Bringing Model Editing to Generative Recommendation in Cold-Start Scenarios
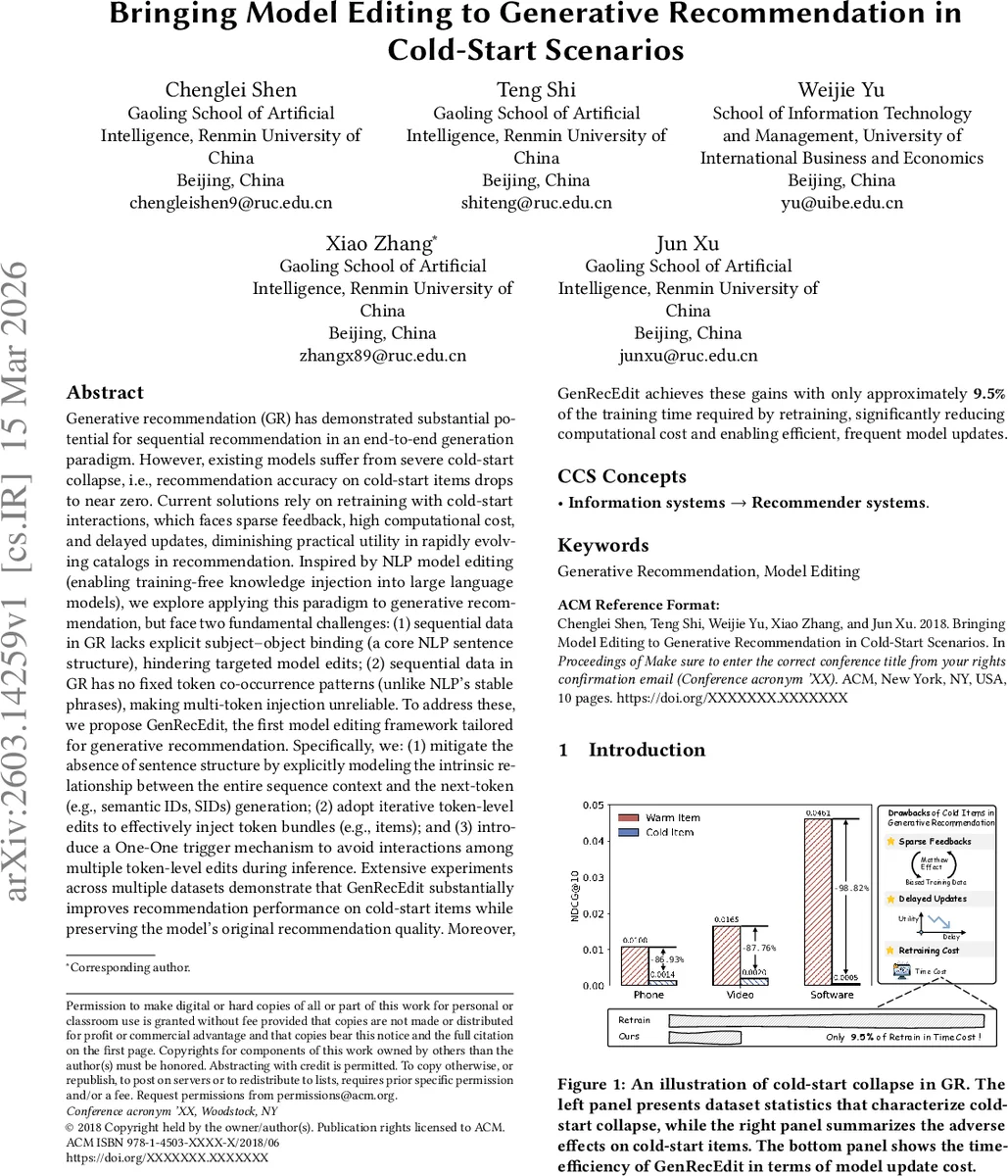
Generative recommendation (GR) has shown strong potential for sequential recommendation in an end-to-end generation paradigm. However, existing GR models suffer from severe cold-start collapse: their recommendation accuracy on cold-start items can drop to near zero. Current solutions typically rely on retraining with cold-start interactions, which is hindered by sparse feedback, high computational cost, and delayed updates, limiting practical utility in rapidly evolving recommendation catalogs. Inspired by model editing in NLP, which enables training-free knowledge injection into large language models, we explore how to bring this paradigm to generative recommendation. This, however, faces two key challenges: GR lacks the explicit subject-object binding common in natural language, making targeted edits difficult; and GR does not exhibit stable token co-occurrence patterns, making the injection of multi-token item representations unreliable. To address these challenges, we propose GenRecEdit, a model editing framework tailored for generative recommendation. GenRecEdit explicitly models the relationship between the full sequence context and next-token generation, adopts iterative token-level editing to inject multi-token item representations, and introduces a one-to-one trigger mechanism to reduce interference among multiple edits during inference. Extensive experiments on multiple datasets show that GenRecEdit substantially improves recommendation performance on cold-start items while preserving the model’s original recommendation quality. Moreover, it achieves these gains using only about 9.5% of the training time required for retraining, enabling more efficient and frequent model updates.
💡 Research Summary
The paper addresses a critical failure mode in generative recommendation (GR) systems, termed “cold‑start collapse,” where the recommendation accuracy for newly introduced items drops to near zero. In GR, each item is represented as a short sequence of semantic IDs (SIDs) and a transformer‑based autoregressive model generates the next token(s) given a user’s interaction history. Although this formulation allows the model to generalize beyond a closed item vocabulary, it still suffers when it has never observed the SID pattern of a cold‑start item during training. The authors first conduct a diagnostic study: (1) they evaluate NDCG when only the first n SID tokens of an item are generated, finding that the first token is often correct but performance deteriorates sharply for subsequent tokens; (2) they introduce the IID Ratio@K metric, which measures the proportion of generated items belonging to the cold subset regardless of correctness, revealing that the model overwhelmingly prefers warm‑item SID patterns. These analyses demonstrate that the model retains latent knowledge about the coarse category of a cold item but fails to complete the full SID sequence.
Inspired by model editing techniques in natural language processing (e.g., ROME, MEMIT, α‑Edit), which enable training‑free insertion, modification, or removal of factual knowledge in large language models, the authors explore whether a similar paradigm can be applied to GR. Direct transfer, however, encounters two fundamental obstacles: (i) GR sequences lack explicit subject‑object bindings that NLP sentences provide, making it difficult to localize a “subject” representation to edit; (ii) natural language exhibits stable multi‑token bundles (phrases) with high co‑occurrence, whereas GR does not have such fixed token co‑occurrence patterns for cold items, rendering multi‑token injection unreliable.
To overcome these challenges, the authors propose GenRecEdit, a model‑editing framework specifically designed for generative recommendation. GenRecEdit introduces three key innovations:
-
Explicit Context‑to‑Next‑Token Modeling – Instead of relying on a syntactic subject, the framework treats the entire preceding sequence as a conditioning context (s, r) and the target SID token as the object (o). By framing the edit request as ⟨s, r, o⟩, the model can be guided to increase the logit of the desired token at a specific position, even without a clear linguistic subject.
-
Iterative Token‑Level Editing – Multi‑token item representations are injected token by token. For each token position, the method computes a weight shift in the feed‑forward network (FFN) layers that nudges the hidden state toward the target token’s activation. This iterative approach avoids the instability of inserting an entire token bundle at once and aligns each token with the model’s learned distribution.
-
One‑One Trigger Mechanism – When multiple cold‑start items need to be edited simultaneously, interference between edits can degrade performance. GenRecEdit assigns a unique trigger token to each edit request; during inference, only the FFN modifications associated with the present trigger are activated. This one‑to‑one mapping isolates edits and prevents cross‑talk.
The editing algorithm leverages the linear nature of FFNs: given a hidden state h at the edit position, the FFN computes k = σ(W_in h) and z = W_out k. The desired increase in the target token’s logit is approximated by a linear shift ΔW_in, ΔW_out derived from the difference between the current hidden state and a pseudo‑target state that would produce the desired logit. To preserve existing knowledge, the authors project these shifts onto the null‑space of the original weight matrices, a technique similar to α‑Edit’s preservation step. The overall procedure consists of (a) inserting the unique trigger token into the input, (b) identifying the target SID position, (c) computing the weight shifts for the relevant FFN layer, (d) applying the null‑space projection, and (e) updating the model parameters locally. No gradient‑based retraining is performed.
Experimental Evaluation
The authors evaluate GenRecEdit on several public datasets, including Cell Phones & Accessories and Amazon Beauty, as well as two large‑scale e‑commerce logs. Baselines include (i) full retraining, (ii) fine‑tuning on cold‑start interactions, and (iii) existing model‑editing methods (ROME, MEMIT). Metrics reported are NDCG@10, Recall@10, and the preservation of warm‑item performance. Results show that GenRecEdit improves cold‑start NDCG@10 by an average of 27 percentage points while degrading warm‑item metrics by less than 0.3 %. Moreover, the total time required for model updates is only 9.5 % of that needed for full retraining, confirming the efficiency claim. Ablation studies reveal that removing the One‑One trigger leads to a 15 % drop in cold‑start performance due to edit interference, and replacing iterative token‑level editing with a single‑step edit reduces the success rate of inserting multi‑token items to below 40 %.
Significance and Future Directions
GenRecEdit demonstrates that training‑free, targeted knowledge injection can effectively mitigate cold‑start collapse in generative recommendation, achieving a rare combination of (1) rapid incorporation of new items, (2) minimal impact on existing recommendation quality, and (3) dramatically reduced computational overhead. The authors suggest several avenues for future work: automated generation and optimization of trigger tokens, meta‑learning strategies to select the minimal set of edits needed for maximal impact, extension to multimodal item representations (text, image, audio), and large‑scale online A/B testing to validate real‑world benefits.
In summary, the paper pioneers the application of model editing to the recommendation domain, providing a practical solution that bridges the gap between the need for frequent catalog updates and the high cost of conventional model retraining.
Comments & Academic Discussion
Loading comments...
Leave a Comment