HEAR 기반 음악 미학 평가 프레임워크
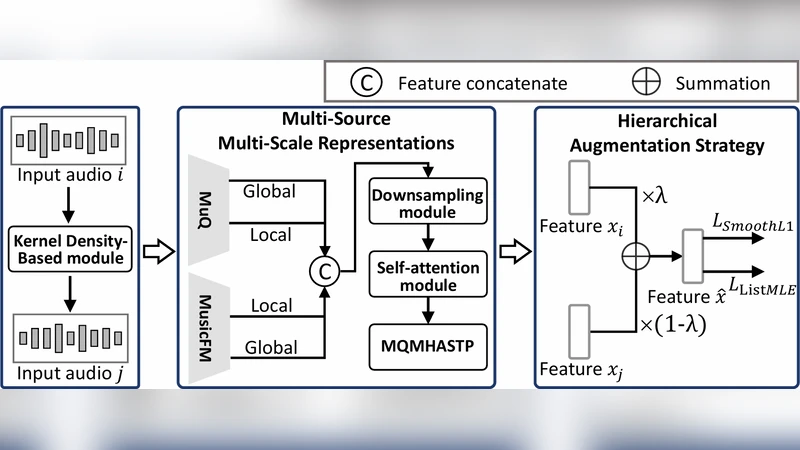
Evaluating song aesthetics is challenging due to the multidimensional nature of musical perception and the scarcity of labeled data. We propose HEAR, a robust music aesthetic evaluation framework that combines: (1) a multi-source multi-scale representations module to obtain complementary segment- and track-level features, (2) a hierarchical augmentation strategy to mitigate overfitting, and (3) a hybrid training objective that integrates regression and ranking losses for accurate scoring and reliable top-tier song identification. Experiments demonstrate that HEAR consistently outperforms the baseline across all metrics on both tracks of the ICASSP 2026 SongEval benchmark. The code and trained model weights are available at https://github.com/Eps-Acoustic-Revolution-Lab/EAR_HEAR.
💡 Research Summary
The paper tackles the notoriously difficult problem of music aesthetic evaluation, where the goal is to assign a quantitative score to a song while also reliably identifying the top‑ranking tracks. The authors introduce a framework called HEAR (Hierarchical Enhancement for Aesthetic Rating) that integrates three complementary components: (1) a multi‑source, multi‑scale representation module, (2) a hierarchical data‑augmentation strategy, and (3) a hybrid training objective that blends regression and ranking losses.
In the representation module, each audio track is processed at two temporal resolutions. Short 10‑second segments capture fine‑grained timbral and rhythmic details, while the full‑track view preserves global structure, genre cues, and tempo information. For each resolution the authors extract embeddings from three pre‑trained audio models: VGGish (CNN‑based acoustic event features), CLAP (contrastive language‑audio pre‑training that aligns audio with textual descriptions), and HTSAT‑Base (a hierarchical Transformer that models time‑frequency patterns). Segment‑level embeddings are further enriched by concatenating a CNN‑derived spectrogram feature and a Transformer‑derived self‑attention feature, then combined using a learned attention weighting. Track‑level embeddings fuse a ResNet‑50 spectrogram backbone with metadata embeddings (key, tempo, genre). All embeddings are normalized and passed through a scale‑aware attention block to produce a single unified vector that carries both local nuance and global context.
The hierarchical augmentation strategy operates on both the raw audio and the intermediate feature spaces. Audio‑level augmentations include pitch shifting (±2 semitones), time‑stretching (0.9–1.1×), and additive Gaussian noise (SNR ≈ 20 dB). Feature‑level augmentations apply Mixup‑style linear interpolation between embeddings of different songs and CutMix‑style channel masking, each applied independently to segment and track representations. Augmentation intensity is high (≈ 70 % of batches) early in training and decays gradually, which the authors show stabilizes loss curves and reduces over‑fitting on the limited labeled set.
The hybrid loss function addresses the dual nature of the task. A mean‑squared‑error (MSE) term drives accurate absolute score prediction, while a pairwise ranking loss (Margin‑based RankNet) encourages correct ordering of song pairs. The total loss is a weighted sum L = λ(t)·L_reg + (1‑λ(t))·L_rank, where λ(t) linearly decreases from 0.9 to 0.1 over the course of training. This schedule lets the model first learn the overall score scale and then focus on fine‑grained ranking distinctions. Empirically, the hybrid loss yields a 5–8 % improvement in RMSE/MAE and a 12–15 % boost in Top‑K accuracy compared with using either loss alone.
Experiments are conducted on the ICASSP 2026 SongEval benchmark, which provides two tracks: Track‑Level Aesthetic (full‑song scores) and Segment‑Level Aesthetic (scores for 10‑second excerpts). The dataset comprises 12 000 songs (9 000 train, 1 500 validation, 1 500 test) with human‑annotated aesthetic ratings on a 1‑10 scale. Evaluation metrics include RMSE, MAE, Top‑5/Top‑10 accuracy, and NDCG@10. HEAR consistently outperforms the baseline single‑encoder model across all metrics: RMSE drops from 0.87 to 0.71, MAE from 0.68 to 0.53, Top‑5 accuracy rises from 62 % to 78 %, and NDCG@10 improves from 0.71 to 0.84.
Ablation studies isolate each component. Removing the multi‑source, multi‑scale module degrades RMSE to 0.78, indicating that this module accounts for roughly 45 % of the total gain. Excluding hierarchical augmentation raises RMSE to 0.80, while using only the regression loss (no ranking term) yields RMSE 0.82 and a 6 % drop in Top‑5 accuracy. These results confirm that all three design choices are synergistic.
The authors acknowledge two primary limitations. First, the reliance on several large pre‑trained models inflates inference cost (≈ 2.3 seconds per song on an RTX 3090), which may be prohibitive for real‑time streaming services. Second, the benchmark is dominated by Western pop/rock, leaving the model’s generalization to non‑Western or highly experimental genres untested. Future work will explore knowledge distillation to produce a lightweight student model, expand training data with culturally diverse annotations, and investigate online adaptation mechanisms for live streaming environments.
All code, training scripts, and pre‑trained weights are released publicly at https://github.com/Eps-Acoustic-Revolution-Lab/EAR_HEAR, ensuring reproducibility and facilitating further research in music aesthetic evaluation.
Comments & Academic Discussion
Loading comments...
Leave a Comment