Revisiting Face Forgery Detection: From Facial Representation to Forgery Detection
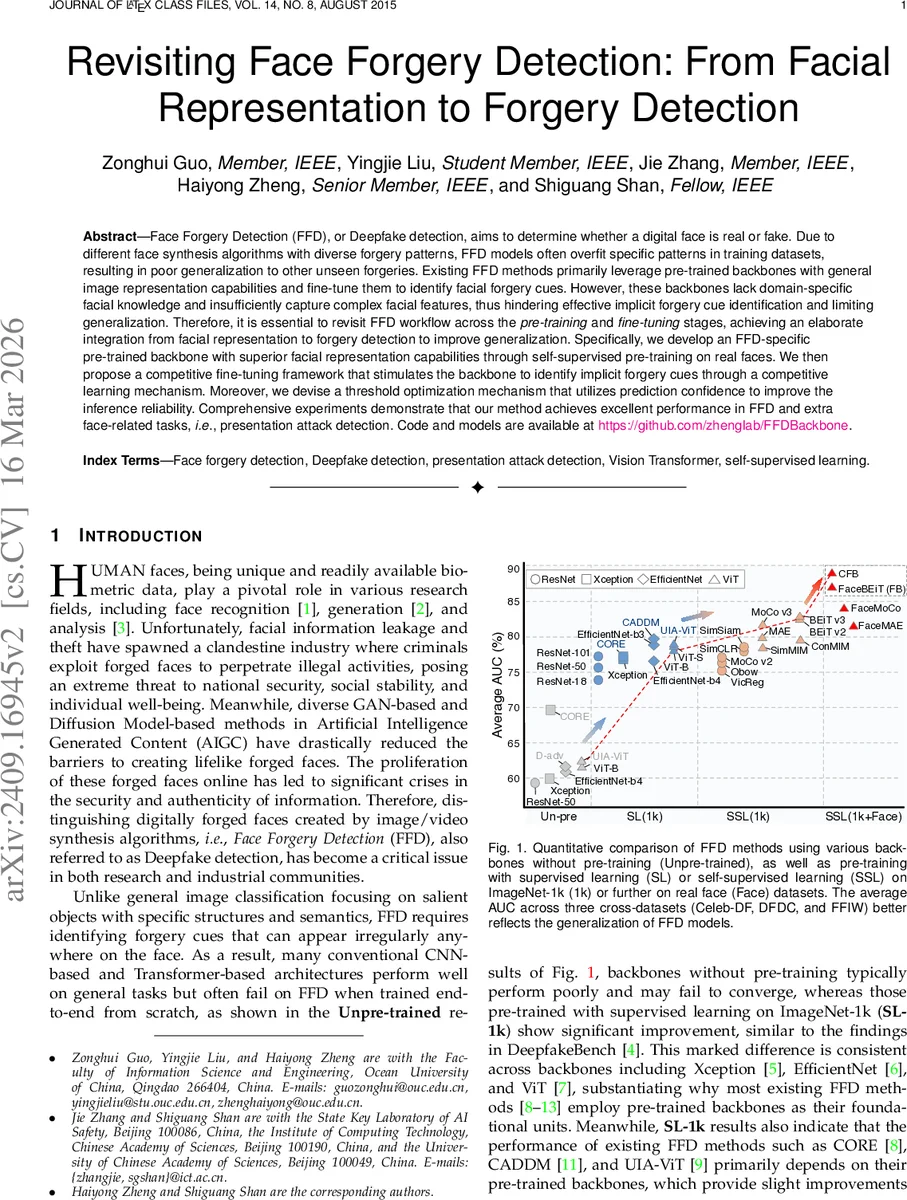
Face Forgery Detection (FFD), or Deepfake detection, aims to determine whether a digital face is real or fake. Due to different face synthesis algorithms with diverse forgery patterns, FFD models often overfit specific patterns in training datasets, resulting in poor generalization to other unseen forgeries. Existing FFD methods primarily leverage pre-trained backbones with general image representation capabilities and fine-tune them to identify facial forgery cues. However, these backbones lack domain-specific facial knowledge and insufficiently capture complex facial features, thus hindering effective implicit forgery cue identification and limiting generalization. Therefore, it is essential to revisit FFD workflow across the \textit{pre-training} and \textit{fine-tuning} stages, achieving an elaborate integration from facial representation to forgery detection to improve generalization. Specifically, we develop an FFD-specific pre-trained backbone with superior facial representation capabilities through self-supervised pre-training on real faces. We then propose a competitive fine-tuning framework that stimulates the backbone to identify implicit forgery cues through a competitive learning mechanism. Moreover, we devise a threshold optimization mechanism that utilizes prediction confidence to improve the inference reliability. Comprehensive experiments demonstrate that our method achieves excellent performance in FFD and extra face-related tasks, \ie, presentation attack detection. Code and models are available at \href{https://github.com/zhenglab/FFDBackbone}{https://github.com/zhenglab/FFDBackbone}.
💡 Research Summary
The paper tackles the persistent generalization problem in Face Forgery Detection (FFD), where models trained on specific forgery patterns often fail on unseen synthesis methods. The authors argue that the backbone network—typically pre‑trained on ImageNet or generic self‑supervised learning (SSL) datasets—lacks facial domain knowledge, limiting its ability to capture subtle forgery cues. To address this, they propose a three‑stage pipeline: (1) Face‑specific self‑supervised pre‑training: Using large collections of real faces (e.g., FFHQ, CelebA‑HQ), they adapt state‑of‑the‑art SSL frameworks such as MAE, MoCo, and BEiT to the facial domain, resulting in FaceMAE, FaceMoCo, and FaceBEiT (collectively “FB”). This step injects facial geometry, texture, and local displacement characteristics into the backbone, producing representations that are more sensitive to manipulation artifacts than generic ImageNet‑SL or standard SSL models. (2) Competitive fine‑tuning (CFB): Instead of a single backbone, two identical FB backbones are trained jointly. An uncertainty‑based fusion module evaluates each backbone’s confidence (e.g., entropy of its softmax output) and dynamically weights their predictions, encouraging them to specialize on complementary forgery cues. A decorrelation constraint penalizes correlated feature maps between the two networks, further promoting diversity. This competitive learning scheme mitigates over‑fitting to any single forgery type and yields consistent gains across cross‑dataset evaluations (Celeb‑DF, DFDC, FFIW). (3) Threshold optimization using prediction confidence: The common practice of fixing the decision threshold at 0.5 is replaced by a data‑driven method that combines the predicted probability with its confidence measure to compute an optimal threshold for each test set. This adaptive threshold improves binary classification accuracy, especially when the test distribution differs from training data. The authors validate the entire framework on three major deep‑fake benchmarks, achieving an average AUC above 90 %, which surpasses prior state‑of‑the‑art methods by 2–3 percentage points. Moreover, they extend the approach to Presentation Attack Detection (PAD), a physical‑world forgery scenario involving printed photos, replay attacks, and 3D masks. The same FB + CFB pipeline, together with the confidence‑based threshold, delivers higher detection rates than dedicated PAD models, demonstrating the method’s versatility. In summary, the work contributes (i) a facial‑domain‑aware SSL pre‑training strategy, (ii) a novel competitive fine‑tuning architecture with decorrelation and uncertainty fusion, and (iii) a practical threshold‑selection mechanism. All code and pretrained models are publicly released, providing a solid foundation for future research on robust, generalizable deep‑fake and anti‑spoofing systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment