SPMTrack: Spatio-Temporal Parameter-Efficient Fine-Tuning with Mixture of Experts for Scalable Visual Tracking
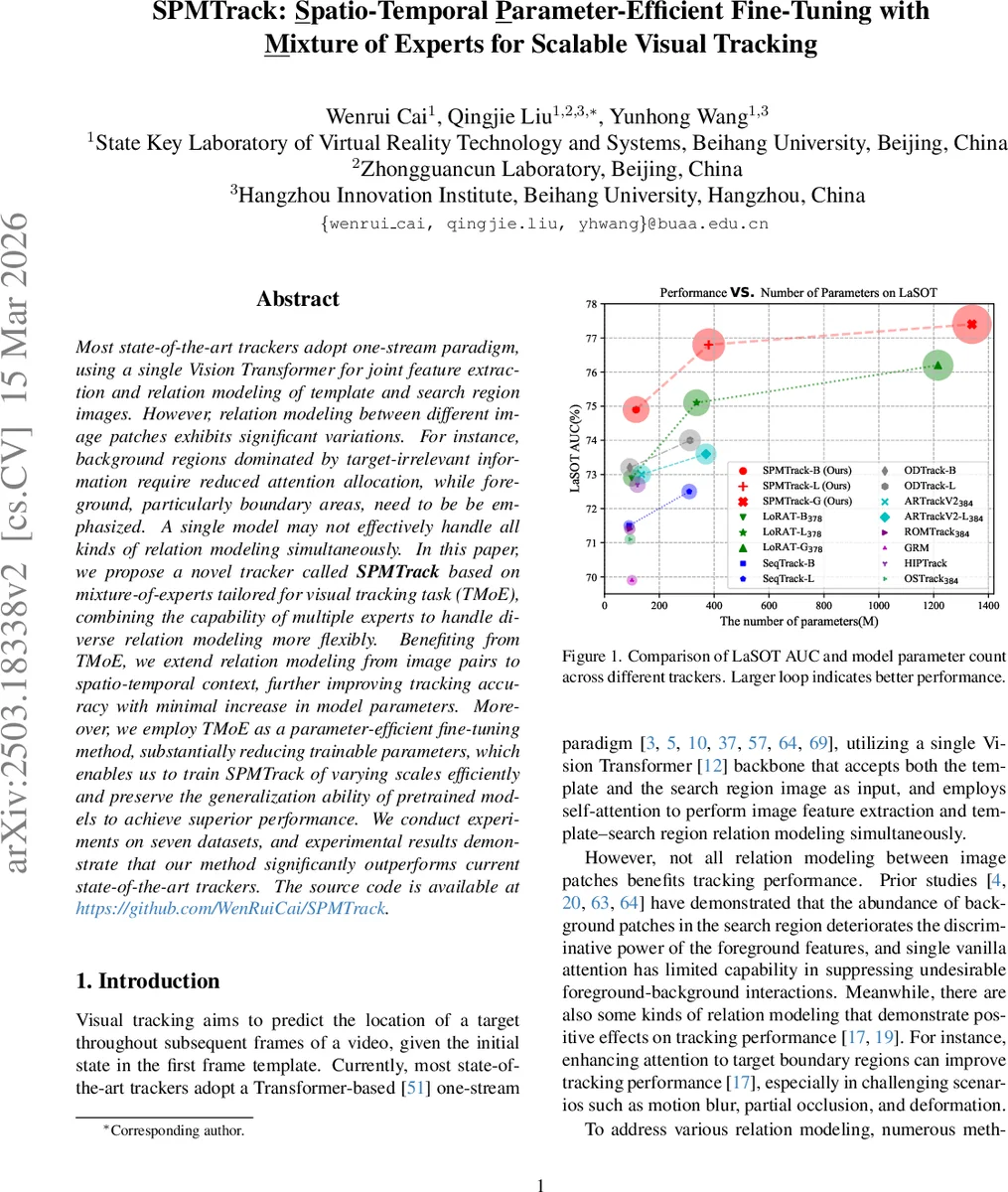
Most state-of-the-art trackers adopt one-stream paradigm, using a single Vision Transformer for joint feature extraction and relation modeling of template and search region images. However, relation modeling between different image patches exhibits significant variations. For instance, background regions dominated by target-irrelevant information require reduced attention allocation, while foreground, particularly boundary areas, need to be be emphasized. A single model may not effectively handle all kinds of relation modeling simultaneously. In this paper, we propose a novel tracker called SPMTrack based on mixture-of-experts tailored for visual tracking task (TMoE), combining the capability of multiple experts to handle diverse relation modeling more flexibly. Benefiting from TMoE, we extend relation modeling from image pairs to spatio-temporal context, further improving tracking accuracy with minimal increase in model parameters. Moreover, we employ TMoE as a parameter-efficient fine-tuning method, substantially reducing trainable parameters, which enables us to train SPMTrack of varying scales efficiently and preserve the generalization ability of pretrained models to achieve superior performance. We conduct experiments on seven datasets, and experimental results demonstrate that our method significantly outperforms current state-of-the-art trackers. The source code is available at https://github.com/WenRuiCai/SPMTrack.
💡 Research Summary
The paper introduces SPMTrack, a visual object tracking framework that leverages a task‑specific Mixture‑of‑Experts (TMoE) module to achieve both flexible relation modeling and parameter‑efficient fine‑tuning. Traditional state‑of‑the‑art trackers follow a one‑stream paradigm: a single Vision Transformer (ViT) processes the template and search region together, using self‑attention to extract features and model their interactions. However, the interaction patterns between image patches vary widely—background patches should receive little attention, while foreground and especially boundary patches require emphasis. A single homogeneous model cannot simultaneously satisfy these divergent needs.
To address this, the authors design TMoE, a specialized MoE component that replaces the linear projection layers in both the multi‑head self‑attention (MSA) and the feed‑forward network (FFN) of a ViT block. Unlike conventional MoE, which typically inserts experts only in FFN layers and uses full‑size feed‑forward sub‑networks as experts, TMoE employs lightweight linear experts throughout. Each TMoE module consists of:
- Shared Expert (ES) – a frozen copy of the original pretrained linear layer, preserving the generic knowledge learned during large‑scale pre‑training.
- Compression Expert (EC) – a linear projection that reduces the input dimension from d to a much smaller r (r ≪ d), thereby lowering the computational burden for the routed experts.
- Routed Experts (ERi, i = 1…Nₑ) – Nₑ linear layers that operate on the compressed representation and produce outputs of the original dimension D.
- Router – a trainable linear layer followed by a Softmax that generates token‑wise routing weights W∈ℝ^{Nₑ}.
For each token x, the module computes yₛ = ES(x), y_c = EC(x), and y_{e_i} = ERi(y_c). The final output is y = yₛ + ∑{i} W_i · y{e_i}. Because all routed experts are densely activated, the model can blend multiple relational patterns on a per‑token basis, allowing it to simultaneously suppress background‑foreground interference, highlight object boundaries, and adapt to other nuanced interactions.
The TMoE block (TMoEBlock) replaces the standard ViT block: the MSA’s Q, K, V, and output projection are each wrapped with a TMoE, and the two linear layers of the FFN are also replaced by TMoE modules. This fine‑grained insertion yields a richer set of expert combinations than applying MoE only to FFN, improving the capacity to model diverse relations without a substantial parameter increase.
Beyond relational flexibility, SPMTrack extends the one‑stream input from a single template‑search pair to a short video clip comprising the initial template and a set of selected historical frames (reference frames). Each frame is patch‑embedded, and a learnable “target state token” H is introduced to carry temporal information across frames. All tokens (reference tokens, search tokens, and H) are concatenated and fed into the Transformer encoder. After processing, the encoder outputs the updated target token H′ and the processed search tokens X′.
The prediction head uses H′ to compute a per‑token weight vector U = H′·X′ (inner product), which re‑weights the search tokens before reshaping them into a spatial feature map. A decoupled double‑MLP head then performs binary classification for the object center and Generalized IoU regression for the bounding box. Because H′ is updated each frame, the weight vector U implicitly injects spatio‑temporal context, allowing the tracker to benefit from past appearance cues without a heavy recurrent architecture.
Parameter‑efficient fine‑tuning: Only the router, compression expert, routed experts, and the prediction head are trainable; the shared experts remain frozen. Consequently, roughly 20 % of the total parameters are updated during training, a reduction of about 80 % compared with full fine‑tuning or recent LoRA‑based trackers. This dramatically lowers GPU memory consumption and training time while preserving the strong generic representations of the pretrained ViT.
Experimental validation: The authors evaluate two model scales—SPMTrack‑B (ViT‑Base, 12 layers, d = 768) and SPMTrack‑L (ViT‑Large, 24 layers, d = 1024)—on seven benchmarks (LaSOT, GOT‑10K, TrackingNet, TNL2K, etc.). Results show that SPMTrack‑B, despite using the smaller backbone, outperforms many state‑of‑the‑art trackers that rely on ViT‑Large, achieving higher AUC/Success scores across all datasets. Ablation studies confirm: (i) increasing the number of routed experts improves performance up to a saturation point; (ii) reducing the compression dimension r saves parameters but harms accuracy if set too low; (iii) freezing the shared expert while training only the routed components yields the best generalization; (iv) incorporating multi‑frame spatio‑temporal context adds 2–3 % AUC gain over a single‑frame baseline.
Contributions and impact:
- TMoE – a novel, lightweight MoE design tailored for visual tracking, applied to both attention and feed‑forward layers.
- SPMTrack – the first tracker that combines TMoE with explicit spatio‑temporal context, achieving state‑of‑the‑art accuracy with a fraction of trainable parameters.
- Parameter‑efficient fine‑tuning – demonstrates that large pretrained ViTs can be adapted to tracking tasks by training only a small subset of parameters, preserving generalization while reducing computational cost.
Limitations and future work: While TMoE reduces trainable parameters, the router and multiple experts still increase memory footprint during inference, especially for very deep ViT‑Large models. Optimizing the routing computation (e.g., top‑k routing, expert pruning) could further improve scalability. Extending TMoE to multimodal tracking (RGB‑T, RGB‑D) or integrating it with recent transformer‑based detection pipelines are promising directions.
In summary, SPMTrack introduces a flexible, expert‑driven architecture that simultaneously addresses the need for diverse relational modeling and efficient adaptation of large vision transformers, setting a new benchmark for visual object tracking.
Comments & Academic Discussion
Loading comments...
Leave a Comment