Clustering without geometry in sparse networks with independent edges
The coexistence of sparsity and clustering (non-vanishing average fraction of triangles per node) is one of the few structural features that, irrespective of finer details, are ubiquitously observed across large real-world networks. This fact calls f…
Authors: Alessio Catanzaro, Remco van der Hofstad, Diego Garlaschelli
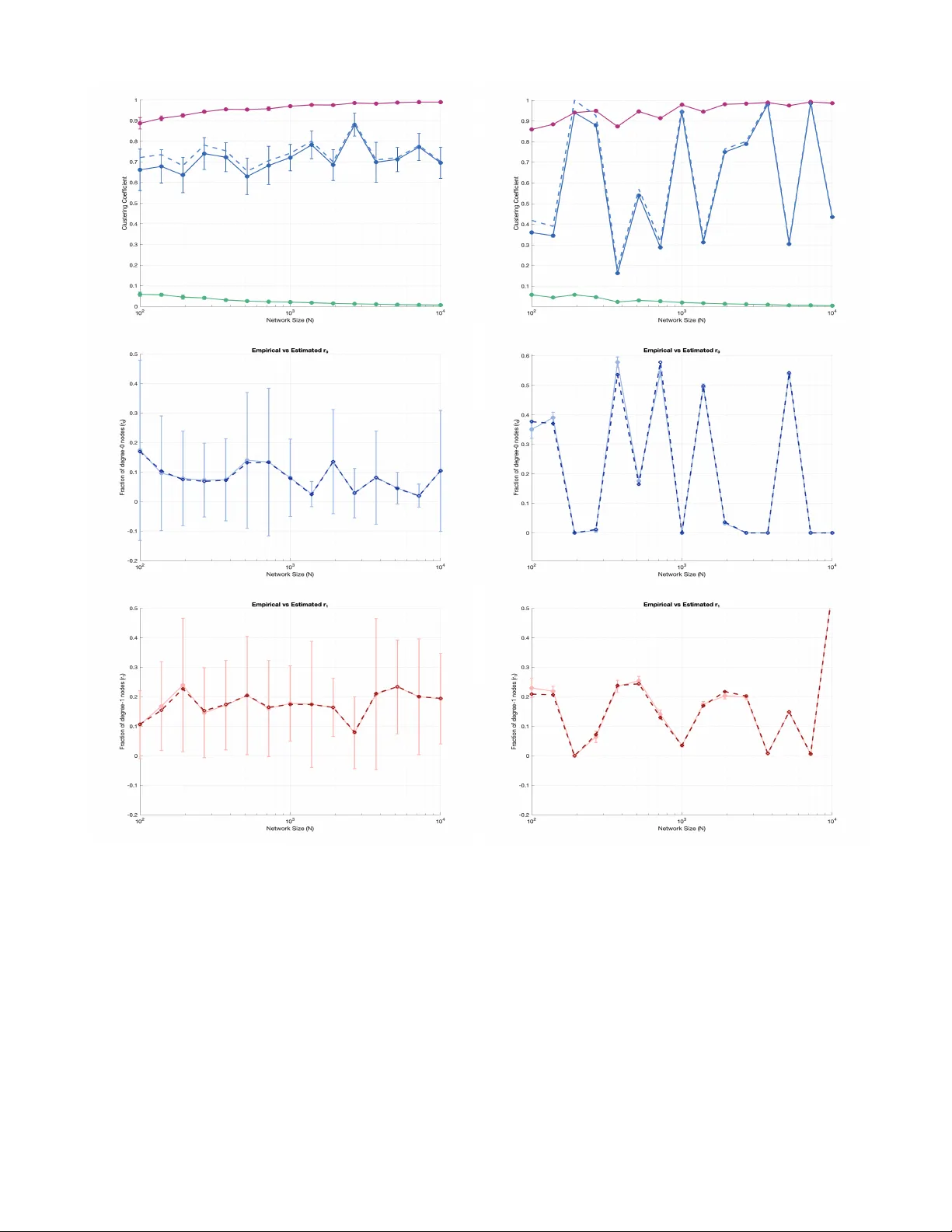
Clustering without geometry in sparse net w orks with indep enden t edges Alessio Catanzaro 1 , 2 , 3 , Remco v an der Hofstad 4 , and Diego Garlaschelli 1 , 2 1 IMT School for A dvanc e d Studies, Luc c a, Italy 2 Instituut-L orentz for The or etic al Physics, L eiden University, The Netherlands 3 Universit` a di Palermo, Palermo, Italy and 4 Dep artment of Mathematics and Computer Scienc e, Eindhoven University of T echnolo gy, The Netherlands. (Dated: March 16, 2026) The co existence of sparsity and clustering (non-v anishing av erage fraction of triangles p er no de) is one of the few structural features that, irresp ectiv e of finer details, are ubiquitously observed across large real-world netw orks. This fact calls for generic mo dels producing sparse clustered graphs. Earlier results suggested that sparse random graphs with indep enden t edges fail to repro duce clustering, unless edge probabilities are assumed to dep end on underlying metric distances that, thanks to the triangle inequalit y , naturally fav our triadic closure. This observ ation has opened a debate on whether clustering implies (latent) geometry in real-w orld netw orks. Alternativ ely , recen t mo dels of higher-order netw orks can replicate clustering by abandoning edge indep endence. In this pap er, we mathematically prov e, and numerically confirm, that a sparse random graph with indep enden t edges, recently identified in the context of net work renormalization as an in v arian t mo del under node aggregation, pro duces finite clustering without any geometric or higher-order constrain t. The underlying mechanism is an infinite-mean no de fitness, whic h also implies a pow er- la w degree distribution. F urther, as a nov el phenomenon that we c haracterize rigorously , we observ e the breakdown of self-a veraging of v arious net work properties. Therefore, as an alternative to geometry or higher-order dep endencies, node aggregation inv ariance emerges as a basic route to realistic netw ork prop erties. Intr o duction: clustering versus ge ometry. While real- w orld net works differ in v arious structural details, the v ast ma jorit y of them are c haracterized b y virtually ubiq- uitous features, the most p opular of which are the broad (i.e., infinite-v ariance) distribution of node degrees (n um- b ers of links p er no de), the (ultr a)smal l-world prop ert y (i.e., av erage shortest path length growing (at most) log- arithmically with the n umber of no des), and the co exis- tence of sp arsity (i.e., v anishing link densit y) and lo c al clustering (i.e., finite av erage density of triangles around no des) in the limit of infinitely large netw orks [1, 2]. While several mo dels based on different generic mech- anisms can successfully replicate broad degree distribu- tions and short path lengths [2, 3], the coexistence of sparsit y and local clustering is m uc h more difficult to replicate – and hence more informative, as it requires sp ecific mec hanisms that can discriminate mo dels at a finer level. The prototypical example of this difficult y is illustrated b y r andom gr aph mo dels with indep endent e dges , where differen t pairs of no des are indep endently connected. In the Erd˝ os-R ´ enyi (ER) mo del [4], where edges are inde- p enden t and iden tically distributed (i.i.d.) with the same connection probability p , it is easy to show that the link densit y (exp ected fraction of realized links) and the lo cal clustering co efficient (defined as the fraction of triangles around a no de, av eraged ov er all no des) hav e the same exp ected v alue p for netw orks with a large num ber n of no des. This automatically implies that, as n diverges, one cannot simultaneously pro duce finite lo cal clustering and v anishing link densit y . T o ov ercome this limitation of the ER mo del, tw o main routes hav e b een explored. One route in tro duces dep endencies betw een edges. This can happen via the addition of explicit triadic in ter- actions in an Exp onen tial Random Graph setting [5, 6] (whic h may how ev er still lead to comparable lev els of den- sit y and clustering), the random sup erp osition of small subgraphs [7] or the monopartite pro jection [8] of ran- dom bipartite netw orks [9] – b oth pro ducing netw orks of o verlapping cliques (the edges of which are all mutually dep enden t) where lo cal clustering can remain v ery large ev en for v anishing density . More recen t attempts general- ize these ideas to higher-order net w orks suc h as simplicial complexes and hypergraphs [10, 11], where edges b elong- ing to the same simplex or hyperedge are mutually dep en- den t. While these more complicated settings can realize the co existence of sparsity and clustering at the exp ense of introducing higher-order dep endencies, whether that co existence can b e achiev ed for more parsimonious mo d- els with indep enden t edges remains an op en question. The second route explores that question explicitly by preserving edge indep endence while introducing hetero- geneit y . More precisely , one can turn the unc onditional link indep endence of the ER mo del into a c onditional one, b y replacing, for each specific pair of no des i and j ( i, j = 1 , . . . , n ), the constant connection probability p with a probability p ij that is a function f ( w i , w j ) of the realized v alues w i , w j of a certain no de-specific v ariable w (called fitness or weigh t, hidden v ariable, latent v ariable, Lagrange multiplier, etc.) that is preliminarily assigned to v ertices via an i.i.d. dra w from a certain probabilit y densit y function (p df ) ρ ( w ) [3, 12 – 14]. Typical c hoices of f ( w i , w j ) are monotonically increasing in b oth arguments (and necessarily symmetric for undirected graphs) – im- plemen ting the idea that, the larger the fitness, the larger the probabilit y that a no de connects to other no des [15]. 2 In the studies carried out so far, it turned out that, while sev eral com binations of f and ρ can generate sparse small-w orld netw orks with a broad degree distri- bution [3, 12–14], they systematically fail to generate (p ositiv e) clustering, casting doubts on whether mo d- els with indep enden t edges can replicate lo cal clustering. The only exception that has b ecome p opular is that of r andom ge ometric gr aphs , where the fitness w acquires the role of a no de c o or dinate (whic h, more generally , can b e a D -dimensional vector), and the connection function f depends on w i and w j through some metric distanc e d ij = d ( w i , w j ) (in which case, f generally loses the prop- ert y of b eing monotonic in w i [16]). A remark able ex- ample of this success is the hyp erb olic mo del [6, 17 – 23], whic h assumes that nodes are sprinkled uniformly at ran- dom in a D -dimensional hyperb olic space and links are formed with a probabilit y that is a certain decreasing function of the geo desic distance b et ween no des. In this setting, the triangle inequalit y ( d ij ≤ d ik + d j k ∀ i, j, k ) guaran tees that pairs of nodes i, j that successfully con- nect to a third no de k are v ery lik ely to connect to each other ( triadic closur e ), prov ably leading to p ositiv e clus- tering [24, 25]. Additionally , hyperb olicity ensures that other desirable prop erties such as p o wer-la w degree dis- tributions emerge [22]. These inv estigations hav e con- vincingly concluded that, in random graphs with condi- tionally indep enden t edges and distance-dependent con- nection probabilities, ge ometry implies clustering . On the other hand, the potential rev erse (non-obvious) implication that clustering implies ge ometry , i.e., that the presence of finite clustering could suffice to indicate that the net w ork is (with high probability) the realization of a random geometric graph, is highly debated [6, 17– 23]. Whether clustering implies geometry is crucial for net work theory (b ecause, if true, it w ould demand for explanations and interpretations of the hidden geome- try of real-world net works [21, 24]), for data science (for instance because techniques such as graph em bedding and top ological data analysis could then b e optimized for real-w orld netw ork geometries), and for the control of pro cesses on netw orks (b ecause geometry could aid net- w ork na vigability [22, 26, 27], and the understanding of ho w clustering impacts epidemic and other processes [5]). In this Letter, we pro ve that positive clustering can emerge indep endently of geometry or higher-order con- strain ts in random graphs with indep endent edges condi- tional on infinite-mean fitness [28, 29]. While the finite- mean case has been systematically found to pro duce v an- ishing clustering, we sho w that in the infinite-mean case clustering is positive and strong. Notably , we find that the infinite-mean fitness also implies the breakdo wn of self-a veraging in certain prop erties, including clustering itself. The Multi-Sc ale Mo del. W e consider the inhomoge- neous random graph mo del introduced in [28] and stud- ied in [29 – 31]. Each no de i is assigned a p ositive weigh t (fitness) w i ( i = 1 , . . . , n ), sampled i.i.d. from a certain p df ρ ( w ). Giv en w i , w j , no des i, j connect with proba- bilit y p ij = 1 − e − δ n w i w j , (1) where the scaling δ n can b e c hosen in such a wa y that the link density v anishes as n → ∞ . The connection probabilit y (1) is also known in the literature as the Norros–Reittu mo del [32] and has b een used for v arious purp oses [33, 34], by considering a finite-mean ρ ( w ). In this work we are ho wev er interested in the sp ecific ‘an- nealed’ regime considered within the framework of net- w ork renormalization [35], where the mo del emerges as a fixed point of a renormalization flo w in the space of mo dels, induced by coarse-graining the netw ork b y ag- gregating nodes into sup er-nodes and recalculating the induced connection probabilit y betw een super-no des [28]. The sp ecific connection rule in (1) mak es the mo del in- v ariant, provided the weigh t of eac h blo ck is defined as (a random v ariable equal to) the sum of the weigh ts of the constituent no des [28]. If one further demands the in v ariance of the weigh t distribution, i.e., that the coarse-grained weigh ts are distributed according to the same pdf as the constituent weigh ts, then ρ ( w ) should b e a p ositiv ely-supp orted, one-sided α -stable law ˜ ρ α ( w ) with stability parameter 0 < α < 1 [36, 37] and tails deca ying as w − 1 − α for large w , hence with diverging mean and higher moments [28, 30]. In this w ay , one gets a Multi-Scale Mo del (MSM) interpretable as describing connections betw een arbitrarily nested (blocks of ) no des, thereb y describing the graph at multiple scales of resolu- tion (coarse-graining) sim ultaneously [28]. Since a stable law ˜ ρ α ( w ) with 0 < α < 1 is known in closed form only for α = 1 2 (L ´ evy distribution), we first follo w [30] and replace it with a pure P areto distribution ρ α ( w ) = αw − 1 − α , w ≥ 1 , 0 < α < 1 , (2) (whic h has exactly the same tail behaviour as an α -stable distribution and serves as an analytically tractable coun- terpart [30, 36]) and then discuss the extension to ac- tual α -stable laws ˜ ρ α ( w ) via b oth analytical and numer- ical arguments. Giv en (2), one can sho w that c ho os- ing δ n = n − 1 /α implies that the link density v anishes as log n/n , i.e., the a verage degree grows only as log n , and the degree distribution is p o w er-law [30]. W e stress that the MSM can b e enriched with addi- tional dy adic features [28, 29] whic h allow the connection probabilities to depend, for instance, on geometric dis- tances b etw een co ordinates assigned to no des. Nonethe- less, to inv estigate whether clustering can b e pro duced without geometry , here w e obviously consider the sim- plest, distance-indep endent v ersion in (1). The L o c al Clustering Co efficient. Abstractly , the clustering co efficient quantifies the tendency of a graph to form closed triangles. Globally , it can b e defined as the ratio betw een the total n umber of closed triangles and the num b er of potential (either op en or closed) trian- gles (also called cherries, or wedges). In our regime with 0 < α < 1, this ratio v anishes for the MSM model [30], in 3 FIG. 1: Clustering functions for different v alues of n and α for the MSM mo del (1) with Pareto w eigh ts (2) . Blue circles: empirical clustering function (4) (versus the reduced degree a = k / √ n ) computed on actual realized graphs sampled from the mo del (obtained by sampling the weigh ts once, and sampling the graph once conditionally on the realized weigh ts). Red curves: our analytical expression (6) for the annealed clustering function. Green curves: our asymptotic calculation (8) v alid for div erging reduced degrees. W e ev aluate and plot all functions only for degrees larger than 1, to a void am biguities in the definition of the clustering co efficient for k < 2. F rom top to b ottom: n = 10 2 , 10 3 , 10 4 . F rom left to righ t: α = 0 . 3 , 0 . 5 , 0 . 7. line with what is observed in sparse real-w orld net works. Our interest here is the (more distinctiv e) lo c al cluster- ing coefficient C v , which quantifies the tendency of the neigh b ours of the sp ecific no de v to form closed triangles around v . F or a node v with degree D v , C v is defined as the ratio b et ween the num b er ∆ v of triangles containing v and the num b er of w edges centered at v . In terms of the adjacency matrix A = ( A ij ) n i,j =1 , this reads C v = ∆ v D v 2 = P i = v P j = v ,i A v i A ij A j v D v ( D v − 1) , D v > 1 . (3) The b eha viour of C v v ersus D v , as w ell as the a v erage v alue C of C v o ver nodes, can effectiv ely characterize real- w orld net works and discriminate among differen t mo dels – esp ecially in determining whether a finite (expected) v alue of C can emerge in large sparse graphs, as observ ed in real-w orld netw orks. Note that C v in (3) is defined only for no des with D v > 1, as only no des with at least t wo neigh b ours can host a triangle. F or no des with D v = 0 , 1, one can either lea v e C v undefined (and exclude it from the calculation of C ) or conv entionally set C v ≡ 0 (and include it in the calculation of C ). W e will consider b oth cases and discuss their implications. Clustering F unction. F or a given graph, we consider the av erage clustering coefficient as a function of the de- gree k of eac h no de, i.e., the empiric al clustering function C ( k ) = 1 N k X v : D v = k ∆ v k 2 , (4) where N k = P v : D v = k δ D v ,k is the num b er of no des with degree k . In terms of exp ectations ( E ) o ver the mo del, w e in tro duce the anne ale d clustering function as ¯ C ( k ) = 1 E [ N k ] E " X v : D v = k ∆ v k 2 # . (5) One of our main results is a rigorous calculation of ¯ C ( k ) in the asymptotic (large n ) limit, v alid for b oth small and large k , which sho ws excellent agreement with the empirical clustering function C ( k ) [38]. In this setting, w e redefine ¯ C ( · ) as a function of the r e duc e d de gr e e a = k / √ n , as this rescaling allo ws us to pro ve that, defining g ( x ) ≡ 1 − e − x , the limiting form of ¯ C ( a ) as n → ∞ is ¯ C ( a ) = α 2 a 2 Z ∞ 0 d x Z ∞ 0 d y g ( a 1 /α τ α x ) x 1+ α g ( a 1 /α τ α y ) y 1+ α g ( xy ) , (6) 4 where τ α ≡ Γ(1 − α ) − 1 /α , and Γ( · ) is the Euler Gamma function. The pro of is in Supplemen tary Information (SI). In Figure 1, w e compare the n umerical ev aluation of the in tegral (6) with the direct computation of the empir- ical clustering function (4) on the actual realizations of the random graph. The agreemen t is remark ably goo d, already for mo derate v alues of n . Hub and L e af Behaviour. T o refine the characteriza- tion of clustering in the model, we in vestigate the limit- ing behavior of the annealed clustering function for nodes in tw o distinct regimes of the degree sp ectrum: le af and hub no des, corresponding to po orly and highly connected ones, resp ectiv ely . F or leaf ( L ) no des, defined as no des with v anishing reduced degree a → 0, we find (see SI) that the function in (6) has the asymptotic plateau ¯ C L ≡ lim a → 0 ¯ C ( a ) = 1 , (7) whic h implies that in the lo w-degree limit the local neigh- b orhoo d of a no de is almost fully clustered (excluding of course no des with k = 0 , 1). F or hub ( H ) no des, defined as no des with diverging reduced degree a → ∞ , we find (see SI) that the function (6) deca ys as ¯ C ( a ) ∼ ¯ C H ( a ) ≡ 2Γ(1 − α ) log a a 2 , a → ∞ . (8) Figure 1 shows that the asymptotics (7) and (8) are in excellen t agreement b oth with the empirical clustering function (4) computed on actual realizations of the ran- dom graph and with the full analytical expression (6) for the annealed clustering function (5). A ver age Clustering Co efficient. The previous results finally allow us to estimate the ov erall exp ected v alue ¯ C of the av erage lo cal clustering co efficien t C by a veraging the annealed clustering function ¯ C ( a ) ov er the distribu- tion P ( a ) of the reduced degree a as ¯ C ≡ Z da ¯ C ( a ) P ( a ) ≃ Z a ∈ L d a ¯ C L ( a ) P ( a ) + Z a ∈ H d a ¯ C H ( a ) P ( a ) , (9) where we ha ve formally split the integral into t w o contri- butions, pro duced b y leaf ( a ∈ L ) and h ub ( a ∈ H ) nodes resp ectiv ely , consisten t with the tw o regimes character- ized asymptotically in (7) and (8). A rigorous definition of this split is pro vided in SI, where we also sho w that, in order to compute ¯ C exactly , it is not necessary to iden- tify precisely the crosso ver v alue(s) of a separating the t wo regions. Notably , it turns out that the in tegral ov er a ∈ H in (9) v anishes, implying that hubs no not con- tribute to the ov erall clustering (see SI). The remaining con tribution of the leaf nodes a ∈ L is alw a ys finite, but its precise v alue dep ends on whether C k for no des with degree k < 2 is defined as C k< 2 ≡ 0 and hence included in the integration ov er L (in which case ¯ C L ( a ) ≡ 0 for 0 ≤ a ≤ 1 / √ n ) or undefined and not included in the FIG. 2: Average lo cal clustering co efficient C and distance to r 0 / 1 v ersus netw ork size n (for α = 0 . 5 ). All results are obtained by sampling the w eights 10 times indep enden tly for eac h v alue of n , sampling a single graph conditionally on eac h realization of the weigh ts, computing the relev an t quan tities on that single graph, and finally calculating a verages and error bars ov er the 10 realizations. The trends show the no de-av eraged lo cal clustering co efficien t C , b oth including (blue symbols) and excluding (purple sym b ols) no des with degree k < 2: note that the latter ev olves smo othly tow ards 1 with shrinking error bars as n increases, while the former fluctuates with non-v anishing error bars (as a result of non-self-a veraging) and b ecomes progressively closer to 1 − r 0 / 1 o ver realizations (dashed blue line), whic h is also fluctuating. The difference b et ween 1 − r 0 / 1 and C computed including no des with k < 2 (green symbols) con verges to zero with shrinking error bars. in tegration. In SI w e find that, dep ending on the choice, lim n →∞ ¯ C = ( 1 if C k< 2 undefined , 1 − r 0 / 1 if C k< 2 ≡ 0 , (10) where r 0 / 1 is the exp ected fraction of no des with degree 0 or 1. W e plot the t w o v ersions of the a verage lo cal clus- tering co efficient in Figure 2, confirming the agreement with the theoretical calculations. This result means that the net w ork is strongly clustered: for almost all no des that can form triangles, almost all triangles are closed. L ack of Self-A ver aging. The result (10) is calculated conditionally on the realized w eights { w i } n i =1 . It shows that, if no des with k < 2 are excluded, ¯ C con verges to the (deterministic) maximum v alue 1, with v anishing fluctu- ations. By contrast, as we show in SI, for finite but large n , the fractions of no des with degree zero and one con- cen trate around functions of the rescaled total weigh t S n = δ n P n j =1 w j , which in turn con verges in distribu- tion to an α -stable random v ariable, and thus remains a fluctuating quan tity . This means that, for given n and α , different realizations of the w eights pro duce different v alues of r 0 / 1 and of ¯ C , if no des with k < 2 are included. Therefore, under this second definition, ¯ C conv erges in distribution to the random v ariable 1 − r 0 / 1 , remain- ing macroscopically fluctuating even in the large graph 5 limit. This b ehaviour follo ws from the infinite-mean na- ture of the w eights and is a notable manifestation of the (rather unique) lack of self-a v eraging in macroscopic net- w ork prop erties (the fractions of no des with k < 2, and ¯ C itself ), which is not t ypically observ ed in mo dels with indep enden t edges and finite-mean weigh ts. All these results are pro v en in SI and confirmed n umerically in Figure 2. Concluding R emarks. This Letter contributes to the op en debate about whether, in models with conditionally indep enden t edges, the co existence of sparsity and lo cal clustering (along with other desirable features suc h as a broad degree distribution and the small-w orld property) can b e attained without ge ometry , i.e., without assuming that the connection probability p ij dep ends on the no de attributes w i and w j necessarily through a function of some metric distance d ( w i , w j ) [6, 17 – 24]. W e consid- ered a geometry-free mo del with indep endent edges and infinite-mean fitness [28, 29], recen tly introduced in the con text of netw ork renormalization [35], and calculated its full clustering function – rigorously pro ving the result- ing finite lo cal clustering in the large n limit and high- ligh ting that clustering do es not imply geometry . The infinite-mean nature of the fitness arises from a require- men t of mo del inv ariance under node aggregation [28] and generates other realistic prop erties including spar- sit y , a p ow er-la w degree distribution [29], and the break- do wn of self-a veraging of v arious net w ork prop erties (in- cluding the fraction of isolated nodes and its con tribution to the av erage clustering itself ), which is a nov el result c haracterized here. The mo del then exp oses, as an alter- nativ e to geometry , the hypothesis of no de aggregation in v ariance as a basic candidate mec hanism pro ducing re- alistic netw ork prop erties. A cknow le dgments This publication is part of the pro jects “Netw ork renormalization: from theoretical ph ysics to the resilience of societies” with file num b er NW A.1418.24.029 of the research programme NW A L3 - Inno v ativ e pro jects within routes 2024, which is (partly) financed by the Dutch Research Council (NWO) un- der the grant https://doi.org/10.61686/AOIJP05368 , and “Redefining renormalization for complex netw orks” with file num b er OCENW.M.24.039 of the research pro- gramme Op en Comp etition Domain Science Pac k age 24- 1, whic h is (partly) financed by the Dutc h Research Council (NWO) under the grant https://doi.org/10. 61686/PBSEC42210 . The w ork of v an der Hofstad is sup- p orted in part by the Netherlands Organisation for Sci- en tific Research (NWO) through the Gravitation Net- works grant 024.002.003. Early in teractions b etw een RvdH and DG to ok place betw een 29 Jan uary and 02 F ebruary 2 024 during the ICTS-NETWORKS workshop “Challenges in Net works” (ICTS/NETW ORKS2024/01) at the International Cen tre for Theoretical Sciences (ICTS-TIFR) in Bangalore, India. [1] G. Caldarelli, Sc ale-fr e e networks: c omplex webs in na- tur e and te chnolo gy (Oxford Univ ersity Press, 2007). [2] M. Newman, Networks (Oxford univ ersity press, 2018). [3] R. V an Der Hofstad, Random graphs and complex net- w orks: V olume 1 (2016). [4] P . Erd˝ os, A. R´ enyi, et al. , On the ev olution of random graphs, Publ. Math. Inst. Hungar. Acad. Sci. (1960). [5] M. E. Newman, Properties of highly clustered netw orks, Ph ysical Review E 68 , 026121 (2003). [6] M. E. Newman, Random graphs with clustering, Ph ysical review letters 103 , 058701 (2009). [7] B. Bollob´ as, S. Janson, and O. Riordan, Sparse random graphs with clustering, Random Structures & Algorithms 38 , 269 (2011). [8] In monopartite pro jections of bipartite netw orks, the original no des are first initially connected (p ossibly in- dep enden tly of eac h other) to ‘auxiliary’ no des of a dif- feren t type (representing for instance the p ossibile affil- iations or memberships of the original no des), and the auxiliary no des are then eliminated while connecting the original no des to each other, if they share connections to the same auxiliary no des. [9] M. E. Newman and J. Park, Wh y social net works are differen t from other types of net works, Ph ysical review E 68 , 036122 (2003). [10] F. Battiston and G. Petri, Higher-or der systems (Springer, 2022). [11] S. Boccaletti, P . De Lellis, C. Del Genio, K. Alfaro- Bittner, R. Criado, S. Jalan, and M. Romance, The struc- ture and dynamics of netw orks with higher order in ter- actions, Physics Rep orts 1018 , 1 (2023). [12] G. Caldarelli, A. Cap occi, P . De Los Rios, and M. A. Munoz, Scale-free netw orks from v arying vertex intrinsic fitness, Physical review letters 89 , 258702 (2002). [13] M. Bogun´ a and R. P astor-Satorras, Class of correlated random net works with hidden v ariables, Ph ysical Review E 68 , 036112 (2003). [14] T. Squartini and D. Garlaschelli, Maximum-entr opy net- works: Pattern dete ction, network r e c onstruction and gr aph c ombinatorics (Springer, 2017). [15] Some popular examples are f ( w i , w j ) = z w i w j , f ( w i , w j ) = Θ( w i + w j − z ), f ( w i , w j ) = z w i w j / (1 + z w i w j ), and f ( w i , w j ) = 1 − e − zw i w j , where z > 0 is a global parameter controlling for the ov erall link density and w i ≥ 0 ∀ i . [16] F or instance, if w i and w j are scalar (one-dimensional) co ordinates and their distance is defined as d ij = | w i − w j | , then w i and w j can simultaneously increase while k eeping d ij (and hence p ij ) unchanged. [17] D. Kriouk o v, Clustering implies geometry in net works, Ph ysical review letters 116 , 208302 (2016). [18] R. Aliakbarisani, M. Bogu ˜ n´ a, and M. ´ A. Serrano, Clus- tering do es not alwa ys imply latent geometry , Ph ysical Review Letters 135 , 197402 (2025). [19] M. ´ A. Serrano and M. Boguna, Clustering in com- plex netw orks. i. general formalism, Physical Review E—Statistical, Nonlinear, and Soft Matter Ph ysics 74 , 056114 (2006). 6 [20] M. ´ A. Serrano and M. Bogun´ a, Clustering in com- plex net works. ii. p ercolation prop erties, Ph ysical Review E—Statistical, Nonlinear, and Soft Matter Ph ysics 74 , 056115 (2006). [21] M. Boguna, I. Bonamassa, M. De Domenico, S. Havlin, D. Kriouko v, and M. ´ A. Serrano, Netw ork geometry , Na- ture Reviews Physics 3 , 114 (2021). [22] D. Kriouko v, F. P apadop oulos, M. Kitsak, A. V ahdat, and M. Bogun´ a, Hyp erbolic geometry of complex net- w orks, Physical Review E—Statistical, Nonlinear, and Soft Matter Physics 82 , 036106 (2010). [23] R. Michielan, N. Litv ak, and C. Stegehuis, Detecting h y- p erbolic geometry in net works: Wh y triangles are not enough, Physical Review E 106 , 054303 (2022). [24] A. Allard, M. ´ A. Serrano, and M. Bogu ˜ n´ a, Geometric description of clustering in directed net works, Nature Ph ysics 20 , 150 (2024). [25] E. Candellero and N. F ountoulakis, Clustering and the h yp erb olic geometry of complex net works, in A lgorithms and Mo dels for the Web Gr aph: 11th International Work- shop, W A W 2014, Beijing, China, De c emb er 17-18, 2014, Pr o c e e dings 11 (Springer, 2014) pp. 1–12. [26] M. Boguna, D. Kriouko v, and K. C. Claffy , Navigabilit y of complex netw orks, Nature Physics 5 , 74 (2009). [27] M. Bogun´ a, F. Papadopoulos, and D. Kriouko v, Sustain- ing the internet with hyperb olic mapping, Nature com- m unications 1 , 62 (2010). [28] E. Garuccio, M. Lalli, and D. Garlaschelli, Multiscale net work renormalization: Scale-in v ariance without geom- etry , Physical Review Research 5 , 043101 (2023). [29] M. Lalli and D. Garlaschelli, Geometry-free renormal- ization of directed netw orks: scale-in v ariance and reci- pro cit y , arXiv preprint arXiv:2403.00235 (2024). [30] L. Av ena, D. Garlaschelli, R. S. Hazra, and M. Lalli, Inhomogeneous random graphs with infinite-mean fitness v ariables, Journal of Applied Probability , 1–26 (2025). [31] A. Catanzaro, R. S. Hazra, and D. Garlasc helli, Sp ectra of random graphs with discrete scale inv ariance, arXiv preprin t arXiv:2509.12407 (2025). [32] I. Norros and H. Reittu, On a conditionally p oissonian graph pro cess, Adv ances in Applied Probability 38 , 59 (2006). [33] G. J. Ro dgers, K. Austin, B. Kahng, and D. Kim, Eigen- v alue sp ectra of complex netw orks, Journal of Physics A: Mathematical and General 38 , 9431 (2005). [34] S. Bhamidi, R. v an der Hofstad, and J. v an Leeu w aarden, Scaling limits for critical inhomogeneous random graphs with finite third moments, Electronic Journal of Proba- bilit y 15 , 1682 (2010). [35] A. Gabrielli, D. Garlaschelli, S. P . Patil, and M. Serrano, Net work renormalization, Nature Reviews Physics 7 , 203 (2025). [36] G. Samorodnitsky and M. S. T aqqu, Stable non-Gaussian r andom pr o c esses: sto chastic mo dels with infinite vari- anc e , V ol. 1 (CRC press, 1994). [37] J. Nolan, Univariate stable distributions: models for he avy taile d data , Springer Series in Op erations Re- searc h and Financial Engineering (Springer, Cham, [2020] © 2020) pp. xv+333. [38] W e also b eliev e that, through a second-moment analy- sis, it could be prov en that in the large n limit, with high probabilit y , the tw o clustering functions become the same. W e will how ev er not prov e this claim in the present w ork. [39] R. Leipus, J. ˇ Siaulys, and D. Konstantinides, Closur e pr operties for he avy-taile d and r elate d distributions—an overview , SpringerBriefs in Statistics (Springer, Cham, 2023) pp. ix+92. [40] B. Bollob´ as, W. F ulton, A. Katok, et al. , Cambridge studies in adv anced mathematics, in R andom gr aphs (Cam bridge Universit y Press Cambridge, UK, 2001). [41] S. Janson, T. Luczak, and A. Ruci´ nski, Wiley- in terscience series in discrete mathematics and optimiza- tion, in R andom Gr aphs (2000). [42] R. V an Der Hofstad, R andom gr aphs and c omplex net- works, : V olume 2 (Cambridge universit y press, 2024). [43] H. V an Den Esker, R. V an Der Hofstad, G. Ho oghiem- stra, and D. Znamenski, Distances in random graphs with infinite mean degrees, Extremes 8 , 111 (2005). [44] A. Baptista, R. J. S´ anchez-Garc ´ ıa, A. Baudot, and G. Bianconi, Zo o guide to netw ork embedding, Journal of Physics: Complexit y 4 , 042001 (2023). [45] M. Ballerini, N. Cabibbo, R. Candelier, A. Ca v agna, E. Cisbani, I. Giardina, V. Lecomte, A. Orlandi, G. Parisi, A. Pro caccini, et al. , Interaction ruling an- imal collective behavior depends on topological rather than metric distance: Evidence from a field study , Pro- ceedings of the national academy of sciences 105 , 1232 (2008). [46] R. V an Der Hofstad, G. Hooghiemstra, and D. Znamen- ski, Random graphs with arbitrary iid degrees, arXiv preprin t math/0502580 (2005). [47] D. J. W atts and S. H. Strogatz, Collective dynamics of ‘small-w orld’netw orks, nature 393 , 440 (1998). 1 SUPPLEMENT AR Y INFORMA TION accompan ying the pap er “Clustering without ge ometry in sp arse networks with indep endent e dges” b y A. Catanzaro, R. v an der Hofstad and D. Garlaschelli S.I. ANNEALED CLUSTERING FUNCTION Theorem 1. L et the vertex sp ac e of the network b e [ n ] = { 1 , . . . , n } . L et ( W v ) v ∈ [ n ] b e i.i.d. Par eto r andom variables, so that their density e quals ρ α ( w ) = α w α +1 , w ≥ 1 , (S1) with α ∈ (0 , 1) , so that E [ W ] = ∞ . Conditional ly on ( W v ) v ∈ [ n ] , e dges ar e pr esent indep endently, with the e dge b etwe en u, v ∈ [ n ] b eing pr esent with pr ob ability p uv = 1 − e − W u W v /n 1 /α . (S2) Thr oughout, we let ( I u,v ) 1 ≤ u 0 , ¯ C ( a ) ≤ 1 . Pr o of. Estimating 1 − e − xy ≤ 1 b ounds ¯ C ( a ) by ¯ C ( a ) ≤ α 2 a 2 Z ∞ 0 [1 − e − xa 1 /α τ α ] x − ( α +1) d x 2 , (S31) for which we note that Z ∞ 0 [1 − e − xa 1 /α τ α ] x − ( α +1) d x = Z ∞ 0 Z xa 1 /α τ α 0 e − y d y x − ( α +1) d x (S32) = Z ∞ 0 e − y Z ∞ y a − 1 /α /τ α x − ( α +1) d x d y = 1 α Z ∞ 0 e − y ( y a − 1 /α /τ α ) − α d y = aτ α α α Z ∞ 0 e − y y − α d y = aτ α α α Γ(1 − α ) = a α , using that τ α = Γ(1 − α ) − 1 /α . Th us, indeed, ¯ C ( a ) ≤ 1. W e next inv estigate ¯ C ( a ) for a ≪ 1: Lemma 2 ( ¯ C ( a ) is close to 1 for a small) . As a ↘ 0 , ¯ C ( a ) = 1 + o (1) . (S33) Pr o of. F or a ≪ 1, w e write ¯ C ( a ) = α 2 a 2 Z ∞ 0 Z ∞ 0 [1 − e − xa 1 /α τ α ][1 − e − y a 1 /α τ α ]( xy ) − ( α +1) d x d y (S34) − α 2 a 2 Z ∞ 0 Z ∞ 0 [1 − e − xa 1 /α τ α ][1 − e − y a 1 /α τ α ]e − xy ( xy ) − ( α +1) d x d y . The first in tegral equals 1 b y Lemma 1, so that ¯ C ( a ) = 1 − ¯ C 1 ( a ) , (S35) where ¯ C 1 ( a ) = α 2 a 2 Z ∞ 0 Z ∞ 0 [1 − e − xa 1 /α τ α ][1 − e − y a 1 /α τ α ]e − xy ( xy ) − ( α +1) d x d y . (S36) 5 W e first b ound the integrals where either x or y is in [0 , a − ε ], for some ε > 0 sufficiently small, as 2 α 2 a 2 Z ∞ 0 Z a − ε 0 [1 − e − xa 1 /α τ α ][1 − e − y a 1 /α τ α ]e − xy ( xy ) − ( α +1) d x d y (S37) ≤ 2 α 2 a 2 Z ∞ 0 [1 − e − xa 1 /α τ α ] x − ( α +1) d xa 1 /α Z a − ε 0 y − α d x ≤ 2 α a ( α − 1) a 1 /α − ε (1 − α ) = o (1) , using (S32) and the fact that 1 /α − ε (1 − α ) > 1 for ε > 0 sufficiently small since α ∈ (0 , 1). Th us, ¯ C 1 ( a ) = o (1) + α 2 a 2 Z ∞ a − ε Z ∞ a − ε [1 − e − xa 1 /α τ α ][1 − e − y a 1 /α τ α ]e − xy ( xy ) − ( α +1) d x d y , (S38) whic h is bounded b y e − a − 2 ε = o (1). This sho ws that ¯ C 1 ( a ) = o (1) for a ↘ 0, and th us pro v es that ¯ C ( a ) = 1 + o (1). F or a → ∞ , the integral should be dominated by small x, y , so that one might consider to expand 1 − e − xy = xy , to obtain ¯ C ( a ) = (1 + o (1)) α 2 a 2 Z ∞ 0 Z ∞ 0 [1 − e − xa 1 /α τ α ][1 − e − y a 1 /α τ α ]( xy ) − α d x d y (S39) = (1 + o (1)) α 2 a 2 a 1 /α τ α 2 α − 2 Z ∞ 0 [1 − e − x ] x − α d x 2 . Ho wev er, the in tegral that is squared is infinite, so that we need to pro ceed alternativ ely . In fact, this analysis is quite intricate, and a careful split is necessary . The main result is as follows: Lemma 3 (Large a asymptotics of ¯ C ( a )) . As a ↗ ∞ , ¯ C ( a ) = 2Γ(1 − α ) log a a 2 + O ( a − 2 ) . (S40) Pr o of. W e again split the integral conv eniently . W e split the integral dep ending on whether x or y is in [0 , a − 1 /α /τ α ] or not. This giv es ¯ C ( a ) = ¯ C 1 ( a ) + ¯ C 2 ( a ) + ¯ C 3 ( a ) , (S41) where ¯ C 1 ( a ) = α 2 a 2 Z ∞ a − 1 /α /τ α Z ∞ a − 1 /α /τ α [1 − e − xa 1 /α τ α ][1 − e − y a 1 /α τ α ][1 − e − xy ]( xy ) − ( α +1) d x d y , (S42) ¯ C 2 ( a ) = α 2 a 2 Z a − 1 /α /τ α 0 Z a − 1 /α /τ α 0 [1 − e − xa 1 /α τ α ][1 − e − y a 1 /α τ α ][1 − e − xy ]( xy ) − ( α +1) d x d y . (S43) W e b ound, again using (S32) and 1 − e − xy ≤ xy , ¯ C 2 ( a ) ≤ α 2 a 2 Z a − 1 /α /τ α 0 Z a − 1 /α /τ α 0 [1 − e − xa 1 /α τ α ][1 − e − y a 1 /α τ α ]( xy ) − α d x d y (S44) = α 2 a 2 Z a − 1 /α /τ α 0 y − α d y 2 = Θ(1) a − 2 ( a − 1 /α ) 2(1 − α ) = o ( a − 2 ) . W e con tinue with ¯ C 3 ( a ), which is the most inv olv ed. W e b ound 1 − e − y a 1 /α τ α ≤ y a 1 /α to obtain ¯ C 3 ( a ) ≤ 2 α 2 a 1 /α a 2 Z a − 1 /α /τ α 0 Z ∞ a − 1 /α /τ α ( xy ) − ( α +1) y [1 − e − xy ]d x d y . (S45) 6 W e b ound 1 − e − xy ≤ ( xy ) ∧ 1. The integral where x ≤ 1 /y is b ounded b y Θ(1) a − 2+1 /α Z a − 1 /α /τ α 0 y − α +1 Z 1 /y 0 x − α d x d y ≤ Θ(1) a − 2+1 /α Z a − 1 /α /τ α 0 d y ≤ Θ(1) a − 2 . (S46) Similarly , the integral where x > 1 /y is b ounded by Θ(1) a − 2+1 /α Z a − 1 /α /τ α 0 y − α Z ∞ 1 /y x − ( α +1) d x d y ≤ Θ(1) a − 2+1 /α Z a − 1 /α /τ α 0 d y ≤ Θ(1) a − 2 . (S47) This shows that ¯ C 3 ( a ) = O ( a − 2 ). W e finally compute ¯ C 1 ( a ), which we rewrite as ¯ C 1 ( a ) = α 2 τ 2 α α Z ∞ 1 Z ∞ 1 [1 − e − x ][1 − e − y ][1 − e − xy a − 2 /α /τ 2 α ]( xy ) − ( α +1) d x d y (S48) = τ 2 α α E [1 − e − W 1 W 2 a − 2 /α /τ 2 α ] + ¯ e 1 ( a ) , where we let ¯ e 1 ( a ) denote the contribution due to e − x and e − y . W e use [30, (4.6)], which states that E [1 − e − δ W 1 W 2 ] = (1 + o (1)) α Γ(1 − α ) δ α log(1 /δ ) . (S49) This gives ¯ C 1 ( a ) = τ 2 α α ατ − 2 α α 2 α Γ(1 − α ) log a a 2 + ¯ e 1 ( a ) = 2Γ(1 − α ) log a a 2 + ¯ e 1 ( a ) . (S50) Finally , ¯ e 1 ( a ) ≤ 2 α 2 τ 2 α α Z ∞ 1 Z ∞ 1 e − x [1 − e − xy a − 2 /α /τ 2 α ]( xy ) − ( α +1) d x d y (S51) = 2 τ 2 α α E e − W 1 (1 − e − W 1 W 2 a − 2 /α /τ 2 α ) = O ( a − 2 ) . This can b e seen by letting X b e defined by P ( X ∈ [ a, b ]) = 1 E e − W 1 ] E e − W 1 1 { X ∈ [ a,b ] } , (S52) so that ¯ e 1 ( a ) = Θ(1) E 1 − e − X W a − 2 /α /τ 2 α . (S53) Since X has thin tails (it has an exponential momen t), the random v ariable X W is regularly v arying with exp onen t α , so that E 1 − e − X W a − 2 /α /τ 2 α = Θ( a − 2 ) , (S54) as claimed. The ab ov e follows from the fact that X W is again heavy-tailed with tail exp onen t α , as prov ed in [39, Prop osition 5.2]. S.I II. COMPUT A TION OF A VERA GE CLUSTERING COEFFICIENT The limiting asymptotics for hubs and leav es allows us to deriv e an estimate of the av erage clustering co efficien t of the net work ¯ C . Indeed, one needs to integrate the annealed clustering function ¯ C ( a ) ov er the distribution P ( a ) of the reduced degree a , and from Figure 1 it is clear that one can split the integral into the tw o leaf ( L ) and hub ( H ) regimes as ¯ C = Z ∞ a min d a ¯ C ( a ) P ( a ) = Z a ∗ a min d a ¯ C L ( a ) P ( a ) + Z ∞ a ∗ d a ¯ C H ( a ) P ( a ) , (S55) 7 where C H ( a ) ∼ 2Γ(1 − α ) log a a 2 (for a > a ∗ ) is the asymptotic clustering function of hubs, while C L ( a ) ∼ 1 (for a min < a < a ∗ ) is the asymptotic plateau for leav es, a min is the minimal reduced degree ab o ve which the clustering function starts to ha ve meaning, and a ∗ is an appropriate crosso ver v alue b etw een the tw o regimes. This crossov er is visible in Figure 1, although its v alue is not easily identified. Luc kily , as we will show in the follo wing computations, the actual v alue of a ∗ is not necessary for the computation of the clustering to go through, and w e can proceed without sp ecifying it. The main issue in the ev aluation of the integral in (S55) is that the degree distribution is not known ev erywhere but only in the tail [30], where it has the asymptotic b eha viour Γ(1 − α ) k − 2 . T ransforming to the distribution P ( a ) of the reduced degree a = k √ n , P ( a ) ∼ Γ(1 − α ) √ n a − 2 . (S56) Nonetheless, the first integral can be ev aluated by realizing that by definition it ev aluates to the fraction of lea ves no des or, equiv alently Z a ∗ a min d a ¯ C L ( a ) P ( a ) = Z a ∗ a min d aP ( a ) = ( 1 − R ∞ a ∗ daP ( a ) if C k< 2 undefined, 1 − r 0 / 1 − R ∞ a ∗ daP ( a ) if C k< 2 = 0 , (S57) and the last term can b e recomprised in the second integral as it is ev aluated on the same interv al, so that the av erage clustering co efficient has the expression ¯ C = ( 1 + R ∞ a ∗ P ( a )( ¯ C H ( a ) − 1) if C k< 2 undefined, 1 − r 0 / 1 + R ∞ a ∗ daP ( a )( ¯ C H ( a ) − 1) if C k< 2 = 0 , (S58) W e can ev aluate this last integral as Z ∞ a ∗ daP ( a )( ¯ C H ( a ) − 1) = Z ∞ a ∗ da 2Γ(1 − α ) log a a 2 − 1 Γ(1 − α ) a 2 √ n (S59) = Γ(1 − α ) √ n 6Γ(1 − α ) log a ∗ + 2Γ(1 − α ) − 9( a ∗ ) 2 9( a ∗ ) 3 = o (1) , and see that it is suppressed b y a square ro ot of n term, whatever the v alue of a ∗ . S.IV. COMPUT A TION OF r 0 / 1 W e start by computing the fraction of no des that are disconnected from the graph as r 0 ≡ 1 n n X i =1 Y j : j = i (1 − p ij ) = 1 n n X i =1 e − δ n w i P j = i w j , (S60) where we recall that δ n = n − 1 /α . Since the j = i term in the sum in the exp onen tial makes little difference, w e can appro ximate r 0 ≈ 1 n n X i =1 e − δ n w i P j w j . (S61) W e next use that most of the weigh ts hav e normal size, and they con tribute most to the sum ov er i ∈ { 1 , . . . , n } . Th us, r 0 ≈ E h e − W S n | S n i , (S62) where we take the exp ectation ov er the P areto v ariable W in the ab ov e, we abbreviate S n = δ n n X j =1 w j , (S63) 8 and condition on this total rescaled weigh t. W e note that the random v ariable S n con verges in distribution to an α -stable distribution, since the random v ariables ( w i ) n i =1 are Pareto v ariables with infinite mean. Th us, r 0 ≈ E h e − W S | S i , (S64) where S is an α -stable random v ariable. Equation (S64) requires some interpretation. What it means is that the prop ortion of v ertices with r 0 degree 0, given the vertex weigh ts ( w i ) n i =1 , is close to the rhs of (S62), i.e., it holds that r 0 ≈ E h e − W S n | S n i , where the rescaled total weigh t S n is defined in (S63). In particular, this means that, when sim ulating the netw ork several times (and thus redrawing the vertex weigh ts), the prop ortion of vertices with degree 0 fluctuates macr osc opic al ly , even in the large graph limit. This is a type of non-self-aver aging phenomenon that is rather unusual in netw ork science. The sim ulations shown in Figures S1 S2 S3 confirm that (S64) is an excellent appro ximation of r 0 , and that it remains truly random in the large-graph limit. W e can also use (S64) us to relate our approximation to [30, Prop osition 4], in which E [ r 0 ] is sho wn to b e approximated by E [ r 0 ] ≈ E h e − Γ(1 − α ) W α i , (S65) whic h indeed equals E e − W S , since, for every a ≥ 0, E h e − a S i = e − Γ(1 − α ) a α . (S66) This follo ws from [30, Theorem 5]. F or a practical computation of the approximation of r 0 , w e use the fact, again for a ≥ 0, E e − aW = αa α Γ( − α, a ) , (S67) where we recall that Γ( r, a ) is the incomplete gamma function. Applying this to (S62), w e are led to r 0 ≈ αS α n Γ( − α, S n ) . (S68) W e sho w in Figures S1 S2 S3 that (S68) is in very go od accordance with the actual fraction of disconnected nodes (cen tral panels). W e extend the ab o v e analysis to the prop ortion r 1 of vertices of degree 1. W e start from r 1 ≡ 1 n X i,k : i = k p ik Y j : j = i,k (1 − p ij ) (S69) = 1 n X i,k : i = k (1 − e − δ n w i w k )e − δ n w i P j : j = i,k w j ≈ X k E h (1 − e − W δ n w k )e − W δ n P j : j = k w j i , where the asymptotics follo ws from the fact that the main contribution in the sum ov er i arises from normal weigh t v ertices, so that the av erage ov er i can b e replaced b y an exp ectation with respect to W . Note that the dominan t contributions to the sum ov er k in (S69) corresp ond to those k for which w k is of the order 1 /δ n = n 1 /α , which means that these are the maximal-weigh t vertices. This will b e the guiding principle to derive the asymptotics of the ab o v e form ula. F or simplicity , and without loss of generality , w e will assume that the weigh ts are or der e d from large to small, so that w 1 ≥ w 2 · · · ≥ w n . W e can rewrite δ n X j : j = k w j = S n − δ n w k = S n − y ( n ) k , (S70) where we recall S n from (S63), and we define the rescaled vertex weigh ts ( y ( n ) k ) k ≥ 1 as y ( n ) k = δ n w k . (S71) In terms of these definitions, we obtain the finite-size approximation r 1 ≈ X k E h (1 − e − W y ( n ) k )e − W ( S n − y ( n ) k ) | ( y ( n ) k ) k ≥ 1 i . (S72) 9 This appro ximation is inspired by the asymptotics prop erties of r 1 . Indeed, as n → ∞ , we hav e the con vergence in distribution S n , ( y ( n ) k ) k ≥ 1 d − → X j ≥ 1 Γ − 1 /α j , (Γ − 1 /α k ) k ≥ 1 , (S73) where d − → denotes con vergence in distribution in the pro duct top ology , (Γ k ) k ≥ 1 are gamma random v ariables, i.e., Γ k = k X i =1 E i , (S74) where ( E i ) i ≥ 1 are indep enden t and iden tically distributed exp onential random v ariables with mean 1. Because of this, we see that the random v ariables in (S72) conv erge in distribution in the large graph limit, so that r 1 d − → X k E h (1 − e − W y k )e − W ( S − y k ) | ( y k ) k ≥ 1 i , (S75) where S , ( y k ) k ≥ 1 ≡ X j ≥ 1 Γ − 1 /α j , (Γ − 1 /α k ) k ≥ 1 . (S76) Th us, as for r 0 , also r 1 con verges in distribution , but it remains to fluctuate even in the large graph limit. F or a practical computation of the approximation of r 0 , we again use (S67) on the representation r 1 ≈ n X k =1 E h e − W ( S n − y ( n ) k ) − e − W S n | ( y ( n ) k ) k ≥ 1 i , (S77) to arrive at r 1 ≈ α n X k =1 h ( S n − y ( n ) k ) α Γ( − α, S n − y ( n ) k ) − S α n Γ( − α, S n ) i , (S78) whic h has the adv antage that it no longer con tains the expectation with resp ect to W . W e show in Figures S1 S2 S3 that (S78) is in v ery goo d accordance with the actual fraction of disconnected no des (b ottom panels). S.V. EXTENSION TO ST ABLE WEIGHTS In this section we briefly discuss how our results can b e extended to the case in which the weigh ts are sampled from a gen uine α -stable distribution ˜ ρ α ( w ) with p ositive supp ort and div erging mean. Throughout, we follow the formalism introduced in [37], and in particular we adopt the first parametrization defined there, corresp onding to k = 0. F or stable laws, our arguments can b e adapted b y replacing the exact expression for the Pareto w eight density , ρ α ( w ) = αw − ( α +1) for w ≥ 1 in (S1), with an asymptotic relation. Sp ecifically , Theorem 1.2 of [37] shows that the densit y of an α -stable law satisfies ˜ ρ α ( w ) = (1 + o (1)) αγ α (1 + β ) c α w α +1 , w ≥ 1 , (S79) where the tail parameter satisfies α ∈ (0 , 1), c α = Γ( α ) π sin π α 2 , γ denotes the scale parameter, and β is the skewness parameter of the stable distribution. In order to work with a distribution supp orted on the p ositive real axis, we c ho ose β = 1 and set the infimum of the supp ort to zero. This c hoice fixes the lo cation parameter to b e δ = γ tan π α 2 . The only remaining free parameter is therefore the scale γ , which w e determine by requiring that the tails of the stable and Pareto distributions coincide asymptotically . Imp osing this matc hing condition yields γ = " π 2 Γ( α ) sin π α 2 # 1 /α . (S80) 10 FIG. S1: Average lo cal clustering co efficient C and distance to r 0 / 1 v ersus netw ork size n (for α = 0 . 3 ). On the left, simulations are done by resampling weigh ts every time an actual netw ork is realized (sample of 10), while on the left for each n weigh ts are extracted only once, and 10 different adjacency matrices are realized from the same w eights. On top we show the no de-a veraged lo cal clustering co efficient C , b oth including (blue sym b ols) and excluding (purple symbols) no des with degree k = 0 , 1 (note that the latter evolv es smo othly tow ards 1 with shrinking error bars as n increases, while the former fluctuates with non-v anishing error bars, as a result of non-self-a veraging). The dashed blue line is 1 minus the av erage of r 0 / 1 o ver realizations. Finally , in green the difference b etw een 1 − r 0 / 1 and C computed including no des with k < 2 (notice the shrinking error bars). In the middle, the light blue line with error bars is the actual v alue of r 0 , while the dashed dark er one is the appro ximation w e deriv e in (S68). A t the b ottom, the ligh t red line with error bars is the actual v alue of r 1 , while the dashed dark er one is the approximation w e derive in (S72). With this choice of parameters, all the results we derived for Pareto-distributed weigh ts extend directly to the case of stable sampling. In particular, since the in tegrals app earing in Section S.I are dominated by con tributions from 11 FIG. S2: Average lo cal clustering co efficient C and distance to r 0 / 1 v ersus netw ork size n (for α = 0 . 5 ). On the left, simulations are done by resampling weigh ts every time an actual netw ork is realized (sample of 10), while on the left for each n weigh ts are extracted only once, and 10 different adjacency matrices are realized from the same w eights. On top we show the no de-a veraged lo cal clustering co efficient C , b oth including (blue sym b ols) and excluding (purple symbols) no des with degree k = 0 , 1 (note that the latter evolv es smo othly tow ards 1 with shrinking error bars as n increases, while the former fluctuates with non-v anishing error bars, as a result of non-self-a veraging). The dashed blue line is 1 minus the av erage of r 0 / 1 o ver realizations. Finally , in green the difference b etw een 1 − r 0 / 1 and C computed including no des with k < 2 (notice the shrinking error bars). In the middle, the light blue line with error bars is the actual v alue of r 0 , while the dashed dark er one is the appro ximation w e deriv e in (S68). A t the b ottom, the ligh t red line with error bars is the actual v alue of r 1 , while the dashed dark er one is the approximation w e derive in (S72). large v alues of w , the asymptotic estimates derived in Section S.I I remain v alid. Similarly , the arguments used in Section S.IV to compute the fraction of disconnected no des and no des of degree one carry ov er almost v erbatim to 12 FIG. S3: Average lo cal clustering co efficient C and distance to r 0 / 1 v ersus netw ork size n (for α = 0 . 7 ). On the left, simulations are done by resampling weigh ts every time an actual netw ork is realized (sample of 10), while on the left for each n weigh ts are extracted only once, and 10 different adjacency matrices are realized from the same w eights. On top we show the no de-a veraged lo cal clustering co efficient C , b oth including (blue sym b ols) and excluding (purple symbols) no des with degree k = 0 , 1 (note that the latter evolv es smo othly tow ards 1 with shrinking error bars as n increases, while the former fluctuates with non-v anishing error bars, as a result of non-self-a veraging). The dashed blue line is 1 minus the av erage of r 0 / 1 o ver realizations. Finally , in green the difference b etw een 1 − r 0 / 1 and C computed including no des with k < 2 (notice the shrinking error bars). In the middle, the light blue line with error bars is the actual v alue of r 0 , while the dashed dark er one is the appro ximation w e deriv e in (S68). A t the b ottom, the ligh t red line with error bars is the actual v alue of r 1 , while the dashed dark er one is the approximation w e derive in (S72). the stable case. The only mo dification is the app earance of a constan t c in (S73), which is no w directly related to the scale parameter of the underlying stable la w. 13 Indeed, in the conv ergence statemen t (S73), the partial sum S n has a strictly α -stable distribution for every n . In terpreting S n as the v alue at time 1 of a stable L´ evy pro cess, the sum c P j ≥ 1 Γ − 1 /α j can b e view ed as the collection of jump sizes of the pro cess, ordered by decreasing magnitude. Correspondingly , the rescaled weigh ts n − 1 /α W i represen t the incremen ts of the pro cess o ver the time in terv als [( i − 1) /n, i/n ], and the v ariables ( y ( n ) k ) n k =1 in (S71) can b e in terpreted as the ordered increments o v er these interv als. Since, with high probabilit y and for large n , eac h in terv al con tains at most one large jump, it follows that (S73) con tinues to hold in this setting, with the first coordinate (corresp onding to the sum) having exactly the same distribution as in the P areto case. Finally , in Figures S5, S6, S7, and S8, w e provide numerical evidence confirming that the results presented in the main text remain v alid when the weigh ts are drawn from an α -stable distribution, in agreement with the argumen ts giv en abov e. FIG. S4: Comparison b etw een pure P areto and Stable distributions in the tail b eha viour . Using the parameter of (S80), w e can matc h the tails of the tw o distributions. F rom left to right α = 0 . 3 , 0 . 5 , 0 . 7, sample of 10 4 . 14 FIG. S5: Clustering functions for different v alues of n and α for the MSM mo del (1) with Stable w eigh ts (S79) . Blue circles: empirical clustering function (4) (versus the reduced degree a = k / √ n ) computed on actual realized graphs sampled from the mo del (obtained by sampling the weigh ts once, and sampling the graph once conditionally on the realized weigh ts). Red curves: our analytical expression (6) for the annealed clustering function. Green curves: our asymptotic calculation (8) v alid for div erging reduced degrees. W e ev aluate and plot all functions only for degrees larger than 1, to a void am biguities in the definition of the clustering co efficient for k < 2. F rom top to b ottom: n = 10 2 , 10 3 , 10 4 . F rom left to righ t: α = 0 . 3 , 0 . 5 , 0 . 7. 15 FIG. S6: Av erage lo cal clustering co efficien t C and distance to r 0 / 1 v ersus net w ork size n , with w eights dra wn from a Stable distribution (for α = 0 . 3 ). On the left, simulations are done b y resampling weigh ts every time an actual netw ork is realized (sample of 10), while on the left for each n weigh ts are extracted only once, and 10 different adjacency matrices are realized from the same weigh ts. On top w e show the node-av eraged lo cal clustering co efficient C , b oth including (blue symbols) and excluding (purple symbols) no des with degree k = 0 , 1 (note that the latter ev olv es smo othly tow ards 1 with shrinking error bars as n increases, while the former fluctuates with non-v anishing error bars, as a result of non-self-av eraging). The dashed blue line is 1 minus the a verage of r 0 / 1 o ver realizations. Finally , in green the difference betw een 1 − r 0 / 1 and C computed including no des with k < 2 (notice the shrinking error bars). In the middle, the light blue line with e rror bars is the actual v alue of r 0 , while the dashed darker one is the approximation we deriv e in (S68). A t the b ottom, the ligh t red line with error bars is the actual v alue of r 1 , while the dashed dark er one is the approximation w e derive in (S72). 16 FIG. S7: Av erage lo cal clustering co efficien t C and distance to r 0 / 1 v ersus net w ork size n , with w eights dra wn from a Stable distribution (for α = 0 . 5 ). On the left, simulations are done b y resampling weigh ts every time an actual netw ork is realized (sample of 10), while on the left for each n weigh ts are extracted only once, and 10 different adjacency matrices are realized from the same weigh ts. On top w e show the node-av eraged lo cal clustering co efficient C , b oth including (blue symbols) and excluding (purple symbols) no des with degree k = 0 , 1 (note that the latter ev olv es smo othly tow ards 1 with shrinking error bars as n increases, while the former fluctuates with non-v anishing error bars, as a result of non-self-av eraging). The dashed blue line is 1 minus the a verage of r 0 / 1 o ver realizations. Finally , in green the difference betw een 1 − r 0 / 1 and C computed including no des with k < 2 (notice the shrinking error bars). In the middle, the light blue line with e rror bars is the actual v alue of r 0 , while the dashed darker one is the approximation we deriv e in (S68). A t the b ottom, the ligh t red line with error bars is the actual v alue of r 1 , while the dashed dark er one is the approximation w e derive in (S72). 17 FIG. S8: Av erage lo cal clustering co efficien t C and distance to r 0 / 1 v ersus net w ork size n , with w eights dra wn from a Stable distribution (for α = 0 . 7 ). On the left, simulations are done b y resampling weigh ts every time an actual netw ork is realized (sample of 10), while on the left for each n weigh ts are extracted only once, and 10 different adjacency matrices are realized from the same weigh ts. On top w e show the node-av eraged lo cal clustering co efficient C , b oth including (blue symbols) and excluding (purple symbols) no des with degree k = 0 , 1 (note that the latter ev olv es smo othly tow ards 1 with shrinking error bars as n increases, while the former fluctuates with non-v anishing error bars, as a result of non-self-av eraging). The dashed blue line is 1 minus the a verage of r 0 / 1 o ver realizations. Finally , in green the difference betw een 1 − r 0 / 1 and C computed including no des with k < 2 (notice the shrinking error bars). In the middle, the light blue line with e rror bars is the actual v alue of r 0 , while the dashed darker one is the approximation we deriv e in (S68). A t the b ottom, the ligh t red line with error bars is the actual v alue of r 1 , while the dashed dark er one is the approximation w e derive in (S72).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment