PureCC: Pure Learning for Text-to-Image Concept Customization
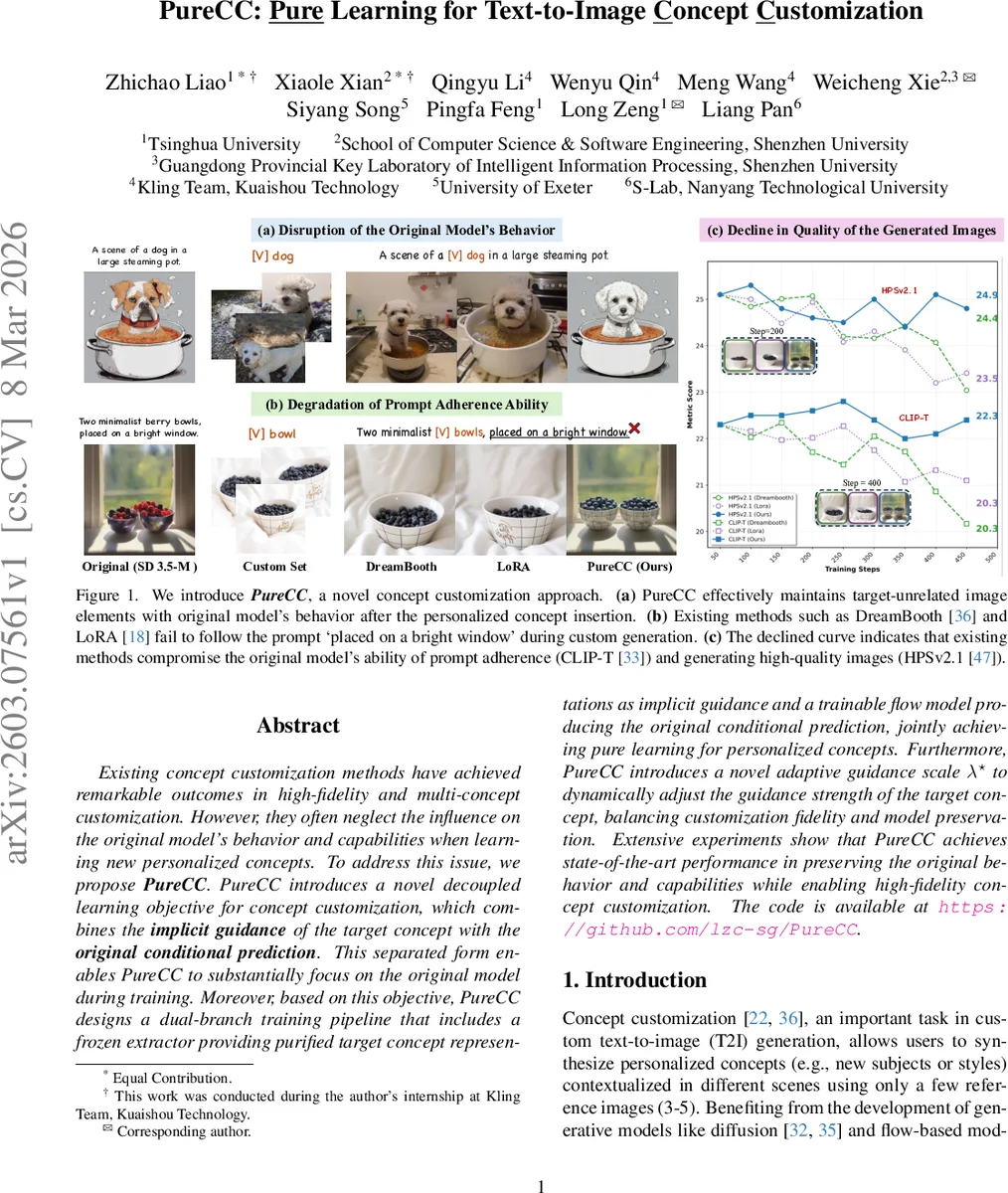
Existing concept customization methods have achieved remarkable outcomes in high-fidelity and multi-concept customization. However, they often neglect the influence on the original model’s behavior and capabilities when learning new personalized concepts. To address this issue, we propose PureCC. PureCC introduces a novel decoupled learning objective for concept customization, which combines the implicit guidance of the target concept with the original conditional prediction. This separated form enables PureCC to substantially focus on the original model during training. Moreover, based on this objective, PureCC designs a dual-branch training pipeline that includes a frozen extractor providing purified target concept representations as implicit guidance and a trainable flow model producing the original conditional prediction, jointly achieving pure learning for personalized concepts. Furthermore, PureCC introduces a novel adaptive guidance scale $λ^\star$ to dynamically adjust the guidance strength of the target concept, balancing customization fidelity and model preservation. Extensive experiments show that PureCC achieves state-of-the-art performance in preserving the original behavior and capabilities while enabling high-fidelity concept customization. The code is available at https://github.com/lzc-sg/PureCC.
💡 Research Summary
PureCC addresses two often‑overlooked problems in text‑to‑image concept customization: (1) disruption of the base model’s behavior on elements unrelated to the target concept, and (2) degradation of the base model’s capabilities such as prompt adherence and image quality. Existing approaches like DreamBooth and LoRA achieve high fidelity for the inserted concept but, because they fine‑tune the whole model or add low‑rank adapters on a very small set of reference images, they inadvertently alter background, lighting, style, and other non‑target aspects. Moreover, the fine‑tuning process drifts the original data distribution, leading to poorer CLIP‑T scores (prompt adherence) and lower HPSv2.1 scores (image quality).
PureCC proposes a fundamentally different learning objective that decouples the target concept from the original conditional prediction. Inspired by classifier‑free guidance (CFG), the target velocity field is expressed as a sum of an original unconditional prediction and a scaled target‑concept guidance:
vₜ^{PureCC} = v_{original,t} + λ·v_{target,t}
Here v_{original,t} is the prediction of a frozen base model conditioned on the null prompt, while v_{target,t} is an implicit guidance derived from a frozen “representation extractor”. λ is a guidance scale analogous to the CFG weight w, but it is adapted dynamically.
The architecture consists of two branches:
- Frozen Representation Extractor – a flow‑based model (SD3.5‑M) first fine‑tuned on the custom set using LoRA and layer‑wise tunable concept embeddings. These embeddings replace the placeholder token
Comments & Academic Discussion
Loading comments...
Leave a Comment