Speech-Omni-Lite: Portable Speech Interfaces for Vision-Language Models
While large-scale omni-models have demonstrated impressive capabilities across various modalities, their strong performance heavily relies on massive multimodal data and incurs substantial computational costs. This work introduces Speech-Omni-Lite, a cost-efficient framework for extending pre-trained Visual-Language (VL) backbones with speech understanding and generation capabilities, while fully preserving the backbones’ vision-language performance. Specifically, the VL backbone is equipped with two lightweight, trainable plug-and-play modules, a speech projector and a speech token generator, while keeping the VL backbone fully frozen. To mitigate the scarcity of spoken QA corpora, a low-cost data construction strategy is proposed to generate Question-Text Answer-Text-Speech (QTATS) data from existing ASR speech-text pairs, facilitating effective speech generation training. Experimental results show that, even with only thousands of hours of speech training data, Speech-Omni-Lite achieves excellent spoken QA performance, which is comparable to omni-models trained on millions of hours of speech data. Furthermore, the learned speech modules exhibit strong transferability across VL backbones.
💡 Research Summary
Speech‑Omni‑Lite presents a cost‑effective framework for endowing pre‑trained vision‑language (VL) backbones with both speech understanding and speech generation capabilities while keeping the backbone parameters frozen. The architecture consists of a pre‑trained discrete speech tokenizer (HuBERT‑LARGE + Finite Scalar Quantization), a lightweight trainable speech projector, the frozen VL backbone (e.g., LLaVA, Qwen2‑VL), a trainable speech token generator, and a pre‑trained speech de‑tokenizer. The speech projector maps discrete speech token embeddings into the VL model’s input embedding space via a small MLP and a few LLaMA decoder layers, enabling the frozen backbone to process speech inputs directly. Conversely, the speech token generator converts the backbone’s hidden states into discrete speech tokens using an encoder‑decoder architecture augmented with multi‑token prediction (MTP) heads for faster decoding; these tokens are finally turned into waveforms by the de‑tokenizer.
A major obstacle for speech‑to‑speech dialogue models is the scarcity of large spoken‑question‑answer (QA) corpora. Speech‑Omni‑Lite circumvents this by constructing Question‑Text‑Answer‑Text‑Speech (QTATS) data from abundant ASR speech‑text pairs. For each ASR pair, the transcript is treated as the answer; a large language model (LLM) is prompted to generate a corresponding question. This reverse‑question generation yields synthetic spoken QA without any dedicated recording or expensive TTS synthesis. The QTATS data serve two training stages: first, a text projector is trained on ASR pairs to align text inputs with the VL backbone; second, the speech token generator is trained on QTATS, using an auxiliary text projector to provide text‑conditioned supervision, thereby mitigating the conditioning mismatch between ASR‑style and QA‑style hidden states.
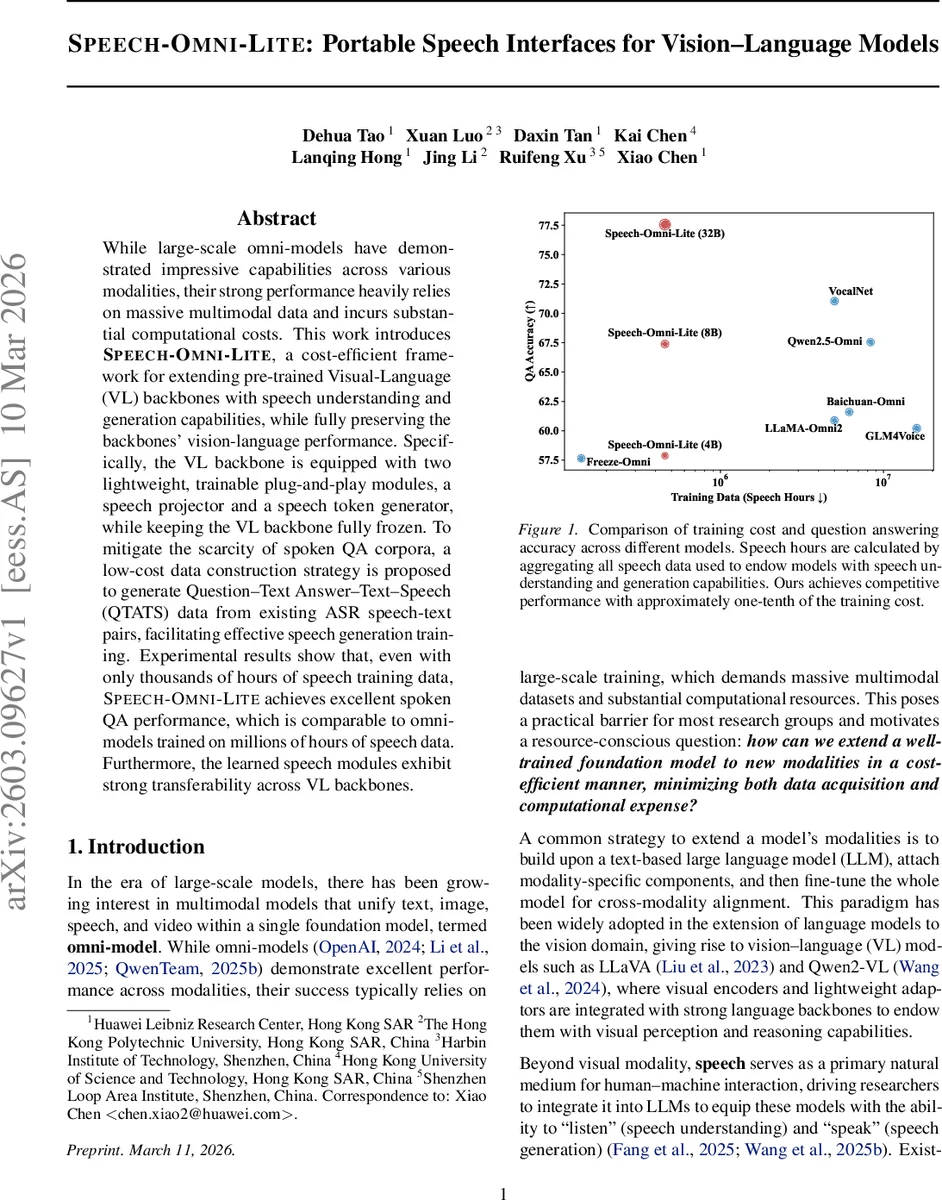
Experimental results demonstrate that, with only a few thousand hours of speech data (≈ 5 k h), Speech‑Omni‑Lite achieves spoken QA accuracy comparable to omni‑models trained on millions of hours of speech (e.g., GLM‑4Voice, VocalNet, LLaMA‑Omni). Figure 1 shows that the model reaches similar QA performance while using roughly one‑tenth of the training cost in terms of data and GPU hours. Moreover, the learned speech projector and token generator transfer seamlessly across different VL backbones, indicating strong modularity and avoiding catastrophic forgetting of vision‑language abilities.
Key contributions are: (1) a frozen‑backbone paradigm that preserves native VL competence while adding speech modalities; (2) compact, trainable speech modules that drastically reduce training overhead and are backbone‑agnostic; (3) a novel low‑cost QTATS construction pipeline that eliminates the need for large spoken QA datasets. Limitations include reliance on ASR‑style alignment for prosodic cues and dependence on LLM quality for question generation. Future work may explore richer paralinguistic alignment, better prompt engineering for QTATS diversity, ultra‑low‑latency tokenizers, and extension to additional modalities such as video or 3D data.
In summary, Speech‑Omni‑Lite offers a practical, scalable recipe for augmenting strong vision‑language models with speech interaction capabilities, achieving high performance with a fraction of the data and compute traditionally required for fully omni‑modal systems. This work paves the way for more accessible multimodal AI development in resource‑constrained settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment