SCOPE: Scene-Contextualized Incremental Few-Shot 3D Segmentation
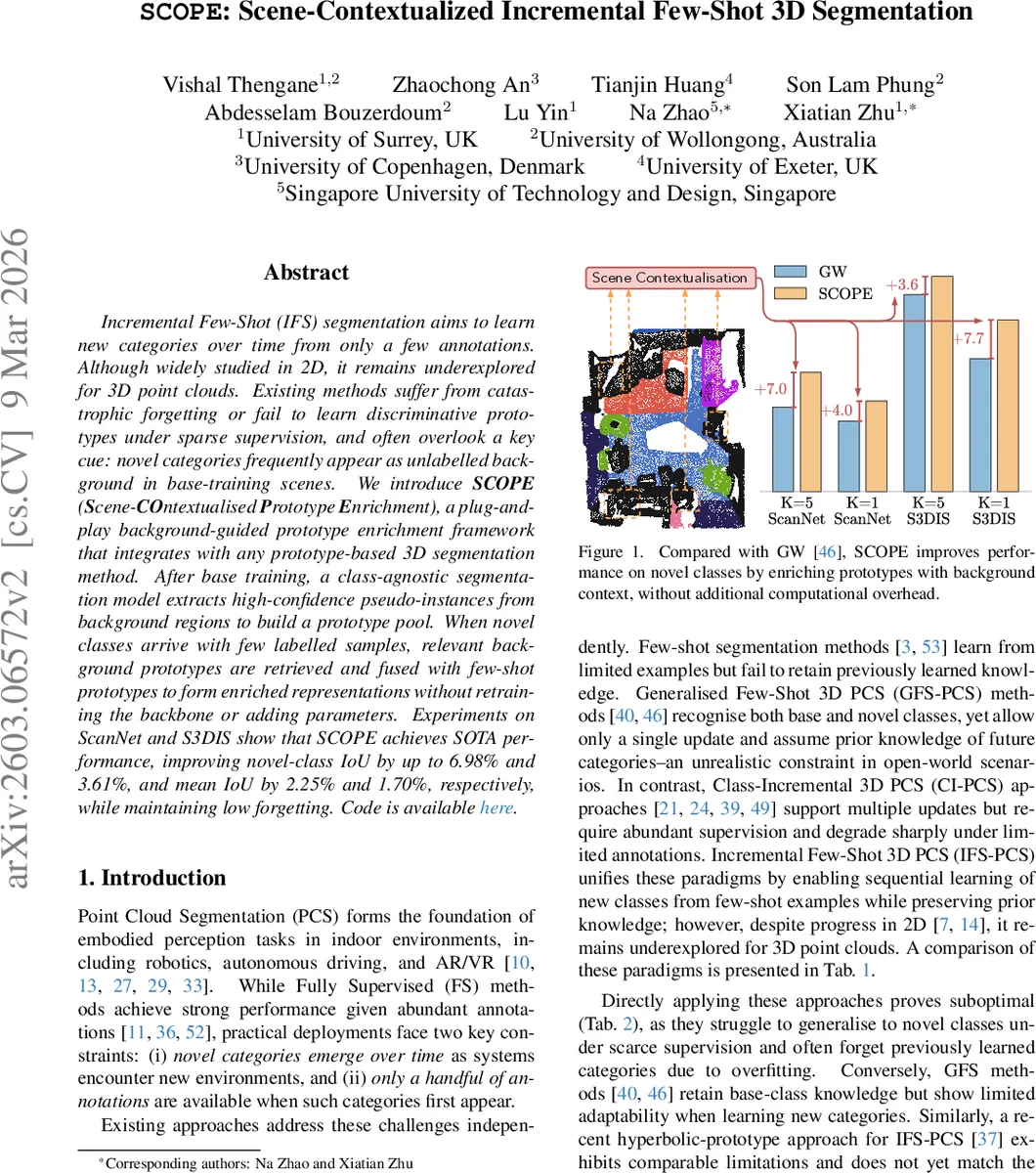
Incremental Few-Shot (IFS) segmentation aims to learn new categories over time from only a few annotations. Although widely studied in 2D, it remains underexplored for 3D point clouds. Existing methods suffer from catastrophic forgetting or fail to learn discriminative prototypes under sparse supervision, and often overlook a key cue: novel categories frequently appear as unlabelled background in base-training scenes. We introduce SCOPE (Scene-COntextualised Prototype Enrichment), a plug-and-play background-guided prototype enrichment framework that integrates with any prototype-based 3D segmentation method. After base training, a class-agnostic segmentation model extracts high-confidence pseudo-instances from background regions to build a prototype pool. When novel classes arrive with few labelled samples, relevant background prototypes are retrieved and fused with few-shot prototypes to form enriched representations without retraining the backbone or adding parameters. Experiments on ScanNet and S3DIS show that SCOPE achieves SOTA performance, improving novel-class IoU by up to 6.98% and 3.61%, and mean IoU by 2.25% and 1.70%, respectively, while maintaining low forgetting. Code is available https://github.com/Surrey-UP-Lab/SCOPE.
💡 Research Summary
**
The paper tackles the under‑explored problem of Incremental Few‑Shot 3D Point Cloud Segmentation (IFS‑PCS), where a model must continually learn new semantic categories from only a few annotated examples while preserving knowledge of previously learned base classes. Existing approaches either suffer from catastrophic forgetting, produce weak prototypes under sparse supervision, or ignore the rich information hidden in background regions of the base training scenes.
SCOPE (Scene‑Contextualised Prototype Enrichment) is introduced as a plug‑and‑play framework that can be attached to any prototype‑based 3D segmenter without modifying its backbone or adding learnable parameters. The method proceeds in three stages:
-
Base Training – A backbone encoder Φ (e.g., a PointNet++ or transformer) is trained on fully labelled base data, producing a set of base class prototypes P_b. All points not belonging to base classes are labeled as background (‑1).
-
Scene Contextualisation – After base training, an off‑the‑shelf class‑agnostic segmentation model Θ (such as a MaskFormer‑style network) is applied offline to the background points of every base scene. Θ outputs a collection of binary masks with confidence scores. Masks whose confidence exceeds a threshold τ and that lie entirely within background are kept as pseudo‑instances. For each pseudo‑instance, the encoder Φ extracts point‑wise features, which are then average‑pooled to obtain an instance prototype µ. All such µ vectors are stored in a global Instance Prototype Bank (IPB) P. The IPB is built once and frozen for all subsequent incremental stages, providing a repository of object‑level cues that may correspond to future novel classes.
-
Incremental Class Registration – When a new class c arrives with K support point clouds, a conventional few‑shot prototype p_c is computed from the support set. Simultaneously, the Contextual Prototype Retrieval (CPR) module searches the IPB for a subset B_c of prototypes that are semantically aligned with c. Alignment is measured by cosine similarity in the embedding space, optionally weighted by the original confidence scores from Θ. Because the retrieved prototypes vary in relevance, an Attention‑Based Prototype Enrichment (APE) module fuses them with p_c. A multi‑head scaled dot‑product attention treats p_c as the query and the retrieved µ’s as keys/values, producing attention weights α_i that highlight the most useful background cues. The enriched prototype is then ˜p_c = p_c + Σ_i α_i µ_i. This enriched representation is used for classification of query points via the usual prototype‑matching operation.
Key properties of SCOPE:
- No backbone retraining – The encoder Φ remains unchanged after base training, satisfying the minimal‑adaptation principle of few‑shot learning.
- Parameter‑free – CPR and APE introduce no additional learnable parameters; they are purely algorithmic operations on existing embeddings.
- Plug‑and‑play – Any prototype‑based 3D segmenter (e.g., GW, CAPL, PIFS) can adopt SCOPE by inserting the CPR‑APE step during incremental updates.
Experimental Evaluation
The authors evaluate SCOPE on two large indoor benchmarks: ScanNet and S3DIS. For each dataset, a set of base classes (≈13–15) is used for initial training, and several novel classes (5–7) are introduced in a few‑shot manner (K=1 or 5). SCOPE is attached to several strong baselines. Results show consistent improvements:
- Novel‑class IoU gains of up to 6.98 % on ScanNet and 3.61 % on S3DIS.
- Mean IoU (across base + novel) improvements of 2.25 % (ScanNet) and 1.70 % (S3DIS).
- Forgetting on base classes remains negligible (≤0.5 % degradation), demonstrating effective knowledge retention.
The computational overhead is minimal. Building the IPB is a one‑time offline step; during incremental updates, CPR and APE scale linearly with the number of retrieved prototypes (typically 10–20) and do not require gradient updates.
Significance and Limitations
SCOPE’s main contribution is the systematic exploitation of background regions as a source of transferable object‑level knowledge. By converting unlabeled background into a rich prototype bank, the method bridges the gap between few‑shot generalisation and incremental learning without sacrificing efficiency. The approach is especially appealing for real‑world robotics or AR applications where new object categories appear over time and dense annotation is infeasible.
Limitations include: (1) the current experiments focus on static indoor scenes; extending to dynamic or outdoor LiDAR data may require more robust class‑agnostic detectors. (2) The quality of the IPB depends on the performance of the off‑the‑shelf Θ; errors in pseudo‑mask generation could propagate to the enriched prototypes. (3) Hyper‑parameters such as the confidence threshold τ, the number of retrieved prototypes, and attention heads are set empirically; automated meta‑learning of these settings could further improve robustness.
Future Directions
Potential extensions involve (a) integrating multi‑modal cues (e.g., RGB images) into the prototype bank, (b) employing self‑supervised pre‑training to boost the class‑agnostic detector, and (c) exploring continual‑learning strategies that dynamically update the IPB as more scenes become available, thereby turning the prototype bank into a lifelong memory.
In summary, SCOPE provides a simple yet powerful mechanism to enrich few‑shot prototypes with contextual background knowledge, achieving state‑of‑the‑art performance on benchmark IFS‑PCS tasks while preserving computational efficiency and modularity.
Comments & Academic Discussion
Loading comments...
Leave a Comment