DOS: Dependency-Oriented Sampler for Masked Diffusion Language Models
Masked diffusion language models (MDLMs) have recently emerged as a new paradigm in language modeling, offering flexible generation dynamics and enabling efficient parallel decoding. However, existing decoding strategies for pre-trained MDLMs predomi…
Authors: Xueyu Zhou, Yangrong Hu, Jian Huang
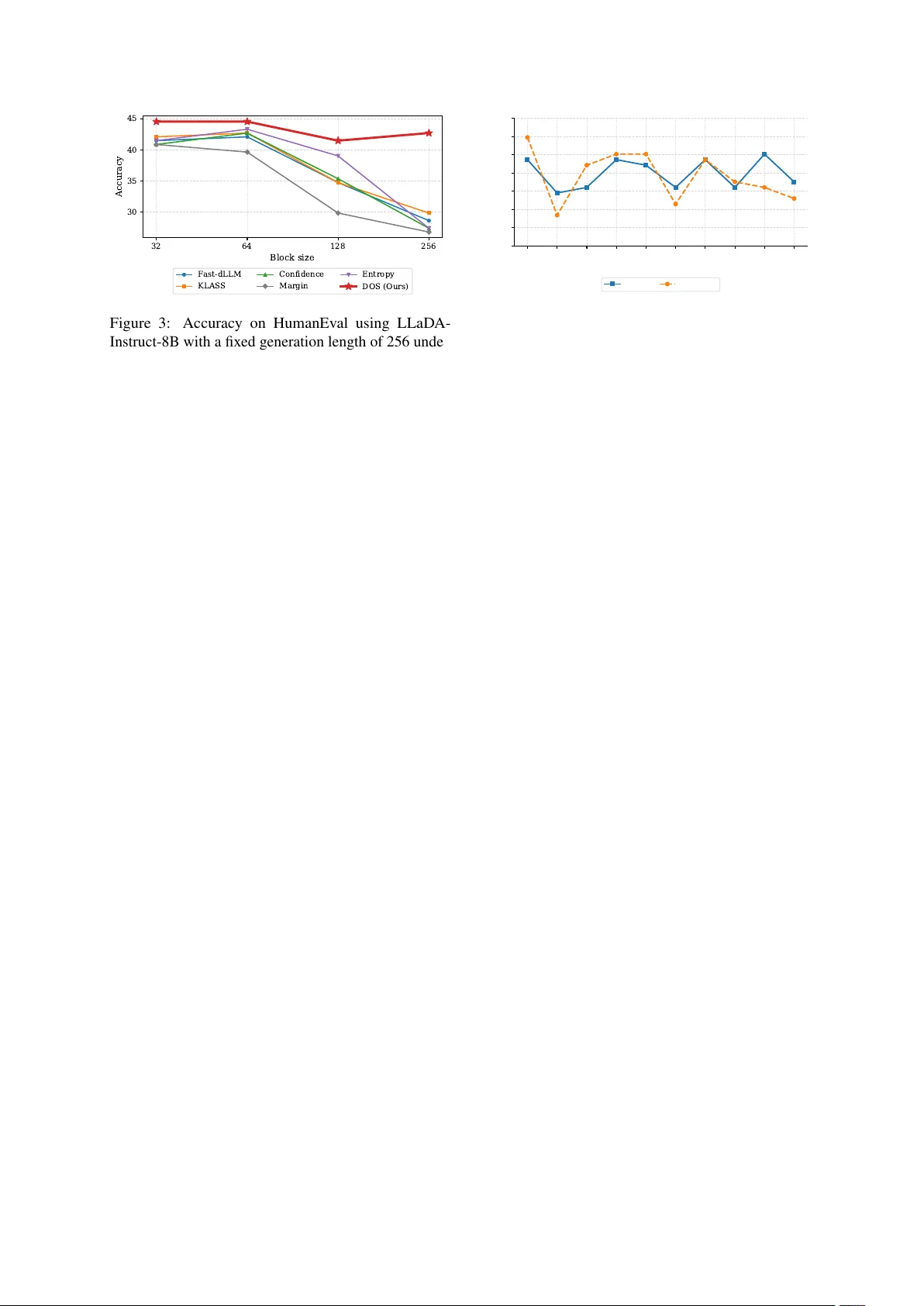
DOS: Dependency-Oriented Sampler f or Masked Diffusion Language Models Xueyu Zhou, Y angrong Hu, and Jian Huang Department of Data Science and AI The Hong K ong Polytechnic Uni versity , Hong K ong, China xue yu.zhou@connect.polyu.hk , yangr ong.hu@connect.polyu.hk , j.huang@polyu.edu.hk Abstract Masked dif fusion language models (MDLMs) hav e recently emerged as a ne w paradigm in language modeling, offering fle xible genera- tion dynamics and enabling ef ficient parallel decoding. Howe ver , existing decoding strate- gies for pre-trained MDLMs predominantly rely on token-le vel uncertainty criteria, while largely ov erlooking sequence-le vel information and inter-tok en dependencies. T o address this limitation, we propose D ependency- O riented S ampler (DOS), a training-free decoding strat- egy that le verages inter -token dependencies to inform token updates during generation. Specif- ically , DOS e xploits attention matrices from transformer blocks to approximate inter -token dependencies, emphasizing information from unmasked tokens when updating mask ed posi- tions. Empirical results demonstrate that DOS consistently achiev es superior performance on both code generation and mathematical reason- ing tasks. Moreov er , DOS can be seamlessly integrated with e xisting parallel sampling meth- ods, leading to improved generation ef ficiency without sacrificing generation quality . 1 Introduction Large language models (LLMs) ha ve achie ved re- markable progress in recent years, demonstrating strong performance in tasks such as code gener- ation and mathematical reasoning ( Achiam et al. , 2023 ; Grattafiori et al. , 2024 ; Guo et al. , 2025 ; Y ang et al. , 2025a ). Built upon transformer archi- tectures ( V aswani et al. , 2017 ), most existing LLMs are trained via next-tok en prediction and generate text in an autoregressi ve (AR) manner ( Radford et al. , 2018 , 2019 ; Bro wn et al. , 2020 ). Despite its strong ef fectiv eness, the AR paradigm inher- ently enforces a strict left-to-right generation order , which limits parallel decoding and constrains the flexibility of generation dynamics ( Xia et al. , 2024 ; Qin et al. , 2025 ; Li et al. , 2025 ). These limita- tions hav e moti vated the e xploration of alternativ e generation paradigms beyond AR modeling. Inspired by the success of dif fusion models in continuous domains ( Ho et al. , 2020 ; Nichol and Dhariwal , 2021 ; Jing et al. , 2022 ; Esser et al. , 2024 ), masked dif fusion language mod- els (MDLMs) hav e recently emerged as a ne w paradigm for text generation ( Austin et al. , 2021a ; Shi et al. , 2024 ; Sahoo et al. , 2024 ; Nie et al. , 2025 ; Y e et al. , 2025 ). MDLMs define a forward noising process that progressively masks tokens in a text sequence, and learn a re verse denoising process to reconstruct the original sequence by predicting its masked tok ens. Compared to AR models, MDLMs enable flexible generation orders and allo w tokens to be predicted in parallel at each denoising step. Some recent studies ( Arriola et al. , 2025 ; Y ang et al. , 2025b ; W ang et al. , 2025 ) further extend MDLMs to the block-wise diffusion model, where the sequence is partitioned into multiple blocks, striking a balance between auto-regressi ve models and dif fusion language models. T o further strengthen generation in pre-trained MDLMs, various decoding strategies have been proposed to restructure the decoding order of masked tokens ( Chang et al. , 2022 ; K oh et al. , 2024 ; Nie et al. , 2025 ; Kim et al. , 2025a ) and improve the ef ficiency of parallel decoding ( W u et al. , 2025 ; Kim et al. , 2025a ; Ben-Hamu et al. , 2025 ). For example, Kim et al. ( 2025a ) analyzes the influence of generation order in MDLMs and proposes a ne w inference strategy , leading to significant im- prov ements in generation quality . Although these methods hav e achiev ed remarkable results, several aspects of the decoding process remain underex- plored. A ke y limitation is that existing decoding strate- gies for MDLMs are primarily based on the output logits of MDLMs and le verage uncertainty-based criteria to guide token updates ( Chang et al. , 2022 ; K oh et al. , 2024 ; Kim et al. , 2025a ; Nie et al. , 2025 ). These criteria mainly focus on token-lev el uncer- 1 F ast-dLLM KLAS S Confidence DOS (Ours) 32 512 32 512 32 512 32 512 0 20 40 60 80 Accuracy (%) F ast-dLLM KLAS S Confidence DOS (Ours) Figure 1: Accuracy on GSM8K using LLaD A-Instruct- 8B ( Nie et al. , 2025 ) with a fixed generation length of 512 tokens. Block size 32 corresponds to block-wise decoding, while 512 represents the single-block set- ting. Existing methods (Fast-dLLM ( W u et al. , 2025 ), KLASS( Kim et al. , 2025b ), Confidence( Chang et al. , 2022 )) degrade under large block sizes, whereas DOS (ours) remains consistent and robust across both set- tings. tainty , while lacking an explicit mechanism to cap- ture sequence-le vel information, particularly inter- token dependencies. As a result, they may amplify the discrepancy between marginal token distribu- tions and the true joint distribution o ver sequences. In addition, some strategies introduce additional heuristic block structures that de viate from the orig- inal objectiv e of MDLMs, possibly inducing a mis- match between training and inference ( W u et al. , 2025 ; Kim et al. , 2025b ). When the imposed block partition is misaligned with the underlying depen- dency structure, it can disrupt the global or ganiza- tion of the sequence and make it dif ficult to gen- erate samples consistent with the target joint dis- tribution, leading to inconsistent and suboptimal generations. As sho wn in Figure 1 , it makes genera- tion sensitiv e to the choice of block size, potentially hindering its e xtension to the pure dif fusion setting. These observ ations highlight the need for decoding strategies that are independent of block structures and can explicitly model inter -token dependencies during generation. From this perspecti ve, we re visit the generation process of diffusion language models from a distri- butional perspecti ve and analyze the role of decod- ing order in recov ering the target joint distrib ution. Based on this analysis, we propose D ependency- O riented S ampler (DOS), a training-free decoding strategy that le verages scores deri ved from the at- tention matrix to guide token updates. Specifically , we e xploit the scaled dot-product attention weights, i.e., sof tmax ( QK ⊤ / √ d ) , as a proxy for inter- token dependenc y ( V aswani et al. , 2017 ) , and use them to induce a dependency-a ware decoding order . This attention-based scoring mechanism enables us to recov er dependencies between unmasked to- kens and masked tokens, f acilitating a dependency- aligned decoding order with respect to the token generation process. Since the attention matrix can be directly obtained from the transformer block in the forward pass, our proposed method does not re- quire any additional training or computational cost. Empirically , DOS achie ves high-quality generation in a single-block setting and still outperforms e xist- ing decoding strategies, e ven when those methods employ multiple decoding blocks. Moreov er , as a general criterion for decoding order , DOS can eas- ily integrate other accelerated sampling methods, improving sampling efficiency while preserving generation quality . 2 Related W orks Discrete Diffusion Language Models Early re- search into discrete diffusion generally falls into two paradigms: transition-based framew orks and score-based methods. D3PM ( Austin et al. , 2021a ) pioneered the adaptation of continuous diffusion concepts ( Ho et al. , 2020 ) to discrete state spaces via corruption processes defined by transition ma- trices. Extending this to continuous time, Campbell et al. ( 2022 ) utilized continuous-time Markov chain (CTMC) theory to formulate the forward-backward dynamics, deri ving a neg ativ e ELBO objecti ve in the continuous limit. Alternativ ely , inspired by the success of denoising score matching ( Song et al. , 2021 ), se veral works ha ve proposed discrete coun- terparts to the Stein score for modeling discrete data distributions ( Meng et al. , 2022 ; Lou et al. , 2024 ). More recently , the focus has shifted towards simplified MDLMs. Studies by Ou et al. ( 2025 ); Sa- hoo et al. ( 2024 ); Shi et al. ( 2024 ) demonstrate that simplified masking mechanisms can significantly enhance performance, ef fectiv ely bridging the gap between diffusion-based and AR models. T ran- sitioning from small-scale experiments to LLMs, recent works hav e begun to inv estigate the scal- ing laws of discrete dif fusion. LLaD A ( Nie et al. , 2025 ) scales the architecture up to 8 billion param- eters, sho wcasing impressi ve reasoning capabilities that were previously unseen in smaller discrete dif- fusion models like GPT -2 ( Radford et al. , 2019 ). Furthermore, Dream ( Y e et al. , 2025 ) introduces a nov el training paradigm by initializing diffusion models with pre-trained AR weights, thereby com- bining the strengths of both generativ e approaches. 2 Decoding Strategies The decoding strategy that determines the order and pace of token genera- tion is piv otal for the ef ficiency and quality of dif fusion language models. While standard ap- proaches like MDLM ( Sahoo et al. , 2024 ) typ- ically employ a stochastic unmasking schedule where masked tokens are updated randomly , this nai ve strategy is often suboptimal for comple x rea- soning tasks in large-scale models. T o address this, recent research focuses on uncertainty-aw are decoding. LLaD A ( Nie et al. , 2025 ) introduces a confidence-based criterion, prioritizing the un- masking of tokens with higher prediction confi- dence. Similarly , other works utilize entropy ( K oh et al. , 2024 ) or mar gin confidence ( Kim et al. , 2025a ) as metrics to determine the decoding or- der . Beyond token-le vel ordering, LLaD A also explores a semi-autoregressi ve block-wise strat- egy , where sequences are generated in parallel blocks; this method has pro ven particularly ef fec- ti ve for structured tasks like coding, significantly outperforming random ordering. Another critical line of research targets acceleration and dynamic scheduling. Instead of using a fix ed top- k selection, Fast-dLLM ( W u et al. , 2025 ) employs a flexible confidence threshold to adapti vely select multiple tokens per step. T o ensure generation stability , KLASS ( Kim et al. , 2025b ) introduces a metric to measure the stabilization between consecutiv e predictions. Furthermore, the EB-sampler ( Ben- Hamu et al. , 2025 ) theoretically deriv es an upper bound for multi-token prediction errors, utilizing this bound to dynamically optimize the number of unmasked tokens at each step, thereby achie ving a balance between speed and accuracy . 3 Preliminaries In this section, we re view the background and train- ing objecti ve of mask ed dif fusion language models, and summarize their forw ard noising and re verse- time generation processes. Let V = { 1 , . . . , V } denote a discrete vocab u- lary of size V , and let x 0 ∈ V L denote a sequence of length L , where x i 0 is the i -th token. T o model the masking process, the state space is extended by introducing a dedicated mask symbol [M] = V + 1 , resulting in an augmented vocab ulary of size V + 1 . Let δ a ∈ R V +1 denote the one-hot vector whose a -th coordinate equals 1. Masked diffusion language models can be for- mulated as a continuous-time masking (noising) process with factorized transitions q ( x t | x s ) = Q L i =1 q ( x i t | x i s ) for 0 ≤ s < t ≤ 1 , where q ( x i t | x i s ) = Cat x i t ; α t α s δ x i s + α s − α t α s δ [M] . For example, LLaD A ( Nie et al. , 2025 ) uses the linear schedule α t = 1 − t , so q ( x i t | x i 0 ) = Cat x i t ; (1 − t ) δ x i 0 + tδ [M] and the process reaches the fully masked state [M] L at t = 1 Conditioned on x 0 , the posterior q ( x s | x t , x 0 ) factorizes as Q L i =1 q ( x i s | x i t , x i 0 ) , with q ( x i s | x i t , x i 0 ) = ( Cat( x i s ; δ x i t ) , x i t = [M] , Cat x i s ; 1 − α s 1 − α t δ [M] + α s − α t 1 − α t δ x i 0 , x i t = [M] . Equation ( 3 ) ( Shi et al. , 2024 ; Sahoo et al. , 2024 ) suggests parameterizing the re verse-time transi- tions by substituting a learned predicted distribu- tion of x 0 into the analytic posterior: p θ ( x s | x t ) = q ( x s | x t , x 0 = f θ ( x t )) = L Y i =1 q ( x i s | x i t , x i 0 = f i θ ( x t )) , where f θ ( x t ) ∈ R L × ( V +1) and f i θ ( x t ) ∈ R V +1 is the model’ s output for the i -th token. f i θ ( x t ) satisfies P V j =1 f i,j θ ( x t ) = 1 and f i, [M] θ ( x t ) = 0 for all i . The training objective is to predict the masked states in each step with the x 0 , which can be simplified as : L ( θ ) = − E t, x 0 , x t h 1 t P L i =1 1 [ x i t = [M] ] log p θ ( x i 0 | x t ) i . By minimizing the training objectiv e, f θ can ap- proximate the conditional distribution of masked tokens gi ven x t . During inference, x i 0 is first pre- dicted from x t using f i θ ( x t ) . For masked states [M] , the predicted x i 0 is decoded with probability α s − α t 1 − α t , while the token remains masked with prob- ability 1 − α s 1 − α t . Unmasked states are kept unchanged. 4 Distributional Analysis of Parallel Decoding 4.1 Distributional Mismatch in Parallel Decoding As discussed abo ve, masked dif fusion models are trained to match marginal distributions by condi- tioning on some unmasked tokens. Howe ver , the ultimate goal of the generation is to reconstruct the target joint distrib ution. As illustrated by the toy example in Figure 2 , dif ferent parallel decoding strategies correspond to dif ferent factorizations of the joint distribution 3 C X 1 X 2 X 3 X 4 (a) p ( x 1 , x 2 , x 3 , x 4 | C ) = [ p ( x 1 | C ) p ( x 2 | C ) p ( x 3 | C ) p ( x 4 | C )] | {z } Step 1 ✘ (b) p ( x 1 , x 2 , x 3 , x 4 | C ) = p ( x 1 , x 3 | C ) p ( x 2 , x 4 | x 1 , x 3 , C ) = [ p ( x 1 | C ) p ( x 3 | C )] | {z } Step 1 ✘ [ p ( x 2 | x 1 , x 3 , C ) p ( x 4 | x 1 , x 3 , C )] | {z } Step 2 ✘ (c) p ( x 1 , x 2 , x 3 , x 4 | C ) = p ( x 2 , x 3 | C ) p ( x 1 , x 4 | x 2 , x 3 , C ) = [ p ( x 2 | C ) p ( x 3 | C )] | {z } Step 1 ✔ [ p ( x 1 | x 2 , x 3 , C ) p ( x 4 | x 2 , x 3 , C )] | {z } Step 2 ✘ (d) p ( x 1 , x 2 , x 3 , x 4 | C ) = p ( x 1 , x 2 | C ) p ( x 3 , x 4 | x 1 , x 2 , C ) = [ p ( x 1 | C ) p ( x 2 | C )] | {z } Step 1 ✔ [ p ( x 3 | x 1 , x 2 , C ) p ( x 4 | x 1 , x 2 , C )] | {z } Step 2 ✔ Figure 2: A toy example for parallel decoding in MDLMs, where C denotes the prompt or unmasked tokens and { X i } 4 i =1 are masked tokens. Different f actorizations of p ( X 1 , X 2 , X 3 , X 4 | C ) correspond to different parallel decoding orders. Only factorizations that respect the underlying dependenc y structure are able to recover the true joint distribution, while improper independence assumptions lead to distrib ution mismatch. p ( X 1 , X 2 , X 3 , X 4 | C ) . Formulation (a) predicts all tokens simultaneously and formulation (b) per - forms parallel decoding under an incorrect block- wise factorization, which induces an in v alid hier- archical dependency structure. Simply imposing a block-wise partition does not resolve this issue, as the block structure itself may still be misaligned with the true dependency structure. Under entrop y-constrained decoding ( Ben- Hamu et al. , 2025 ), masked tokens can be selected at each step by e xplicitly exploring conditional in- dependence among masked positions. In formu- lation (c), this strategy successfully identifies a subset of masked tok ens, such as X 2 and X 3 , that are conditionally independent given C . This en- ables an exact recov ery of their joint distribution p ( X 2 , X 3 | C ) in the first step. Howe ver , such con- ditionally independent subsets are not unique, and more importantly , the independence constraint is imposed only among masked tokens, while the de- pendency structure between the unmasked conte xt C and masked tok ens is not explicitly considered. As a result, although the joint distrib ution of the se- lected subset can be correctly recov ered locally , the ov erall factorization remains inconsistent with the true dependency structure, ultimately prev enting the recov ery of the target joint distrib ution. In contrast, formulation (d) induces a factoriza- tion that is consistent with the underlying structure by explicitly accounting for the dependencies be- tween the unmasked conte xt and masked tok ens. In the first step, mask ed tokens X 1 and X 2 , which are most strongly dependent on the a vailable context C , are prioritized for parallel decoding. Subsequently , the remaining tokens are decoded in parallel via conditioning on the newly unmasked ones. Un- der such a dependency-consistent f actorization, the target joint distrib ution can be correctly recovered through parallel decoding. 4.2 Uncertainty-Based Decoding Methods In this subsection, we revie w and formalize a class of decoding strate gies that rely on token-le vel un- certainty statistics computed from the model’ s out- put distrib utions. Denote the discrete distribution induced by the MDLM f θ at time t with input x t for position i as p i t = f i θ ( x t ) . Definition 1 (Confidence ) ( Chang et al. , 2022 ; Nie et al. , 2025 ) F or MDLM f θ at time t and position i , Confidence selects tokens based on the maximum value of the discrete distribution p i t over the vocab ulary V , defined as conf i t = max v ∈V p i t ( v ) . Definition 2 (Entropy ) ( K oh et al. , 2024 ) F or MDLM f θ at time t and position i , Entropy mea- sur es the uncertainty of the discrete distrib ution p i t over the vocab ulary V , defined as ent i t = − X v ∈V p i t ( v ) log p i t ( v ) . Definition 3 (Margin confidence) ( Kim et al. , 2025a ) F or MDLM f θ at time t 4 Algorithm 1 Attention-Based Dependency Scoring Input: Current sequence state X t +1 ∈ R L × V , MDLM f θ , transformer block index i , masked position set M Output: Dependency score dep ∈ R L 1: outputs ← f θ ( X t +1 ) 2: A ttn ( i ) ← outputs.attentions [ i ] ▷ Multi-head attention weights from the i -th transformer block, A ttn ( i ) ∈ R H × L × L 3: A ttn ← 1 H P H h =1 A ttn ( i ) h ▷ Head-a veraged attention matrix A ttn ∈ R L × L 4: dep ← 0 ∈ R L 5: U ← [ L ] \ M 6: for each m ∈ M do 7: dep ( m ) ← P u ∈U A ttn( m, u ) ▷ Depen- dency of mask ed position m on the unmasked context 8: end for 9: retur n Dependency score dep and position i , Margin confidence considers the differ ence between the highest and the second- highest pr obabilities in the discrete distrib ution p i t , defined as mar gin i t = p i t ( v ∗ ) − max v ∈V \{ v ∗ } p i t ( v ) , wher e v ∗ = arg max v ∈V p i t ( v ) . Despite their differences, these decoding strategies all rely on token-le vel statistics extracted from the output distribution at indi vidual positions. There- fore, they can ef fectiv ely identify confident or un- certain tokens locally and can reco ver mar ginal dis- tributions for each masked token. Howe ver , since methods do not explicitly account for dependen- cies across tokens, decoding strategies built upon them may fail to reconstruct the tar get joint distri- bution ov er the entire sequence. This observation suggests that effecti ve parallel decoding requires a principled strategy that goes beyond tok en-lev el uncertainty and selects tokens based on inter-token dependencies. 5 Methodology In this section, we propose D ependenc y O riented S ampler (DOS) for masked diffusion language models, which explicitly accounts for inter -token dependencies during generation. DOS focuses on the problem of which masked tokens should be decoded at each denoising step. Rather than determining the decoding order solely based on token-le vel uncertainty , our approach selects and updates masked tokens according to their depen- dency on the currently observed context. In this work, we le verage the scaled dot-product attention weights, which e xplicitly model ho w information is aggreg ated across tokens ( V aswani et al. , 2017 ; Clark et al. , 2019 ; V oita et al. , 2019 ; Raganato and T iedemann , 2018 ), as an operational proxy for inter-tok en dependency . Concretely , gi ven the attention matrix e xtracted from a transformer block, each ro w is interpreted as describing how a query token integrates infor- mation from other tokens in the sequence. For example, the entry at row i and column j of the attention matrix reflects how strongly the i -th to- ken depends on information provided by the j -th token during the forward pass. Since we focus on the information aggregated from unmasked tokens when predicting masked tokens, the dependency score for a masked token is defined as the total attention mass assigned to all unmasked tokens. Intuiti vely , a larger score indicates that the predic- tion at this masked position relies more heavily on the observed context, and should therefore be prioritized during decoding. Formally , let M denote the set of masked po- sitions and U = [ L ] \ M the set of unmasked positions. Giv en the multi-head attention weights softmax( QK ⊤ / √ d ) extracted from a transformer block, we av erage across heads to obtain a token- to-token attention matrix A ttn ∈ R L × L . For each masked position m ∈ M , the dependency score is defined as dep ( m ) = X u ∈U A ttn( m, u ) , which measures ho w strongly the prediction at po- sition m attends to the currently unmasked con- text. In contrast to uncertainty-based criteria that are computed independently for each position, the proposed score e xplicitly accounts for inter -token dependencies encoded in the attention structure. The complete attention-based dependency scoring procedure is summarized in Algorithm 1 . Based on these scores, DOS selects a subset of masked tokens with the highest scores to de- code at each step. The decoding order is explicitly dependency-a ware and better reflects the depen- dency structure encoded by the model. Since DOS provides a dependenc y score that ranks masked to- kens, it can be directly combined with existing par- 5 Models Methods HumanEval MBPP GSM8K MA TH500 LLaD A-Instruct-8B Confidence 27.44 22.80 31.69 21.40 Entropy 27.44 19.40 33.13 18.60 Margin 26.83 26.40 33.76 22.20 DOS 42.68 38.40 84.31 41.60 Dream-v0-Instruct-7B Confidence 28.66 39.60 31.08 13.60 Entropy 25.61 33.20 30.55 10.20 Margin 29.27 42.80 30.78 15.20 DOS 59.15 50.60 80.21 45.00 T able 1: Performance of dif ferent decoding strate gies under top-1 sampling, in which all methods generate the entire sequence within a single block. For the code benchmarks (HumanEval and MBPP), the generation length is fixed to 256 tokens, while for the math benchmarks (GSM8K and MA TH500), the generation length is 512 tokens. allel decoding methods, such as top-K selection or entropy-constrained decoding (e.g., EB-Sampler). 6 Experiments In this section, we present a comprehensiv e em- pirical ev aluation of our proposed DOS across a di verse set of benchmarks and compare it against representati ve baseline decoding strategies. 6.1 Datasets W e ev aluate DOS on a range of benchmarks cover - ing dif ferent forms of structured generation, includ- ing code generation and mathematical reasoning: • Code generation : HumanEval ( Chen , 2021 ) and MBPP ( Austin et al. , 2021b ), which consist of Python programming tasks with function-le vel specifications. • Mathematical reasoning : GSM8K ( Cobbe et al. , 2021 ), which contains arithmetic word problems of grade school that require multi- step numerical reasoning and MA TH500 ( Lightman et al. , 2023 ), which is a subset of the MA TH ( Hendrycks et al. , 2021 ) bench- mark and features more challenging problems. 6.2 Baselines W e compare DOS against the following baselines: • Uncertainty-based methods : selecting to- kens at each step based on uncertainty criteria, including confidence ( Chang et al. , 2022 ; Nie et al. , 2025 ), entropy ( K oh et al. , 2024 ), and margin confidence ( Kim et al. , 2025a ). • Entropy-Based (EB) Sampler ( Ben-Hamu et al. , 2025 ): selecting multiple tokens at each step under an entropy-constrained sampling scheme. EB-sampler can be easily integrated with other methods, such as confidence, en- tropy , margin confidence and our proposed method, by ranking tokens according to these criteria. • F ast-dLLM ( W u et al. , 2025 ): selecting mul- tiple tokens with confidence greater than a threshold at each step. • KLASS ( Kim et al. , 2025b ): selecting multi- ple tokens with thresholds on both confidence and token-le vel KL di ver gence, where the KL di ver gence measures the difference between the previous distribution and the current dis- tribution of the gi ven token. W e apply these methods to two open source MDLMs, including LLaD A-Instruct-8B ( Nie et al. , 2025 ) and Dream-v0-Instruct-7B ( Y e et al. , 2025 ). Both models are trained with the masked diffusion objecti ve, without utilizing block-wise masking structures. Further implementation details are pro- vided in Appendix A.2 and hyperparameters are provided in Appendix A.3 . 6.3 Main Result DOS significantly improv es performance under single-block decoding. W e first ev aluate DOS under a single-block decoding setting, where the entire sequence is generated within one diffusion block. As shown in T able 1 , DOS consistently outperforms uncertainty-based decoding strategies across all benchmarks and both MDLMs. In con- trast, confidence, entropy , and margin struggle to generate long sequences within a single block and exhibit de graded performance, particularly on 6 HumanEval MBPP GSM8K MA TH500 Models Methods Acc ↑ NFE ↓ Acc ↑ NFE ↓ Acc ↑ NFE ↓ Acc ↑ NFE ↓ LLaD A-Instruct-8B Fast-dLLM 28.66 83.26 23.00 78.93 33.06 195.46 20.80 219.54 KLASS 29.88 107.99 24.00 97.09 28.43 265.52 19.60 300.48 Confidence + EB 28.66 160.10 22.80 167.43 32.15 299.59 21.00 327.07 Entropy + EB 29.88 175.71 18.80 183.72 25.09 309.12 19.00 334.24 Margin + EB 26.22 159.58 26.60 166.00 38.51 293.45 21.40 324.10 DOS + EB 45.12 115.84 38.80 76.098 84.61 163.48 41.00 244.24 Dream-v0-Instruct-7B Fast-dLLM 28.66 141.62 39.60 127.69 31.08 205.52 13.60 273.58 KLASS 27.44 150.46 38.00 145.09 31.84 239.92 14.20 302.69 Confidence + EB 28.66 199.66 39.60 191.74 31.01 302.89 13.60 384.77 Entropy + EB 25.61 222.15 32.60 214.86 30.63 356.59 10.00 408.54 Margin + EB 29.27 183.25 41.20 177.73 30.86 297.96 15.40 377.15 DOS + EB 58.54 72.47 51.00 68.33 79.98 182.43 45.40 229.36 T able 2: Performance of dif ferent decoding strategies within a single block. EB stands for EB-sampler ( Ben-Hamu et al. , 2025 ), a parallel decoding method that can be combined with dif ferent scores. Acc denotes task accuracy , and NFE denotes the number of model forward ev aluations, reflecting decoding efficiency . For HumanEval and MBPP , the generation length is fixed to 256 tokens, while for GSM8K and MA TH500, the generation length is 512 tokens. mathematical reasoning tasks that require strict logical progression across extended generations. By explicitly le veraging inter-token dependencies, DOS can capture long-range dependencies that gov- ern reasoning structure and achiev e substantial per- formance gains, improving accurac y by large mar - gins on GSM8K and MA TH500. These results demonstrate that dependency-aw are token selec- tion is crucial for generating sequences consistent with the target joint distribution under single-block decoding. DOS integrates seamlessly with parallel decod- ing and impr oves efficiency without sacrificing accuracy . W e next ev aluate whether DOS can be combined with parallel decoding strategies to improv e efficienc y . Specifically , we integrate DOS with the EB sampler, which coordinates parallel updates among masked tok ens under entropy con- straints. As shown in T able 2 , DOS + EB consis- tently improves both accuracy and decoding ef- ficiency for LLaD A and Dream models. Com- pared with the results of EB sampler integrated with uncertainty-based methods, DOS not only im- prov es the accuracy across tasks b ut also achieves at least a 1.3 × speedup on the LLaD A model. Similar trends are observ ed for the Dream model. In addition, compared to alternativ e efficient de- coding baselines such as F ast-dLLM and KLASS, DOS + EB achiev es substantially higher accuracy while maintaining competitiv e decoding efficiency . These results indicate that DOS provides a comple- mentary , dependency-a ware signal that enhances existing parallel decoding methods. Method HumanEval MBPP GSM8K MA TH500 Confidence 40.85 38.20 82.56 38.80 Entropy 41.46 37.80 82.79 40.00 Margin 40.85 37.40 82.64 38.80 Fast-dLLM 41.46 38.80 83.40 39.60 KLASS 42.07 38.60 83.02 40.20 DOS (w/o block) 42.68 ( +0.61 ) 38.40 ( -0.40 ) 84.31 ( +0.91 ) 41.60 ( +1.40 ) DOS (w/ block) 44.51 ( +2.44 ) 38.80 ( +0.00 ) 84.61 ( +1.21 ) 42.40 ( +2.20 ) T able 3: Performance comparison on HumanEv al, MBPP , GSM8K, and MA TH500 using LLaD A-Instruct- 8B. All baseline methods (Confidence, Entropy , Mar gin, Fast-dLLM, and KLASS) adopt the block dif fusion with a fixed block size of 32. DOS (ours) is evaluated both without block partitioning (single-block) and with block partitioning (block size = 32). DOS consistently outperf orms block-based de- coding strategies with and without block parti- tioning. W e further ev aluate DOS against decod- ing strategies with block structures on the LLaD A model. All baseline methods employ block diffu- sion with a fixed block size of 32, whereas DOS is e valuated both with and without block partitioning. As shown in T able 3 , DOS consistently achieves superior performance across all benchmarks, e ven when block partitioning is removed. Although block partitioning improves the performance of ex- isting uncertainty-based decoding strategies, DOS consistently outperforms these methods under both block-based and single-block settings. Moreover , DOS maintains strong performance without rely- ing on block structures and further benefits when block dif fusion is introduced. These results demon- strate that explicitly modeling inter-token depen- dencies is more critical than the choice of block structure for achieving high-quality parallel decod- 7 32 64 128 256 Block size 30 35 40 45 Accuracy F ast-dLLM KLAS S Confidence Margin Entropy DOS (Ours) Figure 3: Accuracy on HumanEval using LLaD A- Instruct-8B with a fixed generation length of 256 under varying block sizes. Existing decoding strategies are sensitiv e to block size and degrade as the block size increases, whereas DOS (ours) demonstrates strong ro- bustness to block size variation and maintains superior consistency across all settings. ing. W e further conduct additional comparisons under block-based decoding with different configu- rations and details are presented in Appendix B . DOS is rob ust to block size and consistently out- perf orms uncertainty-based decoding. W e fur - ther in vestigate the sensiti vity of dif ferent decoding strategies to the choice of block size and the ac- curacy of various methods under different block sizes is reported in Figure 3 . Existing methods are sensiti ve to the block configuration and exhibit noticeable performance fluctuations as the block size increases. In contrast, DOS maintains con- sistently strong performance across a wide range of block sizes and consistently outperforms com- peting methods. These results indicate that DOS provides a more stable and rob ust decoding signal by explicitly modeling inter-token dependencies, making it less sensiti ve to the block configuration. Additional results on the Dream model are provided in Appendix B.2 Effect of T ransf ormer Layer Choice. W e fur- ther explore the role of layer depth in attention- based dependency scoring within the single-block setting. As illustrated in Figure 4 , the performance of DOS and DOS + EB on HumanEval remains ro- bust across the first 10 layers. This phenomenon suggests that the shallow layers can capture the syntactic structures required for ef fecti ve masked- token selection, which is consistent with prior stud- ies ( T enney et al. , 2019 ; Clark et al. , 2019 ; Jaw ahar et al. , 2019 ). Additional experiments are provided in Appendix B.3 . 1 2 3 4 5 6 7 8 9 10 Layer 0.32 0.34 0.36 0.38 0.40 0.42 0.44 0.46 Accuracy DOS DOS+EB Figure 4: Accuracy of DOS and DOS+EB on the HumanEval benchmark using the LLaD A-Instruct-8B model, where the x-axis indicates the transformer layer from which the attention matrix is extracted. 7 Conclusion In this work, we study the decoding process of masked diffusion language models from a dependency-a ware perspectiv e and sho w that ex- isting decoding strategies are limited by their re- liance on token-lev el uncertainty and their sensi- ti vity to heuristic block structures, both of which stem from a lack of explicit modeling of inter -token dependencies. T o address these limitations, we propose the Dependency-Oriented Sampler (DOS), a training-free decoding strategy that lev erages attention-deri ved dependenc y signals to guide the decoding order of masked tokens. By using the attention matrix as a proxy for inter - token dependencies, DOS updates tok ens that are better supported by the current unmasked conte xt, leading to a decoding process that is more aligned with the underlying joint distrib ution. Empirical re- sults on code generation and mathematical reason- ing benchmarks demonstrate that DOS consistently outperforms existing uncertainty-based decoding strategies. Notably , DOS can be seamlessly inte- grated with parallel sampling methods, improving generation ef ficiency without sacrificing quality . Our analysis highlights the importance of re- specting inter-tok en dependencies during sampling and suggests that the choice of decoding order plays a critical role in recovering the target joint distribution in masked dif fusion language models. W e hope this work encourages further inv estiga- tion into dependency-a ware decoding strategies and contributes to a deeper understanding of parallel generation dynamics in diffusion language models. 8 Limitations This work has sev eral limitations that suggest di- rections for future research. First, DOS relies on attention weights extracted from transformer blocks as a proxy for inter- token dependencies. While attention provides an effecti ve and readily av ailable signal for guid- ing decoding order , it does not necessarily corre- spond to explicit causal or structural dependencies among tokens. Some studies hav e explored in- corporating explicit dependency structures, such as directed acyclic graphs (D AGs), into language model training to better capture compositional and dependency-a ware generation dynamics ( Huang et al. , 2022 , 2023 ). Integrating such structured de- pendency representations into the decoding process, or combining them with attention-deri ved signals, may provide a more principled alternativ e and is an interesting direction for future work. Second, our current implementation extracts de- pendency scores from a single transformer layer with head-averaged attention. Although we ob- serve strong performance across dif ferent settings, this design does not fully exploit the hierarchical nature of representations in deep transformers. Ex- tending DOS to integrate information across multi- ple layers, or to selecti vely aggreg ate signals from dif ferent attention heads, could enable richer de- pendency modeling and further improv e decoding performance. Finally , our ev aluation focuses on structured generation tasks, including code generation and mathematical reasoning, where long-range depen- dencies play a critical role. The effecti veness of DOS in other generation settings, such as open- ended dialogue or multilingual generation, remains to be systematically inv estigated. Exploring how dependency-oriented decoding interacts with dif- ferent task characteristics is an important direction for future work. Ethics Statement This work focuses on inference-time decoding strategies for pre-trained masked diffusion lan- guage models. It does not in volve human subjects, data collection, or additional model training. All experiments are conducted on publicly av ailable benchmarks. The proposed method does not intro- duce ne w ethical risks beyond those inherent to the underlying language models. References Josh Achiam, Stev en Adler , Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 techni- cal report. arXiv preprint . Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Ji- aqi Han, Zhihan Y ang, Zhixuan Qi, Subham Sekhar Sahoo, and V olodymyr Kuleshov . 2025. Block dif- fusion: Interpolating between autoregressi ve and dif- fusion language models . In The Thirteenth Interna- tional Confer ence on Learning Repr esentations . Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel T arlow , and Rianne V an Den Berg. 2021a. Structured denoising diffusion models in discrete state-spaces. Advances in neural information pr ocessing systems , 34:17981–17993. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael T erry , Quoc Le, and 1 oth- ers. 2021b. Program synthesis with large language models. arXiv preprint . Heli Ben-Hamu, Itai Gat, Daniel Se vero, Niklas Nolte, and Brian Karrer . 2025. Accelerated sampling from masked diffusion models via entropy bounded un- masking . In The Thirty-ninth Annual Confer ence on Neural Information Pr ocessing Systems . T om Brown, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry , Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information pr ocessing systems , 33:1877–1901. Andrew Campbell, Joe Benton, V alentin De Bortoli, Thomas Rainforth, George Deligiannidis, and Ar- naud Doucet. 2022. A continuous time framework for discrete denoising models. Advances in Neural Information Pr ocessing Systems , 35:28266–28279. Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and W illiam T Freeman. 2022. Maskgit: Masked gen- erativ e image transformer . In Pr oceedings of the IEEE/CVF conference on computer vision and pat- tern r ecognition , pages 11315–11325. Mark Chen. 2021. Evaluating large language models trained on code. arXiv preprint . Ke vin Clark, Urvashi Khandelwal, Omer Levy , and Christopher D. Manning. 2019. What does bert look at? an analysis of bert’ s attention . In Pr oceedings of the 2019 EMNLP W orkshop BlackboxNLP: Analyz- ing and Interpr eting Neural Networks for NLP , pages 276–286. Karl Cobbe, V ineet Kosaraju, Mohammad Bav arian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry T worek, Jacob Hilton, Reiichiro Nakano, and 1 others. 2021. Training verifiers 9 to solve math word problems. arXiv preprint arXiv:2110.14168 . Patrick Esser , Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller , Harry Saini, Y am Levi, Do- minik Lorenz, Axel Sauer, Frederic Boesel, and 1 others. 2024. Scaling rectified flow transformers for high-resolution image synthesis. In F orty-first inter- national confer ence on machine learning . Aaron Grattafiori, Abhimanyu Dube y , Abhinav Jauhri, Abhinav Pande y , Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex V aughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint . Daya Guo, Dejian Y ang, Haowei Zhang, Junxiao Song, Peiyi W ang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Y u, Y u W u, Z. F . W u, Zhibin Gou, Zhihong Shao, Zhu- oshu Li, Ziyi Gao, Aixin Liu, and 175 others. 2025. Deepseek-r1 incenti vizes reasoning in llms through reinforcement learning . Natur e , 645(8081):633–638. Dan Hendrycks, Collin Burns, Saura v Kadav ath, Akul Arora, Stev en Basart, Eric T ang, Dawn Song, and Ja- cob Steinhardt. 2021. Measuring mathematical prob- lem solving with the math dataset. arXiv pr eprint arXiv:2103.03874 . Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. De- noising diffusion probabilistic models. Advances in neural information pr ocessing systems , 33:6840– 6851. Fei Huang, Pei K e, and Minlie Huang. 2023. Directed acyclic transformer pre-training for high-quality non- autoregressi ve text generation . T ransactions of the Association for Computational Linguistics , 11:941– 959. Fei Huang, Hao Zhou, Y ang Liu, Hang Li, and Minlie Huang. 2022. Directed acyclic transformer for non- autoregressi ve machine translation. In Proceedings of the 39th International Conference on Machine Learning, ICML 2022 . Ganesh Jawahar , Benoît Sagot, and Djamé Seddah. 2019. What does bert learn about the structure of language? In ACL 2019-57th Annual Meeting of the Association for Computational Linguistics . Bowen Jing, Gabriele Corso, Jeff rey Chang, Regina Barzilay , and T ommi Jaakkola. 2022. T orsional dif fu- sion for molecular conformer generation. Advances in neural information pr ocessing systems , 35:24240– 24253. Jaeyeon Kim, Kulin Shah, V asilis K ontonis, Sham M. Kakade, and Sitan Chen. 2025a. T rain for the worst, plan for the best: Understanding token ordering in masked diffusions . In F orty-second International Confer ence on Machine Learning . Seo Hyun Kim, Sunwoo Hong, Hojung Jung, Y oun- grok Park, and Se-Y oung Y un. 2025b. KLASS: KL- guided fast inference in masked diffusion models . In The Thirty-ninth Annual Conference on Neural Information Pr ocessing Systems . Hyukhun K oh, Minha Jhang, Dohyung Kim, Sangmook Lee, and K yomin Jung. 2024. Plm-based discrete dif- fusion language models with entropy-adapti ve gibbs sampling. arXiv e-prints , pages arXiv–2411. Jia-Nan Li, Jian Guan, W ei W u, and Chongxuan Li. 2025. Refusion: A dif fusion large language model with parallel autoregressi ve decoding. arXiv preprint arXiv:2512.13586 . Hunter Lightman, V ineet K osaraju, Y uri Burda, Harri- son Edwards, Bowen Baker , T eddy Lee, Jan Leike, John Schulman, Ilya Sutskev er , and Karl Cobbe. 2023. Let’ s verify step by step. In The T welfth Inter- national Confer ence on Learning Repr esentations . Aaron Lou, Chenlin Meng, and Stefano Ermon. 2024. Discrete diffusion modeling by estimating the ratios of the data distribution . In F orty-first International Confer ence on Machine Learning . Chenlin Meng, Kristy Choi, Jiaming Song, and Stefano Ermon. 2022. Concrete score matching: Generalized score matching for discrete data. Advances in Neural Information Pr ocessing Systems , 35:34532–34545. Alexander Quinn Nichol and Prafulla Dhariwal. 2021. Improv ed denoising diffusion probabilistic models. In International conference on machine learning , pages 8162–8171. PMLR. Shen Nie, Fengqi Zhu, Zebin Y ou, Xiaolu Zhang, Jingyang Ou, Jun Hu, JUN ZHOU, Y ankai Lin, Ji- Rong W en, and Chongxuan Li. 2025. Large language diffusion models . In The Thirty-ninth Annual Con- fer ence on Neural Information Pr ocessing Systems . Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Ji- acheng Sun, Zhenguo Li, and Chongxuan Li. 2025. Y our absorbing discrete diffusion secretly models the conditional distributions of clean data . In The Thir- teenth International Confer ence on Learning Repr e- sentations . T ian Qin, David Alvarez-Melis, Samy Jelassi, and Eran Malach. 2025. T o backtrack or not to back- track: When sequential search limits model reason- ing. arXiv preprint . Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutske ver , and 1 others. 2018. Improving language understanding by generativ e pre-training. Alec Radford, Jeffrey W u, Rew on Child, David Luan, Dario Amodei, Ilya Sutskev er , and 1 others. 2019. Language models are unsupervised multitask learn- ers. OpenAI blog , 1(8):9. 10 Alessandro Raganato and Jörg T iedemann. 2018. An analysis of encoder representations in transformer- based machine translation. In Pr oceedings of the 2018 EMNLP workshop BlackboxNLP: analyzing and interpr eting neural networks for NLP , pages 287– 297. Subham Sahoo, Marianne Arriola, Y air Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexan- der Rush, and V olodymyr Kuleshov . 2024. Simple and effecti ve masked diffusion language models. Ad- vances in Neural Information Pr ocessing Systems , 37:130136–130184. Jiaxin Shi, Kehang Han, Zhe W ang, Arnaud Doucet, and Michalis T itsias. 2024. Simplified and general- ized masked dif fusion for discrete data. Advances in neural information pr ocessing systems , 37:103131– 103167. Y ang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar , Stefano Ermon, and Ben Poole. 2021. Score-based generativ e modeling through stochastic differential equations . In International Confer ence on Learning Repr esentations . Ian T enney , Dipanjan Das, and Ellie P avlick. 2019. Bert rediscov ers the classical nlp pipeline. In Pr oceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 4593–4601. Ashish V aswani, Noam Shazeer, Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser , and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information pr ocessing systems , 30. Elena V oita, David T albot, Fedor Moiseev , Rico Sen- nrich, and Iv an T itov . 2019. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In 57th Annual Meeting of the Association for Computational Linguistics , pages 5797–5808. A CL Anthology . Xu W ang, Chenkai Xu, Y ijie Jin, Jiachun Jin, Hao Zhang, and Zhijie Deng. 2025. Diffusion llms can do faster -than-ar inference via discrete dif fusion forcing. arXiv pr eprint arXiv:2508.09192 . Chengyue W u, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. 2025. Fast-dllm: Training-free accelera- tion of diffusion llm by enabling kv cache and parallel decoding. arXiv preprint . Heming Xia, Zhe Y ang, Qingxiu Dong, Peiyi W ang, Y ongqi Li, T ao Ge, T ianyu Liu, W enjie Li, and Zhi- fang Sui. 2024. Unlocking efficienc y in large lan- guage model inference: A comprehensiv e surve y of speculative decoding . In F indings of the Asso- ciation for Computational Linguistics: ACL 2024 , pages 7655–7671, Bangkok, Thailand. Association for Computational Linguistics. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bo wen Y u, Chang Gao, Chengen Huang, Chenxu Lv , and 1 others. 2025a. Qwen3 technical report. arXiv preprint arXiv:2505.09388 . Y icun Y ang, Cong W ang, Shaobo W ang, Zichen W en, Biqing Qi, Hanlin Xu, and Linfeng Zhang. 2025b. Diffusion llm with native v ariable genera- tion lengths: Let [eos] lead the way . arXiv pr eprint arXiv:2510.24605 . Jiacheng Y e, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui W u, Xin Jiang, Zhenguo Li, and Lingpeng Kong. 2025. Dream 7b: Diffusion large language models. arXiv pr eprint arXiv:2508.15487 . 11 A ppendix A Experiment Details A.1 Experimental Setup W e conduct all experiments with LLaD A-Instruct- 8B ( Nie et al. , 2025 ) and Dream-v0-Instruct-7B ( Y e et al. , 2025 ). W e run inference with batch size of 1 on a single NVIDIA L40 GPU with 48 GB memory . For deterministic decoding, we set temperature to 0 and random seed to 42 for all runs. A.2 Baseline Methods This subsection provides implementation details of the key baseline methods used in our experi- ments, including uncertainty-based methods and accelerated samplers. Denote the discrete distrib u- tion induced by the MDLM f θ at time t with input x t for position i as p i t = f i θ ( x t ) . Confidence ( Chang et al. , 2022 ; Nie et al. , 2025 ) For MDLM f θ at time t and position i , Confidence selects tokens based on the maximum value of the discrete distrib ution p i t ov er the v ocabulary V , defined as conf i t = max v ∈V p i t ( v ) . Entropy ( K oh et al. , 2024 ) For MDLM f θ at time t and position i , Entropy measures the un- certainty of the discrete distribution p i t ov er the vocab ulary V , defined as ent i t = − X v ∈V p i t ( v ) log p i t ( v ) . Margin confidence ( Kim et al. , 2025a ) For MDLM f θ at time t and position i , Margin confi- dence considers the dif ference between the highest and the second-highest probabilities in the discrete distribution p i t „ defined as mar gin i t = p i t ( v ∗ ) − max v ∈V \{ v ∗ } p i t ( v ) , where v ∗ = arg max v ∈V p i t ( v ) . F ast-dLLM Fast-dLLM performs confidence- based parallel decoding by unmasking all positions whose confidence exceeds a confidence threshold ϵ . Concretely , at each step t , let M t denote the set of masked positions. It computes the confidence score conf i t and masks the subset of positions S t = i ∈ M t conf i t = max v ∈V p i t ( v ) > ϵ . Compared to fixed-b udget top- K unmasking, this approach yields a dynamic number of updates per iteration and can be integrated with semi- autoregressi ve block decoding for enhanced effi- ciency . Furthermore, while Fast-dLLM supports block-wise KV cache to eliminate redundant com- putations of key and v alue vectors across previ- ous blocks, our ev aluation focuses on decoding strategy rather than hardware-specific wall-clock speed; consequently , we do not utilize block-wise KV cache in our experiments. KLASS. KLASS performs stable-token selection by identifying positions where the predictiv e dis- tribution is stable across steps and reaches high confidence. At each step t , let M t denote the set of masked positions. KLASS selects a subset of stable tokens S t ⊆ M t to be unmasked based on a history length n , a KL-div ergence threshold ϵ KL , and a confidence threshold τ : S t = n i ∈ M t ∀ k ∈ { 1 , . . . , n } , D KL ( p i t − k ∥ p i t − k +1 ) < ϵ KL ∧ conf i t > τ o , where D KL denotes the Kullback-Leibler diver - gence between the predictive distributions of consecuti ve steps at position i , and conf i t = max v ∈V p i t ( v ) is the confidence score. By requir- ing predictions to remain consistent over n steps, KLASS ensures that only stable tok ens are updated in parallel, thereby impro ving generation reliabil- ity . EB-Sampler . The entropy-bounded sampler ac- celerates generation by unmasking a number of tokens per step that satisfy the entropy constraint. Concretely , at each step t , it first ranks all masked positions in M t based on a specific score like confi- dence conf or our proposed dependenc y dep . Then, starting from the highest-ranked token, it selects the largest subset S t ⊆ M t that satisfies the cumu- lati ve entropy constraint: X i ∈S t ent i t − max j ∈S t ent j t ≤ γ , where ent i t = − P v ∈V p i t ( v ) log p i t ( v ) denotes the entropy of the predicti ve distrib ution at position i . A.3 Hyperparameter Choices W e follow prior work whene ver the recommended settings are a vailable, and otherwise tune on a small held-out subset. The main hyperparameters for accelerated baselines are: 12 • EB-Sampler : W e set the entropy tolerance to γ = 0 . 01 for all datasets. • F ast-dLLM : W e set the confidence threshold to ϵ = 0 . 95 for all datasets. • KLASS : W e follow the threshold configu- rations in prior work ( Kim et al. , 2025b ). KLASS uses two thresholds: a confidence threshold (Conf) and a KL-based threshold (KL). The history length n is set to 2 for all datasets. W e report the e xact values used for each dataset and model in T able 4 . • DOS : W e report the optimal layer for DOS and DOS + EB in T able 5 . Entries indicate the transformer layer indices from which the attention matrices are extracted to achiev e the best accuracy under each setting. T ask LLaD A Dream Conf KL Conf KL MA TH 0.6 0.010 0.9 0.005 GSM8K 0.6 0.015 0.9 0.001 HumanEv al 0.9 0.010 0.8 0.001 MBPP 0.7 0.010 0.9 0.001 T able 4: Threshold configurations for KLASS. B Additional Experiment Results B.1 Experiments on LLaD A T able 6 presents the comparativ e results on Hu- manEv al, MBPP , GSM8K, and MA TH500 using the LLaD A-Instruct-8B model with a fixed block size of 32. DOS consistently demonstrates superior generation quality across both T op-1 and parallel sampling settings, proving ef fectiv e regardless of whether block partitioning is applied. Specifically , in the T op-1 regime, DOS achie ves the highest accuracy on all four benchmarks, significantly out- performing standard scoring methods such as Con- fidence and Entrop y . Furthermore, when integrated with the EB-sampler for parallel decoding, DOS maintains this performance adv antage, validating the robustness of our scoring strategy in guiding the model to ward high-quality outputs. In terms of computational efficienc y , F ast-dLLM exhibits a substantial reduction in the number of function ev aluations (NFE), achieving the lo w- est inference cost across tasks. This ef ficiency is HumanEval MBPP GSM8K MA TH500 LLaDA-Instruct-8B DOS (w/o block) 13 9 7 7 DOS (w/ block) 13 9 16 30 DOS + EB (w/o block) 29 5 4 3 DOS + EB (w/ block) 13 1 1 7 Dream-vo-Instruct-7B DOS (w/o block) 1 22 6 7 DOS(w/ block) 6 6 6 7 DOS + EB (w/o block) 6 22 3 3 DOS + EB (w/ block) 6 26 3 1 T able 5: T ransformer layers that yield the best perfor- mance for DOS under different settings. For DOS , w/o block corresponds to single-block decoding where the block length equals the generation length, while w/ block applies block partitioning with a fixed block size of 32. largely attributed to its threshold-based mechanism. Ho wev er , this speed comes with a slight trade-off in accuracy compared to our method. Consequently , a promising av enue for future work is to synergize the precise scoring capability of DOS with dynamic threshold-based strategies similar to Fast-dLLM. Such an integration could potentially yield a more optimal generation process, maintaining the high accuracy of DOS while significantly accelerating inference. B.2 Experiments on Dream T able 7 presents the performance of the Dream- v0-Instruct-7B model across four datasets using both T op-1 and parallel sampling strategies with a fixed block size of 32. Consistent with our pre vious observ ations, the proposed DOS method demon- strates superior performance on the majority of tasks with and without block partitioning, partic- ularly excelling in code generation and complex mathematical reasoning. In the T op-1 setting, DOS (w/ block) achie ves the highest accuracy on Hu- manEv al and MA TH500, significantly outperform- ing standard baselines like Confidence and Entropy . This adv antage extends to the parallel sampling set- ting, where DOS combined with the EB-sampler attains 45.40% accuracy on MA TH500, surpass- ing robust competitors such as KLASS and Fast- dLLM. While DOS remains highly competitiv e ov er- all, we observe a slight performance gap on the GSM8K benchmark compared to KLASS and uncertainty-based methods, suggesting that our scoring mechanism could be further refined for specific arithmetic reasoning patterns. Further - more, we note that Fast-dLLM achieves the low- est NFE, demonstrating impressi ve inference ef fi- ciency , while KLASS shows strong adaptability on 13 HumanEval MBPP GSM8K MA TH500 Methods Acc ↑ NFE ↓ Acc ↑ NFE ↓ Acc ↑ NFE ↓ Acc ↑ NFE ↓ T op-1 Confidence 40.85 256.00 38.20 256.00 82.56 512.00 38.80 512.00 Entropy 41.46 256.00 37.80 256.00 82.79 512.00 40.00 512.00 Margin 40.85 256.00 37.40 256.00 82.64 512.00 38.80 512.00 DOS (w/o block) 42.68 256.00 38.40 256.00 84.31 512.00 41.60 512.00 DOS (w/ block) 44.51 256.00 38.80 256.00 84.61 512.00 42.40 512.00 Parallel Fast-dLLM 41.46 77.54 38.80 54.12 83.40 120.56 39.60 176.07 KLASS 42.07 103.06 38.60 74.18 83.02 178.26 40.20 252.47 Confidence + EB 41.46 104.28 38.60 73.39 82.71 165.33 39.20 249.76 Entropy + EB 42.68 107.88 37.00 77.88 82.64 176.26 38.60 265.76 Margin + EB 40.24 102.44 38.80 71.31 82.49 161.24 37.80 243.58 DOS + EB (w/o block) 45.12 115.84 38.80 76.09 84.61 163.48 41.00 244.24 DOS + EB (w/ block) 43.90 103.05 39.00 80.90 84.00 170.06 41.40 257.55 T able 6: Additional results through top-1 sampling and parallel sampling on HumanEval, MBPP , GSM8K, and MA TH500 using LLaDA-Instruct-8B model ( Nie et al. , 2025 ) with a fixed block size of 32. EB denotes the EB-sampler ( Ben-Hamu et al. , 2025 ), a parallel decoding method that can be combined with different scoring strategies. Acc denotes task accuracy , and NFE denotes the number of model forward e valuations. For HumanEval and MBPP , the generation length is fixed to 256 tokens, while for GSM8K and MA TH500, the generation length is 512 tokens. For DOS , w/o bloc k corresponds to single-block decoding, where the block length equals the generation length, while w/ block applies block partitioning with block size 32. 32 64 128 256 Block size 30 40 50 60 Accuracy F ast-dLLM KLAS S Confidence Margin Entropy DOS (Ours) Figure 5: Accuracy on HumanEval using Dream-v0- Instruct-7B with a fixed generation length of 256 under varying block sizes. Existing decoding strategies are sensitiv e to block size and degrade as the block size increases, whereas DOS (ours) demonstrates strong ro- bustness to block size variation and maintains superior consistency across all settings. MBPP; these baselines offer v aluable insights into ef ficiency optimization and task-specific selection, pointing tow ard promising directions for further enhancing the DOS frame work in future work. Figure 5 sho ws the performance of different de- coding strategies under v arying block sizes on the Dream model. Consistent with the main results, existing uncertainty-based methods e xhibit notice- able performance degradation as the block size in- creases. In contrast, DOS maintains stable perfor- mance across a wide range of block sizes and con- sistently outperforms competing methods. These results further confirm the robustness of DOS to block size choices. B.3 Perf ormance with a Fixed Attention Layer T o examine whether DOS critically relies on care- ful attention-layer selection, we conduct an addi- tional experiment in which the attention matrices are fixed to the first transformer layer across all settings. The results are summarized in T able 8 . Across both LLaD A-Instruct-8B and Dream-v0- Instruct-7B, DOS with the first-layer attention con- sistently achie ves performance comparable to the corresponding baselines under all dif ferent settings. This observation holds for both top-1 sampling and parallel decoding with EB-sampler . With a fixed early-layer attention signal, the proposed dependency-oriented scoring remains suf ficient to guide decoding, demonstrating the rob ustness and practical applicability of DOS. 14 HumanEval MBPP GSM8K MA TH500 Methods Acc ↑ NFE ↓ Acc ↑ NFE ↓ Acc ↑ NFE ↓ Acc ↑ NFE ↓ T op-1 Confidence 58.54 256.00 50.02 256.00 81.50 512.00 40.08 512.00 Entropy 57.32 256.00 50.80 256.00 83.93 512.00 42.20 512.00 Margin 56.71 256.00 50.40 256.00 81.05 512.00 41.80 512.00 DOS (w/o block) 59.15 256.00 50.60 256.00 80.21 512.00 45.00 512.00 DOS (w/ block) 61.59 256.00 50.20 256.00 80.29 512.00 45.00 512.00 Parallel Fast-dLLM 58.54 62.68 50.20 50.04 81.50 134.17 39.80 154.46 KLASS 59.15 78.11 52.20 72.69 84.08 200.85 43.40 277.11 Confidence + EB 57.93 78.86 50.20 71.90 81.96 182.38 39.80 227.54 Entropy + EB 56.10 88.29 50.20 73.00 83.17 192.83 44.20 239.13 Margin + EB 56.10 80.34 50.20 66.90 81.20 179.19 39.40 226.74 DOS + EB (w/o block) 58.54 72.47 51.00 68.33 79.98 182.43 45.40 229.36 DOS + EB (w/ block) 60.37 77.07 50.60 71.88 79.83 190.20 45.00 236.81 T able 7: Additional results through top-1 sampling and parallel sampling on HumanEval, MBPP , GSM8K, and MA TH500 using Dream-v0-Instruct-7B model ( Y e et al. , 2025 ) with a fixed block size of 32. EB denotes the EB-sampler ( Ben-Hamu et al. , 2025 ), a parallel decoding method that can be combined with different scoring strategies. Acc denotes task accuracy , and NFE denotes the number of model forward e valuations. For HumanEval and MBPP , the generation length is fixed to 256 tokens, while for GSM8K and MA TH500, the generation length is 512 tokens. For DOS , w/o bloc k corresponds to single-block decoding, where the block length equals the generation length, while w/ block applies block partitioning with block size 32. HumanEval MBPP GSM8K MA TH500 Methods Acc ↑ NFE ↓ Acc ↑ NFE ↓ Acc ↑ NFE ↓ Acc ↑ NFE ↓ LLaD A-Instruct-8B DOS (w/o block) 41.46 256.00 38.20 256.00 84.23 512.00 41.00 512.00 DOS (w/ block) 42.07 256.00 37.80 256.00 84.23 512.00 40.40 512.00 DOS + EB (w/o block) 43.90 104.93 38.60 76.34 83.55 164.26 39.60 258.37 DOS + EB (w/ block) 40.85 107.11 39.00 80.90 84.00 170.06 40.60 260.90 Dream-vo-Instruct-7B DOS (w/o block) 59.15 256.00 49.80 256.00 79.53 512.00 44.20 512.00 DOS (w/ block) 59.15 256.00 49.80 256.00 79.53 512.00 44.20 512.00 DOS + EB (w/o block) 57.32 75.49 50.00 69.05 79.83 181.63 44.80 230.09 DOS + EB (w/ block) 57.32 79.44 50.00 73.34 79.83 190.81 45.00 236.81 T able 8: Results of DOS and DOS + EB with attention matrices extracted from the first transformer layer . Experi- ments are conducted on LLaD A-Instruct-8B and Dream-v0-Instruct-7B under both single-block and block-based decoding settings. For HumanEv al and MBPP , the generation length is fixed to 256 tokens, while for GSM8K and MA TH500, the generation length is 512 tokens. DOS w/o block denotes single-block decoding where the block length equals the generation length, while DOS w/ bloc k applies block partitioning with a fixed block size of 32. Acc denotes task accuracy , and NFE denotes the number of model forward ev aluations, reflecting decoding ef ficiency . 15 HumanEval MBPP GSM8K MA TH500 Methods Acc ↑ NFE ↓ TPS ↑ T ime ↓ Acc ↑ NFE ↓ TPS ↑ Time ↓ Acc ↑ NFE ↓ TPS ↑ T ime ↓ Acc ↑ NFE ↓ TPS ↑ T ime ↓ T op-1 Confidence 40.85 256.00 4.22 32.40 38.20 256.00 5.07 20.21 82.56 512.00 4.96 66.22 38.80 512.00 6.46 67.59 Entropy 41.46 256.00 4.28 33.07 37.80 256.00 5.04 20.62 82.79 512.00 4.78 68.37 40.00 512.00 6.28 69.57 Margin 40.85 256.00 4.07 33.10 37.40 256.00 4.84 20.56 82.64 512.00 4.78 68.01 38.80 512.00 6.34 69.35 DOS (w/o block) 42.68 256.00 4.71 32.18 38.40 256.00 5.76 19.84 84.31 512.00 5.00 65.47 41.60 512.00 6.56 66.85 DOS (w/ block) 44.51 256.00 4.78 32.26 38.80 256.00 5.78 19.87 84.61 512.00 4.88 65.39 42.40 512.00 6.60 66.72 Parallel Fast-dLLM 41.46 77.54 13.68 10.00 38.80 54.12 24.19 4.32 83.40 120.56 21.01 15.85 39.60 176.07 19.59 23.62 KLASS 42.07 103.06 8.79 15.51 38.60 74.18 15.66 6.53 83.02 178.26 12.58 26.23 40.20 252.47 11.91 37.94 Saber 43.29 67.15 17.32 8.49 36.60 53.71 26.20 4.19 82.64 123.35 20.81 15.79 40.00 176.03 19.80 23.01 WINO 40.85 124.73 7.84 18.03 38.60 94.01 12.50 8.22 77.33 312.18 7.29 43.91 26.80 363.71 8.52 51.50 Confidence + EB 41.46 104.28 10.28 13.42 38.60 73.39 18.24 5.71 82.71 165.33 15.66 21.24 39.20 249.76 13.90 32.80 Entropy + EB 42.68 107.88 10.33 14.12 37.00 77.88 17.40 6.12 82.64 176.26 14.65 22.73 38.60 265.76 13.01 34.94 Margin + EB 40.24 102.44 10.26 13.29 38.80 71.31 18.16 5.61 82.49 161.24 15.87 20.81 37.80 243.58 14.12 32.12 DOS + EB (w/o block) 45.12 115.84 11.38 15.02 38.80 76.09 18.20 6.14 84.61 163.48 15.99 21.17 41.00 244.24 14.32 32.35 DOS + EB (w/ block) 43.90 103.05 12.25 13.39 39.00 80.90 17.16 6.35 84.00 170.06 15.36 21.74 41.40 257.55 13.63 33.49 T able 9: Additional results through top-1 sampling and parallel sampling on HumanEval, MBPP , GSM8K, and MA TH500 using LLaDA-Instruct-8B model ( Nie et al. , 2025 ) with a fixed block size of 32. EB denotes the EB-sampler ( Ben-Hamu et al. , 2025 ), a parallel decoding method that can be combined with different scoring strategies. Acc denotes task accuracy , and NFE denotes the number of model forward e valuations. For HumanEval and MBPP , the generation length is fixed to 256 tokens, while for GSM8K and MA TH500, the generation length is 512 tokens. For DOS , w/o bloc k corresponds to single-block decoding, where the block length equals the generation length, while w/ block applies block partitioning with block size 32. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment