Mixture-of-Depths Attention
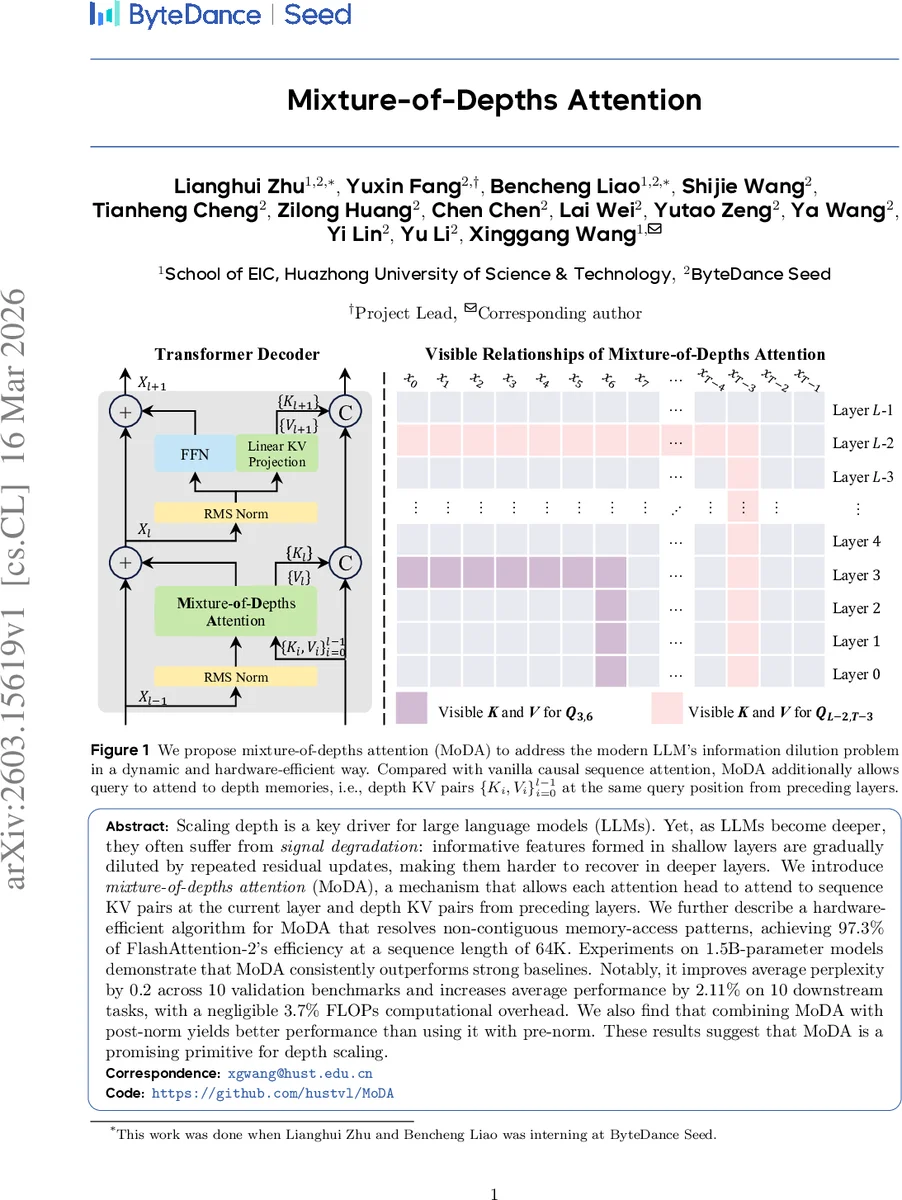
Scaling depth is a key driver for large language models (LLMs). Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2’s efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at https://github.com/hustvl/MoDA .
💡 Research Summary
The paper addresses a fundamental challenge in scaling large language models (LLMs) deeper: as depth increases, useful representations formed in early layers become progressively diluted by repeated residual additions, making them difficult to recover in later layers. To mitigate this “information dilution,” the authors propose Mixture‑of‑Depths Attention (MoDA), a unified attention mechanism that lets each head attend simultaneously to the current layer’s sequence key‑value (KV) pairs and to depth‑wise KV pairs stored from all preceding layers at the same token position.
Conceptually, the authors view a Transformer block as a three‑step pipeline—read, operate, write—along the depth dimension. Traditional residual connections only read the current hidden state and write back by addition, while dense cross‑layer connections read all previous hidden states and concatenate them, preserving information but incurring quadratic cost in depth. Depth‑attention, introduced as an intermediate design, reads historical KV pairs via attention, reducing cost to O(L·D²) but still requiring separate query projections for depth. MoDA builds on depth‑attention by merging depth‑wise and sequence‑wise attention into a single softmax operation, reusing the query projection of the standard sequence attention. Consequently, MoDA adds negligible parameter overhead (O(L·D²/G) where G is the group size in Grouped‑Query Attention) and maintains the same favorable FLOPs scaling as depth‑attention.
From a systems perspective, MoDA faces non‑contiguous memory access because depth KV tensors are stored across layers. The authors design a hardware‑aware kernel that partitions queries, keys, and values into blocks aligned with the group size, loads them from high‑bandwidth memory (HBM) into on‑chip SRAM, and computes the combined attention while sharing online softmax state across sequence and depth keys. This fused kernel achieves 97.3 % of FlashAttention‑2’s throughput at a 64 K token context length, demonstrating that depth‑aware aggregation can be integrated without sacrificing modern GPU efficiency.
Empirically, the authors train decoder‑only models of 700 M and 1.5 B parameters on the 400 B‑token OLMo2 recipe. In the 1.5 B setting, MoDA reduces average C4 validation loss by 0.2 points and improves average downstream task performance (including HellaSwag, WinoGrande, ARC‑Challenge) by 2.11 % relative to the strong open‑source baseline OLMo2. Notably, combining MoDA with post‑norm (instead of the more common pre‑norm) yields further gains, suggesting that MoDA stabilizes gradient flow through deeper stacks. Ablation studies confirm the importance of the unified softmax, the reuse of query projections, and the depth‑KV caching strategy. Scaling experiments show consistent benefits as model size and layer count increase, and attention visualizations reveal reduced “attention‑sink” behavior, indicating more balanced probability mass between sequence and depth information.
Limitations include the current focus on decoder‑only architectures; extending MoDA to encoder‑decoder or multimodal models remains future work. The depth‑KV cache introduces a modest memory overhead (≈3–4 % of total FLOPs), which is acceptable for the reported scales but may become a bottleneck for extremely deep or wide models. Potential extensions involve KV compression, adaptive depth‑KV selection, and validation on models with tens of billions of parameters.
In summary, Mixture‑of‑Depths Attention offers a principled, data‑dependent method for preserving and reusing historical layer information, achieves near‑state‑of‑the‑art hardware efficiency, and delivers measurable perplexity and downstream performance improvements. It positions itself as a promising primitive for depth scaling in next‑generation LLMs.
Comments & Academic Discussion
Loading comments...
Leave a Comment