Survey on Neural Routing Solvers
Neural routing solvers (NRSs) that leverage deep learning to tackle vehicle routing problems have demonstrated notable potential for practical applications. By learning implicit heuristic rules from data, NRSs replace the handcrafted counterparts in …
Authors: Yunpeng Ba, Xi Lin, Changliang Zhou
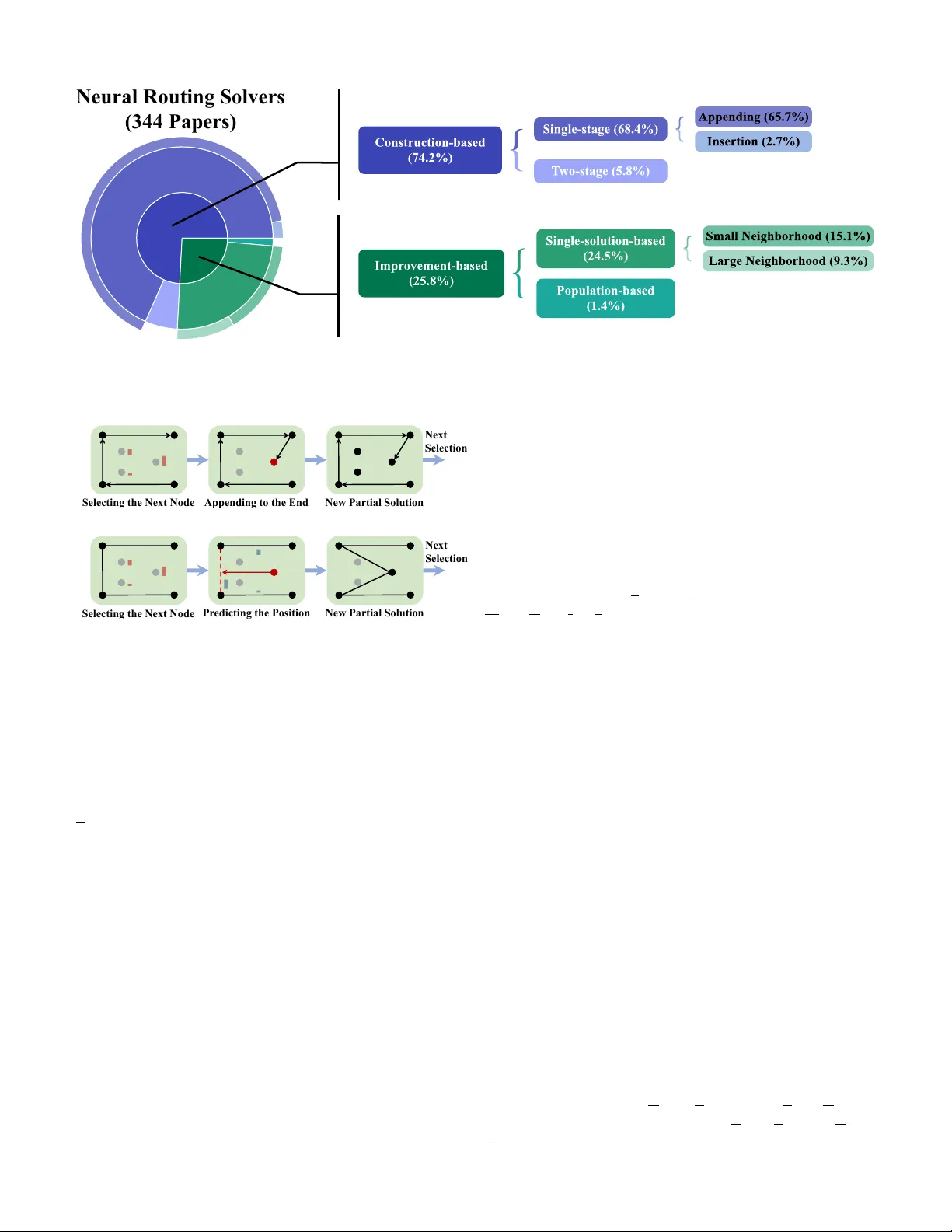
1 Surv e y on Neural Routing Solv ers Y unpeng Ba, Xi Lin, Changliang Zhou, Ruihao Zheng, Zhenkun W ang, Senior Member , IEEE , Xinyan Liang, Member , IEEE , Zhichao Lu, Member , IEEE , Jianyong Sun, Senior Member , IEEE , Y uhua Qian, Member , IEEE , and Qingfu Zhang, F ellow , IEEE Abstract —Neural routing solv ers (NRSs) that leverage deep learning to tackle vehicle routing problems have demonstrated notable potential for practical applications. By learning implicit heuristic rules from data, NRSs replace the handcrafted counter - parts in classic heuristic frameworks, thereby reducing reliance on costly manual design and trial-and-error adjustments. This survey makes two main contrib utions: (1) The heuristic nature of NRSs is highlighted, and existing NRSs are re viewed from the perspective of heuristics. A hierarchical taxonomy based on heuristic principles is further introduced. (2) A generalization- focused evaluation pipeline is proposed to address limitations of the con ventional pipeline. Comparativ e benchmarking of repr esentative NRSs across both pipelines uncovers a series of pre viously unreported gaps in current research. Index T erms —Combinatorial optimization, vehicle routing problem, heuristics, deep learning. I . I N T R O D U C T I O N The vehicle routing problem (VRP) [ 1 ], [ 2 ] is a classic combinatorial optimization problem (COP) that seeks cost- minimizing routes for serving geographically distributed cus- tomers under specific constraints. Its scientific significance and broad practical impact hav e been demonstrated across various fields [ 3 ], such as transportation [ 4 ], logistics [ 5 ], and manufacturing [ 6 ]. As an NP-hard problem [ 7 ], VRPs cannot be solved to optimality in polynomial time, which has driv en decades of research into heuristic algorithms to obtain high-quality approximations within acceptable computation time [ 8 ], [ 9 ]. Howe ver , designing effecti ve heuristics requires substantial domain e xpertise and careful manual tuning, which poses significant challenges for real-world applications. Efforts to automate heuristic design for combinatorial op- timization hav e long been underway . A prominent direction is algorithm selection [ 10 ], which lev erages features across problem instances to choose the most suitable algorithm for a giv en one. This idea has been extended to portfolio-based methods [ 11 ], [ 12 ], where a set of complementary algorithms Y unpeng Ba, Changliang Zhou, Ruihao Zheng, and Zhenkun W ang are with Guangdong Provincial Key Laboratory of Fully Actuated System Control Theory and T echnology , School of Automation and Intelligent Manufacturing, Southern Uni versity of Science and T echnology , Shenzhen, China. (E-mail: { bayp2024, zhoucl2022, zhengrh2024 } @mail.sustech.edu.cn, wangzk3@sustech.edu.cn). Xi Lin and Jianyong Sun are with the School of Mathematics and Statistics, Xi’an Jiaotong University , Xi’an, China. (E-mail: { xi.lin, jy .sun } @xjtu.edu.cn). Xinyan Liang and Y uhua Qian are with the Institute of Big Data Science and Industry , Shanxi Uni versity , T aiyuan, China. (E-mail: liangxinyan48@163.com, jinchengqyh@126.com). Zhichao Lu and Qingfu Zhang are with the Department of Computer Science, City University of Hong Kong, Hong Kong SAR, China. (E-mail: { zhichao.lu, qingfu.zhang } @cityu.edu.hk). Corresponding author: Zhenkun W ang. is maintained and selecti vely applied to maximize perfor- mance for dif ferent instances [ 11 ], [ 12 ]. Another established paradigm is algorithm configuration, which aims to optimize algorithm performance for a target problem by automatically tuning parameters and combining modules [ 13 ], [ 14 ]. Despite their advances, these approaches remain confined to manually specified components and predefined parameter ranges, thus unable to discover or integrate novel algorithmic elements, which fundamentally limits potential performance gains. A recent and transformativ e development that can address this limitation in heuristic design automation is the emer- gence of neural routing solvers (NRSs). NRSs leverage deep learning (DL) models to learn implicit heuristic rules from data [ 41 ], replacing their handcrafted counterparts within heuristic framew orks. Their advantages over traditional heuris- tics primarily lie in two aspects: (1) reducing reliance on manual design by learning from data rather than manual trial-and-error tuning [ 21 ], and (2) enabling GPU-accelerated parallel computation for problem solving. The growing literature on NRSs has been partially re vie wed in se veral surveys, yet a significant gap remains. Surveys organized from a learning perspecti ve [ 15 ]–[ 27 ] typically structure the field around DL techniques related to specific components, which cannot capture algorithmic structure and behavior of NRSs. Other surveys adopting a hybrid perspec- tiv e [ 28 ]–[ 40 ] often introduce secondary attributes to define heuristic categories or restrict attention to NRSs with such attributes, leading to (1) incomplete coverage, forcing a resid- ual “others” category , (2) ambiguous classification, resulting in self-contradictory taxonomies, or (3) limited scope, omitting NRSs without chosen attributes from discussion. Ov erall, these surve ys lack a unified algorithm-lev el perspecti ve on the field. A comparativ e summary is provided in T able I . This surve y of NRSs makes tw o main contributions: (1) a unified algorithm-level revie w from the perspectiv e of heuris- tics, and (2) a generalization-focused ev aluation pipeline. Unified Algorithm-Level Review NRSs are inherently heuristic algorithms powered by DL models. Building on this understanding, a hierarchical taxonomy of NRSs is proposed from the perspectiv e of heuristics, organized by how NRSs construct or improve solutions. This perspectiv e clarifies the relationships among NRSs and highlights their progression from traditional heuristics. Furthermore, category-specific in- sights from heuristics are introduced to corresponding NRSs. Generalization-Focused Evaluation Pipeline A new ev aluation pipeline is proposed to address limitations of the con ventional one, and representative NRSs are benchmarked under both pipelines. The k ey focus of the proposed pipeline is zero-shot in-problem generalization, a critical indicator of 2 T ABLE I C O M PA R I S O N S O F E X I S T I N G S U RV E Y S FO R N R S S Exisiting Surveys Unified Perspectiv e † Algorithm-Level Perspectiv e ‡ Description Learning Perspectiv e ✓ × • Model Structures : GNN, T ransformer , etc. [ 15 ]–[ 20 ]; • Learning Paradigms : SL, RL, etc. [ 16 ], [ 21 ]–[ 25 ]; • Generation Paradigms : AR, N AR, etc. [ 17 ], [ 24 ]; • Reliance on Learned Modules : E2E, Hybrid, etc. [ 18 ], [ 20 ], [ 21 ], [ 23 ], [ 26 ], [ 27 ]. Hybrid Perspectiv e (Heuristic + Others) × ✓ • Residual Categories : Grouping NRSs with failed-to-identify heuristic categories as “Predict” [ 28 ] / “Hybrid” [ 29 ], [ 30 ] / “Non-DRL ” [ 31 ] / “Decomposition” [ 32 ]; • Self-Contradiction : T reating iterative GNN-based NRSs as construction-based [ 33 ]–[ 35 ]; • Scope Limitations : Only concerning RL -based [ 36 ]–[ 39 ] or T ransf ormer -based [ 40 ] NRSs. Heuristic Perspectiv e (Ours) ✓ ✓ • Hierarchical T axonomy : Detailing ho w solutions are constructed / improv ed; • Progression Identification : T racing NRSs from traditional heuristics; • Category-Specific Insights : Transferring from heuristics to NRSs with corresponding categories. † Unified P erspective refers to surve ying the field through single-dimension attributes. ‡ Algorithm-Level Perspective refers to surve ying the field through differences among algorithms as a whole. current progress in NRSs. Results under the new e valuation pipeline reveal that many NRSs are outperformed by simple construction-based heuristics such as nearest neighbor and random insertion, indicating that the con ventional ev aluation pipeline tends to be overly optimistic. In addition, two major challenges in the field are discussed, i.e. , in-problem and cross- problem generalization, and related suggestions are pro vided. The rest of this surve y is or ganized as follows: • Section II introduces essential preliminaries and details of the proposed NRS taxonomy . • Section III , IV , and V respectiv ely revie w and analyze the categories of NRSs identified in the taxonomy . • Section VI proposes a ne w ev aluation pipeline and bench- marks representative NRSs in terms of zero-shot in- problem generalization, where the results rev eal pre vi- ously unreported limitations in NRS development. • Section VII outlines key research challenges and provides corresponding suggestions for future work. • Section VIII concludes this surve y . I I . B A C K G RO U N D S A N D P R O P O S E D T A X O N O M Y A. The F ormulation of V ehicle Routing Problem This subsection introduces a three-index vehicle flow for- mulation [ 42 ] for the Capacitated VRP (CVRP), which is extendable to dif ferent VRP variants. The formulation is defined on a complete directed graph G = ( V , A ) , where the node set V = { 0 , 1 , . . . , n } includes a depot (node 0 ) and n customers. Each arc ( i, j ) ∈ A is associated with a tra vel cost coefficient c ij > 0 . The fleet consists of K vehicles, each with a homogeneous capacity C . Each customer i ∈ V \ { 0 } has a demand d i > 0 , while the depot has d 0 = 0 . T o capture the routing decisions, two sets of binary variables are used: x k ij indicates whether vehicle k traverses arc ( i, j ) , and y k i indicates whether customer i is served by vehicle k . The problem formulation can be defined as follo ws: min X i ∈ V X j ∈ V c ij K X k =1 x k ij (1) s.t. K X k =1 y k i = 1 ∀ i ∈ V \{ 0 } , (2) K X k =1 y k 0 = K , (3) X j ∈ V x k ij = X j ∈ V x k j i = y k i ∀ i ∈ V , k ∈ { 1 , . . . , K } , (4) X i ∈ V d i y k i ≤ C ∀ k ∈ { 1 , . . . , K } , (5) X i ∈ S X j / ∈ S x k ij ≥ y k h ∀ S ⊆ V \{ 0 } , h ∈ S , k ∈ { 1 , . . . , K } , (6) y k i ∈ { 0 , 1 } ∀ i ∈ V , k ∈ { 1 , . . . , K } , (7) x k ij ∈ { 0 , 1 } ∀ i, j ∈ V , k ∈ { 1 , . . . , K } . (8) In this formulation, objective ( 1 ) minimizes the total travel cost. Constraint ( 2 ) ensures that each customer is visited exactly once. Constraint ( 3 ) requires all K vehicles to depart from the depot, and constraint ( 4 ) enforces that a vehicle must arriv e at and depart from the same customer . Constraints ( 5 ) and ( 6 ) impose capacity limit and route connectivity for each vehicle k , respectively . Finally , constraints ( 7 ) and ( 8 ) specify the binary nature of the decision variables. This formulation explicitly identifies vehicle-arc assignments, facilitating the in- corporation of additional constraints ( e .g. , time windows [ 42 ]) and accommodating asymmetric cases. For undirected graphs, directed arc variables x k ij can be replaced with edge variables x k e , where e ∈ E denotes an undirected edge. B. Cate gories of Heuristics T raditional heuristics for solving VRPs can be primarily classified into two cate gories: construction-based methods and improv ement-based methods [ 43 ]. 1) Construction-based Methods: As shown in Fig. 1 , construction-based methods generate a complete solution from scratch. They can be further divided by whether solutions are generated directly on the original graph or on decomposed subgraphs. Specifically , single-stage methods [ 3 ] w ork on the original graph using simple strate gies such as nearest neighbor , insertion [ 44 ], and sweep algorithm [ 45 ]. In contrast, two- stage methods [ 42 ] decompose the problem into different stages, typically separating customer assignment to vehicles from node sequencing within each route. 3 T w o - sta ge In st ance ( Input ) So luti o n ( Out put ) Single - st age ⋯ ⋯ Pr eviou s Partia l So luti on Curr ent Partia l So luti on Co nstruct ion - b as ed Metho d: Co nstruct fr om Scratch Stage 1: Su bg rap hs Stage 2: Com plete So luti on Pop ulat io n - based Single - so lut io n - ba sed ⋯ ⋯ Pr ev iou s So luti o n N ew So luti o n ⋯ ⋯ Pr eviou s Po pu la ti on New Po pu la ti on Impr ov ement - based Met ho d: Impr ov e fr om So lution(s ) Fig. 1. Hierarchical structure of the heuristic taxonomy . There are two main heuristic categories: the non-iterativ e construction-based methods and the iterativ e improvement-based methods. Construction-based methods can be further di vided into single-stage and two-stage methods, based on whether the original graph is decomposed. Improv ement-based methods can be further split into single-solution-based and population-based methods, depending on the number of solutions maintained during the improvement process. 2) Impr ovement-based Methods: Improv ement-based meth- ods, also illustrated in Fig. 1 , iteratively refine one or more complete solutions during the optimization process. They can be further divided based on the number of solutions in volv ed during the search process. Specifically , single-solution-based methods [ 3 ], [ 46 ] focus on refining one solution by e xploring its neighborhood with a small or lar ge size. In contrast, population-based methods [ 47 ], [ 48 ] maintain a population of candidate solutions, and lev erage collective information to guide the search to wards promising regions. C. Generation P aradigms NRSs mainly adopt two generation paradigms to select elements ( i.e. , nodes or edges): the Autore gressiv e (AR) and Non-autoregressi ve (NAR) approaches. 1) Autor e gr essive P aradigm: In this paradigm, nodes or edges are generated sequentially , with each new element con- ditioned on previous ones. This sequential dependency mimics a step-by-step decision-making process, which tends to yield high-quality solutions b ut at the cost of slo wer inference speed. In NRSs, the AR paradigm is well-suited to both construction- based methods that incrementally append or insert a node to a partial solution [ 41 ], and improv ement-based methods that iterativ ely apply a local search move to refine a solution [ 49 ]. 2) Non-Autor e gr essive P aradigm: In contrast, the N AR paradigm generates all elements concurrently in a single forward pass. This massively parallel strategy can significantly improv e computational ef ficiency , though it may compromise solution quality due to the simplified independence assump- tion among elements. In NRSs, the N AR methods typically generate a probability distribution represented as a heatmap, ov er all candidate edges in the solution [ 50 ]. The final solution is then generated through guided stepwise edge selection, and additional refinement steps may be applied afterw ards. D. Major Learning P aradigms T o acquire heuristic rules from data, NRSs primarily rely on two learning paradigms: Supervised Learning (SL) and Reinforcement Learning (RL). 1) Supervised Learning: SL trains a model on a dataset of input-label pairs to learn the mapping [ 51 ]–[ 53 ]. In NRSs, the typical goal is to imitate decisions made by an expert solver , such as predicting the next node to add using a known optimal solution as the label. While this approach enables efficient learning from high-quality data, its performance is inherently bounded by the quality of the labeled data and is unlikely to surpass the expert solver it imitates. 2) Reinfor cement Learning: RL formulates solving VRPs as a sequential decision-making process [ 41 ], [ 54 ], [ 55 ]. A solver agent learns a polic y to get a high-quality solution by taking actions ( e.g. , selecting nodes) based on a given state ( e.g . , the current partial solution) and receiving a scalar reward ( e.g . , the negati ve tour length) as feedback at the end. The objectiv e is to learn a policy that maximizes the cumulativ e rew ard. This paradigm is well-suited for NRSs as it does not require pre-solved instances, allo wing the agent to explore and potentially surpass any known strategy . Nev ertheless, RL- based methods may suffer from issues such as sparse rewards and high memory ov erhead from storing full trajectories. E. Pr oposed T axonomy and Statistics This survey proposes a taxonomy of NRSs from the per- spectiv e of heuristics. As shown in Fig. 2 , this taxonomy classifies NRSs into a multi-level hierarchy based on solution construction or improvement strategies rooted in the classical heuristic taxonomy . It naturally accommodates NRSs with different generation paradigms (AR or NAR) and learning paradigms (SL or RL) across categories. Fig. 2 further reports the statistics of all 344 NRSs across hierarchical le vels. For NRSs, the heuristic taxonomy structure outlined in Sec- tion II-B admits finer distinctions within several subcategories. 4 Neura l Ro uting So lv ers ( 3 4 4 Paper s ) Fig. 2. Hierarchical structure of the proposed NRS taxonomy . Each subcategory is presented with the proportion of existing studies. The statistics are obtained from Google Scholar between January 1, 2015, and November 17, 2025. The paper list is further filtered by content relev ance and supplemented with relev ant experience. Finally , there are a total of 439 papers, including 344 methods across various categories, as well as other related studies such as surveys and benchmarks. Note that an NRS may contribute to the counts of multiple subcategories, due to the adoption of multiple inference strategies. Nex t Sel ecti on Sel ecti ng the Nex t No de Ap pending to th e End New Part ial So lution (a) Appending Nex t Sel ecti on Sel ecti ng the Next No de Pr edi cting the Position N ew Pa rtial So lution (b) Insertion Fig. 3. Illustration of subcategories of single-stage methods. (a) For appending methods, the selected nodes are linked to the end of partial solutions one at a time. (b) For insertion methods, the positions are not limited. For example, single-stage NRSs for construction can be split into appending and insertion variants, depending on ho w nodes or edges are incorporated into a partial solution. Similarly , single-solution NRSs for improvement can be categorized by neighborhood size into small and large neighborhood methods, where the latter aligns with the traditional Lar ge Neighborhood Search (LNS) heuristics. Details of different categories are provided in Section III , IV , and V . I I I . C O N S T R U C T I O N - B A S E D M E T H O D S In NRSs, construction-based methods build solutions incre- mentally from scratch. Similar to classical construction-based heuristics, they can be further split into single-stage and two- stage methods. The key distinction is whether the (partial) solutions are constructed directly on the original graphs or on subgraphs created by a separate decomposition stage. A. Single-Stage Methods Single-stage methods generate complete solutions from scratch without problem decomposition, with representative methods presented in T able II . Currently , most methods employ an appending strategy , sequentially adding selected elements to the end of the partial solution. Ho wever , alternativ e popular construction strategies in traditional heuristics, such as insertion, remain largely unexplored in NRSs. Therefore, although single-stage methods constitute the most active direc- tion in current NRS research according to Fig. 2 , their design space and potential ha ve not yet been fully e xplored. 1) Appending: As illustrated in Fig. 3 , nodes or edges are sequentially attached to the end of a partial solution in appending methods. Related inference strategies include greedy appending, sampling [ 56 ], [ 57 ], beam search [ 50 ], [ 58 ], [ 59 ], (restricted) dynamic programming (DP) [ 60 ], and Monte Carlo tree search (MCTS) based appending [ 61 ]. Given that the appending position is predetermined, the core of these methods lies in stepwise element selection. Traditional heuristics such as nearest neighbor and sweep algorithms [ 45 ] rely on greedy rules based on Cartesian distance or polar angle. Corresponding NRSs replace them with learned ones. In AR appending methods, learned rules sequentially select the next node to append based on the current solution state. Consequently , this approach has driv en efforts to improve the model’ s ability for state representation and reasoning based on the current state. The first NRS Ptr-Net [ 51 ] employs an attention-based pointer mechanism for stepwise node se- lection. PN-RL [ 56 ] introduces RL into NRSs and adopts activ e search to fine-tune on individual test instances. AM [ 41 ] incorporates the Transformer -based encoder-decoder architec- ture, which impro ves state representation ability . Subsequently , POMO [ 54 ] extends this work by le veraging multiple trajec- tories with different starting nodes to enhance exploration. T o mitig ate interference from irrelev ant information of visited nodes during stepwise selections, some methods pe- riodically re-embed feasible nodes [ 84 ], [ 85 ]. This alternating process of re-encoding for updated embeddings and decoding for node selection inevitably incurs substantial computational cost, yet enables more accurate state representation. A more direct alternativ e shifts the computational burden to a stronger decoder that performs stepwise dynamic node re-embedding. As a result, the original H eavy Encoder and Light Decoder (HELD) structure is replaced by a Light Encoder Hea vy Decoder (LEHD) or even a Decoder-only structure. Methods adopting this design, such as BQ [ 53 ] and LEHD [ 52 ], demon- 5 T ABLE II R E P R E S E N TA T I V E C O N S T R U C T I O N - BA S E D S I N G L E - S TAG E N R S S T ertiary Generation Solvable Backbone Learning Method Y ear Remarks Category Paradigm VRPs Paradigm Appending AR TSP LSTM SL Ptr-Net [ 51 ] 2015 The first NRS. RL PN-RL [ 56 ] 2017 The first RL-based NRS. TSP , CVRP , T ransformer RL AM [ 41 ] 2019 The first NRS with the Transformer OP , SDVRP , encoder-decoder model. (S)PCTSP MD AM [ 62 ] 2021 A multi-decoder framework with re-embedding. (A)TSP T ransformer RL MatNet [ 63 ] 2021 Matrix Encoding Network. TSP , CVRP , T ransformer RL Sym-NCO [ 64 ] 2022 Training scheme with symmetricities. PCTSP , OP PDP T ransformer RL MAPDP [ 65 ] 2022 A multi-agent RL-based NRS for PDP . MO TSP , MOCVRP T ransformer RL P-MOCO [ 66 ] 2022 A multi-objective NRS with a preference-conditioned model. (A)TSP , CVRP , OP Transformer SL BQ [ 53 ] 2023 Decoder-only structure. TSP , CVRP T ransformer SL LEHD [ 52 ] 2023 Light-Encoder Heavy-Decoder structure. (Greedy) SIL [ 67 ] 2025 Self-improved Training. (Greedy) RL POMO [ 54 ] 2020 P arallel multiple rollouts. ELG [ 68 ] 2024 Ensemble of local and global policies. INV iT [ 69 ] 2024 Distance-based search space reduction. ICAM [ 55 ] 2025 Distance-biased Attention. L2R [ 70 ] 2025 Learning-based search space reduction. min-max VRPs T ransformer RL DPN [ 71 ] 2024 Decoupling tasks in the encoder for min-max VRPs. (V ariants of) T ransformer RL MTPOMO [ 72 ] 2024 A multi-task generalizable NRS. CVRP , VRPTW MVMoE [ 73 ] 2024 An MoE-based NRS for multi-attribute VRPs. O VRP , VRPB CaD A [ 74 ] 2025 A constraint-prompted dual-attention mechanism. VRPL ReLD [ 75 ] 2025 Enhancing the Light Decoder for generalization. A TSP , CVRP , T ransformer SL GOAL [ 76 ] 2025 A generalist NRS with a single backbone plus CVRPTW , (S)OP , problem-specific adapters. PCTSP , OVRP , SDCVRP , TRP N AR TSP GCN SL GCN [ 50 ] 2019 An NAR NRS with graph ConvNet. A GNN RL DIMES [ 57 ] 2022 Proposing a differentiable parameterization (Greedy) of the solution space. TSP , CVRP GNN GFlo wNet A GFN [ 77 ] 2025 A GFlowNet-based construction-based NRS. Insertion AR TSP GNN RL S2V -DQN [ 78 ] 2017 A GNN-based insertion NRS. TSP , CVRP T ransformer SL L2C-Insert [ 79 ] 2025 An AR SL-based insertion NRS. (Greedy) N AR TSP U-Net SL DMPP [ 80 ] 2022 An NAR NRS with image-based diffusion models. A GNN SL DIFUSCO [ 81 ] 2023 An NAR NRS with graph-based diffusion models. strate improved generalization ability . These two methods typically rely on SL to achieve high sample efficiency . For VRPs with common distance-related objecti ves, the optimal next node to append is often close to the current partial solution. This observation has inspired two distinct strategies. The first is to restrict candidate selection at each step to a local neighborhood based on distance, which dra- matically reduces the computational complexity and difficulty of node selection with little loss in solution quality . The second is to explicitly incorporate node-wise distance infor- mation into specific modules, thereby enhancing the model’ s ability to assess the current state. Examples of the former local policy approach include [ 53 ], [ 68 ]–[ 70 ], [ 86 ], [ 87 ]. Particularly , ELG [ 68 ] introduces an auxiliary local policy on polar-coordinate features in addition to the regular global policy , while INV iT [ 69 ] aggregates multi-scale neighborhood information through nested local views. The latter distance- enhanced modeling strate gy is demonstrated in [ 55 ], [ 68 ], [ 70 ], [ 75 ], [ 86 ], [ 88 ]–[ 90 ]. Specifically , ICAM [ 55 ] introduces a distance-based adaptation function within the attention mech- anism to better capture spatial relationships. AR appending remains an activ e research area in NRSs, with a notable adv antage that lies in learning a relati vely simple stepwise node-selection policy . Howe ver , like tradi- tional construction-based heuristics, these methods generate solutions from scratch, where suboptimal selections in early steps inevitably impact the quality of subsequent decisions. The solution quality can be further improved by iteratively refining solution segments using the same inference mecha- nism, though at the cost of increased computational overhead. 6 T ABLE III R E P R E S E N TA T I V E C O N S T R U C T I O N - BA S E D T W O - S TAG E N R S S Role of the Generation Solvable Backbone Learning Method Y ear Remarks First Stage Paradigm VRPs Paradigm Scale Reduction AR TSP CNN, RL H-TSP [ 82 ] 2023 A two-stage NRS capable for TSP instances with T ransformer 10K nodes. Scale Reduction; AR CVRP T ransformer RL T AM-AM [ 83 ] 2023 A two-stage NRS capable for VRP instances with Constraint Handling over 5K nodes. Such refinement strategies fall under the restricted direct LNS subcategory , which is discussed further in Section IV -B1b . In contrast, NAR appending methods like GCN [ 50 ] and DIMES [ 57 ] select elements in a single pass guided by a pre- dicted heatmap. While this approach enables faster inference, the static nature of heatmap cannot account for the influence of dynamic masked elements or the e volving partial solution, thereby gradually distorting the guidance information and leading to suboptimal performance. T o mitigate this limitation, one potential direction is to dev elop an inference process that dynamically updates the heatmap during element selection. Another plausible direction is to adopt iterati ve refinement, thereby con verting these methods into improvement-based approaches. In such cases, techniques such as population- based strategies or local search can be applied to refine the solutions (see more details in Section IV and V ). 2) Insertion: W ithin single-stage methods, insertion re- mains a notable yet underexplored alternative to the prev alent appending paradigm. As illustrated in Fig. 3 , insertion methods can place unvisited nodes into arbitrary positions of the partial solution, rather than only at the end. This flexibility introduces two coupled decisions, namely , which nodes to insert and where to insert them. While having higher time complexity , insertion can mitigate error accumulation inherent in appending by allo wing corrections in subsequent steps. Only a few studies hav e attempted to learn insertion poli- cies. Among AR insertion approaches, S2V -DQN [ 78 ] selects nodes with the highest predicted values and inserts them at the minimum-cost positions for TSP . Besides, L2C-Insert [ 79 ] selects un visited nodes via a nearest-neighbor rule and learn to determine the insertion positions. A few NAR insertion methods, such as DIFUSCO [ 81 ], incorporate greedy edge insertion guided by predefined priority scores as one inference strategy . These initial efforts, ho we ver , only scratch the surface of insertion. Future research could in vestigate the design of more effecti ve joint policies that explicitly model node- position interactions, while balancing computational overhead with the opportunity to repair earlier suboptimal decisions. B. T wo-Stage Methods T wo-stage methods are designed to address different chal- lenges separately in each stage. The widely used “cluster- first route-second” strategy [ 45 ], [ 91 ] first groups customers into feasible clusters based on constraints and then sequences nodes within each cluster ( i.e . , subgraph) by solving a set of smaller TSPs. It can significantly reduce the problem scale and allows the second stage to focus on sequencing. This strategy has been adopted by a fe w NRSs as shown in T able III . For example, T AM-AM [ 83 ] partitions a large-scale VRP E xcha nge / Mo ve L im ited E le me nts Nex t Iterat io n (a) Small Neighborhood Destr oy and Repair Next Itera tio n 1 3 2 (b) Large Neighborhood Fig. 4. Illustration of subcategories of single-solution-based methods. (a) For small neighborhood methods, an example with the 2-opt operator is presented. At each iteration, two edges are replaced. (b) For large neighbor- hood methods, the classic destroy-and-repair process is illustrated. At each iteration, some nodes are picked out and then reinserted one by one in a prescribed order (indicated by the numbered labels). into clusters of small-scale TSPs in the first stage, and then applies a single-stage solver such as AM for each TSP in the second stage. Other methods, such as H-TSP [ 82 ], solely target the scaling challenge of TSPs by decomposition, which generate open-loop tours per cluster and then connect them to form a complete solution. By lev eraging existing TSP solvers, these methods essentially transfer the core challenge of problem solving to the graph-partitioning step. Furthermore, related improvement-based methods with iterativ e redi vision and refinement are discussed in Section IV -B1b . I V . S I N G L E - S O L U T I O N - B A S E D M E T H O D S F O R I M P R OV E M E N T Single-solution-based methods iteratively improve a com- plete solution by exploring its neighborhood, which is a specific subset of feasible solutions reachable from the current solution through specific modifications. A. Small Neighborhood Methods As presented in Fig. 4 , small neighborhood methods explore neighborhoods with limited sizes defined by local search operators. Based on whether moves are decomposed, they are categorized into immediate and sequential search. Immediate search relies on simple operators such as swap and 2-opt. In contrast, sequential search employs more complex operators like k-opt (k > 2), where each mov e is typically decomposed into a sequence of steps to mitigate decision comple xity . 1) Immediate Sear ch: There are typically tw o steps in each iteration of immediate search methods: (1) selecting a few nodes or edges, and (2) performing a single move via a local search operator . Learned rules in these methods 7 T ABLE IV R E P R E S E N TA T I V E I M P R OV E M E N T - B A S E D S I N G L E - S O L U T I O N - B A S E D S M A L L N E I G H B O R H O O D N R S S Quaternary Generation Solvable Backbone Learning Method Y ear Remarks Category Paradigm VRPs Paradigm Immediate AR CVRP LSTM RL NeuRewriter [ 92 ] 2019 Improvement with separate policies to select node-pairs. TSP , CVRP Transformer RL LIH [ 49 ] 2021 Impro vement with a single policy to select node-pairs. D A CT [ 93 ] 2021 Improv ement with cyclic positional encoding. TSP GCN, FiLM, RL Neural-3-OPT [ 94 ] 2021 Impro vement with the 3-opt operator . LSTM PDP T ransformer RL NCS [ 95 ] 2024 An improvement-based NRS for PDP . N AR TSP GNN SL RGLS [ 96 ] 2022 Predicting regret for guided local search. AR TSP , Transformer , RL NeuOpt [ 97 ] 2023 Impro vement with flexible k-opt. CVRP GRU TSP , PDP , CVRP , SGN SL, UL NeuroLKH [ 98 ] 2021 Introducing DL to LKH. CVRPTW Sequential TSP GCRN SL Att-GCN [ 99 ] 2021 Introducing MCTS-k-opt to N AR NRSs. N AR A GNN RL DIMES [ 57 ] 2022 Proposing a differentiable parameterization of (MCTS-k-opt) the solution space. A GNN SL DIFUSCO [ 81 ] 2023 An N AR NRS with graph-based diffusion models. (MCTS-k-opt) SA G UL UTSP [ 100 ] 2023 A NAR UL-based NRS. / / SoftDist [ 101 ] 2024 A critique of DL-output-heatmap-MCTS-k-opt paradigm. primarily focus on the selection step, implemented either autoregressi vely , such as choosing nodes or edges with an agent, or non-autoregressi vely , such as generating a heatmap to guide iterative node pair or edge selection. AR immediate search methods select moves via learned rules rather than handcrafted distance-based ones. For exam- ple, NeuRewriter [ 92 ] uses two interrelated learned rules to separately select two nodes for a local search mov e, while LIH [ 49 ] and D ACT [ 93 ] employ a single learned rule to select node pairs. DA CT additionally addresses challenges related to positional encoding. In contrast, Neural-3-OPT [ 94 ] learns separate rules to remove and reconnect three edges for each 3-opt mov e. NAR immediate search methods, such as RGLS [ 96 ], use heatmaps predicted by learned rules to guide the improvement process. For example, regret v alues can be predicted for all edges to steer the improvement process in guided local search (GLS) [ 102 ]. Benefiting from fine-grained local search operators, imme- diate search methods typically perform well on small-scale instances. Never theless, their limited neighborhood size makes them prone to local optima and less effecti ve on large-scale problems. Therefore, the dev elopment of such methods has encountered a bottleneck in recent years. 2) Sequential Sear ch: Sequential search methods typically employ k-opt operators with k > 2 to expand the search neigh- borhood for discovering better solutions. Howe ver , increasing k would lead to e xponential gro wth in neighborhood size and, consequently , in computational complexity . A plausible strategy to address this is to decompose a k-opt move into a sequence of basic moves, which treats the improvement process as a Marko v Decision Process. There are various strategies to select a basic mov e at each step. T o begin with, AR methods learn rules for stepwise basic move selections. For example, NeuOpt [ 97 ] dynamically adjusts k to balance coarse- and fine-grained search. Besides, N AR methods prioritize basic mov es based on per-edge values in heatmaps, and can be further split by whether the heatmap is static or updated during inference. (1) NAR methods with static heatmaps typically take advanced heuristic algorithms with k-opt, such as LKH [ 103 ], as their backbone. For example, NeuroLKH [ 98 ] replaces LKH’ s handcrafted edge- preference prediction rule with a learned one to determine edge candidate sets and search priorities. (2) NAR methods with dynamic heatmaps often utilize MCTS to iterativ ely update the heatmaps for guiding the k-opt search. In particular, Att-GCN [ 99 ] merges multiple heatmaps from small-scale subgraphs to generate the heatmap for a large-scale instance. DIMES [ 57 ] incorporates an extra meta-learning-based fine- tuning stage to improv e performance. DIFUSCO [ 81 ] intro- duces a graph-based diffusion frame work for modeling the explicit node or edge selection, while UTSP [ 100 ] eliminates the need for costly labeled datasets via unsupervised learn- ing. Nev ertheless, SoftDist [ 101 ] critically re-e valuates the heatmap-MCTS-k-opt paradigm, particularly questioning the effecti veness of DL-based heatmap generation. This finding highlights fundamental limitations of the current paradigm, underscoring the need for more principled studies. B. Lar ge Neighborhood Methods Large neighborhood methods are grounded in the LNS heuristics [ 116 ], which explore broader solution regions to escape local optima while maintaining manageable computa- tional complexity [ 117 ]. Corresponding NRSs learn different rules to either enhance classical LNS components, such as destroy and repair criteria for perturbation, or to automate the criterion selection. Beyond refining classical LNS, NRSs also introduce nov el paradigms such as search in auxiliary latent spaces. These approaches are identified as direct LNS when 8 T ABLE V R E P R E S E N TA T I V E I M P R OV E M E N T - B A S E D S I N G L E - S O L U T I O N - B A S E D L A R G E N E I G H B O R H O O D N R S S Quaternary Generation Solvable Backbone Learning Method Y ear Remarks Category P aradigm VRPs Paradigm AR CVRP , T ransformer RL NLNS [ 104 ] 2020 LNS with two handcrafted destroy and SD VRP one learned repair criteria. Unrestricted CVRP , GA T , GRU RL EGA TE [ 105 ] 2020 LNS with one destroy and one repair criteria Direct LNS CVRPTW learned by a single model. TSP , CVRP T ransformer SL L2C-Insert [ 79 ] 2025 LNS with one handcrafted destroy and (Iteration) one learned repair criteria. CVRP T ransformer RL L2I [ 106 ] 2020 ILS with both small and large neighborhood search. N AR TSP Transformer SL GenSCO [ 107 ] 2025 ILS with a generation process for local search. AR TSP , CVRP T ransformer SL LEHD [ 52 ] 2023 Iterative random reconstructions of partial solutions (RRC) via appending. SIL [ 67 ] 2025 Iterative parallel reconstructions of partial solutions (PRC) via appending and related iterative training without labels. DRHG [ 108 ] 2025 LNS with restricted ranges (outside hypernodes). TSP , CVRP , T ransformer RL LCP [ 109 ] 2021 Iterativ e re-decompositions and revisions. Restricted PCTSP Direct LNS (A)TSP , OP , CVRP , OVRP , AGNN, RL UDC [ 110 ] 2024 Considering the negativ e impact of sub-optimal (S)PCTSP , T ransformer dividing policies. min-max mTSP / CVRP(TW), VRPMPD T ransformer RL L2D [ 111 ] 2021 Iterativ e subproblem selection and optimization. LSTM, RL RBG [ 112 ] 2022 Iterative re-partitioning, merging, and re-solving. T ransformer (A)TSP , CVRP , GNN, RL GLOP [ 113 ] 2024 An NRS with both NAR and AR paradigms. PCTSP Transformer Indirect LNS NAR TSP A GNN SL T2T [ 114 ] 2023 Integrating local search in diffuse-and-denoise. Fast T2T [ 115 ] 2024 Mapping from different noise lev els to the optima. searching directly on the original solution representation, and indirect LNS when conducted in an auxiliary space. 1) Dir ect LNS: Direct LNS methods search directly on the original decision space. They can be further categorized by the flexibility of allowed modifications: (a) unrestricted direct LNS permits modifications anywhere in the solution sequence, whereas (b) restricted direct LNS limits modifications to certain predefined positions of the solution. a) Unr estricted Dir ect LNS: Unrestricted Direct LNS methods are typically b uilt upon the classic destroy-and- repair paradigm of the LNS heuristic, where neighborhoods are implicitly defined by the destroy and repair criteria. In each iteration, the destroy step removes multiple nodes from the complete solution, and the repair step reinserts them sequentially back into the solution for potential improvement. This approach offers two key advantages: (1) computational scalability [ 102 ], because the number of nodes removed and reinserted ( i.e. , the perturbation strength) is independent of instance size; and (2) solution quality [ 122 ], as e ven a small set of nodes, when destroyed and repaired under effecti ve criteria, can lead to promising improv ement. Current related NRSs typically focus on learning effecti ve destroy or repair criteria. For example, NLNS [ 104 ] incor- porates two handcrafted destroy criteria and a learned repair criterion, while EGA TE [ 105 ] employs a single learned rule to both select nodes for remov al and determine reinsertion sequences. When applied iterativ ely , L2C-Insert [ 79 ] can also be re garded as an LNS variant when its learned insertion rule is treated as the repair criterion, complemented by a handcrafted destroy step. The I terated Local Search (ILS) heuristic [ 123 ] further e xtends LNS by interleaving between large neighbor- hood perturbation to escape the local region and fine-grained local search to refine the solution. In particular , L2I [ 106 ] integrates DL into ILS to select both local search operators and destroy or repair criteria. GenSCO [ 107 ] perturbs solutions via successiv e 2-opt moves, as commonly used in heuristics [ 124 ], and then refines them using a rectified flow model. The effecti veness of LNS heuristics relies not only on well-designed destroy and repair criteria, but also on rules for controlling the perturbation strength, adapting the criteria, determining the insertion orders, and designing more complex acceptance criteria [ 102 ], [ 125 ]–[ 127 ]. Howe ver , the current NRSs have focused predominantly on learning destroy and repair criteria, leaving other critical rules still largely hand- crafted. Therefore, a key future research direction is to auto- mate the design of these rules and to thoroughly inv estigate their interactions. This holistic design principle is crucial for advancing both this subcategory and NRSs more broadly . b) Restricted Dir ect LNS: After the destroy step, typical LNS heuristics encounter scenarios in volving partial solutions and un visited nodes, identical to those faced in construction- based methods. Recent studies have therefore drawn inspira- tion from single-stage and two-stage construction-based meth- ods to dev elop new iterati ve approaches adhering to LNS prin- ciples. Some of them iteratively reconstruct partial solutions with single-stage strate gies. In contrast, others adopt iterative versions of two-stage methods, which repeatedly partition the problem and solve subproblems with existing NRSs or 9 T ABLE VI R E P R E S E N TA T I V E I M P R OV E M E N T - B A S E D P O P U L AT I O N - B A S E D N R S S Search Generation Solvable Backbone Learning Method Y ear Remarks Space Paradigm VRPs Paradigm Continuous NAR TSP , CVRP GR U SL CV AE-Opt [ 118 ] 2021 Latent space search with DE. T ransformer RL COMP ASS [ 119 ] 2023 Latent space search with CMA-ES. Discrete NAR (PC)TSP , (S)OP , GNN RL DeepA CO [ 120 ] 2023 Learning heuristic measures in ACO with RL. CVRP(TW) GFlowNet GF ACS [ 121 ] 2025 Learning heuristic measures in ACO with GFlowNet. heuristics. Though not explicitly framed in classical heuristics, these paradigms can be regarded as position-restricted destroy- and-repair and thus a subcategory of LNS methods. For the extensions of single-stage methods, the appending LEHD [ 52 ] can use a flexible Random Re-Construct (RRC) approach to refine a sampled partial solution at each iteration. From the perspectiv e of LNS, RRC, and its parallel version Parallel local Re-Construction (PRC), destroy random node sequences and adopt the learned appending rule as the repair criterion. Integrating this iterativ e improv ement approach into SL training can further reduce the reliance on high-quality solutions [ 52 ], [ 67 ], [ 128 ] and ev en enable direct training on large-scale instances [ 67 ]. In addition, DRHG [ 108 ] treats par- tial solutions as hypernodes, which are sequentially appended with unconnected nodes during the repair process. Instead of designing more po werful subsolvers, the exten- sions of two-stage methods, such as the so-called “hierarchical search” [ 109 ], [ 112 ], “divide-and-conquer approach” [ 110 ], [ 113 ], [ 129 ], and “learning-augmented local search” [ 111 ], focus on dev eloping appropriate strategies that leverage ex- isting NRSs or heuristics to achiev e better ov erall perfor- mance. F or example, LCP [ 109 ] employs a seeder policy to generate candidate solutions, which are then optimized in parallel by a reviser that iteratively decomposes and recon- structs them. RBG [ 112 ] decomposes a complete solution into non-overlapping re gions, each containing several routes. This di vision is iterati vely updated by a learned re writer that selects regions to split or merge, after which a generator then generates the routes for the updated regions. Both GLOP [ 113 ] and UDC [ 110 ] initially generate a heatmap for decomposition. GLOP partitions the original problem once into sub-TSPs, in which divide-and-conquer steps are further applied. In contrast, UDC employs iterative subproblem re-divisions, and the subproblems are not limited to TSP . These methods hav e gained popularity owing to their ability to extend existing construction-based NRSs through iterative refinement. Howe ver , like two-stage construction-based meth- ods, the subsolvers generally lack global information, which potentially leads to premature con ver gence. Moreov er , they are often presented merely as extensions of construction-based NRSs, without explicitly acknowledging their LNS nature, leading to insufficient attention to holistic algorithm design. A systematic analysis of LNS heuristics could inspire more prin- cipled designs. Promising future research directions include dynamically controlling subproblem sizes, similar to adaptive perturbation degree control in LNS, to balance exploration and exploitation, and identifying suboptimal partial solutions for further improvement while preserving promising ones. 2) Indir ect LNS: LNS methods can be generalized to oper- ate in an auxiliary space rather than the original decision space. The auxiliary space is often continuous, enabling gradient- based methods to guide the search. Moreover , operations performed in this space can simultaneously modify multiple parts of a solution, bypassing the sequential node-by-node selection and positioning required in the original decision space. It enables more extensiv e solution adjustment compared to classical destroy-and-repair perturbations, which typically modify only a small number of edges. A typical example is to use diffusion models for solving TSPs in an N AR manner [ 114 ], [ 115 ]. During inference, the forward noising process gradually increases the confidence of extra edges, which turns a feasible solution into an infeasible one with more edges. Con versely , the rev erse denoising pro- cess decreases the confidence of redundant edges to recover a feasible solution. The stochastic nature of diffusion allows applying an iterativ e noising-denoising process to produce div erse solutions. Incorporating effecti ve guidance, such as the gradient feedback in T2T for denosing [ 114 ], can further im- prov e the solution quality . A subsequent work, Fast T2T [ 115 ], further accelerates denoising via consistency modeling. Although indirect LNS methods differ from classical LNS, heuristics can still of fer v aluable insights. Current implementa- tions typically employ a fixed noise schedule during inference. Howe ver , as stated earlier , adaptiv e perturbation strength is crucial for balancing fine-grained search and escape from local optima [ 102 ]. Therefore, adaptiv ely adjusting re-noising levels based on search progress could be helpful. Additionally , the greedy decoding is often suboptimal, and more well-designed inference strategies deserve greater attention as in other N AR NRSs. Finally , heatmap-guided search is not the only possible paradigm for indirect LNS. Further work is expected to e xplore alternativ e auxiliary search spaces. V . P O P U L A T I O N - B A S E D M E T H O D S F O R I M P R OV E M E N T Population-based methods maintain and e volv e a set of candidate solutions, leveraging collectiv e information from the entire set to guide search [ 48 ], [ 130 ], [ 131 ]. In NRSs, these methods can be implemented either by operating directly on the discrete solution space of the original problem, or by transforming solutions into a continuous latent space for optimization, as illustrated in T able VI . For methods that work in the discrete solution space, DeepA CO [ 120 ] and GF A CS [ 121 ] enhance the classic A nt Colony Optimization (A CO) by replacing handcrafted heuris- tic measures for edges ( e.g . , inv erting the length) with learned scoring rules. Unlike various NAR construction-based NRSs 10 confined to TSP and Maximum Independent Set (MIS), these approaches inherit the flexibility of meta-heuristics, which can tackle a broader range of COPs. For methods that work in continuous latent space, CV AE- Opt [ 118 ] utilizes a Variational Autoencoder (V AE) model to learn the distrib ution of high-quality solutions, then e volv es a population in the latent space via dif ferential ev olution (DE) [ 132 ]. Besides, COMP ASS [ 119 ] parametrizes a con- tinuous polic y distribution and applies Co variance Matrix Adaptation Evolution Strategy (CMA-ES) [ 133 ] to search. Like classic domain-agnostic meta-heuristics, population- based methods e xhibit inherent rob ustness for problems with complex search spaces. A promising future direction is to adapt them to problems with dynamic environments, where traditional population-based heuristics ha ve demonstrated strong suitability [ 102 ]. In addition, gi ven the successful DL- based enhancement of the single-solution-based LKH [ 103 ] (as discussed in Section IV -A2 ), po werful population-based algorithms like HGS [ 130 ] could likewise be integrated with DL techniques to de velop more competiti ve NRSs. V I . E X P E R I M E N TA L S T U D I E S This section inv estigates the in-problem performance of representativ e NRSs, with a focus on their zero-shot gen- eralization ability , a topic of significant interest in recent years. The con ventional ev aluation pipeline is first applied, which emphasizes scalability on synthetic instances and yields promising results. Nevertheless, this pipeline suffers from no- table limitations, including a narrow range of test distributions, conflated in- and out-of-distribution comparisons, and incon- sistent inference settings. Therefore, a generalization-focused ev aluation pipeline is introduced for single-model performance across div erse benchmark instances, with unified inference and complementary metrics. Experimental results under this new pipeline reveal that NRSs trained on narrowly distributed data may be outperformed by ev en simple construction heuristics such as nearest neighbor and random insertion. This contrast suggests that the con ventional pipeline can systematically lead to ov erly optimistic conclusions. Building on these findings, the advantages of the proposed pipeline are discussed, and principles for method selection are outlined. In particular , learning is argued to remain crucial for NRSs, ev en when their performance falls short of prior expectations. The im- plementation details of the experimental studies are available in https://github .com/CIAM- Group/NRS Surve y . A. Selected Methods for Compar ative Evaluation The comparati ve e valuation incorporates two groups of methods: classical and SOT A heuristics that serve as baselines, and representative NRSs. The selected heuristics, chosen for their efficienc y or ef fectiveness, are briefly introduced belo w . • Nearest Neighbor A classic construction-based heuris- tic. At each step, the nearest node to the last node of the partial solution is selected for appending. • Random Insertion A classic construction-based heuris- tic. At each step, a randomly selected node is inserted at the position that minimizes the increase in cost. T ABLE VII S E L E C T E D N R S S F O R C O M PA R AT I V E E V A L U ATI O N Category Method Primary Secondary T ertiary Quaternary Construction Single-stage Appending / BQ [ 53 ] LEHD † [ 52 ] SIL † [ 67 ] ICAM [ 55 ] ELG [ 68 ] INV iT [ 69 ] L2R [ 70 ] DGL [ 137 ] ReLD [ 75 ] Insertion / L2C-Insert † [ 79 ] T wo-stage / / H-TSP [ 82 ] Improvement Single-solution Small Immediate DA CT [ 93 ] Neighborhood Sequential NeuOpt [ 97 ] Unrestricted L2C-Insert ‡ [ 79 ] Direct LNS GenSCO [ 107 ] Large Restricted Direct LNS LEHD ‡ [ 52 ] Neighborhood SIL ‡ [ 67 ] DRHG [ 108 ] Indirect LNS Fast T2T [ 115 ] Population / / GF ACS [ 121 ] † The NRS supports multiple inference strategies and currently employs a construction-based greedy inference. ‡ The NRS supports multiple inference strategies and currently employs an improvement-based one. For LEHD, SIL, and L2C-Insert, RRC, PRC, and insertion-based local reconstruction are adopted, respectively . • LKH-3 [ 134 ] A single-solution-based SO T A heuristic for TSP , widely adopted as a baseline in prior w orks. • HGS [ 135 ] A population-based SO T A heuristic for CVRP , widely adopted as a baseline in prior works. • AILS-II [ 136 ] A single-solution-based SOT A heuristic for CVRP , rarely adopted as a baseline in prior w orks. The selected NRSs comprehensi vely cov er all categories in the proposed taxonomy and are listed in T able VII . All inference experiments of NRSs are uniformly conducted on a single NVIDIA GeForce R TX 3090 GPU with 24GB of memory . Specifically , 20 cores of the Intel(R) Xeon(R) Gold 6348 CPU @ 2.60GHz and 40 GB of memory are allocated to each N AR NRS (GF A CS, GenSCO, and Fast T2T) for potential calculations on the CPU. B. Experiment on Conventional Evaluation Pipeline 1) Experimental Purpose: This pipeline generally ev aluates NRSs on synthetic instances with specific scales, node distri- butions, and optional constraint tightness [ 138 ]. Among these aspects, scalability is the most widely studied one and is also the primary focus of this e xperiment. It is important to note, howe ver , that scalability is not equiv alent to generalization, which will be discussed in detail in Section VI-D1 . 2) Experimental Settings: a) Pr oblem and Instance Setting: TSP unrelated to con- straint tightness is considered due to the lack of a unified setting in the literature. For scale and node distribution, the ev aluation follows common practice by testing on uniformly distributed instances at scales of 100, 1K, and 10K. All instances are drawn from the generated datasets of SIL [ 67 ]. 11 T ABLE VIII E X P E R I M E N TAL R E S U LT S O F C O N V E N T I O N A L E V A L UAT I O N P I P E L I N E Method TSP 100 TSP 1K TSP 10K Gap T ime Gap T ime Gap T ime LKH-3 0.000% 10.97m 0.000% 5.69m 0.000% 49.34m Nearest Neighbor 24.722% 6.72s 25.022% 0.97s 23.864% 2.29s Random Insertion 9.672% 2.04s 13.096% 0.46s 13.966% 4.64s ↑ BQ greedy 0.348% 1.13m 2.294% 1.19m / / ↑ LEHD ∗ greedy 0.576% 26.84s 3.116% 1.64m / / ∥ SIL ∗ greedy / / 1.952% 29.12s 4.061% 6.06m ↑ ICAM aug × 8 0.147% 44.66s 1.647% 3.93m / / ↑ ELG aug × 8 0.224% 3.02m / / / / ↑ INV iT -3V aug † 1.419% 32.44m 5.154% 5.52m 6.678% 1.27h ↑ L2R greedy / / 4.494% 6.48s 4.824% 1.07m ↑ DGL aug † 0.609% 14.16m 2.714% 1.42m 6.792% 10.61m ↑ L2C-Insert ∗ greedy 0.458% 1.24m 4.756% 32.98s 7.760% 1.11m ∥ H-TSP / / 6.673% 46.59s 8.329% 50.92s ∥ D A CT T=10K 0.379% 2.05h / / / / ∥ NeuOpt T=10K 0.018% 1.47h / / / / ↑ L2C-Insert ∗ T=1K 0.0001% 12.01h 0.485% 1.21h 2.086% 15.86m ∥ GenSCO 2-opt 0.0003% 1.96m 0.033% 6.76m / / ↑ LEHD ∗ RRC1K 0.002% 2.36h 0.729% 7.49h / / ∥ SIL ∗ PRC1K / / 0.375% 3.47h 1.824% 5.19h ↑ DRHG T=1K 0.0003% 7.12h 0.420% 3.89h 1.802% 1.05h ∥ Fast T2T ‡ T s =5, T g =5 0.030% 37.29m 0.589% 9.03m / / ∥ GF A CS T=10, K=100 / / 2.615% 3.14h / / ↑ The marked NRS reports generalization performance of single models, typically trained on the smallest-scale instances reported and tested on larger -scale, all with uniform node distribution. ∥ The marked NRS reports in-distribution performance of multiple models on specific scales with uniform node distribution. ∗ The NRS supports multiple inference strategies. † For INV iT and DGL, data augmentation factors vary by scale. Besides, the INV iT model with kNN size of (65, 50, 35) is adopted instead of the unav ailable (50, 35, 15) reported in the original study . ‡ For Fast T2T , the additional 2-opt improvement as a post process is adopted only in TSP 1K, according to the original paper . b) Metrics and Infer ence: T wo metrics are reported for each method: the optimality gap (Gap) and the total inference time (T ime). Specifically , the optimality gap measures the dis- crepancy between the obtained solutions and the best-kno wn solutions, provided by the LKH-3 heuristic, as is common practice in AM [ 41 ]. For NRSs, the released implementations and pretrained models are adopted. Note that each NRS is ev aluated only under a specific configuration on instances with corresponding sizes reported in the original studies. Results for unreported conditions are denoted by “/”. 3) P erformance Evaluation: According to T able VIII , NRSs exhibit promising performance under the con ven- tional pipeline . For construction-based NRSs, all of them outperform simple heuristics (nearest neighbor and ran- dom insertion) within their respectiv e categories. Specifi- cally , ICAM achieves strong in- and out-of-distrib ution results. Besides, L2R maintains competitive performance while reduc- ing inference time by approximately an order of magnitude. For large-scale instances with 10K nodes, where only a few construction-based methods are ev aluated, SIL (Greedy) deliv ers the best performance. In contrast, H-TSP gener - ally underperforms single-stage counterparts, falling short of the expected two-stage advantages on larger instances. F or impro vement-based NRSs, most of them achieve compet- itive performance close to that of the advanced heuristic LKH-3. For example, GenSCO with 2-opt achieves strong in-distribution results within a short runtime. In addition, among the limited NRSs tested at 10K, DRHG performs best, achieving slightly better performance than SIL (PRC) while using only about one-fifth of its inference time. Nev ertheless, GF A CS is outperformed by sev eral construction-based meth- ods (BQ, SIL (Greedy), and ICAM) at the scale of 1K. C. Experiment on the Pr oposed Evaluation Pipeline 1) Experimental Purpose: The con ventional ev aluation pipeline has se veral limitations. First, its testing distributions are limited in scope, typically restricted to specific scales and node distributions [ 139 ]. This restricted coverage poorly represents real-world scenarios. Moreover , the parameterized synthetic instance generators can bias performance to ward certain training distributions. Second, it does not distinguish the e valuation of single-model generalization performance ( i.e. , one model applied to all test instances) and multi-model in-distribution performance ( i.e. , separate models trained and tested per problem scale). Finally , the inference settings are typically inconsistent across different methods. In short, this pipeline inherently f av ors NRSs whose DL models ov erfit to the training distribution and report multi-model in-distribution performance, therefore introducing systematic ev aluation bias. T o address these issues, a ne w e valuation pipeline is intro- duced. It centers on the zero-shot in-problem generalization, which has been the primary focus of advanced NRSs in recent years and therefore serves as a representati ve indicator of progress in the field. Under this pipeline, NRSs are bench- marked on div erse instances that more faithfully reflect the irregular conditions of real-world production and logistics. Distributional biases inherent in synthetically generated in- stances, particularly those with uniformly distributed nodes, are avoided. In addition, the inference settings are consistently standardized across all e valuated NRSs. 2) Experimental Settings: a) Pr oblem and Instance Setting: The proposed ev al- uation pipeline assesses NRSs on representati ve TSP and CVRP . The test instances are drawn from benchmarks and challenge sets, covering diverse data distributions, with scales in (0 , 100 K], and specific edge-weight types ( EUC 2D or CEIL 2D ) to ensure integer Euclidean distance matrices. All selected instances have av ailable best known solutions (BKS) and do not impose additional constraints, such as fixed route numbers or duration limits. The composition of the test instances is detailed as follows. • TSPLIB [ 140 ] a famous dataset with TSP instances from various sources. 77 EUC 2D instances and 4 CEIL 2D are included. Note that the EUC 2D instance linhp 318 is excluded due to a fixed-edge constraint. • National a dataset with 27 EUC 2D TSP instances for countries, based on data from the National Imagery and Mapping Agency . All the instances are included. • VLSI a dataset with 102 EUC 2D TSP instances of industrial applications of the v ery large-scale integration design from the Bonn Institute. Note that 4 instances 12 T ABLE IX E X P E R I M E N TAL R E S U LT S O F T H E P RO P O S E D E V A L UATI O N P I P E L I N E Method (0,1K) [1K, 10K) [10K, 100K] T otal Gap T ime Solved Gap Time Solved Gap Time Solved Gap Solved TSP Nearest Neighbor 25.29% 0.01s 69/69 26.66% 0.29s 109/109 25.01% 22.60s 50/50 25.88% 228/228 Random Insertion 10.60% 0.00s 69/69 15.32% 0.05s 109/109 16.37% 8.93s 50/50 14.12% 228/228 LKH-3 t=n/3, runs=1 0.00% 7.88s 69/69 0.01% 631.34s 109/109 0.08% 14600.50s 50/50 0.03% 228/228 LKH-3 ↓ t=n/3, runs=1 0.00% 9.25s 69/69 0.01% 600.36s 109/109 0.05% 10800.24s 50/50 0.02% 228/228 BQ 5.00% 2.51s 68/69 19.03% 22.74s 92/109 52.00% 187.81s 4/50 14.02% 164/228 LEHD ∗ greedy 4.85% 1.01s 69/69 20.13% 68.27s 106/109 49.35% 1386.01s 11/50 16.19% 186/228 SIL ∗ greedy 8.64% 1.69s 69/69 9.83% 17.69s 109/109 11.11% 430.73s 50/50 9.75% 228/228 ICAM 6.53% 0.25s 69/69 16.62% 21.57s 109/109 21.34% 1050.33s 19/50 13.54% 197/228 ELG 6.05% 0.63s 69/69 18.14% 88.12s 108/109 21.65% 940.35s 6/50 13.70% 183/228 INV iT -3V 7.93% 2.77s 69/69 12.08% 49.03s 109/109 11.52% 1079.50s 42/50 10.67% 220/228 L2R 5.89% 1.60s 69/69 9.22% 15.55s 109/109 8.52% 153.11s 50/50 8.06% 228/228 DGL 6.53% 1.17s 69/69 11.32% 11.67s 109/109 11.14% 58.62s 25/50 9.67% 203/228 L2C-Insert ∗ greedy 4.39% 1.51s 69/69 18.12% 15.34s 109/109 30.94% 145.17s 50/50 16.77% 228/228 H-TSP 6.16% 0.61s 36/69 11.62% 3.15s 100/109 12.29% 21.44s 40/50 10.65% 176/228 D A CT T=1K 16.37% 39.84s 69/69 26.58% 261.73s 83/109 / / 0/50 21.94% 152/228 NeuOpt T=1K 19.90% 81.22s 46/69 / / 0/109 / / 0/50 19.90% 46/228 L2C-Insert ∗ T=1K 1.08% 381.55s 69/69 9.80% 479.98s 109/109 29.15% 615.19s 50/50 11.41% 228/228 GenSCO 14.56% 23.19s 68/69 35.46% 677.31s 104/109 35.17% 14304.70s 25/50 28.21% 197/228 LEHD ∗ RRC1K 1.73% 498.40s 69/69 10.87% 1634.51s 109/109 24.02% 2769.86s 9/50 8.13% 187/228 SIL ∗ PRC1K 0.80% 883.87s 69/69 2.58% 2880.46s 109/109 4.55% 4933.45s 50/50 2.47% 228/228 DRHG T=1K 0.10% 769.53s 69/69 1.46% 2857.55s 109/109 4.46% 3004.28s 50/50 1.71% 228/228 Fast T2T T s =10, T g =10 10.46% 1.41s 45/69 / / 0/109 / / 0/50 10.46% 45/228 GF A CS † T=100, K=100 31.64% 166.94s 66/69 86.77% 2601.13s 22/109 / / 0/50 45.42% 88/228 GF A CS ‡ T=100, K=100 0.72% 174.21s 69/69 3.76% 9142.93s 83/109 / / 0/50 2.38% 152/228 CVRP Nearest Neighbor 21.17% 0.03s 99/99 15.18% 1.08s 5/5 11.80% 14.63s 6/6 20.39% 110/110 Random Insertion 75.00% 0.00s 36/99 / / 0/5 / / 0/6 75.00% 36/110 HGS t=n/3 0.29% 111.24s 99/99 3.59% 1428.41s 5/5 7.86% 6926.41s 6/6 0.85% 110/110 AILS-II t=n/3 0.57% 133.95s 99/99 1.58% 1388.42s 5/5 1.58% 5646.48s 6/6 0.68% 110/110 BQ 8.87% 3.63s 99/99 20.28% 39.97s 5/5 41.52% 202.69s 5/6 10.89% 109/110 LEHD ∗ greedy 11.25% 1.53s 98/99 19.22% 99.43s 5/5 32.80% 852.02s 2/6 12.04% 105/110 SIL ∗ greedy 40.04% 2.48s 65/99 16.09% 26.86s 5/5 10.81% 146.83s 6/6 36.16% 76/110 ICAM 5.00% 0.42s 99/99 11.69% 32.32s 5/5 / / 0/6 5.32% 104/110 ELG 8.03% 1.29s 99/99 18.51% 30.21s 5/5 29.38% 133.08s 2/6 8.93% 106/110 INV iT -3V 13.15% 4.72s 99/99 19.03% 77.33s 5/5 23.91% 496.25s 5/6 13.91% 109/110 L2R 8.16% 2.49s 99/99 11.62% 23.99s 5/5 11.08% 97.12s 6/6 8.48% 110/110 DGL 15.27% 2.22s 99/99 17.96% 22.60s 5/5 18.69% 78.64s 5/6 15.55% 109/110 ReLD 4.10% 0.41s 99/99 10.22% 5.29s 5/5 11.27% 28.87s 3/6 4.58% 107/110 L2C-Insert ∗ greedy 6.87% 2.73s 99/99 22.37% 616.75s 5/5 49.41% 5525.71s 2/6 8.40% 106/110 D A CT T=1K 16.42% 246.51s 74/99 17.70% 479.82s 1/5 / / 0/6 16.44% 75/110 NeuOpt T=1K 26.93% 571.14s 36/99 / / 0/5 / / 0/6 26.93% 36/110 L2C-Insert ∗ T=1K 3.21% 344.05s 99/99 18.87% 6166.21s 5/5 44.29% 32754.86s 2/6 4.72% 106/110 LEHD ∗ RRC1K 3.58% 796.15s 99/99 11.73% 2043.74s 5/5 21.98% 2820.28s 2/6 4.32% 106/110 SIL ∗ PRC1K 21.38% 1307.97s 99/99 8.28% 3471.69s 5/5 7.40% 4251.88s 6/6 20.02% 110/110 DRHG T=1K 11.11% 1114.60s 99/99 17.95% 2529.12s 5/5 16.95% 5376.37s 6/6 11.74% 110/110 GF A CS † T=100, K=100 36.83% 437.38s 99/99 34.09% 9654.33s 3/5 / / 0/6 36.75% 102/110 GF A CS ‡ T=100, K=100 2.60% 405.81s 99/99 7.65% 14884.94s 4/5 / / 0/6 2.80% 103/110 ↓ I nitial P er iod is set as 1K, rather than the original value DIMENSION/2. ∗ The NRS supports more than one inference strategy . † GF A CS without local search at the last generation. The output solution is the best of the population at the last generation. ‡ The original version of GF ACS. The output solution is the best in history (all after local search). ( SRA104815 , ARA238025 , LRA498378 , LRB744710 ) with over 100K nodes are e xcluded. • Dataset of The 8th DIMA CS Implementation Chal- lenge (TSP) a dataset comprises a selection of instances from the TSPLIB library , supplemented by generated instances. T o avoid redundant instances and to satisfy distributional diversity and edge-weight-type consistency , only the 22 generated EUC 2D instances with clustered nodes are included. Note that the instance C316k.0 with ov er 100K clustered nodes is excluded. • CVRPLIB [ 141 ] a famous dataset with 14 sets of CVRP instances from sev eral academic literature and real-world applications. The library encompasses the adopted open- source instances in the 12th DIMA CS Implementa- tion Challenge (CVRP) . 100 EUC 2D instances of Set X [ 141 ] and 10 of Set A GS [ 142 ] are included. b) Metrics: The solvers are ev aluated from the following three perspectiv es: • Effectiveness a solver’ s ability to maintain high perfor- mance across out-of-distribution instances. It is measured 13 by the average gap relativ e to the BKSs. • Efficiency a solver’ s ability to solve the instances in a reasonable time. It is measured by the average computa- tional time a solver requires to output the solutions. • Reliability a solver’ s ability to successfully solve in- stances within the current scope. It is measured by the number of instances a solver can handle before failure, where “f ailure” encompasses Out-of-Memory (OOM) errors, performance breakdo wns ( i.e. , gaps e xceeding 100% [ 67 ], [ 143 ]), or timeouts (per -instance runtime beyond 36,000s for NRSs). Results are reported separately for three instance scale groups: small ((0,1K)), medium ([1K,10K)], and large ([10K,100K]). The overall aggregated results are also pro- vided. Results for unsolv able conditions are denoted by “/”. c) Infer ence: For adv anced heuristics, the termination criterion follo ws common practice in the heuristic litera- ture [ 136 ], where the time budget is set proportional to the instance size. T o align with the inference time of NRSs, this multiple is set to one-third. Furthermore, the runtime required to reach the current best solution or the BKS is reported. Results are averaged ov er 10 independent runs. For NRSs, to facilitate a direct and fair comparison, all methods are ev aluated with greedy inference. In other w ords, special decoding strategies ( e.g . , beam search) are delib- erately excluded, while data augmentation and fine-tuning techniques ( e.g. , activ e search [ 56 ], [ 144 ]) are deactiv ated. Unless otherwise specified, additional operator -based local search processes ( e.g. , 2-opt) are also disabled to preserve experimental fairness and prevent possible shifts in categories of NRSs. All other configurations are kept at their method- specific defaults. For improv ement-based methods, the number of iterations is set as the maximum v alue specified in the original configurations. No additional training is conducted during e valuation. Instead, all publicly av ailable pretrained models (trained on instances with specific scales and uniform node distrib ution) are tested, and the reported result for each NRS corresponds to the best-performing one, selected by prioritizing reliability first and effecti veness second. Complete results are provided in T ables XII and XIII in Appendix A . 3) P erformance Evaluation: Ov erall, the results presented in T able IX lead to conclusions fundamentally dif ferent from those under the con ventional ev aluation pipeline. Overall Perf ormance of NRSs Under the proposed ev aluation pipeline, NRSs generally underperform SOT A heuristics in both effectiveness and efficiency , with the gap widening as the problem size increases. Even with comparable runtime, improv ement-based NRSs still fall short of SO T A heuristics across all scales. In terms of reliability , only a few NRSs (L2R, SIL (PRC), and DRHG) can successfully solve all TSP and CVRP instances , among which L2R is the only construction-based method. For the remaining methods, only SIL (Greedy) and L2C-Insert (with both greedy and iterati ve inference) manage to solve e very TSP instance. Notably , all successful cases discussed abov e benefit from techniques for search space reduction (discussed in Section VII-A ). These results indicate a narro w solvable range of current NRSs. Perf ormance of Construction-based NRSs The perfor - mance of construction-based NRSs is less encouraging than that indicated by the con ventional evaluation pipeline. In terms of effecti veness, many single-stage NRSs underperform simple heuristics from the same subcategory . For CVRP , the effecti veness of appending NRS SIL (Greedy) deteriorates at small and medium scales, whereas BQ, LEHD (Greedy), ELG, INV iT , and DGL degrade on medium- and large-scale instances. All of these NRSs fall short of the nearest neighbor heuristic. Similarly , for TSP , the insertion NRS L2C-Insert (Greedy) is outperformed by random insertion on medium- and large-scale instances. Ne vertheless, a few methods stand out: L2R achie ves strong ef fectiv eness and reliability on both problems, and ReLD attains competitive effecti veness on CVRP despite limited reliability on large instances. In terms of efficienc y , L2C-Insert (Greedy) runs slower than other single- stage methods on CVRP because its released implementation ev aluates all un visited nodes, rather than restricting attention to the nearest one as described in the paper . As the only tw o-stage NRS, H-TSP benefits from its architecture to achie ve inference times comparable to those of the nearest neighbor heuristic while maintaining stable eff ectiv eness on TSP . Nevertheless, its reliability is not strong even in small-scale instances. Perf ormance of Improvement-based NRSs The perfor- mance of improv ement-based NRSs is mixed. Among single- solution-based NRSs, LNS methods (especially the direct ones) generally exhibit superior effectiveness and reliability compared to the small neighborhood counterparts , consis- tent with their recognized adv antages of escaping local optima. For example, DRHG approaches LKH-3’ s effecti veness on TSP across scales. Nevertheless, a few LNS methods exhibit effecti veness deterioration on large-scale instances (LEHD (RRC) and L2C-Insert (Iteration) for both, DRHG for CVRP), and SIL (PRC) degrades on small-scale CVRP instances. In all these deterioration cases, they perform worse than at least one of the tw o simple construction-based heuristics. Besides, L2C-Insert (Iteration) remains inefficient as in its construction-based version. In addition, GenSCO and Fast T2T underperform other lar ge neighborhood NRSs across all ev aluation aspects. Fast T2T adopts a distance-based insertion strategy similar to random insertion and achieves comparable effecti veness, suggesting it f ails to ef fectiv ely le verage infor - mation from out-of-distribution instances. Besides, GenSCO exhibits a performance drop using greedy decoding without explicitly incorporating distance information. This observation suggests that, for the distance-driv en TSP , additional spatial bias during element selection remains important for current N AR NRSs. Lastly , the two small-neighborhood DA CT and NeuOpt incur high computational cost in AR node-pair se- lection and insufficient conv ergence from per-step sampling, resulting in limited ef fectiv eness and reliability . For population-based NRSs, two variants of GF A CS are ev aluated: (1) the original version, which returns the best solution over the entire run, and (2) a variant, which disables local search in the final iteration and outputs the best solution from that iteration. The latter variant aligns with the inference settings of other NRSs, and follows the original study’ s motiv ation that local search primarily facilitates con ver gence 14 during training. The variant shows degraded effecti veness and reliability , indicating that edge weights, shaped by learned edge-prefer ence rules and iterative population dynamics, still pro vide insufficient guidance for constructing high- quality solutions for instances across diverse distributions . D. Discussions 1) Advantages of the Pr oposed Evaluation Pipeline: Com- pared with the con ventional ev aluation pipeline, the proposed pipeline offers sev eral adv antages in the following aspects: • Purpose of Evaluation The proposed pipeline is de- signed specifically to assess the zero-shot generalization performance of NRSs. It enforces a consistent single- model e valuation across methods, thereby enhancing comparability and strengthening the validity of conclu- sions. In contrast, the con ventional pipeline primarily focuses on scalability without clearly specifying whether ev aluation is conducted under a single- or multi-model condition. Consequently , this ambiguity makes fair com- parisons difficult, as some results reflect generalization from a single model, while others report purely in- distribution performance of multiple models, each ev alu- ated only on its matched distribution. • Instance Selection The proposed pipeline draws test instances from well-kno wn benchmarks and challenge sets, rather than ad-hoc synthetic distributions. It thus enables a more comprehensiv e e valuation across diverse distributions while mitigating generator-induced distribu- tion shifts that could bias results, preserving fairness and comparability . Notably , although prior work sometimes reports results on TSPLIB or CVRPLIB, the instances are often restricted to selected scale ranges or specific subsets, which may introduce selection bias. In contrast, the proposed pipeline uses a broader instance pool, pro- viding a more rob ust assessment. • Inference and Metrics For inference, the pipeline enforces a greedy decoding setting and av oids arbitrary add-on enhancements or parameter tuning on specific instances, thereby ensuring a more equitable compar- ison across methods. For the metrics, in addition to effecti veness, the proposed pipeline explicitly introduces reliability as a complementary metric, enabling a more comprehensiv e e valuation of algorithmic performance. 2) Principles for Method Selection: T o ensure fair and informativ e comparisons, two principles for selecting NRSs and baseline heuristics are followed. In-category Comparison of NRSs The primary goal of NRS experiments is to demonstrate the effecti veness of the learned heuristics. Howe ver , NRSs from dif ferent categories may rely on distinct heuristic frameworks, each requiring different levels of domain knowledge and computational re- sources. Therefore, cross-category comparisons may fail to accurately reflect the specific contribution of a DL model to the overall performance. For this reason, comparisons and conclusions are restricted as much as possible to NRSs and traditional heuristics that belong to the same category . Baseline Heuristic Selection Results under the proposed pipeline highlighted a performance gap between many NRSs and traditional heuristics, contradicting sev eral existing claims that such NRSs can outperform SO T A heuristic methods [ 67 ], [ 107 ], [ 112 ]. In man y of those studies, comparisons are conducted either under settings that disadvantage heuristics or against relati vely weak heuristic baselines. For the former cases, when heuristics are allo wed a shorter initial period [ 145 ] under the same time budget, they can achieve better effec- tiv eness and efficienc y on large-scale instances, as shown in T able IX . For the latter cases, widely-used CVRP baselines in the NRS literature, such as HGS and LKH-3, are not selected for comparison in recent heuristics literature [ 136 ], [ 146 ], [ 147 ]. Advanced heuristic methods, such as AILS- II, can achieve more competitiv e performance on medium- and large-scale instances where NRSs are often claimed to outperform traditional heuristics. The evidence abo ve indicates that heuristic baselines in most NRS literature lag behind the SO T A. Accordingly , baseline heuristics in this experiment are selected from the SO T A heuristic literature and appropriately configured to enable a more informative comparison. 3) Does Deep Learning T ruly Help in NRSs?: The ex- perimental results suggest that DL does contribute to good NRS performance. Under the conv entional ev aluation pipeline, most NRSs e xplicitly designed for generalization outperform their handcrafted heuristic counterparts within the same cat- egory and framework on uniformly distributed instances on different scales. Notably , across both pipelines, appending methods like ReLD, ICAM, and L2R, which incorporate distance information as an auxiliary bias, can achiev e stronger generalization performance than the nearest neighbor heuristic. This outperformance suggests that DL models can e xtract useful implicit knowledge complementary to explicit distance information, demonstrating generalization potential. On the other hand, the current generalization capability of NRSs remains limited. Under the proposed pipeline, all NRSs demonstrate lower-than-e xpected effecti veness and, at times, worse reliability . In several cases, their effecti veness even falls below that of simple construction-based heuristics, suggesting that rules learned solely from instances with the uniform node distribution fail to transfer rob ustly across di verse distrib utions. T aken together , these results support a cautiously optimistic conclusion. DL can indeed capture implicit knowledge and yield measurable gains in solving various routing problems. The less fa vorable performance under the proposed pipeline likely stems from overfitting due to a narrow training dis- tribution, rather than a fundamental limitation of NRSs. In addition, the algorithmic frameworks of current NRSs, espe- cially improvement-based ones, are often simpler than those of advanced heuristics, which may also constrain performance. Therefore, NRSs retain clear research value and foreseeable potential for further performance gain in in-problem general- ization. Within the same heuristic framework, DL holds the promise of discov ering rules that outperform or complement handcrafted designs, thereby further improving overall perfor- mance. Moreover , since few-shot adaptation can rapidly align learned implicit knowledge with a target distribution, NRSs offer a viable pathway to practical deployment by combining 15 general-purpose kno wledge with distrib ution-specific patterns to serve a wide range of applications. V I I . C H A L L E N G E S , F RO N T I E R S T R AT E G I E S , A N D F U T U R E D I R E C T I O N S The increasing demand for NRSs to perform effecti vely and reliably in real-world settings has brought significant challenges in generalization. This section elaborates on these challenges, discusses the strate gies explored in the recent literature, and outlines potential future research directions. A. In-pr oblem Gener alization In-problem generalization refers to maintaining stable per- formance across instances from different data distributions of a single problem, including but not limited to variations in scale, node distribution, and constraint tightness. It is influenced by both how models extract and utilize information and by the distribution shift between the training and test data. Correspondingly , related studies are analyzed from two com- plementary perspectiv es: model design and data distribution. Model Design Strategies for improving in-problem gener- alization through model design follow two main lines. On the one hand, a few appending methods [ 52 ], [ 53 ], [ 62 ], [ 67 ], [ 69 ], [ 70 ], [ 84 ] and restricted direct LNS methods [ 108 ] allocate more attention layers to dynamically capture relationships between the partial solution and remaining nodes, and among the remaining nodes themselves. On the other hand, some appending methods [ 55 ], [ 68 ], [ 86 ], [ 88 ]–[ 90 ] incorporate node-wise distances into specific model modules, given VRPs’ typical distance-based objectiv es. Both strategies enable more informed node selection, albeit with different trade-of fs. The former incurs higher memory and runtime o verhead due to stepwise re-embedding, while the latter relies more on handcrafted designs and is applicable only to distance-based objectiv es. These limitations highlight the need for future architectures that jointly improv e state representation and inference efficienc y without restricting to specific objectiv es. Data Distribution Existing strategies related to data dis- tribution generally employ two strategies. The first strategy pre-processes test instances to resemble the training distri- bution. For example, certain two-stage methods [ 82 ], [ 83 ], restricted direct LNS methods [ 52 ], [ 67 ], [ 109 ]–[ 113 ], [ 129 ], and sequential search methods [ 99 ] decompose the original problem into subproblems with scales comparable to those of the training data. Besides, statically [ 57 ], [ 61 ], [ 81 ], [ 99 ], [ 100 ], [ 114 ], [ 115 ], [ 148 ] or dynamically [ 53 ], [ 68 ], [ 69 ], [ 86 ] reducing the search space [ 149 ] has been proven ef fectiv e across categories. Coordinate normalization can further align the test distribution with the training distributions [ 69 ], [ 70 ], [ 99 ], [ 110 ], [ 113 ], [ 150 ]. Howe ver , they often prioritize locally optimal partial solutions, which can trap the complete solution in local optima and de grade final performance. Incorporating global information during search may help mitigate this issue. The second strate gy diversifies the training data, e.g . , by incorporating instances with different scales or node distri- butions [ 55 ], [ 75 ], [ 78 ], [ 86 ], [ 139 ], [ 151 ], [ 152 ]. Given that NRSs are typically trained on narrow distributions and may ov erfit, as our experiments suggest, enriching the training data with di verse distributions may already yield substantial gains. Nev ertheless, identifying representative distrib utions and designing effecti ve training strategies remain challenging. Neither the f actors shaping data distrib utions nor the mecha- nisms through which distrib utions affect model performance are yet systematically understood. A thorough in vestigation of these issues is therefore needed in future work. B. Cr oss-pr oblem Generalization Most NRSs train a specialized model for each problem. This “one problem, one model” paradigm is inefficient because it ignores the structural similarities across VRPs. Therefore, a promising research direction is to develop a general-purpose solver that can handle multiple VRPs without costly problem- specific engineering or retraining from scratch. Existing strate- gies primarily adapt established DL techniques to the AR appending methods. For example, a recent trend for dev eloping general VRP solvers is multi-task learning [ 72 ]–[ 74 ], [ 153 ]– [ 156 ], where a single model is trained and tested on a set of VRP v ariants with combinations of predefined attrib utes. Ho w- ev er, the observed generalization is at best limited to variants with novel attribute combinations and, at worst, amounts to in- domain performance. This reliance on a predefined attribute set fundamentally restricts generalization, since the attrib utes in real-world problems cannot be fully anticipated or enumer- ated in advance. Other strategies employ the model with a shared backbone and problem-specific adapters for different VRPs [ 76 ], [ 157 ]. While this design enables flexible fine- tuning, it introduces unavoidable limitations. Particularly , re- lated constraint handling remains inherently problem-specific and tied to the adapter design, prev enting zero-shot application to unseen problems. Furthermore, this design incurs additional computational overhead during fine-tuning. T o outline potential pathways to ward zero-shot generaliza- tion for unseen VRPs, two promising future research directions are highlighted: input representations and constraint handling. (1) For input repr esentations , existing methods lar gely rely on fixed-length attribute or problem vectors, which inherently limit the range of solvable problems. Accordingly , moving beyond attribute-predefined designs toward more general input representations is thus a critical step for broader applicability . (2) For constraint handling , step-wise masking in AR single- stage methods can enforce hard constraints but introduce man- ual intervention and is inapplicable to certain problems [ 158 ] ( e.g . , TSPTW). T o address both issues, a promising direction is to develop intervention-free constraint-handling mechanisms, especially for cross-problem settings. V I I I . C O N C L U S I O N S This survey systematically revie ws n eural routing solvers (NRSs) from the perspective of heuristics. They are identified as heuristic algorithms in which DL-learned rules replace handcrafted ones. A hierarchical taxonomy is introduced based on ho w solutions are constructed or improved. This perspectiv e enables consistent analysis of connections and de velopmental 16 trends among NRSs, and naturally links their designs to es- tablished heuristic principles within corresponding categories. Besides, a generalization-focused ev aluation pipeline is pro- posed to address limitations of the con ventional one, and repre- sentativ e NRSs are benchmarked under both pipelines. Results under the new pipeline sho w that NRSs trained on a narro w range of instance distributions can be outperformed by simple construction-based heuristics such as nearest neighbor and random insertion, indicating that the con ventional pipeline can lead to ov erly optimistic conclusions. These findings motiv ate further discussion of the new pipeline’ s advantages, principles for method selection, and the role of DL in NRSs despite current performance gaps. Finally , two central challenges in the field, i.e. , in-problem and cross-problem generalization, are analyzed. Related prev ailing strategies are summarized, and sev eral directions for future work are outlined. R E F E R E N C E S [1] G. B. Dantzig and J. H. Ramser , “The truck dispatching problem, ” Management Science , vol. 6, no. 1, pp. 80–91, 1959. [2] G. Clarke and J. W . Wright, “Scheduling of vehicles from a central depot to a number of deliv ery points, ” Operations Resear ch , vol. 12, no. 4, pp. 568–581, 1964. [3] T . Vidal, T . G. Crainic, M. Gendreau, and C. Prins, “Heuristics for multi-attribute vehicle routing problems: A survey and synthesis, ” Eur opean Journal of Operational Researc h , vol. 231, no. 1, pp. 1–21, 2013. [4] J.-F . Cordeau and G. Laporte, “ A tabu search heuristic for the static multi-vehicle dial-a-ride problem, ” T ransportation Research P art B: Methodological , vol. 37, no. 6, pp. 579–594, 2003. [5] V . C. Hemmelmayr , J.-F . Cordeau, and T . G. Crainic, “ An adaptiv e large neighborhood search heuristic for two-echelon vehicle routing problems arising in city logistics, ” Computers & Operations Researc h , vol. 39, no. 12, pp. 3215–3228, 2012. [6] J. Alegre, M. Laguna, and J. Pacheco, “Optimizing the periodic pick-up of raw materials for a manufacturer of auto parts, ” Eur opean Journal of Operational Research , vol. 179, no. 3, pp. 736–746, 2007. [7] J. K. Lenstra and A. R. Kan, “Complexity of vehicle routing and scheduling problems, ” Networks , vol. 11, no. 2, pp. 221–227, 1981. [8] G. Laporte, “The vehicle routing problem: An overview of exact and approximate algorithms, ” Eur opean Journal of Operational Resear ch , vol. 59, no. 3, pp. 345–358, 1992. [9] L. T ang, T . Li, Y . Meng, and J. Liu, “Searching in symmetric solution space for permutation-related optimization problems, ” IEEE T ransac- tions on P attern Analysis and Machine Intelligence , vol. 47, no. 8, pp. 7036–7052, 2025. [10] J. R. Rice, “The algorithm selection problem, ” in Advances in Com- puters . Elsevier , 1976, vol. 15, pp. 65–118. [11] B. A. Huberman, R. M. Lukose, and T . Hogg, “ An economics approach to hard computational problems, ” Science , vol. 275, no. 5296, pp. 51– 54, 1997. [12] C. P . Gomes and B. Selman, “ Algorithm portfolios, ” Artificial Intelli- gence , vol. 126, no. 1-2, pp. 43–62, 2001. [13] F . Hutter , H. H. Hoos, K. Leyton-Bro wn, and T . St ¨ utzle, “Paramils: an automatic algorithm configuration framew ork, ” Journal of Artificial Intelligence Researc h , vol. 36, pp. 267–306, 2009. [14] T . Guo, Y . Mei, M. Zhang, H. Zhao, K. Cai, and W . Du, “Learning- aided neighborhood search for vehicle routing problems, ” IEEE Tr ans- actions on P attern Analysis and Machine Intelligence , vol. 47, no. 7, pp. 5930–5944, 2025. [15] M. V eres and M. Moussa, “Deep learning for intelligent transportation systems: A survey of emerging trends, ” IEEE T ransactions on Intelli- gent transportation systems , vol. 21, no. 8, pp. 3152–3168, 2019. [16] N. V esselinova, R. Steinert, D. F . Perez-Ramirez, and M. Boman, “Learning combinatorial optimization on graphs: A surve y with ap- plications to networking, ” IEEE Access , vol. 8, pp. 120 388–120 416, 2020. [17] Y . Peng, B. Choi, and J. Xu, “Graph learning for combinatorial opti- mization: a survey of state-of-the-art, ” Data Science and Engineering , vol. 6, no. 2, pp. 119–141, 2021. [18] R. Shahbazian, L. D. P . Pugliese, F . Guerriero, and G. Macrina, “Integrating machine learning into vehicle routing problem: Methods and applications, ” IEEE Access , vol. 12, pp. 93 087–93 115, 2024. [19] P . T ao and L. Chen, “Combinatorial optimization: From deep learning to large language models, ” Science China Mathematics , vol. 68, pp. 2519–2537, 2025. [20] E. Alanzi and M. E. B. Menai, “Solving the tra veling salesman problem with machine learning: a revie w of recent advances and challenges, ” Artificial Intelligence Review , vol. 58, no. 9, p. 267, 2025. [21] Y . Bengio, A. Lodi, and A. Prouvost, “Machine learning for combinato- rial optimization: a methodological tour d’horizon, ” European Journal of Operational Research , vol. 290, no. 2, pp. 405–421, 2021. [22] Q. Cappart, D. Ch ´ etelat, E. B. Khalil, A. Lodi, C. Morris, and P . V eli ˇ ckovi ´ c, “Combinatorial optimization and reasoning with graph neural networks, ” Journal of Machine Learning Resear ch , vol. 24, no. 130, pp. 1–61, 2023. [23] A. Bogyrbaye va, M. Meraliyev , T . Mustakhov , and B. Dauletbaye v , “Machine learning to solve vehicle routing problems: A survey , ” IEEE T ransactions on Intelligent Tr ansportation Systems , vol. 25, no. 6, pp. 4754–4772, 2024. [24] Y . Jin, X. Y an, S. Liu, and X. W ang, “ A unified framework for combinatorial optimization based on graph neural networks, ” arXiv pr eprint arXiv:2406.13125 , 2024. [25] M. S. Martins, J. Sousa, and S. V ieira, “ A systematic review on rein- forcement learning for industrial combinatorial optimization problems. ” Applied Sciences , vol. 15, no. 3, 2025. [26] J. Kotary , F . Fioretto, P . V an Hentenryck, and B. Wilder , “End-to- end constrained optimization learning: A survey , ” International Joint Confer ence on Artificial Intelligence , 2021. [27] K. Chung, C. Lee, and Y . Tsang, “Neural combinatorial optimization with reinforcement learning in industrial engineering: a survey , ” Arti- ficial Intelligence Review , vol. 58, no. 5, p. 130, 2025. [28] X. W u, D. W ang, L. W en, Y . Xiao, C. W u, Y . W u, C. Y u, D. L. Maskell, and Y . Zhou, “Neural combinatorial optimization algorithms for solving vehicle routing problems: A comprehensi ve survey with perspectiv es, ” arXiv preprint , 2024. [29] S. Liu, Y . Zhang, K. T ang, and X. Y ao, “Ho w good is neural combina- torial optimization? a systematic evaluation on the traveling salesman problem, ” IEEE Computational Intelligence Magazine , vol. 18, no. 3, pp. 14–28, 2023. [30] J. Sui, S. Ding, X. Huang, Y . Y u, R. Liu, B. Xia, Z. Ding, L. Xu, H. Zhang, C. Y u et al. , “ A survey on deep learning-based algorithms for the traveling salesman problem, ” F r ontiers of Computer Science , vol. 19, no. 6, pp. 1–30, 2025. [31] C. Zhang, Y . W u, Y . Ma, W . Song, Z. Le, Z. Cao, and J. Zhang, “ A revie w on learning to solve combinatorial optimisation problems in manufacturing, ” IET Collaborative Intelligent Manufacturing , vol. 5, no. 1, p. e12072, 2023. [32] R. Bai, X. Chen, Z.-L. Chen, T . Cui, S. Gong, W . He, X. Jiang, H. Jin, J. Jin, G. Kendall et al. , “ Analytics and machine learning in vehi- cle routing research, ” International Journal of Pr oduction Resear ch , vol. 61, no. 1, pp. 4–30, 2023. [33] B. Li, G. W u, Y . He, M. Fan, and W . Pedrycz, “ An overvie w and experimental study of learning-based optimization algorithms for the vehicle routing problem, ” IEEE/CAA Journal of Automatica Sinica , vol. 9, no. 7, pp. 1115–1138, 2022. [34] F . W ang, Q. He, and S. Li, “Solving combinatorial optimization problems with deep neural network: A survey , ” Tsinghua Science and T echnology , vol. 29, no. 5, pp. 1266–1282, 2024. [35] F . Zhou, A. Lischka, B. Kulcsar , J. W u, M. H. Chehreghani, and G. La- porte, “Learning for routing: A guided revie w of recent dev elopments and future directions, ” T ransportation Resear ch P art E: Logistics and T ransportation Review , vol. 202, p. 104278, 2025. [36] N. Mazyavkina, S. Sviridov , S. Ivano v , and E. Burnaev , “Reinforcement learning for combinatorial optimization: A survey , ” Computers & Operations Researc h , vol. 134, p. 105400, 2021. [37] Q. W ang and C. T ang, “Deep reinforcement learning for transporta- tion network combinatorial optimization: A survey , ” Knowledge-Based Systems , vol. 233, p. 107526, 2021. [38] K.-W . Li, T . Zhang, R. W ang, W . Qin, H.-h. He, and H. Huang, “Research revie ws of combinatorial optimization methods based on deep reinforcement learning, ” Acta Automatica Sinica , vol. 47, no. 11, pp. 2521–2537, 2021. [39] Z. Zong, T . Feng, J. W ang, T . Xia, and Y . Li, “Deep reinforcement learning for demand-driven services in logistics and transportation systems: A survey , ” ACM T ransactions on Knowledge Discovery fr om Data , vol. 19, no. 4, pp. 1–42, 2025. 17 [40] I. Araya, O. Rojas, M. V ´ asquez, G. Mar ´ ın, and L. Robles, “What mak es a transformer solv e the tsp? a component-wise analysis, ” Pr eprints , 2026. [41] W . Kool, H. V an Hoof, and M. W elling, “ Attention, learn to solve rout- ing problems!” International Conference on Learning Repr esentations , 2019. [42] P . T oth and D. V igo, The vehicle r outing pr oblem . SIAM, 2002. [43] W . Cook, W . Cunningham, W . Pulleyblank, and A. Schrijver , Combi- natorial Optimization , ser. A Wile y-Interscience publication. W iley , 1997. [44] J. Renaud, F . F . Boctor, and J. Ouenniche, “ A heuristic for the pickup and deli very traveling salesman problem, ” Computers & Operations Resear ch , vol. 27, no. 9, pp. 905–916, 2000. [45] B. E. Gillett and L. R. Miller, “ A heuristic algorithm for the vehicle- dispatch problem, ” Operations Resear ch , vol. 22, no. 2, pp. 340–349, 1974. [46] B. Funke, T . Gr ¨ unert, and S. Irnich, “Local search for vehicle routing and scheduling problems: Re view and conceptual inte gration, ” Journal of Heuristics , vol. 11, no. 4, pp. 267–306, 2005. [47] F . Neri, C. Cotta, and P . Moscato, Handbook of Memetic Algorithms . Springer , 2011, vol. 379. [48] J. Kennedy , “Swarm intelligence, ” in Handbook of Nature-inspir ed and Innovative Computing: Integr ating Classical Models with Emer ging T echnologies . Springer, 2006, pp. 187–219. [49] Y . W u, W . Song, Z. Cao, J. Zhang, and A. Lim, “Learning improv ement heuristics for solving routing problems, ” IEEE T ransactions on Neural Networks and Learning Systems , vol. 33, no. 9, pp. 5057–5069, 2021. [50] C. K. Joshi, T . Laurent, and X. Bresson, “ An efficient graph conv olu- tional network technique for the trav elling salesman problem, ” arXiv pr eprint arXiv:1906.01227 , 2019. [51] O. V inyals, M. Fortunato, and N. Jaitly , “Pointer networks, ” Advances in Neural Information Processing Systems , vol. 28, 2015. [52] F . Luo, X. Lin, F . Liu, Q. Zhang, and Z. W ang, “Neural combinatorial optimization with heavy decoder: T oward large scale generalization, ” Advances in Neural Information Pr ocessing Systems , vol. 36, pp. 8845– 8864, 2023. [53] D. Drakulic, S. Michel, F . Mai, A. Sors, and J.-M. Andreoli, “Bq-nco: Bisimulation quotienting for efficient neural combinatorial optimiza- tion, ” Advances in Neural Information Processing Systems , vol. 36, 2024. [54] Y .-D. Kwon, J. Choo, B. Kim, I. Y oon, Y . Gwon, and S. Min, “Pomo: Policy optimization with multiple optima for reinforcement learning, ” Advances in Neural Information Pr ocessing Systems , vol. 33, pp. 21 188–21 198, 2020. [55] C. Zhou, X. Lin, Z. W ang, X. T ong, M. Y uan, and Q. Zhang, “Instance- conditioned adaptation for large-scale generalization of neural combi- natorial optimization, ” arXiv preprint , 2024. [56] I. Bello, H. Pham, Q. V . Le, M. Norouzi, and S. Bengio, “Neural combinatorial optimization with reinforcement learning, ” International confer ence on learning repr esentations workshop , 2017. [57] R. Qiu, Z. Sun, and Y . Y ang, “Dimes: A differentiable meta solver for combinatorial optimization problems, ” Advances in Neural Information Pr ocessing Systems , vol. 35, pp. 25 531–25 546, 2022. [58] M. Nazari, A. Oroojlooy , L. Snyder , and M. T ak ´ ac, “Reinforcement learning for solving the vehicle routing problem, ” Advances in Neural Information Processing Systems , vol. 31, 2018. [59] J. Choo, Y .-D. Kwon, J. Kim, J. Jae, A. Hottung, K. Tierney , and Y . Gwon, “Simulation-guided beam search for neural combinatorial optimization, ” Advances in Neural Information Pr ocessing Systems , vol. 35, pp. 8760–8772, 2022. [60] W . Kool, H. v an Hoof, J. Gromicho, and M. W elling, “Deep polic y dynamic programming for vehicle routing problems, ” in International Confer ence on Integr ation of Constraint Pr ogramming, Artificial Intel- ligence, and Operations Resear ch . Springer, 2022, pp. 190–213. [61] Z. Xing and S. T u, “ A graph neural network assisted monte carlo tree search approach to traveling salesman problem, ” IEEE Access , vol. 8, pp. 108 418–108 428, 2020. [62] L. Xin, W . Song, Z. Cao, and J. Zhang, “Multi-decoder attention model with embedding glimpse for solving vehicle routing problems, ” in Pr oceedings of the AAAI Conference on Artificial Intelligence , vol. 35, no. 13, 2021, pp. 12 042–12 049. [63] Y .-D. Kwon, J. Choo, I. Y oon, M. Park, D. Park, and Y . Gwon, “Matrix encoding networks for neural combinatorial optimization, ” Advances in Neural Information Pr ocessing Systems , vol. 34, pp. 5138–5149, 2021. [64] M. Kim, J. Park, and J. Park, “Sym-nco: Leveraging symmetricity for neural combinatorial optimization, ” Advances in Neural Information Pr ocessing Systems , vol. 35, pp. 1936–1949, 2022. [65] Z. Zong, M. Zheng, Y . Li, and D. Jin, “Mapdp: Cooperati ve multi- agent reinforcement learning to solve pickup and deli very problems, ” in Pr oceedings of the AAAI Conference on Artificial Intelligence , vol. 36, no. 9, 2022, pp. 9980–9988. [66] X. Lin, Z. Y ang, and Q. Zhang, “Pareto set learning for neural multi- objectiv e combinatorial optimization, ” International Conference on Learning Representations , 2022. [67] F . Luo, X. Lin, Y . W u, Z. W ang, T . Xialiang, M. Y uan, and Q. Zhang, “Boosting neural combinatorial optimization for large-scale vehicle routing problems, ” in International Conference on Learning Represen- tations , 2025. [68] C. Gao, H. Shang, K. Xue, D. Li, and C. Qian, “T owards generalizable neural solvers for vehicle routing problems via ensemble with trans- ferrable local policy , ” in International Joint Conference on Artificial Intelligence , 2024, pp. 6914–6922. [69] H. Fang, Z. Song, P . W eng, and Y . Ban, “Invit: a generalizable routing problem solver with in variant nested vie w transformer , ” in International Confer ence on Machine Learning , 2024, pp. 12 973–12 992. [70] C. Zhou, X. Lin, Z. W ang, and Q. Zhang, “Learning to reduce search space for generalizable neural routing solver, ” arXiv pr eprint arXiv:2503.03137 , 2025. [71] Z. Zheng, S. Y ao, Z. W ang, X. T ong, M. Y uan, and K. T ang, “Dpn: Decoupling partition and navigation for neural solvers of min- max vehicle routing problems, ” International Conference on Machine Learning , 2024. [72] F . Liu, X. Lin, Z. W ang, Q. Zhang, T . Xialiang, and M. Y uan, “Multi-task learning for routing problem with cross-problem zero-shot generalization, ” in Pr oceedings of the 30th A CM SIGKDD Confer ence on Knowledge Discovery and Data Mining , 2024, pp. 1898–1908. [73] J. Zhou, Z. Cao, Y . W u, W . Song, Y . Ma, J. Zhang, and C. Xu, “Mvmoe: Multi-task vehicle routing solver with mixture-of-e xperts, ” Proceedings of Machine Learning Research , vol. 235, pp. 61 804–61 824, 2024. [74] H. Li, F . Liu, Z. Zheng, Y . Zhang, and Z. W ang, “Cada: Cross-problem routing solver with constraint-aware dual-attention, ” International Con- fer ence on Machine Learning , 2024. [75] Z. Huang, J. Zhou, Z. Cao, and Y . Xu, “Rethinking light decoder- based solvers for vehicle routing problems, ” International Conference on Learning Representations , 2025. [76] D. Drakulic, S. Michel, and J.-M. Andreoli, “Goal: A generalist combinatorial optimization agent learning, ” International Conference on Learning Representations , 2025. [77] N. Zhang, J. Y ang, Z. Cao, and X. Chi, “ Adversarial generative flow network for solving vehicle routing problems, ” International Confer ence on Learning Representations , 2025. [78] E. Khalil, H. Dai, Y . Zhang, B. Dilkina, and L. Song, “Learning com- binatorial optimization algorithms over graphs, ” Advances in Neur al Information Processing Systems , vol. 30, 2017. [79] F . Luo, X. Lin, M. Zhong, F . Liu, Z. W ang, J. Sun, and Q. Zhang, “Learning to insert for constructiv e neural vehicle routing solver , ” Advances in Neural Information Pr ocessing Systems, , 2025. [80] A. Graikos, N. Malkin, N. Jojic, and D. Samaras, “Diffusion models as plug-and-play priors, ” Advances in Neural Information Processing Systems , vol. 35, pp. 14 715–14 728, 2022. [81] Z. Sun and Y . Y ang, “Difusco: Graph-based dif fusion solvers for com- binatorial optimization, ” Advances in Neural Information Pr ocessing Systems , vol. 36, pp. 3706–3731, 2023. [82] X. Pan, Y . Jin, Y . Ding, M. Feng, L. Zhao, L. Song, and J. Bian, “H-tsp: Hierarchically solving the large-scale traveling salesman problem, ” in Pr oceedings of the AAAI Conference on Artificial Intelligence , vol. 37, no. 8, 2023, pp. 9345–9353. [83] Q. Hou, J. Y ang, Y . Su, X. W ang, and Y . Deng, “Generalize learned heuristics to solve large-scale vehicle routing problems in real-time, ” in International Conference on Learning Representations , 2023. [84] B. Peng, J. W ang, and Z. Zhang, “ A deep reinforcement learning algo- rithm using dynamic attention model for vehicle routing problems, ” in Artificial Intelligence Algorithms and Applications: 11th International Symposium . Springer, 2019, pp. 636–650. [85] L. Xin, W . Song, Z. Cao, and J. Zhang, “Step-wise deep learning models for solving routing problems, ” IEEE T ransactions on Industrial Informatics , vol. 17, no. 7, pp. 4861–4871, 2020. [86] Y . W ang, Y .-H. Jia, W .-N. Chen, and Y . Mei, “Distance-aware attention reshaping for enhancing generalization of neural solvers, ” IEEE Tr ans- actions on Neural Networks and Learning Systems , v ol. 36, no. 10, pp. 18 900–18 914, 2025. [87] Y . L. Goh, Z. Cao, Y . Ma, Y . Dong, M. H. Dupty , and W . S. Lee, “Hierarchical neural constructive solver for real-world tsp scenarios, ” 18 in Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , 2024, pp. 884–895. [88] Y . Jin, Y . Ding, X. Pan, K. He, L. Zhao, T . Qin, L. Song, and J. Bian, “Pointerformer: Deep reinforced multi-pointer transformer for the trav eling salesman problem, ” in Proceedings of the AAAI Confer ence on Artificial Intelligence , vol. 37, no. 7, 2023, pp. 8132– 8140. [89] J. Son, M. Kim, H. Kim, and J. Park, “Meta-sage: Scale meta- learning scheduled adaptation with guided exploration for mitigating scale shift on combinatorial optimization, ” in International Conference on Machine Learning . PMLR, 2023, pp. 32 194–32 210. [90] J. Li, Y . Ma, Z. Cao, Y . W u, W . Song, J. Zhang, and Y . M. Chee, “Learning feature embedding refiner for solving vehicle routing prob- lems, ” IEEE T ransactions on Neural Networks and Learning Systems , vol. 35, no. 11, pp. 15 279–15 291, 2023. [91] M. L. Fisher and R. Jaikumar , “ A generalized assignment heuristic for vehicle routing, ” Networks , vol. 11, no. 2, pp. 109–124, 1981. [92] X. Chen and Y . Tian, “Learning to perform local rewriting for com- binatorial optimization, ” Advances in Neural Information Pr ocessing Systems , vol. 32, 2019. [93] Y . Ma, J. Li, Z. Cao, W . Song, L. Zhang, Z. Chen, and J. T ang, “Learning to iterativ ely solve routing problems with dual-aspect col- laborativ e transformer, ” Advances in Neural Information Processing Systems , vol. 34, pp. 11 096–11 107, 2021. [94] J. Sui, S. Ding, R. Liu, L. Xu, and D. Bu, “Learning 3-opt heuristics for trav eling salesman problem via deep reinforcement learning, ” in Asian Confer ence on Machine Learning . PMLR, 2021, pp. 1301–1316. [95] D. K ong, Y . Ma, Z. Cao, T . Y u, and J. Xiao, “Efficient neural collabo- rativ e search for pickup and delivery problems, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , vol. 46, no. 12, pp. 11 019– 11 034, 2024. [96] B. Hudson, Q. Li, M. Malencia, and A. Prorok, “Graph neural network guided local search for the traveling salesperson problem, ” in International Conference on Learning Representations , 2022. [97] Y . Ma, Z. Cao, and Y . M. Chee, “Learning to search feasible and infeasible regions of routing problems with flexible neural k-opt, ” Advances in Neural Information Pr ocessing Systems , vol. 36, 2024. [98] L. Xin, W . Song, Z. Cao, and J. Zhang, “Neurolkh: Combining deep learning model with lin-kernighan-helsgaun heuristic for solving the traveling salesman problem, ” Advances in Neural Information Pr ocessing Systems , vol. 34, pp. 7472–7483, 2021. [99] Z.-H. Fu, K.-B. Qiu, and H. Zha, “Generalize a small pre-trained model to arbitrarily large tsp instances, ” in Proceedings of the AAAI Confer ence on Artificial Intelligence , vol. 35, no. 8, 2021, pp. 7474– 7482. [100] Y . Min, Y . Bai, and C. P . Gomes, “Unsupervised learning for solving the travelling salesman problem, ” Advances in Neural Information Pr ocessing Systems , vol. 36, 2024. [101] Y . Xia, X. Y ang, Z. Liu, Z. Liu, L. Song, and J. Bian, “Position: Rethinking post-hoc search-based neural approaches for solving large- scale traveling salesman problems, ” in International Conference on Machine Learning . PMLR, 2024, pp. 54 178–54 190. [102] M. Gendreau, J.-Y . Potvin et al. , Handbook of Metaheuristics . Springer , 2010, vol. 2. [103] K. Helsgaun, “ An effectiv e implementation of the lin–kernighan trav- eling salesman heuristic, ” Eur opean Journal of Operational Resear ch , vol. 126, no. 1, pp. 106–130, 2000. [104] A. Hottung and K. Tierne y , “Neural large neighborhood search for the capacitated vehicle routing problem, ” in Eur opean Conference on Artificial Intelligence . IOS Press, 2020, pp. 443–450. [105] L. Gao, M. Chen, Q. Chen, G. Luo, N. Zhu, and Z. Liu, “Learn to design the heuristics for v ehicle routing problem, ” arXiv pr eprint arXiv:2002.08539 , 2020. [106] H. Lu, X. Zhang, and S. Y ang, “ A learning-based iterative method for solving vehicle routing problems, ” in International Conference on Learning Representations , 2019. [107] Y . Li, L. Chen, H. W ang, R. W ang, and J. Y an, “Generation as search operator for test-time scaling of diffusion-based combinatorial optimization, ” in Advances in Neural Information Pr ocessing Systems , 2025. [108] K. Li, F . Liu, Z. W ang, and Q. Zhang, “Destroy and repair using hyper- graphs for routing, ” in Pr oceedings of the AAAI Confer ence on Artificial Intelligence , vol. 39, no. 17, 2025, pp. 18 341–18 349. [109] M. Kim, J. Park et al. , “Learning collaborativ e policies to solve np- hard routing problems, ” Advances in Neural Information Pr ocessing Systems , vol. 34, pp. 10 418–10 430, 2021. [110] Z. Zheng, C. Zhou, T . Xialiang, M. Y uan, and Z. W ang, “Udc: A unified neural divide-and-conquer framework for large-scale combinatorial optimization problems, ” Advances in Neural Information Pr ocessing Systems , vol. 37, pp. 6081–6125, 2024. [111] S. Li, Z. Y an, and C. W u, “Learning to deleg ate for large-scale vehicle routing, ” Advances in Neural Information Pr ocessing Systems , vol. 34, pp. 26 198–26 211, 2021. [112] Z. Zong, H. W ang, J. W ang, M. Zheng, and Y . Li, “Rbg: Hierarchically solving large-scale routing problems in logistic systems via reinforce- ment learning, ” in Proceedings of the 28th ACM SIGKDD Confer ence on Knowledge Discovery and Data Mining , 2022, pp. 4648–4658. [113] H. Y e, J. W ang, H. Liang, Z. Cao, Y . Li, and F . Li, “Glop: Learning global partition and local construction for solving large-scale routing problems in real-time, ” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 38, no. 18, 2024, pp. 20 284–20 292. [114] Y . Li, J. Guo, R. W ang, and J. Y an, “T2t: From distribution learning in training to gradient search in testing for combinatorial optimization, ” Advances in Neural Information Pr ocessing Systems , vol. 36, 2024. [115] Y . Li, J. Guo, R. W ang, H. Zha, and J. Y an, “Fast t2t: Optimization consistency speeds up dif fusion-based training-to-testing solving for combinatorial optimization, ” in Advances in Neural Information Pro- cessing Systems , 2024. [116] P . Shaw , “Using constraint programming and local search methods to solve vehicle routing problems, ” in International Conference on Principles and Practice of Constraint Pro gramming . Springer, 1998, pp. 417–431. [117] D. Pisinger and S. Ropke, “Large neighborhood search, ” Handbook of Metaheuristics , pp. 99–127, 2019. [118] A. Hottung, B. Bhandari, and K. Tierne y , “Learning a latent search space for routing problems using variational autoencoders, ” in Inter- national Conference on Learning Representations , 2021. [119] F . Chalumeau, S. Surana, C. Bonnet, N. Grinsztajn, A. Pretorius, A. Laterre, and T . Barrett, “Combinatorial optimization with policy adaptation using latent space search, ” Advances in Neural Information Pr ocessing Systems , vol. 36, pp. 7947–7959, 2023. [120] H. Y e, J. W ang, Z. Cao, H. Liang, and Y . Li, “Deepaco: neural- enhanced ant systems for combinatorial optimization, ” Advances in Neural Information Processing Systems , vol. 36, 2024. [121] M. Kim, S. Choi, H. Kim, J. Son, J. Park, and Y . Bengio, “ Ant colony sampling with gflownets for combinatorial optimization, ” in Interna- tional Confer ence on Artificial Intelligence and Statistics . PMLR, 2025, pp. 469–477. [122] S. T . W . Mara, R. Norcahyo, P . Jodiaw an, L. Lusiantoro, and A. P . Rifai, “ A surve y of adaptive large neighborhood search algorithms and applications, ” Computers & Operations Researc h , vol. 146, p. 105903, 2022. [123] T . St ¨ utzle, “Local search algorithms for combinatorial problems: anal- ysis, improvements, and new applications, ” 1999. [124] P . H. V . Penna, A. Subramanian, and L. S. Ochi, “ An iterated local search heuristic for the heterogeneous fleet vehicle routing problem, ” Journal of Heuristics , vol. 19, no. 2, pp. 201–232, 2013. [125] H. R. Lourenc ¸ o, O. C. Martin, and T . St ¨ utzle, “Iterated local search: Framew ork and applications, ” Handbook of Metaheuristics , pp. 129– 168, 2019. [126] J. Brand ˜ ao, “ A memory-based iterated local search algorithm for the multi-depot open vehicle routing problem, ” Eur opean Journal of Operational Researc h , vol. 284, no. 2, pp. 559–571, 2020. [127] D. Pisinger and S. Ropke, “Large neighborhood search, ” in Handbook of Metaheuristics . Springer , 2018, pp. 99–127. [128] J. Pirnay and D. G. Grimm, “Self-improvement for neural combina- torial optimization: Sample without replacement, but impro vement, ” T ransactions on Machine Learning Research , 2024. [129] H. Cheng, H. Zheng, Y . Cong, W . Jiang, and S. Pu, “Select and optimize: Learning to solve lar ge-scale tsp instances, ” in International Confer ence on Artificial Intelligence and Statistics . PMLR, 2023, pp. 1219–1231. [130] T . V idal, T . G. Crainic, M. Gendreau, and C. Prins, “ A unified solution framew ork for multi-attribute vehicle routing problems, ” European Journal of Operational Research , vol. 234, no. 3, pp. 658–673, 2014. [131] T . Back, Evolutionary algorithms in theory and practice: evolution strate gies, evolutionary progr amming, genetic algorithms . Oxford univ ersity press, 1996. [132] K. Price, Differ ential Evolution: a Practical Appr oach to Global Optimization . Springer Science & Business Media, 2006. [133] N. Hansen, “The cma e volution strategy: A tutorial, ” arXiv pr eprint arXiv:1604.00772 , 2016. 19 [134] K. Helsgaun, “ An extension of the lin-kernighan-helsgaun tsp solver for constrained traveling salesman and vehicle routing problems, ” Roskilde: Roskilde University , vol. 12, pp. 966–980, 2017. [135] T . V idal, “Hybrid genetic search for the cvrp: Open-source implemen- tation and swap* neighborhood, ” Computers & Operations Researc h , vol. 140, p. 105643, 2022. [136] V . R. M ´ aximo, J.-F . Cordeau, and M. C. Nascimento, “ Ails-ii: An adaptiv e iterated local search heuristic for the large-scale capacitated vehicle routing problem, ” INFORMS Journal on Computing , vol. 36, no. 4, pp. 974–986, 2024. [137] Y . Xiao, Y . W u, R. Cao, D. W ang, Z. Cao, P . Zhao, Y . Li, Y . Zhou, and Y . Jiang, “Dgl: Dynamic global-local information aggregation for scalable vrp generalization with self-improvement learning, ” in International Joint Confer ence on Artificial Intelligence , 2025, pp. 1–9. [138] F . Luo, Y . Wu, Z. Zheng, and Z. W ang, “Rethinking neural combinato- rial optimization for vehicle routing problems with different constraint tightness degrees, ” Advances in Neural Information Pr ocessing Sys- tems, , 2025. [139] J. Zhou, Y . W u, W . Song, Z. Cao, and J. Zhang, “T owards omni- generalizable neural methods for vehicle routing problems, ” in Inter- national Conference on Machine Learning . PMLR, 2023, pp. 42 769– 42 789. [140] G. Reinelt, “Tsplib — a trav eling salesman problem library , ” ORSA Journal on Computing , vol. 3, no. 4, pp. 376–384, 1991. [141] E. Uchoa, D. Pecin, A. Pessoa, M. Poggi, T . V idal, and A. Subrama- nian, “Ne w benchmark instances for the capacitated vehicle routing problem, ” Eur opean Journal of Oper ational Researc h , vol. 257, no. 3, pp. 845–858, 2017. [142] F . Arnold, M. Gendreau, and K. S ¨ orensen, “Efficiently solving very large-scale routing problems, ” Computers & Operations Research , vol. 107, pp. 32–42, 2019. [143] I. Choi, W .-J. Shin, S. Cho, and H.-J. Kim, “T owards generalizable multi-policy optimization with self-evolution for job scheduling, ” Ad- vances in Neural Information Pr ocessing Systems, , 2025. [144] A. Hottung, Y .-D. Kwon, and K. Tierney , “Efficient active search for combinatorial optimization problems, ” International Conference on Learning Representations , 2022. [145] Z.-H. Fu, S. Sun, J. Ren, T . Y u, H. Zhang, Y . Liu, L. Huang, X. Y an, and P . Lu, “ A hierarchical destroy and repair approach for solving very large-scale travelling salesman problem, ” arXiv preprint arXiv:2308.04639 , 2023. [146] V . R. M ´ aximo and M. C. Nascimento, “ A hybrid adaptiv e iterated local search with div ersification control to the capacitated vehicle routing problem, ” Eur opean Journal of Oper ational Researc h , vol. 294, no. 3, pp. 1108–1119, 2021. [147] J. Christiaens and G. V anden Berghe, “Slack induction by string re- mov als for vehicle routing problems, ” T ransportation Science , v ol. 54, no. 2, pp. 417–433, 2020. [148] A. Lischka, J. W u, R. Basso, M. H. Chehreghani, and B. Kulcs ´ ar , “Less is more-on the importance of sparsification for transformers and graph neural networks for tsp, ” arXiv preprint , 2024. [149] Y . Sun, X. Li, and A. Ernst, “Using statistical measures and machine learning for graph reduction to solve maximum weight clique prob- lems, ” IEEE T ransactions on P attern Analysis and Machine Intelli- gence , vol. 43, no. 5, pp. 1746–1760, 2021. [150] Y . Chen, R. Chen, F . Luo, and Z. W ang, “Improving generalization of neural combinatorial optimization for vehicle routing problems via test- time projection learning, ” Advances in Neural Information Pr ocessing Systems, , 2025. [151] Y . Jiang, Y . W u, Z. Cao, and J. Zhang, “Learning to solve routing problems via distributionally robust optimization, ” in Proceedings of the AAAI Confer ence on Artificial Intelligence , vol. 36, no. 9, 2022, pp. 9786–9794. [152] C. W ang, Z. Y u, S. McAleer, T . Y u, and Y . Y ang, “ Asp: Learn a univ ersal neural solver!” IEEE T ransactions on P attern Analysis and Machine Intelligence , vol. 46, no. 6, pp. 4102–4114, 2024. [153] F . Berto, C. Hua, N. G. Zepeda, A. Hottung, N. W ouda, L. Lan, J. Park, K. Tierney , and J. Park, “Routefinder: T owards foundation models for vehicle routing problems, ” ICML 2024 W orkshop on F oundation Models in the W ild , 2024. [154] S. Liu, Z. Cao, S. Feng, and Y .-S. Ong, “ A mixed-curv ature based pre-training paradigm for multi-task vehicle routing solver, ” in Inter- national Conference on Machine Learning , 2025. [155] Y . L. Goh, Z. Cao, Y . Ma, J. Zhou, M. H. Dupty , and W . S. Lee, “Shield: Multi-task multi-distribution vehicle routing solver with sparsity and hierarchy , ” International Conference of Machine Learning , 2025. [156] Y . Zheng, F . Luo, Z. W ang, Y . W u, and Y . Zhou, “Mtl-kd: Multi- task learning via knowledge distillation for generalizable neural vehicle routing solver , ” Advances in Neural Information Processing Systems, , 2025. [157] Z. Lin, Y . W u, B. Zhou, Z. Cao, W . Song, Y . Zhang, and S. Jayavelu, “Cross-problem learning for solving vehicle routing problems, ” in International Joint Conference on Artificial Intelligence , 2024, pp. 6958–6966. [158] J. Bi, Y . Ma, J. Zhou, W . Song, Z. Cao, Y . W u, and J. Zhang, “Learning to handle complex constraints for vehicle routing problems, ” Advances in Neur al Information Processing Systems , vol. 37, pp. 93 479–93 509, 2024. 20 T ABLE X S O U R C E S O F T H E A D O P T E D M E T H O D S Method Link License LKH-3 [ 134 ] http://webhotel4.ruc.dk/ ∼ keld/research/LKH- 3/ A vailable for academic research use HGS [ 135 ] https://github .com/vidalt/HGS- CVRP MIT License AILS-II [ 136 ] https://github.com/INFORMSJoC/2023.0106 MIT License BQ [ 53 ] https://github .com/naver/bq- nco CC BY -NC-SA 4.0 license LEHD [ 52 ] https://github .com/CIAM- Group/NCO code/tree/main/single objectiv e/LEHD MIT License SIL [ 67 ] https://github .com/CIAM- Group/SIL MIT License ICAM [ 55 ] https://github .com/CIAM- Group/ICAM MIT License ELG [ 68 ] https://github .com/gaocrr/ELG MIT License INV iT [ 69 ] https://github .com/Kasumigaoka- Utaha/INV iT MIT License L2R [ 70 ] https://github .com/CIAM- Group/L2R MIT License DGL [ 137 ] https://github .com/wuyuesong/DGL A vailable for academic research use ReLD [ 75 ] https://github .com/ziweileonhuang/reld- nco MIT License L2C-Insert [ 79 ] https://github.com/CIAM- Group/L2C Insert MIT License H-TSP [ 82 ] https://github .com/Learning4Optimization- HUST/H- TSP MIT License D A CT [ 93 ] https://github .com/yining043/VRP- D ACT MIT License NeuOpt [ 97 ] https://github .com/yining043/NeuOpt MIT License GenSCO [ 107 ] https://github .com/Thinklab- SJTU/GenSCO A vailable for academic research use DRHG [ 108 ] https://github .com/CIAM- Group/DRHG A vailable for academic research use FastT2T [ 115 ] https://github .com/Thinklab- SJTU/Fast- T2T MIT license GF A CS [ 121 ] https://github .com/ai4co/gfacs MIT license T ABLE XI S O U R C E S O F T H E A D O P T E D B E N C H M A R K S Benchmark Instance BKS TSPLIB http://comopt.ifi.uni- heidelberg.de/software/ TSPLIB95/ http://comopt.ifi.uni- heidelberg.de/software/TSPLIB95/STSP .html National https://www .math.uwaterloo.ca/tsp/world/countries. html https://www .math.uwaterloo.ca/tsp/world/summary .html VLSI https://www .math.uwaterloo.ca/tsp/vlsi/index.html https://www .math.uwaterloo.ca/tsp/vlsi/summary .html 8th DIMACS http://dimacs.rutgers.edu/archive/Challenges/TSP/ download.html http://webhotel4.ruc.dk/ ∼ keld/research/LKH/DIMA CS results.html Implementation Challenge http://dimacs.rutgers.edu/archiv e/Challenges/TSP/opts.html CVRPLIB https://galgos.inf.puc- rio.br/cvrplib/index.php/en/ instances Provided in the corresponding .vrp files of the instances. This is the supplementary material for “Survey on Neural Routing Solvers”. A P P E N D I X A E X P E R I M E N T D E TA I L S A. Adopted Resour ces The sources and possible licenses of the adopted methods and benchmark instances are summarized in T able X and XI . All of them are open-sourced and av ailable for academic use. B. Detailed Results of the Pr oposed Pipeline The detailed results of the proposed pipeline, including NRSs with all available models, are presented in T able XII and T able XIII , respectively . 21 T ABLE XII D E TAI L E D E X P E R I M E N TA L R E S U LTS O F T H E P RO P O S E D E V A L UATI O N P I P E L I N E F O R T S P Method (0,1K) [1K, 10K) [10K, 100K] T otal Gap Time Solved Gap Time Solved Gap T ime Solved Gap Solv ed Nearest Neighbor 25.29% 0.01s 69/69 26.66% 0.29s 109/109 25.01% 22.60s 50/50 25.88% 228/228 Random Insertion 10.60% 0.00s 69/69 15.32% 0.05s 109/109 16.37% 8.93s 50/50 14.12% 228/228 LKH-3 t=n/3, runs=1 0.00% 7.88s 69/69 0.01% 631.34s 109/109 0.08% 14600.50s 50/50 0.03% 228/228 LKH-3 ↓ t=n/3, runs=1 0.00% 9.25s 69/69 0.01% 600.36s 109/109 0.05% 10800.24s 50/50 0.02% 228/228 BQ 5.00% 2.51s 68/69 19.03% 22.74s 92/109 52.00% 187.81s 4/50 14.02% 164/228 LEHD ∗ greedy 4.85% 1.01s 69/69 20.13% 68.27s 106/109 49.35% 1386.01s 11/50 16.19% 186/228 SIL ∗ greedy (1K) 6.07% 1.72s 69/69 10.29% 17.31s 106/109 20.71% 434.58s 47/50 11.18% 222/228 SIL ∗ greedy (5K) 9.68% 1.71s 69/69 11.06% 17.83s 109/109 18.75% 422.26s 50/50 12.33% 228/228 SIL ∗ greedy (10K) 6.11% 1.72s 69/69 9.99% 17.87s 109/109 20.85% 414.78s 50/50 11.20% 228/228 SIL ∗ greedy (50K) 9.86% 1.71s 69/69 9.40% 17.87s 109/109 12.48% 427.04s 50/50 10.21% 228/228 SIL ∗ greedy (100K) 8.64% 1.69s 69/69 9.83% 17.69s 109/109 11.11% 430.73s 50/50 9.75% 228/228 ICAM 6.53% 0.25s 69/69 16.62% 21.57s 109/109 21.34% 1050.33s 19/50 13.54% 197/228 ELG 6.05% 0.63s 69/69 18.14% 88.12s 108/109 21.65% 940.35s 6/50 13.70% 183/228 INV iT -3V 7.93% 2.77s 69/69 12.08% 49.03s 109/109 11.52% 1079.50s 42/50 10.67% 220/228 L2R 5.89% 1.60s 69/69 9.22% 15.55s 109/109 8.52% 153.11s 50/50 8.06% 228/228 DGL 6.53% 1.17s 69/69 11.32% 11.67s 109/109 11.14% 58.62s 25/50 9.67% 203/228 L2C-Insert ∗ greedy 4.39% 1.51s 69/69 18.12% 15.34s 109/109 30.94% 145.17s 50/50 16.77% 228/228 H-TSP (1K) 6.16% 0.67s 36/69 12.26% 3.24s 100/109 12.74% 21.93s 40/50 11.12% 176/228 H-TSP (2K) 6.26% 0.64s 36/69 11.83% 3.23s 100/109 12.35% 21.42s 40/50 10.81% 176/228 H-TSP (5K) 6.16% 0.61s 36/69 11.62% 3.15s 100/109 12.29% 21.44s 40/50 10.65% 176/228 H-TSP (10K) 6.10% 0.61s 36/69 11.75% 3.13s 100/109 12.29% 21.37s 40/50 10.72% 176/228 D A CT T=1K (20) 24.54% 39.47s 69/69 26.85% 260.55s 83/109 / / 0/50 25.80% 152/228 D A CT T=1K (50) 17.49% 39.68s 69/69 26.69% 259.77s 83/109 / / 0/50 22.52% 152/228 D A CT T=1K (100) 16.37% 39.84s 69/69 26.58% 261.73s 83/109 / / 0/50 21.94% 152/228 NeuOpt T=1K (20) 35.76% 533.78s 7/69 / / 0/109 / / 0/50 35.76% 7/228 NeuOpt T=1K (50) 20.70% 138.26s 27/69 / / 0/109 / / 0/50 20.70% 27/228 NeuOpt T=1K (100) 12.44% 104.05s 36/69 / / 0/109 / / 0/50 12.44% 36/228 NeuOpt T=1K (200) 19.90% 81.22s 46/69 / / 0/109 / / 0/50 19.90% 46/228 L2C-Insert ∗ T=1K 1.08% 381.55s 69/69 9.80% 479.98s 109/109 29.15% 615.19s 50/50 11.41% 228/228 GenSCO (100) 14.56% 23.19s 68/69 35.46% 677.31s 104/109 35.17% 14304.70s 25/50 28.21% 197/228 GenSCO (500) 19.64% 25.57s 42/69 48.66% 563.68s 68/109 52.89% 17964.48s 14/50 39.31% 124/228 GenSCO (1K) 24.11% 27.76s 29/69 19.27% 268.60s 53/109 90.42% 24542.75s 2/50 22.64% 84/228 LEHD ∗ RRC1K 1.73% 498.40s 69/69 10.87% 1634.51s 109/109 24.02% 2769.86s 9/50 8.13% 187/228 SIL ∗ PRC1K (1K) 0.63% 903.72s 69/69 2.89% 3250.51s 109/109 7.29% 5366.67s 50/50 3.17% 228/228 SIL ∗ PRC1K (5K) 0.86% 888.48s 69/69 2.86% 2889.38s 109/109 6.85% 5046.36s 50/50 3.13% 228/228 SIL ∗ PRC1K (10K) 0.55% 891.35s 69/69 2.63% 2898.09s 109/109 6.36% 4962.70s 50/50 2.82% 228/228 SIL ∗ PRC1K (50K) 0.80% 883.45s 69/69 2.56% 2879.65s 109/109 5.11% 5009.26s 50/50 2.59% 228/228 SIL ∗ PRC1K (100K) 0.80% 883.87s 69/69 2.58% 2880.46s 109/109 4.55% 4933.45s 50/50 2.47% 228/228 DRHG T=1K 0.10% 769.53s 69/69 1.46% 2857.55s 109/109 4.46% 3004.28s 50/50 1.71% 228/228 Fast T2T T s =10, T g =10 (50) 15.72% 1.42s 45/69 / / 0/109 / / 0/50 15.72% 45/228 Fast T2T T s =10, T g =10 (100) 10.46% 1.41s 45/69 / / 0/109 / / 0/50 10.46% 45/228 Fast T2T T s =10, T g =10 (500) 20.68% 1.39s 45/69 / / 0/109 / / 0/50 20.68% 45/228 Fast T2T T s =10, T g =10 (1K) 18.55% 1.40s 45/69 / / 0/109 / / 0/50 18.55% 45/228 Fast T2T T s =10, T g =10 (10K) 43.74% 1.41s 45/69 / / 0/109 / / 0/50 43.74% 45/228 GF A CS † T=100, K=100 (200) 31.64% 166.94s 66/69 86.77% 2601.13s 22/109 / / 0/50 45.42% 88/228 GF A CS † T=100, K=100 (500) 35.06% 175.46s 64/69 86.43% 2590.34s 16/109 / / 0/50 45.33% 80/228 GF A CS † T=100, K=100 (1K) 42.05% 175.18s 64/69 84.88% 2766.93s 10/109 / / 0/50 47.84% 74/228 GF A CS ‡ T=100, K=100 (200) 0.72% 174.21s 69/69 3.76% 9142.93s 83/109 / / 0/50 2.38% 152/228 GF A CS ‡ T=100, K=100 (500) 0.80% 209.26s 69/69 3.31% 6718.88s 65/109 / / 0/50 2.02% 134/228 GF A CS ‡ T=100, K=100 (1K) 0.93% 225.39s 69/69 3.63% 7545.88s 66/109 / / 0/50 2.25% 135/228 () The content in parentheses indicates the node scale of instances with uniformly distributed nodes in the model’ s training set. ↓ I nitial P er iod is set as 1K, rather than the original value DIMENSION/2. ∗ The NRS supports more than one inference strategy . † GF A CS without local search at the last generation. The output solution is the best of the population at the last generation. ‡ The original version of GF ACS. The output solution is the best in history (all after local search). 22 T ABLE XIII D E TAI L E D E X P E R I M E N TA L R E S U LTS O F T H E P RO P O S E D E V A L UATI O N P I P E L I N E F O R C V R P Method (0,1K) [1K, 10K) [10K, 100K] T otal Gap T ime Solved Gap T ime Solved Gap T ime Solved Gap Solved Nearest Neighbor 21.17% 0.03s 99/99 15.18% 1.08s 5/5 11.80% 14.63s 6/6 20.39% 110/110 Random Insertion 75.00% 0.00s 36/99 / / 0/5 / / 0/6 75.00% 36/110 HGS t=n/3 0.29% 111.24s 99/99 3.59% 1428.41s 5/5 7.86% 6926.41s 6/6 0.85% 110/110 AILS-II t=n/3 0.57% 133.95s 99/99 1.58% 1388.42s 5/5 1.58% 5646.48s 6/6 0.68% 110/110 BQ 8.87% 3.63s 99/99 20.28% 39.97s 5/5 41.52% 202.69s 5/6 10.89% 109/110 LEHD ∗ greedy 11.25% 1.53s 98/99 19.22% 99.43s 5/5 32.80% 852.02s 2/6 12.04% 105/110 SIL ∗ greedy (1K) 43.24% 2.62s 58/99 21.73% 27.17s 5/5 15.39% 146.85s 6/6 39.26% 69/110 SIL ∗ greedy (5K) 42.70% 2.49s 62/99 18.34% 26.60s 5/5 12.38% 147.91s 6/6 38.54% 73/110 SIL ∗ greedy (10K) 46.94% 2.54s 62/99 20.78% 27.08s 5/5 12.62% 148.55s 6/6 42.32% 73/110 SIL ∗ greedy (50K) 40.04% 2.48s 65/99 16.09% 26.86s 5/5 10.81% 146.83s 6/6 36.16% 76/110 SIL ∗ greedy (100K) 40.44% 2.54s 60/99 18.32% 26.86s 5/5 10.95% 148.69s 6/6 36.39% 71/110 ICAM 5.00% 0.42s 99/99 11.69% 32.32s 5/5 / / 0/6 5.32% 104/110 ELG 8.03% 1.29s 99/99 18.51% 30.21s 5/5 29.38% 133.08s 2/6 8.93% 106/110 INV iT -3V 13.15% 4.72s 99/99 19.03% 77.33s 5/5 23.91% 496.25s 5/6 13.91% 109/110 L2R 8.16% 2.49s 99/99 11.62% 23.99s 5/5 11.08% 97.12s 6/6 8.48% 110/110 DGL 15.27% 2.22s 99/99 17.96% 22.60s 5/5 18.69% 78.64s 5/6 15.55% 109/110 ReLD 4.10% 0.41s 99/99 10.22% 5.29s 5/5 11.27% 28.87s 3/6 4.58% 107/110 L2C-Insert ∗ greedy 6.87% 2.73s 99/99 22.37% 616.75s 5/5 49.41% 5525.71s 2/6 8.40% 106/110 D A CT T=1K (20) 18.90% 284.37s 64/99 / / 0/5 / / 0/6 18.90% 64/110 D A CT T=1K (50) 16.42% 338.69s 54/99 / / 0/5 / / 0/6 16.42% 54/110 D A CT T=1K (100) 16.42% 246.51s 74/99 17.70% 479.82s 1/5 / / 0/6 16.44% 75/110 NeuOpt T=1K (20) 79.48% 3440.62s 6/99 / / 0/5 / / 0/6 79.48% 6/110 NeuOpt T=1K (50) 74.85% 2953.52s 7/99 / / 0/5 / / 0/6 74.85% 7/110 NeuOpt T=1K (100) 46.93% 868.55s 24/99 / / 0/5 / / 0/6 46.93% 24/110 NeuOpt T=1K (200) 26.93% 571.14s 36/99 / / 0/5 / / 0/6 26.93% 36/110 L2C-Insert ∗ T=1K 3.21% 344.05s 99/99 18.87% 6166.21s 5/5 44.29% 32754.86s 2/6 4.72% 106/110 LEHD ∗ RRC1K 3.58% 796.15s 99/99 11.73% 2043.74s 5/5 21.98% 2820.28s 2/6 4.32% 106/110 SIL ∗ PRC1K (1K) 23.67% 1291.37s 99/99 12.59% 3405.06s 5/5 11.46% 4254.08s 6/6 22.50% 110/110 SIL ∗ PRC1K (5K) 21.58% 1314.59s 99/99 10.12% 3487.80s 5/5 8.60% 4324.59s 6/6 20.35% 110/110 SIL ∗ PRC1K (10K) 22.16% 1297.48s 99/99 9.40% 3442.22s 5/5 8.54% 4223.01s 6/6 20.84% 110/110 SIL ∗ PRC1K (50K) 21.38% 1307.97s 99/99 8.28% 3471.69s 5/5 7.40% 4251.88s 6/6 20.02% 110/110 SIL ∗ PRC1K (100K) 22.24% 1315.62s 99/99 9.13% 3471.46s 5/5 8.02% 4267.11s 6/6 20.87% 110/110 DRHG T=1K 11.11% 1114.60s 99/99 17.95% 2529.12s 5/5 16.95% 5376.37s 6/6 11.74% 110/110 GF A CS † T=100, K=100 (200) 36.83% 437.38s 99/99 34.09% 9654.33s 3/5 / / 0/6 36.75% 102/110 GF A CS † T=100, K=100 (500) 61.11% 606.05s 78/99 86.40% 1701.41s 1/5 / / 0/6 61.43% 79/110 GF A CS † T=100, K=100 (1K) 67.68% 476.95s 64/99 / / 0/5 / / 0/6 67.68% 64/110 GF A CS ‡ T=100, K=100 (200) 2.60% 405.81s 99/99 7.65% 14884.94s 4/5 / / 0/6 2.80% 103/110 GF A CS ‡ T=100, K=100 (500) 2.48% 588.86s 99/99 5.28% 10935.70s 3/5 / / 0/6 2.56% 102/110 GF A CS ‡ T=100, K=100 (1K) 2.55% 511.39s 99/99 5.50% 11283.58s 3/5 / / 0/6 2.63% 102/110 () The content in parentheses indicates the node scale of instances with uniformly distributed nodes in the model’ s training set. ∗ The NRS supports more than one inference strategy . † GF A CS without local search at the last generation. The output solution is the best of the population at the last generation. ‡ The original version of GF ACS. The output solution is the best in history (all after local search).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment