Estimation of the complexity of a network under a Gaussian graphical model
The proportion of edges in a Gaussian graphical model (GGM) characterizes the complexity of its conditional dependence structure. Since edge presence corresponds to a nonzero entry of the precision matrix, estimation of this proportion can be formula…
Authors: Nabaneet Das, Thorsten Dickhaus
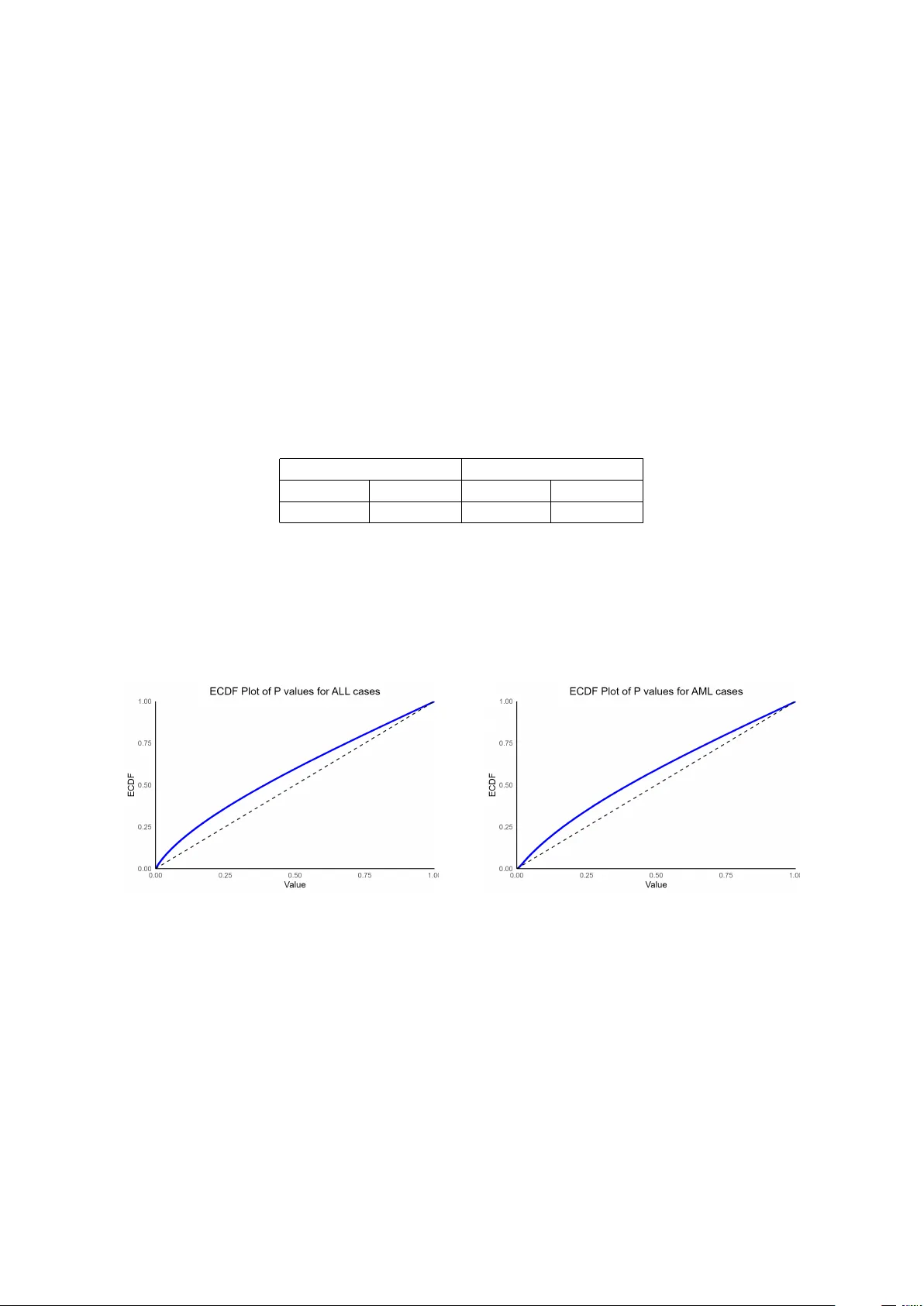
Estimation of the complexit y of a net w ork under a Gaussian graphical mo del Nabaneet Das 1 ∗ , Thorsten Dic khaus 2 † 1 , 2 Institute for Statistics, Univ ersit y of Bremen, 28359, Bremen, German y Abstract The prop ortion of edges in a Gaussian graphical mo del (GGM) c haracterizes the complexit y of its conditional dep endence structure. Since edge presence corresp onds to a nonzero entry of the precision matrix, estimation of this prop ortion can b e form ulated as a large-scale m ultiple testing problem. W e propose an estimator that combines p-v alues from sim ultaneous edge-wise tests, conducted under false disco very rate control, with Storey’s estimator of the prop ortion of true null hypotheses. W e establish weak dep endence conditions on the precision matrix under which the empirical cumulativ e distribution function of the p-v alues con v erges to its p opulation counterpart. These conditions cov er high-dimensional regimes, including those arising in genetic asso ciation studies. Under such dependence, w e characterize the asymptotic bias of the Sch weder–Sp jøtvoll estimator, showing that it is upw ard biased and thus slightly underestimates the true edge prop ortion. Sim ulation studies across a v ariet y of mo dels confirm accurate recov ery of graph complexity . 1 In tro duction Understanding the relationships among m ultiple v ariables is an imp ortant problem in man y areas of science, including biology , finance, and so cial sciences. Accurately capturing these relationships helps us infer net works, iden tify k ey v ariables, and understand underlying mechanisms in complex systems. Gaussian Graphical Mo dels (GGMs) are a widely used framew ork for represen ting conditional dep endencies among jointly Gaussian v ariables. F ormally , let X = ( X 1 , . . . , X k ) T ∼ N ( µ , Σ ) b e a k -dimensional multiv ariate normal v ector with mean µ and cov ariance matrix Σ . A GGM represen ts X as an undirected graph G = ( V , E ), where eac h v ertex i ∈ V corresp onds to a v ariable X i , and an edge ( i, j ) ∈ E indicates that X i and X j are conditionally dep enden t given all other v ariables. Imp ortantly , a well-kno wn result in this framework states that ( i, j ) ∈ E if and only if the corresp onding entry of the precision matrix Ω = Σ − 1 is non-zero, i.e., ω ij = 0 (see Lauritzen ( 1996 )). In this wa y , GGMs link the problem of netw ork inference directly to the estimation of the precision matrix. In the sequel, we refer to the set E as the net work structure of X . In practice, this structure ∗ Email: nabaneet@uni-bremen.de † Email: dickhaus@uni-bremen.de is typically unknown or only partially observ ed, which motiv ates the use of statistical metho ds to estimate E . W e assume that an i.i.d. sample X 1 , . . . , X n is av ailable, with each X i follo wing the same distribution as X . Estimation of the net w ork structure is particularly challenging in high-dimensional settings, where the n um b er of v ariables k ma y b e large relative to the sample size. T raditional approac hes often rely on regularized optimization techniques to estimate sparse precision matrices. P opular metho ds include the graphical Lasso (see F riedman et al. ( 2008 ), d’Aspremon t et al. ( 2008 )), Scaled Lasso ( Sun and Zhang ( 2012 )), and Dantzig selector-based approac hes ( Cai et al. ( 2011 )), whic h encourage sparsity and improv e estimation in high dimensions. Other metho ds based on l 1 minimization tec hnique, can b e found in Meinshausen and B¨ uhlmann ( 2006 ), Y uan ( 2010 ), Zhang ( 2010 ), Cai et al. ( 2011 ), Liu et al. ( 2012 ), and Xue and Zou ( 2012 ). An alternative approac h, prop osed b y Liu ( 2013 ), frames GGM estimation as a multiple testing problem. In this framework, each pair of v ariables corresp onds to a hypothesis test: H 0 ,ij : ω ij = 0 vs H 1 ,ij : ω ij = 0 , 1 ≤ i < j ≤ k . (1) The GF C (GGM estimation with FDR con trol) pro cedure uses regularized estimators - suc h as the Lasso, Scaled Lasso, or Dantzig-t yp e estimators to compute test statistics for eac h pair of v ariables. A key feature of the GFC approach is that it establishes the asymptotic normality of these test statistics, whic h allows for the computation of tw o-sided p-v alues for each edge (see Liu ( 2013 )). By treating GGM estimation as a large-scale multiple testing problem, this pro cedure provides a systematic and statistically principled w ay to infer the graph structure. In this w ork, w e consider the prop ortion of false n ull h yp otheses, which corresp onds to the prop ortion of edges in the graph and th us quantifies the ov erall complexity of the Gaussian graphical mo del. This is a global feature of the graph, in contrast to muc h of the existing literature, whic h primarily focuses on lo cal features suc h as node-wise neigh b orho o ds or pairwise conditional dependencies, t ypically estimated via neigh b orho o d selection or sparse precision matrix metho ds (e.g. Meinshausen and B ¨ uhlmann ( 2006 ), Raskutti et al. ( 2008 ), F riedman et al. ( 2008 )). While these approac hes are well suited for recov ering lo cal graph structure, they do not directly address the estimation of global netw ork c haracteristics such as edge density or o verall graph complexit y . Estimation of the prop ortion of false null h yp otheses is a well-explored topic within the domain of simultaneous statistical inference and serv es as a foundation for data-adaptive pro cedures. One of the most prominen t estimation techniques is the graphical approach introduced by Sc hw eder and Sp jøtv oll ( 1982 ), as formalized in ( 5 ). Building up on this foundational work, Benjamini and Ho ch b erg ( 2000 ) prop osed an adaptive v ersion of the Benjamini–Ho ch b erg (BH) pro cedure. Subsequen tly , Storey ( 2002 ) and Storey et al. ( 2004 ) suggested v arious strategies for selecting the tuning parameters of the Sch weder–Sp jøtv all estimator. F or a comprehensiv e discussion on adaptiv e pro cedures based on this estimator and the corresp onding control of the false discov ery rate (FDR), we refer the reader to Section 3.1.3 and Theorem 5.4 of Dickhaus ( 2014 ). F urther dev elopments fo cusing on the densit y estimation of p-v alues were explored b y Langaas et al. ( 2005 ) and Geno vese and W asserman ( 2004 ). Sp ecifically , Genov ese and W asserman ( 2004 ) discussed the consistency of the densit y-based estimators originally proposed b y Swanepo el ( 1999 ) and Hengartner and Stark ( 1995 ). More recently , Patra and Sen ( 2016 ) in tro duced a consisten t estimator based on the empirical cumulativ e distribution function (ECDF) of p-v alues under a tw o-comp onen t mixture mo del. In parallel with spatial-domain approac hes, a separate line of w ork considers estimators constructed in the frequency domain. Estimators based on the empirical characteristic function hav e b een dev elop ed for normal mixture mo dels in large-scale multiple testing by Jin and Cai ( 2007 ); Jin ( 2008 ), where b oth the null and non-n ull components are assumed to follo w normal distributions, and the goal is to estimate null parameters and the prop ortion of non-n ull signals. This framework, as dev elop ed in Chen ( 2019 ), relaxes the normality assumption for the null while assuming that the alternativ e b elongs to a lo cation-shift family , and establishes uniform consistency of the estimators using Leb esgue–Stieltjes integral equations and harmonic analysis techniques. More recen t work, as presen ted in Chen ( 2025 ), generalizes the approach to composite n ull h yp otheses and broader families of distributions, including the Gamma family , while maintaining the lo cation-shift assumption for the alternativ e. F requency-domain methods pro vide an alternativ e to p-v alue–based approaches and allo w consisten t estimation when the alternativ e distribution is a shifted version of the null. While many existing methods for estimating the prop ortion of false n ull hypotheses assume indep endence among p-v alues, this assumption is often violated in the Gaussian Graphical Mo del setting due to the inherent dep endence among precision matrix entries. Despite this, the Sc hw eder–Sp jøtv all estimator remains an attractive choice due to its simplicity , widespread adoption, and its abilit y to handle weakly dep enden t p-v alues. Moreo ver, it typically pro vides a conserv ative estimate, whic h facilitates the con trol of the FDR. Its v alidity rests on the prop erty that the ECDF of the p-v alues consistently estimates the true CDF under these conditions. In this article, w e com bine the GF C pro cedure of Liu ( 2013 ) with the Sch weder–Sp jøtv all estimator to estimate the prop ortion of false null hypotheses, yielding a consistent and in terpretable measure of graph complexit y . P-v alues for all pairwise conditional dep endence tests are first computed using the GF C procedure. The Sc h weder–Sp jøtv all estimator is then applied, together with the tuning parameter selection metho dology of Storey ( 2002 ); Storey and Tibshirani ( 2003 ), to estimate the prop ortion of edges in the graph. This approach lev erages the adv antages of regularized precision matrix estimation, asymptotic normality of test statistics, and robust m ultiple testing pro cedures. The remainder of the pap er is organized as follows. In Section 2, we describ e the problem setup and present the test statistics deriv ed from the GFC pro cedure of Liu ( 2013 ), along with a brief ov erview of Sc h weder–Sp jøtv all estimator. Section 3 establishes the asymptotic v alidit y of Sch weder–Sp jøtv all estimator, showing that the ECDF of the p-v alues consisten tly estimates the a verage CDF as long as the sum of the absolute v alues of the precision matrix entries remains o ( k 2 ). Section 4 presents simulation studies to ev aluate the numerical p erformance of the estimator. Section 5 illustrates the metho dology using a real data application, and the app endix presents the pro ofs of the theoretical results. 2 Description of the problem W e hav e n observ ations X 1 , ..., X n from a k -v ariate normal distribution with mean vector µ and co v ariance matrix Σ . Without loss of generality , we will assume that µ = 0 k (a k × 1 vector consisting of all zero es). W e are interested in the m ultiple testing problem of ( 1 ). W e b egin by in tro ducing some basic notation. F or any v ector x ∈ R k , let x − i denote the ( k − 1)-dimensional v ector obtained by removing the i -th comp onen t ( x i ) from x = ( x 1 , . . . , x k ) ′ . F or any p × q matrix A , let A i, − j denote the i -th row of A with its j -th en try remov ed, and let A − i,j denote the j -th column of A with its i -th en try remov ed. Finally , let A − i, − j denote the ( p − 1) × ( q − 1) matrix obtained by deleting the i -th row and the j -th column of A . W e consider the testing framew ork of Liu ( 2013 ) where the test statistic T ij for the h yp othesis H 0 ,ij is constructed as follo ws - (I) F or X = ( X 1 , . . . , X k ) ′ ∼ N ( µ , Σ ), w e can write X i = α i + β i X − i + ε i , 1 ≤ i ≤ k, where ε i ∼ N 0 , σ ii − Σ i, − i Σ − 1 − i, − i Σ − i,i is indep endent of X − i , α i = µ i − Σ i, − i Σ − 1 − i, − i µ − i , and ( σ ij ) k × k = Σ . The regression co efficien t v ector β i and the error terms ε i satisfy β i = − ω − 1 ii Ω − i,i and Co v ( ε i , ε j ) = ω ij ω ii ω j j , W e estimate the GGM by recov ering the set of non-null entries of Σ ε , the cov ariance matrix of ε = ( ε 1 , . . . , ε k ) ′ . (I I) F or X l = ( X l 1 , . . . , X lk ) ′ , w e can write X li = α i + β i X l, − i + ε li , 1 ≤ i ≤ k, 1 ≤ l ≤ n. The estimators ˆ β i are obtained using the Lasso or the scaled Lasso, following the GF C pro cedure of Liu ( 2013 ). (I I I) Define the residuals b y ˆ ε li = X li − ¯ X i − ( X l, − i − ¯ X − i ) ˆ β i , and define the sample cov ariance co efficients b etw een the residuals b y ˆ r ij = 1 n n X l =1 ˆ ε li ˆ ε lj . (IV) Define T 1 ,ij = 1 n n X l =1 ˆ ε li ˆ ε lj + n X l =1 ˆ ε 2 li ˆ β i,j + n X l =1 ˆ ε 2 lj ˆ β j − 1 ,i ! . It was sho wn in Liu ( 2013 ) that, under certain regularit y conditions and assuming log k = o ( n ), r n ˆ r ii ˆ r j j T 1 ,ij + b n,ij ω ij ω ii ω j j ! d − → N 0 , 1 + ω 2 ij ω ii ω j j ! as ( n, k ) → ∞ , where b n,ij = ω ii ˆ σ ii,ε + ω j j ˆ σ j j,ε − 1, and ˆ σ ij,ε denotes the ( i, j )-th element of the matrix ˆ Σ ε = 1 n P n l =1 ( ε l − ¯ ε )( ε l − ¯ ε ) ′ . Here, ε l = ( ε l 1 , . . . , ε lk ) ′ and ¯ ε = 1 n P n l =1 ε l . (V) Finally , the test statistic for testing H 0 ,ij is defined as T ij = r n ˆ r ii ˆ r j j T 1 ,ij , 1 ≤ i < j ≤ k . (2) Under assumption (C1), defined b elow, it w as shown in Liu ( 2013 ) that T ij d → N (0 , 1) under H 0 ,ij as ( n, k ) → ∞ . The conv ergence in distribution is uniform for 1 ≤ i < j ≤ k . Condition (C1) is defined as follo ws: (C1) max 1 ≤ i ≤ k σ ii ≤ c 0 , max 1 ≤ i ≤ k ω ii ≤ c 0 , for some c 0 > 0, and log k = o ( n ). The GF C pro cedure of Liu ( 2013 ) for testing H 0 ,ij is implemen ted as follows : F or 0 < α < 1 and T ij ’s defined in ( 2 ), define ˆ t α = inf 0 ≤ t ≤ 2 p log k : G ( t ) k ( k − 1) / 2 max n 1 , P 1 ≤ i t ) o ≤ α . (3) where G ( t ) = P ( | Z | > t ) and Z ∼ N (0 , 1). If the infimum in ( 3 ) do es not exist, then define ˆ t α = 2 √ log k . And finally , w e reject H 0 ,ij if | T ij | > ˆ t α . Under the assumptions of Theorem 3.1 of Liu ( 2013 ), the aforemen tioned pro cedure satisfies F D P απ 0 P → 1 and F D R απ 0 → 1 as ( n, k ) → ∞ , where π 0 = q 0 / { k ( k − 1) / 2 } and q 0 is the num b er of true null h yp otheses. Here π 1 = 1 − π 0 is the prop ortion of edges in the graph represen ting the GGM. In view of the ab ov e testing pro cedure, w e can define the p-v alues of the corresp onding tests as p ij = G ( −| T ij | ) , 1 ≤ i < j ≤ k . (4) Our approach for estimating π 0 in the aforementioned problem is to use the Sch weder–Sp jøtv all estimator on the corresp onding p-v alues, with the tuning parameter c hosen according to the metho d of Storey ( 2002 ); Storey and Tibshirani ( 2003 ). Since the largest p-v alues are most lik ely to b e uniformly distributed, Sch weder and Sp jøtv oll ( 1982 ) suggested that a conserv ative estimator of π 0 is ˆ π 0 ( λ ) = # { P i > λ } n (1 − λ ) = W ( λ ) n (1 − λ ) , 0 ≤ λ < 1 . (5) The estimator in ( 5 ) inv olves a tuning parameter, λ . Cho osing λ requires balancing bias and v ariance for the estimator ˆ π 0 ( λ ). According to Storey and Tibshirani ( 2003 ), for well-behav ed p-v alues, the bias tends to decrease as λ increases, reac hing its minimum as λ approaches 1. Consequen tly , Storey and Tibshirani ( 2003 ) prop osed the follo wing metho d for selecting the tuning parameter λ . Estimation of π 0 based on smo othing splines 1: Fix a set of λ v alues, denoted b y Λ (e.g., Λ = { 0 , 0 . 01 , 0 . 02 , . . . , 0 . 95 } ). 2: F or eac h λ ∈ Λ, compute ˆ π 0 ( λ ) as in ( 5 ). 3: Fit a cubic spline ˆ f to the v alues ˆ π 0 ( λ ). 4: Obtain the final estimate: ˆ π 0 = min { ˆ f (1) , 1 } . In addition to the smo othing-based technique introduced by Storey and Tibshirani ( 2003 ), a b o otstrap-based metho d for selecting the optimal v alue of λ was proposed in Storey et al. ( 2004 ). This metho d builds on the earlier work of Storey ( 2002 ). The prop osed automatic choice of λ aims to estimate the v alue that minimizes the mean squared error (MSE), balancing bias and v ariance. Sp ecifically , it seeks to minimize E ( ˆ π 0 ( λ ) − π 0 ) 2 . The exp ectation is taken with resp ect to the distribution of X 1 , . . . , X n i.i.d. ∼ N ( µ , Σ ), where π 0 denotes the prop ortion of zero en tries in the precision matrix. This con ven tion applies to all subsequent exp ectation op erators throughout the manuscript. The pro cedure for this metho d is summarized b elo w. Bo otstrap-based selection of the tuning parameter λ and estimation of π 0 1: F or eac h λ ∈ Λ, compute ˆ π 0 ( λ ) as in ( 5 ). 2: Generate B b o otstrap samples from the p-v alues. F or each b = 1 , . . . , B , compute the estimators { ˆ π ∗ b 0 ( λ ) } λ ∈ Λ based on the b -th sample. 3: Since E [ ˆ π 0 ( λ )] ≥ π 0 for all λ ∈ [0 , 1), a plug-in estimator of π 0 can b e taken as ˆ π 0 = min λ ′ ∈ Λ { ˆ π 0 ( λ ′ ) } . 4: F or eac h λ ∈ Λ, estimate its resp ective mean squared error (MSE) as [ MSE( λ ) = 1 B B X b =1 h ˆ π ∗ b 0 ( λ ) − min λ ′ ∈ Λ { ˆ π 0 ( λ ′ ) } i 2 . 5: Set the final estimator as ˆ π 0 = min n 1 , argmin λ ∈ Λ \ M S E ( λ ) o . The estimator based on ( 5 ) provides a conserv ativ e estimate of π 0 , and therefore ensures FDR con trol for the adaptiv e procedure whenev er the ECDF of the p -v alues consisten tly estimates the true CDF. In our setting, the vector of p -v alues has length N = k ( k − 1) / 2. The follo wing section outlines conditions under which the ECDF of the p -v alues conv erges to the true cumulativ e distribution function (CDF), thereb y making the estimator based on ( 5 ) an appropriate and reliable c hoice for our problem. 3 Theoretical results W e first state the conditions under whic h the ECDF of the N = k ( k − 1) / 2 p-v alues conv erges to the av erage of the true CDFs, as shown in theorem 3.1 . W e then discuss a few examples of co v ariance matrices that are particularly relev ant for genetic asso ciation studies and satisfy the w eak dep endency conditions of theorem 3.1 . Theorem 3.1 Consider the test statistics in ( 2 ) and the c orr esp onding two-side d p-values ( p ij ) 1 ≤ i m , where m is a banding parameter. W e further assume that m = o ( k ). The banded cov ariance structure naturally holds under m -dep endence. The follo wing lemma sho ws that the assumptions of Theorem 3.1 are satisfied under a banded cov ariance structure. Lemma 3.2 L et Σ b e a k × k b ande d c ovarianc e matrix with b anding p ar ameter m , and let Ω = Σ − 1 = ( ω ij ) k × k denote its pr e cision matrix. Then, the sum of the absolute values of the entries of Ω satisfies k X i =1 k X j =1 | ω ij | = O ( k ) . Pro of : By Theorem 2.4 of Demk o et al. ( 1984 ), if Σ is a k × k m -banded cov ariance matrix, then its precision matrix Ω = Σ − 1 = ( ω ij ) k × k satisfies | ω ij | ≤ C r | i − j | /m , ∀ 1 ≤ i, j ≤ k , for some constant C > 0 and 0 < r < 1 is defined as r = p Cond( Σ ) − 1 p Cond( Σ ) + 1 ! 2 , where Cond( Σ ) = λ max ( Σ ) /λ min ( Σ ) is the condition num b er of Σ . It then follows that k X i =1 k X j =1 | ω ij | ≤ 2 C k − 1 X t =0 ( k − t ) r t 1 , where r 1 = r 1 /m . Since 0 < r 1 < 1, it is easy to see that k − 1 X t =0 ( k − t ) r t 1 = O ( k ) , and hence k X i,j =1 | ω ij | = O ( k ) , whic h establishes the result. Corollary 3.2.1 If the c onditions of The or em 3.1 ar e satisfie d, then ˆ π 0 ( λ ) is asymptotic al ly biase d upwar d s for any λ ∈ [0 , c ] , wher e c < 1 . In p articular, we have ˆ π 0 ( λ ) a.s. − − → π 0 + π 1 1 − ¯ F 1 ( λ ) 1 − λ as ( n, k ) → ∞ . ∀ λ ∈ [0 , c ] , wher e ¯ F 1 ( λ ) = 1 N X ( i,j ) ∈ I 1 Pr( p ij > λ ) c onver ges to a c onc ave function on [0 , c ] as ( n, k ) → ∞ . Remarks (1) Near λ = 1, the Sc hw eder-Sp jøtv all estimator exhibits high v ariance. It is therefore common to search for an optimal λ on a grid that do es not include 1. In R, the smoother metho d of the qvalue pack age computes the final estimator at 0 . 95 b y default. Hence, it is advisable to search for an optimal λ that is b ounded aw ay from 1. (2) Under the conca vity of the alternativ e distribution, if we assume the existence of some c 0 < 1 suc h that the alternative distribution is supp orted on [0 , c 0 ], then the Sc hw eder-Sp jøtv all estimator ev aluated at c 0 , i.e., ˆ π 0 ( c 0 ), is a consistent estimator of π 0 . (3) Since the alternative distribution is asymptotically a concav e function, the Grenander estimator based on the assumption of a decreasing density Langaas et al. ( 2005 ) can also b e used to estimate π 0 . 4 Sim ulation studies W e ge nerated datasets with n = 200 observ ations and k = 100 , 200 , 500 , 1000 features, for v arious choices of the cov ariance matrix Σ . Sp ecifically , we considered three differen t structures for Σ : a blo ck-diagonal matrix, a band graph, and an Erd˝ os–R´ en yi random graph, following the setup in Liu ( 2013 ). Blo c k diagonal Σ : The c hoice of a blo c k-diagonal cov ariance matrix is of interest b ecause it preserves sparsity after inv ersion. In particular, we simulated data under a blo ck-diagonal structure for Σ , consisting of b blo cks of size s (so that bs = k ). Within this blo c k-diagonal structure, the prop ortion of edges is given by π 1 = ( s − 1) / ( k − 1). Two types of within-blo ck correlation structures w ere considered: (i) autor e gr essive of or der 1 (AR(1)) , and (ii) e quic orr elate d . F or application of the GF C pro cedure, w e considered tw o scenarios: the Lasso estimator (GF C L ) and the scaled Lasso estimator (GFC S L ). F or running the simulations, we used the SILGGM pack age in R for implementing the GF C pro cedure, and the qvalue pack age for ev aluating the p erformance of Storey’s estimator with the ‘Bo otstrap’ and ‘Smo other’ metho ds. When eac h blo ck of the cov ariance matrix follows an AR(1) co v ariance structure with in tra-blo c k auto correlation parameter 0 . 5, the resulting ECDF closely aligns with the uniform CDF, corresp onding to the 45 0 line through the origin. This b eha vior reflects the high degree of sparsity induced by the blo ck-diagonal structure. T able 1 displa ys the av erage estimated v alues based on 100 replications. Ov erall, the estimates obtained using Lasso tend to b e slightly higher than those from Scaled Lasso, and in b oth cases, they are v ery close to 1. T able 1: Simulation results under the AR(1) blo c k co v ariance structure π 0 Method k = 100 k = 200 k = 500 k = 1000 Smoother Bootstrap Smoother Bootstrap Smoother Bootstrap Smoother Bootstrap 0.80 GFC L 0.97 0.96 0.99 0.98 0.98 0.98 0.99 0.99 GFC SL 0.96 0.95 0.99 0.98 0.98 0.98 0.99 0.99 0.90 GFC L 0.98 0.97 0.98 0.98 0.99 0.99 0.99 0.99 GFC SL 0.98 0.97 0.98 0.98 0.99 0.99 0.99 0.99 0.95 GFC L 0.95 0.96 0.98 0.98 0.99 0.99 0.99 0.99 GFC SL 0.95 0.96 0.98 0.98 0.99 0.99 0.99 0.99 Note: GF C L represen ts the GF C pro cedure with Lasso-based optimization, and GF C S L represen ts the GF C pro cedure with scaled Lasso. In Figure 1 , we show the ECDF of the p-v alues for data generated from a blo ck-diagonal co v ariance matrix Σ , where each blo ck exhibits equicorrelation with correlation 0 . 5. Suc h equicorrelated blo c ks in tro duce stronger dep endence within the mo del, resulting in concav e p-v alue distributions in b oth scenarios. (a) Ecdf plot of p-v alues based on GFC L (GF C pro cedure with Lasso-based optimization) (b) Ecdf plot of p-v alues based on GF C S L (GF C pro cedure with scaled Lasso) Figure 1: ECDF of p-v alues for a blo ck-diagonal cov ariance structure with equicorrelation within blo c ks( n = 200 , k = 500). T able 2 rep orts the a verage estimated v alues of π 0 . Consisten t with previous observ ations, Lasso-based estimates tend to b e slightly higher than those obtained using Scaled Lasso. Moreov er, b oth the “smo other” and “b o otstrap” approaches contin ue to pro duce conserv ative estimates of π 0 in this setting. T able 2: Simulation results under the equicorrelated ( ρ = 0 . 5) blo c k co v ariance structure π 0 Method k = 100 k = 200 k = 500 k = 1000 Smoother Bootstrap Smoother Bootstrap Smoother Bootstrap Smoother Bootstrap 0.80 GFC L 0.93 0.93 0.97 0.96 0.98 0.98 0.98 0.98 GFC SL 0.91 0.91 0.94 0.94 0.95 0.95 0.94 0.94 0.90 GFC L 0.93 0.94 0.96 0.96 0.98 0.98 0.98 0.98 GFC SL 0.93 0.91 0.92 0.93 0.94 0.94 0.94 0.94 0.95 GFC L 0.94 0.93 0.97 0.97 0.98 0.98 0.99 0.99 GFC SL 0.92 0.91 0.93 0.93 0.95 0.95 0.94 0.94 Note: GF C L represen ts the GF C pro cedure with Lasso-based optimization, and GF C S L represen ts the GF C pro cedure with scaled Lasso. Band Graph : W e consider the same band graph as in Liu ( 2013 ), where Ω = ( ω ij ) satisfies ω ij = 1 , if i = j, 0 . 6 , if | i − j | = 1 , 0 . 3 , if | i − j | = 2 , 0 , if | i − j | ≥ 3 . F or this band graph, out of the k ( k − 1) off-diagonal elemen ts, only 2( k − 1) elements are nonzero. Hence, the prop ortion of nonzero off-diagonal elements is π 1 = 2 /k . As k increases, the precision matrix b ecomes increasingly sparse, and the estimated ˆ π 0 v alues for b oth metho ds rise accordingly , approac hing 1 as exp ected. T able 3: Estimated ˆ π 0 for the band graph precision matrix ( π 0 = 2 /k ) Metho d k = 100 k = 200 k = 500 k = 1000 Smo other Bo otstrap Smo other Bo otstrap Smo other Bo otstrap Smoother Bo otstrap GF C L 0.95 0.94 0.97 0.97 0.98 0.98 0.99 0.99 GF C SL 0.96 0.95 0.97 0.97 0.98 0.98 0.99 0.99 Note: GF C L represen ts the GF C pro cedure with Lasso-based optimization, and GF C S L represen ts the GF C pro cedure with scaled Lasso. Erd˝ os–R ´ en yi random graph : In this case, ω ij = u ij δ ij where u ij ∼ U nif [0 . 4 , 0 . 8] and δ ij ∼ B er ( q ) where q = min { 0 . 05 , 5 /k } . T able 4 provides the ˆ π 0 under differen t combinations. T able 4: Estimated ˆ π 0 for the Erd˝ os –R ´ en yi random graph ( π 0 = 1 − min { 0 . 05 , 5 /k } ) Metho d k = 100 k = 200 k = 500 k = 1000 Smo other Bo otstrap Smo other Bo otstrap Smo other Bo otstrap Smoother Bo otstrap GF C L 0.94 0.93 0.97 0.96 0.98 0.98 0.99 0.99 GF C SL 0.95 0.93 0.97 0.96 0.98 0.98 0.98 0.98 Note: GF C L represen ts the GF C pro cedure with Lasso-based optimization, and GF C S L represen ts the GF C pro cedure with scaled Lasso. W e also accommo date the case where the sparsity of the Erd˝ os–R ´ enyi random graph do es not c hange as k increases. This means that u ij ∼ Ber( q ) for some fixed 0 < q < 1. W e consider q = 0 . 2 , 0 . 1 , and 0 . 05 (i.e., π 0 = 0 . 8 , 0 . 9 , and 0 . 95). In this setting, where the v alue of π 1 is slightly larger, the ECDF of the p -v alues sho ws a mo dest deviation from the uniform [0 , 1] distribution. Nevertheless, the concav e shap e of the ECDF suggests that Storey’s estimator, with an appropriately chosen tuning parameter, can still yield a reas onable estimate of π 0 . F or illustration, we highligh t the ECDF corresp onding to q = 0 . 2, n = 200, and k = 500 in figure 2 . T able 5 presents the estimated ˆ π 0 v alues for these different combinations. T able 5: Estimated ˆ π 0 for the Erd˝ os–R´ enyi random graph with fixed sparsit y π 0 Method k = 100 k = 200 k = 500 k = 1000 Smoother Bootstrap Smoother Bootstrap Smoother Bootstrap Smoother Bootstrap 0.80 GFC L 0.83 0.83 0.87 0.87 0.93 0.93 0.95 0.95 GFC SL 0.80 0.81 0.82 0.83 0.86 0.86 0.88 0.88 0.90 GFC L 0.90 0.90 0.90 0.91 0.94 0.94 0.96 0.96 GFC SL 0.89 0.89 0.89 0.89 0.89 0.89 0.89 0.89 0.95 GFC L 0.95 0.94 0.95 0.94 0.96 0.96 0.96 0.97 GFC SL 0.94 0.94 0.93 0.93 0.91 0.92 0.91 0.91 Note: GF C L represen ts the GF C pro cedure with Lasso-based optimization, and GF C S L represen ts the GF C pro cedure with scaled Lasso. (a) Ecdf plot of p-v alues based on GFC L (GF C pro cedure with Lasso-based optimization) (b) Ecdf plot of p-v alues based on GF C S L (GF C pro cedure with scaled Lasso) Figure 2: Ecdf plot of p-v alues for Erd˝ os–R ´ en yi random graph with a fixed sparsity ( q = 0 . 2 , n = 200 , k = 500) In all cases, the general observ ation is that the estimated ˆ π 0 is close to the true v alue of π 0 . Thus, the GFC pro cedure, com bined with Storey’s estimator, provides a reasonable estimate of the graph’s complexity . How ever, for π 0 = 0 . 95 and k = 1000, this estimator sligh tly underestimates π 0 . It should b e noted that this scenario deviates from our sparsity assumptions of Theorem 3.1 . Interestingly , even with this sligh t violation of the mo del assumptions, the metho d still pro vides a reasonable estimate of the true graph complexit y . 5 Real data analysis T o illustrate the practical p erformance of the prop osed metho d, we consider the leukemia microarra y study of Golub et al. ( 1999 ). The dataset contains expression levels of k = 3051 genes measured on 38 tumor mRNA samples, consisting of 27 acute lymphoblastic leuk emia (ALL) cases and 11 acute my eloid leuk emia (AML) cases. Since the samples arise from t wo biologically distinct p opulations, the assumption of iden tically distributed observ ations is violated. W e therefore first analyze the ALL and AML groups separately . Additionally , w e hav e considered the combined dataset with n = 38 to assess the metho d under p o oled samples. The dataset is a v ailable in the R pac k age multtest . F or b oth groups, as w ell as for the com bined dataset, the condition log k = o ( n ) is not satisfied, as the sample sizes are small relative to the n um b er of genes. This places us in a high-dimensional setting, in which standard regularity conditions for Lasso-based inference ma y not hold. In particular, the GFC L pro cedure pro duces estimates ˆ π 0 that are t ypically close to 1, indicating ov erestimation of the prop ortion of null hypotheses. This o ccurs b ecause the Lasso tuning parameter selected when all v ariables are included is close to zero, so that the resulting regression co efficien ts are nearly iden tical to the ordinary least squares estimator. When k ≫ n , such OLS-based estimates are unstable, and consequen tly the consistency of the Lasso-based estimator is not theoretically guaranteed. F or these reasons, we rep ort results based on the Scaled Lasso pro cedure (GFC S L ), whic h is b etter suited to this high-dimensional setting. T able 6 presents the corresp onding estimates of the prop ortion of null hypotheses ( ˆ π 0 ) for the separate groups as well as the com bined dataset. T able 6: Estimated sparsity levels for the t wo mRNA sample groups, ALL and AML. ALL AML Smo other Bo otstrap Smo other Bo otstrap 0.78 0.78 0.78 0.79 The estimated prop ortions of null hypotheses, ˆ π 0 , indicate that the underlying gene netw orks are sparse. F or b oth groups, the estimated prop ortion of edges in the graphs is approximately 0 . 22. Figure 3 presents the ECDFs of the p-v alues for the t wo groups. Both plots exhibit a concav e pattern, whic h is consisten t with the presence of a mo dest prop ortion of non-n ull h yp otheses and supp orts the sparsity of the inferred net w orks. (a) Empirical CDF of p-v alues based on GF C S L (GF C with Scaled Lasso) for the ALL sample group (b) Empirical CDF of p-v alues based on GFC S L (GF C with Scaled Lasso) for the AML sample group Figure 3: Empirical CDFs of p-v alues for the leukemia microarra y data of Golub et al. ( 1999 ), sho wn separately for the ALL and AML mRNA sample groups. This suggests that most genes act indep enden tly , while a small subset forms connected modules, highligh ting k ey conditional dep endencies in the high-dimensional gene expression data. 6 Concluding Remarks In this pap er, we address the problem of simultaneously testing the en tries of a precision matrix using the metho dology of Liu ( 2013 ), and we show that the Sch weder–Sp jøtv all estimator, with the tuning parameter selected via b o otstrap or smo othing splines, provides a reliable means of estimating the complexit y of the underlying graph. The assumptions of Theorem 3.1 are fairly general, cov ering a wide range of dep enden t structures commonly encountered in applications, particularly in gene-based studies. Due to its ability to accommodate v arious w eakly dep endent structures and its simple formulation based on the ECDF of the p -v alues, Sc hw eder–Sp jøtv all estimator is well-suited for problems with inheren t dependencies among p -v alues. The main theoretical result of Theorem 3.1 relies on assumptions regarding the sum of absolute v alues of the precision matrix entries. Cov ariance matrices with T o eplitz structure and fast decay rates (e.g., exp onen tial deca y) satisfy these assumptions. An interesting direction for future work w ould b e to imp ose a similar criterion directly on the cov ariance matrix. Although the asymptotic small order of the sum of absolute co v ariances alone is not sufficient to guaran tee conv ergence of the ECDF to the a v erage CDF, practical examples and sim ulation results suggest that this criterion ma y hold for a broad class of co v ariance matrices. Another promising direction is to extend the metho dology to copula-based graphical mo dels instead of Gaussian graphical mo dels, as considered in Bauer et al. ( 2012 ). Previous w orks such as Dobra and Lenk oski ( 2011 ); Liu et al. ( 2012 ) ha ve studied semiparametric Gaussian copula mo dels, while multi-attribute Gaussian graphical mo dels hav e b een explored in Li et al. ( 2025 ). Laten t v ariable-based approaches hav e b een inv estigated in Behrouzi and Wit ( 2019 ); Hermes et al. ( 2024 ); Y u et al. ( 2012 ). Moreov er, Neumann et al. ( 2021 ) considered estimation of π 0 under a general copula mo del using a com bination of the indep endent comp onen t b o otstrap of Hall and Miller ( 2009 ) and the Sch w eder-Sp jøtv all estimator. Extending the estimation of net work complexit y to more general copula-based models represents an exciting and c hallenging direction for future research. 7 App endix W e b egin b y stating a few technical lemmas that are essen tial for the pro of of Theorem 3.1 . Define U ij = 1 √ n n X l =1 { ε li ε lj − E [ ε li ε lj ] } . (6) Observ e that ε li ε lj ! ∼ N 2 0 0 ! , " δ ii δ ij δ ij δ j j #! , where δ ij = ω ij ω ii ω j j , δ ii = σ ii − Σ i, − i Σ − 1 − i, − i Σ − i,i . Lemma 7.1 F or any ( i, j ) and ( i ′ , j ′ ) with i < j and i ′ < j ′ , Co v ( U ij , U i ′ j ′ ) = δ ii ′ δ j j ′ + δ ij ′ δ i ′ j . Pro of. By Isserlis’s theorem (see Isserlis ( 1918 )), E ε li ε lj ε li ′ ε lj ′ = E [ ε li ε lj ] E [ ε li ′ ε lj ′ ] + E [ ε li ε li ′ ] E [ ε lj ε lj ′ ] + E [ ε li ε lj ′ ] E [ ε li ′ ε lj ] . F rom this decomp osition, the desired expression for Co v ( U ij , U i ′ j ′ ) follo ws immediately . Lemma 7.2 F or any ( i, j ) and ( i ′ , j ′ ) with i < j and i ′ < j ′ , and for any x ∈ R , we have Co v I { U ij ≤ x } , I { U i ′ j ′ ≤ x } ≤ | ρ ( ij ) , ( i ′ j ′ ) | 1 − | ρ ( ij ) , ( i ′ j ′ ) | + O 1 √ n , wher e ρ ( ij ) , ( i ′ j ′ ) = Corr( U ij , U i ′ j ′ ) with | ρ ( ij ) , ( i ′ j ′ ) | < 1 . Pro of: By Mehler’s iden tity , if ( X , Y ) ∼ N 0 0 ! , 1 ρ ρ 1 ! ! , then Pr( X ≤ x, Y ≤ x ) = ∞ X n =0 ρ n n ! Z x −∞ H n ( u ) ϕ ( u ) du 2 . where ϕ ( u ) is the standard normal densit y and H n ( u ) denotes the Hermite polynomial of degree n , defined by H n ( u ) = ( − 1) n e u 2 / 2 d n du n e − u 2 / 2 . Hence, Co v I { X ≤ x } , I { Y ≤ x } = ∞ X n =1 ρ n n ! Z x −∞ H n ( u ) ϕ ( u ) du 2 . Using the b ound R x −∞ H n ( u ) ϕ ( u ) du ≤ √ n ! and | ρ | < 1, we obtain Co v I { X ≤ x } , I { Y ≤ x } ≤ ∞ X n =1 | ρ | n = | ρ | 1 − | ρ | . This b ound is indep endent of x and extends to the case ( X , Y ) ∼ N µ x µ y ! , σ 2 x ρσ x σ y ρσ x σ y σ 2 y ! ! . By the Berry–Esseen theorem, for any ( i, j ) and ( i ′ , j ′ ) and uniformly in x ∈ R , Co v I { U ij ≤ x } , I { U i ′ j ′ ≤ x } − Cov I { Z 1 ≤ x } , I { Z 2 ≤ x } = O 1 √ n , where Z 1 Z 2 ! ∼ N δ ij δ i ′ j ′ ! , " δ ii δ j j + δ 2 ij δ ii ′ δ j j ′ + δ ij ′ δ i ′ j δ ii ′ δ j j ′ + δ ij ′ δ i ′ j δ i ′ i ′ δ j ′ j ′ + δ 2 i ′ j ′ # ! . Com bining these results, we conclude that uniformly in x , Co v I { U ij ≤ x } , I { U i ′ j ′ ≤ x } ≤ | ρ ( ij ) , ( i ′ j ′ ) | 1 − | ρ ( ij ) , ( i ′ j ′ ) | + O 1 √ n . Lemma 7.3 L et { X i } i ≥ 1 b e r e al-value d r andom variables with ECDF F m ( x ) = 1 m m X i =1 1 { X i ≤ x } , and let ¯ F ( x ) = 1 m P m i =1 F i ( x ) , wher e F i is the distribution function of X i . Assume that sup x ∈ R | F m ( x ) − ¯ F ( x ) | − → 0 almost sur ely. L et h : R → R b e c ontinuous, and define A ( y ) = h − 1 (( −∞ , y ]) for e ach y . Assume that for every y , A ( y ) is a finite union of close d intervals, A ( y ) = k ( y ) [ j =1 [ a j ( y ) , b j ( y )] , k ( y ) ≤ K < ∞ , and that ¯ F is c ontinuous at e ach b oundary p oint a j ( y ) and b j ( y ) . Define X ′ i = h ( X i ) and G m ( y ) = 1 m m X i =1 1 { X ′ i ≤ y } , ¯ G ( y ) = 1 m m X i =1 G i ( y ) , wher e G i is the distribution function of X ′ i . Then sup y ∈ R | G m ( y ) − ¯ G ( y ) | − → 0 almost sur ely . Pro of: F or each fixed y , since X i = h ( X i ), G m ( y ) = 1 m m X i =1 1 { X i ∈ A ( y ) } = µ F m ( A ( y )) , ¯ G ( y ) = µ ¯ F ( A ( y )) . Because A ( y ) is a finite union of interv als, A ( y ) = k ( y ) [ j =1 [ a j ( y ) , b j ( y )] , w e ha ve µ F m ( A ( y )) = k ( y ) X j =1 F m ( b j ( y )) − F m ( a j ( y ) − ) , and b y contin uit y of ¯ F at each b oundary p oint, µ ¯ F ( A ( y )) = k ( y ) X j =1 ¯ F ( b j ( y )) − ¯ F ( a j ( y )) . Th us, | G m ( y ) − ¯ G ( y ) | ≤ k ( y ) X j =1 | F m ( b j ( y )) − ¯ F ( b j ( y )) | + | F m ( a j ( y )) − ¯ F ( a j ( y )) | ≤ 2 k ( y ) sup x | F m ( x ) − ¯ F ( x ) | ≤ 2 K sup x | F m ( x ) − ¯ F ( x ) | . T aking the suprem um o ver y gives sup y | G m ( y ) − ¯ G ( y ) | ≤ 2 K sup x | F m ( x ) − ¯ F ( x ) | . The righ t-hand side conv erges to 0 almost surely b y hypothesis, whic h pro ves the claim. Corollary 7.3.1 L et T 1 , . . . , T m b e r e al-value d test statistics with ECDF F m ( t ) = 1 m m X i =1 1 { T i ≤ t } , and aver age CDF ¯ F ( t ) = 1 m m X i =1 F i ( t ) , wher e F i is the distribution function of T i . Assume sup t ∈ R | F m ( t ) − ¯ F ( t ) | − → 0 almost sur ely . Define two-side d normal p-values P i = 2 1 − Φ( | T i | ) , and let G n ( p ) = 1 n m X i =1 1 { P i ≤ p } , ¯ G ( p ) = 1 m m X i =1 G i ( p ) , wher e G i is the distribution function of P i . Then sup p ∈ [0 , 1] | G m ( p ) − ¯ G ( p ) | − → 0 almost sur ely . Pro of : Let h ( t ) = 2(1 − Φ( | t | )), whic h is contin uous. F or fixed p ∈ (0 , 1), P i ≤ p ⇐ ⇒ | T i | ≥ c p , c p = Φ − 1 (1 − p/ 2) . Th us the preimage set A ( p ) = h − 1 (( −∞ , p ]) is A ( p ) = ( −∞ , − c p ] ∪ [ c p , ∞ ) , a finite union of tw o closed interv als. The b oundary p oints ± c p are con tinuit y p oints of ¯ F except for a countable set of p , which do es not affect the suprem um norm. Hence the map T i 7→ P i satisfies the assumptions of the uniform con vergence with K = 2. Therefore, sup p ∈ [0 , 1] | G m ( p ) − ¯ G ( p ) | = sup p | µ F m ( A ( p )) − µ ¯ F ( A ( p )) | − → 0 almost surely . Pro of of Theorem 3.1 : F rom Liu ( 2013 ), w e ha ve, for any 1 ≤ i < j ≤ k , U ij = r n ˆ r ii ˆ r j j T 1 ,ij + b n,ij ω ij ω ii ω j j + O P log k √ n , where b n,ij → 1 in probabilit y uniformly o v er 1 ≤ i < j ≤ k . Thus, conv ergence of the ECDF of the test statistics is equiv alent to conv ergence of the ECDF of the U ij ’s. By Lemma 7.2 , for any ( i, j ) and ( i ′ , j ′ ) with i < j and i ′ < j ′ , and for any x ∈ R , Co v I { U ij ≤ x } , I { U i ′ j ′ ≤ x } ≤ | ρ ( ij ) , ( i ′ j ′ ) | 1 − | ρ ( ij ) , ( i ′ j ′ ) | + O 1 √ n , where ρ ( ij ) , ( i ′ j ′ ) = Corr( U ij , U i ′ j ′ ) with | ρ ( ij ) , ( i ′ j ′ ) | < 1. Hence, if X i 0 suc h that | ρ ( ij ) , ( i ′ j ′ ) | ≤ M | ω ii ′ ω j j ′ + ω ij ′ ω i ′ j | . Consequen tly , X i λ ) , ¯ F 1 ( λ ) = 1 N X ( i,j ) ∈ I 1 Pr( p ij > λ ) . By Lemma 7.4 , we hav e π 0 ¯ F 0 ( λ ) = π 0 (1 − λ ) + o (1) , so that for any λ ∈ [0 , c ], ˆ π 0 ( λ ) a.s. − − → π 0 + π 1 1 − ¯ F 1 ( λ ) 1 − λ as ( n, k ) → ∞ . Clearly , if π 0 → 1, then Sch weder-Sp jøtv all estimator also con verges to 1 almost surely . Otherwise, since ¯ F 1 ( · ) is asymptotically a concav e function, it follo ws that π 1 1 − ¯ F 1 ( λ ) 1 − λ ≥ 0 a.s. ∀ λ ∈ [0 , c ] . Hence, Sc h weder-Sp jøtv all estimator is asymptotically biased upw ards. References A. Bauer, C. Czado, and T. Klein. P air-copula constructions for non-gaussian dag models. Canadian Journal of Statistics , 40(1):86–109, 2012. doi: h ttps://doi.org/10.1002/cjs.10131. URL https://onlinelibrary.wiley.com/doi/abs/10.1002/cjs.10131 . P . Behrouzi and E. C. Wit. Detecting epistatic selection with partially observed genot yp e data b y using copula graphical mo dels. Journal of the R oyal Statistic al So ciety Series C: Applie d Statistics , 68(1):141–160, 2019. ISSN 0035-9254. doi: 10.1111/rssc.12287. URL https://doi.org/10.1111/rssc.12287 . Y. Benjamini and Y. Ho ch b erg. On the adaptive control of the false discov ery rate in m ultiple testing with indep endent statistics. Journal of e duc ational and Behavior al Statistics , 25(1): 60–83, 2000. P . Billingsley . Pr ob ability and me asur e . John Wiley & Sons, 1995. T. Cai, W. Liu, and X. Luo. A constrained l-1 minimization approac h to sparse precision matrix estimation. Journal of the Americ an Statistic al Asso ciation , 106(494):594–607, 2011. doi: 10.1198/jasa.2011.tm10155. URL https://doi.org/10.1198/jasa.2011.tm10155 . X. Chen. Uniformly consistently estimating the prop ortion of false null hypotheses via leb esgue–stieltjes integral equations. Journal of Multivariate A nalysis , 173:724–744, 2019. ISSN 0047-259X. doi: h ttps://doi.org/10.1016/j.jm v a.2019.06.003. URL https://www. sciencedirect.com/science/article/pii/S0047259X18304688 . X. Chen. Uniformly consisten t prop ortion estimation for comp osite h yp otheses via integral equations:“the case of gamma random v ariables”. A nnals of the Institute of Statistic al Mathematics , pages 1–36, 2025. doi: h ttps://doi.org/10.1007/s10463- 025- 00930- 3. A. d’Aspremon t, O. Banerjee, and L. El Ghaoui. First-order metho ds for sparse cov ariance selection. SIAM Journal on Matrix Analysis and Applic ations , 30(1):56–66, 2008. doi: h ttps: //doi.org/10.1137/060670985. URL https://doi.org/10.1137/060670985 . S. Demk o, W. F. Moss, and P . W. Smith. Deca y rates for in verses of band matrices. Mathematics of c omputation , 43(168):491–499, 1984. ISSN 00255718, 10886842. doi: https://doi.org/10. 2307/2008290. URL http://www.jstor.org/stable/2008290 . T. Dic khaus. Simultaneous statistical inference. With applic ations in the life scienc es. Springer , 2014. doi: h ttps://doi.org/10.1007/978- 3- 642- 45182- 9. URL https://link.springer.com/ book/10.1007/978- 3- 642- 45182- 9 . T. Dickhaus, R. Heller, A.-T. Hoang, and Y. Rinott. A pro cedure for multiple testing of partial conjunction hypotheses based on a hazard rate inequality. Bernoul li , 32(1):274 – 298, 2026. doi: 10.3150/25- BEJ1858. URL https://doi.org/10.3150/25- BEJ1858 . A. Dobra and A. Lenk oski. Copula gaussian graphical mo dels and their application to mo deling functional disability data. The Annals of Applie d Statistics , 5(2A):969–993, 2011. doi: 10. 1214/10- AO AS397. URL https://doi.org/10.1214/10- AOAS397 . J. F riedman, T. Hastie, and R. Tibshirani. Sparse in v erse co v ariance estimation with the graphical lasso. Biostatistics , 9(3):432–441, 2008. doi: 10.1093/biostatistics/kxm045. URL https://doi.org/10.1093/biostatistics/kxm045 . C. Genov ese and L. W asserman. A sto chastic pro cess approach to false discov ery con trol. The Annals of Statistics , 32(3):1035 – 1061, 2004. doi: 10.1214/009053604000000283. URL https://doi.org/10.1214/009053604000000283 . T. R. Golub, D. K. Slonim, P . T ama yo, C. Huard, M. Gaasen b eek, J. P . Mesirov, H. Coller, M. L. Loh, J. R. Do wning, M. A. Caligiuri, et al. Molecular classification of cancer: class disco very and class prediction by gene expression monitoring. Scienc e , 286(5439):531–537, 1999. doi: 10.1126/science.286.5439.53. P . Hall and H. Miller. Using the b o otstrap to quantify the authority of an empirical ranking. A nnals of Statistics , 37:3929–3959, 2009. doi: 10.1214/09- AOS699. URL http://www.jstor. org/stable/25662220 . N. W. Hengartner and P . B. Stark. Finite-sample confidence env elop es for shap e-restricted densities. The Annals of Statistics , 23(2):525–550, 1995. ISSN 00905364, 21688966. URL http://www.jstor.org/stable/2242350 . S. Hermes, J. v an Heerw aarden, and P . Behrouzi. Copula graphical mo dels for heterogeneous mixed data. Journal of Computational and Gr aphic al Statistics , 33(3):991–1005, 2024. doi: 10. 1080/10618600.2023.2289545. URL https://doi.org/10.1080/10618600.2023.2289545 . L. Isserlis. On a formula for the pro duct-momen t co efficien t of an y order of a normal frequency distribution in any num b er of v ariables. Biometrika , 12(1/2):134–139, 1918. J. Jin. Prop ortion of non-zero normal means: Universal oracle equiv alences and uniformly consisten t estimators. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 70(3):461–493, 04 2008. ISSN 1369-7412. doi: 10.1111/j.1467- 9868.2007.00645. x. URL https://doi.org/10.1111/j.1467- 9868.2007.00645.x . J. Jin and T. T. Cai. Estimating the null and the prop ortion of nonnull effects in large-scale multiple comparisons. Journal of the Americ an Statistic al Asso ciation , 102 (478):495–506, 2007. doi: 10.1198/016214507000000167. URL https://doi.org/10.1198/ 016214507000000167 . M. Langaas, B. H. Lindqvist, and E. F erkingstad. Estimating the prop ortion of true null h yp otheses, with application to dna microarra y data. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 67(4):555–572, 2005. ISSN 1369-7412. doi: 10.1111/j. 1467- 9868.2005.00515.x. URL https://doi.org/10.1111/j.1467- 9868.2005.00515.x . S. L. Lauritzen. Gr aphic al mo dels , volume 17. Clarendon Press, 1996. L. Li, Y. Y u, W. Liang, and F. Zou. A nov el approac h for estimating m ulti-attribute gaussian copula graphical mo dels. Statistics & Pr ob ability L etters , 222:110413, 2025. ISSN 0167-7152. doi: h ttps://doi.org/10.1016/j.spl.2025.110413. URL https://www.sciencedirect.com/ science/article/pii/S0167715225000586 . H. Liu, F. Han, M. Y uan, J. Laffert y , and L. W asserman. High-dimensional semiparametric gaussian copula graphical mo dels. The Annals of Statistics , 40(4):2293–2326, 2012. doi: 10.1214/12- AOS1037. URL https://doi.org/10.1214/12- AOS1037 . W. Liu. Gaussian graphical mo del estimation with false disco v ery rate control. The Annals of Statistics , 41(6):2948–2978, 2013. ISSN 00905364, 21688966. doi: 10.1214/13- AOS1169. URL http://www.jstor.org/stable/23566754 . N. Meinshausen and P . B ¨ uhlmann. High-dimensional graphs and v ariable selection with the Lasso. The Annals of Statistics , 34(3):1436 – 1462, 2006. doi: 10.1214/009053606000000281. URL https://doi.org/10.1214/009053606000000281 . A. Neumann, T. Bo dnar, and T. Dic khaus. Estimating the prop ortion of true n ull hypotheses under dep endency: A marginal b o otstrap approach. Journal of Statistic al Planning and Infer enc e , 210:76–86, 2021. ISSN 0378-3758. doi: https://doi.org/10.1016/j.jspi.2020.04.011. URL https://www.sciencedirect.com/science/article/pii/S0378375820300495 . E. P arzen. Mo dern pr ob ability the ory and its applic ations . A Wiley Publication in Mathematical Statistics. John Wiley & Sons, Inc., New Y ork-London, 1960. R. K. P atra and B. Sen. Estimation of a tw o-comp onent mixture mo del with applications to m ultiple testing. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 78(4):869–893, 01 2016. ISSN 1369-7412. doi: 10.1111/rssb.12148. URL https://doi.org/ 10.1111/rssb.12148 . G. Raskutti, B. Y u, M. J. W ain wright, and P . Ra vikumar. Mo del selection in gaussian graphical mo dels: High-dimensional consistency of l 1 regularized mle. A dvanc es in Neur al Information Pr o c essing Systems , 21, 2008. T. Sch w eder and E. Sp jøtvoll. Plots of p-v alues to ev aluate many tests simultaneously . Biometrika , 69(3):493–502, 1982. ISSN 00063444, 14643510. doi: https://doi.org/10.2307/ 2335984. URL http://www.jstor.org/stable/2335984 . J. D. Storey . A direct approach to false discov ery rates. Journal of the R oyal Statistic al So ciety. Series B (Statistic al Metho dolo gy) , 64(3):479–498, 2002. ISSN 13697412, 14679868. doi: h ttps://doi.org/10.1111/1467- 9868.00346. URL http://www.jstor.org/stable/3088784 . J. D. Storey and R. Tibshirani. Statistical significance for genomewide studies. Pr o c e e dings of the National A c ademy of Scienc es , 100(16):9440–9445, 2003. doi: h ttps://doi.org/10.1073/ pnas.153050910. J. D. Storey , J. E. T aylor, and D. Siegmund. Strong control, conserv ativ e p oint estimation and sim ultaneous conserv ative consistency of false disco very rates: a unified approach. Journal of the R oyal Statistic al So ciety Series B: Statistic al Metho dolo gy , 66(1):187–205, 2004. ISSN 1369-7412. doi: 10.1111/j.1467- 9868.2004.00439.x. URL https://doi.org/10.1111/j. 1467- 9868.2004.00439.x . T. Sun and C.-H. Zhang. Scaled sparse linear regression. Biometrika , 99(4):879–898, 2012. ISSN 0006-3444. doi: 10.1093/biomet/ass043. URL https://doi.org/10.1093/biomet/ass043 . J. W. H. Swanepo el. The limiting b eha vior of a mo dified maximal symmetric 2 s -spacing with applications. The A nnals of Statistics , 27(1):24 – 35, 1999. doi: 10.1214/aos/1018031099. URL https://doi.org/10.1214/aos/1018031099 . L. Xue and H. Zou. Regularized rank-based estimation of high-dimensional nonparanormal graphical models. The Annals of Statistics , 40(5):2541–2571, 2012. ISSN 00905364, 21688966. doi: 10.1214/12- AOS1041. URL http://www.jstor.org/stable/41806547 . H. Y u, J. Dau w els, and X. W ang. Copula gaussian graphical mo dels with hidden v ariables. In 2012 IEEE International Confer enc e on A c oustics, Sp e e ch and Signal Pr o c essing (ICASSP) , pages 2177–2180, 2012. doi: 10.1109/ICASSP .2012.6288344. M. Y uan. High dimensional inv erse cov ariance matrix estimation via linear programming. The Journal of Machine L e arning R ese ar ch , 11:2261–2286, 2010. doi: http://jmlr.org/papers/ v11/yuan10b.h tml. URL http://jmlr.org/papers/v11/yuan10b.html . C. Zhang. Estimation of large inv erse matrices and graphical mo del selection. T echnical report, tec hnical rep ort, Rutgers Universit y , Dept. of Statistics and Biostatistics, 2010.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment