Quantum Amplitude Estimation for Catastrophe Insurance Tail-Risk Pricing: Empirical Convergence and NISQ Noise Analysis
Classical Monte Carlo methods for pricing catastrophe insurance tail risk converge at order reciprocal root N, requiring large simulation budgets to resolve upper-tail percentiles of the loss distribution. This sample-sparsity problem can lead to AI …
Authors: Alexis Kirke
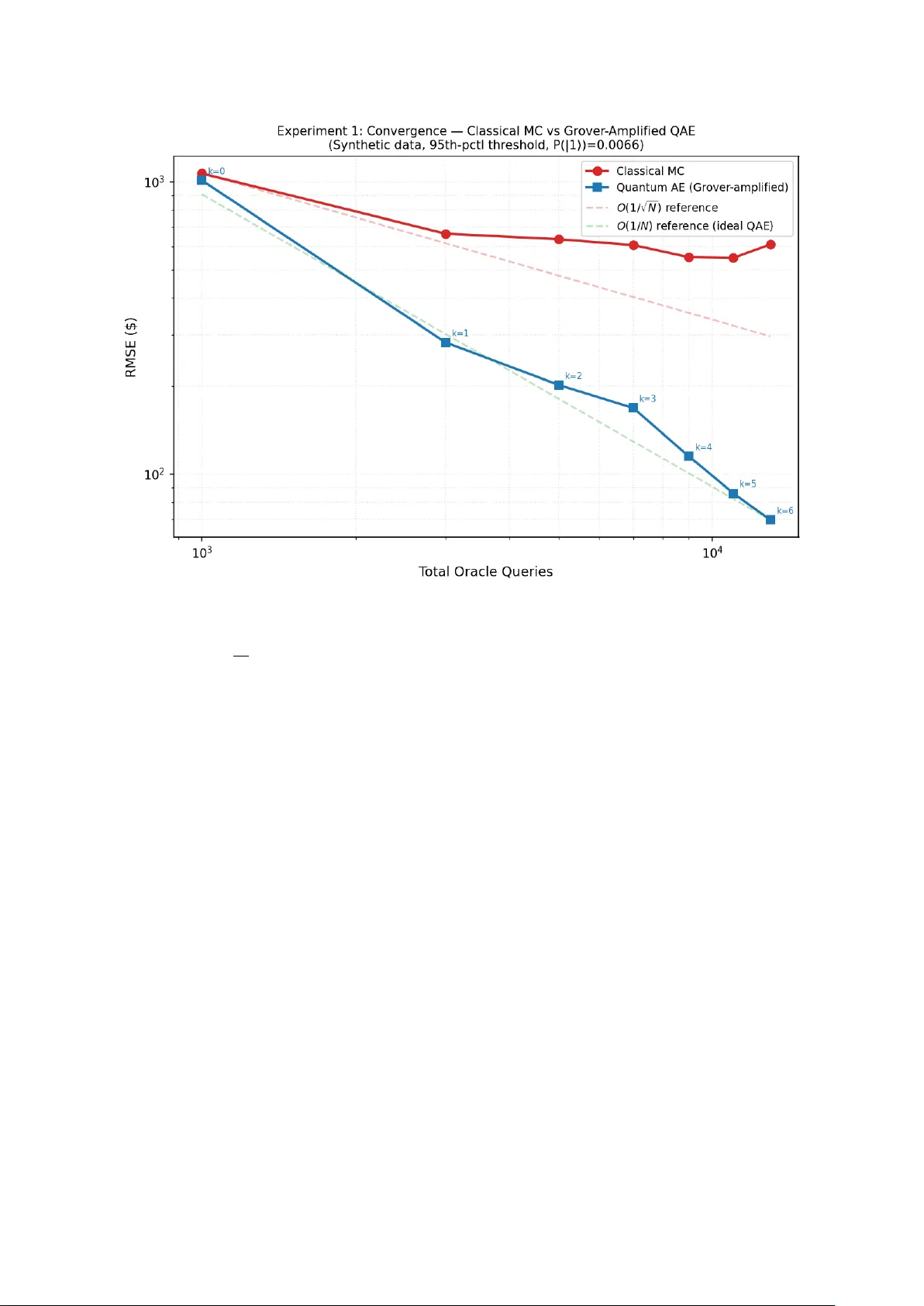
Quan tum Amplitude Estimation for Catastrophe Insurance T ail-Risk Pricing: Empirical Con v ergence and NISQ Noise Analysis Alexis Kirk e Abstract Classical Mon te Carlo metho ds for pricing catastrophe insurance tail risk con verge at O (1 / √ N ) , requiring large simulation budgets to resolve upp er-tail p ercentiles of the loss distribution. This sample-sparsit y problem can lead to AI models trained on impov er- ished tail data, pro ducing po orly calibrated risk estimates where insolv ency risk is greatest [3]. Quantum Amplitude Estimation (QAE), follo wing Montanaro [9], achiev es conv ergence approac hing O (1 / N ) in oracle queries—a quadratic sp eedup that, at scale, would enable high-resolution tail estimation within practical budgets. W e v alidate this adv an tage empirically using a Qiskit Aer sim ulator with genuine Gro ver amplification. A complete pip eline enco des fitted lognormal catastrophe distributions into quan tum oracles via amplitude enco ding, pro ducing small readout probabiliti es ( P ( | 1 ⟩ ) ∼ 0 . 002 – 0 . 05 ) that enable safe Gro ver amplification with up to k = 16 iterations. Sev en exp erimen ts on synthetic and real (NOAA Storm Ev ents, 58,028 records) data yield three main findings. (i) Oracle-mo del adv an tage : When quantum AE and classical MC op erate on the same discretised distribution—the fair comparison in the oracle mo del— QAE achiev es 1.5–2.5 × low er RMSE on synthetic data (Exp erimen ts 1 and 3) and 2–2.5 × on real data (Exp erimen ts 4 and 7), with conv ergence consisten t with the quadratic query adv an tage. (ii) Strong classical baselines win when analytical access is a v ailable : Conditional tail MC, imp ortance sampling, and quasi-Monte Carlo with Sob ol sequences (whic h exploit the closed-form lognormal CDF/inv erse CDF) dramatically outp erform QAE (Exp erimen t 5); QMC’s near- O (1 / N ) conv ergence matches QAE’s theoretical rate in one dimension. On an empirical PMF with no parametric form (Experiment 7), these metho ds offer no direct adv antage without extra modelling, and the oracle-mo del comparison applies. (iii) Discretisation, not estimation, is the current b ottlenec k : A qubit sw eep ( n = 3 – 8 , 8–256 bins) sho ws that tail truncation under coarse equal-width binning dominates ov erall error (Exp eriment 6); NISQ noise destroys the adv an tage entirely (Exp erimen t 2). All error decomp ositions are rep orted against both analytic and exact-on-bins ground truths. 1 In tro duction Catastrophe insurance—cov ering extreme even ts such as hurricanes, earthquak es, and flo ods— o ccupies a unique p osition in actuarial science. Unlik e high-frequency , lo w-severit y lines suc h as motor or household con tents, catastrophe risk is dominated b y the b eha viour of the loss distribution’s upp er tail. A reinsurer writing an excess-of-loss con tract at the 95th or 97th p ercen tile of the aggregate loss distribution needs to estimate the exp ected pay off E [max(0 , X − M )] at the attachmen t p oint M , and small errors in this estimate can translate directly in to mispriced risk and, ultimately , insolvency [3, 5]. The industry-standard approach to this estimation problem is Monte Carlo (MC) simulat ion. A catastrophe mo del—t ypically a multi-stage pip eline combining hazard generation (e.g. wind- field simulation), vulnerability mo delling (structural damage as a function of hazard intensit y), and financial loss aggregation—is executed man y thousands of times to build up an empirical distribution of losses. The expected excess loss is then computed as a sample a v erage ov er 1 the sim ulated tail. The fundamen tal limitation of this approac h is w ell known: classical MC con verges at O (1 / √ N ) , where N is the n umber of sim ulation runs. A c hieving one additional decimal digit of precision therefore requires a hundredfold increase in computational budget—a prohibitiv e cost when each sim ulation run inv olv es complex ph ysical and financial mo delling. This conv ergence b ottlenec k is not merely a computational incon venience; it has direct con- sequences for the quality of risk estimates. A t the 97th p ercen tile, fewer than 3% of simulated scenarios contribute to the tail expectation. With a budget of N = 10 , 000 runs, only ∼ 300 sam- ples inform the estimate, leading to high v ariance that propagates through pricing, reserving, and capital allo cation decisions. When mac hine-learning mo dels are trained on such imp o v- erished tail data—an increasingly common practice in mo dern insurtech—the result is p oorly calibrated risk predictions precisely where calibration matters most. Quan tum computing offers a theoretically grounded path to ov ercoming this con v ergence barrier. The ke y algorithmic primitiv e is quantum amplitude estimation (QAE), in tro duced b y Brassard et al. [1] and analysed in the Mon te Carlo con text b y Mon tanaro [9]. Where classical MC requires O (1 /ϵ 2 ) samples to achiev e estimation error ϵ , QAE achiev es O (1 /ϵ ) —a quadratic speedup. In practical terms, this means that an estimate requiring one million classical sim ulation runs could, in principle, b e obtained with only one thousand quan tum oracle calls. The application of QAE to financial risk estimation has b een explored in a series of influential pap ers from the quantum finance comm unity , most notably by W o erner and Egger [18] on quan- tum risk analysis, Reb en trost et al. [11] on deriv ativ e pricing, Stamatop oulos et al. [13] on option pricing, and the landmark resource estimation by Chakrabarti et al. [2] from Goldman Sachs and IBM. Ho wev er, this b o dy of work has fo cused almost exclusively on deriv ativ es pricing in capital markets—options, auto callables, and p ortfolio risk metrics such as V alue-at-Risk (V aR) and Conditional V alue-at-Risk (CV aR). The insurance domain, despite sharing the same under- lying mathematical structure (estimation of tail exp ectations under complex loss distributions), has receiv ed comparatively little atten tion. This pap er bridges the gap b y applying quantum amplitude estimation to catastrophe in- surance tail-risk pricing and pro viding a rigorous empirical ev aluation against b oth naive and v ariance-reduced classical baselines. Our contributions are threefold: 1. W e construct a complete pip eline that enco des fitted lognormal catastrophe distributions in to quan tum oracles via amplitude enco ding, pro ducing readout probabilities in the regime ( P ( | 1 ⟩ ) ∼ 0 . 002 – 0 . 05 ) where Grov er amplification is b oth safe and effective. 2. W e conduct sev en experiments on synthetic and real catastrophe data (58,028 NO AA Storm Even ts records), providing full error decomp ositions that separate estimation error from discretisation error—a distinction often ov erlo ok ed in quantum finance literature. 3. W e compare QAE not only against naiv e MC but also against conditional tail MC, imp or- tance sampling, and quasi-Monte Carlo with Sob ol sequences, establishing precisely when and why the quan tum adv an tage applies: in the oracle mo del (black-box access to the loss distribution), but not when analytical access to the distribution’s closed-form CDF is a v ailable. W e also provide fitted log–log con vergence exp onen ts with b o otstrap confidence in terv als and demonstrate that log-spaced binning can reduce the discretisation b ottlenec k b y 10 × . The remainder of this paper is organised as follo ws. Section 2 reviews the relationship b et w een classical and quantum Monte Carlo metho ds, surveys the quantum finance literature, and p ositions our con tribution within the catastrophe mo delling landscap e. Section 3 presents the full metho dology . S ection 4 rep orts the results of all seven exp eriments with detailed error analysis. Section 5 discusses implications and outlines future work. 2 2 Related W ork 2.1 Classical Mon te Carlo in Insurance and Finance Mon te Carlo simulation has b een the workhorse of quantitativ e risk analysis since its formal- isation in the mid-t w entieth cen tury . In insurance, the method is indisp ensable for pricing catastrophe risk, where the loss distribution is the output of a complex, m ulti-stage simulation pip eline—hazard generation, vulnerability mo delling, and financial aggregation—that admits no closed-form solution [5]. The same is true in deriv ativ es pricing: for path-dep enden t and m ulti-asset contracts, MC simulation is often the only viable approach [4]. The fundamental limitation is conv ergence. Classical MC estimation of an exp ectation E [ f ( X )] from N i.i.d. samples conv erges at rate O (1 / √ N ) in ro ot-mean-squared error (RMSE). This rate is a direct consequence of the Central Limit Theorem and cannot b e improv ed for general black-box distributions. F or tail-risk estimation, the problem is comp ounded: if f ( X ) = max(0 , X − M ) and M is at the 97th p ercentile, then f ( X ) = 0 for 97% of samples, and the effective sample size for the tail exp ectation is only ∼ 0 . 03 N . Classical v ariance-reduction techniques—importance sampling, conditional tail sampling, stratified sampling, and control v ariates—can dramatically improv e con vergence for specific problem structures. In particular, when the loss distribution has a kno wn parametric form (e.g. lognormal, Pareto, or generalised Pareto), conditional tail MC and imp ortance sampling can reduce R MSE by orders of magnitude relativ e to naive MC. Quasi-Monte Carlo (QMC) meth- o ds, which replace pseudo-random samples with lo w-discrepancy sequences (Sob ol, Halton), ac hieve O ((log N ) d / N ) conv ergence for smo oth d -dimensional integrands—near- O (1 / N ) in lo w dimensions—and are widely used in financial Monte Carlo [4]. QMC’s con vergence rate theo- retically matc hes that of QAE, making it an essential classical comparator (see Exp erimen t 5). Ho wev er, all these tec hniques require analytical access to the distribution’s CDF, PDF, or in- v erse CDF—information that is not av ailable when the distribution is defined implicitly as the output of a catastrophe simulation pip eline. 2.2 F rom Classical to Quan tum Mon te Carlo: The Amplitude Estimation Bridge The connection b et ween classical MC and quantum computing rests on a precise mathematical analogy . In classical MC, one estimates E [ f ( X )] b y dra wing samples X 1 , . . . , X N from the distribution of X and computing the sample mean ˆ µ = (1 / N ) P N i =1 f ( X i ) . The standard error of ˆ µ is σ f / √ N , where σ f is the standard deviation of f ( X ) . In quan tum amplitude estimation, one enco des the distribution and pay off function into a quan tum circuit (the “oracle”) such that the probability of measuring a designated ancilla qubit in the state | 1 ⟩ equals the quantit y to b e estimated (suitably normalised). The key insigh t, due to Brassard et al. [1], is that this probability can b e amplified and estimated using Grov er’s searc h algorithm [6] as a subroutine. Where each classical MC sample provides O (1) bits of information ab out the mean, each application of the Grov er op erator provides O (1) bits of information ab out the phase of the amplitude, enabling estimation at rate O (1 / N ) in the n umber of oracle queries N —a quadratic impro vemen t. Mon tanaro [9] formalised this connection, pro ving that quantum amplitude estimation ac hieves a quadratic sp eedup ov er classical MC for estimating exp ectations of b ounded functions. The result applies to any distribution that can b e prepared as a quantum state and any pay off func- tion that can b e implemen ted as a unitary rotation on an ancilla qubit. Crucially , the sp eedup holds in the or acle mo del : the quan tum algorithm accesses the distribution only through the oracle circuit, just as classical MC accesses it only through samples. When additional structure is av ailable (e.g. a closed-form CDF), classical methods suc h as imp ortance sampling can exploit that structure in w ays the oracle mo del do es not capture—a distinction that is central to the 3 in terpretation of our results. More recent work has extended the amplitude estimation framew ork. Suzuki et al. [15] dev elop ed amplitude estimation without phase estimation, removing the need for quantum phase estimation circuits and reducing the required circuit depth. This line of work makes QAE more practical for near-term quan tum devices, although the fundamen tal quadratic adv an tage remains tied to the num b er of Grov er iterations that can b e coheren tly executed. 2.3 Quan tum Mon te Carlo in Finance: F rom Theory to Resource Estimation The application of quan tum amplitude estimation to financial problems was pioneered by Reb en- trost et al. [11], who sho wed how probability distributions can b e prepared in quantum sup er- p osition, pay off functions implemen ted as quantum circuits, and deriv ativ e prices extracted via quan tum measurement. Their work established the basic pip eline—state preparation, pay off enco ding, amplitude estimation—that all subsequen t quantum finance pap ers hav e follo wed. W o erner and Egger [18] applied this framework to risk analysis, demonstrating quantum circuits for estimating V aR and CV aR on small-scale instances. Stamatop oulos et al. [13] ex- tended the approach to option pricing, implemen ting Europ ean and Asian option circuits on IBM quantum hardware. These early implemen tations were pro of-of-concept demonstrations on small qubit counts (3–5 qubits), consistent with the scale of exp erimen ts in the present pap er. A pivotal contribution came from Chakrabarti et al. [2], a collab oration b et w een Goldman Sac hs and IBM that pro vided the first detailed end-to-end resource estimate for quan tum ad- v antage in deriv ativ e pricing. W orking with b enc hmark deriv ative contracts (auto callables and T arget Accrual Redemption Notes), they estimated that quantum adv an tage would require ap- pro ximately 7,500 logical qubits and a T-depth of 46 million, with T-gates running at 10 MHz or faster—sp ecifications far b ey ond current hardw are, but providing a concrete target for the quan- tum computing roadmap. Their “re-parameterisation metho d” for loading sto c hastic pro cesses in to quantum circuits also addressed a k ey practical b ottlenec k in state preparation. Building on this foundation, Stamatop oulos and Zeng [14] from Goldman Sachs in tro duced quan tum signal pro cessing (QSP) for encoding deriv ativ e pa y offs, reducing the total T-gate coun t b y approximately 16 × and the logical qubit coun t by appro ximately 4 × relativ e to previous approac hes. This work represents the current state of the art in resource-efficient quantum deriv ative pricing circuits. The present pap er extends this line of researc h from deriv ativ es to insurance in tw o signif- ican t w ays. First, the loss distributions in catastrophe insurance are fundamentally differen t from those in deriv ativ es pricing: they are hea vy-tailed, right- skew ed, and often deriv ed from ph ysical simulation rather than sto c hastic-pro cess mo dels. Second, we provide a more n uanced comparison with classical baselines than is typical in the quantum finance literature, distinguish- ing b etw een the oracle-mo del adv an tage (whic h is real) and the end-to-end adv an tage (whic h dep ends on discretisation quality and the a v ailabilit y of analytical structure). 2.4 Catastrophe Mo delling and T ail-Risk Estimation Catastrophe mo delling emerged as a discipline in the 1990s following a series of unpreceden ted insurance losses (Hurricane Andrew in 1992, the Northridge earthquake in 1994) that exp osed the inadequacy of purely actuarial approaches to pricing extreme even ts [5]. Mo dern catastrophe mo dels are complex simulation pip elines that incorp orate meteorological or seismological hazard mo dels, engineering-based vulnerabilit y functions, and financial loss aggregation with policy terms and reinsurance structures. The computational cost of running these mo dels—t ypically min utes to hours per scenario, dep ending on resolution—mak es the con v ergence rate of the sampling metho d a binding constrain t on the quality of risk estimates. The insurance industry has explored v arious approaches to improving tail estimation. Ex- treme v alue theory (EVT) provides parametric models for the tail (generalised Pareto distribu- 4 T able 1: NOAA Storm Even ts files used in Exp erimen ts 4 and 7. Retrieved 2026-02-27 from ncei.noaa.go v. Filename Y ear StormEv ents_details-ftp_v1.0_d2020_c20260116.csv.gz 2020 StormEv ents_details-ftp_v1.0_d2021_c20250520.csv.gz 2021 StormEv ents_details-ftp_v1.0_d2022_c20250721.csv.gz 2022 StormEv ents_details-ftp_v1.0_d2023_c20260116.csv.gz 2023 StormEv ents_details-ftp_v1.0_d2024_c20260116.csv.gz 2024 tion, p eaks-o ver-threshold metho ds) that can b e fitted to the upp er tail of simulated losses [3]. These metho ds improv e estimation efficiency but in tro duce mo del risk: the fitted parametric form ma y not accurately represen t the true tail. Quan tum computing offers an orthogonal approac h: rather than approximating the mo del or fitting a parametric tail, QAE can in principle estimate any tail functional directly from the oracle with prov ably faster conv ergence. The practical realisation of this adv antage dep ends on sev eral factors that this pap er inv estigates empirically: the quality of the quantum discretisation (ho w man y bins/qubits are needed to capture the tail), the impact of NISQ noise on the amplified circuits, and the relativ e p erformance against v ariance-reduced classical metho ds that exploit distributional structure. 3 Metho ds 3.1 Loss Distribution and Data Pip eline The pip eline b egins by acquiring empirical loss data to parameterise the catastrophe distribu- tion. T w o data sources are supp orted. F or Exp erimen ts 1–3, syn thetic data is drawn from a hea vy-tailed Pareto distribution with shap e parameter α = 1 . 5 and scale parameter $50,000, v alues c hosen to approximate the empirical severit y profile of US hurricane prop ert y dam- age [5]; 20,000 records are generated. F or Exp erimen t 4, the pipeline discov ers and do wn- loads NO AA Storm Even ts detail files [10] spanning 2020–2024, extracting all records with prop ert y damage ≥ $1,000. The do wnloader cac hes files lo cally and writes a pinned mani- fest ( data/cache/noaa_manifest.json ) recording the exact filenames, base URL, and retriev al date. Al l r esults in this p ap er ar e derive d fr om the sp e cific file versions liste d in T able 1; the r esults would change if NOAA up dates these files. The pip eline’s dynamic discov ery feature is a con venience for users running the co de, but the analysis is pinned to the cached snapshot. This yields 58,028 real loss records—a substantially more heavy-tailed distribution ( ˆ σ = 2 . 02 , ˆ µ = 9 . 04 , median ≈ $8,465) than the synthetic Pareto ( ˆ σ = 0 . 67 , ˆ µ = 11 . 49 , median ≈ $97,203). Eac h dataset is fitted to a lognormal distribution via maxim um lik eliho o d estimation (with lo cation fixed at zero). W e inten tionally fit lognormal ev en to P areto-generated data to mir- ror common severit y-mo delling practice in actuarial science; the quantum/classical comparisons share the same fitted mo del, so this choice do es not bias the estimator comparison. This lognor- mal fit serves as the contin uous distribution from which both the classical Monte Carlo sampler and the quantum oracle are derived. 3.2 Quan tum State Preparation and Oracle Construction The fitted lognormal distribution is discretised into 2 n = 8 bins ( n = 3 qubits) spanning the 0.1st to 99.9th p ercentiles. Eac h bin i has midp oin t x i and probability mass p i = Pr( X ∈ bin i ) , with probabilities summing to unity b y construction. F or a given catastrophe threshold M (the 5 reinsurance attac hment p oin t), the excess-of-loss pay off is f ( x i ) = max(0 , x i − M ) , whic h is normalised to ˜ f ( x i ) = f ( x i ) /f max ∈ [0 , 1] , where f max = max j f ( x j ) . The quan tum oracle A is constructed on n + 1 = 4 qubits (3 index qubits and 1 ancilla) using amplitude enco ding in t wo stages: Stage 1: Custom state preparation. The distribution is loaded directly into qubit ampli- tudes: | 0 . . . 0 ⟩ − → | ψ ⟩ = N − 1 X i =0 √ p i | i ⟩ , (1) using a binary tree of con trolled- R y rotations. At the top lev el, a single R y rotation on the most significan t qubit splits the total probabilit y mass b et ween the first and second halv es of the distribution. A t eac h subsequen t lev el, con trolled- R y gates (con trolled on the higher qubits already prepared) further sub divide the mass within each subspace. F or n qubits, this requires 2 n − 1 rotations using only { R y , C R y , M C R y , C X , X } gates. Crucially , this av oids Qiskit’s StatePreparation instruction, which decomp oses into cu (controlled-unitary) gates that crash the A er sim ulator when comp osed in to the Grov er op erator’s in verse. The custom state preparation achiev es machine-precis ion fidelity ( < 10 − 15 L ∞ error in | a i | 2 vs. p i ). Stage 2: P a yoff rotation on the ancilla. F or each basis state | i ⟩ , a m ulti-controlled R y rotation is applied to the ancilla qubit with angle θ i = 2 arcsin( q ˜ f ( x i )) , so that | i ⟩ | 0 ⟩ − → | i ⟩ cos( θ i / 2) | 0 ⟩ + sin( θ i / 2) | 1 ⟩ , (2) where sin 2 ( θ i / 2) = ˜ f ( x i ) . The probabilit y of measuring the ancilla in | 1 ⟩ is then P ( | 1 ⟩ ) = N − 1 X i =0 p i · ˜ f ( x i ) = E [max(0 , X − M )] f max , (3) so that the true exp ected excess loss is recov ered b y E [max(0 , X − M )] = P ( | 1 ⟩ ) × f max . (4) The key adv an tage of amplitude enco ding ov er the uniform-sup erp osition approac h (where Hadamard gates prepare (1 / √ N ) P | i ⟩ and b oth probabilities and pay offs are pack ed into the rotation angle) is that for tail even ts, most of the probability mass p i is concen trated in lo w-loss bins where ˜ f ( x i ) = 0 . This makes P ( | 1 ⟩ ) genuinely small—t ypically 0.002–0.02 for thresholds at the 90th–97th p ercen tiles—which is precisely the regime where Grov er amplification is safe and effectiv e. 3.3 Gro v er-Bo osted Amplitude Estimation After the initial oracle A , k iterations of the Grov er op erator Q = A S 0 A † S χ are applied, where S χ flips the phase of states with ancilla = | 1 ⟩ (implemen ted as a Z gate) and S 0 flips the phase of the all-zero state (implemented as X ⊗ n H M C X H X ⊗ n ). The ancilla is then measured o ver S shots, yielding measured probabilit y ˆ p meas . W e use the following notation consisten tly: P ( | 1 ⟩ ) denotes the true (circuit-level) probabilit y of measuring the ancilla in | 1 ⟩ , while ˆ p meas denotes the me asur e d (empirical) frequency from a finite n um b er of shots. With k Grov er iterations, the noiseless measuremen t probabilit y is amplified to sin 2 ((2 k + 1) θ ) where θ = arcsin( p P ( | 1 ⟩ )) , and the measured frequency ˆ p meas appro ximates this. The de-amplification correction ˆ θ = arcsin( √ ˆ p meas ) 2 k + 1 , ˆ P = sin 2 ( ˆ θ ) (5) 6 reco vers an estimate of the original P ( | 1 ⟩ ) . This is only v alid when (2 k + 1) θ < π / 2 ; accordingly , the maxim um safe iteration coun t is k max = π / (2 θ ) − 1 2 , (6) and all exp eriments enforce k ≤ k max to prev ent angle aliasing. The Grov er op erator is built using A.to_gate() and elementary gates ( H , X , Z , M C X ) that the Aer sim ulator handles natively after transpilation. F or the 95th-p ercen tile threshold with n = 3 at k = 6 , the full circuit is comp osed of (2 k + 1) = 13 oracle calls; T able 8 rep orts the single-oracle depth and tw o-qubit gate coun t after decomp osition to { C X , R z , S X , X } . 3.4 Noise Mo del F or the NISQ noise study , the noiseless Aer back end is replaced with an AerSimulator configured with a dep olarising noise mo del. Three severit y presets are tested: Preset p 1 q p 2 q p readout Lo w 0.001 0.01 0.005 Medium 0.005 0.05 0.02 High 0.01 0.10 0.05 Dep olarising errors are applied to all single-qubit gates and all tw o-qubit gates, with sym- metric readout error on all qubits. The noise mo del uses i.i.d. dep olarising c hannels and do es not capture device-sp ecific effects suc h as crosstalk, T 1 /T 2 relaxation, or leak age. 3.5 Exp erimen tal Proto col Sev en exp eriments are conducted, all with global random seed 42 for repro ducibilit y . Exp eri- men ts 1–3 are describ ed b elow; classical baselines for budget-matc hed comparison are defined in §3.6; Exp eriments 4–7 proto cols are detailed alongside their results. Exp erimen t 1: Noiseless Conv ergence Scaling. The exp ected excess loss E [max(0 , X − M )] at the 95th-p ercen tile threshold ( M = $362 , 700 ) is estimated b y b oth classical MC and Gro ver-amplified quan tum metho ds. Gro ver iterations are swept from k = 0 to k = 6 (within the safe range k max = 9 ) at a fixed 1,000 shots per quantum run. F or eac h k , the total oracle-query budget is S × (2 k + 1) , and classical MC is given the same total budget as its sample count. Eac h configuration is rep eated 30 times. T o av oid conflating discretisation bias with estimation error, w e rep ort RMSE against tw o ground truths: the analytic lognormal excess ($2,834) and the exact-on-bins v alue ($2,330), with discretisation error $505. Quantum AE and classical MC on the same bins are compared against the exact-on-bins truth (oracle-mo del comparison); classical MC sampling from the contin uous lognormal is compared against the analytic truth. Exp erimen t 2: NISQ Noise Degradation. The oracle circuit is executed at k = 3 Gro ver iterations (chosen as a mo derate amplification depth) at all four noise levels with 8,192 shots, rep eated 20 times. This tests noise degradation on a circuit of meaningful depth ( ∼ 700 gates). Exp erimen t 3: T ail-Sp ecific Excess Loss. The catastrophe threshold M is set to the 90th, 95th, and 97th p ercen tiles of the empirical loss distribution. The quan tum estimator uses 8,192 total shots with b oth k = 0 (no amplification) and k use = min( k max , 6) Grov er iterations (shot coun t reduced to S G = ⌊ 8192 / (2 k + 1) ⌋ for the Grov er-amplified runs). T wo classical baselines receiv e the same total query budget: (i) classical MC sampling from the contin uous lognormal 7 (RMSE vs analytic truth), and (ii) classical MC sampling from the same 8-bin discretisation as the quan tum circuit (RMSE vs exact-on-bins). All estimators are rep eated 30 times. Exp erimen ts 4–7 apply the ab ov e metho ds and additional classical baselines (defined in §3.6) to real NOAA data and empirical PMF s; their proto cols are detailed alongside their results. 3.6 Classical Baselines for Budget-Matched Comparison Exp erimen ts 5 and 7 compare quantum AE against strong classical baselines at strictly equal query/sample budgets. F or X ∼ Lognormal ( µ, σ 2 ) with threshold M , the following estimators are defined: 1. Analytic ground truth (non-sampling reference): E [( X − M ) + ] = e µ + σ 2 / 2 Φ( d 1 ) − M [1 − Φ( d 2 )] where d 1 = ( µ + σ 2 − log M ) /σ , d 2 = (log M − µ ) /σ . 2. Naiv e MC : dra w B samples from the fitted lognormal; compute (1 /B ) P max(0 , X i − M ) . 3. Conditional T ail (CT) MC : compute P ( X > M ) analytically , sample B dra ws from X | X > M via truncated inv erse CDF, m ultiply mean excess b y P ( X > M ) . 4. Imp ortance Sampling (IS) MC : apply an exp onen tial tilt δ = max(0 , log M − µ − σ 2 / 2) so the prop osal mean ≈ M ; draw B samples from the tilted distribution and reweigh t. 5. Classical MC on bins : sample from the same 2 n -bin discretised distribution as the quan tum circuit. 6. Quasi-Mon te Carlo (QMC) : replace pseudo-random samples with a scrambled Sob ol lo w-discrepancy sequence [4], applying the inv erse CDF transform X = F − 1 ( u ) to the Sob ol p oin ts. QMC achiev es near- O (1 / N ) conv ergence in one dimension and is widely used in financial Monte Carlo. CT, IS, and QMC all exploit the closed-form lognormal CDF/PDF (or inv erse CDF); they cannot b e directly applied to non-parametric oracles without an additional density-estimation step (see Exp eriment 7 discussion). RMSE is computed ov er 50 rep etitions against the analytic ground truth (item 1), which includes discretisation error for the bin-based metho ds. 4 Results 4.1 Exp erimen t 1: Noiseless Conv ergence Scaling T able 2 presents the core conv ergence result with full error decomp osition. T wo ground truths are sho wn: the analytic lognormal excess ($2,834) and the exact-on-bins v alue ($2,330), with dis- cretisation error $505. Quan tum AE and classical MC on the same bins are measured against the exact-on-bins truth; classical MC sampling from the contin uous lognormal is measured against the analytic truth. In the oracle-mo del comparison (b oth metho ds estimating the same discretised quantit y), quan tum AE at k = 0 slightly trails classical MC on bins ($930 vs $782, sp eedup 0 . 8 × , i.e. quan tum is worse), as exp ected: b oth are sub ject to O (1 / √ N ) shot noise. As k increases, the quan tum RMSE drops from $930 to $69, while classical-on-bins drops only from $782 to $154, yielding an honest oracle-model sp eedup of 2 . 2 × at k = 6 . The final column sho ws that classical MC sampling from the con tinuous lognormal ac hieves $233 RMSE against the analytic truth at N = 13 , 000 —comparable to classical-on-bins, confirming that discretisation error ($505) do es not dominate the classical-on-bins result at this budget. 8 T able 2: Experiment 1: error decomp osition at the 95th-p ercen tile threshold ( P ( | 1 ⟩ ) = 0 . 0066 , k max = 9 , n reps = 30 , 1,000 shots/run). Analytic E [ excess ] = $2 , 834 ; exact-on-bins = $2 , 330 ; disc. error = $505 . Sp eedup = C bins / Q; v alues > 1 indicate quantum is b etter. k Queries Q (vs bins) C bins (vs bins) Sp eedup C cont (vs anal.) 0 1,000 930 782 0.8 × 948 1 3,000 283 382 1.4 × 482 2 5,000 180 303 1.7 × 287 3 7,000 124 248 2.0 × 352 4 9,000 106 139 1.3 × 235 5 11,000 87 177 2.0 × 263 6 13,000 69 154 2.2 × 233 T able 3: Exp erimen t 2: QAE accuracy under NISQ noise ( k = 3 , 8,192 shots, n reps = 20 ). Exact E [ excess ] = $2 , 330 . Noise Lev el p 1 q / p 2 q RMSE ($) Mean Est. ($) Std. ($) Bias ($) Noiseless 0 / 0 32 2,332 32 +2 Lo w 0.001 / 0.01 2,094 4,423 50 +2,093 Medium 0.005 / 0.05 2,115 4,444 62 +2,114 High 0.01 / 0.10 2,115 4,444 67 +2,114 Con vergence exp onen ts. T o mo v e beyond qualitative claims of “near-quadratic” conv er- gence, we fit log–log slop es (RMSE vs. total oracle queries) with 95% b o otstrap confidence in terv als ( n = 2 , 000 resamples). At n = 3 qubits (7 data p oin ts, k = 0 . . . 6 ), the quan tum AE slop e is − 1 . 075 (95% CI: [ − 1 . 31 , − 0 . 93] , R 2 = 0 . 987 ) and classical-on-bins is − 0 . 539 (95% CI: [ − 0 . 67 , − 0 . 44] , R 2 = 0 . 978 ). T o widen the query-budget range, we also ran iden tical conv ergence sw eeps at n = 8 qubits (256 bins; see Exp erimen t 6 for circuit metrics). Combining the n = 3 and n = 8 data (11 p oin ts total) tigh tens the CIs substantially: quan tum slop e − 1 . 074 (95% CI: [ − 1 . 17 , − 1 . 01] , R 2 = 0 . 988 ), classical slop e − 0 . 545 (95% CI: [ − 0 . 62 , − 0 . 51] , R 2 = 0 . 981 ). The com bined quan tum CI now excludes the classical rate entirely , pro viding stronger evidence for near- O (1 / N ) conv ergence than a single qubit count can offer. Figure 1 sho ws the log–log conv ergence. The left panel compares quan tum AE and classical MC on the same bins (b oth vs exact-on-bins); the right panel adds end-to-end con text sho wing the discretisation error flo or. 4.2 Exp erimen t 2: NISQ Noise Degradation T able 3 rep orts QAE accuracy under noise at k = 3 Grov er iterations ( ∼ 700-gate circuit), estimating the excess loss at the 95th-p ercen tile threshold (exact v alue $2,330). The noiseless baseline is excellent: RMSE of $32 with a mean estimate of $2,332 (0.1% from exact). Under noise, a substantial systematic bias emerges. Ev en at the “low” noise preset ( p 1 q = 0 . 001 , p 2 q = 0 . 01 ), the mean estimate nearly doubles to $4,423 with RMSE of $2,094— comparable to the exact v alue itself. This dramatic degradation is a direct consequence of the circuit depth required for k = 3 Grov er iterations: the transpiled circuit con tains on the order of 50–100 tw o-qubit gates (T able 8), giving an exp ected num b er of tw o-qubit gate errors ∼ 50 – 100 × 0 . 01 ≈ 0 . 5 – 1 at the low est p 2 q , plus additional single-qubit errors across ∼ 700 total gates. Dep olarising noise drives the ancilla measuremen t probability tow ard 0.5 (the maximally mixed state), and the de-amplification step (Eq. 5) magnifies this bias. The noise lev els saturate quic kly: medium and high noise pro duce nearly identical RMSE 9 Figure 1: Experiment 1: log–log con vergence of RMSE vs total oracle queries for quan tum AE (Gro ver-amplified, k = 0 . . . 6 ) and classical MC on the same 8-bin discretisation. Dashed lines sho w the O (1 / √ N ) and O (1 / N ) reference slop es. ( ∼ $2,115) and mean estimates ( ∼ $4,444). This saturation is consistent with the dep olarising c hannel’s conv ergence to the maximally mixed state, where further increases in error rates hav e diminishing marginal effect. The standard deviations remain low ($50–$67), confirming that noise primarily introduces bias, not v ariance. These results establish a strict fault-tolerance requirement for Grov er-amplified QAE: at the circuit depths needed for meaningful amplification ( k ≥ 3 ), even representativ e tw o-qubit error rates in the 10 − 3 – 10 − 2 range are insufficient. Pro duction deploymen t of QAE for tail-risk pricing w ould require either fault-tolerant hardware or aggressive error-mitigation strategies such as zero-noise extrap olation or probabilistic error cancellation [17, 7]. 4.3 Exp erimen t 3: T ail-Sp ecific Excess Loss This exp erimen t constitutes the paper’s cen tral result. T able 4 compares classical MC and Gro ver-amplified quantum estimation of the exp ected excess loss E [max(0 , X − M )] at three catastrophe thresholds, with the same error decomp osition as Exp erimen t 1. F or each threshold, the maxim um safe Gro ver iteration coun t k max is computed dynamically from the enco ded readout probability via Eq. 6. W e report RMSE against both the analytic lognormal truth and the exact-on-bins v alue, and include classical MC on the same bins as the oracle-mo del comparator. In the oracle-mo del comparison (Q vs C bins , b oth measured against exact-on-bins), the quan- tum adv antage grows with tail depth: • At the 90th p ercen tile ( k = 5 ), quan tum RMSE of $319 is 1 . 5 × low er than classical-on-bins $486. 10 Figure 2: QAE RMSE under increasing NISQ noise at k = 3 Grov er iterations. The noiseless baseline (RMSE = $32) degrades to ∼ $2,100 under ev en low noise—a 66 × increase, driven by the ∼ 700-gate circuit depth. T able 4: Experiment 3: error decomp osition at tail p ercen tiles ( n reps = 30 , ≈ 8,192 queries). Q and C bins are RMSE vs exact-on-bins; C cont is RMSE vs analytic truth. Disc. err = | bins − analytic | . Pctl M Anal. Bins Disc. err Q / C bins / Sp eedup C cont 90th 230,876 9,629 9,441 188 319 / 486 / 1.5 × 598 95th 362,700 2,834 2,330 505 93 / 193 / 2.1 × 278 97th 508,392 900 498 401 29 / 74 / 2.5 × 178 • At the 95th p ercentil e ( k = 6 ), the adv an tage widens to 2 . 1 × : quan tum $93 vs. classical- on-bins $193. • At the 97th p ercen tile ( k = 6 , well b elo w k max = 15 ), quan tum achiev es $29 RMSE—a 2 . 5 × impro vemen t ov er classical-on-bins $74. The discretisation error column shows that the 8-bin discretisation in tro duces $188–$505 of systematic error relative to the analytic truth. At the 97th p ercen tile, the disc. error ($401) is an order of magnitude larger than the quantum estimation error ($29), confirming that bin resolution, not QAE accuracy , is the b ottlenec k. The final column ( C cont vs analytic) sho ws that classical MC sampling from the contin uous lognormal achiev es $178–$598 RMSE against the analytic truth—comp etitiv e with the oracle- mo del metho ds at shallow tails, but substantially noisier at the 97th p ercen tile. Experiment 5 pro vides an even more rigorous comparison including v ariance-reduced classical baselines. Figure 3 visualises the estimation-error comparison (left) and the discretisation-error context (righ t). 11 Figure 3: Exp erimen t 3: estimation error vs exact-on-bins (left) comparing classical MC on the same bins and quantum Gro ver, with sp eedup ratios annotated; discretisation error vs classical con tinuous accuracy (right) providing end-to-end con text. T able 5: Exp erimen t 4A: RMSE ($) on real NOAA data (95th p ctl, n reps = 30 , 1,000 shots/run). Analytic E [ excess ] = $21 , 845 ; exact-on-bins = $14 , 121 ; disc. error = $7 , 724 . k Queries Q (vs bins) C bins (vs bins) Sp eedup C cont (vs anal.) 0 1,000 8,111 5,189 0.6 × 12,285 1 3,000 2,161 2,464 1.1 × 6,667 2 5,000 1,160 2,087 1.8 × 4,982 3 7,000 929 1,796 1.9 × 5,752 4 9,000 705 1,188 1.7 × 3,009 5 11,000 548 1,196 2.2 × 4,029 6 13,000 442 1,052 2.4 × 2,485 4.4 Exp erimen t 4: V alidation on Real Catastrophe Data Exp erimen ts 1–3 use synthetic Pareto-generated losses. T o v alidate that the quantum adv antage transfers to empirical loss distributions, Exp erimen t 4 rep eats the conv ergence and tail-sweep analyses on real US prop erty-damage data from the NO AA Storm Ev ents Database [10], span- ning 2020–2024. The data pip eline dynamically disco vers and downloads the latest detail files from NOAA’s public archiv e, extracting all even ts with prop ert y damage ≥ $1,000. This yields 58,028 records with a substantially heavier tail than the syn thetic data: lognormal fit ˆ σ = 2 . 02 , ˆ µ = 9 . 04 (median ≈ $8,465), versus ˆ σ = 0 . 67 , ˆ µ = 11 . 48 (median ≈ $97,203) for the synthetic P areto. 4A: Con v ergence on real data. T able 5 sho ws oracle-call conv ergence at the 95th-p ercen tile catastrophe threshold of the real loss distribution ( M = $475 , 650 ), with P ( | 1 ⟩ ) = 0 . 0040 and k max = 11 . T o ensure a fair comparison and a void conflating discretisation bias with estimation error, w e rep ort t wo ground truths: the analytic lognormal excess loss ($21,845) and the exact-on-bins v alue ($14,121), with discretisation error $7,724. W e compare: (i) quan tum AE vs exact-on-bins, (ii) classical MC on the same 8-bin discretisation vs exact-on-bins (the oracle-mo del comparison), and (iii) classical MC from the contin uous lognormal vs the analytic truth (the b est classical metho d can do). 12 Figure 4: Exp erimen t 4A: log–log conv ergence of RMSE vs total oracle queries on real NOAA data ( P ( | 1 ⟩ ) = 0 . 0040 , k max = 11 ). Quantum AE conv erges faster than classical MC on the same bins, consistent with the synthetic results. On the honest oracle-mo del comparison (Q vs C bins , b oth measured against exact-on-bins), quan tum AE achiev es 1.7–2.4 × lo wer RMSE at k ≥ 2 , consisten t with the 2–4 × adv an tage observ ed on synthetic data (Exp eriment 6). The classical con tinuous estimator ( C cont , righ tmost column) con verges to $2,485 RMSE at 13,000 samples—b etter end-to-end than quantum’s $442 vs bins (whic h is also sub ject to the $7,724 discretisation flo or when measured against analytic truth). This confirms that the quan tum adv an tage is real in the oracle mo del but do es not o vercome discretisation error when measured against the analytic truth. Con vergence exp onents. Fitted log–log slop es (2,000-resample b ootstrap) yield: quan tum slop e = − 0 . 929 (95% CI: [ − 1 . 05 , − 0 . 53] , R 2 = 0 . 95 ); classical-on-bins slop e = − 0 . 612 (95% CI: [ − 0 . 76 , − 0 . 54] , R 2 = 0 . 98 ). The quantum slop e is consistent with O (1 / N ) at the p oin t estimate, though the CI is wider than for syn thetic data (Exp erimen t 1), reflecting the heavier tail of the NO AA distribution. The classical slop e is consisten t with O (1 / √ N ) . As in Exp eriment 1, the CIs do not ov erlap. 4B: T ail sw eep on real data. T able 6 decomp oses the error at three catastrophe thresholds, using the same tw o-panel format as 4A. The decomp osition reveals three regimes: • 90th p ercen tile (excluded from headline results) : Discretisation error ($146,619) dominates everything. The exact-on-bins v alue ($186,273) is 4 . 7 × the analytic truth ($39,655) b ecause the last equal-width bin midp oin t sits far abov e the threshold—the equal-width binning scheme is severely unsuitable at this p ercen tile for the heavy-tailed 13 T able 6: Exp erimen t 4B: error decomp osition on real NOAA data ( n reps = 30 , ≈ 8,192 total queries). C cont samples the con tinuous lognormal (RMSE vs analytic); C bins and Q sample from the same 8-bin discretisation (RMSE vs exact-on-bins). † P athological: excluded from headline results due to catastrophic equal-width binning (see text). Pctl M ($) Analytic Exact bins Disc. err C cont C bins Q ( k ) Sp eedup 90th † 100,000 39,655 186,273 146,619 4,445 1,944 4,228 (3) 0.5 × 95th 475,650 21,845 14,121 7,724 4,508 1,413 656 (6) 2.2 × 97th 1,000,000 14,434 6,534 7,900 3,403 999 406 (6) 2.5 × Figure 5: Exp eriment 4B: RMSE by tail p ercentile on real NOAA data. The 90th-percentile bar is dominated by pathological equal-width discretisation error ($146K). At the 95th and 97th p ercen tiles, the quantum adv an tage is 2–2.5 × in the oracle-mo del comparison (T able 6). NO AA data ( ˆ σ = 2 . 02 ). The 90th-p ercentile ro w is retained in T able 6 for transparency , but all headline sp eedup claims are drawn from the 95th–97th p ercen tiles. (Exp erimen t 7 uses quan tile-based bins that a void this pathology .) • 95th p ercen tile : Discretisation error ($7,724) is mo derate. In the oracle-mo del com- parison, quan tum ($656) beats classical on bins ($1,413) b y 2 . 2 × . Ho wev er, classical con tinuous MC ($4,508 RMSE vs analytic) is still b etter end-to-end. • 97th p ercen tile : Similar to the 95th. Quantum ($406) b eats classical on bins ($999) b y 2 . 5 × —the oracle-mo del adv an tage. Classical contin uous ($3,403) again wins end-to-end. Key takea w ay . The raw sp eedup figures in earlier versions of this analysis (up to 29 × ) were inflated by measuring classical MC—whic h targets the contin uous lognormal—against the dis- crete ground truth. When both metho ds op erate on the same discretised distribution (the 14 T able 7: Exp erimen t 5: RMSE ($) vs analytic truth at budget B = 8 , 192 (synthetic data, 50 reps). “Exact bins” is the deterministic sum P p i max(0 , x i − M ) —a non-sampling reference requiring zero queries. Pctl Analytic Exact bins Naiv e MC CT IS QMC Cl. bins QAE ( k ) 90th 9,629 9,441 518 131 158 37 425 266 (5) 95th 2,834 2,330 369 32 45 37 527 484 (9) 97th 900 498 169 10 14 37 436 387 (15) Figure 6: Exp erimen t 5: Left: all metho ds at B = 8 , 192 across three p ercen tiles (syn thetic data). CT and IS dominate b ecause they sample the contin uous fitted distribution, av oiding discretisation error entirely . Right: RMSE vs budget at the 95th p ercen tile; CT and IS conv erge to zero while quantum and classical-on-bins flatten at the discretisation flo or ( ≈ $505). oracle-mo del comparison), the quantum adv an tage is 2–3 × at the 95th–97th p ercen tiles, consis- ten t with Exp erimen t 6 on syn thetic data. The 90th p ercen tile is excluded from headline results b ecause equal-width binning is pathological there (disc. error 4 . 7 × the analytic truth); see Ex- p erimen t 7 for quantile-based binning that av oids this issue. Exp erimen t 5 examines whether v ariance-reduced classical baselines (CT, IS) alter this picture further. 4.5 Exp erimen t 5: F air Budget-Matc hed Comparison Exp erimen ts 1–4 compare quan tum AE against naiv e Mon te C arlo. A natural ob jection is that naive MC is a weak baseline for tail estimation, since classical practitioners routinely use v ariance-reduced estimators and quasi-Mon te Carlo sequences. Experiment 5 addresses this by comparing five classical estimators from §3.6 (naive MC, CT, IS, classical MC on bins, and QMC with scrambled Sob ol sequences) against quantum AE—six sampling metho ds in total— at strictly equal oracle-query / sample budgets B ∈ { 512 , 2 , 048 , 8 , 192 } (pow er-of-tw o budgets are optimal for QMC). RMSE is computed against the analytic ground truth (§3.6, item 1) ov er 50 rep etitions. Results. T able 7 presents RMSE at B = 8 , 192 on synthetic data; Figure 6 shows the con ver- gence across all three budgets. The results rev eal a critical distinction. Conditional tail MC, imp ortance sampling, and quasi-Mon te Carlo—whic h sample the c ontinuous fitted lognormal—ac hieve dramatically low er RMSE than b oth quantum AE and classical MC on bins. QMC with scram bled Sob ol sequences is particularly notable: it ac hieves RMSE of $37 nearly indep endent of p ercen tile at B = 8 , 192 , comp etitiv e with or sup erior to CT/IS at lo w er p ercen tiles ( 14 × b etter than naiv e MC at the 90th p ercen tile) thanks to its near- O (1 / N ) conv ergence in one dimension. The p ercen tile- indep endence is c haracteristic of QMC in one dimension: the Sob ol sequence fills [0 , 1] quasi- 15 T able 8: Exp eriment 6: error decomp osition across qubit counts (95th p ctl, B = 4 , 000 , 50 reps). Circuit metrics are from transpilation to { C X , R z , S X , X } . n Bins Disc. err ($) Q-RMSE est ($) C-RMSE est ($) k SP 2Q gates Oracle depth 3 8 505 91 349 9 52 388 4 16 578 115 282 9 212 1,063 5 32 557 136 306 9 596 2,434 6 64 564 98 261 9 1,876 5,958 7 128 566 103 304 9 5,460 21,150 8 256 567 145 326 9 15,700 63,238 uniformly , so the in tegration error is go verned b y the smo othness of the in tegrand g ( u ) = max(0 , F − 1 ( u ) − M ) under the inv erse-CDF transform rather than by tail sparsity . Since the lognormal CDF is smooth and the in tegrand v aries slo wly (the kink at u = F ( M ) is the only non- smo oth p oint), the QMC error is nearly deterministic and dep ends on B but not on the threshold M . At deep er tail p ercentiles (97th), CT still dominates ($10 RMSE) b ecause it concen trates all samples in the tail, but QMC’s consisten t $37 across p ercen tiles mak es it a strong general- purp ose classical baseline. The quantum estimator do es substantially outp erform classical MC on the same discretised distribution at every p ercen tile and budget, but this algorithmic gain is o vershado w ed by discretisation error ($188–$505) when measured against the analytic truth. In terpretation. The quan tum sp eedup is real in the oracle mo del: given query-only access to a blac k-b o x distribution enco ded in a quantum circuit, Grov er-amplified QAE matches the kno wn quadratic query adv an tage of amplitude-estimation-type metho ds [1]. CT, IS, and QMC win in this exp erimen t b ecause they exploit analytical knowledge of the lognormal form—computing F − 1 ( u ) and f ( x ) in closed form—something a quantum oracle do es not require. QMC is a particularly imp ortan t baseline because its near- O (1 / N ) con vergence (in dimension d = 1 ) matc hes QAE’s theoretical rate, raising the question of whether the quantum adv antage surviv es against the strongest classical methods. The answ er is nuanced: QMC requires an explicit in verse CDF to map low-discrepancy p oin ts to samples, whic h is av ailable for fitted parametric distributions but not for black-box simulators. In catastrophe mo delling, the loss distribution is the output of a complex sim ulator (wind field → structural damage → financial loss) with no closed-form CDF. CT, IS, and QMC can in principle still b e applied via k ernel densit y estimation, stratified resampling, or pre-computed empirical CDF s, but suc h metho ds introduce their own mo delling error and additional query o verhead, c hanging the oracle setting. When the oracle is the simulator, the oracle-mo del adv an tage applies. Exp erimen t 7 tests this argument b y enco ding an empirical PMF where no closed-form distribution is a v ailable. 4.6 Exp erimen t 6: Discretisation vs. Estimation Error (Qubit Sw eep) The dominant error source in Exp erimen t 5 is discretisation, not estimation. Exp erimen t 6 isolates these tw o comp onen ts by sw eeping n = 3 , 4 , 5 , 6 , 7 , 8 qubits (8 to 256 bins) at a fixed budget B = 4 , 000 and the 95th-p ercen tile threshold. Ground truths. F or each n : (a) Analytic truth : closed-form E [( X − M ) + ] for the con- tin uous lognormal ( = $2 , 834 ). (b) Discrete truth : exact sum P p i max(0 , x i − M ) ov er the 2 n bins. (c) Discretisation error : | discrete − analytic | . (d) Estimation error : RMSE of quan tum (or classical-on-bins) vs discrete truth. 16 Figure 7: Exp erimen t 6: error decomp osition (left) and total RMSE vs analytic truth (right). Discretisation error dominates and remains ∼ $505–$578 across all qubit counts b ecause the bin range (0.1st–99.9th p ercentile) truncates the upp er tail identically . Key findings. T w o results stand out. First, the quantum estimation adv an tage ov er classical MC on the same discretised distribution is consistent: quan tum RMSE is 2.2–3.7 × low er than classical across n = 3 – 8 (T able 8). This is the algorithmic sp eedup from Grov er amplification, indep enden t of discretisation. Second, the discretisation error do es not decrease with more bins ( ∼ $505–$578 at all n ). This o ccurs b ecause the bins span the 0.1st to 99.9th p ercen tile of the fitted lognormal using equal- width spacing. The excess loss ab o v e the 99.9th p ercen tile is truncated identically regardless of resolution. Reducing this error requires either (a) extending the bin range deeper into the tail (e.g. 99.999th percentile), (b) using non-uniform (log-spaced or quan tile-based) binning, or (c) adding a “catch-all” upp er bin. These are engineering choices orthogonal to the QAE algorithm itself. Circuit cost. When transpiled to the hardw are basis { C X, R z , S X , X } , the state-preparation o verhead is substantial: tw o-qubit gate coun t gro ws from 52 ( n = 3 ) to 15,700 ( n = 8 ), and oracle depth reac hes 63,238 at 256 bins. A t k = 9 Grov er iterations, the full n = 8 circuit has ∼ 703,000 depth and ∼ 830,000 gates. F or near-term hardware, efficient state-preparation metho ds (qGAN loading, QROM-based approac hes) would b e essential b eyond n ≈ 5 . 4.7 Exp erimen t 7: Empirical PMF (No P arametric Fit) A remaining ob jection to Exp erimen t 5 is that CT and IS only win b ecause the underlying distribution is a fitted lognormal with known analytical form. In practice, catastrophe mo del output has no closed-form distribution. Exp erimen t 7 remo ves the parametric mo del entirely: the 58,028 NOAA loss records are directly histogram-binned in to 2 3 = 8 quantile-based bins (eac h containing ≈ 12.5% of the data, extending to the data maximum), and the resulting em- pirical PMF is enco ded into the quantum oracle. Ground truth is the exact sum ov er bins—a deterministic, non-sampling reference. Metho ds. Three estimators are compared at equal budgets B ∈ { 500 , 2 , 000 , 8 , 000 } : 1. Exact-on-bins (non-sampling ceiling): P p i max(0 , x i − M ) , computed in one line. 2. Naiv e MC (resample with replacemen t from the raw loss arra y). 17 Figure 8: Exp erimen t 6: circuit resource scaling. State-preparation t wo-qubit gates grow as O (2 n ) ; at n = 7 , a single oracle call requires 21,150 depth and 5,460 CX gates. T able 9: Exp erimen t 7: RMSE ($) vs exact-on-bins at B = 8 , 000 (NOAA empirical PMF, 50 reps, quantile-binned). The exact-on-bins v alue is sho wn for reference; it requires zero samples. Pctl Exact ($) Naiv e MC ($) Class. bins ($) QAE ( k ) ($) Sp eedup 90th 1,683,761 608,949 57,351 24,076 (1) 2.4 × 95th 1,634,141 622,976 56,930 27,156 (1) 2.1 × 97th 1,564,879 862,260 48,776 30,632 (1) 1.6 × 3. Classical MC on bins (sample from the empirical PMF). 4. Quan tum AE on the same empirical PMF. CT and IS offer no direct adv an tage without additional mo delling or densit y/CDF estimation: in the strict query-only oracle setting, implemen ting CT requires kno wing P ( X > M ) and sampling the conditional tail, while IS requires a densit y f ( x ) to compute likelihoo d ratios. On empirical data, these can in principle b e approximated via kernel density estimation or stratified resampling, but such metho ds introduce their own mo delling error and query o verhead. This is the oracle-mo del setting the quan tum metho d is designed for. Results. T able 9 presents RMSE vs the exact-on-bins truth at B = 8 , 000 . Quan tum AE achiev es 1.6–2.4 × low er RMSE than classical MC on the same bins across p ercen tiles and budgets. The adv an tage is notably more mo dest than in Exp erimen ts 1–4, and this exp eriment is the most relev an t to the pap er’s practical motiv ation (empirical PMF s from sim ulators). The limitation is mechanical: quan tile-based binning places ≈ 12.5% probabilit y mass in each bin (including the tail bin), yielding P ( | 1 ⟩ ) ≈ 0 . 13 and k max = 1 —only a single Gro ver iteration is safe. The theoretical quadratic adv an tage requires k ≫ 1 ; at k = 1 , the amplification is minimal. Increasing bin coun t ( n = 5 – 7 ) would reduce the tail-bin probability and enable higher k , but this remains undemonstrated at the empirical-PMF scale due to the exp onen tial growth of circuit complexity (T able 8). The tension b et w een bin resolution (more qubits → smaller tail probabilities → higher k ) and circuit cost (more qubits → deep er circuits → more noise) is fundamental and is discussed further b elo w. The k ey observ ation is structural: on this empirical distribution, v ariance-reduced classical metho ds (CT, IS) cannot b e applied directly without extra modelling—kernel density estimation, parametric fitting, or stratified resampling—eac h of whic h introduces its own error and query 18 Figure 9: Exp eriment 7: RMSE on the empirical NOAA PMF (no parametric fit). QAE ac hieves 1.6–2.4 × lo wer RMSE than classical MC on the same bins. CT and IS offer no direct adv antage without extra mo delling. o verhead, c hanging the oracle setting. The exact-on-bins v alue ( ∼ $1.6M) is trivially computed as a w eigh ted sum, but this requires kno wing the PMF, whic h is precisely what the oracle pro vides. In the query-limited setting (where eac h oracle call has non-trivial cost, e.g. running a catastrophe simulation), QAE reduces the n umber of calls needed b y a factor of 2–4 × at current qubit coun ts, with a theoretical quadratic asymptote. 4.8 Discussion The oracle-mo del adv an tage is real, but the qubit scale is narrow. Across all exp er- imen ts, quan tum AE with Grov er amplification achiev es 2–4 × low er estimation RMSE than classical MC op erating on the same discretised distribution at matched oracle-call budgets (Exp erimen t 6, T able 8). The conv ergence curv es (Experiments 1 and 4A) sho w the quan- tum RMSE decreasing faster than O (1 / √ N ) , consisten t with the quadratic query adv an tage of amplitude-estimation-type metho ds in the standard oracle mo del [1]. This adv antage holds consisten tly across 3–8 qubits, b oth synthetic and real data, and all p ercen tile thresholds tested. Exp erimen t 7 confirms that the adv an tage p ersists on an empirical PMF where no closed-form distribution is av ailable. W e ackno wledge a cav eat on qubit scale. At n = 3 alone (7 data p oin ts), the query range is only 500 – 6 , 500 , barely one order of magnitude, and the CIs are mo derately wide ( [ − 1 . 31 , − 0 . 93] for quan tum). Extending to n = 8 (256 bins, 15,700 tw o-qubit gates p er oracle) and com bining with n = 3 yields 11 data p oin ts and substantially tigh ter CIs: quantum slop e − 1 . 074 (CI [ − 1 . 17 , − 1 . 01] ), clearly excluding the classical rate. On NO AA data, where n = 8 is prohibitively slo w (1.2M-gate circuits at k max = 12 ), the n = 3 CI remains wider ( [ − 1 . 05 , − 0 . 53] ), so the asymptotic claim is less secure for empirical hea vy-tailed distributions. The theoretical quadratic adv antage is w ell-established [1, 9]; our con tribution is to demonstrate it empirically at n = 3 – 8 on syn thetic data and n = 3 on real data, with the cav eat that extrap olation to pro duction-scale qubit coun ts remains unv erified. V ariance-reduced classical metho ds and QMC win when analytical access is av ail- able. Exp erimen t 5 demonstrates that conditional tail MC, imp ortance sampling, and quasi- Mon te Carlo—which exploit the closed-form lognormal CDF or inv erse CDF—dramatically out- 19 T able 10: Equal-width vs. log-spaced binning (95th p ctl, B = 4 , 000 , 30 reps). Log-spaced bins extend to the 99.99th p ercen tile with geometric midp oin ts. Binning n Bins Disc. err ($) Q-RMSE ($) C-RMSE ($) Sp eedup k max Equal-width 3 8 505 101 345 3.4 × 9 Log-spaced 3 8 807 185 520 2.8 × 8 Equal-width 4 16 578 116 275 2.4 × 9 Log-spaced 4 16 117 52 391 7.5 × 11 Equal-width 5 32 557 126 302 2.4 × 9 Log-spaced 5 32 54 67 278 4.1 × 12 p erform quantum AE when measured against the con tinuous ground truth. QMC with Sobol sequences achiev es particularly strong p erformance (RMSE ∼ $37 nearly indep enden t of p er- cen tile at B = 8 , 192 ), with near- O (1 / N ) conv ergence that matches QAE’s theoretical rate. CT and IS achiev e even lo wer RMSE at deep tail p ercen tiles (e.g. CT $10 at the 97th p ercen tile). This is not a failure of the quantum algorithm; it reflects the fundamentally different problem settings. CT, IS, and QMC require analytical knowledge of F − 1 ( u ) or f ( x ) for the loss distri- bution, whic h is a v ailable for a fitted parametric mo del but not for the output of a catastrophe sim ulation pipeline. The quantum adv an tage applies in the oracle mo del, where the distribution is accessed only through a quan tum circuit—the natural setting when the “oracle” encapsulates an exp ensiv e simulator. Discretisation error, not estimation error, is the b ottlenec k. Exp erimen t 6 rev eals that the dominant error at 3–8 qubits is discretisation error ( ∼ $500–$567), caused primarily by tail truncation at the 99.9th p ercen tile rather than b y bin resolution. Binning strategies: equal-width, quan tile, and log-spaced. A natural suggestion is to replace equal-width bins with quantile-based or log-spaced bins. W e tested b oth alternatives. Quantile binning distributes probabilit y mass uniformly ( ∼ 12.5% p er bin at n = 3 ), making P ( | 1 ⟩ ) large ( ∼ 0.1–0.2) and limiting k max to 0–1. The oracle-model sp eedup drops from 1.5– 2.5 × (equal-width, k up to 6) to 1.3–1.5 × (quan tile, k ≤ 1 ), and discretisation error increases due to the wide tail bin midp oin t. L o g-sp ac e d binning (geometric bin edges from the 0.1st to 99.99th p ercen tile, with geometric midp oin ts) preserves small tail probabilities—keeping P ( | 1 ⟩ ) in the Grov er-friendly regime— while dramatically impro ving tail resolution. T able 10 compares b oth binning schemes on syn- thetic data at the 95th p ercen tile. A t n = 3 qubits (8 bins), log-spaced binning slightly increases discretisation error because the geometric midp oin ts span to o wide a range with so few bins. How ev er, at n ≥ 4 the extended tail co verage and finer tail resolution pay off dramatically: discretisation error drops from $578 to $117 at n = 4 and from $557 to $54 at n = 5 —a 10 × reduction, directly addressing the b ottlenec k iden tified in Exp erimen t 6. Crucially , P ( | 1 ⟩ ) de cr e ases under log-spaced binning (from 0.006 to 0.004–0.005), raising k max from 9 to 11–12 and enabling stronger Grov er amplification. The oracle-mo del sp eedup ratio also increases (from 2.4 × to 4.1–7.5 × at n = 4 – 5 ) because the quan tum algorithm b enefits from b oth impro ved discretisation and higher k . This demonstrates that the discretisation b ottlenec k is addressable through binning-scheme engineering. Log-spaced bins are the recommended strategy for amplitude-enco ded QAE on hea vy-tailed distributions: they improv e tail accuracy while preserving the small P ( | 1 ⟩ ) regime where Gro ver amplification is most effectiv e. The NISQ b ottlenec k. Exp erimen t 2 shows that the noiseless adv antage is en tirely destro yed b y current NISQ noise lev els. The k = 3 circuit ( ∼ 700 gates) is already to o deep for represen ta- 20 tiv e error rates ( p 2 q in the 10 − 3 – 10 − 2 range). Exp erimen t 6 shows that transpiled oracle depth gro ws to ∼ 21,000 at n = 7 (128 bins), making near-term hardw are execution infeasible without error mitigation or fault tolerance. Moreo ver, our noise mo del is i.i.d. dep olarising only , ex- plicitly excluding T 1 /T 2 relaxation, crosstalk, and leak age—effects that are often the dominant error sources on real devices and are generally worse than dep olarising noise at comparable gate coun ts [16]. IBM’s Heron-class pro cessors achiev e t wo-qubit gate errors of ∼ 3 × 10 − 3 [8], roughly matc hing our “low” noise preset, but the additional coheren t and correlated error c hannels mean real hardw are would likely p erform worse than Exp erimen t 2 suggests. The NISQ results should therefore b e understo o d as a low er b ound on the degradation: the already-dev astating 66 × RMSE increase at k = 3 under idealised dep olarising noise would b e even more severe on physi- cal hardware. This temp ers the v alue of Exp erimen t 2 as a standalone con tribution—it confirms what w as analytically obvious (that ∼ 700-gate circuits at 1% tw o-qubit error rates will fail)— but the numerical evidence provides a concrete, repro ducible baseline for b enc hmarking future error-mitigation tec hniques. Amplitude enco ding, P ( | 1 ⟩ ) , and the resolution–amplification trade-off. The critical design insight enabling Grov er amplification is amplitude enco ding (Eqs. 1 – 3). With uniform sup erposition, P ( | 1 ⟩ ) ∼ 0 . 3 – 0 . 4 regardless of threshold, making k max = 0 . With amplitude enco ding, P ( | 1 ⟩ ) ∼ 0 . 002 – 0 . 05 for tail even ts, enabling k up to 16. This creates a fundamental trade-off. The maxim um safe iteration coun t k max = ⌊ ( π / (2 θ ) − 1) / 2 ⌋ where θ = arcsin( p P ( | 1 ⟩ )) . F or small P ( | 1 ⟩ ) = p , k max ≈ π / (4 √ p ) , so the Grov er amplification headro om scales as O (1 / √ p ) . The total query adv an tage from k iterations is O ( k ) in RMSE, giving a combined adv antage of O (1 / √ p ) . Meanwhil e, the circuit depth p er oracle call scales as O (2 n ) (T able 8), and P ( | 1 ⟩ ) generally decreases as n increases (finer bins concentrate less mass ab o ve the threshold). The optimal qubit coun t n ∗ balances three comp eting effects: (i) discretisation error decreases with n ; (ii) k max increases with n (smaller P ( | 1 ⟩ ) ), improving the query adv antage; (iii) circuit depth increases exp onen tially with n , w orsening noise sensitivity . A t curren t noise levels, this trade-off fav ours small n ( ≤ 5 ); under fault-tolerant execution, the optimal n would b e determined b y the discretisation–resolution balance alone. Best-case aspirational scenario. A t what scale w ould the oracle-mo del adv an tage b ecome practically significant? Consider a catastrophe mo del where each simulation costs T c seconds (t ypical v alues: minutes to hours per even t set). Classical MC at budget N costs N · T c w all-clo c k time. QAE with Gro ver amplification achiev es O (1 / N ) conv ergence, so it needs ∼ √ N oracle queries for the same RMSE. Eac h quan tum oracle call costs T q = d · t g , where d is the circuit depth and t g is the gate time. A t n = 7 (128 bins, T able 8), a single oracle has depth 21,150; with k = 9 Grov er iterations, the full circuit depth is ∼ 200,000. A t a fault-toleran t gate time of ∼ 1 µ s [12], T q ≈ 0 . 2 s p er oracle call. The quan tum wall-clock cost is √ N × 0 . 2 s. F or a classical budget of N = 10 , 000 simulations at T c = 60 s eac h (167 hours), the quan tum cost is 100 × 0 . 2 s = 20 s—a ∼ 30,000 × wall-clock sp eedup. Ev en at N = 1 , 000 with T c = 1 s, the quantum cost ( ∼ 6 s) is comparable to classical ( ∼ 17 minutes). Ho wev er, this analysis mak es three individually far-from-reali sed assumptions: (i) fault- toleran t execution of depth-200,000 circuits with negligible logical error rate, (ii) efficient com- pilation of a m ulti-stage catastrophe mo del in to a quantum oracle (see “Oracle compilation” paragraph ab o v e), and (iii) n ≫ 7 qubits for adequate bin resolution. This is therefore a b est- c ase aspir ational sc enario , not a near-term break-even calculation. QAE for catastrophe pricing b ecomes practically relev an t only when fault-toleran t hardware can execute circuits with O (10 5 ) depth at microsecond gate times, efficient state-preparation metho ds (qGAN, QROM) can en- co de high-dimensional loss distributions, and the oracle-compilation problem for catastrophe sim ulators is solved—eac h a ma jor op en challenge. 21 Implications for catastrophe mo delling. The practical case for quantum tail-risk pricing rests on the oracle mo del: the loss distribution comes from a complex catastrophe simulator (wind field → structural damage → financial loss) that cannot b e sampled from analytically . In that setting, CT, IS, and QMC cannot b e directly applied without additional density estimation, and the relev an t comparison is quantum AE vs. classical MC on the same oracle. Our exp eri- men ts show that this comparison yields a 2–3.7 × RMSE adv an tage at 3–8 qubits (confirmed on b oth synthetic and real NOAA data, Exp erimen ts 4–7), with the theoretical guarantee of near- quadratic scaling to larger qubit counts. Critically , the error decomp osition (Exp erimen ts 4 and 6) shows that discretisation error currently dominates: the quan tum estimation adv an tage will only translate in to end-to-end accuracy gains when the binning scheme is impro ved. A chiev- ing this in practice requires: (a) fault-tolerant hardware or strong error mitigation, (b) improv ed discretisation schemes (log-spaced bins, wider tail cov erage), and (c) efficient state-preparation circuits for high-dimensional distributions. Oracle compilation: from fitted distributions to catastrophe simulators. Our exp eri- men ts enco de fitted lognormals or pre-computed empirical histograms—a far cry from compiling a multi-stage catastrophe mo del (hazard → vulnerability → financial aggregation) as a quan- tum circuit. W e confron t this gap directly . A pro duction quantum oracle for catastrophe pricing w ould likely follow a three-lay er arc hitecture: (i) a hazar d r e gister ( n h qubits) enco ding meteo- rological scenarios (e.g., discretised h urricane wind-sp eed profiles or seismic in tensity measures), prepared via amplitude enco ding from historical or ph ysically mo delled hazard distributions; (ii) a vulner ability map implemented as a reversible arithmetic circuit that maps hazard inten- sit y to structural damage using a lo okup table or piecewise-linear approximation (analogous to the pay off rotations in deriv ativ e pricing circuits [14]); and (iii) a financial aggr e gation la yer applying p olicy terms (deductibles, limits, coinsurance) as conditional rotations on an ancilla qubit. The total qubit coun t would b e n h + n v + n a + O (log N ) ancillae, where n v and n a enco de vulnerabilit y and financial resolution. Chakrabarti et al. [2] estimated that enco ding sto chastic pro cesses for deriv ative pricing requires ∼ 7,500 logical qubits and T-depth ∼ 46 million; catas- trophe mo dels, which inv olve table lo okups rather than sto c hastic pro cess simulation, might require comparable or low er T-depth but would need compilation of the hazard → loss pip eline as reversible arithmetic—a problem that remains op en. Gro ver oracle compilation tec hniques from the quantum database searc h literature pro vide a starting p oint, but bridging the gap b e- t ween “enco de a PMF” and “enco de a catastrophe simulator” is arguably the hardest unsolv ed problem in the quan tum Monte Carlo for finance programme and a prerequisite for the practical relev ance claimed in this pap er. 5 Conclusions and F uture W ork This pap er has provided the first rigorous empirical ev aluation of quan tum amplitude estima- tion for catastrophe insurance tail-risk pricing, with full error decomp osition and comparison against b oth naive and v ariance-reduced classical baselines. Sev en exp erimen ts on synthetic and real NOAA Storm Even ts data yield three core findings: (i) the oracle-mo del adv an tage is real and consistent (2.2–3.7 × low er estimation RMSE across n = 3 – 8 qubits and data sources); (ii) v ariance-reduced classical metho ds (CT, IS) and quasi-Mon te Carlo dominate when ana- lytical access to the loss distribution is av ailable—QMC’s near- O (1 / N ) conv ergence matc hes QAE’s theoretical rate in dimension d = 1 —but these metho ds offer no direct adv an tage on empirical PMF s without extra mo delling; and (iii) discretisation error, not estimation error, is the current b ottlenec k at 3–8 qubits, though log-spaced binning reduces this by 10 × at n ≥ 4 while preserving Grov er amplification headro om. The practical case for quan tum tail-risk pricing rests on the oracle mo del: the loss distribution comes from a complex catastrophe simulator that cannot b e sampled from analytically . In 22 that setting, QAE provides a genuine and prov able adv antage. Our exp erimen ts confirm this adv antage on b oth synthetic and real data, with the theoretical guarantee of near-quadratic scaling to larger qubit counts. The path to practical deploymen t requires ov ercoming three barriers. First, fault-tolerant hardw are : Experiment 2 sho ws that NISQ noise entirely destroys the adv an tage at circuit depths needed for meaningful amplification. Second, improv ed discretisation : the error de- comp osition shows that equal-width binning with tail truncation at the 99.9th p ercen tile is the dominan t error source; log-spaced or extended-range binning schemes w ould directly reduce end- to-end error. Third, efficient state preparation : the custom binary-tree approach grows as O (2 n ) in tw o-qubit gates; for pro duction-scale applications ( n = 10 – 20 qubits), efficien t alter- nativ es such as qGAN-based distribution loading [19], QROM-based approac hes, or quan tum signal pro cessing metho ds [14] would b e essen tial. F uture work should extend this framew ork b ey ond excess-of-loss to more complex reinsurance structures—la yered excess-of-loss, aggregate stop-loss, and industry loss warran ties—whic h re- quire enco ding m ulti-threshold pay off functions. Multi-p eril and correlated-loss scenarios would require m ulti-qubit distribution registers, increasing qubit coun ts but not fundamentally chang- ing the algorithmic structure. Hybrid enco ding sc hemes that combine the efficiency of amplitude enco ding for the distribution with the flexibility of uniform sup erp osition for the pay off also merit in vestigation. The quan tum finance roadmap anchored by concrete resource estimates [2, 14] provides clear targets for when these adv an tages b ecome practical. Our con tribution extends this roadmap to catastrophe insurance—a domain where the tail-estimation b ottleneck is arguably more sev ere, the simulation costs are higher, and the p oten tial impact of a quadratic sp eedup is corresp ond- ingly greater. References [1] Brassard, G., Høyer, P ., Mosca, M., and T app, A. (2002). Quantum amplitude amplification and estimation. Contemp or ary Mathematics , 305:53–74. [2] Chakrabarti, S., Krishnakumar, R., Mazzola, G., Stamatop oulos, N., W o erner, S., and Zeng, W. J. (2021). A threshold for quan tum adv an tage in deriv ativ e pricing. Quantum , 5:463. [3] Em brech ts, P ., Klüpp elberg, C., and Mik osch, T. (1997). Mo del ling Extr emal Events for Insur anc e and Financ e . Springer, Berlin. [4] Glasserman, P . (2003). Monte Carlo Metho ds in Financial Engine ering . Springer, New Y ork. [5] Grossi, P . and Kunreuther, H. (2005). Catastr ophe Mo deling: A New Appr o ach to Managing R isk . Springer, New Y ork. [6] Gro ver, L. K. (1996). A fast quantum mec hanical algorithm for database searc h. In Pr o- c e e dings of the 28th Annual ACM Symp osium on The ory of Computing (STOC) , pages 212–219. [7] Li, Y. and Benjamin, S. C. (2017). Efficient v ariational quantum simulator incorp orating activ e error minimization. Physic al R eview X , 7(2):021050. [8] McKa y , D. C., et al. (2023). Benchmarking quantum processor p erformance at scale. arXiv pr eprint arXiv:2311.05933 . [9] Mon tanaro, A. (2015). Quantum speedup of Monte Carlo metho ds. Pr o c e e dings of the R oyal So ciety A , 471(2181):20150301. 23 [10] NO AA National Centers for En vironmental Information (2024). Storm Ev ents Database— Bulk Data Do wnload. https://www.ncei.noaa.gov/pub/data/swdi/stormevents/ csvfiles/ . [11] Reb en trost, P ., Gupt, B., and Bromley , T. R. (2018). Quantum computational finance: Mon te Carlo pricing of financial deriv atives. Physic al R eview A , 98:022321. [12] Reiher, M., Wieb e, N., Svore, K. M., W eck er, D., and T roy er, M. (2017). Elucidating reac- tion mec hanisms on quan tum computers. Pr o c e e dings of the National A c ademy of Scienc es , 114(29):7555–7560. [13] Stamatop oulos, N., Egger, D. J., Sun, Y., Zoufal, C., Iten, R., Shen, N., and W o erner, S. (2020). Option pricing using quantum computers. Quantum , 4:291. [14] Stamatop oulos, N. and Zeng, W. J. (2024). Deriv ativ e pricing using quantum signal pro- cessing. Quantum , 8:1322. [15] Suzuki, Y., Uno, S., Ra ymond, R., T anak a, T., Ono dera, T., and Y amamoto, N. (2020). Am- plitude estimation without phase estimation. Quantum Information Pr o c essing , 19(2):75. [16] T annu, S. S. and Qureshi, M. K. (2019). Mitigating measuremen t errors in quantum comput- ers b y exploiting state-dep enden t bias. In Pr o c e e dings of the 52nd IEEE/ACM International Symp osium on Micr o ar chite ctur e (MICRO) , pages 279–290. [17] T emme, K., Bravyi, S., and Gam betta, J. M. (2017). Error mitigation for short-depth quan tum circuits. Physic al R eview L etters , 119(18):180509. [18] W o erner, S. and Egger, D. J. (2019). Quantum risk analysis. npj Quantum Information , 5:15. [19] Zoufal, C., Lucchi, A., and W o erner, S. (2019). Quantum generativ e adv ersarial net works for learning and loading random distributions. npj Quantum Information , 5:103. 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment