Agile Interception of a Flying Target using Competitive Reinforcement Learning
This article presents a solution to intercept an agile drone by another agile drone carrying a catching net. We formulate the interception as a Competitive Reinforcement Learning problem, where the interceptor and the target drone are controlled by s…
Authors: Timothée Gavin, Simon Lacroix, Murat Bronz
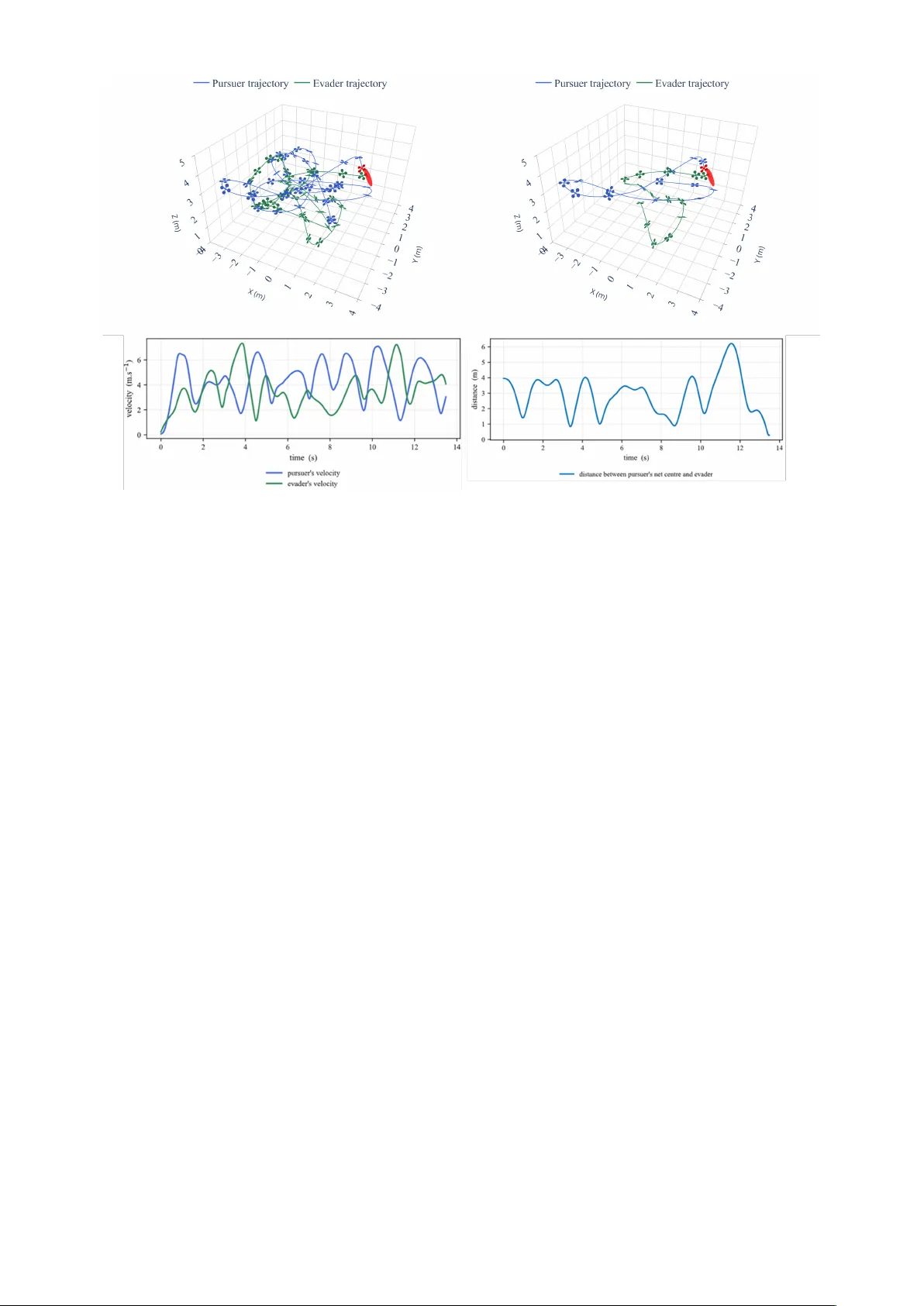
Agile Interception of a Flying T ar get using Competiti v e Reinforcement Learning T imoth ´ ee Gavin IAS Thales LAS Rungis, France timothee.gavin@thalesgroup.com Simon Lacroix RIS LAAS CNRS T oulouse, France simon.lacroix@laas.fr Murat Bronz Dynamic Systems, OPTIM F ´ ed ´ eration EN A C ISAE-SUP AER O ONERA, Universit ´ e de T oulouse T oulouse, France murat.bronz@enac.fr Abstract —This article presents a solution to intercept an agile drone by another agile dr one carrying a catching net. W e formulate the interception as a Competitive Reinfor cement Learning problem, where the interceptor and the target drone are controlled by separate policies trained with Proximal Policy Optimization (PPO). W e introduce a high-fidelity simulation en vironment that integrates a realistic quadr otor dynamics model and a low-lev el control architectur e implemented in J AX, which allows for fast parallelized execution on GPUs. W e train the agents using low-level control, collectiv e thrust and body rates, to achieve agile flights both f or the interceptor and the target. W e compar e the performance of the trained policies in terms of catch rate, time to catch, and crash rate, against common heuristic baselines and show that our solution outperf orms these baselines for inter ception of agile targets. Finally , we demonstrate the performance of the trained policies in a scaled real-w orld scenario using agile drones inside an indoor flight arena. Index T erms —Reinf orcement Learning, Multi-Agent Systems, Interception, Agile Flight I . I N T R O D U C T I O N The interception of agile aerial targets using autonomous drones is a challenging and increasingly relev ant problem in robotics and security . The increasing presence of unmanned aerial v ehicles (U A Vs) in unauthorized, restricted airspaces poses significant safety and security risks and has spurred interest in developing effecti ve interception strategies [1] In particular , scenarios such as airspace protection, infrastructure security , and event safety require the ability to capture or neu- tralize unauthorized drones with high precision and minimal collateral risk. Deploying interceptor drones equipped with nets is a promising approach, but it demands adv anced control capabilities to match or exceed the agility of ev asiv e targets. T raditional interception methods often rely on accurate models, preplanned strategies, or predictable target behaviour [2]. Howe ver , modern quadrotor drones can perform highly dynamic manoeuvres, and will actively ev ade capture, ren- dering their trajectories unpredictable and challenging the effecti veness of classical methods [3]. Recent adv ances in deep reinforcement learning (RL) hav e demonstrated the potential to learn complex, high-dimensional control policies for drones directly from interaction with the en vironment. In particular in drone racing, RL-trained policies hav e achie ved superhuman performance in highly dynamic and agile flight tasks [4]. Ho wev er, the drone racing problem Fig. 1: A competitiv e reinforcement learning approach to train both a pursuer and an e vader drone for agile interception tasks. Both agents learn low-le vel control policies that enable them to perform dynamic maneuvers in a high-fidelity simulation en vironment. typically inv olve navigating static or slowly moving gates, while interception requires reacting to an adversarial agent that activ ely attempts to ev ade capture. Competitiv e Multi-Agent RL (MARL) hav e shown out- standing results in adversarial settings, such as games [5], [6]. In this work, we formulate the agile interception problem as a competitiv e multi-agent RL task, where both the interceptor (pursuer) and the target (ev ader) are controlled by independent policies trained using Proximal Policy Optimization (PPO) in a co-evolution framew ork. Our approach integrates a high- fidelity quadrotor dynamics model, enabling both agents to learn agile, physically realistic manoeuvres from low-le vel control inputs. Through extensiv e simulation and real-world experiments, we show that RL training leads to robust and adaptiv e interception and ev ading strategies, outperforming heuristic control approaches. The main contributions of this paper are: • A competiti ve MARL frame work for agile drone inter - ception, with both pursuer and ev ader learning from low- lev el control. • Integration of a realistic quadrotor dynamics model to enable physically realistic and agile flight behaviors. • Empirical e valuation demonstrating superior performance ov er standard baselines in simulation. The remainder of the paper is organized as follows. Section II re views related work on interception and agile flight. Section IV and III detail our agile flight simulation environment and our training methodology . Section V presents experimental results and comparisons. Section VI and VII conclude and discuss future directions. I I . R E L AT E D - W O R K O N T H E A G I LE I N T E R C E P T I O N P RO B L E M A. Agile flight Agile flights in multi-rotors drones are typically character- ized by the ability to perform large-angle manoeuvres, sustain high linear and angular accelerations, maintain precise control near dynamic limits and do so reliably in real-time, often in complex and cluttered en vironments. T raditionally , achie ving such agility relied on trajectory optimization coupled with con- trollers like Model Predictive Control (MPC), often requiring pre-planned paths and accurate system models [7]. Howe ver , these methods can be brittle when faced with unexpected dis- turbances of real-world flights. Reinforcement Learning (RL) has emerged as a po werful alternative, enabling the learning of complex, non-linear control policies directly from interaction. Research, such as work from [4] and [8], has demonstrated RL ’ s capability to achiev e highly dynamic and agile flights for quadrotors, pushing the boundaries of autonomous aerial manoeuvring beyond what traditional methods could easily achiev e, particularly in tasks requiring aggressiv e, near-limits flight. B. Interception T raditional interception methods uses heuristic or optimal control methods that often rely on accurate models, pre- planned strategies, or predictable target behaviour . [2]. These approaches have been historically designed for the control of missiles and the interception of fixed-wing manned air- craft. Optimal control methods requires accurate model of the pursuer and the ev ader to compute interception trajec- tories [9]. Such model may not be available or may be too computationally expensiv e for real-time adaptation against unpredictable targets. Heuristic guidance laws, such as Pro- portional Navigation (PN) or Pure Pursuit, offer computa- tionally simpler alternativ es and are widely used in missile guidance. Howe ver , these methods often assume relatively simple target manoeuvres and can struggle against highly agile or adversarial ev aders. Among recent works, [10] hav e proposed heuristic methods for drone interception of agile manoeuvring targets, but these still assume a predictable target model. More recently , learning-based solutions, particularly MARL have shown promise for de veloping complex control policies in adversarial settings. MARL has been explored for pursuit-ev asion games in v arious contexts, including simulated en vironments like Multi-Agent Particle Environments (MPE) [11] and initiatives like the D ARP A AlphaDogfight Trials, demonstrating the potential to learn sophisticated tactics [12]. For quadrotors, [13] present a RL approach for quadrotor interception in an urban environment, and [14] uses RL to giv e low-le vel commands for interception, howe ver both these works consider only the pursuit side, assuming fixed ev ader behaviours. The closest work to ours we found is [15] which uses RL to train both the pursuer and the ev ader in a co- ev olution framework. Howe ver , like most RL approaches [13], they use high-le vel control inputs (e.g., velocity commands) and simplify the dynamics of the quadrotors, which limits the agility of the learned behaviours. Overall, while RL has demonstrated potential in interception tasks, existing work either ignore the adversarial aspect of a learning ev ader , or often lacks the integration of highly dynamic capabilities in both the pursuer and the ev ader . C. Our approac h Building upon the challenges highlighted in agile flight and interception, our approach directly addresses the need for highly dynamic capabilities in both the pursuer and the ev ader . W e recognize that interception is fundamentally a dynamic, adversarial interaction requiring controllers that can operate effecti vely near the physical limits of the hardware. While RL has demonstrated remarkable success in achie ving agile flight and has been applied to interception problems, to our knowledge, none have focused on training both an agile pursuer and an agile ev ader using low-le vel commands within a competiti ve RL framework. Our work fills this gap by formulating the problem as a competitiv e multi-agent RL task where both agents learn physically plausible, agile manoeuvres through interaction in a realistic environment, to foster robust and adaptiv e strategies. I I I . A G I L E F L I G H T S I M U L A T I O N E N V I RO N M E N T W e use a high-fidelity simulator of the quadrotor dynamics. The simulator models air-drag, the low-le vel control archi- tecture, the motor speeds, and the transmission delays. This quadrotor model was taken from [16] which include a lo w- lev el control architecture taking mass-normalized collectiv e thrust and body rates as inputs. W e also implemented a high-lev el controller: an SE(3) controller [17], following the implementation from [18]. This controller , combined with the low-le vel quadrotor model, allow us to giv e alternate high- lev el commands to the quadrotors, such as position, velocity , or acceleration commands. The control architecture is illustrated in Figure 2. Our simulator also computes the collision between quadrotors, the elements of the arena and the net carried by the pursuers. This fidelity facilitates the transfer of policies trained in simulation to the real world. The simulation framework is entirely written using J AX [19]. This Python library allows the code to be just-in-time compiled and lowered to GPU during runtime, resulting in SE(3) Controller or Policy Network Attitude Autopilot Quadrotor X ref T , ω b ω mot X = [ p, V , a, R ] 100 Hz 1 kHz Fig. 2: Control architecture used for the quadrotor dynamics simulation. fast ex ecution times of up to millions of steps per second by lev eraging the parallelization capabilities of GPUs. I V . I N T E R C E P T I O N O F A N A G IL E T A R G E T U S I N G R E I N F O R C E M E N T L E A R N I N G Drone neutralisation methods are classified as kinetic or non-kinetic [1]. Non-kinetic approaches, such as jamming or spoofing, are ineffecti ve against autonomous drones. Kinetic methods, including projectiles or collisions, and electromag- netic weapons, risk causing uncontrolled crashes and debris. Using a net, towed or projected by the pursuer, avoids these issues by safely capturing the target; here, we consider a net taut to the pursuer and released upon capture. A. Reinforcement Learning Reinforcement Learning is a type of machine learning for sequential decision-making. In a rollout phase, an ag ent interacts with an uncertain envir onment which provides it with a partial observations of its state , takes a series of actions following a policy and receives a scalar feedback in the form of r ewar ds . These sequences of observe-act-re ward, repeated ov er time, form the r ollouts . The collected rollouts are then used to update the policy in a learning phase, which will then be employed in the rollout phase of the next training iteration. The goal of the agent is to learn a policy that maximizes the expected cumulative rew ard over time. Multi-Agent Reinforcement Learning (MARL) extends RL to scenarios with multiple agents interacting in a shared en vironment. MARL suffers from the curse of dimensionality and non-stationarity , as the en vironment dynamics change as other agents learn and adapt their policies. Recent works in MARL adopted centralized training with decentralized ex ecution (CTDE) [11], where agents hav e access to global information during training but operate based on local observ a- tions during execution. In competitiv e settings, this alleviates non-stationarity by allowing the agents to access the state and actions of their opponents during training. B. Pursuit-evasion pr oblem W e study a pursuit–ev asion scenario with two quadrotors, a pursuer and an evader , operating in an obstacle-free rect- angular arena of size L × L × H . At the beginning of each episode, the agents’ initial positions are drawn uniformly at random inside the arena. The pursuer seeks to capture the Fig. 3: Schematic of the interception problem. Capture hap- pens when the distance d between the ev ader’ s centre comes within a capture distance of the pursuer’ s net. ev ader as quickly as possible, whereas the e vader tries to e vade capture. Capture occurs when the ev ader’ s centre comes within a captur e distance of the pursuer’ s rigid, circular net of radius R , which is mounted on the pursuer and aligned with its body frame, and represented in Figure 3. Because a single pursuer cannot intercept a faster e vader alone, we assume the pursuer’ s and the ev ader’ s manoeuvring capabilities are identical. T arget detection, state estimation, and trajectory prediction are not addressed in this work. Both the ev ader and the pursuer are forbidden to exit the boundaries of the arena. In this setting the ev ader can quickly learn to fly close to the arena walls to stay safe, exploiting the pursuer’ s fear to av oid boundary violations. T o discourage this behaviour and promote agile ev asi ve flight in the central region, a narrow buf fer zone is added adjacent to every wall; only the ev ader is penalized for entering this zone and thus, the ev ader is constrained in a smaller volume in the centre of the arena. 1) Observation, actions, and re war ds: At time step t , each agent’ s i ∈ (pursuer , ev ader) observation o i is composed of the following elements: self-state observation o self i , ob- servation of the opponent o opp i , and the observation of the arena bounds and the ground o env i . The self-state observa- tion is o self i = [ v i , vec ( R i ))] containing the agent’ s linear velocity v i , and its rotation matrix R i , with vec ( · ) being the flattening function. The observation of the opponent is o opp i = [ p o − p i , v o − v i ] containing the position and v elocity of the opponent expressed relativ e to the agent in world coor- dinates. The observation of the arena bounds and the ground is o env i = [ norm ( p o − p i )] o ∈ bounds + ground and is composed of the Euclidean distances from the agent to each arena boundary and to the ground. W e normalize the observations before feeding them to the neural network. Relative positions are normalized by the maximum range of view k p i , and velocities are normalized by a maximum velocity parameter for each agent k v i . The control policies are trained using Proximal Policy Optimization (PPO) [20]. This Actor-Critic method uses two neural networks for each agent: a policy network and a value network. The policy network produces an action a i for each agent, which is a vector of body rates a ω i and a collectiv e thrust a th i . The value networks are only used during training time and hav e access to privile ged information about the opponent’ s state, which is not av ailable to the policy network. This alleviates the non-stationarity of the en vironment due to the simultaneous learning of both agents [11]. The input of the value network of each agent is the concatenation of the position, velocity , and rotation matrix of each agent, as well as the action taken by the opponent at this time step. This input is normalized before being fed to the neural network. The rew ard of the pursuer r P and the ev ader r E are giv en by: r P = r catch − r dist − r coll − r fail − r cmd , r E = − r catch + r dist − r coll − r fail − r cmd − r bnd . in which r catch rew ards the pursuer for catching the ev ader , r dist penalizes the pursuer for being far from the ev ader , r fail penalizes any agent for crashing or going out of bounds, r coll penalizes any agent for colliding with the body of their oppo- nent, and r cmd discourages dynamically infeasible commands. Instead of terminating the episode upon collision between agents, we apply a soft continuous penalty r coll to both agents, allowing for gradual learning of collision av oidance while maintaining focus on the primary tasks of pursuit and ev asion. W e still terminate the episode if any agent crashes on the ground or goes out of bounds and apply a hard penalty r fail . Howe ver , neither the e vader nor the pursuer receiv e a reward when the opponent reaches a failure state to promote actual pursuit-ev asion behaviours rather than forcing the opponent to crash. Additionally , we add r bnd to the ev ader’ s reward function, which penalizes it for approaching the arena bounds. Specifically , the reward terms are: r catch = λ catch · 1 catch , r dist = λ dist · p e − c net 2 , r coll = λ coll 1 contact , r fail = λ fail 1 fail , r cmd = λ cmd ∥ a ω ∥ . r bnd = ϕ bnd ( d bnd ) , in which the indicator functions return 1 when their condition is met : 1 catch when catching the ev ader , 1 contact for inter- agent contact, 1 fail for reaching a failure state because of a ground crash or leaving the arena bounds. c net is the pursuer’ s catching net-centre position, and a ω are the commanded body rates. ϕ bnd is a function that penalizes the ev ader for approaching the arena bounds, triggering under a set threshold and gro wing exponentially the shorter the distance to the arena bounds d bnd . λ catch , λ dist , λ coll , λ term , λ cmd are positiv e hyperparameters that balance the different reward terms and hav e been tuned to obtain the desired behaviour and listed in T able I. T ABLE I: Reward coefficients. Coefficient V alue Coefficient V alue λ catch 10.0 λ coll 0.1 λ dist 0.001 λ fail 30.0 λ cmd 2e-04 λ bnd 1.0 C. T raining details Rollouts are generated in parallel across 1024 environments. Episodes start from uniformly sampled initial positions in the L × L × H arena; no domain–randomisation of the platform dynamics is applied. Episodes last up to T = 10 s (1000 time steps) unless terminated earlier due to capture, crash, or arena exit. Each policy network is a two-layer multilayer perceptron with 256 ReLU units per hidden layer . The output layer produces the mean and standard-deviation of a multiv ariate Gaussian, followed by a tanh squashing to obtain bounded continuous actions. The value networks mirrors this architec- ture but ends with a linear output. The entire pipeline is written in Python using J AX [19], enabling just-in-time compilation and parallelized execution. Running on a single machine equipped with an NVIDIA R TX 4090 (24 GB VRAM), an AMD Ryzen 9 7950X3D (16 cores, 4.2 GHz) and 128 GB RAM, the system collects and processes approximately 3 . 5 × 10 5 en vironment steps per second. W e train for a total of 2 × 10 9 en vironment steps, corresponding to roughly 1h35 of wall-clock training time. T raining hyperparameters are listed in T able II. V . E X P E R I M E N TA L R E S U L T S A. T raining Results Figure 4 compares the learning curves of the pursuer and the ev ader . The pursuer cumulated return initially rises as the drone learns to fly and av oid crashes and the first interception happens. Because the ev ader’ s reward contains an additional boundary term, its learning progress is intrinsically slower; it does not reach high-speed flight as early as the pursuer . The pursuer therefore overfits to an increasingly predictable ev ader . Howe ver , as the ev ader also learns to fly and e vade, the pursuer’ s return decreases drastically as it can no longer catch the e vader . This also translates into the av erage episode length which first increases as both agents learn to hover and av oid crashes, but soon falls sharply as the pursuer discovers a quick capture strategy . Eventually , the pursuer finds a new strategy to catch the ev ader again, the av erage episode length T ABLE II: Training hyperparameters. Hyperparameter V alue Number of parallel en vironments (per agent) 1024 Rollout length 128 Learning rate 5 × 10 − 4 Discount factor 0.99 Number of PPO epochs per training data batch 15 Number of minibatches per PPO epoch 1 Discount factor 0.99 Lambda v alue for GAE computation 0.95 Clipping v alue for PPO updates 0.2 Entropy 0.01 Critic weight in loss function 0.5 Maximum norm of the gradients for a weight update 0.5 Decay learning rates False T otal number of training steps 4 × 10 9 (a) A verage cumulated reward ov er training. (b) A verage episode length. Fig. 4: Comparison of learning curves and average episode length. decreases and the return of the pursuer increases as it learns to catch the ev ader more consistently . This behaviour is typical of co-e volutionary learning [21], and happens multiple times during the training as both agent cycle through periods of adaptation and counter-adaptation. Both curves con verge to a near-stationary value, suggesting that the joint policy profile is approaching a Nash equilibrium. B. Evaluation in Simulation W e compare the performances of the trained policies with baseline heuristic methods. For the pursuer , Pure-Pursuit (PP), a classical interception strategy where the pursuer follows a straight line towards the position of the ev ader , and Fast- Response Proportional Navigation [10] which is an ev olution of Proportional Navigation for manoeuvring multi-rotors. For the ev ader , a hov ering strategy where the e vader tries to main- tain a fixed position in space, and an Artificial Potential Field strategy where the e vader is repelled by the pursuer and the boundaries of the arena. W e use the potential field formulation from [22]. In the sake of comparison, these heuristic methods only access the position and velocity of the opponent agent, as our RL policies only access this information. How to estimate the state of the ev ader in high-speed manoeuvring flights is not T ABLE III: Performances of the pursuer and the e vader in a 40x40x14m (Large) and a 8x8x5m (Small) arena. Pursuer mode Evader Mode Small arena Large arena PP Hov . APF DRL Hov . APF DRL Catch Rate (%) 96.4 19.5 58.3 100 15.9 24.6 Evade Rate (%) 0.0 47.9 40.0 0.0 66.6 74.6 of which timeout 0.0 0.0 0.8 0.0 0.0 1.1 Crash rates (%) Pursuer 0.0 47.9 39.3 0.0 53.2 73.5 Evader - 32.0 0.6 - 25.9 0.3 Double 3.6 0.6 1.0 0.0 0.3 0.5 Time to Catch (s) Mean 2.05 8.29 5.29 6.65 8.72 8.32 Std 1.66 3.48 4.05 3.90 2.94 3.11 FRPN [10] Hov . APF DRL Hov . APF DRL Catch Rate (%) 97.4 19.6 37.7 97.5 68.8 49.2 Evade Rate (%) 0.1 43.1 59.9 0.0 1.0 47.3 of which timeout 0.0 1.2 0.1 0.0 0.0 20.2 Crash rates (%) Pursuer 0.1 42.0 59.8 0.0 1.0 27.1 Evader - 36.4 1.3 - 30.2 3.2 Double 2.5 0.8 1.1 2.5 0.0 0.3 Time to Catch (s) Mean 2.03 8.49 6.88 2.70 4.97 6.72 Std 1.33 3.15 4.03 1.29 3.44 3.67 DRL (Ours) Hov . APF DRL Hov . APF DRL Catch Rate (%) 90.7 71.8 78.8 20.7 34.0 66.5 Evade Rate (%) 6.6 6.9 16.5 75.6 50.4 31.9 of which timeout 1.0 0.3 2.3 74.0 8.1 14.7 Crash rates (%) Pursuer 5.6 6.6 14.2 1.6 42.3 17.2 Evader - 20.3 4.1 - 15.4 1.5 Double 0.4 1.0 0.6 3.7 0.2 0.1 Time to Catch (s) Mean 2.62 4.18 3.78 8.96 7.61 6.62 Std 2.76 3.89 3.60 2.46 3.55 3.34 Hov .: Hovering, APF: Artificial Potential Field text in blue : best pursuer against this column’ s ev ader text in orange : best evader against this row’ s pursuer in the scope of this paper . The heuristic baselines give velocity or acceleration commands that are then con verted to body rates and collectiv e thrust using the SE(3) controller described in Section III. The main comparison metrics are the catch rate of the pursuer , the ev ade rate of the ev ader, the time to catch and the crash rate. The catch rate is the percentage of episodes where the pursuer successfully catches the ev ader before a timeout of 10 seconds. The ev ade rate is the percentage of episodes in which the ev ader av oids capture for 10 seconds or the pursuer crashes. W e also identify three different crash rates: pursuer crash rate and ev ader crash rate are the percentage of episodes where either the pursuer or the ev ader crashes alone, and double-crash rate is the percentage of episodes where both agents crash simultaneously . Finally , the time to catch is the time taken by the pursuer to catch the ev ader . T ime-to-catch is naturally biased tow ards lower values as it only consider successful catches, thus a weaker pursuer can appear to hav e a better time to catch as it would only succeed in catching the easiest targets without crashing. T o alle viate Fig. 5: Ev asive manoeuvres: from top left to bottom right, the e vader (green) performs a vertical escape, a div e, a sharp turn, and a sudden stop followed by a feint. Fig. 6: a high roll angle catch: the pursuer (blue) intercepts the ev ader (green) with a roll angle of more than 45 degrees. this issue, we use a right-censored metric for the time to catch: if the episode ends because of a crash or a timeout, the time to catch is considered to be of 10 seconds. W e ev aluate the performances of our strategies in two different settings. First in a lar ge arena of size 40 × 40 × 14 meters, with the ev ader constrained in a smaller volume of size 20 × 20 × 4 meters in the centre of the arena. In this setting, the agents can reach higher speeds and perform long-range manoeuvres with lo w risk of crashing into the boundaries. This is to the adv antage of the heuristic pursuer baselines, which do not account for the presences of boundaries. Then in a smaller arena of size 8 × 8 × 5 meters, with the ev ader constrained in a volume of size 6 × 6 × 4 meters in the centre of the arena, closer to indoor voliere flight conditions. In this setting, the agents are more constrained by the boundaries and ha ve to perform tighter manoeuvres. For each setting, a specific pursuer and an ev ader model was trained for this specific arena size. For each combination of pursuer and ev ader strategies, we run 10,000 episodes and report the av eraged metrics in T able III. The learned e v ader outperforms the moving heuristic ev aders in all settings, achieving a higher ev ade rate and lower crash rate against all pursuers. The learned ev ader is particularly ef fective against the heuristic pursuers, which ha ve a high crash rate when facing agile manoeuvres. Against FRPN in the larger arena where it is less crash-prone, half of the successful e vasions are due to timeouts, sho wing that the learned ev ader can consistently av oid capture for the full duration of the episode. This shows that we successfully trained an agile ev ader that can exploit the full 3D space to av oid capture while av oiding crashes. All the pursuer heuristic baselines performances drop when facing the agile learned ev aders. Their crash rate is high, as it does not take into account for the presence of boundaries. This effect is exacerbated in the smaller arena. In comparison, the learned pursuer that was trained to a void crashes sho ws a much lower crash rate against the agile learned ev ader . The learned pursuer has also the highest catch rate and lowest time to catch against the agile learned e vader , showing that it has learned effecti ve interception strategies ag ainst agile manoeuvres while respecting arena boundaries and minimizing crashes. The low time-to-catch shows that the learned pursuer succeeds against the hardest-to-catch, most time-consuming ev aders where the other methods fail or crash. Howe ver , the performances of the learned pursuers drop significantly when facing the heuristic e vaders, especially the hov ering one. While the learned pursuer still display a low crash rate, its catch rate is much lower than the heuristic pursuers in the lar ger arena. This suggests that the learned pur- suer has overfitted to the strategies of the agile learned ev ader encountered during training, and fails to find effecti ve intercep- tion strategies against less agile e vaders. This is especially true against the hovering ev ader . It seems to be a very easy target to catch, but this situation was likely not encountered during training, as the ev ader was always trying to escape. Moreov er , the pursuer’ s observation do not encode history information, and cannot infer that the ev ader is stationary from its current observed state (position, velocity). As a result, it did not learn to exploit the lack of movement to optimize its interception strategy . In fact, it must expect it to flee at any moment. This is less pronounced in the smaller arena, where the boundaries further constrain the ev ader’ s movements. It is likely that the learned pursuer encountered more trajectories where the ev ader was close to stationary during training, allowing it to learn some interception strategies against this type of target. As a result, the learned pursuer still achiev es a higher catch rate and faster time to catch than the heuristic pursuers against Fig. 7: Simulation results: A full pursuit-ev asion episode using the trained policies. The trajectory on the right is a shortened version of the full episode for more visibility . W e can see the pursuer first missing the ev ader in a first attempt, then successfully catching it after a second attempt. all moving e vaders in the smaller arena, primarily due to its ability to av oid boundaries and crashes. C. Qualitative Results in Simulation In this section, we present qualitativ e results of our trained policies in the small arena setting ( 8 × 8 × 5 m). As shown in Figure 5, the ev ader learned a di verse set of agile evasi ve manoeuvres, including high accelerations, high velocity flights, sudden stops, sharp turns, vertical movements, and feints. In response, the pursuer learned to anticipate these manoeuvres. W e observed the pursuer catching the e v ader with very high roll and pitch angles ( > 45 degrees) (Figure 6). Despite being not specifically enforced by the rew ard function to turn the heading towards the ev ader , the pursuer learned to do so in order to maximize the surface of the catching net facing the ev ader, which increases the chances of a successful capture. It also learned to catch the ev ader using both sides of the catching net, to intercept an ev ader that went behind it without turning around. One trajectory obtained is shown in Figure 7. Both the pursuer and the ev ader display agile manoeuvres in a very restricted arena, with velocities of up to ∼ 7 . 5 m/s. The pursuer (in blue) is able to catch the ev ader (in green) after 13 seconds of intense chase, showcasing the ability of the learned policies to sustain high intensity flights while av oiding crashes. D. Real-W orld Demonstration W e demonstrated the trained policies in a real-world sce- nario in our indoor flight arena of size 8 × 8 × 5 meters. The policies have been directly transferred from simulation to reality without any additional fine-tuning or adaptation. For this flight, the ev ader was simulated on a ground station computer , while the pursuer was flying a real quadcopter equipped with a Betaflight [23] flight controller . The flight logs were recorded, including and action commands, and analysed afterward to identify successful catches and the collisions between the pursuer and the e vader . The state of the real drone is estimated using a motion capture system (OptiT rack) that provides accurate position and orientation data at 200 Hz and transferred to the simulation. The neural network policy was ex ecuted remotely on the ground station computer and the outputted control commands transferred to the drones via an RF link at 100 Hz. W e adopted this Hardware-In-The- Loop setup to ensure safety during the flights, but it is not a limitation of our approach as the trained policies can be ex ecuted on-board in a decentralized way . The pursuer managed to fly without crashing or exiting the arena during 28 seconds, and successfully caught the ev ader 7 times during this period. A portion of the recorded trajectory is shown in Figure 8. The flight logs were analysed to identify the error between the simulation and the real-world execution. At each time step, we computed the error between the expected next state from the simulation and the actual next state recorded from the Fig. 8: A portion of the real-world flight trajectory . The pursuer (blue) successfully caught the ev ader (green). real-world flight with the actions given to the policy network. W ith a period between time steps at 100Hz of 0.01 seconds, the position RMSE is 0.009 m on the xy plane and 0.003 m on the z axis, while the velocity RMSE is 0.070 m/s on the xy plane and 0.040 m/s on the z axis. V I . C O N C L U S I O N In this work, we addressed the challenging problem of intercepting an agile aerial target using a pursuer drone equipped with a catching net. W e formulated this task as a competitive multi-agent reinforcement learning problem, training independent policies for both the pursuer and the ev ader using PPO with low-le vel control inputs (collectiv e thrust and body rates). A key element of our approach was the integration of a high-fidelity quadrotor dynamics model and a multi-agent reinforcement learning framework for the training of both the pursuer and the ev ader . Our simulation results demonstrated that the trained policies outperformed classical heuristic baselines in simulated inter- ception tasks of agile ev ader, achie ving higher catch rates and demonstrating greater robustness against crashes, particularly when facing agile, learned opponents. Furthermore, the dev el- opment of our simulation en vironment entirely within the J AX framew ork proved crucial, enabling massi vely parallelized ex ecution and drastically accelerating the training process, which made extensi ve RL training computationally feasible. While comprehensive quantitati ve ev aluation in the physical world remains challenging, we successfully demonstrated the learned policies on agile quadrotors in our indoor flight arena, validating the potential for zero-shot sim-to-real transfer and showcasing the practical applicability of our approach. Overall, this research highlights the ef fectiveness of Multi- Agent Competitiv e Reinforcement Learning for generating highly agile and reactive control policies for complex robotic interaction tasks like drone interception. V I I . L I M I TA T I O N S While our approach demonstrates promising results for agile drone interception, sev eral limitations should be acknowl- edged. First, the sim-to-real gap remains a significant challenge. Although our simulation uses quadrotor dynamics identified from real flight data, trained policies remain sensitiv e to mismatches between the simulated model and actual hardware. Uncertainties in parameters like mass, inertia, or motor limits can degrade real-world performance. Incorporating domain randomization during training could improve robustness to such discrepancies. Second, we observed instances where agents appeared to overfit to certain interaction patterns. When opponents deviated from typical behaviors (e.g., flying erratically or hov ering), agents sometimes responded suboptimally or failed (e.g., crashing), rather than robustly pursuing their objectiv es. When training only against the latest version of the opponent, agents are prone to forget how to deal with previously encoun- tered strategies, and it limits the generalization capabilities of the learned policies. Expanding the diversity of opponent strategies met during training, for example via Self-Play or Population-Based Training [6], could mitigate ov erfitting and improv e generalization. Third, we assume perfect state information for both agents during training and ex ecution. Incorporating realistic sensor models and handling partial observability are important for real-world deployment, where robust perception of the target in high-velocity flights and state estimation are required but were not addressed in this study . Fourth, the current study focuses on a one-vs-one ”dog- fight” scenario within a bounded, obstacle-free arena. Extend- ing the approach to handle multiple pursuers and/or ev aders, operate in cluttered environments, or address dif ferent objec- tiv es like area defense requires further in vestigation. Finally , while we demonstrated feasibility in real-world flights, the quantitativ e evaluation was primarily conducted in simulation. A more extensi ve real-world experimental cam- paign would be necessary to rigorously quantify performance metrics like catch rate and time-to-catch under physical con- ditions. R E F E R E N C E S [1] S. Park, H. T . Kim, S. Lee, H. Joo, and H. Kim, “Survey on Anti-Drone Systems: Components, Designs, and Challenges, ” IEEE Access , vol. 9, pp. 42 635–42 659, 2021. [2] R. Y anushevsky , Modern Missile Guidance , 2nd ed. Boca Raton: CRC Press, Sep. 2018. [3] T . H. Chung, G. A. Hollinger , and V . Isler , “Search and pursuit-e vasion in mobile robotics, ” Autonomous Robots , vol. 31, no. 4, pp. 299–316, Nov . 2011. [Online]. A vailable: https://doi.org/10.1007/s10514- 011- 9241- 4 [4] E. Kaufmann, L. Bauersfeld, A. Loquercio, M. M ¨ uller , V . Koltun, and D. Scaramuzza, “Champion-level drone racing using deep reinforcement learning, ” Nature , vol. 620, no. 7976, pp. 982–987, 2023. [Online]. A vailable: https://doi.or g/10.1038/s41586- 023- 06419- 4 [5] “Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm, ” Dec. 2017, arXiv:1712.01815 [cs]. [Online]. A vailable: http://arxi v .org/abs/1712.01815 [6] “Dota 2 with Large Scale Deep Reinforcement Learning, ” Dec. 2019, arXiv:1912.06680 [cs]. [Online]. A vailable: http://arxiv .org/abs/1912. 06680 [7] D. Mellinger and V . Kumar , “Minimum snap trajectory generation and control for quadrotors, ” in 2011 IEEE international conference on r obotics and automation . IEEE, 2011, pp. 2520–2525. [8] X. W ang, J. Zhou, Y . Feng, J. Mei, J. Chen, and S. Li, “Dashing for the golden snitch: Multi-drone time-optimal motion planning with multi-agent reinforcement learning, ” arXiv preprint , 2024. [Online]. A vailable: https://arxiv .org/abs/2409.16720 [9] M. Geisert and N. Mansard, “T rajectory generation for quadrotor based systems using numerical optimal control, ” in 2016 IEEE international confer ence on robotics and automation (ICRA) . IEEE, 2016, pp. 2958– 2964. [10] M. Pliska, M. Vrba, T . B ´ a ˇ ca, and M. Saska, “T owards safe mid-air drone interception: Strategies for tracking & capture, ” IEEE Robotics and A utomation Letters , 2024. [11] R. Lowe, Y . WU, A. T amar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-Agent Actor-Critic for Mixed Cooperative-Competiti ve Environ- ments, ” in Advances in Neural Information Pr ocessing Systems , vol. 30. Curran Associates, Inc., 2017. [12] A. P . Pope, J. S. Ide, D. Mi ´ covi ´ c, H. Diaz, J. C. T wedt, K. Alcedo, T . T . W alker, D. Rosenbluth, L. Ritholtz, and D. Jav orsek, “Hierarchical reinforcement learning for air combat at darpa’s alphadogfight trials, ” IEEE T ransactions on Artificial Intelligence , vol. 4, no. 6, pp. 1371– 1385, 2023. [13] R. Zhang, Q. Zong, X. Zhang, L. Dou, and B. Tian, “Game of Drones: Multi-U A V Pursuit-Evasion Game W ith Online Motion Planning by Deep Reinforcement Learning, ” IEEE T ransactions on Neural Networks and Learning Systems , vol. 34, no. 10, pp. 7900–7909, Oct. 2023. [Online]. A vailable: https://ieeexplore.ieee.org/abstract/document/ 9712866 [14] J. Chen, C. Y u, G. Li, W . T ang, S. Ji, X. Y ang, B. Xu, H. Y ang, and Y . W ang, “Online planning for multi-uav pursuit-ev asion in unknown en vironments using deep reinforcement learning, ” 2024. [15] J. Xiao and M. Feroskhan, “Learning Multi-Pursuit Evasion for Safe T argeted Navigation of Drones, ” IEEE Tr ansactions on Artificial Intelligence , v ol. 5, no. 12, pp. 6210–6224, Dec. 2024, [cs]. [Online]. A vailable: http://arxiv .org/abs/2304.03443 [16] J. Heeg, Y . Song, and D. Scaramuzza, “Learning quadrotor control from visual features using differentiable simulation, ” arXiv preprint arXiv:2410.15979 , 2024. [17] T . Lee, M. Leok, and N. H. McClamroch, “Geometric tracking control of a quadrotor uav on se (3), ” in 49th IEEE conference on decision and contr ol (CDC) . IEEE, 2010, pp. 5420–5425. [18] S. Folk, J. Paulos, and V . Kumar , “Rotorpy: A python-based multirotor simulator with aerodynamics for education and research, ” arXiv preprint arXiv:2306.04485 , 2023. [19] J. Bradbury , R. Frostig, P . Hawkins, M. J. Johnson, C. Leary , D. Maclau- rin, G. Necula, A. Paszk e, J. V anderPlas, S. W anderman-Milne, and Q. Zhang, “J AX: composable transformations of Python+NumPy pro- grams, ” 2018. [20] J. Schulman, F . W olski, P . Dhariwal, A. Radford, and O. Klimov , “Proximal Policy Optimization Algorithms, ” T ech. Rep., Aug. 2017. [21] T . Bansal, J. Pachocki, S. Sidor , I. Sutske ver , and I. Mordatch, “Emer gent complexity via multi-agent competition, ” CoRR , vol. abs/1710.03748, 2017. [Online]. A vailable: http://arxiv .org/abs/1710.03748 [22] Z. Zhang, D. Zhang, Q. Zhang, W . Pan, and T . Hu, “Dacoop- a: Decentralized adaptive cooperative pursuit via attention, ” 2023. [Online]. A vailable: https://arxiv .org/abs/2310.15699 [23] “The betaflight open source flight controller firmware project. ” 2022. [Online]. A vailable: https://github.com/betaflight/betaflight
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment