VERDICT: Verifiable Evolving Reasoning with Directive-Informed Collegial Teams for Legal Judgment Prediction
Legal Judgment Prediction (LJP) predicts applicable law articles, charges, and penalty terms from case facts. Beyond accuracy, LJP calls for intrinsically interpretable and legally grounded reasoning that can reconcile statutory rules with precedent-…
Authors: Hui Liao, Chuan Qin, Yongwen Ren
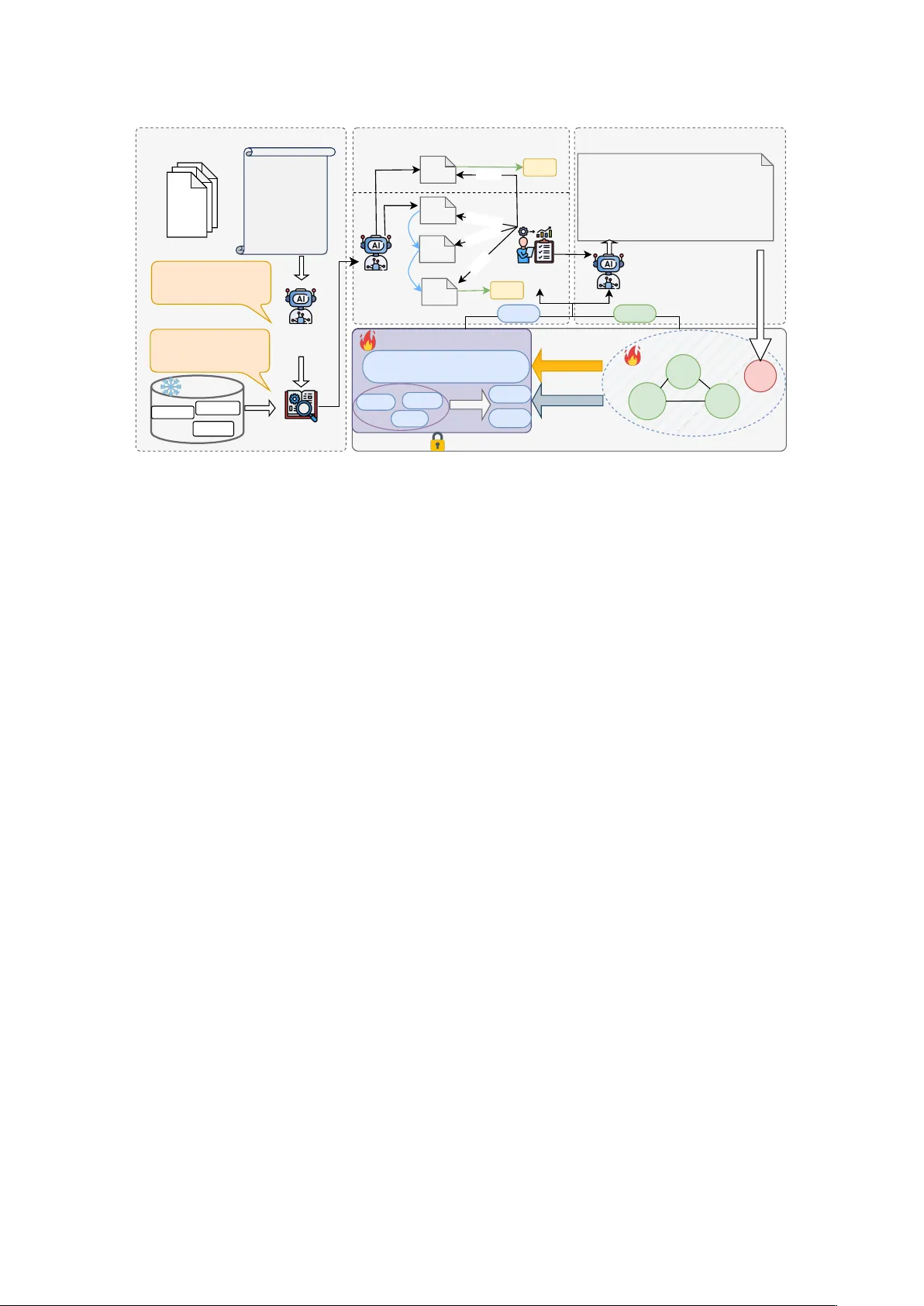
VERDICT : V erifiable Evolving Reasoning with Dir ectiv e-Informed Collegial T eams for Legal J udgment Pr ediction Hui Liao 1 , Chuan Qin 2 , Y ongwen Ren 1 , Hao Li 3 , Zhenya Huang 1 , Y any ong Zhang 1 , Chao W ang 1 1 Uni versity of Science and T echnology of China 2 Chinese Academy of Sciences 3 iFL YTEK AI Research {liaohui2002, yovren}@mail.ustc.edu.cn , chuanqin0426@gmail.com haoli5@iflytek.com , {huangzhy, yanyongz, wangchaoai}@ustc.edu.cn Abstract Legal Judgment Prediction (LJP) predicts appli- cable law articles, charges, and penalty terms from case facts. Beyond accuracy , LJP calls for intrinsically interpretable and legally grounded reasoning that can reconcile statutory rules with precedent-informed standards. Ho wev er , exist- ing methods often behave as static, one-shot predictors, providing limited procedural sup- port for verifiable reasoning and little capabil- ity to adapt as jurisprudential practice ev olves. W e propose VERDICT , a self-refining collabo- rativ e multi-agent frame work that simulates a virtual colle gial panel . VERDICT assigns spe- cialized agents to complementary roles (e.g., fact structuring, legal retriev al, opinion draft- ing, and supervisory verification) and coordi- nates them in a traceable draft–verify–re vise workflo w with explicit Pass/Reject feedback, producing verifiable reasoning traces and re- vision rationales. T o capture ev olving case experience, we further introduce a Hybrid Ju- risprudential Memory (HJM) grounded in the Micr o-Dir ective P aradigm , which stores prece- dent standards and continually distills vali- dated multi-agent verification trajectories into updated Micro-Directives for continual learn- ing across cases. W e ev aluate VERDICT on CAIL2018 and a ne wly constructed CJO2025 dataset with a strict future time-split for tempo- ral generalization. VERDICT achie ves state-of- the-art performance on CAIL2018 and demon- strates strong generalization on CJO2025. T o facilitate reproducibility and further research, we release our code and the dataset at https: //anonymous.4open.science/r/ARR- 4437 . 1 Introduction Legal Judgment Prediction (LJP) predicts applica- ble law articles, char ges, and penalty terms from case facts, and is increasingly used to support high- volume judicial workflo ws and public legal ser - vices ( The Supreme People’ s Court of the PRC , 2024 ; Cui et al. , 2023 ; Feng et al. , 2022 ). Ho wev er , in this high-stakes setting, accurac y alone is insuf- ficient: models must produce legally grounded and explainable predictions that align facts with consti- tuti ve elements and sentencing factors. This is diffi- cult because judicial decisions must reconcile rigid statutory rules with ev olving, conte xt-dependent ju- risprudential standards. Existing systems often rely on lexical shortcuts or statute-only retrie v al, yield- ing decisions that are hard to justify when rules and standards di verge. Existing approaches largely follo w two paradigms, each with clear bottlenecks. Discrimi- nati ve methods—ranging from dependenc y-aware models like T opJudge ( Zhong et al. , 2018 ) to graph-interaction networks like LAD AN ( Xu et al. , 2020 )—often learn decision boundaries from frequent lexical and structural correlations. While effecti ve on static benchmarks, they of fer limited support for explicit f act-to-element alignment, making predictions brittle for no vel fact patterns where such correlations are unreliable. Generati ve LLM-based approaches, such as LegalReasoner ( Shi et al. , 2025 ) or PLJP ( W u et al. , 2023 ), provide fluent case understanding and flexible reasoning, yet they may hallucinate or produce conclusions without verifiable legal support ( Huang et al. , 2023 ). Retriev al-Augmented Generation (RA G) partially mitigates this by grounding outputs in retrie ved statutes ( W u et al. , 2023 ). Ho wev er , it typically treats le gal kno wledge as a static repository , struggling to operationalize the e volving jurisprudential tension between rigid Rules (statutes) and flexible Standards (precedents) ( Kaplo w , 2013 ), especially when statutory text and case-based standards point to competing outcomes. Despite recent explorations, current LJP research remains constrained by three critical unresolved issues. First, intrinsic interpretability is still insuffi- cient. In the le gal domain, the transparency of the reasoning process is as crucial as outcome accu- 1 racy ( Bibal et al. , 2021 ). Y et, most models operate as "black boxes" or one-shot predictors, lacking the traceable, multi-stage deliberation process re- quired to construct explainable reasoning chains. Second, models struggle to distinguish fine-grained legal nuances, particularly when semantic similar - ity div erges from legal logic. Generic encoders often conflate scenarios (e.g., "Theft" vs. "Embez- zlement") based on surface-le vel textual overlap, failing to align facts with specific constitutiv e el- ements and boundary conditions essential for ac- curate qualification. Third, current systems suf fer from the absence of dynamic experience accumu- lation. Unlike human judges who refine criteria through practice, most approaches treat knowledge as static, lacking the cognitiv e mechanism to distill abstract "Standards" into precise, e volving Micro- Directi ves that can be continuously updated from ne wly adjudicated cases. T o address these limitations, we present VER- DICT , which inte grates Directiv e-Informed mem- ory with a Collegial T eam of agents. VERDICT org anizes judgment prediction as a traceable and explainable deliberation-and-verification w orkflow: the Court Clerk Agent e xtracts legally salient f act points; the Judicial Assistant Agent retrieves and filters applicable statutes and precedents; the Case- handling Judge Agent drafts a grounded opinion linking facts to le gal elements; the Adjudication Su- pervisor Agent verifies the draft against statutes and a case-updated jurisprudential memory of prece- dent standards and Micro-Directi ves, and issues ex- plicit Pass/Reject signals with correcti ve feedback to trigger re vision; and the Presiding Judge Agent consolidates the verified draft into the final verdict. T o more faithfully emulate how collegial panels rec- oncile statutory rules with precedent-informed dis- cretion, we draw on the Micr o-Directive P aradigm from computational law ( Casey and Niblett , 2016 ), which bridges rigid “Rules” and flexible “Stan- dards” by distilling context-sensiti v e yet testable Micro-Directi ves. Building on this view , VER- DICT incorporates a Hybrid Jurisprudential Mem- ory (HJM) that stores precedent standards and e volving Micro-Directives, and continuously dis- tills v alidated multi-agent verification trajectories into refined directiv es for continual learning across cases rather than static, one-shot inference. • W e propose VERDICT ( V erifiable E v olving R easoning with D irectiv e- I nformed C ollegial T eams), a self-refining multi-agent system that simulates a virtual colle gial panel via a trace- able draft–verify–re vise loop, producing verifi- able reasoning traces for judgment prediction. • W e design a Hybrid Jurisprudential Mem- ory (HJM) grounded in the Micr o-Directive P aradigm , which maintains precedent standards and ev olving Micro-Directi ves and updates them by distilling verified multi-agent trajectories, en- abling continual learning across cases. • W e conduct comprehensi ve experiments on the widely used CAIL2018 benchmark and our ne wly constructed CJO2025 dataset. VER- DICT achieves state-of-the-art performance on CAIL2018 and demonstrates strong temporal generalization on CJO2025. 2 Related W ork 2.1 Legal Judgment Pr ediction Paradigms LJP approaches hav e e volved from discriminati v e classification to generati ve reasoning. Early dis- criminati ve models employed CNNs ( Kim , 2014 ) and BER T ( Devlin et al. , 2019 ) for text classifica- tion. T o capture logical hierarchies, dependency- aw are models like T opJudge ( Zhong et al. , 2018 ) and MPBFN ( Y ang et al. , 2019 ) utilized Directed Acyclic Graphs. Subsequent works, such as LAD AN ( Xu et al. , 2020 ), NeurJudge ( Y ue et al. , 2021 ), and CTM ( Liu et al. , 2022 ), introduced graph distillation and contrastiv e learning to distin- guish subtle legal nuances. Ho wev er , these models rely heavily on high-frequenc y patterns ( Xiao et al. , 2018 ), leading to poor generalization in emerg- ing scenarios. Recently , Large Language Models (LLMs) hav e shifted the paradigm. While GPT -4 sho ws promise in exams ( Katz et al. , 2024 ), generic LLMs on benchmarks lik e LegalBench ( Guha et al. , 2023 ) still suffer from hallucinations ( Huang et al. , 2023 ). T o enhance reasoning, general strategies like Chain-of-Thought ( W ei et al. , 2022 ) and Self- Refine ( Madaan et al. , 2023 ; Shinn et al. , 2023 ) hav e been proposed. Specific to law , LegalRea- soner ( Shi et al. , 2025 ) introduces step-wise verifi- cation to correct logical errors, while A TRIE ( Luo et al. , 2025 ) utilizes retrie val to automate le gal con- cept interpretation. Similarly , PLJP ( W u et al. , 2023 ) combines domain models with retriev al- augmented generation (RA G). Ho we ver , these ap- proaches primarily rely on static internal knowl- edge or fixed retrie val corpora. They lack the dy- namic, experience-based e v olution mechanism of human judges, often failing to adapt to the chang- 2 ing adjudication criteria ov er time. 2.2 Multi-Agent Systems and Knowledge Evolution Multi-Agent Systems (MAS) solv e complex tasks through role specialization. Frame works like MetaGPT ( Hong et al. , 2023 ) and ChatDe v ( Qian et al. , 2024 ) utilize standardized operating proce- dures (SOPs), while AutoGen ( W u et al. , 2024 ) and AgentNet ( Y ang et al. , 2025 ) enable decentralized coordination. A critical gap in legal MAS, ho we ver , is dynamic knowledge management. Existing mem- ory modules like G-Memory ( Zhang et al. , 2025 ) treat interactions as static records rather than e volv- ing wisdom. They fail to distill abstract “Standard” into precise directiv es ov er time. Our VERDICT addresses this by integrating a cogniti ve dual-layer memory into a “V irtual Collegial Panel”, enabling agents to ev olve their jurisprudential understanding through continuous practice. 3 Method In this section, we describe our proposed frame- work, VERDICT (V erifiable Evolving Reasoning with Directiv e-Informed Collegial T eams), as illus- trated in Figure 1 . 3.1 Problem F ormulation In this work, we focus on the task of Legal Judg- ment Prediction (LJP). Gi ven a Legal Fact de- scription formally defined as a token sequence s d = { w d 1 , . . . , w d l d } encompassing the case narra- ti ve, our objecti ve is to predict the judgment result j = ( a, c, t ) . This target consists of three het- erogeneous components: Law Articles a ∈ Y a , representing specific articles from the Criminal Law; Charges c ∈ Y c , defined by the constitu- ti ve elements of the crime; and Imprisonment T erms t ∈ Y t , which are categorized into eleven distinct classes following standard con ventions. Ul- timately , the goal is to learn a mapping function F : s d → ( a, c, t ) to generate the accurate judicial reasoning and verdict based on the input f acts. 3.2 T raceable Multi-Agent Judicial W orkflow In real-world le gal scenarios, Legal Judgment Pre- diction (LJP) is ne ver an isolated classification task but a comple x collaborativ e process cov ering case filing, research, drafting, deliberation, and final adjudication. T o replicate this procedure, we de- sign a multi-agent system simulating a real-world “V irtual Collegial Panel. ” W e formally define the judicial judgment pre- diction system as a collaborativ e frame work based on a Directed Acyclic Graph (D A G), denoted as M = ⟨U , A , S , P ⟩ . Here, U represents the input space (i.e., the set of input cases); A is the set of agents; S denotes the intermediate states of the rea- soning chain (e.g., drafts, feedback); and P gov erns the execution flow among nodes. Heterogeneous agents interact via a unified protocol, utilizing a context assembly function Ψ( · ) to construct the prompt for each agent. W e illustrate the detailed prompt designs for all agents in Appendix E . The inference process e volv es through the following specialized roles: Pre-Adjudication Analysis: Court Clerk Agent & Judicial Assistant Agent Acting as the cornerstone of the workflow , the Court Clerk Agent ( a cler k ) is responsible for e x- tracting key factual points o ext (e.g., subjective criminal intent, specific criminal acts, and conse- quences) from the raw case dossier u ∈ U . Sub- sequently , the Judicial Assistant Agent ( a assist ) serves as the bridge to the Statutory Library D law , ex ecuting a two-stage retrie val process. It first ob- tains a T op- K coarse candidate set S v ec via dense vector retrie val based on o ext , and then leverages the agent’ s robust semantic understanding to filter noise from the coarse set, identifying the reliable reference statute set S statute : S v ec ← Searc h( o ext , D law , K ) , (1) S statute ∼ π assist ( · | Ψ( o ext , S v ec )) . (2) Drafting Phase: Case-handling Judge Agent This component functions as the core reasoning engine. Unlike generic LLMs, we employ the ju- risprudentially aligned expert model π ∗ θ (detailed in Sec. 3.3 ) to synthesize facts o ext and statutes S statute . Crucially , this agent forms a refinement loop with the Supervisor . Let h t be the feedback from the previous round ( h 0 is null), the judge gen- erates a draft y ( t ) draf t utilizing its internalized le gal logic: y ( t ) draf t ∼ π ∗ θ ( · | Ψ( o ext , S statute , h t )) . (3) Note that at this stage, the agent relies solely on model parameters and does not access the external memory M . Review Phase: Adjudication Supervisor Agent T o ensure the judgment is not only legally valid but also appropriate, the Adjudication Supervisor 3 Input Cases Presiding Judge Agent Hybrid Jurisprudential Memory (HJM) Standards Archive CaseB CaseD CaseA CaseC Micro-Directives Base article database Act: Beating. Conseq: Minor Injury . Loc: Public. Court Clerk Agent Case Judge Agent Art.234 Art.235 Art.293 Supervisor Agent Judicial Assistant ... ... Fact: Drunk Zhang beat stranger Li at a public BBQ stall for 'looking at him', causing Minor Injury and chaos. Pre-Adjudication Analysis Drafting&Review Final Adjudication archived Fact : Drunk Zhang beat... Court Clerk : Beating,Injury ... Judicial Assistant : Art. 234,Art. 293 ... Case Judge: Intentional Injury ... Supervisor: Undermined public order .. . Presiding Judge : (Art. 293) Directive Directive Random attacks in public to vent anger ,then picking quarrels, not Injury Retrieval: Art. 234,Art. 293,Art. 292... Inductive Refine Directive Case Directive Directive Directive Merge Draft REJECT Draft1 Draft2 Draft3 REJECT P ASS P ASS verdict verdict Figure 1: The overall inference frame work of VERDICT . It illustrates the interaction between the T raceable Multi- Agent W orkflow and the Hybrid Jurisprudential Memory (HJM) . The process evolv es through Preparation, Drafting & Revie w , and Final Adjudication phases. Note that the Case Judge agent is instantiated using our domain-specific aligned expert model. Agent ( a super ) intervenes. Unlike the drafter , this agent has access to the full Hybrid Jurisprudential Memory . Le veraging implicit kno wledge from ju- dicial precedents S std in the Contextual Standards Archi ve M std and rele vant Micro-Directi v es S dir in the Evolving Micro-Directiv e Base M dir , a super strictly scrutinizes the draft y ( t ) draf t . If distinct dis- crepancies are found (e.g., compliant with statutes but violating a micro-directiv e on sentencing), it issues a rejection signal with correcti ve advice: ( f lag t , f dbk t ) ∼ π super ( · | Ψ( u, y ( t ) draf t ,S statute , S std , S dir )) , here, f l ag t ∈ { Pass , Reject } serves as the judg- ment signal, and f dbk t provides natural language suggestions (e.g., "Incorrect charge qualification"). The system accumulates this feedback into the inter- action history: h t ← h t − 1 ⊕ f dbk t . Subsequently , the workflo w branches based on f l ag t : a P ass sig- nal (or reaching the maximum turn limit T max ) adv ances the verified draft to the F inal Adjudica- tion phase, whereas a Reject triggers a redrafting iteration using the updated context h t . Final Adjudication Phase: Presiding J udge Agent Finally , the Presiding J udge Agent ( a pres ) aggre- gates the refined draft and the comprehensi ve con- text to render the final explainable verdict with the complete reasoning process. As the ultimate decision-maker , a pres also possesses the capability to access the full memory bank to ensure global consistency , and performs case archiving: y f inal ∼ π pres · | Ψ( u, S statute , S std , S dir , y ( f inal ) draf t ) . (4) 3.3 Domain-Specific Expert Alignment T o equip the Case-handling Judge with effecti ve reasoning, we implement a two-stage alignment pipeline focusing on constructing logic-dri ven data. 3.3.1 Protocol-A ware Instruction T uning W e first align the model with the protocol using a teacher model. By filtering inference results against ground truth, we retain accurate samples as the SFT set D train to standardize output formats, while isolating erroneous predictions into an error set D f ault . This splits the data into demonstrations for SFT and hard negati v es for the next stage. 3.3.2 Logic-Driven Contrastiv e Alignment T o fix the logical hallucinations in D f ault , we de- sign an iterativ e correction mechanism. For an ini- tial incorrect prediction (defined as the Loser ˆ y l ) in D f ault , a reflection model M R analyzes the logical gap and pro vides advice r . This guides the e xpert model M E to regenerate a legally v alid response (defined as the W inner ˆ y w ): ˆ y w = M E ( u, S, ˆ y l ⊕ r ) . (5) 4 W e collect successfully corrected trajectories to construct the preference dataset D pref , explicitly contrasting logic loopholes with reasoning: D pref = { ( u, ˆ y w , ˆ y l ) | ˆ y l ∈ D f ault , V ( ˆ y w ) = 1 } . (6) Where V ( · ) is a v alidation function checking consistency with the statutes. Finally , we apply standard Direct Preference Optimization (DPO) ( Rafailo v et al. , 2023 ) on D pref to sharpen the model’ s decision boundaries on these confusing legal concepts. 3.4 The Hybrid Jurisprudential Memory (HJM) Mechanism T o endow the system with continual learning and long-tail generalization, we construct the HJM, theoretically grounded in the “Micro-Directi ve Paradigm” ( Casey and Niblett , 2016 ). This ar- chitecture addresses the traditional jurispruden- tial dilemma between rigid “Rule” (clear but in- flexible statutes) and vague “Standard” (flexible but noisy precedents). Casey and Niblett posit that AI can bridge this dichotomy by generating “Micro-Directi ve”—precise norms possessing both the context-sensiti vity of Standards and the e x- ante clarity of Rules. Inspired by this, our frame- work simulates the dynamic e volution from “fuzzy Standard” to “precise Directi ves, ” distilling judi- cial experience into an intermediate modality be- tween abstract law and concrete cases. Specif- ically , we operationalize this process by map- ping empirical standards to the Contextual Stan- dards Archiv e ( M std ) and instantiating ev olved directi ves as the Ev olving Micro-Directiv e Base ( M dir ). Formally , the memory is defined as M = ⟨M std , M dir , D law , Φ trans ⟩ . 3.4.1 Memory Structure and Retrie val The Contextual Standards Archive ( M std ): Con- structed as an undirected graph G std , where each node v i = ⟨ txt i , h i , Λ i , c i ⟩ represents an empir- ical “Standard Precedent. ” Edges enforce intra- class consistency: ( v i , v j ) ∈ E ⇐ ⇒ h ⊤ i h j ≥ τ ∧ (Λ i ≡ Λ j ) . The Evolving Micro-Directiv e Base ( M dir ): Maintains dynamic units m dir = ⟨ r txt , S conf , C pos/neg , Λ anchor ⟩ . Here, r txt of fers precise, context-specific interpretation anchored to statute Λ anchor , backed by confidence S conf and supporting precedents. Multi-dimensional Retriev al. T o ensure jurispru- dential rele vance, we design a scoring mechanism Directive Evolution Contrastive Refinement a3 Inductive Generation Directive m Directive n-1 Directive n T op-N Package Contrastive Pairs Directive' 1 Directive' 2 Directive Base Directive m-1 Updated Base Directive' k Cases Clustering Directive 1 a4 a2 a1 a2 b2 b3 a2 a3 a1 a4 b1 b2 b3 Success Trajectory Failure Trajectory Figure 2: The evolutionary mechanism of the Hybrid Jurisprudential Memory . The lifecycle strate gy Φ trans transforms archi ved empirical Standards into precise and compact Micro-Directiv es through three phases. for retrieving memory unit m gi ven the current case u curr and candidate statutes S statute : Score( m ) = α · IoU(Λ m , S statute ) + β · T op o( m, N g raph ) + γ · SemSim( m, u curr ) . The score is a weighted sum of three metrics : a statute/charge overlap metric IoU(Λ m , S statute ) , a graph-topology metric T op o( m, N g raph ) , and a semantic-similarity metric SemSim( m, u curr ) . IoU measures the intersection-ov er-union between the tag set carried by m and S statute , enforcing le- gal applicability e ven under large f actual variation. T op o measures whether (and how strongly) m is reached/co-acti vated along the acti v ation-diffusion from u curr , enabling associativ e recall of logically central but text-dissimilar precedents. SemSim measures factual/le xical proximity between m and u curr and serves as a surface-le vel anchor for re- trie val. More details can be seen in Appendix D . 3.4.2 Evolutionary Mechanism: Fr om Standards to Directi ves As illustrated in Figure 2 , we design a lifecycle strategy Φ trans consisting of standard archiving and a three-phase e volution process that (i) induces ne w Micro-Directiv es from consistent Standards, (ii) sharpens directiv e boundaries via contrastiv e e vidence, and (iii) consolidates and removes direc- ti ves to keep the memory compact. Standard Archi ving. Faithful recording of correct judicial practice ensures a pure experience pool. T o capture the complete adjudication logic, we utilize a dense vector model E ( · ) to encode the case facts u , the verified r easoning trace τ , and the verdict 5 y f inal into persistent embeddings. Φ archiv e ( u ) = ( E ( u ⊕ τ ⊕ y final ) , if y final = ℓ gt buf fer , otherwise (7) where E is the embedding function (instantiated as Qwen3-Embedding-8B model) that maps the serial- ized trajectory to the vector store, and τ represents the multi-step reasoning chain validated by the Su- pervisor Agent. Phase A: Inductiv e Generation. This phase con- verts a batch of consistent Standards into an initial, coarse-grained Micro-Directi ve. Triggered when ne w nodes in M std reach a threshold B , the sys- tem identifies common patterns within a same-label cluster V batch . A meta-LLM summarizes these consistent precedents and produces a ne w coarse- grained directi ve r new . Phase B: Contrastive Refinement. This phase refines the coarse directi ve r new into a boundary- aw are directiv e by injecting discriminati ve con- straints into its te xt. W e construct strictly aligned positi ve and negati v e pairs ( T + vs. T − ) that share identical statutes/charges b ut di verge in reasoning. The meta-LLM compares the pairs to identify criti- cal branching features (e.g., distinguishing “subjec- ti ve moti ve” from “objecti ve danger”) and updates the directiv e content r txt with precise conditions and exceptions. Phase C: Directiv e Evolution. T o prev ent memory fragmentation, we implement a dynamic survi val mechanism. The confidence S conf of a directi ve acts as its lifespan, accumulating with successful verification and decaying upon rejection. Periodi- cally , we group semantically repetitive directi ves into a cluster C sim and consolidate them into a uni- fied node: r new = Summarize ( { r txt | m ∈ C sim } ) , S conf ( m new ) = X m ∈C sim S conf ( m ) . (8) Here, Summarize ( · ) le verages a meta-LLM to ab- stract the logical content r txt . The new confidence score is the sum of indi vidual scores, clipped at a maximum threshold τ max . Directiv es falling be- lo w a safety threshold are eliminated, ensuring the memory remains compact and high-quality . 4 Experiments 4.1 Experiment Setup 4.1.1 Datasets W e ev aluate VERDICT on two datasets to assess standard performance and temporal generaliza- tion (details in Appendix A ). CAIL2018. W e use the standard CAIL-Small benchmark ( Xiao et al. , 2018 ) to v erify fundamental adjudication capabil- ities. CJO2025. T o rigorously test generalization and pre vent data leakage, we constructed a dataset of judgments from after Jan 1, 2025. Postdating the kno wledge cutoff of current backbones, CJO2025 serves as an emer ging scene. 4.1.2 Implementation Details Our VERDICT framew ork adopts a heteroge- neous agent design. The core expert model is fine-tuned from Qwen2.5-7B-Instruct via Protocol- A ware SFT and Logic-Driv en DPO, while auxiliary agents (e.g., Court Clerk, Supervisor) are instan- tiated using the DeepSeek-V3. For the memory module (HJM), we utilize high-dimensional vec- tor encoding for retriev al. Detailed experimental setups, including hardware specifications, hyperpa- rameter settings for LoRA fine-tuning, and infer- ence configurations, are comprehensiv ely provided in Appendix C . 4.1.3 Metrics Follo wing standard protocols in LJP research ( Xiao et al. , 2018 ), we treat Law Article, Charge, and T erm of Penalty prediction as multi-label classifi- cation tasks. W e employ fiv e metrics to compre- hensi vely e valuate performance: Accuracy (Acc), Macro-Precision (MP), Macro-Recall (MR), and Macro-F1 (Ma-F). Additionally , considering the complexity of legal reasoning, we report Hit@2, which measures whether the ground truth label is present in the top-2 predicted candidates. Note that for T erm of Penalty , we categorize prison terms into 10 distinct intervals consistent with prior work( Xu et al. , 2020 ) 4.2 Baselines W e compare VERDICT against 10 representa- ti ve baselines spanning four distinct paradigms: (1) General T ext Encoders, including CNN ( Kim , 2014 ) and BER T ( De vlin et al. , 2019 ); (2) Dependency-A ware Models that model subtask cor - relations, such as T opJudge ( Zhong et al. , 2018 ) and EPM ( Feng et al. , 2022 ); (3) Structure & 6 Law Article Charge T erm of Penalty Acc% MP% MR% MF1% Hit@2 Acc% MP% MR% MF1% Hit@2 Acc% MP% MR% MF1% 1 CNN 69.52 62.14 58.35 60.18 74.15 73.56 70.45 65.23 67.74 79.66 33.24 28.56 25.14 26.74 2 BERT 76.54 73.21 70.45 71.80 81.87 75.85 78.45 76.12 77.26 82.25 29.80 32.14 29.56 30.79 3 MLAC 73.02 69.27 66.14 64.23 79.54 74.73 72.65 69.56 68.36 81.27 36.45 34.50 29.95 29.64 4 T opJudge 78.60 76.59 74.84 73.72 84.31 81.17 81.87 80.57 79.96 86.13 35.70 32.81 31.03 31.49 5 MPBFN 76.83 74.57 71.45 70.57 82.29 76.17 78.88 75.65 75.68 84.33 36.18 33.67 30.08 29.43 6 EPM 83.98 80.82 77.55 78.10 88.17 79.10 84.55 80.22 81.43 86.52 36.69 35.60 32.70 32.99 7 LADAN 78.70 74.95 75.61 73.83 85.30 80.86 81.69 80.40 80.05 86.92 36.14 31.85 29.67 29.28 8 NeurJudge 78.74 80.34 81.92 79.66 86.06 79.04 82.60 80.92 80.70 87.40 37.44 34.07 32.77 31.94 9 CTM 81.72 79.67 77.67 76.82 85.79 81.22 77.51 78.17 77.99 87.13 37.35 32.17 29.15 30.57 10 PLJP 83.21 84.62 79.47 74.87 89.21 79.32 76.84 74.32 76.32 86.20 38.24 34.80 32.22 32.48 11 OURS 85.35 88.82 82.07 83.29 93.49 82.40 89.33 80.89 82.36 90.64 39.76 35.77 33.98 34.08 T able 1: Performance Comparisons on CAIL2018. The best results are bolded and the second-best are underlined Law Article Charge T erm of Penalty Acc% MP% MR% MF1% Hit@2 Acc% MP% MR% MF1% Hit@2 Acc% MP% MR% MF1% 1 T opJudge 71.30 68.89 74.2 71.28 80.35 72.19 71.82 69.45 70.53 83.26 36.83 27.45 24.96 26.10 2 EPM 75.23 76.45 74.89 76.10 87.77 73.42 74.15 69.88 72.20 85.72 43.44 25.10 28.77 26.65 3 LADAN 71.23 72.45 70.98 71.12 85.70 70.23 71.45 69.89 70.67 84.10 37.92 28.32 27.70 27.14 4 NeurJudge 73.69 74.40 80.14 72.44 84.20 74.30 71.59 77.5 70.56 86.17 42.87 25.40 26.37 25.14 5 CTM 76.71 68.30 71.07 69.57 83.18 73.17 72.25 71.40 70.31 85.18 41.17 24.50 26.67 25.33 6 PLJP 86.30 87.23 83.25 85.50 90.33 83.20 84.14 79.82 80.32 89.32 44.25 27.4 22.37 24.30 7 DeepSeek 83.01 76.32 71.60 73.67 86.70 81.44 68.30 73.22 73.10 86.67 35.38 29.10 28.72 26.57 8 AutoGen 84.26 77.08 74.51 74.96 87.20 77.99 50.90 45.01 45.79 84.11 29.32 18.87 24.26 19.45 9 G-Memory 86.52 77.32 78.41 75.46 88.45 82.45 79.32 77.53 78.10 83.70 31.77 28.76 29.55 28.10 10 OURS 90.56 90.45 87.26 87.94 96.26 85.84 85.86 80.46 80.66 93.67 45.68 34.04 30.71 29.32 T able 2: Robustness e v aluation on CJO2025. The best results are bolded and the second-best are underlined Kno wledge-Enhanced Models utilizing graph struc- tures or retrie val, represented by NeurJudge ( Y ue et al. , 2021 ) and PLJP ( W u et al. , 2023 ); and (4) LLMs and Agentic Systems, co vering the founda- tion model DeepSeek-V3 ( Liu et al. , 2024 ) and multi-agent framew orks like AutoGen ( W u et al. , 2024 ) and G-Memory ( Zhang et al. , 2025 ). For fair comparison, all LLM-based baselines are equipped with RA G using the statutory library . Detailed de- scriptions and implementation settings are provided in Appendix B . 4.3 Overall Perf ormance As presented in T able 1 and T able 2 , VERDICT demonstrates superior performance across both standard benchmarks and rigorous emerging scene. State-of-the-Art on CAIL2018 . VERDICT out- performs all baselines across all tasks. Notably , it surpasses dependenc y-aware models (e.g., T op- Judge) by 6.75% in Law Article Accuracy , at- tributing to the ef fectiv e disentanglement of com- plex f acts by our multi-agent topology . Compared to retrie val-augmented models (PLJP), VERDICT maintains a clear lead (85.35% vs. 83.21%), prov- ing that deep logical alignment offers higher preci- sion than simple in-context learning. Generalization on CJO2025 . The results on the future-split dataset highlight the framew ork’ s ro- bustness. While traditional SOT A models (e.g., NeurJudge) suffer significant performance drops (78.7% → 73.7%) due to ov erfitting historical pat- terns, VERDICT achie ves a remarkable 90.56% accuracy . Furthermore, our specialized legal frame- work significantly outperforms generic agentic sys- tems (AutoGen: 84.26%, G-Memory: 86.52%), providing strong evidence that the specialized “V irtual Collegial P anel” and jurisprudence-based “Micro-Directi ve” memory are essential for rigor - ous legal reasoning. 4.4 Ablation result Results of ablation experiment: From T able 3 , we can conclude that: 1) The performance im- prov ement of V anilla+ (Expert model for the Case Judge agent; base Qwen2.5-7B-Instruct for others) ov er V anilla (Qwen2.5-7B-Instruct for all agents) demonstrates that equipping the core reasoning role with domain alignment brings fundamental g ains. 2) The substantial performance gap of w/o Mem- ory on the dataset CJO2025 (e.g., Law Article Acc drops from 90.56% to 86.55%) demonstrates the critical ef fects of the Hybrid Jurisprudential Mem- ory in mitigating catastrophic forgetting. 3) The results of w/o M dir prov e the importance of the “Micro-Directi ve Paradigm”; relying solely on raw precedents fails to achie v e precise logic transfer . 4) Considering the topological dependence of the fi ve specialized agents benefits the model performance 7 Method CJO2025 CAIL2018 Law Article Charge Prison T erm Law Article Charge Prison T erm Acc Ma-F Acc Ma-F Acc Ma-F Acc Ma-F Acc Ma-F Acc Ma-F V anilla 82.12 76.54 77.61 72.10 27.06 19.76 73.04 72.01 67.95 69.13 26.07 25.01 V anilla+ 83.08 78.83 79.21 71.68 28.17 22.18 76.40 75.52 70.80 72.18 24.14 25.25 w/o Memory 86.55 83.70 81.30 79.40 44.71 24.10 82.60 82.10 79.13 81.50 35.77 30.20 w/o MAS 87.32 85.42 83.48 80.32 39.50 30.15 83.10 81.50 79.80 82.30 36.20 28.10 w/o Expert 87.57 87.37 82.60 79.17 42.77 28.40 84.35 79.22 81.70 79.20 39.32 26.10 w/o M dir 88.46 84.72 84.32 80.16 45.07 29.02 84.12 83.01 80.30 79.77 38.32 27.87 VERDICT 90.56 87.94 85.84 80.66 45.68 29.32 85.35 83.29 82.40 82.36 39.76 29.08 T able 3: Ablation experiments. The best results are bolded and the second-best are underlined. Input Case (Sample from CJO2025) On January 15, 2025, defendant Zhang was drinking at a public BBQ stall . Due to a tri vial conflict (stranger Li looked at him), Zhang felt provok ed. Zhang beat Li with a beer bottle , resulting in chaos at the stall. Forensic e xamination confirmed that Li suffered a Minor Injury . Zhang claimed he was just venting anger and had no personal grudge against Li. V anilla PLJP VERDICT (Ours) Logic: Keyw ord Matching The model focuses on high-frequency patterns without deep reasoning. Internal Monologue: “Detected keyw ords ‘beat’ and ‘Minor Injury’ . In training data, ‘Minor Injury’ strongly correlates with Art. 234. ” Logic: Precedents Retrie val Retriev es precedents but lacks system- atic adjudication experience. Reasoning Pr ocess: “Retriev ed precedents labeled Art. 234 and Art. 293. Ho wever , since the in- put’ s objective r esult (‘Minor Injury’) shows high textual similarity with Art. 234 cases, the model aligns with them and ignores the motiv e nuance in Art. 293 precedents. ” Logic: Retrieval + Refinement Uses Micro-Dir ectives & Supervisor . Agent Interaction Loop: 1. Assistant: Retrieves directive “Public Place + V enting Anger → Art. 293”. 2. Case Judge: Drafts Art. 234 based on injury result. 3. Supervisor: REJECTS draft. “Logic Error: Location is public ; Moti ve is pr ovo- cation . Social order violation > Personal injury . Apply Art. 293. ” Wrong Pr ediction ✗ Art. 234 (Intentional Injury) Wrong Pr ediction ✗ Art. 234 (Intentional Injury) Correct J udgment ✓ Art. 293 (Picking Quarrels) Figure 3: Case study comparison. The red highlights indicate misleading surface features (resulting in Intentional Injury), while the green highlights denote contextual e vidence supporting Picking Quarrels. V anilla falls into the keyw ord trap; PLJP fails to resolve the statutory conflict; VERDICT correctly identifies the crime’ s nature via the Supervisor’ s logical rectification. as w/o MAS shows, indicating that the multi-agent workflo w acts as a capability multiplier . 5) The performance decline in w/o Expert v alidates the ne- cessity of our domain-specific alignment pipeline. Since the expert is fine-tuned via protocol-aware SFT and logic-driv en DPO, this result confirms that rigorous preference optimization is essential for standardizing judicial reasoning. 4.5 Case study Figure 3 illustrates a challenging case from CJO2025 inv olving a public assault. While base- line models V anilla (Qwen2.5-7B-Instruct for all agents) and PLJP are misled by the e xplicit “Minor Injury” feature into predicting Intentional Injury (Art. 234), VERDICT succeeds through its self- refining mechanism. Specifically , the Supervisor Agent retrie ves a ke y Micro-Directi ve prioritizing “public order violation” ov er “personal injury” in prov ocation contexts. This enables the system to reject the initial erroneous draft and correctly iden- tify the charge as Picking Quarrels and Prov oking T rouble (Art. 293). 5 Conclusion W e presented VERDICT , a self-refining multi- agent system that improves interpretability and gen- eralization for Legal Judgment Prediction. By sim- ulating a virtual colle gial panel and lev eraging a Hybrid Jurisprudential Memory (HJM) that ev olves Micr o-Dir ectives from v alidated verification trajec- tories, VERDICT provides legally grounded, re- vie wable reasoning while adapting to shifting ju- risprudential patterns. Evaluations on CAIL2018 and the future time-split CJO2025 dataset demon- strate state-of-the-art results and strong robustness to distribution shifts. 8 Limitations Due to computational resource constraints, the core expert agent (Case-handling Judge) in VERDICT was fine-tuned primarily on a 7B-parameter back- bone. While this hybrid setup (incorporating API- based general agents) demonstrates superior per - formance, we hav e not yet conducted a systematic study on fine-tuning lar ger-scale foundation mod- els. Additionally , the multi-agent interactiv e work- flo w in volving iterati ve retrie v al and self-refining loops inevitably increases inference latency com- pared to simple end-to-end classifiers. Ho wev er , in the high-stakes domain of Le gal Judgment Predic- tion (LJP), we prioritize interpretability and judicial accuracy o ver real-time response speed, consider- ing this trade-off essential for ensuring trustworthy and rigorous adjudication.Furthermore, this study focuses on the Ci vil Law system. W e plan to v ali- date the frame work’ s generalizability to Common Law systems in future research, exploring its ef- fecti veness in en vironments hea vily dependent on case law and stare decisis. Ethics Statement Regarding data priv acy , we strictly adhere to ethical regulations; for the CAIL2018 benchmark, we use the of ficial anonymized version, and for our ne wly constructed CJO2025 dataset, we implemented rig- orous data cleaning to remove all Personal Identifi- able Information (PII) before use. Furthermore, the design intent of our system—simulating a virtual collegial panel to generate reasoning—is to func- tion as an intelligent assistant providing sugges- tions rather than replacing human decision-making. W e advocate that human judges must remain the final safeguard to re vie w AI-generated results and protect judicial fairness. W e also acknowledge that historical training data may contain inherent soci- etal biases, and mitigating such biases remains a critical direction for our future work. References Adrien Bibal, Michael Lognoul, Alexandre De Streel, and Benoît Frénay . 2021. Le gal requirements on explainability in machine learning. Artificial Intelli- gence and Law , 29(2):149–169. Anthony J Case y and Anthony Niblett. 2016. The death of rules and standards. Ind. LJ , 92:1401. Junyun Cui, Xiaoyu Shen, and Shaochun W en. 2023. A survey on legal judgment prediction: Datasets, metrics, models and challenges. IEEE Access , 11:102050–102071. Jacob Devlin, Ming-W ei Chang, Kenton Lee, and Kristina T outanov a. 2019. Bert: Pre-training of deep bidirectional transformers for language understand- ing. In Proceedings of the 2019 conference of the North American chapter of the association for com- putational linguistics: human language technolo gies, volume 1 (long and short papers) , pages 4171–4186. Qian Dong and Shuzi Niu. 2021. Legal judgment pre- diction via relational learning. In Proceedings of the 44th international A CM SIGIR confer ence on r esear ch and development in information r etrieval , pages 983–992. Y i Feng, Chuan yi Li, and V incent Ng. 2022. Legal judg- ment prediction via ev ent extraction with constraints. In Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages 648–664. Neel Guha, Julian Nyarko, Daniel Ho, Christopher Ré, Adam Chilton, Alex Chohlas-W ood, Austin Peters, Brandon W aldon, Daniel Rockmore, Diego Zam- brano, and 1 others. 2023. Legalbench: A collab- orati vely b uilt benchmark for measuring legal reason- ing in large language models. Advances in neural information pr ocessing systems , 36:44123–44279. Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Y uheng Cheng, Jinlin W ang, Ceyao Zhang, Zili W ang, Ste ven Ka Shing Y au, Zijuan Lin, and 1 others. 2023. Metagpt: Meta programming for a multi-agent collaborativ e framew ork. In The T welfth International Confer ence on Learning Repr esenta- tions . Quzhe Huang, Mingxu T ao, Chen Zhang, Zhenwei An, Cong Jiang, Zhibin Chen, Zirui W u, and Y ansong Feng. 2023. Lawyer llama technical report. arXiv pr eprint arXiv:2305.15062 . Louis Kaplow . 2013. Rules versus standards: An eco- nomic analysis. In Scientific Models of Le gal Rea- soning , pages 11–84. Routledge. Daniel Martin Katz, Michael James Bommarito, Shang Gao, and Pablo Arredondo. 2024. Gpt-4 passes the bar exam. Philosophical T ransactions of the Royal Society A , 382(2270):20230254. Y oon Kim. 2014. Con volutional neural networks for sentence classification . In Pr oceedings of the 2014 Confer ence on Empirical Methods in Natural Language Pr ocessing (EMNLP) , pages 1746–1751, Doha, Qatar . Association for Computational Linguis- tics. Aixin Liu, Bei Feng, Bing Xue, Bingxuan W ang, Bochao W u, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others. 2024. Deepseek-v3 technical report. arXiv pr eprint arXiv:2412.19437 . 9 Dugang Liu, W eihao Du, Lei Li, W eike Pan, and Zhong Ming. 2022. Augmenting legal judgment prediction with contrasti ve case relations. In Pr oceedings of the 29th international confer ence on computational linguistics , pages 2658–2667. Bingfeng Luo, Y ansong Feng, Jianbo Xu, Xiang Zhang, and Dongyan Zhao. 2017. Learning to predict charges for criminal cases with legal basis . In Pr o- ceedings of the 2017 Conference on Empirical Meth- ods in Natural Languag e Pr ocessing , pages 2727– 2736, Copenhagen, Denmark. Association for Com- putational Linguistics. Kangcheng Luo, Quzhe Huang, Cong Jiang, and Y an- song Feng. 2025. Automating legal interpretation with LLMs: Retriev al, generation, and ev aluation . In Pr oceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 4015–4047, V ienna, Austria. Association for Computational Linguistics. Aman Madaan, Niket T andon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wie greffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Y iming Y ang, and 1 others. 2023. Self-refine: Iterativ e refinement with self-feedback. Advances in Neural Information Pr ocessing Systems , 36:46534–46594. Chen Qian, W ei Liu, Hongzhang Liu, Nuo Chen, Y ufan Dang, Jiahao Li, Cheng Y ang, W eize Chen, Y usheng Su, Xin Cong, and 1 others. 2024. Chatdev: Com- municativ e agents for software de velopment. In Pr o- ceedings of the 62nd Annual Meeting of the Associa- tion for Computational Linguistics (V olume 1: Long P apers) , pages 15174–15186. Rafael Rafailo v , Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Y our language model is secretly a rew ard model. Advances in neural information pr ocessing systems , 36:53728–53741. W eijie Shi, Han Zhu, Jiaming Ji, Mengze Li, Jipeng Zhang, Ruiyuan Zhang, Jia Zhu, Jiajie Xu, Sirui Han, and Y ike Guo. 2025. Leg alReasoner: Step-wised verification-correction for le gal judgment reasoning . In Pr oceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 7297–7313, V ienna, Austria. Association for Computational Linguistics. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Y ao. 2023. Re- flexion: Language agents with verbal reinforcement learning. Advances in Neural Information Pr ocess- ing Systems , 36:8634–8652. The Supreme People’ s Court of the PRC. 2024. W ork report of the supreme people’ s court. Retrie ved from http://www.court.gov.cn . Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elic- its reasoning in large language models. Advances in neural information pr ocessing systems , 35:24824– 24837. Qingyun W u, Gagan Bansal, Jieyu Zhang, Y iran W u, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, and 1 others. 2024. Au- togen: Enabling next-gen llm applications via multi- agent conv ersations. In F irst Confer ence on Lan- guage Modeling . Y iquan W u, Siying Zhou, Y ifei Liu, W eiming Lu, Xi- aozhong Liu, Y ating Zhang, Changlong Sun, Fei W u, and Kun Kuang. 2023. Precedent-enhanced legal judgment prediction with LLM and domain-model collaboration . In Pr oceedings of the 2023 Confer ence on Empirical Methods in Natural Language Pr ocess- ing , pages 12060–12075, Singapore. Association for Computational Linguistics. Chaojun Xiao, Haoxi Zhong, Zhipeng Guo, Cunchao T u, Zhiyuan Liu, Maosong Sun, Y ansong Feng, Xi- anpei Han, Zhen Hu, Heng W ang, and 1 others. 2018. Cail2018: A large-scale legal dataset for judgment prediction. arXiv preprint . Nuo Xu, Pinghui W ang, Long Chen, Li Pan, Xiaoyan W ang, and Junzhou Zhao. 2020. Distinguish con- fusing law articles for le gal judgment prediction . In Pr oceedings of the 58th Annual Meeting of the Asso- ciation for Computational Linguistics , pages 3086– 3095, Online. Association for Computational Lin- guistics. W enmian Y ang, W eijia Jia, Xiaojie Zhou, and Y utao Luo. 2019. Legal judgment prediction via multi- perspectiv e bi-feedback network. In Pr oceedings of the 28th International J oint Confer ence on Artifi- cial Intelligence , IJCAI’19, page 4085–4091. AAAI Press. Y ingxuan Y ang, Huacan Chai, Shuai Shao, Y uanyi Song, Siyuan Qi, Renting Rui, and W einan Zhang. 2025. Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems. arXiv pr eprint arXiv:2504.00587 . Linan Y ue, Qi Liu, Binbin Jin, Han Wu, Kai Zhang, Y anqing An, Mingyue Cheng, Biao Y in, and Dayong W u. 2021. Neurjudge: A circumstance-aware neural frame work for le gal judgment prediction. In Pr oceed- ings of the 44th international A CM SIGIR conference on resear ch and development in information r etrieval , pages 973–982. Guibin Zhang, Muxin Fu, Guancheng W an, Miao Y u, Kun W ang, and Shuicheng Y an. 2025. G-memory: T racing hierarchical memory for multi-agent systems. arXiv pr eprint arXiv:2506.07398 . Haoxi Zhong, Zhipeng Guo, Cunchao Tu, Chaojun Xiao, Zhiyuan Liu, and Maosong Sun. 2018. Legal judg- ment prediction via topological learning. In Pr oceed- ings of the 2018 confer ence on empirical methods in natural languag e pr ocessing , pages 3540–3549. 10 A Dataset Details A.1 CAIL2018 W e utilize the CAIL2018 dataset ( Xiao et al. , 2018 ), specifically the CAIL-Small configuration, as our primary training platform. This subset encom- passes the most prev alent case samples within crim- inal justice. W e filter out cases with missing ele- ments and truncate te xt lengths to fit model context windo ws A.2 Construction of CJO2025 T o strictly eliminate data contamination risks—where test samples might inadver - tently exist in the vast pre-training corpora of backbone LLMs (e.g., Qwen2.5)—we constructed a strict future-split dataset named CJO2025 . This dataset exclusiv ely comprises cases adjudicated after January 1, 2025 , retriev ed from the same authoritati ve source as CAIL2018, China Judg- ments Online 1 . Gi ven its distinct temporal nature, CJO2025 serves as a strictly unseen testbed rather than a training corpus, designed to rigorously assess model generalization in dynamic legal en vironments. T o ensure consistent e valuation metrics, we filter the dataset to retain only the label categories (law articles and char ges) that intersect with the CAIL2018 benchmark. This temporal cutoff ensures the data is unseen by the pre-trained LLMs used in this work (DeepSeek-V3, Qwen2.5), providing a rigorous test bed for temporal robustness. T able 4 presents the statistical distribution of charges and prison terms for both datasets. T ype CAIL2018 CJO2025 # Law Article 99 67 # Charge 115 73 # Prison T erm 11 11 # Sample 134739 8199 A vg. # words in Fact 288.6 332.13 T able 4: Statistics of the datasets. B Detailed Baselines Description T o rigorously ev aluate the effecti veness of VER- DICT , we compare it against a wide range of base- lines. W e categorize these methods into four dis- tinct paradigms based on their modeling strategies: 1 https://wenshu.court.gov.cn/ General T ext Encoders. These methods treat LJP as a standard multi-label text classification task without explicit modeling of le gal dependencies. • CNN ( Kim , 2014 ): Utilizes multiple conv olu- tion kernels of varying window sizes to cap- ture local n-gram features (e.g., k eywords lik e “theft” or “injury”) from case descriptions, fol- lo wed by max-pooling for classification. • BER T ( De vlin et al. , 2019 ): Employs a multi- layer bidirectional Transformer encoder pre- trained on large-scale corpora. It captures deep semantic context and long-range depen- dencies in legal texts using the [CLS] token representation. Dependency-A ware Models. These approaches explicitly model the topological dependencies among the three LJP subtasks (Law Article → Charge → T erm of Penalty). • MLA C ( Luo et al. , 2017 ): Proposes a topo- logical multi-task learning frame work where the predicted probability distrib utions of law articles serve as input features for char ge pre- diction, passing dependencies sequentially . • T opJudge ( Zhong et al. , 2018 ): Formalizes the LJP task as a Directed Acyclic Graph (D A G) and utilizes a topological structure to model the logical constraints among subtasks. • MPBFN ( Y ang et al. , 2019 ): Introduces a Multi-Perspecti ve Bi-Feedback Network that enables information flow not only in a forward direction but also allows backward verifica- tion (e.g., inferring law articles from char ges) to resolve inconsistencies. • EPM ( Feng et al. , 2022 ): F ocuses on e vent-centric extraction, enforcing consis- tency across subtasks by identifying key le- gal e vents and their arguments within the case fact. Structure & Knowledge-Enhanced Models. These models incorporate external le gal knowledge or graph structures to handle complex cases. • LAD AN ( Xu et al. , 2020 ): Specifically de- signed to distinguish confusing law articles. It applies Graph Distillation mechanisms to capture subtle nuances between semantically similar charges. 11 • CTM ( Liu et al. , 2022 ): Le verages contrastiv e learning with metric learning objectiv es to align case facts with le gal articles in a shared semantic space, enhancing the separation of confusing classes. • NeurJudge ( Y ue et al. , 2021 ): Splits the un- structured case text into factual components and constructs a graph to model the interac- tions between intermediate results, enhancing interpretability . • R-F ormer ( Dong and Niu , 2021 ): Utilizes a relation-aw are transformer to b uild a global consistency graph, effecti v ely capturing the logical connections between case descriptions and judgment results. • PLJP ( W u et al. , 2023 ): A recent strong baseline that integrates domain-specific pre- trained models with Retrie val-Augmented Generation (RA G), using similar precedents to guide prediction. LLMs and Agentic Systems. T o ensure a fair comparison, all baselines in this category are equipped with RA G using the same statutory li- brary as VERDICT . • DeepSeek-V3 ( Liu et al. , 2024 ): A state-of- the-art open-source foundation model. W e e valuate its performance in a zero-shot set- ting to establish a baseline for general LLM capabilities in the legal domain. • A utoGen ( W u et al. , 2024 ): A representativ e con versational multi-agent framew ork. W e construct a standard multi-agent debate work- flo w using AutoGen to benchmark against generic agentic collaboration without domain- specific memory . • G-Memory ( Zhang et al. , 2025 ): A cutting- edge general-purpose agent framew ork featur- ing a graph-based memory mechanism. W e compare against it to highlight the necessity of our jurisprudence-specific "Micro-Directi ve" design. C Detailed Implementation Settings All experiments are conducted on a server equipped with 6 × NVIDIA A100 (40GB) GPUs. T raining Setup. For parameter-ef ficient fine- tuning, we apply LoRA with rank r = 64 , α = 32 , and a dropout rate of 0.05. In the SFT phase, the model is trained for 2 epochs with a batch size of 64, an initial learning rate of 1 × 10 − 5 , and a maximum sequence length of 4096, optimized by AdamW with a cosine scheduler . In the DPO phase, the learning rate is adjusted to 5 × 10 − 5 . Inference Configuration. During multi-agent in- ference, we set the temperature to 0 and T op- p to 0.9 to ensure logical rigor , limiting the maximum refinement turns ( T max ) to 3 to pre vent infinite loops. Regarding the memory retrie val mechanism defined in Eq. 7 , we empirically set the weighting coef ficients to α = 0 . 4 , β = 0 . 3 , and γ = 0 . 3 . Retriev al Settings. For the Hybrid Jurispru- dential Memory (HJM), we utilize Qwen3- Embedding-8B for vector encoding and Chro- maDB for index management. W e retrie ve the T op- 3 similar precedents and T op-3 micro-directiv es as context support, with the directi ve pruning thresh- old set to 0.3. D Details of Multi-dimensional Retriev al Score W e detail the three components in Eq. ( 7 ) and their intended roles. (1) Statute/charge overlap via IoU . Each mem- ory unit m stores a set of statute/charge tags Λ m . Gi ven the current case’ s candidate statute set S statute , we compute: IoU(Λ m , S statute ) = | Λ m ∩ S statute | | Λ m ∪ S statute | . (9) Unlike generic text retriev al, this term forces the retrie ver to prioritize jurisprudential applicabil- ity . Even when two cases differ greatly in fac- tual descriptions (e.g., different tools or settings), a high ov erlap in applicable statutes/charges yields a strong score, supporting cross-scenario analogical reasoning. (2) T opological co-occurrence f or associativ e recall. T o strictly map the jurisprudential sub- space, we construct the graph N g raph by linking case nodes only if they share identical Law Arti- cles and Charg es . The score T op o( m, N g raph ) is calculated via a two-step dif fusion process: 1. Seed Activation : W e first retrie ve the top- K semantic neighbors of the current case u curr to form a seed set S seed . 12 2. Diffusion & Counting : W e expand S seed via k -hop propagation on N g raph to obtain an ac- ti vation set S act . The score is defined as the co-acti vation frequenc y: T op o( m, N g raph ) = X v ∈ S act I ( v → m ) (10) where I ( v → m ) indicates whether an acti vated neighbor v is historically associated with the mem- ory unit m . This mechanism recalls implicit kno wl- edge centrally located in the rele vant legal sub- space. (3) Semantic similarity as a factual anchor . This metric ensures factual alignment. W e utilize a dense embedding model E ( · ) to compute the co- sine similarity between the memory unit m and the current case u curr : SemSim( m, u curr ) = Cos ( E ( m ) , E ( u curr )) ≈ 1 − dist ( E ( m ) , E ( u curr )) (11) In our implementation, we use the normalized dis- tance ( 1 − distance ) as the scoring basis, acting as a soft gatekeeper to filter out associations that drift too far from the surface f acts. E Detailed Prompt Design T o ensure reproducibility , we provide the specific system prompts used for each agent in the VER- DICT framew ork, as illustrated in Figure 4 to Fig- ure 8 . Simulating a "V irtual Collegial P anel," the workflo w coordinates fiv e specialized roles: Court Clerk , Judicial Assistant , Case-handling J udge , Adjudication Supervisor , and Presiding Judge . V ariables enclosed in {{}} (e.g., {{CASE_FACT}} ) represent dynamic inputs populated during the in- ference process. 13 Prompt 1: Court Clerk Agent (Event Extraction) System Instruction: You are a legal fact extraction agent ( Court Clerk ). Your duty is to extract core points from the raw legal facts, focusing on key dimensions such as the perpetrator’s subjective intent, specific criminal acts, consequences caused, and the severity of the circumstances. Do not make any conviction or sentencing judgments, and do not output article numbers or charges. Input Case: {{CASE_FACT}} Output Format: Finish[1. Point 1; 2. Point 2; ...] Figure 4: System prompt for the Court Clerk Agent , responsible for distilling objectiv e event points from raw facts. Prompt 2: Judicial Assistant Agent (Retrieval & Rerank) System Instruction: You are a legal assistant with extensive criminal law knowledge ( Judicial Assistant ). Your duty is to filter and re-rank candidate law articles (retrieved via vector similarity) based on the case facts and event points. Articles with higher reference value for ruling this case should be ranked earlier. Try not to omit relevant ones (select about 5). If existing candidates are insufficient, use your own knowledge to suggest more reasonable articles. Input: - Facts: {{CASE_FACT}} - Event Points: {{EVENT_POINTS}} - Candidate Articles: {{EXTRA_CONTEXT}} Retrieval Rules: - Fine-ranking basis: Compare the article’s description of criminal acts with the defendant’s intent, means, object, and results (attempted/completed, severity). Priority goes to articles that constrain the target charge. - Only output the final result, no analysis required. Output Format: Finish[[Article_ID_1, Article_ID_2, ...]] (e.g., Finish[[272, 384, 185]]) Figure 5: System prompt for the Judicial Assistant Agent , performing semantic re-ranking of precedents and statutes. Prompt 3: Case-handling Judge Agent (Drafting & Refinement) System Instruction: You are a judge with extensive criminal law knowledge ( Case-handling Judge ). Carefully analyze the legal facts and event points. Based on dimensions like subjective intent, core criminal acts, results, and severity, and combining knowledge from candidate articles (for reference only), recommend the most relevant criminal law article for this case. Input Context: - Facts & Event Points: {{CASE_FACT}}, {{EVENT_POINTS}} - Candidates: {{CANDIDATES_FOR_JUDGE}} - (Optional) Supervisor Opinion: {{VERIFICATION_OPINION}} Task Logic: 1. Analyze the criminal behavior (distinguish primary/secondary, chronological order). 2. Refinement Loop: If the Supervisor Agent thinks your previous recommendation was inaccurate, re-recommend the most relevant article based on the Supervisor’s feedback. Output Format: Provide the predicted article ID and explanation: {’predicted_article’: , ’explanation’: ’’} Figure 6: System prompt for the Case-handling Judge Agent . It includes logic for initial drafting and iterative refinement based on feedback. 14 Prompt 4: Adjudication Supervisor Agent (V erification) System Instruction: You are a verification agent with extensive legal knowledge ( Adjudication Supervisor ). Your task is to check if the article recommended by the "Case-handling Judge" is suitable as a reference for the final ruling. Check for reasonableness or obvious errors (e.g., confusing primary/secondary issues, sequence, or missing deep semantics) from dimensions like intent, acts, and results. Combine knowledge from reference articles, insights, and precedents (if any) to give an opinion on whether a re-judgment is needed. Input: - Facts & Judgment Output: {{CASE_FACT}}, {{JUDGMENT_OUT}} - Reference Law & Precedents: {{LAW_CTX}}, {{PRECEDENTS_TEXT}} Output Format: No analysis process needed, just the result: Finish[{"need_rejudge": , "suggestions": ""}] Figure 7: System prompt for the Adjudication Supervisor Agent , responsible for logical consistency checks and issuing correction signals. Prompt 5: Presiding Judge Agent (Final Decision) System Instruction: You are the final decision-making agent ( Presiding Judge ) with professional judging capability. Your duty is to synthesize outputs from all agents and auxiliary info to make the final decision: Article, Charge, and Penalty Term. Sentencing Guidance: - Unit for ‘imprisonment‘ is "months". - Determine reasonable values based on the sentencing range of the selected article and case circumstances (e.g., severity). Output Requirements: - Synthesize opinions from the Case Judge and Supervisor. - thought : Briefly explain the reasoning process. - finish : Output format: Finish[{"relevant_articles": [int], "accusation": [str], "term_of_imprisonment": {"death_penalty": bool, "life_imprisonment": bool, "imprisonment": int}}] Figure 8: System prompt for the Presiding J udge Agent , synthesizing the multi-agent workflo w into a standard verdict. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment