Forecasting and Manipulating the Forecasts of Others
When actions reshape opponents' signals, each agent's optimal response depends on an infinite hierarchy of beliefs about beliefs (Townsend, 1983) that has resisted exact analysis for four decades. We provide the first exact equilibrium characterizati…
Authors: Sam Babichenko
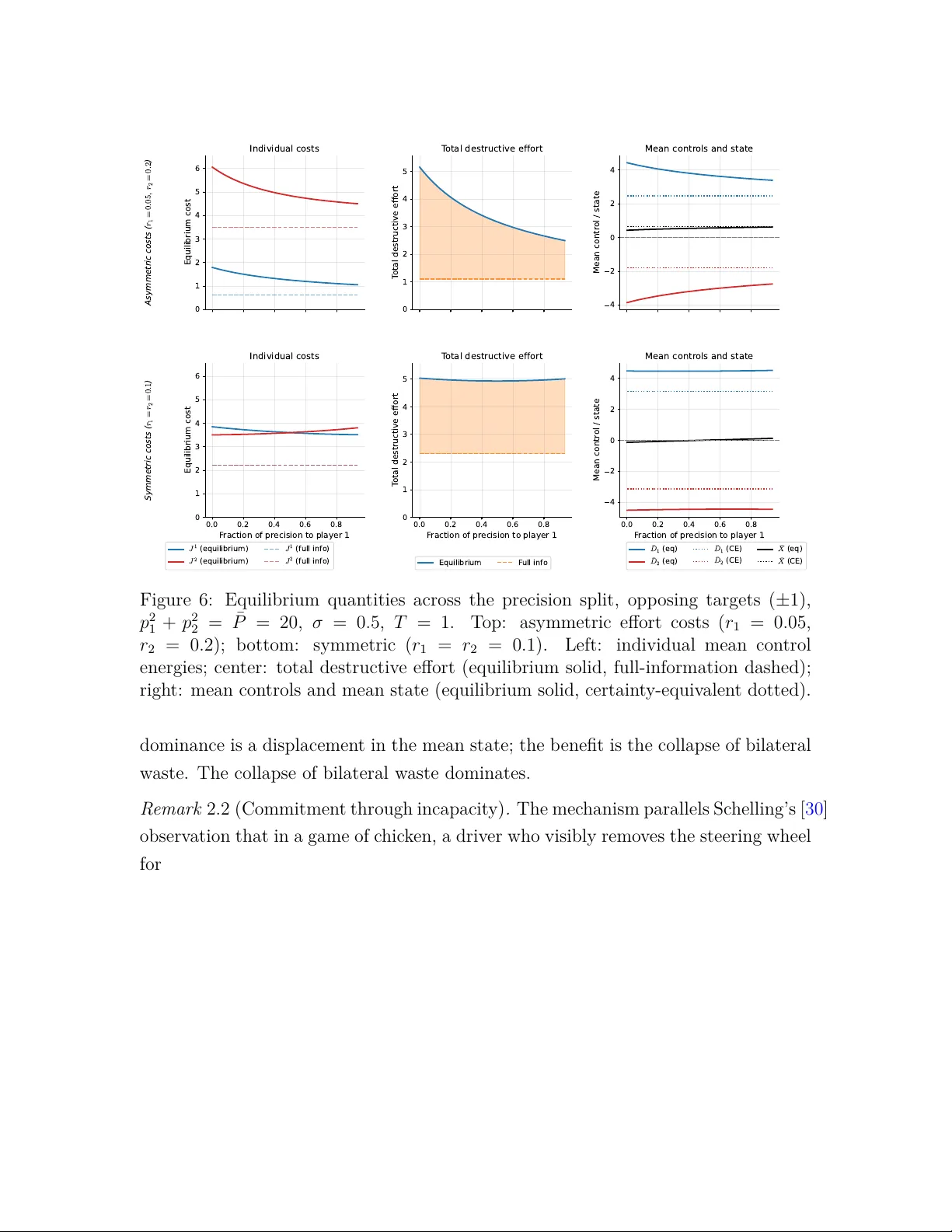
F orecasting and Manipulating the F orecasts of Others Sam Babic henk o ∗ Abstract When actions reshap e opp onen ts’ signals, each agen t’s optimal resp onse de- p ends on an infinite hierarch y of b eliefs ab out b eliefs (T o wnsend, 1983) that has resisted exact analysis for four decades. W e pro vide the first exact equilib- rium characterization of finite-play er contin uous-time linear–quadratic games with endogenous signals. Estimating primitive sho c ks rather than the state collapses the b elief hierarc h y on to deterministic impulse-resp onse maps, reduc- ing Nash equilibrium to a deterministic fixed p oin t with no truncation and no large-p opulation limit. The characterization yields an information wedge pric- ing the marginal v alue of shifting opp onen ts’ p osteriors; it v anishes precisely when signals are exogenous. In a t w o-play er benchmark, nearly all w elfare gains from po oling information come from eliminating bilateral b elief manipulation rather than from improving state estimation. This strategic c hannel also gov- erns optimal precision allo cation: a planner should concen trate information on the efficien t play er, since arming the inefficien t pla y er maximizes the arms race while starving them of information collapses it. 1 In tro duction Dynamic games with disp ersed priv ate information perv ade economics: firms in- fer competitors’ pricing from mark et outcomes, traders learn from the order flow ∗ Departmen t of Statistics and Applied Probabilit y , South Hall, Univ ersity of California, Santa Barbara, CA 93106, USA. E-mail: sam@sb abichenko.c om . I am grateful to my advisor T omo yuki Ic hiba for guidance and supp ort throughout this pro ject. I thank Javier Birc henall for v aluable discussions on the economic applications. Thiha Aung, Olivier Mulkin, Y an Lashchev, and Daniel Na ylor provided encouragemen t and companionship throughout m y do ctoral studies. Replication co de is a v ailable at https://github.com/sbabichenko/Noise- State- Games . 1 their own trades generate, central banks know their announcements reshap e priv ate agen ts’ signals. In eac h setting, actions feed back in to the information environ- men t, generating an infinite hierarc h y of b eliefs that T o wnsend [ 32 ] iden tified and Sargen t [ 29 ] show ed resists finite-dimensional analysis even in linear–Gaussian en- vironmen ts. Bergemann and Morris [ 5 ] identify dynamic decen tralized information design as a central op en problem. F our decades after T o wnsend, this pap er resolves the hierarch y: estimating primitiv e sho cks rather than the state collapses the in- finite regress on to deterministic impulse-resp onse maps, reducing Nash equilibrium to a deterministic fixed p oint. No truncation or large-p opulation limit is needed: a researc her who sp ecifies pa yoffs, a state equation, and a signal structure gets bac k equilibrium impulse-resp onse functions; the b elief hierarch y is handled internally . The conceptual mo ve parallels Harsan yi’s [ 12 ] resolution of the b elief hierarch y in incomplete-information games: just as a common prior o ver a type space closes the static regress, the common probabilit y space of primitiv e sho c ks closes the dynamic one, with all higher-order conditional exp ectations follo wing by linear projection onto deterministic impulse-resp onse maps. The difference is that Harsanyi’s types are dra wn once while noise unfolds contin uously and actions reshap e signals, so the closure requires a fixed p oint: the maps go v erning b elief up dating must b e consistent with the strategy profile they induce (Section 4 ). The resolution pro duces a new ob ject—the information we dge V i t —that prices the marginal v alue of shifting opp onen ts’ p osteriors. If play er i increases effort by a small amoun t, the state drifts, opp onen t k ’s signal c hanges, k revises their p osterior and adjusts their action, and the wedge is the presen t v alue of that en tire chain. It v anishes precisely when signals do not dep end on actions, delineating the b oundary where strategic b elief manipulation matters. The wedge organizes four findings, ordered b y their economic con tent. W elfare decomp osition. In a t wo-pla y er game with opp osing targets, the simplest setting exhibiting the full bilateral externality , nearly all w elfare gains from p o oling information come from eliminating the c hannel b y which agents manipulate each other’s p osteriors, not from improving state estimation (Section 2 ). The estimation b enefit of p o oling is identical whether agents co op erate or comp ete; the order-of- magnitude difference isolates the strategic externalit y . 2 Information starv ation. Allo wing asymmetric effort costs, optimal precision al- lo cation under comp etition is sharply asymmetric and in the opp osite direction from what strategic in tuition suggests. One might exp ect a planner to balance precision to limit manipulation—concentrating information arms the efficient pla yer, so strate- gic restraint should push to w ard equalit y . Instead, concentrating information on the efficien t pla y er c ol lapses the arms race, while shifting it tow ard the inefficient pla yer maximizes bilateral w aste (Section 2.5 ). Separation failure. Certain ty equiv alence fails: with multiple agents and endoge- nous signals, impro ving one pla yer’s information c hanges their p olicy rule itself, not merely their state estimate, b ecause the optimal action dep ends on what opp onen ts ha v e and hav e not learned. In any p olicy ev aluation exercise—central bank trans- parency , disclosure regulation, market structure reform—the information structure cannot b e treated as a parameter that shifts b eliefs while leaving decision rules fixed; the w edge couples the t w o, and the equilibrium m ust b e recomputed. The obstruction arises wherever actions en ter the state and signals are not fully revealing—the regime Grossman and Stiglitz [ 10 ] show ed is generic when information acquisition is costly . Exogenous-signal reduction. Any mo del that treats signals as exogenous, in- cluding mean-field limits, frequency-domain solutions with fixed sp ectral densities, and team-theoretic b enc hmarks, is implicitly assuming aw a y the strategic c hannel that drives the first three findings. The wedge mak es this precise: when con trols do not enter the state dynamics, V i t ≡ 0 for all i and t , and the equilibrium reduces to n indep enden t single-agen t LQG problems against a common exogenous state (Corol- lary 4.3 ). Section 2 previews the economic consequences in a tw o-pla y er game; Section 4 dev elops the general theory . 1.1 Related Literature The join t determination of filtering and equilibrium has been approac hed from sev eral directions; eac h ac hiev es tractability by restricting or remo ving the informational externalit y that the presen t pap er resolv es exactly . 3 Higher-order exp ectations and the social v alue of information. The infinite regress of “forecasting the forecasts of others” w as iden tified by T o wnsend [ 32 ] and sho wn b y Sargent [ 29 ] to resist finite-dimensional recursive analysis even in linear– Gaussian en vironmen ts. Morris and Shin [ 23 ] demonstrated that the so cial v alue of public information can b e negativ e when agents ov erweigh t common signals; Angele- tos and P av an [ 1 ] characterized the efficient use of information in static co ordination games, sho wing that w elfare losses dep end on the gap b et w een equilibrium and so- cially optimal degrees of co ordination. W o o dford [ 34 ] sho wed that imperfect common kno wledge generates p ersisten t real effects of monetary p olicy through higher-order exp ectations, with the infinite hierarch y truncated by assuming exogenous priv ate signals. Section 2 pro vides a dynamic coun terpart: the information w edge V i t prices the strategic channel through which actions reshap e beliefs, and nearly all welfare gains from p o oling come from eliminating this c hannel rather than from impro ving state estimation. F requency-domain metho ds and exogenous-signal mo dels. A substan tial lit- erature solves disp ersed-information mo dels in the frequency domain [ 11 , 16 , 27 ], culminating in Huo and T aka y ama [ 14 ], who obtain finite-state represen tations for equilibrium aggregates under exogenous ARMA signals. These metho ds succeed b e- cause the filtering environmen t is inv arian t to changes in control la ws—the sp ectral factorization can be solv ed indep enden tly of the p olicy . When con trols en ter the state dynamics, the signal pro cess dep ends on the p olicy , the endogenous-information case that Huo and T akay ama [ 14 ] show cannot admit a finite-state represen tation in gen- eral. The noise-state technique resolves this case exactly: the b elief hierarc hy collapses on to a deterministic fixed p oint with no finite-state appro ximation required. Common-information approac hes. The common-information approach condi- tions on a shared information base to obtain a recursive reduction [ 24 ]. The approach handles asymmetric information but resolv es it through a co ordinator’s b eliefs; the c hannel b y which play er i ’s action shifts play er k ’s p osterior, which shifts k ’s action, whic h shifts i ’s signal, is not captured. T eam theory . The decen tralized decision problem with shared ob jectives originates with Marschak and Radner [ 22 ]; Radner [ 26 ] established certaint y equiv alence and 4 linear optimal p olicies for Linear–Quadratic–Gaussian (LQG) teams. T eam-theoretic solutions b ypass the b elief hierarch y b ecause a so cial planner with aligned ob jectives solv es a single-agent con trol problem—the fixed-p oint structure never arises. The information w edge V i t displa y ed in Section 2 is an equilibrium ob ject: it prices the v alue of shifting an opp onent’s p osterior, which requires distinct ob jectives to b e w ell-defined. Mean-field LQG games. Mean-field games take large-p opulation limits in which no single agen t’s action measurably affects any other agen t’s signal [ 7 , 13 ]. Car- mona and Delarue [ 8 ] provide a comprehensive t w o-v olume treatment including LQG sp ecifications with common noise. The bilateral informational externality is absent b y construction in the mean-field limit; the information wedge V i t of Section 2 is a finite- n ob ject that v anishes in an y limit where individual actions b ecome negligible. T runcation of the b elief hierarch y . Nimark [ 25 ] approximates the higher-order b elief hierarch y b y truncation at finite order—the closest existing metho d in spirit to the presen t pap er. The deterministic impulse-resp onse system deriv ed here provides an exact b enc hmark against which truncation error can b e assessed. Applied contin uous-time filtering games. Kyle [ 18 ], Bac k [ 3 ], and F oster and Visw anathan [ 9 ] solve strategic trading problems with priv ate information, each ex- ploiting sp ecial structure (a single informed trader, correlated-signal symmetry) to close the b elief hierarch y through mo del-sp ecific conjectures. Sannik o v [ 28 ] solv es a con tin uous-time principal–agent problem by sho wing that the agent’s con tin uation v alue serv es as a sufficien t statistic for the principal’s problem, yielding a recursiv e c haracterization despite the agent’s priv ate action. The technique relies on the bilat- eral structure: the principal observes output directly , so the agen t’s deviation c hanges her pa yoff but not her p osterior, and the w edge V i t is absen t. With multiple agents exerting unobserv able effort on a shared outcome, eac h agen t infers others’ effort from the shared output, the noise-state path replaces the scalar contin uation v alue, and the b elief hierarch y reapp ears. The present pap er provides a general framework that nests these as special cases: in the Kyle–Bac k em b edding (Section 5 ), the information w edge corresp onds to the strategic comp onen t of price impact, and the characteriza- tion extends to m ulti-trader settings where guess-and-v erify breaks do wn. 5 Rational inattention. Sims [ 31 ] in tro duced rational inatten tion; Ma ´ ck o wiak and Wiederholt [ 20 ] sho w ed that firms optimally attend to idiosyncratic ov er aggregate conditions, generating sluggish price adjustmen t (see Ma ´ ck ow iak, Ma ´ tejka, and Wieder- holt [ 21 ] for a survey). These mo dels take the strategic environmen t as giv en when solving the atten tion problem; the first-order conditions derived here (Section D.3 ) extend the framework to settings where the marginal v alue of precision dep ends on the equilibrium through the information w edge. Information design. Kamenica and Gentzk ow [ 15 ] established Bay esian p ersua- sion; Bergemann and Morris [ 4 , 5 ] in tro duced Bay es correlated equilibrium and sur- v ey the field, identifying dynamic decentralized settings as a cen tral op en problem. Viv es [ 33 ] develops the in terpla y b et w een information acquisition and comp etition in financial markets that the Kyle–Back em b edding of Section 5 op erationalizes dynam- ically . Bergemann, Heumann, and Morris [ 6 ] pro vide precision comparativ e statics in static co ordination games where the effect of signal precision on pay offs admits direct analysis; dynamically , the information wedge couples the v alue of precision to the equilibrium, so that filtering and control no longer separate. The equilibrium c haracterization derived here (Section 4 ) pro vides the mapping from signal structures to equilibrium outcomes that dynamic information design requires as an input. 2 Bilateral b elief manipulation in a t w o-pla y er game Before dev eloping the general framew ork, we display its consequences in the sim- plest game exhibiting the full bilateral externality: t wo symmetric pla y ers with scalar state, opp osing targets, and equal signal precision. Neither pla yer observ es the state directly; eac h receives a priv ate diffusion signal whose precision p > 0 is common kno wledge. Eac h pla yer’s con trol en ters the state dynamics and reshap es the op- p onen t’s signal, generating the bilateral informational externality of T o wnsend [ 32 ]. The general theory (Sections 3 – 4 ) collapses this hierarch y onto deterministic impulse- resp onse maps and pro duces an ob ject, the information we dge V i t , that prices the marginal v alue of shifting the opp onen t’s p osterior. 6 Primitiv e sho c ks W 0 (fundamen tal), W 1 , W 2 (signal noise) Priv ate signal Y 1 t (precision p ) State / fundamental X t Priv ate signal Y 2 t (precision p ) Filter / b elief c W 1 t ( · ) A ctions D i t = ¯ D i t + R t 0 D i t ( u ) d u c W i t ( u ) Filter / b elief c W 2 t ( · ) Figure 1: Information-to-action feedback in the w orked example. Actions mov e X t and shift opp onen ts’ b eliefs, so equilibrium mean actions dep end on precision p . 2.1 Primitiv es and ob jectiv es Fix a horizon [0 , T ]. The state X t ∈ R satisfies dX t = D 1 t + D 2 t dt + dW 0 t , X 0 = x 0 , (2.1) where W 0 is a standard Bro wnian motion. Play er i ∈ { 1 , 2 } do es not observe X directly; instead they observ e the priv ate diffusion channel d Y 1 t = √ p X t dt + dW 1 t , d Y 2 t = √ p X t dt + dW 2 t , (2.2) with ( W 0 , W 1 , W 2 ) mutually indep enden t. Play er i c ho oses D i adapted to their priv ate observ ation history F i t = σ ( Y i s : s ≤ t ). R unning costs are symmetric tracking losses with quadratic effort p enalty r > 0: J 1 ( D 1 ; D 2 ) = E Z T 0 ( X t − 1) 2 + r ( D 1 t ) 2 dt, J 2 ( D 2 ; D 1 ) = E Z T 0 ( X t +1) 2 + r ( D 2 t ) 2 dt. (2.3) Pla y er 1 wan ts the state near +1; pla yer 2 w an ts it near − 1. There is no terminal cost in this work ed example. The mo del is in v ariant under the sign/lab el symmetry ( X , Y 1 , Y 2 , D 1 , D 2 ) 7→ ( − X, Y 2 , Y 1 , − D 2 , − D 1 ). 2.2 What the general theory deliv ers The equilibrium c haracterization dev elop ed in Sections 3 – 4 pro duces three ob jects that organize the analysis of this game; w e describ e them informally here and derive them in full generalit y b elow. 7 Noise-state and linear strategies. All randomness originates in the three prim- itiv e Brownian motions W = ( W 0 , W 1 , W 2 ). Pla y er i ’s noise-state c W i t ( u ) := E [ W u | F i t ] (0 ≤ u ≤ t ) is the running conditional mean of the en tire primitive noise path. In equilibrium, eac h pla y er’s con trol tak es the form D i t = ¯ D i t + Z t 0 D i t ( u ) d u c W i t ( u ) , (2.4) where ¯ D i t is a deterministic mean action and D i t ( u ) is a deterministic impulse-response k ernel gov erning how play er i ’s action at time t resp onds to news ab out the u -th sho c k. The key structural result (Corollary 4.5 ) is that the b est resp onse to an y such strategy profile, o ver all admissible controls, is itself of this form—so equilibrium reduces to a deterministic fixed p oin t in the maps ( ¯ D i , D i ). Unresolv ed impulse resp onse. The state’s impulse resp onse to the u -th sho ck decomp oses in to what play er i has learned and what remains hidden: X t ( u ) = c X i t ( u ) + f X i t ( u ). The unresolved comp onen t f X i t ( u ) is the p ortion of the u -th sho c k’s effect on the state that play er i has not yet resolv ed—large when the sho ck is recen t or precision lo w, shrinking as observ ations accum ulate. It serves as the Kalman gain in the noise- state up date (Theorem 4.1 ). Information w edge. In the single-agen t problem, the backw ard equation for the costate (the shadow v alue of the state) is standard. With tw o agents and endogenous signals, a new term app ears: the information we dge ¯ V 1 t = P 2 ( t ) Z t 0 f X 2 t ( z ) · ¯ H 2 t ( z ) dz , (2.5) where f X 2 t ( z ) is the unresolv ed comp onent of the state’s resp onse to the z -th sho c k from pla y er 2’s p erspective and ¯ H 2 t ( z ) is the mean b elief adjoint —the shadow v alue to play er 1 of ha ving shifted play er 2’s estimate of the z -th sho ck (Theorem 4.2 ). The w edge enters the mean costate equation as d dt ¯ H X t = − ( ¯ X t − 1) − ¯ V 1 t , distorting mean actions relative to the single-agent b enc hmark. 8 2.3 Computation Equilibrium is computed by iterating the b est-resp onse op erator on the deterministic impulse-resp onse system (Section 4 ), discretized on a uniform grid of N = 40 p oin ts; no Mon te Carlo simulation is needed. Parameters: T = 1, x 0 = 0, r = 0 . 1, no terminal cost. The Picard residual reaches 10 − 5 in 19 iterations ( ≈ 10 ms in C++), deca ying geometrically . 1 A t longer horizons the binding constraint is numerical resolution (the filtering kernel dev elops near-singularities) rather than economic. 2.4 Mean actions, separation failure, and the w elfare cost of b elief manipulation Since the sto chastic integral in ( 2.4 ) has zero unconditional mean, E [ D i t ] = ¯ D i t iso- lates the deterministic tug-of-war ov er the target ± 1, while the kernel term captures impulse resp onses to p osterior sho c ks. Separation failure. Under p erfect information, the mean p olicy is indep enden t of signal precision. Decentralized information breaks this: precision c hanges the sp eed of opp onents’ up dating, creating an incen tive to act on p osteriors rather than on the state. The mechanism is the information w edge ( 2.5 ): it couples the costate to the unresolv ed kernel f X 2 t ( z ) through the b elief adjoin t, introducing a dep endence of the equilibrium p olicy on precision that is absen t in the single-agent problem. More precisely , in the single-agen t case the p olicy kernel factors as D i t ( u ) = S ( t ) · X t ( u ) for a scalar Riccati gain S ( t ) indep endent of signal precision. With t w o agen ts, the w edge prev en ts this factorization: c hanging p changes the unresolv ed k ernel, which c hanges the b elief adjoint, which c hanges the p olicy kernel indep enden tly of the state estimate (Prop osition 4.6 ). The w edge across precision asymmetries. Figures 3 – 4 display the information w edge and its consequences when play er 1’s precision is fixed at p 1 = 3 and play er 2’s precision p 2 v aries. Information p o oling as a Pigouvian in terv en tion. Figure 5 compares equilib- rium costs under priv ate signals with those under a p o oled signal of precision P 1 + P 2 , 1 An interactiv e bro wser visualization is av ailable at https://sbabichenko.com/lqg . 9 0.0 0.2 0.4 0.6 0.8 1.0 t 0 2 4 6 8 ¯ D 1 ( t ) P l a y e r 1 m e a n c o n t r o l p a t h ¯ D 1 ( t ) v s p e r f e c t i n f o ( c o l o r = p ) p = 1 p = 2 p = 3 p = 5 p = 1 0 P erfect info Figure 2: Equilibrium mean con trol ¯ D 1 t as a function of signal precision p , with the p erfect-information b enc hmark (dashed). Low precision makes opp onen ts’ p osteriors sluggish, amplifying the incen tiv e to manipulate b eliefs; as p → ∞ the mean p olicy con v erges to the p erfect-information limit. 0.0 0.2 0.4 0.6 0.8 1.0 t 6 4 2 0 2 4 6 8 ¯ D i ( t ) Mean contr ols ¯ D 1 ( s o l i d ) ¯ D 2 ( d a s h e d ) 0.0 0.2 0.4 0.6 0.8 1.0 t 0.2 0.1 0.0 0.1 0.2 ¯ X ( t ) Mean state path p 2 = 1 p 2 = 2 p 2 = 3 p 2 = 5 p 2 = 1 0 p 2 = 2 0 0.0 0.2 0.4 0.6 0.8 1.0 t 0 2 4 6 8 10 12 14 | ¯ D 1 | + | ¯ D 2 | Aggr egate mean effort P erfect info 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 p 2 A s y m m e t r i c e q u i l i b r i u m : p 1 = 3 f i x e d , p 2 v a r i e s ( r = 0 . 1 , T = 1 ) Figure 3: Asymmetric equilibrium with p 1 = 3 fixed and p 2 v arying. Left: mean con trols ¯ D 1 t (solid) and ¯ D 2 t (dashed) diverge as the precision gap widens. Center: the mean state path ¯ X t tilts to w ard the b etter-informed pla yer’s target. Right: aggregate mean effort | ¯ D 1 | + | ¯ D 2 | exceeds the p erfect-information b enc hmark (gra y dashed), with the excess gro wing in the precision asymmetry . for b oth comp etitive (opp osing targets ± 1) and co op erativ e (common target 0) sp ec- ifications. P o oling is P areto-impro ving in b oth cases, but the gains differ by an order of magnitude: roughly 0 . 02–0 . 05 under co op eration v ersus 0 . 3–0 . 5 under comp etition. Since the estimation b enefit of po oling enters iden tically regardless of the target struc- ture, the difference isolates the strategic externality channel priced by V i t : nearly all of the welfare gain from mandatory disclosure comes from eliminating bilateral b elief manipulation, not from impro ving state estimation. R emark 2.1 (Impulse resp onses do not dep end on targets) . The equilibrium impulse- 10 0.0 0.2 0.4 0.6 0.8 1.0 t 0.0 0.2 0.4 0.6 0.8 1.0 1.2 V 1 ( t ) P l a y e r 1 w e d g e V 1 ( t ) p 2 = 1 p 2 = 2 p 2 = 3 p 2 = 5 p 2 = 1 0 p 2 = 2 0 0.0 0.2 0.4 0.6 0.8 1.0 t 1.0 0.8 0.6 0.4 0.2 0.0 V 2 ( t ) P l a y e r 2 w e d g e V 2 ( t ) p 2 = 1 p 2 = 2 p 2 = 3 p 2 = 5 p 2 = 1 0 p 2 = 2 0 I n f o r m a t i o n w e d g e s ( p 1 = 3 f i x e d , p 2 v a r i e s ) Figure 4: Mean information wedges ¯ V 1 t and ¯ V 2 t as p 2 v aries ( p 1 = 3 fixed). Both w edges are hump-shaped in t , confirming that b elief manipulation is most v aluable at intermediate dates. Increasing the opp onen t’s precision amplifies the wedge: a b etter-informed opp onen t reacts more sharply to drift, raising the marginal v alue of manipulating their p osterior. The wedges v anish at the terminal date, consisten t with the zero terminal condition on the b elief adjoin t. resp onse maps—how play ers resp ond to sho c ks—do not dep end on the targets ± 1. All filtering ob jects, unresolved comp onents, and p olicy resp onse maps are identical whether pla yers co op erate or comp ete; only the deterministic tug-of-war o v er mean actions sees the strategic structure, through the information w edge. 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 p 2 2.6 2.8 3.0 3.2 3.4 3.6 3.8 Cost C o m p e t i t i v e ( θ = ± 1 ) J 1 p r i v a t e J 1 p o o l e d J 2 p r i v a t e J 2 p o o l e d 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 p 2 0.225 0.250 0.275 0.300 0.325 0.350 0.375 Cost C o o p e r a t i v e ( θ = 0 , 0 ) J 1 p r i v a t e J 1 p o o l e d J 2 p r i v a t e J 2 p o o l e d E q u i l i b r i u m c o s t s : p r i v a t e v s p o o l e d ( p 1 = 3 , r = 0 . 1 ) Figure 5: Equilibrium costs under priv ate signals (dashed) and p o oled signals (solid) with p 1 = 3 fixed and p 2 v arying. Left: opp osing targets ( ± 1). Right: common target (0). P o oling is P areto-improving in b oth cases, but the gain is an order of magnitude larger under comp etition, where it eliminates the bilateral b elief-manipulation exter- nalit y priced by V i t . Blue: play er 1; red: play er 2. 11 2.5 Optimal precision allo cation Information p o oling is a blunt instrument: it merges all signals into a common c han- nel, eliminating some of the bilateral externality but forecloses targeted allocation. Giv en a fixed precision budget, how should a planner distribute it b etw een the t w o pla y ers? Setup. Retain the state dynamics ( 2.1 ) and observ ation channels ( 2.2 ) with opp os- ing targets ( ± 1), but allow asymmetric precisions ( p 1 , p 2 ) sub ject to p 2 1 + p 2 2 = ¯ P and asymmetric effort costs ( r 1 , r 2 ) with r 1 < r 2 , so that play er 1 is the more efficient mo v er of the state. The quadratic budget reflects diminishing returns to concen tra- tion. A planner c ho oses the split to minimize aggregate equilibrium cost; for each candidate allo cation we solv e the full equilibrium via Picard iteration. P arameters: ¯ P = 20, T = 1, with the fundamen tal volatilit y in ( 2.1 ) reduced to σ = 0 . 5. What one migh t exp ect. Under co op eration the answer is straigh tforw ard: giv e precision to the efficient play er, p erhaps sharing some to ease the inefficient play er’s burden. Under comp etition, concen trating precision arms the efficien t play er to pull the state tow ard their target, so one migh t exp ect the planner to comp ensate by bal- ancing precision to limit manipulation. The presumed tradeoff is pro ductiv e efficiency v ersus strategic restraint. Information starv ation. The tradeoff is real but the strategic-restrain t side is far weak er than exp ected (Figure 6 , top row, r 1 = 0 . 05, r 2 = 0 . 2). Concen trating all precision on the efficient play er do es shift the mean state further from zero, but the effect on total effort dominates: destructiv e effort drops by nearly half. The pro ductiv e-efficiency and strategic-restraint c hannels p oint in the same direction: the presumed tradeoff do es not exist. The mec hanism is information starvation : denying the inefficient pla y er signal access collapses their abilit y to exert mean control (top left panel: pla y er 2’s effort falls to near zero). With play er 2 largely neutralized, play er 1 has less reason to manipulate as w ell, and b oth pla y ers’ effort falls. Conv ersely , giving all precision to the inefficient pla yer pro duces the w orst outcome: the cheap mo v er pushes hard against a well-informed opp onent who retaliates sharply , maximizing bilateral w aste. The planner’s optimal resp onse is not to balance information but to create an information monop oly for the efficien t play er. The cost of one-sided 12 0 1 2 3 4 5 6 Equilibrium cost A s y m m e t r i c c o s t s ( r 1 = 0 . 0 5 , r 2 = 0 . 2 ) Individual costs 0 1 2 3 4 5 T otal destructive effort T otal destructive effort 4 2 0 2 4 Mean contr ol / state Mean contr ols and state 0.0 0.2 0.4 0.6 0.8 F raction of pr ecision to player 1 0 1 2 3 4 5 6 Equilibrium cost S y m m e t r i c c o s t s ( r 1 = r 2 = 0 . 1 ) Individual costs 0.0 0.2 0.4 0.6 0.8 F raction of pr ecision to player 1 0 1 2 3 4 5 T otal destructive effort T otal destructive effort 0.0 0.2 0.4 0.6 0.8 F raction of pr ecision to player 1 4 2 0 2 4 Mean contr ol / state Mean contr ols and state J 1 ( e q u i l i b r i u m ) J 2 ( e q u i l i b r i u m ) J 1 ( f u l l i n f o ) J 2 ( f u l l i n f o ) Equilibrium F ull info ¯ D 1 ( e q ) ¯ D 2 ( e q ) ¯ D 1 ( C E ) ¯ D 2 ( C E ) ¯ X ( e q ) ¯ X ( C E ) Figure 6: Equilibrium quantities across the precision split, opp osing targets ( ± 1), p 2 1 + p 2 2 = ¯ P = 20, σ = 0 . 5, T = 1. T op: asymmetric effort costs ( r 1 = 0 . 05, r 2 = 0 . 2); b ottom: symmetric ( r 1 = r 2 = 0 . 1). Left: individual mean con trol energies; center: total destructiv e effort (equilibrium solid, full-information dashed); righ t: mean con trols and mean state (equilibrium solid, certaint y-equiv alen t dotted). dominance is a displacemen t in the mean state; the b enefit is the collapse of bilateral w aste. The collapse of bilateral w aste dominates. R emark 2.2 (Commitment through incapacity) . The mec hanism parallels Sche lling’s [ 30 ] observ ation that in a game of c hick en, a driv er who visibly remo v es the steering wheel forces the opp onen t to sw erve. Here precision is common knowledge and enters the equilibrium through deterministic k ernels, so denying the inefficien t play er signal ac- cess is a credible and observ able disarmament: b oth play ers b enefit not from c hosen restrain t but from one side’s visible inabilit y to figh t. Separation failure in a picture. The righ t panels display separation failure di- rectly: certain ty-equiv alent mean con trols (dotted) are inv ariant to the precision split, while equilibrium mean controls (solid) slop e with the allo cation through the b elief adjoin ts. Under symmetric effort costs (bottom row) the pattern is symmetric around 13 the equal split, confirming that the asymmetry ab o v e is driven by cost differences in- teracting with the information channel. 3 The Decen tralized LQG Game Informal description of the game. The games w e study hav e three features: (i) m ultiple agents share a common ev olving state but observe it through priv ate noisy c hannels; (ii) eac h agent’s action feeds back into the state dynamics and thereb y in to every other agent’s signal pro cess; and (iii) agents minimize individual quadratic ob jectiv es o ver a finite horizon. F eatures (i)–(ii) generate the infinite b elief hierar- c h y iden tified by T ownsend; feature (iii) pro vides the linear–Gaussian structure that mak es it tractable. 3.1 State dynamics and ob jectiv es Consider n play ers in teracting o v er a finite time horizon [ 0 , T ] on a filtered probabilit y space (Ω , F , F , P ). State dynamics. The state X t ∈ R d ev olv es as dX t = A ( t ) X t + n X i =1 D i t dt + Σ( t ) dW 0 t , X 0 = x 0 , (3.1) where A ( t ) ∈ R d × d is deterministic and b ounded, W 0 is a d -dimensional Brownian motion, Σ( t ) ∈ R d × d is deterministic and b ounded, and D i t ∈ R d is play er i ’s control. R emark 3.1 (Con trol matrices and dimensions) . All results extend to D i t = B i ( t ) U i t with control U i t b y appropriately mo difying the cost function and first order condi- tions. Ob jectiv es. The linear state-cost co efficien t G X,i t = ¯ G X,i t + R t 0 G X,i t ( r ) dW r is a sto c hastic pro cess with deterministic mean ¯ G X,i t ∈ R d and deterministic k ernel G X,i t ( r ) ∈ R d × ( n +1) d ; deterministic co efficients are the sp ecial case G X,i t ( r ) ≡ 0. Each pla y er i 14 incurs the random cost C i ( D i ; D − i ) := Z T 0 X ⊤ t G X X ,i ( t ) X t + 2( G X,i t ) ⊤ X t + G i ( t ) + ( D i t ) ⊤ G DD ,i ( t ) D i t dt + X ⊤ T G X X ,i ( T ) X T + 2( G X,i T ) ⊤ X T , (3.2) where G X X ,i ( t ) and G DD ,i ( t ) are symmetric p ositive semidefinite matrices (with G DD ,i ( t ) p ositiv e definite), and D − i := ( D j ) j = i denotes opp onents’ con trols. Each play er i seeks to minimize J i ( D i ; D − i ) := E h C i ( D i ; D − i ) i . (3.3) Opp onen ts’ con trols en ter play er i ’s cost only through X t , whic h they mov e via ( 3.1 ) and which pla yer i observes through ( 3.4 ). 3.2 Information structure Observ ations. Pla yer i do es not observe X t directly . Eac h play er monitors the ev olving state through priv ate information sources: analyst rep orts, proprietary sen- sors, researc h output, market data feeds. Some sources arrive without cost (publicly p osted prices, mandatory disclosures, direct observ ation of one’s o wn action) while others m ust b e actively acquired or pro cessed. The sources may b e discrete (a finite set of news feeds) or con tinuous (a flow of independent measuremen ts whose aggregate is naturally mo deled by a Bro wnian sheet [ 17 ]). In this pap er we take each play er’s information-pro cessing capacit y as exogenous: the men u of sources and the attention allocated to each are fixed and common kno wl- edge. The observ ation pro cess summarizing the play er’s information ab out the state then takes the form d Y i t = Γ i ( t ) X t dt + E i dW t , Y i 0 = 0 , (3.4) where Γ i ( t ) ∈ R d × d is a deterministic observ ation gain and E i ∈ R d × ( n +1) d is the blo c k selector extracting play er i ’s noise c hannel ( W i t := E i W t ). All Bro wnian mo- tions { W 0 , W 1 , . . . , W n } are mutually indep enden t. The precision matrix P i ( t ) := Γ i ( t ) ⊤ Γ i ( t ) measures the Fisher information rate ab out the state p er unit time; the gain Γ i is the primitiv e, and P i is derived. The blo c k-selector form is without 15 loss: replacing E i b y a general inv ertible noise loading Σ i ( t ) amoun ts to substituting Γ i, ⊤ (Σ i Σ i, ⊤ ) − 1 for Γ i, ⊤ throughout. Notation for primitiv e sho cks. W e collect all primitiv e noises into a single v ector W t := ( W 0 t , . . . , W n t ) ⊤ ∈ R ( n +1) d . The block pro jector Π i := E i, ⊤ E i is the iden tity on the i -th blo ck and zero elsewhere: Π i v = (0 , . . . , 0 , v i , 0 , . . . , 0). The blo ck-selector structure ensures that eac h play er’s observ ation noise is an indep enden t comp onen t of W , giving the noise-state its direct/indirect decomp osition (Theorem 4.1 ): pla y er i (almost) directly observ es Π i W and infers ( I − Π i ) W from drift-based learning. Pla y er i ’s information at time t is their observ ation history , F i t := σ ( Y i s : s ≤ t ). An admissible control is F i t -adapted with E [ R T 0 ∥ D i t ∥ 2 dt ] < ∞ , where ∥ · ∥ denotes the Euclidean norm on R d . Unresolv ed impulse resp onse. F or each pla yer i , define f X i t ( u ) := X t ( u ) − c X i t ( u ) , the comp onent of the state’s impulse resp onse to the u -th sho ck that play er i has not y et resolved at time t —large when the sho ck is recen t or the observ ation c hannel weak, and shrinking as observ ations accum ulate. F ormally , f X i t ( u ) = Cov( X t , dW u | F i t ) /du ; it serv es as the filtering gain in the noise-state update (Theorem 4.1 ), with its explicit form ula in ( A.12 ). Throughout Sections 4 – 5 the gain Γ i ( · ) is fixed; Section 6 discusses the extension to endogenous precision. 3.3 Nash Equilibrium Because each play er’s drift dep ends on opp onents’ estimates c X k t := E [ X t | F k t ], opti- mal actions generate an infinite hierarc hy of conditional exp ectations. The following equilibrium concept fixes opponents’ strategy maps rather than their realized actions, whic h is essential for the closure results in Section 4 . Definition 3.1 (Nash equilibrium in priv ate-signal strategies) . Throughout, a pla y er’s c hoice is a strategy map: for each t ∈ [ 0 , T ], the action D i t is a (progressively measur- able) functional of the priv ate observ ation history Y i ·∧ t . W e write D i t = D i t [ Y i ], where 16 the brack et notation D i t [ · ] denotes the map from the observ ation path ( Y i s ) s ≤ t to the action at time t . W e require E R T 0 ∥ D i t ∥ 2 dt < ∞ . A profile D ∗ = ( D ∗ , 1 , . . . , D ∗ ,n ) is a Nash equilibrium if for ev ery pla yer i and ev ery admissible alternative strategy map f D i [ · ], J i ( D ∗ ,i ; D ∗ , − i ) ≤ J i ( f D i ; D ∗ , − i ) , where the inequality compares the costs induced by the corresp onding strategy pro- files. Equiv alen tly: in a unilateral deviation by i , opp onen ts’ maps are held fixed and are applied to the deviated signal paths. In a unilateral deviation by i , opp onen ts’ strategy maps Y k ·∧ t 7→ D k t [ Y k ] are held fixed and applied to the p erturb ed observ ation histories; in the noise-state linear class these maps ha v e deterministic co efficients that do not c hange when the state path c hanges. Holding opp onents’ strategy maps fixed under deviations (rather than their real- ized actions or b eliefs) is substantiv e here b ecause signals are endogenous: changing one play er’s control law changes the state dynamics, whic h c hanges ev ery opp onent’s signal, filtering problem, and realized action, ev en though their decision rules hav e not changed. This pap er aims to establish that the class of noise-state linear strategies is closed under best resp onses and to deriv e a deterministic impulse-resp onse system whose fixed p oints corresp ond to Nash equilibria in that class. R emark 3.2 (Sub jective equilibrium and p olicy ev aluation) . The best-resp onse closure (Corollary 4.5 ) do es not require pla yer i to kno w opp onen ts’ maps correctly . A policy- mak er can let each agen t optimize under its o wn b eliefs, then ev aluate welfare through the realized state dynamics ( 3.1 ); common kno wledge of rationalit y is sufficien t for Nash equilibrium but not required to apply the characterization as a b est-resp onse op erator. Noise-state. F or eac h play er i and eac h t ∈ [0 , T ], the noise-state encountered informally in Section 2.2 is defined as the conditional mean path of the aggregated primitiv e noise: c W i t ( u ) := E [ W u | F i t ] , 0 ≤ u ≤ t. (3.5) 17 In linear–Gaussian settings, the conditional la w of primitive sho cks is Gaussian with deterministic conditional cov ariance, so c W i t ( · ) is a complete (path-v alued) summary of play er i ’s priv ate information. Definition 3.2 ((Primitive-noise) Linear Pro cess) . An L 2 sto c hastic pro cess L = ( L t ) t ∈ [0 ,T ] is a (primitiv e-noise) Linear pro cess if there exist deterministic functions ¯ L : [0 , T ] → R m , L : [0 , T ] 2 → R m × ( n +1) d , suc h that, for ev ery t ∈ [0 , T ], L t = ¯ L ( t ) + Z t 0 L ( t, s ) dW s , Z t 0 ∥ L ( t, s ) ∥ 2 ds < ∞ . When conv enien t, we extend L ( t, s ) by 0 for s > t . R emark 3.3 (Impulse-resp onse notation) . W e write X t ( s ) for the deterministic impulse resp onse, not the random v ariable X t ev aluated at an argumen t; the sho c k index s distinguishes the t w o. The same subscript- t , parenthetical-shock conv en tion applies to all t wo-time resp onse maps. R emark 3.4 (Prop erties of primitive-noise linear pro cesses) . By construction, primitiv e- noise linear pro cesses are F -adapted Gaussian pro cesses. Moreo v er, by Itˆ o isometry the square-in tegrabilit y condition ab o v e is equiv alent to L t ∈ L 2 for eac h t . By the martingale representation theorem, an y L 2 F t -measurable random v ariable has a sto c hastic integral represen tation against W ; the defining restriction of the linear class is that the in tegrand L ( t, · ) is deterministic. Equiv alen tly , Definition 3.2 is the con tin uous-time analogue of an MA( ∞ ) represen tation: L ( t, s ) pla ys the role of the mo ving-a verage coefficient at lag t − s , with the Itˆ o in tegral replacing the infinite sum against i.i.d. inno v ations. Definition 3.3 (Noise-state Linear con trol / strategy) . Fix a pla yer i and recall their noise-state path c W i t ( · ) ( 3.5 ). An admissible control D i = ( D i t ) t ∈ [0 ,T ] is a noise-state linear con trol if it is affine in the noise state. That is, if there exist deterministic functions ¯ D i : [0 , T ] → R d , D i : [0 , T ] 2 → R d × ( n +1) d , 18 (i) Candidate Opp onen ts use Noise-State Linear controls (ii) Closure State & filters ha ve det. resp onse maps (iii) Deviations Fixed maps ⇒ det. propagation (iv) Best resp onse F OC ⇒ control noise-state linear (v) Fixed p oin t BR map closes ⇐ ⇒ Nash eq. Figure 7: The Noise-State Linear fixed-p oin t lo op. (i) Assume opp onen ts use Noise- state Linear con trols. (ii) The state and filtering equations ha v e deterministic impulse resp onses. (iii) Under fixed strategy maps, unobserved deviations propagate deter- ministically . (iv) The maximum principle pro duces a b est resp onse that is itself noise-state linear, closing the lo op. (v) A fixed p oint of this b est-resp onse map is a Nash equilibrium. suc h that, for ev ery t ∈ [0 , T ], D i t = ¯ D i t + Z t 0 D i t ( u ) d u c W i t ( u ) , Z t 0 ∥ D i t ( u ) ∥ 2 du < ∞ , and we extend D i t ( u ) by 0 for u > t . Equiv alently , this defines the strategy map Y i ·∧ t 7− → D i t [ Y i ] := ¯ D i t + Z t 0 D i t ( u ) d u c W i t [ Y i ]( u ) . 4 Main results This section deriv es the ob jects preview ed in Section 2 in the general n -pla yer mo del of Section 3 . The strategy is analogous to Harsanyi’s [ 12 ]: just as a common prior o v er a t yp e space closes the b elief hierarch y in static incomplete-information games, the common probabilit y space of primitiv e sho cks W = ( W 0 , . . . , W n ) closes it here, with all higher-order conditional exp ectations following by linear projection onto deterministic impulse-resp onse maps. The difference is that Harsanyi’s types are drawn once while noise unfolds contin uously and actions reshap e signals, so the closure requires a fixed p oin t: the maps go v erning b elief updating m ust be consisten t with the strategy profile they induce (Figure 7 ). 19 Filtering closure. Recall the noise-state c W i t ( · ) ( 3.5 ). W e record the deterministic- k ernel represen tation of the estimated-noise increment and its inno v ations gain in noise-state co ordinates. T wo-time kernels throughout live on the causal triangle ∆ T := { ( t, s ) ∈ [0 , T ] 2 : 0 ≤ s ≤ t ≤ T } , extended b y 0 off ∆ T . W e write d u for incremen ts in the path index u at fixed estimation time t , and d t for up dates in t at fixed u . The state is assumed to admit the linear form X t = ¯ X t + R t 0 X t ( s ) dW s , where X t ( s ) ∈ R d × ( n +1) d is a deterministic impulse-resp onse k ernel mapping primitiv e sho c ks into the ph ysical state. Theorem 4.1 (Linear Filtering Closure) . Fix a player i . A ssume the state admits the primitive-noise line ar form X t = ¯ X t + Z t 0 X t ( s ) dW s , and player i observes d Y i t = Γ i ( t ) X t dt + E i dW t , with deterministic P i ( t ) ⪰ 0 and blo ck sele ctor E i . L et Π i := E i, ⊤ E i and c X i t := E [ X t | F i t ] , and define the innovation dI i t := d Y i t − Γ i ( t ) c X i t dt . (i) The estimate d-noise p ath incr ements admit the de c omp osition d u c W i t ( u ) = Π i dW u + Z t 0 F i t ( u, s ) dW s du, u < t, (4.1) wher e the deterministic kernel F i is given explicitly by F i t ( u, s ) = f X i s ( u ) ⊤ Γ i ( s ) E i + E i, ⊤ Γ i ( u ) f X i u ( s ) + Z t max( u,s ) f X i r ( u ) ⊤ P i ( r ) f X i r ( s ) dr . (4.2) (ii) The mixe d ( t, u ) -up date satisfies d t d u c W i t ( u ) = f X i t ( u ) ⊤ Γ i ( t ) dI i t du. The unr esolve d kernel f X i is determine d algebr aic al ly fr om F i by ( A.12 ) ; the filter- ing kernel F i is the unique solution of the forwar d evolution system ( A.14 ) – ( A.15 ) (Definition A.1 ). 20 R emark 4.1 (Regression interpretation and scale separation) . Discretizing time, each observ ation increment is affine in the noise incremen ts ∆ W 1: k , so by join t Gaussianit y the conditional mean E [∆ W 1: k | ∆ Y i 1: k ] is a deterministic linear pro jection; each lay er of “b eliefs ab out b eliefs” is a further deterministic comp osition of pro jections, whic h is why the regress closes. The decomp osition in part (i) reflects a scale separation: the direct comp onen t Π i dW u is O (1) (play er i observes their o wn noise contemporane- ously), while the indirect comp onen t captures drift-based inference ab out unobserved sho c ks at scale O ( dt ). Best-resp onse closure and information w edges. When opp onen ts use noise- state linear strategies, a play er’s b est resp onse ov er the full admissible L 2 class remains noise-state linear; the maximum principle yields a closed backw ard system of deter- ministic adjoint kernels including the information w edge V i ( t ) that prices bilateral b elief manipulation. Theorem 4.2 (Multiplay er b elief-adjoin t kernels and information w edges) . Fix a player i and supp ose e ach opp onent k = i uses a noise-state line ar str ate gy with deterministic impulse-r esp onse maps, which pins down a deterministic forwar d en- vir onment (state impulse r esp onse X ( · , · ) , filtering obje cts ( P k , f X k , F k ) , and p olicy kernels D k ). Structur e. A l l obje cts b elow ar e line ar pr o c esses (Definition 3.2 ): deterministic me an plus a sto chastic inte gr al against W with deterministic kernel. The single- agent c ostate ac quir es an additional c oupling term: player i ’s action shifts the state, which shifts opp onent k ’s signal, p osterior, and action, fe e ding b ack into the state. This channel intr o duc es b elief-adjoin t pr o c esses H k,i t ( u ) that tr ack the shadow value of p erturbing opp onent k ’s noise-state estimate. Backwar d system. The physic al c ostate H X,i t and b elief-adjoints H k,i t ( u ) ar e line ar pr o c esses satisfying d dt H X,i t = − G X X ,i ( t ) X t + G X,i t − A ( t ) ⊤ H X,i t − X k = i P k ( t ) Z t 0 f X k t ( z ) H k,i t ( z ) dz | {z } =: V i t , information wedge , (4.3) d dt H k,i t ( u ) = − D k t ( u ) ⊤ H X,i t + X t ( u ) ⊤ P k ( t ) Z t 0 f X k t ( z ) H k,i t ( z ) dz , k = i, (4.4) 21 with terminal c onditions H X,i T = G X X ,i ( T ) X T + G X,i T and H k,i T ( · ) = 0 . A l l c o efficients— P k ( t ) , f X k t ( z ) , D k t ( u ) , and X t ( u ) —ar e determine d by opp onents’ fr ozen str ate gy maps and do not change when player i deviates. The first two terms in ( 4.3 ) ar e the standar d single-agent c ostate e quation; the thir d term V i t is the information we dge, absent in the single-agent pr oblem. In the b elief-adjoint e quation ( 4.4 ) , the for cing − D k t ( u ) ⊤ H X,i t tr ansmits the physic al c ostate into the b elief channel thr ough opp onent k ’s p olicy kernel: the lar ger D k t ( u ) , the mor e opp onent k ’s action at time t r esp onds to the u -th sho ck, and the mor e valuable it is for player i to have shifte d k ’s estimate of that sho ck. The inte gr al term is a self- c oupling thr ough which b elief p erturb ations pr op agate forwar d via the filtering gain f X k ; the same inner pr o duct R t 0 f X k t ( z ) H k,i t ( z ) dz that defines the we dge in ( 4.3 ) drives the self-c oupling in ( 4.4 ) , so the b elief-adjoint fe e ds b ack into itself thr ough the channel it pric es. Sinc e al l c o efficients in ( 4.3 ) – ( 4.4 ) ar e deterministic, taking exp e ctations r e c overs a close d system for the me an c o efficients ( ¯ H X,i , ¯ H k,i ) ; matching the c o efficient of dW r r e c overs a close d system for the r esp onse-map c o efficients ( H X,i ( · , r ) , H k,i ( · , · , r )) . The two subsystems de c ouple and ar e solve d sep ar ately in the numeric al scheme of Se ction 2 . The me an we dge ¯ V i t is the gener al- n c ounterp art of the obje ct displaye d in Figur es 4 – 5 ; the kernel we dge V i t ( r ) distorts e quilibrium impulse r esp onses. Both vanish when signals ar e exo genous. Corollary 4.3 (Exogenous-signal reduction) . If c ontr ols do not enter the state dy- namics, then V i t ≡ 0 for al l i and t , the b elief-adjoint e quations ( 4.4 ) de c ouple, and the e quilibrium r e duc es to n indep endent single-agent LQG pr oblems against a c ommon exo genous state. R emark 4.2 (Mean-field approximation error) . Mean-field mo dels zero b oth w edge comp onen ts by construction: in the contin uum limit no single agen t’s action mea- surably affects an y other agent’s signal. Eliminating b oth comp onen ts in a finite- n mo del requires either exogenous signals (Corollary 4.3 ) or n → ∞ with v anishing individual impact—the first is ruled out when information is costly [ 10 ], and concen- tration of informed trading pushes real mark ets to w ard finite n . In the Kyle–Back em b edding (Section 5 ), the sign symmetry W 7→ − W zeros the mean wedge while the k ernel wedge remains active; this symmetry breaks in any market with asymmetric p ositions. 22 Lemma 4.4 (Strict conv exity of the b est-resp onse problem) . Fix opp onents’ str ate gy maps D − i in the deterministic impulse-r esp onse class (henc e fixe d line ar op er ators fr om signal histories to actions). Then player i ’s induc e d obje ctive D i 7→ J i ( D i ; D − i ) is a strictly c onvex functional on the admissible L 2 c ontr ol sp ac e. Conse quently, the spike-variation stationarity c ondition ( B.8 ) is not only ne c essary but sufficient: any admissible c ontr ol satisfying it is the unique glob al b est r esp onse. Pr o of sketch. With opp onents’ maps fixed and linear, the closed-lo op drift of X is affine in D i , so ( X , D − i ) dep end affinely on D i . The cost ( 3.3 ) is quadratic with G DD ,i ( t ) ≻ 0, hence strictly conv ex in D i . Corollary 4.5 (Noise-state linear b est resp onse (global closure)) . Under the c on- ditions of The or em 4.2 , fix an opp onents’ pr ofile D − i of noise-state line ar str ate gies (Definition 3.3 ). If D i is a b est r esp onse to D − i over the ful l admissible L 2 c ontr ol class, then for a.e. t ∈ [0 , T ] , G DD ,i ( t ) D i t + E [ H X,i t | F i t ] = 0 , i.e., D i t = − ( G DD ,i ( t )) − 1 E [ H X,i t | F i t ] . Sinc e H X,i t is a line ar pr o c ess and E [ H X,i t | F i t ] = ¯ H X,i t + R t 0 H X,i t ( u ) d c W i t ( u ) , every b est r esp onse over the ful l admissible class is itself a noise-state line ar c ontr ol. Pr o of. With opponents’ maps fixed and linear, the inno v ation dI i t := d Y i t − Γ i ( t ) c X i t dt is a standard ( F i , P )-Bro wnian motion whose law do es not dep end on D i (Liptser– Shiry aev [ 19 ], Theorem 7.12). Since c W i t ( · ) is a deterministic linear functional of I i [0 ,t ] (Theorem 4.1 in inno v ations co ordinates), play er i ’s con trol is a deterministic affine functional of the exogenous pro cess I i . The induced ob jectiv e is strictly conv ex (Lemma 4.4 ), so the stationarit y condition ( B.8 ) is necessary and sufficient, yielding the stated formula. The exogeneit y of I i is a prop erty of the b est-resp onse problem: the resp onse-maps mediating b et w een I i and the noise-state dep end on the full strat- egy profile through the forw ard closure, so the equilibrium remains a gen uine fixed p oin t (Theorem D.5 ). R emark 4.3 . Since every b est resp onse ov er the full admissible L 2 class is noise- state linear (Corollary 4.5 ), any Nash equilibrium in noise-state linear con trols is automatically a Nash equilibrium of the unrestricted game; whether equilibria outside this class exist is discussed in Section 6 . 23 R emark 4.4 (Single-pla y er reduction) . When n = 1, V i t ≡ 0 and the ansatz H X,i t ( r ) = S ( t ) X ( t, r ) reduces the backw ard system to the standard matrix Riccati equation for S , reco vering classical separated LQG control. Prop osition 4.6 (F ailure of separation) . F or n ≥ 2 with endo genous signals, the e quilibrium p olicy kernel D i t ( u ) do es not factor as S ( t ) · X t ( u ) for any matrix-value d function S , unless the information we dge vanishes (Cor ol lary 4.3 ). A change in signal pr e cision alters the p olicy kernel itself, not mer ely the estimate to which it is applie d. Pr o of. With n ≥ 2 the information w edge couples the costate to b elief adjoints H k,i t ( u ), whic h dep end on f X k t ( u )—the p ortion of the state resp onse opp onent k has not yet learned. This in tro duces ( t, u )-dep endence that cannot factor through X t ( u ). P erturbing P i c hanges f X k through the equilibrium, c hanging H k,i and hence the p ol- icy k ernel indep enden tly of the state estimate. The factorization holds if and only if V i t ≡ 0. R emark 4.5 (Risk-sensitiv e extension) . The framew ork extends to the en tropic risk measure J i θ i := θ − 1 i log E [ e θ i C i ]: the b est-resp onse FOC is identical to Corollary 4.5 with c W i t replaced by a risk-adjusted noise-state that tilts conditional means and rescales conditional precision through the quadratic cost k ernel (App endix B.6 , The- orem B.1 ). R emark 4.6 (Infinite horizon and the frequency domain) . Under time-homogeneous primitiv es, resp onse maps b ecome time-in v ariant K ( t, u ) = k ( t − u ) and the fixed p oint b ecomes one in transfer functions, extending [ 14 , 16 , 27 ] to endogenous signals, where the transfer function of the equilibrium filter is itself an equilibrium ob ject. Rational transfer functions corresp ond to finite-dimensional Marko v sufficien t statistics, so the p ole structure of equilibrium k ernels diagnoses whether an exact state-space reduction exists. Reference: impulse-resp onse ob jects. F or conv enience, w e collect the kernel ob jects introduced ab o v e. 24 W = ( W 0 , . . . , W n ) primitive noise E i , Π i selector / pro jector c W i t ( u ) noise-state X t ( s ) state impulse resp onse F i t ( u, s ) filtering impulse resp onse e X i t ( u ) unresolv ed state resp onse D i t ( u ) p olicy impulse resp onse D i t ( s ) primitiv e-noise con trol H X,i t ph ysical costate (linear pro cess) H k,i t ( u ) b elief adjoints (linear pro cess) V i t information wedge (linear pro cess) 5 T rading under asymmetric informedness The noise-state tec hnique extends to strategic trading with asymmetric priv ate learn- ing, a setting where guess-and-verify breaks do wn once traders differ in precision or learn contin uously from priv ate sources. The price eac h trader faces decomp oses into an exogenous comp onen t and a history-linear function of their o wn demand, with Kyle’s lambda pla ying the role of G DD ,i ; the quadratic structure is distributed across time, so the first-order condition yields an in tegral equation whose time deriv ative pins down the optimal trading rate. 5.1 Mo del and em b edding There are n informed traders and a comp etitive market maker. A fundamen tal V t := σ V W V t is driven by a Bro wnian motion W V indep enden t of ( W 0 , . . . , W n ), with selector E V . All play ers observ e aggregate order flow d Z t = P j D j t dt + σ 0 dW 0 t ; trader i additionally observ es a priv ate signal d Y i t = Γ i ( t ) V t dt + dW i t . The mark et mak er observ es only Z and p osts the comp etitiv e price P t := E [ V T | F 0 t ]. T rader i maximizes exp ected profit π i := E [ R T 0 D i t ( V T − P t ) dt ]. By the symmetry W 7→ − W , all mean terms v anish. Stac king trader i ’s t w o observ ation channels into a single equation reco vers the ob- serv ation mo del of Section 3 (App endix E ), so the filtering machinery of App endix A applies verbatim. Price decomp osition. Fix opp onen ts’ noise-state linear strategy maps. The mar- k et mak er’s filtering gains are deterministic, so the price decomp oses as P t = P − i t + Z t 0 ℓ ( t, s ) D i s ds, (5.1) 25 where P − i t is a linear pro cess indep enden t of D i off equilibrium (the price that would obtain if trader i submitted zero demand) and ℓ ( t, s ) is a deterministic kernel enco ding ho w eac h unit of past demand at time s has mo ved the current price by time t . The profit b ecomes π i = E Z T 0 D i t ( V T − P − i t ) | {z } exogenous mispricing dt − E Z T 0 D i t Z t 0 ℓ ( t, s ) D i s ds | {z } endogenous price impact dt. The first term is linear in D i ; the second is a quadratic form in the history of D i through the deterministic k ernel ℓ : − ( V T − P − i t ) pla ys the role of G X,i , and the in tegrated price-impact term plays the role of D i, ⊤ G DD ,i D i , distributed across time rather than concen trated at each instan t. Kyle’s lam b da and strict concavit y . Define the aggregate primitive-noise de- mand k ernel D Σ ,t ( s ) := P j D j ( t, s ). Since E V E 0 , ⊤ = 0, all price information comes through drift-based inference: dP t = λ ( t ) dI 0 t . (5.2) Assumption 5.1 (P ersisten t price informativeness) . λ ( t ) > 0 for al l t ∈ [0 , T ] . This is the economically relev an t case: if aggregate order flow w ere temp orarily unin- formativ e ( λ = 0), traders could trade at zero price impact—an arbitrage opp ortunity that w ould restore informativ eness. The condition plays the role of G DD ,i ( t ) ≻ 0 in the LQG framework (Lemma 4.4 ), ensuring strict conca vity of the profit in D i and hence necessit y and sufficiency of the first-order condition, just through the temp o- rally distributed quadratic form rather than p oint wise at eac h t . 5.2 Best-resp onse c haracterization Fix pla yer i and supp ose ev ery opp onent k = i uses a noise-state linear strategy as in Section 4 . Because the quadratic structure is cross-temp oral, the first-order condition do es not directly yield D i t ( u ); instead, the optimality condition equates the conditional mispricing to the integrated future impact cost (App endix E ): b V i t − P t | {z } H i, v al t ( u ): information rent density = E " Z T t l ( τ , t ) D i τ ( u ) dτ |F i t # | {z } H i, imp t : impact cost density , (5.3) 26 where δ P τ is the price p erturbation propagated by the deviation system ( E.1 )–( E.3 ). The left side is trader i ’s informational adv antage ov er the market maker; the righ t side is the presen t v alue of price distortion from a marginal unit of demand. Since the integral runs ov er [ t, T ], it do es not isolate D i t ( u )—only the en tire future trading plan weigh ted by price impact. Differen tiating b oth sides in t , the Leibniz b oundary term pro duces − λ ( t ) D i t ( u )— where λ ( t ) en ters as the endogenous control cost and D i t ( u ) first app ears explicitly . Solving: λ ( t ) D i t = − d dt H i, v al t + E " Z T t ∂ l ∂ t ( τ , t ) D i τ dτ |F i t # , (5.4) with terminal condition D i T ( u ) = λ ( T ) − 1 H i, v al T ( u ). The deriv ative d dt H i, v al and the deviation system determining δ P τ are given in App endix E . 6 Conclusion Conditioning on primitiv e Brownian sho cks collapses the T o wnsend b elief hierarc h y on to deterministic impulse-response maps, yielding the first exact equilibrium c harac- terization of finite-pla y er contin uous-time LQG games with endogenous signals. The information wedge V i t prices bilateral b elief manipulation and v anishes when signals are exogenous. The tw o-pla y er example shows that nearly all w elfare gains from disclosure come from eliminating this c hannel; the Kyle–Back embedding sho ws the tec hnique extends b ey ond quadratic costs to strategic trading with endogenous price impact, asymmetric precisions, and contin uous priv ate learning. F urther directions. The main open question is whether the deterministic impulse- resp onse class is without loss of generality . A natural program pro ceeds in three steps: (i) a Blac kw ell reduction showing that under quadratic costs the b est resp onse de- p ends on the p osterior π i t := L ( W [0 ,t ] | F i t ) only through its mean and cov ariance; (ii) a b elief-of-b elief collapse in which play er i ’s estimate of π k t factors through a deterministic op erator—the p osterior analogue of the kernel maps ( F i , f X i ); (iii) a con traction argumen t on the v ariance functional V ( D ) := P i E RR ∥ D i ( t, s, π i t ) − E [ D i ( t, s, π i t )] ∥ 2 ds dt , whic h v anishes exactly in the deterministic impulse-resp onse class. The precision optimization (App endix C.2 ) rev eals that multi-pla yer rational inatten tion couples the filtering and con trol problems that separate in single-agen t 27 settings: the marginal v alue of precision dep ends on the equilibrium through the state kernel. Extending the framework to rational inatten tion requires care: v ary- ing the gain Γ i directly changes the filtration in a non-monotone w ay , breaking the en v elop e argumen t. The difficult y disapp ears when the control v ariable is the p ort- folio of indep endent sources monitored (a Brownian sheet formulation), since eac h additional source strictly enlarges the filtration. The total precision decomp oses as P i = P i 0 + τ i , the marginal v alue of a source is the v alue of optimally exploiting its indep endent incremen t, and the env elop e theorem applies cleanly (App endix C ). Ov erlapping source p ortfolios endogenize cross-play er noise correlations, amplifying the b elief-manipulation c hannel priced by V i t . An alternative to the mean-field limit is games on vertex-transitiv e graphs, where graph symmetry p ermits a representativ e-agent reduction while preserving the in- formation w edge. The natural conjecture is that equilibrium impulse-resp onse maps inherit the graph symmetry , reducing the fixed p oin t to a single no de coupled to its neigh b orho o d—in terp olating b et w een the mean-field limit (complete graph, v anishing edge weigh ts, ¯ V i t = 0) and the finite- n case. Sto chastic co efficien ts (Remark D.2 ) and global uniqueness are natural next steps; the dissipative structure of Lemma D.3 sug- gests sufficien t regularity to preclude m ultiplicity , but a pro of requires monotonicity estimates b eyond the Gr¨ on wall b ounds used here. A Filtering Roadmap. W e iden tify the k ernel equations for F i via formal calculations, then de- fine F i as their unique solution (uniqueness follows from L 2 -pro jection). The pip eline pro ceeds in three steps. Subsection A.1 derives the dynamics of t 7→ c W i t ( u ) from a characterizing identit y for conditional exp ectations. Subsection A.2 sp ecializes the abstract dynamics to the physical observ ation mo del, iden tifying f X i t ( u ) as the filtering gain and establishing the algebraic identit y f X i = X ( I − Π i ) − X ∗ F i . Subsection A.3 defines F i as the primitiv e filtering ob ject through its forw ard ev olution equation, deriv es the explicit three-term formula, and verifies uniqueness. 28 A.1 Dynamics of the noise-state Fix a play er i . Recall the noise-state c W i t ( u ) := E [ W u | F i t ], 0 ≤ u ≤ t , and the observ ation c hannel d Y i t = ¯ C ( t ) + Z t 0 C ( t, s ) dW s dt + E i dW t , Y i 0 = 0 , where C ( t, s ) is deterministic. Since ¯ C is deterministic, we may assume without loss that ¯ C ≡ 0 by replacing Y i t with Y i t − R t 0 ¯ C ( r ) dr . Prop osition A.1 (Linear closure for c W ) . The map u 7→ c W i t ( u ) is a line ar pr o c ess: ther e exists a deterministic indir e ct-r esp onse map F i t ( · , · ) such that c W i t ( u ) = Π i W u + Z t 0 Z u 0 F i t ( z , s ) dz dW s , 0 ≤ u ≤ t. Prop osition A.2 (Dynamics of c W i t ( u )) . Ther e exist deterministic matrix-value d functions B Y ( u, t ) and B ( u ; t, s ) such that, for e ach fixe d u , c W i t ( u ) − c W i t 0 ( u ) = Z t t 0 Z r 0 B ( u ; r, s ) d c W i r ( s ) dr + Z t t 0 B Y ( u, r ) d Y i r , t ≥ t 0 ≥ u, (A.1) or e quivalently in differ ential form, d t c W i t ( u ) = Z t 0 B ( u ; t, s ) d c W i t ( s ) dt + B Y ( u, t ) d Y i t , (A.2) with B Y ( u, t ) = Z t 0 ∂ s C i t ( u, s ) C ( t, s ) ⊤ ds + E i, ⊤ 1 { u ≥ t } , (A.3) B ( u ; t, s ) = − B Y ( u, t ) C ( t, s ) , (A.4) wher e C i t ( u, s ) := Cov( W u , W s | F i t ) is the deterministic c onditional err or c ovarianc e kernel. Pr o of. W e use the characterizing identit y for conditional exp ectations via exp onen tial test martingales. Fix a deterministic v ector function r ( · ) and define φ r t b y φ r 0 = 1 and dφ r t = i φ r t ( d Y i t ) ⊤ r ( t ). A necessary and sufficien t condition characterizing c W i t ( u ) 29 is E h c W i t ( u ) φ r t i = E h W u φ r t i for all r ( · ) . (A.5) W e compute the time deriv ativ e of each side indep endently , then matc h. L eft-hand side. Apply Itˆ o’s pro duct rule to c W i t ( u ) φ r t , using the ansatz ( A.2 ) and dφ r t = i φ r t ( d Y i t ) ⊤ r ( t ): d c W i t ( u ) φ r t = i c W i t ( u ) φ r t ( d Y i t ) ⊤ r ( t ) + φ r t d t c W i t ( u ) + d ⟨ c W i ( u ) , φ r ⟩ t . The quadratic co v ariation con tributes d ⟨ c W i ( u ) , φ r ⟩ t = i φ r t B Y ( u, t ) r ( t ) dt . T aking exp ectations and collecting the dt terms gives d dt E h c W i t ( u ) φ r t i = i E " φ r t c W i t ( u ) Z t 0 C ( t, s ) d c W i t ( s ) ⊤ + B Y ( u, t ) # r ( t ) + E " φ r t Z t 0 B ( u ; t, s ) + B Y ( u, t ) C ( t, s ) d c W i t ( s ) # . (A.6) R ight-hand side. Expand E [ W u φ r t ] using the SDE for φ r and apply the to wer prop ert y in the form E [ φ r s L ] = E [ φ r s E [ L | F i s ]]. Define the conditional second-momen t k ernel M i s ( u, z ) := E [ W u W ⊤ z | F i s ] = C i s ( u, z ) + c W i s ( u ) c W i s ( z ) ⊤ . Then E W u Z s 0 C ( s, z ) dW ⊤ z F i s = Z s 0 ∂ z M i s ( u, z ) C ( s, z ) ⊤ dz . Splitting M i s = C i s + c W i s c W i, ⊤ s separates this in to a cov ariance piece and a pro duct- of-means piece: Z s 0 ∂ z M i s ( u, z ) C ( s, z ) ⊤ dz = Z s 0 ∂ z C i s ( u, z ) C ( s, z ) ⊤ dz + c W i s ( u ) Z s 0 C ( s, z ) d c W i s ( z ) ⊤ . (A.7) Differen tiating E [ W u φ r t ] and collecting dt terms then gives d dt E h W u φ r t i = i E " φ r t Z t 0 ∂ s C i t ( u, s ) C ( t, s ) ⊤ ds + c W i t ( u ) Z t 0 C ( t, s ) d c W i t ( s ) ⊤ + E i, ⊤ 1 { u ≥ t } # r ( t ) . (A.8) Co efficient matching. Equating ( A.6 ) and ( A.8 ) for all r ( · ) and all t yields tw o condi- 30 tions. Matching the terms m ultiplying r ( t ) (after canceling the common c W i t ( u ) R C d c W i, ⊤ terms that app ear on b oth sides via ( A.7 )) gives ( A.3 ). Requiring the residual drift in ( A.6 ) to v anish giv es Z t 0 B ( u ; t, s ) + B Y ( u, t ) C ( t, s ) d c W i t ( s ) = 0 , hence B ( u ; t, s ) = − B Y ( u, t ) C ( t, s ), whic h is ( A.4 ). A.2 Sp ecialization to the ph ysical observ ation mo del W e no w sp ecialize to the observ ation equation of Section 3 , d Y i t = Γ i ( t ) X t dt + E i dW t , whic h corresp onds to setting C ( t, s ) = Γ i ( t ) X t ( s ) in the general framework of Prop o- sition A.2 . Inno v ation pro cess. Define the inno v ation dI i t := d Y i t − Γ i ( t ) c X i t dt, where c X i t := E [ X t | F i t ]. By the inno v ations theorem for Gaussian linear filtering (Liptser–Shiry aev [ 19 ], Theorem 7.12), I i is a standard ( F i , P )-Bro wnian motion. Inno v ation form of the dynamics. Substituting C ( t, s ) = Γ i ( t ) X t ( s ) in to Prop o- sition A.2 and using dI i t = d Y i t − Γ i ( t ) c X i t dt , the dynamics ( A.2 ) b ecome d t c W i t ( u ) = Z t 0 ∂ s C i t ( u, s ) X t ( s ) ⊤ ds Γ i ( t ) dI i t + E i, ⊤ 1 { u ≥ t } dI i t . (A.9) Iden tifying f X i as the filtering gain. F or u < t , the indicator term in ( A.9 ) is lo cally constant in u , so the mixed ( t, u )-up date takes the form d t d u c W i t ( u ) = f X i t ( u ) ⊤ Γ i ( t ) dI i t du, 0 ≤ u < t ≤ T . (A.10) T o verify the gain co efficien t, recall that X t − c X i t = R t 0 f X i t ( s ) dW s and that the innov a- tion ( A.17 ) has martingale comp onen t E i dW t and absolutely con tin uous comp onen t 31 Γ i ( t ) R t 0 f X i t ( s ) dW s dt . The gain in ( A.10 ) equals the conditional cross-co v ariance den- sit y Cov( dW u , Γ i ( t )( X t − c X i t ) dt | F i t ) /dt ; b y Itˆ o isometry applied to R t 0 f X i t ( s ) dW s , this picks out f X i t ( u ). Th us f X i t ( u ) ⊤ Γ i ( t ) is the Kalman gain for updating the u -th noise incremen t: it maps observ ation innov ations at time t in to revisions of the noise estimate at the earlier time u . R emark A.1 (Conditional cross-cov ariance interpretation) . The iden tification ab o v e can b e restated as f X i t ( u ) = Co v X t , dW u | F i t du . In tegrating in u reco v ers the full conditional cross-co v ariance Co v X t , W u | F i t = Z u 0 f X i t ( s ) ds = Z t 0 X t ( s ) ∂ s C i t ( s, u ) ds, (A.11) where the second equality follo ws from X t − c X i t = R t 0 X t ( s ) d f W i t ( s ) and Itˆ o isometry against f W i t ( u ). Algebraic iden tit y for f X i in terms of F i . Recall the induced estimated-state k ernel c X i t ( s ) := X t ( s )Π i + R t 0 X t ( z ) F i t ( z , s ) dz . Since f X i t ( u ) := X t ( u ) − c X i t ( u ), f X i t ( u ) = X t ( u )( I − Π i ) − Z t 0 X t ( z ) F i t ( z , u ) dz . (A.12) This identit y is algebraic: once F i is determined (Section A.3 ), f X i follo ws with no further fixed-p oint step. R emark A.2 (State uncertain t y as a contraction) . The conditional state co v ariance satisfies Σ X X ,i ( t ) = Z t 0 X t ( s ) f X i t ( s ) ⊤ ds, (A.13) whic h follo ws from Itˆ o isometry applied to X t − c X i t = R t 0 f X i t ( s ) dW s . R emark A.3 (Kalman-filter interpretation) . Iden tit y ( A.13 ) sa ys that the d × d state uncertain t y Σ X X ,i ( t ) is obtained b y “pro jecting” the unresolv ed kernel f X i t ( s ) back through the state impulse resp onse X t ( s ). In the single-pla y er case with no endoge- nous drift, this reduces to the classical relation b etw een the Kalman gain and the error cov ariance. In the m ulti-pla y er setting the identit y p ersists b ecause opp onen ts’ strategy maps ha ve deterministic co efficients. 32 A.3 The filtering k ernel F i W e define F i as the primitive filtering object through its evolution equation. The unresolv ed k ernel f X i is then a deriv ed quantit y via the algebraic iden tity ( A.12 ). Definition A.1 (Filtering kernel system) . Fix play er i . A deterministic causal k ernel F i on ∆ T solv es the filtering kernel system if, with f X i defined b y ( A.12 ), it satisfies F i 0 = 0 and ∂ t F i t ( u, s ) = f X i t ( u ) ⊤ P i ( t ) f X i t ( s ) , u, s < t, (A.14) F i t ( u, t ) = f X i t ( u ) ⊤ Γ i ( t ) E i , F i t ( t, u ) = E i, ⊤ Γ i ( t ) f X i t ( u ) . (A.15) Since ( A.12 ) expresses f X i as a deterministic linear functional of F i , the sys- tem ( A.14 )–( A.15 ) is a closed forward ODE for F i (quadratic through the substi- tution). Prop osition A.3 (Explicit formula) . Inte gr ating ( A.14 ) fr om max ( u, s ) to t and adding the b oundary c ontributions gives F i t ( u, s ) = f X i s ( u ) ⊤ Γ i ( s ) E i + E i, ⊤ Γ i ( u ) f X i u ( s ) + Z t max( u,s ) f X i r ( u ) ⊤ P i ( r ) f X i r ( s ) dr . (A.16) The thr e e terms ar e: (i) the unr esolve d r esp onse at observation time s , pr oje cte d thr ough the observation channel; (ii) the drift c omp onent of the innovation at time u , r eve aling information ab out e arlier incr ements at s ≤ u ; (iii) ac cumulate d indir e ct infer enc e fr om observations at times r ∈ [max ( u, s ) , t ] . R emark A.4 (Self-adjoin tness) . Under ( u, s ) 7→ ( s, u ) with transpose, the first t w o terms in ( A.16 ) exchange and the integral is in v ariant (since P i ( r ) is symmetric). Hence F i t ( u, s ) = F i t ( s, u ) ⊤ , confirming that the induced map is an orthogonal pro- jection. R emark A.5 (Uniqueness) . If F i and ˜ F i b oth yield the density representation of Theorem 4.1 (i), Itˆ o isometry giv es F i t ( u, s ) = ˜ F i t ( u, s ) a.e. R emark A.6 (Computation) . In the numerical scheme of Section 2 , f X i is computed from F i via ( A.12 ) at eac h time step, and the integral in ( A.16 ) is accum ulated forw ard alongside the F i up date. 33 W e now con ve rt the innov ations-based c haracterization of Subsections A.1 – A.2 in to primitive-noise co ordinates. The goal is to construct the deterministic k ernel F i suc h that for ev ery t ∈ [0 , T ] and u < t , d u c W i t ( u ) = Π i dW u + Z t 0 F i t ( u, s ) dW s du. A.3.1 Deriv ation Recall the inno v ation form of the estimated-noise dynamics (equation ( A.9 )): for u ≤ t , d u c W i t ( u ) = E i, ⊤ dI i u + Z t u f X i s ( u ) ⊤ Γ i ( s ) dI i s du, where the first term is the direct observ ation at time u and the second is the accu- m ulated drift-based revision ov er ( u, t ]. T o pass from inno v ations to primitive noise, w e expand each dI i s in terms of dW . Expanding the inno v ation. The ph ysical-measure decomp osition of the inno v a- tion is dI i t = E i dW t + Γ i ( t ) ( X t − c X i t ) dt. The first piece is the martingale comp onent; the second is absolutely contin uous. Substituting the linear forms and using f X i t ( r ) := X t ( r ) − c X i t ( r ) (the definition of f X i and ( A.13 )): dI i t = E i dW t + Γ i ( t ) Z t 0 f X i t ( r ) dW r dt. (A.17) Expanding the direct term. Substituting ( A.17 ) at t = u in to E i, ⊤ dI i u : E i, ⊤ dI i u = E i, ⊤ E i dW u | {z } = Π i dW u + E i, ⊤ Γ i ( u ) Z u 0 f X i u ( r ) dW r du. (A.18) The first piece con tributes the Π i dW u in the density represen tation. The second is absolutely con tin uous in u with primitive-noise density E i, ⊤ Γ i ( u ) f X i u ( s ) at source- noise index s ≤ u . 34 Expanding the in tegral term. Substituting ( A.17 ) into R t u f X i s ( u ) ⊤ Γ i ( s ) dI i s : Z t u f X i s ( u ) ⊤ Γ i ( s ) dI i s = Z t u f X i s ( u ) ⊤ Γ i ( s ) E i dW s | {z } (a) martingale + Z t u f X i s ( u ) ⊤ P i ( s ) Z s 0 f X i s ( r ) dW r ds | {z } (b) abs. contin uous . T erm (a) con tributes f X i s ( u ) ⊤ Γ i ( s ) E i at source-noise index s ∈ ( u, t ]. Applying sto c hastic F ubini to term (b) and reading off the co efficient of dW r : (b) = Z t 0 Z t max( u,r ) f X i s ( u ) ⊤ P i ( s ) f X i s ( r ) ds dW r . Assem bling the densit y . Collecting the co efficien t of dW s du from all three con- tributions and noting that causality ( f X i s ( u ) = 0 for u > s ) automatically zero es the irrelev an t indicators: F i t ( u, s ) = f X i s ( u ) ⊤ Γ i ( s ) E i + E i, ⊤ Γ i ( u ) f X i u ( s ) + Z t max( u,s ) f X i r ( u ) ⊤ P i ( r ) f X i r ( s ) dr . (A.19) The three terms ha v e the same in terpretation as in Prop osition A.3 . R emark A.7 (Boundary condition and ev olution) . Ev aluating ( A.19 ) at s = t (using f X i u ( t ) = 0 for u < t ): F i t ( u, t ) = f X i t ( u ) ⊤ Γ i ( t ) E i , F i t ( t, u ) = E i, ⊤ Γ i ( t ) f X i t ( u ) , whic h are eac h other’s transp oses. Differentiating ( A.19 ) in t at fixed u, s < t gives the evolution ∂ t F i t ( u, s ) = f X i t ( u ) ⊤ P i ( t ) f X i t ( s ) , whic h is manifestly self-adjoin t under ( u, s ) 7→ ( s, u ) ⊤ . A.3.2 F ormal c haracterization Definition A.2 (Filtering kernel system (definition of F i )) . Fix play er i . The inputs are the state kernel X ( · , · ) and the unresolv ed k ernel f X i from Subsection A.2 . The 35 output is the primitiv e-noise density k ernel F i of Theorem 4.1 (i). A deterministic kernel F i is said to b e admissible if it is causal ( F i t ( u, s ) = 0 when max { u, s } > t ) and, together with the induced kernel F i t ( u, s ) = f X i s ( u ) ⊤ Γ i ( s ) E i + E i, ⊤ Γ i ( u ) f X i u ( s ) + Z t max( u,s ) f X i r ( u ) ⊤ P i ( r ) f X i r ( s ) dr , u, s ≤ t. (A.20) W e define F i to b e the unique causal solution of ( A.12 )–( A.20 ). Prop osition A.4 (V erification: primitiv e-noise density of the noise-state) . L et F i b e the kernel define d by Definition A.1 . Then for every t ∈ [0 , T ] and u < t , d u c W i t ( u ) = Π i dW u + Z t 0 F i t ( u, s ) dW s du. Mor e over, F i is unique among deterministic c ausal kernels with this pr op erty. Pr o of of uniqueness. If F i and ˜ F i b oth satisfy the density represen tation, then R t 0 ( F i t ( u, s ) − ˜ F i t ( u, s )) dW s = 0 a.s. for each ( t, u ). By Itˆ o isometry , R t 0 ∥ F i t ( u, s ) − ˜ F i t ( u, s ) ∥ 2 ds = 0, hence F i t ( u, s ) = ˜ F i t ( u, s ) a.e. B Con trol First Order Conditions This app endix derives the stationarity condition ( B.8 ) and the closed backw ard sys- tem for the adjoint kernels ( ¯ H X , H X , { ¯ H k , H k } k = i ). By the inno v ations exogeneity established in Corollary 4.5 , the b est-resp onse problem for pla yer i (opp onen ts’ maps fixed) is an optimization ov er deterministic impulse-resp onse maps w eigh ting the ex- ogenous innov ation I i . 2 B.1 The b est-resp onse problem in inno v ations co ordinates Fix a baseline noise-state linear profile and a deviating pla y er i . By the inno v ations exogeneit y established in Corollary 4.5 , c W i t ( · ) is a deterministic linear functional of 2 T o av oid circularity: opp onents’ deterministic k ernels mak e I i a standard Brownian motion indep enden t of D i [ 19 , Theorem 7.12]; Lemma 4.4 then gives strict conv exit y ov er the full L 2 class; the F OC derived here is therefore necessary and sufficient, yielding the deterministic-k ernel b est resp onse of Corollary 4.5 . 36 I i [0 ,t ] , and I i is a standard ( F i , P )-Bro wnian motion inv arian t to D i . Pla y er i ’s control D i t = ¯ D i t + Z t 0 D i t ( u ) d u c W i t ( u ) is a deterministic affine functional of I i , and the optimization is o v er ( ¯ D i , D i ) with no self-referen tial signal dep endence. Since the state dynamics are linear in D i and the cost is quadratic with G DD ,i ( t ) ≻ 0, the induced ob jectiv e is strictly conv ex: the stationarit y condition derived b elo w is the unique global optim um. B.2 Spik e v ariation and the first-v ariation system W e use spike v ariations to exp ose the adjoint structure. Fix t ∈ [0 , T ) and v ∈ L 2 (Ω , F i t ; R d ). The spike p erturbation D i,ρ,ε s := D i s + ρ v 1 [ t,t + ε ] ( s ) induces the nor- malized first v ariation δ X s := lim ε ↓ 0 1 ε ∂ ∂ ρ X ρ,ε s ρ =0 with δ X t = v . Because opp onen ts apply fixed linear maps with deterministic kernels, the map v 7→ ( δ X s , { δ w k s ( · ) } k = i ) is exactly linear in v with deterministic co efficien ts. The deviator’s own innov ation is unaffected ( δ I i s = 0), since δ X s ∈ F i t implies δ c X i s = δ X s . Opp onen ts’ filter resp onse. F or each k = i , δ ( d u c W k s ( u )) = δ w k s ( u ) du with δ w k t ( · ) ≡ 0 and ∂ s δ w k s ( u ) = f X k s ( u ) ⊤ P k ( s ) δ X s − Z s 0 X s ( r ) δ w k s ( r ) dr , 0 ≤ u ≤ s. (B.1) The opp onen t con trol v ariation is δ D k s = R s 0 D k s ( u ) δ w k s ( u ) du , giving the coupled state system d ds δ X s = A ( s ) δ X s + X k = i Z s 0 D k s ( u ) δ w k s ( u ) du, δ X t = v . (B.2) B.3 T ransition k ernels The coupled system ( B.1 )–( B.2 ) has b ounded deterministic co efficien ts and admits a unique deterministic t wo-parameter ev olution family . Definition B.1 (Blo c k transition kernels) . F or s ≥ t , define Φ X X ( s, t ) ∈ R d × d and 37 Φ X k ( s, t, u ) ( k = i , u ∈ [0 , t ]) b y δ X s = Φ X X ( s, t ) v + X k = i Z t 0 Φ X k ( s, t, u ) η k ( u ) du, for initial data δ X t = v , δ w k t ( · ) = η k ( · ). In the spik e deviation η k ≡ 0, so δ X s = Φ X X ( s, t ) v . These blo cks satisfy ∂ ∂ t Φ X X ( s, t ) = − Φ X X ( s, t ) A ( t ) − X k = i Z t 0 Φ X k ( s, t, z ) f X k t ( z ) ⊤ P k ( t ) dz , (B.3) ∂ ∂ t Φ X k ( s, t, u ) = − Φ X X ( s, t ) D k t ( u ) + Z t 0 Φ X k ( s, t, z ) f X k t ( z ) ⊤ P k ( t ) X t ( u ) dz , (B.4) with Φ X X ( t, t ) = I and Φ X k ( t, t, u ) = 0. R emark B.1 (Fixed co efficien ts off equilibrium) . Ev ery co efficien t in ( B.3 )–( B.4 )— D k t ( u ), f X k t ( z ) ⊤ P k ( t ), and X t ( u )—is determined by opp onen ts’ frozen strategy maps. A unilateral deviation b y play er i changes the true state kernel X through δ D i , but opp onen ts con tinue to filter and act as though the original state kernel obtained. The transition kernels therefore ha ve fixed co efficien ts; the deviation in the true state en ters only through the forcing G X X ,i ( t ) X t ( r ) in the backw ard system. B.4 First v ariation of costs and the adjoin t k ernels Fix play er i and suppress play er sup erscripts on w eigh t matrices. Using δ X s = Φ X X ( s, t ) v and the linear form of X s , the normalized cost v ariation is δ J i t ( v ) = 2 E " v ⊤ G DD ,i ( t ) D i t + ¯ H X t + Z T 0 H X t ( u ) d c W i t ( u ) F i t # , (B.5) where ¯ H X t := Z T t Φ X X ( s, t ) ⊤ h G X X ( s ) ¯ X s + ¯ G X,i s i ds + Φ X X ( T , t ) ⊤ h G X X ,i ( T ) ¯ X T + ¯ G X,i T i , (B.6) H X t ( u ) := Z T t Φ X X ( s, t ) ⊤ h G X X ( s ) X s ( u ) + G X,i s ( u ) i ds + Φ X X ( T , t ) ⊤ h G X X ,i ( T ) X T ( u ) + G X,i T ( u ) i . (B.7) 38 Stationarit y condition (globally necessary and sufficien t). Setting δ J i t ( v ) = 0 for all F i t -measurable v gives G DD ,i ( t ) D i t + ¯ H X t + Z T 0 H X t ( u ) d c W i t ( u ) = 0 a.s., (B.8) with equilibrium co efficien ts ¯ D i t = − G DD ,i ( t ) − 1 ¯ H X t and D i t ( u ) = − G DD ,i ( t ) − 1 H X t ( u ). Equiv alen tly , D i t = − ( G DD ,i ( t )) − 1 E [ ¯ H X t + R T 0 H X t ( u ) dW u | F i t ]: the con trol is the conditional exp ectation of the full-information action (a certain t y-equiv alence prop ert y). B.5 Closed bac kw ard system for the adjoint k ernels Define the b elief-adjoin t ob jects ¯ H k t ( u ) := Z T t Φ X k ( s, t, u ) ⊤ h G X X ( s ) ¯ X s + ¯ G X,i s i ds + Φ X k ( T , t, u ) ⊤ h G X X ,i ( T ) ¯ X T + ¯ G X,i T i , (B.9) H k t ( u, r ) := Z T t Φ X k ( s, t, u ) ⊤ h G X X ( s ) X s ( r ) + G X,i s ( r ) i ds + Φ X k ( T , t, u ) ⊤ h G X X ,i ( T ) X T ( r ) + G X,i T ( r ) i . (B.10) Then ( ¯ H X , { ¯ H k } , H X , { H k } ) satisfy d dt ¯ H X t = − h G X X ,i ( t ) ¯ X t + ¯ G X,i t i − A ( t ) ⊤ ¯ H X t − X k = i Z t 0 P k ( t ) f X k t ( z ) ¯ H k t ( z ) dz , (B.11) d dt ¯ H k t ( u ) = − D k t ( u ) ⊤ ¯ H X t + Z t 0 X t ( u ) ⊤ P k ( t ) f X k t ( z ) ¯ H k t ( z ) dz , (B.12) d dt H X t ( r ) = − h G X X ,i ( t ) X t ( r ) + G X,i t ( r ) i − A ( t ) ⊤ H X t ( r ) − X k = i Z t 0 P k ( t ) f X k t ( z ) H k t ( z , r ) dz , (B.13) d dt H k t ( u, r ) = − D k t ( u ) ⊤ H X t ( r ) + Z t 0 X t ( u ) ⊤ P k ( t ) f X k t ( z ) H k t ( z , r ) dz , (B.14) with terminal conditions ¯ H X T = G X X ,i ( T ) ¯ X T + ¯ G X,i T , ¯ H k T ( · ) = 0, H X T ( r ) = G X X ,i ( T ) X T ( r )+ G X,i T ( r ), H k T ( · , r ) = 0. 39 B.6 Risk-sensitiv e extension: exp onen tial utilit y F OC Theorem B.1 (Risk-sensitiv e extension) . R eplac e ( 3.3 ) with the entr opic risk me a- sur e J i θ i := θ − 1 i log E h e θ i C i i , θ i > 0 , (B.15) wher e C i is the r andom c ost ( 3.2 ) . A T aylor exp ansion gives J i θ i = E [ C i ] + θ i 2 V ar( C i ) + O ( θ 2 i ) , so θ i governs the de gr e e of risk aversion (the risk-neutr al c ase θ i → 0 r e c ov- ers ( 3.3 ) ). Under a line ar pr ofile, the b est-r esp onse F OC is identic al to Cor ol lary 4.5 with c W i t r eplac e d by the risk-adjuste d noise-state c W i,θ t := I − θ i C t K t − 1 c W i t + θ i C t k t , wher e C t := C i t ( u, s ) = Co v( W u , W s | F i t ) is the deterministic c onditional c ovarianc e kernel of W given F i t (deterministic by Gaussianity of the c onditional law under the line ar pr ofile), K t is the symmetric quadr atic kernel of C i in the Wiener-chaos r epr esentation ( B.17 ) , and k t is the c orr esp onding line ar kernel ( B.16 ) . The formula is valid when I − θ i C 1 / 2 t K t C 1 / 2 t ≻ 0 , which holds for θ i sufficiently smal l or T sufficiently short. The filtering structur e is unchange d; c ertainty e quivalenc e fails b e c ause the quadr atic c ost kernel r esc ales c onditional pr e cision via ( I − θ i C t K t ) − 1 while k t shifts the c onditional me an. W e now derive this result. Replace ( 3.3 ) with J i θ i := θ − 1 i log E [ e θ i C i ], where C i is the random cost ( 3.2 ). The spik e v ariation of Section B.2 carries ov er; differentiating J i θ i in the spik e amplitude gives δ J i θ i ,t ( v ) = E h Z i δ C i t ( v ) i , Z i := e θ i C i E [ e θ i C i ] , with δ C i t ( v ) identical to ( B.5 ). Quadratic structure of the cost. Expanding C i via the linear forms X s = ¯ X s + R s 0 X s ( u ) dW u and D i s = ¯ D i s + R s 0 D i s ( u ) dW u and applying sto c hastic F ubini yields the Wiener-c haos represen tation C i = c 0 + Z T 0 ℓ ( r ) ⊤ dW r + 1 2 Z T 0 Z T 0 dW ⊤ r K ( r, s ) dW s , 40 where c 0 absorbs deterministic and trace terms, and the linear and symmetric quadratic k ernels are ℓ ( r ) := Z T r X t ( r ) ⊤ G X X ,i ( t ) ¯ X t + ¯ G X,i t + G X,i t ( r ) ⊤ ¯ X t + D i t ( r ) ⊤ G DD ,i ( t ) ¯ D i t dt + X T ( r ) ⊤ G X X ,i ( T ) ¯ X T + ¯ G X,i T + G X,i T ( r ) ⊤ ¯ X T , (B.16) K ( r, s ) := Z T max( r,s ) X t ( r ) ⊤ G X X ,i ( t ) X t ( s ) + X t ( r ) ⊤ G X,i t ( s ) + G X,i t ( r ) ⊤ X t ( s ) + D i t ( r ) ⊤ G DD ,i ( t ) D i t ( s ) dt + X T ( r ) ⊤ G X X ,i ( T ) X T ( s ) + X T ( r ) ⊤ G X,i T ( s ) + G X,i T ( r ) ⊤ X T ( s ) . (B.17) Tilted conditional FOC. Since C i is quadratic in W , the w eigh t Z i tilts a Gaussian measure b y a quadratic form, preserving Gaussianity . Setting δ J i θ i ,t ( v ) = 0 for all F i t - measurable v and applying the tow er prop ert y giv es G DD ,i ( t ) D i t + E Q i M i t F i t = 0 , E Q i [ · | F i t ] := E [ Z i ( · ) | F i t ] E [ Z i | F i t ] , whic h has the structure of ( B.8 ) under the tilted measure. Risk-adjusted noise-state. Since M i t is linear in W with deterministic k ernels, the FOC reduces to computing the tilted conditional mean c W i,θ t := E Q i [ W r | F i t ]. Under the deterministic-k ernel profile, L ( W | F i t ) is Gaussian with mean m t := c W i t and deterministic co v ariance C t := C i t . The quadratic tilt shifts this to C − 1 t,θ = C − 1 t − θ i K t , m t,θ = C t,θ ( C − 1 t m t + θ i k t ) , pro vided I − θ i C 1 / 2 t K t C 1 / 2 t ≻ 0 (satisfied for | θ i | small or T short). Here C t and K t act as integral op erators on L 2 ([0 , t ]; R ( n +1) d ), so ( I − θ i C t K t ) − 1 is the resolven t (Neumann series) ( I − θ i C t K t ) − 1 f = f + θ i C t K t f + θ 2 i ( C t K t ) 2 f + · · · , con v ergen t precisely when ∥ θ i C 1 / 2 t K t C 1 / 2 t ∥ op < 1. Rearranging giv es c W i,θ t = ( I − θ i C t K t ) − 1 ( c W i t + θ i C t k t ) , 41 and substituting in to the tilted F OC yields G DD ,i ( t ) D i t + ¯ H X t + Z T 0 H X t ( r ) d r c W i,θ t ( r ) = 0 , (B.18) where c W i,θ t ( r ) := h ( I − θ i C t K t ) − 1 c W i t + θ i C t k t i ( r ) . (B.19) The risk-adjusted noise-state c W i,θ t differs from the risk-neutral noise-state c W i t in tw o w a ys: the linear kernel k t ( B.16 ) shifts the conditional mean of W in the direction that reduces exp ected cost, while the quadratic kernel K t ( B.17 ) rescales conditional precision through ( I − θ i C t K t ) − 1 , amplifying the w eight on directions of W -space along whic h cost v ariance is large. As θ i → 0, c W i,θ t → c W i t and ( B.18 ) recov ers ( B.8 ). C Endogenous Signal Precision This app endix identifies the obstruction to precision optimization in the multi-pla y er setting. C.1 Wh y precision v ariation is hard In single-agent LQG, the separation principle makes precision optimization straigh t- forw ard: the p olicy gain S ( t ) do es not dep end on signal precision, so the v alue of information can b e computed indep enden tly of the control problem. With m ultiple agen ts and endogenous signals, separation fails (Prop osition 4.6 ): the p olicy k ernel D i t ( u ) dep ends on precision through the information wedge, so the marginal v alue of precision dep ends on the equilibrium. A deep er difficult y concerns the observ ation mo del itself. The observ ation equa- tion ( 3.4 ), d Y i t = Γ i ( t ) X t dt + E i dW t , treats each pla y er’s information channel as exogenously given. This is adequate when the analyst asks: “holding the information structure fixed, what is the equilibrium?” It do es not extend to a play er choosing whic h sources to monitor, b ecause rescaling the gain Γ i → Γ i + δ Γ i c hanges the filtration in a w ay that is not monotone. Concretely , the filtrations generated by Γ i X dt + dW i and (Γ i + δ Γ i ) X dt + dW i 42 are generically incomparable: neither contains the other. A play er op erating at the p erturb ed precision cannot reconstruct the noise-state path c W i t ( · ) they w ould ha v e main tained under the original gain—they ha v e different information, not more infor- mation. This breaks the env elop e argument that makes single-agent rational inatten- tion tractable: the play er at P i + δ P i cannot implement the control they w ould hav e c hosen at P i . The incomparabilit y disapp ears when precision is increased b y adding an indepen- den t source (the Brownian-sheet form ulation of Section 3.2 ). Monitoring an additional c hannel strictly enlarges the filtration, and the marginal v alue of the source is the v alue of optimally exploiting its indep enden t increment. The full rational-inattention game—in which source p ortfolios are chosen endogenously—requires this formulation and is left to future w ork. C.2 T w o c hannels from a precision p erturbation Despite the incomparability , one can compute the first-order effect of a gain p er- turbation on equilibrium ob jects by linearizing the forw ard–bac kward system. The calculation reveals t wo c hannels through which δ P i affects cost. Fix an equilibrium profile and spike-perturb pla y er i ’s gain at time t 0 . By the en v elop e theorem, δ D i has no first-order cost effect (the FOC is satisfied). But the primitiv e-noise control D i τ ( r ) = D i τ ( r )Π i + R τ 0 D i τ ( u ) F i τ ( u, r ) du resp onds at first order through δ F i : the filtering kernel shifts, changing whic h part of the fixed p olicy kernel is resolved b y the play er’s own information. The v ariation of the unresolved adjoin t decomp oses as δ f H X,i t ( s ) = − Z t s H X,i t ( u ) δ F i t ( u, s ) du | {z } (a) filtering channel + Z T t 0 G i ( t, τ ) g δ D i t ( τ , s ) dτ | {z } (b) equilibrium channel , (C.1) where G i is the cost propagator and g δ D i is the unresolved comp onen t of the con trol v ariation induced by δ F i . Channel (a) resolves more of the fixed adjoint—the standard v alue-of-information effect present in single-agen t problems. Channel (b) arises because the same δ F i shifts the pro jection b oundary , pushing part of D i τ outside the play er’s curren t resolution. This is the equilibrium channel: it op erates through the information wedge, and 43 v anishes precisely when V i t = 0 (exogenous signals, Corollary 4.3 ). Multi-pla y er rational inattention therefore couples the filtering and control problems that separate in single-agen t settings: the marginal v alue of precision dep ends on the equilibrium through the wedge, and optimizing attention requires solving for the equilibrium first. D W ell-p osedness of the deterministic impulse-resp onse fixed p oin t This app endix form ulates the equilibrium as a dynamic programming problem on the impulse-resp onse state space, records the a priori b ounds that follow from the pro jection structure of the filtering map, and establishes w ell-p osedness: con traction for short horizons, existence for arbitrary horizons. Notation. C denotes a generic constan t dep ending on ( n, d, L, λ ); C ( M ) when it also dep ends on a p olicy-norm b ound M . D.1 Standing assumptions Assumption D.1. Ther e exist L > 0 and λ > 0 such that, for al l t ∈ [0 , T ] and al l i , ∥ A ( t ) ∥ + ∥ Σ( t ) ∥ + ∥ P i ( t ) ∥ + ∥ G X X ,i ( t ) ∥ + ∥ ¯ G X,i t ∥ + ∥ G X,i ( t, · ) ∥ L ∞ + ∥ G X X ,i ( T ) ∥ + ∥ ¯ G X,i T ∥ + ∥ G X,i ( T , · ) ∥ L ∞ ≤ L and G DD ,i ( t ) ⪰ λ I d . D.2 The k ernel state space and its dynamics A t time t the kernel state is Z t := ¯ X t , X t ( · ) , { F j t } n j =1 ∈ R d × L 2 ([0 , t ]; R d × ( n +1) d ) × n Y j =1 L 2 sym ([0 , t ] 2 ; R ( n +1) d × ( n +1) d ) . (D.1) The unresolv ed kernel f X j is not a state v ariable; it is determined algebraically from ( Z t ) by f X j t ( u ) = X t ( u )( I − Π j ) − Z t 0 X t ( z ) F j t ( z , u ) dz . (D.2) 44 Under a noise-state linear profile D = { ( ¯ D j , D j ) } n j =1 , the k ernel state evolv es by ˙ ¯ X ( t ) = A ( t ) ¯ X t + P k ¯ D k t , (D.3) ˙ X t ( s ) = A ( t ) X t ( s ) + P k D k t ( s ) , X ( s, s ) = Σ( s ) , (D.4) ∂ t F j t ( u, s ) = f X j t ( u ) ⊤ P j ( t ) f X j t ( s ) , F j 0 = 0 , (D.5) with b oundary F j t ( u, t ) = f X j t ( u ) ⊤ Γ j ( t ) E j , and primitive-noise con trol D k t ( s ) := D k t ( s )Π k + R t 0 D k t ( u ) F k t ( u, s ) du . The p olicy D en ters ( D.3 )–( D.4 ) but do es not enter ( D.5 ) directly: F j dep ends on D only through X via ( D.2 ). D.3 The Hamilton–Jacobi–Bellman equation Since the k ernel-state dynamics ( D.3 )–( D.5 ) are deterministic, the equilibrium con- tin uation cost V i ( t, Z ) satisfies a first-order terminal-v alue PDE (no diffusion term): ∂ t V i + D ¯ X V i · ˙ ¯ X + ⟨ D X V i , ˙ X ⟩ + n X j =1 ⟨ D F j V i , ˙ F j ⟩ + ℓ i ( t, Z , D ) = 0 , V i ( T , · ) = g i ( · ) , (D.6) where ⟨· , ·⟩ denotes the L 2 pairing. Play er i ’s con trol en ters ˙ ¯ X and ˙ X but not ˙ F j , so the Hamiltonian minimization yields ¯ D i t = − ( G DD ,i ( t )) − 1 D ¯ X V i , D i t ( u ) = − ( G DD ,i ( t )) − 1 D X V i ( u ) , (D.7) reco v ering Corollary 4.5 along the equilibrium path. The remaining P j ⟨ D F j V i , ˙ F j ⟩ term captures the indirect cost of opp onen ts’ filter ev olution; differentiating through D i → X → f X k → F k iden tifies the mean information wedge as a shadow price: ¯ V i t = X k = i Z t 0 P k ( t ) f X k t ( z ) ¯ H k,i t ( z ) dz = X k = i ⟨ D F k V i , ∂ X ˙ F k ⟩ . (D.8) The kernel w edge V i t ( r ) admits the same in terpretation with ¯ H k,i replaced by H k,i ( · , · , r ). 45 D.4 A priori b ounds from pro jection structure The filtering k ernel F j t parametrizes a p ortion of the conditional pro jection ( P j t f )( u ) := Π j f ( u )+ R t 0 F j t ( u, s ) f ( s ) ds , an orthogonal pro jection on L 2 ([0 , t ]; R ( n +1) d ) (Remark A.4 ). Lemma D.2 (Pro jection b ounds) . F or e ach j and t ≥ 0 : (i) ∥P j t ∥ op = 1 ; (ii) b oth P j t and I − P j t ar e L 2 -c ontr actions; (iii) ∥F j t ∥ op ≤ 2 wher e F j t := P j t − Π j . Pr o of. Standard prop erties of orthogonal pro jections; (iii) is the triangle inequalit y . Lemma D.3 (Dissipation) . {P j t } t ≥ 0 is non-de cr e asing in the p ositive semidefinite or der, and ∥ f X j ( t, · ) ∥ L 2 ([0 ,t ]) ≤ ∥ X ( t, · ) ∥ L 2 ([0 ,t ]) for al l t . Pr o of. Equation ( D.5 ) adds a p ositiv e semidefinite increment to F j t , so P j t is non- decreasing. Since f X j ( t, · ) = ( I − P j t ) X ( t, · ) by ( D.2 ), Lemma D.2 (ii) gives the b ound. These b ounds hold uniformly in the precision paths, the p olicy profile, and the horizon T . The quadratic right-hand side of ( D.5 ) is self-limiting: as P j t gro ws to w ard I , the complementary pro jection contracts, driving f X j → 0 and decelerating F j . This prev en ts finite-time blowup despite the quadratic nonlinearit y—the noise- state analogue of Kalman v ariance collapse. D.5 W ell-posedness Definition D.1. B M T := n D = { ( ¯ D i , D i ) } n i =1 : ¯ D i ∈ C ([0 , T ]; R d ) , D i ∈ L ∞ (∆ T ) , ∥ D ∥ ≤ M o , where ∥ D ∥ := max i ( ∥ ¯ D i ∥ C + ∥ D i ∥ L ∞ ). Definition D.2 (Best-resp onse op erator) . T ( D ) := n ( − ( G DD ,i ) − 1 ¯ H X,i, D , − ( G DD ,i ) − 1 H X,i, D ) o n i =1 , where the adjoints solv e the backw ard system of Theorem 4.2 at the forward en viron- men t induced by D . Fixed p oin ts are Nash equilibria (Corollary 4.5 , Remark 4.3 ). The following estimates are pro ved b y Gr¨ on w all arguments on the forward sys- tem ( D.3 )–( D.5 ) (using the a priori b ounds of Lemmas D.2 – D.3 to con trol the quadratic nonlinearit y in ( D.5 )) and b y bac kw ard Gr¨ on wall on the linear adjoin t system ( B.11 )– ( B.14 ) (using Cauc hy–Sc hw arz on the b elief-adjoin t coupling integrals R t 0 P k f X k ¯ H k,i dz ). 46 Prop osition D.4 (Bounds and Lipschitz contin uity) . Under A ssumption D.1 , for D ∈ B M T : (i) The forwar d system has a unique glob al solution with ∥ ¯ X ∥ C + ∥ X ∥ L ∞ ≤ K fwd , ∥ f X j ( t, · ) ∥ L 2 ≤ K fwd √ T , ∥P j t ∥ op = 1 . (ii) The b ackwar d system has a unique solution with ∥ ¯ H X,i ∥ C + ∥ H X,i ∥ L ∞ ≤ K bwd , and time derivatives b ounde d by C ( M ) K bwd . (iii) Both maps D 7→ ( ¯ X , X , f X j ) and D 7→ ( ¯ H X,i , H X,i ) ar e Lipschitz with c onstants C fwd ( T , M ) and C bwd ( T , M ) r esp e ctively, b oth b ounde d by C ( M ) T e C ( M ) T . Her e K fwd , K bwd ≤ C ( M ) e C ( M ) T . Pr o of sketch. F or the forw ard system: ( ¯ X , X ) solve linear equations with b ounded co efficien ts once D k is con trolled. Since D k in v olves F k through a linear integral, and ∥F k t ∥ op ≤ 2 (Lemma D.2 ), the coupled system for ϕ ( t ) := ∥ X ∥ L ∞ (∆ t ) closes as ϕ ( t ) ≤ C ( M ) + C ( M ) R t 0 ϕ ( r ) dr . F or the Lipschitz b ound: the v ariation δ D k decomp oses in to a direct term b ounded b y C ( M ) ∥ δ D ∥ and an indirect term through δ F k , whic h couples to δ f X k and back to δ X via ( D.2 ). A Gr¨ on wall argumen t on the aggregate Ψ( t ) := ∥ δ X ∥ L ∞ (∆ t ) + max j sup r ≤ t ∥ δ f X j ( r , · ) ∥ L 2 giv es Ψ( T ) ≤ C ( M ) T e C ( M ) T ∥ δ D ∥ ; the factor of T arises b ecause the p olicy enters through integrals of length ≤ T . The backw ard estimates follo w from linearity of the adjoin t system, Cauc hy– Sc h warz on coupling terms, and backw ard Gr¨ on w all. Theorem D.5 (Short-horizon equilibrium) . Under A ssumption D.1 , ther e exists T ∗ > 0 dep ending only on ( n, d, L, λ ) such that for T ∈ (0 , T ∗ ] , T is a c ontr action on B M 0 T for a suitable M 0 . In p articular, ther e exists a unique Nash e quilibrium in noise- state line ar str ate gies with b ounde d kernels, Pic ar d iter ates c onver ge ge ometric al ly, and the e quilibrium is Nash over the ful l admissible L 2 class. Pr o of. By Prop osition D.4 (iii), Lip( T ) ≤ λ − 1 C ( M 0 ) T e C ( M 0 ) T . Self-mapping ( T : B M 0 T → B M 0 T ) holds b ecause at M = 0 the b elief-adjoin t decouples ( D k ≡ 0 kills the forcing in ( B.12 )), giving finite K bwd (0 , T ); the intermediate v alue theorem yields M 0 . Since M 0 is b ounded as T → 0, c ho osing T ∗ small enough makes Lip( T ) ≤ 1 2 . Ba- nac h’s theorem gives existence, uniqueness, and geometric conv ergence. Corollary 4.5 extends to the full L 2 class. 47 Theorem D.6 (Global existence) . Under A ssumption D.1 , for every T > 0 ther e exists a Nash e quilibrium over the ful l admissible L 2 class. Pr o of sketch. Apply the Schauder fixed-p oin t theorem to T on B M 0 T , w orking in the top ology τ := ( C ([0 , T ]) × L 2 (∆ T )) n . Self-mapping holds by the same argument as ab o v e. τ -closedness of B M 0 T : w eak- ∗ low er semicontin uit y of the L ∞ norm pre- serv es the b ound under L 2 limits. τ -contin uit y of T : on the b ounded set B M 0 T , L 2 -con v ergence of p olicy kernels propagates through the forw ard linear equations (via Cauc hy–Sc hw arz) and the linear backw ard system. τ -precompactness of the im- age: the uniform time-deriv ativ e b ound on ¯ H X,i (Prop osition D.4 (ii)) giv es equicon- tin uit y of ¯ D i, new in C ([0 , T ]); the same b ound gives p oint wise-in- u equicontin uit y of D i, new ( t, u ) in t , whic h with the uniform L ∞ b ound yields L 2 -equicon tin uity of t 7→ D i, new ( t, · ) and hence sequential compactness in L 2 (∆ T ) b y the vector-v alued Arzel` a–Ascoli theorem ([ 2 , Theorem 1.3.2]). R emark D.1 (Uniqueness b ey ond the contrac tion regime) . Theorem D.6 gives exis- tence but not uniqueness for T > T ∗ . The dissipation of Lemma D.3 suggests enough structure to preclude multiplicit y , but a proof requires monotonicit y estimates b ey ond the Gr¨ on w all b ounds used here. In Section 2 , Picard iteration conv erges to the same limit from m ultiple initial conditions for all parameter v alues tested. R emark D.2 (Sto c hastic co efficien ts) . If primitiv es dep end on a public factor pro- cess ξ t (e.g. a finite-state Mark o v c hain representing regime switc hes), the k ernel state augmen ts to ( Z t , ξ t ). The pro jection b ounds of Lemmas D.2 – D.3 are algebraic and hold pathwise, so forward well-posedness extends betw een jumps of ξ . Eac h jump triggers a regime transition in which filtering gains, strategies, and the information w edge shift discontin uously , while Z is contin uous across jumps. The backw ard ODE b ecomes a BSDE driven by jumps of ξ ; the Gr¨ on wall argumen ts extend to path wise b ounds conditional on the regime path. E Kyle–Bac k deriv ations This app endix derives the price-impact kernel l ( τ , t ), the first-order condition ( 5.3 ), and the bac kw ard ODE ( 5.4 ), with all opp onen ts’ noise-state linear strategy maps held fixed. 48 E.1 The price-impact k ernel and Kyle’s lam b da A unit spike p erturbation of trader i ’s demand at time t triggers a coupled forw ard resp onse: the mark et maker revises the price, each opp onent revises their estimate, adjusts their trading, and the adjustmen ts feed bac k in to prices. Let δ D Σ ,τ denote the aggregate demand p erturbation and δ w j τ ( u ) the noise-state density p erturbation for observer j . The deviation system is: δ D Σ ,τ = X k = i Z τ 0 D k τ ( u ) δ w k τ ( u ) du, (E.1) ∂ τ δ w 0 τ ( u ) = e C 0 ( τ , u ) ⊤ σ − 1 0 δ D Σ ,τ − Z τ 0 C 0 ( τ , r ) δ w 0 τ ( r ) dr ! , (E.2) ∂ τ δ w k τ ( u ) = e C k ( τ , u ) ⊤ σ − 1 0 δ D Σ ,τ 0 − Z τ 0 C k ( τ , r ) δ w k τ ( r ) dr ! , k = i, (E.3) with initial conditions δ w j t ≡ 0, δ D Σ ,t = 1, and δ I i τ = 0 (the deviator’s o wn inno v ation is unaffected). Equation ( E.1 ) closes the lo op: each opp onent’s noise-state shift propagates through their p olicy k ernel bac k into aggregate demand, whic h in turn shifts the mark et mak er’s and other opp onen ts’ noise-states. Price-impact kernel. Define the price-impact kernel as the price resp onse to a unit demand impulse at time t : l ( τ , t ) := σ V Z τ 0 E V δ w 0 τ ( u ) du, τ ≥ t. (E.4) This is the object ℓ ( t, s ) of the price decomposition ( 5.1 ): the market mak er’s filtering gains are deterministic, so l ( τ , t ) is deterministic. Kyle’s lam b da. Since E V E 0 , ⊤ = 0, the mark et maker learns ab out the fundamen- tal only through drift-based inference, and the instan taneous price impact is l ( t, t ) = λ ( t ) := σ V Z t 0 E V e C 0 ( t, u ) ⊤ du. (E.5) 49 E.2 Leibniz differen tiation and the bac kw ard ODE Differen tiating ( 5.3 ) in t , Leibniz on the impact side pro duces − λ ( t ) D i t plus E [ R T t ∂ l ∂ t ( τ , t ) D i τ dτ | F i t ]. The v alue side requires more care. V alue side. The conditional mispricing H i, v al t = b V i t − P t = σ V E V c W i t ( t ) − c W 0 t ( t ) can b e written as σ V E V Z t 0 " Z t 0 F i t ( u, s ) − F 0 t ( u, s ) du # dW s . The integrand k ernel is deterministic and evolv es through ∂ t F j t ( v , u ) = e C j ( t, v ) ⊤ e C j ( t, u ). Differen tiating b y Leibniz: dH i, v al t = σ V E V Z t 0 " Z t 0 e C i ( t, u ) ⊤ e C i ( t, s ) − e C 0 ( t, u ) ⊤ e C 0 ( t, s ) du # dW s dt + dM t , (E.6) where dM t collects the martingale increment from the b oundary at s = t . The re- maining b oundary term (from the upp er limit of the inner integral) v anishes b ecause E V E i, ⊤ = E V E 0 , ⊤ = 0: neither play er’s observ ation noise correlates with the funda- men tal. T o condition on F i t , note that e C i ( t, · ) is by definition the comp onen t of the drift k ernel that play er i has not resolved—it is orthogonal to F i t . The e C i cross terms therefore v anish under conditioning, and dW s pro jects to d c W i t ( s ), giving E " dH i, v al t dt F i t # = − σ V E V Z t 0 " Z t 0 e C 0 ( t, u ) ⊤ e C 0 ( t, s ) du # d c W i t ( s ) . References [1] George-Marios Angeletos and Alessandro P a v an. Efficien t use of information and so cial v alue of information. Ec onometric a , 75(4):1103–1142, 2007. doi: 10.1111/ j.1468- 0262.2007.00783.x . [2] W olfgang Arendt, Charles J. K. Batt y , Matthias Hieb er, and F rank Neubran- der. V e ctor-V alue d Laplac e T r ansforms and Cauchy Pr oblems , v olume 96 of Mono gr aphs in Mathematics . Birkh¨ auser, 2nd edition, 2011. doi: 10.1007/ 978- 3- 0348- 0087- 7. 50 [3] Kerry Bac k. Insider trading in con tin uous time. The R eview of Financial Studies , 5(3):387–409, 1992. doi: 10.1093/rfs/5.3.387. [4] Dirk Bergemann and Stephen Morris. Ba y es correlated equilibrium and the comparison of information structures in games. The or etic al Ec onomics , 11(2): 487–522, 2016. doi: 10.3982/TE1808. [5] Dirk Bergemann and Stephen Morris. Information design: A unified persp ective. Journal of Ec onomic Liter atur e , 57(1):44–95, 2019. doi: 10.1257/jel.20181489. [6] Dirk Bergemann, Tib or Heumann, and Stephen Morris. Information and volatil- it y . Journal of Ec onomic The ory , 158:427–465, 2015. doi: 10.1016/j.jet.2014.12. 002. [7] Pierre Cardaliaguet, F ran¸ cois Delarue, Jean-Michel Lasry , and Pierre-Louis Li- ons. The Master Equation and the Conver genc e Pr oblem in Me an Field Games , v olume 201 of A nnals of Mathematics Studies . Princeton Universit y Press, Princeton, 2019. [8] Ren´ e Carmona and F ran¸ cois Delarue. Pr ob abilistic The ory of Me an Field Games with A pplic ations , v olume I–I I of Pr ob ability The ory and Sto chastic Mo del ling . Springer, 2018. doi: 10.1007/978- 3- 319- 56436- 4. [9] F. Douglas F oster and S. Viswanathan. Strategic trading when agents forecast the forecasts of others. The Journal of Financ e , 51(4):1437–1478, 1996. doi: 10.1111/j.1540- 6261.1996.tb04075.x . [10] Sanford J. Grossman and Joseph E. Stiglitz. On the imp ossibility of informa- tionally efficient mark ets. A meric an Ec onomic R eview , 70(3):393–408, 1980. [11] Lars Peter Hansen and Thomas J. Sargent. Linear rational exp ectations mo dels for dynamically in terrelated v ariables. In Rob ert E. Lucas, Jr. and Thomas J. Sargen t, editors, R ational Exp e ctations and Ec onometric Pr actic e , volume 1, pages 127–156. Univ ersity of Minnesota Press, Minneap olis, 1981. [12] John C. Harsanyi. Games with incomplete information play ed b y “Ba y esian” pla y ers, I–I II. Part I. the basic mo del. Management Scienc e , 14(3):159–182, 1967. doi: 10.1287/mnsc.14.3.159. 51 [13] Minyi Huang, Roland P . Malham ´ e, and P eter E. Caines. Large p opulation sto c hastic dynamic games: Closed-lo op McKean–Vlasov systems and the Nash certain t y equiv alence principle. Communic ations in Information and Systems , 6 (3):221–252, 2006. [14] Zhen Huo and Naoki T aka y ama. Rational exp ectations models with higher-order b eliefs. W orking pap er, 2023. [15] Emir Kamenica and Matthew Gen tzk ow. Bay esian p ersuasion. A meric an Ec o- nomic R eview , 101(6):2590–2615, 2011. doi: 10.1257/aer.101.6.2590. [16] Kenneth Kasa. F orecasting the forecasts of others in the frequency domain. Journal of Ec onomic Dynamics and Contr ol , 24(5–7):875–902, 2000. doi: 10. 1016/S0165- 1889(99)00085- 6. [17] Dav ar Khoshnevisan. Multip ar ameter Pr o c esses: A n Intr o duction to R andom Fields . Springer, 2002. doi: 10.1007/b97363. [18] Alb ert S. Kyle. Contin uous auctions and insider trading. Ec onometric a , 53(6): 1315–1335, 1985. doi: 10.2307/1913210. [19] Rob ert S. Liptser and Alb ert N. Shiry aev. Statistics of R andom Pr o c esses , vol- ume I–I I. Springer, 2nd edition, 2001. [20] Bartosz Ma ´ cko wiak and Mirk o Wiederholt. Optimal sticky prices under rational inatten tion. A meric an Ec onomic R eview , 99(3):769–803, 2009. doi: 10.1257/aer. 99.3.769. [21] Bartosz Ma´ ck owiak, Filip Mat ˇ ejka, and Mirko Wiederholt. Rational inatten tion: A review. Journal of Ec onomic Liter atur e , 61(1):226–273, 2023. doi: 10.1257/ jel.20211524. [22] Jacob Marschak and Roy Radner. Ec onomic The ory of T e ams . Y ale Universit y Press, New Ha ven, 1972. [23] Stephen Morris and Hyun Song Shin. So cial v alue of public informa- tion. A meric an Ec onomic R eview , 92(5):1521–1534, 2002. doi: 10.1257/ 000282802762024610. 52 [24] Ashutosh Na yyar, Adit y a Maha jan, and Demosthenis T eneketzis. Decen tralized sto c hastic con trol with partial history sharing: A common information approach. IEEE T r ansactions on A utomatic Contr ol , 58(7):1644–1658, 2013. [25] Kristoffer P . Nimark. Dynamic higher order exp ectations. W orking pap er, Cor- nell Universit y , 2017. [26] Roy Radner. T eam decision problems. The A nnals of Mathematic al Statistics , 33(3):857–881, 1962. doi: 10.1214/aoms/1177704455. [27] Giacomo Rondina and T o dd B. W alk er. Confounding dynamics. Journal of Ec onomic The ory , 196:105293, 2021. doi: 10.1016/j.jet.2021.105293. [28] Y uliy Sanniko v. A con tinuous-time v ersion of the principal-agen t problem. The R eview of Ec onomic Studies , 75(3):957–984, 2008. doi: 10.1111/j.1467- 937X. 2008.00486.x. [29] Thomas J. Sargen t. Equilibrium with signal extraction from endogenous v ari- ables. Journal of Ec onomic Dynamics and Contr ol , 15(2):245–273, 1991. doi: 10.1016/0165- 1889(91)90012- P. [30] Thomas C. Sc helling. The Str ate gy of Conflict . Harv ard Universit y Press, Cam- bridge, MA, 1960. [31] Christopher A. Sims. Implications of rational inatten tion. Journal of Monetary Ec onomics , 50(3):665–690, 2003. doi: 10.1016/S0304- 3932(03)00029- 1. [32] Rob ert M. T ownsend. F orecasting the forecasts of others. Journal of Politic al Ec onomy , 91(4):546–588, 1983. doi: 10.1086/261166. [33] Xavier Vives. Information and L e arning in Markets: The Imp act of Market Micr ostructur e . Princeton Universit y Press, Princeton, NJ, 2008. ISBN 978-0- 691-12743-9. [34] Michael W o odford. Imp erfect common knowledge and the effects of monetary p olicy . In Philipp e Aghion, Roman F rydman, Joseph Stiglitz, and Mic hael W o o d- ford, editors, K now le dge, Information, and Exp e ctations in Mo dern Macr o e c o- nomics: In Honor of Edmund S. Phelps , pages 25–58. Princeton Universit y Press, 2003. 53
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment