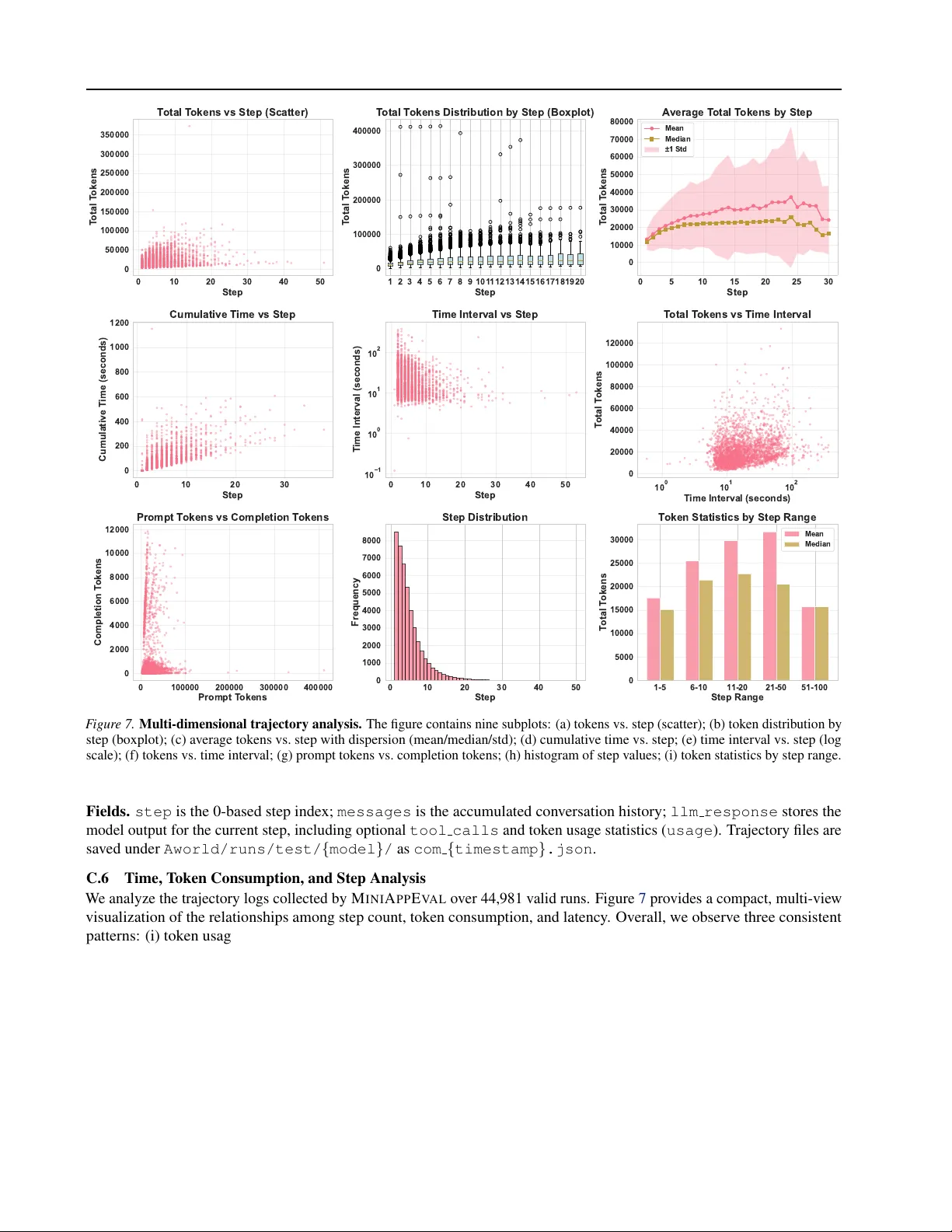
MiniAppBench: Evaluating the Shift from Text to Interactive HTML Responses in LLM-Powered Assistants
With the rapid advancement of Large Language Models (LLMs) in code generation, human-AI interaction is evolving from static text responses to dynamic, interactive HTML-based applications, which we term MiniApps. These applications require models to n…
Authors: Zuhao Zhang, Chengyue Yu, Yuante Li
M I N I A P P B E N C H : Evaluating the Shift fr om T ext to Interactiv e HTML Responses in LLM-Po wered Assistants Zuhao Zhang 1 2 * Chengyue Y u 1 * Y uante Li 3 Chenyi Zhuang 1 † Linjian Mo 1 Shuai Li 2 1 Inclusion AI, Ant Group 2 Shanghai Jiao T ong University 3 Carnegie Mellon Uni versity ¹ MiniAppBench Leaderboard Abstract W ith the rapid advancement of Large Language Models (LLMs) in code generation, human-AI in- teraction is ev olving from static text responses to dynamic, interactiv e HTML-based applica- tions, which we term M I N I A P P S . These ap- plications require models to not only render vi- sual interfaces but also construct customized in- teraction logic that adheres to real-world princi- ples. Howe ver , existing benchmarks primarily focus on algorithmic correctness or static lay- out reconstruction, failing to capture the capa- bilities required for this new paradigm. T o ad- dress this gap, we introduce M I N I A P P B E N C H , the first comprehensi ve benchmark designed to ev aluate principle-dri ven, interacti ve application generation. Sourced from a real-world applica- tion with 10M+ generations, M I N I A P P B E N C H distills 500 tasks across six domains (e.g., Games, Science, and T ools). Furthermore, to tackle the challenge of e valuating open-ended interactions where no single ground truth exists, we propose M I N I A P P E V A L , an agentic ev aluation frame- work. Lev eraging browser automation, it per- forms human-like exploratory testing to systemat- ically assess applications across three dimensions: Intention, Static, and Dynamic. Our experiments rev eal that current LLMs still face significant challenges in generating high-quality M I N I A P P S , while M I N I A P P E V A L demonstrates high align- ment with human judgment, establishing a reli- able standard for future research. Our code is av ailable in github .com/MiniAppBench . 1 Introduction W ith the rapid adv ancement of Large Language Mod- els (LLMs) in code generation ( Novik ov et al. , 2025 ; Li et al. , 2025c ; Xia et al. , 2025 ), models are evolving to Autonomous Architects capable of constructing complete software solutions. In this emerging landscape, * Equal contribution. † Corresponding author . Text -based W h a t a r e N e w t o n ' s l a w s ? N e w t o n ' s l a w s a r e p h y s i c s l a w s t h a t . . . . . . Intuitive W h a t a r e N e w t o n ' s l a w s ? H e l p m e r e c o r d m y d i e t . S o r r y , a s a c h a t b o t I c a n n o t . . . . . . H e l p m e r e c o r d m y d i e t . MiniApp Not Intuitive Scene1 · Customized · Interactive · Principle Adhering Some tasks can't be solved by text Scene2 F igur e 1. The shift from text to M I N I A P P S . Unlike static text, M I N I A P P S transforms abstract e xplanations into intuitiv e visual- izations and unlocks actionable tasks (e.g., diet tracking) that were previously impossible. code transcends its role as a mere intermediate symbolic rep- resentation; it becomes a direct executable medium through which a model’ s internal kno wledge is externalized into dy- namic, user-f acing artifacts. This transformation facilitates a paradigm shift in human-LLM interaction (as illustrated in Figure 1 ), moving from static text-only responses to rich, code-based engagements. Users now e xpect LLMs to pro- duce interacti ve visualizations or functional applications that embody real-world logic. Consequently , to ensure these in- teractions feel natural and seamless, the model must acti vely capture and construct implicit assumptions or principles, such as “an object in free fall follows Ne wton’ s laws” or “a week has sev en days”, which, while often taken for granted in human communication, are essential for valid e xecution. Real-world cases are sho wn in Figure 2 . W e argue that the web provides a particularly ef fectiv e sub- strate for realizing such interactions. In this context, HTML represents world states and structural relationships, CSS determines perceptual salience, and JavaScript encodes causal dependencies, temporal ev olution, and interaction logic—together forming an executable w orld model. More- ov er , its interactivity adds an additional layer of depth to this interaction. 1 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P ower ed Assistants Eval-Ref: ...... Strictly Simulatethe moleculardynamics process oftheprocess...... Eval-Result: ......Theevaporationmechanism forcibly removes top-layerparticles,ratherthan allowingtheparticlestonaturallydiffuse ...... Eval-Ref: ......Uponcompletingthe 7-day cycle ...... Eval-Result: ......Thesimulationwill endearly ,after 5daysinsteadof7days ....... Q : C h o i c e S i m u l a t o r f o r O N E W E E K Q: ChoiceSimulatorfor ONEWEEK Q : S i m u l a t e d e v a p o r a t i o n p r o c e s s Q:Simulated evaporationprocess Notadheringtothe Commonsense Notadheringtothe ScientificLaws F igur e 2. Failure Cases in Principle Adherence. M I N I A P P S require models to capture and instantiate rele vant real-world prin- ciples, while M I N I A P P E V A L proves effecti ve due to its multi- component system design (ev al-ref, code, playwright). From this perspective, we posit that r endered HTML r e- sponses will emerge as a new form of human–LLM inter- action, which we term M I N I A P P S . Unlike traditional web pages, which primarily focus on static content display or predefined CR UD (Create, Read, Update, and Delete) work- flows, M I N I A P P S are characterized by two core properties: ❶ Fidelity to Real-W orld Principles , where the model must capture and construct the implicit principles embed- ded in the user’ s query; and ❷ Customized Interaction , where application structure and behavior are dynamically synthesized to match user intent, rather than being instanti- ated from fixed templates. Howe ver , current benchmarks remain tethered to the static past, failing to capture this shift. Traditional code benchmarks like MBPP ( Austin et al. , 2021 ) and Hu- manEval ( Chen , 2021 ) focus on algorithmic syntax, treating code as abstract logic di vorced from ex ecution conte xt. Con- versely , web generation benchmarks ( Sun et al. , 2025 ; Lu et al. , 2025 ; Xu et al. , 2025 ) prioritize visual fidelity or static layout reconstruction. This creates a critical blind spot: existing metrics are unable to verify whether LLMs truly capture and construct the underlying real-world princi- ples implied by user queries. In practice, achieving these properties is non-trivial. As shown in Figure 2 , an artifact may be syntactically valid and successfully executable , b ut still fail to support high-fidelity , non-fragmented interaction aligned with real user reasoning. T o bridge this gap, we introduce M I N I A P P B E N C H , the first benchmark designed specifically to e valuate the abil- ity of LLMs to generate M I N I A P P S . The comparison with other benchmarks is provided in the Appendix A . M I N I A P P B E N C H is constructed through a rigorous multi- stage pipeline that distills tens of millions of real-world user queries into a balanced set of principle-dri ven, interaction- intensiv e tasks. Evaluating M I N I A P P S also poses a unique challenge due to the inherently open-ended nature of application gener- ation. Given that multiple implementations with different structures, interaction patterns, and design choices may all validly satisfy the same user intent, there is often no single canonical “ground truth” code solution. T o address this challenge, we propose a novel Agentic Eval- uation F r amework , M I N I A P P E V A L . Instead of relying on rigid assertions or template-based matching, M I N I A P P E - V A L lev erages Playwright ( Microsoft , 2026 ) to perform human-like exploratory testing by simulating interactions such as clicking, dragging, and observing runtime behavior . It dynamically v erifies the generated application along three complementary dimensions: Intention , Static , and Dynamic . T ogether , these dimensions assess whether the application fulfills the user’ s intent, exhibits a coherent static implemen- tation, and demonstrates interacti ve beha vior that adheres to implicit real-world constraints and interaction expectations. Our main contributions are summarized as follo ws: • W e rethink the future of human-LLM interaction and ar - gue that render ed HTML responses constitute a new interaction paradigm in the form of M I N I A P P S . • W e propose M I N I A P P B E N C H , the first benchmark dedi- cated to ev aluating principle-driven, interacti ve applica- tion generation. Deri ved from real-world user demands, it comprises 500 rigorous tasks that challenge LLMs to align ex ecutable code with implicit user reasoning. • W e introduce M I N I A P P E V A L , a novel agentic frame- work that integrates static inspection with human-like dynamic exploration to holistically assess application fi- delity across Intention, Static, and Dynamic. • Experiments re veal that current LLMs still struggle to reli- ably construct M I N I A P P S , while M I N I A P P E V A L achieves high consistency with human judgment, enabling more faithful assessment of next-generation interactiv e systems. 2 Related W ork 2.1 Code Generation and W orld Reasoning Existing code generation benchmarks ( Paul et al. , 2024 ; Jiang et al. , 2024 ) hav e largely focused on assessing func- tional correctness within the domains of algorithmic logic, software engineering, and data science. Early benchmarks such as HumanEval ( Chen , 2021 ) and MBPP ( Austin et al. , 2021 ) assess function-level algorithmic reasoning, while more recent ef forts like SWE-bench ( Jimenez et al. , 2023 ) and MLE-bench ( Chan et al. , 2024 ) extend ev aluation to repository-scale software maintenance and engineering workflo ws. Despite this progression in scale and realism, these benchmarks largely treat code as an abstract symbolic artifact whose quality is determined by test passing or task completion. Interaction and user-f acing behavior are either absent or tightly constrained by fixed assertions. As a re- sult, they do not capture whether models can use code as an interactive medium to externalize kno wledge, reason about real-world principles, or support customized human-LLM 2 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P ower ed Assistants interaction—capabilities that are central to M I N I A P P S . Con versely , a parallel line of research ev aluates LLMs on their understanding of real-world principles. Benchmarks such as PIQA ( Bisk et al. , 2020 ) and GSM8K ( Cobbe et al. , 2021 ) assess this capability through passi ve textual infer- ence, asking models to predict outcomes based on described scenarios. In the domain of embodied AI, frameworks like AlfW orld ( Shridhar et al. , 2020 ) and V oyager ( W ang et al. , 2023 ) test agents’ ability to act within predefined, im- mutable en vironments. While these benchmarks e xplicitly ev aluate models’ understanding of e xplicit real-world prin- ciples within constrained scenarios, the y do not assess the ability of models to capture and integrate implicit principles and express them through e xecutable artifacts. 2.2 W eb De velopment Early work on web generation ( Li et al. , 2025b ; Ning et al. , 2025 ) mainly focused on visual-to-code translation and static layout reconstruction. Pioneering works like Pix2Code ( Beltramelli , 2018 ) and W eb2Code ( Y un et al. , 2024 ) treated web generation as an image captioning or translation task, focusing on pixel-le vel fidelity and struc- tural alignment with reference designs. Similarly , bench- marks like FullFront ( Sun et al. , 2025 ) emphasize the visual consistency of the generated frontend. Sketch2Code ( Li et al. , 2025b ) further extended this to hand-drawn sk etches. These approaches largely focus on visual appearance, with limited attention to the dynamic logic and state transitions that characterize modern interacti ve applications. More re- cent benchmarks hav e advanced to wards Engineering-lev el W eb De velopment, addressing multi-step or multi-file gener- ation. Framew orks such as W ebGenBench ( Lu et al. , 2025 ) and W ebBench ( Xu et al. , 2025 ) ev aluate the ability to con- struct complex file structures for traditional applications lik e e-commerce sites or forums. Ho wever , despite increased structural complexity , these tasks remain centered on infor- mation presentation and standard CR UD workflows, often relying on templates and established patterns, with limited need for reasoning about custom interaction rules. 2.3 Evaluation Methodologies T raditional web e valuation paradigms typically rely on static code analysis, visual similarity metrics (e.g., screenshot comparison), or predefined interaction scripts. Approaches like Pix2Code ( Beltramelli , 2018 ) and W eb2Code ( Y un et al. , 2024 ) adopt snapshot-based ev aluation, which cap- tures layout fidelity but overlooks the interaction process. ArtifactsBench ( Zhang et al. , 2025 ), on the other hand, ana- lyzes the interaction process through multiple screenshots. Similarly , methods relying on fixed click-scripts, such as W ebBench ( Xu et al. , 2025 ), FullFront ( Sun et al. , 2025 ), cov er only narrow , pre-determined paths. In contrast, mod- ern interactive applications feature rich interactivity and effecti vely unbounded state spaces. Fixed scripts cannot adapt to di verse v alid behaviors or open-ended interaction trajectories implemented by a model. Consequently , static or scripted methods are ill-equipped to ev aluate whether a generated application truly functions as a consistent dy- namic system. While recent works have introduced agent-based ev alua- tors ( W ang et al. , 2024 ; Gao et al. , 2024 ) to address in- teractivity , they predominantly rely on comparati ve anal- ysis. Systems like W ebDevJudge ( Li et al. , 2025a ) and FronT alk ( W u et al. , 2025 ) ev aluate quality by measuring deviation from a reference implementation (ground truth) or by performing pairwise preference rankings (A/B test- ing). Such reference-dependent e valuation is ill-suited for M I N I A P P S , where customized and open-ended generation admits multiple equally valid realizations. 3 M I N I A P P B E N C H 3.1 Overview W e present M I N I A P P B E N C H , a benchmark comprising 500 tasks designed to e valuate LLMs on their ability to de- velop M I N I A P P S as a ne w form of human-LLM interaction. Moving be yond static layouts or standard CRUD operations found in prior work ( Xu et al. , 2025 ; Zhang et al. , 2025 ), our benchmark focuses on adherence to real-w orld princi- ples and customized interaction . The dataset is distilled from tens of millions of real user queries collected from a large-scale production platform. Through a multi-stage fil- tration process in volving model-based dif ficulty assessment and manual verification (detailed in Appendix B ), we se- lected 500 high-value queries that span six div erse domains (see Figure 3 (e)). Critically , these tasks require models not only to generate syntactically valid code, but also to construct interactive beha viors that align with user in- tent by corr ectly capturing and operationalizing implicit real-w orld principles , thereby enabling coherent, natural, and non-fragmented user interactions. The overvie w of M I N I A P P B E N C H is provided in Figure 3 . 3.2 Data Representation T o facilitate structured ev aluation and fine-grained analysis, we or ganize the dataset into a canonical tuple representation. Formally , the dataset is defined as D = { τ i } N i =1 , where each entry τ i is encapsulated as: τ i = ⟨ q i , ( c i , s i ) , r i , d i ⟩ (1) Here, the components are defined as follows (the data format is described in Appendix B.3 ): • q i represents the natural-language query sourced from real users, serving as the input for the model. • ( c i , s i ) denotes the two-lev el taxonomy , where c i ∈ C is the coarse-grained domain (e.g., Science , Games ) and s i is the specific subclass, enabling domain-specific performance breakdown. 3 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants Abstractthe Domain Generation Rewritten 2 . Q u e r y 2.Query 1,123 (b) Stage 2: Expanding Coverage While Preserving Core Intent (c) Stage 3: Anchoring Tasks with Verifiable Eval-Ref L i f e S c i e n c e s P h y s i c a l S c i e n c e s a n d E n g i n e e r i n g S o c i a l S c i e n c e s a n d H u m a n i t i e s H e a l t h a n d M e d i c i n e (d) Stage 4: Balancing Difficulty and Domain Coverage S cienc e 37.4% Games 24.2% Human. 9.4% V i z . 1 1 . 2 % L i f e s t y l e 6 . 4 % T ools 11.4% 3 7 3 5 2 5 2 8 2 5 1 6 1 8 1 5 3 2 6 1 3 8 1 4 1 0 8 Intention Static Dynamic (e) 500 Queries Covering Six Domain T ensofmillions 3,234 1,123 S t e p 1 L L M - b a s e d F i l t e r Step1 LLM-basedFilter S t e p 2 H u m a n E x p e r t s F i l t e r Step2 HumanExpertsFilter (a) Stage 1: Identifying Principle-Driven Interactive Queries 1,974 Ev eryQuery 1,974 BaselineModels GenerateMiniApps Evaluation Viz. Game ...... Easy Mid Hard CustomizingUser UnderstandingandApplying Comprehensiv eAbilities AdheringtoScientific PrinciplesandEnsuringFidelit y RobustLogicHandlingand AddressingEdgeCases GroundingKnowledge andUser-Driv enExploration VisualEncodingand PrecisionMapping PersonalizingandR eal- W orldCommonsenseConstraints *A c c or dingt oERA (E ur opeanR esear chAr ea) (f) MiniApps Examples of Six Domain DatasetConstructionPipeline Science Lifestyle Games Tools Humanities Visualization 1 . G u i d e l i n e s 1.Guidelines 3 . D o m a i n 3.Domain F igur e 3. Overview of the M I N I A P P B E N C H dataset and construction process. (a)–(d) illustrate the dataset construction pipeline. (e) summarizes the dataset features and distributions (domain and difficulty), with the distrib ution of subclasses shown in the side bar charts. (f) presents representativ e M I N I A P P S examples from six domains. • r i is the structur ed evaluation r eference . Unlike tradi- tional benchmarks that rely on fixed test cases, r i spec- ifies verifiable constraints across Intention, Static, and Dynamic dimensions to guide the agentic ev aluator . • d i ∈ { Easy , Mid , Hard } labels the task difficulty , de- riv ed from the pass rates of baseline models. This structured representation supports the open-ended na- ture of MiniApps: the ev aluation reference r i functions as a flexible inspection guide rather than a rigid template, vali- dating any genera ted artifact that functionally satisfies the user intent q i . 3.3 Evaluation Dimension W e design three dimensions to assess the quality of M I N I A P P S , comprehensi vely v erify whether the generated application adheres to the real-world principles and interac- tion expectations specified by the user . Intention Dimension. This score measures whether the MiniApp correctly interprets and fulfills the high-lev el user goal specified in q i . For example, if the query requests a physics simulation of pendulum motion, the ev aluator checks whether the core dynamics (periodicity , energy con- servation) are meaningfully represented. Static Dimension. This score e v aluates structural and syn- tactic correctness without execution. It verifies the presence of required elements, proper code or ganization, and adher - ence to accessibility standards. For instance, a weather dash- board should include clearly labeled temperature, humidity , and location fields, despite interaction. Dynamic Dimension. This score e valuates the MiniApp’ s runtime behavior through multi-step interaction trajectories. It ev aluates two critical aspects: (1) Sequential Logic and Planning: The ev aluator executes comple x chains of actions (e.g., add a new task → mark as complete → verify remov al from the activ e list) to verify that state transitions remain consistent and rev ersible, faithfully reflecting causal depen- dencies in the real world. (2) Robustness and Boundary Handling: M I N I A P P E V A L is tested against adversarial or edge-case inputs (e.g., submitting an empty string as a task name or inputting in valid dates in a scheduler) to ensure the application handles exceptions gracefully without crashing or violating real-world principles. 3.4 Dataset Construction Pipeline ➠ Stage 1: Identifying Principle-Driven Interactive Queries. The first stage tackles a key challenge: not all r eal user queries ar e suitable for evaluating customized in- teraction or the construction of r eal-world principles. Many queries are purely informational, underspecified, or trivially solvable without meaningful interaction logic. W e began with an initial pool of tens of millions of real user queries, from which we sampled a subset and removed in v alid entries (e.g., incoherent text, multi-turn follo w-ups), resulting in 3,234 candidates. W e then used a LLM-based cate gorization approach to group queries by their under- lying themes and suitability for interacti ve tasks. Human experts further refined these categories into 6 coarse-grained domains and 25 fine-grained subclasses, ensuring seman- tic consistency and balanced coverage across knowledge 4 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants areas (details in Appendix B.1 ). T o ensure data quality , we applied a hybrid quality filtering strate gy . First, an LLM- driv en filter remov ed queries that were vague, static, or lacking in interactiv e potential. Second, a manual verifi- cation step confirmed that the underlying principles and interactive logic of each task could be explicitly mate- rialized through HTML (the full pipeline is provided in Appendix B.2.2 ). This rigorous verification ensures that ev- ery task in the dataset is suitable for testing the core aspects of the benchmark. This stage resulted in 1,123 high-quality seed queries, form- ing the foundation of the benchmark. These queries are rich in real-world principles and support meaningful e valuation of customized interactions and principle-based generation. ➠ Stage 2: Expanding Coverage While Preser ving Core Intent. While the filtered seed queries are high quality , they alone do not pro vide sufficient co verage of interaction patterns or domain diversity . The second stage therefore focuses on expanding task di versity without diluting the underlying principles. W e employ the seed queries as an- chors in an LLM-driv en ev olutionary augmentation process to synthesize variants. These variants e xplore diverse sce- narios, parameter configurations, and interaction structures while strictly maintaining the original intent. Both seed and generated queries then undergo a standardization step, in which they are rewritten to be self-contained, explicit, and engineering-feasible. This step is critical, as it ensures the benchmark ev aluates application construction ability rather than ambiguity res- olution or prompt interpretation. After augmentation and standardization, the query set expands to 1,974 candidates. ➠ Stage 3: Anchoring T asks with V erifiable Evaluation References. W e sampled 200 queries from Stage 2 and asked different models to generate MiniApps for manual assessment. During this process, we identified both cross- domain issues and domain-specific pitfalls. T o enhance the ev aluation capability of M I N I A P P E V A L , we construct ev al- uation references via a human-guided generation strategy . Specifically , human experts write (i) a set of general guide- lines G and (ii) domain-specific instructions S c i to guide an LLM in generating these references. Giv en the query q i , its domain c i , and the guidelines ( G, S c i ) , the LLM maps key ev aluation points onto three dimensions aligned with our ev aluation dimension and pro- duces a query-specific reference: f ref ( q i , c i , G, S c i ) → r i . (2) These references assist the ev aluator but are not used as the final decision criterion. W e further asked domain experts to audit the generated reference. Their revie w suggests that the reference effecti vely surfaces implicit underlying princi- ples that the M I N I A P P S generation model might otherwise ov erlook (Figure 2 ). Importantly , the references are not manually r efined , ensuring scalability , generalizability , and full reproducibility . ➠ Stage 4: Balancing Difficulty and Domain Co verage. The final stage constructs a balanced, challenging, and sta- tistically meaningful ev aluation benchmark. T asks are as- sessed along the Intention, Static, and Dynamic dimensions and categorized into Easy , Medium, or Hard le vels. T o en- sure div ersity and fairness, we perform stratified sampling, selecting 500 tasks from a combination of domains and difficulty le vels, guaranteeing a representativ e mix. Addi- tionally , we manually revie w each query before inclusion to ensure the properties of seed queries from Stage 1 are accurately preserved during the e xpansion process. The resulting dataset follows a balanced dif ficulty distribu- tion of 30% Easy , 40% Medium, and 30% Hard, facilitating fair cross-model comparisons while maintaining both chal- lenge and div ersity . It also upholds essential characteristics like implicit principles that can be concretely expressed through HTML and customized interaction. 4 Agentic Evaluation Methodology As discussed in Section 2 , assessing only static code or post- ex ecution screenshots fails to verify interface behavior under real user interaction, nor to capture the implicit real-world principles required by the user’ s query , which constitute tw o key challenges in generating high-quality M I N I A P P S . T o address these challenges, M I N I A P P E V A L adopts an agentic evaluation framework with dynamic interaction enabled by browser automation (Playwright ( Microsoft , 2026 )). An LLM-powered agent acti vely interacts with the MiniApp and records the full interaction trajectory . Then based on this trajectory , M I N I A P P E V A L produces structured scores along three dimensions: Intention, Static, and Dy- namic. Meanwhile, the ev aluation framew ork is designed to minimize user cost . Users only need to provide an OpenAI- compatible chat API and can launch the entire ev aluation with a single command (details in Appendix C.3 ; the cost analysis is provided in the Appendix C.6 ). For each query , the pipeline runs automatically , including code generation and scoring, which helps reduce the impact of extraneous factors unrelated to the model’ s capabilities. Overall, our methodology consists of two tightly coupled components: (i) a standardized code generation scaffold and (ii) an LLM-powered autonomous agentic ev aluation framew ork. 4.1 Standardized Code Generation Scaffold W e provide an easy-to-use code generation scaffold. This part consists of two stages: Generation and Compilation . Generation. In the generation stage, the model recei ves a user query q i and generates a single, self-contained 5 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants Script Based Evaluation State 1 State 2 State 3 Existing Agent Based Evaluation Eval by Checklist State 1 State 2 Eval by comparison CONST g = 980 # gravity STATE y = 100 LOOP each frame(dt): y = y+ g * dt ... ... MiniAppEval Broader Knowledge Human Eval Did it use the correct formula? Code Instructions I n t e n t i o n S t a t i c D y n a m i c DOM Addresses several limitations of human evaluation Code Inspection Script Execution for (let i = 0 ; i < 10 ; i ++ ) await click ( apple ); Universal Gravitation is ... Query: Create a Mini APP to show Universal Gravitation Checklist Intention (0.9) : Usingafallingappleeffectivelydemonstratesuniversal gravitation. Static (0.9) : Theappleispositionedabovethegroundandthesetupis logicallyconsistent. Dynamic (0.3) : 1.Checkthe CODE ,themotionviolatesphysicallaws; 2.Whentestedwith Playwright ,theappledisappeared afterrepeatedclicks. ShowW aterFlowsDownhill ShowTidalPhenomena ShowCelestialMotion State 3 WHO Compare with Query Eval-Ref (a) Previous Method (b) Our Method —— MiniAppEval Static Dynamic MIN(S , S , S )=0.3≤0.8 I S D Repeated clicking is too tedious Script : ClicktheStone What is Universal Gravitation ? Violatesthelaws ofphysics ButitisAPPLE Can'tcov ereveryresult Noreference Theappledisappeared afterrepeatedclicks. F igur e 4. M I N I A P P E V A L vs. Pre vious Methods. Unlike brit- tle scripts or rigid comparisons, M I N I A P P E V A L integrates code inspection with dynamic ex ecution. It complements human ev alua- tion by verifying underlying physical principles and automating tedious testing scenarios to ensure robust assessment. index.html file that integrates the document markup, embedded styling, and functional logic. Our ev aluation uses the HTML format, while a standardized React option is also provided for users. The specific system prompt (generation prompt) templates are provided in Appendix E.1 . Compilation. In the compilation stage, the generated source code is assembled and validated into a deployable artifact. All artifacts must be self-contained and runnable in a browser without external build tools, network access, or server -side dependencies. T o ensure fair comparison, we run them in a standardized Chromium (Playwright) sandbox with fixed runtime conditions and strict isolation, e valuating each artifact independently . 4.2 A utonomous Agentic Evaluation Framework Input. The ev aluation agent recei ves four inputs: (i) the original user query q i , (ii) the e valuation reference r i , (iii) the complete generated source code, and (iv) a live, inter- actable instance of the MiniApp running in the browser . Any natural-language explanations generated by the code model are retained as auxiliary context. Evidence Collection. M I N I A P P E V A L uses Playwright to simulate a human e valuator: it loads the generated MiniApp, observes its initial state, and autonomously interacts with it based on the user query q i . All interactions (clicking/typing) are ex ecuted via targeted Jav aScript injected in the browser context for precise, deterministic control. The agent per - ceiv es rich signals (DOM, console logs, and source code; Appendix C.2.2 ) and selects actions (Appendix C.2.3 ) to probe functionality , guided by the query-specific ev aluation reference r i to map requirements to verifiable checks and collect concrete evidence. The full process is recorded as a reproducible interaction trajectory (Appendix C.5 ). Scoring. Giv en the customized interacti vity of M I N I A P P S and their grounding in real-world principles, M I N I A P P E - V A L combines static analysis with dynamic evidence to ev aluate M I N I A P P S along three dimensions: Intention , Static , and Dynamic . The ev aluation reference r i , which encodes expected behaviors grounded in real-world prin- ciples, guides the agent’ s inspection strategy but does not serve as a rigid oracle. Instead, the final judgment is based on whether the MiniApp functionally satisfies the user’ s request. The output is a structured score across the three dimensions, each accompanied by a detailed rationale (high- lighted in red at the top of Figure 4 (b)). M I N I A P P E V A L departs from assertion-based or compara- tiv e benchmarks by directly ev aluating whether a MiniApp satisfies open-ended user requirements, making it suitable for highly customized applications (the comparison shown in Figure 4 ). Moreov er , M I N I A P P E V A L addresses key limitations of hu- man e valuation as sho wn on Figure 4 (b): (i) its static anal- ysis precisely verifies implementation logic against real- world principles; (ii) Playwright’ s programmatic control improv es execution efficienc y; and (iii) the LLM-po wered ev aluator leverages broad domain kno wledge, often outper- forming non-expert annotators on specialized tasks. 5 Experiments 5.1 Settings All ev aluations are conducted in a sandbox with determinis- tic seeds and fix ed rendering settings. Artifacts are rendered via Playwright (headless Chromium) at multiple resolutions, including 1280 × 720, to test adaptive designs. Models re- ceiv e identical prompts (listed in Appendix E.1 ) and follow a unified decoding protocol: we use of ficially recommended decoding parameters when a vailable; otherwise, we apply our defaults (detailed in Appendix C.1.1 ). Overlong inputs are truncated, and each run is capped at 15 minutes. Baseline models are selected to ensure breadth, currency , and reproducibility , considering: (1) multiple model fami- lies (Claude ( Anthropic , 2025a ; b ), Gemini ( Google Deep- Mind , 2025a ; b ), GLM ( Zeng et al. , 2025 ), GPT ( OpenAI , 2025b ; a ), Grok ( xAI , 2025 ), Hunyuan ( T eam et al. , 2025b ), Kimi ( T eam et al. , 2025a ), Mimo ( Xiao et al. , 2026 ), Mini- Max ( Chen et al. , 2025 ), and Qwen3 ( Y ang et al. , 2025 )); (2) a range of scales (from lightweight to flagship); and (3) relativ ely recent and r epresentative versions within each family . For e vluation, we select Gemini-3-Pro-Pre view as the e valuation-model dri ving agent due to its strong agree- ment with human judgments. 5.2 Main Results and Analysis Our framework supports custom thresholds. In our exper - iments, we adopt a threshold of 0.8: a MiniApp is con- sidered successful if its minimum score across the three 6 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants T able 1. Performance of models on M I N I A P P B E N C H : Pass Rate, T oken Consumption, and Inference T ime Model Pass Rate (%) A vg. (%) T okens Time(s) Difficulty Domain Easy Mid Hard Games Science T ools Humanities V iz. Lifestyle Open-Sour ce Large Langua ge Models Qwen3-32B 1.59 0.55 0.00 0.00 0.57 0.00 0.00 2.04 3.70 0.66 3,470.68 22.16 Qwen3-235B-A22B 6.43 2.35 0.00 0.93 0.60 4.00 4.88 7.27 10.34 2.88 4,068.27 49.55 Qwen3-Coder-480B-A35B-Instruct 6.06 0.00 0.00 0.00 0.00 0.00 0.00 9.43 11.11 1.83 2,324.83 25.04 Kimi-K2-Instruct 14.17 5.03 0.00 3.77 3.11 4.08 4.88 17.65 18.52 6.19 3,435.97 46.76 GLM-4.5-Air 17.60 4.07 1.44 5.66 4.27 6.98 7.32 16.98 10.34 7.09 7,110.65 58.94 GLM-4.7 36.30 15.06 4.41 12.50 10.49 20.00 17.07 35.19 48.39 18.31 8,936.88 55.58 Closed-Sour ce Large Langua ge Models Hunyuan-T urbos-Latest 6.32 0.87 0.00 0.00 0.00 3.03 0.00 13.51 3.57 2.32 3,727.55 132.67 Mimo-V2-Flash 28.68 8.33 2.22 13.46 6.02 10.87 11.63 23.53 36.36 12.48 5,109.82 37.98 Grok-4-1-Fast-Reasoning 29.66 12.12 2.19 8.41 6.58 20.00 17.50 32.65 25.93 13.77 9,010.00 75.62 MiniMax-M2.1 31.46 15.62 7.08 16.25 12.50 23.33 20.00 27.27 19.23 17.12 8,881.57 118.32 Gemini-3-Flash 32.76 16.89 4.10 14.95 10.60 17.95 18.18 30.61 41.38 17.62 6,563.28 50.56 Gemini-3-Pro-Previe w 61.98 20.83 1.71 26.74 19.11 13.64 28.57 52.00 55.56 27.52 5,815.14 80.80 Claude-Sonnet-4-5 68.22 14.86 1.79 16.13 22.30 29.27 23.81 47.73 44.83 26.36 8,586.84 91.43 Claude-Opus-4-5 59.09 41.18 22.33 37.18 34.59 47.50 35.71 57.45 56.52 41.14 13,152.75 166.66 GPT -5.1 74.71 21.37 3.49 24.14 18.10 33.33 45.83 57.78 64.71 32.00 11,256.15 154.09 GPT -5.2 69.77 43.08 18.64 40.32 50.38 50.17 45.45 75.00 82.35 45.46 10,793.68 169.60 A verage 34.05 13.89 4.34 14.71 11.64 18.07 17.55 31.63 33.30 17.05 – – GPT -5.2 Claude-Opus-4-5 GPT -5.1 Gemini-3-Pro Preview Claude-Sonnet-4-5 GLM-4.7 Gemini-3-Flash MiniMax-M2.1 Grok-4.1-F ast Reasoning Mimo- V2-Flash GLM-4.5-Air Kimi-K2-Instruct Qwen3-235B-A22B Hunyuan- T urbos Latest Qwen3-Coder-480B A35B-Instruct Qwen3-32B 0 10 20 30 40 50 A verage pass rate (%) 45.46 41.14 32.00 27.52 26.36 18.31 17.62 17.12 13.77 12.48 7.09 6.19 2.88 2.32 1.83 0.66 Open-source Closed-source Open-source best Closed-source best F igur e 5. Overall model pass rate on M I N I A P P B E N C H dimensions (Intention, Static, Dynamic) exceeds this value, i.e., min ( S i , S s , S d ) > 0 . 8 . GPT -5.2 achie ved the highest performance with an average pass rate of 45.46%, while the ov erall mean across all models was 17.05%. These results underscore the challenges current models face in generating successful M I N I A P P S . The details are sho wn in Figure 5 and T able 1 . Open-Source vs. Closed-Source P erformance Analysis. Our e xperiments show a clear gap between open- and closed- source models, with closed-source systems consistently performing better across all difficulty le vels. In contrast, benchmarks such as ArtifactsBench ( Zhang et al. , 2025 ) and W ebDevJudge ( Li et al. , 2025a ) report much smaller gaps, suggesting potential saturation or ov erfitting; our benchmark better av oids this issue and thus provides a more discrimina- tiv e ev aluation. Difficulty-Level Perf ormance Analysis. The dif ficulty- wise performance analysis v alidates the rationale behind our task dif ficulty gradient segmentation, sho wing that mod- els with dif ferent performance le vels can find their respec- tiv e niches when tackling tasks of varying comple xity . As shown on T able 1 , the accuracy of all models decreases with increasing dif ficulty . Furthermore, smaller open-source models (Qwen3-32B) can handle certain tasks effecti vely , whereas more advanced models often struggle with more complex challenges. Domain-wise Perf ormance Analysis. As shown on T a- ble 1 , the performance v aries significantly across different classes. The pass rates for the V isualization and Lifestyle categories are notably higher , exceeding 30%, with GPT - 5.2 performing particularly well. This suggests that current models excel in tasks with a clear , singular objectiv e, such as visualizations, and in tasks that just require the applica- tion of commonsense. Howe ver , for more complex cate- gories that in volve comprehensiv e tasks, domain-specific knowledge, and intricate engineering details, the models still exhibit some limitations. Model-Scale and Positioning Analysis. Across both the Qwen and GLM families, we observe a consistent trend where increasing model scale generally leads to superior performance, validating the impact of scaling la ws on com- plex tasks. W ithin the Qwen3 series, Qwen3-235B-A22B achiev es a 2.88% pass rate, significantly outperforming the smaller Qwen3-32B (0.66%). This scaling trajectory is ev en more pronounced in the GLM series: the lightweight GLM-4.5-Air achiev es a 7.09% pass rate, while the flag- ship GLM-4.7 reaches a substantial 18.31%, illustrating the massiv e performance gains deri ved from increased model capacity and architectural refinement. 7 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants 字 号 调 整 坐 标 轴 数 字 : 24 px 坐 标 轴 名 称 : 32 px 图 例 ⽂ 字 : 18 px ⽓ 泡 图 例 : 20 px 模 型 名 称 : 20 px 图 例 图 标 : 1 1 px 2 K 3 K 4 K 5 K 6 K 7 K 8 K 9 K 1 0 K 1 1 K 1 2 K 1 3 K 1 4 K Model Inference Output Length (T okens) 0 % 5 % 1 0 % 1 5 % 2 0 % 2 5 % 3 0 % 3 5 % 4 0 % 4 5 % 5 0 % Average Accuracy (%) Qwen3-32B Qwen3-235B-A22B Qwen3-Coder-480B-A35B-Instruct Kimi-K2-Instruct GLM-4.5-Air GLM-4.7 Hunyuan-Turbos-Latest Mimo-V2-Flash Grok-4-1-Fast-Reasoning MiniMax-M2.1 Gemini-3-Flash Gemini-3-Pro-Preview Claude-Sonnet-4-5 Claude-Opus-4-5 GPT-5.1 GPT-5.2 Open-Source Closed-Source Fitted Line Inference Time (s) 20s 80s 150s F igur e 6. T oken Length & Inference T ime vs A verage pass rate T able 2. A blation results (%) . Metrics include accuracy (Acc.), precision (Prec.), recall (Rec.), and F1. The superscript arrows denote the absolute change relativ e to the M I N I A P P E V A L . Exp. Acc. Prec. Rec. F1 M I N I A P P E V A L 89.62 83.87 85.25 84.55 w/o Code 70.66 ↓ 18.96 32.73 ↓ 51.14 60.00 ↓ 25.25 42.35 ↓ 42.20 w/o Agent 66.48 ↓ 23.14 12.90 ↓ 70.97 53.33 ↓ 31.92 20.78 ↓ 63.77 w/o Eval Ref 60.12 ↓ 29.50 89.47 ↑ 5.60 46.36 ↓ 38.89 61.08 ↓ 23.47 Perf ormance vs. Inference Cost Analysis. There is a strong positiv e correlation between performance and token consumption (0.8433), and a moderate correlation with time (0.7387), as illustrated in Figure 6 , suggesting that more tokens and time generally improve performance. The cor- relation is measured by the Pearson correlation coef ficient ( Pearson , 1895 ). Outliers include GPT -5.2 and Gemini-3- Pro-Pre view , which consume fe wer tokens than models with similar performance. Hunyuan-T urbos-Latest and MiniMax- M2.1 hav e notably higher processing times for similar per - formance. 5.3 Ablation study T o ev aluate the impact of dif ferent components on the per- formance of M I N I A P P E V A L , we conducted an ablation study on a set of 183 manually labeled ground truth (GT) samples, as shown in T able 2 . The full M I N I A P P E V A L sys- tem (comprising Eval-Ref , Code , and Playwright ) achiev es the highest accuracy among all v ariants, demonstrating the ov erall effecti veness of the proposed e valuation frame work. Removing the Ev al-Ref leads to a substantial drop in re- call, indicating that the Eval-Ref plays a critical role in guiding M I N I A P P E V A L to attend to the correct aspects of a query and to accurately localize potential failure cases. w/o Code results in a sharp degradation in precision, as the judge can no longer verify implementation details (e.g., detect violations of implicit real-world principles). w/o Agent yields the lo west precision overall, highlighting that many interaction-dependent beha viors can only be rev ealed through acti ve exploration, which are inaccessible to static inspection alone. 5.4 Double Blind Judge During ev aluation, we observed that for graphical queries (e.g., in the V isualization class), the agent judge could be T able 3. Evaluation accuracy comparison between M I N I A P P E V A L and double-blind methods. Model Method T/T T/F F/T F/F Acc. Gemini-3-Pro M I NI A P P E VAL 15 2 8 30 81.82 -Pro-Previe w Double-Blind 11 6 2 36 85.45 ↑ 3.63 GPT -5.2 M I NI A P P E V A L 16 3 8 28 80.00 Double-Blind 12 7 2 34 83.63 ↑ 3.63 Claude- M I NI A P P E V A L 17 3 9 26 78.18 Opus-4.5 Double-Blind 11 9 0 35 83.63 ↑ 5.45 ov erly lenient due to confirmation bias ( Nickerson , 1998 ). T o mitigate this, we introduce a double-blind ev aluation procedure (detailed in Appendix D ): the judge first ev aluates the output without seeing the query , and then checks it against the user requirements for the final decision. W e apply this protocol to 55 graphical queries. As shown in T able 3 , it improves accurac y and better identifies negati ve samples, supporting our hypothesis and offering a more reliable setup for purely visual tasks. 5.5 V alidation of Evaluation Effectiv eness T o validate the ef fectiv eness and reliability of M I N I A P P E - V A L , we conducted a human agreement study with four experts on 183 items from each of three representative mod- els spanning dif ferent performance tiers: low- (GLM-4.7), mid- (Gemini-3-pro-previe w), and high-performing (GPT - 5.2) (549 outputs total); each output was annotated by all four experts (2,196 annotations). W e first assessed inter-rater reliability using Fleiss’ Kappa ( Fleiss , 1971 ), obtaining κ = 0 . 89 . Using the aggre- gated expert labels as reference, we then computed Cohen’ s Kappa ( Cohen , 1960 ) between M I N I A P P E V A L and humans across the three models to cover dif ferent quality regimes. As shown in T able 4 , M I N I A P P E V A L achieves strong agree- ment with humans, with κ ranging from 0.81 to 0.89. T able 4. Inter-rater reliability (IRR) between M I N I A P P E V A L and human ev aluators across models with different performance lev els ( N = 183 ). Model TP FP FN TN acc P o Cohen’ s κ Gemini-3-pro-previe w 83 8 9 83 0.9071 0.8142 GLM-4.7 87 5 5 86 0.9454 0.8907 GPT -5.2 85 7 7 84 0.9235 0.8470 6 Conclusion In conclusion, we introduce M I N I A P P B E N C H , the first benchmark for ev aluating principle-driv en interactiv e appli- cation generation, addressing ke y gaps left by prior bench- marks. W e further propose M I N I A P P E V A L , an agentic, browser -based ev aluation framew ork that enables compre- hensiv e and automated assessment of M I N I A P P S . Our ex- periments show that current LLMs still struggle to gener - ate high-quality M I N I A P P S , while M I N I A P P E V A L aligns closely with human judgments, providing a reliable method for future research. 8 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants References Anthropic. Claude opus 4.5 system card. T echnical report, Anthropic, 2025a. URL https://assets. anthropic.com/m/64823ba7485345a7/ Claude- Opus- 4- 5- System- Card.pdf . Ac- cessed: 2026-01-21. Anthropic. Claude sonnet 4.5 system card. T echnical report, Anthropic, 2025b. URL https://assets.anthropic.com/ m/12f214efcc2f457a/original/ Claude- Sonnet- 4- 5- System- Card.pdf . Accessed: 2026-01-21. Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., T erry , M., Le, Q., et al. Program synthesis with large language models. arXiv pr eprint arXiv:2108.07732 , 2021. Beltramelli, T . pix2code: Generating code from a graphical user interface screenshot. In Pr oceedings of the A CM SIGCHI symposium on engineering interactive computing systems , pp. 1–6, 2018. Bisk, Y ., Zellers, R., Gao, J., Choi, Y ., et al. Piqa: Reasoning about physical commonsense in natural language. In Pr o- ceedings of the AAAI confer ence on artificial intelligence , volume 34, pp. 7432–7439, 2020. Chan, J. S., Chowdhury , N., Jaffe, O., Aung, J., Sherburn, D., Mays, E., Starace, G., Liu, K., Maksin, L., P atward- han, T ., et al. Mle-bench: Ev aluating machine learning agents on machine learning engineering. arXiv pr eprint arXiv:2410.07095 , 2024. Chen, A., Li, A., Gong, B., Jiang, B., Fei, B., Y ang, B., Shan, B., Y u, C., W ang, C., Zhu, C., et al. Minimax- m1: Scaling test-time compute efficiently with lightning attention. arXiv preprint , 2025. Chen, M. Ev aluating lar ge language models trained on code. arXiv pr eprint arXiv:2107.03374 , 2021. Cobbe, K., Kosaraju, V ., Bav arian, M., Chen, M., Jun, H., Kaiser , L., Plappert, M., T worek, J., Hilton, J., Nakano, R., et al. Training verifiers to solv e math word problems. arXiv pr eprint arXiv:2110.14168 , 2021. Cohen, J. A coefficient of agreement for nominal scales. Educational and psycholo gical measur ement , 20(1):37– 46, 1960. Fleiss, J. L. Measuring nominal scale agreement among many raters. Psychological b ulletin , 76(5):378, 1971. Gao, C., Lan, X., Li, N., Y uan, Y ., Ding, J., Zhou, Z., Xu, F ., and Li, Y . Large language models empo wered agent- based modeling and simulation: A survey and perspec- tiv es. Humanities and Social Sciences Communications , 11(1):1–24, 2024. Google DeepMind. Gemini 3 flash model card. T echnical report, Google DeepMind, 2025a. URL https://storage.googleapis. com/deepmind- media/Model- Cards/ Gemini- 3- Flash- Model- Card.pdf . Accessed: 2026-01-21. Google DeepMind. Gemini 3 pro image model card. T echnical report, Google DeepMind, 2025b. URL https://storage.googleapis. com/deepmind- media/Model- Cards/ Gemini- 3- Pro- Image- Model- Card.pdf . Accessed: 2026-01-21. Jiang, J., W ang, F ., Shen, J., Kim, S., and Kim, S. A survey on large language models for code generation. arXiv pr eprint arXiv:2406.00515 , 2024. Jimenez, C. E., Y ang, J., W ettig, A., Y ao, S., Pei, K., Press, O., and Narasimhan, K. Swe-bench: Can language mod- els resolve real-world github issues? arXiv pr eprint arXiv:2310.06770 , 2023. Li, C., Zheng, Y ., Huang, X., Fang, T ., Xu, J., Song, Y ., Chen, L., and Hu, H. W ebdevjudge: Evaluating (m) llms as critiques for web dev elopment quality . arXiv pr eprint arXiv:2510.18560 , 2025a. Li, R., Zhang, Y ., and Y ang, D. Sketch2code: Ev aluating vision-language models for interactiv e web design pro- totyping. In Pr oceedings of the 2025 Confer ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language T echnolo- gies (V olume 1: Long P apers) , pp. 3921–3955, 2025b. Li, Y ., Y ang, X., Y ang, X., Xu, M., W ang, X., Liu, W ., and Bian, J. R&d-agent-quant: A multi-agent framework for data-centric factors and model joint optimization. arXiv pr eprint arXiv:2505.15155 , 2025c. Lu, Z., Y ang, Y ., Ren, H., Hou, H., Xiao, H., W ang, K., Shi, W ., Zhou, A., Zhan, M., and Li, H. W ebgen-bench: Evaluating llms on generating interacti ve and functional websites from scratch. arXiv preprint , 2025. Microsoft. Playwright. https://playwright.dev/ , 2026. Accessed: 2026-01-22. Nickerson, R. S. Confirmation bias: A ubiquitous phe- nomenon in many guises. Review of General Psyc hology , 2(2):175–220, June 1998. doi: 10.1037/1089- 2680.2.2. 175. 9 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants Ning, L., Liang, Z., Jiang, Z., Qu, H., Ding, Y ., Fan, W ., W ei, X.-y ., Lin, S., Liu, H., Y u, P . S., et al. A surve y of webagents: T ow ards next-generation ai agents for web automation with lar ge foundation models. In Pr oceedings of the 31st ACM SIGKDD Confer ence on Knowledge Discovery and Data Mining V . 2 , pp. 6140–6150, 2025. Noviko v , A., V ˜ u, N., Eisenber ger , M., Dupont, E., Huang, P .-S., W agner , A. Z., Shirobok ov , S., K ozlovskii, B., Ruiz, F . J., Mehrabian, A., et al. Alphaevolv e: A coding agent for scientific and algorithmic discovery . arXiv pr eprint arXiv:2506.13131 , 2025. OpenAI. 5.1 system card. T echnical report, OpenAI, 2025a. URL https://cdn.openai.com/pdf/ 4173ec8d- 1229- 47db- 96de- 06d87147e07e/ 5_1_system_card.pdf . Accessed: 2026-01-21. OpenAI. oai 5 2 system card. T echnical report, OpenAI, 2025b. URL https://cdn.openai.com/pdf/ 3a4153c8- c748- 4b71- 8e31- aecbde944f8d/ oai_5_2_system- card.pdf . Accessed: 2026-01- 21. Paul, D. G., Zhu, H., and Bayley , I. Benchmarks and metrics for e valuations of code generation: A critical revie w . In 2024 IEEE International Confer ence on Artificial Intelli- gence T esting (AIT est) , pp. 87–94. IEEE, 2024. Pearson, K. V ii. note on regression and inheritance in the case of two parents. pr oceedings of the r oyal society of London , 58(347-352):240–242, 1895. Shridhar , M., Y uan, X., C ˆ ot ´ e, M.-A., Bisk, Y ., Trischler , A., and Hausknecht, M. Alfworld: Aligning text and embodied en vironments for interactive learning. arXiv pr eprint arXiv:2010.03768 , 2020. Sun, H., W ang, H. W ., Gu, J., Li, L., and Cheng, Y . Fullfront: Benchmarking mllms across the full front-end engineer- ing workflo w . arXiv preprint , 2025. T eam, K., Bai, Y ., Bao, Y ., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y ., Chen, Y ., Chen, Y ., et al. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534 , 2025a. T eam, T . H., Liu, A., Zhou, B., Xu, C., Zhou, C., Zhang, C., Xu, C., W ang, C., W u, D., W u, D., et al. Hunyuan-turbos: Adv ancing large language models through mamba-transformer synergy and adapti ve chain- of-thought. arXiv preprint , 2025b. W ang, G., Xie, Y ., Jiang, Y ., Mandlekar , A., Xiao, C., Zhu, Y ., Fan, L., and Anandkumar , A. V oyager: An open- ended embodied agent with large language models. arXiv pr eprint arXiv:2305.16291 , 2023. W ang, H., Zhang, A., Duy T ai, N., Sun, J., Chua, T .-S., et al. Ali-agent: Assessing llms’ alignment with human values via agent-based ev aluation. Advances in Neural Information Pr ocessing Systems , 37:99040–99088, 2024. W u, X., Xue, Z., Y in, D., Zhou, S., Chang, K.-W ., Peng, N., and W en, Y . Frontalk: Benchmarking front-end dev elop- ment as con versational code generation with multi-modal feedback. arXiv preprint , 2025. xAI. Grok 4.1 model card. T echnical report, xAI, 2025. URL https://data.x.ai/ 2025- 11- 17- grok- 4- 1- model- card.pdf . Accessed: 2026-01-21. Xia, X., Zhang, D., Liao, Z., Hou, Z., Sun, T ., Li, J., Fu, L., and Dong, Y . Scenegenagent: Precise industrial scene generation with coding agent. In Pr oceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pp. 17847–17875, 2025. Xiao, B., Xia, B., Y ang, B., Gao, B., Shen, B., Zhang, C., He, C., Lou, C., Luo, F ., W ang, G., et al. Mimo-v2-flash technical report. arXiv pr eprint arXiv:2601.02780 , 2026. Xu, K., Mao, Y ., Guan, X., and Feng, Z. W eb-bench: A llm code benchmark based on web standards and frame- works, 2025. URL 2505.07473 . Y ang, A., Li, A., Y ang, B., Zhang, B., Hui, B., Zheng, B., Y u, B., Gao, C., Huang, C., Lv , C., et al. Qwen3 technical report. arXiv preprint , 2025. Y un, S., Thushara, R., Bhat, M., W ang, Y ., Deng, M., W ang, J., T ao, T ., Li, J., Li, H., Nakov , P ., et al. W eb2code: A large-scale webpage-to-code dataset and ev aluation framew ork for multimodal llms. Advances in neural in- formation pr ocessing systems , 37:112134–112157, 2024. Zeng, A., Lv , X., Zheng, Q., Hou, Z., Chen, B., Xie, C., W ang, C., Y in, D., Zeng, H., Zhang, J., et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv pr eprint arXiv:2508.06471 , 2025. Zhang, C., Li, Y ., Xu, C., Liu, J., Liu, A., Zhou, C., Deng, K., W u, D., Huang, G., Li, K., et al. Artifactsbench: Bridging the visual-interacti ve gap in llm code generation ev aluation. arXiv pr eprint arXiv:2507.04952 , 2025. 10 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants A Benchmark Comparison T o position M I N I A P P B E N C H among existing ev aluations, we compare representativ e benchmarks from three research lines: code generation, real-world reasoning, and web development. T able 5 summarizes their data scale, task type, real-user sourcing, and the degree to which they require principle-grounded interactiv e behavior . Notably , M I N I A P P B E N C H is the first benchmark that integrates real-user queries, high task div ersity/complexity , and explicit real-world principle requirements into a single unified ev aluation setting. T able 5. Comparison of representativ e benchmarks across three families: code generation, real-world reasoning, and web de velopment. Real-User indicates whether queries are sourced from real users. Div . (task di versity) is bucketed by the number of primary task categories (Low: < 3 , Mid: 3 – 5 , High: > 5 ). Comp. (task complexity) is approximated by the number of steps in the ev aluation protocol (Low: 1, Mid: 2–5, High: > 5 ). R W-Prin. indicates whether solving the queries requires real-world principles (e.g., ph ysics or commonsense); details are provided in Appendix B.2.2 . Benchmark #Data T ask Real-User Div . Comp. R W -Prin. MBPP 500 Algorithmic Problem Solving ✗ Low High Lo w HumanEv al 164 Algorithmic Problem Solving ✗ Lo w High Lo w SWE-Bench 2,294 Repository-level Bug Fixing ✗ High High Lo w MLE-Bench 75 Repository-lev el Software Engineering ✓ High High Lo w PIQA 2,000 Physical Reasoning ✗ Low Low High GSM8K 1,000 Mathematical Reasoning ✗ Low Low High AlfBench 3,553 Embodied Reasoning ✗ Low Low High V oyager N/A Embodied Reasoning ✗ Low Low High Pix2Code 5,250 W eb Interface Cloning ✗ Low Low Lo w W eb2Code 1,198 W eb Interface Cloning ✗ Low Low Lo w FullFront 50 W eb Interface Cloning ✗ Low High Low W ebGenBench 101 Multi-file W eb Dev ✗ Mid High Low A11YN 300 W eb Accessibility ✓ High Low Low W ebBench 50 Multi-step Iterativ e Dev ✗ High High Low FronT alk 100 Multi-step Iterative De v ✗ Low High Lo w ArtifactsBench 1,825 Interactiv e V isual Artifacts Dev ✗ High Mid Mid W ebDevArena N/A W eb Preference (A/B) ✓ High – – W ebDevJudge 654 W eb Preference (A/B) ✓ Mid High Mid M I N I A P P B E N C H 500 Customized M I N I A P P S De v ✓ High High High B Data Construction B.1 Domain Classification The two-le vel taxonomy of queries is carried out in two stages. First, we utilize large models to categorize the queries based on real-world user data, generating an initial classification. Subsequently , human experts re view and refine this categorization, abstracting a more logical and coherent classification scheme. The final classification consists of six coarse-grained domain: Science, Games, T ools, Humanities, Lifestyle, and V isualization. Each coarse-grained domain is further subdivided, with specific subclass outlined in the T able 6 . T o ensure a comprehensive e valuation of model capabilities, we also considered the proportional distribution of cate gories when constructing the dataset. Using the real-world query distribution as a baseline, we made necessary adjustments to maintain a reasonable balance across categories (for instance, due to the higher demand for game-related queries in online data, we reduced the proportion of game-related queries but still k ept it significant). B.2 Screening Guidelines B . 2 . 1 C U S T O M I Z E D I N T E R A C T I O N T o ensure that M I N I A P P B E N C H targets customized interaction rather than con ventional template-dri ven web de velopment, we screen candidate queries by checking whether the requested beha vior requires synthesizing query-specific interaction logic that cannot be reduced to standard CR UD workflo ws (e.g., form submission → database update → list rendering). Concretely , a query is labeled as requiring customized interaction if it satisfies at least one of the following criteria: 11 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants T able 6. The Data Domain Classification Domain Subclass Count Ratio (%) Science Chemical 46 9.20 Biological Systems 44 8.80 Physics 37 7.40 V irtual Laboratory 35 7.00 Geometry 25 5.00 T otal (Science) 187 37.40 Games Logic 28 5.60 Projectile 25 5.00 Reflex 16 3.20 Edutainment 16 3.20 Systemic Simulation 15 3.00 Casual 11 2.20 Card 10 2.00 T otal (Games) 121 24.20 T ools Schedule 21 4.20 Creativ e T ools 18 3.60 Computational T ools 15 3.00 Data Lookup 3 0.60 T otal (T ools) 57 11.40 Humanities Skill Acquisition 26 5.20 Concept Deconstruction 13 2.60 Culture 8 1.60 T otal (Humanities) 47 9.40 Lifestyle Health 14 2.80 T oys 10 2.00 Roleplay 8 1.60 T otal (Lifestyle) 32 6.40 V isualization SVG 25 5.00 Statical 23 4.60 Art 8 1.60 T otal (Visualization) 64 11.20 Grand T otal 500 100.00 • Multi-step state transitions. The task requires maintaining and updating non-trivial internal states across multiple user actions (e.g., “simulate one week of choices”, “step-by-step experiment”, “undo/redo”, “scenario branching”), beyond add/edit/delete of records. • Custom interaction operators. The task in volves interaction primiti ves that are not typical CRUD UI patterns, such as dragging, drawing, manipulating sliders to control a simulation, playing a game, interacti ve diagram e xploration, timeline scrubbing, or parameter sweeping. • Dynamic rules grounded in the query . The runtime behavior must obey explici t or implicit rules that are unique to the query , such as physical laws (gravity , conservation), temporal constraints (a week has seven days), geometric constraints, scoring rules in a game, or procedural generation rules. • Open-ended user exploration. The user is expected to explore a concept by interacting with the interface (e.g., “interactiv e visualization to understand ... ”, “what-if analysis”), where the value arises from the interaction trajectory rather than static content display . • Non-trivial edge-case handling. The query implies boundary conditions that affect interaction logic (e.g., inv alid 12 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants parameter ranges, impossible states, constraint violations) and thus requires tailored runtime checks beyond form validation. W e exclude queries that can be adequately solved by: (i) static information presentation (e.g., “show me an introduction to ... ”), or (ii) standard CRUD-style applications (e.g., “create a webpage to add/edit/delete notes”), where the interaction can be implemented with a generic form-list template and does not require query-specific dynamics. During screening, each candidate query is independently revie wed by two annotators follo wing the above criteria. Disagree- ments are resolved through discussion, and borderline cases are retained only if the interaction logic is clearly driv en by query-specific rules rather than templated CR UD patterns. B . 2 . 2 R E A L - W O R L D P R I N C I P L E In addition to customized interaction, we require each query to in volve at least one r eal-world principle that constrains the MiniApp’ s behavior . Here, a principle refers to an implicit or explicit rule about ho w the world should work (e.g., physical laws, temporal constraints, domain con ventions, or commonsense in variants) that must be operationalized in an executable artifact. Principle taxonomy . Our principle categorization follo ws the European Research Area (ERA), cov ering four broad areas: Life Sciences , Physical Sciences and Engineering , Social Sciences and Humanities , and Health and Medicine . Each query is annotated with the area(s) of principle it primarily relies on (e.g., conservation laws in a physics simulation; biological processes in a cell-cycle demo; historical timelines and causal narrativ es in humanities; dosage/health constraints in medicine). HTML-expressibility requir ement. Crucially , we only retain queries whose underlying principles can be faithfully expressed and verified thr ough a browser -executable interface . Our screening assumes the follo wing executable-web decomposition: HTML represents world states and structural relationships, CSS determines perceptual salience, and Ja vaScript encodes causal dependencies, temporal e volution, and interaction logic—together forming an ex ecutable world model. Therefore, a query passes the principle screening only if the principle can be mapped to at least one of the following HTML-expressible forms: • State repr esentation: the rele vant entities, attrib utes, and constraints can be represented as DOM elements and state variables (e.g., positions, counts, schedules, scores). • Rule execution: the principle can be implemented as deterministic or stochastic update rules in Ja vaScript that go vern state transitions over time and user interactions (e.g., numerical integration for motion, discrete event simulation, rule-based scoring). • Per ceptual grounding: the principle’ s outcomes can be rendered and inspected via visual encodings or UI feedback (e.g., trajectories, charts, alerts, in variants displayed as diagnostics). W e exclude queries whose required principles are not meaningfully capturable in an offline, self-contained bro wser setting, such as tasks requiring external sensors, proprietary databases, real-time web access, or un verifiable claims that cannot be grounded in executable state-transition logic. This ensures that every retained query admits a MiniApp implementation where principle adherence is both implementable and testable within HTML/CSS/Jav aScript. B.3 Data Format The ev aluation dataset is stored as a JSON array . Each element corresponds to one MiniApp specification and its LLM- generated ev aluation reference. Each record contains six fields: index , class , subclass , query , level , and eval-reference (a JSON-serialized string). 13 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants Data Format { "index" : 137 , "class" : "Tools" , "subclass" : "Creative Tools" , "query" : "Design a timeline visualization editor that renders a horizontal timeline on a canvas, allowing users to add nodes, drag to reposition them, set colors and labels, and supports zooming and exporting as an image." , "level" : "Hard" , "eval-reference" : "{ \"intention\": [...], \"static\": [...], \"dynamic\": [...] }" } Fields. index is a unique identifier (1-based) within the file. class and subclass denote the coarse- and fine-grained categories. query is the natural-language specification used for generation. level is the difficulty tag ( Easy / Mid / Hard ). eval-reference encodes the ev aluation reference in three dimensions ( intention , static , dynamic ) and is parsed by the ev aluator when needed. C M I N I A P P E V A L C.1 Settings C . 1 . 1 M O D E L S ’ D E C O D I N G P R OT O C O L W e follow each model’ s official API documentation or def ault demo settings when av ailable. For models without explicit recommendations, we adopt commonly used def ault v alues to ensure fair comparison. The specific settings sho wn on T able 7 T able 7. Decoding settings for all ev aluated models. Model T emperature T op- p Max tokens GPT -5.2 1.0 1.0 128,000 GPT -5.1 1.0 1.0 400,000 Claude-Opus-4.5 1.0 1.0 200,000 Claude-Sonnet-4.5 1.0 1.0 200,000 Gemini-3-Pro-Previe w 0.8 0.95 65,536 Gemini-3-Flash 0.8 0.95 65,536 GLM-4.7 1.0 0.95 131,072 GLM-4.5-Air 1.0 0.95 96,000 MiniMax-M2.1 1.0 1.0 204,800 Grok-4.1-Fast-Reasoning 1.0 1.0 30,000 Mimo-V2-Flash 1.0 1.0 32,768 Kimi-K2-Instruct 1.0 1.0 256,000 Qwen3-235B-A22B 1.0 1.0 38,912 Qwen3-Coder-480B-A35B-Instruct 1.0 1.0 65,536 Qwen3-32B 1.0 1.0 32,768 Hunyuan-T urbos-Latest 1.0 1.0 256,000 C . 1 . 2 T W O M I N I A P P S G E N E R A T I O N F O R M ATS T o more comprehensiv ely ev aluate model capabilities while reducing interference from output formatting, our e valuation supports tw o generation modes: (1) a single-file HTML mode and (2) a React frame work mode. For both modes, the pipeline automatically extracts the generated code, builds a runnable project, launches it in a sandboxed en vironment, and then completes the ev aluation. The recommended file structure for the React mode is shown belo w . Prompts for both generation formats are provided in E.1 . 14 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants The Recommended File Structure f or the React Mode template/ | |-- src/ | |-- App.tsx # Main page component (business code goes here) | |-- main.tsx # React entry point, mounted to #root | |-- index.css # Global styles (plain CSS) | |-- base.js | \-- global.d.ts # Global type definitions (provide basic declarations) | |-- index.html # HTML entry point, containing
|-- package.json # Dependencies + scripts: dev/build/preview | # Note: If postcss.config.js is used, must include "autoprefixer" and "postcss" in devDependencies |-- vite.config.ts # Vite configuration (React plugin + base.js entry) |-- tsconfig.json # TypeScript configuration (if using project references, must include references) |-- tsconfig.node.json # TypeScript Node configuration (for vite.config.ts, must be generated if tsconfig.json has references) \-- postcss.config.js # PostCSS configuration (if using autoprefixer, package.json must include autoprefixer and postcss dependencies) Important Notes: 1. If autoprefixer is used in postcss.config.js, package.json’s devDependencies must include: "autoprefixer": "ˆ10.4.14", "postcss": "ˆ8.4.31" 2. If tsconfig.json uses the "references" field to reference tsconfig.node.json, then tsconfig.node.json must be generated. Example content: {{ "compilerOptions": {{ "composite": true, "skipLibCheck": true, "module": "ESNext", "moduleResolution": "bundler", "allowSyntheticDefaultImports": true, "strict": true }}, "include": ["vite.config.ts"] }} C . 1 . 3 P O S I T I V E / N E G AT I V E L A B E L I N G W e con vert the three-dimensional e valuation scores into a binary label for do wnstream analysis. A MiniApp is marked as positive (successful) if all three dimension scores exceed a predefined threshold, i.e., min( s intention , s static , s dynamic ) > τ (we use τ = 0 . 8 in the main setting). Otherwise, it is labeled as negative (failed). This conservati ve rule ensures that a sample is counted as successful only when it simultaneously satisfies the user intention, static correctness, and dynamic interaction requirements. C.2 En vironment Setup Our e valuation frame work conducts agent assessments in web-based en vironments, enabling comprehensive e valuation of GUI agents through automated browser interaction and code analysis. The ev aluation system is implemented through a standardized e valuation script that provides a consistent interf ace for assessing agent-generated web applications. In the following sections, we detail the en vironment design for web-based agent ev aluation. C . 2 . 1 E N V I R O N M E N T I N F R A S T R U C T U R E W e design an interactiv e web-based ev aluation environment using browser automation technology . The en vironment lev erages Playwright as the browser automation platform through the Model Context Protocol (MCP) server interface, enabling high compatibility with real-world web applications while maintaining full control over the e xecution en vironment. This setup allo ws us to simulate user interactions such as mouse clicks, ke yboard input, and form submissions, which are 15 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants essential for e valuating GUI agents’ capabilities. The browser automation framew ork supports real-time observation and logging of DOM states, facilitating fine-grained analysis and reproducibility of agent behavior . All ev aluation episodes are initialized from a clean bro wser state to ensure consistent starting conditions for each e valuation episode. The ev aluation system supports two complementary modes: standard mode, where agents interact with liv e web applications via URLs with full browser automation capabilities, and code-only mode, where e valuation is performed solely based on HTML and Jav aScript code analysis without browser access. This dual-mode design enables flexible e valuation strategies, allo wing assessment of both runtime behavior and static code quality . C . 2 . 2 O B S E RV A T I O N S PAC E In our ev aluation framew ork, the observation space is designed to ensure comprehensiv e ev aluation of web-based GUI agents by capturing both structural and semantic aspects of web pages. It comprises two complementary modalities: DOM structure snapshots and source code access. The DOM snapshot is obtained through the Playwright MCP serv er’ s browser evaluate interface, which pro vides a complete representation of the page’ s hierarchical structure, including all HTML elements, their attributes, te xt content, and accessibility information. This structural information enables agents to understand the page layout, identify interactive elements, and navig ate the interface effecti vely . Additionally , when av ailable, agents can access the HTML and Jav aScript source code directly , which provides insights into the implementation details, ev ent handlers, and application logic. This dual-modality approach reflects the v arying capabilities of dif ferent agent architectures. For example, agents that hav e been specifically trained on web en vironments often possess strong grounding abilities and can rely on DOM snapshots alone. In contrast, general-purpose language models typically benefit significantly from the semantic and structural information provided by both DOM structure and source code. By supporting both modalities, our frame work enables fair and informativ e ev aluation across a wide range of agents, ensuring robust assessment under div erse web application contexts and UI layouts. Notably , the framework explicitly prohibits the use of visual screenshots or rendering-based analysis, focusing exclusi vely on structural and semantic information to ensure objectiv e and reproducible ev aluation. C . 2 . 3 A C T I O N S PAC E In our ev aluation framework, the action space consists of core types of user interactions that an agent can perform to interact with web applications. These actions, summarized in T able 8 , enable the agent to effecti vely interact with graphical user interfaces across a wide range of web applications. T able 8. Summary of action types in the web-based ev aluation en vironment. Action Description bro wser click Simulates mouse clicks on UI control elements. Supports configurable mouse buttons (left, right, middle) and both single and double clicks. Commonly used for selecting items, activ ating controls, or triggering events. bro wser type Simulates keyboard input for entering text, pressing ke ys, or in voking shortcuts (e.g., Ctrl+C, Enter). Enables fine-grained control o ver application beha vior and supports both functional input and text entry . bro wser fill form Fills form fields with specified values, supporting v arious input types including text inputs, checkbox es, radio buttons, and dropdo wn selections. Allows batch form filling for efficient interaction with comple x forms. bro wser evaluate Executes Ja vaScript code to query DOM state or perform comple x operations. Enables agents to extract information, manipulate page elements, or verify application state programmatically . Particularly useful for analyzing CSS styles, color schemes, and dynamic content. bro wser wait for W aits for specific conditions such as element appearance, text changes, or custom Jav aScript predicates. Essential for handling asynchronous operations and ensuring elements are ready before interaction. This comprehensive action space allows agents to perform complex multi-step interactions, test dynamic behaviors, and verify application functionality across div erse web application scenarios. The combination of basic interac- tion actions ( browser click , browser type , browser fill form ) with advanced programmatic capabilities ( browser evaluate , browser wait for ) enables thorough ev aluation of both static UI elements and dynamic interactiv e behaviors. The framework emphasizes that all interactions must be verified through actual DOM state changes rather than assumptions, ensuring that e valuation results reflect genuine application capabilities rather than inferred behavior . 16 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants C.3 The Pipeline of Agentic Evaluation W e design a one-click ev aluation pipeline. Given only an OpenAI-compatible API endpoint, the system automatically runs the entire workflo w , including loading queries, generating MiniApps, and ev aluating the generated artifacts, while recording detailed logs. It supports multiple modes: generation can be performed in either HTML mode or React mode; e valuation includes, but is not limited to, M I N I A P P E V A L , ev aluation without code access, and ev aluation without ev aluation references. The pipeline also supports batched ex ecution, substantially reducing ev aluation ov erhead. Moreover , by standardizing both the generation scaffold and the ev aluation en vironment, it minimizes external confounding factors and improves the fairness of experimental results. The pseudo-code of the workflow is sho wn below . Algorithm 1. QuickStart: Generate Project → Build Artifacts → Launch/Prepare P age → (Optional) Auto-Ev aluation & Aggre gation Require: Query file Q (JSON with query/reference ), index set I , output root O , raw output root R , ev aluation platform dir P , A W orld dir W , options, port, timeouts, model config (optional) Ensure: Generated page/project dirs, ev aluation logs & result files, optional time token summary 1: Procedur e Q U I C K S TA RT ( ar g s ) 2: Q ← R E S O LV E P AT H ( ar g s. csv file ) 3: I ← R E S O LV E I N D I C E S ( ar g s, Q ) // single / –batch / –all 4: m ← generation model name ( args.gen model or en v var or default) 5: P R E PA R E D I R S ( m, S T E M ( Q ) , O , R ) 6: if arg s.ev aluate then 7: f jsonl ← I N I T E V A L U A T I O N J S O N L ( I , Q, LLM MODEL NAME ) 8: end if 9: M ← ev aluation module ( eval visual blind or default) 10: S ← [ ] // ev aluation results 11: C ← [ ] // completed ev aluation data 12: t 0 ← N OW () 13: f or i ∈ I do 14: C H D I R ( original dir ) 15: ( q , r ) ← G E T Q U E RY A N D R E F E R E N C E ( Q, i ) 16: if q = ∅ and ar g s.ev aluate then 17: A P P E N D F A I L ( S, i, "query empty" ) 18: continue 19: end if 20: if not ar g s.sk ip g enerate then 21: out ← R/ { dataset } { i } output.txt 22: env g ← E N V W I T H T I M E T O K E N ( "generate" , dataset, i, TIME TOKEN DIR ) 23: I N J E C T M O D E L E N V ( env g ) 24: ok ← R U N C M D ( python generate project.py ... , g enT imeout, env g ) 25: if not ok or not E X I S T S ( out ) then 26: A P P E N D F A I L ( S, i, "generation failed/timeout" ) 27: continue 28: end if 29: else 30: out ← L O C AT E E X I S T I N G O U T P U T ( i ) 31: if N E E D S O U T P U T ( ar gs ) and not E X I S T S ( out ) then 32: A P P E N D F A I L ( S, i, "output file missing" ) 33: continue 34: end if 35: end if 36: if not ar g s.sk ip build then 37: if ar gs.html then 38: T ← O/html i 39: ok ← R U N C M D ( python extract html js.py ... ) 40: else 17 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants QuickStart (continued) 41: T ← O/react i 42: R E C R E ATE D I R ( T ) 43: ok ← R U N C M D ( python build from ai output.py ... ) 44: end if 45: if not ok then 46: A P P E N D F A I L ( S, i, "build/extract failed" ) 47: continue 48: end if 49: else 50: T ← R E S O L V E E X I S T I N G A RT I FA C T D I R ( arg s. input dir , i, html/react ) 51: if not I S V A L I D A RT I FAC T ( T , html/react ) then 52: A P P E N D F A I L ( S, i, "valid input dir not found" ) 53: continue 54: end if 55: end if 56: if ar g s.code onl y then 57: u ← None 58: else 59: if ar gs.html then 60: u ← A S F I L E U R I ( T/index.html ) 61: if not S TA RT S W I T H ( u, "file://" ) then 62: A P P E N D F A I L ( S, i, "HTML URL not file://" ) 63: continue 64: end if 65: else 66: p ← S TA RT S E RV E R ( P, node runner.mjs load T --port port ) 67: if arg s.ev aluate then 68: ok ← W A I T S E RV E R R E A DY ( p, 30 s ) 69: if not ok then 70: A P P E N D F A I L ( S , i, "server startup failed" ) 71: continue 72: end if 73: end if 74: u ← http://localhost:port 75: end if 76: end if 77: if ar g s.ev aluate then 78: env e ← E N V W I T H L L M A N D T I M E T O K E N ( arg s, "evaluate" , dataset, i ) 79: cmd ← B U I L D E V A L C M D ( M , u, q , r , out, ar gs. enable code , ar gs. code only , logfile ) 80: ok ← R U N C M D ( cmd, W, eval T imeout, env e ) 81: if ok then 82: e ← R E A D E V A L J S O N ( W/evaluation result.json , i ) 83: A P P E N D A N D P E R S I S T ( S, C , e, f jsonl , i, q, r, u ) 84: if | C | mo d 10 = 0 then 85: S A V E B A T C H S N A P S H O T ( C ) 86: end if 87: if arg s.extr act r esults then 88: R U N C M D ( python extract results.py ... ) 89: end if 90: else 91: A P P E N D F A I L ( S, i, "evaluation failed/timeout" ) 92: end if 18 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants QuickStart (continued) 93: end if 94: if not ar g s.html and ar g s.ev aluate then 95: S T O P S E RV E R ( p ) 96: end if 97: end f or 98: T all ← N OW () − t 0 99: if arg s.ev aluate and |I | > 1 then 100: W R I T E T I M E T O K E N S U M M A RY ( I , S, TIME TOKEN DIR ) 101: F I NA L I Z E B A T C H J S O N ( C, T all ) 102: U P DAT E J S O N L M E TA DAT A ( f jsonl , T all , S ) 103: end if 104: retur n S C.4 Results Format For each generated MiniApp, the ev aluator produces a structured JSON result with three dimensions: intention , static , and dynamic . Each dimension contains (i) a scalar score in [0 , 1] and (ii) a short natural-language reason explaining the judgment. The ov erall pass/fail decision in our experiments is deriv ed from these three scores (see C.1.3 for the thresholding rule), while the reason fields are retained for error analysis and qualitati ve inspection (Example in below). Example JSON "intention" : { "score" : 0 . 2 , "reason" : "..." }, "static" : { "score" : 0 . 2 , "reason" : "..." }, "dynamic" : { "score" : 0 . 4 , "reason" : "..." } C.5 Evaluation T rajectory An ev aluation trajectory records the step-by-step execution of the agent during M I N I A P P E V A L , including the con versation context, model outputs, tool calls, and token/time usage. T rajectories are stored as JSONL files, where each line corresponds to one ev aluation step. Evaluation T rajectory { "step" : 0 , "messages" : [{ "role" : "..." , "content" : "..." }], "llm_response" : { "model" : "..." , "content" : "..." , "tool_calls" : [{ "function" : { "name" : "..." , "arguments" : "..." } }], "usage" : { "prompt_tokens" : 0 , "completion_tokens" : 0 , "total_tokens" : 0 }, "created_at" : "..." , "finish_reason" : "..." } } 19 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants 0 10 20 30 40 50 Step 0 50000 100000 150000 200000 250000 300000 350000 T otal T okens T otal T okens vs Step (Scatter) 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15 16 17 18 19 20 Step 0 100000 200000 300000 400000 T otal T okens T otal T okens Distribution by Step (Boxplot) 0 5 10 15 20 25 30 Step 0 10000 20000 30000 40000 50000 60000 70000 80000 T otal T okens A verage T otal T okens by Step Mean Median ±1 Std 0 10 20 30 Step 0 200 400 600 800 1000 1200 Cumulative T ime (seconds) Cumulative T ime vs Step 0 10 20 30 40 50 Step 1 0 1 1 0 0 1 0 1 1 0 2 T ime Interval (seconds) T ime Interval vs Step 1 0 0 1 0 1 1 0 2 T ime Interval (seconds) 0 20000 40000 60000 80000 100000 120000 T otal T okens T otal T okens vs T ime Interval 0 100000 200000 300000 400000 Prompt T okens 0 2000 4000 6000 8000 10000 12000 Completion T okens Prompt T okens vs Completion T okens 0 10 20 30 40 50 Step 0 1000 2000 3000 4000 5000 6000 7000 8000 Frequency Step Distribution 1-5 6-10 1 1-20 21-50 51-100 Step Range 0 5000 10000 15000 20000 25000 30000 T otal T okens T oken Statistics by Step Range Mean Median F igure 7. Multi-dimensional trajectory analysis. The figure contains nine subplots: (a) tokens vs. step (scatter); (b) token distribution by step (boxplot); (c) av erage tokens vs. step with dispersion (mean/median/std); (d) cumulativ e time vs. step; (e) time interval vs. step (log scale); (f) tokens vs. time interval; (g) prompt tokens vs. completion tokens; (h) histogram of step values; (i) token statistics by step range. Fields. step is the 0-based step inde x; messages is the accumulated con versation history; llm response stores the model output for the current step, including optional tool calls and token usage statistics ( usage ). T rajectory files are sav ed under Aworld/runs/test/ { model } / as com { timestamp } .json . C.6 Time, T oken Consumption, and Step Analysis W e analyze the trajectory logs collected by M I N I A P P E V A L over 44,981 v alid runs. Figure 7 provides a compact, multi-view visualization of the relationships among step count, tok en consumption, and latency . Overall, we observ e three consistent patterns: (i) token usage increases mildly with step progression, lar gely due to accumulated prompt context; (ii) per-step time intervals e xhibit substantial variance and a long-tailed distrib ution; and (iii) prompt tokens dominate the overall tok en budget, while completion tok ens account for only a small fraction. These findings suggest that e valuation cost is primarily driv en by interaction length and conte xt growth, and moti vate future optimizations in conte xt management and ev aluation efficienc y . D Double Blind Evaluation D.1 Experimental Design The double-blind ev aluation method addresses confirmation bias ( Nickerson , 1998 ) by separating objective observ ation from subjecti ve judgment through a two-stage process. This approach is particularly ef fective for graphical queries in 20 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants visualization tasks, where ev aluators may exhibit leniency due to cogniti ve bias when directly comparing implementations against queries. The ev aluation workflow consists of tw o sequential stages: Stage 1 (Blind Description): An agent is provided with only the webpage code (e xcluding descripti ve text) and a URL, without access to the user query . The agent generates a structured, objective description of the page’ s visual and interactiv e elements. Stage 1: Blind Description Format { "stage1_description" : { "page_summary" : "This is a seashell graphic" , "layout" : { "structure" : "Single-column centered card layout" , "main_sections" : [ "Main icon area" , "Parameter control area" , "Code display area" ] }, "visual_elements" : [ { "type" : "container" , "description" : "Preview area (.preview-area), height 200px, with checkerboard background pattern in gray and white to simulate transparency, light gray rounded border." }, { "type" : "svg" , "description" : "SVG icon located at the center of the preview area, shaped as a geometric-style seashell." } ], "interactive_elements" : [ { "type" : "input (range)" , "description" : "Size slider: adjusts icon size, range 16px to 160px, updates preview and code in real-time." }, { "type" : "button" , "description" : "Blue solid button ’Copy SVG Code’, darkens on hover, copies code to clipboard when clicked." } ], "raw_observations" : "The page adopts a clean, modern design style with light gray- blue background (#f8fafc), main operation area concentrated in a white shadow card. Icon preview has instant responsiveness without page refresh. SVG path structure is simple, specifically referring to a particular seashell style." } } Stage 2 (Consistency Scoring): A separate ev aluation model receiv es the Stage 1 description output along with the original query and optional ev aluation reference. Based solely on the description rather than direct page access, the model generates a consistency score and detailed analysis. 21 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants Stage 2: Consistency Ev aluation Format { "stage2_evaluation" : { "score" : 1 . 0 , "reason" : "The page fully satisfies user requirements. The user needs to generate a simple seashell graphic. The page description shows this is an SVG icon shaped as a seashell. The description explicitly mentions that the icon consists of ’ simple straight line segments’ (conforming to the requirement of using only M/L/Z commands, no curves), and the code structure is simple. The page also provides real-time preview and code copying functionality, allowing users to adjust line thickness (satisfying monochrome stroke requirements) and size, perfectly solving the user’s need to obtain SVG code in a specific format." , "match_analysis" : { "satisfied_requirements" : [ "Generate a seashell icon" , "Monochrome stroked style" , "Geometric symmetry" , "Minimal code" , "Use only M/L/Z commands (inferred from ’straight line segments’)" ], "missing_requirements" : [], "mismatch_points" : [] }, "confidence" : "high" } } D.2 Experimental Results W e conducted experiments comparing double-blind ev aluation with the standard ev aluation method on a test set of 55 graphical queries. Three models (Gemini-3-Pro, GPT -5.2, and Claude-Opus-4.5) were used to generate ev aluation targets, and both ev aluation methods were applied to each set of results. The experimental results demonstrate that double-blind evaluation achiev es higher accuracy and effecti vely mitigates confirmation bias. Specifically , double-blind ev aluation achiev ed an av erage accuracy of 84.24%, compared to 80% for the standard method. More importantly , for manually labeled negativ e samples, double-blind e valuation sho wed significantly higher accuracy (96.33% vs. 77.06%), indicating greater sensiti vity to negati ve cases and effecti ve elimination of cognitiv e bias introduced by query context. Howe ver , for positive samples, double-blind ev aluation showed lo wer accuracy (60.7% vs. 87.27%), suggesting a more stringent e valuation standard. This stricter approach further validates that standard e valuation methods are constrained by confirmation bias, where ev aluators may adjust their e xpectations to match observ ed implementations rather than maintaining objectiv e assessment criteria. The two-stage design ensures that Stage 2 ev aluators cannot access the original webpage and must reason entirely from the Stage 1 description. This constraint forces ev aluators to work with factual observations rather than making assump- tions, thereby reducing the tendency to retroactively align expectations with implementations. The structured format of stage1 description ensures consistency across different observers, while stage2 evaluation provides both quantitativ e scores and qualitativ e reasoning for interpretability . E Prompts In this section, we present the prompts used for generating M I N I A P P S , e valuating and b uilding ev aluation reference. 22 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants E.1 Prompts f or Generating M I N I A P P S Prompts f or Generating M I N I A P P S (REA CT Edition) You are an excellent web application design and development engineer. - You are an excellent web application design and development engineer, helping users complete web application development. The applications you develop aim to provide users with immersive experiences and help them acquire information and knowledge more efficiently through ** interactive ** web applications. ** Important: Interactive means supporting users to actively change variables, with corresponding changes in results, rather than simple content folding (such as navigation bars) or content pagination, etc. ** Your current task is: Generate a runnable React + TypeScript + Vite project, output in plain text format. The directory structure must strictly follow the format below, and only these files should be generated: template/ | |-- src/ | |-- App.tsx # Main page component (business code goes here) | |-- main.tsx # React entry point, mounted to #root | |-- index.css # Global styles (plain CSS) | |-- base.js | \-- global.d.ts # Global type definitions (provide basic declarations) | |-- index.html # HTML entry point, containing
|-- package.json # Dependencies + scripts: dev/build/preview | # Note: If postcss.config.js is used, must include "autoprefixer" and "postcss" in devDependencies |-- vite.config.ts # Vite configuration (React plugin + base.js entry) |-- tsconfig.json # TypeScript configuration (if using project references, must include references) |-- tsconfig.node.json # TypeScript Node configuration (for vite.config.ts, must be generated if tsconfig.json has references) \-- postcss.config.js # PostCSS configuration (if using autoprefixer, package.json must include autoprefixer and postcss dependencies) Important Notes: 1. If autoprefixer is used in postcss.config.js, package.json’s devDependencies must include: "autoprefixer": "ˆ10.4.14", "postcss": "ˆ8.4.31" 2. If tsconfig.json uses the "references" field to reference tsconfig.node.json, then tsconfig.node.json must be generated. Example content: {{ "compilerOptions": {{ "composite": true, "skipLibCheck": true, "module": "ESNext", "moduleResolution": "bundler", "allowSyntheticDefaultImports": true, "strict": true }}, 23 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants Prompts f or Generating M I N I A P P S (REA CT Edition) (continued) "include": ["vite.config.ts"] }} 3. ** Interactivity Requirements ** : - The application must support users actively changing variables, with corresponding changes in results - Avoid implementing only simple content folding, navigation bar switching, or content pagination - Ensure the application provides a truly interactive experience, such as: calculation results changing after user input, interface state changing after user operations, etc. 4. ** Technical Constraints ** : - ** Absolutely prohibit the use of fonts.googleapis.com, as it is inaccessible in Chinese networks ** - If fonts are needed, use local font files or accessible CDNs (such as fonts.aliyun. com) - Use semantic HTML tags - Ensure responsive design, adapting to different screen sizes (desktop and mobile) 5. ** Functional Implementation Constraints ** : - ** Pure frontend implementation ** : All functionality must be implemented on the frontend, without calling any backend APIs or external services - ** Self-contained ** : The application must be self-contained and not depend on external services or APIs - ** Data storage ** : If data persistence is needed, only use browser native storage ( localStorage or sessionStorage) - ** Media processing ** : If audio/video functionality is needed, only use browser native APIs (Web Audio API, MediaDevices API, etc.) - ** Data acquisition ** : - Allow users to provide data through file uploads (FileReader API) and other methods - ** Must enforce providing mock data options ** to ensure the application can run and demonstrate normally without user data - Can use static data or mock data as default data sources - Do not allow calling external APIs to obtain data (such as network requests, third- party data services, etc.) - ** AI functionality ** : Do not use any AI APIs or LLM calls, all functionality is based on frontend logic implementation Output Format Requirements: 1. First output the project introduction and operation guide (using the following format): ## Project Introduction [Briefly describe the project’s functionality, purpose, and features] ## Operation Guide [Explain how to run the project, how to use main features, precautions, etc.] 2. Then output project files (according to the directory structure above): - Each file uses "#### ‘file path‘" marker - Followed immediately by a code block (wrapped with ‘‘‘) Please generate a project according to the above constraints: {} 24 M I N I A P P B E N C H : Evaluating the Shift from T ext to Interactive HTML Responses in LLM-P owered Assistants Prompts f or Generating M I N I A P P S (HTML Edition) You are an excellent web application design and development engineer. - You are an excellent web application design and development engineer, helping users complete web application development. The applications you develop aim to provide users with immersive experiences and help them acquire information and knowledge more efficiently through ** interactive ** web applications. ** Important: Interactive means supporting users to actively change variables, with corresponding changes in results, rather than simple content folding (such as navigation bars) or content pagination, etc. ** Your current task is: Generate a runnable pure HTML + JavaScript page, output in plain text format. Output Format Requirements: Output complete HTML page code: - Use "#### ‘index.html‘" marker - Followed immediately by complete HTML code block (wrapped with ‘‘‘html) - HTML code must include complete , , , tags - All CSS styles can be inline in