OfficeQA Pro: An Enterprise Benchmark for End-to-End Grounded Reasoning
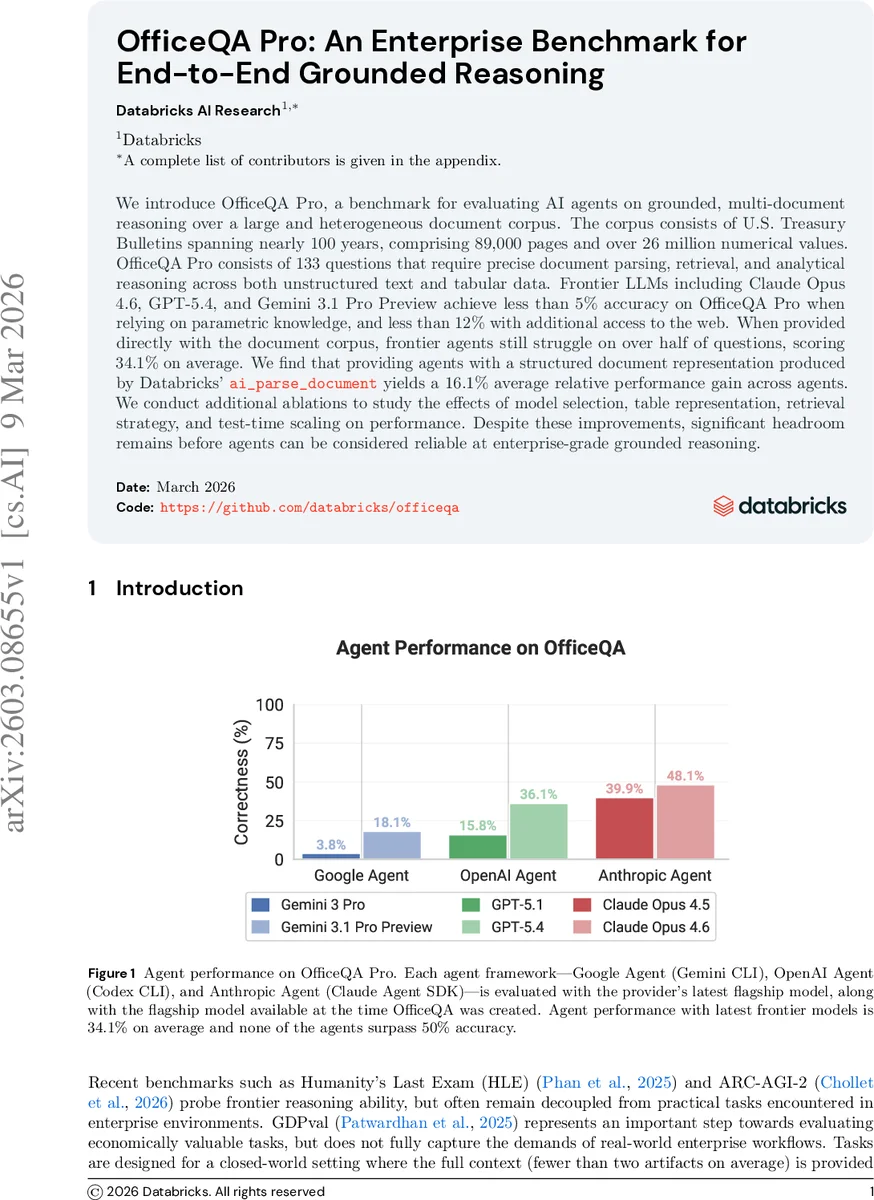
We introduce OfficeQA Pro, a benchmark for evaluating AI agents on grounded, multi-document reasoning over a large and heterogeneous document corpus. The corpus consists of U.S. Treasury Bulletins spanning nearly 100 years, comprising 89,000 pages and over 26 million numerical values. OfficeQA Pro consists of 133 questions that require precise document parsing, retrieval, and analytical reasoning across both unstructured text and tabular data. Frontier LLMs including Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro Preview achieve less than 5% accuracy on OfficeQA Pro when relying on parametric knowledge, and less than 12% with additional access to the web. When provided directly with the document corpus, frontier agents still struggle on over half of questions, scoring 34.1% on average. We find that providing agents with a structured document representation produced by Databricks’ ai_parse_document yields a 16.1% average relative performance gain across agents. We conduct additional ablations to study the effects of model selection, table representation, retrieval strategy, and test-time scaling on performance. Despite these improvements, significant headroom remains before agents can be considered reliable at enterprise-grade grounded reasoning.
💡 Research Summary
OfficeQA Pro is a newly introduced benchmark designed to evaluate the grounded reasoning capabilities of AI agents in realistic enterprise settings. The benchmark is built on a massive corpus of United States Treasury Bulletins spanning nearly a century (1939‑2025), comprising 89 000 pages and more than 26 million numeric entries. Unlike many existing academic benchmarks that focus on closed‑world or single‑document tasks, OfficeQA Pro requires agents to locate, parse, and analytically combine information from multiple heterogeneous documents, including dense tables, charts, and scanned PDFs with varying OCR quality.
The dataset contains 133 “Pro” questions (plus an auxiliary set of 113 “Easy” questions for development). Each question is carefully crafted to be unambiguous, have a single numeric or textual answer, and to reflect realistic financial‑analysis workflows. The questions demand a range of capabilities: 11 % span three or more bulletins, 22 % need external web data such as historical CPI values, 3 % involve visual reasoning over figures or graphs, and 62 % require advanced numerical analysis (e.g., ordinary‑least‑squares regression, time‑series adjustments, unit conversions). Human annotators with a numerate college‑graduate background can solve the questions reliably, providing a strong human baseline.
The creation pipeline follows a rigorous two‑phase verification process. First, annotators generate questions and answers directly from the PDFs, and a second independent annotator reproduces the answer to ensure reproducibility. Then, state‑of‑the‑art AI agents (Claude Opus 4.6, GPT‑5.4, Gemini 3.1 Pro) are run on the same items; any divergent AI outputs trigger a third human review to determine whether the discrepancy stems from a model failure, an ambiguous question, or an incorrect ground truth. This loop guarantees that the final benchmark is free from hidden ambiguities and that the ground‑truth answers are truly verifiable.
Evaluation is deterministic: a prediction is correct only if it matches the ground‑truth exactly (0 % absolute relative error). Additional thresholds of 0.1 %, 1 %, and 5 % are reported to illustrate how models perform under relaxed precision requirements. The metric normalizes punctuation, mathematical symbols, and common abbreviations, and applies fuzzy matching for non‑numeric responses.
Four experimental configurations are explored for large language models (LLMs): (1) Prompt‑Only (no external context), (2) Web‑Search Enabled (native internet search), (3) Oracle PDF + Web Search (the exact PDF pages needed for the question are supplied), and (4) Oracle Parsed PDF + Web Search (pages are pre‑processed by Databricks’ ai_parse_document into a structured text‑table representation). System prompts for each setting are provided in the appendix.
Results reveal a stark performance gap. In the Prompt‑Only setting, all models achieve under 3 % accuracy at the strict 0 % error threshold, rising only to 17‑24 % when a generous 5 % error margin is allowed. Enabling web search improves accuracy modestly (still below 12 % at 0 % error). Providing the exact PDF pages raises average accuracy to 34.1 %, but no model exceeds 48 % on any metric. When the same pages are supplied in the parsed, structured format, average relative performance improves by 16.1 % across agents, indicating that high‑quality document parsing is a critical bottleneck.
Ablation studies examine (a) model choice (Claude Opus 4.6 outperforms GPT‑5.4 and Gemini 3.1 by a few points), (b) table representation (JSON‑style tables beat flat‑text tables by 3‑5 % points), (c) retrieval strategy (dense vector retrievers marginally outperform BM25), and (d) test‑time scaling (doubling the token limit yields only 1‑2 % gains at the cost of latency). Even with these optimizations, the best agents remain well below the human baseline (≈85 % accuracy).
The authors conclude that current frontier LLMs, even when equipped with autonomous tool use, are far from reliable for enterprise‑grade grounded reasoning. The primary challenges lie in (i) robust OCR and layout extraction for legacy scanned documents, (ii) accurate parsing of complex multi‑level tables, (iii) precise numerical computation and regression analysis, and (iv) effective multi‑document retrieval and synthesis.
Future research directions proposed include: integrating high‑fidelity OCR/layout models, coupling LLMs with domain‑specific computation engines (e.g., Pandas, R), leveraging long‑term vector stores for corporate knowledge bases, designing human‑in‑the‑loop verification interfaces, and extending the benchmark to full multimodal reasoning over charts and graphs.
By releasing OfficeQA Pro (code and data at https://github.com/databricks/officeqa) and providing extensive baselines, the paper offers the community a rigorous, enterprise‑focused testbed to measure progress toward truly grounded, trustworthy AI systems for real‑world business analytics.
Comments & Academic Discussion
Loading comments...
Leave a Comment