Exploiting Label-Aware Channel Scoring for Adaptive Channel Pruning in Split Learning
Split learning (SL) transfers most of the training workload to the server, which alleviates computational burden on client devices. However, the transmission of intermediate feature representations, referred to as smashed data, incurs significant com…
Authors: Jialei Tan, Zheng Lin, Xiangming Cai
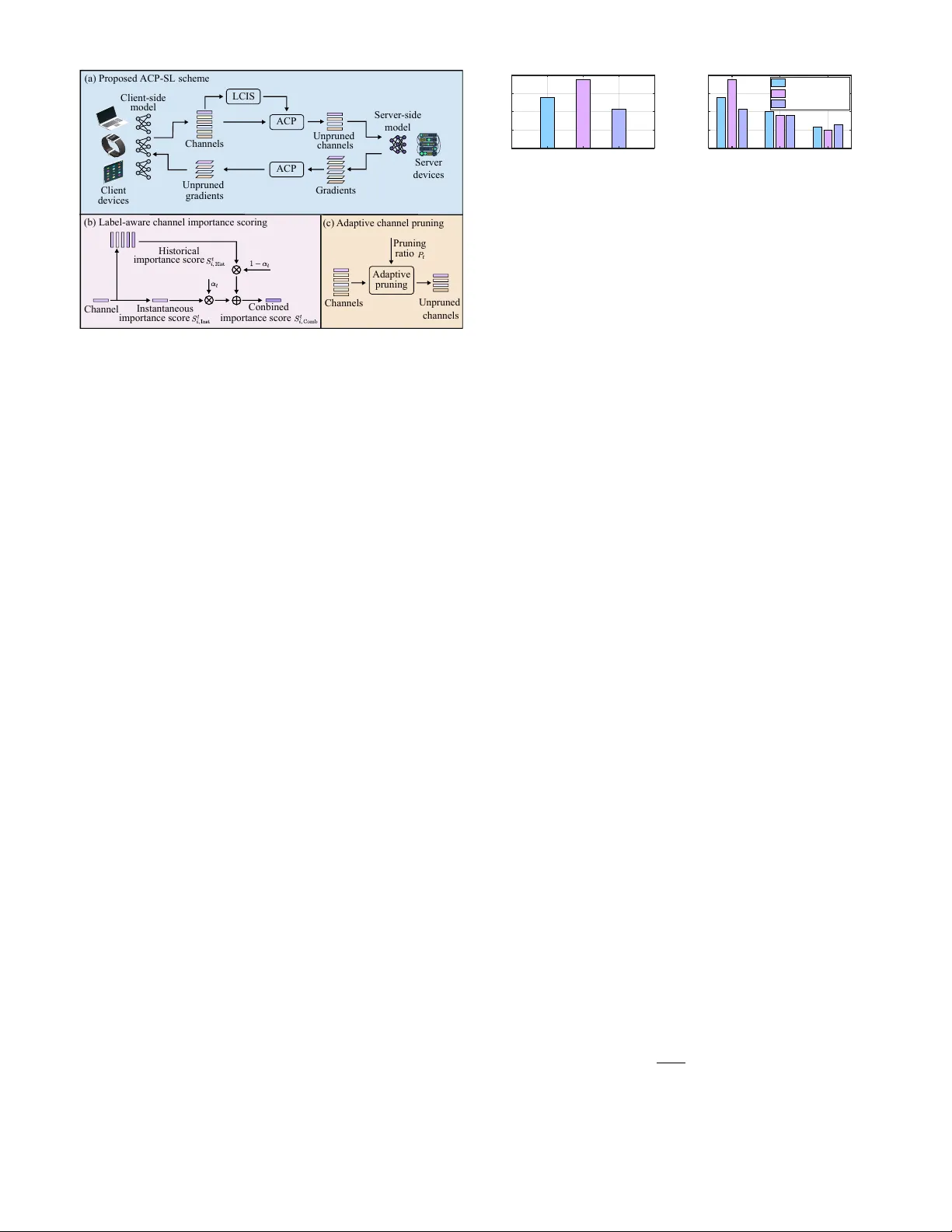
1 Exploiting Label-A ware Channel Scoring for Adapti v e Channel Pruning in Split Learning Jialei T an, Zheng Lin, Xiangming Cai, Senior Member , IEEE, Ruoxi Zhu, Zihan Fang, Pingping Chen, Senior Member , IEEE , and W ei Ni, F ellow , IEEE Abstract —Split learning (SL) transfers most of the training workload to the server , which alleviates computational b urden on client devices. Howe ver , the transmission of intermediate feature repr esentations, referred to as smashed data, incurs significant communication overhead, particularly when a large number of client devices ar e in volv ed. T o address this challenge, we propose an adapti ve channel pruning-aided SL (A CP-SL) scheme. In A CP-SL, a label-aware channel importance scoring (LCIS) module is designed to generate channel importance scores, distinguishing important channels fr om less important ones. Based on these scores, an adapti ve channel pruning (A CP) module is developed to prune less important channels, thereby compressing the corresponding smashed data and reducing the communication overhead. Experimental results show that A CP- SL consistently outperf orms benchmark schemes in test accuracy . Furthermore, it r eaches a target test accuracy in fewer training rounds, thereby reducing communication overhead. Index T erms —Internet of things, split learning, channel prun- ing, communication overhead. I . I N T R O D U C T I O N W ith the proliferation of the Internet of Things (IoT) de- vices, an unprecedented amount of data is being generated. According to the International Data Corporation, the global data v olume is projected to reach approximately 290 zettabytes by 2027 [1]–[4]. This unprecedented v olume of data provides abundant support for machine learning (ML) algorithms [5]– [11]. Con ventional ML schemes typically adopt a centralized learning paradigm, in which massi v e raw data from client devices is transmitted to a central server for model training. Howe ver , this approach exposes raw data, leading to significant priv acy leakage risks, and incurs substantial communication ov erhead, making practical deplo yment challenging [12]. Federated learning (FL) has emerged to address the inherent limitations of centralized learning [13]–[15]. In FL, client devices first train local models using their local datasets and then transmit the updated models to a serv er for model aggregation. As deep learning models continue to grow in size and complexity , the full-model on-device training paradigm in FL becomes increasingly impractical. For example, the recent on-device lar ge model Mistral 7B presented in [16] Jialei T an, Xiangming Cai, and Pingping Chen are with the School of Physics and Information Engineering, Fuzhou Univ ersity , Fuzhou 350108, China (e-mail: tanjlei@163.com; xiangming.cai@fzu.edu.cn; ppchen.xm@gmail.com). Zheng Lin is with the Department of Electrical and Electronic Engineering, The Univ ersity of Hong Kong, Hong Kong. (e-mail: linzheng@eee.hku.hk). Ruoxi Zhu is with the School of Electrical Engineering and T elecommuni- cations, Uni versity of Ne w South W ales Sydne y , Sydney , NSW 2052, Australia (e-mail: ruoxi.zhu@student.unsw .edu.au). Zihan Fang is with the Hong Kong JC STEM Lab of Smart City and the Department of Computer Science, City Univ ersity of Hong Kong, Kowloon, Hong K ong SAR, China (e-mail: zihanfang3-c@my .cityu.edu.hk). W ei Ni is with Data61, CSIRO, Marsfield, NSW 2122, Australia, and the School of Computing Science and Engineering, and the Univ ersity of Ne w South W ales, Kennington, NSW 2052, Australia (e-mail: wei.ni@ieee.org). contains 7 billion parameters, making it challenging to train such models on resource-constrained edge devices via FL. T o overcome the limitations of FL, split learning (SL) par- titions a model along the layer dimension into client-side and server -side components, thereby shifting most of the training workload to the server and reducing the computational burden on client devices [17], [18]. During training, the client and server e xchange intermediate feature representations, referred to as smashed data. As the number of clients increases, the high communication overhead caused by smashed data transmission becomes a bottleneck for SL [19]–[21]. Recent studies have proposed v arious smashed data com- pression techniques to address the above-mentioned issue. For instance, a SplitFedZip scheme was proposed in [22], which employs an auto-encoder architecture to learn more compact intermediate representations. In [23], a binarization SL scheme was proposed to uniformly compress client-side smashed data to 1 bit, thereby reducing communication overhead. Furthermore, a RandT opk SL scheme was proposed in [24], which retains the top- k elements with the largest magnitudes along with a small portion of non-top- k components, enabling communication-efficient SL. Although these schemes alle viate the communication o ver - head caused by large smashed data transmission, they typically apply uniform compression across all channels, ov erlooking the effect of the unequal importance of different channels on training performance. Specifically , some channels include task- relev ant semantic information [25], whereas others are less informativ e or may ev en introduce noise. Ignoring these dis- parities can lead to suboptimal compression, potentially o ver - compressing smashed data associated with important channels while under-compressing smashed data corresponding to less important channels. T o address these challenges, we propose a communication- efficient adapti ve channel pruning-aided SL (A CP-SL) scheme, aimed at reducing communication overhead without degrading its test accuracy . The proposed A CP-SL scheme comprises tw o modules: label-a ware channel importance scoring (LCIS) and adaptiv e channel pruning (A CP). The LCIS module quantifies the importance scores of all channels, which are then used as a criterion for the ACP module to adapti vely adjust the channel- wise pruning ratio at each iteration for channel pruning. Specifically , a larger channel importance score indicates that the channel is important and should be preserved by the A CP module. In contrast, a lower score indicates that the channel is less important, which is pruned by the A CP module. The contrib utions of this paper are summarized as follo ws: 1) W e propose the LCIS module to quantify the impor- tance score of each channel to model training. Using these scores, the LCIS module distinguishes important channels from less important ones. 2 ACP-SL (b) Label-aware channel importance scoring (c) Adaptive channel pruning Channel Historical Conbined Server -side model Unpruned channels Gradients Unpruned gradients Client-side model Channels LCIS Client devices Channels Server devices (a) Proposed scheme importance score Instantaneous importance score importance score ACP ACP Adaptive pruning Unpruned channels Pruning ratio Fig. 1. Block diagram of the proposed ACP-SL scheme. 2) W e propose the A CP module to adaptiv ely adjust the pruning ratio for channel pruning based on channel importance scores, thereby compressing smashed data. The A CP module preserves important channels essential for model training while pruning less important ones, re- ducing communication o verhead caused by transmitting the smashed data associated with these less important channels. 3) Experimental results demonstrate that the proposed A CP-SL achiev es higher test accuracy than the bench- mark schemes. A CP-SL also requires fe wer training rounds to reach a tar get test accuracy compared to the benchmarks, thereby reducing communication overhead. The remainder of this paper is organized as follo ws. Sec- tion II presents the proposed ACP-SL scheme. Section III pro- vides experimental results and discussions. Finally , Section IV concludes the paper . I I . P R O P O S E D AC P - S L S C H E M E Fig. 1 illustrates the block diagram of the proposed ACP- SL scheme. The global model is partitioned into client-side and server-side models, deployed on client devices and a server , respectively . Each A CP-SL iteration consists of six stages: (i) the client performs forward propagation of the client-side model on its local dataset to generate smashed data; (ii) the proposed LCIS module quantifies the importance score of each channel; (iii) the proposed A CP module employs an adaptive pruning ratio to prune channels based on these importance scores; (i v) the smashed data corresponding to unpruned channels is transmitted to the server , where for- ward and backward propagations of the server-side model are performed to compute gradients; (v) the ACP module employs the same pruning ratio to prune these gradients; and (vi) the client receiv es the unpruned gradients, performs local backpropagation, and updates the parameters of the client-side model. The proposed A CP-SL scheme comprises two modules: LCIS and ACP . Specifically , the LCIS module quantifies the importance score of each channel to model training, distin- guishing important channels from less important ones, while the A CP module lev erages these scores to adaptiv ely adjust Channelgr oup 1 2 3 Trainingloss 0 0.6 1.2 1.8 2.4 (a) Training loss of channel groups over a training round Traininground 20 50 80 Trai ni ngl oss 0 0.6 1.2 1.8 2.4 Channelgr oup1 Channelgr oup2 Channelgr oup3 (b) Training loss of channel groups over multiple training rounds Fig. 2. Effect of channel importance on the training loss of SL. the channel pruning ratio. In the following, we elaborate on the principles of the proposed LCIS and A CP modules. A. Label-A ware Channel Importance Scoring In con ventional SL schemes, dif ferent channels generally contribute unequally to model training. After performing the channel group ablation e xperiments, Fig. 2 illustrates the ef fect of channel importance on the training loss of SL, where ResNet-18 is adopted as the network model and MNIST is used as the dataset. As observed in Fig. 2, the importance across channel groups can be highly dif ferent, and the im- portance of each channel group varies across training rounds. Intuitiv ely , communication overhead incurred by transmit- ting excessiv e smashed data corresponding to less important channels limits the practical deployment of conv entional SL schemes. Consequently , pruning these less important channels in the smashed data can reduce transmission overhead and improv e communication ef ficiency . An important channel exhibits high intra-label similarity and lower inter-label similarity . In other words, samples with the same label are tightly clustered, while samples from dif ferent labels are substantially separated. Accordingly , the proposed LCIS module le verages both intra-label similarity and inter- label similarity to quantify the channel importance score, which is then used as a criterion for channel pruning in ACP . Specifically , the proposed LCIS module quantifies the channel importance score through three stages: 1) calculating instan- taneous channel importance score, 2) calculating historical channel importance score, and 3) combining instantaneous and historical scores. These stages are elaborated as follows. 1) Calculation of Instantaneous Channel Importance Scor e: At iteration t , the instantaneous channel importance score consists of two components: the intra-label similarity score and the inter -label similarity score. The intra-label similarity score measures the degree to which samples belonging to the same label are clustered within channel i . For a dataset with K labels, the label-wise mean feature map corresponding to channel i for label n , n ∈ { 1 , . . . , K } , is expressed as ¯ A t i,n = 1 | B n | X b ∈ B n A t i,b , (1) where A t i,b denotes the feature map of sample b corresponding to channel i at iteration t , B n is the set of samples with label n , and | B n | is the number of samples in B n . Thus, the intra- 3 label similarity score between the feature map A t i,b and the mean feature map ¯ A t i,n is formulated as S t i, Intra = 1 K K X n =1 1 | B n | X b ∈ B n ⟨ A t i,b , ¯ A t i,n ⟩ F ! , (2) where ⟨· , ·⟩ F denotes the Frobenius inner product. Finally , S t i, Intra is normalized across all N channels to generate the normalized intra-label similarity score, denoted by ¯ S t i, Intra , which is gi ven by ¯ S t i, Intra = S t i, Intra P N i =1 S t i, Intra . (3) The inter-label similarity score measures the degree of similarity among different labels. It is defined as the av erage similarity score over all pairs of label-wise mean feature maps, formulated as S t i, Inter = 1 K 2 K − 1 X n =1 K X m = n +1 ⟨ ¯ A t i,n , ¯ A t i,m ⟩ F , (4) where ¯ A t i,n and ¯ A t i,m are the mean feature maps correspond- ing to label n and label m , respectively; and K 2 denotes the number of label-wise mean feature maps pairs. Similarly , the normalized inter -label similarity score is obtained as ¯ S t i, Inter = S t i, Inter P N i =1 S t i, Inter . (5) Consequently , the instantaneous importance score of chan- nel i at iteration t is expressed as S t i, Inst = ¯ S t i, Intra − ¯ S t i, Inter . (6) According to (6), a larger intra-label similarity score ¯ S t i, Intra and a lo wer inter-label similarity score ¯ S t i, Inter result in a larger instantaneous channel importance score S t i, Inst for channel i . 2) Calculation of Historical Channel Importance Scor e: The instantaneous channel importance score S t i, Inst is sensitiv e to the instantaneous noise and outliers, which may lead to pruning important channels. Consequently , a historical channel importance score is introduced to alleviate the adverse effect of such incorrect pruning. The historical channel importance score S t i, Hist is quantified as the average of t instantaneous channel importance scores, { S τ i, Inst } t τ =1 , and formulated as S t i, Hist = 1 t t X τ =1 S τ i, Inst . (7) 3) Combination of Instantaneous and Historical Scor es: When model training merely employs the instantaneous chan- nel importance score S t i, Inst , the test accuracy may improve rapidly during the initial phase. Howe ver , the accuracy sub- sequently degrades due to the the adverse effects of instan- taneous noise and outliers, as S t i, Inst is sensiti ve to such perturbations. In contrast, the historical channel importance score S t i, Hist , computed as the av erage of { S τ i, Inst } t τ =1 , is robust to noise and outliers. As a result, the instantaneous channel importance score S t i, Inst and the historical channel Traininground 20 40 60 80 100 T estacc uracy (%) 0 25 50 75 100 S t i; In st S t i; H ist S t i; Co mb (a) T rain loss vs. training round Traininground 20 40 60 80 100 Trainingloss 0 0.2 0.4 0.6 0.8 S t i; In st S t i; H ist S t i; Co mb (b) T est accuracy vs. training round Fig. 3. Effects of the instantaneous channel importance score S t i, Inst , the historical channel importance score S t i, Hist , and the combined channel importance score S t i, Comb on the training loss and test accuracy of SL. importance score S t i, Hist are combined to form the overall channel importance score, e xpressed as S t i, Comb = α t S t i, Inst + (1 − α t ) S t i, Hist , (8) where α t ∈ [0 , 1] denotes the weighting coef ficient. A large coefficient, α t ≥ 1 2 , is applied during the initial phase of training, and a small coefficient, α t < 1 2 , is used in the later phase. The weighting coef ficient is generated using a linearly decaying function, as gi v en by α t = 1 − t T , (9) where t denotes the iteration index, and T represents the total number of iterations. Subsequently , the resulting combined channel importance score S t i, Comb is fed into the ACP module for channel pruning. Fig. 3 sho ws the effects of the instantaneous channel im- portance score S t i, Inst , the historical channel importance score S t i, Hist , and the combined channel importance score S t i, Comb on the training loss and test accuracy of SL. The pruning ratio is set to 0 . 99 . As observed in Fig. 3, the training loss of the model using S t i, Comb consistently decreases compared to those using S t i, Inst and S t i, Hist . Although the model using S t i, Inst achiev es the highest test accurac y at the 20 th training round, its accuracy declines at the 40 th, 60 th, 80 th, and 100 th rounds. In contrast, the test accuracy of the model using S t i, Comb steadily increases, as the combined channel importance score integrates the initial gains of the instantaneous score with the robustness to noise and outliers provided by the historical score. B. Adaptive Channel Pruning Pruning less important channels to reduce the volume of smashed data is essential for achieving communication- efficient SL. Ho wev er , most existing SL schemes employ static compression strategies for all smashed data, without consider- ing the v arying importance of dif ferent channels across itera- tions. This may result in over -compressing the smashed data corresponding to important channels while under-compressing the smashed data corresponding to less important ones. T o address this limitation, we propose the A CP module, which utilizes the combined channel importance scores S t i, Comb to adaptiv ely adjust the channel-wise pruning ratio and compress the smashed data accordingly . At iteration t , the proposed A CP module computes the instantaneous channel group importance score by a veraging 4 the combined channel importance scores S t i, Comb across all N channels, expressed as D t Inst = 1 N N X i =1 S t i, Comb . (10) Subsequently , a historical channel group importance score is defined as the av erage of t instantaneous channel group importance scores, { D τ Inst } t τ =1 , formulated as D t Hist = 1 t t X τ =1 D τ Inst . (11) By dividing the historical channel group importance score D t Hist by the instantaneous channel group importance score D t Inst , a scaling f actor W t is obtained as follo ws: W t = D t Hist D t Inst . (12) Notably , the scaling factor W t is used to adaptiv ely adjust the channel-wise pruning ratio. Specifically , if D t Inst is larger than D t Hist , then W t < 1 , resulting in a reduced pruning ratio to preserve important channels and their corresponding smashed data. Otherwise, the channels are considered less important and are pruned, and the corresponding smashed data is further compressed to reduce communication overhead. T o a void sudden fluctuations in the pruning ratio, it is constrained within an interval of [ P min , P max ] , where P min and P max denote the minimum and maximum pruning ratios, respectiv ely . Thus, the adapti v e channel-wise pruning ratio at iteration t in the proposed A CP module is formulated as [26] P t = max ( P min , min ( W t · P base , P max )) . (13) where P base denotes the pre-defined base pruning ratio. No- tably , the A CP module utilizes the pruning ratio to adap- tiv ely prune less important channels, thereby compressing the smashed data compression and reducing communication ov erhead. I I I . E X P E R I M E N TA L R E S U LT S A N D D I S C U S S I O N S A. Experimental Setup Implementation Details: Experiments are conducted on an NVIDIA R TX 3090 GPU. T o implement the SL en vironment on this single-GPU platform, clients are activ ated one at a time to simulate the training interactions between the client-side and server -side models, thereby ensuring a practical experimental setup. Datasets and Models: Both CIF AR-10 and Fashion-MNIST are used as datasets to e v aluate the performance of the proposed A CP-SL scheme. Experiments are conducted under both independent and identically distributed (IID) and non-IID settings. Under the IID setting, samples are randomly shuffled and uniformly assigned to clients. Under the non-IID setting, heterogeneous client data partitions are generated using a Dirichlet distribution with parameter β = 0 . 5 . The network model is ResNet-18, with the first four layers deployed on all clients as the client-side model and the remaining layers on the server as the server -side model. Traininground 0 20 40 60 80 100 120 T estacc uracy (%) 0 20 40 60 80 ProposedACP-SL Quantiza ti on-SL RandT opk-SL Standard-SL (a) CIF AR-10 (IID). Traininground 0 20 40 60 80 100 120 T estacc uracy (%) 0 20 40 60 80 ProposedACP-SL Quantiza ti on-SL RandT opk-SL Standard-SL (b) CIF AR-10 (non-IID). Traininground 0 20 40 60 80 100 120 82 85 88 91 94 T estacc uracy (%) ProposedACP-SL Quantiza ti on-SL RandT opk-SL Standard-SL (c) Fashion-MNIST (IID). Traininground 0 20 40 60 80 100 120 T estacc uracy (%) 10 30 50 70 90 ProposedACP-SL Quantiza ti on-SL RandT opk-SL Standard-SL (d) Fashion-MNIST (non-IID). Fig. 4. T est accuracy on CIF AR-10 and Fashion-MNIST under IID and non- IID settings. Benchmarks: T o ev aluate the effecti v eness of the proposed A CP-SL, we benchmark it against three baseline schemes: Standard-SL, RandT opk-SL [24], and Quantization-SL [27]. • Standard-SL : The standard SL scheme does not perform channel pruning and transmits the full smashed data without compression. • RandT opk-SL [24]: The RandT opk SL scheme transmits k elements of smashed data, comprising primarily the largest-magnitude elements along with a small fraction randomly selected from the remaining elements. • Quantization-SL [27]: The quantization SL scheme ap- plies quantization-based compression to smashed data. Hyperparameters: In the experiment, the learning rate of the stochastic gradient descent (SGD) is 0 . 00015 . The minimum pruning ratio P min is 0 . 6 , the base pruning ratio P base is 0 . 7 , and the maximum pruning ratio P max is 0 . 8 . The mini-batch size is 128 , and the number of clients is 5 . B. Comparison between A CP-SL and Benc hmarks Fig. 4 compares the proposed A CP-SL scheme with that of benchmarks under both IID and non-IID settings. The proposed A CP-SL scheme consistently achiev es higher test accuracy than all benchmarks. Specifically , on the CIF AR- 10 dataset, the ACP-SL scheme attains test accuracies of ap- proximately 75 . 88 % and 71 . 43 %, surpassing Quantization-SL by about 5 . 11 % and 3 . 72 %, under IID and non-IID settings, respectiv ely . On the Fashion-MNIST dataset, the A CP-SL scheme achieves test accuracies of approximately 92 . 90 % and 85 . 09 %, exceeding Quantization-SL by approximately 1 . 40 % and 7 . 24 %, under IID and non-IID settings, respectiv ely . The proposed A CP-SL scheme achieves the above- mentioned performance gain ov er the benchmark schemes primarily because it adopts the adaptiv e pruning ratio to prune less important channels, thereby compressing the correspond- ing smashed data. Meanwhile, important channels and their associated smashed data are preserved, which helps impro ve model performance, ev entually leading to higher test accuracy . In contrast, Quantization-SL compresses smashed data indis- criminately without considering their relati v e importance. Such indiscriminate compression may degrade model performance and consequently limit achie v able test accurac y . 5 Traininground 0 20 40 60 80 100 120 20 40 60 80 T e stacc uracy (%) Pro pose d LCIS ` 0 -bas ed meth od Ran dom me tho d (a) CIF AR-10. Traininground 0 20 40 60 80 100 120 T e stacc uracy (%) 10 30 50 70 90 Pro pose d LCIS ` 0 -bas ed meth od Ran dom me tho d (b) Fashion-MNIST . Fig. 5. Ablation experiment results of the proposed LCIS on CIF AR-10 and Fashion-MNIST under the non-IID setting. Traininground 0 20 40 60 80 100 120 T estacc uracy (%) 0 20 40 60 80 Prop ose d AC P F -bas ed metho d R -b ased meth od (a) CIF AR-10. Traininground 0 20 40 60 80 100 120 T estacc uracy (%) 10 30 50 70 90 Prop ose d AC P F -bas ed metho d R -b ased meth od (b) Fashion-MNIST . Fig. 6. Ablation experiment results of the proposed ACP on CIF AR-10 and Fashion-MNIST under the non-IID setting. The number of training rounds required to achiev e a target test accuracy is defined as the communication ov erhead of an SL scheme. As illustrated in Figs. 4a and 4b, on the CIF AR-10 dataset under the non-IID setting, the A CP-SL scheme requires about 46 training rounds to reach a test accuracy of 65 %, which is 12 fewer rounds than that required by Quantization- SL. This result indicates that the proposed A CP-SL incurs lower communication o verhead than Quantization-SL on the CIF AR-10 dataset. Similarly , as shown in Figs. 4c and 4d, on the Fashion-MNIST dataset, A CP-SL requires fewer training rounds than Quantization-SL to achiev e test accuracies of 91 % and 75 % under the IID and non-IID settings. C. Ablation Study 1) Effect of LCIS on the P erformance of ACP-SL: Fig. 5 examines the effect of the proposed LCIS on the test accuracy of the proposed A CP-SL scheme. In the ℓ 0 -based method, each channel is assigned to a channel importance score based on the number of non-zero elements in its corresponding feature map. Specifically , the channels corresponding to the feature maps containing more non-zero elements are considered more important and recei ve higher scores, while those corresponding to the feature maps with fewer non-zero elements are regarded as less important and receive lo wer scores. In the random method, a channel importance score is randomly assigned to each channel. In Fig. 5, it is observ ed that the proposed A CP-SL scheme using LCIS achiev es higher test accuracy than both ℓ 0 -based and random methods. The reason is that the random method does not differentiate between important and unimportant channels, and the feature map used in the ℓ 0 -based method is less effecti ve than the label-wise feature map employed in the proposed LCIS. 2) Effect of A CP on the P erformance of ACP-SL: Fig. 6 presents the effect of the proposed ACP on the test accuracy of the proposed ACP-SL scheme. The F -based method uses a fixed pruning ratio for channel pruning, while the R -based method employs a random pruning ratio. As shown in Fig. 6, the ACP-SL scheme using the proposed A CP demonstrates higher test accurac y than the F -based and R -based methods. This is attributed to the fact that the proposed A CP combines both the instantaneous and historical channel group importance scores to generate an adaptiv e pruning ratio for channel pruning, whereas the benchmark methods rely solely on fixed or random pruning ratios, which degrades model performance and decreases test accurac y . I V . C O N C L U S I O N S In this paper , we proposed the A CP-SL scheme to reduce the communication ov erhead incurred by transmitting smashed data. In A CP-SL, the LCIS module was introduced to ev aluate the importance of each channel to model training and as- sign corresponding importance scores. Based on these scores, the ACP module adaptively prunes less important channels, thereby reducing the volume of transmitted smashed data and lo wering communication ov erhead. Experimental results showed that A CP-SL achiev es at least a 3 . 72 % impro vement in test accuracy on the CIF AR-10 dataset compared to the bench- mark schemes. Additionally , A CP-SL reaches a test accuracy of 65 % in approximately 46 training rounds, reducing the required number of rounds by 12 compared to Quantization- SL, to achieve the same accuracy . These results indicate that the proposed A CP-SL ef fectively reduces communication ov erhead while maintaining superior model performance. R E F E R E N C E S [1] J. Rydning, “W orldwide IDC global datasphere forecast, 2023–2027: It’ s a distributed, div erse, and dynamic (3D) datasphere, ” IDC Market Forecast, T ech. Rep. US50554523, Dec. 2023. [2] Z. Lin, G. Zhu, Y . Deng, X. Chen, Y . Gao, K. Huang, and Y . Fang, “Efficient P arallel Split Learning over Resource-Constrained Wireless Edge Networks, ” IEEE T rans. Mobile Comput. , vol. 23, no. 10, pp. 9224–9239, 2024. [3] Z. Fang, Z. Lin, S. Hu, Y . Ma, Y . T ao, Y . Deng, X. Chen, and Y . Fang, “Hfedmoe: Resource-aware heterogeneous federated learning with mixture-of-experts, ” arXiv preprint , 2026. [4] Z. Lin, G. Qu, W . W ei, X. Chen, and K. K. Leung, “Adaptsfl: Adaptive Split Federated Learning in Resource-Constrained Edge Networks, ” IEEE T rans. Netw . , 2025. [5] M. Hong, Z. Lin, Z. Lin, L. Li, M. Y ang, X. Du, Z. F ang, Z. Kang, D. Luan, and S. Zhu, “Conflict-aware client selection for multi-server federated learning, ” arXiv preprint , 2026. [6] Z. Lin, Y . Zhang, Z. Chen, Z. Fang, X. Chen, P . V epakomma, W . Ni, J. Luo, and Y . Gao, “HSplitLoRA: A Heterogeneous Split Parameter - Efficient Fine-Tuning Framework for Large Language Models, ” arXiv pr eprint arXiv:2505.02795 , 2025. [7] J. Peng, Z. Chen, Z. Lin, H. Y uan, Z. Fang, L. Bao, Z. Song, Y . Li, J. Ren, and Y . Gao, “SUMS: Sniffing Unknown Multiband Signals under Low Sampling Rates, ” IEEE T rans. Mobile Comput. , 2024. [8] Z. Zhang, T . Duan, L. W ang, Z. Fang, Z. Lin, Y . Lu, J. W u, X. Du, M. Y ang, Z. Chen et al. , “Transformer -based multipath congestion control: A decoupled approach for wireless uplinks, ” arXiv preprint arXiv:2603.04550 , 2026. [9] Z. Lin, W . W ei, Z. Chen, C.-T . Lam, X. Chen, Y . Gao, and J. Luo, “Hi- erarchical Split Federated Learning: Conv ergence Analysis and System Optimization, ” IEEE T rans. Mobile Comput. , 2025. [10] Z. Fang, Z. Lin, S. Hu, Y . T ao, Y . Deng, X. Chen, and Y . Fang, “Dynamic uncertainty-aware multimodal fusion for outdoor health monitoring, ” arXiv pr eprint arXiv:2508.09085 , 2025. [11] T . Duan, Z. Zhang, Z. Lin, S. Guo, X. Guan, G. W u, Z. Fang, H. Meng, X. Du, J.-Z. Zhou et al. , “LLM-Dri ven Stationarity-A ware Expert Demonstrations for Multi-Agent Reinforcement Learning in Mobile Systems, ” arXiv preprint , 2025. [12] Z. Lin, G. Qu, X. Chen, and K. Huang, “Split Learning in 6G Edge Networks, ” IEEE W ir el. Commun. , 2024. 6 [13] N. Jia, Z. Qu, B. Y e, Y . W ang, S. Hu, and S. Guo, “ A comprehensive survey on communication-efficient federated learning in mobile edge en vironments, ” IEEE Commun. Surveys Tuts. , vol. 27, no. 6, pp. 3710– 3741, Dec. 2025. [14] Z. Fang, Z. Lin, Z. Chen, X. Chen, Y . Gao, and Y . Fang, “ Automated Federated Pipeline for P arameter-Ef ficient Fine-T uning of Large Lan- guage Models, ” IEEE Tr ans. Mobile Comput. , 2025. [15] Z. Lin, Z. Chen, Z. Fang, X. Chen, X. W ang, and Y . Gao, “Fedsn: A federated learning frame work ov er heterogeneous leo satellite networks, ” IEEE T ransactions on Mobile Computing , vol. 24, no. 3, pp. 1293–1307, 2024. [16] A. Q. Jiang, A. Sablayrolles, A. Mensch et al. , “Mistral 7B, ” arXiv pr eprint arXiv:2310.06825 , 2023. [17] J. Zhang, W . Ni, and D. W ang, “Federated split learning with model pruning and gradient quantization in wireless networks, ” IEEE T rans. V eh. T echnol. , vol. 74, no. 4, pp. 6850–6855, Apr. 2025. [18] Z. Lin, Z. Chen, X. Chen, W . Ni, and Y . Gao, “HASFL: Heterogeneity- aware Split Federated Learning ov er Edge Computing Systems, ” IEEE T r ans. Mobile Comput. , 2026. [19] Z. Lin, X. Hu, Y . Zhang, Z. Chen, Z. Fang, X. Chen, A. Li, P . V epakomma, and Y . Gao, “SplitLoRA: A Split Parameter -Efficient Fine-T uning Framew ork for Large Language Models, ” arXiv pr eprint arXiv:2407.00952 , 2024. [20] Y . Oh, J. Lee, C. G. Brinton, and Y .-S. Jeon, “Communication-efficient split learning via adapti ve feature-wise compression, ” IEEE T rans. Neural Netw . Learn. Syst. , vol. 36, no. 6, pp. 10 844–10 858, Jun. 2025. [21] H. Ao, H. Tian, W . Ni, J. Zhang, and D. Niyato, “Federated split learn- ing via low-rank approximation: A communication-efficient approach, ” IEEE T rans. W ir eless Commun. , vol. 25, pp. 11 253–11 269, Jan. 2026. [22] C. Shiranthika, H. H. employment, P . Saeedi, and I. V . Baji ´ c, “SplitFedZip: Learned compression for data transfer reduction in Split- Federated learning, ” arXiv preprint , 2024. [23] N. D. Pham, A. Abuadbba, Y . Gao, K. T . Phan, and N. Chilamkurti, “Binarizing split learning for data priv acy enhancement and computation reduction, ” IEEE Tr ans. Inf. F orensics Security , vol. 18, pp. 3088–3100, 2023. [24] F . Zheng, C. Chen, L. L yu, and B. Y ao, “Reducing communication for split learning by randomized top- k sparsification, ” in Proc. Int. Joint Conf. Artif. Intell. (IJCAI) , Macao, China, Aug. 2023, pp. 4665–4673. [25] Z. Liu, J. Li, Z. Shen, G. Huang, S. Y an, and C. Zhang, “Learning efficient con volutional networks through network slimming, ” in Pr oc. IEEE Int. Conf. Comput. V is. (ICCV) , 2017, pp. 2736–2744. [26] Y . He, J. Lin, Z. Liu, H. W ang, L.-J. Li, and S. Han, “AMC: Automated model compression and acceleration with reinforcement learning, ” in Pr oc. Eur . Conf. Comput. V is. (ECCV) , 2018, pp. 784–800. [27] B. Jacob, S. Kligys, B. Chen, M. Zhu, M. T ang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and training of neural networks for efficient integer-arithmetic-only inference, ” in Pr oc. IEEE/CVF Conf. Comput. V is. P attern Recognit. (CVPR) , 2018, pp. 2704–2713.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment