Fuse4Seg: Image Fusion for Multi-Modal Medical Segmentation via Bi-level Optimization
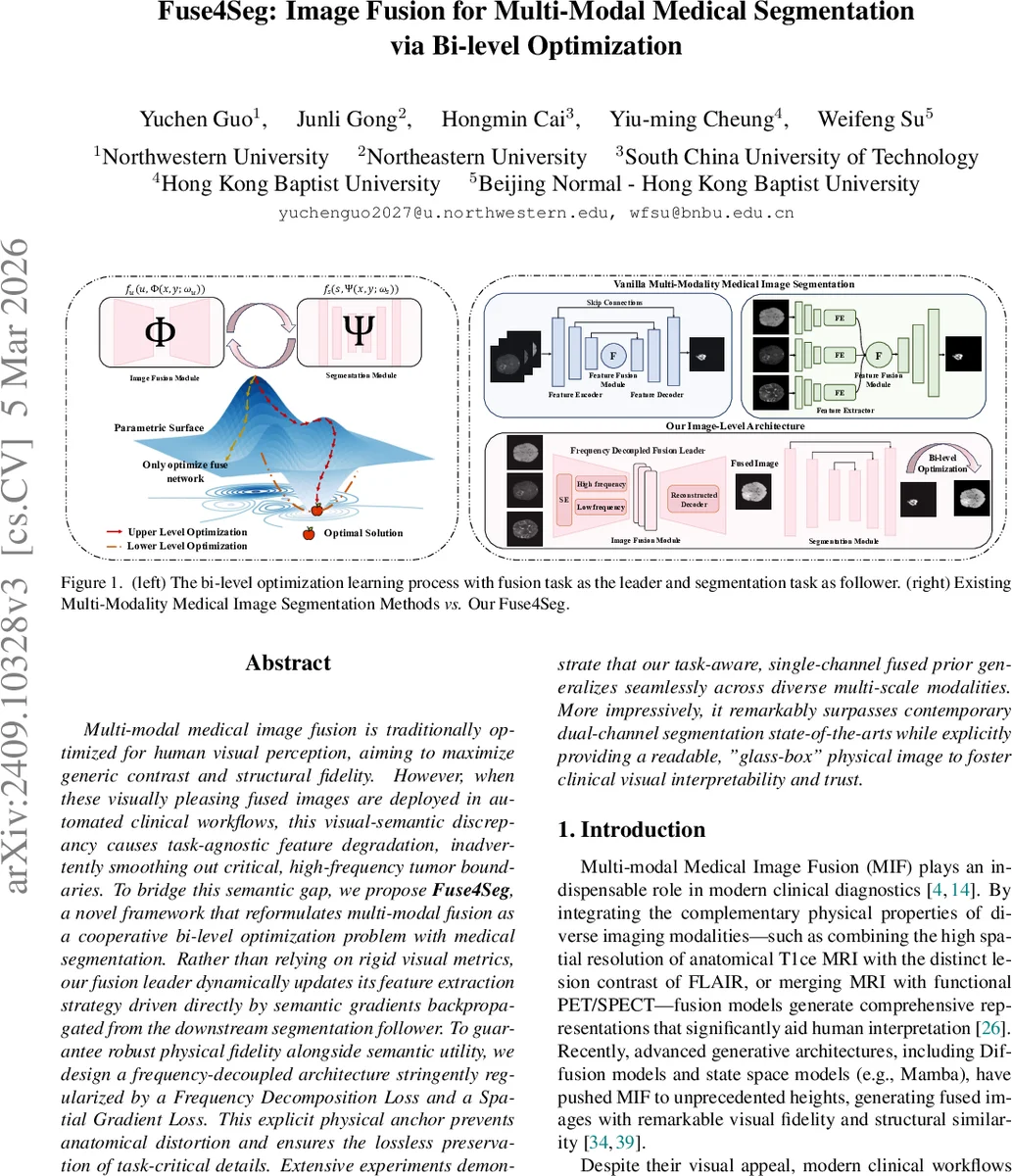
Multi-modal medical image fusion is traditionally optimized for human visual perception, aiming to maximize generic contrast and structural fidelity. However, when these visually pleasing fused images are deployed in automated clinical workflows, this visual-semantic discrepancy causes task-agnostic feature degradation, inadvertently smoothing out critical, high-frequency tumor boundaries. To bridge this semantic gap, we propose Fuse4Seg, a novel framework that reformulates multi-modal fusion as a cooperative bi-level optimization problem with medical segmentation. Rather than relying on rigid visual metrics, our fusion leader dynamically updates its feature extraction strategy driven directly by semantic gradients backpropagated from the downstream segmentation follower. To guarantee robust physical fidelity alongside semantic utility, we design a frequency-decoupled architecture stringently regularized by a Frequency Decomposition Loss and a Spatial Gradient Loss. This explicit physical anchor prevents anatomical distortion and ensures the lossless preservation of task-critical details. Extensive experiments demonstrate that our task-aware, single-channel fused prior generalizes seamlessly across diverse multi-scale modalities. More impressively, it remarkably surpasses contemporary dual-channel segmentation state-of-the-arts while explicitly providing a readable, “glass-box” physical image to foster clinical visual interpretability and trust.
💡 Research Summary
Fuse4Seg introduces a novel paradigm that tightly couples multi‑modal medical image fusion with downstream segmentation through a cooperative bi‑level (Stackelberg) optimization framework. Traditional fusion methods are optimized for human visual perception—maximizing contrast, entropy, or structural similarity—without regard for the semantic needs of automated analysis. Consequently, when such visually appealing fused images are fed into segmentation networks, high‑frequency tumor boundaries are often smoothed out, leading to task‑agnostic feature degradation.
In Fuse4Seg, the fusion network (leader) generates a single‑channel fused prior (x_f = \Phi(x_1, x_2; \theta_f)) from two modalities (e.g., T1‑ce and FLAIR). The segmentation network (follower) consumes (x_f) and predicts a mask (\hat y = \Psi(x_f; \theta_s)). The joint problem is formulated as:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment