Evaluating song aesthetics is challenging due to the multidimensional nature of musical perception and the scarcity of labeled data. We propose HEAR, a robust music aesthetic evaluation framework that combines: (1) a multi-source multi-scale representations module to obtain complementary segment- and track-level features, (2) a hierarchical augmentation strategy to mitigate overfitting, and (3) a hybrid training objective that integrates regression and ranking losses for accurate scoring and reliable top-tier song identification. Experiments demonstrate that HEAR consistently outperforms the baseline across all metrics on both tracks of the ICASSP 2026 SongEval benchmark. The code and trained model weights are available at https://github.com/Eps-Acoustic-Revolution-Lab/EAR_HEAR.
💡 Deep Analysis
Deep Dive into HEAR 기반 음악 미학 평가 프레임워크.
Evaluating song aesthetics is challenging due to the multidimensional nature of musical perception and the scarcity of labeled data. We propose HEAR, a robust music aesthetic evaluation framework that combines: (1) a multi-source multi-scale representations module to obtain complementary segment- and track-level features, (2) a hierarchical augmentation strategy to mitigate overfitting, and (3) a hybrid training objective that integrates regression and ranking losses for accurate scoring and reliable top-tier song identification. Experiments demonstrate that HEAR consistently outperforms the baseline across all metrics on both tracks of the ICASSP 2026 SongEval benchmark. The code and trained model weights are available at https://github.com/Eps-Acoustic-Revolution-Lab/EAR_HEAR
.
📄 Full Content
With the rapid development of generative music models, automated music aesthetic evaluation has become increasingly important, yet remains challenging. Existing approaches, such as Audiobox-Aesthetics [1], employ simple Transformer-based architectures to predict multidimensional aesthetic scores but struggle to capture rich musical characteristics. While SongEval [2] establishes a high-quality benchmark, its limited data scale challenges the training of robust aesthetic evaluators. To this end, we propose a robust framework with the following main contributions:
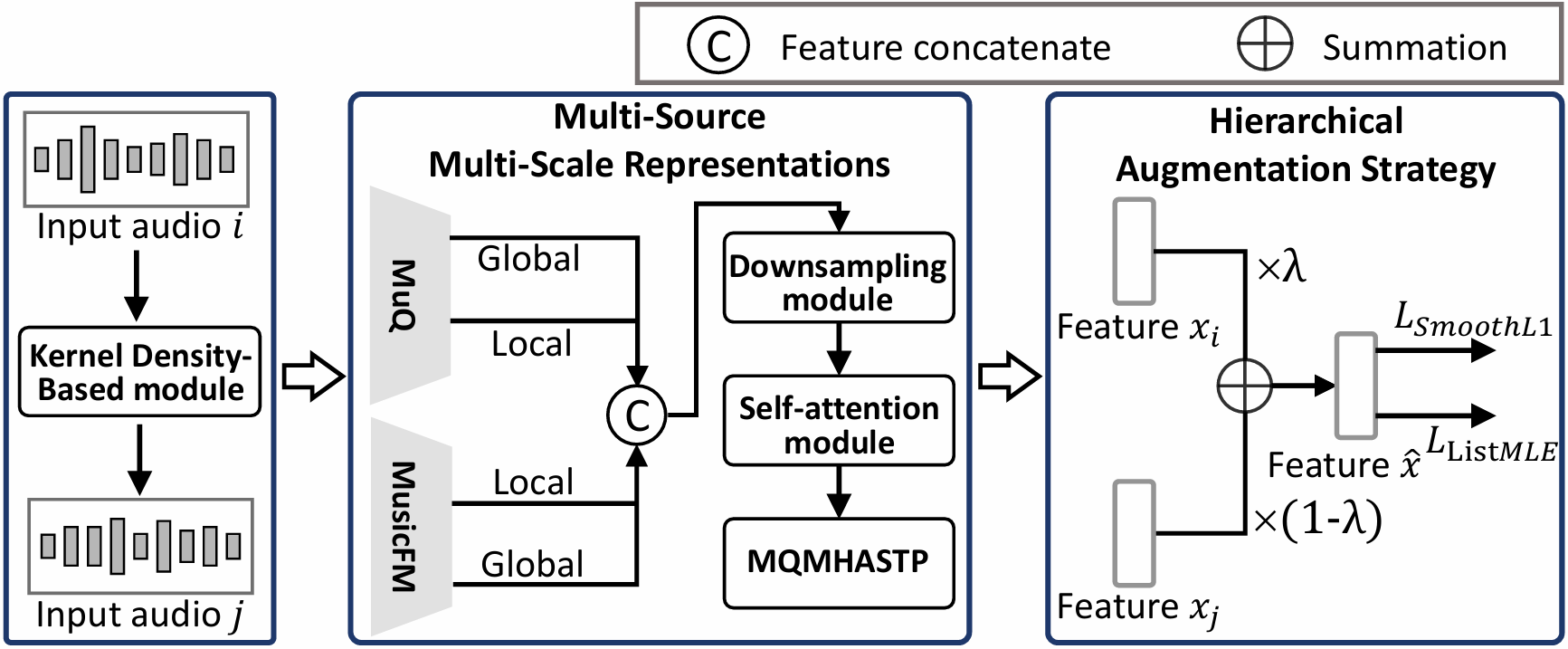
Inspired by Songformer [3], we employ both MuQ [4] and MusicFM [5] to extract complementary local segment-level and global track-level multi-scale music representations, followed by downsampling, self-attention, and a Multi-Query Multi-Head Attention Statistical Pooling (MQMHASTP) module [6], which enables the model to capture how temporal, spectral, harmonic, and content cues contribute to different aesthetic dimensions while converting variable-length features into fixed-length representations.
We introduce a Hierarchical Augmentation strategy that operates at both data and feature levels. At the data level, we apply a conservative audio augmentation pipeline to expand arXiv:2511.18869v2 [cs.SD] 30 Dec 2025
the training set, with details summarized in Section 3.1.1. At the feature level, we employ C-Mixup [7], which performs conditional mixing by sampling neighboring examples with higher probability in the label space via Kernel Density Estimation (KDE):
where d(i, j) denotes the Euclidean distance between the labels of two examples. A mixed feature-label pair is then obtained by convex combination:
with λ sampled from a Beta distribution, i.e., λ ∼ Beta(α, α).
To jointly support aesthetic score prediction and top-tier song identification, we adopt a hybrid objective L total combining SmoothL1 loss [8] for regression and the listwise ranking loss ListMLE [9] for modeling relative ordering among samples:
where β weights the ranking term to mitigate sensitivity to unreliable orderings from subjective scores, especially among similar samples.
All experiments are conducted on the SongEval dataset [2], which contains 2,399 songs annotated across five aesthetic dimensions. Following the official protocol, 200 samples are used for validation, while the remaining data are augmented using eight data-level strategies summarized in Table 1 for training. The model is trained using the Adam optimizer with a learning rate of 1×10 -5 and a weight decay of 1×10 -3 with a batch size of 8. The hyperparameter β, weighting the ranking objective, is set to 0.15 for Track 1 and 0.05 for Track 2.
For C-Mixup, the bandwidth parameter σ of the Gaussian kernel is set to 1, and α in Beta distribution is set to 2.
Table 1. Data-level augmentation settings used for training.
We evaluate the model using four official metrics: the Linear Correlation Coefficient (LCC) [10] measures the linear alignment between predicted and ground-truth scores, while Spearman’s Rank Correlation Coefficient (SRCC) [11] and Kendall’s Tau Rank Correlation (KTAU) [12] assess ranking consistency. Top-Tier Accuracy (TTA) measures top-tier song identification via an F1 score with official thresholding.
As shown in
We presented a robust framework HEAR for multidimensional music aesthetic evaluation, which effectively addresses the challenges of limited labeled data and complex musical perception. Our method synergistically combines multisource multi-scale representations, a hierarchical augmentation strategy, and a hybrid training objective. Experiments on the ICASSP 2026 SongEval benchmark confirm that our approach consistently surpasses baseline methods, achieving superior performance in both aesthetic scoring and top-tier song identification.