoning, we need to observe models at different stages of alignment. Because we can- not access the intermediate checkpoints of Qwen’ s training process, we select Llama-3.1-8B-Instruct as a baseline reference, as it has only undergone standard supervised fine-tuning (SFT) for instruc- tion follo wing ( Grattafiori et al. , 2024 ). W e then compare it with DeepSeek-R1-Distill-Llama-8B , which is distilled from the Llama-3 architecture. Through the distillation process, the model lev er - ages additional reasoning data generated by a stronger teacher , which inherently boosts its math- ematical capabilities and allows it to represent a higher aligned state similar to Qwen3 ( DeepSeek- AI , 2025 ). T raining Data. Our primary training dataset is D APO-Math-17K ( Y u et al. , 2025 ), an open- source dataset specifically designed for RL. W e utilize it to ensure that our models are trained on high-quality mathematical tasks. Additionally , to ensure that our observations are not biased to ward a specific data distribution, we further train the model on DeepMath-103K ( He et al. , 2025 ) in Appendix D . Evaluation Benchmarks. All models are ev al- uated on a comprehensive suite of standardized benchmarks. Our test suite includes the traditional mathematical benchmarks: MA TH500 ( Light- man et al. , 2024 ), Minerva Math ( Lewko wycz et al. , 2022 ), OlympiadBench ( He et al. , 2024 ), AIME24 ( Zhang and Math-AI , 2024 ), and AMC23 . 1 Furthermore, we integrate AIME26 ( Zhang and Math-AI , 2026 ) into our test suite. Because AIME26 was released strictly after the release dates of all e v aluated models, it serves as the out-of-distribution (OOD) touchstone to ver - ify zero-contamination reasoning improv ements. 3.2 Early Stopping In our experiments, we observe a common phe- nomenon: all unsupervised RL methods eventually 1 https://maa.org/math-competitions/ suf fer from policy collapse on the validation set as training progresses. Because of this inherent instability , training until con ver gence is not feasi- ble. Instead, we adopt an early stopping strategy . As long as a method demonstrates a performance improv ement over the initial base model, we halt the training at its peak validation accurac y and test the checkpoint. Con versely , we define a training run as a com- plete “ collapse ” only if the model’ s performance continuously degrades from the v ery beginning of the training process, showing no signs of impro ve- ment. For these explicitly collapsed cases, we do not report the detailed numerical metrics in our main results, as the base model represents the best performance. Other details of the implementation are in the Appendix C . 4 Results As illustrated in T able 2 , our unsupervised rein- forcement learning methods except CP demonstrate highly competiti ve performance. On the Qwen3- 1.7B and Qwen3-8B models, the LP method achie ves the highest o verall accurac y e ven outper - forming supervised baseline S-RL across all bench- marks. Besides, other unsupervised rewards also dramatically outperform base model. Other ad- ditional discussions about boundary cases are in Appendix D . Aligned Stages of Base Models. Interestingly , the base model capability significantly impacts training stability under unsupervised settings. For the DeepSeek-Distill-Llama-8B model, the perfor- mance gains are more modest than Qwen series. Al- though unsupervised methods (particularly LP and Ent) still manage to improv e upon the base model, the margin of impro vement is significantly smaller than that observed in the Qwen family , and S-RL maintains a clear lead. In contrast, Llama3.1-8B, representing the weakest reasoning ability , suffers from an immediate collapse across all unsupervised methods. According to Section 3.1 , this suggests that aligned stages of base models affect the rob ust- ness of unsupervised RL. Reward Formulations. Our controlled varia- tions of the rewards rev eal how unsupervised re- wards shape reasoning. LP emerges as the most ef fectiv e unsupervised method across almost all settings. Stripping away the entropy calculation 5 Model Method MA TH-500 Olympiad Minerva AIME 24 AMC 23 AIME 26 A VG P@1 P@5 P@10 P@1 P@5 P@10 P@1 P@5 P@10 P@1 P@5 P@10 P@1 P@5 P@10 P@1 P@5 P@10 P@1 P@5 P@10 Qwen3-1.7B Base 70.2 81.4 84.9 30.1 41.6 46.9 30.6 42.0 46.0 6.0 14.2 19.1 47.2 61.4 68.0 7.1 15.5 20.0 42.7 54.0 58.5 S-RL 78.8 89.5 91.8 39.5 52.0 56.0 35.4 49.2 53.9 17.9 31.0 37.8 56.6 76.0 82.1 12.7 26.0 31.1 51.0 63.3 67.0 Ent 79.8 90.4 92.4 41.4 54.9 58.8 34.4 48.3 52.9 22.5 42.6 49.3 61.3 81.8 88.1 14.0 27.9 31.6 52.2 65.1 68.7 A vgEnt 78.2 89.7 91.9 39.8 52.8 56.7 36.1 50.0 54.5 20.2 38.8 49.1 58.3 80.3 87.9 16.0 34.7 42.0 51.2 64.3 68.1 LP 80.0 90.4 92.4 42.6 55.3 59.1 34.4 47.9 52.4 20.0 34.2 39.3 57.8 79.7 86.8 14.4 28.0 33.6 52.7 65.0 68.5 CH2 79.5 90.6 93.2 41.3 53.5 57.3 35.2 48.6 52.7 20.6 35.8 40.4 59.5 78.7 85.6 14.8 29.8 35.0 52.1 64.5 68.1 CP Collapse ( × ) Qwen3-8B Base 67.9 80.5 84.4 28.4 41.2 46.7 29.8 39.9 44.8 7.7 19.9 23.1 41.7 64.1 73.6 9.2 16.6 22.1 41.0 53.4 58.3 S-RL 88.4 93.8 95.0 51.7 60.1 63.4 46.0 55.7 58.3 36.2 52.7 60.4 76.2 87.9 89.1 36.2 48.8 50.0 62.6 70.6 73.1 Ent 86.6 93.1 94.5 49.9 58.2 61.0 43.9 54.4 58.2 31.7 48.0 53.5 74.1 89.4 91.5 34.2 49.8 54.6 60.7 69.3 71.9 A vgEnt 81.5 89.5 91.2 43.9 54.0 57.2 44.2 54.4 57.9 25.4 38.6 42.9 62.0 81.6 88.4 19.2 36.3 43.1 55.7 65.6 68.6 LP 88.7 94.2 95.2 52.3 61.1 64.2 46.1 56.2 59.1 39.2 55.8 59.1 78.8 93.0 94.9 36.7 51.1 54.1 63.1 71.5 73.8 CH2 86.0 92.9 94.3 49.0 59.2 62.5 44.0 53.4 56.4 30.8 46.4 50.4 73.1 88.9 91.8 28.1 39.9 42.5 59.9 69.2 71.8 CP Collapse ( × ) Llama3.1-8B Base 45.5 69.4 77.2 13.2 29.8 38.2 21.4 39.8 47.1 5.2 14.3 20.8 22.7 51.6 66.4 0.4 2.1 4.2 24.9 44.1 52.1 S-RL 46.3 69.0 76.4 14.1 31.0 38.8 25.7 45.5 52.3 4.6 13.2 18.7 23.6 46.8 56.1 1.2 3.1 3.3 26.4 45.4 52.7 Unsupervised Collapse ( × ) DeepSeek-Distill Llama-8B Base 69.4 87.1 90.8 35.7 52.9 58.8 22.7 40.2 47.8 16.5 30.3 37.9 50.8 80.6 86.9 14.4 27.4 32.7 43.9 61.5 67.0 S-RL 72.7 90.2 93.7 39.3 56.9 62.4 24.4 42.7 49.9 24.4 44.9 54.9 59.4 86.9 91.1 22.5 40.0 44.6 47.4 65.4 70.6 Ent † 70.0 88.1 91.9 36.4 54.6 60.6 21.8 39.9 47.2 18.1 37.9 47.5 53.4 83.8 88.5 17.3 31.2 36.1 44.4 62.8 68.4 A vgEnt † 69.3 86.6 90.4 35.6 52.6 58.5 23.2 40.6 48.0 16.7 36.8 45.2 53.8 81.7 87.5 15.2 27.2 29.6 44.0 61.4 66.9 LP † 70.5 88.5 92.5 36.6 53.9 59.5 22.2 40.7 48.3 21.7 43.1 52.8 50.8 81.4 87.0 17.5 33.8 39.4 44.7 62.9 68.4 CH2 † 69.5 86.8 90.6 36.7 54.3 59.9 21.8 38.6 46.1 20.6 40.9 50.3 54.7 83.7 88.7 17.3 30.4 34.0 44.5 62.1 67.5 CP Collapse ( × ) T able 2: Main Results on Mathematical Reasoning Benchmarks. Performance comparison across models, rew ard formulations, and training settings. All training is conducted on the D APO-Math-17K dataset. S-RL refers to Supervised RL. Bold denotes the overall best performance, and underlined indicates the best result among unsupervised methods within each model. P@k means Pass@k. † indicates a semi-collapse phenomenon. For the DeepSeek-Distill model, these unsupervised methods experience a v ery brief initial period of improv ement where the peak performance slightly exceeds the base model, b ut the training rapidly collapses shortly afterward. and strictly punishing the length is sufficient to force the model into generating concise, logical steps. Ent and CH2 also show strong gains over the Base model. Ho we ver , they slightly lag be- hind pure LP . A vgEnt removes the implicit length penalty by a veraging the entropy drastically re- duces performance. CP re verses the penalty to encourage longer responses univ ersally results in a complete collapse across all models, which means this re ward’ s length penalty strength is stronger than uncertainty penalty . These prove our theoret- ical claim: penalizing uncertainty without strictly bounding the structural length is not strong enough. Length penalty is more ef fectiv e than uncertainty penalty . 5 Why it Doesn’t Collapse: Manifold En velopment T o demystify the internal mechanisms of these un- supervised rewards, we introduce a two-step ana- lytical frame work using DTW clustering and 3D phase space projection. Step1. T emporal Clustering of T oken Entropies. Instead of analyzing static entropy values, we fo- cus on the temporal dynamics : how the entropies of specific tokens ev olves throughout the training process. Because a model’ s generated response for the same prompt changes across training steps, we use the (prompt, token) pair as a unique an- chor to track the exact entropy trajectory of each token over time. W e then apply Soft-DTW ( Cu- turi and Blondel , 2018 ) to group these trajectories based on the shape of their evolution rather than their absolute v alues. Furthermore, while previous work ( W ang et al. , 2025 ) simplifies reasoning into binary high and low entropy states, we deliberately set the number of clusters to K = 3 . This allo ws us to capture the crucial intermediate phase of logical connecti ves and transitions that bridge direct cal- culations and comple x decision-making. Detailed formalizations of this algorithm are provided in Appendix A . Bridging T rajectories and Semantics. As illus- trated in T able 3 , applying T ime-Series K-means consistently yields three distinct clusters. Remark- ably , acr oss all our experimental settings , the entropy centroids always stratify into a clear low , medium, and high pattern. Crucially , these three entropy lev els naturally align with the semantic roles of the tokens during mathematical reasoning. 6 Entropy Cluster Semantic Representati ve T okens (T op Frequency) Characteristics Low (Execution) Arithmetic Qwen : 1 , 2 , 3 , 0 , + , - DeepSeek : + , 2 , 4 , - , 3 , 1 Llama : 4 , 2 , = , + , 1 , 3 Operators and concrete numerical digits. Syntax Qwen : by , ’t , to , be , ( , ) DeepSeek : ’t , ) , be , by , of , to Llama : of , { , }{ , \ , frac , $ Structural formatting and LaT eX syntax. Medium (Logic) Formulation Qwen : Let , The , this , it DeepSeek : Let , this , here , each Llama : need , let , given , find , solve Establishing variables and condi- tions. T ransitions Qwen : Wait , But , ? , Therefore , So DeepSeek : ? , but , should , So , Wait Llama : However , To , must , also , Now Step-by-step reasoning deduc- tions. High (Thinking) Exploration Qwen : perhaps , maybe , suppose , Hmm DeepSeek : maybe , perhaps , wait , Hmm , think Llama : First , start , break , analyze Macro-planning and expressing uncertainty . V erification Qwen : confirm , verify , actually , If , assume DeepSeek : consider , double , Because , Or Llama : denote , determine , considering Halting to verify or initiating branch paths. T able 3: Semantic Interpretation of Entr opy Clusters Across Models. W e extract the representati ve tokens for the Qwen, DeepSeek-Distill, and Llama. T o ensure objectiv e categorization, these tokens are rigorously filtered by retaining only the core samples (the 50% closest to the respecti ve cluster centroids in the DTW space) and ranked strictly by their occurrence frequenc y . Across all three model families, these high-frequenc y tokens consistently align with the semantic functions of Execution, Logic, and Thinking. Specifically , they correspond to the Execution (low entropy), Logic (medium entropy), and Thinking (high entropy) phases. Detailed visualizations of these clustering trajectories across different models are provided in Appendix B . Step2. 3D phase space projection By treating the entropy values of these three distinct cogni- ti ve states as independent coordinate ax es, we can project the high-dimensional, opaque training dy- namics into a measurable 3D phase space. This mapping represents a dimensionality reduction process . W e compress the high-dimensional model parameters and internal states into the a verage en- tropy of three semantic clusters. This reduction is effecti ve in unsupervised RL because entropy serves as the primary optimization objecti ve. Con- sequently , the three-dimensional phase space cap- tures the most significant beha vioral shifts during training. This coordinate system allows us to vi- sualize and measure ho w the polic y navigates the reasoning manifold. Exploration Boundaries. By calculating the Con ve x Hull of these temporal trajectories across the v alidation set, we can quantify the model’ s ex- ploration boundaries. V isualizing these boundaries in Figure 2 rev eals three distinct spatiotemporal phenomena: Str ong Manifold Constr aints (Suc- cess), Exploration Stagnation (F ailure T ype I), and W eak Constraints (F ailure T ype II). T o ensure a fair comparison, we dynamically truncate these trajec- tories as declared in Section 3.2 . Chronologically , the accuracy of collapsed configurations drops to zero significantly earlier than the performance peak of successful runs. Therefore, the trajectory of a successful run naturally stops at its validation peak. Con v ersely , the trajectory of a collapsed model ter- minates exactly at this premature zero-accurac y step. This precise truncation explicitly excludes the meaningless post-collapse stages. Additional visualizations demonstrating this consistent pat- tern across other configurations are provided in Appendix E . Success: Str ong Manif old Constraints. A highly capable base model nativ ely restricts the reasoning space. For example, Qwen3-8B under LP successfully maintains an optimal e xploration volume. Figure 2 (a) visually confirms this tightly bounded manifold. F ailure T ype I: Exploration Stagnation. Qwen3-8B trained with CP suf fers from se vere Exploration Sta gnation . The exploration manifold for CP shrinks drastically to a negligible v olume of 0.006. Figure 2 (a) clearly illustrates this trapped phase space. The model completely loses its 7 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 Thinking T okens Mean Ent 0.0 0.1 0.2 0.3 0.4 0.5 0.6 Logic T okens Mean Ent 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 0.200 Execution T okens Mean Ent S-RL (V ol: 0.012) Ent (V ol: 0.017) A vgEnt (V ol: 0.028) CH2 (V ol: 0.025) LP (V ol: 0.020) CP (V ol: 0.006) (a) Qwen3-8B Boundaries 0.0 0.5 1.0 1.5 2.0 2.5 Thinking T okens Mean Ent 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 Logic T okens Mean Ent 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Execution T okens Mean Ent S-RL (V ol: 0.016) Ent (V ol: 0.851) A vgEnt (V ol: 0.071) CH2 (V ol: 0.853) LP (V ol: 0.893) CP (V ol: 0.014) (b) DS-Distill Boundaries 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 Thinking T okens Mean Ent 0 1 2 3 4 5 Logic T okens Mean Ent 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 Execution T okens Mean Ent S-RL (V ol: 0.348) Ent (V ol: 8.125) A vgEnt (V ol: 2.792) CH2 (V ol: 1.348) LP (V ol: 4.935) CP (V ol: 0.436) (c) Llama3.1-8B Boundaries Figure 2: V isualization of 3D Semantic Manif old Boundaries. The three axes define the phase space corresponding to the mean entropy of the Thinking , Logic , and Execution semantic clusters, as established in Section 5 . (a-c) Exploration Manifolds: The translucent polygons denote the 3D conv ex hulls encompassing all aggregated trajectory points for specific training methods. The legend identifies the training method and provides the calculated volume of its corresponding hull. DS-Distill denotes DeepSeek-R1-Distill-Llama-8B. generati ve di versity . F ailure T ype II: W eak Constraints. Model ca- pability progressi vely weakens from Qwen3-8B do wn to Llama3.1-8B. This decreasing capacity triggers a sev ere loss of boundary control. DS- Distill represents a transitional state with moder- ately expanded boundaries in Figure 2 (b). W e observe the absolute opposite extreme when apply- ing Ent to the weakest Llama3.1-8B model. Fig- ure 2 (c) rev eals a pathological Manifold Explo- sion . The Ent con vex hull abnormally expands to an enormous volume of 8.125. This massive space indicates a complete loss of constraints instead of healthy di versity . 6 Related W ork While entropy was traditionally employed as a reg- ularization term in standard supervised PPO ( Schul- man et al. , 2017 ), recent unsupervised RL ap- proaches have adopted uncertainty as a primary optimization signal. In this domain, existing litera- ture generally falls into two main directions. The first direction focuses on self-consistency and se- mantic clustering, such as T est-Time RL (TTRL; Zuo et al. , 2025 ) and Entropy Minimized Policy Optimization (EMPO; Zhang et al. , 2025 ), which incenti vize models to con ver ge on consistent rea- soning pathways. The second, emerging direction relies on direct token-le vel entropy minimization. For instance, RENT ( Prabhudesai et al. , 2025 ) uti- lizes negati ve token entropy as an intrinsic re ward, and Agarwal et al. ( 2025 ) comprehensi vely demon- strates the effecti veness of entropy minimization across v arious fine-tuning and RL stages. Our work distinguishes itself from these studies through two primary dimensions: (a) Algorith- mic Decoupling. By decoupling uncertainty from length penalization within a systematic experimen- tal matrix, we rev eal that the implicit length penalty serves as another catalyst for mathematical reason- ing. (b) Mechanistic Interpretability . Rather than treating the unsupervised RL training process as a black box, we elucidate the internal mechanisms dri ving this capability emergence. The geomet- ric diagnostic lens allows us to identifies when a model successfully en velops rob ust reasoning man- ifolds and why specific optimization trajectories deteriorate into policy collapse. 7 Conclusion In this work, we presented a comprehensi ve in ves- tigation into unsupervised RL for eliciting latent reasoning capabilities in LLMs. Moving beyond uncertainty penalty , we newly introduce length penalty . T o uncover the underlying mechanisms of these re wards, we propose a no vel interpretability frame work. By applying DTW clustering to token- le vel entrop y trajectories o ver the training progress, we successfully disentangled the response tokens into three distinct semantic phases. Our geomet- ric analysis rev ealed the difference between suc- cessful cases and failures. In conclusion, our find- ings bridge the gap between empirical algorithmic design and mechanistic understanding in unsuper - vised LLM reasoning. 8 Limitations While this work provides a novel geometric per- specti ve on unsupervised RL, se veral limitations warrant ackno wledgment and outline a venues for future research. Scale. Due to the substantial computational over - head required by unsupervised RL, our e v aluation is currently restricted to base models up to 8B pa- rameters. Theoretical Gaps in T raining Dynamics. Our DTW clustering shows that the entrop y centroids of dif ferent cognitiv e states (Execution, Logic, Think- ing) remain stable throughout the entire training process. W e hypothesize this stability is an intrin- sic structural bias inherited from the base model’ s pre-training, but a formal optimization proof is left for future work. Mathematical Formalization of the Manif old. In this study , the “Reasoning Manifold" and its topological barriers are primarily introduced as geometric metaphors grounded in empirical ther- modynamic metrics. W e do not provide a strict formulation of these boundaries. Formalizing the exact mathematical representation of these reason- ing manifolds and pro ving bounds on the policy’ s KL diver gence or gradient norm when confined by these barriers remain a next step for the inter- pretability . References Shi vam Agarwal, Zimin Zhang, Lifan Y uan, Jiawei Han, and Hao Peng. 2025. The unreasonable effectiv eness of entropy minimization in llm reasoning . Preprint , Donald J. Berndt and James Clifford. 1994. Using dynamic time warping to find patterns in time se- ries. In Pr oceedings of the 3rd International Con- fer ence on Knowledge Discovery and Data Mining , AAAIWS’94, page 359–370. AAAI Press. Marco Cuturi and Mathieu Blondel. 2018. Soft-dtw: a differentiable loss function for time-series . Pr eprint , DeepSeek-AI. 2025. Deepseek-r1: Incentivizing rea- soning capability in llms via reinforcement learning . Pr eprint , arXi v:2501.12948. Leo Gao, John Schulman, and Jacob Hilton. 2022. Scaling laws for reward model overoptimization . Pr eprint , arXi v:2210.10760. Aaron Grattafiori, Abhimanyu Dube y , Abhinav Jauhri, Abhinav Pandey , Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur , Alan Schel- ten, Alex V aughan, Amy Y ang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Y ang, Archi Mi- tra, Archie Sravankumar , Artem K orenev , Arthur Hinsvark, and 542 others. 2024. The llama 3 herd of models . Preprint , arXi v:2407.21783. Chaoqun He, Renjie Luo, Y uzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jin yi Hu, Xu Han, Y u- jie Huang, Y uxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. 2024. Olympiadbench: A challenging benchmark for promoting agi with olympiad-lev el bilingual multimodal scientific prob- lems . Preprint , arXi v:2402.14008. Zhiwei He, T ian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Y ue W ang, Linfeng Song, Dian Y u, Zhen- wen Liang, W enxuan W ang, Zhuosheng Zhang, Rui W ang, Zhaopeng Tu, Haitao Mi, and Dong Y u. 2025. Deepmath-103k: A large-scale, challenging, decon- taminated, and verifiable mathematical dataset for advancing reasoning . Aitor Lewk owycz, Anders Andreassen, Da vid Dohan, Ethan Dyer , Henryk Michale wski, V inay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Y uhuai W u, Behnam Neyshab ur , Guy Gur-Ari, and V edant Misra. 2022. Solving quan- titativ e reasoning problems with language models . Pr eprint , arXi v:2206.14858. Hunter Lightman, V ineet K osaraju, Y uri Burda, Harri- son Edwards, Bowen Baker , T eddy Lee, Jan Leike, John Schulman, Ilya Sutske ver , and Karl Cobbe. 2024. Let’ s verify step by step . In The T welfth Inter- national Confer ence on Learning Repr esentations . Mihir Prabhudesai, Lili Chen, Alex Ippoliti, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. 2025. Maximizing confidence alone improves reasoning . Pr eprint , arXi v:2505.22660. John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . 2017. Prox- imal policy optimization algorithms . Pr eprint , Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Hao wei Zhang, Mingchuan Zhang, Y . K. Li, Y . W u, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models . Pr eprint , Shenzhi W ang, Le Y u, Chang Gao, Chujie Zheng, Shix- uan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Y ang, Zhenru Zhang, Y uqiong Liu, An Y ang, An- drew Zhao, Y ang Y ue, Shiji Song, Bowen Y u, Gao Huang, and Junyang Lin. 2025. Beyond the 80/20 rule: High-entropy minority tokens driv e effecti ve reinforcement learning for llm reasoning . Pr eprint , 9 An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bo wen Y u, Chang Gao, Chengen Huang, Chenxu Lv , Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran W ei, Huan Lin, Jialong T ang, and 41 others. 2025. Qwen3 technical report . Preprint , Qiying Y u, Zheng Zhang, Ruofei Zhu, Y ufeng Y uan, Xiaochen Zuo, Y u Y ue, W einan Dai, T iantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Y uxuan T ong, Chi Zhang, Mofan Zhang, W ang Zhang, and 16 others. 2025. Dapo: An open-source llm re- inforcement learning system at scale . Pr eprint , Qingyang Zhang, Haitao W u, Changqing Zhang, Peilin Zhao, and Y atao Bian. 2025. Right question is al- ready half the answer: Fully unsupervised LLM rea- soning incentivization . In The Thirty-ninth Annual Confer ence on Neural Information Pr ocessing Sys- tems . Y ifan Zhang and T eam Math-AI. 2024. American in vi- tational mathematics examination (aime) 2024. Y ifan Zhang and T eam Math-AI. 2026. American in vi- tational mathematics examination (aime) 2026. Y uxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Y uchen Zhang, Xin- wei Long, Ermo Hua, Biqing Qi, Y oubang Sun, Zhiyuan Ma, Lifan Y uan, Ning Ding, and Bowen Zhou. 2025. TTRL: T est-time reinforcement learn- ing . In The Thirty-ninth Annual Conference on Neu- ral Information Pr ocessing Systems . A Detailed Algorithm f or T rajectory Construction T o provide a rigorous definition of the methodology described in Section 5 , we formalize the data col- lection, temporal anchoring, and clustering process in Algorithm 1 . The core challenge is that the generated response for the same prompt p changes across training steps t (e.g., a model might output “Hmm, 5” at step 10, but simply “5” at step 50). T o solv e this, we use the tuple ( p, y ) as a unique semantic anchor , mapping the discrete token y back to its prompt p . This al- lo ws us to track the exact temporal ev olution of the token’ s uncertainty (entropy) regardless of when it appears in the generation sequence, ultimately forming the trajectory T p,y for DTW clustering. Data Construction. W e track the generation pro- cess on the validation set e very 5 training steps. A trajectory is defined as a sequence of entropy v alues anchored to a specific (prompt, token) pair . Let T i,j = [ h t 1 ,j , h t 2 ,j , . . . , h t M ,j ] denote the en- tropy trajectory for the i -th token in j -th prompt’ s response. The endpoint of training corresponds to the effective con ver gence point , defined as: (1) the step of peak v alidation accuracy for unsupervised methods (early stopping), (2) the onset of the ac- curacy plateau for supervised baselines, or (3) the point of collapse (0% accuracy) for f ailed runs. Clustering Algorithm. W e employ Time-Series K-means with a Soft-DTW metric to cluster these trajectories. Unlike Euclidean distance, DTW aligns sequences that may v ary in phase or speed, allo wing us to group tokens based on the shape of their entropy e volution (e.g., “rising” vs. “con ver g- ing”) rather than their absolute values at specific steps. Cluster Selection. While W ang et al. ( 2025 ) sim- plifies the reasoning process into a binary classifica- tion of high- and lo w-entropy tokens, we hypothe- size that mathematical deri vations contain an inher- ent intermediate state. From a semantic perspecti ve, this middle phase consists of logical connectives and sequential transitions that bridge direct calcula- tion and complex decision-making. T o capture this structural nuance, we deliberately set the number of clusters to K = 3 . B Detailed DTW Clustering T rajectories As established in the main text (T able 3 ), the Time- Series K-means clustering consistently stratifies the generated tokens into three distinct semantic phases based on their temporal entropy e v olution: Execu- tion (low entropy), Logic (medium entropy), and Thinking (high entropy). Crucially , as visualized in the follo wing figures, the most frequent tokens within each cluster perfectly match the semantic categories we defined in T able 3 . An insight from this empirical data is the algo- rithm’ s ability to capture the cognitiv e state be- hind token casing. For instance, the capitalized token Wait is consistently categorized into the Medium Entropy (Logic) cluster , whereas its low- ercase counterpart wait robustly falls into the High Entropy (Thinking) cluster . This distinction reflects the underlying generation mechanism: Wait typi- cally initiates a new sentence, serving as a struc- tured, template-dri ven transition. Con versely , a lo wercase wait generally emerges mid-sentence as a spontaneous self-interruption or correction, which naturally carries a much higher degree of 10 uncertainty and branching potential. T o demonstrate that this clear phase separation is a robust and uni versal phenomenon, this section provides the visual trajectories of these clusters across all ev aluated models, context lengths, and re ward formulations. A universal geometric fea- ture observable across all these figures is that the middle portion of the centroid trajectories remains remarkably flat. This extended stable plateau di- rectly marks the magnitude of the uncertainty , serv- ing as a clear and intuitive visual indicator that distinctly separates the Low , Medium, and High entropy le vels throughout the training process. Figure 3 shows the clustering results on the smaller Qwen3-1.7B model, confirming that the phase separation occurs ev en at a reduced parame- ter scale. For our primary testbed, Qwen3-8B, we display the optimization dynamics under the stan- dard training setup in Figure 4 . T o ensure these pat- terns are rob ust against v arying experimental con- ditions, we further e v aluate the Qwen3-8B model with an e xtended 8K context windo w in Figure 5 , and under a deeper RL interv ention setting in Fig- ure 6 . Furthermore, to v erify that these findings are not strictly tied to the Qwen family’ s pre-training, we extend our visual analysis to other architectures. Figure 7 illustrates the trajectories for DeepSeek- R1-Distill-Llama-8B, a model that already pos- sesses strong initial alignment for reasoning tasks. Finally , Figure 8 presents the clustering results on the Llama3.1-8B base architecture. Across all these di verse models and settings, the structural separa- tion of the Execution, Logic, and Thinking clusters remains highly consistent. C Experiments’ Settings The detailed hyperparameters for our unsupervised reinforcement learning training are provided in Ap- pendix T able 5 . Additionally , our generation hyper - parameters for the validation phase roughly follo w the recommended settings from the Qwen3 T echni- cal Report ( Y ang et al. , 2025 ). D Additional Boundary Conditions As illustrated in T able 4 , we di vide the additional boundary conditions into: Maximum Response Length. Previous studies typically constrain the generation by setting a maxi- mum sequence length of 4K ( Agarwal et al. , 2025 ). Ho wev er , this joint constraint is sensitive to the v arying lengths of the input questions, leading to inconsistent actual generation budgets across dif- ferent prompts. T o eliminate this factor , our initial e valuations illustrated in Section 4 adopt a more rig- orous setting by independently bounding the maxi- mum r esponse length to 4K tokens. Under this set- ting, LP achie ves the strongest performance among all unsupervised RL methods. W e suspect this is be- cause LP explicitly penalizes length y generations, forcing the model to conclude its reasoning within the budget and thereby av oiding early truncation. T o verify this hypothesis and observe the methods’ ef fectiv eness under an abundant generation bud- get, we extended the maximum response length to 8K. When ev aluated at 8K, CH2 achiev es the high- est ov erall av erage score, while LP remains highly ef fectiv e. Datasets. Furthermore, to ensure these observa- tions are not artifacts of a specific data distribution, we conducted cross-dataset generalization tests us- ing the DeepMath corpus. The results demonstrate that the performance trends remain consistent: LP achie ves the highest av erage score among unsuper- vised methods, strictly comparable to the perfor- mance of S-RL. This confirms that our findings regarding these unsupervised rew ard formulations generalize across dif ferent mathematical datasets. E 3D Exploration Boundaries (Con vex Hulls) T o quantitatively compare ho w dif ferent re ward formulations shape the reasoning space, we visu- alize the 3D e xploration boundaries of the seman- tic phases. By computing the con vex hull of the prompt-le vel trajectories in the 3D entropy space (Execution, Logic, and Thinking), we can assess the di versity and extent of the model’ s exploratory behavior . A well-re gularized reward (e.g., Ent) maintains a healthy , expansi ve e xploration volume, whereas ov erly aggressi ve or misaligned penalties result in restricted boundaries or entropy collapse. A larger hull v olume indicates a broader explo- ration of reasoning patterns, while a collapsed vol- ume (e.g., con ver ging to a plane or a point) signifies mode collapse or rigid generation. Figures 9 and 10 visualize these conv ex hulls across the dif ferent model groups and settings. 11 Algorithm 1 T oken-Le vel Entropy T rajectory Construction and Semantic Clustering Require: V alidation dataset D v al , Set of training e valuation steps K = { t 1 , t 2 , . . . , t M } Require: T arget number of clusters C = 3 (Execution, Logic, Thinking) Ensure: Semantic clusters C and their corresponding centroids 1: Initialize an empty hash map T to store trajectories, ke yed by ( p, y ) . 2: for each e v aluation step t ∈ K do 3: Load model checkpoint M t 4: f or each prompt p ∈ D v al do 5: Generate response sequence R p,t using M t ( p ) 6: Extract response tokens Y p,t = [ y 1 , y 2 , . . . , y N ] 7: Extract token-le vel entropies H p,t = [ h 1 , h 2 , . . . , h N ] 8: f or i = 1 to N do 9: T [( p, y i )] . append_record ( step = t, entropy = h i ) 10: end f or 11: end f or 12: end for 13: T v alid ← ∅ 14: for each unique anchor ( p, y ) in T do 15: Extract raw entrop y sequence S = [ h t a , . . . , h t b ] from T [( p, y )] 16: if length ( S ) ≥ 2 then ▷ Filter isolated tokens without temporal dynamics 17: Normalize time axis of S to ˆ t ∈ [0 , 1] based on the ef fectiv e con ver gence point 18: T v alid ← T v alid ∪ {S } 19: end if 20: end for 21: Initialize Time-Series K-Means model K DTW with k = C and metric = Soft-DTW 22: C , Centroids ← K DTW . fit_predict ( T v alid ) 23: return C 12 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 4 Execution T okens ( n = 15717 , Steps= 190 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ this ▸ So ▸ we ▸ there ▸ Wait ▸ but Logic T okens ( n = 15152 , Steps= 190 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ consider ▸ Thus ▸ Hence ▸ maybe ▸ suppose Thinking T okens ( n = 7352 , Steps= 190 ) (a) Supervised RL 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 't Execution T okens ( n = 15426 , Steps= 105 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ So ▸ Wait ▸ But ▸ Let ▸ but ▸ this Logic T okens ( n = 12432 , Steps= 105 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ However ▸ perhaps ▸ consider ▸ re ▸ maybe ▸ Calcul Thinking T okens ( n = 6522 , Steps= 105 ) (b) Ent 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 T oken Entropy Tokens : ▸ ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ = Execution T okens ( n = 20323 , Steps= 200 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Tokens : ▸ this ▸ So ▸ we ▸ but ▸ Wait ▸ Let Logic T okens ( n = 17426 , Steps= 200 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Tokens : ▸ However ▸ maybe ▸ rec ▸ consider ▸ H ▸ perhaps Thinking T okens ( n = 7497 , Steps= 200 ) (c) A vgEnt Figure 3: T oken Entr opy T rajectories on Qwen3-1.7B (Part 1 of 2). Clustering results e valuated on the AIME 24 dataset across six dif ferent re ward formulations. The consistent emergence of Ex ecution, Logic, and Thinking clusters is observ ed despite the smaller parameter scale. The text boxes within each subplot display the top frequency tokens corresponding to that cluster . 13 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 9 Execution T okens ( n = 16474 , Steps= 145 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ this ▸ we ▸ But ▸ Therefore ▸ let ▸ So Logic T okens ( n = 13779 , Steps= 145 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ consider ▸ Thus ▸ Hence ▸ suppose ▸ quite Thinking T okens ( n = 6039 , Steps= 145 ) (d) CH2 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ to ▸ by ▸ 1 ▸ 3 ▸ 0 ▸ 2 Execution T okens ( n = 15088 , Steps= 80 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ we ▸ it ▸ Therefore ▸ Wait ▸ ? ▸ this Logic T okens ( n = 11550 , Steps= 80 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ suppose ▸ consider ▸ Thus ▸ tackle ▸ re Thinking T okens ( n = 5043 , Steps= 80 ) (e) LP 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 T oken Entropy Tokens : ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ ) ▸ be Execution T okens ( n = 13888 , Steps= 95 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Tokens : ▸ ? ▸ Wait ▸ but ▸ So ▸ Let ▸ no Logic T okens ( n = 12486 , Steps= 95 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Tokens : ▸ However ▸ perhaps ▸ consider ▸ maybe ▸ re ▸ actually Thinking T okens ( n = 6963 , Steps= 95 ) (f) CP Figure 3: T oken Entropy T rajectories on Qwen3-1.7B (Part 2 of 2). (Continued from previous page.) 14 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 9 Execution T okens ( n = 17137 , Steps= 150 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ Wait ▸ The ▸ it ▸ would ▸ but ▸ Then Logic T okens ( n = 15509 , Steps= 150 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ However ▸ perhaps ▸ maybe ▸ Thus ▸ consider ▸ Hence Thinking T okens ( n = 8250 , Steps= 150 ) (a) Supervised RL 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 T oken Entropy Tokens : ▸ ▸ by ▸ 1 ▸ 3 ▸ 0 ▸ 2 Execution T okens ( n = 19635 , Steps= 130 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Tokens : ▸ Wait ▸ So ▸ Let ▸ But ▸ Therefore ▸ we Logic T okens ( n = 13274 , Steps= 130 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Tokens : ▸ However ▸ maybe ▸ perhaps ▸ consider ▸ Thus ▸ verify Thinking T okens ( n = 8438 , Steps= 130 ) (b) Ent 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 T oken Entropy Tokens : ▸ ▸ by ▸ of ▸ 1 ▸ 3 ▸ 0 Execution T okens ( n = 24740 , Steps= 235 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Tokens : ▸ But ▸ we ▸ Therefore ▸ Let ▸ let ▸ this Logic T okens ( n = 16732 , Steps= 235 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Tokens : ▸ perhaps ▸ maybe ▸ consider ▸ rec ▸ suppose ▸ may Thinking T okens ( n = 7851 , Steps= 235 ) (c) A vgEnt Figure 4: T oken Entropy T rajectories on Qwen3-8B (Standard Setup) (Part 1 of 2). V isualizations of the optimization dynamics under standard context length on our primary testbed model. The text boxes within each subplot display the top frequency tokens corresponding to that cluster . 15 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ by ▸ 1 ▸ 3 ▸ 0 ▸ 2 Execution T okens ( n = 20406 , Steps= 195 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ So ▸ Let ▸ Wait ▸ Therefore ▸ But ▸ we Logic T okens ( n = 17082 , Steps= 195 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ consider ▸ However ▸ As ▸ suppose ▸ redo Thinking T okens ( n = 6979 , Steps= 195 ) (d) CH2 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ by ▸ 1 ▸ 3 ▸ 0 ▸ 2 Execution T okens ( n = 18384 , Steps= 140 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ Wait ▸ we ▸ The ▸ Let ▸ I ▸ this Logic T okens ( n = 15629 , Steps= 140 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ However ▸ consider ▸ suppose ▸ Thus ▸ maybe Thinking T okens ( n = 7772 , Steps= 140 ) (e) LP 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 4 ▸ pose Execution T okens ( n = 16816 , Steps= 140 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ it ▸ but ▸ ? ▸ Wait ▸ But ▸ : Logic T okens ( n = 14896 , Steps= 140 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ However ▸ perhaps ▸ But ▸ consider ▸ suppose ▸ maybe Thinking T okens ( n = 8299 , Steps= 140 ) (f) CP Figure 4: T oken Entropy T rajectories on Qwen3-8B (Standard Setup) (Part 2 of 2). (Continued from previous page.) 16 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 9 ▸ be Execution T okens ( n = 22335 , Steps= 135 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ The ▸ Therefore ▸ Wait ▸ ? ▸ But ▸ this Logic T okens ( n = 19458 , Steps= 135 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ consider ▸ suppose ▸ ??? ▸ verify ▸ Thus Thinking T okens ( n = 8816 , Steps= 135 ) (a) Supervised RL 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ of ▸ 1 ▸ 3 ▸ 2 ▸ 9 ▸ be Execution T okens ( n = 19811 , Steps= 75 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ we ▸ The ▸ Therefore ▸ Wait ▸ So ▸ Let Logic T okens ( n = 16914 , Steps= 75 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ However ▸ maybe ▸ consider ▸ confirm ▸ re Thinking T okens ( n = 8160 , Steps= 75 ) (b) Ent 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ 3 ▸ 0 ▸ 9 ▸ 2 ▸ 1 Execution T okens ( n = 21150 , Steps= 105 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ this ▸ The ▸ it ▸ Therefore ▸ Wait ▸ Let Logic T okens ( n = 19961 , Steps= 105 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ However ▸ maybe ▸ consider ▸ perhaps ▸ But ▸ suppose Thinking T okens ( n = 10346 , Steps= 105 ) (c) A vgEnt Figure 5: T oken Entropy T rajectories on Qwen3-8B (8K Context) (Part 1 of 2). These visualizations demonstrate that the emergence of reasoning clusters remains consistent when scaling the context windo w to 8K. The text boxes within each subplot display the top frequency tokens corresponding to that cluster . 17 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 T oken Entropy Tokens : ▸ to ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 9 Execution T okens ( n = 23242 , Steps= 135 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Tokens : ▸ So ▸ The ▸ Therefore ▸ Wait ▸ we ▸ ? Logic T okens ( n = 19412 , Steps= 135 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Tokens : ▸ perhaps ▸ suppose ▸ consider ▸ Thus ▸ Where ▸ rec Thinking T okens ( n = 8534 , Steps= 135 ) (d) CH2 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 9 ▸ + Execution T okens ( n = 19830 , Steps= 70 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ The ▸ Wait ▸ But ▸ this ▸ Let ▸ we Logic T okens ( n = 16247 , Steps= 70 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ consider ▸ Thus ▸ suppose ▸ maybe ▸ note Thinking T okens ( n = 8025 , Steps= 70 ) (e) LP 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ 3 ▸ 0 ▸ 9 ▸ by ▸ 2 Execution T okens ( n = 21524 , Steps= 125 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ it ▸ ? ▸ But ▸ Let ▸ no ▸ I Logic T okens ( n = 19671 , Steps= 125 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ suppose ▸ actually ▸ However ▸ consider ▸ wait Thinking T okens ( n = 10154 , Steps= 125 ) (f) CP Figure 5: T oken Entr opy T rajectories on Qwen3-8B (8K Context) (P art 2 of 2). (Continued from pre vious page.) 18 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 9 Execution T okens ( n = 20820 , Steps= 300 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ Let ▸ The ▸ ? ▸ Wait ▸ But ▸ it Logic T okens ( n = 18324 , Steps= 300 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ However ▸ consider ▸ rec ▸ ??? ▸ Is Thinking T okens ( n = 9655 , Steps= 300 ) (a) Supervised RL 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ to ▸ 1 ▸ 2 ▸ 3 ▸ 4 Execution T okens ( n = 21962 , Steps= 205 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ Therefore ▸ The ▸ we ▸ compute ▸ But ▸ since Logic T okens ( n = 17624 , Steps= 205 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ But ▸ consider ▸ maybe ▸ Well ▸ note Thinking T okens ( n = 8997 , Steps= 205 ) (b) Ent 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ by ▸ 1 ▸ 3 ▸ 0 ▸ 2 Execution T okens ( n = 22787 , Steps= 195 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ Let ▸ Therefore ▸ we ▸ The ▸ Wait ▸ this Logic T okens ( n = 16457 , Steps= 195 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ However ▸ perhaps ▸ maybe ▸ consider ▸ suppose ▸ But Thinking T okens ( n = 8875 , Steps= 195 ) (c) A vgEnt Figure 6: T oken Entr opy T rajectories on Qwen3-8B (DeepMath Dataset) (Part 1 of 2). Trajectories analyzed under deeper RL interv entions, illustrating the robustness of the intrinsic phase separation. The text boxes within each subplot display the top frequency tokens corresponding to that cluster . 19 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ 1 ▸ 2 ▸ 4 ▸ 5 ▸ 6 Execution T okens ( n = 21566 , Steps= 325 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ Therefore ▸ ? ▸ Wait ▸ The ▸ but ▸ would Logic T okens ( n = 20157 , Steps= 325 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ consider ▸ Thus ▸ But ▸ maybe ▸ redo Thinking T okens ( n = 10999 , Steps= 325 ) (d) CH2 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 5 Execution T okens ( n = 18752 , Steps= 150 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ Wait ▸ we ▸ this ▸ it ▸ Therefore ▸ The Logic T okens ( n = 15920 , Steps= 150 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ perhaps ▸ However ▸ maybe ▸ consider ▸ note ▸ suppose Thinking T okens ( n = 8609 , Steps= 150 ) (e) LP 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 T oken Entropy Tokens : ▸ by ▸ 1 ▸ 3 ▸ 0 ▸ 2 ▸ 5 Execution T okens ( n = 15385 , Steps= 70 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Tokens : ▸ but ▸ Let ▸ ? ▸ Wait ▸ But ▸ The Logic T okens ( n = 12621 , Steps= 70 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Tokens : ▸ However ▸ perhaps ▸ consider ▸ maybe ▸ actually ▸ suppose Thinking T okens ( n = 6765 , Steps= 70 ) (f) CP Figure 6: T oken Entropy T rajectories on Qwen3-8B (DeepMath Dataset) (Part 2 of 2). (Continued from previous page.) 20 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 T oken Entropy Tokens : ▸ 1 ▸ 2 ▸ 't ▸ 4 ▸ 0 ▸ by Execution T okens ( n = 22092 , Steps= 110 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 Tokens : ▸ this ▸ but ▸ Wait ▸ it ▸ Let ▸ that Logic T okens ( n = 19063 , Steps= 110 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 Tokens : ▸ let ▸ perhaps ▸ maybe ▸ wait ▸ 've ▸ since Thinking T okens ( n = 11930 , Steps= 110 ) (a) Supervised RL 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ 't ▸ - ▸ ) ▸ , ▸ to ▸ of Execution T okens ( n = 18811 , Steps= 55 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ this ▸ ? ▸ ). ▸ it ▸ The ▸ should Logic T okens ( n = 13805 , Steps= 55 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ maybe ▸ wait ▸ perhaps ▸ But ▸ 've ▸ That Thinking T okens ( n = 7816 , Steps= 55 ) (b) Ent 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 T oken Entropy Tokens : ▸ of ▸ 1 ▸ 3 ▸ + ▸ \\ ▸ 2 Execution T okens ( n = 21428 , Steps= 55 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ this ▸ ). ▸ that ▸ it ▸ have ▸ here Logic T okens ( n = 15354 , Steps= 55 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Tokens : ▸ maybe ▸ perhaps ▸ Hmm ▸ wait ▸ Because ▸ 've Thinking T okens ( n = 8541 , Steps= 55 ) (c) A vgEnt Figure 7: T oken Entropy T rajectories on DeepSeek-R1-Distill-Llama-8B (Part 1 of 2). Analysis conducted on an architecture with a highly-aligned initial state, further isolating the impact of the re ward signal. The text boxes within each subplot display the top frequency tokens corresponding to that cluster . 21 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 T oken Entropy Tokens : ▸ + ▸ 't ▸ ▸ - ▸ 2 ▸ ) Execution T okens ( n = 18820 , Steps= 70 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Tokens : ▸ ). ▸ this ▸ Let ▸ ? ▸ here ▸ . Logic T okens ( n = 15296 , Steps= 70 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Tokens : ▸ maybe ▸ perhaps ▸ 've ▸ But ▸ wait ▸ let Thinking T okens ( n = 10800 , Steps= 70 ) (d) CH2 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 T oken Entropy Tokens : ▸ ) ▸ 't ▸ + ▸ , ▸ of ▸ 1 Execution T okens ( n = 17643 , Steps= 50 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Tokens : ▸ this ▸ ? ▸ Wait ▸ here ▸ but ▸ should Logic T okens ( n = 13720 , Steps= 50 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Tokens : ▸ maybe ▸ perhaps ▸ wait ▸ But ▸ 've ▸ let Thinking T okens ( n = 7789 , Steps= 50 ) (e) LP 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 T oken Entropy Tokens : ▸ by ▸ 1 ▸ 2 ▸ 3 ▸ ) ▸ 't Execution T okens ( n = 17372 , Steps= 60 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 Tokens : ▸ this ▸ but ▸ Let ▸ should ▸ that ▸ it Logic T okens ( n = 15246 , Steps= 60 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 Tokens : ▸ let ▸ wait ▸ maybe ▸ perhaps ▸ consider ▸ 've Thinking T okens ( n = 9602 , Steps= 60 ) (f) CP Figure 7: T oken Entropy T rajectories on DeepSeek-R1-Distill-Llama-8B (P art 2 of 2). (Continued from previous page.) 22 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.5 1.0 1.5 2.0 T oken Entropy Tokens : ▸ 3 ▸ : ▸ 6 ▸ 4 ▸ }{ ▸ 1 Execution T okens ( n = 20582 , Steps= 125 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.5 1.0 1.5 2.0 Tokens : ▸ find ▸ need ▸ let ▸ given ▸ ). ▸ first Logic T okens ( n = 9542 , Steps= 125 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.5 1.0 1.5 2.0 Tokens : ▸ Hence ▸ First ▸ identify ▸ Calcul ▸ indicates ▸ proceed Thinking T okens ( n = 4492 , Steps= 125 ) (a) Supervised RL 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 T oken Entropy Tokens : ▸ , ▸ of ▸ $ ▸ = ▸ 4 ▸ to Execution T okens ( n = 12562 , Steps= 40 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 Tokens : ▸ need ▸ let ▸ Now ▸ use ▸ know ▸ one Logic T okens ( n = 3163 , Steps= 40 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 Tokens : ▸ To ▸ First ▸ The ▸ Since ▸ Now ▸ We Thinking T okens ( n = 1576 , Steps= 40 ) (b) Ent 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.5 1.0 1.5 2.0 2.5 T oken Entropy Tokens : ▸ 2 ▸ { ▸ 1 ▸ \\ ▸ frac ▸ }{ Execution T okens ( n = 13981 , Steps= 30 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.5 1.0 1.5 2.0 2.5 Tokens : ▸ problem ▸ us ▸ have ▸ it ▸ our ▸ all Logic T okens ( n = 5384 , Steps= 30 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.5 1.0 1.5 2.0 2.5 Tokens : ▸ start ▸ First ▸ 'll ▸ break ▸ denote ▸ Let Thinking T okens ( n = 2128 , Steps= 30 ) (c) A vgEnt Figure 8: T oken Entr opy T rajectories on Llama3.1-8B (Part 1 of 2). Clustering e valuation on the Llama base architecture to verify cross-model generalizability of the mechanistic interpretations. The text boxes within each subplot display the top frequency tokens corresponding to that cluster . 23 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 T oken Entropy Tokens : ▸ , ▸ of ▸ to ▸ = ▸ 1 ▸ 2 Execution T okens ( n = 12365 , Steps= 45 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Tokens : ▸ let ▸ given ▸ need ▸ it ▸ However ▸ To Logic T okens ( n = 3971 , Steps= 45 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Tokens : ▸ First ▸ Now ▸ start ▸ To ▸ understand ▸ 'll Thinking T okens ( n = 1536 , Steps= 45 ) (d) CH2 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 T oken Entropy Tokens : ▸ of ▸ + ▸ , ▸ = ▸ 4 ▸ { Execution T okens ( n = 11210 , Steps= 35 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 Tokens : ▸ given ▸ it ▸ need ▸ these ▸ find ▸ $. Logic T okens ( n = 4810 , Steps= 35 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 Tokens : ▸ To ▸ start ▸ First ▸ Since ▸ 'll ▸ Therefore Thinking T okens ( n = 1854 , Steps= 35 ) (e) LP 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 T oken Entropy Tokens : ▸ , ▸ 1 ▸ of ▸ 2 ▸ = ▸ 4 Execution T okens ( n = 16246 , Steps= 35 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 Tokens : ▸ need ▸ However ▸ given ▸ also ▸ We ▸ To Logic T okens ( n = 6845 , Steps= 35 ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized Training Process 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 Tokens : ▸ First ▸ break ▸ Given ▸ start ▸ 'll ▸ Understand Thinking T okens ( n = 2720 , Steps= 35 ) (f) CP Figure 8: T oken Entropy T rajectories on Llama3.1-8B (Part 2 of 2). (Continued from previous page.) 24 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 Thinking T okens Mean Ent 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Logic T okens Mean Ent 0.00 0.05 0.10 0.15 0.20 0.25 Execution T okens Mean Ent S-RL (V ol: 0.021) Ent (V ol: 0.022) A vgEnt (V ol: 0.067) CH2 (V ol: 0.018) LP (V ol: 0.019) CP (V ol: 0.006) (a) Qwen3-1.7B 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 Thinking T okens Mean Ent 0.0 0.1 0.2 0.3 0.4 0.5 0.6 Logic T okens Mean Ent 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 0.200 0.225 Execution T okens Mean Ent S-RL (V ol: 0.012) Ent (V ol: 0.017) A vgEnt (V ol: 0.028) CH2 (V ol: 0.025) LP (V ol: 0.020) CP (V ol: 0.006) (b) Qwen3-8B (Standard Setup) 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Thinking T okens Mean Ent 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 Logic T okens Mean Ent 0.00 0.05 0.10 0.15 0.20 0.25 Execution T okens Mean Ent S-RL (V ol: 0.014) Ent (V ol: 0.016) A vgEnt (V ol: 0.017) CH2 (V ol: 0.028) LP (V ol: 0.011) CP (V ol: 0.005) (c) Qwen3-8B (8K Context) 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Thinking T okens Mean Ent 0.0 0.1 0.2 0.3 0.4 0.5 0.6 Logic T okens Mean Ent 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 Execution T okens Mean Ent S-RL (V ol: 0.011) Ent (V ol: 0.022) A vgEnt (V ol: 0.014) CH2 (V ol: 0.012) LP (V ol: 0.014) CP (V ol: 0.005) (d) Qwen3-8B (Deep Setting) Figure 9: 3D Exploration Boundaries of Semantic Phases (Qwen Models). The con ve x hulls illustrate the volume of the entropy phase space explored by the models under six dif ferent reward formulations. 25 Model Method MA TH-500 Olympiad Minerva AIME 24 AMC 23 AIME 26 A VG P@1 P@5 P@10 P@1 P@5 P@10 P@1 P@5 P@10 P@1 P@5 P@10 P@1 P@5 P@10 P@1 P@5 P@10 P@1 P@5 P@10 Qwen3-8B (8K) Base 85.1 91.9 93.7 46.9 56.7 60.8 42.2 51.4 54.4 38.3 53.2 59.0 70.5 85.9 90.4 28.1 42.0 46.9 58.5 67.5 70.8 S-RL 90.9 94.8 95.7 56.4 64.9 68.0 47.7 56.1 58.7 50.2 66.5 71.8 86.1 93.1 94.6 43.8 58.3 63.6 66.4 73.6 76.0 Ent 91.7 95.7 96.5 58.3 67.7 70.8 47.7 55.9 58.1 53.5 76.5 82.1 86.4 96.4 97.5 49.4 66.4 70.4 67.7 75.6 77.8 A vgEnt 89.9 94.4 95.5 54.3 62.3 65.3 46.8 56.0 58.9 44.4 61.7 69.6 82.8 93.4 94.7 44.4 60.9 66.7 64.8 72.3 74.8 LP 91.9 95.8 96.6 58.4 67.3 70.2 47.5 56.2 59.4 53.1 75.3 82.8 87.8 94.5 96.2 50.0 65.4 70.0 67.8 75.4 77.7 CH2 91.4 95.6 96.5 59.0 69.0 72.0 53.8 64.8 68.1 51.2 72.9 79.1 87.0 95.4 98.0 47.5 64.9 69.5 68.9 77.5 80.0 CP Collapse ( × ) Qwen3-8B (DeepMath) Base 67.9 80.5 84.4 28.4 41.2 46.7 29.8 39.9 44.8 7.7 19.9 23.1 41.7 64.1 73.6 9.2 16.6 22.1 41.0 53.4 58.3 S-RL 90.1 94.7 95.3 55.9 64.2 66.8 54.4 65.9 68.8 41.2 61.2 68.7 81.9 95.7 98.1 39.6 55.0 60.2 66.8 74.9 77.1 Ent 89.0 94.4 95.3 52.5 63.2 66.3 51.4 61.9 64.6 35.8 56.5 64.2 77.5 93.6 96.9 30.0 53.7 61.1 64.0 73.5 76.0 A vgEnt 79.9 88.5 91.1 41.7 52.2 56.0 38.9 49.0 52.7 24.2 37.9 43.7 61.1 75.6 80.1 19.2 30.8 35.8 53.3 63.3 66.8 LP 90.2 94.9 95.7 54.8 64.2 67.3 53.1 63.9 67.1 39.4 63.1 68.4 81.9 93.8 94.9 38.3 57.3 61.2 66.0 74.7 77.1 CH2 89.7 94.6 95.3 54.3 64.1 67.1 52.5 64.2 67.7 36.2 57.0 65.2 79.5 93.1 94.9 34.0 55.5 60.6 65.3 74.4 76.9 CP Collapse ( × ) T able 4: Boundary Conditions Results. W e expand our e valuation across two dimensions: (1) 8K training and ev aluations results; and (2) cross-dataset generalization tests utilizing DeepMath. Notions follow T able 2 . 0.0 0.5 1.0 1.5 2.0 2.5 Thinking T okens Mean Ent 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 Logic T okens Mean Ent 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Execution T okens Mean Ent S-RL (V ol: 0.016) Ent (V ol: 0.851) A vgEnt (V ol: 0.071) CH2 (V ol: 0.853) LP (V ol: 0.893) CP (V ol: 0.014) (a) DeepSeek-R1-Distill-Llama-8B 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 Thinking T okens Mean Ent 0 1 2 3 4 5 Logic T okens Mean Ent 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 Execution T okens Mean Ent S-RL (V ol: 0.348) Ent (V ol: 8.125) A vgEnt (V ol: 2.792) CH2 (V ol: 1.348) LP (V ol: 4.935) CP (V ol: 0.436) (b) Llama3.1-8B Figure 10: 3D Exploration Boundaries of Semantic Phases (Other Architectur es). The con ve x hulls illustrate the volume of the entrop y phase space explored by the models under six dif ferent rew ard formulations. 26 Hyperparameter V alue Optimization Actor Learning Rate 1 × 10 − 6 Learning Rate W armup Steps 10 W eight Decay 0.1 Mini-batch Size 24 Prompt Batch Size 8 Reinfor cement Learning Responses per Prompt ( K ) 16 PPO Clip Ratio ( ϵ ) 0.2 Loss Aggregation Mode seq-mean-token-mean Max Prompt Length 1024 Generation (Rollout & V alidation) T raining T emperature 0.6 T raining T op- p 1.0 T raining T op- k -1 V alidation T op- p 0.95 V alidation T op- k 20 T able 5: Hyperparameters for the RL trainings. 27
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment